Abstract
Capture the Flag (CTF) is an important form of competition in cybersecurity, which tests participants’ knowledge and problem-solving abilities. We propose a multi-agent framework based on large language models to simulate human participants and attempt to automate the solutions of common CTF problems, especially in cryptographic and miscellaneous challenges. We implement the collaboration of multiple expert agents and access external tools to give the language model a basic level of practical competence in the field of cybersecurity. We primarily test two capabilities of the large model: to analyze, reason, and determine solutions to CTF problems, and to assist with problem-solving by generating code or utilizing unannotated existing external tools. We construct a benchmark based on the puzzles from the book “Ghost in the Wires” and the THUCTF competition. The experiment results showed that our agents performed well on the former and were significantly improved with some human hints, compared with related work. We also discuss the challenges that language models face in cybersecurity challenges and the effect of leveraging reasoning models.
1. Introduction
In the field of cybersecurity, Capture the Flag (CTF) is an important contest format. Participants are required to solve multiple types of challenges in a variety of areas, including web hacking, reverse engineering, cryptography, and more, to obtain the final flag. CTF competitions have become an important form of talent development, skill training, and cutting-edge sharing in cybersecurity.
Automated approaches have been widely applied in various areas of cybersecurity, including penetration testing and cryptography. For instance, in the context of classical ciphers, techniques like dictionary-based enumeration combined with fuzzy matching and other natural language processing methods can effectively decrypt certain simple cipher texts. However, traditional automation methods are typically tailored to specific algorithms and tricks or rely on human-defined scripts and templates, resulting in limited flexibility. Consequently, whether in real-world cybersecurity practices or in CTF competitions, such methods are often employed as an auxiliary to human experts, with their effectiveness highly dependent on the expertise and judgment of users.
The emergence of Large Language Models (LLMs) has endowed machines with human-like capabilities in learning and reasoning, paving the way for the development of intelligent agents capable of autonomous decision-making and task execution. However, due to the wide-ranging topics, non-linear thinking, and complex interactions involved in CTF challenges, current research on using LLMs to automatically solve these problems remains limited, exhibiting a low degree of automation.
Our research represents an exploration and an attempt in this direction. Specifically, to simulate the general human problem-solving process (involving understanding the problem, devising strategies, and testing potential solutions), we designed a multi-agent framework composed of distinct modules for analysis (acting with human reasoning), decision-making (generating structured commands), and execution (interacting with the operating system environment). These modules work collaboratively in a cyclic “think-decide-act-reflect” manner, allowing the system to iteratively explore challenges and gradually approach a solution.
In implementation, the large language model agent interacts with the system by executing commands, writing code, browsing and interacting with web pages, and reading and analyzing files. That enables the agent to autonomously carry out the entire problem-solving process in the way that the problems were originally designed. Human intervention is not necessary, but users can still monitor the agent’s behavior and provide guidance to steer its reasoning when necessary.
To measure the ability of LLM agents in cybersecurity automation, we constructed a CTF problem dataset from the attached challenges of cybersecurity biography Ghost in the Wires (GITW) and from past THUCTF competitions hosted by Tsinghua University, focusing primarily on Crypto and Misc categories. These two sources represent distinct levels of difficulty: GITW for effectively evaluating LLM agent performance, and THUCTF for realistic open-ended scenarios.
We evaluated our agent and baseline models on this dataset. The experimental results show that, on the GITW test set, our agent outperformed the ChatGPT-4o (2024-08-06 version) base model by 14.5% when both were provided with human hints, and achieved a performance gain of 2.7% to 5.3% without any hints. On the THUCTF benchmark, our agent was able to generate correct solution plans for 10% of the problems and independently solved 4.3% of them.
Our main contributions are as follows:
- We develop a multi-agent framework that utilizes the LLM to emulate human-like reasoning and decision-making, as well as external tools to solve CTF challenges in an autonomous manner.
- We construct a dataset based on GITW and THUCTF, which serve as benchmarks for evaluating the reasoning capabilities of LLMs in the context of CTF competitions. These datasets represent both guided and realistic problem-solving scenarios.
- We evaluate and analyze the performance of our agent in comparison to the base model on these datasets. Through quantitative and qualitative analysis, we demonstrate the potential of LLM-based agents in this domain while also identifying current limitations and areas for improvement.
2. Related Work
2.1. Capture the Flag
In cybersecurity, CTF is an engaging and competitive event in which participants solve security-related challenges to find hidden “flags”. As an education tool, CTF not only offers a simulated environment that mirrors real-world security scenarios, enabling students to develop and refine their hacking skills, but also plays a crucial role in promoting cybersecurity awareness [1,2,3,4,5,6]. As a springboard for advancing cybersecurity technologies, integrated with real-world security concerns, CTF leverages collective intelligence to inspire systematic guidelines and practical solutions for contemporary cybersecurity issues, and proposes effective frameworks for team cooperation [7,8,9]. Within a CTF competition, participants typically assume specialized roles and collaborate closely as a team to address a wide array of security problems, including cryptography, miscellaneous problem-solving, penetration testing, and more.
Traditional CTF methods rely heavily on manual operations. Participants have to be proficient in command-line tools, on-site programming, and web exploration, and flexibly apply their knowledge of system internals, cryptography, reverse engineering, and networking. With the growing popularity of large language models (LLMs), recent research efforts have begun exploring the integration of artificial intelligence to assist in solving CTF challenges.
2.2. LLM for Cybersecurity
Generative AI has been gaining attention in cybersecurity domains [10]. Meanwhile, prior work has extensively explored the application of LLMs in various domains of cybersecurity. In network security, LLMs have been applied to penetration testing [11], traffic analysis [12,13], and intrusion detection [14]. In the area of software and system security, refs. [15,16] address tasks vulnerability detection and [17,18] automated patch generation. Other domains include digital forensics [19] and hardware threat modeling [20].
To enable LLMs to address cybersecurity tasks effectively, researchers have pursued both non-invention methods and invention methods. Non-invention methods utilize LLMs’ in-context learning (ICL) ability, using prompting engineering techniques [21,22] or retrieval augmentations [23] to develop an LLM framework or agent to flexibly leverage LLM without training. On the other hand, invention methods fine-tune LLMs on cybersecurity-specific domains such as automated patching or exploit detection [24,25].
To our best knowledge, existing research primarily focuses on isolated cybersecurity tasks, while the development of general-purpose, cybersecurity-oriented LLM systems remains underexplored. Recognizing this gap, we take CTF as a starting point to develop a multi-agent system capable of addressing multiple types of security challenges. Our work aligns most strongly with [26], which proposes an automatic framework based on LLM, but does not explore the potential of a multi-agent LLM system. In contrast, ref. [27] introduces a multi-model framework but is limited to penetration testing and does not consider broader compatibility across different cybersecurity scenarios in the design. Our approach goes beyond penetration testing by developing a CTF-oriented framework that addresses the CTF task categories Miscellaneous and Cryptography. Similarly, while [28] introduces a multi-agent LLM system for deciphering challenges, it under-utilizes external resources such as online knowledge bases, limiting its capacity to fully explore the solution space.
2.3. LLM Agents
With the growing popularity of large language models (LLMs), the capabilities and breadth of LLM-based agents have evolved significantly, equipping them with preliminary skills applicable to CTF tasks. Recent models, such as [29,30], have showcased significant skill in coding tasks, while [22,31] further boost models’ reasoning ability as well as coding skill in a black-box way. Concurrently, approaches such as [32,33] leverage LLMs’ in-context learning (ICL) capabilities to facilitate interaction with external environments, including tasks like web navigation. Ref. [23] enhances natural language generation by retrieving task-specific information from external sources, thereby reducing reliance on parametric memory and broadening the applicability of LLMs. In parallel, research on multi-agent systems [34,35] demonstrates the potential of coordinated agent collaboration, often surpassing the effectiveness of single-agent systems across various domains.
3. Method
In this section, we present the framework, detailing the design of the agents as well as the interaction paradigm between the modules.
3.1. Overview
Our framework, illustrated in Figure 1, is designed as a workflow that emulates human reasoning, with decision-making and analysis at its core, and the execution of decisions facilitated by external tools. This design reflects the typical cognitive processes and resource utilization involved in solving a CTF challenge. Based on this insight, we divide the tasks assigned to agents into two categories: the first simulates human reasoning, focusing on analyzing and monitoring the information generated throughout the problem-solving process and proposing potential actions; the second simulates the execution of actions using various external tools to process the available information and return the results to the reasoning agents.
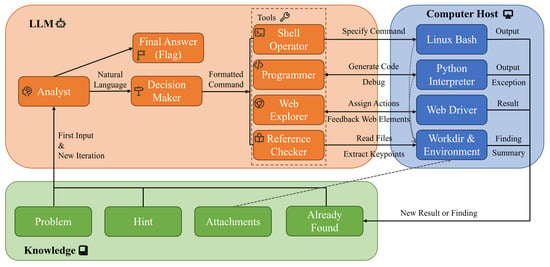
Figure 1.
An overview of our multi-agent CTF automation framework. The LLM module orchestrates a set of expert agents, including analyst (for collecting and analyzing the problem content), decision maker (for invoking suitable tool and generating formatted command), shell operator, programmer, web explorer, reference checker, and serves as the core pipeline for executing the “think-decide-act-reflect” loop. The Knowledge module aggregates information specific to the given CTF problem, including challenge descriptions, clues, hints, and other relevant context. The Computer Host module provides an execution environment for tool invocation, enabling agents to interact with it through various modalities.
Enhancing agents with the ability to invoke external tools proves to be an effective approach in solving CTF challenges, as many such tasks involve rigorous and complex computational procedures that are prone to failure due to hallucinations. We equip agents with four primary external capabilities: (1) performing basic interactive operations via terminal control; (2) generating and executing code to accomplish core problem-solving tasks; (3) leveraging web browsing to expand the range of accessible tools; (4) summarizing and extracting content from attachments.
For both human players and intelligent agents, establishing a clear analytical backbone throughout the problem-solving process is essential. For language models in particular, intermediate interactions resulting from tool invocation can consume a substantial amount of context length, and the progressively expanding analysis can obscure the main logic. Therefore, adopting a multi-agent architecture becomes a natural solution, allowing different agents to handle heterogeneous tasks while maintaining control over dialogue length and context relevance.
Figure 2 presents an example of our agents solving a classical cipher challenge. The agents first identify the cipher as Base64 encoding and generate a script to decode it, resulting in another ciphertext. They then determine that the new ciphertext likely uses a substitution cipher, hypothesize that it may be encrypted using the Vigenère cipher, and utilize a web-based decryption tool to recover the plaintext question. Then the answer to the question is given, and the test is passed. In this process, the agent directly solves simpler ciphers through programming, while delegating more complex or computation-intensive tasks to efficient external tools.
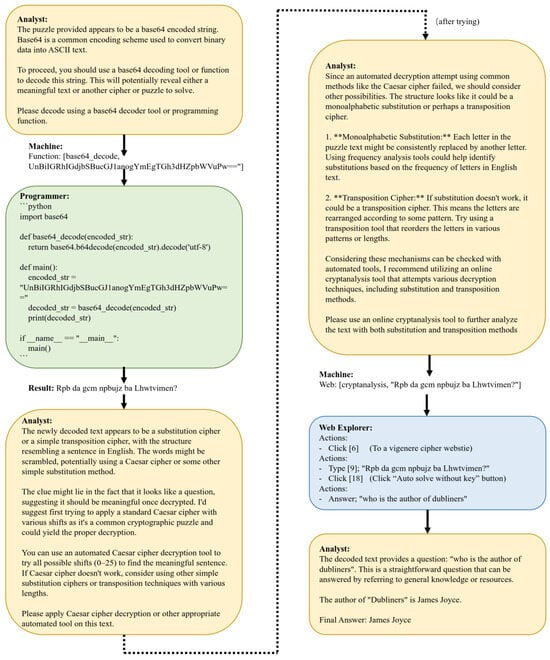
Figure 2.
An example of solving a CTF challenge. Rounded rectangles with different background colors represent distinct agents (Analyst, Programmer, and Web Explorer). Each iteration begins with the Analyst and leads to a specific action. The “Machine” field denotes the formal instruction generated by the Decision Maker based on the Analyst’s reasoning. The “Result” field is the new information propagated to the next iteration. Chat messages are arranged in Markdown format.
3.2. Components of the LLM Agents
The LLM agents serve as the core intelligence driving the entire problem-solving process. Each agent has distinct roles, including reasoning, decision-making, and task-specific execution. Performance is enhanced through prompt engineering, contextual processing techniques, and more.
3.2.1. Analyst
The analyst simulates the human cognitive process. Initially, it takes the challenge description as input and looks for the clues using natural language. It then proposes potentially effective next-step actions, which are executed by other agents, with results returned to the analyst. This cycle repeats—analyzing all gathered clues and proposing new actions—until a final solution is obtained. The analyst maintains persistent memory to plan and track the overall problem-solving process.
The separation of “thinking” and “execution” introduced by the analyst aligns well with the natural process of solving CTF challenges: humans rarely extract insights solely from the problem statement; rather, they rely on various tools and utility programs, while not necessarily understanding their internal workings.
3.2.2. Decision Maker
The decision maker has a straightforward role. It takes the unstructured output from the analyst and produces a structured instruction that the framework can act upon.
The decision maker’s output is constrained to the following formats:
- Shell: Execute a command through interaction with a terminal.
- –
- Decrypt: Attempt to solve a problem using automated decryption tools. It is actually a shell operation, but common enough to warrant a dedicated instruction. We link this directive to the open-source project Ciphey [36], see Section 3.3.1.
- Program: Generate a piece of code to perform a specific task.
- Web: Open a browser to complete a task or search for specific information.
- Refer: Review the problem’s attachment files and extract relevant information or clues.
While the task of generating structured outputs could be integrated into the analyst’s responsibilities, we separate it for following key reasons: (1) the analyst is encouraged to explore multiple perspectives and may not consistently identify the optimal decision in long contexts, nor easily shift strategies after failed attempts; (2) the expressions used in reasoning and in execution may differ—for instance, while the analyst may identify a string as “morse-like,” there are several encoding variants that differ in compatibility with automated tools, requiring further refinement by the decision maker; (3) modularizing this process allows the analyst’s output to remain completely unconstrained, enabling human users to directly substitute their own reasoning in place of the analyst, thus enhancing the framework’s potential for human-AI collaboration.
It is worth noting that some models based on deep thinking before response share similarities with our analyst-decision maker design. In later experiments, we integrated the Deepseek-R1 model [30] to replace the prompt-based analyst and decision maker, which also produced promising results.
Among the five types of instructions listed above, all except for automated decryption require further interaction with LLM-based agents. The following four sections explain the implementation details of these capabilities.
3.2.3. Shell Operator
Many CTF problems include attachments or auxiliary data whose size is high or require additional processing, making them impractical to input directly into the model. To address this, we launch a real shell environment and place the attachments in the working directory for inspection. The shell operator is responsible for issuing shell commands as needed—such as reading files, writing outputs, or running specific scripts—which are executed in the real environment.
Ideally, the shell operator’s main task is to extract supplementary information from the attachments and provide it to the analyst. It is generally not expected to solve the core part of the challenge since single-line shell commands are typically insufficient for complete problem solving.
3.2.4. Programmer
The programmer receives the problem statement, along with outputs from the analyst and decision maker, and generates a Python script. This script is executed locally, and its output becomes the final result of the current iteration. If the code execution fails, the error message is returned to the programmer for revision. If repeated attempts are unsuccessful, the system assumes that the earlier analysis or decision may be flawed and passes the error upstream as feedback for reanalysis or alternative approaches.
3.2.5. Web Explorer
The web explorer controls a real browser to perform specific tasks. In each interaction, the browser’s interactive elements (e.g., buttons, input fields) are extracted and formatted as a JSON structure, along with a screenshot of the current webpage. This information is passed to the agent, which analyzes the page and determines the appropriate operation.
Web explorer is available and can take actions such as clicking, dragging, typing, scrolling, and navigating back. These actions are executed through a WebDriver, and the resulting state is fed back to the web explorer in the next step. When the task is completed, the obtained information is recorded as the final result for that iteration.
Our prompt design for the web explorer is inspired by WebVoyager [37]. Unlike typical browsing agents, our web explorer is tasked with using online tool websites and actively engaging in complex interactions to obtain results. To support this, we annotate as many interactive elements as possible and design a home page listing a curated set of model-friendly tool websites. This significantly improves interaction efficiency and stability.
Overall, the shell operator and web explorer endow the language model with the ability to invoke external tools. Aside from the integrated decryption utility, our framework does not hardcode any external tool interfaces. This decision is based on the complexity and diversity of tools involved in CTF solving, as well as our intent to leverage the agent’s learning and exploration capabilities. In later evaluations, the web explorer’s behavior in challenging situations demonstrated the value of this design choice.
3.2.6. Reference Checker
The reference checker receives a problem-related attachment and a specific task, and it analyzes the file to extract valuable information. If deemed necessary, the full content of the file can also be passed directly to the analyst in the next iteration. Compared to shell-based file access, the reference checker excels in extracting key information and simplifying the core analysis workflow. It is particularly well-suited for handling textual documents in long-context scenarios.
3.3. Non-LLM Components
Due to the inherent limitations of LLMs, agents often struggle to handle low-level details effectively through reasoning alone. A common solution is to augment the agents with external tools, which they can invoke via function interfaces or within simulated environments, as well as to provide access to external knowledge bases. In our framework, we equip agents with a shell environment and a visually annotated browser interface, and supply external knowledge derived from specific CTF challenge hints.
3.3.1. Local Shell Environment
The Shell Operator is capable of executing commands in a real terminal, granting access to a variety of commonly used software packages. We provide tools frequently used by CTF participants, and agents are also permitted to invoke basic system functionalities as needed.
Additionally, for certain commonly used but syntactically complex functions, we offer agents standardized function interfaces. For instance, we integrate Ciphey, a natural language processing-based cryptographic tool, allowing the Decision Maker to call it directly. Such automated function-calling tools reduce overhead and improve stability for simpler tasks.
3.3.2. Browser and Annotated Web Pages
The Web Explorer can issue commands to interact with a real browser. Since web exploration involves both interactive elements and visual input via screenshots, each actionable item on the webpage must be indexed. To support this, we annotate webpage elements. Our design draws inspiration from the GPT-4V-Act project [38], and takes some heuristic improvements. First, a JavaScript script identifies interactive elements. These are then highlighted with bounding boxes and labeled numerically. The resulting annotated screenshot, along with a simplified DOM tree, is passed to the agent for decision-making.
As some interactive websites have complex or poorly structured front-ends, we apply several techniques to improve annotation quality. These include using event listeners to identify active elements, analyzing nested and parallel structures when many interactives are present, and filtering out visually abnormal elements (e.g., with irregular dimensions).
3.4. Human Hints and Supervision
CTF challenges are typically designed with non-linear logic and often contain misleading information, which presents a significant challenge to the LLMs’ reasoning capabilities. While our prompts encourage agents to recover from errors through iterative attempts, in some cases, they may become stuck and unable to recover. In such situations, external human hints have been shown to be both reasonable and highly effective in improving performance.
Furthermore, given the potential risks of terminal operations and unsupervised browsing, human oversight during the automated process is necessary to ensure the agents stay on track.
Therefore, human hints and supervision are integrated into the system. To preserve the evaluative value of the agents’ performance, we limit external intervention during assessments to minimal cues, including the name of the encryption algorithm involved, descriptions of non-standard techniques used in the challenge, officially released hints, and essential keys learned from other challenges. Supervision is restricted to intervening when agents execute dangerous commands or repeatedly fail, and even then, only instructing them to abort the current course of action without providing direct guidance.
4. Implementation
This section details the implementation aspects of our multi-agent framework, covering the core code structure, the deployment environment, and the integration of external tools.
4.1. Framework Code Implementation
The core functionality of our multi-agent framework was meticulously implemented and comprised approximately 2000 lines of code and a prompt for each agent. This implementation encapsulates the fundamental architectural design, including the iterative pipeline structure that orchestrates the agents’ workflow. Each iteration within this pipeline facilitates a structured approach to problem-solving, allowing agents to sequentially process information, formulate strategies, and execute actions. The idea and examples of our prompt design can be found in Appendix A and the Supplementary File.
The framework provides well-defined interfaces for environment interaction, allowing agents to perceive the state of their operational environment and execute actions that modify it. Furthermore, provisions for human intervention are integrated, offering operators the ability to monitor agent activities, debug, or interrupt risky behavior when necessary.
4.2. Operating System Deployment
The multi-agent framework is deployed on a dedicated system running Ubuntu 24.04.7. This environment is configured with our custom multi-agent program, its dependencies, a collection of CTF tools, and the Chromium browser with its WebDriver for web interaction. All operational commands from LLM agents are executed directly on the host machine.
A critical design decision regarding deployment concerned the choice between containerization and virtualization. Given that browser interaction is a core capability of our agent and inherently requires a desktop environment, and considering the known compatibility challenges and overheads associated with running Linux desktop environments reliably within Docker containers, we opted to package the entire system as a virtual machine rather than a Docker image for deployment. This VM-based approach provides a complete, isolated desktop environment, mitigating potential display server or graphics issues often encountered in containerized desktop setups.
4.3. External Tools
External tools are provided through different channels to ensure abundance, optimal performance, and accessibility for the agents. We installed commonly used CTF tools directly within the operating system to meet the agents’ immediate calling requirements, ensuring these essential utilities are readily available for various security analysis tasks. Concurrently, to streamline web-based interactions and enhance efficiency for agents focused on web exploration, we designed a custom browser homepage. This homepage provides convenient entry points to frequently accessed websites and resources, thereby simplifying navigation and accelerating information retrieval. Table 1 shows some typical tools we provided to agents.

Table 1.
Some examples of external tools provided to agents. We categorize external tools by type of functionality and approach to access. The external tools here are not exhaustive of what agents can use, and agents can still obtain more tools by installing packages or searching on the web.
It is worth noting that our agents are not strictly limited to utilizing only the tools explicitly provided in the aforementioned table. Our implementation is designed with extensibility, allowing agents to dynamically install necessary tool packages via software package managers (like apt and pip). Furthermore, agents possess the capability to directly use search engines to discover and leverage more suitable tool websites or online services as needed, demonstrating a high degree of adaptability and self-sufficiency in acquiring new resources.
5. Evaluation
5.1. Dataset
5.1.1. Puzzles from Ghost in the Wires
Ghost in the Wires (GITW) is the biography of hacker Kevin Mitnick, comprising 38 chapters. In the original English edition, the author attached a cipher puzzle to each chapter. These puzzles are primarily encrypted using simple substitution algorithms such as Caesar ciphers and Vigenère ciphers.
The Chinese edition of GITW introduced a completely new set of CTF-style puzzles when it was published. Each chapter contains three progressively challenging sub-problems. The first sub-problem typically requires information retrieval from the text, while the latter two demand reasoning based on cybersecurity knowledge and searching techniques, closely similar to real CTF challenges.
We selected the GITW puzzles for two main technical reasons: (1) the puzzles are mainly of the Crypto and Misc categories, which makes them more interpretable and runnable for LLM agents; (2) the Chinese version was published over a decade ago, and the difficulty level remains moderate while covering a broad range of topics, making it suitable for assessing the current capabilities of large language models.
Our dataset includes the following: all 38 original puzzles from the English version; all 76 cybersecurity-related puzzles from the Chinese version, consisting of 44 Crypto problems and 32 Misc problems, where 55 are plain-text among all.
5.1.2. THUCTF Challenges
THUCTF is a CTF competition organized by the Blue-Lotus and Redbud CTF teams of Tsinghua University. The competition features a well-defined difficulty gradient across problems and covers a wide range of cybersecurity domains. Its design makes it a strong representative of contemporary high-difficulty CTF competitions.
Our dataset collects materials from six editions of THUCTF, spanning from 2018 to 2023, including all 30 Crypto challenges and all 40 Misc challenges.
The general statistics of the datasets that we collected for evaluation are summarized in Table 2.
Table 2.
An overview of the dataset used for evaluation. GITW refers to puzzles from English and Chinese books of Ghost In The Wires, where the puzzles in the Chinese book include both plain text and multimodal problems. THUCTF is a real CTF competition dataset, of which we chose Crypto and Misc problems as experiments.
5.2. Experimental Methodology
5.2.1. Baselines
We compare our multi-agent framework against the native ChatGPT-4o equipped with specially designed prompts. Although we aim to analyze the improvements brought by external tools to large models in solving CTF challenges, solving such problems solely with the capabilities of LLM is largely infeasible. Taking ciphertext analysis tasks as an example, token-based natural language processing cannot effectively segment ciphertexts, which prevents the model from understanding their structure or identifying the encryption methods used. Forcing LLMs to attempt these tasks often results in hallucinations during reasoning, leading to unsatisfactory performance.
Therefore, we adopt the native ChatGPT-4o with enabled function calling and web search capabilities as our baseline to assess the general performance of LLMs when supported by basic programming and search functionalities.
To ensure fairness in comparison, we designed prompts for ChatGPT-4o that closely align with our agent framework. Specifically, we retained the identical background descriptions and information guidance used in our analyst agent within the ChatGPT-4o prompts. The distinction lies in output formatting: rather than constraining ChatGPT-4o’s response structure, we instruct it to utilize its built-in code execution and web search capabilities as needed to achieve optimal performance. Additionally, we conducted manual verification and evaluation of the results to ensure the reasonableness and fairness of the assessment process.
5.2.2. Comparative Methods
To provide a comprehensive comparison and benchmark our proposed approach, we selected two prominent agent projects within the CTF domain: NYUCTF Agents [28,39] and HackSynth [27]. These projects represent influential efforts in automated CTF participation. Consider:
NYUCTF Agents: We evaluated NYUCTF Agents by specifically utilizing their D-CIPHER Multiagent System. To ensure compatibility, our datasets were converted into the JSON format acceptable by their system. This allowed for a direct evaluation against a sophisticated multi-agent architecture designed for CTF challenges.
HackSynth: HackSynth implements benchmarks derived from PicoCTF and OverTheWire, and we adapted our datasets to a similar format. It is worth noting that HackSynth’s support for file operations was not fully robust in its original implementation. Therefore, we applied minor modifications to its codebase to enable the normal execution of our tests, and these modifications did not alter HackSynth’s core logic or performance characteristics.
For a fair and consistent comparison across all methods, including our own, we employed GPT-4o as the underlying base model for all agents. Furthermore, all comparative experiments were conducted and scored under the exact same stringent standards and evaluation metrics as our proposed work, ensuring an unbiased assessment of relative performance.
5.2.3. Our Framework Deployment
To eliminate the influence of model performance discrepancies, our multi-agent framework is also powered by the GPT-4o model. Additionally, as mentioned earlier, we also experimented with the Deepseek-R1 model on the GITW-ZH dataset to evaluate the impact of different reasoning models on our framework.
Given that the problems in the GITW and THUCTF datasets differ in style and objectives, we crafted distinct prompt templates for each, but kept minimum changes (for example, the format of the flag).
5.2.4. Experimental Design
Environment Setup: Some THUCTF tasks require a containerized environment. We deployed these directly on the local host machine and used prompts to inform the model about how to interact with the environment. Our framework, NYUCTF Agents and HackSynth, supports direct interaction with the container via the terminal. For ChatGPT-4o, we provided similar prompts requesting terminal commands, which were then executed manually on the local machine, with the results fed back to the model.
Input Format: For problems with plain text attachments that can be extracted without loss of essential information, the text along with the prompt was directly fed into the model. For tasks involving multiple files, multimodal content, or requiring terminal interaction, we provided a file list and instructed the model to operate within a terminal environment.
Result Evaluation: Tasks in the GITW dataset typically involve two stages: analysis and question answering. We recorded performance on both parts separately. If the model successfully produced the plaintext, the decryption was considered successful. If the question could be answered through a simple keyword search in the GITW origin over the plaintext without the need for web access or complex reasoning, we considered the task complete. Otherwise, the model was prompted to continue reasoning or search for information until a final answer was produced, at which point the task was marked as fully solved. As previously mentioned, we also tested the effect of human hints on LLM. Detailed rules of the hints can be found in Appendix B. For the THUCTF dataset, successful extraction of the final flag is used as the sole criterion for task completion. If a model solved the task entirely autonomously, the result was marked as Execution Success. Considering the difficulty and complexity of the THUCTF Dataset, we added an observation on our framework’s reasoning ability: If the agent gave a right plan to solve the problem but did not execute it successfully due to some ability limits, the result was marked as Planning Success.
In addition, for the GITW-ZH dataset, which is held as a real competition when published, we compare the performance of our framework with that of the top three human contestants in the competition, in order to analyze the gap between our framework and top-performing human participants.
5.3. Result
5.3.1. GITW Dataset
EN Puzzles: There are a total of 38 English puzzles, among which our framework successfully solved 32, achieving an accuracy of 84.2%. Among the six unsolved puzzles, four failures were due to the ciphertexts employing relatively long keys, which led the agent to fail in adjusting the search space during tool-based enumeration. The remaining two puzzles were not solved because the agent failed to correctly identify the encryption algorithm used.
ZH Puzzles: The result is shown on Figure 3. Among a total of 76 Chinese puzzles, our multi-agent framework (based on 4o) was able to independently solve 17 of them, resulting in a success rate of 22.4%. With human-provided hints, our framework solved 33 puzzles, corresponding to a 43.4% success rate. A significant portion of the unsolved puzzles involved multimodal content. After removing multimodal-related puzzles, 52 remained, among which our framework solved 17 independently and 32 with hints, achieving success rates of 30.9% and 58.2%, respectively. Focusing specifically on cryptography-related problems, there are a total of 44 puzzles. Our framework solved 13 of them independently and 28 with hints, yielding success rates of 29.5% and 63.6%, respectively.
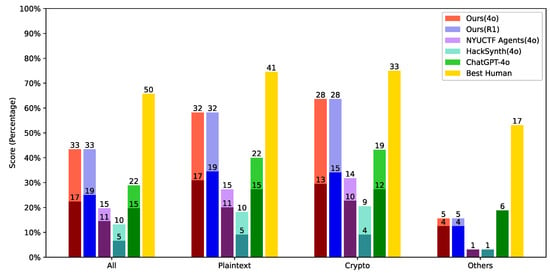
Figure 3.
Results on the GITW-ZH dataset, categorized by challenge type, where “others” includes misc, reserve, pwn, etc. For each LLM bar, the dark segment indicates the number of problems solved fully autonomously, while the light segment represents those solved with minimal human hints. The “Best Human” bar shows the actual performance of a top human player from the original competition. The height of the bars represents the success rate, and the numerical labels represent the success numbers.
In comparison, NYUCTF Agents obtained a success rate of 14.5% (independently) and 19.7% (with hints), HackSynth obtained 6.6% (independently) and 13.2% (with hints), while ChatGPT-4o (with official function calling and web search) obtained 19.7% (independently) and 28.9% (with hints).
We further analyze the problem-solving strategies adopted by the agents when tackling specific questions, as illustrated in Figure 4. For the agent powered by GPT-4o, the proportions of questions solved using local tools, code generation, and web-based tools are 12.1%, 39.4%, and 45.5%, respectively, which highlights the effectiveness of our proposed approach.
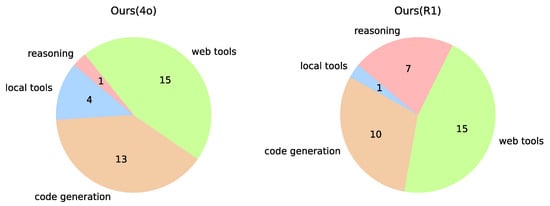
Figure 4.
The distribution of solution methods applied to the GITW challenges. For some challenges solved using multiple methods, only the most significant one is recorded.
Moreover, the differences in reasoning paths between agents using GPT-4o and Deepseek-R1 further demonstrate the impact of the reasoning model on problem-solving performance. Specifically, although our framework achieves the same score when using GPT-4o and R1 as the base models with human hints, Deepseek-R1 shows a stronger tendency to directly perform calculations during the reasoning process and performs excellently. This characteristic enables it to demonstrate better reasoning performance on diverse and non-standard problems, which also explains why it outperforms GPT-4o in scenarios without human hints. Case 2 in Section 5.4 will fully illustrate this phenomenon.
5.3.2. THUCTF Dataset
The result is shown in Figure 5. As a real-world contemporary competition, THUCTF presents significant challenges for both human participants and AI agents. Out of a total of 70 problems, our framework successfully solved 3 and produced correct solution plans for 7, achieving a success rate of 4.29% and a planning success rate of 10%. Among these, our framework solved two problems in the Crypto category and one in the Misc category, and generated correct solution plans for five Crypto problems and two Misc problems, respectively. Both NYUCTF Agents and HackSynth passed 1 Crypto problem and 0 Misc Problem. Due to the difficulty of collecting essential information for interaction, the baseline model ChatGPT-4o did not pass any problem in the test.
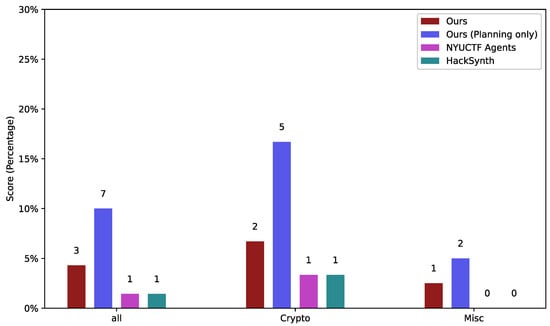
Figure 5.
Results on the THUCTF dataset; all agents based on GPT-4o were run. Planning only indicates cases where agents had already produced a correct solution plan but may have failed to complete the task in the execution environment.
In this context, our framework encountered various challenges, including failure to extract key information and clues from the problem statements, difficulty in understanding the intended objectives of the tasks, and inability to generate appropriate exploit scripts.
5.4. Case Study
Figure 6 shows several real cases of solving challenges, revealing the advantage of our framework as well as its challenges.

Figure 6.
Several real cases of our framework attempting to solve challenges. Only the key steps that led to critical clues or eventual failure are shown; other steps are omitted for brevity.
- Case 1: Extension of External Tool Usage
In the GITW-ZH-3.3 test, the problem involved a Monoalphabetic Substitution Cipher. Initially, the agent failed to correctly identify the encryption scheme and attempted to decrypt the ciphertext using a Vigenère cipher tool via the browser. However, after this attempt failed, the agent recognized that its initial assumption about the cipher type was likely incorrect. It then proactively used a Cipher Identifier Tool available on the same website, followed the suggested identification result, navigated to the correct decryption tool, and ultimately obtained the correct answer. This case illustrates the agent’s emerging ability to generalize tool usage, demonstrating not only basic tool invocation but also the capacity to adjust strategy, recover from failure, and make use of auxiliary web-based resources in a goal-directed manner.
- Case 2: Analytical Capabilities of the Reasoning Model Itself
In the GITW-ZH-13.3 test, the problem presented the ciphertext:
9\4|2\8\’7/8\4|3|6/7|4/4\4/6|2\5/3/2\6\4/5/9/6|2\6\3|6/3/4|2\7|7|9/4|6/
8|3\4/6|4/?.
The intended solution required interpreting each digit-symbol pair as a unit and mapping it to a letter. When GPT-4o was used as the base model of our framework, the agent failed to identify the correct strategy for decoding the ciphertext. In contrast, when powered by Deepseek-R1, the agent demonstrated more flexible and exploratory reasoning during its internal “Thinking” process. It attempted multiple interpretations of the format and eventually discovered the correct decoding strategy by recognizing the structure as a variant of the Telephone Keypad encoding. This allowed the agent to correctly solve the problem.
This case highlights the impact of reasoning models on problem-solving effectiveness. Deepseek-R1 exhibited greater adaptability in ambiguous scenarios and was able to identify non-obvious semantic patterns.
- Case 3: Failure Case of THUCTF Problems
Within the THUCTF dataset, the causes of failure differ, one of the most common being the agent’s inability to effectively process the information provided. This results in poor performance even on seemingly simple problems.
In the THUCTF Emojicorre problem, the ciphertext consisted of a large sequence of emoji characters, suggesting that each emoji likely corresponded to a letter in a substitution cipher. The agent successfully inferred that. However, instead of performing any preprocessing or transformation, it directly inputs the emoji string into the QuipQiup [40] website, a tool designed for solving letter-based substitution ciphers. Since QuipQiup does not support emoji characters and operates only on alphabetical inputs, the tool failed to produce a meaningful result. This case highlights the agent’s limitations in adapting input formats to tool requirements and reflects a broader issue: the lack of robustness in reasoning and data preprocessing when faced with a changing situation.
5.5. Failure Analysis
We have summarized the reasons for our framework’s failures in some cases from the GITW-ZH dataset, as shown in the Table 3.
Table 3.
Failure analysis of our framework on GITW-ZH test.
The primary reason is that the agent is unable to analyze the problem and plan correctly. Specifically, some problems might involve complex structures or use rare encryption methods, requiring meticulous observation and analysis, which poses a significant challenge for LLMs. A secondary reason is that some multimodal information cannot be effectively processed. Although we provide tools for such operations, incorrect tool selection or excessively long tool outputs might prevent LLMs from identifying key clues. Furthermore, some failures are caused by the inability to find suitable tools or by code errors.
5.6. Token Consumption
To evaluate the efficiency of our multi-agent framework, we conducted a comprehensive analysis of token consumption across different components and interaction patterns. We measured token consumption at two granularities: average consumption per completed task and average consumption per invocation of each agent module.
Table 4 provides a detailed breakdown of token consumption for each agent module. Web Explorer consumes the highest number of tokens, as each web operation requires a round of conversation, and it needs to input both the webpage’s DOM information and screenshots into the model, both of which require a considerable number of tokens. The second highest consumer is Analyst, due to its need to output natural language analysis while maintaining conversation history. It should be noted that Programmer and Web Explorer are not invoked every time; their invocation rates in the GITW-ZH task are approximately 40% and 50%, respectively, which means that token consumption can be reduced for simpler challenges.
Table 4.
The Average Token Consumption of our framework successfully passed on the challenges on the GITW-ZH dataset.
6. Discussion
6.1. The Effect of External Tools
In the evaluation on the GITW Dataset, a key factor contributing to the improved success rate of our agent was its effective use of external tools. Most of the challenges in this dataset involved classical ciphers, which would require significant time to solve via brute-force enumeration alone. In contrast, certain external tools are specifically optimized for these tasks and can produce results within a much shorter timeframe.
During testing, our agents exhibited a degree of transferability in both invoking and adapting to external tools. For instance, after identifying a problem as involving a particular cipher, the agent first attempted to write a decoding script. When the execution of the code failed, it made efforts to debug and fix the issue; upon repeated failure, it shifted strategy and searched the web for relevant tools. However, since our experiments include lots of cryptography-related tasks, most of the integrated tools tested were also cipher-specific. This highlights a current limitation in tool coverage and indicates significant room for future improvement in adapting external tools to a broader range of problem types.
6.2. LLM’s Limitations
As previously discussed, LLMs are not equipped with the capability to analyze the encryption algorithms used in most ciphertext problems in principle. While there are some heuristic techniques from traditional cryptanalysis that can be mimicked—such as identifying high-frequency words like “the” in classical ciphers to reconstruct partial substitution tables and subsequently infer or break the encryption scheme—these approaches typically require extensive trial-and-error and rely heavily on reasoning, making them difficult to replicate purely through code execution. In evaluation, the model occasionally attempts such strategies, but these attempts almost invariably fail.
Moreover, large models struggle to analyze problems involving non-standard or obfuscated encryption techniques. For example, some problems encode numbers by the count of dot characters, or replace Morse code symbols “.-” with binary strings such as “01”. These seemingly simple transformations often confuse the model: it may misinterpret the dots as Morse code or regard the “0–1” string as a binary number. In such cases, only manual hints can effectively guide the agent toward a correct interpretation.
These limitations collectively contribute to the agent’s poor performance on THUCTF problems. The models often lack a thorough understanding of algorithmic details, are unable to engage in iterative coding-based exploration to grasp problem semantics, and are easily misled by irrelevant clues embedded in the question.
After changing the base model of our framework to Deepseek-R1, the agent shows better reasoning ability, especially more robust in the face of situations such as symbol confusion. This suggests that enhancing the model’s ability to persistently reason and analyze such problems—potentially through fine-tuning on domain-specific tasks—may offer a viable path to improving its performance.
6.3. Ethical Considerations
The deployment of LLM-based agents in CTF competitions raises several important ethical considerations. Our work shows that LLMs still lack the knowledge and reasoning capabilities for fully independent competitive participation, making them more suitable as auxiliary consultation tools for human contestants. This shift may influence learning pathways and competitive strategies, necessitating new guidelines for competition fairness and the permissible extent of AI assistance.
Our research approach focuses on mimicking human operational logic and automation engineering rather than developing novel attack methodologies. The multi-agent framework operates within the same conceptual boundaries as human contestants, utilizing similar tools and reasoning patterns. As such, our work presents no significant direct risks to competition integrity or cybersecurity practices.
From a broader perspective, LLM automation in cybersecurity presents both opportunities and risks. While such technologies can enhance cybersecurity professionals’ efficiency in threat detection and vulnerability assessment, we must remain vigilant about potential malicious exploitation by adversarial actors. This duality underscores the importance of responsible research practices and proactive development of corresponding defensive measures alongside offensive capabilities.
7. Conclusions
We propose the application of a multi-agent framework to the automated solving of CTF challenges and design a dedicated execution and evaluation framework tailored to the practical requirements of such tasks. Our agents demonstrate strong reasoning capabilities on relatively concise and representative problems, exhibiting more stable and effective performance over longer problem-solving processes, and efficiently leveraging external tools to aid in solution generation.
Our framework provides an interpretable solution for CTF problem-solving. The multi-agent approach effectively simulates the cognitive processes and decision-making patterns employed by human competitors when tackling CTF challenges. The transparent reasoning mechanisms inherent in our system not only enhance the explainability of the solution process but may also offer valuable insights to human players, potentially serving as a learning tool to improve their problem-solving strategies.
On the Chinese version of the GITW dataset, our framework achieved success rates of 22.4% in the autonomous setting and 43.4% with human-provided hints. These results show that our framework significantly outperforms ChatGPT-4o and some other related works, even when they are equipped with basic code execution and web search functionalities.
In tests more closely resembling current standard CTF competitions, our framework showed slight performance improvements and revealed the limitations of LLMs’ inherent reasoning capabilities. Optimizing in this area presents a promising direction for future research.
In tests more closely resembling current standard CTF competitions, our framework showed slight performance improvements but also revealed its limitations. That highlights the existing limitations of LLMs in the CTF domain and, more broadly, in cybersecurity applications. These limitations primarily manifest in constrained reasoning capabilities and poor generalization across diverse problem types. While human-provided hints and enriched external tools demonstrate effectiveness in mitigating these issues, the fundamental enhancement of base model performance emerges as a critical direction for future exploration. Such improvements could potentially bridge the gap between current automated approaches and the sophisticated reasoning required for complex cybersecurity challenges.
Supplementary Materials
The following supporting information can be downloaded at: https://www.mdpi.com/article/10.3390/app15137159/s1.
Author Contributions
Conceptualization, J.Z. (Jianwei Zhuge); methodology, Z.H.; software, Z.H.; validation, Z.H., J.Z. (Jinjing Zhuge); investigation, J.Z. (Jinjing Zhuge); resources, J.Z. (Jianwei Zhuge); data curation, Z.H.; writing—original draft preparation, Z.H. and J.Z. (Jinjing Zhuge); writing—review and editing, J.Z. (Jianwei Zhuge); visualization, Z.H.; supervision, J.Z. (Jianwei Zhuge); project administration, J.Z. (Jianwei Zhuge); funding acquisition, J.Z. (Jianwei Zhuge). All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by National Key R&D Program Project under grant number 2024YFE0203800.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The original contributions presented in the study are included in the article/Supplementary Material, further inquiries can be directed to the corresponding author.
Acknowledgments
We gratefully acknowledge the assistance of THUCSTA in the construction of the THUCTF dataset.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| CTF | Capture the Flag |
| LLM | Large Language Model |
| GITW | Ghost in the Wires |
| CoT | Chain of Thoughts |
| VM | Virtual Machine |
Appendix A. Agent Prompts
Appendix A.1. Overview
In our practice, the design of prompts follows several key principles:
- Clearly define the task and output format for each agent to ensure the proper functioning of the workflow.
- To enhance generalizability in complex problem settings, we rely on rule-based guidance rather than extensive examples.
- Adapting prompts to the common characteristics of the dataset is necessary. The prompts provided below are those used in the GITW evaluation.
We illustrate our design using the prompts of the Analyst and Programmer agents.
Appendix A.2. Analyst
The Analyst is primarily responsible for analyzing the task information and generating insights. Considering the inherently hidden nature of clues in CTF challenges, we combined the Chain of Thought (CoT) and Step-back prompting strategies. In the GITW evaluation, given the features of the challenges, we use prompts such as those shown below.
Your job is to imitate a human CTF player. A CTF puzzle is originally a cipher text that appears no exactly meaning. it needs some method to be decrypted. after decrypt, finally it would become a meaningful question you can answer, or already a result (plaintext, number, etc)
Given a puzzle in form of a cipher text, here are some tips to help you analyze (you don’t need to output in that format, just make your analyze clear and concise):
1. Judge if it is encoded or encrypted by some standard algorithm like base64, caesar, vigenere, etc. If it is indeed encrypted but the algorithm is unknown, don’t guess it but use automated tools to judge.
2. Otherwise you need to analyze the structure of the text, propose a method to transform the text being meaningful or a standard encrypted text. consider its relationship to some meaningful value, like letter/words/sentence.
3. Propose a method to solve the problem, like using some decrypt algorithm or transform rule. ATTENTION that you don’t solve it directly. As a human, you just analyze the problem, and concrete operation would be taken by machine. Before you get the decrypted text, you can’t judge if it has become a plaintext, so just propose to “decrypt” instead of “decrypt to plaintext”.
4. Firstly you can call an automated program to decrypt. But it doesn’t always work, then you should turn to internet or some kind of function (also you don’t need to do it directly, just point out that). Advanced decryption can be taken by both web and function, but usually web suits those with complicated algorithm or brute-force trying, while function performs better in decoding by less resource.
5. If the input is a plain text with a question, you can propose to refer some resources for key. More precisely, the problem is from book Ghost in the Wire, and you may need the original text.
Remember that at the end of every output you must propose a determined operation so that the task can continue.
Your output should be short and contain only essential message. DON’T do any decryption or computation by yourself! Just propose what should do by natural language.
If your analyze works, you may get a new cipher text or a question and you can continue then. Otherwise you need to propose a new method to retry.
If you think you find the final answer, output “Final Answer: [answer]” to check your idea, otherwise never output words “Final Answer”. Remember that a question sentence is not the final answer, instead you should propose to refer some resources to find the key.
Appendix A.3. Programmer
When generating code, LLMs tend to produce generic examples, which can lead to unusable outputs within the agent workflow. To address this, we constrain the model with predefined rules and one-shot example. We use a prompt such as the following:
You are a programmer and need write python 3.12 codes to solve CTF puzzle.
A CTF puzzle is a cipher text that appears no exactly meaning and it needs some method to be decrypted. A human player, who has proposed the most likely way to work it out, needs you to finish it.
Your code should strictly follow these rules:
1. The script is NOT a demo. That means you cannot set any unknown argument as you want (including the cipher key and so on). Instead, try all possible conditions if necessary (for example, to decrypt a caesar cipher, you must try all offsets from 1 to 25).
2. The cipher text should be stored as a constant value instead of getting from ‘input()‘, because it has been given in the puzzle.
3. The script should contain a main function.
4. Normally your job doesn’t need any third library to accomplish, so don’t import them except the standard libs. If you really need that, use “!pip install package” to make sure it exists.
Your output should follow the format like (no other sentences):
“‘ python
code
”’
Appendix B. Human Prompting Rules
In our experimental setup, human prompts were provided to the LLM agents when necessary to guide their problem-solving process on certain challenges. This appendix details the specific rules and principles governing the creation and application of these human prompts.
Appendix B.1. General Principles
All human prompts adhered to a consistent set of principles designed to ensure fairness, transparency, and reproducibility across experiments.
- Consistency of Principles: Every prompt, regardless of the challenge or the specific issue it addressed, followed the overarching guidelines outlined below.
- Identical Prompts Across Models: When evaluating different LLM agents against the same challenge, if a human prompt was deemed necessary, the prompt used is exactly the same. This ensured that any differences in model performance were attributable to the models themselves, rather than variations in the provided guidance.
Appendix B.2. Specific Prompting Rules
The following specific rules dictated when and how human prompts were introduced:
Appendix B.2.1. Rule 1: Minimal Clues for Critical Characteristics
When an LLM agent was struggling to independently identify or analyze a critical characteristic of a problem, a minimal clue was provided. This clue aimed to point the model toward the relevant concept without revealing the detailed solution process or specific steps. For instance, if a challenge involved a particular cryptographic algorithm, the prompt might specify the algorithm’s name but not its step-by-step application or key details.
- Example: For challenge GITW-zh-5.3, which implicitly required knowledge of a specific substitution cipher, the prompt provided was the following: A1Z26. This clue directly indicated the cipher type without explaining its mechanism.
Appendix B.2.2. Rule 2: Clarifying Final Goal for Non-Standard Challenges
The GITW-zh benchmark includes a variety of challenges, some of which are non-standard or have unconventional objectives that might not be immediately apparent to an LLM. In cases where the model failed to recognize the ultimate goal or the expected format of the final output, a prompt was used to clarify the objective.
- Example: For challenge GITW-zh-5.2, where the model struggled to infer the nature of the desired solution, the prompt given was the following: final result is six digits. This clarified the expected format of the output.
Appendix B.2.3. Rule 3: Supplementary Information for Interconnected Challenges
Some challenges within the GITW-zh benchmark are interconnected, meaning that the solution or a critical piece of information derived from one challenge is a prerequisite for successfully solving a subsequent challenge. In these scenarios, necessary supplementary information was provided to establish the link between challenges. It is crucial to note that if a human prompt consisted solely of such inter-challenge linking information, the challenge was not considered to have been completed through human prompting. This is because such information is fundamental to the logical progression of the challenge sequence and does not provide a direct hint toward the internal solution of the current challenge itself.
- Example: For challenge GITW-zh-8.3, the prompt provided was the following: key = Metro Plaza Hotel Bonnie. This key was the explicit solution obtained from the preceding challenge, GITW-zh-8.2. Providing this information was necessary for the agent to even begin solving GITW-zh-8.3, but it did not assist in the internal logic or steps required to solve GITW-zh-8.3 given the key.
References
- Hanafi, A.H.A.; Rokman, H.; Ibrahim, A.D.; Ibrahim, Z.A.B.; Zawawi, M.N.A.; Rahim, F.A. A CTF-Based Approach in Cyber Security Education for Secondary School Students. Electron. J. Comput. Sci. Inf. Technol. 2021, 7, 1–7. [Google Scholar]
- McDaniel, L.; Talvi, E.; Hay, B.N. Capture the Flag as Cyber Security Introduction. In Proceedings of the 2016 49th Hawaii International Conference on System Sciences (HICSS), Koloa, HI, USA, 5–8 January 2016; pp. 5479–5486. [Google Scholar]
- Chicone, R.; Burton, T.M.; Huston, J.A. Using Facebook’s Open Source Capture the Flag Platform as a Hands-on Learning and Assessment Tool for Cybersecurity Education. Int. J. Concept. Struct. Smart Appl. 2018, 6, 18–32. [Google Scholar] [CrossRef]
- Leune, K.; Petrilli, S.J. Using Capture-the-Flag to Enhance the Effectiveness of Cybersecurity Education. In Proceedings of the 18th Annual Conference on Information Technology Education, New York, NY, USA, 4–7 October 2017. [Google Scholar]
- Vykopal, J.; Švábenský, V.; Chang, E.C. Benefits and Pitfalls of Using Capture the Flag Games in University Courses. In Proceedings of the 51st ACM Technical Symposium on Computer Science Education, Portland, OR, USA, 11–14 March 2020. [Google Scholar]
- Uralov, J. The Role of CTF (Capture the FLAG) Competitions in Increasing Students’ Interest in Cyber Security: An Innovative Approach in Education. Univers. Tech. Sci. 2024, 4, 62–64. [Google Scholar] [CrossRef]
- Venkatagiri, S.; Mukhopadhyay, A.; Hicks, D.; Brantly, A.F.; Luther, K. CoSINT: Designing a Collaborative Capture the Flag Competition to Investigate Misinformation. In Proceedings of the 2023 ACM Designing Interactive Systems Conference, Pittsburgh, PA, USA, 10–14 July 2023. [Google Scholar]
- Chang, S.Y.; Yoon, K.; Wuthier, S.; Zhang, K. Capture the Flag for Team Construction in Cybersecurity. arXiv 2022, arXiv:2206.08971. [Google Scholar]
- Kartasasmita, D.G.; Timur, F.G.C.; Reksoprodjo, A.H. Enhancing Competency of Cybersecurity Through Implementation of the “CAPTURE THE FLAG” On College in Indonesia. Int. J. Humanit. Educ. Soc. Sci. (IJHESS) 2023, 3, 875–890. [Google Scholar]
- Renaud, K.; Warkentin, M.; Westerman, G. From ChatGPT to HackGPT: Meeting the Cybersecurity Threat of Generative AI; MIT Sloan Management Review: Cambridge, MA, USA, 2023. [Google Scholar]
- Deng, G.; Liu, Y.; Mayoral-Vilches, V.; Liu, P.; Li, Y.; Xu, Y.; Zhang, T.; Liu, Y.; Pinzger, M.; Rass, S. PentestGPT: An LLM-empowered Automatic Penetration Testing Tool. arXiv 2023, arXiv:2308.06782. [Google Scholar]
- Yu, N.; Davies, L.; Zhong, W. A Dual-Approach Framework for Enhancing Network Traffic Analysis (DAFENTA): Leveraging NumeroLogic LLM Embeddings and Transformer Models for Intrusion Detection. In Proceedings of the 2024 IEEE International Conference on Big Data (BigData), Washington, DC, USA, 15–18 December 2024; pp. 7262–7271. [Google Scholar]
- Cui, T.; Lin, X.; Li, S.; Chen, M.; Yin, Q.; Li, Q.; Xu, K. TrafficLLM: Enhancing Large Language Models for Network Traffic Analysis with Generic Traffic Representation. arXiv 2025, arXiv:2504.04222. [Google Scholar]
- Adjewa, F.; Esseghir, M.; Merghem-Boulahia, L. LLM-based Continuous Intrusion Detection Framework for Next-Gen Networks. arXiv 2024, arXiv:2411.03354. [Google Scholar] [CrossRef]
- Boi, B.; Esposito, C.; Lee, S. Smart Contract Vulnerability Detection: The Role of Large Language Model (LLM). ACM SIGAPP Appl. Comput. Rev. 2024, 24, 19–29. [Google Scholar] [CrossRef]
- Lu, G.; Ju, X.; Chen, X.; Pei, W.; Cai, Z. GRACE: Empowering LLM-based software vulnerability detection with graph structure and in-context learning. J. Syst. Softw. 2024, 212, 112031. [Google Scholar] [CrossRef]
- Xia, C.; Zhang, L. Automated Program Repair via Conversation: Fixing 162 out of 337 Bugs for $0.42 Each using ChatGPT. In Proceedings of the International Symposium on Software Testing and Analysis, Seattle, WA, USA, 17–21 July 2023. [Google Scholar]
- Xia, C.; Zhang, L. Conversational Automated Program Repair. arXiv 2023, arXiv:2301.13246. [Google Scholar]
- Wickramasekara, A.; Breitinger, F.; Scanlon, M. Exploring the potential of large language models for improving digital forensic investigation efficiency. Forensic Sci. Int. Digit. Investig. 2025, 52, 301859. [Google Scholar] [CrossRef]
- Meng, X.; Srivastava, A.; Arunachalam, A.; Ray, A.; Silva, P.H.; Psiakis, R.; Makris, Y.; Basu, K. Unlocking Hardware Security Assurance: The Potential of LLMs. arXiv 2023, arXiv:2308.11042. [Google Scholar] [CrossRef]
- Xian, Y.; Lampert, C.H.; Schiele, B.; Akata, Z. Zero-Shot Learning—A Comprehensive Evaluation of the Good, the Bad and the Ugly. arXiv 2020, arXiv:1707.00600. [Google Scholar] [CrossRef]
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Chi, E.H.; Xia, F.; Le, Q.; Zhou, D. Chain of Thought Prompting Elicits Reasoning in Large Language Models. arXiv 2022, arXiv:2201.11903. [Google Scholar]
- Lewis, P.; Perez, E.; Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal, N.; Kuttler, H.; Lewis, M.; Yih, W.-T.; Rocktäschel, T.; et al. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. arXiv 2020, arXiv:2005.11401. [Google Scholar]
- Paul, R.; Hossain, M.M.; Siddiq, M.L.; Hasan, M.; Iqbal, A.; Santos, J.C.S. Enhancing Automated Program Repair through Fine-tuning and Prompt Engineering. arXiv 2023, arXiv:2304.07840. [Google Scholar] [CrossRef]
- Ali, T.; Kostakos, P. HuntGPT: Integrating Machine Learning-Based Anomaly Detection and Explainable AI with Large Language Models (LLMs). arXiv 2023, arXiv:2309.16021. [Google Scholar] [CrossRef]
- Shao, M.; Chen, B.; Jancheska, S.; Dolan-Gavitt, B.; Garg, S.; Karri, R.; Shafique, M. An Empirical Evaluation of LLMs for Solving Offensive Security Challenges. arXiv 2024, arXiv:2402.11814. [Google Scholar] [CrossRef]
- Muzsai, L.; Imolai, D.; Lukács, A. HackSynth: LLM Agent and Evaluation Framework for Autonomous Penetration Testing. arXiv 2024, arXiv:2412.01778. [Google Scholar] [CrossRef]
- Udeshi, M.; Shao, M.; Xi, H.; Rani, N.; Milner, K.; Putrevu, V.S.C.; Dolan-Gavitt, B.; Shukla, S.K.; Krishnamurthy, P.; Khorrami, F.; et al. D-CIPHER: Dynamic Collaborative Intelligent Multi-Agent System with Planner and Heterogeneous Executors for Offensive Security. arXiv 2025, arXiv:2502.10931. [Google Scholar] [CrossRef]
- Grattafiori, A.; Dubey, A.; Jauhri, A.; Pandey, A.; Kadian, A.; Al-Dahle, A.; Letman, A.; Mathur, A.; Schelten, A.; Vaughan, A.; et al. The Llama 3 Herd of Models. arXiv 2024, arXiv:2407.21783. [Google Scholar] [CrossRef]
- Bi, X.; Chen, D.; Chen, G.; Chen, S.; Dai, D.; Deng, C.; Ding, H.; Dong, K.; Du, Q.; Fu, Z.; et al. DeepSeek LLM: Scaling Open-Source Language Models with Longtermism. arXiv 2024, arXiv:2401.02954. [Google Scholar] [CrossRef]
- Schick, T.; Dwivedi-Yu, J.; Dessì, R.; Raileanu, R.; Lomeli, M.; Zettlemoyer, L.; Cancedda, N.; Scialom, T. Toolformer: Language Models Can Teach Themselves to Use Tools. arXiv 2023, arXiv:2302.04761. [Google Scholar]
- Yao, S.; Zhao, J.; Yu, D.; Du, N.; Shafran, I.; Narasimhan, K.; Cao, Y. ReAct: Synergizing Reasoning and Acting in Language Models. arXiv 2022, arXiv:2210.03629. [Google Scholar]
- Wang, B.; Fang, H.; Eisner, J.; Durme, B.V.; Su, Y. LLMs in the Imaginarium: Tool Learning through Simulated Trial and Error. In Proceedings of the Annual Meeting of the Association for Computational Linguistics, Bangkok, Thailand, 11–16 August 2024. [Google Scholar]
- Tran, K.T.; Dao, D.; Nguyen, M.D.; Pham, Q.V.; O’Sullivan, B.; Nguyen, H.D. Multi-Agent Collaboration Mechanisms: A Survey of LLMs. arXiv 2025, arXiv:2501.06322. [Google Scholar] [CrossRef]
- Qian, C.; Xie, Z.; Wang, Y.; Liu, W.; Zhu, K.; Xia, H.; Dang, Y.; Du, Z.; Chen, W.; Yang, C.; et al. Scaling Large Language Model-based Multi-Agent Collaboration. arXiv 2025, arXiv:2406.07155. [Google Scholar] [CrossRef]
- Bee, A. Ciphey: Automatically Decrypt Encryptions Without Knowing the Key or Cipher, Decode Encodings, and Crack Hashes. 2020. Available online: https://github.com/bee-san/Ciphey (accessed on 22 April 2025).
- He, H.; Yao, W.; Ma, K.; Yu, W.; Dai, Y.; Zhang, H.; Lan, Z.; Yu, D. WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models. arXiv 2024, arXiv:401.13919. [Google Scholar] [CrossRef]
- Dupont, D. GPT-4V-Act: AI Agent Using GPT-4V(ision) Capable of Using a Mouse/Keyboard to Interact with Web UI. 2023. Available online: https://github.com/ddupont808/GPT-4V-Act (accessed on 22 April 2025).
- Shao, M.; Jancheska, S.; Udeshi, M.; Dolan-Gavitt, B.; Xi, H.; Milner, K.; Chen, B.; Yin, M.; Garg, S.; Krishnamurthy, P.; et al. NYU CTF Dataset: A Scalable Open-Source Benchmark Dataset for Evaluating LLMs in Offensive Security. arXiv 2024, arXiv:2406.05590. [Google Scholar]
- Olson, E. Quipqiup: Cryptoquip and Cryptogram Solver. 2014. Available online: https://quipqiup.com (accessed on 22 April 2025).
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).