4.1. GrAImes Evaluation of Human-Written Microfiction by the Experts Group
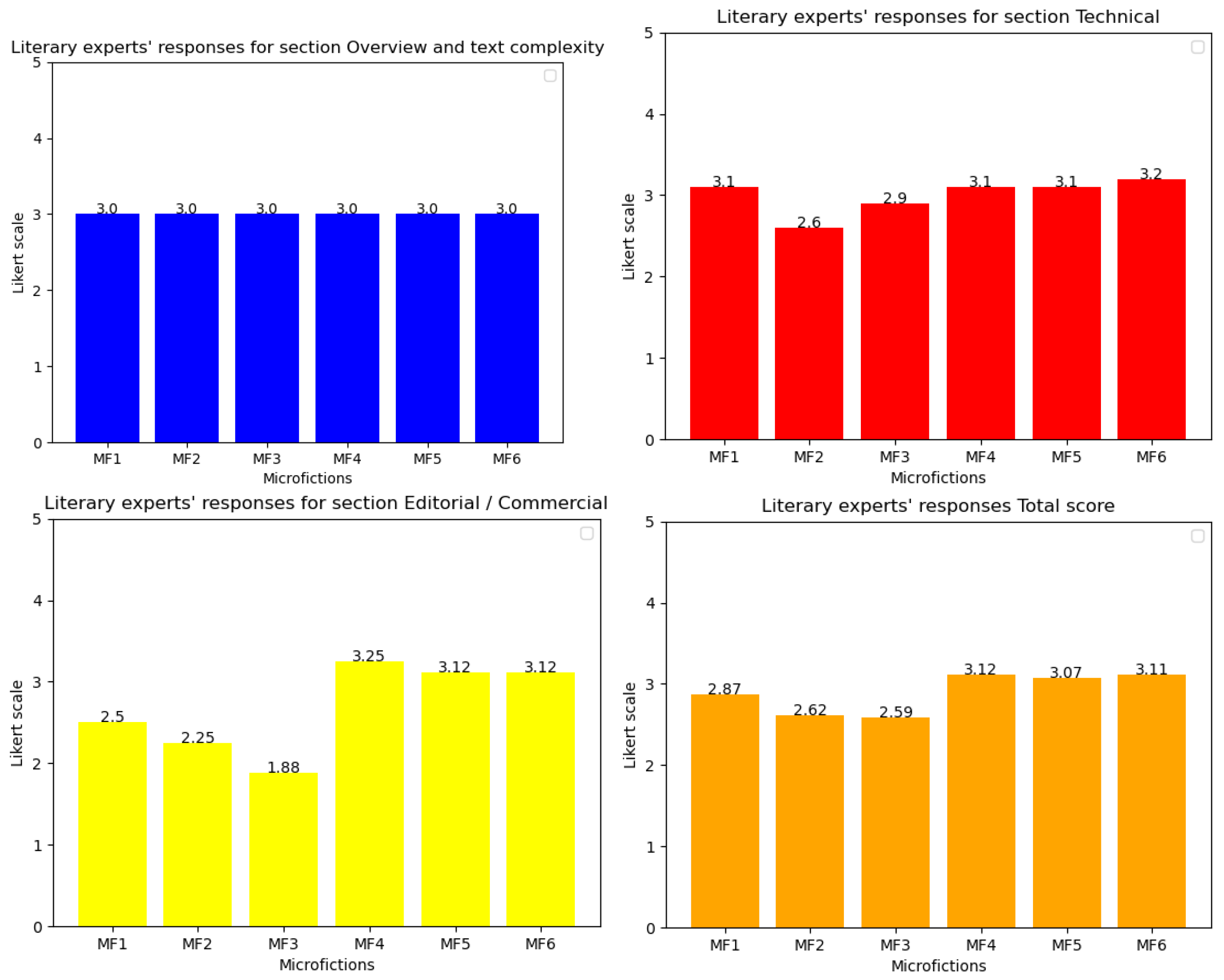
GrAImes was evaluated by literary experts, all of whom were Spanish speakers, with one non-native speaker among them. We selected six microfictions written in Spanish and provided them to the experts along with the fifteen questions from our evaluation protocol. The six microfictions included two written by a well-known author with published books (MF 1 and 2), two by an author who has been published in magazines and anthologies (MF 3 and 6), and two by an emerging writer (MF 4 and 5).
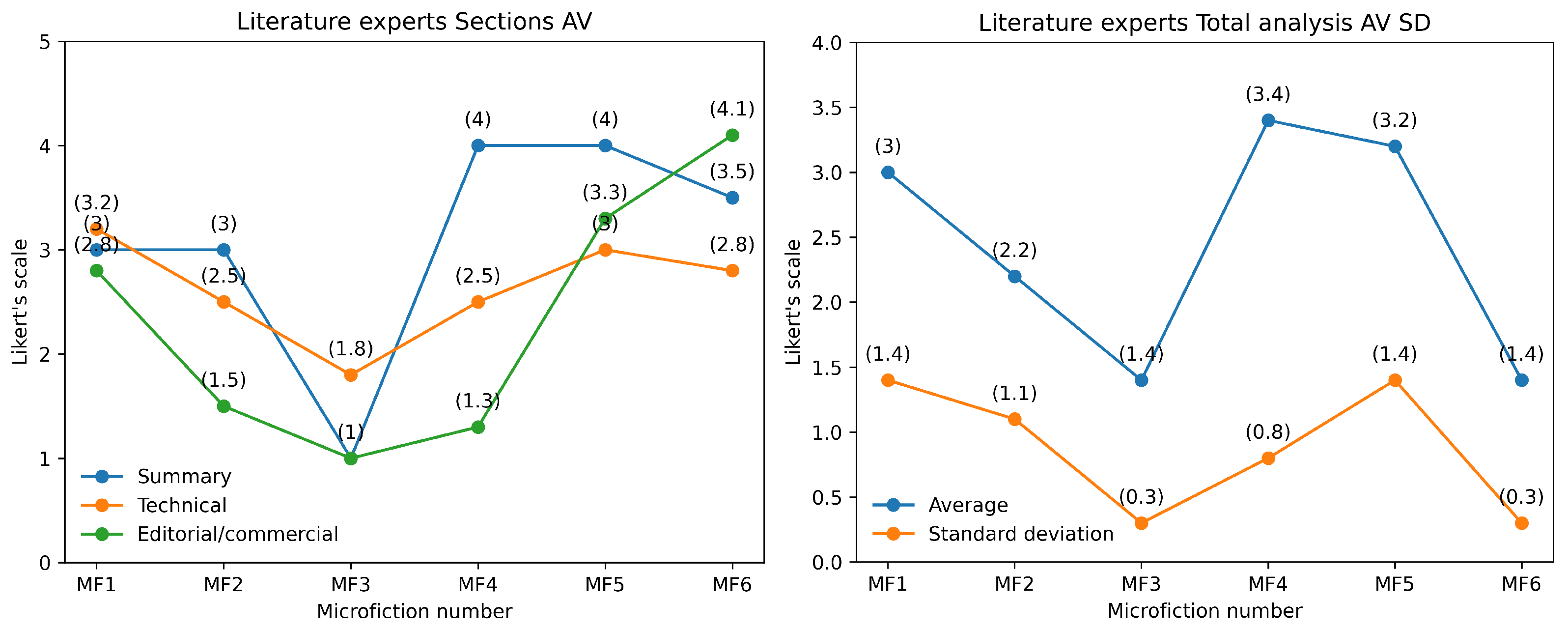
From the responses obtained and displayed in
Table 4 and
Table 5, and
Figure 4 and
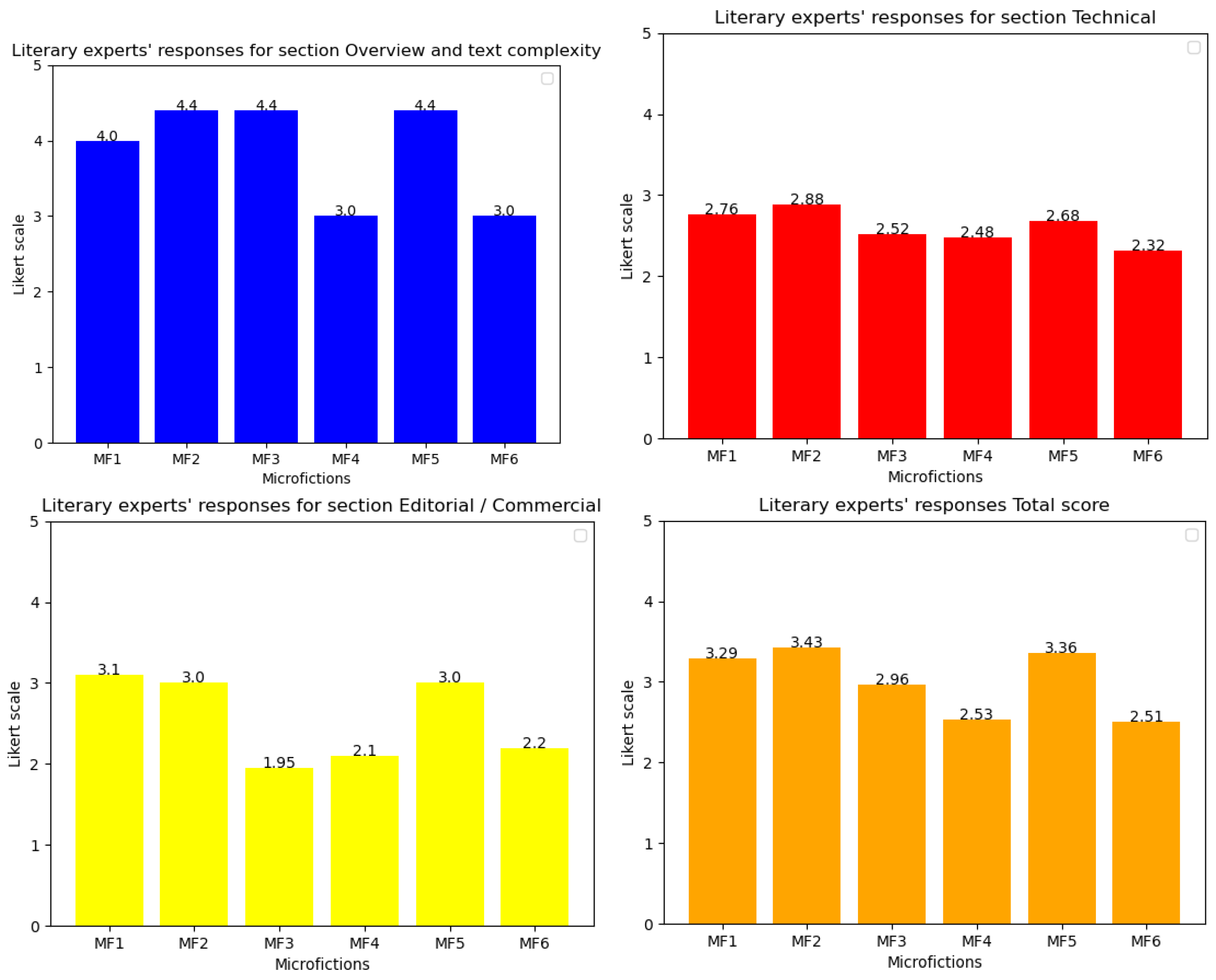
Figure 5, it can be concluded that the literary experts rated microfictions 1 and 2 (authored by the expert writer) more favorably. However, the responses show a high standard deviation, indicating that while the evaluations were generally positive, there was significant variation among the experts. Additionally, the lowest-ranked microfictions were 4 and 6, which had a lower response average, also exhibited a lower standard deviation, suggesting greater agreement among the judges. These texts were written by the emerging author (MF 4) and medium-experience author (MF 6).
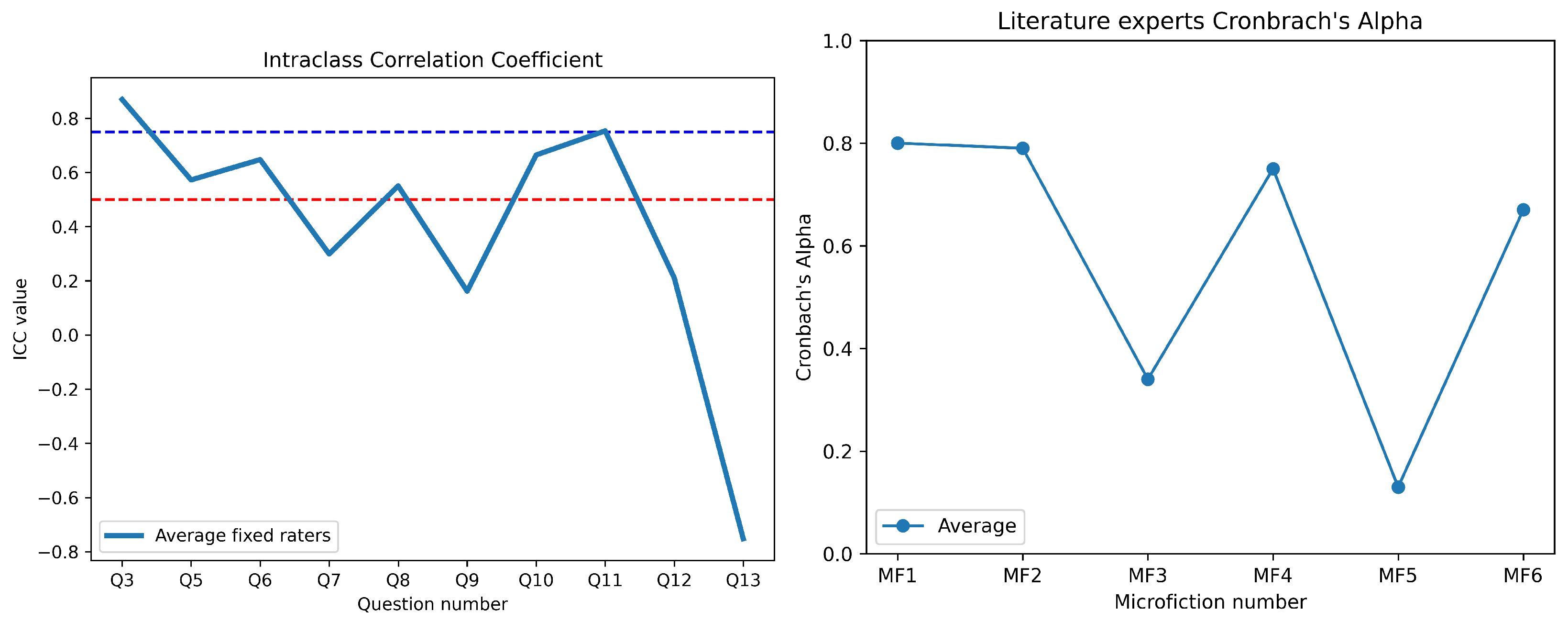
These results suggest a direct correlation between the authors’ expertise and the internal consistency of the texts. The microfictions written by the expert author (MF 1 and MF 2) exhibited the highest Cronbach’s alpha values of 0.80 and 0.79, respectively, indicating good to acceptable internal consistency (see
Table 6 and
Figure 6). This suggests that the Expert group evaluated the microfiction written by expert writers with higher coherence and internal consistency.
Microfictions written by the author with medium experience (MF 4 and MF 6) displayed Cronbach’s alpha values of 0.75 and 0.67, respectively (see
Table 7), which fall within the acceptable to questionable range. While the evaluations of these microfictions maintained moderate internal consistency, they exhibited higher standard deviations (SD = 1 and SD = 1.1) compared to the microfictions by the expert author. This could imply that expert evaluators are able to coherently distinguish between a good text from an emerging author and a less-effective one from a medium-experienced author.
Conversely, the texts written by the author with low expertise (MF 3 and MF 5) demonstrated the lowest internal consistency, with Cronbach’s alpha values of 0.34 and 0.13, respectively. These values are classified as unacceptable, suggesting significant inconsistencies within the text. The standard deviation (SD = 0.9 for both) was lower than that of the expert and medium-experience authors, which may indicate a lack of variability in linguistic structures or a more rigid and less developed writing style. The low consistency of these texts highlights the challenges faced by less experienced authors in maintaining logical coherence and plot story structure.
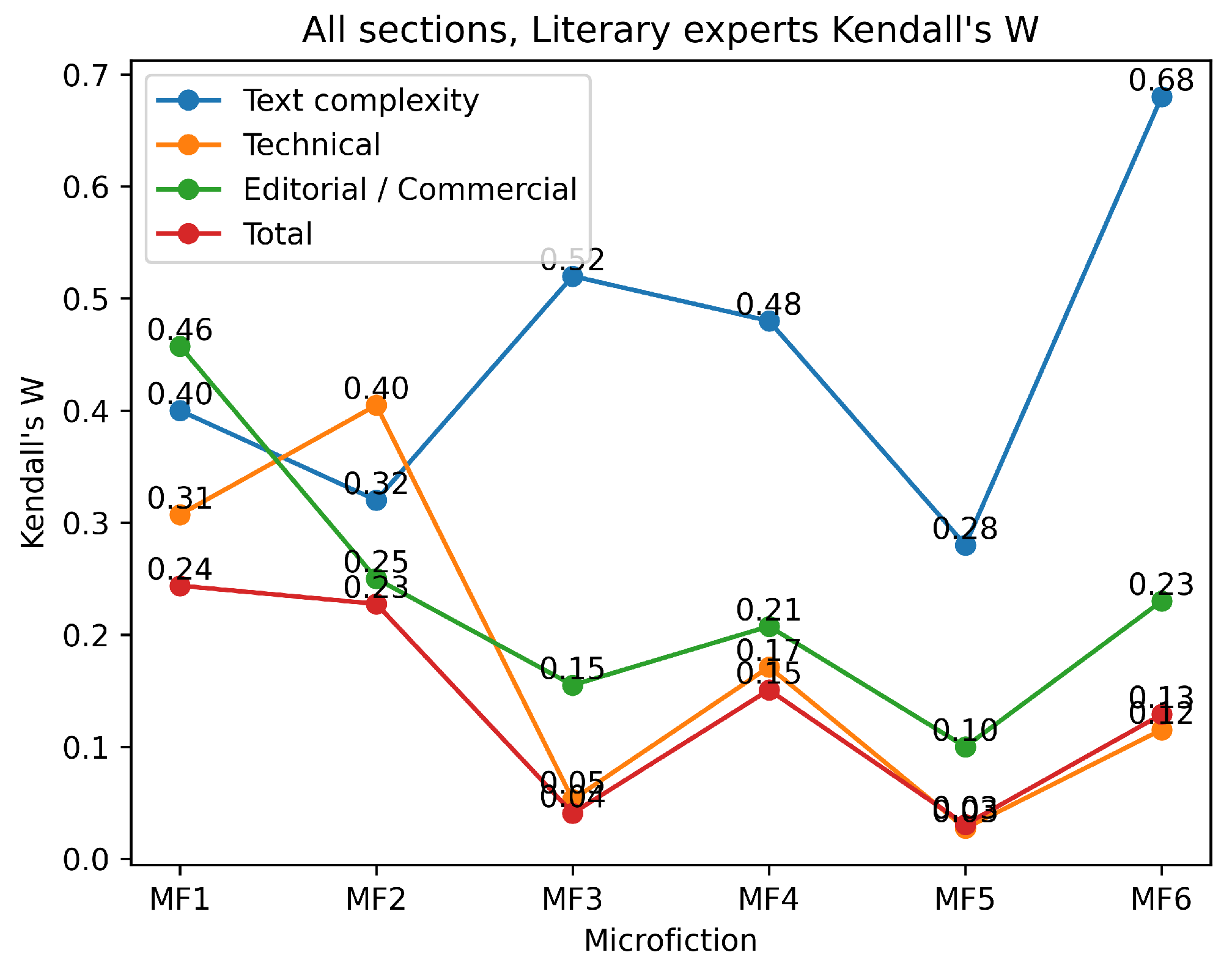
The results of the Kendall’s W analysis (see
Figure 7) indicate varying levels of agreement among the experts, with the highest concordance observed for MF1 and MF2, both of which were written by the expert author. In contrast, MF3 and MF5, which were authored by less experienced writers, showed lower levels of agreement. These findings suggest that the author’s expertise aligns with the evaluations made by literary experts.
Additionally, the average values of the microfiction provide further insight (see
Table 7). The expert-authored texts had the highest AV (3 and 3.1), followed by the medium-experience author (2.5 and 2.4), while the less-experienced author scored the lowest (2 and 2.9). This pattern reinforces the idea that writing expertise influences not only internal consistency but also the overall perception of text quality.
These findings align with existing research [
59] on the relationship between writing expertise and textual coherence. Higher expertise leads to better-structured and logically consistent texts, whereas lower expertise results in fragmented and inconsistent writing. The judges provided higher ratings to microfictions written by the more experienced author and lower ratings to those written by the emerging author. This is consistent with the purpose of our evaluation protocol, which aims to provide a tool for quantifying and qualifying a text based on its literary purpose as a microfiction.
Among the evaluated questions (see the Likert scale answer column in
Table 2), Question 3 exhibited the highest ICC (0.87), indicating excellent reliability and strong agreement among respondents. Its relatively high average score (AV = 3.5) and moderate standard deviation (SD = 1) suggest that participants consistently rated this question favorably. Similarly, Question 11 (ICC = 0.75) demonstrated good reliability, although its AV (2.4) was lower, suggesting that respondents agreed on a more moderate evaluation of the item (see
Table 7).
Moderate reliability was observed for Questions 10 and 6, with ICC values of 0.67 and 0.65, respectively. The AV scores (3.6 and 3.4) suggest that the the MFs were generally well-rated; however, the higher standard deviation of Question 10 (SD = 1.7) indicates a greater spread of responses, possibly due to varying interpretations or differences in respondent perspectives. Questions 5 and 8, with ICC values of 0.57 and 0.55, respectively, fall into the questionable reliability range. Notably, Question 8 had the lowest AV (1.8), indicating that respondents found it more difficult or unclear, which may have contributed to the reduced agreement among responses.
In contrast, Questions 7, 12, and 9 exhibited low ICC values (0.29, 0.21, and 0.16, respectively), suggesting weak reliability and higher response variability. The AV values for these items ranged from 2.2 to 2.3, further indicating inconsistent interpretations among the participants. The standard deviations for these questions (SD = 1.1–1.4) suggest a broad range of opinions, reinforcing the need for potential revisions to improve clarity and consistency.
A particularly notable finding is the negative ICC value for Question 13 (−0.72). Negative ICC values typically indicate systematic inconsistencies which may stem from ambiguous wording, multiple interpretations, or flaws in question design. With an AV of 2.0 and an SD of 1.2, it is evident that responses to this item lacked coherence.
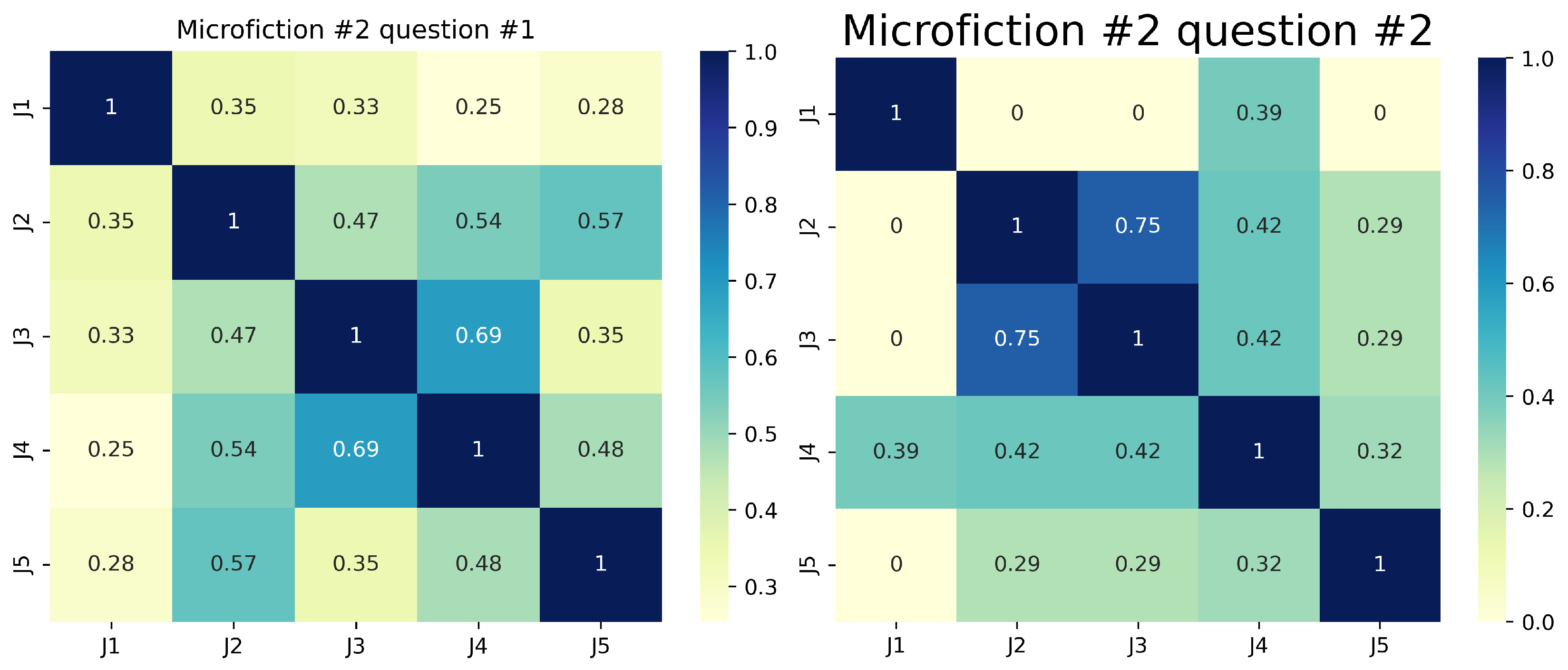
Regarding the responses to the five open-answer questions (numbers 1, 2, 4, 14, and 15 in
Table 2), we used Sentence-BERT [
60] and semantic cosine similarity [
61] to look for lexical and semantic similarities between the GrAImes open-answer questions. These results reveal key insights into evaluation agreement and interpretation variability across the six microfiction. For Question 1 (plot comprehension), agreement was often weak (e.g., J1-J4 semantic cosine similarity = 0.21 for MF1), suggesting narrative ambiguity or divergent reader focus. Question 2 (theme identification) showed inconsistent alignment (e.g., J2-J3 similarity = 0.67 for MF2 vs. J1-J3 = 0.10 for MF1; see
Figure 8), indicating subjective thematic interpretation. Question 4 (interpretation specificity) had polarized responses, with perfect agreement in some cases (e.g., J1-J2 = 1.00 for MF3) and stark divergence in others (J2-J3 = 0.00 for MF4), reflecting conceptual or terminological disparities. Questions 14 (gifting suitability) and 15 (publisher alignment) demonstrated higher consensus (e.g., perfect agreement among four judges for MF4 on Question 4), likely due to more objective criteria. However, J5 consistently emerged as an outlier (e.g., similarity ≤ 0.11 for MF1 on Question 15), underscoring individual bias. Our protocol’s value lies in quantifying these disparities; clearer questions (14–55) reduced variability, while open-ended ones (1–2) highlighted the need for structured guidelines to mitigate judge-dependent subjectivity, particularly in the case of ambiguous or complex microfiction.
On the two extra questions given to the literary experts (see
Section 3.2.2), the majority of experts (3 out of 5) found the microfiction evaluation protocol sufficiently clear for use, while a minority (2 out of 5) expressed concerns regarding ambiguous or unclear criteria. A strong consensus (4 out of 5 experts) agreed that the protocol can effectively evaluate the literary value of microfiction. However, the presence of one dissenting opinion highlights the need for adjustments in specific criteria to ensure more precise assessment.
4.2. GrAImes Evaluation of Monterroso- and ChatGPT3.5-Generated Microfiction Evaluated by the Enthusiast Group
Next, we applied GrAImes to assess a collection of six microfictions crafted by advanced AI tools. These tools included two models: the renowned Monterroso short story creator inspired by the style of renowned Guatemalan author Augusto Monterroso, and ChatGPT-3.5. The literature enthusiasts who participated in this study evaluated the microfictions based on parameters such as coherence, thematic depth, stylistic originality, and emotional resonance.
A total of six microfictions were generated, three by the Monterroso tool (MFs 1, 2, and 3) and three by ChatGPT-3.5 (MFs 4, 5, and 6). The microfictions were evaluated on a Likert scale ranging from 1 to 5, with ratings provided by a panel of 16 reader enthusiasts. The average and standard deviation (SD) of the ratings were calculated for each microfiction. The results of the analysis are presented in
Table 8, and
Figure 9 and
Figure 10.
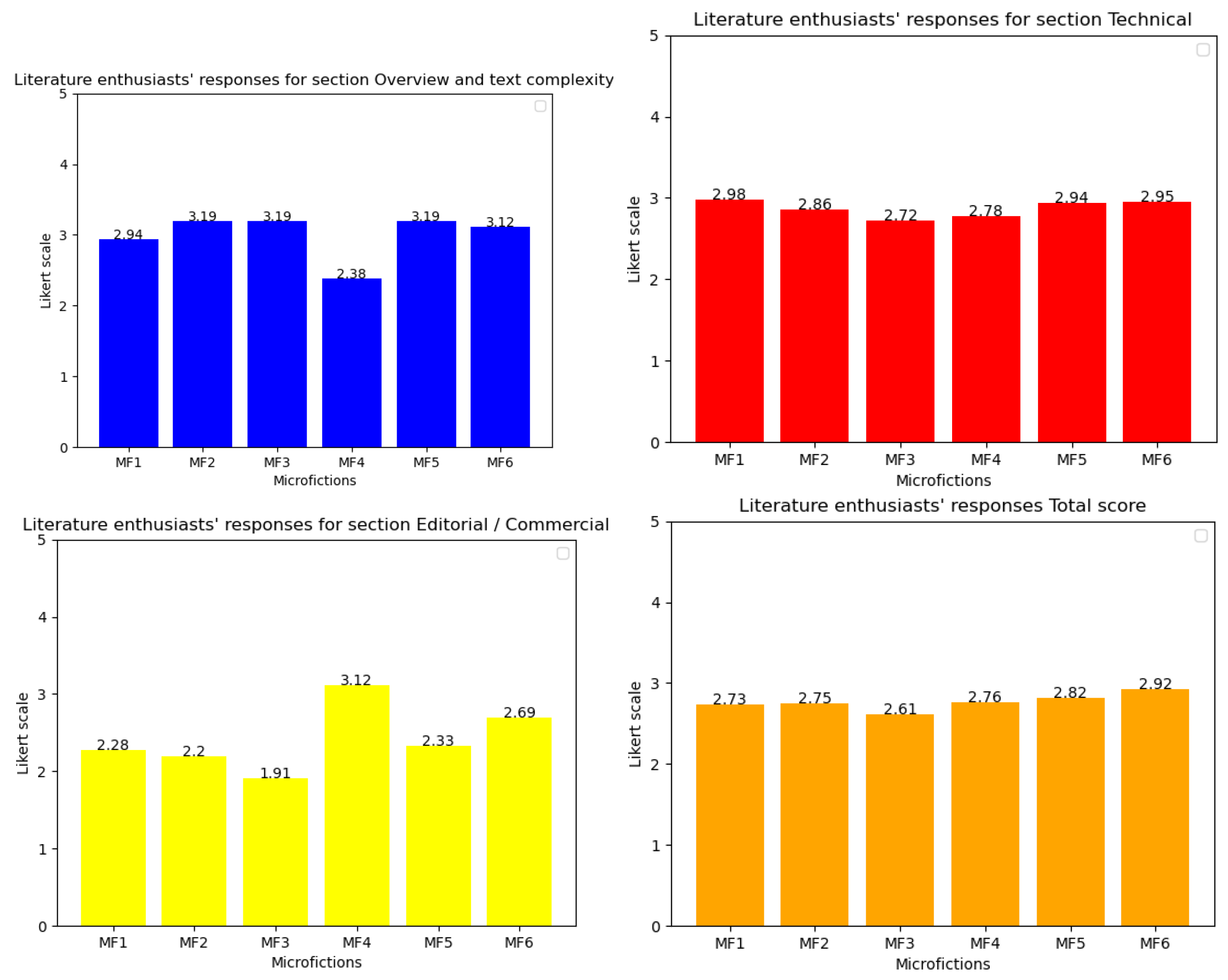
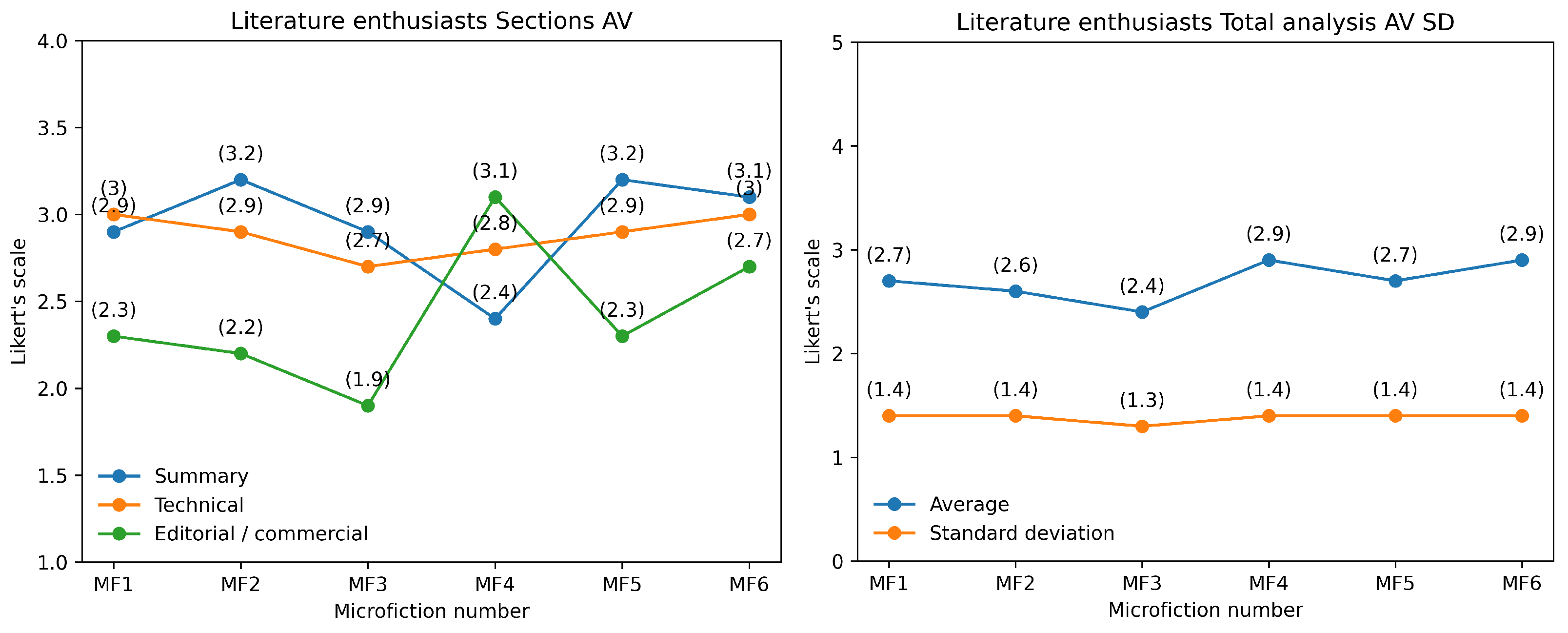
The results indicate that the ChatGPT-generated microfictions (4, 5, 6) have slightly higher average ratings (2.7–2.9) compared to the Monterroso-generated microfictions (1, 2, 3), which have average ratings ranging from 2.4 to 2.7 (see
Table 9,
Table 10,
Table 11 and
Table 12 and
Figure 11). The standard deviation values are consistent across most microfictions, indicating a relatively narrow range of ratings.
The most consistent responses pertained to the credibility of the stories (AV = 3.1, SD = 1.0), indicating strong agreement among participants on the narratives’ believability. This suggests that regardless of their other literary attributes, the microfictions maintained a sense of realism that resonated with readers. The question regarding whether the text required the reader’s participation or cooperation to complete its form and meaning received the highest average rating (AV = 3.6, SD = 1.3). This suggests that the generated microfictions engaged actively the readers, requiring interpretation and involvement in order to fully grasp their meaning. The relatively low SD indicates moderate consensus on this aspect.
Questions concerning literary innovation, e.g., whether the texts proposed a new vision of language (AV = 2.7, SD = 1.3), reality (AV = 2.6, SD = 1.4), or genre (AV = 2.4, SD = 1.4), showed moderate variation in responses. This suggests that while some readers perceived novelty in these areas, others did not find the texts to be particularly innovative. Similarly, answers to the question of whether the texts reminded readers of other books (AV = 3.2, SD = 1.4) present a comparable level of divergence in opinions. The lowest-rated questions relate to the desire to read more texts of this nature (AV = 2.3), readers’ willingness to recommend them (AV = 2.2), and their inclination to gift them to others (AV = 2.1), all with SD = 1.4. These results suggest that while the generated microfictions may have some engaging qualities, they do not strongly motivate further exploration or endorsement.
Interestingly, the question about whether the texts propose interpretations beyond the literal received the highest standard deviation (SD = 1.6, AV = 2.9). This indicates significant variation in responses, suggesting that some readers found deeper layers of meaning while others perceived the texts as more straightforward.
The intra-class correlation coefficient (ICC) analysis of the GrAImes answers (see
Table 13 and
Figure 12) revealed varying degrees of reliability among the 16 literature enthusiast raters when assessing texts generated by Monterroso and ChatGPT-3.5. Three questions demonstrated poor reliability (ICC < 0.50), reflecting high variability in responses, with Question 8 exhibiting a negative ICC (−0.44) suggesting severe inconsistency, possibly due to misinterpretation or extreme subjectivity. In contrast, Questions 5 and 6 showed excellent reliability (ICC > 0.90), indicating strong inter-rater agreement, while Questions 9, 11, 12, and 13 displayed moderate reliability (ICC 0.6––0.70), implying acceptable but inconsistent consensus. These findings highlight the need to refine ambiguous or subjective questions in order to improve evaluative consistency in microfiction assessment.
This study assessed microfiction based on ability to propose interpretations beyond the literal meaning, finding notable differences between texts generated by the Monterroso (MFs 1–3) and ChatGPT-3.5 (MFs 4–6) models. Monterroso’s MF 2 had the highest average score (AV = 3.2), showing stronger ability to suggest multiple interpretations, while ChatGPT-3.5’s MF 4 had the lowest score (AV = 2.4), indicating limited interpretive depth. Standard deviation values were consistent across all MFs (1.5 to 1.7), showing moderate response variability among the literature enthusiasts. Thus, while certain MFs were seen as being more interpretively rich, the response variability was similar for all texts.
The technical quality of the MFs was assessed through questions related to credibility (Question 5), reader participation (Question 6), and innovation in reality, genre, and language (Questions 7–9). MF 6, generated by ChatGPT-3.5, scored highest in credibility (AV = 4.3), while MF 1 generated by Monterroso scored the lowest (AV = 1.9). This indicates a clear distinction in perceived realism between the two sources as evaluated by the literature enthusiasts. In terms of reader participation, MF 1 scored highest (AV = 4.6), suggesting that it effectively engaged readers in completing its form and meaning. MF 4 scored the lowest in this category (AV = 2.4), highlighting potential weakness in ChatGPT-3.5’s generated texts. Innovation in language (Question 9) was rated highest for MF 1 (AV = 3.4), while MF 5 scored the lowest (AV = 2.4). Overall, the technical quality of the MFs generated by Monterroso (MFs 1–3) was slightly higher (AV = 2.7–3.0) compared to those generated by ChatGPT-3.5 (AV = 2.8–3.0), with MF 3 scoring the lowest (AV = 2.7). The consistent SD values (ranging from 0.9 to 1.7) reflect similar levels of variability in responses from the literature enthusiasts.
The editorial and commercial appeal of the MFs was evaluated based on their resemblance to other texts (Question 10), reader interest in similar texts (Question 11), and willingness to recommend or gift the texts (Questions 12–13). MF 4, generated by ChatGPT-3.5, scored highest in resemblance to other texts (AV = 3.9), while MF 2 scored the lowest (AV = 2.8). This suggests that the texts generated by ChatGPT-3.5 may be more reminiscent of existing literature as perceived by literature enthusiasts. In terms of reader interest, MF 4 also scored the highest (AV = 3.0) while MF 3 scored the lowest (AV = 1.7); similarly, MF 4 was the most recommended (AV = 2.8) and most likely to be gifted (AV = 2.8), indicating stronger commercial appeal compared to Monterroso’s generated texts. Overall, the MFs generated by ChatGPT-3.5 (MFs 4–6) outperformed the Monterroso-generated MFs (MFs 1–3) in editorial and commercial appeal, with MF 4 achieving the highest average score (AV = 3.1) and MF 3 the lowest (AV = 1.9). The SD values (ranging from 0.9 to 1.7) indicate moderate variability in the responses from the literature enthusiasts.
The total analysis of the MFs (see
Table 14) reveals that the ChatGPT-3.5 texts (MFs 4–6) generally outperformed the Monterroso-generated texts (MFs 1–3) in terms of editorial and commercial appeal, while Monterroso’s texts showed slightly better technical quality. MF 4, generated by ChatGPT-3.5, achieved the highest overall score (AV = 2.9), while MF 3 generated by Monterroso scored the lowest (AV = 2.4). The standard deviation values were consistent across all categories (SD ≈ 1.3–1.4), indicating similar levels of variability in responses from literature enthusiasts. These findings suggest that while the ChatGPT-3.5 texts may have stronger commercial potential, the Monterroso texts exhibit slightly higher technical sophistication. The evaluation by literature enthusiasts provides valuable insights into how general audiences perceive and engage with these microfiction examples.
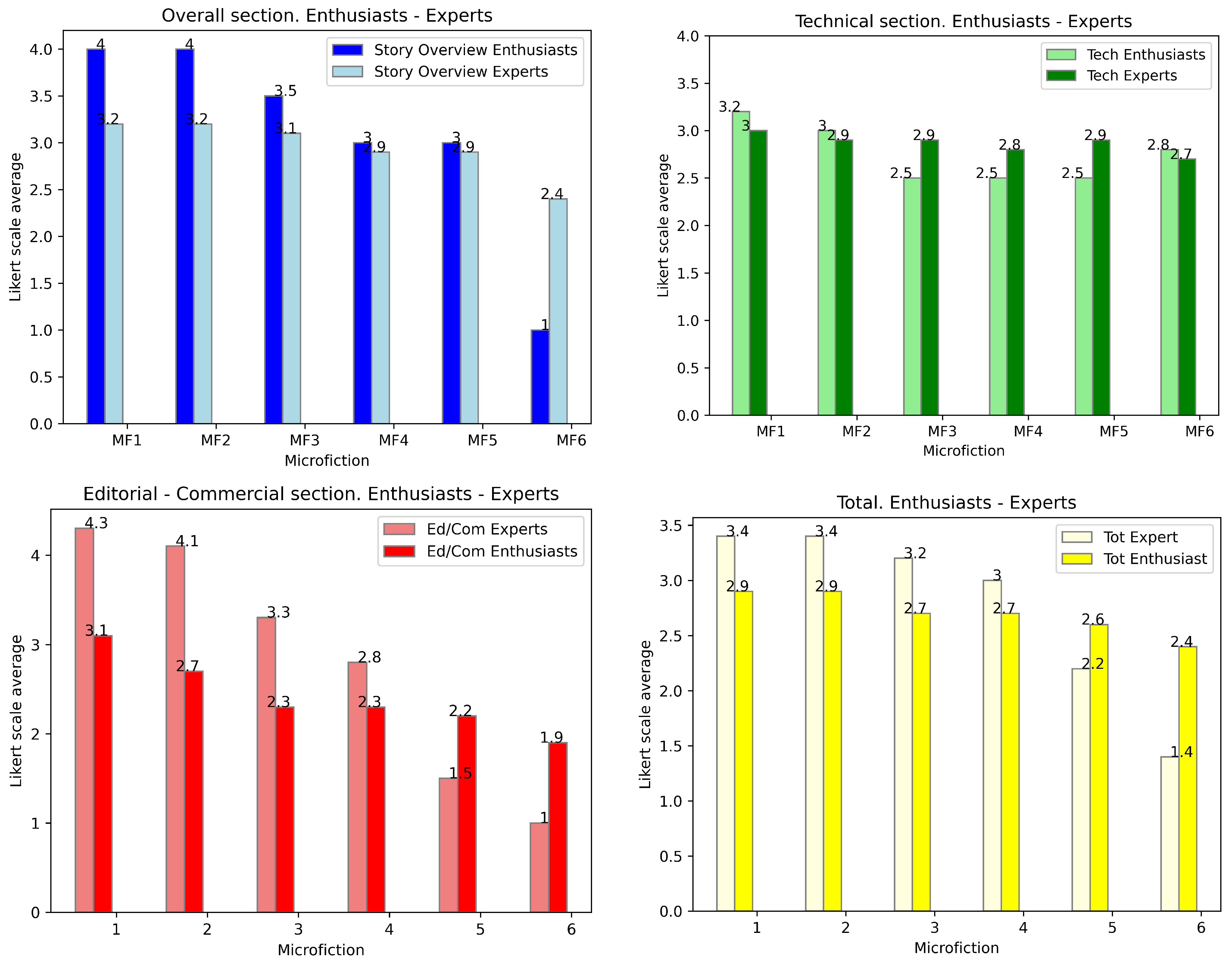
The evaluation of six microfictions by the Enthusiast group leader revealed notable differences between the microfictions generated by Monterroso (MFs 1–3) and those generated by ChatGPT-3.5 (MFs 4–6); see
Table 15 and
Figure 13,
Figure 14,
Figure 15 and
Figure 16. In terms of story overview and text complexity, MFs 4 and 5 scored the highest (AV = 4) for proposing multiple interpretations (see
Table 15), while MF 3 scored the lowest (AV = 1, SD = 0), indicating a lack of depth. On technical aspects, MF 1 and MFs 4–6 were rated highly for credibility (AV = 5, SD = 0), whereas MF 3 scored poorly (AV = 2, SD = 1.4). MFs 1 and 5 excelled in requiring reader participation (AV = 5, SD = 0), while MFs 4 and 6 scored lower (AV = 3.5, SD = 0.7). However, all microfictions struggled to propose new visions of reality, language, or genre, with most scores ranging between 1 and 2.
In the editorial/commercial category, MFs 4–6 outperformed MFs 1–3. MFs 4 and 6 were most reminiscent of other texts (AV = 5 and 4.5, respectively) and were more likely to be recommended or given as presents (AV = 4, SD = 1.4). In contrast, MFs 1–3 scored poorly in these areas, with MF 3 consistently receiving the lowest ratings (AV = 1, SD = 0). Overall, the ChatGPT-3.5 microfictions (MFs 4–6) achieved higher total scores (AV = 3.4, SD = 0.8) compared to those generated by Monterroso (AV = 2.2, SD = 1.1).
One of the most notable results in this evaluation concerns the interpretative engagement of readers. The highest-rated question, “Does the text require your participation or cooperation to complete its form and meaning?”, received an average score (AV) of 4.3 with a standard deviation (SD)of 0.5. This suggests that the evaluated texts demand significant reader interaction, a crucial trait of literary complexity (see
Table 16).
Conversely, aspects related to innovation in language and genre were rated lower. The question “Does it propose a new vision of the language itself?” obtained an AV of 1.2, which was the lowest among all items, along with an SD of 1.2, indicating high variability in responses. Similarly, the question “Does it propose a new vision of the genre it uses?” received an AV of 1.6 and an SD of 0.6, further emphasizing the expert perception that the generated texts did not significantly redefine literary conventions.
Regarding textual credibility, the question “Is the story credible?” was rated highly, with an AV of 4.2 and an SD of 0.7. This suggests that the narratives effectively maintain verisimilitude, an essential criterion for reader immersion. Additionally, evaluators were asked whether the texts reminded them of other literary works, yielding an AV of 3.4 and an SD of 0.8, indicating a moderate level of intertextuality.
GrAImes was also used to examine subjective aspects of reader appreciation. The questions “Would you recommend it?” and “Would you like to read more texts like this?” received AV scores of 2.7 and 2.8, respectively, with higher SD values (1.4 and 1.6), reflecting diverse expert opinions. Similarly, the willingness to offer the text as a gift scored an AV of 2.3 with an SD of 0.9, suggesting a moderate level of appreciation but not a strong endorsement.
There are currently no existing state-of-the-art references available for direct comparison with the present study, highlighting the novelty of our approach. This study introduces an innovative evaluation protocol for microfiction validated by literary experts, and contributes to the field by assessing both human-written and AI-generated texts. The absence of direct SOTA comparisons is due to the lack of prior work that simultaneously addresses the evaluation of microfiction across these two distinct origins. This gap in the literature underscores the significance of our research, which seeks to establish a comprehensive framework for assessing literary quality that can be applied to both human-written and AI-generated works. Our focus on this specific research area is justified by the increasing prominence of AI in literary production and the need for reliable expert-validated evaluation tools to assess the literary merit of AI-generated texts in comparison to traditional human-authored literature.


 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}