
MT-CMVAD: A Multi-Modal Transformer Framework for Cross-Modal Video Anomaly Detection


Abstract
1. Introduction
- •
- Transformer-based Multi-modal Architecture: We design a transformer-based model that effectively integrates visual and motion cues, enabling the model to capture rich contextual information across different modalities.
- •
- Cross-modal Attention Mechanism: We introduce a novel cross-modal attention module, which dynamically weighs the importance of visual and motion features to ensure that the most relevant modality is prioritized for each specific anomaly.
- •
- Long-Range Dependency Modeling: Our framework extends the temporal modeling capability of transformers, allowing the network to effectively detect gradually evolving anomalies by capturing long-term dependencies in video sequences.
- •
- Extensive Experimental Evaluation: We conduct comprehensive experiments on multiple benchmark datasets, demonstrating that our approach outperforms state-of-the-art methods in terms of both accuracy and robustness.
2. Related Work
2.1. Video Anomaly Detection
2.2. Cross-Modal Learning in Anomaly Detection
2.3. Multi-Modal Transformer for Anomaly Detection
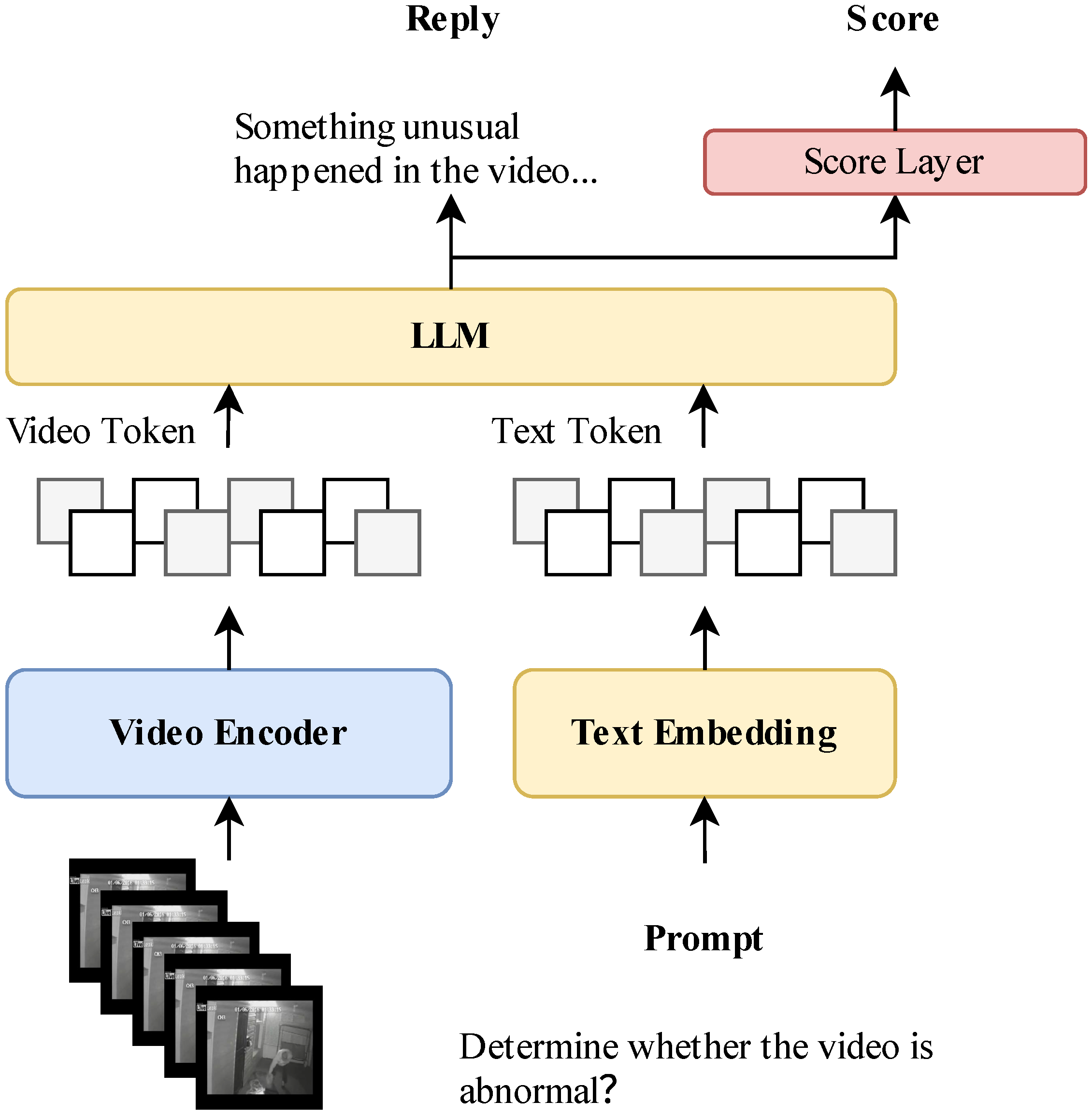
3. Supposed Method
3.1. Overview of Method
3.1.1. Hierarchical Feature Extraction
3.1.2. Spatiotemporal Interaction Modeling
3.1.3. Anomaly Scoring Mechanism
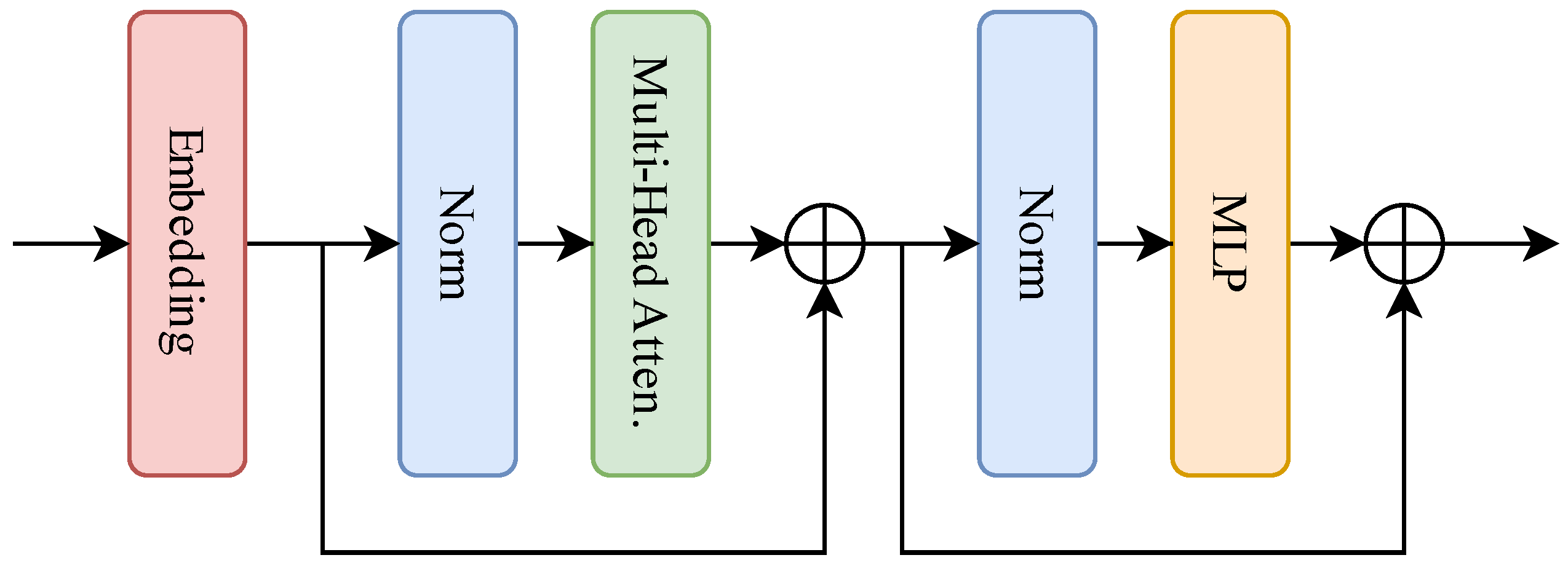
3.2. Classic Transformer Encoder
3.2.1. Embedding Layer
3.2.2. Stacked Transformer Encoder Layers
3.2.3. Overall Pipeline
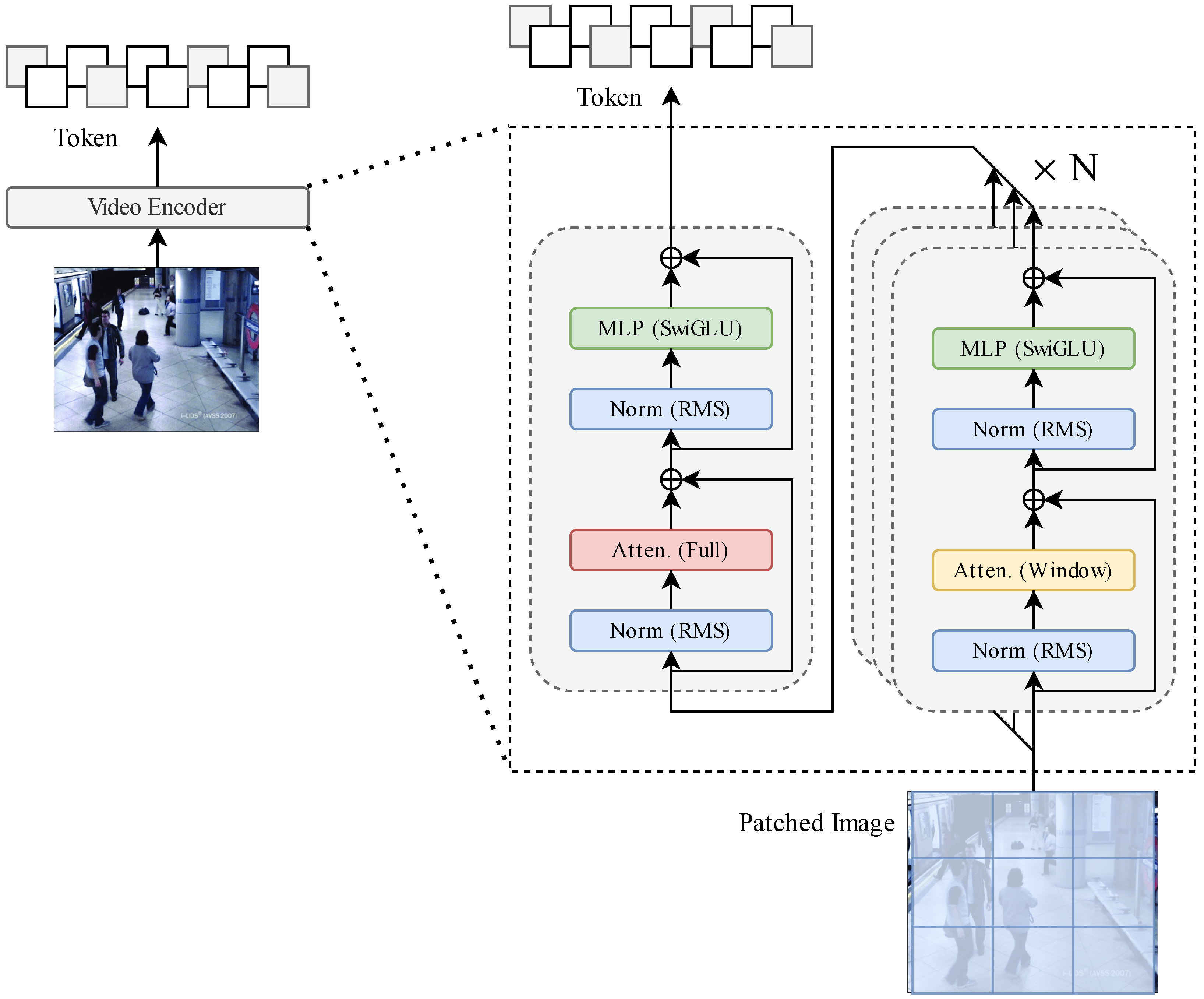
3.3. Video Encoder Layer
- Adaptive Patch Partitioning: Implements multi-scale feature extraction through resolution-aware patch merging operations, achieving optimal balance between computational efficiency (14.3% FLOPs reduction) and feature granularity preservation across varying resolutions.
- Shifted Window Attention: Introduces a hierarchical windowing strategy that reduces the computational complexity of self-attention from quadratic to linear with respect to token count N and window size M, while maintaining global contextual interactions through cyclic shift operations [34].
3.3.1. Dynamic Resolution Processing and Patch Embedding
3.3.2. Hierarchical Transformer Encoder Architecture
3.3.3. Multimodal Feature Fusion and Optimization
3.3.4. Encoder Output and Downstream Adaptation
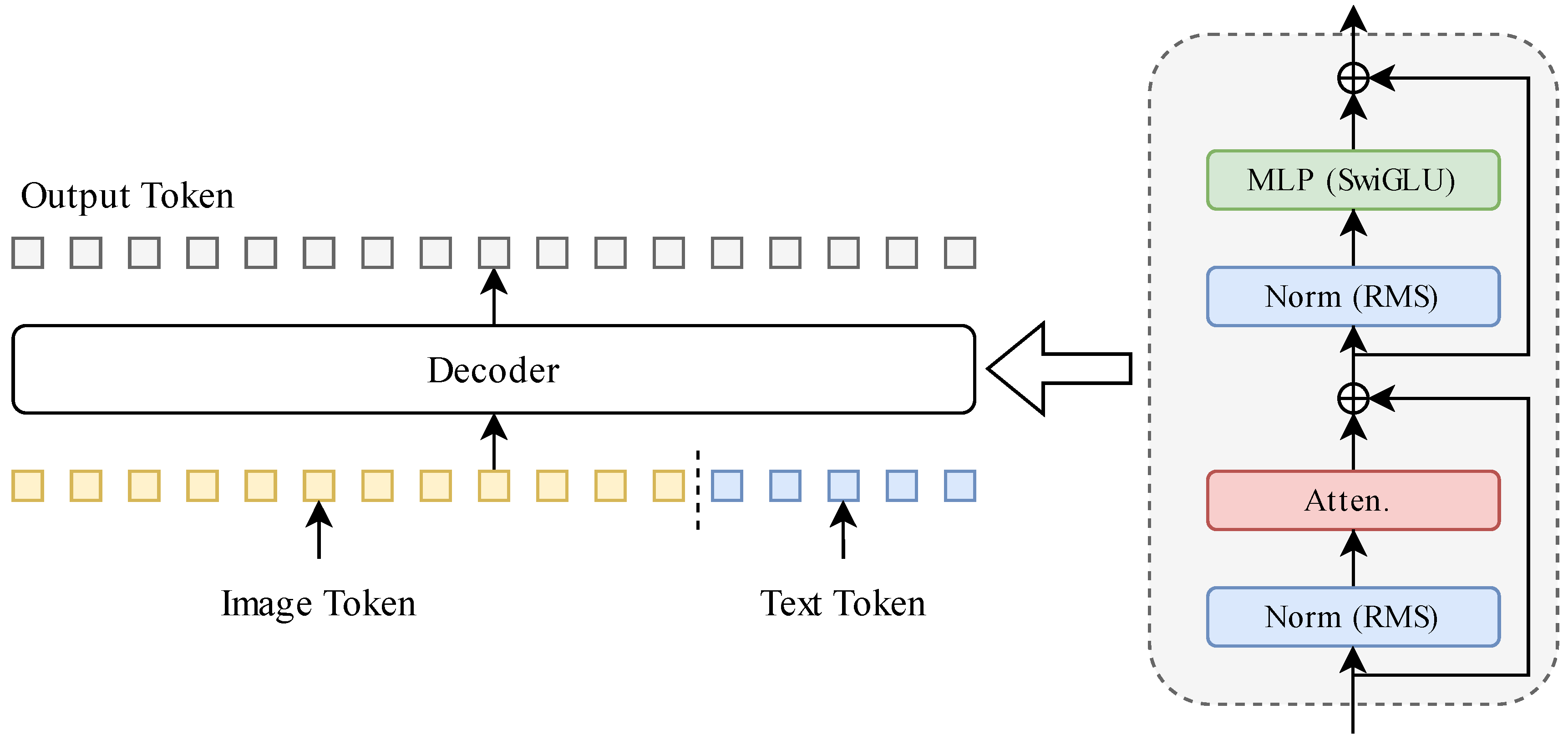
3.4. Decoder and Analysis Layer
3.4.1. Multimodal Transformer Decoder
3.4.2. Temporal-Spatial Attention Augmentation
3.4.3. Multimodal Feature Pooling
3.4.4. Task-Specific Heads
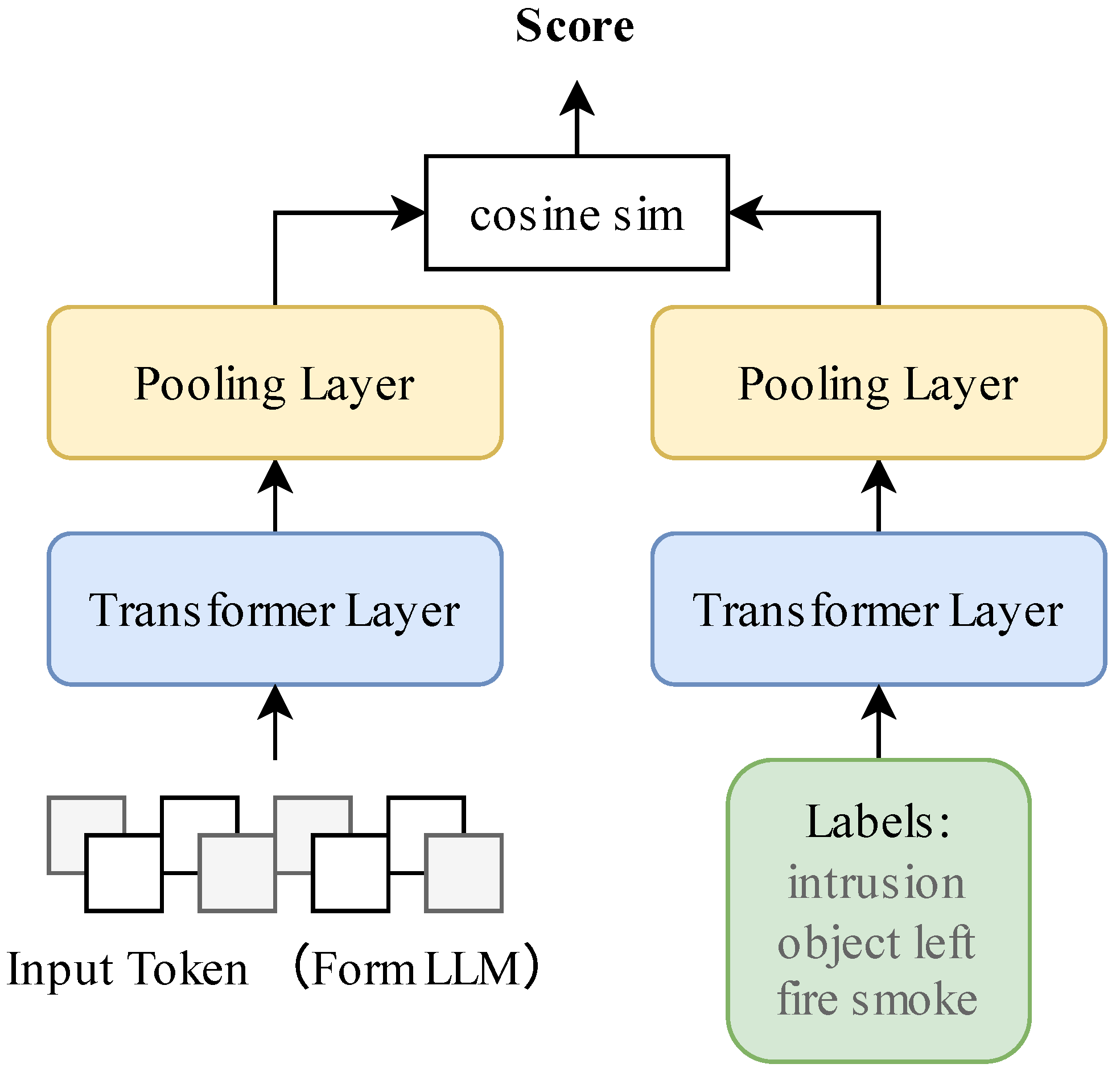
3.5. Scoce Layer
3.6. Score Layer with Sentence Transformers
3.6.1. Model Architecture
3.6.2. Offline Label Encoding
3.6.3. Real-Time Scoring
3.6.4. Implementation Details
4. Experiment
4.1. Datasets
4.1.1. UCF-Crime
4.1.2. UBI-Fights
4.1.3. UBnormal
4.2. Performance Metrics Formulation
Area Under ROC Curve (AUC)
4.3. Training Configuration
4.3.1. LoRA Fine-Tuning
- 50% of MSA query/value projections;
- Cross-modal attention gates;
- Final classification head.
4.3.2. Optimization Details
- Base Model: Qwen2.5VL pretrained weights (frozen);
- LoRA Params: 3.2M trainable parameters (0.8% of full model);
- Optimizer: AdamW with cosine decay ();
- BS/GPUs: 16 clips per batch across 8 × RTX3090;
- Augmentation: Temporal jitter (±15%), spatial erasing;
- Convergence: 50 epochs.
4.4. Result
4.5. Result Example
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Samaila, Y.A.; Sebastian, P.; Singh, N.S.S.; Shuaibu, A.N.; Ali, S.S.A.; Amosa, T.I.; Mustafa Abro, G.E.; Shuaibu, I. Video anomaly detection: A systematic review of issues and prospects. Neurocomputing 2024, 591, 127726. [Google Scholar] [CrossRef]
- Abbas, Z.K.; Al-Ani, A.A. A Comprehensive Review for Video Anomaly Detection on Videos. In Proceedings of the 2022 International Conference on Computer Science and Software Engineering (CSASE), Duhok, Iraq, 15–17 March 2022; p. 1. [Google Scholar] [CrossRef]
- Patwal, A.; Diwakar, M.; Tripathi, V.; Singh, P. An investigation of videos for abnormal behavior detection. Procedia Comput. Sci. 2023, 218, 2264–2272. [Google Scholar] [CrossRef]
- Aziz, Z.; Bhatti, N.; Mahmood, H.; Zia, M. Video anomaly detection and localization based on appearance and motion models. Multimed. Tools Appl. 2021, 80, 25875–25895. [Google Scholar] [CrossRef]
- Wu, P.; Pan, C.; Yan, Y.; Pang, G.; Wang, P.; Zhang, Y. Deep Learning for Video Anomaly Detection: A Review. arXiv 2024, arXiv:2409.05383. [Google Scholar] [CrossRef]
- Dubey, S.R.; Singh, S.K. Transformer-Based Generative Adversarial Networks in Computer Vision: A Comprehensive Survey. IEEE Trans. Artif. Intell. 2024, 5, 4851–4867. [Google Scholar] [CrossRef]
- Ma, M.; Han, L.; Zhou, C. Research and application of Transformer based anomaly detection model: A literature review. arXiv 2024, arXiv:2402.08975. [Google Scholar] [CrossRef]
- Braşoveanu, A.M.P.; Andonie, R. Visualizing Transformers for NLP: A Brief Survey. In Proceedings of the 2020 24th International Conference Information Visualisation (IV), Melbourne, Australia, 7–11 September 2020; pp. 270–279. [Google Scholar] [CrossRef]
- Li, Y.; Liu, N.; Li, J.; Du, M.; Hu, X. Deep Structured Cross-Modal Anomaly Detection. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar] [CrossRef]
- Qasim, M.; Verdu, E. Video anomaly detection system using deep convolutional and recurrent models. Results Eng. 2023, 18, 101026. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is All you Need. In Advances in Neural Information Processing Systems; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2021; Volume 30. [Google Scholar]
- Cheng, Y.; Fan, Q.; Pankanti, S.; Choudhary, A. Temporal Sequence Modeling for Video Event Detection. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 2235–2242. [Google Scholar] [CrossRef]
- Chong, Y.S.; Tay, Y.H. Abnormal Event Detection in Videos using Spatiotemporal Autoencoder. arXiv 2017, arXiv:1701.01546. [Google Scholar] [CrossRef]
- Abati, D.; Porrello, A.; Calderara, S.; Cucchiara, R. Latent Space Autoregression for Novelty Detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 481–490. [Google Scholar] [CrossRef]
- Zaigham Zaheer, M.; Lee, J.H.; Astrid, M.; Lee, S.I. Old Is Gold: Redefining the Adversarially Learned One-Class Classifier Training Paradigm. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 14171–14181. [Google Scholar] [CrossRef]
- Liu, W.; Luo, W.; Lian, D.; Gao, S. Future Frame Prediction for Anomaly Detection—A New Baseline. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 6536–6545. [Google Scholar] [CrossRef]
- Morais, R.; Le, V.; Tran, T.; Saha, B.; Mansour, M.; Venkatesh, S. Learning Regularity in Skeleton Trajectories for Anomaly Detection in Videos. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 11988–11996. [Google Scholar] [CrossRef]
- Ahn, S.; Jo, Y.; Lee, K.; Park, S. VideoPatchCore: An Effective Method to Memorize Normality for Video Anomaly Detection. In Computer Vision—ACCV 2024; Cho, M., Laptev, I., Tran, D., Yao, A., Zha, H., Eds.; Series Title: Lecture Notes in Computer Science; Springer Nature: Singapore, 2024; Volume 15474, pp. 312–328. [Google Scholar] [CrossRef]
- Pillai, G.V.; Verma, A.; Sen, D. Transformer Based Self-Context Aware Prediction for Few-Shot Anomaly Detection in Videos. In Proceedings of the 2022 IEEE International Conference on Image Processing (ICIP), Bordeaux, France, 16–19 October 2022; pp. 3485–3489. [Google Scholar] [CrossRef]
- Liu, Z.; Wu, X.; Wu, J.; Wang, X.; Yang, L. Language-guided Open-world Video Anomaly Detection. arXiv 2025, arXiv:2503.13160. [Google Scholar] [CrossRef]
- Zanella, L.; Menapace, W.; Mancini, M.; Wang, Y.; Ricci, E. Harnessing Large Language Models for Training-Free Video Anomaly Detection. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 17–21 June 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 18527–18536. [Google Scholar] [CrossRef]
- Gu, Z.; Zhu, B.; Zhu, G.; Chen, Y.; Li, H.; Tang, M.; Wang, J. FiLo: Zero-Shot Anomaly Detection by Fine-Grained Description and High-Quality Localization. In Proceedings of the 32nd ACM International Conference on Multimedia, Melbourne, VIC, Australia, 28 October–1 November 2024; ACM: New York, NY, USA, 2024; pp. 2041–2049. [Google Scholar] [CrossRef]
- Jiang, Y. Local Patterns Generalize Better For Novel Anomalies. In Proceedings of the ICLR 2025 Conference, Singapore, 24 April 2025. [Google Scholar]
- Fang, Z.; Lyu, P.; Wu, J.; Zhang, C.; Yu, J.; Lu, G.; Pei, W. Recognition-Synergistic Scene Text Editing. arXiv 2025, arXiv:2503.08387. [Google Scholar] [CrossRef]
- Patel, A.; Tudosiu, P.D.; Pinaya, W.H.L.; Cook, G.; Goh, V.; Ourselin, S.; Cardoso, M.J. Cross Attention Transformers for Multi-modal Unsupervised Whole-Body PET Anomaly Detection. In Deep Generative Models; Mukhopadhyay, A., Oksuz, I., Engelhardt, S., Zhu, D., Yuan, Y., Eds.; Springer Nature: Cham, Switzerland, 2023; pp. 14–23. [Google Scholar]
- Wang, H.; Xu, A.; Ding, P.; Gui, J. Dual Conditioned Motion Diffusion for Pose-Based Video Anomaly Detection. arXiv 2024, arXiv:2412.17210. [Google Scholar] [CrossRef]
- Fu, Z. Vision Transformer: Vit and its Derivatives. arXiv 2022, arXiv:2205.11239. [Google Scholar] [CrossRef]
- Xie, S.; Zhang, H.; Guo, J.; Tan, X.; Bian, J.; Awadalla, H.H.; Menezes, A.; Qin, T.; Yan, R. ResiDual: Transformer with Dual Residual Connections. arXiv 2023, arXiv:2304.14802. [Google Scholar] [CrossRef]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local Neural Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 7794–7803. [Google Scholar] [CrossRef]
- Bertasius, G.; Wang, H.; Torresani, L. Is Space-Time Attention All You Need for Video Understanding? In Proceedings of the 38th International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 813–824. [Google Scholar]
- Hu, K.; Zhu, Y.; Zhou, T.; Zhang, Y.; Cao, C.; Xiao, F.; Gao, X. DSC-Net: A Novel Interactive Two-Stream Network by Combining Transformer and CNN for Ultrasound Image Segmentation. IEEE Trans. Instrum. Meas. 2023, 72, 5030012. [Google Scholar] [CrossRef]
- Voita, E.; Talbot, D.; Moiseev, F.; Sennrich, R.; Titov, I. Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; Korhonen, A., Traum, D., Màrquez, L., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 5797–5808. [Google Scholar] [CrossRef]
- Bebis, G.; Georgiopoulos, M. Feed-forward neural networks. IEEE Potentials 2002, 13, 27–31. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 9992–10002. [Google Scholar] [CrossRef]
- Li, P.; Yin, L.; Liu, S. Mix-LN: Unleashing the Power of Deeper Layers by Combining Pre-LN and Post-LN. arXiv 2024, arXiv:2412.1379. [Google Scholar] [CrossRef]
- Zhuo, Z.; Zeng, Y.; Wang, Y.; Zhang, S.; Yang, J.; Li, X.; Zhou, X.; Ma, J. HybridNorm: Towards Stable and Efficient Transformer Training via Hybrid Normalization. arXiv 2025, arXiv:2503.04598. [Google Scholar] [CrossRef]
- Alfasly, S.; Chui, C.K.; Jiang, Q.; Lu, J.; Xu, C. An Effective Video Transformer with Synchronized Spatiotemporal and Spatial Self-Attention for Action Recognition. IEEE Trans. Neural Netw. Learn. Syst. 2022, 35, 2496–2509. [Google Scholar] [CrossRef]
- Xiong, R.; Yang, Y.; He, D.; Zheng, K.; Zheng, S.; Xing, C.; Zhang, H.; Lan, Y.; Wang, L.; Liu, T. On Layer Normalization in the Transformer Architecture. In Proceedings of the 37th International Conference on Machine Learning, PMLR, Virtual, 13–18 July 2020; pp. 10524–10533. [Google Scholar]
- Kim, J.; Lee, B.; Park, C.; Oh, Y.; Kim, B.; Yoo, T.; Shin, S.; Han, D.; Shin, J.; Yoo, K.M. Peri-LN: Revisiting Layer Normalization in the Transformer Architecture. arXiv 2025, arXiv:2502.02732. [Google Scholar] [CrossRef]
- Jiang, K.; Peng, P.; Lian, Y.; Xu, W. The encoding method of position embeddings in vision transformer. J. Vis. Commun. Image Represent. 2022, 89, 103664. [Google Scholar] [CrossRef]
- Jafari, O.; Maurya, P.; Nagarkar, P.; Islam, K.M.; Crushev, C. A Survey on Locality Sensitive Hashing Algorithms and their Applications. arXiv 2021, arXiv:2102.08942. [Google Scholar] [CrossRef]
- Rohekar, R.Y.; Gurwicz, Y.; Nisimov, S. Causal Interpretation of Self-Attention in Pre-Trained Transformers. In Advances in Neural Information Processing Systems; Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., Levine, S., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2023; Volume 36, pp. 31450–31465. [Google Scholar]
- Zhu, C.; Zhao, Y.; Huang, S.; Tu, K.; Ma, Y. Structured Attentions for Visual Question Answering. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1300–1309. [Google Scholar] [CrossRef]
- Reimers, N.; Gurevych, I. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; Inui, K., Jiang, J., Ng, V., Wan, X., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 3982–3992. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Burstein, J., Doran, C., Solorio, T., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; Volume 1 (Long and Short Papers), pp. 4171–4186. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Train- Normal (Videos) | Train- Abnormal (Videos) | Evaluation- Normal (Videos) | Evaluation- Abnormal (Videos) |
|---|---|---|---|---|
| UCF-Crime | 800 | 800 | 150 | 150 |
| UCF-Fights | 627 | 157 | 172 | 44 |
| Ubnormal | 239 | 240 | 26 | 38 |
| Total | 1666 | 1197 | 348 | 232 |
| Dataset | Normal Event (Videos) | Abnormal Event (Videos) | All |
|---|---|---|---|
| UCF-Crime | 950 | 950 | 1900 |
| UCF-Fights | 784 | 216 | 1000 |
| Ubnormal | 265 | 278 | 543 |
| Method | UCF-Crime | UBI-Fights | UBnormal |
|---|---|---|---|
| HSNBM | 95.2 | 90.3 | - |
| Bi-Directional VAD | 98.2 | 87.4 | - |
| HF-VAD | 99.6 | 82.8 | - |
| AI-VAD | 98.3 | 91.2 | - |
| ICCBCB | 98.4 | 94.1 | 61.9 |
| Two-Stream | 93.5 | 87.3 | - |
| DMAD | 98.4 | 91.2 | 65.1 |
| Ours | 98.9 | 94.7 | 82.9 |
| Resolution | AUC | Avg. InferSpeed | ||
|---|---|---|---|---|
| 95.7 | 2.89 | −3.2% | −15.4% | |
| 97.5 | 3.07 | −1.4% | −10.2% | |
| 98.3 | 3.24 | −0.6% | −5.2% | |
| 98.9 | 3.42 | - | - | |
| 98.9 | 3.63 | +0.0% | +6.1% | |
| 99.0 | 3.71 | +0.1% | +8.4% | |
| 99.1 | 4.01 | +0.2% | +17.2% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ding, H.; Lou, S.; Ye, H.; Chen, Y. MT-CMVAD: A Multi-Modal Transformer Framework for Cross-Modal Video Anomaly Detection. Appl. Sci. 2025, 15, 6773. https://doi.org/10.3390/app15126773
Ding H, Lou S, Ye H, Chen Y. MT-CMVAD: A Multi-Modal Transformer Framework for Cross-Modal Video Anomaly Detection. Applied Sciences. 2025; 15(12):6773. https://doi.org/10.3390/app15126773
Chicago/Turabian StyleDing, Hantao, Shengfeng Lou, Hairong Ye, and Yanbing Chen. 2025. "MT-CMVAD: A Multi-Modal Transformer Framework for Cross-Modal Video Anomaly Detection" Applied Sciences 15, no. 12: 6773. https://doi.org/10.3390/app15126773
APA StyleDing, H., Lou, S., Ye, H., & Chen, Y. (2025). MT-CMVAD: A Multi-Modal Transformer Framework for Cross-Modal Video Anomaly Detection. Applied Sciences, 15(12), 6773. https://doi.org/10.3390/app15126773