1. Introduction
Maritime vessel monitoring plays a vital role in ensuring maritime safety, protecting marine resources, facilitating crew operations, and supporting rescue missions at sea. Traditionally, monitoring relied on coast guard patrols or visible light technology. However, these approaches often fail to provide effective surveillance due to the unpredictability of natural conditions, such as weather and light interference [
1,
2,
3]. As a result, developing reliable vessel monitoring technologies has become an essential task not only for coastal nations but also for global research communities.
Currently, vessel monitoring primarily leverages advanced technologies such as infrared imagery, optical remote sensing, and SAR imagery [
4,
5,
6]. SAR, an active microwave-based imaging system, has garnered significant attention due to its ability to operate under all weather conditions, detect metallic objects, and capture terrain features. SAR’s potential in maritime traffic monitoring, illegal fishing detection [
7], and maritime emergency operations has been well-established in the literature [
8,
9,
10]. The technology’s capacity for wide-area, high-resolution remote sensing, and its all-weather, all-day, multi-angle observation capabilities, have propelled advancements in spaceborne and airborne SAR systems.
However, despite the advantages, challenges persist in the effective real-time detection of vessels from SAR images. These challenges include issues such as detecting small and low-resolution targets, which may appear as mere bright spots, leading to missed detections or false positives [
11,
12]. Additionally, the varying scale of ship targets in SAR images further complicates detection efforts, emphasizing the need for more effective detection algorithms and end-to-end solutions [
13,
14].
The evolution of vessel detection algorithms can be divided into two main periods. Initially [
15], traditional detection methods based on Constant False Alarm Rate (CFAR) [
16,
17,
18] relied on expert knowledge and manually extracted features, which limited their robustness in dynamic environments [
19]. Although these methods performed well on simple, singular SAR images, their effectiveness often fell short in complex maritime environments [
20].
With advances in technology, Convolutional Neural Networks (CNNs) have demonstrated exceptional performance in image and video analysis tasks [
21], and are widely used in computer vision fields such as semantic segmentation [
22], object detection [
23], and image description [
24]. CNNs can automatically learn stable features of objects from large datasets, reducing reliance on manual feature extraction and enhancing model robustness. Therefore, in the task of vessel detection in SAR images, CNN-based detection algorithms offer significant advantages over traditional methods.
Recent advances in deep learning have driven the development of two categories of CNN-based vessel detection: two-stage detectors and single-stage detectors [
25,
26,
27]. Two-stage detectors, such as Faster R-CNN [
28], Libra R-CNN [
29], and Mask R-CNN [
30], identify objects through two separate classification and regression processes. In contrast, single-stage detectors, such as the YOLO series [
31,
32,
33], SSD [
34], and FCOS [
35], use fully convolutional networks to simultaneously perform classification and regression tasks in an end-to-end manner [
36]. This gives them a speed advantage over two-stage detectors, although the latter may have an edge in accuracy.
Due to the vast resolution differences in SAR images, where the largest and smallest pixel areas in the same dataset can differ by nearly a thousandfold, detection models need to handle multi-scale targets effectively. Feature Pyramid Networks (FPNs) [
37] are one effective solution to this issue. They extract and represent features hierarchically, efficiently handling images of varying sizes and resolutions. Other algorithms, such as Scale-Invariant Feature Transform (SIFT) [
38] and Speeded-Up Robust Features (SURF) [
39], also offer multi-scale feature extraction capabilities, but they may be less efficient than FPNs in terms of computational cost and handling image variations.
To further enhance the detection performance of small targets, some studies have modified network connections to enable independent predictions at different feature layers without increasing the computational burden of the original model. Additionally, to address the challenges of multi-scale vessel detection, researchers have developed various enhanced feature fusion networks [
40]. For example, Cui et al. proposed the Dense Attention Pyramid Network (DAPN) [
41], which uses the convolutional block attention module (CBAM) to connect the top and bottom parts of the feature pyramid, extracting rich features that incorporate resolution and semantic information to solve multi-scale detection problems. Although DAPN demonstrates moderate performance in scene adaptability, it provides an effective solution for multi-scale vessel detection.
Zhou et al. [
42] developed MSSD Net, a novel detector that incorporates the FC-FPN module, an improved FPN that enhances the fusion of feature maps by introducing learnable fusion coefficients. Sun et al. [
43] proposed the Bi-DFFM module, which uses both top-down and bottom-up pathways to achieve higher-level feature integration, thereby improving the recognition capability for multi-scale vessels. H. Wu et al. [
44] establishes the CTF net by proposing a detection algorithm that combines convolution and transformers to improve SAR ship detection by balancing global and local features. These innovative methods offer new possibilities for improving the efficiency and accuracy of detecting vessels of varying sizes in SAR images. This detector enhances the model’s ability to detect vessels of different sizes through techniques like optimizing Feature Pyramid Networks (FPN). Despite these advancements, detecting vessels in complex maritime environments, especially in dense or cluttered areas, remains a significant hurdle. Firstly, many existing multi-scale vessel recognition models achieve high detection accuracy in simple scenarios, such as individual vessels in open waters (as shown in
Figure 1a), where interference factors are minimal. However, vessel targets presented in SAR images are far more varied, often moving through complex maritime environments such as offshore operations, nearshore navigation, docking states, national defense missions and civilian rescue operations. The complexity of the background significantly increases when vessels are near the coastline, particularly when multiple vessels are densely arranged (as shown in
Figure 1b). This makes it difficult for most models to accurately identify each vessel, leading to missed detections.
Secondly, the detection of small vessel targets is particularly challenging. During the feature extraction process, repeated downsampling often leads to the loss of feature information for small-scale targets. These targets occupy fewer pixels in the image, making it difficult for the model to capture sufficient detail. Therefore, improving the recognition capability for small-scale targets is critical for enhancing the model’s performance in multi-scale vessel detection.
To address the challenges in SAR ship detection, this paper introduces Small Target-YOLOv8 (ST-YOLOv8), a specialized architecture optimized for balancing detection accuracy and computational efficiency in marine environments. The selection of YOLOv8 Nano as the baseline model was validated through rigorous benchmarking against contemporary object detectors (
Table 1). While Faster R-CNN demonstrates robust performance for small object detection, its substantial computational cost and parameter count render it unsuitable for resource-constrained SAR applications. RetinaNet achieves comparable inference speeds but requires meticulous tuning of focal loss hyperparameters, exhibiting instability when processing SAR-inherent speckle noise. Although SSD maintains non-negligible throughput, its limited feature pyramid resolution compromises small target detection capabilities.
In contrast, the adopted YOLOv8 [
45] Nano exhibits superior computational efficiency with a lightweight parameter count, while maintaining competitive performance on the AP_S metric of the COCO dataset [
46], making it the optimal choice for this study.
Moreover, YOLOv8 excels in multi-scale target detection. It effectively identifies and locates targets of varying sizes, whether they are small objects or large ones occupying most of the image, providing precise detection results. This capability is especially important in complex real-world scenarios, as it can handle targets of various sizes and shapes. Through comparative experiments and ablation studies on the SSDD and SSDv0, we demonstrate the superior performance of ST-YOLOv8 in complex maritime environments. The contributions of this study are as follows:
- (1)
Introduction of ST-YOLOv8, an advanced vessel detection model tailored for SAR imagery, with innovations in handling multi-scale targets and small object detection.
- (2)
Optimization of detection accuracy, leveraging techniques C_OREPA Model, ASPP Model, and Shuffle Attention Model to improve feature extraction and model robustness.
- (3)
Improve the YOLOv8 loss function by using W-IoU [
47] to mitigate the impact of low-quality bounding boxes and enhance detection accuracy.
Comprehensive evaluation, through experiments on real-world SAR datasets, demonstrating the effectiveness of the proposed model in complex maritime scenarios. In summary, this study not only advances the field of vessel detection in SAR imagery but also provides a robust solution to the ongoing challenges of multi-scale and small object detection in dynamic maritime environments.
2. Method
2.1. Network Architecture
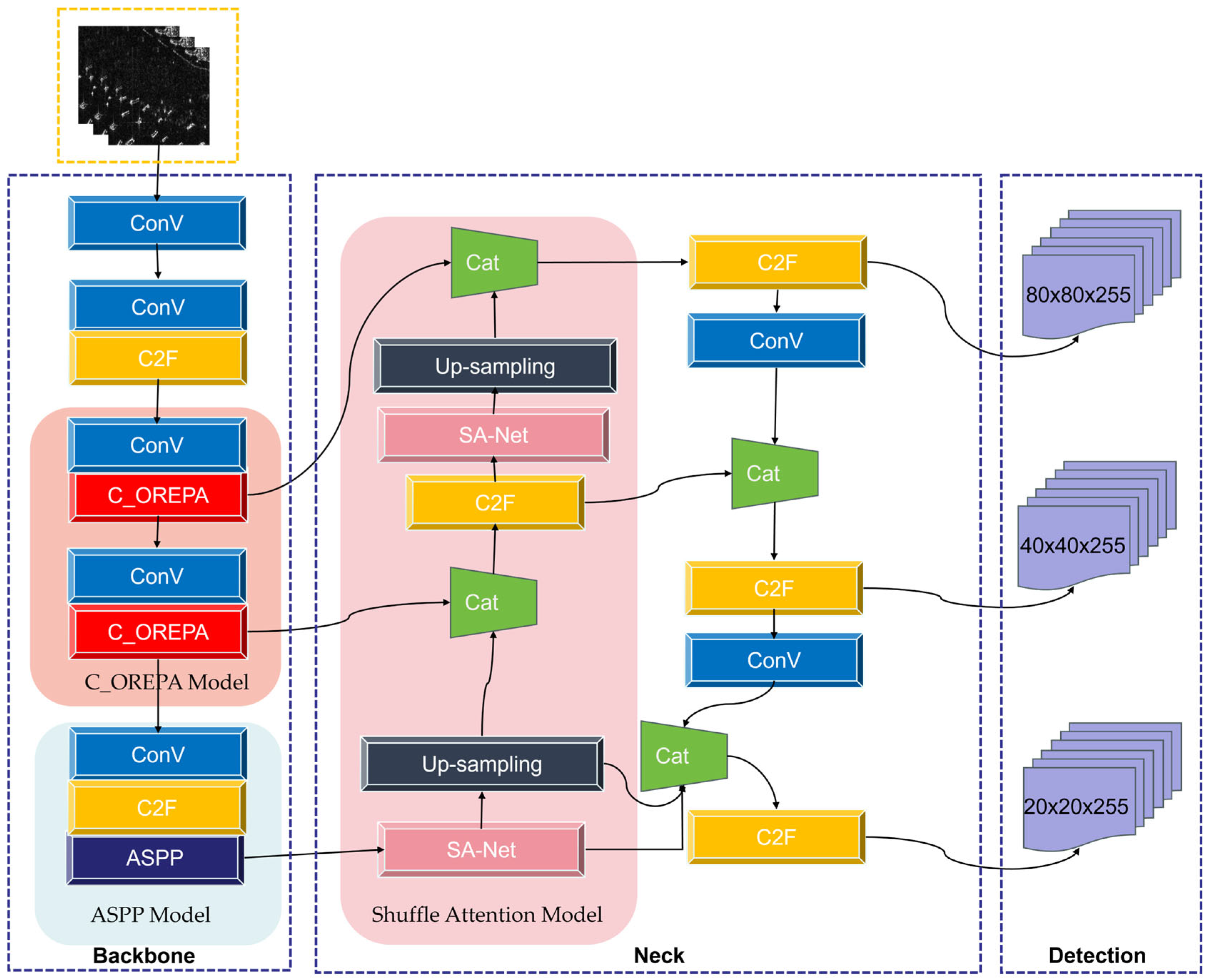
To more effectively detect multi-scale vessels in SAR image data, especially small vessels in complex backgrounds, we propose an optimized ST-YOLOv8 algorithm for multi-scale vessels and complex scenarios in SAR images. This algorithm maintains robust performance for multi-scale vessel detection. In the backbone network of the baseline model, the C_OREPA module and the ASPP module were integrated, and the SA module was added to the neck network. Firstly, the preprocessed SAR images are passed through a convolutional group and then into the feature extraction network reconstructed by OPERA for feature extraction. Subsequently, these features are processed through the ASPP module for feature fusion, resulting in enhanced spatial and semantic data (P1, P2, P3). Feature maps of various scales, augmented by SA at each stage, are then upsampled before entering the detection network. Finally, the W-IoU loss function is used to continuously optimize the prediction results. The results of detection are obtained through Non-Maximum Suppression (NMS).
Figure 2 shows us the model structure of ST-YOLOv8.
2.2. C_OREPA Model
Online Reparameterized Convolution (OREPA) [
48] is a method designed to reduce the training cost and complexity of deep learning models through online convolutional reparameterization. It primarily involves two stages: firstly, optimizing the performance of online blocks using a specialized linear scaling layer; secondly, reducing training overhead by compressing complex training-time modules into a single convolution. This approach significantly reduces memory and computational costs during training, while also enhancing training speed.
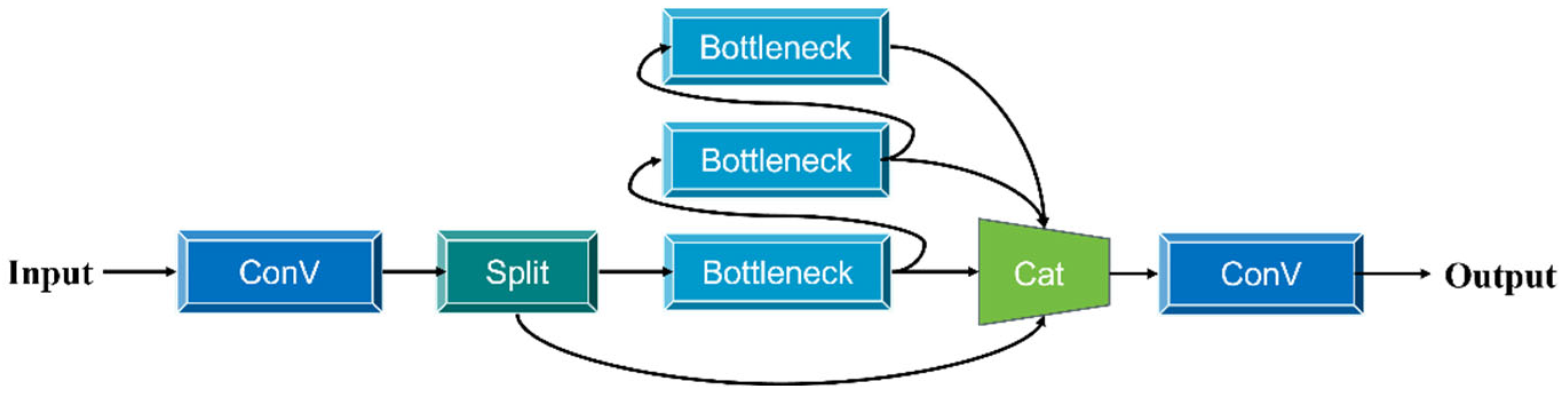
Figure 3 provides a detailed description of the composition of the C2f model.
The C2f module is an improved convolutional module used in YOLOv8. It enhances the model’s performance and efficiency by introducing additional skip connections and Split operations. The C2f module first splits the input tensor into two parts. One part passes directly through multiple bottlenecks, while the other undergoes shortcut connections after each operational layer. The final output is produced through a convolution operation.
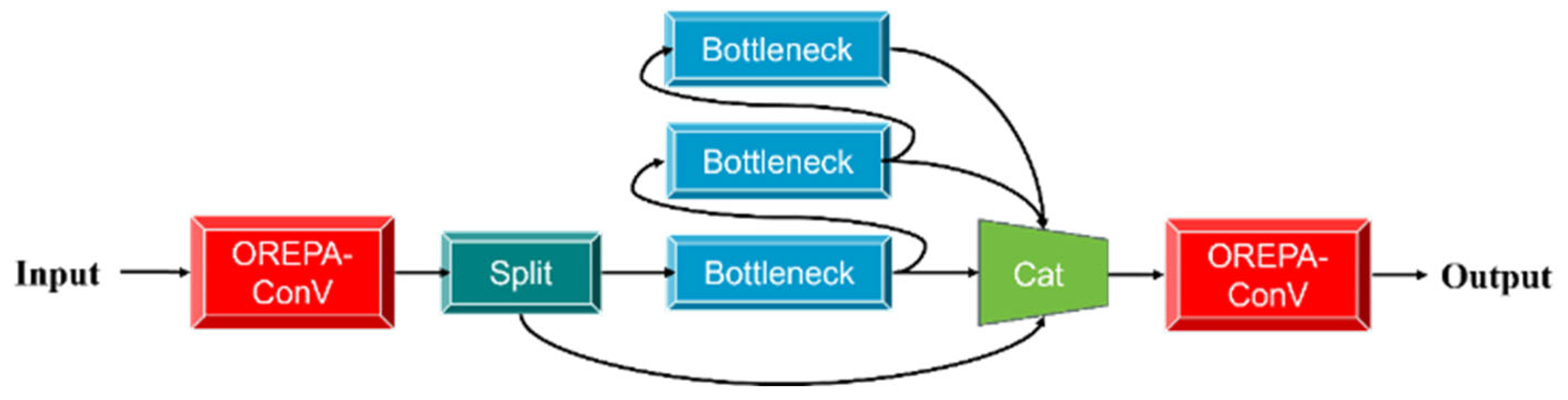
Figure 4 illustrates how the C_OREPA module works. The core idea of OREPA is to dynamically combine multiple convolution branches during training and reparameterize them into a single standard convolution layer during inference, achieving efficient computation.
Here are the formulas:
Dynamic Combination during Training, the weights of multiple convolution branches are dynamically combined using learnable vectors:
During inference, all branch weights are merged into a single standard convolution weight:
This process simplifies complex convolution operations into a single standard convolution.
The proposed C_OREPA module enhances computational efficiency by replacing the original C2f block through decoupling spatial and channel operations via grouped convolutions. This design achieves a notable reduction in parameters while maintaining a high level of original feature expressiveness, as validated through ablation experiments. Furthermore, integrating OREPA’s online re-parameterization within the C2f architecture enables replacement of complex convolutions with dynamically re-parameterized kernels. These kernels adaptively adjust weights during training to accommodate varying data distributions, thereby reducing computational complexity and improving end-to-end training/inference performance. This synergistic approach maintains model validity through kernel-level optimization while enhancing adaptability to diverse task requirements.
2.3. ASPP Model
To enhance small object detection performance in YOLOv8, we incorporate the Atrous Spatial Pyramid Pooling (ASPP) module at the backbone–neck junction, which significantly improves multi-scale feature representation capabilities. By replacing conventional pooling operations with atrous convolutions of varying dilation rates (6, 12, 18), ASPP constructs a hierarchical feature pyramid that captures contextual information across scales. This architecture addresses the inherent limitations of traditional pooling layers in small object detection [
49].
ASPP (Atrous Spatial Pyramid Pooling), an advanced feature extraction module in deep convolutional neural networks, can be regarded as an enhanced version of traditional pooling layers. Its core design principle originates from an improvement upon Spatial Pyramid Pooling (SPP), where the introduction of atrous convolution (dilated convolution) technology enables multi-scale feature fusion while preserving the spatial resolution of feature maps.
From a functional perspective, ASPP shares the same fundamental objective as conventional pooling layers—to extract comprehensive and efficient deep feature representations of input data through hierarchical feature abstraction. However, unlike traditional pooling layers, which rely on a single fixed-scale feature extraction approach, ASPP constructs a multi-scale feature extraction pyramid structure by employing parallel atrous convolutional layers with different dilation rates. This innovative design allows the module to simultaneously capture contextual information at varying scales: smaller dilation rates focus on local fine-grained features, while larger dilation rates capture broader semantic contexts.
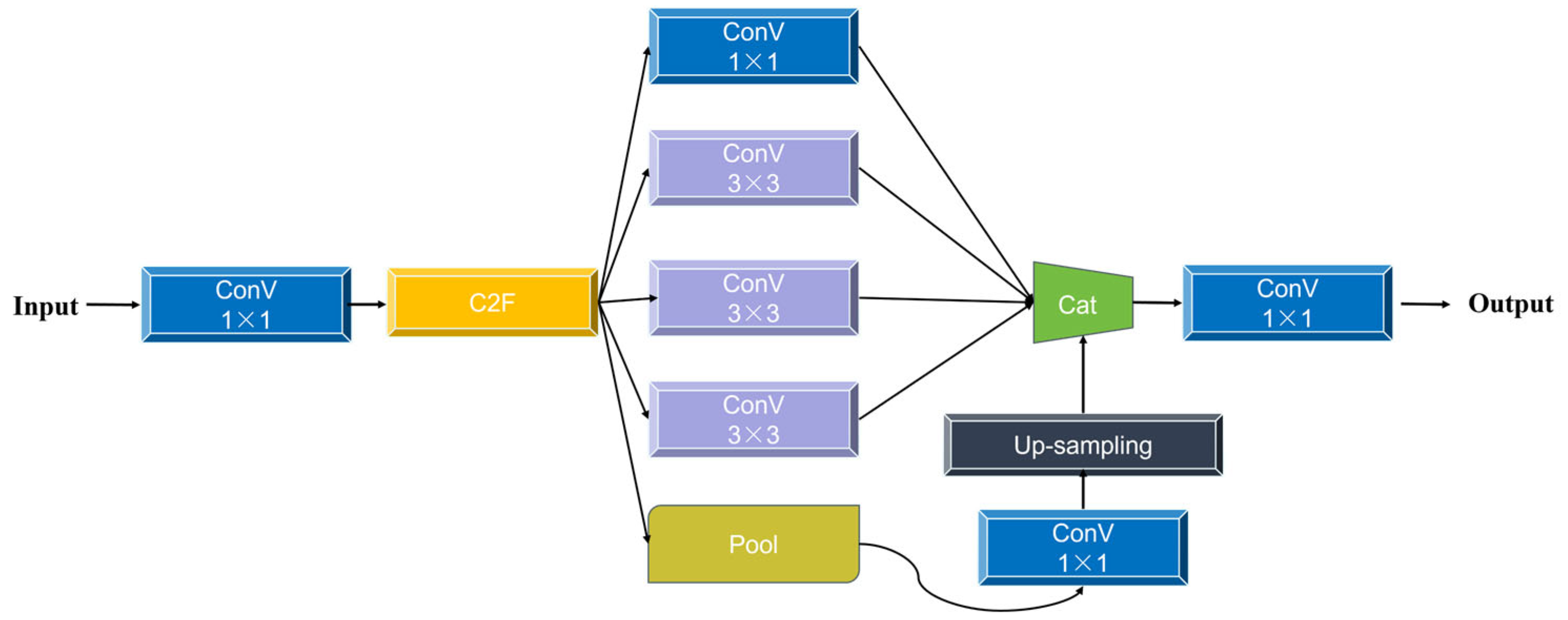
In terms of implementation, the ASPP module typically consists of four parallel feature extraction branches: a standard 1 × 1 convolutional branch and three 3 × 3 atrous convolutional branches with different dilation rates (e.g., 6, 12, 18), supplemented by a global average pooling branch to incorporate image-level contextual information. This multi-scale feature fusion mechanism enhances the network’s capability to process visual data with complex spatial structures. By integrating ASPP at the junction between the backbone and neck of YOLOv8, the receptive field is expanded, thereby improving multi-scale object detection performance—particularly in the recognition of small and densely clustered objects. The structure of the ASPP module is illustrated in the following
Figure 5.
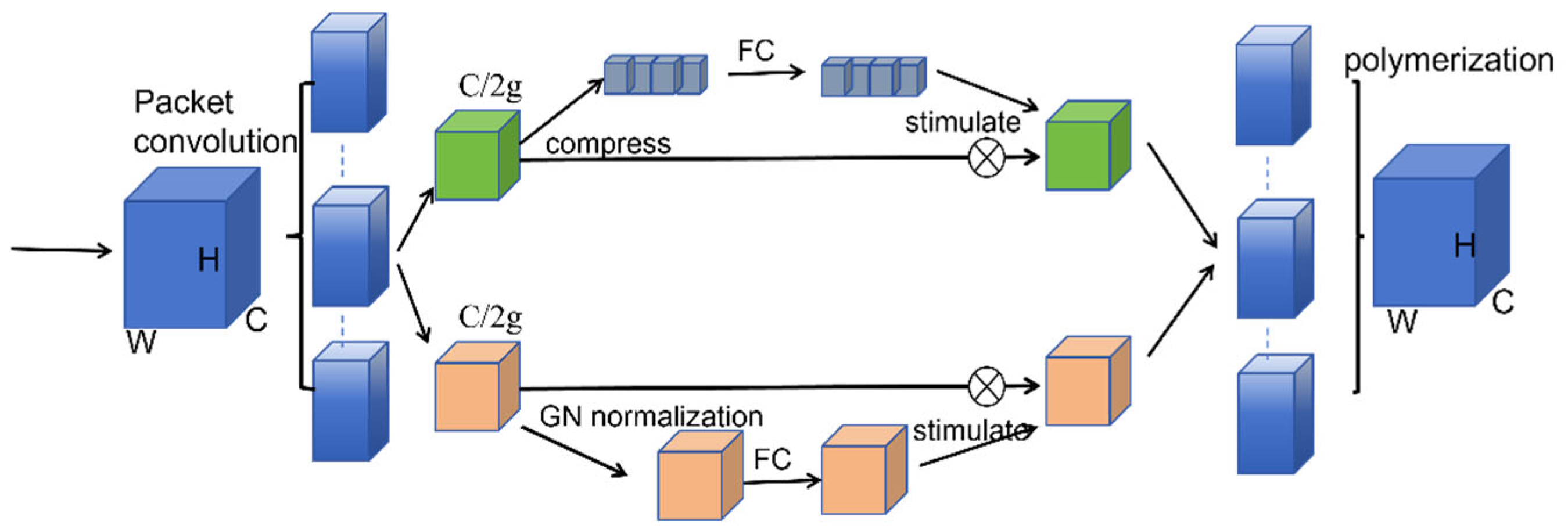
2.4. Shuffle Attention Model
Shuffle Attention (SA) introduces a novel mechanism to enhance feature representation learning by dynamically reallocating channel-wise attention weights. Unlike conventional attention modules that employ uniform channel scaling (e.g., SE-Blocks [
50]) or sequential channel-spatial processing (e.g., CBAM), SA partitions feature channels into non-overlapping subgroups and computes attention weights in parallel across these subgroups. This group-wise attention computation significantly reduces computational complexity while preserving feature discriminability.
The proposed method comprises two sequential operations, as shown in
Figure 6: intra-group attention calibration and inter-group feature shuffling. After parallel attention weighting within each subgroup, a stochastic channel shuffle operation is performed to redistribute features across subgroups. This procedure achieves two key advantages: it promotes feature diversity by enabling cross-group information exchange, and it mitigates overfitting risks through inherent stochasticity in feature redistribution. Experimental evaluations demonstrate that the shuffle operation effectively reduces model reliance on dominant features, thereby enhancing generalization capability [
51].
When integrated into the YOLOv8 detection framework, SA yields substantial performance improvements, particularly in complex scenarios. During upsampling stages, the module bridges semantic gaps between multi-scale features through enhanced cross-channel interaction, leading to superior feature fusion quality. Quantitative results show notable detection accuracy gains for small objects and in cluttered environments, attributed to the module’s dual benefits of computational efficiency and adaptive feature sampling.
2.5. Loss Functions
Object detection, as a core problem in computer vision, heavily relies on the design of its loss functions to achieve optimal performance. As a crucial component of object detection loss functions, a well-designed bounding box loss function can significantly enhance the performance of detection models. Recent studies often assume that the training data samples are of high quality and focus on enhancing the regression capabilities of bounding box loss functions. However, it is noteworthy that object detection training datasets often contain low-quality samples. Overly focusing on regressing bounding boxes for these low-quality samples can negatively impact model performance. Focal-EIoU v1 addresses this issue, but its static focusing mechanism does not fully exploit the potential of non-monotonic focusing mechanisms. Wise-IoU (W-IoU) is a bounding box regression loss function based on a dynamic focusing mechanism, significantly improving the performance of object detection models. Traditional IoU loss functions treat all samples equally during bounding box regression, ignoring the differences in difficulty among samples, while W-IoU dynamically adjusts sample weights, allowing the model to focus more on hard-to-learn samples (e.g., small or occluded targets), thereby enhancing detection accuracy. The core idea of W-IoU is to use a Dynamic Focusing Factor (DFF) to adjust the loss weight, formulated as
The meanings of each element are as follows:
x and y: The coordinates of the center point of the predicted bounding box.
xgt and ygt: The coordinates of the center point of the ground-truth bounding box.
Wg and Hg: The width and height of the minimum enclosing box, which is the smallest rectangle that contains both the predicted and ground-truth bounding boxes.
: The sum of the squares of the width and height of the minimum enclosing box. The symbol ∗ may indicate a specific processing method, such as taking the average or maximum value, depending on the implementation details.
This formula calculates the squared distance between the center points of the predicted and ground-truth bounding boxes, normalized by the sum of the squares of the width and height of the minimum enclosing box, and then takes the exponential of this value. This term is used to adjust the Wiou loss function, such that the greater the distance between the center points of the predicted and ground-truth bounding boxes, the larger the loss. This encourages the model to predict bounding boxes that are closer to the center of the ground-truth boxes.
Among them, Bp is the hypothetical prediction box, and Bg is the real box
Area (Bp ∩ Bg) is the intersection area between the predicted box and the real box.
Area (Bp) and Area (Bg) are the areas of the predicted box and the real box, respectively.
3. Experiment and Results
3.1. Experiment Environment and Datasets
All experiments were conducted on a Windows 11 Pro system using PyTorch 1.7.1 with CUDA 11.0 acceleration, equipped with an Intel i5-12400F processor, 16 GB RAM, and an RTX 3060 GPU. Models were trained using SGD optimization with Nesterov momentum (0.937), L2 weight regularization (5 × 10−4), batch size 32, and initial learning rate 0.01 across 100–300 epochs. Overfitting mitigation included data augmentation, learning rate decay, and early stopping with 15-epoch patience, with hyperparameters refined through iterative validation.
To validate the reliable performance of the model across various datasets, experiments were conducted using the SSDD and the SSDv0 to evaluate the proposed method. In addition to typical open-sea ship views, these two datasets include a variety of scenarios such as nearshore areas, ports, and islands.
To enhance the dataset’s complexity and robustness, a series of advanced techniques were implemented. Specifically, data augmentation strategies including random scaling (0.8×–1.2×) and random cropping (85–100% area) were employed to expand the diversity of the SSDD, enriching the range of scenarios and features available for model training. Furthermore, cross-dataset validation was performed by evaluating model performance across both SSDD and SSDv0 datasets, providing a comprehensive assessment of generalization capabilities across different data distributions. Complementary subset analysis was also conducted to examine model behavior under varied operational conditions, offering granular insights into performance characteristics across specific data partitions.
To further examine the robustness of the models, subsets of the SSDD and SSDv datasets were created to simulate diverse environmental conditions. These included variations in weather conditions, sea states, and target densities, which allowed for a thorough assessment of the models’ ability to perform reliably under different real-world scenarios. Through these meticulous approaches, a more comprehensive and reliable evaluation framework was established, ensuring that the models could effectively handle the inherent complexity and variability of the datasets. A detailed introduction to SSDD and SSDv0 follows below. Some of the detailed values are presented in
Table 2. The annotation boxes in the dataset are all directly provided by the dataset.
The SSDD comprises 1160 SAR images of varying sizes, sourced from three satellite sensors. The image resolution spans from 1 million to 15 million pixels. The dataset encompasses diverse imaging scenarios, including complex environments such as docks and nearshore areas, as well as simpler open-sea scenes. Each SAR image contains a variable number of ship targets, with differing sizes and types. Specifically, small, medium, and large ships constitute 60.2%, 36.8%, and 3% of the total vessels, respectively.
The SSDv0 dataset is primarily constructed using SAR data from China’s Gaofen-3 and Sentinel-1 satellites. Specifically, it consists of 102 scenes from Gaofen-3 and 108 scenes from Sentinel-1 SAR images, forming a high-resolution SAR ship target deep learning sample library. The current library contains 43,819 ship patches. The imaging modes of Gaofen-3 include Strip-Map (UFS), Fine Strip-Map 1 (FSI), Full Polarization 1 (QPSI), Full Polarization 2 (QPSII), and Fine Strip-Map 2 (FSII), with resolutions of 3 m, 5 m, 8 m, 25 m, and 10 m, respectively. Sentinel-1 SAR data, on the other hand, are acquired in Strip Mode (S3 and S6) and Wide Swath Mode. These diverse imaging modes and resolutions provide a rich source of data for deep learning applications in ship detection.
3.2. Experimental Evaluation Indicators
To evaluate the effectiveness of ST-YOLOv8, mean average precision (mAP) [
52], precision, recall [
53], and F1-score [
54] were used as evaluation metrics. The definitions of these metrics are as follows:
In these formulas, stands for mean average precision, which is calculated as the average of (the average precision of the -th instance or class) over instances or classes. (average precision) is defined as the integral of (precision at a given recall ) with respect to (the differential of recall) from 0 to 1. represents the ratio of true positives ( the number of correctly predicted positive samples) to the sum of true positives and false positives (, the number of incorrectly predicted positive samples). is the ratio of true positives () to the sum of true positives and false negatives (, the number of incorrectly predicted negative samples). is the harmonic mean of precision and recall, calculated as times the product of precision and recall divided by the sum of precision and recall, combining the two metrics to evaluate the model’s performance comprehensively.
3.3. Results and Discussion
The ablation experiment adopted the YOLOv8 Nano algorithm as the baseline model. (Referred to as YOLOv8n for short in the following text.) Known for its fast and accurate object detection capabilities, YOLOv8n served as the starting point for evaluating other improvement strategies. To ensure the practical applicability of our experimental results, we selected two different datasets for evaluation: SSDD and SSDv0.
The SSDD likely includes target detection samples from various complex environments, whereas the SSDv0 focuses specifically on ship detection tasks. This provides a diverse testing environment to assess the performance of ST-YOLOv8 across different scenarios.
During the experiments, certain components of YOLOv8n were systematically removed or replaced to observe how these changes affected the performance of ST-YOLOv8. Comprehensive tests were conducted on each improvement strategy, including but not limited to detection speed (time required for the model to process an image and produce predictions), accuracy (the proportion of correctly identified targets), recall (the model’s ability to identify all targets), and IoU (Intersection over Union, measuring the overlap between predicted and ground truth bounding boxes). Multiple iterations were performed for each strategy to ensure the stability and reliability of the results. Experimental results were organized to show in
Table 3,
Table 4,
Table 5,
Table 6,
Table 7 and
Table 8 form for easier comparison and analysis.
3.3.1. Ablation Experiment
To systematically evaluate the contributions of individual components and their synergistic interactions within the proposed framework, comprehensive ablation experiments were conducted on two benchmark datasets: SSDD and SSDv0. The experimental protocol was divided into two complementary stages: Single-Module Impact Assessment and Progressive Module Integration Analysis. This two-tiered ablation strategy provides rigorous empirical evidence for both the standalone efficacy and collaborative interactions of the proposed architectural innovations.
Firstly, in this paper, the SPPF module in YOLOv8n is replaced with the ASPP model. In the Ablation Experiment,
Table 3 shows that ASPP significantly improves the performance of SAR ship target detection. This improvement is mainly because traditional downsampling increases the receptive field but reduces spatial resolution. In contrast, dilated convolution expands the receptive field while maintaining resolution. Different dilation rates provide the network with various receptive fields, enabling the model to capture multi-scale contextual information.
Table 4 shows that adding the ASSP module improves the recall rate and precision to 93.1% and 80%, respectively, indicating that the SA module reduces missed detections caused by unknown feature extraction in the YOLOv8n algorithm.
Table 3 and
Table 4 present a performance comparison of different improvement strategies on the SSDD, while
Table 5 and
Table 6 focus on results from the SSDv0. These data include both quantitative metrics, such as accuracy and recall, and qualitative analyses, such as the model’s performance in detecting specific object types. Through these detailed experiments and analyses, a scientific basis for further optimization of ST-YOLOv8 was provided, and directions for future research were identified. Specifically,
Table 3 and
Table 5 illustrate the performance changes when individual new modules are incorporated into the base model. This approach allows us to clearly observe the distinct contributions of each module to the overall model performance.
Table 4 and
Table 6, on the other hand, demonstrate the process of incrementally integrating these modules into the complete model. Through comparative analysis, these tables highlight the cumulative enhancement of model performance achieved by the combined integration of these modules.
Finally, the application of the W-IoU loss function introduces a dynamic non-monotonic focusing mechanism and a focusing coefficient. This enables the model to handle small targets more precisely and accurately, thereby improving performance in object detection tasks.
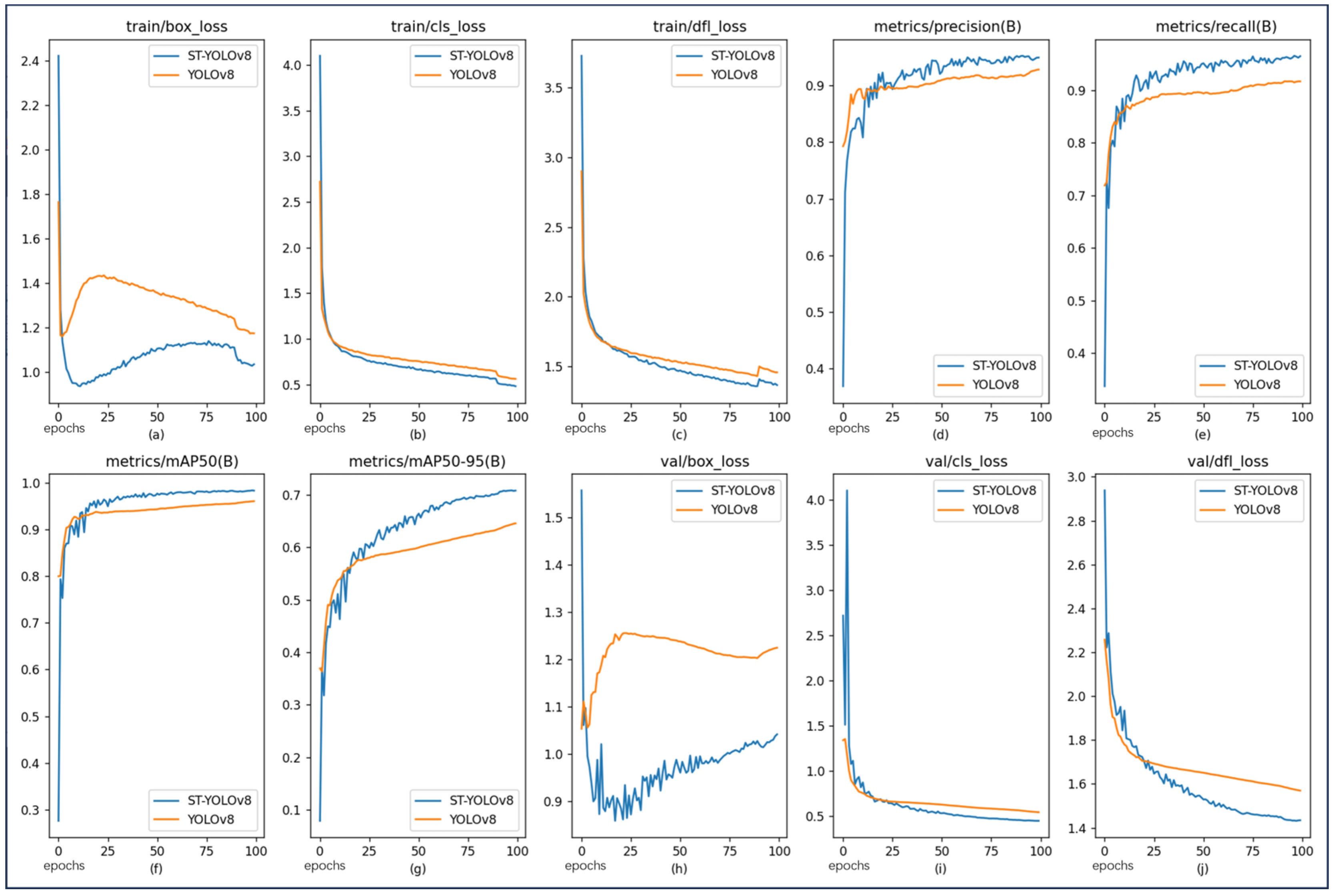
The loss function is considered a fundamental component in object detection tasks, as it quantifies the discrepancy between the predicted and true values, thereby directly influencing the overall performance of the model. Among the various loss components, including box loss, classification loss, and distribution focal loss, superior performance is demonstrated by ST-YOLOv8, primarily due to the incorporation of W-IoU. This enhancement results in more accurate bounding box predictions, which improve both localization and classification precision. When a comparison is made with YOLOv8n, significant improvements are achieved by ST-YOLOv8 across three key evaluation metrics: precision, recall, and mAP. Specifically, detection accuracy is enhanced, and recall is improved, ensuring that fewer objects are missed during detection. Additionally, the increase in mean average precision reflects a more robust model that excels in both the quality and quantity of detections. The marked improvements in these metrics are clearly illustrated in
Figure 7, demonstrating the effectiveness of the proposed enhancements and highlighting the significant performance gains of ST-YOLOv8 over its predecessor, YOLOv8n. The importance of the W-IoU modification in driving improved detection capabilities across diverse object categories and detection scenarios is underscored by this comparative advantage.
The proposed methodology demonstrates enhanced comprehensiveness and integration, rendering it particularly advantageous for the training process. As illustrated in the comparative analyses
Figure 8, ST-YOLOv8 exhibits superior performance relative to YOLOv8n across all evaluated metrics.
Figure 8 presents the detection performance of both models when applied to diverse SAR ship imagery datasets. Notably, under complex environmental conditions, ST-YOLOv8 demonstrates significantly improved capability in detecting multi-scale ship targets compared to the baseline YOLOv8n architecture.
This study further validates the effectiveness of the proposed algorithm for SSDv0 detection, with results illustrated in
Figure 8. Among them, the first row is for small targets in large sea areas, and the second row is for small targets with complex backgrounds. The comparison demonstrates that ST-YOLOv8 achieves superior recognition accuracy.
Figure 8a shows the true distribution of ships in the image. As shown in
Figure 8b, YOLOv8n fails to detect small and medium-sized ships (highlighted by the blue circle), primarily because their limited pixel coverage leads to false negatives. In contrast,
Figure 8c presents the results of our proposed ST-YOLOv8 model, which accurately identifies small ship targets with higher confidence.
For multi-scale SAR images of docked ships with complex backgrounds (e.g., medium-sized ships near the shore),
Figure 8e reveals that YOLOv8n not only misses ships at the image boundary but also generates false positives by misclassifying coastal structures as vessels (marked in yellow). This error stems from the model’s susceptibility to interference from cluttered dock backgrounds.
Compared to the YOLOv8n model, the proposed model incorporates SA, enabling it to focus more on ship features and ignore irrelevant background information. Therefore, this model has higher recognition accuracy when facing the pier background. In the SAR images of densely arranged multi-scale ships, the experimental results indicate that the YOLOv8n model exhibits more severe misdetection, represented by yellow circles, when it encounters ships closer to the shore.
The ST-YOLOv8 model demonstrates better performance when dealing with densely parked multi-scale ships, as the model combines depthwise separable convolutions with different dilation rates and atrous convolutions, which collectively improve its multi-scale feature extraction capability. Even when faced with overlapping small targets, the model maintains good recognition performance.
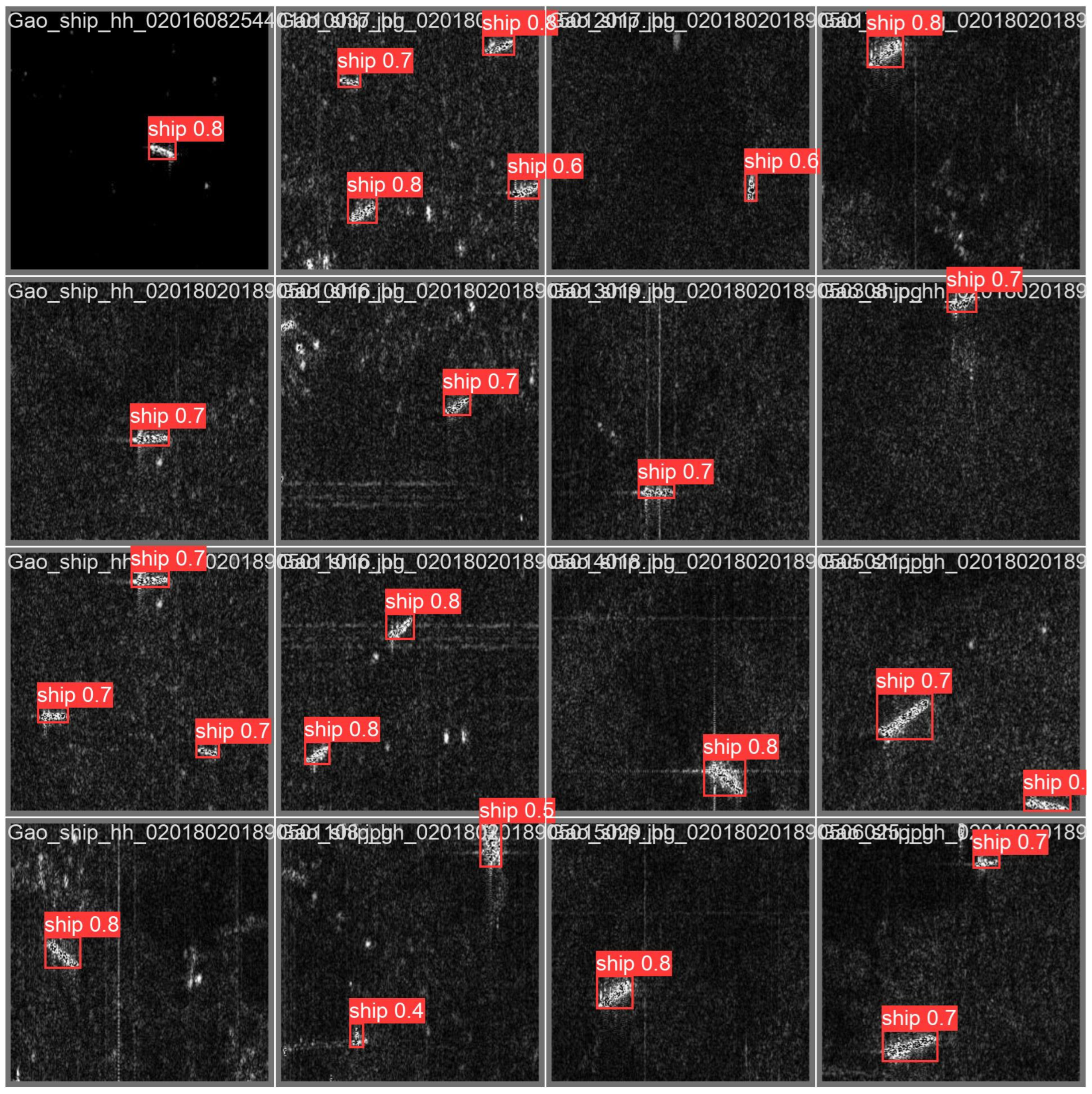
In the validation experiments on the SSDv0 dataset, as illustrated in
Figure 9, a visual analysis was conducted on 16 representative image tiles (average size: 256 × 256 pixels) containing densely distributed small ship targets (ranging from 8 × 8 to 32 × 32 pixels). The ST-YOLO model successfully detected all small ship targets across these tiles, identifying a total of 26 valid objects (with all targets in each image being correctly recognized), significantly reducing the missed detection rate compared to the baseline model. The Intersection over Union (IoU) values predominantly exceeded 0.6. Notably, in the complex sea clutter background of the second tile from the left in the fourth row, ST-YOLO effectively distinguished a blurred ship target measuring 16 × 20 pixels (confidence score: 0.4), demonstrating the efficacy of the proposed multi-scale feature enhancement module in extracting small target features. Quantitative analysis revealed that this set of tiles achieved the highest average precision, further highlighting the superior performance of ST-YOLO in small ship target detection tasks.
3.3.2. Comparison with Other Methods
This section presents comparative experiments using five popular ship detection models: Faster R-CNN, SSD, DAPN, Quad-FPN, Retina Net, CTF-Net, and YOLOv5 on the SSDD and SSDv0, alongside the proposed ST-YOLOv8 model. Faster R-CNN improves the R-CNN series algorithms by introducing the Region Proposal Network (RPN) to reduce the computational cost of candidate regions and improve detection speed. SSD is a single-shot detection algorithm that performs target detection on feature maps of different scales, capable of detecting objects of varying sizes. DAPN enhances the model’s ability to perceive important features by introducing channel attention and spatial attention mechanisms, improving detection accuracy, and is used for image recognition and target detection. Quad-FPN is a variant of the Feature Pyramid Network (FPN) used for object detection tasks. It enhances the model’s ability to detect multi-scale targets by constructing a four-layer feature pyramid to fuse features at different scales. It boosts the model’s ability to detect multi-scale targets by constructing a four-layer feature pyramid to fuse features at different scales. Focal loss helps the model focus more on hard-to-classify samples during the training process. These algorithms have their own advantages and application scenarios in the field of object detection, using different mechanisms to improve detection accuracy and speed. The experimental results show that ST-YOLOv8 achieved the best mAP (95.60%) on SSDD and 94.3% on SSDv0.
This is attributed to the reallocation of the model’s relevant parameters, elimination of irrelevant information, reduction in false alarm rates for targets such as islands, improvement in recall, and enhanced sensitivity to medium and small ships. These adjustments enable the model to effectively extract discriminative features for detecting multi-scale ships in complex backgrounds.
Table 7 presents the actual performance of different models on the SSDD and SSDv0.
Table 8 provides a detailed comparison of our proposed model with other state-of-the-art models in terms of model size, number of parameters, computational speed, and floating-point operations. As shown in the table, our model achieves the smallest model size and the fewest number of parameters among all the compared models except YOLOv5n. However, the detection capability of YOLOv5n in
Table 7 is not satisfactory. Our model can better demonstrate that it still performs relatively well under the condition of a compact structure, thereby highlighting its superior efficiency. This significant balance between model complexity and computational performance highlights the outstanding capabilities of the model we proposed, positioning it as a highly effective solution compared to other models.
4. Discussion
In the proposed ST-YOLOv8 model, the introduction of key design choices such as the ASPP module and Wise-IoU loss function has led to significant improvements in detection performance, particularly evident in the enhancement of precision, recall, and F1 score for small target ship detection in SAR images. The ASPP module, by capturing multi-scale contextual information through atrous convolutions with varying dilation rates, enables the model to more accurately identify ship targets, thereby reducing false positives and contributing to a noticeable increase in precision. Additionally, by expanding the receptive field, the ASPP module aids the model in capturing smaller targets, leading to an improvement in recall. The combined effect of these enhancements results in a higher F1 score, indicating a better balance between precision and recall.
Furthermore, the adoption of the Wise-IoU loss function further refines the model’s detection capabilities. By dynamically adjusting sample weights, the Wise-IoU loss function allows the model to focus more on challenging samples during training, such as small targets or occluded objects. This dynamic focusing mechanism leads to a further increase in precision by reducing the impact of low-quality bounding boxes. Although the improvement in recall is relatively modest, the overall effect is still positive, contributing to a slight increase in recall and a subsequent elevation in the F1 score, demonstrating an optimized balance between precision and recall. Additionally, the model’s generalization capabilities are expected to improve further in addressing complex sea conditions and weather variations in SAR images, adapting to diverse application scenarios, particularly in defense monitoring, maritime security, and ship search and rescue. By incorporating domain-specific prior knowledge or adaptive multimodal data fusion techniques, ST-YOLOv8’s detection performance can be further enhanced, enabling it to play a key role in more specialized tasks in the future.
Synthetic Aperture Radar (SAR) ship detection has garnered significant attention due to its military applications, such as maritime surveillance and strategic target identification. However, the potential misuse of SAR technology in military contexts poses considerable risks. For instance, unauthorized detection and tracking of civilian vessels could lead to unwarranted harassment or even escalation of conflicts. Additionally, the high-resolution imaging capabilities of SAR systems may inadvertently capture sensitive information, raising privacy concerns.
To mitigate these risks, it is imperative to implement robust data encryption and anonymization techniques to safeguard sensitive information. Additionally, clear regulatory frameworks and ethical guidelines should be established to govern the use of SAR technology and vessel monitoring systems, ensuring that privacy is respected while maintaining the benefits of advanced maritime surveillance.
5. Conclusions
Maritime SAR images contain ships of various sizes, but existing detection algorithms face challenges in identifying ships of different sizes, particularly smaller vessels in complex scenes. To address this, the ST-YOLOv8 model, which is based on YOLOv8n, is proposed and integrates the C_OREPA module. At the junction of the backbone and neck networks, the SA mechanism and ASPP are incorporated into the model. Spatial and channel attention are combined through the inclusion of the SA mechanism, enhancing accuracy while maintaining low computational cost, and detection performance is significantly improved. The receptive field is expanded by ASPP through global pooling and large dilation rate convolutional kernels. Feature maps from different levels are effectively fused by the model, further improving the detection rate of small vessels in complex scenes. Finally, the W-IoU loss function has been introduced to enhance the recognition of multi-scale ships by focusing on regions containing ship information. Detection accuracy is improved, and background interference is reduced. To improve the detection accuracy of small targets and reduce dependence on environmental variables, the highest detection accuracy and strong generalization capability are demonstrated by ST-YOLOv8 in comparisons on the SSDv0 and SSDD. The low recognition accuracy in complex environments is primarily caused by detection errors and missed detections. Compared to YOLOv8n’s accuracy on the SSDD, ST-YOLO improves it from 89% to 94.1%, the recall rate from 76.7% to 82%, and F1 score from 82.3% to 87.6%. On the SSDv0, accuracy increased from 83.3% to 92.7%, recall rate from 76% to 84.5%, and F1 score from 79.4% to 88.1%. The best results are achieved by the ST-YOLOv8 model compared with other popular ship detection algorithms such as Faster R-CNN, SSD, DAPN, Quad-FPN, and Retina Net, with an accuracy of 94.1% and an mAP of 95.6% on the SSDD, and an accuracy of 92.7% and an mAP of 94.3% on the SSDv0. Multi-scale ships in SAR images are effectively detected by ST-YOLOv8, making it crucial for defense and civilian search and rescue missions. In search and rescue missions, the enhancement of model accuracy and the reduction in false alarm rates play a crucial role in improving response times, monitoring illegal activities, and optimizing port management. Specifically, higher model accuracy enables more precise target identification, thereby significantly reducing the time wasted on ineffective searches and shortening the overall response time. Moreover, a lower false alarm rate allows surveillance systems to more accurately detect illegal activities, minimizing unnecessary alerts and resource allocation, and thereby enhancing the efficiency of monitoring. Additionally, in port management, high-precision models can effectively track ship dynamics in real-time, optimize the allocation of port resources, and reduce congestion, ultimately improving overall operational efficiency. These improvements not only enhance the efficiency of mission execution but also provide robust support for safety management in relevant fields.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}