Subway vehicles contain many key systems and key components. The reliability of key systems and key components directly affects the travel safety of most passengers and provides an important basis for the maintenance of subway vehicles. At present, urban rail transit metro vehicle failure prediction research mainly focuses on subsystems and passenger flow, while in the actual maintenance process, the failure rate of key components is an important indicator of vehicle maintenance. At the same time, there will be excessive maintenance and under repair in maintenance. Therefore, it is very important to carry out a prediction study on the failure rate of the key components of metro vehicles, which can provide data to support the safety of metro vehicle maintenance as well as the accuracy of the maintenance plan, thus reducing maintenance cost.
Su Hang et al. [
1] established a reliable BP neural network by choosing appropriate network parameters and realized a subway signal equipment fault prediction system through the MATLAB v7.0 visual graphical interface GUI; based on the prediction of the BP neural network, Wei Qianzhou et al. [
2] combined the particle swarm algorithm with the BP neural network to form a new prediction model, and predicted the failure of subway shield doors; Xiang Ling et al. [
3], since the particle swarm algorithm and bp neural network were prone to algorithmic instability problems, proposed combining the ant colony algorithm with the BP neural network, constructed a new model of PSD residual life prediction, and effectively proved the stability and accuracy of the proposed GA–BP algorithm through experimental examples; Li Bowen et al. [
4] proposed an improved BP neural network algorithm for predicting faults in rail circuits with a dragonfly algorithm to optimize and improve the weights and thresholds of the initial BP neural network, used track voltage data collected by the electric workshop to train the improved BP neural network, and predicted and analyzed the rail out 1 and rail out 2 voltage values of the track circuit to obtain the probability of the occurrence of the red band and the trend of the track circuit; Burak Kizilöz et al. [
5] proposed a serial (STDM) and artificial neural network (ANN) combination model for the daily failure rate of the water distribution network, which can improve prediction accuracy; Qingfu Li et al. [
6] proposed a back-propagation neural network based on the optimization of genetic algorithms to simulate and predict pipeline failures, so as to improve the accuracy of pipeline failure prediction; Zhiru Wang et al. [
7] applied the theory of task-driven behaviors and the theory of the system to reveal the general framework of MRTS applied the task-driven behavioral theory and system theory to reveal a general framework for escalator accident mechanisms and used Lasso-Logistic Regression (LLR) for escalator damage prediction; Wang Hao [
8] proposed a two-stage train delay prediction method based on data smoothing and multi-model fusion, which is effective in predicting train delays; Wang Lei et al. [
9] built a model combining analytical ripple and GM(2,1) for online aging monitoring and life prediction of electrolytic capacitors for power supply in urban rail transit systems; Dong Xianguang et al. [
10] built a Weibull distribution combined with ratio–ratio to construct a prediction model with Bayesian assurance of data accuracy to predict the number of meter faults; Du Ying et al. [
11] came up with a novel model based on the Bayesian neural network (BNN) for predicting the number of distribution faults for predicting weather-related failures in distribution systems caused by wind, rain and lightning, through which confidence intervals for the prediction results can be obtained, providing sufficient information to guide the risk management of utility companies; Yingjie Tian et al. [
12,
13] proposed a Bayesian and hyperellipsoid-based brake system reliability analysis, by which the accuracy of brake system reliability analysis can be improved; Rodney Kizito et al. [
14] proposed an LSTM model based on the PdM background for predicting equipment failures, estimating the probability of failure and the RUL, and compared it with the random forest model to obtain a method that performs relatively well in fault classification and outperforms RF in RUL prediction.
There are still some problems with the above fault prediction methods; for example, the problems with machine learning methods are mainly the high cost of prediction and the large amount of data needed for support. The BP neural network and Bayesian method has the problem of high requirements for initial data and parameter selection and is prone to the problem of gradient explosion. The LSTM method can deal with the problem of gradient explosion, but it has limitations for the processing of long sequence data. In the subway vehicle overhaul process, failure rate [
15] is an important indicator in the reliability assessment, which cannot be ignored, and is often combined with time series in the prediction process. Time series [
16] analysis is a statistical method used to analyze and process dynamic data for predicting future trends by analyzing and mining the previous development of specific data, which, after being combined with the failure rate, will lead to a relatively small amount of data and relatively short time sequences, making it difficult to make accurate predictions using the above model.
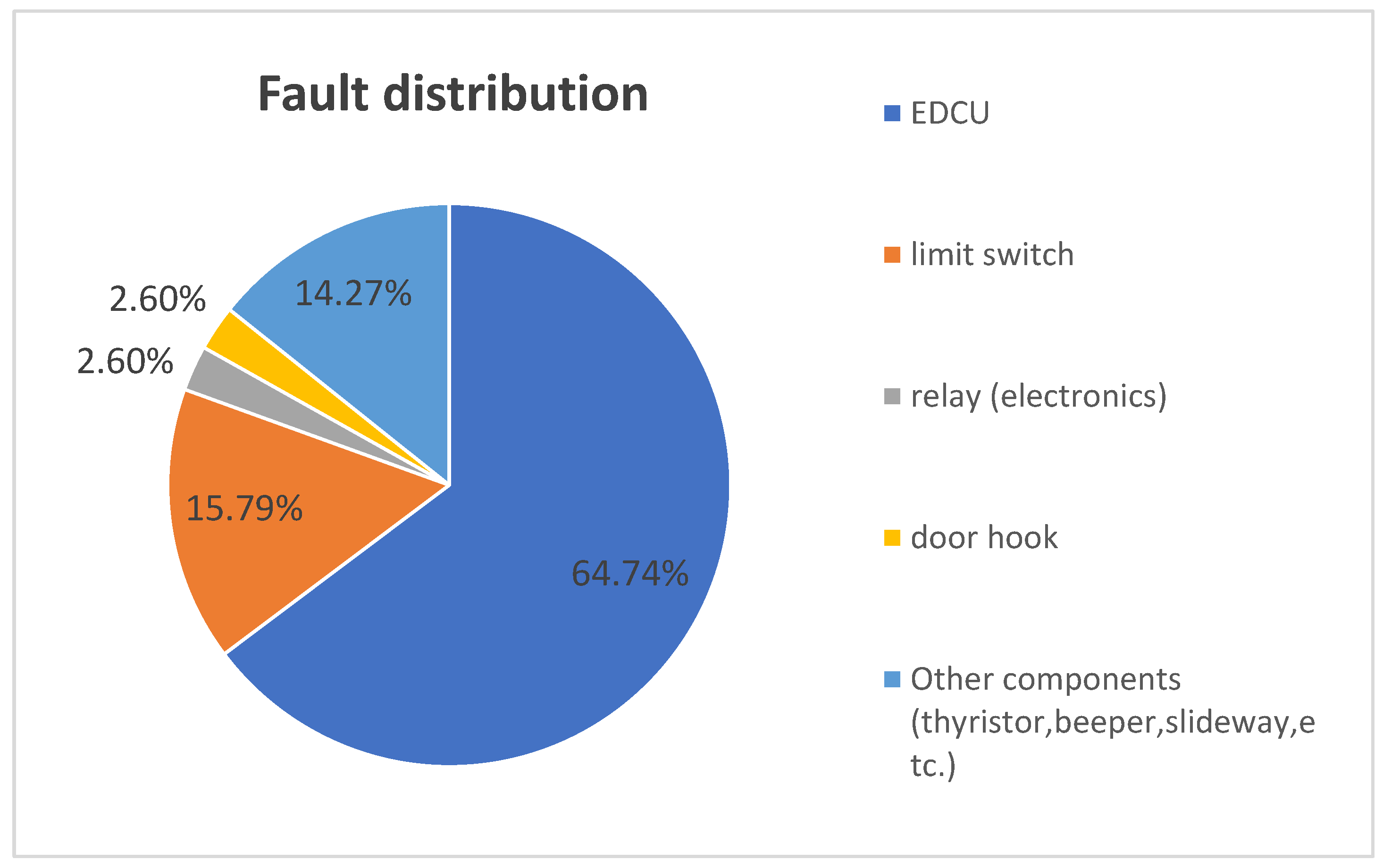
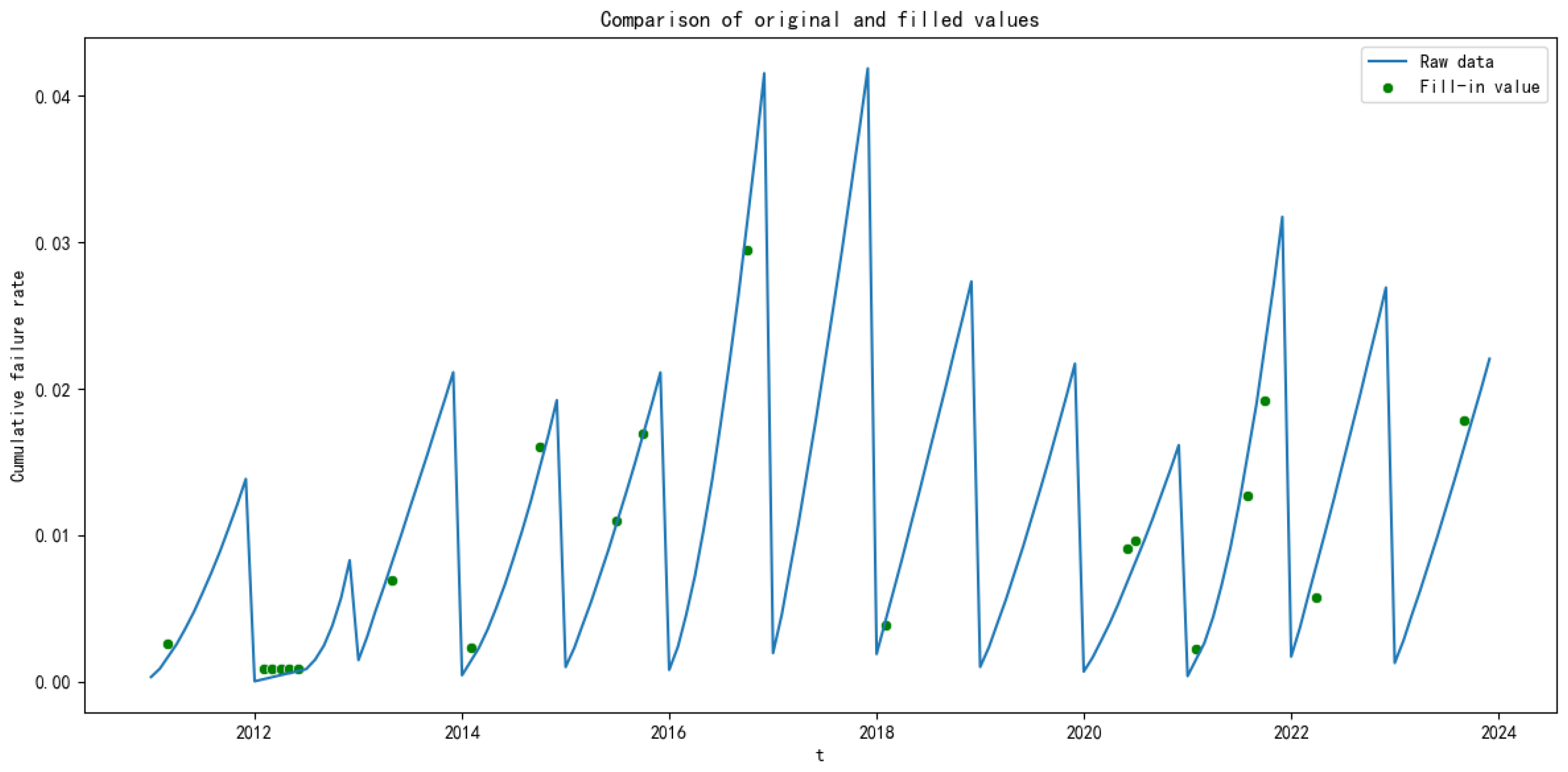
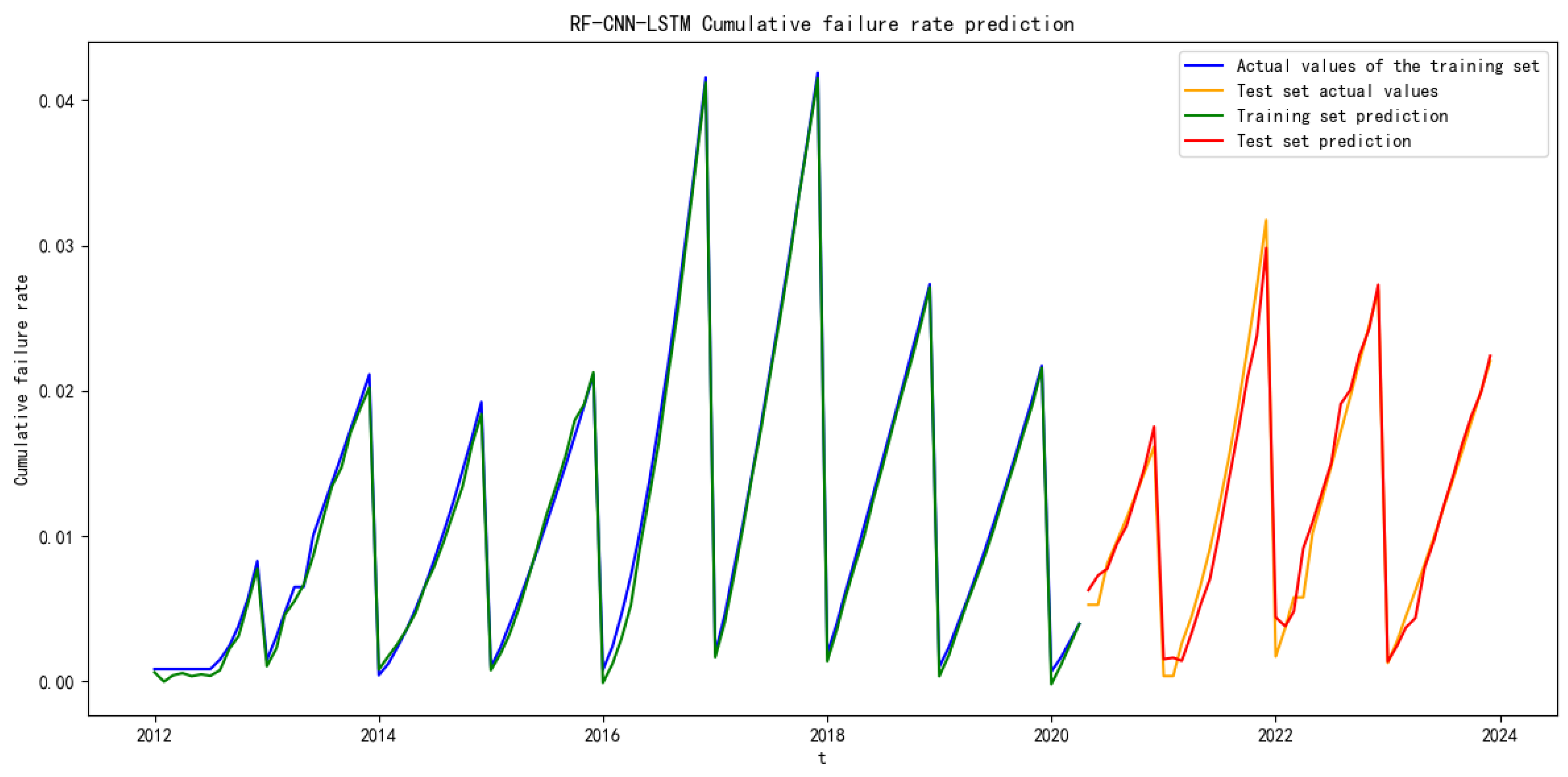
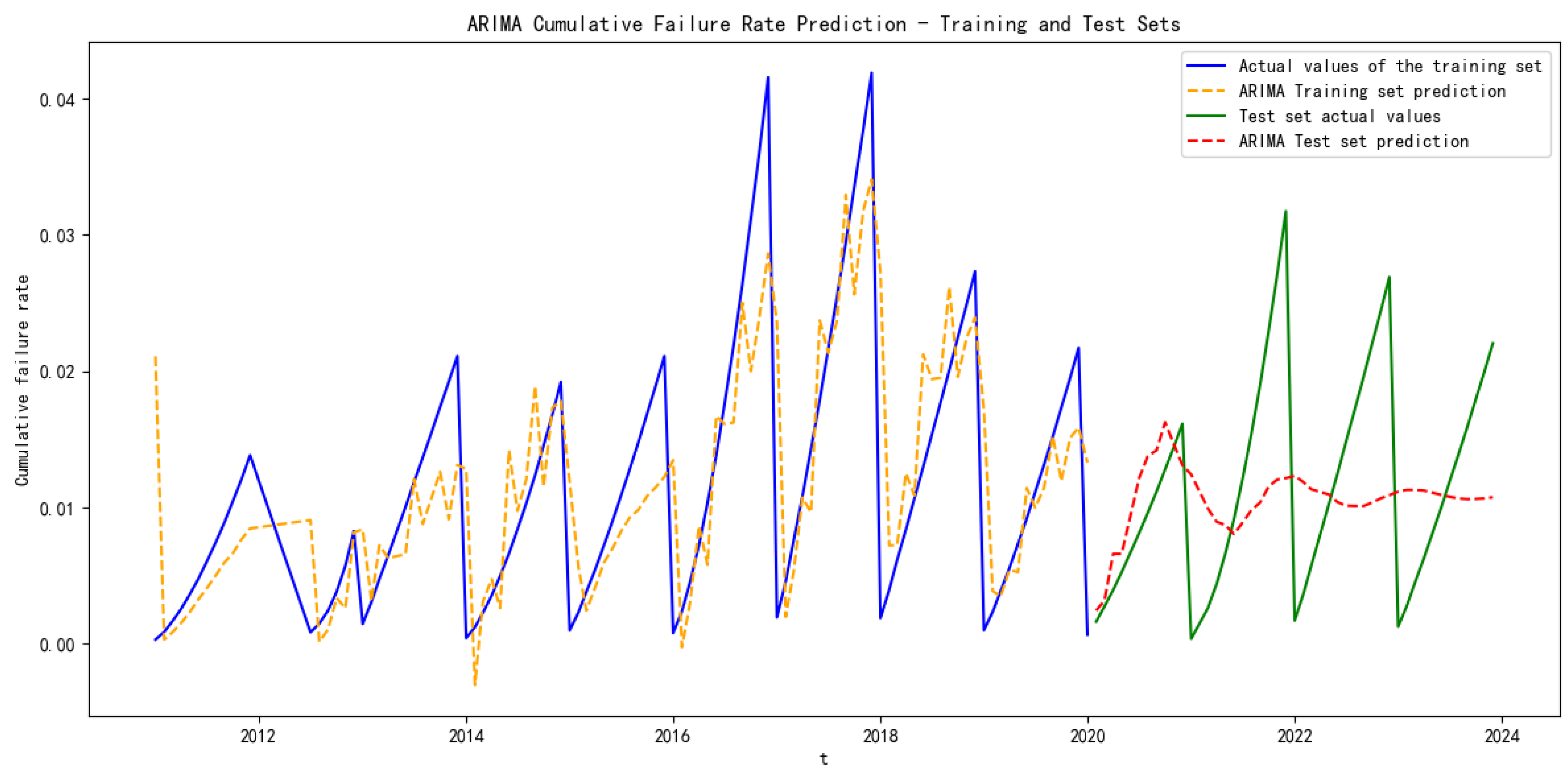
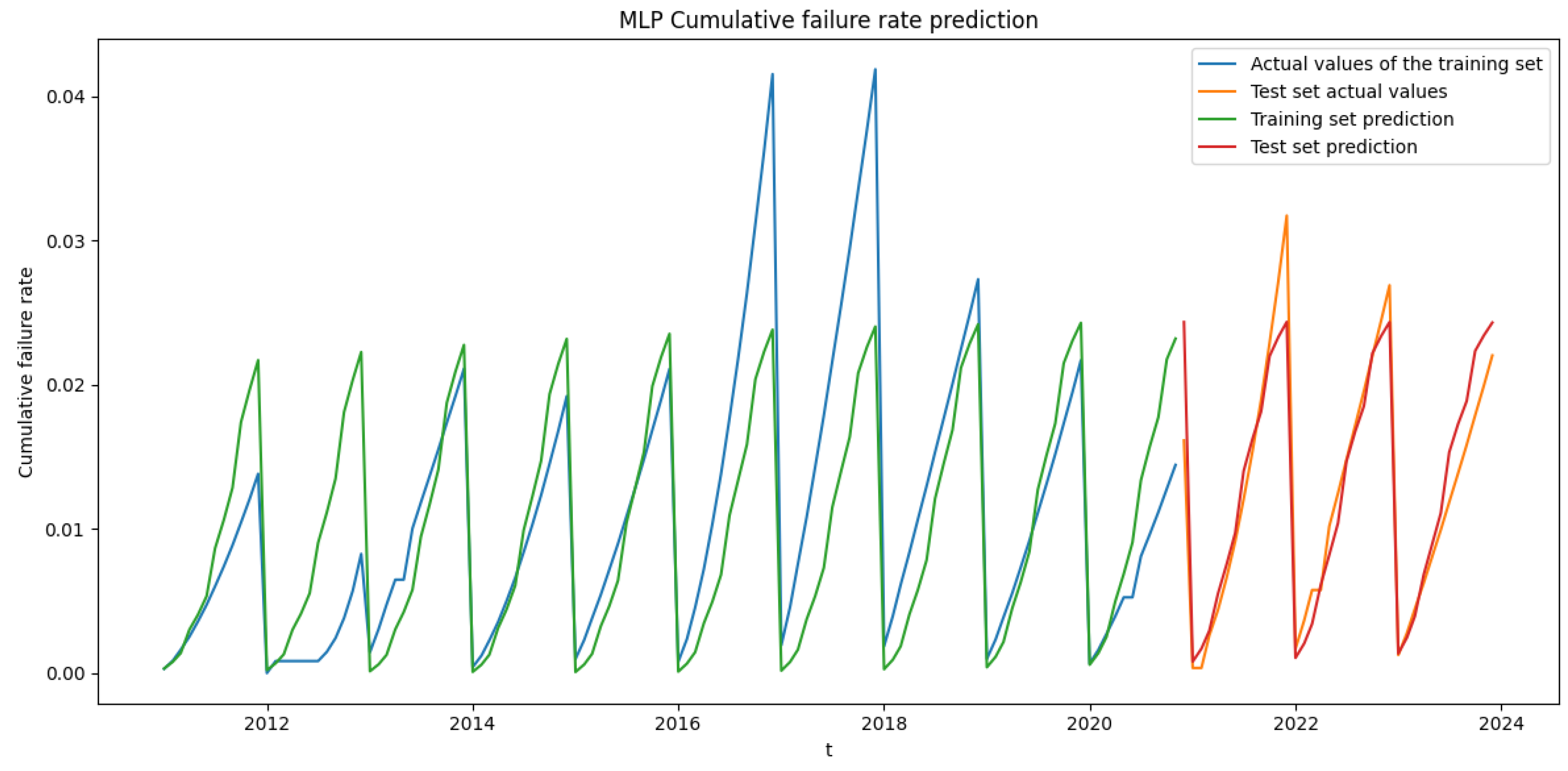
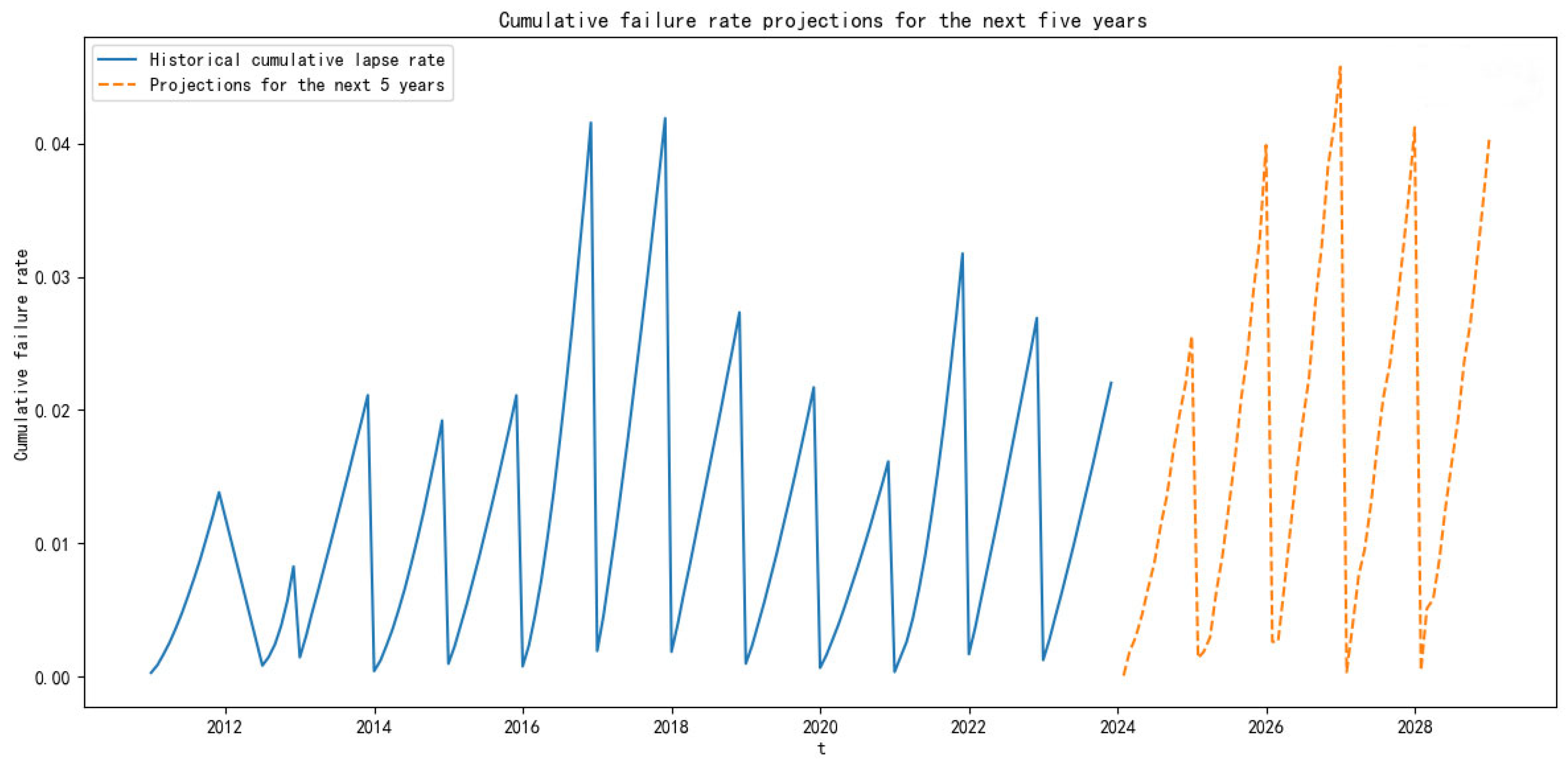
This paper proposes a combination model based on Random Forest (RF), Convolutional Neural Networks (CNN), and Long Short-Term Memory (LSTM) to predict the failure rate of the key components of subway vehicles. Based on the actual subway failure rate data, Random Forest is applied to check for missing values in the data to ensure the quality of the prediction data, then CNN is used to extract the data features, and finally LSTM is used to predict the failure rate of key subway components. The ARIMA model, multilayer perceptron neural network model, LSTM model and the proposed RF–CNN–LSTM model are compared, and the R-squared accuracy and adjusted R-squared accuracy are introduced to evaluate the model’s prediction accuracy. Taking the door controller of the door system, a key component of the subway, as an example, the RF–CNN–LSTM model is used to predict failure rate and provide support for the preventive maintenance of EDCUs.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}