
DRKG: Faithful and Interpretable Multi-Hop Knowledge Graph Question Answering via LLM-Guided Reasoning Plans


Abstract
1. Introduction
- (1)
- Synergistic reasoning plan–knowledge retrieval mechanism: We propose a novel framework that synchronously addresses interpretability deficits and path divergence in multi-hop KGQA through reasoning instructions. This mechanism equips the model with dual capabilities: generating human-understandable reasoning plans via LLMs and ensuring faithful knowledge retrieval through hop constraints and logical boundary control.
- (2)
- Hybrid supervised fine-tuning and reinforcement learning: Our methodology integrates supervised fine-tuning for foundational semantic understanding with reinforcement learning enhanced by path constraints and keyword-aware reward functions. The reinforcement learning phase improves reasoning robustness in complex scenarios by penalizing overstepping or understepping hop behaviors in generated plans.
- (3)
- State-of-the-art performance: DRKG achieves 100% accuracy in the MetaQA dataset and outperforms the best baseline models by 1–5% in the PathQuestion, WebQuestionsSP, and ComplexWebQuestions benchmarks.
- (4)
- Comprehensive reliability analysis: We conduct systematic ablation studies to examine critical factors affecting multi-hop KGQA performance, analyze parameter sensitivity, and provide empirically validated configuration recommendations.
2. Literature Review
2.1. Embedded Methods
2.2. Symbolic Methods
2.3. LLM-Driven Methods
3. Limitations of Existing Work
- (1)
- Insufficient Interpretability: Embedding methods rely on black-box vector operations, making it impossible for users to trace the specific paths on which the answers are based. Although some LLM methods generate intermediate plans, the plans are disconnected from the retrieval process, potentially resulting in “seemingly reasonable but actually wrong” reasoning chains.
- (2)
- Semantic Gap: There is a semantic mismatch between natural language questions and structured knowledge representation. For example, the word “leader” in a question may correspond to CEO, founder, or director in the knowledge graph, and traditional methods struggle to achieve precise alignment. Although LLM can understand language diversity, the relationship descriptions it generates may not be consistent with the relationship labels in the knowledge graph (e.g., expressing “direct” as “direct works”).
- (3)
- Knowledge Hallucination and Path Divergence: LLM-driven models may generate relationships that do not exist in the knowledge graph, leading to incorrect answers. In multi-hop scenarios, embedding methods may deviate from the correct path due to vector combination errors (e.g., wrongly jumping from “director” to “screenwriter”).
- (4)
- Poor Dynamic Knowledge Adaptability: Symbolic methods rely on static knowledge graphs and have difficulty handling real-time updated knowledge (such as information about newly released movies). Most methods do not consider the noise in the knowledge graph (such as incorrect edges or missing entities), resulting in interruption of the reasoning chain.
4. Approach
4.1. Problem Definition
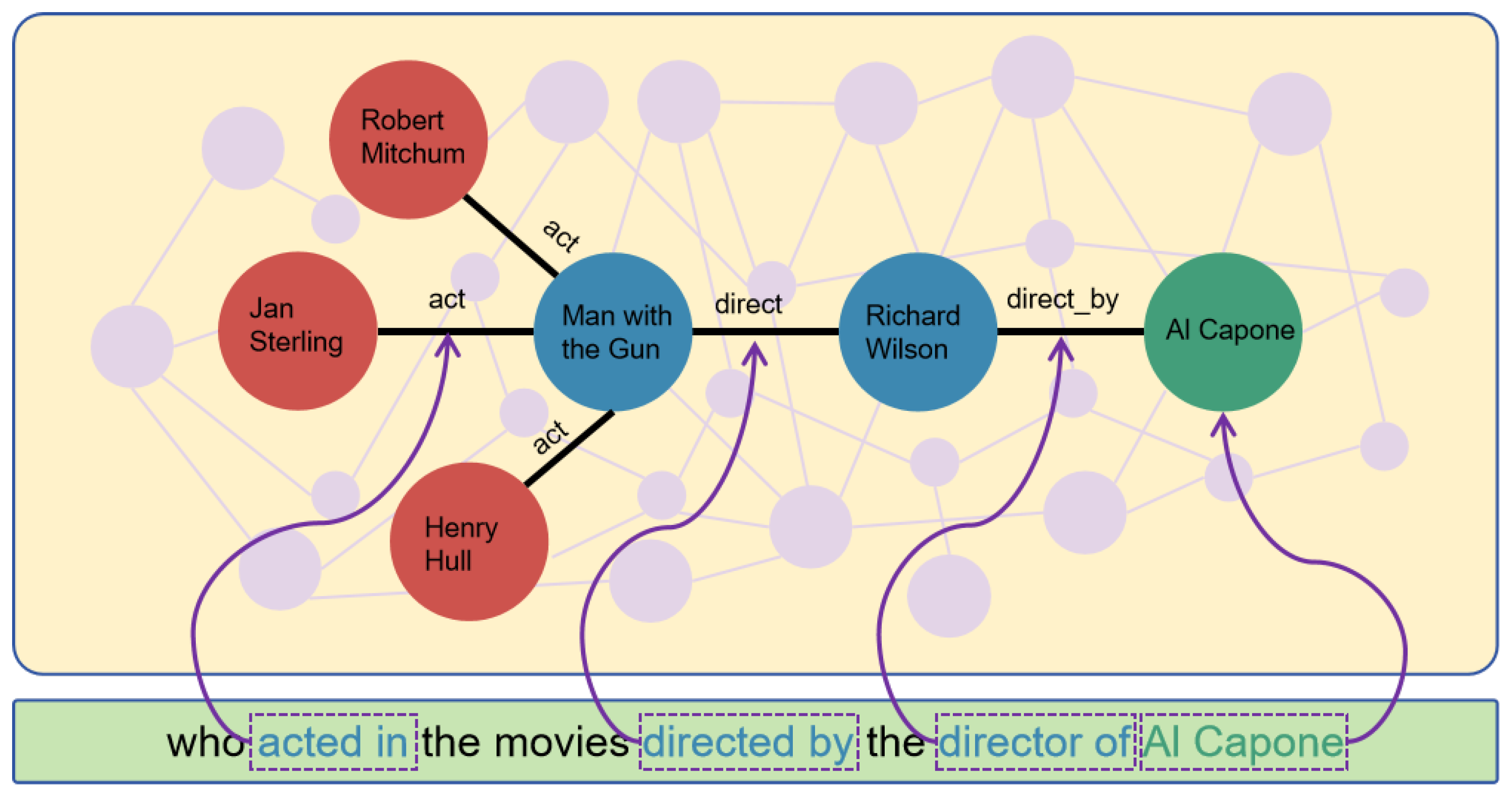
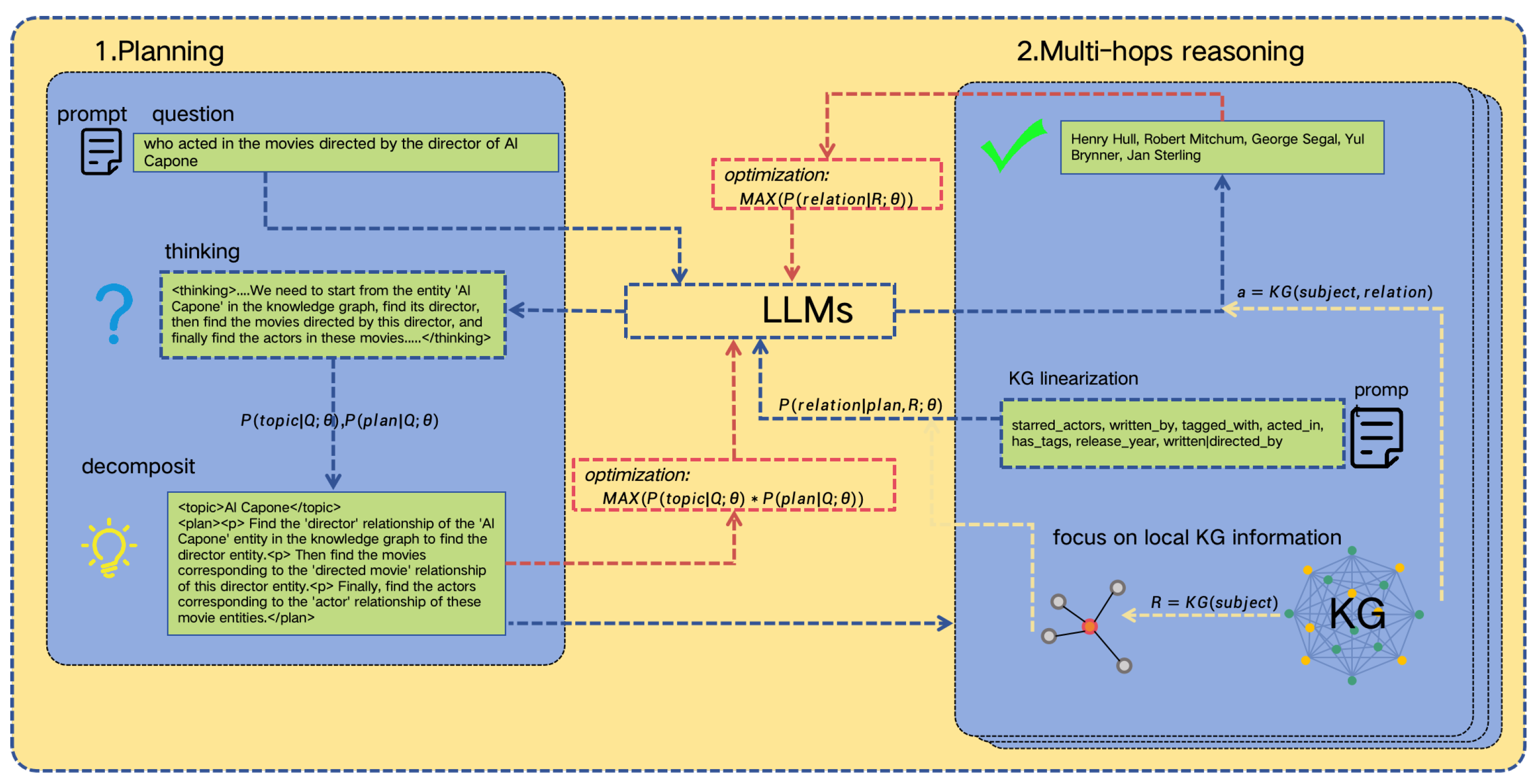
4.2. Decomposition and Reasoning
4.3. Interpretability
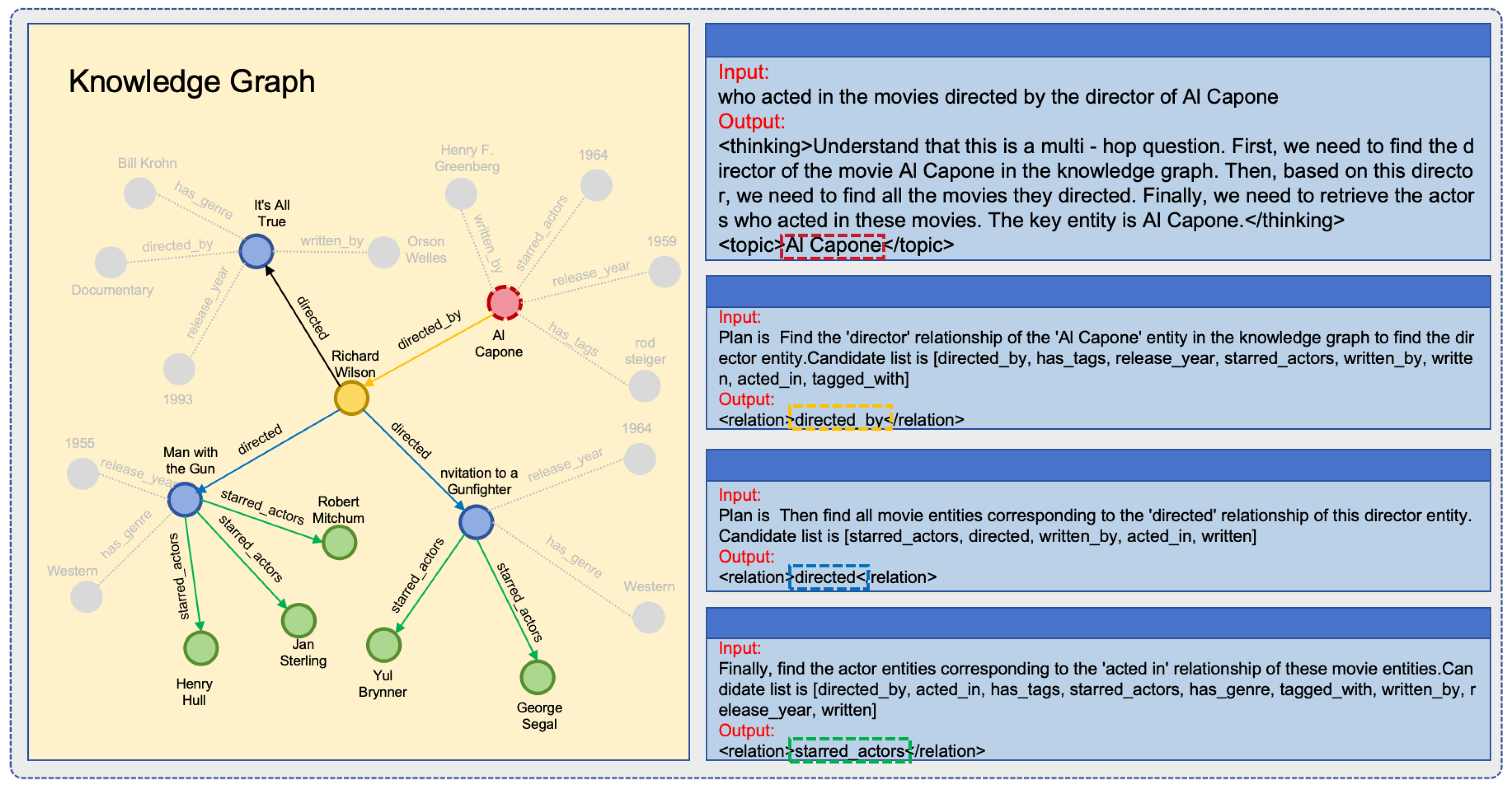
- Step 0:
- Identify the topic entity Al Capone, and generate reasoning plans from the question semantics.
- Step 1:
- From the topic entity, retrieve all the relations directed_by, has_tags, release_year, starred_actors, written_by, written, acted_in, tagged_with, and match the reasoning plan Plan is Find the ’director’ relationship of the ’Al Capone’ entity in the knowledge graph to find the director entity, selecting the directed_by relation. Richard Wilson can then be retrieved from the knowledge graph.
- Step 2:
- Based on Step 1, retrieve all the relations of the entity Richard Wilson as a candidate list (starred_actors, directed, written_by, acted_in, written), and match the reasoning plan Plan is Then find all movie entities corresponding to the ’directed’ relationship of this director entity, selecting the directed relation. Man with the Gun, It’s All True, Invitation to a Gunfighter can then be retrieved from the knowledge graph.
- Step 3:
- Based on Step 2, retrieve the relations of Richard Wilson as a candidate list (directed_by, acted_in, has_tags, starred_actors, has_genre, tagged_with, written_by, release_year, written), and match the reasoning path Finally, find the actor entities corresponding to the ’acted in’ relationship of these movie entities, ultimately obtaining the answer Robert Mitchum, Jan Sterling, Yul Brynner, George Segal.
4.4. Training
4.4.1. Data Preprocessing
4.4.2. Supervised Fine-Tuning
4.4.3. Reinforcement Learning
4.4.4. Implementation Details
5. Experiment
5.1. Datasets
5.2. Evaluation Metrics
5.3. Baseline Models
5.4. Results
5.4.1. Overall Evaluation
5.4.2. MetaQA Dataset Analysis
5.4.3. PathQuestion Dataset Analysis
5.4.4. WebQSP and CWQ Dataset Analysis
5.5. Ablation Studies
5.6. Reliability
5.7. Interpretability of Scenarios in the Medical Field
6. Discussion
6.1. Interpretable Reasoning and Performance Gains
6.2. Bridging the Semantic Gap
6.3. Broader Implications
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hogan, A.; Blomqvist, E.; Cochez, M.; d’Amato, C.; Melo, G.D.; Gutierrez, C.; Kirrane, S.; Gayo, J.E.; Navigli, R.; Neumaier, S.; et al. Knowledge graphs. ACM Comput. Surv. 2021, 54, 1–37. [Google Scholar] [CrossRef]
- Bollacker, K.; Evans, C.; Paritosh, P.; Sturge, T.; Taylor, J. Freebase: A collaboratively created graph database for structuring human knowledge. In Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data, Vancouver, BC, Canada, 9–12 June 2008; Association for Computing Machinery: New York, NY, USA, 2008; pp. 1247–1250. [Google Scholar]
- Vrandečić, D.; Krötzsch, M. Wikidata: A free collaborative knowledgebase. Commun. ACM 2014, 57, 78–85. [Google Scholar] [CrossRef]
- Liu, J.; Wang, T. Multi-hop knowledge base question answering by case retrieval. In Proceedings of the 3rd International Conference on Artificial Intelligence, Automation, and High-Performance Computing (AIAHPC 2023), Wuhan, China, 31 March–2 April 2023; Volume 12717, pp. 809–818. [Google Scholar]
- Yang, J.; Hu, X.; Xiao, G.; Shen, Y. A survey of knowledge enhanced pre-trained language models. In Proceedings of the 3rd ACM Transactions on Asian and Low-Resource Language Information Processing; Association for Computing Machinery: New York, NY, USA, 2024. [Google Scholar]
- Mavi, V.; Jangra, A.; Jatowt, A. A survey on multi-hop question answering and generation. arXiv 2022, arXiv:2204.09140. [Google Scholar]
- Saxena, A.; Tripathi, A.; Talukdar, P. Improving multi-hop question answering over knowledge graphs using knowledge base embeddings. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 4498–4507. [Google Scholar] [CrossRef]
- Wang, J.; Li, W.; Liu, F.; Sheng, B.; Liu, W.; Jin, Q. Hic-KGQA: Improving multi-hop question answering over knowledge graph via hypergraph and inference chain. Knowl.-Based Syst. 2023, 277, 110810. [Google Scholar] [CrossRef]
- Shi, J.; Cao, S.; Hou, L.; Li, J.; Zhang, H. TransferNet: An Effective and Transparent Framework for Multi-hop Question Answering over Relation Graph. arXiv 2021, arXiv:2104.07302. [Google Scholar]
- Jiang, J.; Zhou, K.; Zhao, W.X.; Wen, J.R. Unikgqa: Unified retrieval and reasoning for solving multi-hop question answering over knowledge graph. arXiv 2022, arXiv:2212.00959. [Google Scholar]
- Sukhbaatar, S.; Weston, J.; Fergus, R. End-to-end memory networks. In Proceedings of the Annual Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 2440–2448. [Google Scholar]
- Miller, A.; Fisch, A.; Dodge, J.; Karimi, A.H.; Bordes, A.; Weston, J. Key-value memory networks for directly reading documents. arXiv 2016, arXiv:1606.03126. [Google Scholar]
- Sun, H.; Bedrax-Weiss, T.; Cohen, W. PullNet: Open Domain Question Answering with Iterative Retrieval on Knowledge Bases and Text. arXiv 2019, arXiv:1904.09537. [Google Scholar]
- Sun, H.; Dhingra, B.; Zaheer, M.; Mazaitis, K.; Salakhutdinov, R.; Cohen, W.W. Open domain question answering using early fusion of knowledge bases and text. arXiv 2018, arXiv:1809.00782. [Google Scholar]
- Schlichtkrull, M.; Kipf, T.N.; Bloem, P.; Van Den Berg, R.; Titov, I.; Welling, M. Modeling relational data with graph convolutional networks. In Lecture Notes in Computer Science, Proceedings of the Semantic Web—15th International Conference, Heraklion, Crete, Greece, 3–7 June 2018; Springer International Publishing: Cham, Switzerland, 2018; pp. 593–607. [Google Scholar]
- Abujabal, A.; Yahya, M.; Riedewald, M.; Weikum, G. Automated template generation for question answering over knowledge graphs. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; International World Wide Web Conferences Steering Committee: Geneva, Switzerland, 2017; pp. 1191–1200. [Google Scholar]
- AlAgha, I. Using linguistic analysis to translate arabic natural language queries to SPARQL. arXiv 2015, arXiv:1508.01447. [Google Scholar] [CrossRef]
- Luz, F.F.; Finger, M. Semantic parsing natural language into SPARQL: Improving target language representation with neural attention. arXiv 2018, arXiv:1803.04329. [Google Scholar]
- Sun, Y.; Zhang, L.; Cheng, G.; Qu, Y. SPARQA: Skeleton-based semantic parsing for complex questions over knowledge bases. Proc. AAAI Conf. Artif. Intell. 2020, 34, 8952–8959. [Google Scholar] [CrossRef]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. 2018. Available online: https://scholar.google.com.hk/scholar?hl=zh-CN&as_sdt=0%2C5&q=Improving+language+understanding+by+generative+pre-training&btnG= (accessed on 10 June 2025).
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI blog 2018, 1, 9. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. Llama: Open and efficient foundation language models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Touvron, H.; Martin, L.; Stone, K.; Albert, P.; Almahairi, A.; Babaei, Y.; Bashlykov, N.; Batra, S.; Bhargava, P.; Bhosale, S.; et al. Llama 2: Open foundation and fine-tuned chat models. arXiv 2023, arXiv:2307.09288. [Google Scholar]
- Team GLM; Zeng, A.; Xu, B.; Wang, B.; Zhang, C.; Yin, D.; Zhang, D.; Rojas, D.; Feng, G.; Zhao, H.; et al. ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools. arXiv 2024, arXiv:2406.12793. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Zhao, W.X.; Zhou, K.; Li, J.; Tang, T.; Wang, X.; Hou, Y.; Min, Y.; Zhang, B.; Zhang, J.; Dong, Z.; et al. A survey of large language models. arXiv 2023, arXiv:2303.18223. [Google Scholar]
- Chowdhery, A.; Narang, S.; Devlin, J.; Bosma, M.; Mishra, G.; Roberts, A.; Barham, P.; Chung, H.W.; Sutton, C.; Gehrmann, S.; et al. Palm: Scaling language modeling with pathways. J. Mach. Learn. Res. 2023, 24, 1–113. [Google Scholar]
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Xia, F.; Chi, E.; Le, Q.V.; Zhou, D. Chain-of-thought prompting elicits reasoning in large language models. Adv. Neural Inf. Process. Syst. 2022, 35, 24824–24837. [Google Scholar]
- Shengyu, Z.; Linfeng, D.; Xiaoya, L.; Sen, Z.; Xiaofei, S.; Shuhe, W.; Jiwei, L.; Hu, R.; Tianwei, Z.; Wu, F.; et al. Instruction tuning for large language models: A survey. arXiv 2023, arXiv:2308.10792. [Google Scholar]
- Huang, L.; Yu, W.; Ma, W.; Zhong, W.; Feng, Z.; Wang, H.; Chen, Q.; Peng, W.; Feng, X.; Qin, B.; et al. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions. ACM Trans. Inf. Syst. 2025, 43, 1–55. [Google Scholar] [CrossRef]
- Lin, S.; Hilton, J.; Evans, O. Truthfulqa: Measuring how models mimic human falsehoods. arXiv 2021, arXiv:2109.07958. [Google Scholar]
- Sun, J.; Xu, C.; Tang, L.; Wang, S.; Lin, C.; Gong, Y.; Ni, L.M.; Shum, H.Y.; Guo, J. Think-on-graph: Deep and responsible reasoning of large language model with knowledge graph. arXiv 2023, arXiv:2307.07697. [Google Scholar]
- Luo, L.; Li, Y.F.; Haffari, G.; Pan, S. Reasoning on graphs: Faithful and interpretable large language model reasoning. arXiv 2023, arXiv:2310.01061. [Google Scholar]
- Luo, H.; Tang, Z.; Peng, S.; Guo, Y.; Zhang, W.; Ma, C.; Dong, G.; Song, M.; Lin, W.; Zhu, Y.; et al. Chatkbqa: A generate-then-retrieve framework for knowledge base question answering with fine-tuned large language models. arXiv 2023, arXiv:2310.08975. [Google Scholar]
- Yani, M.; Krisnadhi, A.A. Challenges, techniques, and trends of simple knowledge graph question answering: A survey. Information 2021, 12, 271. [Google Scholar] [CrossRef]
- Lan, Y.; He, G.; Jiang, J.; Jiang, J.; Zhao, W.X.; Wen, J.R. Complex knowledge base question answering: A survey. IEEE Trans. Knowl. Data Eng. 2022, 35, 11196–11215. [Google Scholar] [CrossRef]
- Zhang, Y.; Dai, H.; Kozareva, Z.; Smola, A.; Song, L. Variational reasoning for question answering with knowledge graph. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Zhou, M.; Huang, M.; Zhu, X. An interpretable reasoning network for multi-relation question answering. arXiv 2018, arXiv:1801.04726. [Google Scholar]
- Yih, W.T.; Richardson, M.; Meek, C.; Chang, M.W.; Suh, J. The value of semantic parse labeling for knowledge base question answering. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; pp. 201–206. [Google Scholar]
- Berant, J.; Chou, A.; Frostig, R.; Liang, P. Semantic parsing on freebase from question-answer pairs. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013; pp. 1533–1544. [Google Scholar]
- Talmor, A.; Berant, J. The web as a knowledge-base for answering complex questions. arXiv 2018, arXiv:1803.06643. [Google Scholar]
- Huang, X.; Zhang, J.; Xu, Z.; Ou, L.; Tong, J. A knowledge graph based question answering method for medical domain. PeerJ Comput. Sci. 2021, 7, e667. [Google Scholar] [CrossRef] [PubMed]
- Hu, N.; Chen, J.; Wu, Y.; Qi, G.; Bi, S.; Wu, T.; Pan, J.Z. Benchmarking large language models in complex question answering attribution using knowledge graphs. arXiv 2024, arXiv:2401.14640. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method Categories | Advantages | Limitations | Interpretability |
|---|---|---|---|
| Embedded Methods | Efficient retrieval | Black-box reasoning | Low |
| Symbolic Methods | Path transparency | Highly dependent template | High |
| LLM-Driven Methods | Strong semantic understanding | Knowledge illusion | Middle |
| Input: {PROMPT} Who acted in the movies directed by director [Al Capone]? |
| Output: <thinking>Understand that this is a multi-hop question. First, we need to find the director of the movie [Al Capone] from the knowledge graph. Then, for the obtained director entity, we need to find all the movies they directed. Finally, we need to find the actors who acted in these movies. The key entity is [Al Capone].</thinking> |
| <topic>Al Capone</topic> |
| <plan><p> Find the ‘director’ relationship of the ‘Al Capone’ entity in the knowledge graph to find the director entity. <p> Next, find the content corresponding to the ‘directed movie’ relationship of this director entity. <p> Finally, find the ‘actor’ relationship of these movie entities to obtain the actor entities.</p></plan> |
| Knowledge Graph | Number of Entities | Number of Relations |
|---|---|---|
| MetaQA | 41,159 | 12 |
| PathQuestion | 2258 | 14 |
| WebQSP | 16,069 | 594 |
| CWQ | 38,671 | 1577 |
| Dataset | Number of Training Data | Number of Development Data | Number of Test Data |
|---|---|---|---|
| MetaQA (1-hop) | 96,106 | 9992 | 9947 |
| MetaQA (2-hop) | 118,980 | 14,872 | 14,872 |
| MetaQA (3-hop) | 114,196 | 14,274 | 14,274 |
| PathQuestion (2-hop) | 1526 | - | 382 |
| PathQuestion (3-hop) | 4158 | - | 1040 |
| WebQSP | 2848 | 250 | 1639 |
| CWQ | 27,639 | 3519 | 3531 |
| Hit@1 | F1 | |
|---|---|---|
| MetaQA (1-hop) | 100 | 100 |
| MetaQA (2-hop) | 100 | 100 |
| MetaQA (3-hop) | 100 | 100 |
| PathQuestion (2-hop) | 96.6 | 96.6 |
| PathQuestion (3-hop) | 89.3 | 89.3 |
| WebQSP | 88.16 | 84.05 |
| CWQ | 66.99 | 58.04 |
| MetaQA (1-hop) | MetaQA (2-hop) | MetaQA (3-hop) | |
|---|---|---|---|
| MemN2N | 78.50 | 30.50 | 19.00 |
| KVMemN2N | 93.50 | 84.30 | 53.80 |
| IRN | 85.90 | 71.30 | 35.60 |
| GraftNet | 97.0 | 94.8 | 77.7 |
| PullNet | 97.0 | 99.9 | 91.4 |
| EmbedKGQA | 97.5 | 98.8 | 94.8 |
| TransferNet | 97.5 | 100 | 100 |
| UNIKGQA | 98.0 | 99.9 | 99.9 |
| Hic-KGQA | 98.6 | 99.9 | 99.3 |
| DRKG (Ours) | 100 | 100 | 100 |
| PathQuestion (2-hop) | PathQuestion (3-hop) | |
|---|---|---|
| MemN2N | 89.9 | 77.0 |
| KVMemN2N | 93.7 | 87.9 |
| IRN | 96.0 | 87.7 |
| DRKG (Ours) | 96.6 | 89.3 |
| WebQSP | CWQ | |||
|---|---|---|---|---|
| Hit@1 | F1 | Hit@1 | F1 | |
| GraftNet | 66.4 | 60.4 | 36.8 | 32.7 |
| PullNet | 68.1 | - | 45.9 | - |
| EmbedKGQA | 66.6 | - | - | - |
| TransferNet | 71.4 | - | 48.6 | - |
| UNIKGQA | 77.2 | 72.2 | 51.2 | 49 |
| Hic-KGQA | 70.8 | - | 50.9 | - |
| ROG | 85.7 | 70.8 | 62.6 | 56.2 |
| DRKG (Ours) | 88.16 | 84.05 | 66.99 | 58.04 |
| MetaQA(3-hop) | PQ(3-hop) | WebQSP | CWQ | |||||
|---|---|---|---|---|---|---|---|---|
| hit@1 | F1 | hit@1 | F1 | hit@1 | F1 | hit@1 | F1 | |
| ES1 | 70.9 | 76.22 | 33.4 | 33.4 | 53.27 | 73.59 | 13.5 | 15.92 |
| ES2 | 28.63 | 73.91 | 41.6 | 41.6 | 44.49 | 52.03 | 28.51 | 23.21 |
| DRKG | 100 | 100 | 89.3 | 89.3 | 78.16 | 74.05 | 66.99 | 58.04 |
| Temperature | Top-k | Top-p | MetaQA | PathQuestion | ||
|---|---|---|---|---|---|---|
| ACR | AV | ACR | AV | |||
| 0.1 | 10 | 0.1 | 100.0 | 0.0 | 87.65 | |
| 0.1 | 10 | 0.5 | 100.0 | 0.0 | 83.29 | |
| 0.5 | 50 | 0.1 | 98.72 | ≈ | 76.82 | |
| 0.5 | 50 | 0.5 | 98.13 | ≈ | 76.42 | |
| 0.8 | 10 | 0.95 | 87.63 | 53.15 | ||
| 1.0 | 100 | 1.0 | 84.63 | 50.30 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.; Sun, S.; Hu, X. DRKG: Faithful and Interpretable Multi-Hop Knowledge Graph Question Answering via LLM-Guided Reasoning Plans. Appl. Sci. 2025, 15, 6722. https://doi.org/10.3390/app15126722
Chen Y, Sun S, Hu X. DRKG: Faithful and Interpretable Multi-Hop Knowledge Graph Question Answering via LLM-Guided Reasoning Plans. Applied Sciences. 2025; 15(12):6722. https://doi.org/10.3390/app15126722
Chicago/Turabian StyleChen, Yan, Shuai Sun, and Xiaochun Hu. 2025. "DRKG: Faithful and Interpretable Multi-Hop Knowledge Graph Question Answering via LLM-Guided Reasoning Plans" Applied Sciences 15, no. 12: 6722. https://doi.org/10.3390/app15126722
APA StyleChen, Y., Sun, S., & Hu, X. (2025). DRKG: Faithful and Interpretable Multi-Hop Knowledge Graph Question Answering via LLM-Guided Reasoning Plans. Applied Sciences, 15(12), 6722. https://doi.org/10.3390/app15126722