1. Introduction
The exponential growth of the esports industry has transformed competitive gaming into a global phenomenon. Titles like League of Legends [
1] have established extensive professional scenes, attracted millions of viewers, and generated a significant economic impact [
2,
3]. As competition intensifies, teams, analysts, and coaches increasingly rely on match data to evaluate performance, plan strategies, and study opponents. These analyses often uncover trends and patterns that are difficult to observe without computational tools [
4]. However, the large volume and complexity of these data present significant challenges. A single match of League of Legends can generate detailed JSON records of player actions, in-game events, and time series data, often exceeding 100 kilobytes in size [
5]. This makes manual analysis and automated processing both time-consuming and computationally demanding.
Recent advances in large language models (LLMs) have opened new possibilities for automated analysis of esports data. These models excel at natural language comprehension, summarization, and generating expert-like commentary [
6]. However, a key limitation of most LLMs is their restricted input size, typically ranging from 4096 to 8192 tokens. While extended-context models like GPT-4o support up to 128,000 tokens [
7], the detailed JSON records from a single League of Legends match can still approach or exceed this limit in complex scenarios.
Existing summarization methods, such as manual extraction or adaptive data chunking [
8,
9], lack structured and quantitative identification of high-impact events critical to rigorous esports analysis. Current approaches do not systematically utilize measurable momentum metrics to identify pivotal in-game events, creating a clear research gap. The summarization techniques employed in esports analytics draw theoretically from structured data reduction and summarization principles from the information retrieval domain, which emphasize identifying events based on measurable momentum and probability metrics [
10,
11]. Empirical studies have shown that accurately representing momentum shifts enhances the interpretability of match summaries [
12,
13], a capability inadequately addressed by simplistic chunking methods. Hence, this study addresses two research questions. (1) Can structured summarization effectively reduce the data size while maintaining analytical accuracy for esports analysis? (2) Does integrating momentum-based win probability metrics objectively enhance the identification of pivotal game events for LLM-based analytics?
We propose the League of Legends Match Data Compactor, a tool designed to transform extensive match data into concise summaries suitable for LLM analysis. LoL-MDC systematically extracts the explicitly defined and quantifiable information, including match metadata, player and team statistics, simplified timeline views, and key events. The key events are identified algorithmically using a measurable advantage metric—defined as the cumulative difference between team-level gold or experience scores computed at each minute—and a corresponding Pythagorean expectation-based winning probability model. This structured and reproducible approach objectively prioritizes events based on the quantifiable momentum impact, ensuring analytical precision and clarity. Unlike general adaptability claims, this method’s applicability to other esports titles can be empirically validated by substituting game-specific metrics (e.g., net worth in Dota 2or objective control in Valorant), though empirical validation beyond League of Legends remains a subject for future research.
Importantly, the primary contribution of the LoL-MDC extends beyond a mere reduction in data size. Its structured approach using momentum and probability metrics directly addresses the ambiguity and disorganization inherent in raw JSON match logs, improving the correctness and interpretability of analytical insights generated by LLMs. This paper evaluates the effectiveness of the LoL-MDC through quantitative experiments measuring data size reduction and qualitative evaluations assessing analytical accuracy improvements provided by compacted data. The results demonstrate a measurable reduction in data size of over 97% and substantial improvement in the quality and correctness of analytical insights provided by LLMs compared with using unstructured JSON data.
The remainder of this paper is structured as follows.
Section 2 reviews the related literature on esports data analysis and LLMs in gaming.
Section 3 outlines the detailed algorithmic implementation of the LoL-MDC.
Section 4 presents experimental results and analysis. Finally,
Section 5 summarizes the contributions and outlines future empirical validations needed to confirm generalizability to other competitive gaming scenarios.
3. LoL-MDC: League of Legends Match Data Compactor
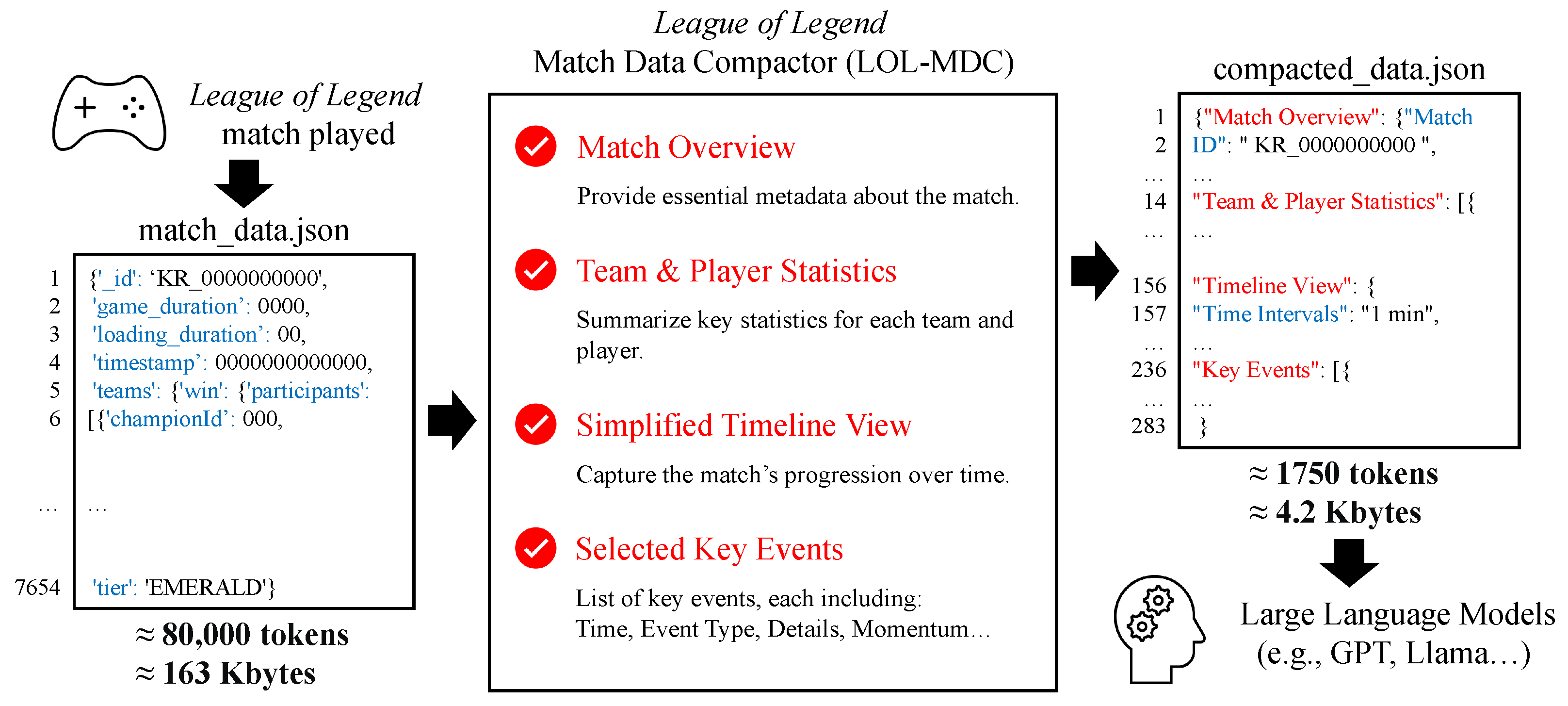
The League of Legends Match Data Compactor is an automated tool designed to compress and curate extensive League of Legends match data into a concise, structured format suitable for LLMs. By processing raw JSON files, the LoL-MDC extracts essential match information—including match overviews, team and player statistics, simplified timelines, and pivotal events—while significantly reducing the data size. As shown in
Figure 1, the system employs advanced techniques such as algorithmically calculating winning probability metrics using a generalized Pythagorean expectation formula and identifying momentum shifts through quantitative advantage metrics to ensure high-quality summarization for effective narrative and strategic analysis. We note here that while the process shown in
Figure 1 suggests linear steps, the actual order is configurable. The term “LLM-ready” indicates that the final JSON output adheres to common tokenization and formatting standards for seamless integration into prevalent large language models.
3.1. Match Overview
The match overview provides a high-level summary that establishes the contextual framework for further analysis. It includes essential metadata such as the match identifier, game title, patch version, participating teams, match date and time, match duration, and the winning side. By focusing on key reference points, this component ensures the summarized data remains directly usable by LLMs while eliminating redundant details.
To generalize this component for other esports titles, the metadata fields can be replaced with title-specific equivalents, such as game-specific roles or identifiers. This modular design makes the compactor broadly applicable to various gaming ecosystems.
3.2. Team and Player Statistics
A detailed analysis of individual and team performances is critical for understanding competitive gameplay. The LoL-MDC compiles key performance metrics at both the player and team levels. For players, it includes identifiers such as names, chosen champions, and roles or positions, along with performance metrics like kills, deaths, assists, gold earned, creep score, damage dealt, and vision score. At the team level, it aggregates these metrics to provide an overview, capturing total kills, deaths, assists, and objectives secured, such as dragons, barons, towers, and rift heralds, which collectively illustrate the game’s flow.
This component can be adapted for other games by substituting terminology and metrics. For example, champions in League of Legends can be replaced with heroes in Dota 2 [
24] or agents in Valorant [
25], and objectives can be customized to align with game-specific milestones. This adaptability ensures relevance across different titles.
3.3. Simplified Timeline View
Static statistics alone often fail to capture the dynamic flow of a match. The LoL-MDC addresses this by incorporating a simplified timeline view, highlighting momentum shifts and strategic turning points throughout the game. This timeline uses two forms of data: primary and secondary. Primary data include raw sequential metrics such as gold earned or experience points (XP) collected by each player over time. Secondary data comprise calculated metrics derived from primary data. Specifically, we compute an advantage metric at each one-minute interval, defined as the difference in aggregated metrics (such as gold or XP) between the two teams. This advantage metric quantifies the relative lead or deficit between teams, calculated by
where
is the chosen metric (gold or XP) for player
i at minute
t. The winning probability calculated from each metric is then obtained with a generalized Pythagorean expectation:
where
The exponent
is a tunable parameter that can be periodically updated through learning from historical match data.
The final winning probability
is then computed by averaging the probabilities
derived from multiple metrics (e.g., gold and XP):
where
denotes the set of selected metrics (e.g., {gold or XP}), and each metric-specific probability
is individually calculated using the generalized Pythagorean expectation given in Equation (
2).
3.4. Selected Key Events
Key events play a decisive role in determining the narratives and outcomes of esports matches. The LoL-MDC identifies these moments by analyzing match logs for high-impact events such as securing objectives, executing multi-elimination sequences, or achieving critical milestones. Each event is annotated with its timing, event type, and relevant details, along with momentum indicators before and after the event. This ensures the preservation of pivotal moments that define the match’s storyline.
To algorithmically identify these moments from match logs, we define the momentum impact of events occurring between minutes
t and
as follows:
Events are then ranked based on Equation (
5), where the top-
N events are retained. The overall extraction procedure is summarized in Algorithm 1. Here, we note that the timestamp is extends up to 60,000 to fit the minute scale.
Events with the most significant momentum shifts, measured by changes in the winning probability metric from the timeline view, are prioritized. For example, a critical dragon kill or Baron steal that shifts the team advantage can be saved. The number of key events included (e.g., top five events) can be adjusted based on the level of detail desired. When momentum metrics are unavailable, alternative indicators from the timeline can be used.
| Algorithm 1 Key event extraction. |
- 1:
Input: event_logs, winning_probabilities, N - 2:
key_events ← [ ] - 3:
for each event e in event_logs do - 4:
- 5:
winning_probabilities[t] - 6:
winning_probabilities[] - 7:
- 8:
append to key_events - 9:
end for - 10:
sort key_events by (descending) - 11:
return top N events
|
The final output of the LoL-MDC is a concise, structured JSON file that fits within the token limitations of modern LLMs while retaining essential match information. As shown in
Figure 2, the compacted JSON file is designed for both human readability and machine interpretability, ensuring its utility for a wide range of esports analytics applications.
3.5. Cross-Game Adaptability and Examples
While this paper focuses on League of Legends, the principles underlying the LoL-MDC can be adapted to a wide range of esports titles by tailoring its components to reflect the unique characteristics of each game. Esports titles typically share fundamental structural characteristics such as defined player roles, team-based metrics, quantifiable performance indicators (kills, objectives, and scores), and critical momentum-shifting events. These similarities enable the LoL-MDC framework to be readily adapted across different competitive gaming environments. Below are specific examples illustrating how the LoL-MDC can be applied to other games.
Aside from the match overview, which can be easily customized by replacing metadata fields with game-specific details, team and player statistics can be adapted by substituting terms and metrics. For instance, “champion” in League of Legends could be replaced with “hero” in Dota 2 [
24] or “agent” in Valorant [
25]. Additional metrics, such as “headshots” for Counter-Strike [
26] or “damage blocked” for Overwatch [
27], can be incorporated to reflect the unique gameplay mechanics of these titles.
The timeline view and key events are particularly flexible. In Dota 2, the timeline could use “net worth difference” as the primary data, while in Overwatch, key events could include milestones like “payload checkpoint reached”. Similarly, in Counter-Strike, events such as “bomb defusal” or “round ace” could be captured to highlight pivotal moments.
By customizing each component—match overview, statistics, timeline, and key events—the LoL-MDC can serve as a versatile framework for esports analytics across a variety of games. This adaptability ensures that the tool remains relevant and effective in supporting AI-driven analysis for competitive gaming ecosystems.
4. Experiments
In this section, the proposed LoL-MDC is evaluated to verify its effectiveness in compacting curated League of Legends match data into a manageable format for LLMs. The experiments are divided into two parts: quantitative evaluation and qualitative evaluation. The quantitative evaluation measures the compactor’s efficiency in reducing data size and token counts across different game versions and language settings. It also examines the contributions of each component (match overview, team and player statistics, timeline view, and selected key events) to the compacted data. The qualitative evaluation assesses the usability of compacted data by comparing the responses of a commercial LLM chatbot to those using raw JSON files and curated expert summaries. Specifically, these experiments aim to verify two primary hypotheses: (1) the LoL-MDC significantly reduces token counts and data size without losing analytically critical match details, and (2) the structured format provided by the LoL-MDC enhances the accuracy and coherence of LLM-generated insights compared with less structured data.
4.1. Datasets and Experimental Set-Up
The dataset used for the experiments consists of JSON files internally curated by the analytics team at LOL.PS [
28], one of the largest League of Legends statistics websites. Each match record was initially obtained from the Match-V5 endpoint of the Riot Games API [
5]. A single raw response from this endpoint typically exceeds 300 kB (approximately 120,000 tokens), containing comprehensive metadata and numerous auxiliary fields, which makes it impractical for direct use with LLM prompts. To address this issue, we utilized an intermediate, internally curated version containing the variables essential for performance analytics—match metadata, per-team and per-player statistics, one-minute aggregated gold and experience (XP) timelines, and high-level event logs (objectives, multi-kills, and turret destructions)—to describe the match information. This curated version removes redundant low-level frame details and purely cosmetic fields, reducing the JSON file size to approximately 160 kB per match while preserving all critical information. Throughout the remainder of this paper, we refer to this curated version as the “raw” dataset and use it as our baseline for evaluating the performance and effectiveness of our proposed compactor. This curated “raw” dataset, while not fully identical to the original Riot API response, closely mirrors realistic formats regularly utilized by professional esports analysts and serves as a practical baseline for our evaluations.
The experiments focused on matches from two regions: North America (NA) using English (en_US) and Korea (KR) using Korean (ko_KR) language settings. Data were collected for two patch versions, 14.21 and 14.22, to evaluate the robustness of the LoL-MDC across different configurations. For each patch version, 10,000 curated matches were processed to assess the compactor’s efficiency in reducing data size and token counts. Additionally, a subset of five anonymized matches was selected for qualitative evaluation, where GPT-4o responses were compared using raw and compacted JSON inputs. For the hyperparameters in the LoL-MDC, we set a 1 min interval for timeline view generation and selected the top five key events to summarize pivotal moments effectively.
To evaluate tokenization efficiency, we utilized two open-source tokenizers:
o200k_base [
29] and
cl100k_base [
30]. The
o200k_base tokenizer is employed by GPT-4o and GPT-4o-mini models, while the
cl100k_base tokenizer is used by OpenAI models such as GPT-4, GPT-4-turbo, GPT-3.5-turbo, and embedding models. These tokenizers represent different encoding strategies and token capacities, enabling us to analyze how the LoL-MDC performs across diverse LLM architectures. File size reduction was measured in bytes, and token counts were calculated using the respective tokenizers to ensure consistency and comparability.
Qualitative evaluations assessed the ability of compacted data to answer analytical questions by comparing LLM responses generated from raw JSON and compacted JSON files. To ensure consistency, all experiments used the standardized prompt as shown in
Listing 1.
Listing 1. Standarized prompt for JSON based question-answering.
You are an expert esports analyst with a specialization in analyzing
competitive gaming data.
Your task is to evaluate and summarize the given match data and
provide accurate and detailed~insights.
[JSON]
{
…
}
[Question]
What was the total gold earned by the winning team?
4.2. Quantitative Evaluation
The quantitative evaluation assesses the compactor’s ability to reduce the data size and token counts without losing critical match information. We note here that the direct comparisons with alternative summarization methods such as chunked JSON or LLM-assisted summarizers were beyond the intended scope, as our primary objective was to assess the effectiveness of structured summarization optimized for LLM input. The analysis includes results from the North America (NA) region using English and the Korea (KR) region using Korean across two patch versions: 14.21 and 14.22. The evaluation highlights the LoL-MDC’s performance in different languages and configurations, demonstrating its robustness and adaptability.
4.2.1. Global Reduction Analysis
Table 1 and
Table 2 present the overall statistics for the NA and KR regions, respectively. For matches from the NA region with patch 14.22, the LoL-MDC reduced the average decompressed size from 149,324 bytes to 3929 bytes, achieving over 97% reduction. Token counts were reduced from 75,849 to 1591 using
cl100k_base and from 75,008 to 1576 using
o200k_base. Similar results were observed for patch 14.21, with compacted sizes averaging 4220 bytes and token counts reduced by over 97.5%.
For matches from the KR region, the LoL-MDC achieved comparable results across both patch versions. For patch 14.22, the average decompressed size of 163,989 bytes was reduced to 4241 bytes. Token counts were reduced from 84,478 to 1751 using cl100k_base and from 83,598 to 1695 using o200k_base. Patch 14.21 followed a similar trend, with decompressed sizes reduced from 162,954 bytes to 4227 bytes and token counts reduced by 97.4%.
The results indicate that the LoL-MDC achieved consistent performance across regions, languages, and configurations. While slight differences in the compacted sizes and token counts arose due to regional variations, such as naming conventions and text length, the overall reductions consistently exceeded 97% in all cases. These findings confirm the LoL-MDC’s adaptability to diverse datasets while preserving essential analytical content.
4.2.2. Component-Level Analysis
The compacted match data generated by the LoL-MDC were divided into four main components: match overview, team and player statistics, timeline view, and selected key events.
Table 3 and
Table 4 summarize the compacted sizes and token counts for these components in the NA and KR regions for the 14.22 patch, respectively. This analysis highlights the relative size of each component and their adaptability for different configurations.
Team and player statistics consistently accounted for the largest portion of the compacted data. In the NA region, this component averaged 2197.53 bytes, corresponding to approximately 900 tokens in cl100k_base and 889 tokens in o200k_base. In the KR region, the size was slightly larger at 2286.33 bytes, with 956 tokens in cl100k_base and 913 tokens in o200k_base. The increased size in the KR region is primarily due to linguistic differences, such as longer champion names and player IDs in Korean.
In contrast, match overview was consistently the smallest component across both regions. It averaged about 220 bytes and 79 tokens regardless of tokenizer or region. This component contains metadata such as the match ID, game title, patch version, participating teams, and match duration. Its small size reflects its role as a concise summary of the match’s context.
The timeline view and selected key events occupied intermediate positions in terms of size. In the NA region, the timeline view averaged 681.31 bytes, translating to approximately 349 tokens in both tokenizers. The selected key events averaged 735.96 bytes, corresponding to 246 tokens in cl100k_base and 242 tokens in o200k_base. The KR region followed a similar pattern, with the timeline view averaging 773.86 bytes and the selected key events averaging 866.91 bytes.
The sizes of these components, particularly the timeline view and selected key events, demonstrated the flexibility of their size. For example, the size of the timeline view depends on the time intervals used to aggregate data; shorter intervals result in finer-grained data but increase the size, whereas longer intervals reduce granularity and compact the representation. Similarly, the size of the selected key events is directly influenced by the number of events recorded. Saving only a few key events minimizes its size, whereas recording more events increases the component’s footprint. This adaptability allows the LoL-MDC to balance data granularity with token limitations.
4.3. Qualitative Evaluation
To evaluate the usability of the LoL-MDC, we conducted a qualitative analysis by comparing the answers generated by GPT-4o using raw JSON input files and compacted JSON input files. GPT-4o was selected for its extended context capabilities and strong natural language understanding, which allow it to effectively analyze esports data and generate detailed responses. The analysis focused on answering a series of structured questions using a sampled dataset of five anonymized matches from 14.22 KR matches, with Match 1 visualized in
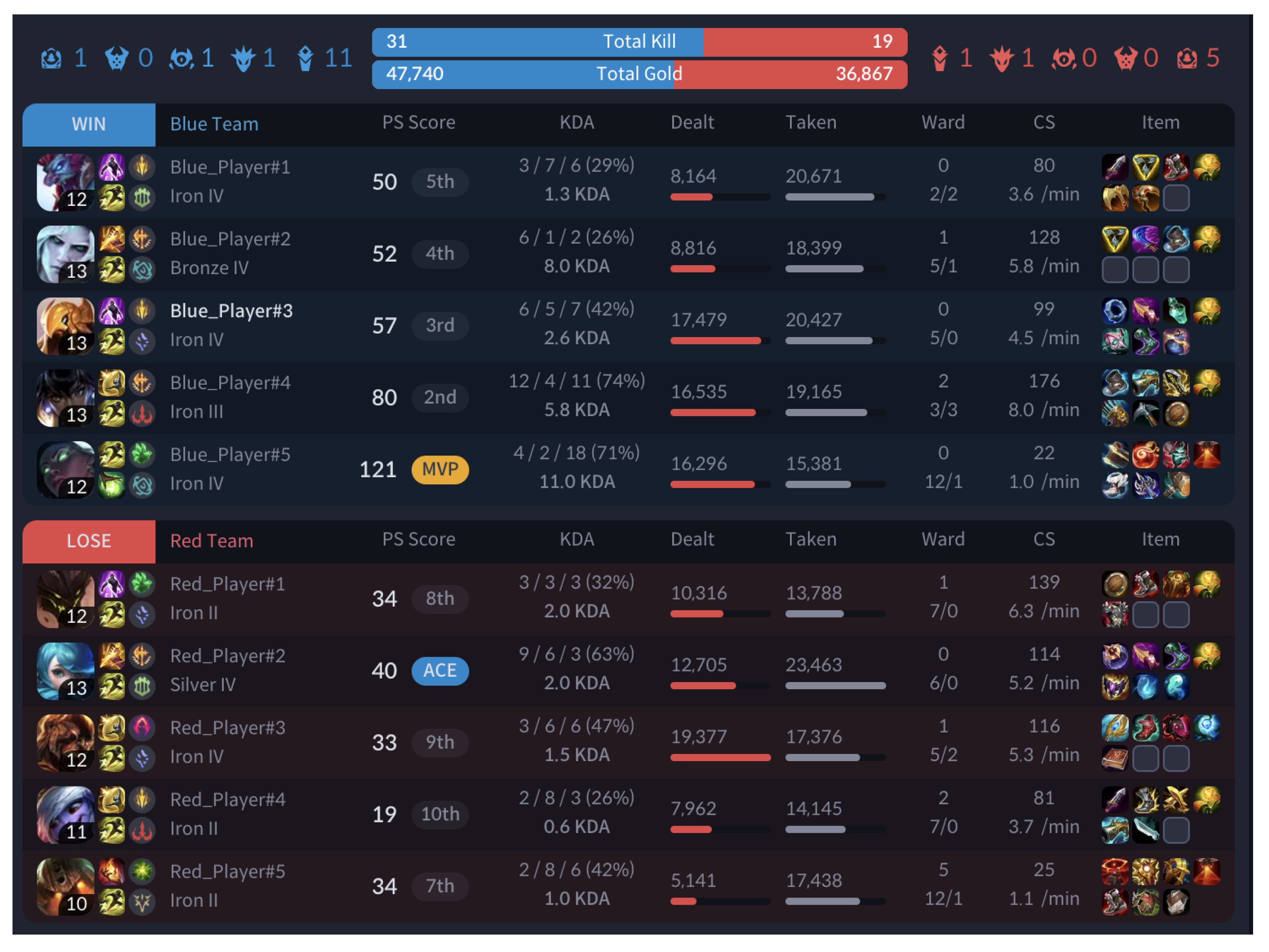
Figure 3 to illustrate the statistics provided by LOL.PS.
Match 1’s statistics, as displayed in
Figure 3, include player-level details such as kills, deaths, assists (KDA), damage dealt, damage taken, wards placed, creep score (CS), and items used. Additionally, team-level information, such as total kills and gold, provides a holistic summary of the game. This dataset served as the foundation for evaluating the performance of compacted JSON input files compared with raw JSON input files.
The qualitative evaluation consisted of three categories of questions designed to analyze the effectiveness of compacted data in generating meaningful answers compared with raw JSON data. For each question type, we provide examples of the prompts used and the answers generated.
4.3.1. General Questions
General questions focus on extracting basic match statistics and team-level performance metrics. The following questions were used:
What was the total gold earned by the winning team?
What was the KDA of the winning team’s SUPPORT and his or her champion?
Which team had a higher total creep score?
How many objectives (e.g., dragons or barons) were secured by each team?
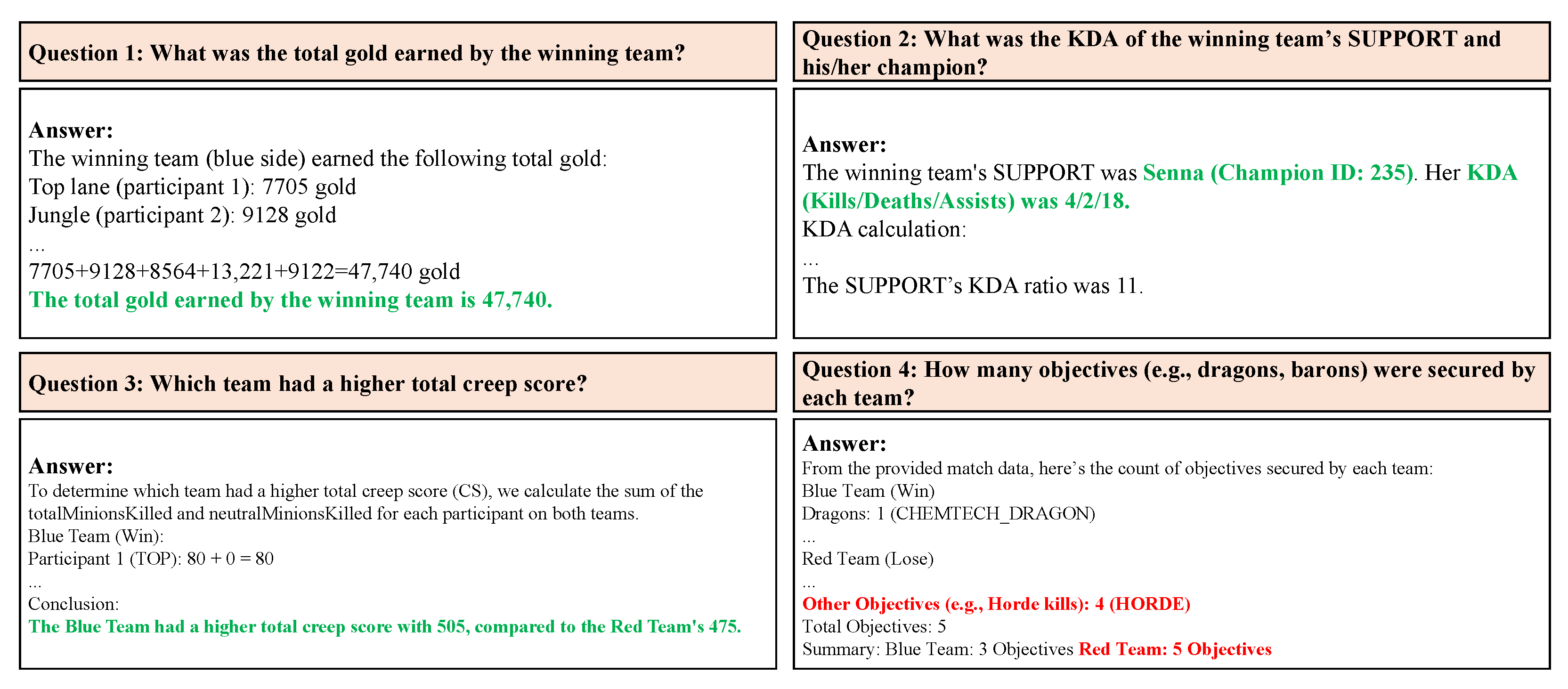
Figure 4 and
Figure 5 display the responses generated by GPT-4o using raw JSON and compacted JSON inputs, respectively. While the raw JSON inputs did not exceed the token constraints in this case, the chatbot failed to answer Question 4 (the number of creeps) correctly. Despite the presence of creep score data elsewhere in the JSON files, the model struggled to extract and synthesize the information accurately. It provided correct answers for the remaining three questions, including the total gold, KDA, and objectives.
In contrast, the compacted JSON inputs enabled GPT-4o to provide accurate and complete answers for all four questions. The chatbot successfully identified the total gold, KDA, objectives, and creep score, demonstrating the value of the LoL-MDC in structuring input data for effective analysis. This phenomenon was kept for all five utilized matches, which highlights the compactor’s ability to enhance the usability of match data by organizing information in a way that facilitates accurate LLM responses.
4.3.2. Match Overview Questions
The match overview questions were designed to summarize the match concisely and identify key details. The following questions were used:
Summarize the match in one sentence, highlighting the winning team and their key strengths.
Who was the MVP and why?
What were the most significant moments that shifted the momentum of the game?
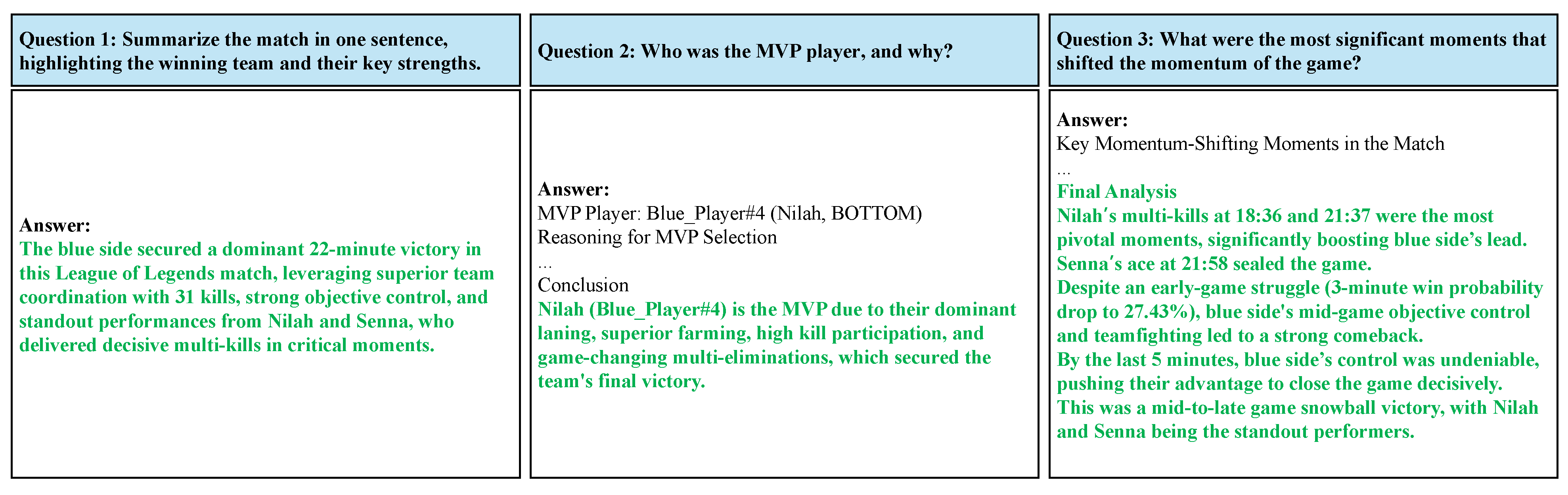
Figure 6 and
Figure 7 show the responses generated using raw and compacted JSON inputs. When provided with raw JSON inputs, GPT-4o exhibited hallucinations in its responses, as shown in its answer to Question 2. Additionally, the chatbot’s output contained unreadable, system-like encrypted values, such as “Players 9 and 10” or “Timestamp: 132,244” instead of an exact champion name or description. These issues made it difficult for users to interpret the match summary and key moments effectively.
In contrast, the compacted JSON inputs allowed GPT-4o to generate structured and accurate match overviews. The chatbot correctly identified the MVP with a coherent explanation, highlighted significant momentum shifts, and provided a readable summary of the match. Compared with the raw JSON inputs, which often resulted in vague or misleading outputs, the compacted JSON inputs consistently produced high-quality responses, demonstrating its effectiveness in enabling structured high-level match analysis.
4.3.3. Match-Comparing Questions
Match-comparing questions required analyzing trends and differences across five anonymized matches. The following questions were used:
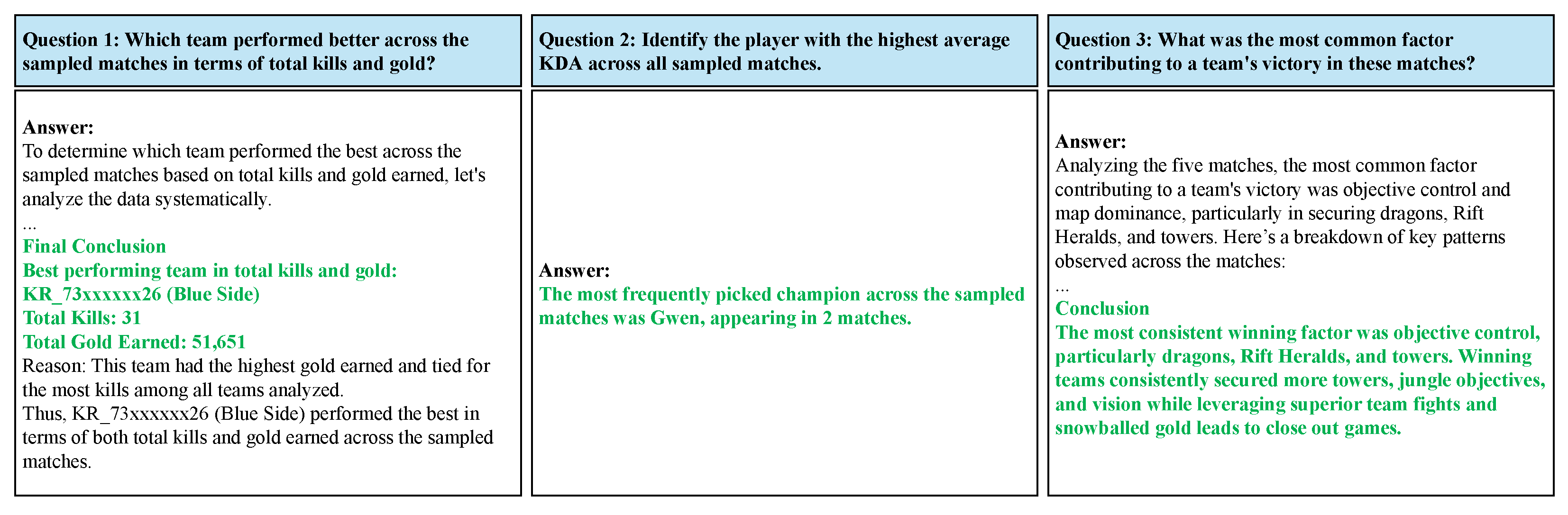
Which team performed better across the sampled matches in terms of total kills and gold?
What was the most frequently picked champion across the sampled matches?
What was the most common factor contributing to a team’s victory in these matches?
When using raw JSON files, GPT-4o was unable to process more than two matches simultaneously due to token constraints, making meaningful match comparisons infeasible. As a result, no valid multi-match responses could be generated, preventing the chatbot from identifying overarching trends or patterns across the dataset.
In contrast, compacted JSON files enabled GPT-4o to analyze all five matches simultaneously, facilitating detailed comparisons across multiple metrics as shown in
Figure 8. The chatbot successfully identified the best-performing team, the most frequently picked champion, and the most common victory factors. This demonstrates the LoL-MDC’s effectiveness in structuring match data for large-scale trend analysis, overcoming the limitations imposed by raw JSON inputs.
4.4. Findings and Contributions
The findings from this study confirm that the LoL-MDC is highly effective at compacting esports match data while preserving its analytical value. The compactor achieved up to 97% reductions in data size and token counts, enabling efficient analysis within the input constraints of LLMs. It demonstrated compatibility with tokenization schemes such as o200k_base and cl100k_base, making it suitable for diverse LLM architectures. By preserving match narratives, key events, and performance metrics, the LoL-MDC enables meaningful insights that align closely with expert analyses.
The qualitative evaluation further highlights the advantages of compacted JSON inputs for question-answering tasks. Using compacted JSON files, GPT-4o generated coherent and accurate responses across all question categories, including general match statistics, high-level overviews, and cross-match comparisons. In contrast, raw JSON inputs often led to incomplete or incorrect answers due to the token limitations of LLMs. These findings validate the LoL-MDC’s ability to transform complex match data into manageable and insightful formats, enabling LLMs to answer a wide range of analytical questions effectively. Our qualitative evaluation demonstrates that the compacted format provided by the LoL-MDC did more than remove redundant metadata. It improves the accuracy and coherence of LLM-generated responses compared with the baseline JSON files, indicating practical analytical advantages beyond data size reduction.
Additionally, the modular design of the compactor ensures scalability across patch versions and adaptability to other esports titles, further broadening its application scope. The ability to adjust components such as the timeline view intervals and the number of selected key events enables analysts to balance data granularity with computational efficiency. The experimental results also emphasize the LoL-MDC’s computational efficiency, allowing it to process entire tournaments or seasons within feasible timeframes. These contributions position the LoL-MDC as a robust and versatile tool for advancing esports analytics and unlocking new possibilities for AI applications in competitive gaming.
5. Conclusions
This paper introduced the League of Legends Match Data Compactor, a tool designed to transform voluminous esports match data into concise, structured formats optimized for LLMs. By leveraging curated JSON data from LOL.PS, the LoL-MDC demonstrated an ability to reduce data sizes by up to 97% while retaining critical analytical information. This enables LLMs to efficiently process multiple matches simultaneously within token constraints, addressing practical challenges in esports analytics.
Quantitative evaluations highlighted the LoL-MDC’s effectiveness in significantly reducing data sizes and token counts, ensuring compatibility with tokenization schemes such as o200k_base and cl100k_base. Qualitative results indicated that the compacted format improved the coherence and accuracy of LLM-generated summaries, enabling more effective extraction of player performances and pivotal match moments compared with less structured data. These findings provide preliminary evidence of the LoL-MDC’s potential to enhance AI-driven analytics for esports.
Limitations
and Future Research
While the results of this study indicate promising directions for the use of the LoL-MDC in esports analytics, several areas require further investigation to strengthen the generalizability and robustness of our findings. The qualitative evaluation was based on a limited sample of five matches, suggesting the need for larger-scale evaluations to confirm broader applicability. Additionally, our assessments relied on subjective interpretations of LLM-generated outputs without systematically quantifying response consistency or the frequency of hallucinations. To address these issues, we plan to deploy the LoL-MDC on an accessible web platform, allowing users and esports analysts to interact with the model directly and provide structured feedback.
Future research will also involve systematic experiments to evaluate hallucination frequency, inter-rater reliability, explicit control of LLM parameters such as temperature settings, benchmarking against alternative NLP summarization methods, and detailed assessments of LLM performance metrics, including accuracy, latency, computational cost, and scalability, under realistic conditions.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}