
Object Tracking Algorithm Based on Multi-Layer Feature Fusion and Semantic Enhancement


Abstract
1. Introduction
- (1)
- The object semantic enhancement model is constructed by using a multi-layer feature fusion method. Specifically, multi-layer features are fused through the cross-attention mechanism to ensure that the detailed description of the object is associated with the background context and enhance the expression ability of the search features.
- (2)
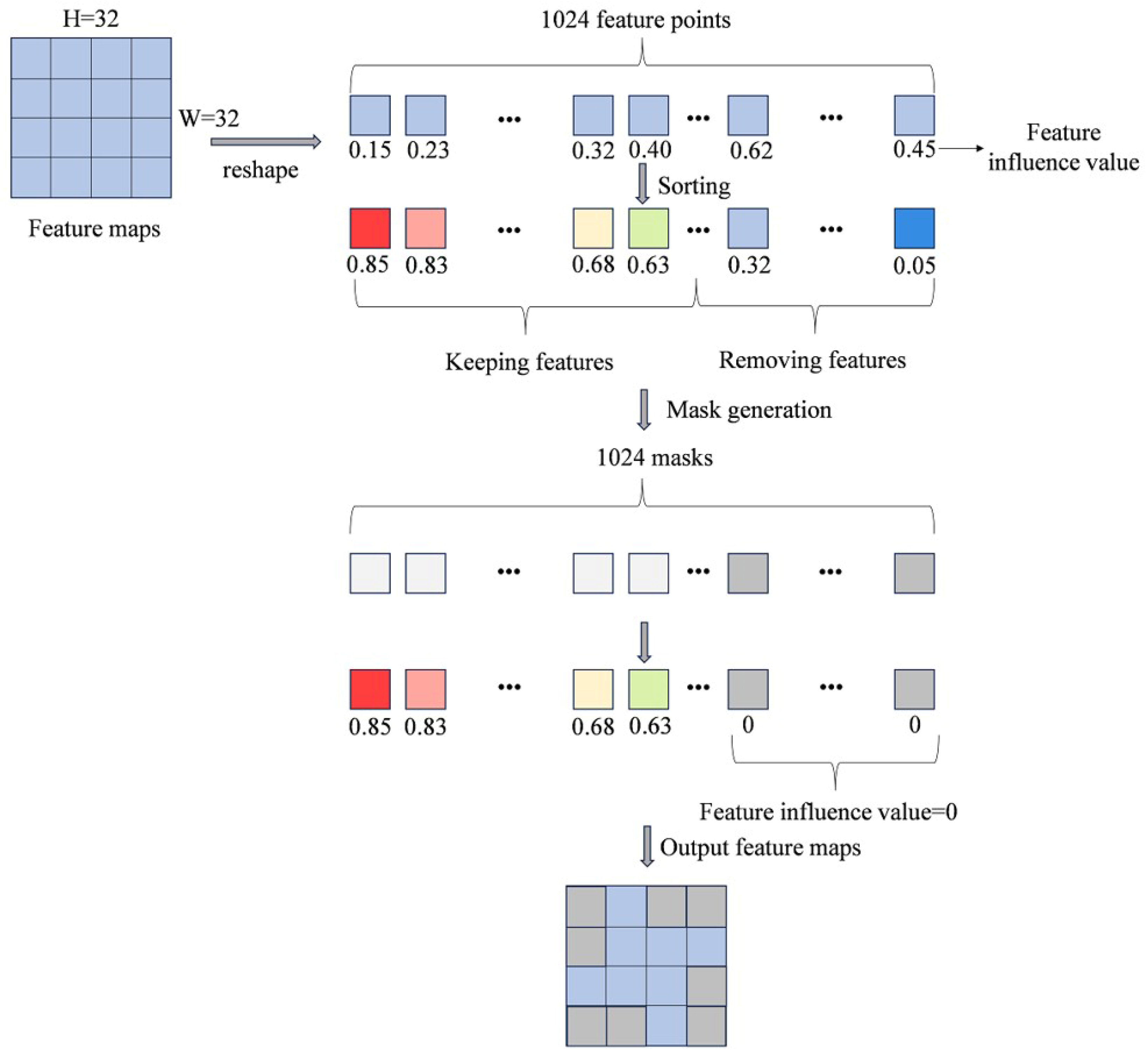
- The dynamic mask strategy is proposed. We introduce dynamic masks into the output features of cross-attention, further focusing on object information and significantly reducing the impact of background clutter.
- (3)
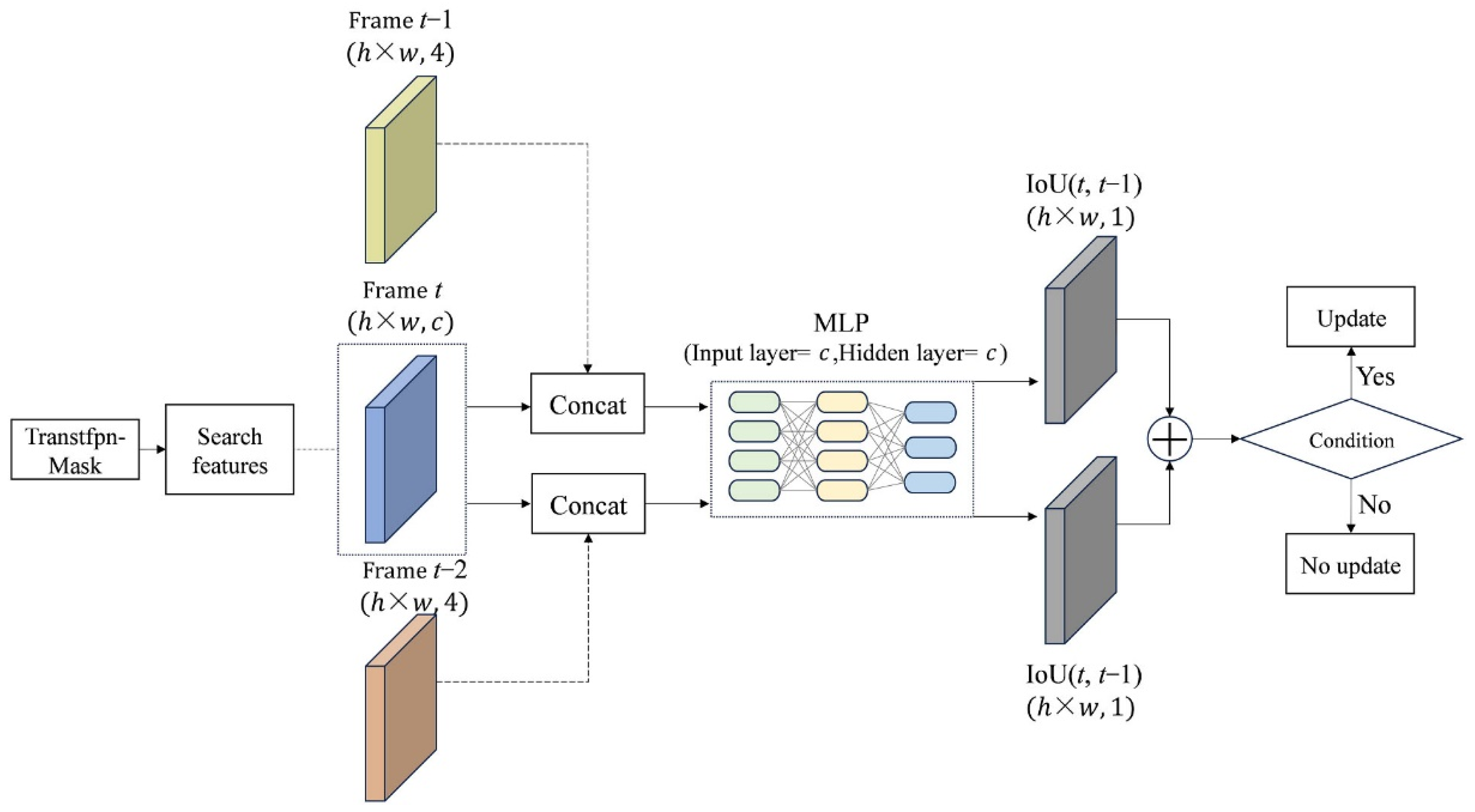
- The object template update mechanism guided by the judgment conditions [22] is employed. In particular, when the prediction result of the current frame exhibits high correlation with the adjacent two frames, a new template image is generated by cropping around the current predicted frame. This updated template is then fed back into the network input, enabling the template to better adapt to appearance variations in the object and changes in the scene background throughout the video sequence, thus maintaining tracking effectiveness over time.
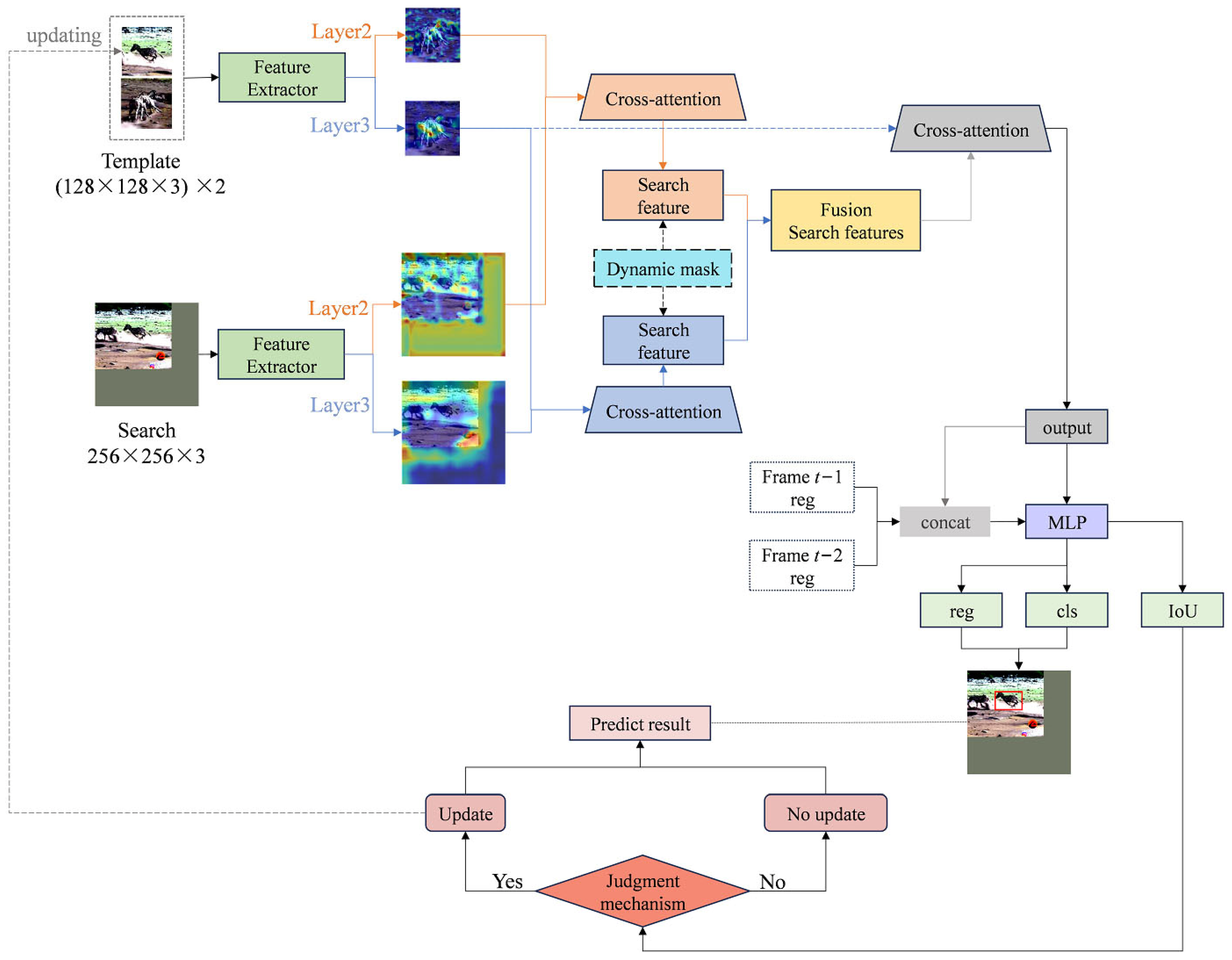
2. Method
2.1. Construction of Object Semantic Enhancement Model
2.1.1. Extraction of Multi-Layer Fusion Features
2.1.2. Object Semantic Model Under Multiple Cross-Attention
- (1)
- Cross-attention learning
- (2)
- Feature fusion strategy
- (3)
- Feature visualization
2.1.3. An Object Enhancement Model Integrating Mask Features
2.2. Object Template Update Mechanism
3. Experimental Results and Analysis
3.1. Experimental Environment and Settings
3.2. Datasets
- (1)
- LaSOT [25]: Launched at CVPR in 2019, the LaSOT (Large-scale Single Object Tracking) dataset has become a cornerstone in the realm of single-object tracking, offering a demanding and representative benchmark for evaluating object tracking algorithms. This dataset comprises 1550 video sequences, which are thoughtfully divided among training, testing, and validation sets. Spanning 85 object categories, with each category containing 20 sequences, the dataset amasses over 3.87 million frames, making it one of the most extensive collections in the single-object tracking domain at the time of its release. The LaSOT dataset is distinguished by its comprehensive attribute labeling, with each sequence meticulously annotated with 14 attributes. These attributes encompass a wide range of challenges, such as illumination variation (IV), fast motion (FM), full occlusion (FOC), object deformation (DEF), partial occlusion (POC), motion blur (MB), background clutter (BC), scale variation (SV), occlusion variation (OV), camera motion (CM), rotation (ROT), low resolution (LR), aspect ratio change (ARC), and viewpoint change (VC). This detailed labeling accurately captures the diverse and complex scenarios that objects may encounter within video sequences. In constructing the dataset, the creators adhered to principles of high-quality dense annotation, long-term tracking sequences, balanced categorization, and thorough labeling. These principles ensured the dataset’s high quality and richness, providing a robust and reliable foundation for single-object tracking research. As a result, the LaSOT dataset has significantly propelled advancements and breakthroughs in this field.
- (2)
- OTB-100 [26]: As a classic dataset in the field of single-object tracking, the OTB-100 (Visual Object Tracking Benchmark) builds upon the foundation of OTB-2013 by adding 50 new video sequences, bringing the total number of videos to 100. These sequences encompass 11 challenging attributes: low resolution (LR), illumination variation (IV), occlusion (OCC), fast motion (FM), motion blur (MB), in-plane rotation (IPR), background clutter (BC), out-of-plane rotation (OPR), deformation (DEF), occlusion variation (OV), and scale variation (SV). The dataset includes both grayscale and color images. Notably, each video sequence features at least 3–5 of these challenging attributes, creating a demanding environment for evaluating and comparing various object tracking algorithms. This setup effectively tests the robustness and performance of these algorithms.
- (3)
- UAV123 [27]: Comprising 123 video sequences and over 110,000 frames, the UAV123 dataset is designed to evaluate the performance of object tracking algorithms on unmanned aerial vehicles (UAVs). It provides videos captured in diverse and complex environments, assisting researchers in developing and testing robust and reliable tracking algorithms. The videos feature a wide range of scenes, including cities, villages, and coastlines, as well as various object types such as pedestrians, vehicles, and bicycles, which closely simulate real-world scenarios that drones may encounter during object tracking. The dataset’s video sequences are annotated with 12 challenging attributes: aspect ratio change (ARC), background clutter (BC), out-of-view (OV), camera motion (CM), fast motion (FM), similar objects (SOB), full occlusion (FOC), illumination variation (IV), viewpoint change (VC), low resolution (LR), partial occlusion (POC), and scale variation (SV).
3.3. Analysis of Experimental Results
3.3.1. Qualitative Analysis
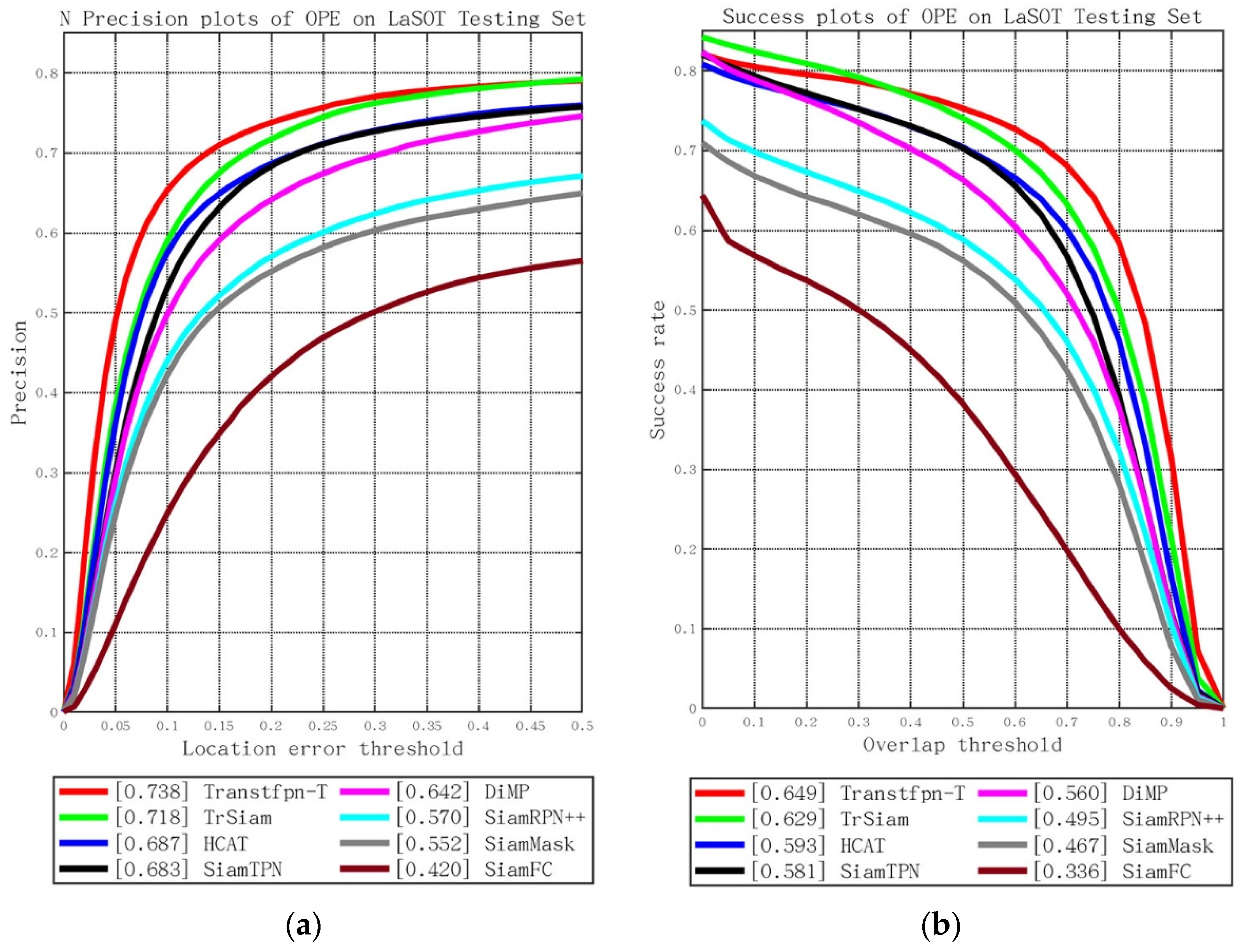
3.3.2. Quantitative Analysis
3.4. Analysis of Algorithm Limitations
4. Summary
- (1)
- Introducing an occlusion detection mechanism to dynamically control the frequency and content of template updates, enabling the model to better adapt to various scenarios and enhance robustness.
- (2)
- Incorporating temporal contextual information to improve the model’s ability to recognize objects when they temporarily go out of view.
- (3)
- Embedding the mask learning process into the training pipeline to achieve end-to-end optimization and enable the adaptive adjustment of the mask threshold. Instead of relying on manually set fixed thresholds, the model will be able to dynamically learn the optimal masking strategy for different scenarios during training, further improving the flexibility and generalization capability of the algorithm.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4 December 2017; pp. 5998–6008. [Google Scholar]
- Bertinetto, L.; Valmadre, J.; Henriques, J.F.; Vedaldi, A.; Torr, P.H. Fully-Convolutional Siamese Networks For Object Tracking. In Proceedings of the Computer Vision–ECCV 2016 Workshops, Amsterdam, The Netherlands, 8–10 and 15–16 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 850–865. [Google Scholar]
- Li, B.; Yan, J.; Wu, W.; Zhu, Z.; Hu, X. High Performance Visual Tracking With Siamese Region Proposal Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8971–8980. [Google Scholar]
- Zhu, Z.; Wang, Q.; Li, B.; Wu, W.; Yan, J.; Hu, W. Distractor-Aware Siamese Networks For Visual Object Tracking. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 101–117. [Google Scholar]
- Li, B.; Wu, W.; Wang, Q.; Zhang, F.; Xing, J.; Yan, J. Siamrpn++: Evolution Of Siamese Visual Tracking With Very Deep Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4282–4291. [Google Scholar]
- Wang, Q.; Zhang, L.; Bertinetto, L.; Hu, W.; Torr, P.H. Fast Online Object Tracking And Segmentation: A Unifying Approach. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1328–1338. [Google Scholar]
- Mei, Y.; Yan, N.; Qin, H.; Yang, T.; Chen, Y. SiamFCA: A new fish single object tracking method based on siamese network with coordinate attention in aquaculture. Comput. Electron. Agric. 2024, 216, 108542. [Google Scholar] [CrossRef]
- Lu, J.; Li, S.; Guo, W.; Zhao, M.; Yang, J.; Liu, Y.; Zhou, Z. Siamese graph attention networks for robust visual object tracking. Comput. Vis. Image Underst. 2023, 229, 103634. [Google Scholar] [CrossRef]
- Yan, B.; Peng, H.; Fu, J.; Wang, D.; Lu, H. Learning Spatio-Temporal Transformer For Visual Tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 10448–10457. [Google Scholar]
- Lan, J.P.; Cheng, Z.Q.; He, J.Y.; Li, C.; Luo, B.; Bao, X.; Xiang, W.; Geng, Y.; Xie, X. Procontext: Exploring Progressive Context Transformer For Tracking. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing, Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Xie, F.; Chu, L.; Li, J.; Lu, Y.; Ma, C. VideoTrack: Learning To Track Objects via Video Transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 22826–22835. [Google Scholar]
- Lin, L.; Fan, H.; Zhang, Z.; Xu, Y.; Ling, H. Swintrack: A simple and strong baseline for transformer tracking. Adv. Neural Inf. Process. Syst. 2022, 35, 16743–16754. [Google Scholar]
- Xing, D.; Evangeliou, N.; Tsoukalas, A.; Tzes, A. Siamese Transformer Pyramid Networks For Real-Time UAV Tracking. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 2139–2148. [Google Scholar]
- Cao, Z.; Fu, C.; Ye, J.; Li, B.; Li, Y. Hift: Hierarchical Feature Transformer For Aerial Tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 15457–15466. [Google Scholar]
- Cui, Y.; Jiang, C.; Wang, L.; Wu, G. Mixformer: End-to-end tracking with iterative mixed attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 13608–13618. [Google Scholar]
- Wang, N.; Zhou, W.; Wang, J.; Li, H. Transformer Meets Tracker: Exploiting Temporal Context For Robust Visual Tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 1571–1580. [Google Scholar]
- Zheng, Y.; Zhang, Y.; Xiao, B. Target-Aware Transformer Tracking. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 4542–4551. [Google Scholar] [CrossRef]
- Wang, Z.; Kamata, S.-I. Multiple Mask Enhanced Transformer For Robust Visual Tracking. In Proceedings of the IEEE 2022 4th International Conference on Robotics and Computer Vision, Wuhan, China, 25–27 September 2022; pp. 43–48. [Google Scholar]
- Wu, Q.; Yang, T.; Liu, Z.; Wu, B.; Shan, Y.; Chan, A.B. Dropmae: Masked Autoencoders With Spatial-Attention Dropout For Tracking Tasks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 14561–14571. [Google Scholar]
- Zhu, Q.; Huang, X.; Guan, Q. TabCtNet: Target-aware bilateral CNN-transformer network for single object tracking in satellite videos. Int. J. Appl. Earth Obs. Geoinf. 2024, 128, 103723. [Google Scholar] [CrossRef]
- Chen, X.; Yan, B.; Zhu, J.; Wang, D.; Yang, X.; Lu, H. Transformer Tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 8126–8135. [Google Scholar]
- Wang, J.; Wang, Y.; Que, Y.; Huang, W.; Wei, Y. Object Tracking Algorithm Based on Integrated Multi-Scale Templates Guided by Judgment Mechanism. Electronics 2024, 13, 4309. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning For Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Loshchilov, I. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Fan, H.; Lin, L.; Yang, F.; Chu, P.; Deng, G.; Yu, S.; Bai, H.; Xu, Y.; Liao, C.; Ling, H. Lasot: A High-Quality Benchmark For Large-Scale Single Object Tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5374–5383. [Google Scholar]
- Wu, Y.; Lim, J.; Yang, M.-H. Online Object Tracking: A Benchmark. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2411–2418. [Google Scholar]
- Mueller, M.; Smith, N.; Ghanem, B. A benchmark and simulator for uav tracking. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 445–461. [Google Scholar]
- Di Nardo, E.; Ciaramella, A. Tracking Vision Transformer With Class And Regression Tokens. Inf. Sci. 2023, 619, 276–287. [Google Scholar] [CrossRef]
- Yu, Y.; Xiong, Y.; Huang, W.; Scott, M.R. Deformable Siamese Attention Networks For Visual Object Tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 6728–6737. [Google Scholar]
- Chen, X.; Kang, B.; Wang, D.; Li, D.; Lu, H. Efficient Visual Tracking Via Hierarchical Cross-Attention Transformer. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 461–477. [Google Scholar]
- Bhat, G.; Danelljan, M.; Gool, L.V.; Timofte, R. Learning Discriminative Model Prediction For Tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6182–6191. [Google Scholar]
- Blatter, P.; Kanakis, M.; Danelljan, M.; Van Gool, L. Efficient Visual Tracking With Exemplar Transformers. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 2–7 January 2023; pp. 1571–1581. [Google Scholar]
- Liang, L.; Chen, Z.; Dai, L.; Wang, S. Target signature network for small object tracking. Eng. Appl. Artif. Intell. 2024, 138, 109445. [Google Scholar] [CrossRef]
- Nai, K.; Chen, S. Learning a novel ensemble tracker for robust visual tracking. IEEE Trans. Multimed. 2023, 26, 3194–3206. [Google Scholar] [CrossRef]
- Yang, X.; Zeng, D.; Wang, X.; Wu, Y.; Ye, H.; Zhao, Q.; Li, S. Adaptively bypassing vision transformer blocks for efficient visual tracking. Pattern Recognit. 2025, 161, 111278. [Google Scholar] [CrossRef]
- Wei, Z.; He, Y.; Cai, Z. Enhanced Object Tracking by Self-Supervised Auxiliary Depth Estimation Learning. arXiv 2024, arXiv:2405.14195. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Factors | IV | SV | OCC | DEF | MB | IPR |
| Suc (%) | 63.8 | 67.2 | 62.5 | 60.6 | 68.4 | 64.5 |
| Factors | OPR | OV | BC | LR | FM | |
| Suc (%) | 62.8 | 63.2 | 56.4 | 58.6 | 66.2 |
| Feature Points Retention Rate | Precision (Pre) | Success (Suc) |
|---|---|---|
| 40% | 0.886 | 0.677 |
| 50% | 0.892 | 0.681 |
| 60% | 0.888 | 0.689 |
| 70% | 0.895 | 0.686 |
| 80% | 0.887 | 0.679 |
| 90% | 0.690 | 0.479 |
| Map of Feature Influence Values Distribution of Search Feature | Generated Mask Map | Feature Influence Value Distribution Map After Mask Application | |
|---|---|---|---|
| The output of the first cross-attention | 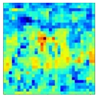 |  | 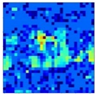 |
| The output of the second cross-attention | 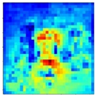 |  | 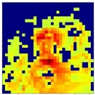 |
| The output of the third cross-attention |  |  |  |
| The output of the fourth cross-attention |  |  |  |
| Algorithm | Depth Features | Template Type | OTB-100 | LaSOT | ||
|---|---|---|---|---|---|---|
| Pre | Suc | Pre | Suc | |||
| TransT | Layer3 | Initial frame | 0.851 | 0.639 | 0.624 | 0.541 |
| Transfpn | Layer2 + Layer3 | Initial frame | 0.848 | 0.648 | 0.635 | 0.545 |
| Transfpn-Mask | Layer2 + Layer3 | Initial frame + update frame | 0.888 | 0.689 | 0.718 | 0.620 |
| Transfpn-T | Layer2 + Layer3 | Initial frame + update frame | 0.894 | 0.684 | 0.738 | 0.649 |
| Tracking Algorithm | Norm Precision | Success |
|---|---|---|
| Transtfpn-T | 0.885 | 0.687 |
| TransT | 0.876 | 0.681 |
| TaTrack [17] | - | 0.641 |
| SiamRPN++ [5] | 0.804 | 0.611 |
| SiamFC [1] | 0.694 | 0.468 |
| ViTCRT [28] | - | 0.686 |
| TrSiam [16] | 0.865 | 0.663 |
| SiamAttn [29] | 0.845 | 0.650 |
| SiamTPN [13] | 0.823 | 0.636 |
| HCAT [30] | 0.812 | 0.627 |
| DiMP [31] | 0.849 | 0.642 |
| E.T.Track [32] | - | 0.623 |
| TSN [33] | 0.791 | 0.613 |
| HSET [34] | 0.762 | 0.544 |
| ABTrack [35] | 0.823 | 0.652 |
| HiFT [14] | 0.787 | 0.589 |
| Algorithm Name | OTB-100 | LaSOT | ||
|---|---|---|---|---|
| Norm Precision | Success | Norm Precision | Success | |
| TransT | 0.752 | 0.564 | 0.544 | 0.473 |
| Transtfpn | 0.762 | 0.587 | 0.550 | 0.475 |
| Transtfpn-Mask | 0.801 | 0.624 | 0.653 | 0.569 |
| Transtfpn-T | 0.860 | 0.654 | 0.660 | 0.580 |
| Tracking Algorithm | Norm Precision | Success |
|---|---|---|
| Transtfpn-T | 0.738 | 0.649 |
| TransT | 0.624 | 0.541 |
| TrSiam [16] | 0.718 | 0.629 |
| HCAT [30] | 0.687 | 0.593 |
| ViTCRT [28] | 0.678 | 0.646 |
| E.T.Track [32] | - | 0.591 |
| SiamTPN [13] | 0.683 | 0.581 |
| TaTrack [17] | 0.661 | 0.578 |
| DiMP [31] | 0.642 | 0.560 |
| SiamRPN++ [5] | 0.570 | 0.495 |
| SiamMask [6] | 0.552 | 0.467 |
| SiamAttn [29] | 0.648 | 0.560 |
| SiamFC [1] | 0.420 | 0.336 |
| TSN [33] | 0.532 | 0.325 |
| HSET [34] | 0.354 | 0.372 |
| ABTrack [35] | 0.733 | 0.634 |
| MDETrack [36] | 0.661 | 0.591 |
| Factors | Algorithm Name | OTB-100 | LaSOT | UAV123 | |||
|---|---|---|---|---|---|---|---|
| Pre | Suc | Pre | Suc | Pre | Suc | ||
| Fast motion | TransT | 0.871 | 0.662 | 0.434 | 0.373 | 0.860 | 0.656 |
| Transtfpn-T | 0.866 | 0.684 | 0.583 | 0.505 | 0.863 | 0.658 | |
| Motion blur | TransT | 0.883 | 0.684 | 0.562 | 0.487 | - | |
| Transtfpn-T | 0.851 | 0.685 | 0.713 | 0.623 | - | ||
| Deformation | TransT | 0.852 | 0.606 | 0.640 | 0.559 | - | |
| Transtfpn-T | 0.877 | 0.658 | 0.754 | 0.670 | - | ||
| Illumination variation | TransT | 0.837 | 0.638 | 0.609 | 0.524 | 0.816 | 0.617 |
| Transtfpn-T | 0.841 | 0.673 | 0.775 | 0.675 | 0.808 | 0.612 | |
| Low resolution | TransT | 0.808 | 0.586 | 0.506 | 0.431 | 0.772 | 0.542 |
| Transtfpn-T | 0.956 | 0.714 | 0.651 | 0.564 | 0.794 | 0.558 | |
| Occlusion | TransT | 0.814 | 0.605 | - | - | ||
| Transtfpn-T | 0.851 | 0.656 | - | - | |||
| Out of view | TransT | 0.850 | 0.632 | 0.512 | 0.439 | 0.857 | 0.663 |
| Transtfpn-T | 0.718 | 0.566 | 0.656 | 0.575 | 0.867 | 0.672 | |
| Scale variation | TransT | 0.896 | 0.672 | 0.621 | 0.538 | 0.860 | 0.667 |
| Transtfpn-T | 0.889 | 0.694 | 0.737 | 0.647 | 0.870 | 0.674 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Wang, Y.; Yuan, D.; Que, Y.; Huang, W.; Wei, Y. Object Tracking Algorithm Based on Multi-Layer Feature Fusion and Semantic Enhancement. Appl. Sci. 2025, 15, 7228. https://doi.org/10.3390/app15137228
Wang J, Wang Y, Yuan D, Que Y, Huang W, Wei Y. Object Tracking Algorithm Based on Multi-Layer Feature Fusion and Semantic Enhancement. Applied Sciences. 2025; 15(13):7228. https://doi.org/10.3390/app15137228
Chicago/Turabian StyleWang, Jing, Yanru Wang, Dan Yuan, Yuxiang Que, Weichao Huang, and Yuan Wei. 2025. "Object Tracking Algorithm Based on Multi-Layer Feature Fusion and Semantic Enhancement" Applied Sciences 15, no. 13: 7228. https://doi.org/10.3390/app15137228
APA StyleWang, J., Wang, Y., Yuan, D., Que, Y., Huang, W., & Wei, Y. (2025). Object Tracking Algorithm Based on Multi-Layer Feature Fusion and Semantic Enhancement. Applied Sciences, 15(13), 7228. https://doi.org/10.3390/app15137228