
GenAI-Powered Text Personalization: Natural Language Processing Validation of Adaptation Capabilities


Abstract
1. Introduction
1.1. Personalized Learning
1.2. Evaluating Text Differences Using Natural Language Processing
1.3. Current Research
2. Experiment 1: LLM Text Personalization
2.1. Introduction Experiment 1
2.2. Materials and Method Experiment 1
2.2.1. LLM Selection and Implementation Details
2.2.2. Reader Profiles Experiment 1
2.2.3. Text Corpus
2.2.4. Procedure Experiment 1
2.3. Results Experiment 1
2.3.1. Main Effect of Reader Profile on Variations in Linguistic Features of Modified Texts
2.3.2. Main Effect of LLMs
2.4. Discussion Experiment 1
3. Experiment 2: Prompt Refinements
3.1. Introduction Experiment 2
3.2. Materials and Method Experiment 2
3.2.1. LLM Selection Experiment 2
3.2.2. Reader Profiles Experiment 2
3.2.3. Procedure Experiment 2
3.3. Results Experiment 2
3.3.1. Academic Writing
3.3.2. Conceptual Density and Cohesion
3.3.3. Syntactic and Lexical Complexity
3.4. Discussion Experiment 2
4. General Discussion
4.1. Text Readability and Reader Alignment
4.2. Variability Across LLMs
4.3. Limitations and Future Directions
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| PK | Prior knowledge |
| RS | Reading skills |
| GenAI | Generative AI |
| LLM | Large Language Model |
| RAG | Retrieval-Augmented Generation |
| NLP | Natural Language Processing |
| ITS | Intelligent Tutoring System |
| iSTART | Interactive Strategy Training for Active Reading and Thinking |
| FKGL | Flesch–Kincaid Grade Level |
| WAT | Writing Analytics Tool |
Appendix A. LLM Descriptions
- Version Used: Claude 3.5;
- Date Accessed: 31 August 2024;
- Accessed via https://poe.com web deployment, default configurations were used;
- Training Size: Claude is trained on a large-scale, diverse dataset derived from a broad range of online and curated sources. The exact size of the training data remains proprietary;
- Number of Parameters: The exact number of parameters for Claude 3.5 is not disclosed by Anthropic, but it is estimated to be between 70–100 billion parameters.
- Version Used: Llama 3.1;
- Date Accessed: 31 August 2024;
- Accessed via https://poe.com web deployment, default configurations were used;
- Llama 3.1 was trained on 2 trillion tokens sourced from publicly available datasets, including books, websites, and other digital content.;
- Number of Parameters: Llama 3.1 consists of 70 billion parameters.
- Version Used: Gemini Pro 1.5;
- Date Accessed: 31 August 2024;
- Accessed via https://poe.com web deployment, default configurations were used;
- Training Size: Gemini is trained on 1.5 trillion tokens, sourced from a wide variety of publicly available and curated data, including text from books, websites, and other large corpora;
- Number of Parameters: Gemini 1.0 operates with 100 billion parameters.
- Version Used: GPT-4o;
- Date Accessed: 31 August 2024;
- Accessed via https://poe.com web deployment, default configurations were used;
- Training Size: GPT-4 was trained on an estimated 1.8 trillion tokens from diverse sources, including books, web pages, academic papers, and large text corpora;
- Number of Parameters: The exact number of parameters for GPT-4 is not publicly disclosed but is in the range of 175 billion parameters.
Appendix B. Single-Shot Prompt Experiment 1
- Analyze the input text and determine its reading level (e.g., Flesch–Kincaid Grade Level), linguistic complexity (e.g., sentence length and vocabulary), and the assumed background knowledge required for comprehension.
- Analyze the reader profile and identify key information: age, reading level (e.g., beginner, intermediate, advanced), prior knowledge (specific knowledge related to the text’s topic), reading goals (e.g., learning new concepts, enjoyment, research, pass an exam), interests (what topics or themes are motivating for the reader?), accessibility needs (specify any learning disabilities or preferences that require text adaptations, dyslexia, or visual impairments).
- Reorganize information and modify the syntax, vocabulary, and tone to tailor to the readers’ characteristics.
- If the reader has less knowledge about the topic, then provide sufficient background knowledge or relatable examples and analogies to support comprehension and engagement. If the reader has strong background knowledge and high reading skills, then increase the depth of information and avoid overly explaining details.
- [Insert Reader 1 Description].
- [Insert Text].
Appendix C. Augmented Prompt Experiment 2

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Components | Augmented Prompt |
|---|---|
| Personification | Imagine you are a cognitive scientist specializing in reading comprehension and learning science |
| Task objectives |
|
| Chain-of-thought | Explain the rationale behind each modification approach and how each change helps the reader grasp the scientific concepts and retain information |
| RAG | Refer to the attached pdf files. Apply these empirical findings and theoretical frameworks from these files as guidelines to tailor text
|
| Reader profile | [Insert Revised Reader Profile Description from Table 2] |
| Text input | [Insert Text] |
Appendix D. Articles Used in RAG Process
Appendix E. Quality Assessment Rubric
- Given the reader’s characteristics, what factors of the modified text make it suitable and engaging for the specific reader?
- If I were the student,
- ○
- Does the text capture my attention and interest?
- ○
- Do I feel interested in/engaged with the text?
- Readability: reading level, overall length, syntax and word, and tone and style
- Structure and organization: Does the text present information in a way that is easily processed considering the reader’s characteristics (age, reading level, reading disability)?
- Titles, headings, and subheadings (cohesion, clear flow).
- Language used and word choice.
- Engagement: Does the text capture and maintain the reader’s interest throughout? Consider factors like motivation and interest and writing tone.
- Depth of information: level of technicality, focus, and emphasis. Which version provides sufficient detail and scientific rigor suitable for the reader’s background knowledge?
- Accessibility: Does the text accommodate potential learning/reading disabilities (e.g., dyslexia)?
- Are scientific concepts conveyed clearly and at an appropriate level?
- Are there features that facilitate memory and comprehension? (summary section— summarize the main points and reiterate important concepts, bullet points, highlighted key terms, relatable examples, and analogies)
- Quality of examples?
References
- Abbes, F.; Bennani, S.; Maalel, A. Generative AI and gamification for personalized learning: Literature review and future challenges. SN Comput. Sci. 2024, 5, 1154. [Google Scholar] [CrossRef]
- McNamara, D.S.; Magliano, J. Toward a comprehensive model of comprehension. Psychol. Learn. Motiv. 2009, 51, 297–384. [Google Scholar]
- Calloway, R.C.; Helder, A.; Perfetti, C.A. A measure of individual differences in readers’ approaches to text and its relation to reading experience and reading comprehension. Behav. Res. Methods 2023, 55, 899–931. [Google Scholar] [CrossRef] [PubMed]
- Smith, R.; Snow, P.; Serry, T.; Hammond, L. The role of background knowledge in reading comprehension: A critical review. Read. Psychol. 2021, 42, 214–240. [Google Scholar] [CrossRef]
- Leong, J.; Pataranutaporn, P.; Danry, V.; Perteneder, F.; Mao, Y.; Maes, P. Putting things into context: Generative AI-enabled context personalization for vocabulary learning improves learning motivation. In Proceedings of the CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 11–16 May 2024; pp. 1–15. [Google Scholar]
- Crossley, S.A.; Skalicky, S.; Dascalu, M.; McNamara, D.; Kyle, K. Predicting text comprehension, processing, and familiarity in adult readers: New approaches to readability formulas. Discourse Process. 2017, 54, 340–359. [Google Scholar] [CrossRef]
- Crossley, S.A.; Heintz, A.; Choi, J.S.; Batchelor, J.; Karimi, M.; Malatinszky, A. A large-scaled corpus for assessing text difficulty. Behav. Res. Methods 2023, 55, 491–507. [Google Scholar] [CrossRef]
- Natriello, G. The adaptive learning landscape. Teach. Coll. Rec. 2017, 119, 1–22. [Google Scholar] [CrossRef]
- du Boulay, B.; Poulovassilis, A.; Holmes, W.; Mavrikis, M. What does the research say about how artificial intelligence and big data can close the achievement gap? In Enhancing Learning and Teaching with Technology: What the Research Says; Luckin, R., Ed.; Routledge: London, UK, 2018; pp. 256–285. [Google Scholar]
- Kucirkova, N. Personalised learning with digital technologies at home and school: Where is children’s agency? In Mobile Technologies in Children’s Language and Literacy; Oakley, G., Ed.; Emerald Publishing: Bingley, UK, 2018; pp. 133–153. [Google Scholar]
- Dong, L.; Tang, X.; Wang, X. Examining the effect of artificial intelligence in relation to students’ academic achievement in classroom: A meta-analysis. Comput. Educ. Artif. Intell. 2025, 8, 100400. [Google Scholar] [CrossRef]
- Pesovski, I.; Santos, R.; Henriques, R.; Trajkovik, V. Generative AI for customizable learning experiences. Sustainability 2024, 16, 3034. [Google Scholar] [CrossRef]
- Eccles, J.S.; Wigfield, A. From expectancy-value theory to situated expectancy-value theory: A developmental, social cognitive, and sociocultural perspective on motivation. Contemp. Educ. Psychol. 2020, 61, 101859. [Google Scholar] [CrossRef]
- Bonifacci, P.; Viroli, C.; Vassura, C.; Colombini, E.; Desideri, L. The relationship between mind wandering and reading comprehension: A meta-analysis. Psychon. Bull. Rev. 2023, 30, 40–59. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Huang, R.T.; Sommer, M.; Pei, B.; Shidfar, P.; Rehman, M.S.; Martin, F. The efficacy of AI-enabled adaptive learning systems from 2010 to 2022 on learner outcomes: A meta-analysis. J. Educ. Comput. Res. 2024, 62, 1568–1603. [Google Scholar] [CrossRef]
- Pane, J.F.; Steiner, E.D.; Baird, M.D.; Hamilton, L.S.; Pane, J.D. Informing Progress: Insights on Personalized Learning Implementation and Effects; Res. Rep. RR-2042-BMGF; Rand Corp.: Santa Monica, CA, USA, 2017. [Google Scholar]
- Walkington, C.; Bernacki, M.L. Personalizing algebra to students’ individual interests in an intelligent tutoring system: Moderators of impact. Int. J. Artif. Intell. Educ. 2019, 29, 58–88. [Google Scholar] [CrossRef]
- Simon, P.D.; Zeng, L.M. Behind the scenes of adaptive learning: A scoping review of teachers’ perspectives on the use of adaptive learning technologies. Educ. Sci. 2024, 14, 1413. [Google Scholar] [CrossRef]
- Kim, J.S.; Burkhauser, M.A.; Mesite, L.M.; Asher, C.A.; Relyea, J.E.; Fitzgerald, J.; Elmore, J. Improving reading comprehension, science domain knowledge, and reading engagement through a first-grade content literacy intervention. J. Educ. Psychol. 2021, 113, 3–26. [Google Scholar] [CrossRef]
- Hattan, C.; Alexander, P.A.; Lupo, S.M. Leveraging what students know to make sense of texts: What the research says about prior knowledge activation. Rev. Educ. Res. 2024, 94, 73–111. [Google Scholar] [CrossRef]
- Major, L.; Francis, G.A.; Tsapali, M. The effectiveness of technology-supported personalized learning in low- and middle-income countries: A meta-analysis. Br. J. Educ. Technol. 2021, 52, 1935–1964. [Google Scholar] [CrossRef]
- FitzGerald, E.; Jones, A.; Kucirkova, N.; Scanlon, E. A literature synthesis of personalised technology-enhanced learning: What works and why. Res. Learn. Technol. 2018, 26, 1–13. [Google Scholar] [CrossRef]
- Mesmer, H.A.E. Tools for Matching Readers to Texts: Research-Based Practices, 1st ed.; Guilford Press: New York, NY, USA, 2008; pp. 1–234. [Google Scholar]
- Lennon, C.; Burdick, H. The Lexile Framework as an Approach for Reading Measurement and Success. Available online: https://metametricsinc.com/wp-content/uploads/2017/07/The-Lexile-Framework-for-Reading.pdf (accessed on 10 June 2025).
- Stenner, A.J.; Burdick, H.; Sanford, E.E.; Burdick, D.S. How accurate are Lexile text measures. J. Appl. Meas. 2007, 8, 307–322. [Google Scholar]
- Gligorea, I.; Cioca, M.; Oancea, R.; Gorski, A.T.; Gorski, H.; Tudorache, P. Adaptive learning using artificial intelligence in e-learning: A literature review. Educ. Sci. 2023, 13, 1216. [Google Scholar] [CrossRef]
- Sharma, S.; Mittal, P.; Kumar, M.; Bhardwaj, V. The role of large language models in personalized learning: A systematic review of educational impact. Discov. Sustain. 2025, 6, 243. [Google Scholar] [CrossRef]
- Martínez, P.; Ramos, A.; Moreno, L. Exploring large language models to generate easy-to-read content. Front. Comput. Sci. 2024, 6, 1394705. [Google Scholar] [CrossRef]
- Xiao, C.; Xu, S.X.; Zhang, K.; Wang, Y.; Xia, L. Evaluating reading comprehension exercises generated by LLMs: A showcase of ChatGPT in education applications. In Proceedings of the 18th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2023), Toronto, ON, Canada, 13 July 2023; pp. 610–625. [Google Scholar]
- Hadzhikoleva, S.; Rachovski, T.; Ivanov, I.; Hadzhikolev, E.; Dimitrov, G. Automated test creation using large language models: A practical application. Appl. Sci. 2024, 14, 9125. [Google Scholar] [CrossRef]
- Chu, Z.; Wang, S.; Xie, J.; Zhu, T.; Yan, Y.; Ye, J.; Wen, Q. LLM agents for education: Advances and applications. arXiv 2025, arXiv:2503.11733. [Google Scholar]
- Dunn, T.J.; Kennedy, M. Technology-enhanced learning in higher education: Motivators and demotivators of student engagement. Comput. Educ. 2019, 129, 13–22. [Google Scholar]
- Caccavale, F.; Gargalo, C.L.; Gernaey, K.V.; Krühne, U. Towards Education 4.0: The role of Large Language Models as virtual tutors in chemical engineering. Educ. Chem. Eng. 2024, 49, 1–11. [Google Scholar] [CrossRef]
- Alamri, H.A.; Watson, S.; Watson, W. Learning technology models that support personalization within blended learning environments in higher education. TechTrends 2021, 65, 62–78. [Google Scholar] [CrossRef]
- Crossley, S.A. Linguistic features in writing quality and development: An overview. J. Writ. Res. 2020, 11, 415–443. [Google Scholar] [CrossRef]
- Gao, R.; Merzdorf, H.E.; Anwar, S.; Hipwell, M.C.; Srinivasa, A.R. Automatic assessment of text-based responses in post-secondary education: A systematic review. Comput. Educ. Artif. Intell. 2024, 6, 100206. [Google Scholar] [CrossRef]
- McNamara, D.S.; Graesser, A.C.; McCarthy, P.M.; Cai, Z. Automated Evaluation of Text and Discourse with Coh-Metrix, 1st ed.; Cambridge University Press: Cambridge, UK, 2014; pp. 1–312. [Google Scholar]
- Lupo, S.M.; Tortorelli, L.; Invernizzi, M.; Ryoo, J.H.; Strong, J.Z. An exploration of text difficulty and knowledge support on adolescents’ comprehension. Read. Res. Q. 2019, 54, 457–479. [Google Scholar] [CrossRef]
- Allen, L.K.; Creer, S.C.; Öncel, P. Natural language processing as a tool for learning analytics—Towards a multi-dimensional view of the learning process. In Proceedings of the Artificial Intelligence in Education Conference (AIED 2022), Durham, UK, 27–31 July 2022. [Google Scholar]
- Nagy, W.; Townsend, D. Words as tools: Learning academic vocabulary as language acquisition. Read. Res. Q. 2012, 47, 91–108. [Google Scholar] [CrossRef]
- Snow, C.E. Academic language and the challenge of reading for learning about science. Science 2010, 328, 450–452. [Google Scholar] [CrossRef] [PubMed]
- Frantz, R.S.; Starr, L.E.; Bailey, A.L. Syntactic complexity as an aspect of text complexity. Educ. Res. 2015, 44, 387–393. [Google Scholar] [CrossRef]
- Ozuru, Y.; Dempsey, K.; McNamara, D.S. Prior knowledge, reading skill, and text cohesion in the comprehension of science texts. Learn. Instr. 2009, 19, 228–242. [Google Scholar] [CrossRef]
- Van den Broek, P.; Bohn-Gettelmann, S.; Kendeou, P.; White, M.J. Reading comprehension and the comprehension-monitoring activities of children with learning disabilities: A review using the dual-process theory of reading. Educ. Psychol. Rev. 2015, 27, 641–644. [Google Scholar]
- O’Reilly, T.; McNamara, D.S. Reversing the reverse cohesion effect: Good texts can be better for strategic, high-knowledge readers. Discourse Process. 2007, 43, 121–152. [Google Scholar] [CrossRef]
- Pressley, M.; Afflerbach, P. Verbal Protocols of Reading: The Nature of Constructively Responsive Reading; Routledge: New York, NY, USA, 2012. [Google Scholar]
- Smallwood, J.; Schooler, J.W. The restless mind. Psychol. Bull. 2006, 132, 946–957. [Google Scholar] [CrossRef]
- Unsworth, N.; McMillan, B.D. Mind wandering and reading comprehension: Examining the roles of working memory capacity, interest, motivation, and topic experience. J. Exp. Psychol. Learn. Mem. Cogn. 2013, 39, 832–848. [Google Scholar] [CrossRef]
- Lind, F.; Gruber, M.; Boomgaarden, H.G. Content analysis by the crowd: Assessing the usability of crowdsourcing for coding latent constructs. Commun. Methods Meas. 2017, 11, 191–209. [Google Scholar] [CrossRef]
- Beck, I.L.; McKeown, M.G.; Sinatra, G.M.; Loxterman, J.A. Revising social studies text from a text-processing perspective: Evidence of improved comprehensibility. Read. Res. Q. 1991, 26, 251–276. [Google Scholar] [CrossRef]
- Potter, A.; Shortt, M.; Goldshtein, M.; Roscoe, R.D. Assessing academic language in tenth-grade essays using natural language processing. Assess. Writ. 2025, in press. [CrossRef]
- Srivastava, A.; Rastogi, A.; Rao, A.; Shoeb, A.A.M.; Abid, A.; Fisch, A.; Wang, G. Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. arXiv 2022, arXiv:2206.04615. [Google Scholar]
- Gao, T.; Jin, J.; Ke, Z.T.; Moryoussef, G. A comparison of DeepSeek and other LLMs. arXiv 2025, arXiv:2502.03688. [Google Scholar]
- Rosenfeld, A.; Lazebnik, T. Whose LLM is it anyway? Linguistic comparison and LLM attribution for GPT-3.5, GPT-4 and Bard. arXiv 2024, arXiv:2402.14533. [Google Scholar]
- Reviriego, P.; Conde, J.; Merino-Gómez, E.; Martínez, G.; Hernández, J.A. Playing with words: Comparing the vocabulary and lexical diversity of ChatGPT and humans. Mach. Learn. Appl. 2024, 18, 100602. [Google Scholar] [CrossRef]
- Lee, N.; Hong, J.; Thorne, J. Evaluating the consistency of LLM evaluators. arXiv 2024, arXiv:2412.00543. [Google Scholar]
- Arner, T.; McCarthy, K.S.; McNamara, D.S. iSTART StairStepper—Using comprehension strategy training to game the test. Computers 2021, 10, 48. [Google Scholar] [CrossRef]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Reynolds, L.; McDonell, K. Prompt programming for large language models: Beyond the few-shot paradigm. In Proceedings of the Extended Abstracts of the 2021 CHI Conference on Human Factors in Computing Systems, Yokohama, Japan, 8–13 May 2021; pp. 1–7. [Google Scholar]
- Zhou, Y.; Muresanu, A.I.; Han, Z.; Paster, K.; Pitis, S.; Chan, H.; Ba, J. Large language models are human-level prompt engineers. arXiv 2023, arXiv:2305.10412. [Google Scholar]
- Barthakur, A.; Dawson, S.; Kovanovic, V. Advancing learner profiles with learning analytics: A scoping review of current trends and challenges. In Proceedings of the 13th International Learning Analytics and Knowledge Conference (LAK23), Arlington, TX, USA, 13–17 March 2023; pp. 606–612. [Google Scholar]
- Hu, S. The effect of artificial intelligence-assisted personalized learning on student learning outcomes: A meta-analysis based on 31 empirical research papers. Sci. Insights Educ. Front. 2024, 24, 3873–3894. [Google Scholar] [CrossRef]
- Lagos-Castillo, A.; Chiappe, A.; Ramirez-Montoya, M.S.; Rodríguez, D.F.B. Mapping the intelligent classroom: Examining the emergence of personalized learning solutions in the digital age. Contemp. Educ. Technol. 2025, 17, ep543. [Google Scholar] [CrossRef] [PubMed]
- Baird, M.D.; Pane, J.F. Translating standardized effects of education programs into more interpretable metrics. Educ. Res. 2019, 48, 217–228. [Google Scholar] [CrossRef]
- Marvin, G.; Hellen, N.; Jjingo, D.; Nakatumba-Nabende, J. Prompt engineering in large language models. In Proceedings of the International Conference on Data Intelligence and Cognitive Informatics, Tirunelveli, India, 27–28 June 2023; pp. 387–402. [Google Scholar]
- Sahoo, P.; Singh, A.K.; Saha, S.; Jain, V.; Mondal, S.; Chadha, A. A systematic survey of prompt engineering in large language models: Techniques and applications. arXiv 2024, arXiv:2402.07927. [Google Scholar]
- Bisk, Y.; Zellers, R.; Bras, R.L.; Gao, J.; Choi, Y. Experience grounds language. arXiv 2020, arXiv:2004.10151. [Google Scholar]
- Lewis, P.; Perez, E.; Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal, N.; Kiela, D. Retrieval-augmented generation for knowledge-intensive NLP tasks. Adv. Neural Inf. Process. Syst. 2020, 33, 9459–9474. [Google Scholar]
- Zhao, R.; Chen, H.; Wang, W.; Jiao, F.; Do, X.L.; Qin, C.; Joty, S. Retrieving multimodal information for augmented generation: A survey. arXiv 2023, arXiv:2303.10868. [Google Scholar]
- Kintsch, W. Revisiting the construction-integration model of text comprehension and its implications for instruction. In Theoretical Models and Processes of Literacy, 6th ed.; Routledge: New York, NY, USA, 2018; pp. 178–203. [Google Scholar]
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Xia, F.; Chi, E.; Zhou, D. Chain-of-thought prompting elicits reasoning in large language models. Adv. Neural Inf. Process. Syst. 2022, 35, 24824–24837. [Google Scholar]
- Cain, K.; Oakhill, J. Children’s Comprehension Problems in Oral and Written Language: A Cognitive Perspective; Guilford Press: New York, NY, USA, 2008. [Google Scholar]
- Perfetti, C.; Stafura, J. Word knowledge in a theory of reading comprehension. Sci. Stud. Read. 2014, 18, 22–37. [Google Scholar] [CrossRef]
- Muñoz-Ortiz, A.; Gómez-Rodríguez, C.; Vilares, D. Contrasting linguistic patterns in human and LLM-generated news text. Artif. Intell. Rev. 2024, 57, 265. [Google Scholar] [CrossRef]
- Unsworth, N.; Engle, R.W. The nature of individual differences in working memory capacity: Active maintenance in primary memory and controlled search from secondary memory. Psychol. Rev. 2007, 114, 104–132. [Google Scholar] [CrossRef]
- Eccles, J.S.; Wigfield, A. Motivational beliefs, values, and goals. Annu. Rev. Psychol. 2002, 53, 109–132. [Google Scholar] [CrossRef] [PubMed]
- Fletcher, J.M.; Lyon, G.R.; Fuchs, L.S.; Barnes, M.A. Learning Disabilities: From Identification to Intervention, 2nd ed.; Guilford Press: New York, NY, USA, 2018; pp. 1–350. [Google Scholar]
- Ladson-Billings, G. Culturally relevant pedagogy 2.0: Aka the remix. Harv. Educ. Rev. 2014, 84, 74–84. [Google Scholar] [CrossRef]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language Models are Unsupervised Multitask Learners. OpenAI Blog. 2019. Available online: https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf (accessed on 10 June 2025).
- Dornburg, A.; Davin, K. To what extent is ChatGPT useful for language teacher lesson plan creation? arXiv 2024, arXiv:2407.09974. [Google Scholar]
- Bang, Y.; Cahyawijaya, S.; Lee, N.; Dai, W.; Su, D.; Wilie, B.; Fung, P. A multitask, multilingual, multimodal evaluation of ChatGPT on reasoning, hallucination, and interactivity. arXiv 2023, arXiv:2302.04023. [Google Scholar]
- Ji, Z.; Lee, N.; Frieske, R.; Yu, T.; Su, D.; Xu, Y.; Fung, P. Survey of hallucination in natural language generation. ACM Comput. Surv. 2023, 55, 1–38. [Google Scholar] [CrossRef]
- Maynez, J.; Narayan, S.; Bohnet, B.; McDonald, R. On faithfulness and factuality in abstractive summarization. arXiv 2020, arXiv:2005.00661. [Google Scholar]
- Ward, B.; Bhati, D.; Neha, F.; Guercio, A. Analyzing the impact of AI tools on student study habits and academic performance. arXiv 2024, arXiv:2412.02166. [Google Scholar]
- Zheng, L.; Niu, J.; Zhong, L.; Gyasi, J.F. The effectiveness of artificial intelligence on learning achievement and learning perception: A meta-analysis. Interact. Learn. Environ. 2023, 31, 5650–5664. [Google Scholar] [CrossRef]
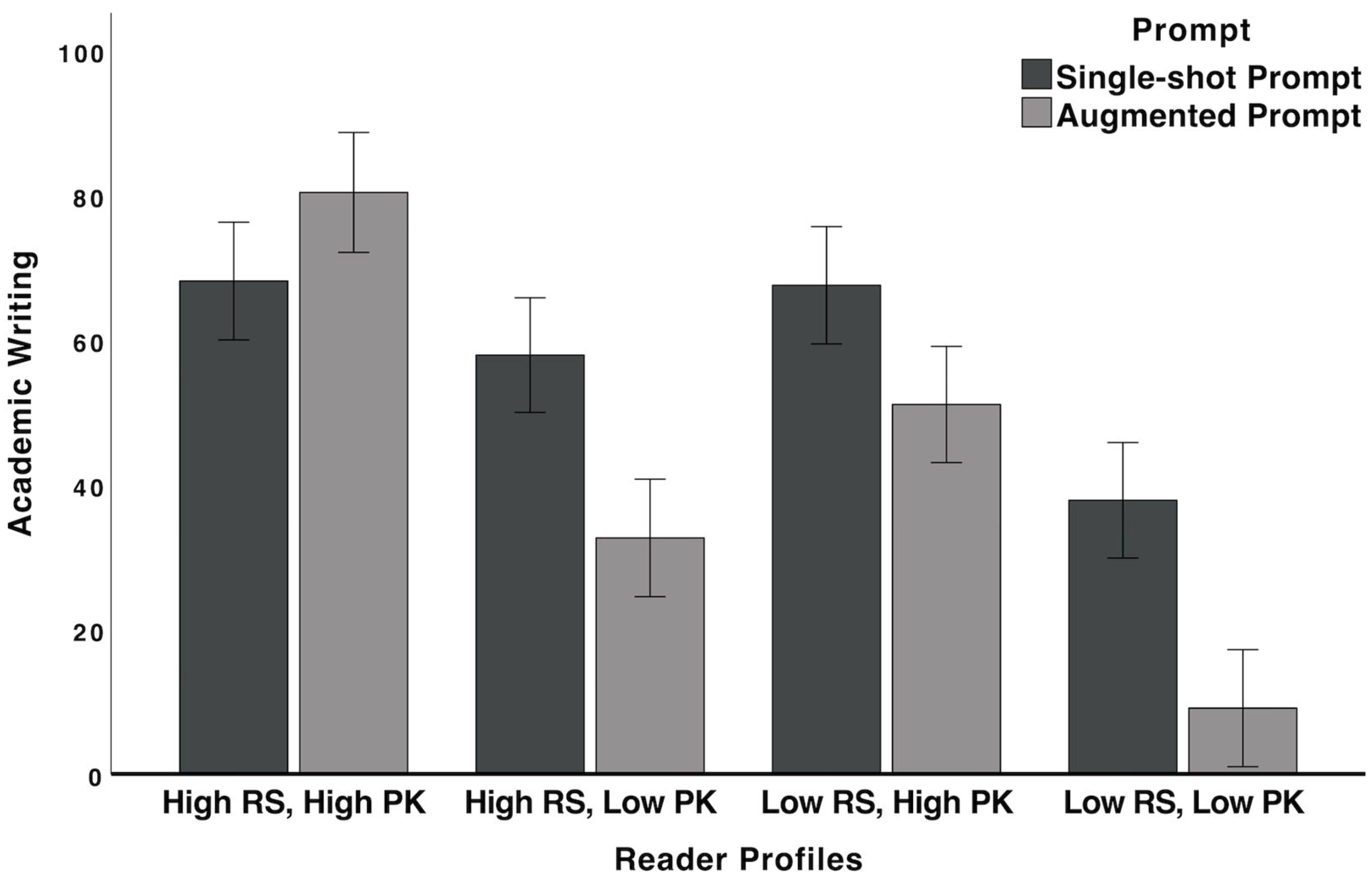
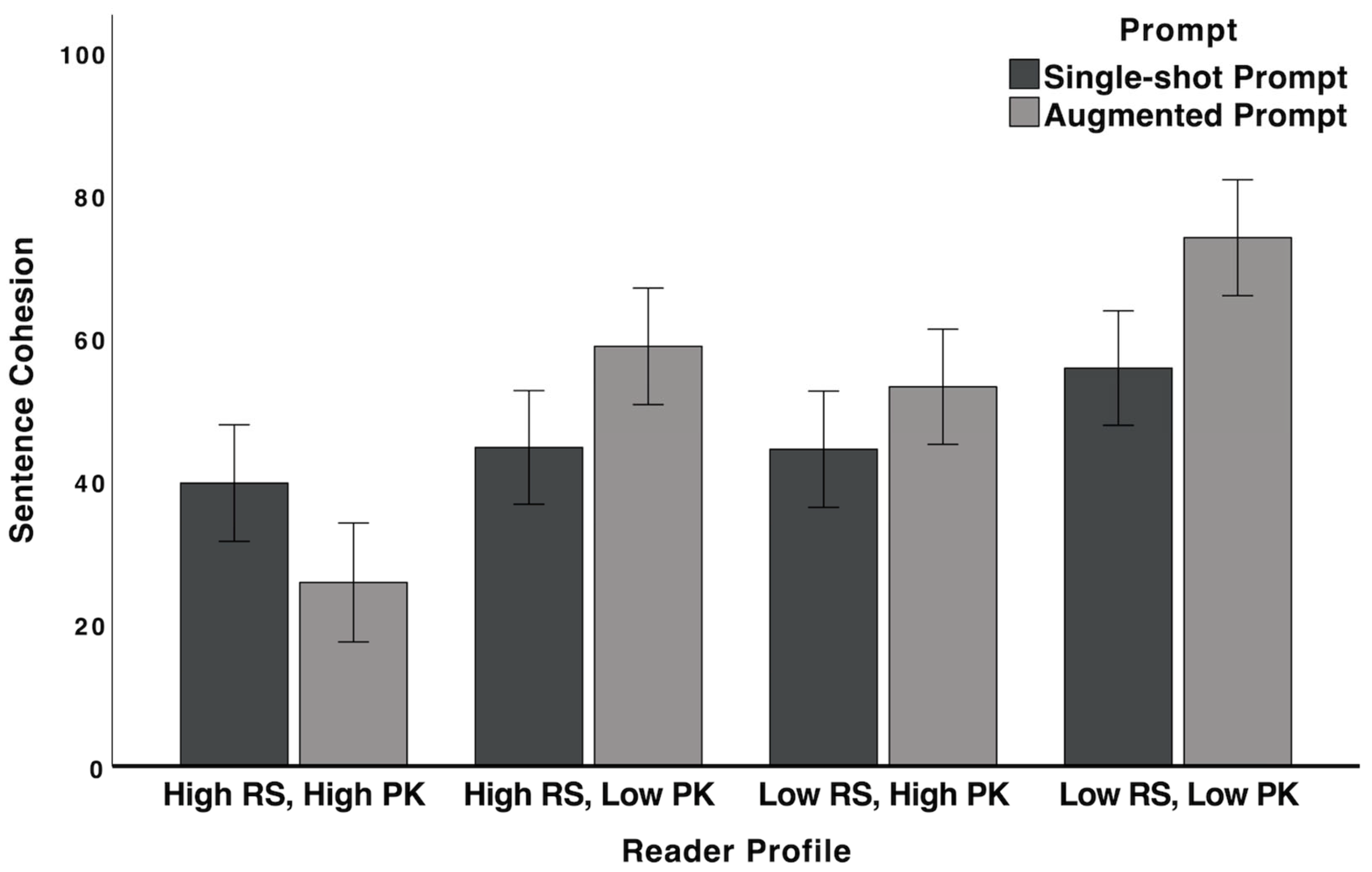
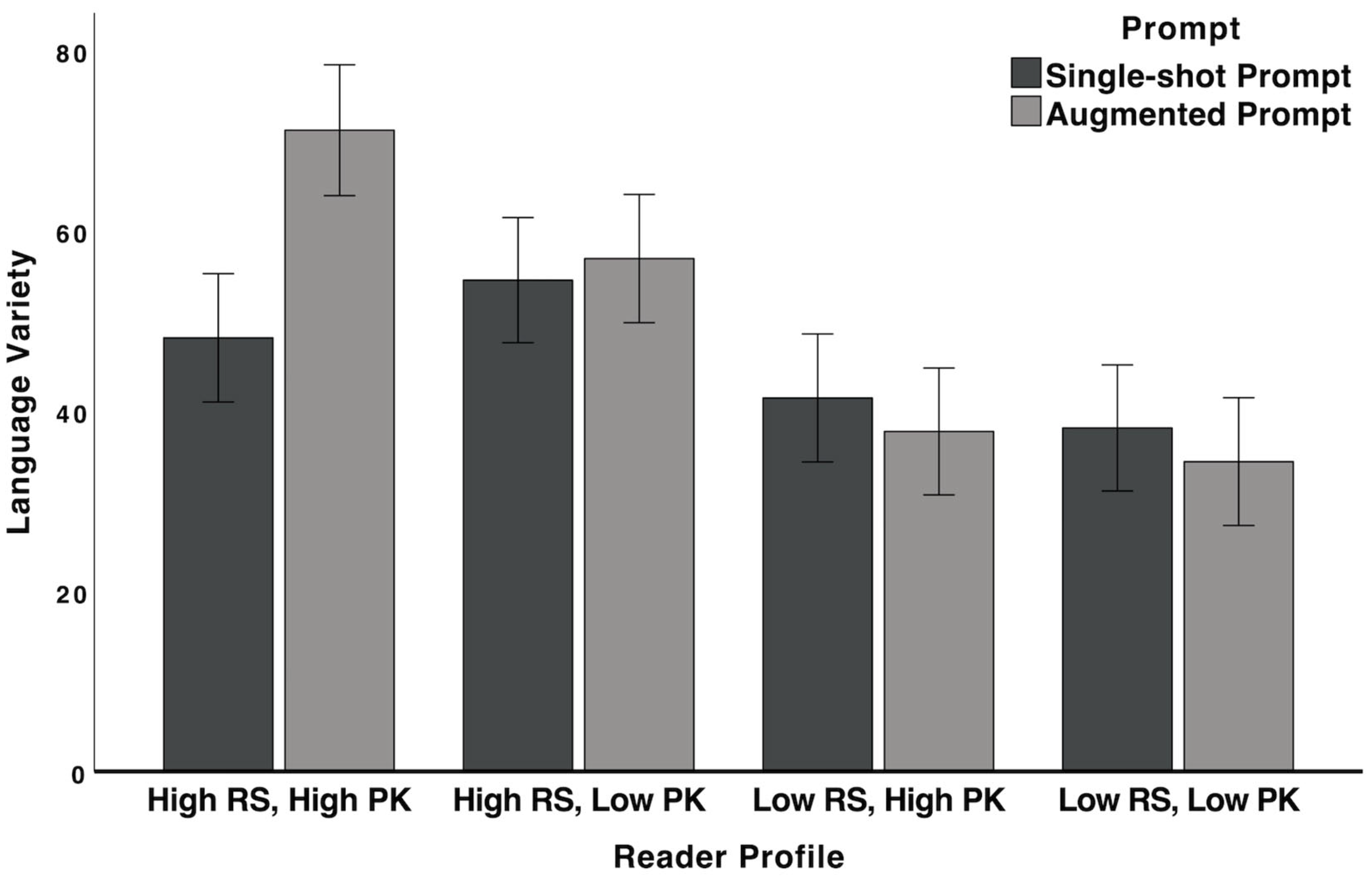
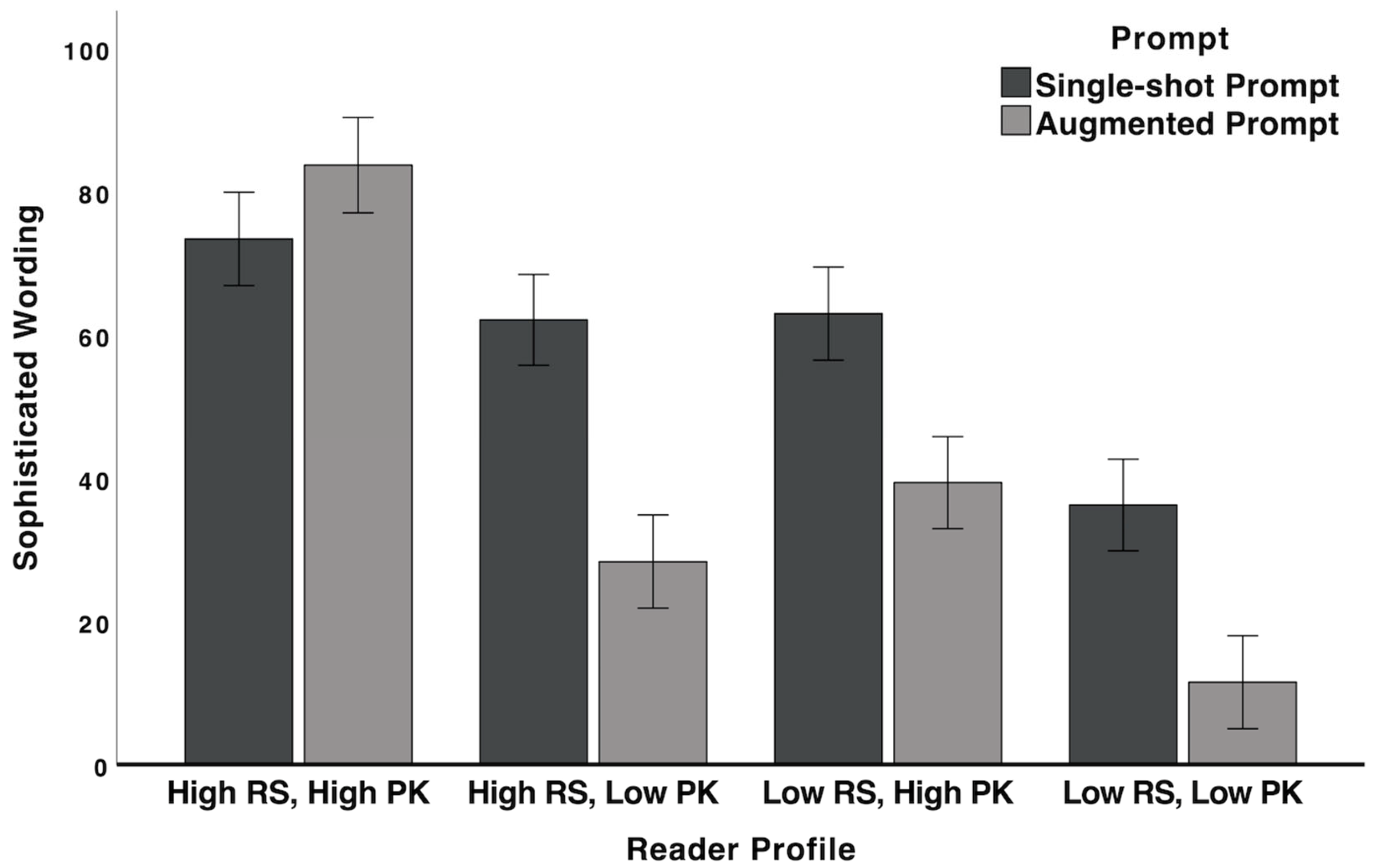
| Features | Metrics and Descriptions |
|---|---|
| Overall Readability | Flesch–Kincaid Grade Level (FKGL): Indicates text difficulty based on sentence length and word length Academic writing: The extent to which the texts include domain-specific words and sophisticated sentence structures, commonly found in academic writing texts Development of ideas: The extent to which ideas and concepts are developed and elaborated throughout a text |
| Conceptual Density and Cohesion | Noun-to-verb ratio: Text with a high noun-to-verb ratio results in dense information and complex sentences that require greater cognitive effort to process Sentence cohesion: The extent to which the text contains connectives and cohesion cues (e.g., repeating ideas and concepts) |
| Syntax Complexity | Sentence length: Longer sentences often have more clauses and complex structure Language variety: Indicates the extent to which text varies in the language used (sentence structures and wordings) |
| Lexical Complexity | Sophisticated wording: Lower measures indicate the vocabulary familiar and common, whereas higher measures indicate more advanced words Academic frequency: Indicates the extent of sophisticated vocabulary are used, which are also common in academic texts |
| Descriptions | |
|---|---|
| Reader 1 (High RS/High PK *) |
|
| Reader 2 (High RS/Low PK *) |
|
| Reader 3 (Low RS/High PK *) |
|
| Reader 4 (Low RS/Low PK *) |
|
| Domain | Text Title | Word Count | FKGL * |
|---|---|---|---|
| Biology | Bacteria | 468 | 12.10 |
| Biology | The Cells | 426 | 11.61 |
| Chemistry | Chemistry of Life | 436 | 12.71 |
| Biology | Genetic Equilibrium | 441 | 12.61 |
| Biology | Food Webs | 492 | 12.06 |
| Biology | Patterns of Evolution | 341 | 15.09 |
| Biology | Causes and Effects of Mutations | 318 | 11.35 |
| Physics | What are Gravitational Waves? | 359 | 16.51 |
| Biochemistry | Photosynthesis | 427 | 11.44 |
| Biology | Microbes | 407 | 14.38 |
| Reader Profiles | Linguistic Features Aligned for Reader | ||
|---|---|---|---|
| Overall Readability | Conceptual Density and Cohesion | Syntax and Lexical Complexity | |
| Reader 1 (High RS/High PK) |
|
|
|
| Reader 2 (High RS/Low PK) |
|
|
|
| Reader 3 (Low RS/High PK) |
|
|
|
| Reader 4 (Low RS/Low PK) |
|
|
|
| Linguistic Features | Reader 1 (High RS/High PK *) | Reader 2 (High RS/Low PK *) | Reader 3 (Low RS/ High PK *) | Reader 4 (Low RS/Low PK *) | Main Effects of Profile | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| M | SD | M | SD | M | SD | M | SD | F (3, 320) | p | η2 | |
| FKGL | 16.97 | 2.36 | 10.63 | 1.76 | 9.84 | 1.89 | 8.50 | 1.39 | 355.64 | <0.001 | 0.79 |
| Academic Writing | 89.93 | 12.53 | 45.08 | 24.86 | 37.20 | 23.25 | 17.17 | 15.95 | 228.05 | <0.001 | 0.70 |
| Idea Development | 57.38 | 28.05 | 47.40 | 25.37 | 48.19 | 23.94 | 45.19 | 23.95 | 4.97 | 0.002 | 0.05 |
| Sentence Cohesion | 55.00 | 32.55 | 50.30 | 29.19 | 40.85 | 23.96 | 48.81 | 26.84 | 2.67 | 0.04 | 0.03 |
| Noun-to-Verb Ratio | 2.81 | 0.62 | 1.93 | 0.25 | 1.84 | 0.31 | 1.87 | 0.25 | 133.37 | <0.001 | 0.58 |
| Sentence Length | 20.91 | 6.59 | 18.70 | 4.46 | 14.75 | 3.27 | 16.31 | 3.64 | 30.42 | <0.001 | 0.24 |
| Language Variety | 75.75 | 21.26 | 54.07 | 21.43 | 27.14 | 18.46 | 33.88 | 18.85 | 112.79 | <0.001 | 0.54 |
| Sophisticated Word | 90.23 | 9.97 | 42.87 | 19.35 | 31.17 | 17.71 | 23.50 | 13.59 | 342.11 | <0.001 | 0.78 |
| Academic Frequency | 9591.39 | 1425.57 | 8708.02 | 1328.34 | 7763.13 | 1426.14 | 8016.06 | 1308.47 | 30.42 | <0.001 | 0.24 |
| Linguistic Features | Claude | Llama | Gemini | ChatGPT | Main Effects of LLMs | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| M | SD | M | SD | M | SD | M | SD | F (3, 320) | p | η2 | |
| FKGL | 11.13 | 4.34 | 11.87 | 3.18 | 11.23 | 3.91 | 11.72 | 3.53 | 3.35 | 0.02 | 0.03 |
| Academic Writing | 44.43 | 34.11 | 54.14 | 32.34 | 45.47 | 34.45 | 45.34 | 31.29 | 4.70 | 0.01 | 0.05 |
| Idea Development | 59.97 | 22.63 | 33.77 | 16.90 | 51.52 | 23.93 | 52.91 | 30.29 | 19.58 | <0.001 | 0.17 |
| Sentence Cohesion | 30.38 | 24.15 | 60.86 | 24.71 | 52.65 | 25.32 | 51.06 | 31.06 | 20.30 | <0.001 | 0.17 |
| Noun-to-Verb Ratio | 2.25 | 0.80 | 2.11 | 0.48 | 2.06 | 0.43 | 2.03 | 0.43 | 6.27 | <0.001 | 0.06 |
| Sentence Length | 14.71 | 3.91 | 18.68 | 5.06 | 18.55 | 4.25 | 18.73 | 6.22 | 17.68 | <0.001 | 0.16 |
| Language Variety | 47.61 | 28.43 | 38.07 | 27.84 | 55.51 | 25.77 | 49.64 | 25.68 | 12.21 | <0.001 | 0.11 |
| Sophisticated Word | 46.21 | 31.90 | 46.55 | 26.74 | 47.58 | 30.07 | 47.43 | 32.51 | 0.15 | 0.93 | 0.00 |
| Academic Frequency | 7851.69 | 1465.06 | 9420.10 | 1569.22 | 8646.06 | 1291.46 | 8342.75 | 1412.02 | 21.48 | <0.001 | 0.18 |
| Descriptions | |
|---|---|
| Reader 1 (High RS/High PK *) | Age: 25 Educational level: Senior Major: Chemistry (Pre-med) ACT English composite score: 32/36 (performance is in the 96th percentile) ACT Reading composite score: 32/36 (performance is in the 96th percentile) ACT Math composite score: 28/36 (performance is in the 89th percentile) ACT Science composite score: 30/36 (performance is in the 94th percentile) Science background: Completed eight required biology, physics, and chemistry college-level courses (comprehensive academic background in the sciences, covering advanced topics in biology, chemistry, and physics, well-prepared for higher-level scientific learning and analysis) Reading goal: Understand scientific concepts and principles |
| Reader 2 (High RS/Low PK *) | Age: 20 Educational level: Sophomore Major: Psychology ACT English composite score: 32/36 (performance is in the 96th percentile) ACT Reading composite score: 31/36 (performance is in the 94th percentile) ACT Math composite score: 18/36 (performance is in the 42th percentile) ACT Science composite score: 19/36 (performance is in the 46th percentile) Science background: Completed one high-school-level chemistry course (no advanced science course) Limited exposure and understanding of scientific concepts Interests/Favorite subjects: arts, literature Reading goal: Understand scientific concepts and principles |
| Reader 3 (Low RS/High PK *) | Age: 20 Educational level: Sophomore Major: Health Science ACT English composite score: 19/36 (performance is in the 44th percentile) ACT Reading composite score: 20/36 (performance is in the 47th percentile) ACT Math composite score: 32/36 (performance is in the 97th percentile) ACT Science composite score: 30/36 (performance is in the 94th percentile) Science background: Completed one physics, one astronomy, and two college-level biology courses (substantial prior knowledge in science, having completed multiple college-level courses across several disciplines, strong foundation in scientific principles and concepts) Reading goal: Understand scientific concepts Reading disability: Dyslexia |
| Reader 4 (Low RS/Low PK *) | Age: 18 Educational level: Freshman Major: Marketing ACT English composite score: 17/36 (performance is in the 33rd percentile) ACT Reading composite score: 18/36 (performance is in the 36th percentile) ACT Math composite score: 19/36 (performance is in the 48th percentile) ACT Science composite score: 17/36 (performance is in the 34th percentile) Science background: Completed one high-school-level biology course (no advanced science course) Limited exposure and understanding of scientific concepts Reading goal: Understand scientific concepts |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huynh, L.; McNamara, D.S. GenAI-Powered Text Personalization: Natural Language Processing Validation of Adaptation Capabilities. Appl. Sci. 2025, 15, 6791. https://doi.org/10.3390/app15126791
Huynh L, McNamara DS. GenAI-Powered Text Personalization: Natural Language Processing Validation of Adaptation Capabilities. Applied Sciences. 2025; 15(12):6791. https://doi.org/10.3390/app15126791
Chicago/Turabian StyleHuynh, Linh, and Danielle S. McNamara. 2025. "GenAI-Powered Text Personalization: Natural Language Processing Validation of Adaptation Capabilities" Applied Sciences 15, no. 12: 6791. https://doi.org/10.3390/app15126791
APA StyleHuynh, L., & McNamara, D. S. (2025). GenAI-Powered Text Personalization: Natural Language Processing Validation of Adaptation Capabilities. Applied Sciences, 15(12), 6791. https://doi.org/10.3390/app15126791