
Advancing Software Vulnerability Detection with Reasoning LLMs: DeepSeek-R1′s Performance and Insights


Abstract
1. Introduction
- A novel LLM-based framework for code vulnerability detection is proposed, which explicitly incorporates reasoning traces through DeepSeek-R1. This enables interpretable detection workflows that go beyond traditional black-box results.
- A first systematic comparative study is conducted between reasoning models (e.g., DeepSeek-R1) and widely used non-reasoning LLMs (e.g., GPT-4o, Claude-3.5, DeepSeek-V3), highlighting their respective strengths and limitations in detecting different software vulnerabilities.
- The impact of multi-step logical reasoning on detection performance is empirically analyzed. A case study and detailed error analysis further reveal the strengths and current limitations of reasoning-based LLMs, offering valuable insights for future research on code remediation.
2. Related Works
2.1. Code Vulnerability Detection
2.2. Large Language Models
2.3. LLMs in Vulnerability Detection
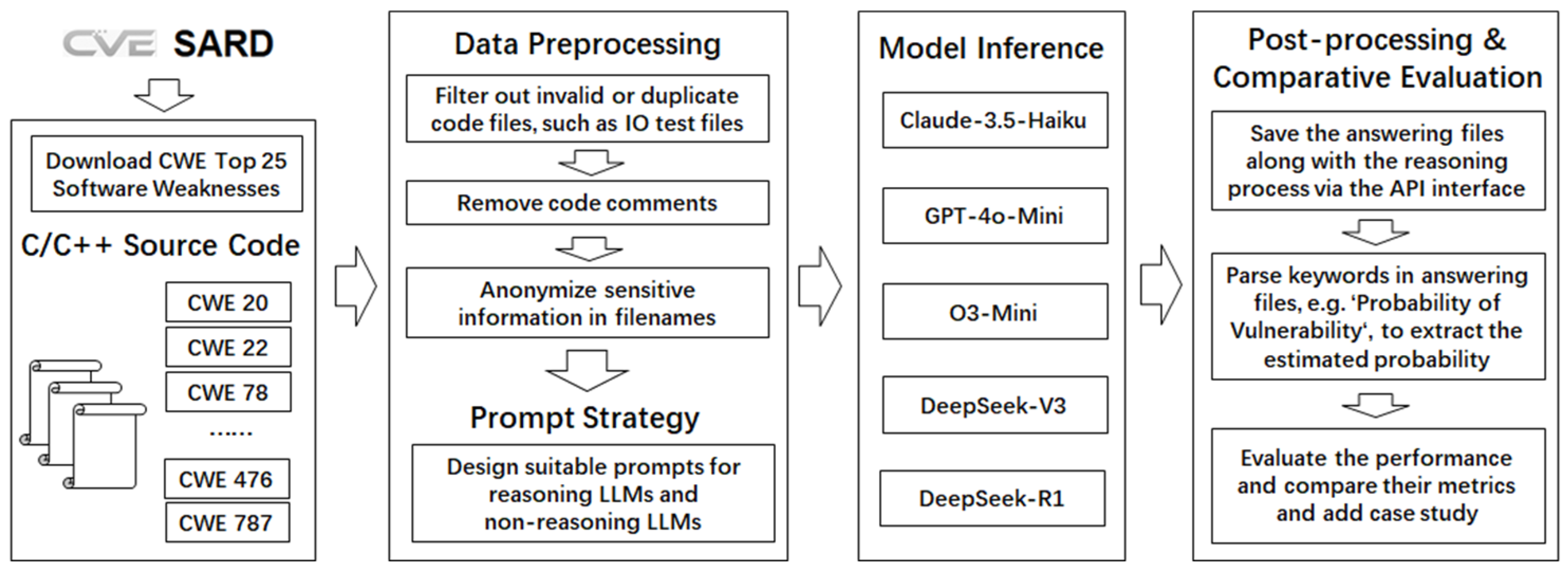
3. Methodology
3.1. Framework Overview
3.2. Data Collection
3.3. Data Preprocessing
| Algorithm 1: Pseudocode for Data Preprocessing Stage Algorithm |
| Input: SARD—Source code dataset with SARIF metadata Output: CleanedDataset—Clean dataset without biases begin 1. NonEssentialFiles in SARD: io.c, std_testcase.h, and std_testcase_io.h 2. TargetFiles = FilterNonEssentialFiles(SARD) 3. LabeledFiles = FilterNonAnnotatedFiles(TargetFiles) 4. ProcessedFiles = RemoveComments(LabeledFiles) 5. CleanedDataset = AnonymizeFilenames(ProcessedFiles) return CleanedDataset (*.code) end |
3.4. Prompting Strategies
| Algorithm 2: Pseudocode for Prompt Strategy Stage Algorithm |
| Function DesignUnifiedPromptStrategy() Output: UnifiedPrompt—Unified prompting strategy for all models begin 1. // Role assignment strategy based on [39,40] RoleDescription ← DefineRoleAssignment() 2. TaskInstruction ← DefineTask() 3. BasePrompt = RoleDescription + TaskInstruction 4. // COT prompting strategy based on [49] ReasoningGuidance ← AddSimpleStepGuidance() 5. // Standardized output requirement OutputFormat ← StandardizeOutput() 6. // Merge all components into a unified prompt (same for all models) UnifiedPrompt ← Concatenate(BasePrompt, ReasoningGuidance, OutputFormat) return UnifiedPrompt end |
“Assume you are a highly experienced expert in code vulnerability analysis. You are given a C/C++ source code file. Your task is to determine whether it contains any vulnerabilities. Additionally, provide a total probability estimate of the code containing vulnerabilities. If no vulnerabilities are found, the probability should be 0. The probability is a floating-point value between 0 and 1. Please provide your analysis step by step.”
4. Experiments
4.1. Comparative Methods
- Claude-3.5-Haiku: Claude-3.5-Haiku is optimized for high-throughput applications, offering extremely fast response times and low computational cost. Its advantages lie in scenarios that demand rapid, large-scale inference with minimal latency. However, its reasoning capabilities are relatively shallow, and it currently only supports textual inputs, limiting its effectiveness on tasks that require multi-step logical inference.
- GPT-4o-Mini: GPT-4o-Mini is a lightweight variant of OpenAI’s multimodal model family, emphasizing low-cost deployment and efficient multimodal handling. It demonstrates strong performance in general-purpose natural language tasks. Nonetheless, its performance degrades on lengthy or structurally complex code, and it struggles with maintaining reasoning consistency over long contexts.
- O3-Mini: O3-Mini is optimized for fast response and efficient reasoning, exhibiting strong performance in STEM-related tasks, especially those involving structured problem solving. It balances speed and reasoning quality well, making it suitable for tasks requiring intermediate logical depth.
- DeepSeek-V3: As a high-performance open-source model, DeepSeek-V3 stands out in code generation, mathematical reasoning, and programming-oriented tasks. It is particularly effective in logic-intensive scenarios and can produce high-quality code snippets. Despite its strength in text-based tasks, its capabilities in multimodal reasoning and language adaptability remain limited.
- DeepSeek-R1: DeepSeek-R1 leverages reinforcement learning and advanced optimization techniques to enhance its reasoning capabilities. It excels in mathematical reasoning, program analysis, and complex logic tasks. Although it currently lacks robust multimodal processing and may occasionally mix Chinese and English in its outputs, DeepSeek-R1 is well-suited for high-precision tasks requiring structured analytical thinking.
4.2. Evaluation Metrics
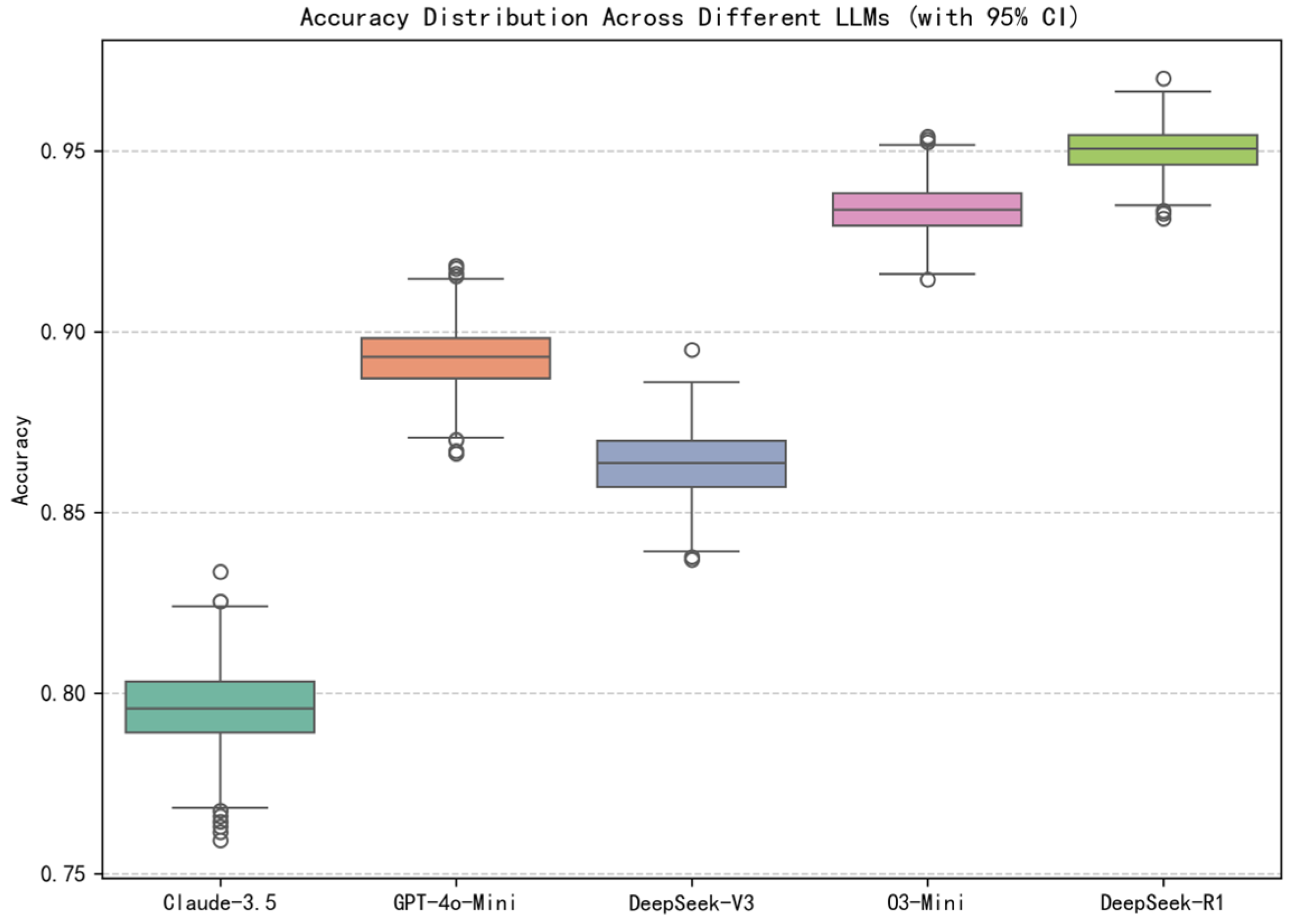
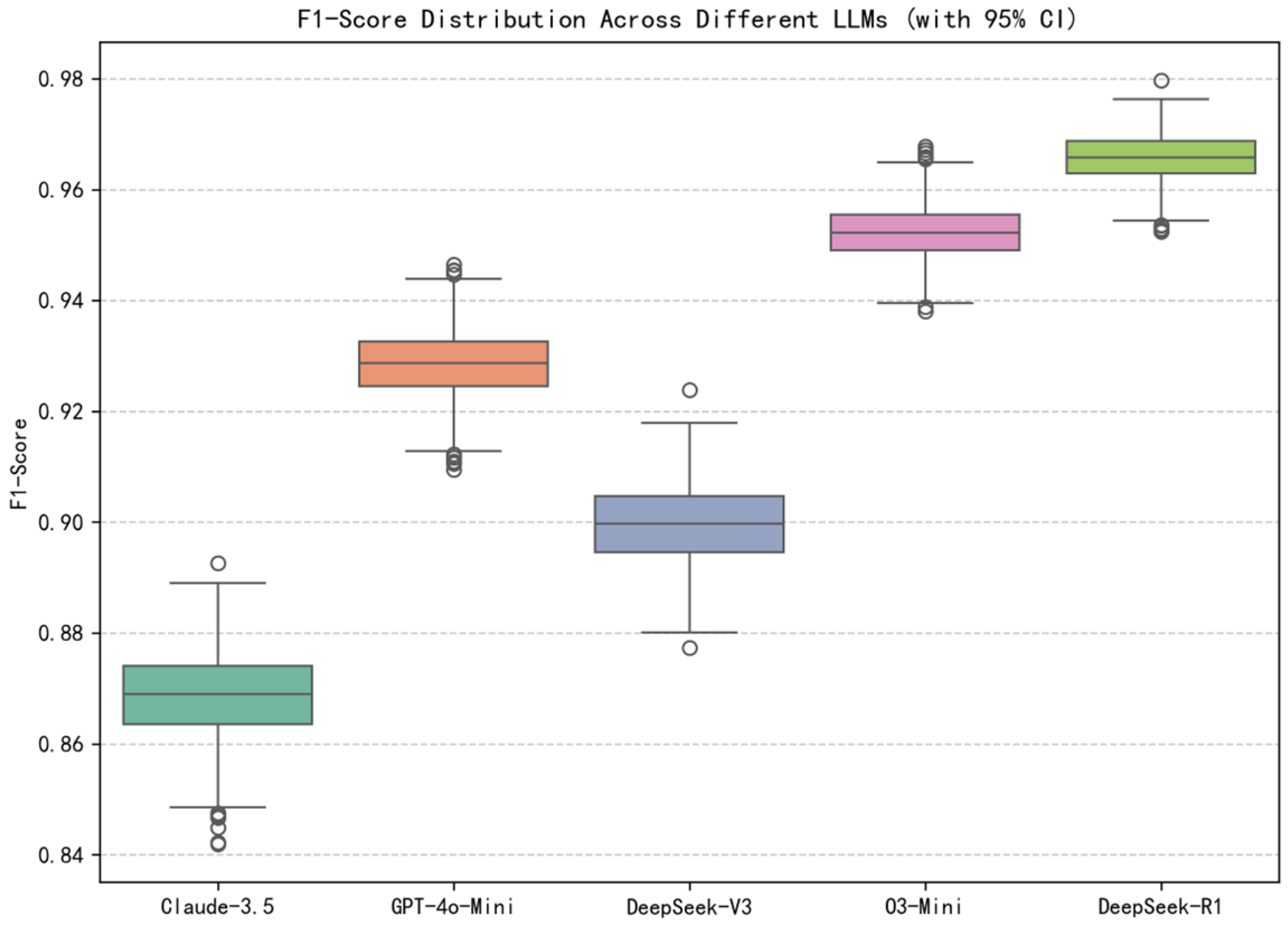
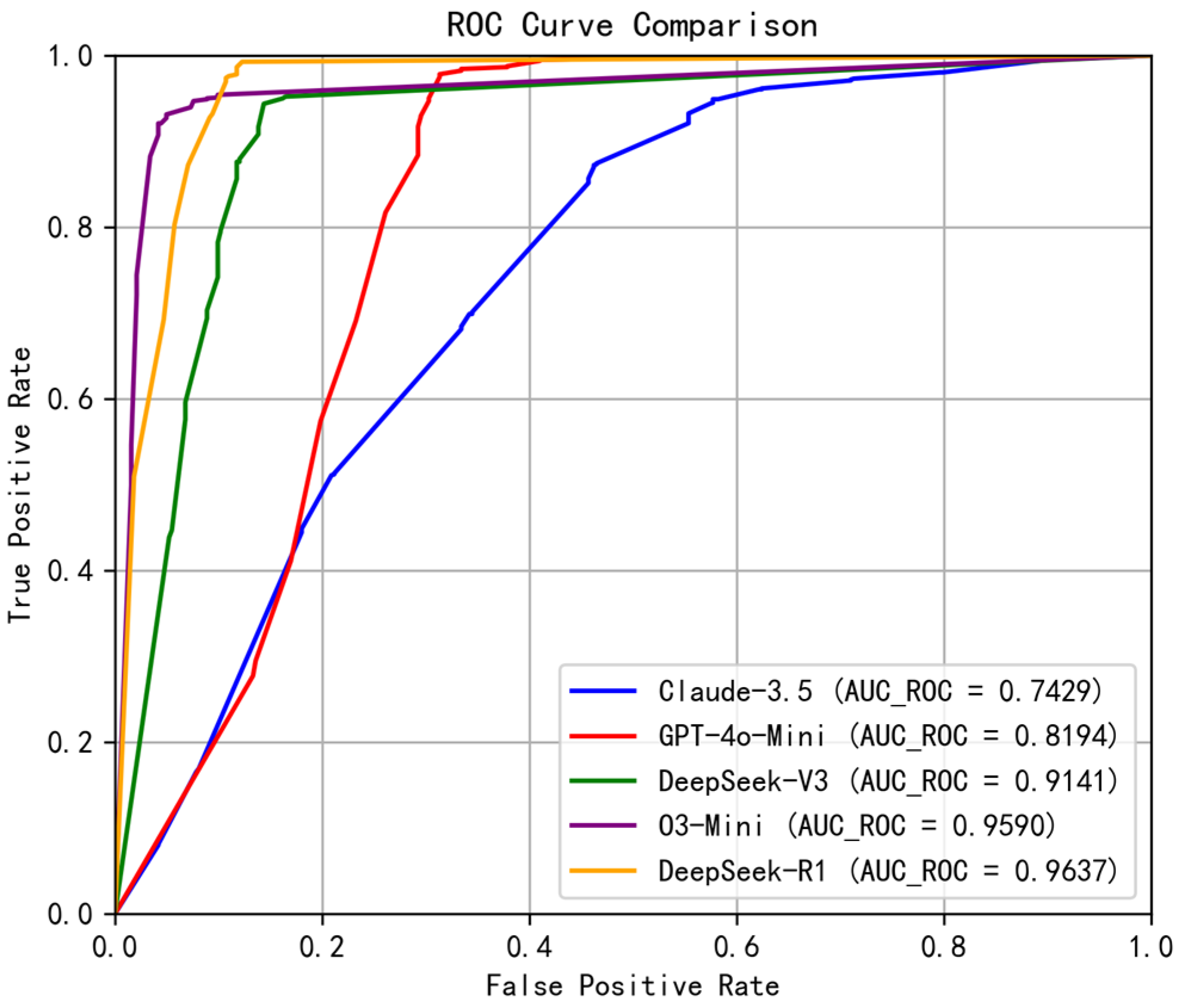
4.3. Experimental Results
4.3.1. Performance Comparison
4.3.2. Category-Wise Analysis
4.3.3. Cost Comparison
4.3.4. Case Study of Reasoning Traces
4.3.5. Error Analysis of DeepSeek-R1
5. Conclusions and Answers to Research Questions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AST | Abstract Syntax Tree |
| BLSTM | Bidirectional Long Short-Term Memory |
| CI | Confidence Interval |
| COT | Chain-Of-Thought |
| CWE | Common Weakness Enumeration |
| FRAMES | Factuality Retrieval And reasoning Measurement Set |
| GCN | Graph Convolutional Network |
| GNN | Graph Neural Network |
| GPQA | Graduate-Level Google-Proof QA Benchmark |
| LLM | Large Language Model |
| MCC | Matthews Correlation Coefficient |
| MMLU | Measuring Massive Multitask Language Understanding |
| NLP | Natural Language Processing |
| OASIS | Organization for the Advancement of Structured Information Standards |
| PR | Precision-Recall |
| ROC | Receiver Operating Characteristic |
| SARIF | Static Analysis Results Interchange Format |
| SARD | Software Assurance Reference Dataset |
References
- Li, Y.; Huang, C.L.; Wang, Z.F.; Yuan, L.; Wang, X.C. Survey of Software Vulnerability Mining Methods Based on Machine Learning. J. Softw. 2020, 31, 2040–2061. [Google Scholar]
- Zhan, Q.; Pan, S.Y.; Hu, X.; Bao, L.F.; Xia, X. Survey on Vulnerability Awareness of Open Source Software. J. Softw. 2024, 35, 19–37. [Google Scholar]
- Meng, Q.; Zhang, B.; Feng, C.; Tang, C. Detecting buffer boundary violations based on SVM. In Proceedings of the 3rd International Conference on Information Science and Control Engineering (ICISCE), Beijing, China, 8–10 July 2016; pp. 313–316. [Google Scholar]
- Gao, C.; Zheng, Y.; Li, N.; Li, Y.F.; Qin, Y.R.; Piao, J.H.; Quan, Y.H.; Chang, J.X.; Jin, D.P.; He, X.N.; et al. A survey of graph neural networks for recommender systems: Challenges, methods, and directions. ACM Trans. Recomm. Syst. 2023, 1, 1–51. [Google Scholar] [CrossRef]
- Wang, S.J.; Hu, L.; Wang, Y.; He, X.N.; Sheng, Q.Z.; Orgun, M.A.; Cao, L.B.; Ricci, F.; Yu, P.S. Graph learning based recommender systems: A review. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence (IJCAI), Montreal, QC, Canada, 19–27 August 2021; pp. 4644–4652. [Google Scholar]
- Li, Z.; Zou, D.; Xu, S.; Ou, X.; Jin, H.; Wang, S.J.; Deng, Z.; Zhong, Y. Vuldeepecker: A deep learning-based system for vulnerability detection. In Proceedings of the 25th Annual Network and Distributed System Security Symposium, San Diego, CA, USA, 18–21 February 2018. [Google Scholar]
- Wu, S.Z.; Guo, T.; Dong, G.W.; Wang, J. Software vulnerability analyses: A road map. J. Tsinghua Univ. Sci. Technol. 2012, 52, 1309–1319. [Google Scholar]
- Chang, E.Y. Prompting large language models with the Socratic method. In Proceedings of the 2023 IEEE 13th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 8–11 March 2023; pp. 351–360. [Google Scholar]
- Chakrabarty, T.; Padmakumar, V.; Brahman, F.; Muresan, S. Creativity Support in the Age of Large Language Models: An Empirical Study Involving Emerging Writers. arXiv 2023, arXiv:2309.12570. [Google Scholar]
- Tian, H.; Lu, W.; Li, T.O.; Tang, X.; Cheung, S.C.; Klein, J.; Bissyande, T.F. Is ChatGPT the Ultimate Programming Assistant–How far is it? arXiv 2023, arXiv:2304.11938. [Google Scholar]
- Zhou, X.; Cao, S.; Sun, X.; Lo, D. Large language model for vulnerability detection and repair: Literature review and the road ahead. ACM Trans. Softw. Eng. Methodol. 2024, 34, 145. [Google Scholar] [CrossRef]
- Shestov, A.; Levichev, R.; Mussabayev, R.; Maslov, E.; Cheshkov, A.; Zadorozhny, P. Finetuning Large Language Models for Vulnerability Detection. arXiv 2024, arXiv:2401.17010. [Google Scholar] [CrossRef]
- Hanif, H.; Maffeis, S. Vulberta: Simplified source code pre-training for vulnerability detection. In Proceedings of the 2022 International Joint Conference on Neural Networks (IJCNN), Padua, Italy, 18–23 July 2022; pp. 1–8. [Google Scholar]
- Fu, M.; Tantithamthavorn, C.; Nguyen, V.; Le, T. ChatGPT for vulnerability detection, classification, and repair: How far are we? In Proceedings of the 30th Asia-Pacific Software Engineering Conference (APSEC), Seoul, Republic of Korea, 6–9 December 2023; pp. 632–636. [Google Scholar]
- Bsharat, S.M.; Myrzakhan, A.; Shen, Z. Principled instructions are all you need for questioning LLaMA-1/2, GPT-3.5/4. arXiv 2023, arXiv:2312.16171. [Google Scholar]
- Pham, N.H.; Nguyen, T.T.; Nguyen, H.A.; Nguyen, T.N. Detection of recurring software vulnerabilities. In Proceedings of the ACM International Conference on Automated Software Engineering, New York, NY, USA, 20–24 September 2010; pp. 447–456. [Google Scholar]
- Li, Z.; Zou, D.Q.; Wang, Z.L.; Jin, H. Survey on Static Software Vulnerability Detection for Source Code. Chin. J. Netw. Inf. Secur. 2019, 5, 5–18. [Google Scholar]
- Zivkovic, T.; Nikolic, B.; Simic, V.; Pamucar, D.; Bacanin, N. Software Defects Prediction by Metaheuristics Tuned Extreme Gradient Boosting and Analysis Based on Shapley Additive Explanations. Appl. Soft Comput. 2023, 146, 110659. [Google Scholar] [CrossRef]
- Cha, S.K.; Avgerinos, T.; Rebert, A.; Brumley, D. Unleashing Mayhem on Binary Code. In Proceedings of the 2012 IEEE Symposium on Security and Privacy (SP’12), San Francisco, CA, USA, 20–23 May 2012; pp. 380–394. [Google Scholar]
- LibFuzzer: A Library for Coverage-Guided Fuzz Testing. Available online: http://llvm.org/docs/LibFuzzer.html (accessed on 10 October 2024).
- Cheng, X.; Wang, H.; Hua, J.; Zhang, M.; Xu, G.; Yi, L. Static detection of control-flow-related vulnerabilities using graph embedding. In Proceedings of the 24th Int. Conf. on Engineering of Complex Computer Systems (ICECCS), Guangzhou, China, 10–13 November 2019; pp. 41–50. [Google Scholar]
- Feng, Z.; Guo, D.; Tang, D.; Duan, N.; Feng, X.; Gong, M.; Shou, L.; Qin, B.; Liu, T.; Jiang, D.; et al. CodeBERT: A pre-trained model for programming and natural languages. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 1536–1547. [Google Scholar]
- Guo, D.; Ren, S.; Lu, S.; Feng, Z.; Tang, D.; Liu, S.; Zhou, L.; Duan, N.; Svyatkovskiy, A.; Fu, S.; et al. GraphCodeBERT: Pre-training code representations with data flow. In Proceedings of the 35th AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021; pp. 229–237. [Google Scholar]
- Petrovic, A.; Jovanovic, L.; Bacanin, N.; Antonijevic, M.; Savanovic, N.; Zivkovic, M.; Milovanovic, M.; Gajic, V. Exploring Metaheuristic Optimized Machine Learning for Software Defect Detection on Natural Language and Classical Datasets. Mathematics 2024, 12, 2918. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 15. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- OpenAI. GPT-4 Technical Report. arXiv 2023, arXiv:2303.08774. [Google Scholar]
- OpenAI. Hello GPT-4. Available online: https://openai.com/index/hello-gpt-4o/ (accessed on 15 February 2025).
- Arrieta, A.; Ugarte, M.; Valle, P.; Parejo, J.A.; Segura, S. Early external safety testing of OpenAI’s O3-Mini: Insights from the pre-deployment evaluation. arXiv 2025, arXiv:2501.17749. [Google Scholar]
- Anthropic AI. Model Card and Evaluations for Claude Models. 2023. Available online: https://www-cdn.anthropic.com/bd2a28d2535bfb0494cc8e2a3bf135d2e7523226/Model-Card-Claude-2.pdf (accessed on 10 June 2025).
- Anthropic. Claude 3.5 Haiku. 2024. Available online: https://www.anthropic.com/claude/haiku (accessed on 15 February 2025).
- Anthropic. The Claude 3 Model Family: Opus, Sonnet, Haiku. 2024. Available online: https://www-cdn.anthropic.com/de8ba9b01c9ab7cbabf5c33b80b7bbc618857627/Model_Card_Claude_3.pdf (accessed on 15 February 2025).
- Guo, D.; Zhu, Q.; Yang, D.; Xie, Z.; Dong, K.; Zhang, W.; Chen, G.; Bi, X.; Wu, Y.; Li, Y.K.; et al. DeepSeekCoder: When the Large Language Model Meets Programming—The Rise of Code Intelligence. arXiv 2024, arXiv:2401.14196. [Google Scholar]
- Liu, A.; Feng, B.; Xue, B.; Wang, B.; Wu, B.; Lu, C.; Zhao, C.; Deng, C.; Zhang, C.; Ruan, C.; et al. DeepSeek-V3 Technical Report. arXiv 2024, arXiv:2412.19437. [Google Scholar]
- Guo, D.; Yang, D.; Zhang, H.; Song, J.; Zhang, R.; Xu, R.; Zhu, Q.; Ma, S.; Wang, P.; Bi, X.; et al. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning. arXiv 2025, arXiv:2501.12948. [Google Scholar]
- Hendrycks, D.; Burns, C.; Basart, S.; Zou, A.; Mazeika, M.; Song, D.; Steinhardt, J. Measuring massive multitask language understanding. arXiv 2020, arXiv:2009.03300. [Google Scholar]
- Rein, D.; Hou, B.L.; Stickland, A.C.; Petty, J.; Pang, R.Y.; Dirani, J.; Michael, J.; Bowman, S.R. GPQA: A graduate-level google-proof Q&A benchmark. arXiv 2023, arXiv:2311.12022. [Google Scholar]
- Krishna, S.; Krishna, K.; Mohananey, A.; Schwarcz, S.; Stambler, A.; Upadhyay, S.; Faruqui, M. Fact, Fetch, and Reason: A Unified Evaluation of Retrieval-Augmented Generation. arXiv 2024, arXiv:2409.12941. [Google Scholar]
- Espejel, J.L.; Ettifouri, E.H.; Alassan, M.S.Y.; Chouham, E.M.; Dahhane, W. GPT-3.5, GPT-4, or BARD? Evaluating LLMs reasoning ability in zero-shot setting and performance boosting through prompts. Nat. Lang. Process. J. 2023, 5, 100032. [Google Scholar] [CrossRef]
- Zhang, C.; Liu, H.; Zeng, J.; Yang, K.; Li, Y.; Li, H. Prompt-enhanced software vulnerability detection using ChatGPT. arXiv 2023, arXiv:2308.12697. [Google Scholar]
- Ranaldi, L.; Pucci, G. When large language models contradict humans? Large language models’ sycophantic behaviour. arXiv 2023, arXiv:2311.09410. [Google Scholar]
- Wang, G.; Sun, Z.; Gong, Z.; Ye, S.; Chen, Y.; Zhao, Y.; Liang, Q.; Hao, D. Do advanced language models eliminate the need for prompt engineering in software engineering? arXiv 2024, arXiv:2411.02093. [Google Scholar]
- Zhang, B.; Du, T.; Tong, J.K.; Zhang, X.; Chow, K.; Cheng, S.; Wang, X.; Yin, J. SecCoder: Towards Generalizable and Robust Secure Code Generation. arXiv 2024, arXiv:2410.01488. [Google Scholar]
- Nori, H.; Lee, Y.T.; Zhang, S.; Carignan, D.; Edgar, R.; Fusi, N.; King, N.; Larson, J.; Li, Y.; Liu, W.; et al. Can generalist foundation models outcompete special-purpose tuning? Case study in medicine. arXiv 2023, arXiv:2311.16452. [Google Scholar]
- Nori, H.; Usuyama, N.; King, N.; McKinney, S.M.; Fernandes, X.; Zhang, S.; Horvitz, E. From Medprompt to O1: Exploration of Run-Time Strategies for Medical Challenge Problems and Beyond. arXiv 2024, arXiv:2411.03590. [Google Scholar]
- MITRE. 2024 CWE Top 25 Most Dangerous Software Weaknesses. Available online: https://cwe.mitre.org/top25/archive/2024/2024_cwe_top25.html (accessed on 10 October 2024).
- Software Assurance Reference Dataset (SARD). Available online: https://samate.nist.gov/SARD/ (accessed on 10 October 2024).
- OASIS Static Analysis Results Interchange Format Technical Committee. Static Analysis Results Interchange Format (SARIF), Version 2.1.0. Available online: https://docs.oasis-open.org/sarif/sarif/v2.1.0/sarif-v2.1.0.pdf (accessed on 10 June 2025).
- Wang, B.; Min, S.; Deng, X.; Shen, J.; Wu, Y.; Zettlemoyer, L.; Sun, H. Towards understanding chain-of-thought prompting: An empirical study of what matters. arXiv 2022, arXiv:2212.10001. [Google Scholar]
- McNemar, Q. Note on the sampling error of the difference between correlated proportions or percentages. Psychometrika 1947, 12, 153–157. [Google Scholar] [CrossRef] [PubMed]
- Edwards, A. Note on the “correction for continuity” in testing the significance of the difference between correlated proportions. Psychometrika 1948, 13, 185–187. [Google Scholar] [CrossRef]
- Alibaba Cloud. Available online: https://www.aliyun.com/solution/tech-solution/deepseek-r1-for-platforms (accessed on 10 March 2025).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CWE Type | Description | Total Samples | Selected Samples |
|---|---|---|---|
| CWE-20 | Improper Input Validation | 13 | 13 |
| CWE-22 | Improper Limitation of a Pathname to a Restricted Directory | 14 | 14 |
| CWE-78 | Improper Neutralization of Special Elements used in an OS Command | 8080 | 129 |
| CWE-79 | Improper Neutralization of Input During Web Page Generation | 20 | 20 |
| CWE-89 | Improper Neutralization of Special Elements used in an SQL Command | 384 | 127 |
| CWE-119 | Improper Restriction of Operations within the Bounds of Memory Buffer | 1267 | 412 |
| CWE-125 | Out-of-bounds Read | 15 | 15 |
| CWE-190 | Integer Overflow or Wraparound | 6590 | 120 |
| CWE-287 | Improper Authentication | 2 | 2 |
| CWE-400 | Uncontrolled Resource Consumption | 1430 | 120 |
| CWE-416 | Use After Free | 633 | 138 |
| CWE-476 | NULL Pointer Dereference | 1526 | 127 |
| CWE-787 | Out-of-bounds Write | 109 | 109 |
| Total Samples | Vulnerable Samples (Ratio) | Non-Vulnerable Samples (Ratio) |
|---|---|---|
| 1346 | 963 (71.55%) | 383 (28.45%) |
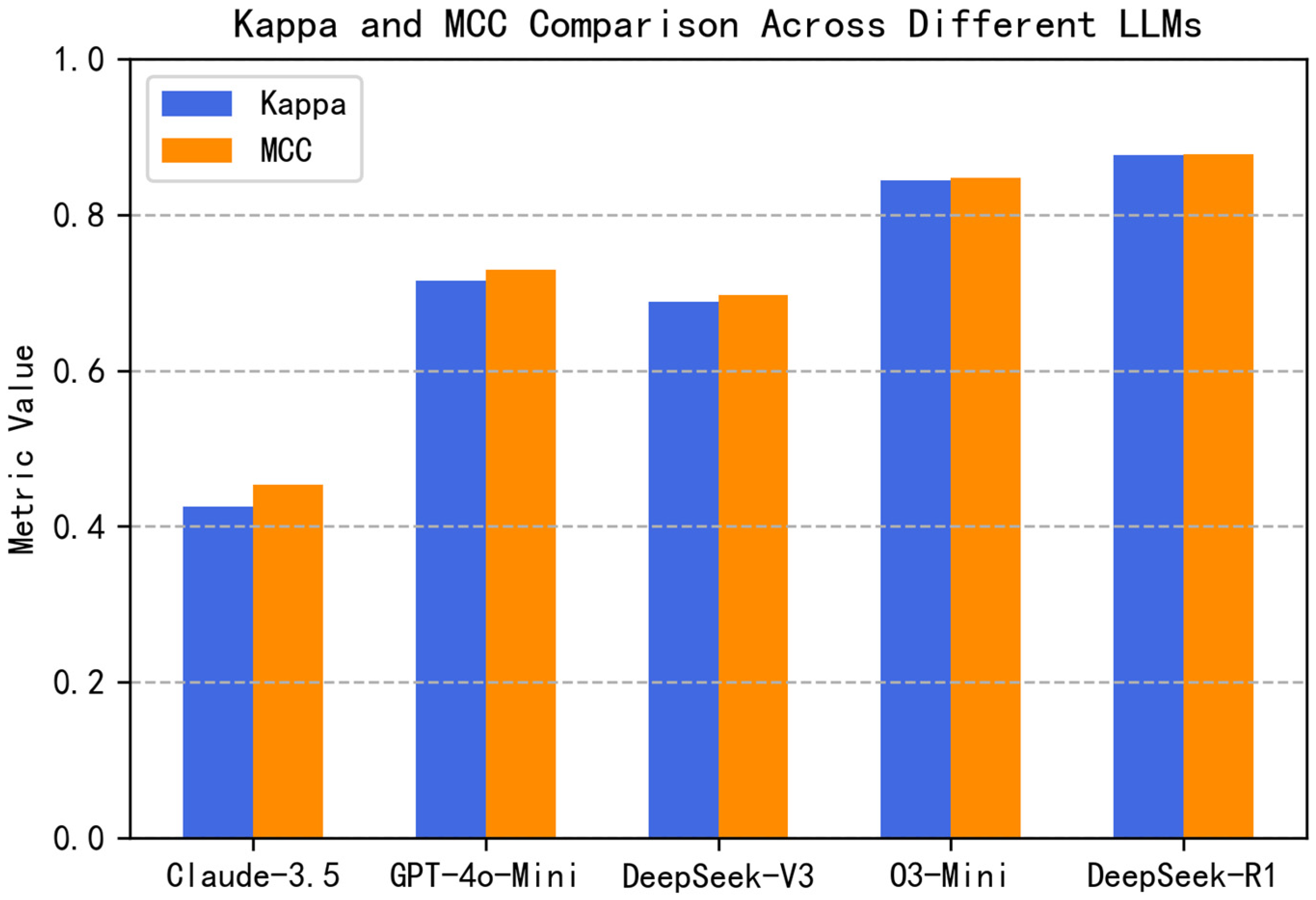
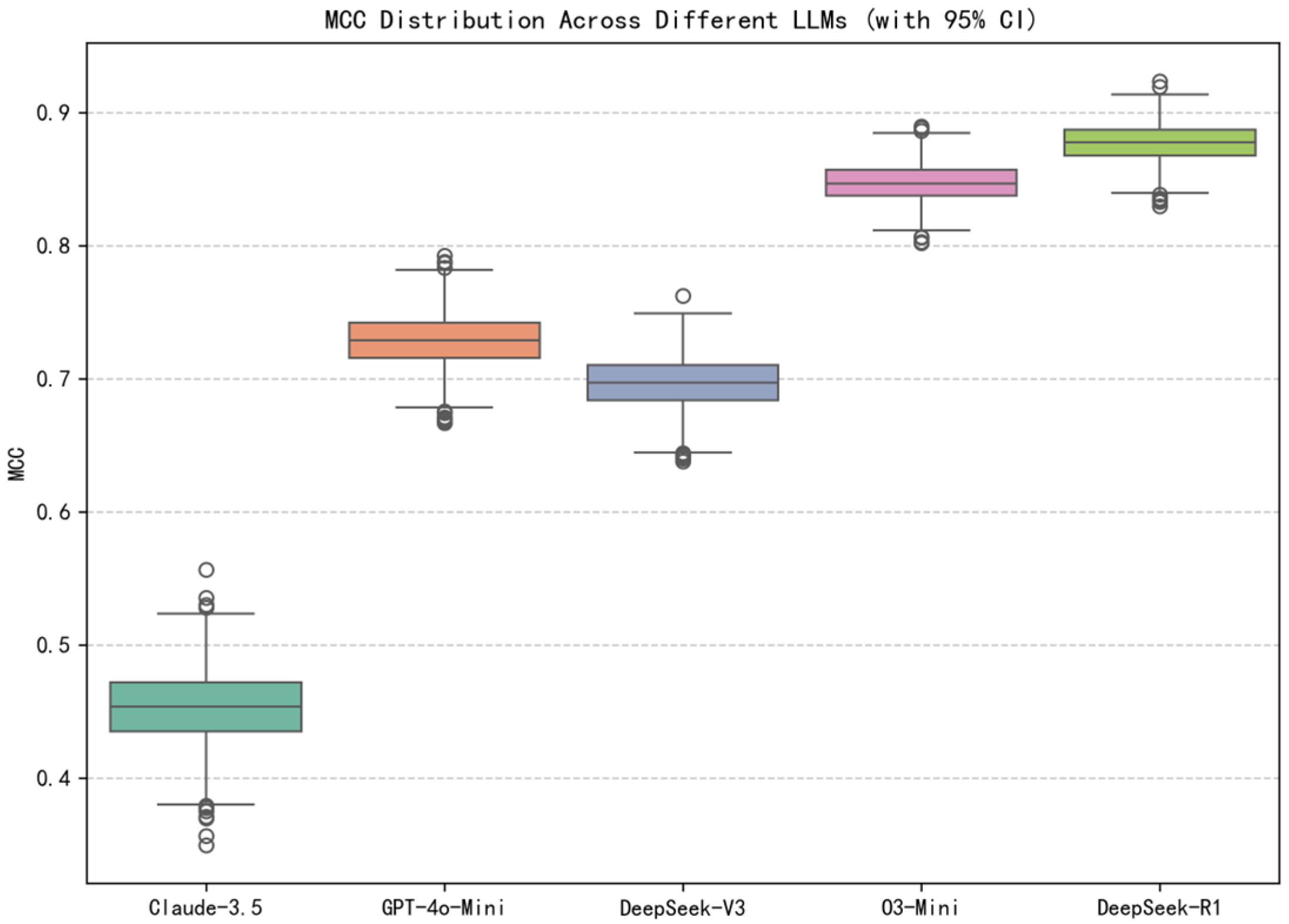
| Model | Accuracy * | F1-Score | mAP | AUC-ROC | Kappa | MCC |
|---|---|---|---|---|---|---|
| Claude-3.5-Haiku | 0.7964 | 0.8690 | 0.8364 | 0.7429 | 0.4250 | 0.4534 |
| GPT-4o-Mini | 0.8930 | 0.9288 | 0.8670 | 0.8194 | 0.7158 | 0.7290 |
| DeepSeek-V3 | 0.8637 | 0.8998 | 0.9411 | 0.9141 | 0.6885 | 0.6973 |
| O3-Mini | 0.9338 | 0.9524 | 0.9743 | 0.9590 | 0.8438 | 0.8472 |
| DeepSeek-R1 | 0.9507 | 0.9659 | 0.9756 | 0.9637 | 0.8770 | 0.8779 |
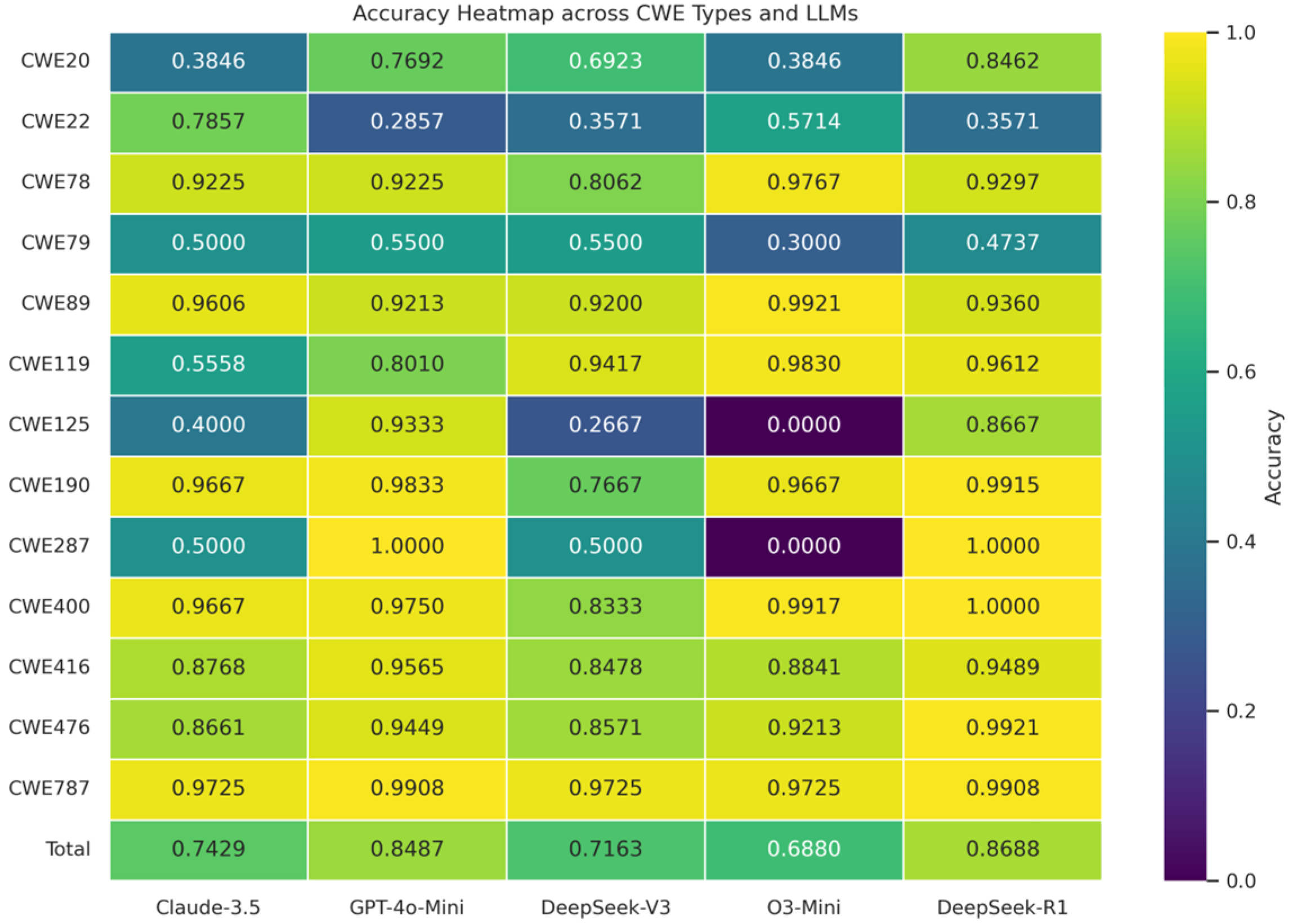
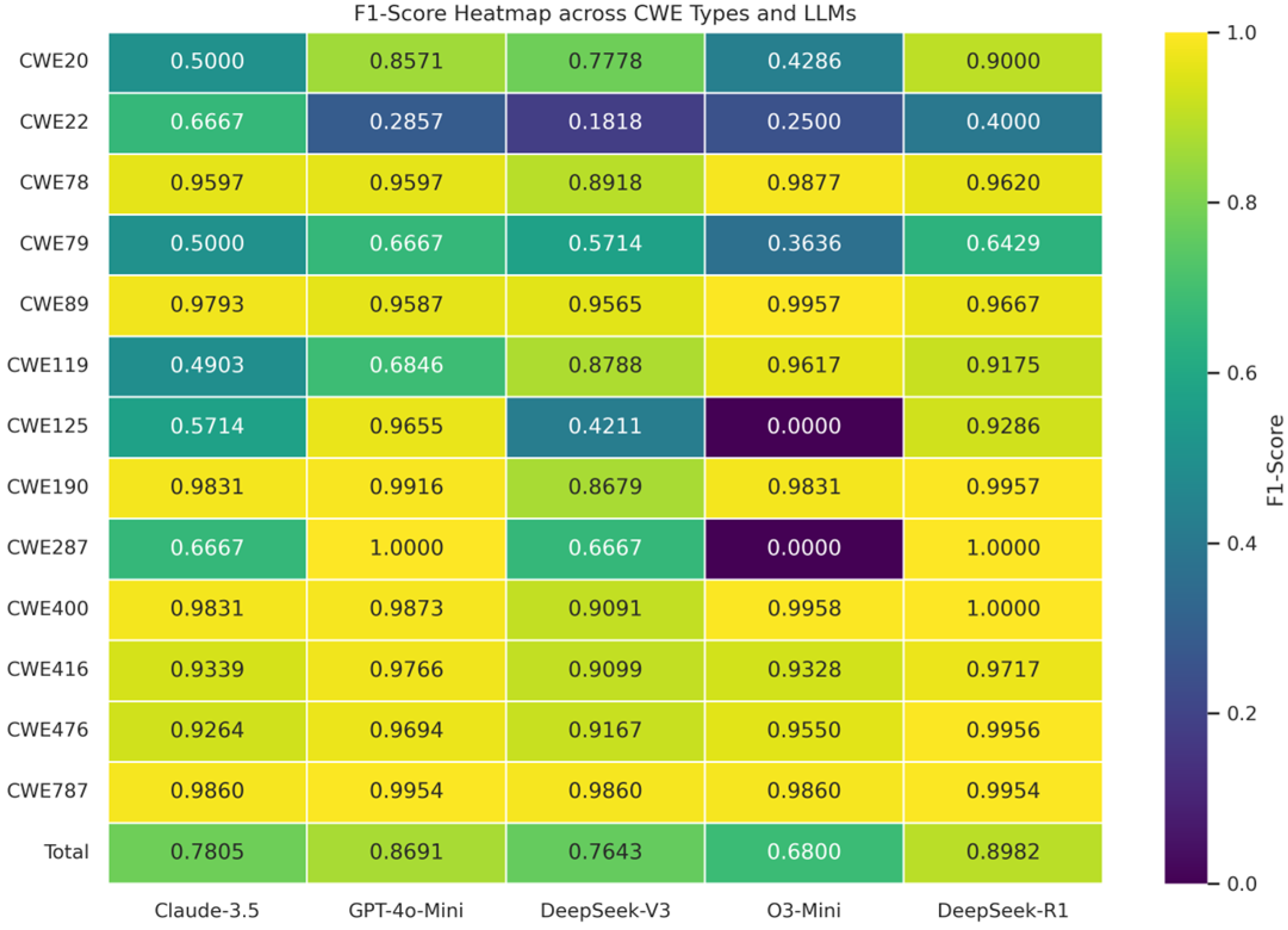
| CWE Type | Claude-3.5-Haiku | GPT-4o-Mini | DeepSeek-V3 | O3-Mini | DeepSeek-R1 | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Accuracy | F1-Score | Accuracy | F1-Score | Accuracy | F1-Score | Accuracy | F1-Score | Accuracy | F1-Score | |
| CWE-20 | 0.3846 | 0.5000 | 0.7692 | 0.8571 | 0.6923 | 0.7778 | 0.3846 | 0.4286 | 0.8462 | 0.9000 |
| CWE-22 | 0.7857 | 0.6667 | 0.2857 | 0.2857 | 0.3571 | 0.1818 | 0.5714 | 0.2500 | 0.3571 | 0.4000 |
| CWE-78 | 0.9225 | 0.9597 | 0.9225 | 0.9597 | 0.8062 | 0.8918 | 0.9767 | 0.9877 | 0.9297 | 0.9620 |
| CWE-79 | 0.5000 | 0.5000 | 0.5500 | 0.6667 | 0.5500 | 0.5714 | 0.3000 | 0.3636 | 0.4737 | 0.6429 |
| CWE-89 | 0.9606 | 0.9793 | 0.9213 | 0.9587 | 0.9200 | 0.9565 | 0.9921 | 0.9957 | 0.9360 | 0.9667 |
| CWE-119 | 0.5558 | 0.4903 | 0.8010 | 0.6846 | 0.9417 | 0.8788 | 0.9830 | 0.9617 | 0.9612 | 0.9175 |
| CWE-125 | 0.4000 | 0.5714 | 0.9333 | 0.9655 | 0.2667 | 0.4211 | 0.0000 | 0.0000 | 0.8667 | 0.9286 |
| CWE-190 | 0.9667 | 0.9831 | 0.9833 | 0.9916 | 0.7667 | 0.8679 | 0.9667 | 0.9831 | 0.9915 | 0.9957 |
| CWE-287 | 0.5000 | 0.6667 | 1.0000 | 1.0000 | 0.5000 | 0.6667 | 0.0000 | 0.0000 | 1.0000 | 1.0000 |
| CWE-400 | 0.9667 | 0.9831 | 0.9750 | 0.9873 | 0.8333 | 0.9091 | 0.9917 | 0.9958 | 1.0000 | 1.0000 |
| CWE-416 | 0.8768 | 0.9339 | 0.9565 | 0.9766 | 0.8478 | 0.9099 | 0.8841 | 0.9328 | 0.9489 | 0.9717 |
| CWE-476 | 0.8661 | 0.9264 | 0.9449 | 0.9694 | 0.8571 | 0.9167 | 0.9213 | 0.9550 | 0.9921 | 0.9956 |
| CWE-787 | 0.9725 | 0.9860 | 0.9908 | 0.9954 | 0.9725 | 0.9860 | 0.9725 | 0.9860 | 0.9908 | 0.9954 |
| Total | 0.7429 | 0.7805 | 0.8487 | 0.8691 | 0.7163 | 0.7643 | 0.6880 | 0.6800 | 0.8688 | 0.8982 |
| Model | Input Price (USD $/1M) | Output Price (USD $/1M) | Total Tokens * (M) | Total Cost (USD $) |
|---|---|---|---|---|
| Claude-3.5-Haiku | 0.25 | 1.25 | 6.057 | 11.62 |
| GPT-4o-Mini | 0.15 | 0.6 | 6.463 | 1.53 |
| O3-Mini | 1.1 | 4.4 | 8.797 | 19.96 |
| DeepSeek-V3 | 0.276 (¥2 CNY) | 1.1 (¥8 CNY) | 6.184 | 2.85 (¥20.67 CNY) |
| DeepSeek-R1 | 0.552 (¥4 CNY) | 2.21 (¥16 CNY) | 7.803 | 9.38 (¥68.04 CNY) |
| Model | Input Tokens (M) | Output Tokens (M) | Total Tokens (M) |
|---|---|---|---|
| DeepSeek-V3 | 4.758 | 1.426 | 6.184 |
| DeepSeek-R1 | 4.722 | 3.081 | 7.803 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qin, W.; Suo, L.; Li, L.; Yang, F. Advancing Software Vulnerability Detection with Reasoning LLMs: DeepSeek-R1′s Performance and Insights. Appl. Sci. 2025, 15, 6651. https://doi.org/10.3390/app15126651
Qin W, Suo L, Li L, Yang F. Advancing Software Vulnerability Detection with Reasoning LLMs: DeepSeek-R1′s Performance and Insights. Applied Sciences. 2025; 15(12):6651. https://doi.org/10.3390/app15126651
Chicago/Turabian StyleQin, Wenting, Lijie Suo, Liangchen Li, and Fan Yang. 2025. "Advancing Software Vulnerability Detection with Reasoning LLMs: DeepSeek-R1′s Performance and Insights" Applied Sciences 15, no. 12: 6651. https://doi.org/10.3390/app15126651
APA StyleQin, W., Suo, L., Li, L., & Yang, F. (2025). Advancing Software Vulnerability Detection with Reasoning LLMs: DeepSeek-R1′s Performance and Insights. Applied Sciences, 15(12), 6651. https://doi.org/10.3390/app15126651