

Edge Convolutional Networks for Style Change Detection in Arabic Multi-Authored Text


Abstract
1. Introduction
2. Background
2.1. Task Definition
2.2. Arabic Language
3. Related Work
3.1. Statistical-Based Methods
3.2. ML-Based Methods
3.3. DNN-Based Methods
3.4. Hybrid-Based Methods
4. Proposed Solution: ECNN-ASCD
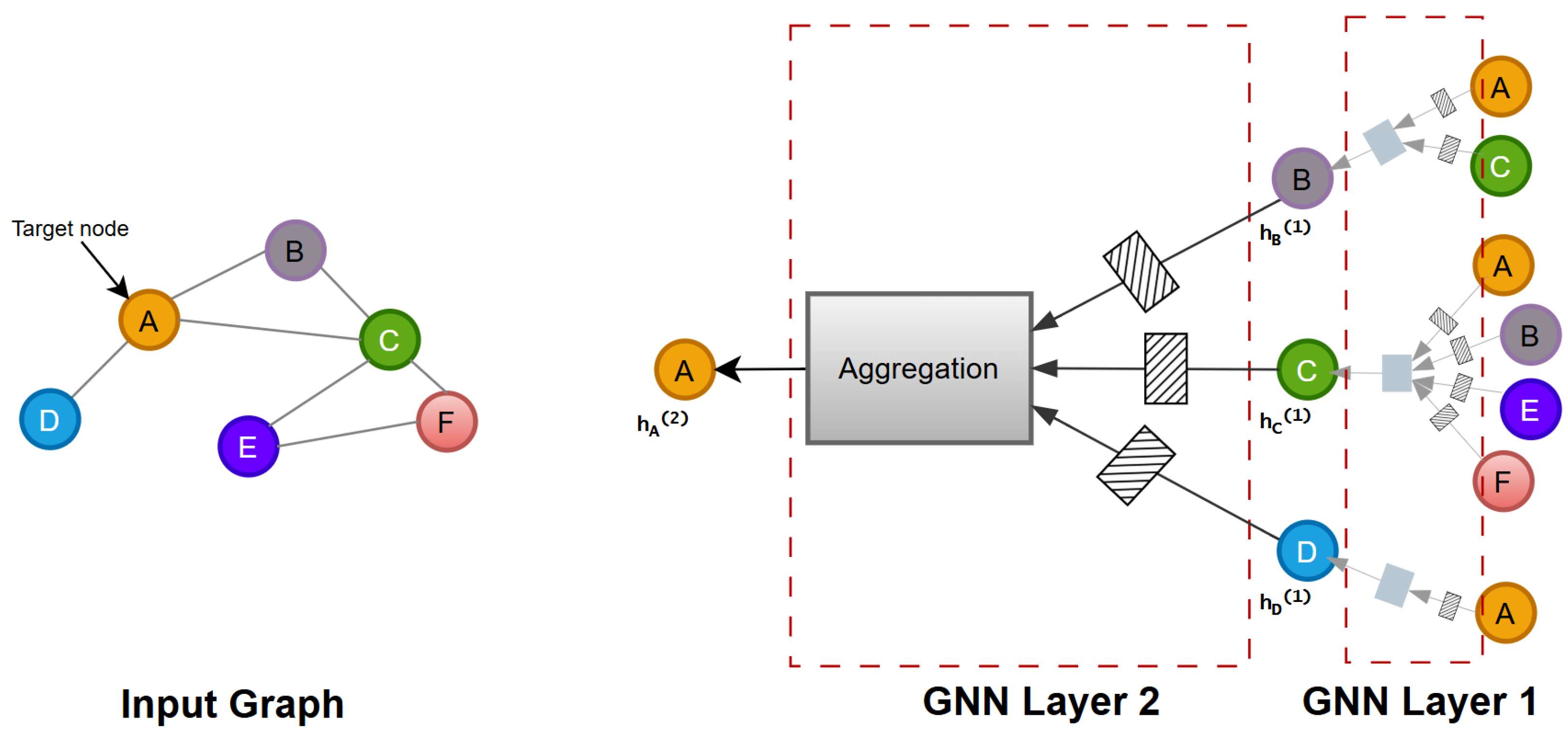
4.1. GNNs
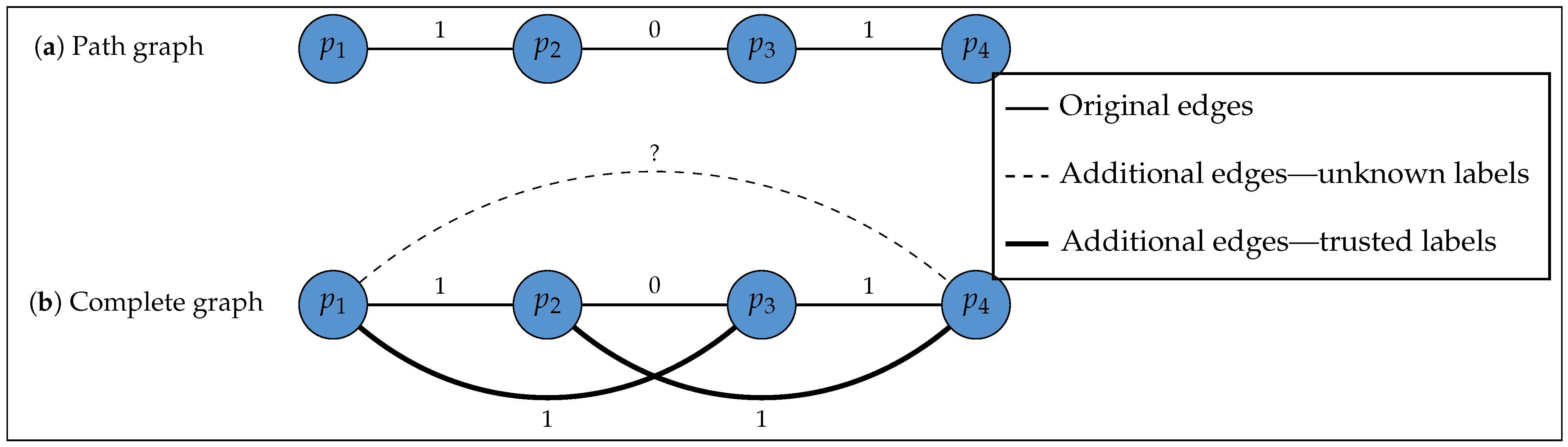
4.2. Graph Design
| Algorithm 1 Preprocessing |
Input: : A dataset, B: Boundaries’ list as ground-truth labels Output: : Dataset representations at the paragraph level
|
| Algorithm 2 Graph design |
Input: : A dataset, B: Boundaries’ list as ground-truth labels Output: : A graph with nodes and edges
|
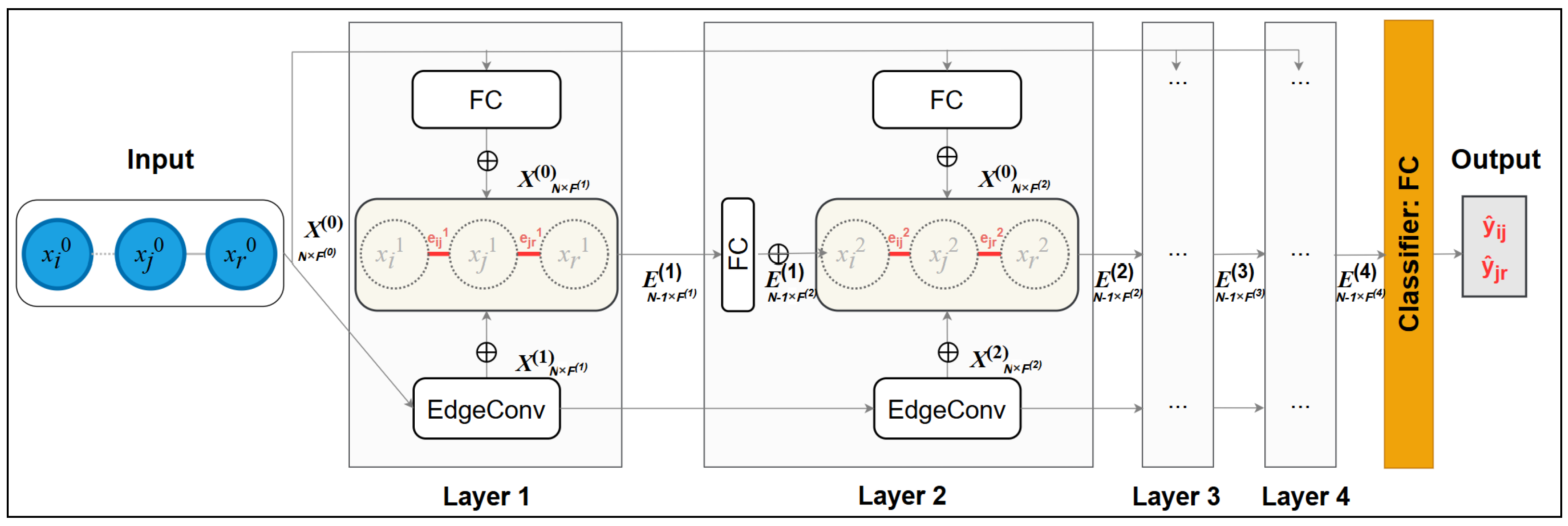
4.3. GNNs for the SCD Task
| Algorithm 3 An ECNN-ASCD layer |
Input: : A graph at the layer with their node and edge representations, : The original node representations Output: : A graph at the k layer with updated node and edge representations
|
5. ECNN-ASCD Evaluation
5.1. Experiment Settings
- Datasets: AraSCD (https://github.com/abeersaad0/SCD/tree/main, accessed on 30 April 2025) is a large Arabic dataset for SCD. It holds 30,000 documents extracted from several publicly available Arabic linguistic resources. It contains three classes of instances according to difficulty level: hard, medium, and easy. The criteria for this classification focus on categories of texts and the time period during which these texts were written. AraSCD encompasses three categories of text, poetry, books, and newspapers, which exhibit diverse author backgrounds and may enrich AraSCD with varying writing styles. Hard instances were written by five poets during a single era; medium instances were authored by both three poets of the same age and two writers who wrote two books on a similar domain; and easy instances encompass texts written by two poets from two different eras, two writers of two books covering two distinct topics, and one newspaper writer. Table 4 provides an overview of its statistics. Each level has the same number of documents. The average lengths of documents and paragraphs are measured as the average number of paragraphs and words, respectively, per document. The average number of style changes is measured per document. The percentage of style changes signifies the ratio of changes relative to all boundaries in the dataset.
- Baseline models: Two baseline models were evaluated on each test set in AraSCD. First, Baseline-Predicting 0 (Baseline-Pr0) assigns the value 0 to all predicted labels, implying no style changes across all boundaries in the test sets. Hence, this baseline model predicts that all documents are single-authored. Second, Baseline-Predicting 1 (Baseline-Pr1), in contrast, assigns the value 1 to all predicted labels, suggesting that changes in writing styles occur across all test set boundaries. As a result, this baseline model suggests that all documents are written by multiple authors.
- Other models for comparison: Since no prior Arabic work had been conducted, two models were developed in this study for comparison purposes with the results of ECNN-ASCD. First, a basic machine learning model named BERT-MLP was developed. It encodes the input using AraBERTv02 (https://huggingface.co/aubmindlab/bert-base-arabertv02, accessed on 30 April 2025), which is the same selected pretrained model for ECNN-ASCD. BERT-MLP classifies the input based on two FC layers with 128 neurons. It is worth noting that the classification in the FC layers maps one sample in the input with one predicted output. Thus, a sample for BERT-MLP is a boundary represented by concatenating two sequential paragraphs separated by a [SEP] token. Second, GCNN-ASCD was developed based on the GCN module. For a fair comparison, GCNN-ASCD maintained the same ECNN-ASCD architecture except for replacing the EdgeConv module with the GCN module in all the layers.
- Environment setup: All the experiments were run on a computer with an Intel(R) i7 processor up to 5.60 GHz, 64-bit, ASUS TUF RTX 4090 24 GB OC GAMING, and 64 GB (2 × 32 GB) DDR5 5600 Mhz.
- Technical setup: Python 3.12 and the PyTorch 2.4 framework were used to develop the models. Each input document is used as a single batch to update the weights, as the test phase in the real scenario is applied to at least one document. The hyperparameter settings that were used during the training for model optimization are summarized in Table 5.
- Evaluation metrics: The F1 score metric (https://scikit-learn.org/1.5/modules/generated/sklearn.metrics.f1_score.html, accessed on 30 April 2025) is a common performance measure used in classification tasks [87]. The macro-averaged F1 score measures a macro-average of correctly predicted style change detection positions compared to the total number of positions without considering the proportion of each class, change or no change, in the dataset. We recall that the SCD task considers the style change case as the positive class for evaluating models. The macro-averaged F1 score is used in evaluating solutions submitted for PAN competitions from 2020 to 2024 [4,5,6,7,11]. The other two metrics can be derived from the confusion matrix, which are precision and recall, as shown in Equations (5)–(7). Precision measures how many correctly classified change positions are among all predicted change positions. The high precision indicates that the classifier classifies the correct change positions more than it incorrectly classifies as change positions. Recall measures how many correctly classified change positions are among all ground-truth change positions. The higher the recall, the more correctly the change positions are classified. The macro-averaged precision and recall metrics were used to compare ECNN-ASCD’s performance with that of the other models on AraSCD.
5.2. Results and Discussion
5.2.1. Hyperparameter Tuning
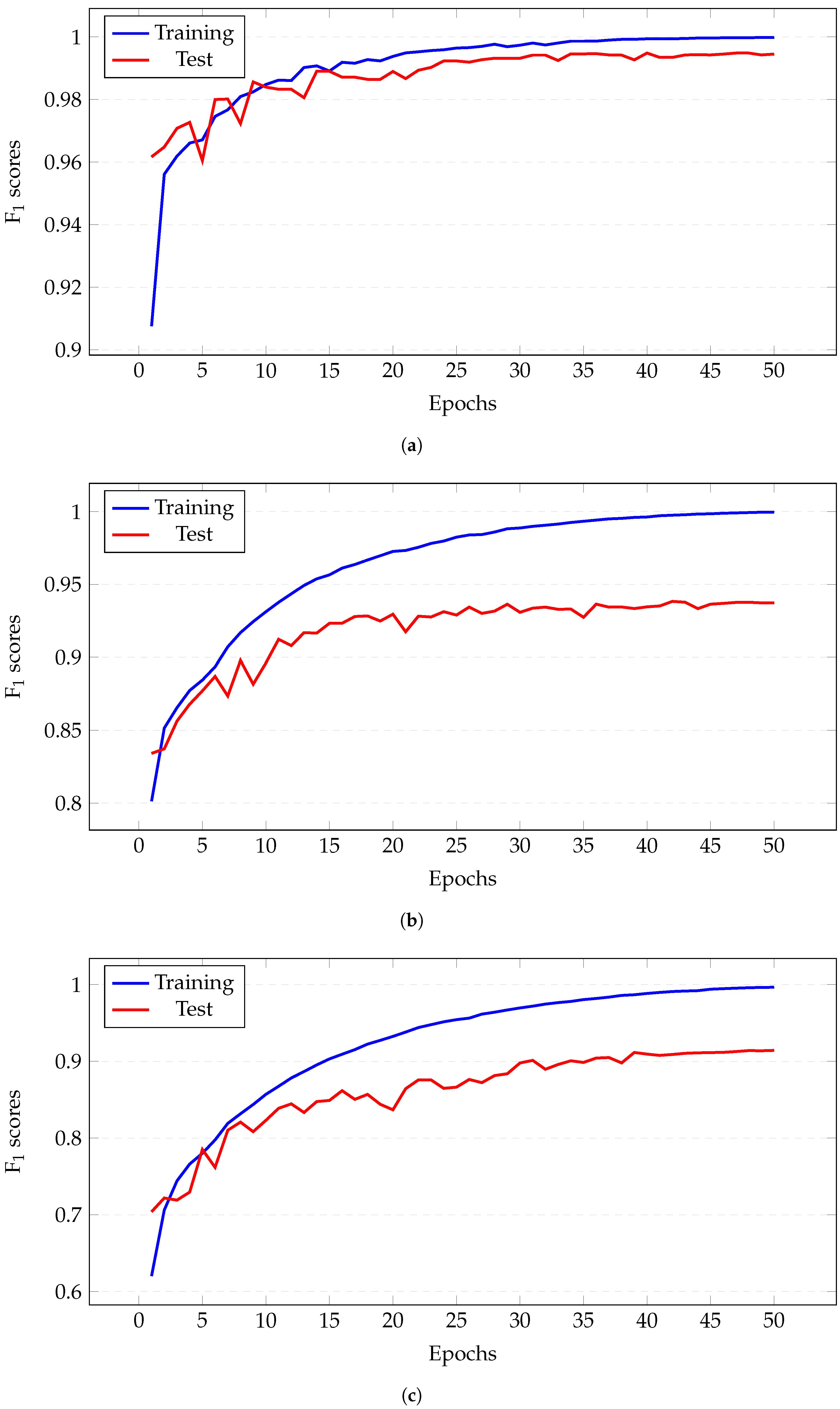
5.2.2. Ablation Experiments
5.2.3. Performance Comparison
5.3. Proposed Solution for English: ECNN-ESCD
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| Baseline-Pr0 | Baseline-Predicting 0 |
| Baseline-Pr1 | Baseline-Predicting 1 |
| CNN | Convolutional Neural Network |
| DNN | Deep Neural Network |
| ECNN-ASCD | Edge Convolutional Neural Network for the Arabic Style Change Detection |
| ECNN-ESCD | Edge Convolutional Neural Network for the English Style Change Detection |
| FC | Fully Connected |
| GCN | Graph Convolutional Network |
| GNN | Graph Neural Network |
| LR | learning Rate |
| LSTM | Long Short-Term Memory |
| ML | Machine Learning |
| NLP | Natural Language Processing |
| SCD | Style Change Detection |
| SOTA | State of the Art |
Appendix A. Examples of Predictions from ECNN-ASCD
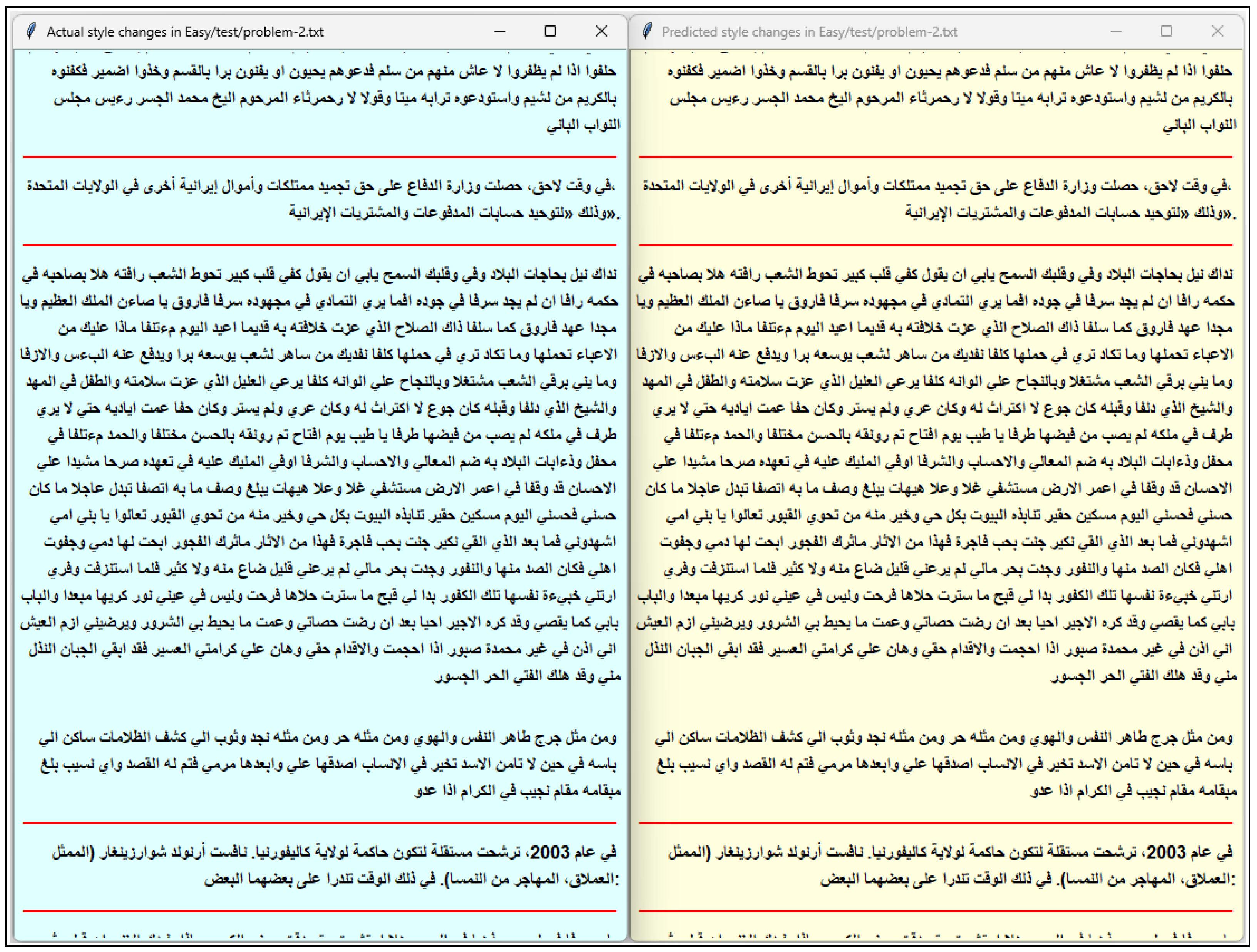
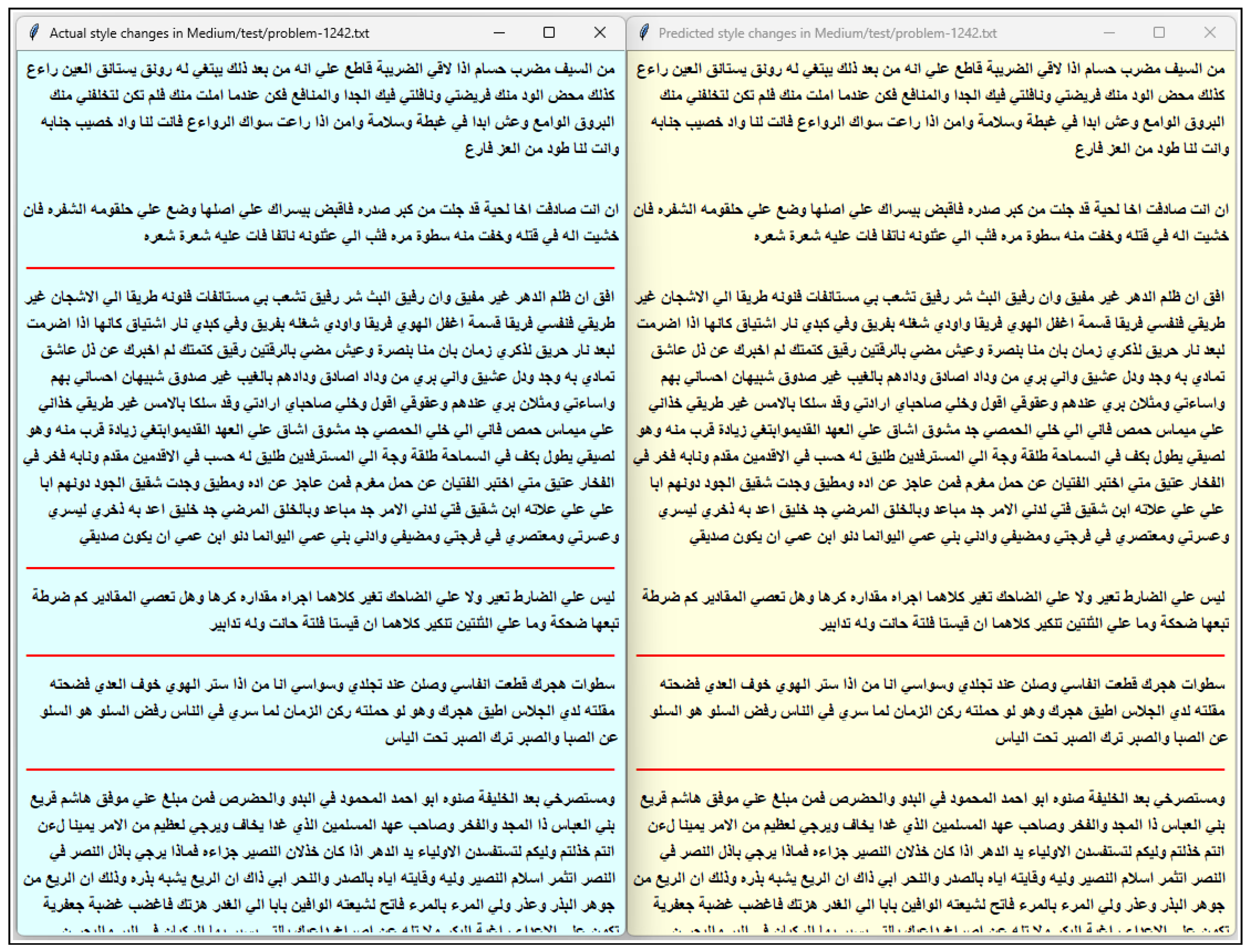
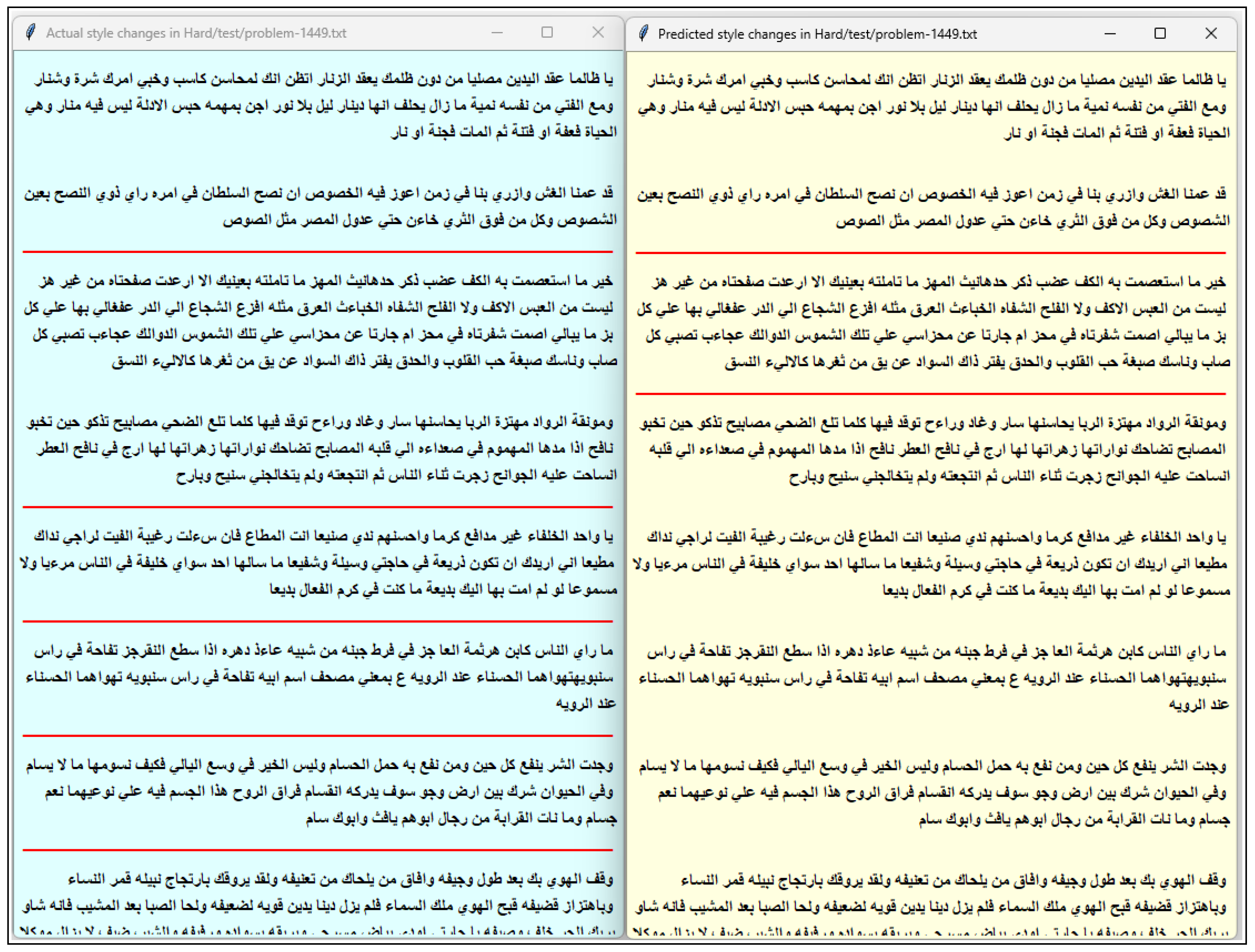
References
- Tschuggnall, M.; Stamatatos, E.; Verhoeven, B.; Daelemans, W.; Specht, G.; Stein, B.; Potthast, M. Overview of the Author Identification Task at PAN-2017: Style Breach Detection and Author Clustering. In Working Notes of CLEF 2017—Conference and Labs of the Evaluation Forum; CEUR Workshop Proceedings; CEUR-WS.org: Dublin, Ireland, 2017; Volume 1866, p. 22. [Google Scholar]
- Kestemont, M.; Tschuggnall, M.; Stamatatos, E.; Daelemans, W.; Specht, G.; Stein, B.; Potthast, M. Overview of the Author Identification Task at PAN-2018. In Working Notes of CLEF 2018—Conference and Labs of the Evaluation Forum; CEUR Workshop Proceedings; CEUR-WS.org: Avignon, France, 2018; Volume 2125, p. 25. [Google Scholar]
- Zangerle, E.; Tschuggnall, M.; Specht, G.; Stein, B.; Potthast, M. Overview of the Style Change Detection Task at PAN 2019. In Working Notes of CLEF 2019—Conference and Labs of the Evaluation Forum; CEUR Workshop Proceedings; CEUR-WS.org: Lugano, Switzerland, 2019; Volume 2380, p. 11. [Google Scholar]
- Zangerle, E.; Mayerl, M.; Specht, G.; Potthast, M.; Stein, B. Overview of the Style Change Detection Task at PAN 2020. In Working Notes of CLEF 2020—Conference and Labs of the Evaluation Forum; CEUR Workshop Proceedings; CEUR-WS.org: Thessaloniki, Greece, 2020; Volume 2696, p. 11. [Google Scholar]
- Zangerle, E.; Mayerl, M.; Potthast, M.; Stein, B. Overview of the Style Change Detection Task at PAN 2021. In Working Notes of CLEF 2021—Conference and Labs of the Evaluation Forum; CEUR Workshop Proceedings; CEUR-WS.org: Bucharest, Romania, 2021; Volume 2936, pp. 1760–1771. [Google Scholar]
- Zangerle, E.; Mayerl, M.; Potthast, M.; Stein, B. Overview of the Style Change Detection Task at PAN 2022. In Working Notes of CLEF 2022—Conference and Labs of the Evaluation Forum; CEUR Workshop Proceedings; CEUR-WS.org: Bologna, Italy, 2022; Volume 3180, pp. 2344–2356. [Google Scholar]
- Zangerle, E.; Mayerl, M.; Potthast, M.; Stein, B. Overview of the Multi-Author Writing Style Analysis Task at PAN 2023. In Working Notes of CLEF 2023—Conference and Labs of the Evaluation Forum; CEUR Workshop Proceedings; CEUR-WS.org: Thessaloniki, Greece, 2023; pp. 2513–2522. [Google Scholar]
- Rexha, A.; Kröll, M.; Ziak, H.; Kern, R. Authorship Identification of Documents with High Content Similarity. Scientometrics 2018, 115, 223–237. [Google Scholar] [CrossRef] [PubMed]
- Akiva, N.; Koppel, M. Identifying Distinct Components of a Multi-author Document. In Proceedings of the 2012 European Intelligence and Security Informatics Conference, Odense, Denmark, 22–24 August 2012; pp. 205–209. [Google Scholar]
- Alshamasi, S.; Menai, M.B. Ensemble-Based Clustering for Writing Style Change Detection in Multi-Authored Textual Documents. In CLEF 2022 Labs and Workshops, Notebook Papers; CEUR Workshop Proceedings; CEUR-WS.org: Bologna, Italy, 2022; Volume 3180, p. 18. [Google Scholar]
- Zangerle, E.; Mayerl, M.; Potthast, M.; Stein, B. Overview of the Multi-Author Writing Style Analysis Task at PAN 2024. In Working Notes of CLEF 2024—Conference and Labs of the Evaluation Forum; CEUR Workshop Proceedings; CEUR-WS.org: Grenoble, France, 2024; Volume 3740, pp. 2424–2431. [Google Scholar]
- Scarselli, F.; Gori, M.; Tsoi, A.C.; Hagenbuchner, M.; Monfardini, G. The Graph Neural Network Model. IEEE Trans. Neural Netw. 2009, 20, 61–80. [Google Scholar] [CrossRef]
- Embarcadero-Ruiz, D.; Gómez-Adorno, H.; Embarcadero-Ruiz, A.; Sierra, G. Graph-Based Siamese Network for Authorship Verification. In Working Notes of CLEF 21—Conference and Labs of the Evaluation Forum; CEUR Workshop Proceedings; CEUR-WS.org: Bucharest, Romania, 2021; Volume 2936, p. 11. [Google Scholar]
- Embarcadero-Ruiz, D.; Gómez-Adorno, H.; Embarcadero-Ruiz, A.; Sierra, G. Graph-Based Siamese Network for Authorship Verification. In Working Notes of CLEF 22—Conference and Labs of the Evaluation Forum; CEUR Workshop Proceedings; CEUR-WS.org: Bologna, Italy, 2022; Volume 3180, p. 277. [Google Scholar]
- Valdez-Valenzuela, A.; Martinez-Galicia, J.A.; Gomez-Adorno, H. Heterogeneous-Graph Convolutional Network for Authorship Verification. In Working Notes of CLEF 2023—Conference and Labs of the Evaluation Forum; CEUR Workshop Proceedings; CEUR-WS.org: Thessaloniki, Greece, 2023; p. 8. [Google Scholar]
- Zhang, Y.; Qi, P.; Manning, C.D. Graph Convolution over Pruned Dependency Trees Improves Relation Extraction. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 2205–2215. [Google Scholar]
- Yu, B.; Mengge, X.; Zhang, Z.; Liu, T.; Yubin, W.; Wang, B. Learning to Prune Dependency Trees with Rethinking for Neural Relation Extraction. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 8–13 December 2020; pp. 3842–3852. [Google Scholar]
- Li, B.; Fan, Y.; Sataer, Y.; Gao, Z.; Gui, Y. Improving Semantic Dependency Parsing with Higher-Order Information Encoded by Graph Neural Networks. Appl. Sci. 2022, 12, 4089. [Google Scholar] [CrossRef]
- Hu, Y.; Shen, H.; Liu, W.; Min, F.; Qiao, X.; Jin, K. A Graph Convolutional Network With Multiple Dependency Representations for Relation Extraction. IEEE Access 2021, 9, 81575–81587. [Google Scholar] [CrossRef]
- Sun, K.; Zhang, R.; Mao, Y.; Mensah, S.; Liu, X. Relation Extraction with Convolutional Network over Learnable Syntax-Transport Graph. Proc. AAAI Conf. Artif. Intell. 2020, 34, 8928–8935. [Google Scholar] [CrossRef]
- Zhou, L.; Wang, T.; Qu, H.; Huang, L.; Liu, Y. A Weighted GCN with Logical Adjacency Matrix for Relation Extraction. In ECAI 2020; iOS Press: Amsterdam, The Netherlands, 2020; pp. 1–8. [Google Scholar]
- Mandya, A.; Bollegala, D.; Coenen, F. Graph Convolution over Multiple Dependency Sub-graphs for Relation Extraction. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 8–13 December 2020; pp. 6424–6435. [Google Scholar]
- Jin, Z.; Yang, Y.; Qiu, X.; Zhang, Z. Relation of the Relations: A New Paradigm of the Relation Extraction Problem. arXiv 2020, arXiv:2006.03719. [Google Scholar]
- Tian, Y.; Chen, G.; Song, Y.; Wan, X. Dependency-driven Relation Extraction with Attentive Graph Convolutional Networks. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Online, 1–6 August 2021; pp. 4458–4471. [Google Scholar]
- Zhao, K.; Xu, H.; Cheng, Y.; Li, X.; Gao, K. Representation Iterative Fusion Based on Heterogeneous Graph Neural Network for Joint Entity and Relation Extraction. Knowl.-Based Syst. 2021, 219, 9. [Google Scholar] [CrossRef]
- Liu, P.; Wang, L.; Zhao, Q.; Chen, H.; Feng, Y.; Lin, X.; He, L. ECNU_ICA_1 SemEval-2021 Task 4: Leveraging Knowledge-enhanced Graph Attention Networks for Reading Comprehension of Abstract Meaning. In Proceedings of the 15th International Workshop on Semantic Evaluation (SemEval-2021), Online, 10–31 January 2021; pp. 183–188. [Google Scholar]
- Guo, Z.; Zhang, Y.; Lu, W. Attention Guided Graph Convolutional Networks for Relation Extraction. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 241–251. [Google Scholar]
- Li, Z.; Sun, Y.; Zhu, J.; Tang, S.; Zhang, C.; Ma, H. Improve Relation Extraction with Dual Attention-Guided Graph Convolutional Networks. Neural Comput. Appl. 2021, 33, 1773–1784. [Google Scholar] [CrossRef]
- Farghaly, A.; Shaalan, K. Arabic Natural Language Processing: Challenges and Solutions. ACM Trans. Asian Lang. Inf. Process. 2009, 8, 1–22. [Google Scholar] [CrossRef]
- Habash, N.; Soudi, A.; Buckwalter, T. On Arabic transliteration. In Arabic Computational Morphology: Knowledge-Based and Empirical Methods; Springer: Dordrecht, The Netherlands, 2007; pp. 15–22. [Google Scholar]
- Wintner, S. Morphological processing of semitic languages. In Natural Language Processing of Semitic Languages; Zitouni, I., Ed.; Springer: Berlin/Heidelberg, Germany, 2014; pp. 43–66. [Google Scholar]
- Ahmed, M.A.; Trausan-Matu, S. Using natural language processing for analyzing Arabic poetry rhythm. In Proceedings of the 2017 16th RoEduNet Conference: Networking in Education and Research (RoEduNet), Targu Mures, Romania, 21–23 September 2017; pp. 1–5. [Google Scholar]
- Khan, J.A. Style Breach Detection: An Unsupervised Detection Model. In CLEF 2017 Labs and Workshops, Notebook Papers; CEUR Workshop Proceedings; CEUR-WS.org: Dublin, Ireland, 2017; Volume 1866, p. 10. [Google Scholar]
- Khan, J.A. A Model for Style Change Detection at a Glance. In CLEF 2018 Labs and Workshops, Notebook Papers; CEUR Workshop Proceedings; CEUR-WS.org: Avignon, France, 2018; Volume 2125, p. 8. [Google Scholar]
- Karas, D.; Spiewak, M.; Piotr, S. OPI-JSA at CLEF 2017: Author Clustering and Style Breach Detection. In CLEF 2017 Labs and Workshops, Notebook Papers; CEUR Workshop Proceedings; CEUR-WS.org: Dublin, Ireland, 2017; Volume 1866, p. 12. [Google Scholar]
- Ramachandran, K.M.; Tsokos, C.P. Mathematical Statistics with Applications in R, 3rd ed.; Elsevier: Philadelphia, PA, USA, 2020. [Google Scholar]
- Cox, D.R. The Regression Analysis of Binary Sequences. J. R. Stat. Soc. Ser. Methodol. 1959, 21, 238. [Google Scholar] [CrossRef]
- Ho, T.K. Random decision forests. In Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, Canada, 14–16 August 1995; Volume 1, pp. 278–282. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Alvi, F.; Algafri, H.; Alqahtani, N. Style Change Detection using Discourse Markers. In CLEF 2022 Labs and Workshops, Notebook Papers; CEUR Workshop Proceedings; CEUR-WS.org: Bologna, Italy, 2022; Volume 3180, p. 6. [Google Scholar]
- Jacobo, G.X.; Dehesa-Corona, V.; Rojas-Reyes, A.; Gomez-Adorno, H. Authorship Verification Machine Learning Methods For Style Change Detection In Texts. In Working Notes of CLEF 2023—Conference and Labs of the Evaluation Forum; CEUR Workshop Proceedings; CEUR-WS.org: Thessaloniki, Greece, 2023; p. 7. [Google Scholar]
- Nath, S. Style Change Detection. Ph.D. Thesis, Université de Neuchâtel, Neuchâtel, Switzerland, 2021. [Google Scholar]
- Singh, R.; Weerasinghe, J.; Greenstadt, R. Writing Style Change Detection on Multi-Author Documents. In CLEF 2021 Labs and Workshops, Notebook Papers; CEUR Workshop Proceedings; CEUR-WS.org: Bucharest, Romania, 2021; Volume 2936, p. 9. [Google Scholar]
- Safin, K.; Ogaltsov, A. Detecting a Change of Style Using Text Statistics. In CLEF 2018 Labs and Workshops, Notebook Papers; CEUR Workshop Proceedings; CEUR-WS.org: Avignon, France, 2018; Volume 2125, p. 6. [Google Scholar]
- Zlatkova, D.; Kopev, D.; Mitov, K.; Atanasov, A.; Hardalov, M.; Koychev, I.; Nakov, P. An Ensemble-Rich Multi-Aspect Approach for Robust Style Change Detection. In CLEF 2018 Labs and Workshops, Notebook Papers; CEUR Workshop Proceedings; CEUR-WS.org: Avignon, France, 2018; Volume 2125, p. 14. [Google Scholar]
- MacQueen, J. Some Methods for Classification and Analysis of Multivariate Observations. Berkeley Symp. Math. Stat. Probab. 1967, 5, 281–297. [Google Scholar]
- Elamine, M.; Mechti, S.; Belguith, L.H. An Unsupervised Method for Detecting Style Breaches in a Document. In Proceedings of the 2019 IEEE/ACS 16th International Conference on Computer Systems and Applications (AICCSA), Abu Dhabi, United Arab Emirates, 3–7 November 2019; pp. 1–6. [Google Scholar]
- Mandic, L.; Milkovic, F.; Doria, S. Combining the Powers of Clustering Affinities in Style Change Detection. Course Project Reports; University of Zagreb: Zagreb, Croatia, 2019. [Google Scholar]
- Zuo, C.; Zhao, Y.; Banerjee, R. Style Change Detection with Feed-forward Neural Networks. In CLEF 2019 Labs and Workshops, Notebook Papers; CEUR Workshop Proceedings; CEUR-WS.org: Lugano, Switzerland, 2019; Volume 2380, p. 9. [Google Scholar]
- Nath, S. Style Change Detection by Threshold Based and Window Merge Clustering Methods. In CLEF 2019 Labs and Workshops, Notebook Papers; CEUR Workshop Proceedings; CEUR-WS.org: Lugano, Switzerland, 2019; Volume 2380, p. 11. [Google Scholar]
- Castro-Castro, D.; Rodríguez-Losada, C.A.; Muñoz, R. Mixed Style Feature Representation and B0-maximal Clustering for Style Change Detection. In CLEF 2020 Labs and Workshops, Notebook Papers; CEUR Workshop Proceedings; CEUR-WS.org: Thessaloniki, Greece, 2020; Volume 2696, p. 7. [Google Scholar]
- Nath, S. Style Change Detection using Siamese Neural Networks. In CLEF 2021 Labs and Workshops, Notebook Papers; CEUR Workshop Proceedings; CEUR-WS.org: Bucharest, Romania, 2021; Volume 2936, p. 11. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Lecun, Y. Generalization and Network Design Strategies. Connectionism in Perspective; Elsevier: Amsterdam, The Netherlands, 1989; Volume 19, p. 18. [Google Scholar]
- Deibel, R.; Löfflad, D. Style Change Detection on Real-World Data using an LSTM-powered Attribution Algorithm. In CLEF 2021 Labs and Workshops, Notebook Papers; CEUR Workshop Proceedings; CEUR-WS.org: Bucharest, Romania, 2021; Volume 2936, p. 11. [Google Scholar]
- Schaetti, N. Character-based Convolutional Neural Network for Style Change Detection. In CLEF 2018 Labs and Workshops, Notebook Papers; CEUR Workshop Proceedings; CEUR-WS.org: Avignon, France, 2018; Volume 2125, p. 6. [Google Scholar]
- Müller, P. Style Change Detection. Bachelor’s Thesis, ETH Zurich, Zürich, Switzerland, 2019. [Google Scholar]
- Jurafsky, D.; Martin, J.H. Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition; Prentice Hall series in artificial intelligence; Prentice Hall: Upper Saddle River, NJ, USA, 2000. [Google Scholar]
- Bromley, J.; Guyon, I.; LeCun, Y.; Säckinger, E.; Shah, R. Signature Verification using a ‘Siamese’ Time Delay Neural Network. In Proceedings of the the 6th International Conference on Neural Information Processing Systems, San Francisco, CA, USA, 29 November–2 December 1993; NIPS’93. pp. 737–744. [Google Scholar]
- Hosseinia, M.; Mukherjee, A. A Parallel Hierarchical Attention Network for Style Change Detection. In CLEF 2018 Labs and Workshops, Notebook Papers; CEUR Workshop Proceedings; CEUR-WS.org: Avignon, France, 2018; Volume 2125, p. 7. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; p. 16. [Google Scholar]
- Lao, Q.; Ma, L.; Yang, W.; Yang, Z.; Yuan, D.; Tan, Z.; Liang, L. Style Change Detection Based On Bert And Conv1d. In CLEF 2022 Labs and Workshops, Notebook Papers; CEUR Workshop Proceedings; CEUR-WS.org: Bologna, Italy, 2022; Volume 3180, p. 6. [Google Scholar]
- Zi, J.; Zhou, L. Style Change Detection Based On Bi-LSTM And Bert. In CLEF 2022 Labs and Workshops, Notebook Papers; CEUR Workshop Proceedings; CEUR-WS.org: Bologna, Italy, 2022; Volume 3180, p. 5. [Google Scholar]
- Liu, G.; Yan, Z.; Wang, T.; Zhan, K. ARTW: A Model of Author Recognition based on Writing Style by Recognizing Style Crack. In Proceedings of the ICISS 2022: 2022 the 5th International Conference on Information Science and Systems, Beijing, China, 26–28 August 2022; pp. 130–135. [Google Scholar]
- Safin, K.; Kuznetsova, R. Style Breach Detection with Neural Sentence Embeddings. In CLEF 2017 Labs and Workshops, Notebook Papers; CEUR Workshop Proceedings; CEUR-WS.org: Dublin, Ireland, 2017; Volume 1866, p. 7. [Google Scholar]
- Kiros, R.; Zhu, Y.; Salakhutdinov, R.; Zemel, R.S.; Torralba, A.; Urtasun, R.; Fidler, S. Skip-Thought Vectors. In Proceedings of the 28th International Conference on Neural Information Processing Systems, Cambridge, MA, USA, 8–13 December 2015; Volume 1, p. 11. [Google Scholar]
- Rodríguez-Losada, C.A.; Castro-Castro, D. Three Style Similarity: Sentence-embedding, Auxiliary Words, Punctuation. In CLEF 2022 Labs and Workshops, Notebook Papers; CEUR Workshop Proceedings; CEUR-WS.org: Bologna, Italy, 2022; Volume 3180, p. 11. [Google Scholar]
- Reimers, N.; Gurevych, I. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 3982–3992. [Google Scholar]
- Bojanowski, P.; Grave, E.; Joulin, A.; Mikolov, T. Enriching Word Vectors with Subword Information. Trans. Assoc. Comput. Linguist. 2017, 5, 12. [Google Scholar] [CrossRef]
- He, P.; Liu, X.; Gao, J.; Chen, W. DeBERTa: Decoding-enhanced BERT with Disentangled Attention. In Proceedings of the International Conference on Learning Representations ICLR 2021, Vienna, Austria, 4–8 May 2021; p. 17. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Clark, K.; Luong, M.T.; Le, Q.V.; Manning, C.D. ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators. In Proceedings of the 8th International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020; p. 18. [Google Scholar]
- Muennighoff, N.; Wang, T.; Sutawika, L.; Roberts, A.; Biderman, S.; Le Scao, T.; Bari, M.S.; Shen, S.; Yong, Z.X.; Schoelkopf, H.; et al. Crosslingual Generalization through Multitask Finetuning. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics, Toronto, ON, Canada, 9–14 July 2023; Volume 1, pp. 15991–16111. [Google Scholar]
- Iyer, A.; Vosoughi, S. Style Change Detection Using BERT. In CLEF 2020 Labs and Workshops, Notebook Papers; CEUR Workshop Proceedings; CEUR-WS.org: Thessaloniki, Greece, 2020; Volume 2696, p. 9. [Google Scholar]
- Zhang, Z.; Han, Z.; Kong, L. Style Change Detection based on Prompt. In CLEF 2022 Labs and Workshops, Notebook Papers; CEUR Workshop Proceedings; CEUR-WS.org: Bologna, Italy, 2022; Volume 3180, p. 4. [Google Scholar]
- Zhang, Z.; Han, Z.; Kong, L.; Miao, X.; Peng, Z.; Zeng, J.; Cao, H.; Zhang, J.; Xiao, Z.; Peng, X. Style Change Detection Based On Writing Style Similarity. In CLEF 2021 Labs and Workshops, Notebook Papers; CEUR Workshop Proceedings; CEUR-WS.org: Bucharest, Romania, 2021; Volume 2936, p. 4. [Google Scholar]
- Lin, T.M.; Chen, C.Y.; Tzeng, Y.W.; Lee, L.H. Ensemble Pre-trained Transformer Models for Writing Style Change Detection. In CLEF 2022 Labs and Workshops, Notebook Papers; CEUR Workshop Proceedings; CEUR-WS.org: Bologna, Italy, 2022; Volume 3180, p. 9. [Google Scholar]
- Str, E. Multi-label Style Change Detection by Solving a Binary Classification Problem. In CLEF 2021 Labs and Workshops, Notebook Papers; CEUR Workshop Proceedings; CEUR-WS.org: Bucharest, Romania, 2021; Volume 2936, p. 12. [Google Scholar]
- Jiang, X.; Qi, H.; Zhang, Z.; Huang, M. Style Change Detection: Method Based On Pre-trained Model And Similarity Recognition. In CLEF 2022 Labs and Workshops, Notebook Papers; CEUR Workshop Proceedings; CEUR-WS.org: Bologna, Italy, 2022; Volume 3180, p. 6. [Google Scholar]
- Kucukkaya, I.E.; Sahin, U.; Toraman, C. ARC-NLP at PAN 2023: Transition-Focused Natural Language Inference for Writing Style Detection. In Working Notes of CLEF 2023—Conference and Labs of the Evaluation Forum; CEUR-WS.org: Thessaloniki, Greece, 2023; p. 10. [Google Scholar]
- Ye, Z.; Zhong, C.; Qi, H.; Han, Y. Supervised Contrastive Learning for Multi-Author Writing Style Analysis. In Working Notes of CLEF 2023—Conference and Labs of the Evaluation Forum; CEUR Workshop Proceedings; CEUR-WS.org: Thessaloniki, Greece, 2023; p. 6. [Google Scholar]
- Hashemi, A.; Shi, W. EnhancingWriting Style Change Detection using Transformer-based Models and Data Augmentation. In Working Notes of CLEF 2023—Conference and Labs of the Evaluation Forum; CEUR Workshop Proceedings; CEUR-WS.org: Thessaloniki, Greece, 2023; p. 9. [Google Scholar]
- Huang, M.; Huang, Z.; Kong, L. Encoded Classifier Using Knowledge Distillation for Multi-Author Writing Style Analysis. In Working Notes of CLEF 2023—Conference and Labs of the Evaluation Forum; CEUR Workshop Proceedings; CEUR-WS.org: Thessaloniki, Greece, 2023; p. 6. [Google Scholar]
- Peng, C.; Xia, F.; Naseriparsa, M.; Osborne, F. Knowledge Graphs: Opportunities and Challenges. Artif. Intell. Rev. 2023, 56, 13071–13102. [Google Scholar] [CrossRef]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. arXiv 2017, arXiv:1609.02907. [Google Scholar]
- Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M.; Solomon, J.M. Dynamic Graph CNN for Learning on Point Clouds. ACM Trans. Graph. 2019, 38, 1–12. [Google Scholar] [CrossRef]
- Minaee, S.; Kalchbrenner, N.; Cambria, E.; Nikzad, N.; Chenaghlu, M.; Gao, J. Deep Learning-based Text Classification: A Comprehensive Review. ACM Comput. Surv. 2022, 54, 1–40. [Google Scholar] [CrossRef]
- Liu, X.; Chen, H.; Lv, J. Team foshan-university-of-guangdong at PAN: Adaptive Entropy-Based Stability-Plasticity for Multi-Author Writing Style Analysis. In Working Notes of CLEF 2024—Conference and Labs of the Evaluation Forum; CEUR Workshop Proceedings; CEUR-WS.org: Grenoble, France, 2024; Volume 3740, pp. 2750–2754. [Google Scholar]
- Mohan, T.M.; Sheela, T.V.S. BERT-Based Similarity Measures Oriented Approach for Style Change Detection. In Accelerating Discoveries in Data Science and Artificial Intelligence II; Springer: Cham, Switzerland, 2024; Volume 438, pp. 83–94. [Google Scholar]
- Lin, T.M.; Wu, Y.H.; Lee, L.H. Team NYCU-NLP at PAN 2024: Integrating Transformers with Similarity Adjustments for Multi-Author Writing Style Analysis. In Working Notes of CLEF 2024—Conference and Labs of the Evaluation Forum; CEUR Workshop Proceedings; CEUR-WS.org: Grenoble, France, 2024; Volume 3740, pp. 2716–2721. [Google Scholar]
- Huang, Y.; Kong, L. Team Text Understanding and Analysis at PAN: Utilizing BERT Series Pre-training Model for Multi-Author Writing Style Analysis. In Working Notes of CLEF 2024—Conference and Labs of the Evaluation Forum; CEUR Workshop Proceedings; CEUR-WS.org: Grenoble, France, 2024; Volume 3740, pp. 2653–2657. [Google Scholar]
- Wu, Q.; Kong, L.; Ye, Z. Team bingezzzleep at PAN: A Writing Style Change Analysis Model Based on RoBERTa Encoding and Contrastive Learning for Multi-Author Writing Style Analysis. In Working Notes of CLEF 2024—Conference and Labs of the Evaluation Forum; CEUR Workshop Proceedings; CEUR-WS.org: Grenoble, France, 2024; Volume 3740, pp. 2963–2968. [Google Scholar]
- Chen, Z.; Han, Y.; Yi, Y. Team Chen at PAN: Integrating R-Drop and Pre-trained Language Model for Multi-author Writing Style Analysis. In Working Notes of CLEF 2024—Conference and Labs of the Evaluation Forum; CEUR Workshop Proceedings; CEUR-WS.org: Grenoble, France, 2024; Volume 3740, pp. 2547–2553. [Google Scholar]
- Wu, B.; Han, Y.; Yan, K.; Qi, H. Team baker at PAN: Enhancing Writing Style Change Detection with Virtual Softmax. In Working Notes of CLEF 2024—Conference and Labs of the Evaluation Forum; CEUR Workshop Proceedings; CEUR-WS.org: Grenoble, France, 2024; Volume 3740, pp. 2951–2955. [Google Scholar]
- Sheykhlan, M.K.; Abdoljabbar, S.K.; Mahmoudabad, M.N. Team karami-sh at PAN: Transformer-based Ensemble Learning for Multi-Author Writing Style Analysis. In Working Notes of CLEF 2024—Conference and Labs of the Evaluation Forum; CEUR Workshop Proceedings; CEUR-WS.org: Grenoble, France, 2024; Volume 3740, pp. 2676–2681. [Google Scholar]
- Liu, C.; Han, Z.; Chen, H.; Hu, Q. Team Liuc0757 at PAN: A Writing Style Embedding Method Based on Contrastive Learning for Multi-Author Writing Style Analysis. In Working Notes of CLEF 2024—Conference and Labs of the Evaluation Forum; CEUR Workshop Proceedings; CEUR-WS.org: Grenoble, France, 2024; Volume 3740, pp. 2716–2721. [Google Scholar]
- Zamir, M.T.; Ayub, M.A.; Gul, A.; Ahmad, N.; Ahmad, K. Stylometry Analysis of Multi-authored Documents for Authorship and Author Style Change Detection. arXiv 2024, arXiv:2401.06752. [Google Scholar]
- Liang, X.; Zeng, F.; Zhou, Y.; Liu, X.; Zhou, Y. Fine-Tuned Reasoning for Writing Style Analysis. In Working Notes of CLEF 2024—Conference and Labs of the Evaluation Forum; CEUR Workshop Proceedings; CEUR-WS.org: Grenoble, France, 2024; Volume 3740, pp. 2710–2715. [Google Scholar]
- Lv, J.; Yi, Y.; Qi, H. Team fosu-stu at PAN: Supervised Fine-Tuning of Large Language Models for Multi Author Writing Style Analysis. In Working Notes of CLEF 2024—Conference and Labs of the Evaluation Forum; CEUR Workshop Proceedings; CEUR-WS.org: Grenoble, France, 2024; Volume 3740, pp. 2781–2786. [Google Scholar]
- Sanjesh, R. eam riyahsanjesh at PAN: Multi-feature with CNN and Bi-LSTM Neural Network Approach to Style Change Detection. In Working Notes of CLEF 2024—Conference and Labs of the Evaluation Forum; CEUR Workshop Proceedings; CEUR-WS.org: Grenoble, France, 2024; Volume 3740, pp. 2881–2885. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar]
- Gong, L.; Cheng, Q. Exploiting Edge Features for Graph Neural Networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 9203–9211. [Google Scholar]
- Zhou, Y.; Huo, H.; Hou, Z.; Bu, L.; Mao, J.; Wang, Y.; Lv, X.; Bu, F. Co-embedding of edges and nodes with deep graph convolutional neural networks. Sci. Rep. 2023, 13, 26. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Riddell, A.; Juola, P. Mode Effects’ Challenge to Authorship Attribution. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, Online, 19–23 April 2021; pp. 1146–1155. [Google Scholar]
- Ríos-Toledo, G.; Posadas-Durán, J.P.F.; Sidorov, G.; Castro-Sánchez, N.A. Detection of changes in literary writing style using N-grams as style markers and supervised machine learning. PLoS ONE 2022, 17, 25. [Google Scholar] [CrossRef] [PubMed]
- Amelin, K.; Granichin, O.; Kizhaeva, N.; Volkovich, Z. Patterning of writing style evolution by means of dynamic similarity. Pattern Recognit. 2018, 77, 45–64. [Google Scholar] [CrossRef]
- Gomez Adorno, H.M.; Rios, G.; Posadas Durán, J.P.; Sidorov, G.; Sierra, G. Stylometry-based Approach for Detecting Writing Style Changes in Literary Texts. Computación y Sistemas 2018, 22, 7. [Google Scholar] [CrossRef]
- Alsheddi, A.S.; Alhenaki, L.S. English and Arabic Chatbots: A Systematic Literature Review. Int. J. Adv. Comput. Sci. Appl. 2022, 13, 662–675. [Google Scholar] [CrossRef]
- ŞAHiN, E.; Arslan, N.N.; Özdemir, D. Unlocking the black box: An in-depth review on interpretability, explainability, and reliability in deep learning. Neural Comput. Appl. 2025, 37, 859–965. [Google Scholar]
- Huertas-Tato, J.; Martín, A.; Camacho, D. Understanding writing style in social media with a supervised contrastively pre-trained transformer. Knowl. Based Syst. 2024, 296, 12. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Document 1 | Document 2 | ||
|---|---|---|---|
| This paragraph was written by the first author. | This paragraph was written by the first author. | Author 1 | |
| Author 1 | This paragraph has two sentences. They were written by the first author. | Two sentences are in this paragraph. The second author wrote both sentences. | Author 2 |
| This paragraph as well was written by the first author. | The second author wrote this paragraph too. | ||
| This paragraph was also written by the first author. | This paragraph also was written by the first author. | Author 1 | |
| Para. level | [0, 0, 0] | [1, 0, 1] | |
| Sent. level | [0, 0, 0, 0] | [1, 0, 0, 1] | |
| Document 1 | Document 2 | ||
|---|---|---|---|
| هذه الفقرة كتبت من المؤلف الأول. | هذه الفقرة كتبت من المؤلف الأول. | Author 1 | |
| هذه الفقرة تتكون من جملتين. وكتبت كلاهما | يمكن صياغة الفقرة الثانية من خلال جملتين | ||
| Author 1 | من المؤلف الأول. | منفصلتين. حيث قام المؤلف الثاني بكتابتهما. | Author 2 |
| هذه الفقرة كتبها المؤلف الأول. | هذه الفقرة كتبها المؤلف الأول. | Author 1 | |
| Para. level | [0, 0] | [1, 1] | |
| Sent. level | [0, 0, 0] | [1, 0, 1] | |
| Symbol | Definition |
|---|---|
| : input graph, : node set, and E: edge set | |
| || = n | n number of nodes |
| Nodes in | |
| Edges in located between every two consecutive nodes i and j | |
| Set of one-hop neighbors of node i in | |
| Degree of node i | |
| Trainable weight matrix at layer k | |
| Node feature matrix for n nodes | |
| f-dimensional node embedding of node i at layer k | |
| Edge feature matrix for edges | |
| f-dimensional node embedding of edge at layer k | |
| Aggregation function | |
| Nonlinear activation function | |
| ⊕ | Summation operation |
| Level | # Doc. | Avg. Doc. Leng. | Avg. Para. Leng. | Avg. Style Change |
|---|---|---|---|---|
| Easy | 10,000 | 11.4221 para. | 150.2 words | 4.52 changes (43.33%) |
| Medium | 10,000 | 14.4912 para. | 125.0 words | 5.66 changes (41.96%) |
| Hard | 10,000 | 14.7409 para. | 124.4 words | 5.82 changes (42.32%) |
| Hyperparameter | Seed | Optimizer | Dropout | Batch | Max Sequence Length | Warmup Rate |
|---|---|---|---|---|---|---|
| Value | 42 | Adam * | 0.5 | 1 | 256 | 0.1 |
| Layer | 2 | AraBERT | 0.001 | 20 | 0.9868 | 0.9004 | 0.8332 |
| 3 | AraBERT | 0.001 | 20 | 0.9911 | 0.9199 | 0.8536 | |
| 4 | AraBERT | 0.001 | 20 | 0.9918 | 0.9214 | 0.8684 | |
| 5 | AraBERT | 0.001 | 20 | 0.9915 | 0.9236 | 0.8663 | |
| Encoder | 4 | RoBERTa-Davlan | 0.001 | 20 | 0.9679 | 0.8693 | 0.7795 |
| 4 | RoBERTa-jhu | 0.001 | 20 | 0.9883 | 0.8782 | 0.7726 | |
| 4 | mBERT | 0.001 | 20 | 0.9516 | 0.8354 | 0.4935 | |
| 4 | CamelBERT | 0.001 | 20 | 0.9903 | 0.9179 | 0.8578 | |
| 4 | AraBERT | 0.001 | 20 | 0.9918 | 0.9214 | 0.8684 | |
| LR | 4 | AraBERT | 0.00002 | 20 | 0.98260 | 0.90487 | 0.84113 |
| 4 | AraBERT | 0.001 | 20 | 0.9918 | 0.9214 | 0.8684 | |
| Epoch | 4 | AraBERT | 0.001 | 20 | 0.9918 | 0.9214 | 0.8684 |
| 4 | AraBERT | 0.001 | 50 | 0.9945 | 0.9381 | 0.9120 |
| Components | Easy ( | Medium ( | Hard ( | Decision |
|---|---|---|---|---|
| Basic GCN | 0.7968 | 0.6958 | 0.3640 | - |
| Basic EdgeConv | Added | |||
| Warmup | Added | |||
| Prev-X | Added | |||
| X0 | Added | |||
| Attention | Removed | |||
| X0-Convergent (ECNN-ASCD) | Added |
| Solution | Easy | Medium | Hard | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Precision | Recall | Precision | Recall | Precision | Recall | ||||
| Baseline-Pr0 | 0.3632 | 0.285 | 0.500 | 0.3678 | 0.291 | 0.500 | 0.364 | 0.286 | 0.500 |
| Baseline-Pr1 | 0.3005 | 0.215 | 0.500 | 0.2948 | 0.209 | 0.500 | 0.2996 | 0.214 | 0.500 |
| BERT-MLP | 0.9653 | 0.9673 | 0.9635 | 0.8508 | 0.8758 | 0.8416 | 0.6761 | 0.7072 | 0.6752 |
| GCNN-ASCD | 0.9465 | 0.9517 | 0.9429 | 0.8352 | 0.8469 | 0.8294 | 0.6914 | 0.6923 | 0.6907 |
| ECNN-ASCD | 0.9945 | 0.9949 | 0.9941 | 0.9381 | 0.9402 | 0.9363 | 0.9120 | 0.9147 | 0.9099 |
| ECNN-ASCD | GCNN-ASCD | BERT_MLP | Base-0 | Base-1 | |
|---|---|---|---|---|---|
| ECNN-ASCD | |||||
| GCNN-ASCD | ⇑ | ||||
| BERT_MLP | ⇑ | ⇐ | |||
| Base-0 | ⇑ | ⇑ | ⇑ | ||
| Base-1 | ⇑ | ⇑ | ⇑ | ⇑ |
| ECNN-ASCD | GCNN-ASCD | BERT_MLP | Base-0 | Base-1 | |
|---|---|---|---|---|---|
| ECNN-ASCD | |||||
| GCNN-ASCD | ⇑ | ||||
| BERT_MLP | ⇑ | ⇐ | |||
| Base-0 | ⇑ | ⇑ | ⇑ | ||
| Base-1 | ⇑ | ⇑ | ⇑ | ⇑ |
| ECNN-ASCD | GCNN-ASCD | BERT_MLP | Base-0 | Base-1 | |
|---|---|---|---|---|---|
| ECNN-ASCD | |||||
| GCNN-ASCD | ⇑ | ||||
| BERT_MLP | ⇑ | ⇑ | |||
| Base-0 | ⇑ | ⇑ | ⇑ | ||
| Base-1 | ⇑ | ⇑ | ⇑ | ⇑ |
| Level | # Doc. | Avg. Doc. Leng. | Avg. Para. Leng. | Avg. Style Change |
|---|---|---|---|---|
| PAN 2021 (Task 2) | 16,000 | 6.8836 para. | 44.2091 words | 3.1556 changes (53.63%) |
| PAN 2022 (Task 3) | 10,000 | 15.9652 para. | 19.9412 words | 8.1380 changes (54.38%) |
| PAN 2021-Task 2 | PAN 2022-Task 3 | ||
|---|---|---|---|
| Solution | Solution | ||
| Zamir et al. [97] | 0.7750 | Lin et al. [77] | 0.7156 |
| Zhang et al. [76] | 0.7510 | Jiang et al. [79] | 0.6720 |
| ECNN-ESCD | 0.7373 | Zhang et al. [75] | 0.6581 |
| Str [78] | 0.7070 | Zi and Zhou [63] | 0.6483 |
| Huertas-Tato et al. [110] | 0.7043 | Lao et al. [62] | 0.6314 |
| Deibel and Löfflad [55] | 0.6690 | Huertas-Tato et al. [110] | 0.6312 |
| Singh et al. [43] | 0.6570 | ECNN-ESCD | 0.6215 |
| Nath [52] | 0.6470 | Alvi et al. [40] | 0.5636 |
| - | - | Rodríguez-Losada and Castro-Castro [67] | 0.5565 |
| - | - | Alshamasi and Menai [10] | 0.4995 |
| Baseline (random) | 0.470 | Baseline (random) | 0.4809 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alsheddi, A.S.; Menai, M.E.B. Edge Convolutional Networks for Style Change Detection in Arabic Multi-Authored Text. Appl. Sci. 2025, 15, 6633. https://doi.org/10.3390/app15126633
Alsheddi AS, Menai MEB. Edge Convolutional Networks for Style Change Detection in Arabic Multi-Authored Text. Applied Sciences. 2025; 15(12):6633. https://doi.org/10.3390/app15126633
Chicago/Turabian StyleAlsheddi, Abeer Saad, and Mohamed El Bachir Menai. 2025. "Edge Convolutional Networks for Style Change Detection in Arabic Multi-Authored Text" Applied Sciences 15, no. 12: 6633. https://doi.org/10.3390/app15126633
APA StyleAlsheddi, A. S., & Menai, M. E. B. (2025). Edge Convolutional Networks for Style Change Detection in Arabic Multi-Authored Text. Applied Sciences, 15(12), 6633. https://doi.org/10.3390/app15126633