
Face Anti-Spoofing Based on Deep Learning: A Comprehensive Survey



Abstract
1. Introduction
1.1. Related Works
1.2. Motivation and Contribution
- (1)
- This article comprehensively surveys face presentation attacks and detection methods based on DL, including face anti-spoofing on smartphones.
- (2)
- This survey covers 229 multiple articles, categorizing them into smaller sub-topics, and provides a comprehensive discussion.
- (3)
- This survey reveals the current challenges and future research trends about face anti-spoofing and provides a reference basis for research in face authentication.
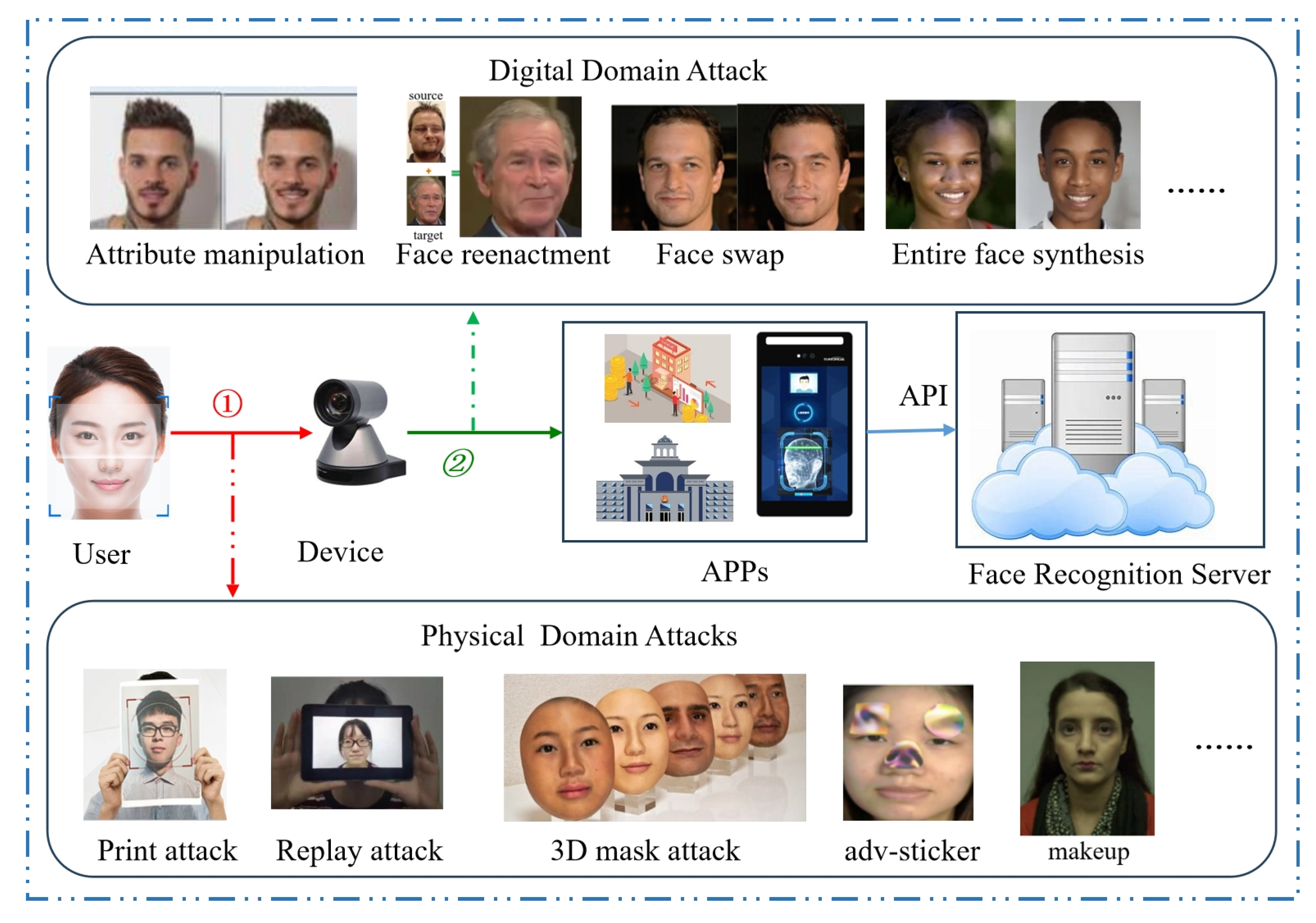
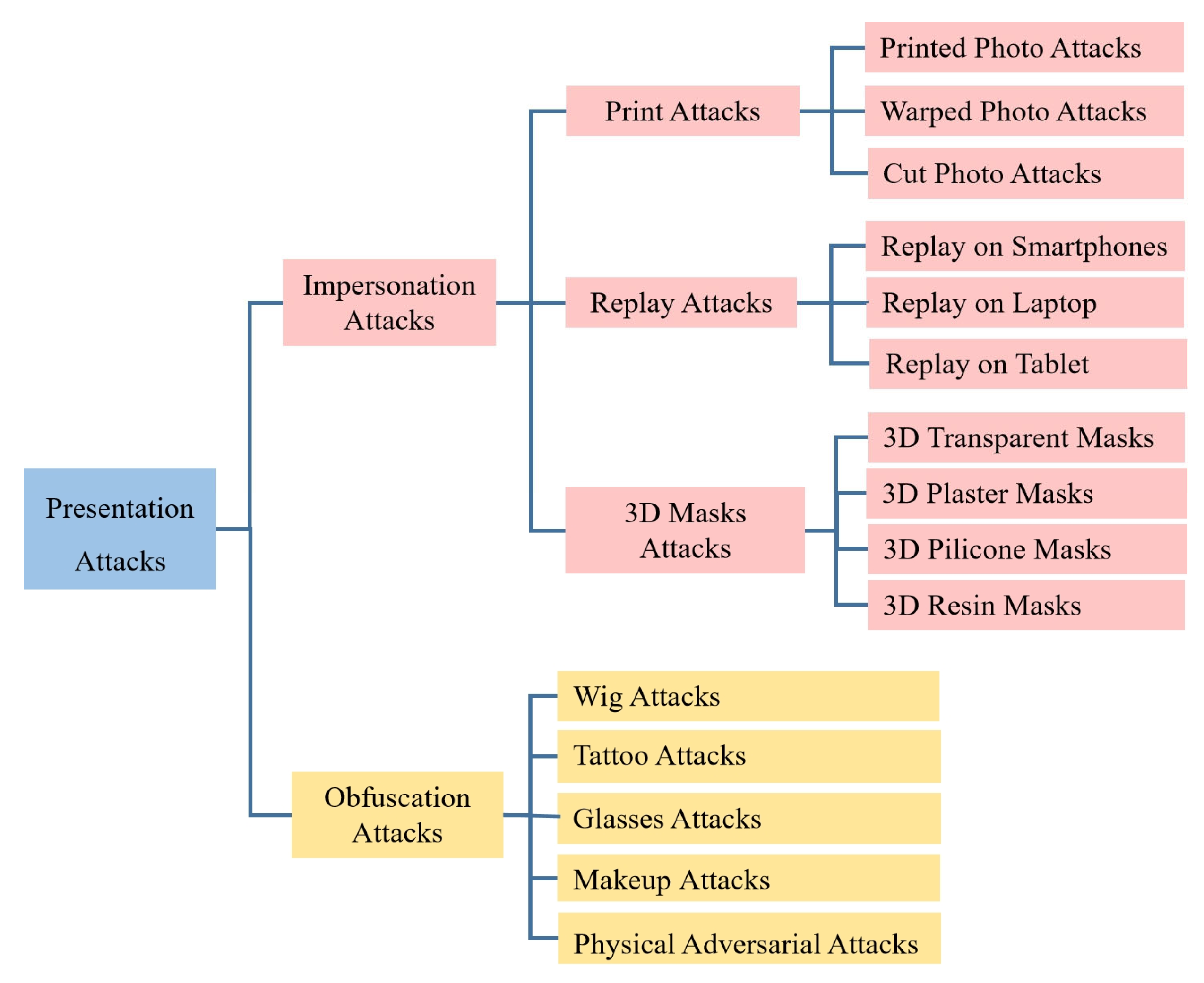
2. Attack Types
2.1. Impersonation Attacks

2.2. Obfuscation Attacks
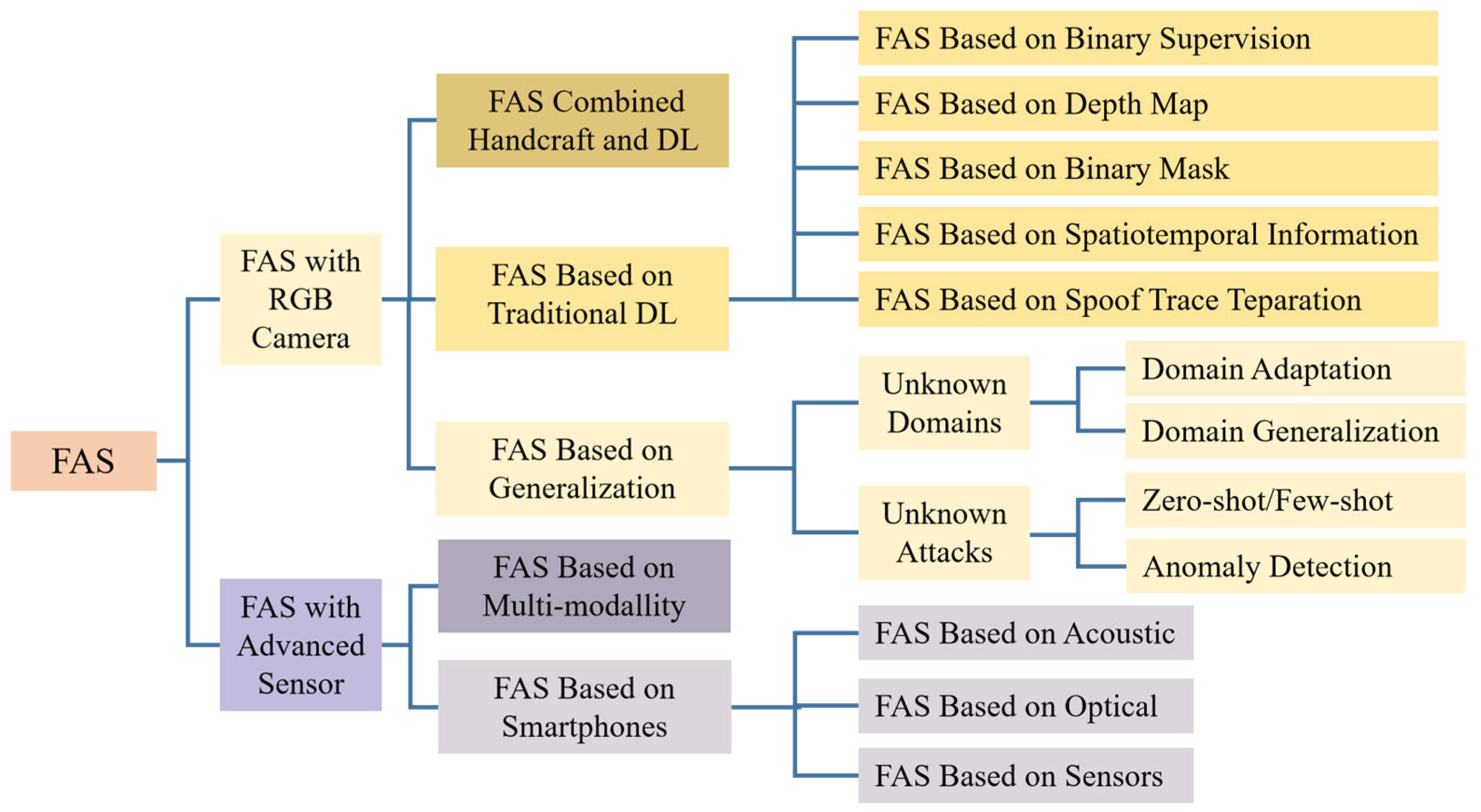
3. Face Anti-Spoofing
3.1. FAS with RGB Camera
3.1.1. FAS Combining Handcraft and DL
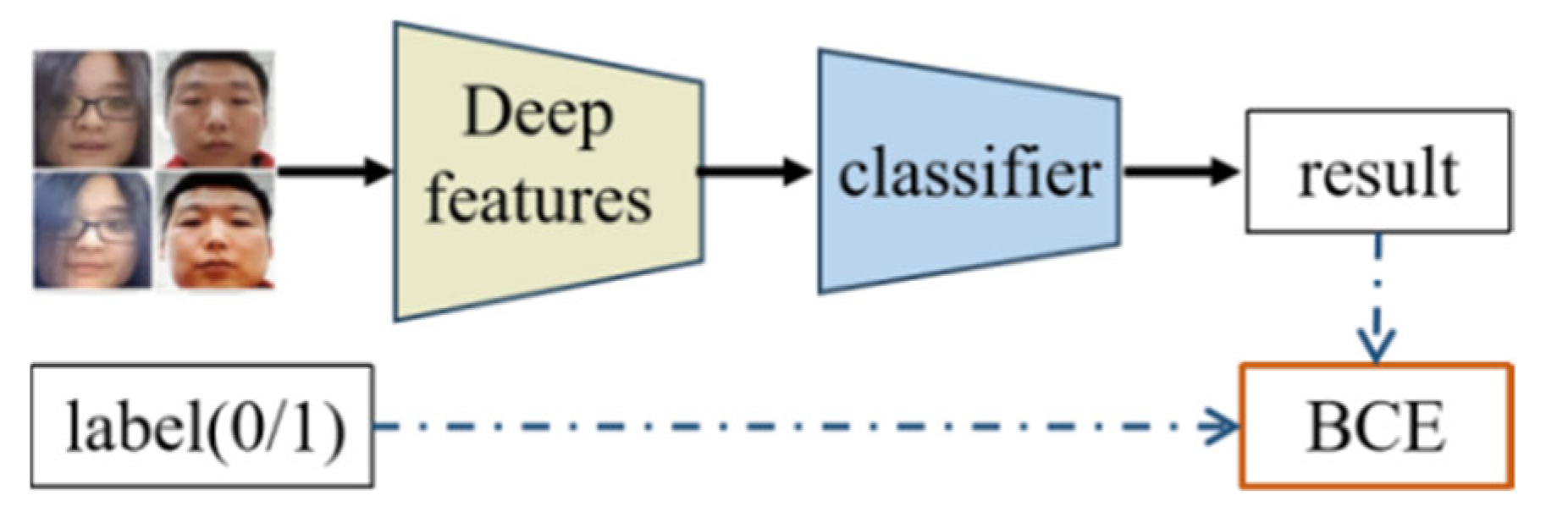
3.1.2. FAS Based on Traditional DL
- A.
- FAS Based on Binary Supervision
- B.
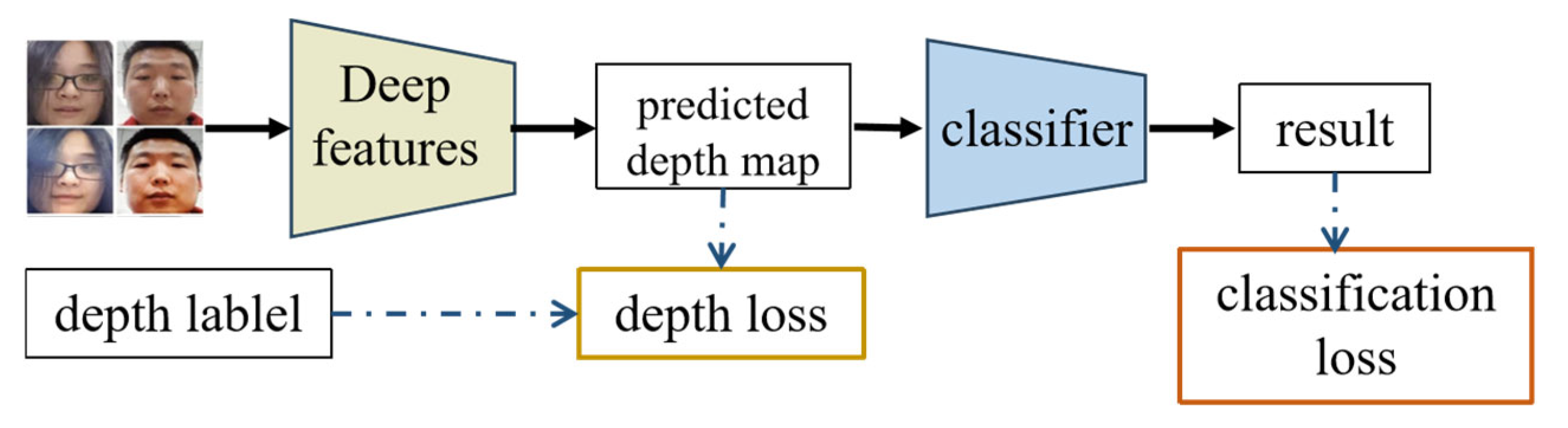
- FAS Based on Depth Maps
- C.
- FAS Based on Binary Masks
- D.
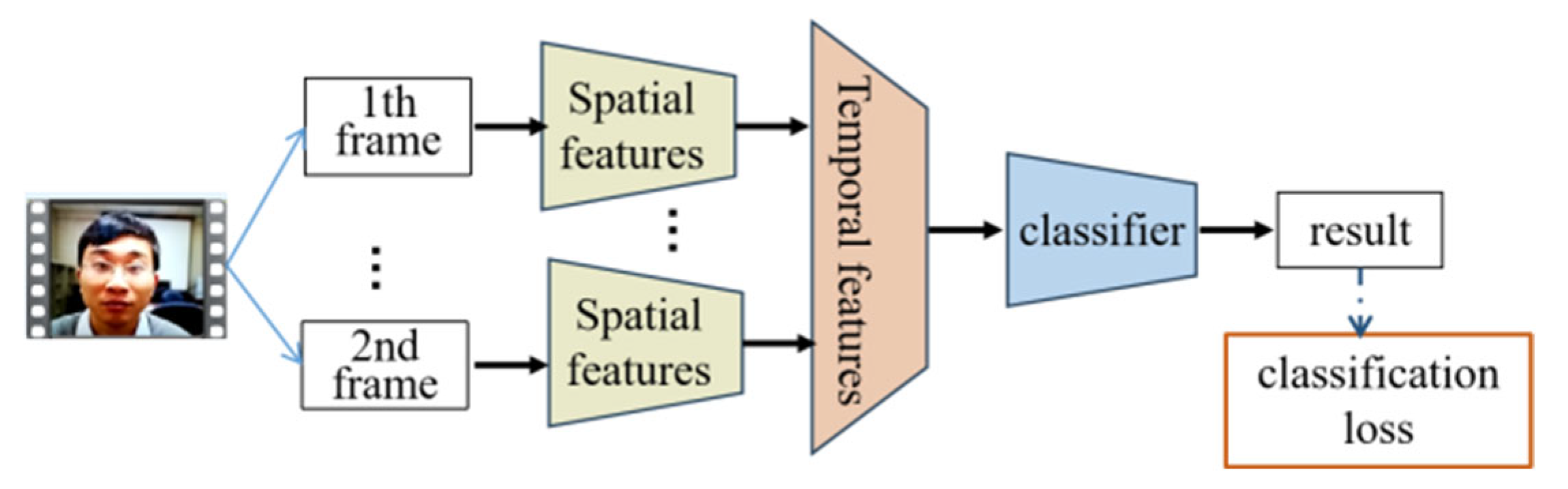
- FAS Based on Spatiotemporal Information
- E.
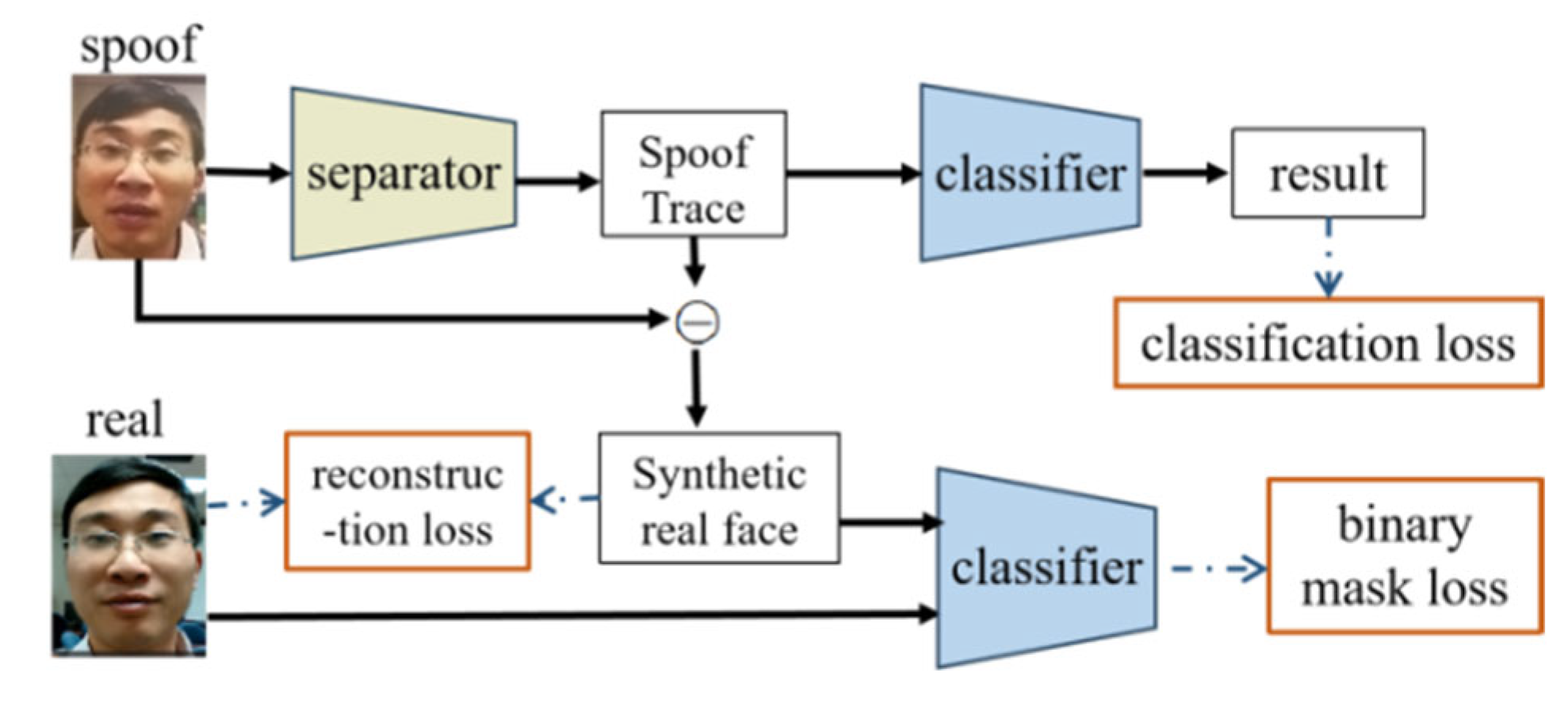
- FAS Based on Spoof Trace Separation
3.1.3. FAS Based on Generalization
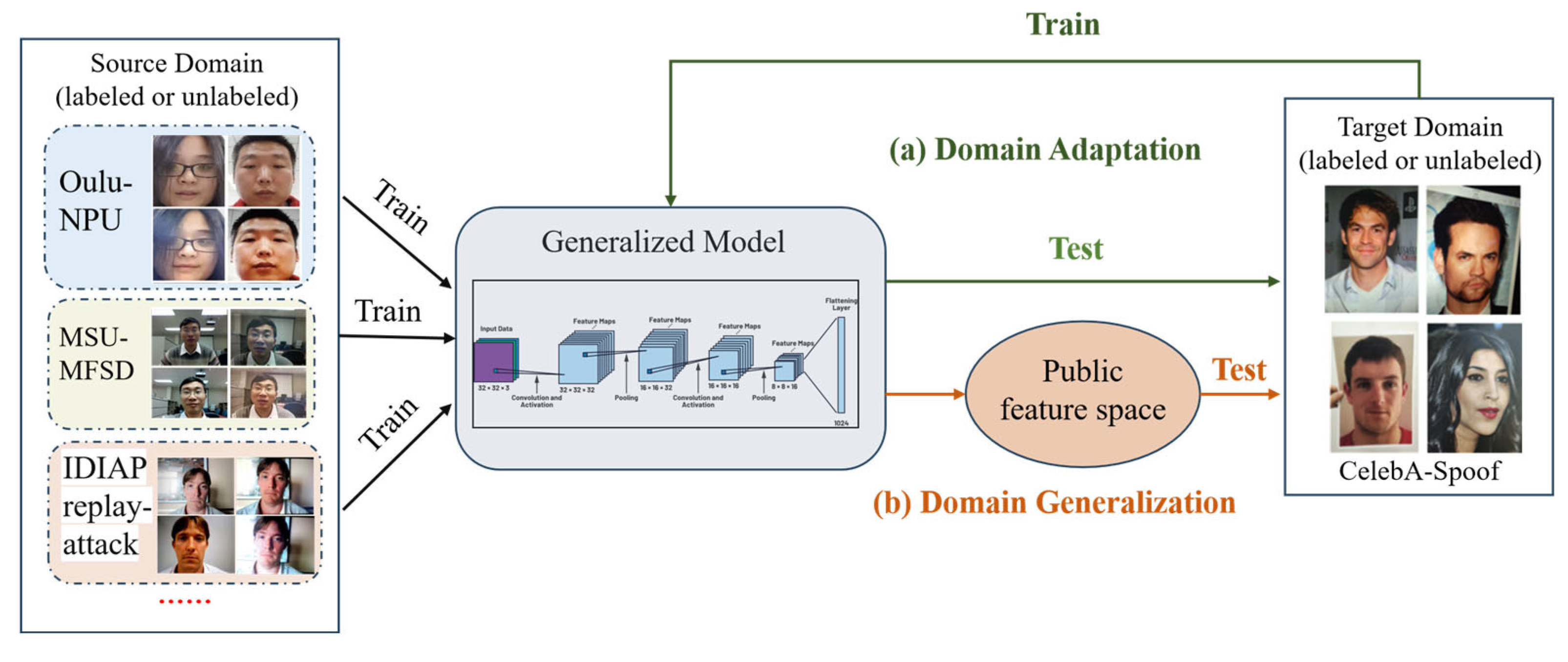
- A.
- Domain Adaptation
- B.
- Domain generalization
- C.
- Generalization Methods on Unknown attacks
3.2. FAS with Advanced Sensors
3.2.1. FAS Based on Multi-Modality
3.2.2. FAS Based on Smartphones
4. Datasets for Face Anti-Spoofing
5. Research Challenges and Future Research Directions
5.1. FAS-Based Generalization
5.2. Multimodal Domain Generalization
5.3. FAS Based Unsupervised Domain Generalization
5.4. Timeliness Issues
5.5. Unified Detection
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| DL | Deep learning |
| CNN | Conventional neural network |
| GAN | Generative adversarial network |
| FR | Face recognition |
| FRS | Face recognition system |
| ViT | Vision Transformer |
| PA | Presentation attack |
| FAS | Face anti-spoofing |
| FLD | Face liveness detection |
| BCE | Binary Cross Entropy |
References
- Ibrahim, R.M.; Elkelany, M.; Ake, A.; El-Afifi, M.I. Trends in Biometric Authentication: A review. Nile J. Commun. Comput. Sci. 2023, 6, 63–75. [Google Scholar]
- Korchenko, O.; Tereikovskyi, I.; Ziubina, R.; Tereikovska, L.; Korystin, O.; Tereikovskyi, O.; Karpinskyi, V. Modular Neural Network Model for Biometric Authentication of Personnel in Critical Infrastructure Facilities Based on Facial Images. Appl. Sci. 2025, 15, 2553. [Google Scholar] [CrossRef]
- Pramanik, S.; Dahlan, H.A.B. Face age estimation using shortcut identity connection of convolutional neural network. Int. J. Adv. Comput. Sci. Appl. 2022, 13, 514–521. [Google Scholar] [CrossRef]
- Guo, J.; Zhao, Y.; Wang, H. Generalized spoof detection and incremental algorithm recognition for voice spoofing. Appl. Sci. 2023, 13, 7773. [Google Scholar] [CrossRef]
- Minaee, S.; Abdolrashidi, A.; Su, H.; Bennamoun, M.; Zhang, D. Biometrics recognition using deep learning: A survey. Artif. Intell. Rev. 2023, 56, 8647–8695. [Google Scholar] [CrossRef]
- Pecolt, S.; Błażejewski, A.; Królikowski, T.; Maciejewski, I.; Gierula, K.; Glowinski, S. Personal Identification Using Embedded Raspberry Pi-Based Face Recognition Systems. Appl. Sci. 2025, 15, 887. [Google Scholar] [CrossRef]
- Jaber, A.G.; Muniyandi, R.C.; Usman, O.L.; Singh, H.K.R. A Hybrid Method of Enhancing Accuracy of Facial Recognition System Using Gabor Filter and Stacked Sparse Autoencoders Deep Neural Network. Appl. Sci. 2022, 12, 11052. [Google Scholar] [CrossRef]
- Abdurrahim, S.H.; Samad, S.A.; Huddin, A.B. Review on the effects of age, gender, and race demographics on automatic face recognition. Vis. Comput. 2018, 34, 1617–1630. [Google Scholar] [CrossRef]
- Wang, M.; Deng, W. Deep face recognition: A survey. Neurocomputing 2021, 429, 215–244. [Google Scholar] [CrossRef]
- Kong, C.; Wang, S.; Li, H. Digital and physical face attacks: Reviewing and one step further. APSIPA Trans. Signal Inf. Process. 2022, 12, e25. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 2, 2672–2680. [Google Scholar]
- Alrawahneh, A.A.-M.; Abdullah, S.N.A.S.; Abdullah, S.N.H.S.; Kamarudin, N.H.; Taylor, S.K. Video authentication detection using deep learning: A systematic literature review. Appl. Intell. 2025, 55, 239. [Google Scholar] [CrossRef]
- Lim, J.S.; Stofa, M.M.; Koo, S.M.; Zulkifley, M.A. Micro Expression Recognition: Multi-scale Approach to Automatic Emotion Recognition by using Spatial Pyramid Pooling Module. Int. J. Adv. Comput. Sci. Appl. 2021, 12. [Google Scholar]
- Dang, M.; Nguyen, T.N. Digital face manipulation creation and detection: A systematic review. Electronics 2023, 12, 3407. [Google Scholar] [CrossRef]
- Yu, Z.; Qin, Y.; Li, X.; Zhao, C.; Lei, Z.; Zhao, G. Deep learning for face anti-spoofing: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 5609–5631. [Google Scholar] [CrossRef]
- Raheem, E.A.; Ahmad, S.M.S.; Adnan, W.A.W. Insight on face liveness detection: A systematic literature review. Int. J. Electr. Comput. Eng. 2019, 9, 5165–5175. [Google Scholar] [CrossRef]
- Jia, S.; Guo, G.; Xu, Z. A survey on 3D mask presentation attack detection and countermeasures. Pattern Recognit. 2020, 98, 107032. [Google Scholar] [CrossRef]
- Safaa El-Din, Y.; Moustafa, M.N.; Mahdi, H. Deep convolutional neural networks for face and iris presentation attack detection: Survey and case study. IET Biom. 2020, 9, 179–193. [Google Scholar] [CrossRef]
- Abdullakutty, F.; Elyan, E.; Johnston, P. A review of state-of-the-art in Face Presentation Attack Detection: From early development to advanced deep learning and multi-modal fusion methods. Inf. Fusion 2021, 75, 55–69. [Google Scholar] [CrossRef]
- Khairnar, S.C.; Gite, S.S.; Thepade, S.D. A Bibliometric Analysis of Face Presentation Attacks Based on Domain Adaptation. 2021. Available online: https://digitalcommons.unl.edu/libphilprac/5454/ (accessed on 20 February 2025).
- Vakhshiteh, F.; Nickabadi, A.; Ramachandra, R. Adversarial attacks against face recognition: A comprehensive study. IEEE Access 2021, 9, 92735–92756. [Google Scholar] [CrossRef]
- Sharma, D.; Selwal, A. A survey on face presentation attack detection mechanisms: Hitherto and future perspectives. Multimed. Syst. 2023, 29, 1527–1577. [Google Scholar] [CrossRef] [PubMed]
- Zheng, Z.; Wang, Q.; Wang, C. Spoofing attacks and anti-spoofing methods for face authentication over smartphones. IEEE Commun. Mag. 2023, 61, 213–219. [Google Scholar] [CrossRef]
- Zhou, K.; Liu, Z.; Qiao, Y.; Xiang, T.; Loy, C.C. Domain Generalization: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 4396–4415. [Google Scholar] [CrossRef]
- Zhang, Z.; Yan, J.; Liu, S.; Lei, Z.; Yi, D.; Li, S.Z. A face antispoofing database with diverse attacks. In Proceedings of the 2012 5th IAPR International Conference on Biometrics (ICB), New Delhi, India, 29 March–1 April 2012; pp. 26–31. [Google Scholar]
- Di, W.; Hu, H.; Jain, A.K. Face Spoof Detection With Image Distortion Analysis. IEEE Trans. Inf. Forensics Secur. 2015, 10, 746–761. [Google Scholar] [CrossRef]
- Liu, A.; Zhao, C.; Yu, Z.; Wan, J.; Su, A.; Liu, X.; Tan, Z.; Escalera, S.; Xing, J.; Liang, Y. Contrastive context-aware learning for 3d high-fidelity mask face presentation attack detection. IEEE Trans. Inf. Forensics Secur. 2022, 17, 2497–2507. [Google Scholar] [CrossRef]
- Liu, Y.; Stehouwer, J.; Jourabloo, A.; Liu, X. Deep tree learning for zero-shot face anti-spoofing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4680–4689. [Google Scholar]
- Sharif, M.; Bhagavatula, S.; Bauer, L.; Reiter, M.K. A general framework for adversarial examples with objectives. ACM Trans. Priv. Secur. (TOPS) 2019, 22, 1–30. [Google Scholar] [CrossRef]
- Yin, B.; Wang, W.; Yao, T.; Guo, J.; Kong, Z.; Ding, S.; Li, J.; Liu, C. Adv-makeup: A new imperceptible and transferable attack on face recognition. arXiv 2021, arXiv:2105.03162. [Google Scholar] [CrossRef]
- Komkov, S.; Petiushko, A. Advhat: Real-world adversarial attack on arcface face id system. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 819–826. [Google Scholar]
- Wei, X.; Guo, Y.; Yu, J. Adversarial sticker: A stealthy attack method in the physical world. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 2711–2725. [Google Scholar] [CrossRef]
- Bigun, J.; Fronthaler, H.; Kollreider, K. Assuring liveness in biometric identity authentication by real-time face tracking. In Proceedings of the 2004 IEEE International Conference on Computational Intelligence for Homeland Security and Personal Safety, CIHSPS, Venice, Italy, 21–22 July 2004; pp. 104–111. [Google Scholar]
- Ali, A.; Deravi, F.; Hoque, S. Liveness Detection Using Gaze Collinearity. In Proceedings of the 2012 Third International Conference on Emerging Security Technologies, Lisbon, Portugal, 5–7 September 2012; pp. 62–65. [Google Scholar]
- Pan, G.; Sun, L.; Wu, Z.; Lao, S. Eyeblink-based Anti-Spoofing in Face Recognition from a Generic Webcamera. In Proceedings of the 2007 IEEE 11th International Conference on Computer Vision, Rio De Janeiro, Brazil, 14–21 October 2007; pp. 1–8. [Google Scholar]
- Jiang-Wei, L. Eye blink detection based on multiple Gabor response waves. In Proceedings of the 2008 International Conference on Machine Learning and Cybernetics, Kunming, China, 12–15 July 2008; pp. 2852–2856. [Google Scholar]
- Wang, L.; Ding, X.; Fang, C. Face live detection method based on physiological motion analysis. Tsinghua Sci. Technol. 2009, 14, 685–690. [Google Scholar] [CrossRef]
- Kollreider, K.; Fronthaler, H.; Faraj, M.I.; Bigun, J. Real-Time Face Detection and Motion Analysis With Application in “Liveness” Assessment. IEEE Trans. Inf. Forensics Secur. 2007, 2, 548–558. [Google Scholar] [CrossRef]
- Nowara, E.M.; Sabharwal, A.; Veeraraghavan, A. PPGSecure: Biometric Presentation Attack Detection Using Photopletysmograms. In Proceedings of the 2017 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017), Washington, DC, USA, 30 May–3 June 2017; pp. 56–62. [Google Scholar]
- Liu, S.; Yuen, P.C.; Zhang, S.; Zhao, G. 3D mask face anti-spoofing with remote photoplethysmography. In Computer Vision–ECCV 2016, Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016, Proceedings, Part VII 14; Springer: Berlin/Heidelberg, Germany, 2016; pp. 85–100. [Google Scholar]
- Heusch, G.; Marcel, S. Pulse-based Features for Face Presentation Attack Detection. In Proceedings of the 2018 IEEE 9th International Conference on Biometrics Theory, Applications and Systems (BTAS), Redondo Beach, CA, USA, 22–25 October 2018; pp. 1–8. [Google Scholar]
- Wei, B.; Hong, L.; Nan, L.; Wei, J. A liveness detection method for face recognition based on optical flow field. In Proceedings of the 2009 International Conference on Image Analysis and Signal Processing, Kuala Lumpur, Malaysia, 18–19 November 2009; pp. 233–236. [Google Scholar]
- Kollreider, K.; Fronthaler, H.; Bigun, J. Non-intrusive liveness detection by face images. Image Vis. Comput. 2009, 27, 233–244. [Google Scholar] [CrossRef]
- Bharadwaj, S.; Dhamecha, T.I.; Vatsa, M.; Singh, R. Computationally Efficient Face Spoofing Detection with Motion Magnification. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Portland, OR, USA, 23–28 June 2013; pp. 105–110. [Google Scholar]
- Tirunagari, S.; Poh, N.; Windridge, D.; Iorliam, A.; Suki, N.; Ho, A.T.S. Detection of Face Spoofing Using Visual Dynamics. IEEE Trans. Inf. Forensics Secur. 2015, 10, 762–777. [Google Scholar] [CrossRef]
- Maatta, J.; Hadid, A.; Pietikainen, M. Face spoofing detection from single images using micro-texture analysis. In Proceedings of the 2011 International Joint Conference on Biometrics (IJCB), Washington, DC, USA, 11–13 October 2011; pp. 1–7. [Google Scholar]
- de Freitas Pereira, T.; Anjos, A.; De Martino, J.M.; Marcel, S. LBP − TOP Based Countermeasure against Face Spoofing Attacks. In Computer Vision—ACCV 2012 Workshops; Springer: Berlin/Heidelberg, Germany, 2013; pp. 121–132. [Google Scholar]
- Boulkenafet, Z.; Komulainen, J.; Hadid, A. Face Spoofing Detection Using Colour Texture Analysis. IEEE Trans. Inf. Forensics Secur. 2016, 11, 1818–1830. [Google Scholar] [CrossRef]
- Patel, K.; Han, H.; Jain, A.K. Secure Face Unlock: Spoof Detection on Smartphones. IEEE Trans. Inf. Forensics Secur. 2016, 11, 2268–2283. [Google Scholar] [CrossRef]
- Boulkenafet, Z.; Komulainen, J.; Hadid, A. Face Anti-Spoofing using Speeded-Up Robust Features and Fisher Vector Encoding. IEEE Signal Process. Lett. 2016, 24, 141–145. [Google Scholar] [CrossRef]
- Komulainen, J.; Hadid, A.; Pietikainen, M. Context based face anti-spoofing. In Proceedings of the 2013 IEEE Sixth International Conference on Biometrics: Theory, Applications and Systems (BTAS), Arlington, VA, USA, 29 September–2 October 2013; pp. 1–8. [Google Scholar]
- Tan, X.; Li, Y.; Liu, J.; Jiang, L. Face Liveness Detection from a Single Image with Sparse Low Rank Bilinear Discriminative Model. In Computer Vision—ECCV 2010, Proceedings of the 11th European Conference on Computer Vision, Heraklion, Crete, Greece, 5–11 September 2010, Proceedings, Part VI 11; Springer: Berlin/Heidelberg, Germany, 2010; pp. 504–517. [Google Scholar]
- Galbally, J.; Marcel, S. Face Anti-spoofing Based on General Image Quality Assessment. In Proceedings of the 2014 22nd International Conference on Pattern Recognition, Stockholm, Sweden, 24–28 August 2014; pp. 1173–1178. [Google Scholar]
- Sun, X.; Huang, L.; Liu, C. Multispectral face spoofing detection using VIS–NIR imaging correlation. Int. J. Wavelets Multiresolution Inf. Process. 2018, 16, 1840003. [Google Scholar] [CrossRef]
- Steiner, H.; Kolb, A.; Jung, N. Reliable face anti-spoofing using multispectral SWIR imaging. In Proceedings of the 2016 International Conference on Biometrics (ICB), Halmstad, Sweden, 13–16 June 2016; pp. 1–8. [Google Scholar]
- Kim, S.; Ban, Y.; Lee, S. Face Liveness Detection Using a Light Field Camera. Sensors 2014, 14, 22471–22499. [Google Scholar] [CrossRef]
- Sepas-Moghaddam, A.; Malhadas, L.; Correia, P.L.; Pereira, F. Face spoofing detection using a light field imaging framework. IET Biom. 2018, 7, 39–48. [Google Scholar] [CrossRef]
- Wang, Y.; Nian, F.; Li, T.; Meng, Z.; Wang, K. Robust face anti-spoofing with depth information. J. Vis. Commun. Image Represent. 2017, 49, 332–337. [Google Scholar] [CrossRef]
- Yang, J.; Lei, Z.; Li, S.Z. Learn convolutional neural network for face anti-spoofing. arXiv 2014, arXiv:1408.5601. [Google Scholar] [CrossRef]
- Feng, L.; Po, L.-M.; Li, Y.; Xu, X.; Yuan, F.; Cheung, T.C.-H.; Cheung, K.-W. Integration of image quality and motion cues for face anti-spoofing: A neural network approach. J. Vis. Commun. Image Represent. 2016, 38, 451–460. [Google Scholar] [CrossRef]
- Li, L.; Xia, Z.; Jiang, X.; Ma, Y.; Roli, F.; Feng, X. 3D face mask presentation attack detection based on intrinsic image analysis. Iet Biom. 2020, 9, 100–108. [Google Scholar] [CrossRef]
- Li, L.; Xia, Z.; Wu, J.; Yang, L.; Han, H. Face presentation attack detection based on optical flow and texture analysis. J. King Saud Univ.-Comput. Inf. Sci. 2022, 34, 1455–1467. [Google Scholar] [CrossRef]
- Li, L.; Feng, X.; Boulkenafet, Z.; Xia, Z.; Li, M.; Hadid, A. An original face anti-spoofing approach using partial convolutional neural network. In Proceedings of the 2016 Sixth International Conference on Image Processing Theory, Tools and Applications (IPTA), Oulu, Finland, 12–15 December 2016; pp. 1–6. [Google Scholar]
- Asim, M.; Ming, Z.; Javed, M.Y. CNN based spatio-temporal feature extraction for face anti-spoofing. In Proceedings of the 2017 2nd International Conference on Image, Vision and Computing (ICIVC), Chengdu, China, 2–4 June 2017; pp. 234–238. [Google Scholar]
- Shao, R.; Lan, X.; Yuen, P.C. Joint discriminative learning of deep dynamic textures for 3D mask face anti-spoofing. IEEE Trans. Inf. Forensics Secur. 2018, 14, 923–938. [Google Scholar] [CrossRef]
- Agarwal, A.; Vatsa, M.; Singh, R. CHIF: Convoluted histogram image features for detecting silicone mask based face presentation attack. In Proceedings of the 2019 IEEE 10th International Conference on Biometrics Theory, Applications and Systems (BTAS), Tampa, FL, USA, 23–26 September 2019; pp. 1–5. [Google Scholar]
- Liang, Y.-C.; Qiu, M.-X.; Lai, S.-H. FIQA-FAS: Face Image Quality Assessment Based Face Anti-Spoofing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 1462–1470. [Google Scholar]
- Khammari, M. Robust face anti-spoofing using CNN with LBP and WLD. IET Image Process. 2019, 13, 1880–1884. [Google Scholar] [CrossRef]
- Yu, Z.; Li, X.; Wang, P.; Zhao, G. Transrppg: Remote photoplethysmography transformer for 3d mask face presentation attack detection. IEEE Signal Process. Lett. 2021, 28, 1290–1294. [Google Scholar] [CrossRef]
- Li, L.; Xia, Z.; Hadid, A.; Jiang, X.; Zhang, H.; Feng, X. Replayed video attack detection based on motion blur analysis. IEEE Trans. Inf. Forensics Secur. 2019, 14, 2246–2261. [Google Scholar] [CrossRef]
- Chen, F.M.; Wen, C.; Xie, K.; Wen, F.Q.; Sheng, G.Q.; Tang, X.G. Face liveness detection: Fusing colour texture feature and deep feature. IET Biom. 2019, 8, 369–377. [Google Scholar] [CrossRef]
- Chen, H.; Chen, Y.; Tian, X.; Jiang, R. A cascade face spoofing detector based on face anti-spoofing R-CNN and improved retinex LBP. IEEE Access 2019, 7, 170116–170133. [Google Scholar] [CrossRef]
- Sharifi, O. Score-level-based face anti-spoofing system using handcrafted and deep learned characteristics. Int. J. Image Graph. Signal Process. 2019, 14, 15. [Google Scholar] [CrossRef]
- Solomon, E.; Cios, K.J. FASS: Face anti-spoofing system using image quality features and deep learning. Electronics 2023, 12, 2199. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015, Proceedings of the 18th International Conference, Munich, Germany, 5–9 October 2015, Proceedings, Part III 18; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Zhang, Y.; Yin, Z.; Li, Y.; Yin, G.; Yan, J.; Shao, J.; Liu, Z. Celeba-spoof: Large-scale face anti-spoofing dataset with rich annotations. In Computer Vision–ECCV 2020, Proceedings of the 16th European Conference, Glasgow, UK, 23–28 August 2020, Proceedings, Part XII 16; Springer: Berlin/Heidelberg, Germany, 2020; pp. 70–85. [Google Scholar]
- Lucena, O.; Junior, A.; Moia, V.; Souza, R.; Valle, E.; Lotufo, R. Transfer learning using convolutional neural networks for face anti-spoofing. In Image Analysis and Recognition, Proceedings of the 14th International Conference, ICIAR 2017, Montreal, QC, Canada, 5–7 July 2017, Proceedings 14; Springer: Berlin/Heidelberg, Germany, 2017; pp. 27–34. [Google Scholar]
- Nagpal, C.; Dubey, S.R. A performance evaluation of convolutional neural networks for face anti spoofing. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Guo, J.; Zhu, X.; Xiao, J.; Lei, Z.; Wan, G.; Li, S.Z. Improving face anti-spoofing by 3D virtual synthesis. In Proceedings of the 2019 International Conference on Biometrics (ICB), Crete, Greece, 4–7 June 2019; pp. 1–8. [Google Scholar]
- Xu, X.; Xiong, Y.; Xia, W. On improving temporal consistency for online face liveness detection system. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 824–833. [Google Scholar]
- Almeida, W.R.; Andaló, F.A.; Padilha, R.; Bertocco, G.; Dias, W.; Torres, R.d.S.; Wainer, J.; Rocha, A. Detecting face presentation attacks in mobile devices with a patch-based CNN and a sensor-aware loss function. PLoS ONE 2020, 15, e0238058. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Lu, Y.-D.; Yang, S.-T.; Lai, S.-H. Patchnet: A simple face anti-spoofing framework via fine-grained patch recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 20281–20290. [Google Scholar]
- Atoum, Y.; Liu, Y.; Jourabloo, A.; Liu, X. Face anti-spoofing using patch and depth-based CNNs. In Proceedings of the 2017 IEEE International Joint Conference on Biometrics (IJCB), Denver, CO, USA, 1–4 October 2017; pp. 319–328. [Google Scholar]
- Yu, Z.; Zhao, C.; Wang, Z.; Qin, Y.; Su, Z.; Li, X.; Zhou, F.; Zhao, G. Searching central difference convolutional networks for face anti-spoofing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5295–5305. [Google Scholar]
- Yu, Z.; Wan, J.; Qin, Y.; Li, X.; Li, S.Z.; Zhao, G. NAS-FAS: Static-dynamic central difference network search for face anti-spoofing. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3005–3023. [Google Scholar] [CrossRef] [PubMed]
- Zheng, W.; Yue, M.; Zhao, S.; Liu, S. Attention-based spatial-temporal multi-scale network for face anti-spoofing. IEEE Trans. Biom. Behav. Identity Sci. 2021, 3, 296–307. [Google Scholar] [CrossRef]
- George, A.; Marcel, S. Deep pixel-wise binary supervision for face presentation attack detection. In Proceedings of the 2019 International Conference on Biometrics (ICB), Crete, Greece, 4–7 June 2019; pp. 1–8. [Google Scholar]
- Hossain, M.S.; Rupty, L.; Roy, K.; Hasan, M.; Sengupta, S.; Mohammed, N. A-DeepPixBis: Attentional angular margin for face anti-spoofing. In Proceedings of the 2020 Digital Image Computing: Techniques and Applications (DICTA), Melbourne, Australia, 29 November–2 December 2020; pp. 1–8. [Google Scholar]
- Sun, W.; Song, Y.; Chen, C.; Huang, J.; Kot, A.C. Face spoofing detection based on local ternary label supervision in fully convolutional networks. IEEE Trans. Inf. Forensics Secur. 2020, 15, 3181–3196. [Google Scholar] [CrossRef]
- Yu, Z.; Li, X.; Niu, X.; Shi, J.; Zhao, G. Face anti-spoofing with human material perception. In Computer Vision–ECCV 2020, Proceedings of the 16th European Conference, Glasgow, UK, 23–28 August 2020, Proceedings, Part VII 16; Springer: Cham, Switzerland, 2020; pp. 557–575. [Google Scholar]
- Kim, T.; Kim, Y.; Kim, I.; Kim, D. Basn: Enriching feature representation using bipartite auxiliary supervisions for face anti-spoofing. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27–28 October 2019; pp. 494–503. [Google Scholar]
- Zhang, X.; Ng, R.; Chen, Q. Single image reflection separation with perceptual losses. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4786–4794. [Google Scholar]
- Yu, Z.; Li, X.; Shi, J.; Xia, Z.; Zhao, G. Revisiting pixel-wise supervision for face anti-spoofing. IEEE Trans. Biom. Behav. Identity Sci. 2021, 3, 285–295. [Google Scholar] [CrossRef]
- Roy, K.; Hasan, M.; Rupty, L.; Hossain, M.S.; Sengupta, S.; Taus, S.N.; Mohammed, N. Bi-fpnfas: Bi-directional feature pyramid network for pixel-wise face anti-spoofing by leveraging fourier spectra. Sensors 2021, 21, 2799. [Google Scholar] [CrossRef]
- Zhang, K.-Y.; Yao, T.; Zhang, J.; Tai, Y.; Ding, S.; Li, J.; Huang, F.; Song, H.; Ma, L. Face anti-spoofing via disentangled representation learning. In Computer Vision–ECCV 2020, Proceedings of the 16th European Conference, Glasgow, UK, 23–28 August 2020, Proceedings, Part XIX 16; Springer: Berlin/Heidelberg, Germany, 2020; pp. 641–657. [Google Scholar]
- Li, X.; Wan, J.; Jin, Y.; Liu, A.; Guo, G.; Li, S.Z. 3DPC-Net: 3D point cloud network for face anti-spoofing. In Proceedings of the 2020 IEEE International Joint Conference on Biometrics (IJCB), Houston, TX, USA, 28 September–1 October 2020; IEEE: Piscataway, NJ, USA; pp. 1–8. [Google Scholar]
- Lin, C.; Liao, Z.; Zhou, P.; Hu, J.; Ni, B. Live Face Verification with Multiple Instantialized Local Homographic Parameterization. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 814–820. [Google Scholar]
- Yang, X.; Luo, W.; Bao, L.; Gao, Y.; Gong, D.; Zheng, S.; Li, Z.; Liu, W. Face anti-spoofing: Model matters, so does data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3507–3516. [Google Scholar]
- Wang, Z.; Yu, Z.; Zhao, C.; Zhu, X.; Qin, Y.; Zhou, Q.; Zhou, F.; Lei, Z. Deep spatial gradient and temporal depth learning for face anti-spoofing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5042–5051. [Google Scholar]
- Cai, R.; Li, H.; Wang, S.; Chen, C.; Kot, A.C. DRL-FAS: A novel framework based on deep reinforcement learning for face anti-spoofing. IEEE Trans. Inf. Forensics Secur. 2020, 16, 937–951. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, Q.; Deng, W.; Guo, G. Learning multi-granularity temporal characteristics for face anti-spoofing. IEEE Trans. Inf. Forensics Secur. 2022, 17, 1254–1269. [Google Scholar] [CrossRef]
- Liu, W.; Pan, Y. Spatio-Temporal Based Action Face Anti-Spoofing Detection via Fusing Dynamics and Texture Face Keypoints Cues. IEEE Trans. Consum. Electron. 2024, 70, 2401–2413. [Google Scholar] [CrossRef]
- Jourabloo, A.; Liu, Y.; Liu, X. Face de-spoofing: Anti-spoofing via noise modeling. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 290–306. [Google Scholar]
- Liu, Y.; Stehouwer, J.; Liu, X. On disentangling spoof trace for generic face anti-spoofing. In Computer Vision–ECCV 2020, Proceedings of the 16th European Conference, Glasgow, UK, 23–28 August 2020, Proceedings, Part XVIII 16; Springer: Berlin/Heidelberg, Germany, 2020; pp. 406–422. [Google Scholar]
- Feng, H.; Hong, Z.; Yue, H.; Chen, Y.; Wang, K.; Han, J.; Liu, J.; Ding, E. Learning generalized spoof cues for face anti-spoofing. arXiv 2020, arXiv:2005.03922. [Google Scholar] [CrossRef]
- Wu, H.; Zeng, D.; Hu, Y.; Shi, H.; Mei, T. Dual spoof disentanglement generation for face anti-spoofing with depth uncertainty learning. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 4626–4638. [Google Scholar] [CrossRef]
- Wang, Y.-C.; Wang, C.-Y.; Lai, S.-H. Disentangled representation with dual-stage feature learning for face anti-spoofing. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 1–6 January 2024; pp. 1955–1964. [Google Scholar]
- Ge, X.; Liu, X.; Yu, Z.; Shi, J.; Qi, C.; Li, J.; Kälviäinen, H. DiffFAS: Face Anti-Spoofing via Generative Diffusion Models. arXiv 2024, arXiv:2409.08572. [Google Scholar] [CrossRef]
- Yu, Y.; Du, Z.; Luo, H.; Xiao, C.; Hu, J. Fourier-Based Frequency Space Disentanglement and Augmentation for Generalizable Face Anti-Spoofing. IEEE J. Biomed. Health Inform. 2024; in press. [Google Scholar] [CrossRef]
- Yang, Q.; Pan, S.J. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- HassanPour Zonoozi, M.; Seydi, V. A survey on adversarial domain adaptation. Neural Process. Lett. 2023, 55, 2429–2469. [Google Scholar] [CrossRef]
- Li, H.; Li, W.; Cao, H.; Wang, S.; Huang, F.; Kot, A.C. Unsupervised domain adaptation for face anti-spoofing. IEEE Trans. Inf. Forensics Secur. 2018, 13, 1794–1809. [Google Scholar] [CrossRef]
- Li, H.; Wang, S.; He, P.; Rocha, A. Face anti-spoofing with deep neural network distillation. IEEE J. Sel. Top. Signal Process. 2020, 14, 933–946. [Google Scholar] [CrossRef]
- Wang, G.; Han, H.; Shan, S.; Chen, X. Unsupervised adversarial domain adaptation for cross-domain face presentation attack detection. IEEE Trans. Inf. Forensics Secur. 2020, 16, 56–69. [Google Scholar] [CrossRef]
- Jia, Y.; Zhang, J.; Shan, S.; Chen, X. Unified unsupervised and semi-supervised domain adaptation network for cross-scenario face anti-spoofing. Pattern Recognit. 2021, 115, 107888. [Google Scholar] [CrossRef]
- El-Din, Y.S.; Moustafa, M.N.; Mahdi, H. Adversarial unsupervised domain adaptation guided with deep clustering for face presentation attack detection. arXiv 2021, arXiv:2102.06864. [Google Scholar] [CrossRef]
- Zhou, Q.; Zhang, K.-Y.; Yao, T.; Yi, R.; Sheng, K.; Ding, S.; Ma, L. Generative domain adaptation for face anti-spoofing. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 335–356. [Google Scholar]
- Tu, X.; Ma, Z.; Zhao, J.; Du, G.; Xie, M.; Feng, J. Learning generalizable and identity-discriminative representations for face anti-spoofing. ACM Trans. Intell. Syst. Technol. (TIST) 2020, 11, 1–19. [Google Scholar] [CrossRef]
- Wang, J.; Zhang, J.; Bian, Y.; Cai, Y.; Wang, C.; Pu, S. Self-domain adaptation for face anti-spoofing. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 19–21 May 2021; pp. 2746–2754. [Google Scholar]
- Quan, R.; Wu, Y.; Yu, X.; Yang, Y. Progressive transfer learning for face anti-spoofing. IEEE Trans. Image Process. 2021, 30, 3946–3955. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Yu, Z.; Du, Z.; Zhu, L.; Shen, H.T. A comprehensive survey on source-free domain adaptation. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 5743–5762. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, Y.; Dai, W.; Gou, M.; Huang, C.-T.; Xiong, H. Source-Free Domain Adaptation with Contrastive Domain Alignment and Self-Supervised Exploration for Face Anti-Spoofing. Springer Nature: Cham, Switzerland; pp. 511–528.
- Liu, Y.; Chen, Y.; Dai, W.; Gou, M.; Huang, C.-T.; Xiong, H. Source-free domain adaptation with domain generalized pretraining for face anti-spoofing. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 5430–5448. [Google Scholar] [CrossRef]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; J’egou, H.E. Training data-efficient image transformers & distillation through attention. In Proceedings of the International Conference on Machine Learning, Virtual Event, 13–18 July 2020. [Google Scholar]
- Wang, J.; Lan, C.; Liu, C.; Ouyang, Y.; Qin, T.; Lu, W.; Chen, Y.; Zeng, W.; Philip, S.Y. Generalizing to unseen domains: A survey on domain generalization. IEEE Trans. Knowl. Data Eng. 2022, 35, 8052–8072. [Google Scholar] [CrossRef]
- Shao, R.; Lan, X.; Li, J.; Yuen, P.C. Multi-adversarial discriminative deep domain generalization for face presentation attack detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10023–10031. [Google Scholar]
- Jia, Y.; Zhang, J.; Shan, S.; Chen, X. Single-side domain generalization for face anti-spoofing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2019; pp. 8484–8493. [Google Scholar]
- Wang, Y.; Song, X.; Xu, T.; Feng, Z.; Wu, X.-J. From RGB to depth: Domain transfer network for face anti-spoofing. IEEE Trans. Inf. Forensics Secur. 2021, 16, 4280–4290. [Google Scholar] [CrossRef]
- Liu, S.; Zhang, K.-Y.; Yao, T.; Bi, M.; Ding, S.; Li, J.; Huang, F.; Ma, L. Adaptive normalized representation learning for generalizable face anti-spoofing. In Proceedings of the 29th ACM International Conference on Multimedia, Chengdu, China, 20–24 October 2021; pp. 1469–1477. [Google Scholar]
- Chen, B.; Yang, W.; Li, H.; Wang, S.; Kwong, S. Camera invariant feature learning for generalized face anti-spoofing. IEEE Trans. Inf. Forensics Secur. 2021, 16, 2477–2492. [Google Scholar] [CrossRef]
- Wang, Z.; Yu, Z.; Wang, X.; Qin, Y.; Li, J.; Zhao, C.; Liu, X.; Lei, Z. Consistency regularization for deep face anti-spoofing. IEEE Trans. Inf. Forensics Secur. 2023, 18, 1127–1140. [Google Scholar] [CrossRef]
- Liao, C.-H.; Chen, W.-C.; Liu, H.-T.; Yeh, Y.-R.; Hu, M.-C.; Chen, C.-S. Domain invariant vision transformer learning for face anti-spoofing. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 2–7 January 2023; pp. 6098–6107. [Google Scholar]
- Liu, A.; Xue, S.; Gan, J.; Wan, J.; Liang, Y.; Deng, J.; Escalera, S.; Lei, Z. CFPL-FAS: Class Free Prompt Learning for Generalizable Face Anti-spoofing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–23 June 2023; pp. 222–232. [Google Scholar]
- Fang, H.; Liu, A.; Jiang, N.; Lu, Q.; Zhao, G.; Wan, J. VL-FAS: Domain Generalization via Vision-Language Model For Face Anti-Spoofing. In Proceedings of the ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; pp. 4770–4774. [Google Scholar]
- Wang, X.; Zhang, K.-Y.; Yao, T.; Zhou, Q.; Ding, S.; Dai, P.; Ji, R. TF-FAS: Twofold-element fine-grained semantic guidance for generalizable face anti-spoofing. In Proceedings of the European Conference on Computer Vision, Paris, France, 26–27 March 2025; pp. 148–168. [Google Scholar]
- Wang, Z.; Wang, Z.; Yu, Z.; Deng, W.; Li, J.; Gao, T.; Wang, Z. Domain generalization via shuffled style assembly for face anti-spoofing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 4123–4133. [Google Scholar]
- Zhou, Q.; Zhang, K.-Y.; Yao, T.; Lu, X.; Yi, R.; Ding, S.; Ma, L. Instance-aware domain generalization for face anti-spoofing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–23 June 2023; pp. 20453–20463. [Google Scholar]
- Zhou, Q.; Zhang, K.-Y.; Yao, T.; Lu, X.; Ding, S.; Ma, L. Test-time domain generalization for face anti-spoofing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–23 June 2023; pp. 175–187. [Google Scholar]
- Sun, Y.; Liu, Y.; Liu, X.; Li, Y.; Chu, W.-S. Rethinking domain generalization for face anti-spoofing: Separability and alignment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–23 June 2023; pp. 24563–24574. [Google Scholar]
- Le, B.M.; Woo, S.S. Gradient alignment for cross-domain face anti-spoofing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–23 June 2023; pp. 188–199. [Google Scholar]
- Cai, R.; Li, Z.; Wan, R.; Li, H.; Hu, Y.; Kot, A.C. Learning meta pattern for face anti-spoofing. IEEE Trans. Inf. Forensics Secur. 2022, 17, 1201–1213. [Google Scholar] [CrossRef]
- Zheng, T.; Yu, Q.; Chen, Z.; Wang, J. FAMIM: A Novel Frequency-Domain Augmentation Masked Image Model Framework for Domain Generalizable Face Anti-Spoofing. In Proceedings of the ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; pp. 4470–4474. [Google Scholar]
- Liu, Y.; Chen, Y.; Gou, M.; Huang, C.-T.; Wang, Y.; Dai, W.; Xiong, H. Towards unsupervised domain generalization for face anti-spoofing. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 20654–20664. [Google Scholar]
- Pérez-Cabo, D.; Jiménez-Cabello, D.; Costa-Pazo, A.; López-Sastre, R.J. Learning to learn face-pad: A lifelong learning approach. In Proceedings of the 2020 IEEE International Joint Conference on Biometrics (IJCB), Houston, TX, USA, 28 September–1 October 2020; pp. 1–9. [Google Scholar]
- Qin, Y.; Zhao, C.; Zhu, X.; Wang, Z.; Yu, Z.; Fu, T.; Zhou, F.; Shi, J.; Lei, Z. Learning meta model for zero-and few-shot face anti-spoofing. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 11916–11923. [Google Scholar]
- Yang, B.; Zhang, J.; Yin, Z.; Shao, J. Few-shot domain expansion for face anti-spoofing. arXiv 2021, arXiv:2106.14162. [Google Scholar] [CrossRef]
- George, A.; Marcel, S. On the effectiveness of vision transformers for zero-shot face anti-spoofing. In Proceedings of the 2021 IEEE International Joint Conference on Biometrics (IJCB), Shenzhen, China, 4–7 August 2021; pp. 1–8. [Google Scholar]
- Nguyen, S.M.; Tran, L.D.; Le, D.V.; Masayuki, A. Self-attention generative distribution adversarial network for few-and zero-shot face anti-spoofing. In Proceedings of the 2022 IEEE International Joint Conference on Biometrics (IJCB), Ljubljana, Slovenia, 25–28 September 2023; pp. 1–9. [Google Scholar]
- Huang, H.-P.; Sun, D.; Liu, Y.; Chu, W.-S.; Xiao, T.; Yuan, J.; Adam, H.; Yang, M.-H. Adaptive transformers for robust few-shot cross-domain face anti-spoofing. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 37–54. [Google Scholar]
- Pérez-Cabo, D.; Jiménez-Cabello, D.; Costa-Pazo, A.; López-Sastre, R.J. Deep anomaly detection for generalized face anti-spoofing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Fatemifar, S.; Arashloo, S.R.; Awais, M.; Kittler, J. Spoofing attack detection by anomaly detection. In Proceedings of the ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 14–17 May 2019; pp. 8464–8468. [Google Scholar]
- Baweja, Y.; Oza, P.; Perera, P.; Patel, V.M. Anomaly detection-based unknown face presentation attack detection. In Proceedings of the 2020 IEEE International Joint Conference on Biometrics (IJCB), Houston, TX, USA, 28 September–1 October 2020; pp. 1–9. [Google Scholar]
- George, A.; Marcel, S. Learning one class representations for face presentation attack detection using multi-channel convolutional neural networks. IEEE Trans. Inf. Forensics Secur. 2020, 16, 361–375. [Google Scholar] [CrossRef]
- Fatemifar, S.; Arashloo, S.R.; Awais, M.; Kittler, J. Client-specific anomaly detection for face presentation attack detection. Pattern Recognit. 2021, 112, 107696. [Google Scholar] [CrossRef]
- Huang, P.-K.; Chiang, C.-H.; Chen, T.-H.; Chong, J.-X.; Liu, T.-L.; Hsu, C.-T. One-Class Face Anti-spoofing via Spoof Cue Map-Guided Feature Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–23 June 2023; pp. 277–286. [Google Scholar]
- Jiang, F.; Liu, Y.; Si, H.; Meng, J.; Li, Q. Cross-Scenario Unknown-Aware Face Anti-Spoofing With Evidential Semantic Consistency Learning. IEEE Trans. Inf. Forensics Secur. 2024, 19, 3093–3108. [Google Scholar] [CrossRef]
- Costa-Pazo, A.; Jiménez-Cabello, D.; Vázquez-Fernández, E.; Alba-Castro, J.L.; López-Sastre, R.J. Generalized presentation attack detection: A face anti-spoofing evaluation proposal. In Proceedings of the 2019 International Conference on Biometrics (ICB), Crete, Greece, 4–7 June 2019; pp. 1–8. [Google Scholar]
- Zhang, S.; Wang, X.; Liu, A.; Zhao, C.; Wan, J.; Escalera, S.; Shi, H.; Wang, Z.; Li, S.Z. A dataset and benchmark for large-scale multi-modal face anti-spoofing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 919–928. [Google Scholar]
- Liu, A.; Wan, J.; Escalera, S.; Jair Escalante, H.; Tan, Z.; Yuan, Q.; Wang, K.; Lin, C.; Guo, G.; Guyon, I. Multi-modal face anti-spoofing attack detection challenge at cvpr2019. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Parkin, A.; Grinchuk, O. Recognizing multi-modal face spoofing with face recognition networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Shen, T.; Huang, Y.; Tong, Z. FaceBagNet: Bag-of-local-features model for multi-modal face anti-spoofing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Liu, A.; Tan, Z.; Wan, J.; Escalera, S.; Guo, G.; Li, S.Z. Casia-surf cefa: A benchmark for multi-modal cross-ethnicity face anti-spoofing. In Proceedings of the IEEE/CVF winter Conference on Applications of Computer Vision, Virtual, 5–9 January 2021; pp. 1179–1187. [Google Scholar]
- Yu, Z.; Qin, Y.; Li, X.; Wang, Z.; Zhao, C.; Lei, Z.; Zhao, G. Multi-modal face anti-spoofing based on central difference networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 13–19 June 2020; pp. 650–651. [Google Scholar]
- Yang, Q.; Zhu, X.; Fwu, J.-K.; Ye, Y.; You, G.; Zhu, Y. PipeNet: Selective modal pipeline of fusion network for multi-modal face anti-spoofing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 13–19 June 2020; pp. 644–645. [Google Scholar]
- Liu, A.; Tan, Z.; Wan, J.; Liang, Y.; Lei, Z.; Guo, G.; Li, S.Z. Face anti-spoofing via adversarial cross-modality translation. IEEE Trans. Inf. Forensics Secur. 2021, 16, 2759–2772. [Google Scholar] [CrossRef]
- Liu, W.; Wei, X.; Lei, T.; Wang, X.; Meng, H.; Nandi, A.K. Data-fusion-based two-stage cascade framework for multimodality face anti-spoofing. IEEE Trans. Cogn. Dev. Syst. 2021, 14, 672–683. [Google Scholar] [CrossRef]
- Liu, A.; Liang, Y. Ma-vit: Modality-agnostic vision transformers for face anti-spoofing. arXiv 2023, arXiv:2304.07549. [Google Scholar] [CrossRef]
- Liu, A.; Tan, Z.; Yu, Z.; Zhao, C.; Wan, J.; Liang, Y.; Lei, Z.; Zhang, D.; Li, S.Z.; Guo, G. Fm-vit: Flexible modal vision transformers for face anti-spoofing. IEEE Trans. Inf. Forensics Secur. 2023, 18, 4775–4786. [Google Scholar] [CrossRef]
- He, D.; He, X.; Yuan, R.; Li, Y.; Shen, C. Lightweight network-based multi-modal feature fusion for face anti-spoofing. Vis. Comput. 2023, 39, 1423–1435. [Google Scholar] [CrossRef]
- Lin, X.; Wang, S.; Cai, R.; Liu, Y.; Fu, Y.; Tang, W.; Yu, Z.; Kot, A. Suppress and Rebalance: Towards Generalized Multi-Modal Face Anti-Spoofing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–23 June 2023; pp. 211–221. [Google Scholar]
- Yu, Z.; Cai, R.; Cui, Y.; Liu, X.; Hu, Y.; Kot, A.C. Rethinking vision transformer and masked autoencoder in multimodal face anti-spoofing. Int. J. Comput. Vis. 2024, 132, 5217–5238. [Google Scholar] [CrossRef]
- Antil, A.; Dhiman, C. MF2ShrT: Multimodal feature fusion using shared layered transformer for face anti-spoofing. ACM Trans. Multimed. Comput. Commun. Appl. 2024, 20, 1–21. [Google Scholar] [CrossRef]
- Zhou, B.; Lohokare, J.; Gao, R.; Ye, F. EchoPrint: Two-factor authentication using acoustics and vision on smartphones. In Proceedings of the 24th Annual International Conference on Mobile Computing and Networking, New Delhi, India, 29 October–2 November 2018; pp. 321–336. [Google Scholar]
- Chen, H.; Wang, W.; Zhang, J.; Zhang, Q. Echoface: Acoustic sensor-based media attack detection for face authentication. IEEE Internet Things J. 2019, 7, 2152–2159. [Google Scholar] [CrossRef]
- Kong, C.; Zheng, K.; Wang, S.; Rocha, A.; Li, H. Beyond the pixel world: A novel acoustic-based face anti-spoofing system for smartphones. IEEE Trans. Inf. Forensics Secur. 2022, 17, 3238–3253. [Google Scholar] [CrossRef]
- Zhang, D.; Meng, J.; Zhang, J.; Deng, X.; Ding, S.; Zhou, M.; Wang, Q.; Li, Q.; Chen, Y. Sonarguard: Ultrasonic face liveness detection on mobile devices. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 4401–4414. [Google Scholar] [CrossRef]
- Xu, Z.; Liu, T.; Jiang, R.; Hu, P.; Guo, Z.; Liu, C. AFace: Range-flexible Anti-spoofing Face Authentication via Smartphone Acoustic Sensing. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2024, 8, 1–33. [Google Scholar] [CrossRef]
- Tang, D.; Zhou, Z.; Zhang, Y.; Zhang, K. Face flashing: A secure liveness detection protocol based on light reflections. arXiv 2018, arXiv:1801.01949. [Google Scholar] [CrossRef]
- Ebihara, A.F.; Sakurai, K.; Imaoka, H. Efficient face spoofing detection with flash. IEEE Trans. Biom. Behav. Identity Sci. 2021, 3, 535–549. [Google Scholar] [CrossRef]
- Farrukh, H.; Aburas, R.M.; Cao, S.; Wang, H. FaceRevelio: A face liveness detection system for smartphones with a single front camera. In Proceedings of the 26th Annual International Conference on Mobile Computing and Networking, London, UK, 21–25 September 2020; pp. 1–13. [Google Scholar]
- Zhang, J.; Tai, Y.; Yao, T.; Meng, J.; Ding, S.; Wang, C.; Li, J.; Huang, F.; Ji, R. Aurora guard: Reliable face anti-spoofing via mobile lighting system. arXiv 2021, arXiv:2102.00713. [Google Scholar] [CrossRef]
- Kim, Y.; Gwak, H.; Oh, J.; Kang, M.; Kim, J.; Kwon, H.; Kim, S. CloudNet: A LiDAR-based face anti-spoofing model that is robust against light variation. IEEE Access 2023, 11, 16984–16993. [Google Scholar] [CrossRef]
- Xu, W.; Song, W.; Liu, J.; Liu, Y.; Cui, X.; Zheng, Y.; Han, J.; Wang, X.; Ren, K. Mask does not matter: Anti-spoofing face authentication using mmWave without on-site registration. In Proceedings of the 28th Annual International Conference on Mobile Computing and Networking, Sydney, NSW, Australia, 17–21 October 2022; pp. 310–323. [Google Scholar]
- Xu, W.; Liu, J.; Zhang, S.; Zheng, Y.; Lin, F.; Xiao, F.; Han, J. Anti-spoofing facial authentication based on cots rfid. IEEE Trans. Mob. Comput. 2023, 23, 4228–4245. [Google Scholar] [CrossRef]
- Zheng, Z.; Wang, Q.; Wang, C.; Zhou, M.; Zhao, Y.; Li, Q.; Shen, C. Where are the dots: Hardening face authentication on smartphones with unforgeable eye movement patterns. IEEE Trans. Inf. Forensics Secur. 2022, 18, 1295–1308. [Google Scholar] [CrossRef]
- Yu, Z.; Qin, Y.; Xu, X.; Zhao, C.; Wang, Z.; Lei, Z.; Zhao, G. Auto-fas: Searching lightweight networks for face anti-spoofing. In Proceedings of the ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Virtual, 4–9 May 2020; pp. 996–1000. [Google Scholar]
- Kong, C.; Zheng, K.; Liu, Y.; Wang, S.; Rocha, A.; Li, H. M3 FAS: An Accurate and Robust MultiModal Mobile Face Anti-Spoofing System. IEEE Trans. Dependable Secur. Comput. 2024, 21, 5650–5666. [Google Scholar] [CrossRef]
- Chingovska, I.; Anjos, A.; Marcel, S. On the effectiveness of local binary patterns in face anti-spoofing. In Proceedings of the 2012 BIOSIG-Proceedings of the International Conference of Biometrics Special Interest Group (BIOSIG), Darmstadt, Germany, 6–7 September 2012; pp. 1–7. [Google Scholar]
- Kose, N.; Dugelay, J.-L. Shape and texture based countermeasure to protect face recognition systems against mask attacks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Portland, OR, USA, 23–28 June 2013; pp. 111–116. [Google Scholar]
- Pinto, A.; Schwartz, W.R.; Pedrini, H.; de Rezende Rocha, A. Using visual rhythms for detecting video-based facial spoof attacks. IEEE Trans. Inf. Forensics Secur. 2015, 10, 1025–1038. [Google Scholar] [CrossRef]
- Costa-Pazo, A.; Bhattacharjee, S.; Vazquez-Fernandez, E.; Marcel, S. The replay-mobile face presentation-attack database. In Proceedings of the 2016 international conference of the Biometrics Special Interest Group (BIOSIG), Darmstadt, Germany, 21–23 September 2016; pp. 1–7. [Google Scholar]
- Boulkenafet, Z.; Komulainen, J.; Li, L.; Feng, X.; Hadid, A. OULU-NPU: A mobile face presentation attack database with real-world variations. In Proceedings of the 2017 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017), Washington, DC, USA, 30 May–3 June 2017; pp. 612–618. [Google Scholar]
- Liu, Y.; Jourabloo, A.; Liu, X. Learning deep models for face anti-spoofing: Binary or auxiliary supervision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 389–398. [Google Scholar]
- Fang, H.; Liu, A.; Wan, J.; Escalera, S.; Zhao, C.; Zhang, X.; Li, S.Z.; Lei, Z. Surveillance face anti-spoofing. IEEE Trans. Inf. Forensics Secur. 2023, 19, 1535–1546. [Google Scholar] [CrossRef]
- Wang, D.; Guo, J.; Shao, Q.; He, H.; Chen, Z.; Xiao, C.; Liu, A.; Escalera, S.; Escalante, H.J.; Lei, Z. Wild face anti-spoofing challenge 2023: Benchmark and results. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–23 June 2023; pp. 6380–6391. [Google Scholar]
- Fang, M.; Huber, M.; Damer, N. Synthaspoof: Developing face presentation attack detection based on privacy-friendly synthetic data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–23 June 2023; pp. 1061–1070. [Google Scholar]
- Erdogmus, N.; Marcel, S. Spoofing face recognition with 3D masks. IEEE Trans. Inf. Forensics Secur. 2014, 9, 1084–1097. [Google Scholar] [CrossRef]
- Raghavendra, R.; Raja, K.B.; Busch, C. Presentation attack detection for face recognition using light field camera. IEEE Trans. Image Process. 2015, 24, 1060–1075. [Google Scholar] [CrossRef]
- Galbally, J.; Satta, R. Three-dimensional and two-and-a-half-dimensional face recognition spoofing using three-dimensional printed models. IET Biom. 2016, 5, 83–91. [Google Scholar] [CrossRef]
- Bhattacharjee, S.; Marcel, S. What you can’t see can help you-extended-range imaging for 3d-mask presentation attack detection. In Proceedings of the 2017 International Conference of the Biometrics Special Interest Group (BIOSIG), Darmstadt, Germany, 20–22 September 2017; pp. 1–7. [Google Scholar]
- Agarwal, A.; Yadav, D.; Kohli, N.; Singh, R.; Vatsa, M.; Noore, A. Face presentation attack with latex masks in multispectral videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 81–89. [Google Scholar]
- Bhattacharjee, S.; Mohammadi, A.; Marcel, S. Spoofing deep face recognition with custom silicone masks. In Proceedings of the 2018 IEEE 9th International Conference on Biometrics Theory, Applications and Systems (BTAS), Redondo Beach, CA, USA, 22–25 October 2018; pp. 1–7. [Google Scholar]
- George, A.; Mostaani, Z.; Geissenbuhler, D.; Nikisins, O.; Anjos, A.; Marcel, S. Biometric face presentation attack detection with multi-channel convolutional neural network. IEEE Trans. Inf. Forensics Secur. 2019, 15, 42–55. [Google Scholar] [CrossRef]
- Rostami, M.; Spinoulas, L.; Hussein, M.; Mathai, J.; Abd-Almageed, W. Detection and continual learning of novel face presentation attacks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 14851–14860. [Google Scholar]
- Song, C.; Hong, Y.; Lan, J.; Zhu, H.; Wang, W.; Zhang, J. Supervised Contrastive Learning for Snapshot Spectral Imaging Face Anti-Spoofing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–23 June 2023; pp. 980–985. [Google Scholar]
- Bioucas-Dias, J.M.; Figueiredo, M.A. A new TwIST: Two-step iterative shrinkage/thresholding algorithms for image restoration. IEEE Trans. Image Process. 2007, 16, 2992–3004. [Google Scholar] [CrossRef]
- Fang, H.; Liu, A.; Yuan, H.; Zheng, J.; Zeng, D.; Liu, Y.; Deng, J.; Escalera, S.; Liu, X.; Wan, J. Unified physical-digital face attack detection. arXiv 2024, arXiv:2401.17699. [Google Scholar] [CrossRef]
- Zhang, R.; Xu, Q.; Yao, J.; Zhang, Y.; Tian, Q.; Wang, Y. Federated domain generalization with generalization adjustment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–23 June 2023; pp. 3954–3963. [Google Scholar]
- Cho, J.; Nam, G.; Kim, S.; Yang, H.; Kwak, S. Promptstyler: Prompt-driven style generation for source-free domain generalization. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 15702–15712. [Google Scholar]
- Wu, J.; Yu, X.; Liu, B.; Wang, Z.; Chandraker, M. Uncertainty-aware physically-guided proxy tasks for unseen domain face anti-spoofing. arXiv 2020, arXiv:2011.14054. [Google Scholar] [CrossRef]
- Peng, X.; Wei, Y.; Deng, A.; Wang, D.; Hu, D. Balanced multimodal learning via on-the-fly gradient modulation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 8238–8247. [Google Scholar]
- Li, Y.; Hu, J.; Wen, Y.; Evangelidis, G.; Salahi, K.; Wang, Y.; Tulyakov, S.; Ren, J. Rethinking vision transformers for mobilenet size and speed. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 16889–16900. [Google Scholar]
- Liu, H.; Kong, Z.; Ramachandra, R.; Liu, F.; Shen, L.; Busch, C. Taming self-supervised learning for presentation attack detection: In-image de-folding and out-of-image de-mixing. arXiv 2021, arXiv:2109.04100. [Google Scholar] [CrossRef]
- Muhammad, U.; Yu, Z.; Komulainen, J. Self-supervised 2d face presentation attack detection via temporal sequence sampling. Pattern Recognit. Lett. 2022, 156, 15–22. [Google Scholar] [CrossRef]
- Zhang, X.; Zhou, L.; Xu, R.; Cui, P.; Shen, Z.; Liu, H. Towards unsupervised domain generalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 4910–4920. [Google Scholar]
- Harary, S.; Schwartz, E.; Arbelle, A.; Staar, P.; Abu-Hussein, S.; Amrani, E.; Herzig, R.; Alfassy, A.; Giryes, R.; Kuehne, H. Unsupervised domain generalization by learning a bridge across domains. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5280–5290. [Google Scholar]
- Qi, L.; Liu, J.; Wang, L.; Shi, Y.; Geng, X. Unsupervised domain generalization for person re-identification: A domain-specific adaptive framework. arXiv 2021, arXiv:2111.15077. [Google Scholar] [CrossRef]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2019; pp. 9729–9738. [Google Scholar]
- Chen, T.; Kornblith, S.; Swersky, K.; Norouzi, M.; Hinton, G.E. Big self-supervised models are strong semi-supervised learners. Adv. Neural Inf. Process. Syst. 2020, 33, 22243–22255. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Mehta, S.; Rastegari, M. Mobilevit: Light-weight, general-purpose, and mobile-friendly vision transformer. arXiv 2021, arXiv:2110.02178. [Google Scholar] [CrossRef]
- Deb, D.; Liu, X.; Jain, A.K. Unified detection of digital and physical face attacks. In Proceedings of the 2023 IEEE 17th International Conference on Automatic Face and Gesture Recognition (FG), Waikoloa Beach, HI, USA, 5–8 January 2023; pp. 1–8. [Google Scholar]
- Al-Refai, R.; Nandakumar, K. A unified model for face matching and presentation attack detection using an ensemble of vision transformer features. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 2–7 January 2023; pp. 662–671. [Google Scholar]
- Yu, Z.; Cai, R.; Li, Z.; Yang, W.; Shi, J.; Kot, A.C. Benchmarking joint face spoofing and forgery detection with visual and physiological cues. IEEE Trans. Dependable Secur. Comput. 2024, 21, 4327–4342. [Google Scholar] [CrossRef]
- Shi, Y.; Gao, Y.; Lai, Y.; Wang, H.; Feng, J.; He, L.; Wan, J.; Chen, C.; Yu, Z.; Cao, X. Shield: An evaluation benchmark for face spoofing and forgery detection with multimodal large language models. arXiv 2024, arXiv:2402.04178. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Year | Ref. Count | Topics and Observation | Disadvantages | Our Article |
|---|---|---|---|---|---|
| [16] | 2019 | 208 | Various indicators of FLD | It does not cover DL-based FAS algorithms. | We provide a systematic introduction to DL-based methods. |
| [17] | 2020 | 57 | FAS methods on 3D masks | The number of DL-based algorithms was very small. | |
| [18] | 2020 | 58 | The application of CNN in face and iris attack detection | Did not address the generalization of FAS methods. | We provide a detailed introduction to the cross-domain FAS, including DA, domain generalization (DG), zero-/few-shot learning, and anomaly detection. |
| [19] | 2021 | 163 | DL-based methods and FAS on multi-modal fusion | Sufficient discussion on generalization. | |
| [20] | 2021 | 23 | Face presentation attacks and detection based on domain adaptation (DA) | Lacked other classification | |
| [21] | 2021 | 115 | A literature review on face adversarial attacks and defenses | Lack of a consistent evaluation framework, and omission of experimental datasets. | Our review summarizes detection methods for various types of presentation attacks, including adversarial attacks. |
| [10] | 2022 | 253 | A literature review on face attacks and detection methods from the perspectives of digital and physical domains. | The introduction of face adversarial attacks and defenses methods in general. | |
| [15] | 2022 | 252 | A comprehensive review on FAS based on DL | The discussion of cross-domain FAS issues requires a more in-depth examination, and the analysis of FAS on smartphones requires improvement. | We include not only DL-based methods but also FAS methods combining with handcrafted and DL approaches, as well as smartphone-based detection methods. |
| [22] | 2023 | 188 | A comprehensive review of FAS based on DL and traditional handcraft features | The discussion on cross-domain FAS needs to be more in-depth. Moreover, the analysis of FAS on smartphones needs to be improved. | |
| [23] | 2023 | 15 | A survey on FAS techniques for smartphones | Lack of discussion on standardized evaluation and insufficient exploration of future directions. | |
| [24] | 2023 | 275 | A survey on DG methods across various application domains | Although the review includes a summary of methods for FAS, it needs a systematic approach. | We provide a detailed introduction to the cross-domain generalization of FAS |
| Methods | Main Idea | Ref. | Attacks | Advantages | Disadvantages |
|---|---|---|---|---|---|
| Methods based on motion | Gaze tracking | [33,34] | 2D-P | Taking into account motion characteristics, they can effectively resist print attacks. | It is difficult to deal with replay videos attacks, longer detection time. |
| Eye blinking | [35,36] | ||||
| Nodding and Smiling | [37] | ||||
| Lip reading | [38] | ||||
| Methods based on life information | rPPG | [39,40,41] | 3D-M | High accuracy under specific constraints. | Video input is required but lacks robustness when highly affected by external lighting and individual movements. |
| Optical flow | [42,43] | 2D-P, 2D-R | |||
| Micro-movements | [44,45] | 2D-P, 3D-M | High accuracy and strong generalization for print attacks. | ||
| Methods based on texture | LBP, LBP-TOP | [46,47] | 2D-P | With a small amount of calculation and a relatively stable environment, it can effectively resist print and replay attacks. | It is easily affected by recording equipment, lighting conditions, and image quality, and its generalization capability across datasets is not strong. |
| Color texture | [48] | ||||
| SIFT | [49] | ||||
| SURF | [50] | ||||
| HOG | [51] | ||||
| DoG | [52] | ||||
| Methods based on image quality | Image specular reflection, color distribution, and sharpness | [26,53] | 2D-P | Relatively strong cross-dataset generalization ability for single-type spoofed faces while offering a fast processing speed. | It is more sensitive to changes in the external environment and difficult to resist high-resolution matte photo and video attacks. |
| Methods based on hardware | Infrared image | [54,55] | 2D-P, 2D-R | High accuracy | It requires the addition of expensive hardware devices, and the time of processing images increases. |
| Light field | [56,57] | ||||
| Depth map | [58] |
| Strategies | Main Idea and Ref. | Datasets | Attacks | Advantages | Disadvantages | ||
|---|---|---|---|---|---|---|---|
| 2D-P | 2D-R | 3D-M | |||||
| Cascade model fusion: Traditionally, handcrafted feature extraction is used as a preprocessing step, followed by further processing of the extracted features using a DL to achieve finer features. | Dense optical flow-based motion features, shearlet-based image quality features and DNN [60] | CASIA MFSD | √ | √ | Cascaded models can progressively refine and extract more complex features, thereby enhancing their classification capability. | (1) If the feature extraction in the preceding model has issues, subsequent steps will be affected, leading to a decline in the overall performance. (2) There may be feature gaps or incompatibilities between handcrafted features and deep features, resulting in performance saturation. | |
| Replay-Attack | √ | √ | |||||
| 3D-MAD | √ | ||||||
| Image reflectance and 1D CNN [61] | 3D-MAD | √ | |||||
| HKBU-M V2 | √ | ||||||
| The optical flow-based motion features and texture cues, attention module and CNN [62] | Replay-Attack | √ | √ | ||||
| OULU-NPU | √ | √ | |||||
| HKBU-MARs V1 | √ | ||||||
| Cascade model fusion: The DL and handcrafted feature extraction processes are sequential. The DL model is used to extract deep features, which are then subjected to handcrafted feature processing for further operations or analysis. | VGG features, PCA and SVM [63] | CASIA MFSD | √ | √ | |||
| Replay-Attack | √ | √ | |||||
| CNN, LBP-TOP and SVM [64] | CASIA MFSD | √ | √ | ||||
| Replay-Attack | √ | ||||||
| CNN features and optical flow-based motion features [65] | 3DMAD | √ | |||||
| CNN filters, texure encoding and SVM [66] | SMAD | √ | |||||
| FIQA and Resnet [67] | SiW | √ | √ | ||||
| SiW-M | √ | √ | √ | ||||
| Feature-level fusion: During the feature extraction stage, traditional handcrafted features are fused with deep features extracted by DL models. | LBP, SWLD, and CNN [68] | CASIA MFSD | √ | √ | The synergy between features enhances the model’s capabilities. | Aligning and processing features from different sources is necessary, which increases the complexity and reduces the model’s interpretability. | |
| Replay-Attack | √ | √ | |||||
| Combination rPPG and ViT [69] | 3D-MAD | √ | |||||
| HKBU-M V2 | √ | ||||||
| 1D CNN and motion blur features with LSP [70] | Replay-Attack | √ | √ | ||||
| OULU-NPU | √ | √ | |||||
| Color texture features with RI-LBP and CNN [71] | NUAA [52] | √ | |||||
| CASIA MFSD | √ | √ | |||||
| Decision-level fusion: Handcrafted features and deep features are processed separately by independent classifiers (or detectors). The final prediction result is obtained through decision fusion, such as voting or weighted voting. | Retinex-LBP and R-CNN [72] | CASIA MFSD | √ | √ | Fusion occurs only at the final decision stage, without the need to align or process the features themselves, offering high flexibility. | Independent processing may lead to information redundancy or conflict, and the algorithm highly depends on the fusion strategy. | |
| Replay-Attack | √ | √ | |||||
| OULU-NPU | √ | √ | |||||
| CNN features and OVLBP [73] | Replay-Attack | √ | √ | ||||
| Image quality features and deep features using ResNet50 [74] | OULU-NPU | √ | √ | ||||
| CASIA-MASD | √ | √ | |||||
| Replay-Attack | √ | √ | |||||
| MSU MFSD | √ | √ | |||||
| SiW | √ | √ | |||||
| Ref. | Main Idea | Supervision | Datasets | Attacks | Advantage | Disadvantage | |||
|---|---|---|---|---|---|---|---|---|---|
| 2D-P | 2D-R | 3D-M | OA | ||||||
| [78] | Transfer learning and CNN | BCE | Replay-Attack | √ | √ | The method is simple and intuitive, providing clear training signals and stable training based on mature technology. | It is prone to failure when faced with high-fidelity attacks, such as high-definition spoofing videos. | ||
| 3DMAD | √ | ||||||||
| [79] | Analysis of effectiveness on CNN | BCE | MSU-MFSD | √ | √ | ||||
| [82] | 3D virtual synthesis as input | BCE | Replay-Attack | √ | √ | ||||
| CASIA-MASD | √ | √ | |||||||
| [83] | Fine-grained multi-class supervision | Multi-level BCE | SiW | √ | √ | ||||
| OULU-NPU | √ | √ | |||||||
| SiW-M | √ | √ | √ | √ | |||||
| [84] | Learning compact spaces with small intra-class distances and large inter-class distances | Contrast loss, triple loss | Replay-Attack | √ | √ | ||||
| CASIA-MFSD | √ | √ | |||||||
| OULU-NPU | √ | √ | |||||||
| RECORD-MPAD | √ | √ | |||||||
| [85] | Supervising FAS patch model via asymmetric corner softmax loss to relax intra-class constraints | softmax loss | Replay-Attack | √ | √ | ||||
| CASIA-MFSD | √ | √ | |||||||
| OULU-NPU | √ | √ | |||||||
| MSU-MFSD | √ | √ | |||||||
| SiW | √ | √ | |||||||
| Ref. | Main Idea | Supervision | Datasets | Attacks | Advantages | Disadvantages | |||
|---|---|---|---|---|---|---|---|---|---|
| 2D-P | 2D-R | 3D-M | OA | ||||||
| [86] | Dual CNN method combining global and local features of face. | Depth map | Replay-Attack | √ | √ | It can better capture the 3D structure and details of the human face; reduce artifacts caused by changes in lighting and angles, etc.; and has strong applicability. | The process of synthesizing 3D shape labels is costly and time-intensive. For 3D mask attacks or mannequin model attacks, since these attacks also have real depth information, they are more difficult to detect. | ||
| CASIA-MFSD | √ | √ | |||||||
| MSU-USSA | √ | √ | |||||||
| [87] | CDCN can capture detailed patterns via aggregating intensity and gradient information, and the MAFM module obtain afiner-grained features. | Depth map | Replay-Attack | √ | √ | ||||
| CASIA-MFSD | √ | √ | |||||||
| OULU-NPU | √ | √ | |||||||
| MSU-MFSD | √ | √ | |||||||
| SiW | √ | √ | |||||||
| SiW-M | √ | √ | √ | √ | |||||
| [88] | An efficient static-dynamic representation for mining the FAS-aware spatio-temporal discrepancy and Meta-NAS for robust searching. | Depth map | Replay-Attack | √ | √ | ||||
| CASIA-MFSD | √ | √ | |||||||
| OULU-NPU | √ | √ | |||||||
| MSU-MFSD | √ | √ | |||||||
| SiW | √ | √ | |||||||
| SiW-M | √ | √ | √ | √ | |||||
| CASIA-SURF | √ | ||||||||
| 3DMAD | √ | ||||||||
| HKBU-M V2 | √ | ||||||||
| [89] | A dual-stream spatial-temporal network was designed to explore depth information and multiscale information. | Time, depth map | Replay-Attack | √ | √ | ||||
| CASIA-MFSD | √ | √ | |||||||
| OULU-NPU | √ | √ | |||||||
| SiW | √ | √ | |||||||
| NUAA | √ | ||||||||
| Ref. | Main Idea | Supervision | Datasets | Attacks | Advantages | Disadvantages | |||
|---|---|---|---|---|---|---|---|---|---|
| 2D-P | 2D-R | 3D-M | OA | ||||||
| [90] | Binary mask and deep pixel-wise supervision | Binary mask label | Replay-Attack | √ | √ | Binary mask labels are easier to generate, able to identify facial regions and backgrounds, capture subtle features, and are attack-type agnostic. | Complex attacks (such as cutting out eyes, nose, and mouth and simulating real human blinking and mouth movements) may not be accurately detected. | ||
| OULU-NPU | √ | √ | |||||||
| [91] | Angular margin-based BCE, a learnable attention module, and binary masks supervision | Binary mask label | OULU-NPU | √ | √ | ||||
| Replay-Mobile | √ | √ | |||||||
| [92] | Pixel-level supervised learning of facial images using local ternary labels (real face, fake, background) | Local ternary label | Replay-Attack | √ | √ | When there is not enough training data, more refined classification can be achieved. | Local ternary labels need to be accurately annotated. | ||
| CASIA-MFSD | √ | √ | |||||||
| OULU-NPU | √ | √ | |||||||
| SiW | √ | √ | |||||||
| [93] | Intrinsicmaterial-based patterns via aggregating multi-level bilateral micro-information | Depth map, reflection and patch map | OULU-NPU | √ | √ | New perspective: material perception | The limited scope of the datasets cannot fully demonstrate the effectiveness of material perception. | ||
| SiW | √ | √ | |||||||
| CASIA-MFSD | √ | √ | |||||||
| Replay-Attack | √ | √ | |||||||
| MSU-MFSD | √ | √ | |||||||
| SiW-M | √ | √ | √ | √ | |||||
| [94] | Auxiliary supervisions | Depth map, reflection map | SiW | √ | √ | Focusing on the complementary information of the face enriches the feature representation. | Dependent on the quality of auxiliary supervision. | ||
| OuluNPU | √ | √ | |||||||
| CASIA-FASD | √ | √ | |||||||
| Replay-Attack | √ | √ | |||||||
| [96] | Plugged-and-played pyramid supervision | Depth map, Predicted Depth Maps | CASIA-MFSD | √ | √ | Both performance improvement and interpretability enhancement | Needs a large amount of data with fine-grained pixel/patch-level annotated labels | ||
| Replay-Attack | √ | √ | |||||||
| MSU-MFSD | √ | √ | |||||||
| OULU-NPU | √ | √ | |||||||
| SiW-M | √ | √ | √ | √ | |||||
| [97] | Bi-directional feature pyramid network and fourier spectra supervision | Fourier spectra BCE | OULU-NPU | √ | √ | Introducing Fourier spectra enhances the accuracy of spoof detection. | The model’s generalization ability is limited. | ||
| Replay-Mobile | √ | √ | |||||||
| [98] | Liveness and content features via disentangled representation learning | Depth map Texture map | CASIA-MFSD | √ | √ | Separating spoof and real features enhances feature discrimination ability and detection accuracy. | Disentanglement relies on precise data annotation. | ||
| Replay-Attack | √ | √ | |||||||
| SiW | √ | √ | |||||||
| OULU-NPU | √ | √ | |||||||
| [99] | Discriminative features via fine-grained 3D point cloud supervision | 3D point cloud | CASIA-MFSD | √ | √ | Capturing facial depth and geometric features and handling various types of spoofing attacks. | Obtaining 3D point cloud data is challenging. | ||
| Replay-Attack | √ | √ | |||||||
| SiW | √ | √ | |||||||
| OULU-NPU | √ | √ | |||||||
| Ref. | Main Idea | Backbone | Datasets | Attacks | Advantages | Disadvantages | ||
|---|---|---|---|---|---|---|---|---|
| 2D-P | 2D-R | 3D-M | ||||||
| [100] | Utilizing local planar homography for capturing fine-grained facial motion cues. | Resnet | Replay-Attack | √ | √ | Contributing to the verification accuracy, the MPEM enhances the recall rate of the attack videos. | Local planar homography involving complex calculations | |
| OULU-NPU | √ | √ | ||||||
| [101] | Fusing global temporal and local spatial information from the video stream | CNN LSTM | Replay-Attack | √ | √ | Automatically focuses on important regions, enabling network behavior analysis and improving model interpretability. | Lots of experiments and dataset requirements complicate the research process and make reproduction more difficult. | |
| CASIA-MFSD | √ | √ | ||||||
| OULU-NPU | √ | √ | ||||||
| SiW | √ | √ | ||||||
| [102] | Combining spatial gradient and temporal depth information | CNN | Replay-Attack | √ | √ | The framework may process spatial gradient and temporal depth simultaneously to improve detection accuracy. | Processing spatial and temporal features is computationally intensive. | |
| CASIA-MFSD | √ | √ | ||||||
| OULU-NPU | √ | √ | ||||||
| SiW | √ | √ | ||||||
| 3DMAD | √ | |||||||
| [103] | Deep reinforcement learning(DRL), global spatial features and local temporal learning | ResNet18 RNN | Replay-Attack | √ | √ | Reinforcement learning improves recognition accuracy. | Weak generalization ability. | |
| CASIA-MFSD | √ | √ | ||||||
| OULU-NPU | √ | √ | ||||||
| MSU-MFSD | √ | √ | ||||||
| SiW | √ | √ | ||||||
| ROSE-YOUTU | √ | √ | √ | |||||
| [104] | Multi-granularity temporal characteristics learning using ViT | ViT | Replay-Attack | √ | √ | Multi-granularity temporal features may capture more dynamic information and effectively improve the accuracy of FAS. | Increasing the computational complexity and requiring higher hardware resources. | |
| CASIA-MFSD | √ | √ | ||||||
| OULU-NPU | √ | √ | ||||||
| MSU-MFSD | √ | √ | ||||||
| SiW | √ | √ | ||||||
| CASIA-SURF | √ | |||||||
| CFA | √ | √ | √ | |||||
| MLFP | √ | |||||||
| [105] | Merging motion trajectories, history cues, and texture differences around the facial local key points with a attention module and skip fusion strategy. | Swin- Transformer | FAAD [105] | √ | √ | √ | The model performs excellently under varying lighting conditions and motion scales. | Performance is influenced by the datasets, and user interaction may be needed. |
| MMI [105] | √ | √ | ||||||
| Ref. | Main Idea | Backbone | Datasets | Attacks | Advantages | Disadvantages | |||
|---|---|---|---|---|---|---|---|---|---|
| 2D-P | 2D-R | 3D-M | OA | ||||||
| [106] | Utilizing noise modeling to obtain a spoof noise, and using it for classification | CNN | Replay-Attack | √ | √ | Utilizing multi-layer feature decoupling to improve model robustness on specific datasets. | The only defense against printed photos and video replays | ||
| CASIA-MFSD | √ | √ | |||||||
| OULU-NPU | √ | √ | |||||||
| [107] | Using adversarial learning to disentangle the spoof traces | GAN | OULU-NPU | √ | √ | Resisting diverse attacks and improving the detection accuracy. | Adversarial training needs high computing resources. | ||
| SiW | √ | √ | |||||||
| SiW-M | √ | √ | √ | √ | |||||
| [108] | Utilizing U-Net to generate spoof cue maps with anomaly detection, and a auxiliary classifier made spoof cues more discriminative. | ResNet18 U-Net | Replay-Attack | √ | √ | General spoof cues can be learned to solve the problem of over-fitting and improve generalization. | Models require large amounts of diverse data. | ||
| CASIA-MFSD | √ | √ | |||||||
| OULU-NPU | √ | √ | |||||||
| SiW | √ | √ | |||||||
| [109] | Learning a joint distribution of the identity representation and the spoofing pattern representation in the latent space | CDCN | Replay-Attack | √ | √ | Improves the model’s generalization ability and detection accuracy. | Generating paired live and spoofing images increase the complexity and time cost of training. | ||
| CASIA-MFSD | √ | √ | |||||||
| OULU-NPU | √ | √ | |||||||
| SiW | √ | √ | |||||||
| SiW-M | √ | √ | √ | √ | |||||
| [110] | Effectively separating spoof-related features from irrelevant ones by incorporating reconstruction techniques. | ResNet18 U-Net [76] | Replay-Attack | √ | √ | Recognizes various spoofing attacks and improves their generalization across different attack types and conditions | Reliance on reconstruction may introduce additional complexity and computational overhead | ||
| CASIA-MFSD | √ | √ | |||||||
| MSU-MFSD | √ | √ | |||||||
| SiW | √ | √ | |||||||
| SiW-M | √ | √ | √ | √ | |||||
| [111] | Using image style, image quality, and diffusion models for domain shift | UNet | Replay-Attack | √ | √ | To solve the problem of domain shift, and also alleviate the scarcity of labeled data with novel type attacks | Generating high-fidelity images may require significant computational resources. | ||
| CASIA-MFSD | √ | √ | |||||||
| OULU-NPU | √ | √ | |||||||
| MSU-MFSD | √ | √ | |||||||
| WMCA | √ | √ | √ | √ | |||||
| PADISI | √ | √ | √ | √ | |||||
| [112] | Fourier frequency space disentanglement and data augmentation | DepthNet | Replay-Attack | √ | √ | The frequency domain analysis can capture subtle spoofing patterns. | Relying on low-level texture features may impact detection performance. | ||
| CASIA-MFSD | √ | √ | |||||||
| OULU-NPU | √ | √ | |||||||
| MSU-MFSD | √ | √ | |||||||
| Ref. | Main Idea | Backbone | Datasets | Attacks | Advantages | Disadvantages | |||
|---|---|---|---|---|---|---|---|---|---|
| 2D-P | 2D-R | 3D-M | OA | ||||||
| [115] | MMD, Kernel Hilbert Space, and kernel mean matching (KMM) | AlexNet | Replay-Attack | √ | √ | Reduces the statistical distance between domains and has strong interpretability | MMD distance can not fully reflect the differences among domains. | ||
| CASIA-MFSD | √ | √ | |||||||
| MSU-MFSD | √ | √ | |||||||
| ROSE-Youtu | √ | √ | √ | ||||||
| [116] | Knowledge distillation and MMD | AlexNet | CASIA-MFSD | √ | √ | ||||
| Replay-Attack | √ | √ | |||||||
| MSU-MFSD | √ | √ | |||||||
| MSU-USSA | √ | √ | |||||||
| ROSE-Youtu | √ | √ | √ | ||||||
| [117] | Adversarial training, disentangled representation learning | ResNet18 | Replay-Attack | √ | √ | Uses domain-independent features for classification | The decoupling strategy is simple and does not combine with prior knowledge. | ||
| CASIA-MFSD | √ | √ | |||||||
| MSU-MFSD | √ | √ | |||||||
| ROSE-Youtu | √ | √ | √ | ||||||
| Oulu-NPU | √ | √ | |||||||
| CASIA-SUR | √ | ||||||||
| [118] | Marginal and conditional distribution alignment | ResNet18 | CASIA-MFSD Replay-Attack MSU-MFSD CASIA-SURF | √ | √ | Flexibly switches between unsupervised and semi-supervised. | Conditional distribution is relatively simple. | ||
| √ | √ | ||||||||
| √ | √ | ||||||||
| √ | |||||||||
| [119] | Deep clustering and DA | MobileNetV3 | Replay-Attack | √ | √ | Combined with deep depth, the distinguishing ability of feature representation is improved. | The model requires a large amount of calculation. | ||
| MSU-MFSD | √ | √ | |||||||
| Replay-Mobile | √ | √ | |||||||
| [120] | Directly stylizes the target data in the source-domain style via GAN translation. | GAN CNN | OULU-NPU | √ | √ | Improving the generalization by feature alignment from source and target domains using GAN | Self-generating adversarial samples takes a lot of time. | ||
| CASIA-MFSD | √ | √ | |||||||
| Replay-Attack | √ | √ | |||||||
| MSU-MFSD | √ | √ | |||||||
| [121] | Total pairwise confusion loss and fast domain adaption | CNN VGG-16 | MSU-MFSD | √ | √ | Jointly addresses face recognition and face anti-spoofing in a mutually boosting way. | The multi-task training slightly decreases the interest performance of face anti-spoofing. | ||
| CASIA-MFSD | √ | √ | |||||||
| Replay-Attack | √ | √ | |||||||
| OULU-NPU | √ | √ | |||||||
| SiW | √ | √ | |||||||
| WMCA | √ | √ | √ | √ | |||||
| [122] | Meta-learning to achieve self-domain adaptation without a large amount of labeled data | CNN | MSU-MFSD | √ | √ | Unsupervised meta-learning reduces reliance on annotated data, lowering annotation costs and time. | Depending on differences between source and target domains | ||
| CASIA-MFSD | √ | √ | |||||||
| Replay-Attack | √ | √ | |||||||
| OULU-NPU | √ | √ | |||||||
| [123] | Semi-supervised transfer, the unlabeled data with reliable pseudo labels, temporal consistency | CNN ResNet18 | MSU-MFSD | √ | √ | Only a few pieces of labeled training data. | Noise or inconsistency may affect the quality of pseudo labels. | ||
| CASIA-MFSD | √ | √ | |||||||
| Replay-Attack | √ | √ | |||||||
| OULU-NPU | √ | √ | |||||||
| [126] | Source-free domain adaptation, source-oriented regularization, and contrastive domain alignment | DeiT-S [127] | MSU-MFSD | √ | √ | It enables effective domain adaptation without access to source domain data through generalized pretraining. | When the number of real or fake faces is extremely imbalanced, this work might not be robust enough. | ||
| CASIA-MFSD | √ | √ | |||||||
| Replay-Attack | √ | √ | |||||||
| OULU-NPU | √ | √ | |||||||
| Celebi-Spoof | √ | √ | √ | ||||||
| 3DMAD | √ | ||||||||
| HKBU-M V2 | √ | ||||||||
| CASIA-SURF 3D | √ | ||||||||
| Ref. | Main Idea | Backbone | Advantages | Disadvantages |
|---|---|---|---|---|
| [129] | Using adversarial training, deep supervision and dual-force triple-mining constraints | DepthNet | Extract domain-independent discriminative features | Difficulty in fitting multiple discriminators |
| [130] | Leveraging single-side adversarial learning and asymmetric triplet loss for enhancing the generalization ability | ResNet18 | Asymmetric processing improves the generalization performance | Asymmetric design needs to be improved |
| [131] | Transferring an input face image from the RGB domain to the depth domain | DenseNet | Alleviates the difficulties caused by appearance variations in lighting, image quality, and image capturing device. | Ignoring the temporal information may not work well for 3D spoofing attaches such as silicone masks. |
| [132] | To utilize AFNM to adaptively fuse normalized features from BN and IN and use DCC to aggregate the multiple source samples of the same class | CNN | Obtains domain-agnostic and discriminative representations for FAS. | To evaluate the method with extremely limited source domains. |
| [133] | Camera-invariant features and reconstructing images by low-frequency and high-frequency. | CNN | The camera-invariant feature learning enables the model to maintain stable performance under different camera devices. | Training and deployment costs are high. |
| [134] | Consistency regularization | CDCN | Consistency regularization ensures the consistency of feature representations. | It heavily relies on consistency under specific conditions, such as viewpoints and lighting. |
| [135] | A domain-invariant ViT, a concentration loss, and a separation loss | ViT | ViT reduces differences between domains and improves detection accuracy and robustness. | ViT has large data requirements and high computational complexity in visible light. |
| [136] | Using CFPL to learn semantic prompts based on content and style features | ViT | Learns more generalizable feature representations without relying on class labels. | It relies on a large amount of data. |
| [137] | Vision-language model (VLM) and a sample-level visual text optimization model | ViT-B | The method improves the precision and discriminative capability of feature extraction. | VLM may require substantial computational resources |
| [138] | Combining twofold element fine-grained semantic guidance: material and depth features | ViT-B/16 | Strong generalization capability. | The dual feature and semantic mechanisms increase the model’s complexity. |
| [139] | Domain generalization through shuffled style assembly and recombination | DepthNet ResNet-18 | Through domain style alignment, the negative impact of style differences across various domains is effectively mitigated. The model can maintain high robustness and generalization when facing different environmental conditions, such as camera devices and lighting variations. | Due to environmental changes such as variations in lighting, camera quality, and angles, style alignment may be inaccurate. This can cause the model to struggle in learning domain-invariant features effectively, impacting its generalization capability. |
| [140] | Learns the generalizable feature by weakening the features’ sensitivity to instance-specific styles | CNN | ||
| [141] | Test-time style projection (TTSL) and diverse style shifts simulation (DSSS) | ResNet18 ViT | ||
| [142] | Encouraging domain separability while aligning the live-to-spoof transition across all domains. | ResNet-18 | This is achieved by aligning gradient updates or loss functions to enhance the model’s robustness across different domains. | The effectiveness is limited when facing highly diverse data domains, and significant tuning may be required to achieve optimal performance. |
| [143] | By aligning gradient updates for the model converging to an optimal flat minimum | ResNet-18 | ||
| [144] | Designs a hierarchical fusion network to extract meta-features using meta-learning. | ResNet50 | Integrating RGB images and MP information has advanced the research on hybrid methods. | The meta-model extractor needs optimization. |
| [145] | Introduces frequency-domain augmentation and a self-supervised learning | ViT-Tiny | -- | Insufficient experimental validation. |
| [146] | Identity-agnostic representations, in-domain nearest neighbors | ResNet50 | Fully unsupervised | Limited sample size may affect the model’s adaptability to complex scenarios. |
| Ref. | O&C&I→M | O&M&I→C | O&C&M→I | I&C&M→O | ||||
|---|---|---|---|---|---|---|---|---|
| HTER↓ | AUC↑ | HTER↓ | AUC↑ | HTER↓ | AUC↑ | HTER↓ | AUC↑ | |
| [129] | 27.98 | 80.02 | 22.19 | 84.99 | 17.69 | 88.06 | 24.50 | 84.51 |
| SSDG-M [130] | 25.17 | 81.83 | 18.21 | 94.61 | 16.67 | 90.47 | 23.11 | 85.45 |
| SSDG-R [132] | 15.61 | 91.54 | 11.71 | 96.59 | 7.38 | 97.17 | 10.44 | 95.94 |
| [131] | 18.26 | 89.40 | 21.43 | 88.81 | 19.40 | 86.87 | 22.03 | 87.71 |
| [132] | 15.67 | 91.90 | 16.03 | 91.04 | 10.83 | 96.75 | 17.85 | 89.26 |
| [134] | 14.4 | 93.3 | 13.5 | 96.0 | 10.0 | 95.5 | 17.8 | 89.8 |
| [135] | 13.06 | 94.04 | 3.71 | 99.29 | 2.86 | 99.14 | 8.67 | 96.92 |
| [136] | 2.50 | 99.42 | 5.43 | 98.41 | 1.43 | 99.28 | 2.56 | 99.10 |
| [137] | 7.92 | 97.05 | 5.00 | 98.90 | 3.13 | 99.31 | 4.00 | 98.64 |
| [138] | 3.44 | 99.42 | 0.81 | 99.92 | 2.24 | 99.67 | 2.26 | 99.48 |
| [139] | 13.72 | 93.63 | 8.88 | 96.79 | 6.67 | 98.75 | 10.00 | 96.67 |
| [140] | 8.86 | 97.14 | 10.62 | 94.50 | 5.41 | 98.19 | 8.70 | 96.40 |
| [141] | 10.00 | 96.15 | 6.50 | 97.78 | 7.91 | 96.83 | 8.14 | 96.49 |
| [142] | 5.95 | 96.55 | 8.78 | 95.37 | 6.58 | 97.54 | 10.00 | 96.23 |
| [143] | 8.60 | 97.16 | 4.29 | 98.87 | 5.00 | 97.56 | 8.20 | 95.16 |
| [144] | 5.24 | 97.28 | 9.11 | 96.09 | 15.35 | 90.67 | 12.40 | 94.26 |
| [145] | 5.71 | 97.71 | 9.89 | 95.60 | 8.42 | 96.05 | 12.66 | 94.40 |
| [146] | 7.14 | 97.31 | 11.44 | 95.59 | 6.28 | 98.61 | 12.18 | 94.36 |
| Ref. | Main Idea | Backbone | Datasets | Attacks | Advantages | Disadvantages | |||
|---|---|---|---|---|---|---|---|---|---|
| 2D-P | 2D-R | 3D-M | OA | ||||||
| [28] | Deep tree learning, zero-Shot learning, and multiple classification | CNN | Replay-Attack | √ | √ | Zero-shot/ few-shot learning can use existing spoofing types without access to any samples of novel attacks or a small number of samples. Through technologies such as meta-learning or transfer learning, these methods can learn and infer, allowing for better adaptation to new or unknown attacks. | When attack samples are scarce or of poor quality, they may cause performance fluctuations. A small number of samples may limit feature expression capabilities. Zero-shot/few-shot learning (such as meta-learning or GAN) may increase the demand for computational resource and time requirements. | ||
| CASIA-MFSD | √ | √ | |||||||
| MSU-MFSD | √ | √ | |||||||
| SiW-M | √ | √ | √ | √ | |||||
| [147] | Leverage meta-learning models to adaptively update in the face of new attacks. | ResNet | CASIA-MFSD | √ | √ | ||||
| Replay-Attack | √ | √ | |||||||
| 3DMAD | √ | ||||||||
| MSU-MFSD | √ | √ | |||||||
| Replay-Mobile | √ | √ | |||||||
| HKBU-M V2 | √ | ||||||||
| Oulu-NPU | √ | √ | |||||||
| Rose-Youtu | √ | √ | √ | ||||||
| SiW | √ | √ | |||||||
| CSMAD | √ | ||||||||
| [148] | By training a meta-model, it can quickly adapt to new tasks and new environments and maintain good performance even with zero or few samples. | PR-Net | CASIA-MFSD | √ | √ | ||||
| MSU-MFSD | √ | √ | |||||||
| MSU-USSA | √ | √ | |||||||
| SiW | √ | √ | |||||||
| 3DMAD | √ | ||||||||
| Oulu-NPU | √ | √ | |||||||
| Replay-Attack | √ | √ | |||||||
| CASIA-SURF | √ | ||||||||
| [149] | Models can quickly scale and adapt to small amounts of new domain data | ResNet-18 | Celeba-Spoof | √ | √ | √ | |||
| MSU-MFSD | √ | √ | |||||||
| Oulu-NPU | √ | √ | |||||||
| SiW | √ | √ | |||||||
| [150] | Using unsupervised pretraining and finetuning with a small amount of annotated data | ViT | WMCA | √ | √ | √ | √ | ||
| SiW-M | √ | √ | √ | √ | |||||
| [151] | Self-attention mechanism | Resnet-50 | 3DMAD | √ | |||||
| CSMAD | √ | ||||||||
| SiW-M | √ | √ | √ | √ | |||||
| [152] | Adaptive Transformer performs feature extraction and attention mechanism optimization through hierarchical structures. | ViT | CASIA-MFSD | √ | √ | ||||
| Replay attack | √ | √ | |||||||
| MSU-MFSD | √ | √ | |||||||
| Oulu-NPU | √ | √ | |||||||
| CASIA-SURF | √ | ||||||||
| CASIA-CeFA | √ | √ | √ | ||||||
| WMCA | √ | √ | √ | √ | |||||
| Ref. | Main idea | Backbone | Datasets | Attacks | Advantages | Disadvantages | |||
|---|---|---|---|---|---|---|---|---|---|
| 2D-P | 2D-R | 3D-M | OA | ||||||
| [153] | Anomaly detection, metric learning, and introducing a few-shot a posteriori probability estimation | ResNet-50 | CASIA-MFSD | √ | √ | By learning normal facial features and detecting significant abnormal samples, the anomaly detection method maintains good performance in different datasets and scenarios. It can identify attack types that do not appear in the training set, and have strong adaptability and generalization capabilities. | It relies on high-quality normal samples and may be sensitive to environmental changes and the diversity of normal faces, resulting in increased false positive rates. | ||
| Replay-Attack | √ | √ | |||||||
| MSU-MFSD | √ | √ | |||||||
| GRAD-GPAD [160] | √ | √ | √ | ||||||
| UVAD | √ | ||||||||
| [154] | A one-class classifier with Gaussian distribution based statistical hypothesis and client-specific extension of anomaly detection | VGG16 | Replay-Attack | √ | √ | ||||
| Replay-Mobile | √ | √ | |||||||
| Rose-Youtu | √ | √ | √ | ||||||
| [155] | Pseudo-negative class using Gaussian distribution and pairwise confusion loss | VGGFace | Replay-Attack | √ | √ | ||||
| Rose-Youtu | √ | √ | √ | ||||||
| Oulu-NPU | √ | √ | |||||||
| SiW | √ | √ | |||||||
| [156] | One-class representation and a Gaussian Mixture Model | MCCNN | WMCA | √ | √ | √ | √ | ||
| SiW-M | √ | √ | √ | √ | |||||
| MLFP | √ | ||||||||
| [157] | Using client-specific information in a one-class anomaly detection and representations derived from CNNs | VGG16 | Replay-Mobile | √ | √ | ||||
| Replay-Attack | √ | √ | |||||||
| Rose-Youtu | √ | √ | √ | ||||||
| [158] | One-class representation using SCMs for zero responses for real faces | CNN | CASIA-MFSD | √ | √ | By not relying on spoof attacks, estimating SCMs and guiding feature learning enhance the detection capability for unseen attacks. | The design of SCMs guidance and the memory bank increases the complexity of the model. | ||
| Replay-Attack | √ | √ | |||||||
| MSU-MFSD | √ | √ | |||||||
| Oulu-NPU | √ | √ | |||||||
| SiW | √ | √ | |||||||
| 3DMAD | √ | ||||||||
| HKBU-MARs | √ | ||||||||
| CASIA-SURF | √ | ||||||||
| [159] | A regularized evidential DL strategy and an entropy optimization-based semantic consistency learning strategy | ResNet-18 | CASIA-MFSD | √ | √ | It could generalize well to cross-scenario target domains with both known and unknown PAs with different types and quantities. | -- | ||
| Replay-Attack | √ | √ | |||||||
| MSU-MFSD | √ | √ | |||||||
| Oulu-NPU | √ | √ | |||||||
| Rose-Youtu | √ | √ | √ | ||||||
| HQ-WMCA | √ | √ | √ | √ | |||||
| Ref. | Main Idea | Backbone | Datasets | Attacks | Advantages | Disadvantages | |||
|---|---|---|---|---|---|---|---|---|---|
| 2D-P | 2D-R | 3D-M | OA | ||||||
| [163] | Leveraging complementary information across modalities. | ResNet18 ResNet34 ResNet50 | CASIA-SURF | √ | High detection accuracy | Having a heavy parameter load | |||
| [164] | Bag-of-local-features and randomly erasing a certain modality | ResNext | CASIA-SURF | √ | MFE enhances generalization | High computa- tional overhead and training time. | |||
| [166] | High-frequency features and multi-modal features | CDCN | CFA | √ | √ | √ | Improving the model’s ability under different racial conditions | --- | |
| [167] | Using selective modality pipeline fusion network | CNN SENet154 | CFA | √ | √ | √ | Selective fusion reduces the impact of redundant information | The modality selection strategy may lead to instability in performance. | |
| [168] | Adversarial cross-modality alignment | CycleGAN | CASIA-SURF | √ | Adversarial cross-modality alignment enhances the model’s generalization ability | The adversarial training process is complex and computationally expensive. | |||
| CFA | √ | √ | √ | ||||||
| WMCA | √ | √ | √ | √ | |||||
| SiW | √ | √ | |||||||
| OULU-NPU | √ | √ | |||||||
| CASIA-MFSD | √ | √ | |||||||
| Replay-Attack | √ | √ | |||||||
| MSU-MFSD | √ | √ | |||||||
| [169] | Nonlinearly fuses low-level and high-level features from different modalities. | ResNet50 | MIPD [169] | √ | √ | √ | Good performance against multi-material 3D mask spoofing | 2D spoofing detection may be subpar in complex scenarios. | |
| CASIA-SURF | √ | ||||||||
| [170] | Paying attention to the modal independence | ViT | CASIA-SURF | √ | Improving generalization for different modal data | Higher computational complexity | |||
| MSU-MFSD | √ | √ | |||||||
| [171] | Flexibly adjusting the structure for different modalities | ViT | CASIA-SURF | √ | Improving adaptability to different modalities | Same as above | |||
| MSU-MFSD | √ | √ | |||||||
| [172] | Patch-level images from multi-modal data and uses a lightweight network | LMFFNet [172] | CASIA-SURF | √ | Reducing parameters while maintaining accuracy | Weaker robustness to illumination changes and complex backgrounds | |||
| Replay-Attack | √ | √ | |||||||
| CASIA-MASD | √ | √ | |||||||
| [173] | U-Adapter and ReGrad strategy to address modality unreliability and imbalance | ViT | CFA | √ | √ | √ | Enhancing the generalization by addressing the modality unreliabi- lity and imbalance | Needs to further adopt more efficient uncertainty estimation techniques. | |
| PADISI-Face | √ | √ | √ | √ | |||||
| CASIA-SURF | √ | ||||||||
| WMCA | √ | √ | √ | √ | |||||
| [174] | A modality- asymmetric masked autoencoder, self- supervised without costly annotated labels | ViT | WMCA | √ | √ | √ | √ | Being robust under various missing-modality cases | Weaker generalization and discriminative capacity of this method |
| CASIA-SURF | √ | ||||||||
| CFA | √ | √ | √ | ||||||
| [175] | Uses overlapping patches, parameter sharing in the ViT and a hybrid feature block | ViT | WMCA | √ | √ | √ | √ | Computationally efficient | Need further enhancement of generalization. |
| CASIA-SURF | √ | ||||||||
| Methods | Ref. | Clues | Advantages | Disadvantages | Attacks | Special Hardware |
|---|---|---|---|---|---|---|
| FAS based on acoustic | [176] | 3D geometric structure | Acoustic-based FAS can effectively detect spoofing attacks using readily available smartphone sensors without additional hardware. | The effectiveness of acoustic signals may be affected by environmental noise or interference. | 2D, adv | No |
| [177] | 3D geometric structure | 2D, adv | No | |||
| [178] | RGB-based models and 3D geometric structure | 2D, 3D | No | |||
| [179] | 3D geometric structure | 2D, 3D | No | |||
| [180] | 3D geometric structure | 2D, 3D | No | |||
| FAS based on optical | [181] | Motion, 3D geometric structure | This can be performed using existing cameras and flashes, making it easy to implement | Strong dependence on lighting and poor user experience | 2D, 3D, adv | No |
| [182] | 3D geometric structure | 2D, 3D | No | |||
| [183] | 3D geometric structure | Simple and fast | Not detecting 3D attacks | 2D | No | |
| [184] | The depth map and the material map | Simple, fast, yet effective | Needing an extra light source to generate the reflection frames | 2D, 3D | No | |
| [185] | 3D geometric structure | LiDAR is insensitive to variations in lighting. | Limited by the availability of LiDAR devices. | 2D, 3D | LiDAR | |
| FAS based on sensors | [186] | Material differences | Offering strong resistance to mask spoofing attacks | Relying on the widespread adoption and cost of millimeter-wave radar | 2D, 3D, adv | mmWave radar |
| [187] | Material differences | RFID device support, lower hardware requirements | Compatibility may be limited | 2D, 3D, adv | RFID | |
| Others | [188] | Motion, biometric | Eye movement patterns are highly individual-specific and difficult to forge | Need for high-precision eye-tracking equipment | 2D, 3D, adv | No |
| [189] | Neural architecture search (NAS) and pixel-wise binary supervision | Lightweight and fast | Not detecting 3D attacks | 2D | No | |
| [190] | Combining visual and auditory modalities | Enhancing generalization capability | The computation is relatively complex. | 2D | No |
| No. | Datasets | Year | Attack Types | Model | #Sub | #Live/ Spoof | Setup |
|---|---|---|---|---|---|---|---|
| 1 | CASIA- MFSD [25] | 2012 | Print (flat, wrapped, cut), Replay (tablet) | RGB | 50 | 150/ 450 (V) | Seven scenarios and three levels of image quality |
| 2 | Replay- Attack [191] | 2012 | Print (flat), Replay (tablet, phone) | RGB | 50 | 200/ 1000 (V) | Lighting and holding |
| 3 | Kose and Dugelay [192] | 2013 | Print (flat), Replay (tablet, phone) | RGB | 35 | 200/ 198 (I) | -- |
| 4 | MSU-MFSD [68] | 2015 | Replay (monitor) | RGB | 404 | 70/ 210(V) | Indoor scenario; two types of cameras |
| 5 | UVAD [193] | 2015 | Replay (monitor) | RGB | 404 | 808/ 16,268 (V) | Different lighting, background and places in two sections |
| 6 | REPLAY- Mobile [194] | 2016 | Print (flat), Replay (monitor) | RGB | -- | 390/ 640 (V) | Five lighting conditions |
| 7 | MSU-USSA [49] | 2016 | Print (flat), Replay (laptop, tablet, phone) | RGB | 1140 | 1140/ 9120 (I) | Uncontrolled; two types of cameras |
| 8 | HKBU-MV2 [40] | 2016 | Mask (hard resin) from Thatsmyface and REAL-f | RGB | 12 | 504/ 504 (V) | Seven cameras from stationary and mobile devices and six lighting settings |
| 9 | OULU-NPU [195] | 2017 | Print (flat), Replay (phone) | RGB | 55 | 720/ 2880 (V) | Lighting & background in 3 section |
| 10 | SiW [196] | 2018 | Print (flat, wrapped), Replay (phone, tablet, monitor | RGB | 165 | 1320/ 3300 (V) | Four sessions with variations of distance, pose, illumination and expression |
| 11 | Rose- Youtu [115] | 2018 | Print (flat), Replay (monitor, laptop), Mask (paper, crop-paper) | RGB | 20 | 500/2850 (V) | Five front-facing phone camera; Five different illumination conditions |
| 12 | CelebA- Spoof [77] | 2020 | Print (flat, wrapped), Replay (monitor, tablet, phone), Mask (paper). | RGB | 10,177 | 6384/ 469,153 (I) | Four illumination conditions; indoor & outdoor; rich annotations |
| 13 | CASIA- SURF 3DMask [87] | 2020 | Mask (mannequin with 3D print). | RGB | 48 | 288/ 864(V) | High-quality identity-preserved; Three decorations and six environments |
| 14 | RECOD- MPAD [84] | 2020 | Print (flat), Replay (monitor). | RGB | 45 | 450/ 1800 (V) | Outdoor environment and low-light & dynamic sessions |
| 15 | HiFiMask [27] | 2021 | Mask (transparent, plaster, resin). | RGB | 75 | 13650/ 40,950 (V) | three mask decorations; seven recording devices; six lighting conditions (periodic/random); six scenes |
| 16 | SiW-M [28] | 2022 | Print (flat), Replay, Mask (hard resin, plastic, silicone, paper, Mannequin), Makeup (cosmetics, impersonation, Obfuscation), Partial (glasses, cut paper). | RGB | 493 | 660/ 968 (V) | Indoor environment with pose, lighting and expression variations |
| 17 | SuHiFiMask [197] | 2023 | 2D image, Video replay, 3D Mask with materials Resin, Plaster, Silicone, Paper | RGB | 101 | 10195/ 10,195 (V) | Long distance using surveillance cameras, recording in three scenes, three lighting types, and four types of weather |
| 18 | WFAS [198] | 2023 | Print (newspaper, poster, photo, album, picture book, scan photo, packging, cloth), Display (phone, tablet, TV, computer), Mask, 3D Model (garage kit, doll, adult doll, waxwork). | RGB | 469,920 | 529,571/ 853,729 (I) | Internet, unconstrained settings. |
| 19 | SynthASpoof [199] | 2023 | 1 Print, 3 Replay. | RGB | 25,000 | 25,000/ 78,800 (I&V) | -- |
| No. | Datasets | Year | Attack Types | Modal | #Sub | #Live/ Spoof | Setup |
|---|---|---|---|---|---|---|---|
| 1 | 3DMAD [200] | 2014 | Mask (paper, hard resin) | RGB Depth | 17 | 170/ 85 (V) | Three sessions (2 weeks interval) |
| 2 | GUC-LiFFAD [201] | 2015 | Print (Inkjet paper, Laserjet paper), Replay (tablet) | Light field | 80 | 1798/ 3028 (V) | Distance of 1.5∼2 m in constrained conditions |
| 3 | 3DFS-DB [202] | 2016 | Mask (plastic) | RGB Depth | -- | 260/260 (V) | Head movement with rich angles |
| 4 | ERPA [203] | 2017 | Print (flat), Replay (monitor), Mask (resin, silicone) | RGB Depth, NIR, Thermal | 5 | Total 86 (V) | Subject positioned close (0.3∼0.5 m) to the two types of cameras |
| 5 | MLFP [204] | 2017 | Mask (latex, paper) | VIS, NIR, Thermal | 10 | 150/1200 (V) | Indoor and outdoor with fixed and random backgrounds |
| 6 | CSMAD [205] | 2018 | Mask (custom silicone) | RGB, Depth, NIR, Thermal | 14 | 104/ 159 (V + I) | Four lighting conditions |
| 7 | WMCA [206] | 2019 | Print (flat), Replay (tablet), Partial (glasses), Mask (plastic, silicone, and paper, Mannequin) | RGB, Depth, NIR, Therma | 72 | 347/1332 (V) | Six sessions with different backgrounds and illumination; pulse data for bonafide recordings |
| 8 | CASIA-SURF [161] | 2019 | Print (flat, wrapped, cut) | RGB, Depth, NIR | 1000 | 3000/ 18,000 (V) | Background removed; Randomly cut eyes, nose or mouth areas |
| 9 | CASIA-SURF CeFA [165] | 2021 | Print (flat, wrapped), Replay, Mask (3D print, silica gel) | RGB, Depth, NIR | 1607 | 300/ 27,900 (V) | Three ethnicities; outdoor & indoor; decoration with wig and glasses |
| 10 | PADISI-Face [207] | 2021 | Print (flat), Replay (tablet, phone), Partial (glasses, funny eye), Mask (plastic, silicone, transparent, Mannequin | RGB, Depth, NIR, SWIR, Thermal | 360 | 1105/ 924 (V) | Indoor, fixed green background, 60-frame sequence of 1984 × 1264 pixel images |
| 11 | HySpeFAS [208] | 2024 | Print attacks, 3D mask attacks, Medical masks, Makeup attacks | SSI | 6760 | Train: 520/ 3380 (I) VAL: 208/ 728 (I) Test: 1924 | Hyperspectral images were expertly reconstructed from SSI images utilizing the TwIST [209]. Each hyperspectral image boasts 30 spectral channels, offering a rich and diverse spectral representation. |
| 12 | UniAttackData [210] | 2024 | Physical Attacks: Print (flat, wrapped), Replay, Mask (3D print, silica gel). Digital Attacks: Adv (6), DeepFake (6) | RGB, Depth, NIR | 1800 | 29706 (V) (Live: 1800, Fake: 27,906) | -- |
| 13 | Echoface- Spoof [190] | 2024 | Print (A4 paper), Replay (Pad Pro (2388 × 1668), iPad Air 3 (2224 × 1668)) | RGB, Acoustic | -- | 250,000 (I, A) (82,715, 166,637) | Samsung Edge Note (2560 × 1440) Samsung Galaxy S9 (3264 × 2448) Samsung Galaxy S21 (4216 × 2371) Xiaomi Redmi7 (3264 × 2448) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xing, H.; Tan, S.Y.; Qamar, F.; Jiao, Y. Face Anti-Spoofing Based on Deep Learning: A Comprehensive Survey. Appl. Sci. 2025, 15, 6891. https://doi.org/10.3390/app15126891
Xing H, Tan SY, Qamar F, Jiao Y. Face Anti-Spoofing Based on Deep Learning: A Comprehensive Survey. Applied Sciences. 2025; 15(12):6891. https://doi.org/10.3390/app15126891
Chicago/Turabian StyleXing, Huifen, Siok Yee Tan, Faizan Qamar, and Yuqing Jiao. 2025. "Face Anti-Spoofing Based on Deep Learning: A Comprehensive Survey" Applied Sciences 15, no. 12: 6891. https://doi.org/10.3390/app15126891
APA StyleXing, H., Tan, S. Y., Qamar, F., & Jiao, Y. (2025). Face Anti-Spoofing Based on Deep Learning: A Comprehensive Survey. Applied Sciences, 15(12), 6891. https://doi.org/10.3390/app15126891