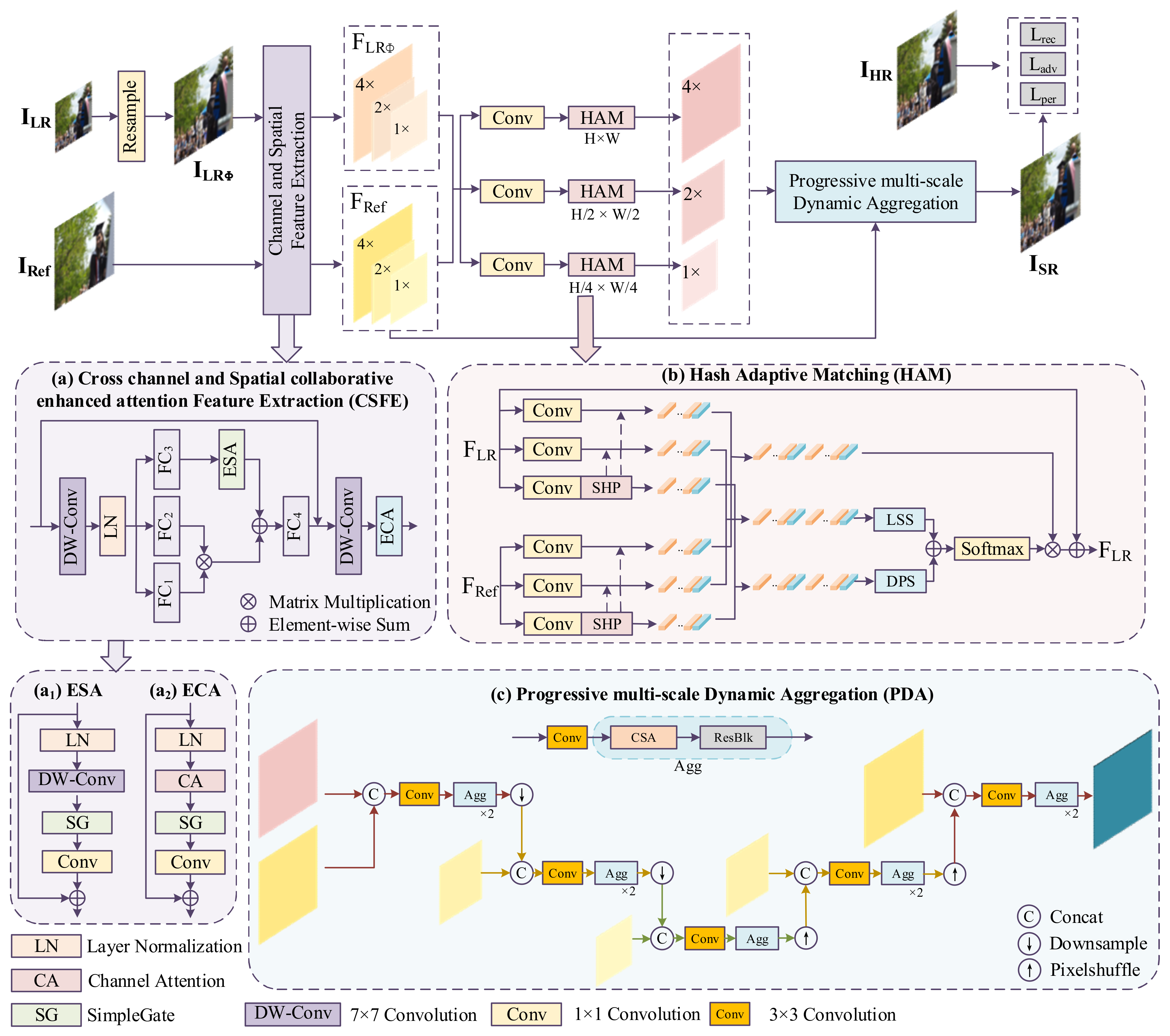
In this section, we first present the overall structure of the proposed method. We then introduce the cross-channel and spatial collaborative enhancement attention feature extraction module, the hash adaptive matching module, and the progressive multi-scale dynamic aggregation module.
3.3. Hash Adaptive Matching Module
Inspired by SISR self-similarity technology [
29], we introduce self-similarity information within LR images based on the similarity calculation between LR images and Ref images. By combining the similarities within and between images, a hash adaptive matching (HAM) method is proposed to enhance the accuracy of matching, thereby more effectively guiding the super-resolution reconstruction process and achieving higher-quality image detail restoration.
In order to facilitate the calculation of global attention, the features of the input LR and Ref images
and
are first reshaped into one-dimensional feature vectors
and
. The traditional non-local attention mechanism requires a similarity calculation between all feature vectors pair-wise, which is computationally intensive. To reduce the complexity of this process, the HAM method uses the spherical hash partition (SHP) strategy [
30]. This strategy divides the feature space based on the angular distance relationship between features, aggregates similar features into the same hash bucket, and performs attention calculation only in locally relevant regions.
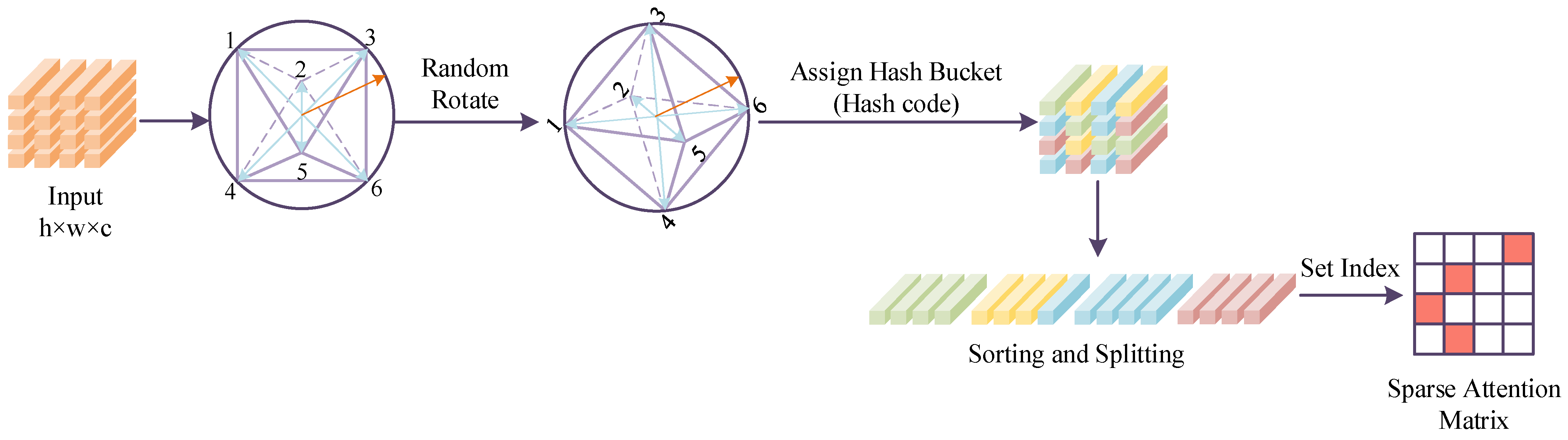
Specifically, as shown in
Figure 2, the basic idea of SHP is to nest a polyhedral structure within a unit sphere, use a hash function to map the eigenvectors to the outer surface of the sphere, and randomly rotate the polyhedral structure to ensure that the mapping process has sufficient randomness and directional coverage. Each feature vector selects the nearest vertex as its final hash index based on its angle with the vertices of the polyhedron. If the directions of two feature vectors are similar, that is, the angle between them is small, then they will be classified into the same hash bucket and identified as highly correlated features. Among them, the random rotation matrix has independent and identically distributed Gaussian components, ensuring the independence and uniformity of each hash mapping process in terms of direction.
To obtain m hash buckets, we must first project the target tensor onto a hypersphere and randomly rotate it using a matrix. The process of random rotation is as follows:
Here, is a size matrix c × m, c represents the dimension of input features, and m represents the number of hash buckets. Each element is an independent Gaussian variable N (0,1) sampled from below. This matrix is used to randomly project input features and is not strictly a rotation matrix. Map the feature vector x onto the sphere to obtain x′.
The hash computation process is as follows:
The hash code is defined as
. After performing hash computation on all feature tensors, obtain multiple hash buckets, we need to divide the space into buckets of related elements, so we calculate the similarity within each bucket.
represents the index of the bucket:
Here, represents each feature tensor, is the index, and denotes the global feature.
The hash results are sorted and partitioned into blocks, each containing a fixed number of feature tensors, with an attention range defined for each block. The attention mechanism extends beyond block boundaries to incorporate adjacent regions. To address the issue of relevant features being dispersed into different buckets, multiple independent hash operations are performed, and their results are aggregated to minimize the error probability.
The attention process of the feature vector within the LR image, as well as between the LR and Ref images, can be expressed as follows:
where
and
represent the
and
feature vectors on
, respectively,
is a feature embedding layer,
.
represents the similarity measure between the two feature vectors, can be expressed as follows:
The learnable similarity scoring function
allows the model to flexibly learn the contextual relevance of feature vectors
, as well as the bias information in the specific feature space. This can be explicitly expressed as:
where
is the feature embedding layer,
and
are the learnable linear transformation matrices,
and
are the corresponding bias vectors, and
is the ReLU activation function.
The fixed dot product similarity scoring function
directly computes the correlation between feature vectors using the dot product, and it can be expressed as:
where
and
share the same feature embedding layer, which is used for feature mapping.
Finally, the HAM module achieves efficient cross-image matching by processing the global features of both the LR and Ref images. The overall operation is as follows:
where
and
represent the feature outputs of the LR and Ref images, respectively, after cross-image attention fusion.
3.4. Progressive Multi-Scale Dynamic Aggregation
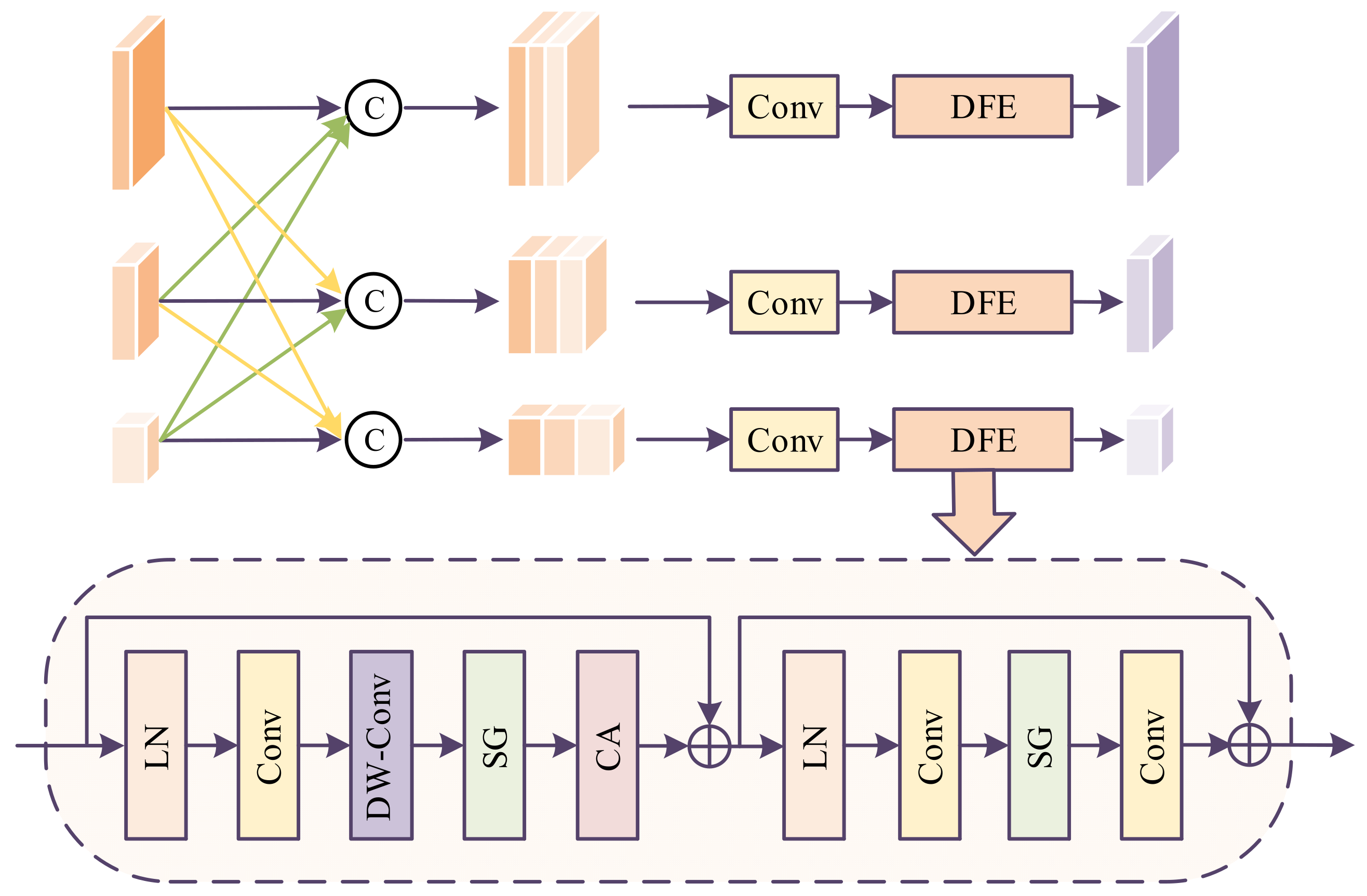
The LR images corresponding to each scale are fed into the multi-scale feature interaction (MSI) module to facilitate cross-scale feature interaction, thereby further enhancing and integrating the feature representations, as shown in
Figure 3.
The features of the second scale are upsampled once, and the features of the third scale are upsampled twice. These two features are then concatenated with the features from the first scale along the channel dimension. Afterward, a convolution operation is applied to reduce the number of channels to one-third, followed by a feature extraction module for further feature extraction.
The features of the first scale are downsampled once, and the features of the third scale are upsampled once. These two features are concatenated along the channel dimension with the features from the second scale. Then, a convolution operation is applied to reduce the number of channels to one-third, followed by feature extraction through the feature extraction module.
The features from the first scale are downsampled twice, and the features from the second scale are downsampled once. These two features are then concatenated along the channel dimension with the features from the third scale. Afterward, convolution is applied to compress the number of channels to one-third, followed by feature extraction using a feature extraction module.
After feature interaction through the MSI module, the LR image features at three scales are input into the PDA, where progressive dynamic aggregation is performed multiple times at each scale to complete the super-resolution reconstruction.
The aligned low-resolution (LR) image features are concatenated with the reference (Ref) image features, which are subsequently fed into a convolutional layer. A dynamic decoupling filter, namely the channel–spatial attention (CSA) mechanism, is then employed to extract texture information across both spatial and channel domains. The structure of CSA is shown in the
Figure 4.
In the spatial domain, CSA extracts features through the spatial gate (SG) module and convolution. The SG module captures the local correlation between pixels and dynamically generates weights related to the texture, thereby enhancing the spatial feature representation of the image. Additionally, the convolution operation further refines the spatial domain features, ensuring that the texture details of local regions are fully preserved.
In the channel domain, CSA utilizes the channel attention (CA) module to adaptively adjust the weight distribution of channel features. CA models the importance of different channels and dynamically optimizes the feature representation ability, enabling efficient processing and expression of multi-channel features.
Following the channel-wise and spatial domain output operations, a filtering normalization process was implemented to standardize the feature representations.
where
and
represent the spatial and channel filters before filter normalization, respectively.
and
are used to compute the mean and standard deviation of the filters, while
,
,
, and
are learnable scaling and shift parameters, similar in function to the scale and shift parameters in batch normalization [
31], used to control the normalized numerical range. The four parameters are defined as 1 during network initialization and updated through backpropagation training of the entire network. The decoupled dynamic filtering operation can be expressed as:
where
represents the output feature value at the
-th pixel and k-th channel, and
represents the input feature value at the
-th pixel and
-th channel.
represents the set of pixels within the convolution window centered on pixel
-th, using a fixed size 3 × 3 convolution.
represents the channel filter, generated by channel attention, calculates dynamic weights based on relative position (distance difference between pixels). This weight is used to control which spatial regions contribute more to the current pixel. For example, if the distance between one pixel and another is close and the spatial attention value is high, then it indicates that these two pixels have a higher correlation in computation.
represents the spatial filter, a dynamic weight generated by the spatial gate, used to control the importance of different channels. By learning the weights of each channel, the model can automatically adjust the weights between channels based on the specific requirements of input features.
and
represent the spatial coordinates of the pixels, and
is used to calculate the relative position between two pixels. This formula represents that for the
-th channel and the
-th pixel, the decoupled dynamic filter weights the pixel contributions within its neighborhood
based on channel attention and spatial attention to complete feature reconstruction.
Finally, the features after decoupled dynamic filtering are passed through the ResBlock to achieve dynamic aggregation.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}