3.1. Problem Description
The primary objective of a communication system is to effectively and reliably transmit information-bearing messages to the receiver. Within such systems, the information sequence is subjected to source encoding, channel encoding, and modulation at the transmitter, enabling it to be transmitted through the channel as symbols. At the receiver, inverse operations are performed to reconstruct the transmitted information. Communication systems typically pursue two optimization goals. Firstly, the reliability metric aims to minimize the discrepancy between the estimated sequence at the receiver and the transmitted sequence at the transmitter. In technical communication, this is evaluated using metrics like the BER, while in semantic communication, it considers semantic differences. Secondly, the efficiency metric aims to minimize the length of transmitted symbols. These objectives often conflict with each other. Shannon’s separation theorem states that in technical communication systems, these objectives correspond to channel encoding and source encoding, respectively, and are optimized independently.
This study analyzes the problem of semantic communication from the perspective of optimal decoding, focusing on the process where an information sequence
, with
is transmitted.
represents the set of transmitted information symbols. Initially,
X is encoded and modulated at the transmitter using the function described in Equation (
1), resulting in
, where
and
denotes the set of transmitted symbols. Subsequently, after transmission through the channel, the receiver acquires the sequence
. The receiver task is to estimate
from
O, and
is then decoded into
using a semantic decoding function specified by Equation (
2). The optimization objectives of the communication system are twofold: Firstly, to minimize information errors by aligning the probability distribution of
as close as possible to
S. Here, the function
is bijective and reversible, ensuring that recovering
S is equivalent to recovering
X. Secondly, the system aims to minimize the length
t of the sequence
S, thereby improving the efficiency.
The relationship between
and
is shown in Equation (
3):
where
and
denote the channel impulse response (CSI) and noise at time
t, and ⊗ signifies the convolution operator. The process is a typical Markov process, and the optimal decoding and demodulating process involves solving the following:
In fact,
is often unavailable, hence Bayesian equation in Equation (
5) is commonly employed to modify it:
where
represents the channel conditional transition probability. The design of the communication system assumes that the channel is memoryless, so the following formula is valid:
Therefore, the optimization goal of the optimal decoding system is as follows:
In Equation (
7),
represents the probability of the transmitted symbol sequence occurring within the entire set of transmitted symbols
. For a specific received sequence,
is a fixed value and cannot be optimized. Therefore, the final optimization objective is set by Equation (
8).
The problem now revolves around identifying a transmission system where the receiver can access both and . The length of t determines the coding rate. If such a system exists, it would be optimal in view of the current coding rate. The two components of this requirement will be analyzed separately in the subsequent sections.
First,
represents the probability distribution of the received signal at the receiver through the channel. For an AWGN channel, this distribution is given by Equation (
9):
where
denotes the noise power. Considering fading channels beyond AWGN channels, if
can be accurately estimated at time
i, then based on Equation (
3),
follows a normal distribution, as expressed in Equation (
10):
When remains constant, the fading channel effectively behaves like an AWGN channel.
The ‘⊗’ in Equation (
10) corresponds to channel equalization in classical technical communication systems, where
represents the constellation sequences corresponding to the transmitted semantic symbol. In digital communication, the estimated
is utilized to equalize
by multiplying the conjugate transposed matrix of
and
. However, we use
to convolve
to the advantage of the design of our subsequent system.
Thus, our objective transforms into identifying a function that maps the sequence X to the sequence S, while accurately modeling the probability of S. This probability model should be consistent and computable at both transmitter and receiver ends, where the length of S reflects the coding rate at the transmitter. In technical communication systems, determining the probability distribution of S is challenging, often assuming an equiprobable transmission of information bits. LLMs process text into numerical token sequences and predict the probabilities of subsequent tokens in natural language, closely resembling our problem. These models can effectively model . In subsequent sections, we detail the use of LLMs for the probabilistic modeling of text. Assuming that is accessible, we continue discussing the function .
The goal of
is to minimize the length
t of
S, thereby maximizing data transmission rates, ensuring that
reaches its maximum:
When transmitted symbols are independent and equiprobable, the mapping process from
X to
S approaches the entropy limit in compression. This scenario mirrors source coding achieving the entropy limit without channel coding in technical communication [
2]. The optimal decoding strategy involves comparing the Euclidean distance between the received signal and the transmission constellation. Bit errors are irreparable without prior information; once an error occurs at the receiver, the information becomes unrecoverable. However, technical communication systems typically exhibit some correlations among elements within
S, enabling the receiver to correct erroneous symbols using prior knowledge. This correlation is analogous to the use of parity bits in channel coding within technical communication systems. Channel coding fundamentally entails computing parity bits from information bits using a corresponding generator matrix, thereby facilitating error recovery through receiver-side correlation. Viterbi decoding principles maximize the probability of information bits given the posterior distribution of received symbols. Hence, from both technical and semantic perspectives, an ideal communication system should possess the following characteristics:
DeepSC [
5] employs a Transformer-based architecture for joint semantic encoding and decoding. The encoder maps input text
X to a fixed-length semantic vector
, while the decoder reconstructs
from noisy channel outputs. Its training objective is to minimize semantic loss (e.g., sentence similarity) rather than bit-level errors, enabling robustness in low-SNR regimes but limiting error-free transmission at high SNRs.
3.2. System Model
In this subsection, the application of LLMs for modeling the problems outlined in the previous subsection is expounded. LLMs undergo an unsupervised pre-training process aimed at predicting the probability of the next token in a training set, given preceding text. Tokens, which represent encoded forms of human language beyond individual characters, are derived from extensive natural language data and undergo the phase of tokenizer training, akin to a data compression process [
37]. Frequently used methods such as Byte Pair Encoding (BPE) and WordPiece [
38] serve as forms of data compression, aligning with the function
discussed earlier. The embedding layer after tokenization further represents semantic information from this encoding.
Consider a scenario where both the transmitter and receiver share identical background knowledge from a common knowledge base. If all possible sequences of transmitted information can be enumerated, then
becomes computable, resolving the problem stated in the foregoing subsection. The objective of LLM training is to predict token probabilities after the tokenization of text, while dataset construction aims to comprehensively cover all human languages. Assuming text information, Alice and Bob, needing communication, should possess the same knowledge base (
X distribution equivalence) for effective language interaction. Assuming a comprehensive collection of their language usage into dataset
, and given adequate computational resources for both parties, algorithms like BPE or WordPiece tokenize
’s text. The goal is to train a tokenizer with a vocabulary size
V. If
m bits represent a token, then
. Tokenization’s compression effect—where UTF-8 encodes sequence
X of length
n into sequence
W of length
t—should satisfy the expression
Assuming
V approaches infinity and the number of training iterations tends to infinity, tokenization achieves maximum data compression. For a dataset
D, this tokenization results in each token in the vocabulary becoming approximately equiprobable. Consequently, the encoding of transmitted information reaches its shortest form. If such tokenization is applied to train an LLM, the model may fail to converge, as the output
remains constant. Therefore, by controlling the size of
V, one can regulate the degree of compression through tokenization, thereby managing the redundancy of information carried by transmitted bits. This effectively controls the coding rate of source–channel encoding [
39].
Next, tokens are fed into LLMs for unsupervised pre-training. The model output can be approximated as
where
N denotes the context length of the LLM. As LLMs evolve,
N tends to increase. Given the contextual dependencies inherent in natural language sequences, the tokens
are not independent. Thus, the equation addressing the causal system is
The semantic knowledge base is established through the unsupervised pre-training phase of LLMs by Equation (
14), which learns the joint probability distribution
of token sequences from massive text corpora.
The loss function for unsupervised pre-training of LLMs is
It is observed that Equation (
14) and the loss function Equation (
15) are equivalent. This distribution serves two critical functions: (1) it guides the beam search decoder by ranking candidate sequences based on linguistic plausibility, and (2) it enables semantic error correction by assigning near-zero probabilities to implausible sequences. The knowledge base is static after pre-training and requires no fine-tuning for deployment. By designing a high-dimensional constellation diagram for
W and modulating it,
W can becomes
S. It should be noted that because the vocabulary size is generally large, it is difficult to represent it with one modulation symbol. Therefore, multiple modulation symbols are needed to represent a token, which we call a high-dimensional constellation diagram. Since
W and
S are in one-to-one correspondence, they share identical probability distributions. To train a semantic system for optimal decoding, the loss function is formulated as follows:
The two components of Equation (
16) are evidently independent, enabling separate training of the system parts. The second component can be expressed as follows:
Equation (
17) represents the channel condition transition probability. Once the channel and modulation scheme are determined, this equation can be specified as Equation (
10). For modulation schemes akin to those in classical communication (e.g., QAM or QPSK), Equation (
17) can be directly applied without additional training.
Therefore, language sequences can be semantically encoded through the tokenization and training of LLMs. Probabilistic modeling is subsequently performed on these encoded sequences. Achieving a zero loss in LLM training suggests optimal decoding within this transmission system, where loss indicates deviation from optimal decoding. Notably, through the training of tokenization and LLMs, an optimal transmission system can be attained across various coding rates, obviating the need for further LLM fine-tuning. This training process aligns seamlessly with the typical training methodologies of LLMs, requiring no adjustments for semantic communication.
The system structure depicted in
Figure 1 illustrates the pre-training process. We constructed the dataset by collecting all possible transmitted contents from both the sender and receiver. A tokenizer with a vocabulary size of
V was trained using algorithms such as BPE and WordPiece. This tokenizer converts the text into tokens, which are later used to train an LLM. The loss function for the LLM is defined in Equation (
15). Upon completion of the LLM training, the model serves as a knowledge base for semantic communication by providing
to supply shared knowledge to the receiver. At the receiving end, the LLM plays a crucial role in the decoder by offering priors for the transmitted sequence. The method for achieving optimal decoding will be discussed in subsequent sections. The LLM-SC has the following characteristics:
The system assumes that D comprises all possible content that can be transmitted between the transmitter and receiver. While achieving this in real life poses challenges, current training corpora for LLMs strive to encompass all languages used by humans. Furthermore, this assumption is becoming increasingly feasible as LLM technology evolves rapidly.
The system prioritizes decoding sentences with higher probabilities of occurrence in the real world. Sequences for which cannot be transmitted, as the receiver would be unable to decode such sequences where the probability is zero. Consequently, the system cannot transmit sentences that are impossible in the real world, as these sentences convey no meaningful information. Therefore, the system integrates both technical and semantic information.
3.3. Decoding Algorithm of LLM-SC
After training, a pre-trained LLM can compute the probability in Equation (
14) of a sent sequence
given a received sequence
, representing the likelihood of the sequence
S transforming into
O after transmission through a channel. This decoding process can be applied using any pre-trained LLM, and in this subsection, we delve into the specific decoding algorithm.
According to Equation (
8), assuming the transmitted sequence length does not exceed the maximum context length of the LLM, the optimal decoding strategy involves
The first term in Equation (
18) reflects the prior probability distribution of transmitted tokens, while the second term quantifies the Euclidean distance between received symbols and constellation points. The direct exploration of all possible sequences to select the one with the highest probability, known as maximum likelihood decoding, poses computational challenges with complexity
, where
V is the number of possible states (sets of transmit symbols) and
t is the sequence length, typically imposing engineering constraints.
where
denotes the noise power spectral density (PSD), typically
. Here,
represents the
i-th transmitted token that undergoes modulation into
and transmission through the channel. Equation (
19) represents a typical hidden Markov model prediction problem, commonly addressed using dynamic programming algorithms to find the path with the maximum probability. The Viterbi algorithm provides optimal sequence decoding for hidden Markov models by dynamically tracking maximal-probability paths. However, its
complexity is prohibitive for large vocabularies (
32,000). To mitigate complexity, beam search, a heuristic algorithm prevalent in NLP, is adapted. Beam search sets up a search tree using breadth-first search, sacrificing optimality for efficiency. In beam search, the beam width
K governs its operation. At each timestep, it retains the top
K sequences by score, expanding each to generate
candidates. From these, the next
K best sequences are selected to continue expansion.
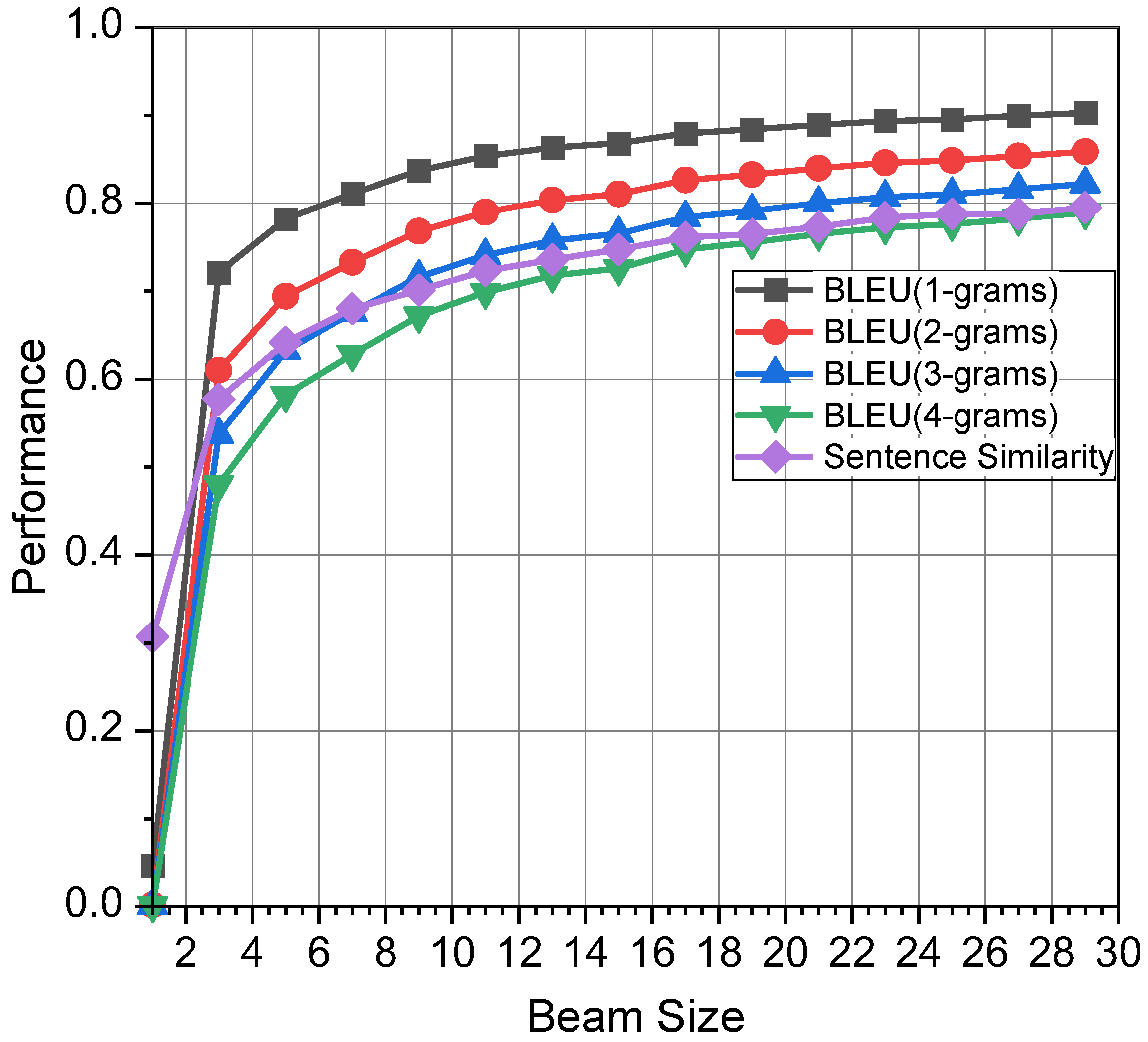
Beam search transitions into the Viterbi algorithm when , and into a greedy decoding algorithm when . It strikes a balance between the optimality of Viterbi and the efficiency of greedy decoding, making it suitable for scenarios where minor errors are acceptable given the expansive search space.
Our decoding approach is modified using the scoring function described by Equation (
20). Specifically, a max heap of size
K is maintained to store high-scoring sequences. Then,
K sequences are used to predict the next symbol and these are added to the heap. Then, we extract the current top
K for the next iteration:
Beam search decoding with a computational complexity of
facilitates parallelized computation across
K sequences. Algorithm 1 outlines the workflow, designed to demodulate text efficiently. By adjusting
K, computational efficiency against decoding accuracy can be balanced. Beam search offers a feasible, though suboptimal, approach leveraging the capabilities of LLMs. The specific decoding process is illustrated in
Figure 1.
Algorithm 1 details beam search decoding, where
The output
W is the highest-scoring token sequence after
t iterations.
| Algorithm 1 Beam search for text decoding |
|
3.4. Performance Metrics
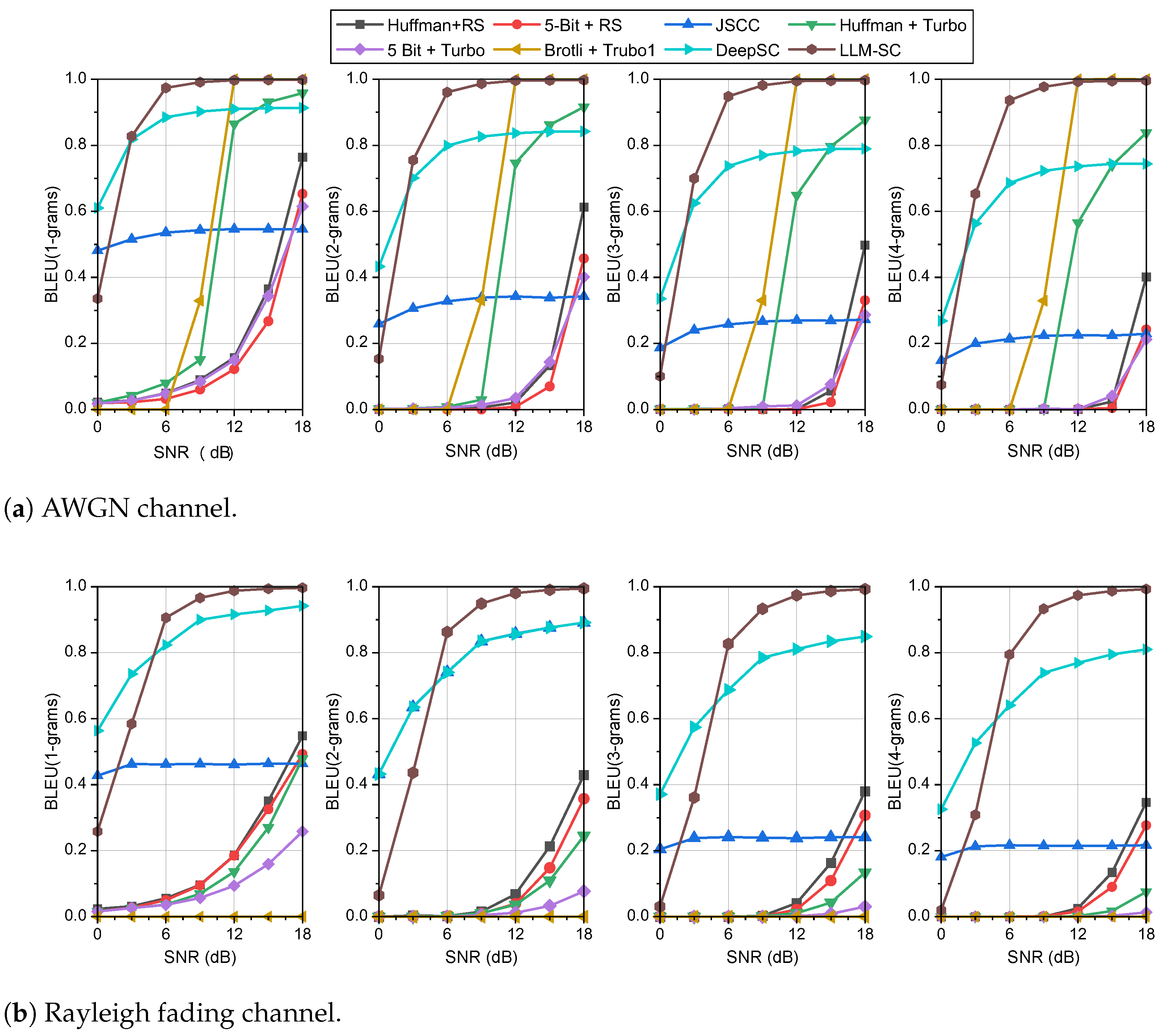
Performance metrics are essential for evaluating proposed methods in communication systems. In end-to-end communication, BER is commonly adopted as the training target by both transmitters and receivers, yet it often overlooks broader communication goals. BER may not accurately reflect the performance of semantic communication systems. Consequently, novel metrics such as Bilingual Evaluation Understudy (BLEU) and Word Error Rate (WER) have been proposed, focusing on word-level similarity between transmitter and receiver outputs. However, these metrics do not fully capture the similarity between entire sentences. To address this gap, metrics utilizing pre-trained models like BERT have emerged for evaluating semantic similarity. This paper selects evaluation metrics that encompass both traditional technical communication systems and emerging semantic communication paradigms, providing a comprehensive assessment of the proposed method.
(1) BLEU: BLEU is a metric commonly used to evaluate the quality of machine-generated text against one or more reference texts. Originally developed for machine translation, it has been adapted in semantic communication systems where assessing the quality of generated outputs is crucial. BLEU calculates a score based on the precision of
n-grams (continuous sequences of
n items, typically words) between the generated output and the reference texts. It quantifies how closely the generated text matches the reference texts in terms of these
n-grams, providing a numerical assessment of similarity and fluency. For a transmitted sentence
s of length
and its decoded counterpart
with length
, the BLEU score is calculated as follows:
where
are weights assigned to
n-grams, and
denotes the
n-gram score:
Here, represents the frequency count function for the k-th elements in n-grams. BLEU captures contextual relationships to some extent but primarily evaluates superficial similarity of n-grams without considering semantic equivalence. Consequently, BLEU may assign a lower score even when the generated text is semantically aligned with the reference, due to differences in expressions or the use of synonyms.
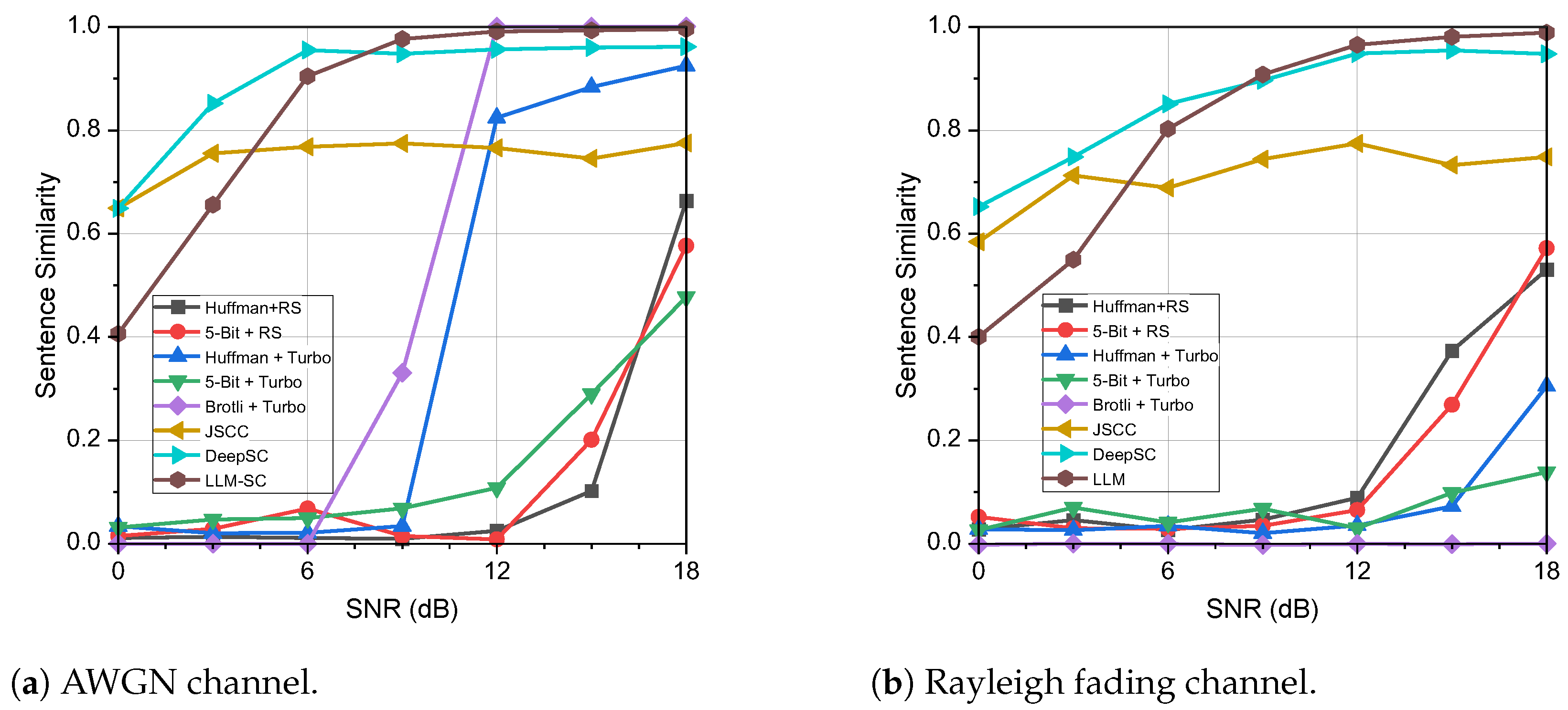
(2) Sentence similarity: For addressing the issue of polysemous words, Xie et al. introduce a novel evaluation metric for sentence similarity [
5]. Sentence similarity assesses the semantic equivalence between two sentences using a pre-trained model. Such models, exemplified by BERT [
23], are natural language processing models trained extensively on diverse corpora. The semantic similarity between sentences
s and
, both from the sender and receiver perspectives, is computed as follows:
where
, based on BERT, represents a highly parameterized pre-trained model designed for extracting semantic information from text.
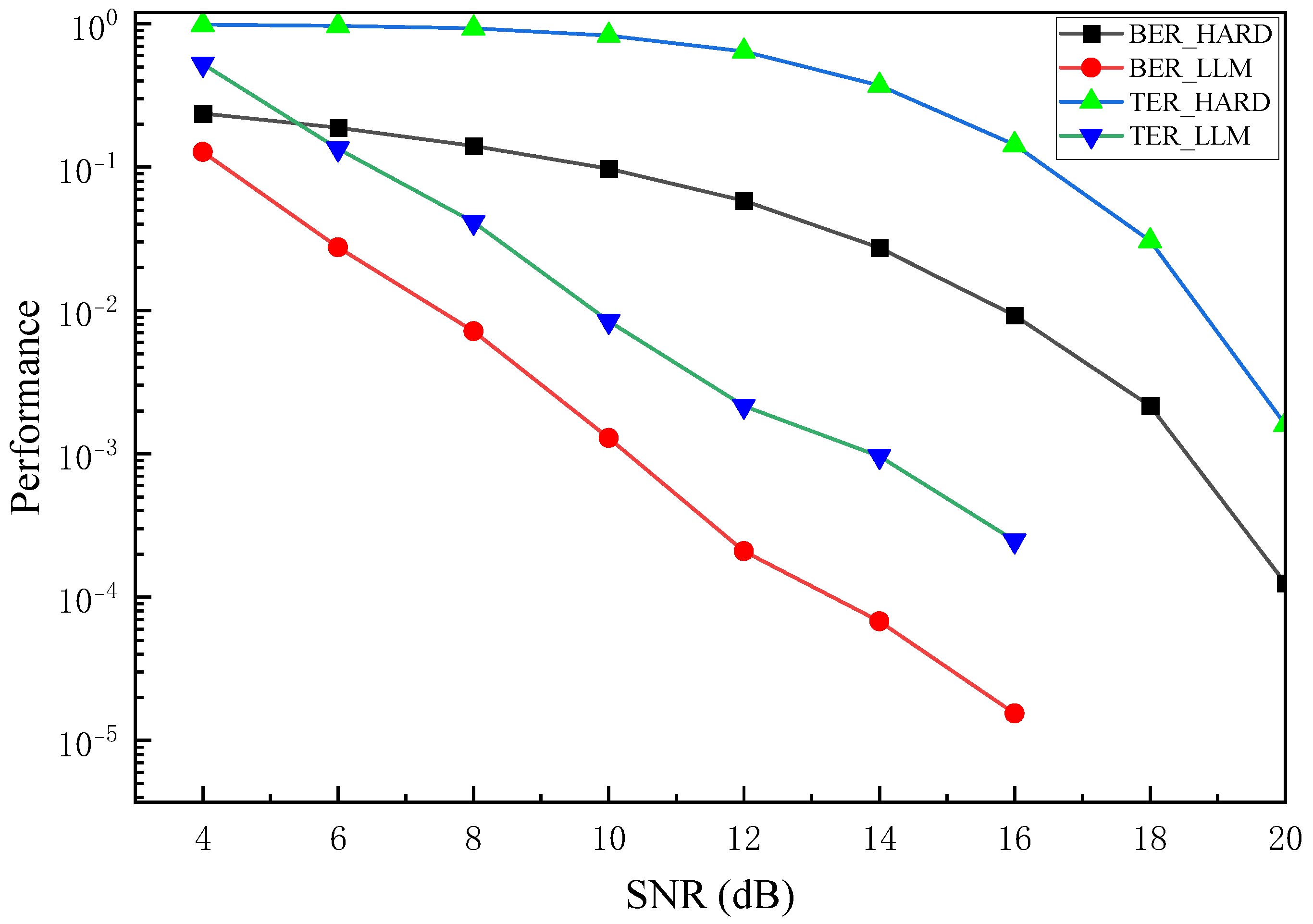
(3) BER: BER is a widely adopted metric for assessing the performance of communication systems, quantifying the likelihood of correctly receiving a transmitted symbol. A low BER signifies the system’s capability to accurately recover transmitted symbols. However, bit-level errors often inadequately reflect the performance of semantic transmission systems. For instance, occasional bit errors per word may yield a negligible BER, yet render the received text unintelligible due to the absence of correctly received words. Conversely, texts with notably high BER can remain understandable if crucial semantic elements are correctly deciphered. Leveraging LLM-SC, which achieves error-free transmission and facilitates communication compatible across technical and semantic levels, BER serves as a pertinent evaluation metric.
(4) Token Error Rate (TER): The token acts as the fundamental unit for transmission and demodulation in LLM-SC. In addition to BER, errors in tokens reflect the challenge of accurately comprehending a sentence. For instance, a low BER combined with errors uniformly distributed across
t tokens results in a high TER, indicating persistent difficulty in sentence comprehension by the receiver. Conversely, errors concentrated within a specific token, despite a potentially high BER, do not impair semantic understanding, thereby maintaining system effectiveness. This metric bears resemblance to the WER discussed in [
40]. While each token can correspond to a word, they encompass a broader spectrum of entities and constitute the basic input units for LLMs.


 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}