
HIEN: A Hybrid Interaction Enhanced Network for Horse Iris Super-Resolution



Abstract
1. Introduction
- •
- We construct a horse iris dataset and propose a Hybrid Interaction Enhanced Network (HIEN) for SR. The proposed network enables effective interaction between local features and global relationships at each stage, thereby capturing both fine textures and global context simultaneously.
- •
- We designed PATB with an integrated CQG, which directly generates query vectors from the initial input features. This enables effective interaction between original context and refined features, enhancing the model’s ability to capture long-range dependencies and refine features contextually.
- •
- We designed an ERDB that uses depthwise separable convolutions to reduce both parameter count and FLOPs by about 80% compared to standard Residual Dense Blocks, while maintaining local feature representation and significantly improving network efficiency.
- •
- The proposed network effectively restores fine details of horse irises and improves recognition accuracy, which holds great value for advancing the informatization and intelligent management of horse farms.
2. Materials and Methods
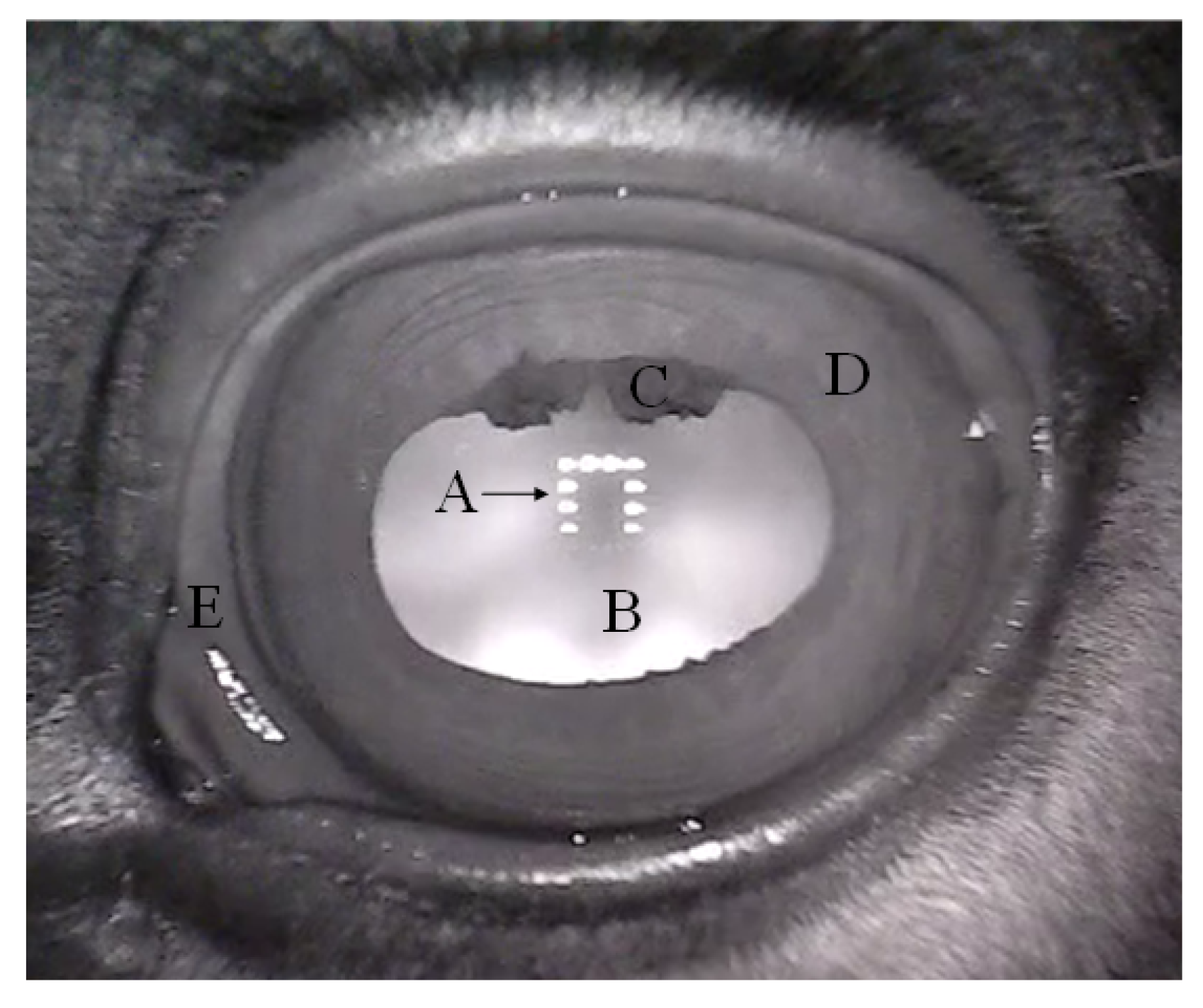
2.1. Horse Iris Dataset
2.2. Method
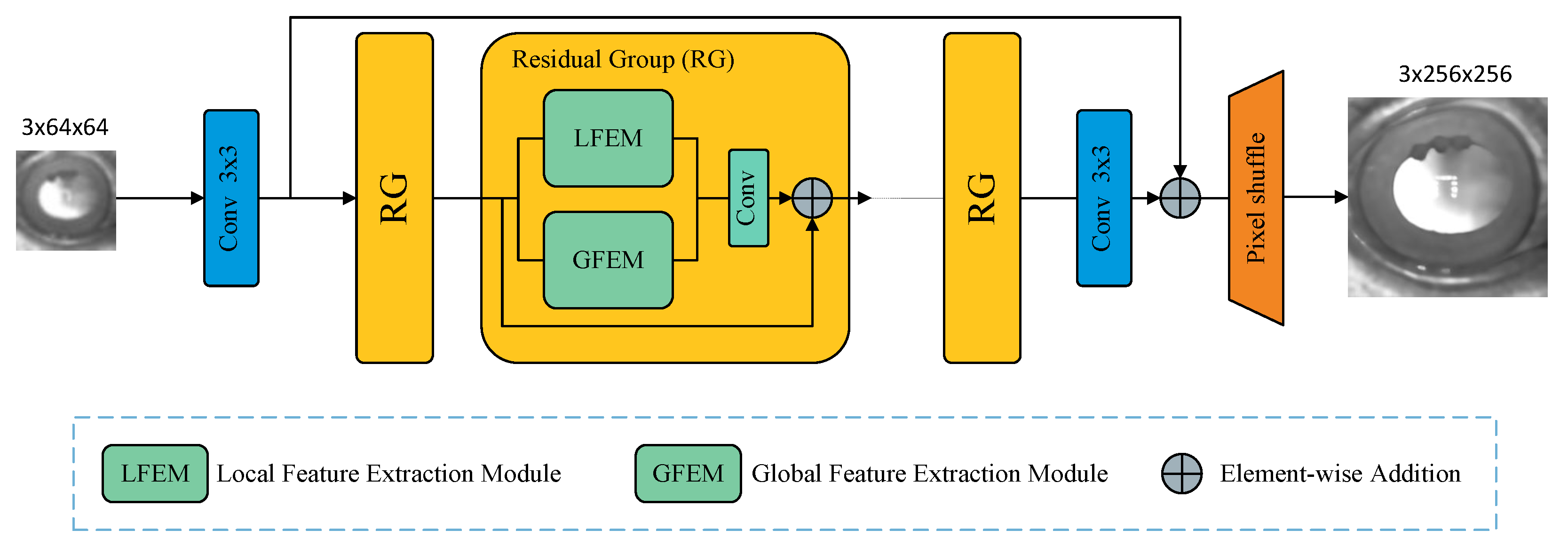
2.2.1. Network Architecture
Shallow Feature-Extraction Module
Deep Feature-Extraction Module
Image-Reconstruction Module
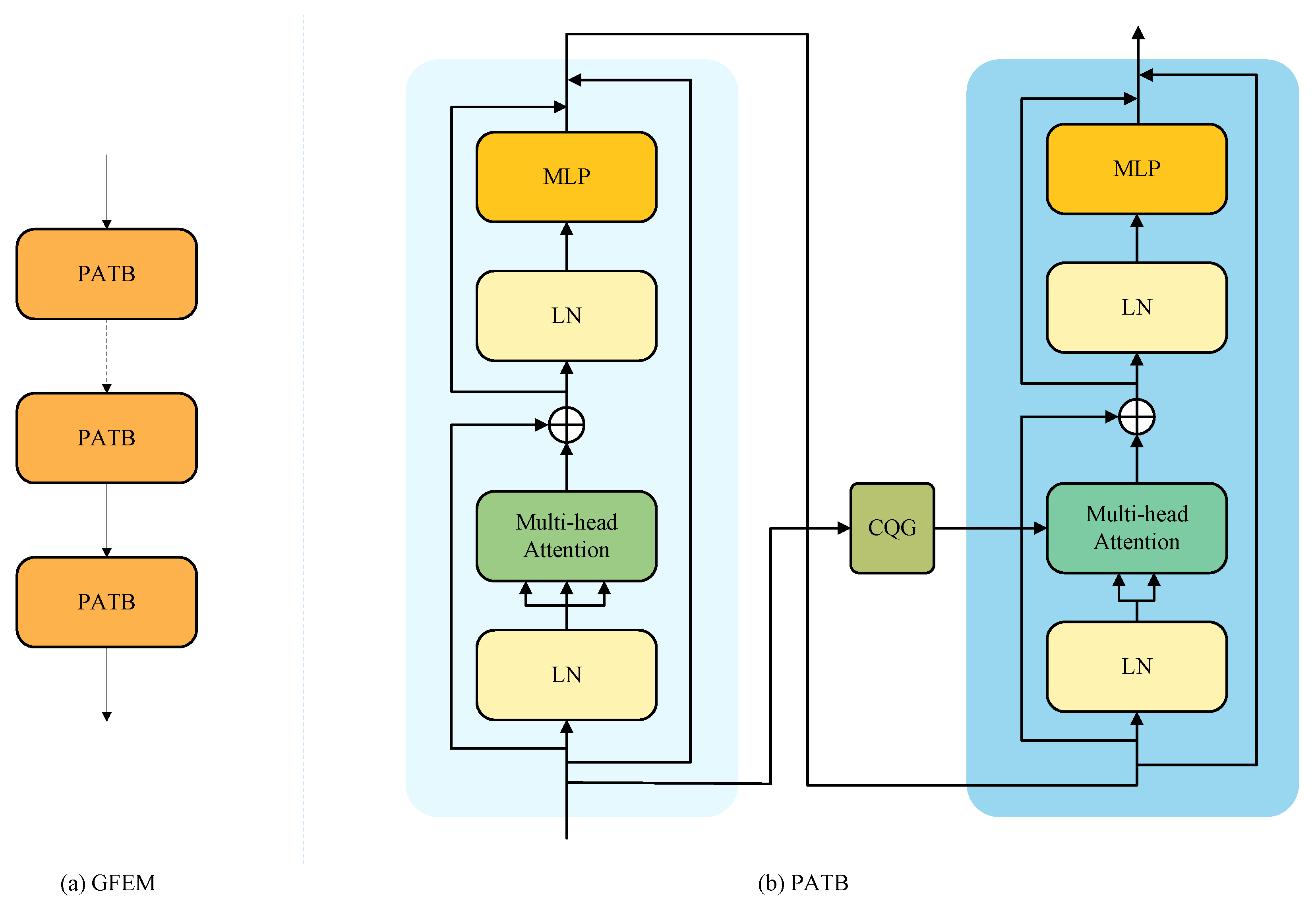
2.2.2. Paired Asymmetric Transformer Block
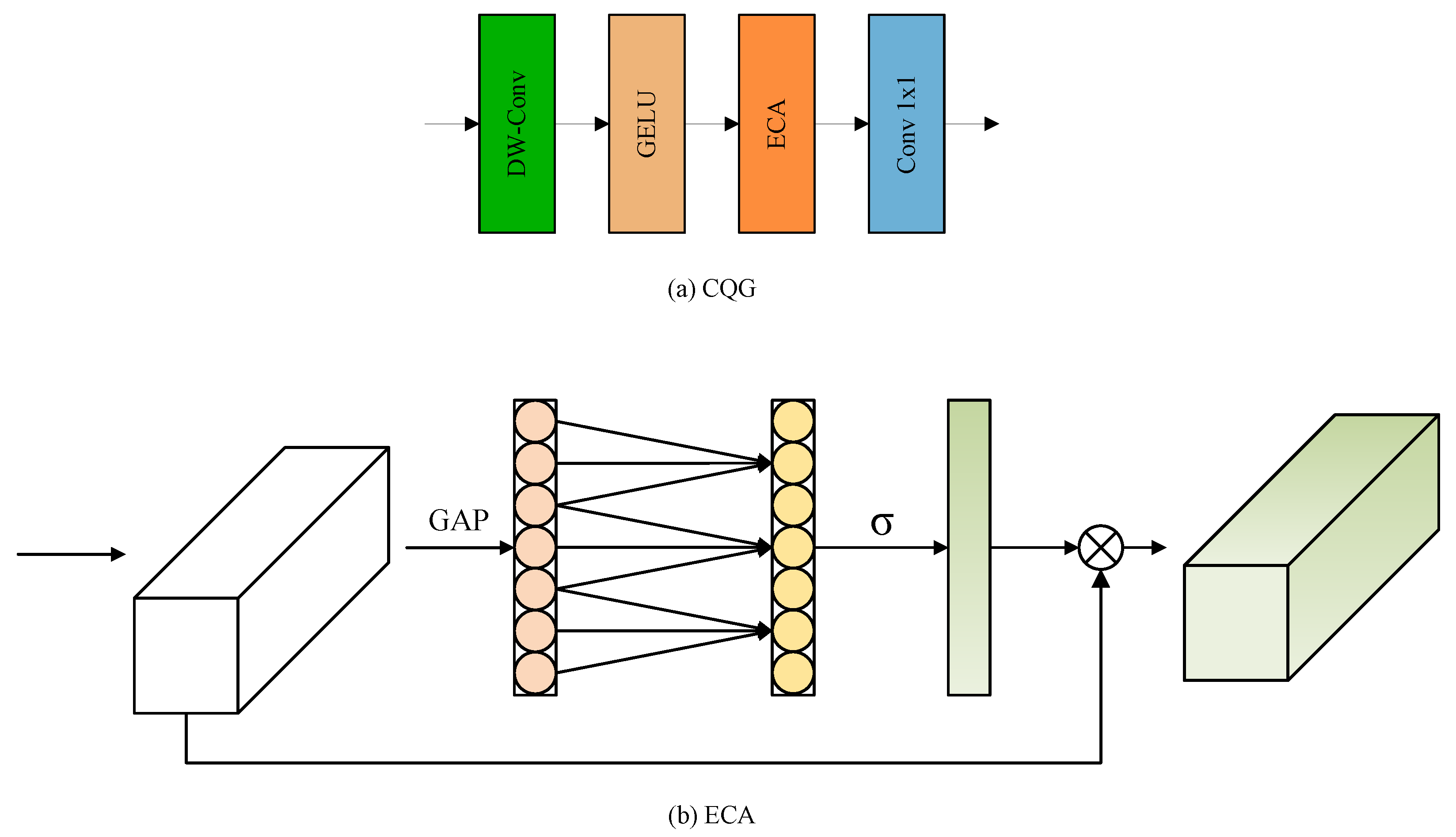
2.2.3. Contextual Query Generator
2.2.4. Efficient Residual Dense Block
3. Experiment and Results
3.1. Experimental Setup and Evaluation Metrics
3.1.1. Implementation Details
3.1.2. Evaluation Protocols
3.2. Comparison with State-of-the-Arts Models
3.2.1. Quantitative Results
3.2.2. Visual Results
3.3. Ablation Experiments
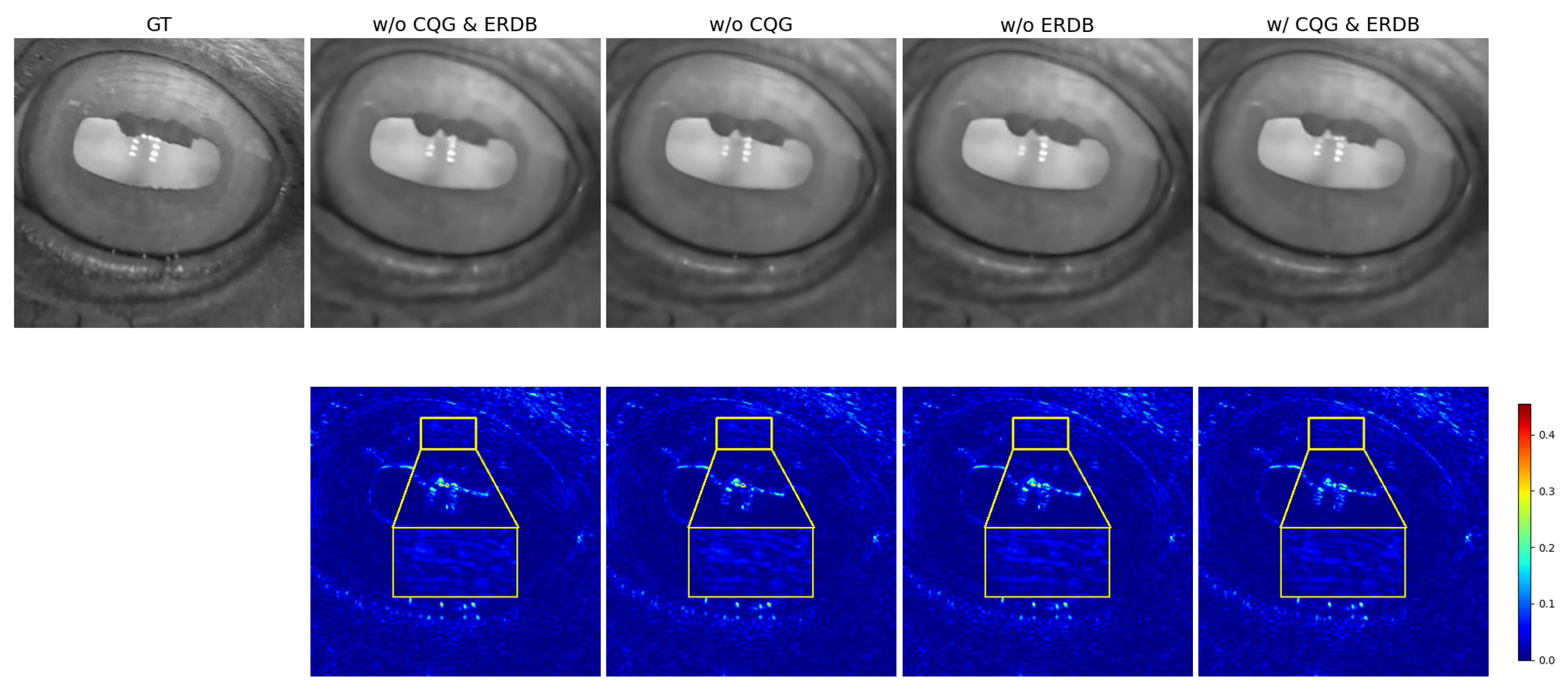
3.3.1. Module Ablation
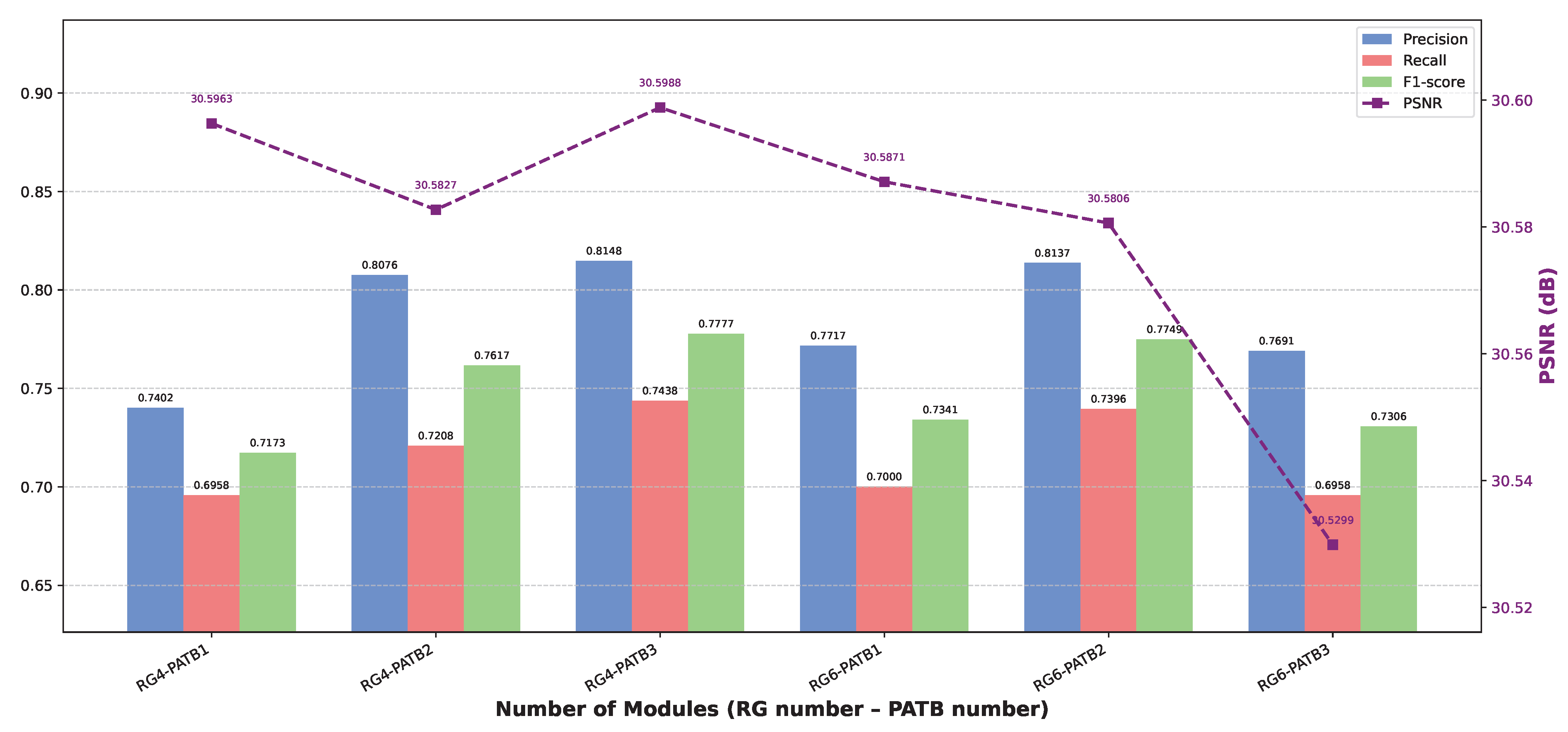
3.3.2. Ablation on Number of Modules
3.4. Efficiency and Complexity Analysis
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Monterrubio, C.; Pérez, J. Horses in leisure events: A posthumanist exploration of commercial and cultural values. J. Policy Res. Tour. Leis. Events 2020, 13, 147–171. [Google Scholar] [CrossRef]
- Górecka-Bruzda, A.; Jaworska, J.; Stanley, C.R. The Social and Reproductive Challenges Faced by Free-Roaming Horse (Equus caballus) Stallions. Animals 2023, 13, 1151. [Google Scholar] [CrossRef] [PubMed]
- Rozi, P.; Mattohti, W.; Ababakri, G.; Li, P.; Chen, Y.; Yuan, L. Isolation, structure identification, and antioxidant activity of collagen peptides from horse bone marrow. J. Food Meas. Charact. 2024, 18, 4074–4087. [Google Scholar] [CrossRef]
- Jarraya, I.; Said, F.B.; Hamdani, T.M.; Neji, B.; Beyrouthy, T.; Alimi, A.M. Biometric-Based Security System for Smart Riding Clubs. IEEE Access 2022, 10, 132012–132030. [Google Scholar] [CrossRef]
- Borisova, A.V.; Shemarykin, A.E.; Datsyshin, A.A.; Koroleva, G.V. Geometric morphometry as a new method of differentiation of intrabreed types in horse breeding. BIO Web Conf. 2024, 108, 01013. [Google Scholar] [CrossRef]
- Bussiman, F.; Alves, A.A.C.; Richter, J.; Hidalgo, J.; Veroneze, R.; Oliveira, T. Supervised Machine Learning Techniques for Breeding Value Prediction in Horses: An Example Using Gait Visual Scores. Animals 2024, 14, 2723. [Google Scholar] [CrossRef]
- Miller, M.; Byfield, R.; Crosby, M.; Lin, J. Networked Wearable Sensors for Monitoring Health and Activities of an Equine Herd: An IoT Approach to Improve Horse Welfare. IEEE Sensors J. 2024, 24, 29211–29218. [Google Scholar] [CrossRef]
- Santos, R.D.; Moutinho, F.; Prazeres, J.; Leithardt, V.R.Q.; Matos-Carvalho, J.P. Horses Identification Through Deep Learning Algorithms. In Proceedings of the 2024 8th International Young Engineers Forum on Electrical and Computer Engineering (YEF-ECE), Caparica/Lisbon, Portugal, 5 July 2024; pp. 14–19. [Google Scholar] [CrossRef]
- Godoi, T.L.O.S.; de Souza, R.N.; de Godói, F.N.; de Almeida, F.Q.; de Medeiros, M.A. Physiological and behavioral response of foals to hot iron or freeze branding. J. Vet. Behav. 2021, 48, 41–48. [Google Scholar] [CrossRef]
- Awad, A. From classical methods to animal biometrics: A review on cattle identification and tracking. Comput. Electron. Agric. 2016, 123, 423–435. [Google Scholar] [CrossRef]
- Suzaki, M.; Yamakita, O.; Horikawa, S.; Kuno, Y.; Aida, H.; Sasaki, N.; Kusunose, R. A horse identification system using biometrics. Syst. Comput. Jpn. 2001, 32, 12–23. [Google Scholar] [CrossRef]
- Graf, P.; König von Borstel, U.; Gauly, M. Importance of personality traits in horses to breeders and riders. J. Vet. Behav. 2013, 8, 316–325. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image Super-Resolution Using Deep Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 295–307. [Google Scholar] [CrossRef]
- Ribeiro, E.; Uhl, A. Exploring Texture Transfer Learning via Convolutional Neural Networks for Iris Super Resolution. In Proceedings of the 2017 International Conference of the Biometrics Special Interest Group (BIOSIG), Darmstadt, Germany, 20–22 September 2017; pp. 1–5. [Google Scholar] [CrossRef]
- Kashihara, K. Iris Recognition for Biometrics Based on CNN with Super-resolution GAN. In Proceedings of the 2020 IEEE Conference on Evolving and Adaptive Intelligent Systems (EAIS), Bari, Italy, 27–29 May 2020; pp. 1–6. [Google Scholar] [CrossRef]
- XIA, Y.; LI, P.; WANG, J.; ZHANG, Z.; LI, D.; HE, Z. Hierarchical Iris Image Super Resolution based on Wavelet Transform. In Proceedings of the 2022 4th International Conference on Image Processing and Machine Vision (IPMV), Hong Kong, China, 25–27 March 2022; pp. 37–43. [Google Scholar] [CrossRef]
- Lu, H.; Zhu, X.; Cui, J.; Jiang, H. An Iris Image Super-Resolution Model Based on Swin Transformer and Generative Adversarial Network. Algorithms 2024, 17, 92. [Google Scholar] [CrossRef]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local Neural Networks. arXiv 2017, arXiv:1711.07971v3. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. arXiv 2021, arXiv:2103.14030. [Google Scholar] [CrossRef]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network. arXiv 2016, arXiv:1609.05158. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar] [CrossRef]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H. Restormer: Efficient Transformer for High-Resolution Image Restoration. arXiv 2021, arXiv:2111.09881. [Google Scholar] [CrossRef]
- Liang, J.; Cao, J.; Sun, G.; Zhang, K.; Gool, L.V.; Timofte, R. SwinIR: Image Restoration Using Swin Transformer. arXiv 2021, arXiv:2108.10257. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q. EfficientNetV2: Smaller Models and Faster Training. In Proceedings of the Proceedings of the 38th International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; Volume 139, pp. 10096–10106. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. arXiv 2019, arXiv:1910.03151. [Google Scholar] [CrossRef]
- Hendrycks, D.; Gimpel, K. Gaussian Error Linear Units (GELUs). arXiv 2016, arXiv:1606.08415. [Google Scholar]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual Dense Network for Image Super-Resolution. arXiv 2018, arXiv:1802.08797v2. [Google Scholar]
- Hayat, M.; Aramvith, S.; Bhattacharjee, S.; Ahmad, N. Attention GhostUNet++: Enhanced Segmentation of Adipose Tissue and Liver in CT Images. arXiv 2025, arXiv:2504.11491. [Google Scholar] [CrossRef]
- Raghu, M.; Unterthiner, T.; Kornblith, S.; Zhang, C.; Dosovitskiy, A. Do Vision Transformers See Like Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 2021, 34, 12116–12128. [Google Scholar]
- Chen, Z.; Zhang, Y.; Gu, J.; Kong, L.; Yang, X. Recursive Generalization Transformer for Image Super-Resolution. arXiv 2023, arXiv:2303.06373. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Gonzalez, R.C.; Woods, R.E. Digital Image Processing, 2nd ed.; Prentice Hall: Upper Saddle River, NJ, USA, 2002. [Google Scholar]
- Wang, Z.; Bovik, A.; Sheikh, H.; Simoncelli, E. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for MobileNetV3. arXiv 2019, arXiv:1905.02244. [Google Scholar] [CrossRef]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Lee, K.M. Enhanced Deep Residual Networks for Single Image Super-Resolution. arXiv 2017, arXiv:1707.02921. [Google Scholar] [CrossRef]
- Li, Z.; Yang, J.; Liu, Z.; Yang, X.; Jeon, G.; Wu, W. Feedback Network for Image Super-Resolution. arXiv 2019, arXiv:1903.09814. [Google Scholar] [CrossRef]
- Niu, B.; Wen, W.; Ren, W.; Zhang, X.; Yang, L.; Wang, S.; Zhang, K.; Cao, X.; Shen, H. Single Image Super-Resolution via a Holistic Attention Network. arXiv 2020, arXiv:2008.08767. [Google Scholar] [CrossRef]
- Zhang, X.; Zeng, H.; Guo, S.; Zhang, L. Efficient Long-Range Attention Network for Image Super-resolution. arXiv 2022, arXiv:2203.06697. [Google Scholar] [CrossRef]
- Li, A.; Zhang, L.; Liu, Y.; Zhu, C. Feature Modulation Transformer: Cross-Refinement of Global Representation via High-Frequency Prior for Image Super-Resolution. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; pp. 12480–12490. [Google Scholar] [CrossRef]
- Zheng, M.; Sun, L.; Dong, J.; Pan, J. SMFANet: A lightweight self-modulation feature aggregation network for efficient image super-resolution. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September 2024; pp. 359–375. [Google Scholar]
- Liu, Q.; Zhuang, C.; Gao, P.; Qin, J. CDFormer:When Degradation Prediction Embraces Diffusion Model for Blind Image Super-Resolution. arXiv 2024, arXiv:2405.07648v1. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Training Set | Test Set | Validation Set |
|---|---|---|---|
| Number of Horses | 76 | 16 | 16 |
| Number of Images | 2280 | 480 | 480 |
| Stage | Module / Key Operation | Output Tensor Shape |
|---|---|---|
| Input | Low-Resolution Image | 3 × 64 × 64 |
| 1. Shallow Feature Extraction | 3 × 3 Convolution | 180 × 64 × 64 |
| 2. Deep Feature Extraction | ||
| 2a. Local Path | LFEM with ERDBs | 180 × 64 × 64 |
| 2b. Global Path | GFEM with PATBs | 180 × 64 × 64 |
| 2c. Feature Fusion | Addition + Convolution | 180 × 64 × 64 |
| 3. Image Reconstruction | PixelShuffle + Convolution | 3 × 256 × 256 |
| Output | Super-Resolved Image | 3 × 256 × 256 |
| Method | Year | PSNR | SSIM | Precision | Recall | F1-Score |
|---|---|---|---|---|---|---|
| Bicubic | - | 26.5949 | 0.7631 | 0.5713 | 0.4646 | 0.5125 |
| EDSR | 2017 | 30.3418 | 0.8502 | 0.7388 | 0.6938 | 0.7156 |
| RDN | 2018 | 30.5361 | 0.8533 | 0.7394 | 0.6979 | 0.7181 |
| SRFBN | 2019 | 30.5082 | 0.8541 | 0.7381 | 0.6917 | 0.7141 |
| HAN | 2020 | 30.7414 | 0.8572 | 0.7389 | 0.6958 | 0.7167 |
| SwinIR | 2021 | 30.5412 | 0.8542 | 0.8044 | 0.7083 | 0.7533 |
| ELAN | 2022 | 30.3353 | 0.8507 | 0.7337 | 0.6979 | 0.7154 |
| CRAFT | 2023 | 30.2476 | 0.8501 | 0.7386 | 0.6958 | 0.7166 |
| SMFAN | 2024 | 30.4431 | 0.8497 | 0.7371 | 0.6979 | 0.7170 |
| CDFormer | 2024 | 30.4809 | 0.8631 | 0.7804 | 0.7229 | 0.7506 |
| RGT | 2024 | 30.5905 | 0.8551 | 0.7688 | 0.6938 | 0.7294 |
| HIEN | Ours | 30.5988 | 0.8552 | 0.8148 | 0.7438 | 0.7777 |
| Block | PSNR | SSIM | Precision | Recall | F1-Score |
|---|---|---|---|---|---|
| w/o CQG & ERDB | 30.5450 | 0.8550 | 0.7726 | 0.7083 | 0.7391 |
| w/o CQG | 30.5974 | 0.8553 | 0.8000 | 0.7021 | 0.7479 |
| w/o ERDB | 30.5860 | 0.8553 | 0.8047 | 0.7063 | 0.7523 |
| w/ CQG & ERDB | 30.5988 | 0.8552 | 0.8148 | 0.7438 | 0.7777 |
| RG Number | PATB Number | PSNR | SSIM | Precision | Recall | F1-Score |
|---|---|---|---|---|---|---|
| 4 | 1 | 30.5963 | 0.8548 | 0.7402 | 0.6958 | 0.7173 |
| 4 | 2 | 30.5827 | 0.8553 | 0.8076 | 0.7208 | 0.7617 |
| 4 | 3 | 30.5988 | 0.8552 | 0.8148 | 0.7438 | 0.7777 |
| 6 | 1 | 30.5871 | 0.8546 | 0.7717 | 0.7000 | 0.7341 |
| 6 | 2 | 30.5806 | 0.8547 | 0.8137 | 0.7396 | 0.7749 |
| 6 | 3 | 30.5299 | 0.8531 | 0.7691 | 0.6958 | 0.7306 |
| Metric | Value | Description |
|---|---|---|
| Number of Parameters (M) | 8.42 | Total trainable parameters of the model |
| Model Size (MB) | 43.55 | Total size of trainable parameters |
| FLOPs (G) | 47.71 | Computation cost for a input |
| Peak Training VRAM (GB) | 5.06 | Maximum GPU memory usage during training |
| Peak Inference VRAM (MB) | 514 | Maximum GPU memory usage during inference |
| Inference Latency (ms) | 120.83 | Average runtime per image |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, A.; Guo, B.; Liu, X.; Liu, W. HIEN: A Hybrid Interaction Enhanced Network for Horse Iris Super-Resolution. Appl. Sci. 2025, 15, 7191. https://doi.org/10.3390/app15137191
Zhang A, Guo B, Liu X, Liu W. HIEN: A Hybrid Interaction Enhanced Network for Horse Iris Super-Resolution. Applied Sciences. 2025; 15(13):7191. https://doi.org/10.3390/app15137191
Chicago/Turabian StyleZhang, Ao, Bin Guo, Xing Liu, and Wei Liu. 2025. "HIEN: A Hybrid Interaction Enhanced Network for Horse Iris Super-Resolution" Applied Sciences 15, no. 13: 7191. https://doi.org/10.3390/app15137191
APA StyleZhang, A., Guo, B., Liu, X., & Liu, W. (2025). HIEN: A Hybrid Interaction Enhanced Network for Horse Iris Super-Resolution. Applied Sciences, 15(13), 7191. https://doi.org/10.3390/app15137191