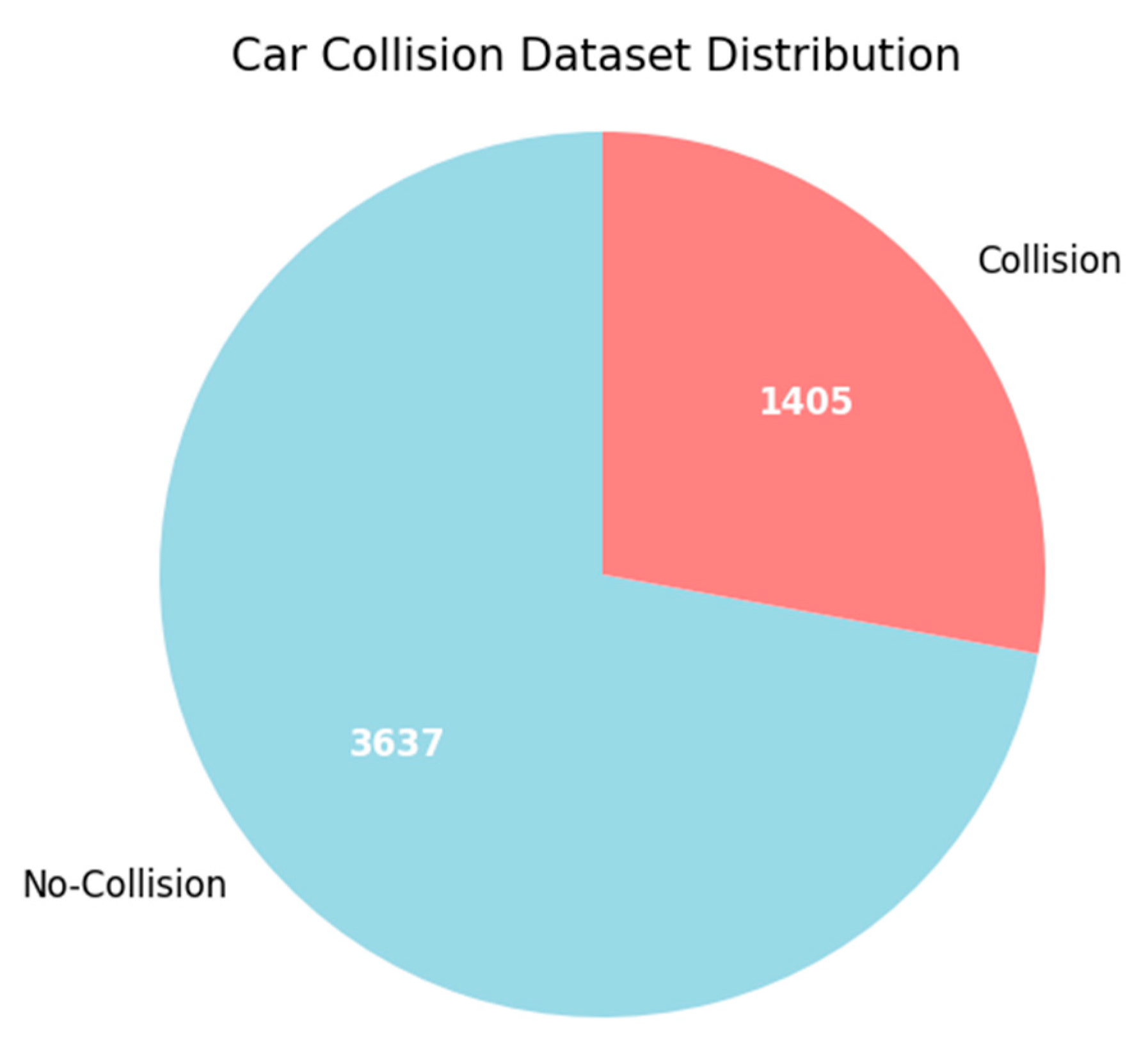
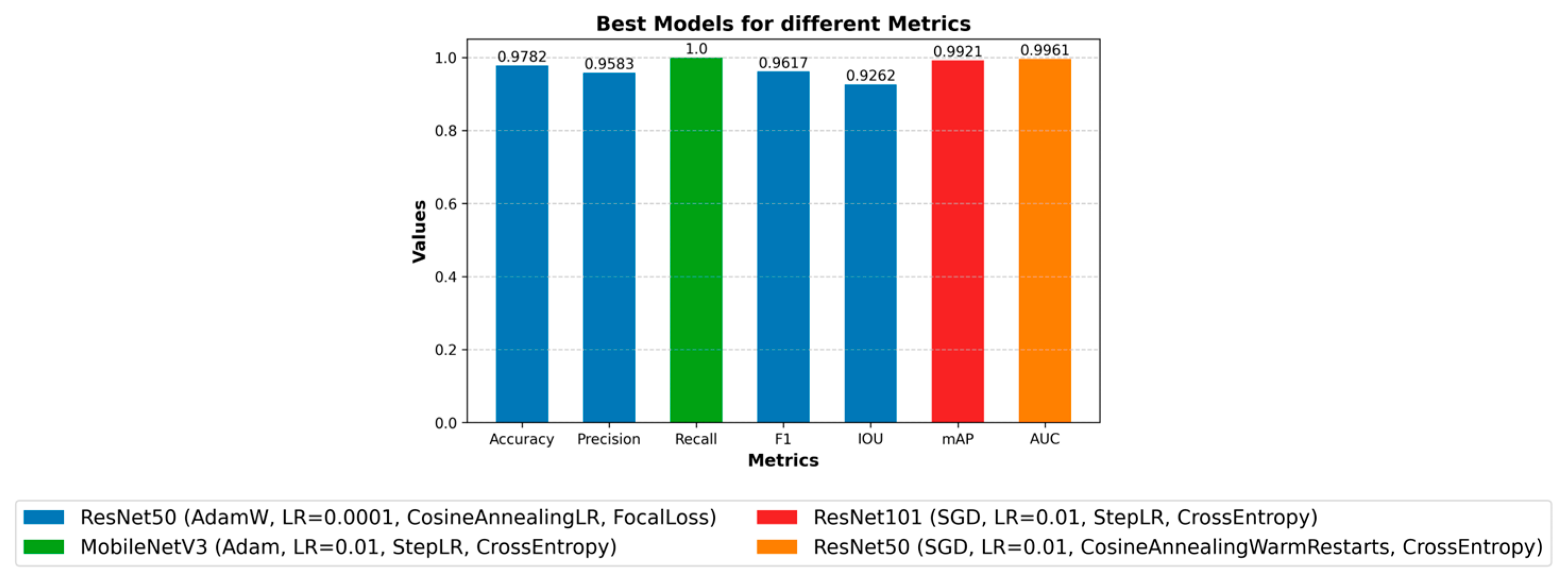
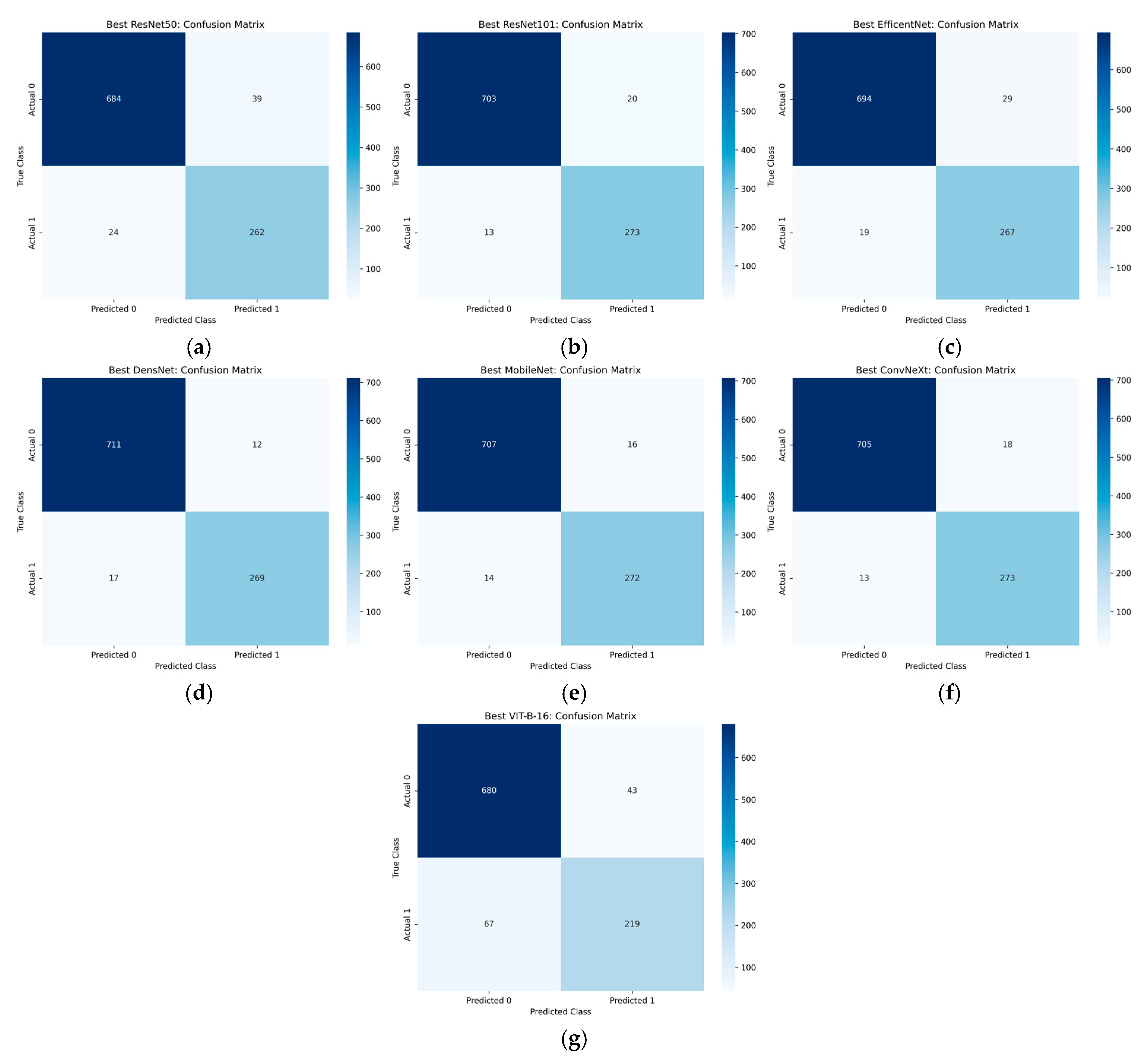
1. Introduction
Road traffic accidents represent one of the most critical public health issues of the modern era, exacting a devastating toll on human life and global economies. According to the World Health Organization (WHO), approximately 1.19 million lives are lost annually due to road collisions, with an additional 50 million individuals sustaining severe injuries [
1]. These road accidents also impact the GDP of countries, as countries allocate nearly 3% of their annual GDP to address medical expenses, infrastructure repairs, and productivity losses linked to traffic incidents. These numbers rise even more in developing countries, where traffic safety rules are sometimes lenient and emergency response systems are inadequate, which fuels poverty and public health inequality in developing countries [
2]. Moreover, according to the National Safety Council (NSC) [
3], in 2023, car collisions claimed 19,400 lives out of the 44,762 total motor vehicle deaths in the United States, making up over 43% of the fatalities.
The inherent unpredictability of road accidents poses a difficult challenge to efforts to mitigate them. Collisions frequently arise from dynamic, non-linear interactions among human error, environmental conditions, and mechanical failures—factors that defy straightforward modeling [
4,
5]. Traditional reactive approaches, such as post-accident crash analysis or manual surveillance, suffer from critical limitations: they are labor-intensive, prone to human error, and incapable of enabling real-time intervention [
6]. For instance, delayed accident detection on highways or in construction zones increases secondary risks, including prolonged congestion and delayed emergency response, which collectively increase economic losses and public frustration. The advancement in computer vision and deep learning offers transformative potential to address these gaps. Automated systems capable of real-time collision detection could revolutionize road safety by enabling proactive measures, from rerouting traffic to dispatching first-aid teams within seconds of an incident [
7].
Recent research has leveraged deep learning for traffic-related applications, including vehicle detection [
8,
9,
10], pedestrian tracking [
11], and accident severity assessment [
12,
13,
14]. Zhou [
15] proposed an attention-based Stack ResNet for Citywide Traffic Accident Prediction framework which combines static spatial data with dynamic spatio-temporal information using a ResNet-based model and an attention mechanism to prioritize temporally relevant features and incorporates a speed inference module to address missing speed data. Jaspin et al. [
16] proposed an automated, real-time Accident Detection and Severity Classification System that leverages YOLOv5 to identify accidents in video images and a machine learning classifier to categorize them into mild, moderate, or severe levels, triggering rapid alerts to authorities. To reduce latency and network usage in emergency detection, Banerjee et al. [
17] proposed a Deep Learning-Based Car Accident Detection Framework which employs a 2D CNN on edge nodes for local video processing while offloading essential data to the cloud for further analysis.
Huang et al. [
18] proposed the challenge of detecting near-accidents at traffic intersections in real-time, such as sudden lane changes or pedestrian crossings. They introduce a two-stream (spatial and temporal) convolutional network architecture designed for real-time detection, tracking, and near-accident prediction. The spatial stream uses the YOLO algorithm to detect vehicles and potential accident regions in individual video frames, while the temporal stream analyzes motion features across multiple frames to generate vehicle trajectories. By combining these spatial and temporal features, the system computes collision probabilities, flagging high-risk regions when trajectories intersect or come too close. Le et al. [
19] proposed a two-stream deep learning network called Attention R-CNN to tackle the inability of traditional object detection methods to recognize not just the presence of objects but also their characteristic properties, such as whether they are safe, dangerous, or crashed, present in autonomous driving systems. The first stream leverages a modified Faster R-CNN to detect object bounding boxes and their classes, while the second stream, employs an attention mechanism to integrate global scene context with local object features, enabling the recognition of properties like “crashed” or “dangerous”. Javed et al. [
20] address the shortcomings of existing accident detection systems, such as high false-positive rates, vehicle-specific compatibility issues, and high implementation costs, which delay emergency responses and increase road fatalities in smart cities. They developed a low-cost IoT kit equipped with sensors to collect real-time data like speed, gravitational force, and sound, which is transmitted to the cloud. A deep learning model based on YOLOv4, fine-tuned with ensemble transfer learning and dynamic weights, processes this data alongside video footage from a Pi camera to verify accidents and minimize false detections. Amrouche et al. [
21] proposed a convolutional neural network (CNN)-based model for car crash detection using dashcam images, aiming to enable rapid and precise accident identification. Praveen et al. [
22] proposed a framework that integrates IoT sensors with machine learning to enable real-time accident detection and risk prediction. IoT sensors installed on vehicles continuously collect data such as speed, acceleration, brake force, and lane deviation, transmitting this information wirelessly to a central system. The data are then processed using the Adaptive Random Forest algorithm that dynamically learns from incoming data to identify patterns indicative of accidents or high-risk situations. When parameters exceed predefined thresholds, such as excessive speed or sudden braking, the system issues alerts to drivers and may activate safety mechanisms like automatic braking. Pre-trained models have shown promising results in transfer learning scenarios, adapting to specialized tasks with limited data [
23,
24]. However, their application to car collision detection using dashcam images remains underexplored, particularly in optimizing hyperparameter configurations for real-world deployment.
This study provides a systematic evaluation of SOTA deep learning architectures for car collision detection to test their adaptability and performance under different hyper parameter settings. We fine-tune seven pre-trained models (
Table 1) under varied hyperparameter configurations (
Table 2) to identify optimal trade-offs between accuracy, computational efficiency, and localization reliability. The proposed framework holds significant practical implications. By automating collision detection, municipalities can reduce reliance on error-prone manual monitoring, accelerate emergency response times, and dynamically optimize traffic signals to mitigate congestion.
The rest of this paper is organized as follows: The
Section 2 outlines the processes of data collection, data labeling, model selection, model customization, loss functions, optimizers, schedulers, and the training pipeline. The
Section 3 explains the benchmark metrics for each model, and the
Section 4 presents comparative findings of all the best models selected for each performance metric. The
Section 5 explores the effects of different parameters in detail, while the Conclusion provides a summary and final remarks.
3. Evaluation Metrics
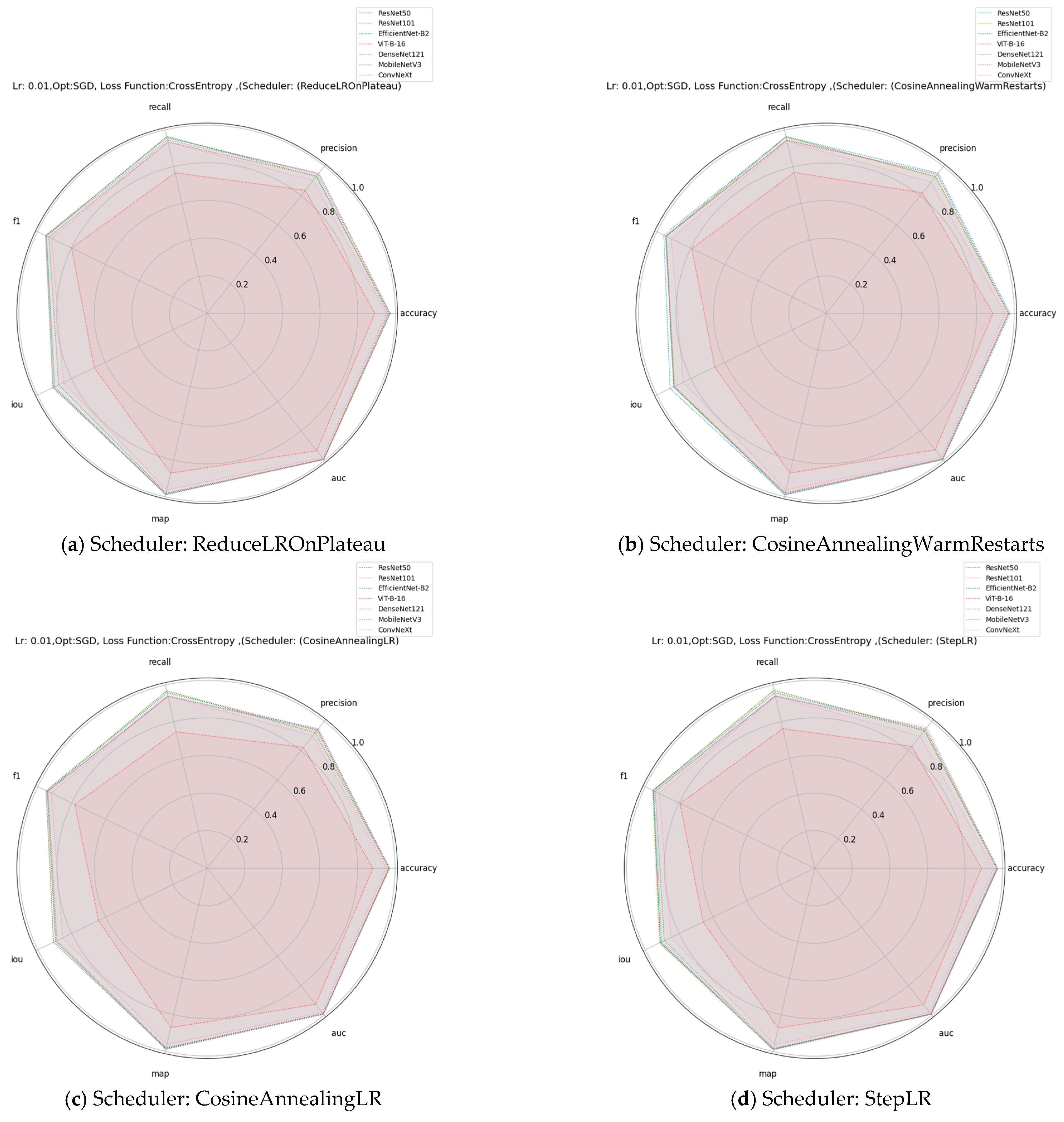
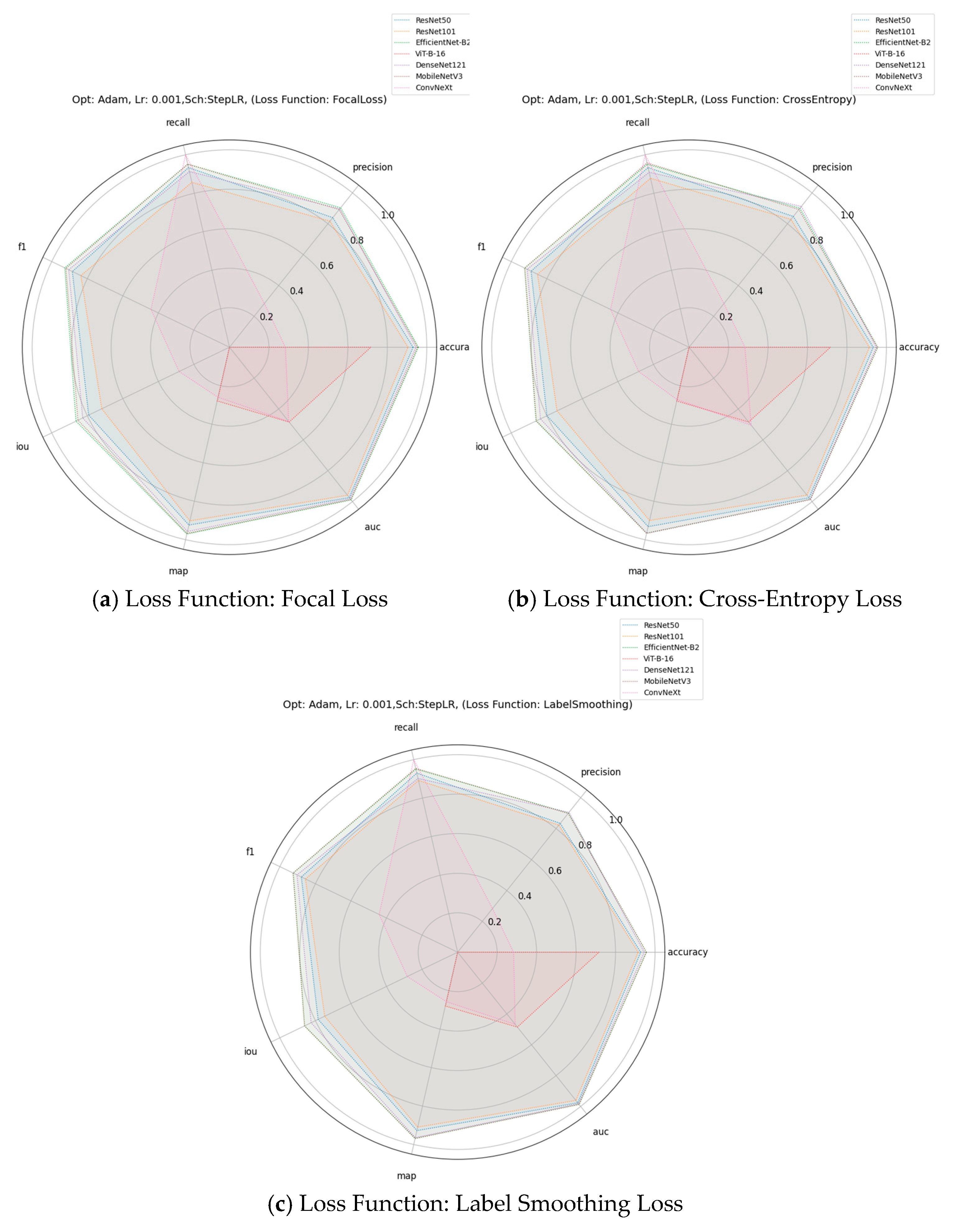
In this study, we investigated the impact of various training parameters on the performance of deep learning models applied to the car collision detection task. The parameters analyzed include learning rates, optimizers, learning rate schedulers, and loss functions. We evaluated their effects on eight key performance metrics: accuracy, precision, recall, F1-score, intersection over union (IoU), mean average precision (mAP), and area under the curve (AUC).
Below are the formal definitions and mathematical formulas of each metric:
3.1. Accuracy
Accuracy is the ratio of correctly predicted instances (both collision and non-collision) to the total instances. It measures overall correctness but may be skewed in imbalanced datasets. While accuracy provides a general measure of performance, it can be misleading in imbalanced datasets (e.g., if collision events are rare). A model predicting mostly non-collisions may still achieve high accuracy without effectively detecting actual collisions.
where:
True Positives (TP) represent cases where the model correctly identifies a collision event, such as accurately detecting an actual vehicle collision.
True Negatives (TN) indicate instances where the model correctly identifies the absence of a collision, such as confirming no collision in a safe driving scenario.
False Positives (FP) occur when the model incorrectly predicts a collision when none has occurred.
False Negatives (FN) denote cases where the model fails to detect an actual collision, such as missing a critical crash event, which could compromise safety.
3.2. Precision
Precision represents the proportion of true collision predictions among all predicted collisions. Precision is critical in minimizing false positives, i.e., incorrectly predicting a collision when there is none. High precision ensures that collision alerts are trustworthy, which is especially important in real-world safety-critical applications to avoid unnecessary emergency responses.
3.3. Recall
Recall is the proportion of actual collisions correctly identified by the model. Recall is vital in minimizing missed collisions (false negatives). In safety-critical systems, failing to detect a collision is far more dangerous than issuing a false alert, making recall a crucial performance indicator.
3.4. F1-Score
The F1-score is the harmonic mean of precision and recall, which balances both metrics. The F1-score is particularly useful in imbalanced scenarios, such as collision detection, where one class (non-collision) may dominate. It offers a single measure that balances both precision and recall.
3.5. Intersection over Union (IoU)
IoU measures the overlap between predicted and ground-truth collision regions, normalized by their union. In binary classification settings, it reduces to comparing predicted collision frames with actual ones. IoU quantifies the accuracy of the model in predicting the location and presence of collision-critical events in space or time. It is particularly useful when spatial localization is required. This quantifies the spatial localization accuracy of collision-critical regions in frames.
3.6. Mean Average Precision (mAP)
mAP is the average of precision values across all recall levels, computed over different confidence thresholds. mAP evaluates how well the model maintains high precision across different levels of recall, giving insight into performance consistency over varying detection thresholds. It is especially useful when predictions are confidence-scored (e.g., collision likelihood).
3.7. AUC-ROC
AUC represents the area under the Receiver Operating Characteristic (ROC) curve, which plots the True Positive Rate (TPR) against the False Positive Rate (FPR).
AUC-ROC reflects the model’s ability to distinguish between collision and non-collision events. A higher AUC indicates better separability and overall classification capability across all decision thresholds.
where f = FPR.
All the above evaluation metrics were employed to comprehensively assess the deep learning model’s performance in car collision detection. Accuracy measures overall correctness but may mislead with imbalanced datasets where collisions are rare. Precision minimizes the incorrect prediction of a collision when there is none, while recall ensures all true collisions are detected, which is crucial for safety-critical applications. The F1-score balances precision and recall, offering a single measure of detection efficacy. IoU measures the overlapping between predicted and ground-truth collision regions whereas AUC reflects the model’s ability to distinguish between collision and non-collision events. Together, these metrics provide a robust evaluation framework for this safety-critical application.
7. Limitations and Future Work
In this paper, we evaluated the models for car collision detection using only static frames. In the future, we will incorporate temporal video sequences to improve car collision detection robustness and assess the generalization of the models under temporal settings. Additionally, for practical deployment, we will evaluate the models’ performance on real-time video streams, optimizing for low latency and ensuring they can handle the demands of live processing. Furthermore, we will create a larger and more diverse dataset by incorporating more videos, improving the models’ ability to handle varied scenarios. Moreover, we will explore the impact of additional hyperparameters and settings, including batch size, weight decay, momentum, advanced data augmentation techniques, and input resolution, to further enhance model performance and robustness.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}