
WordMap: Text Mining Application of Enhanced Corpus Segmentation and Semantic Topic Recognition


Abstract
1. Introduction
2. Literature Review
3. Research Design and Assessment Model
3.1. Research Design
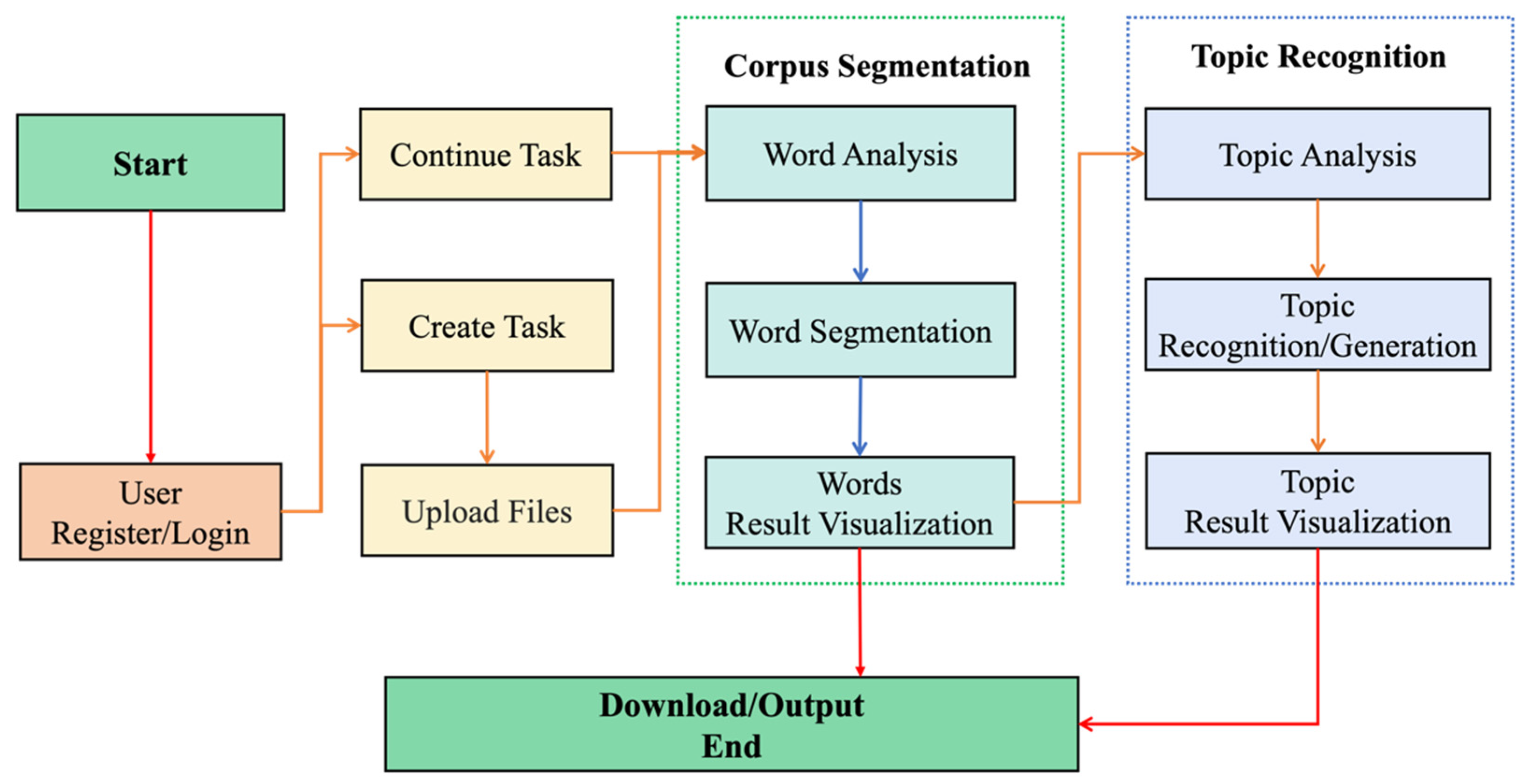
3.1.1. System Process
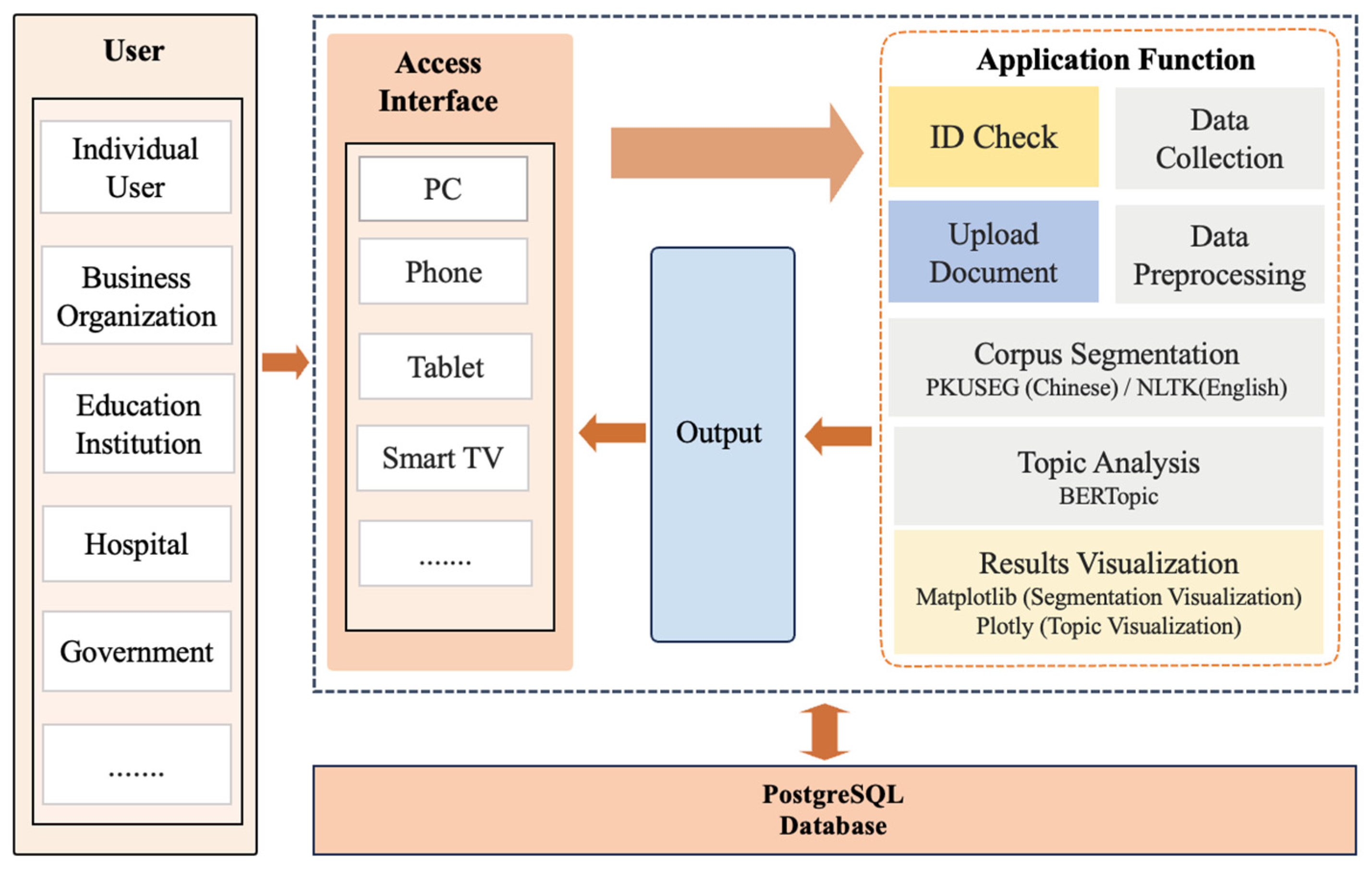
3.1.2. Modular Architecture
3.1.3. User Interface
3.2. Module Implementation
3.2.1. Corpus Segmentation
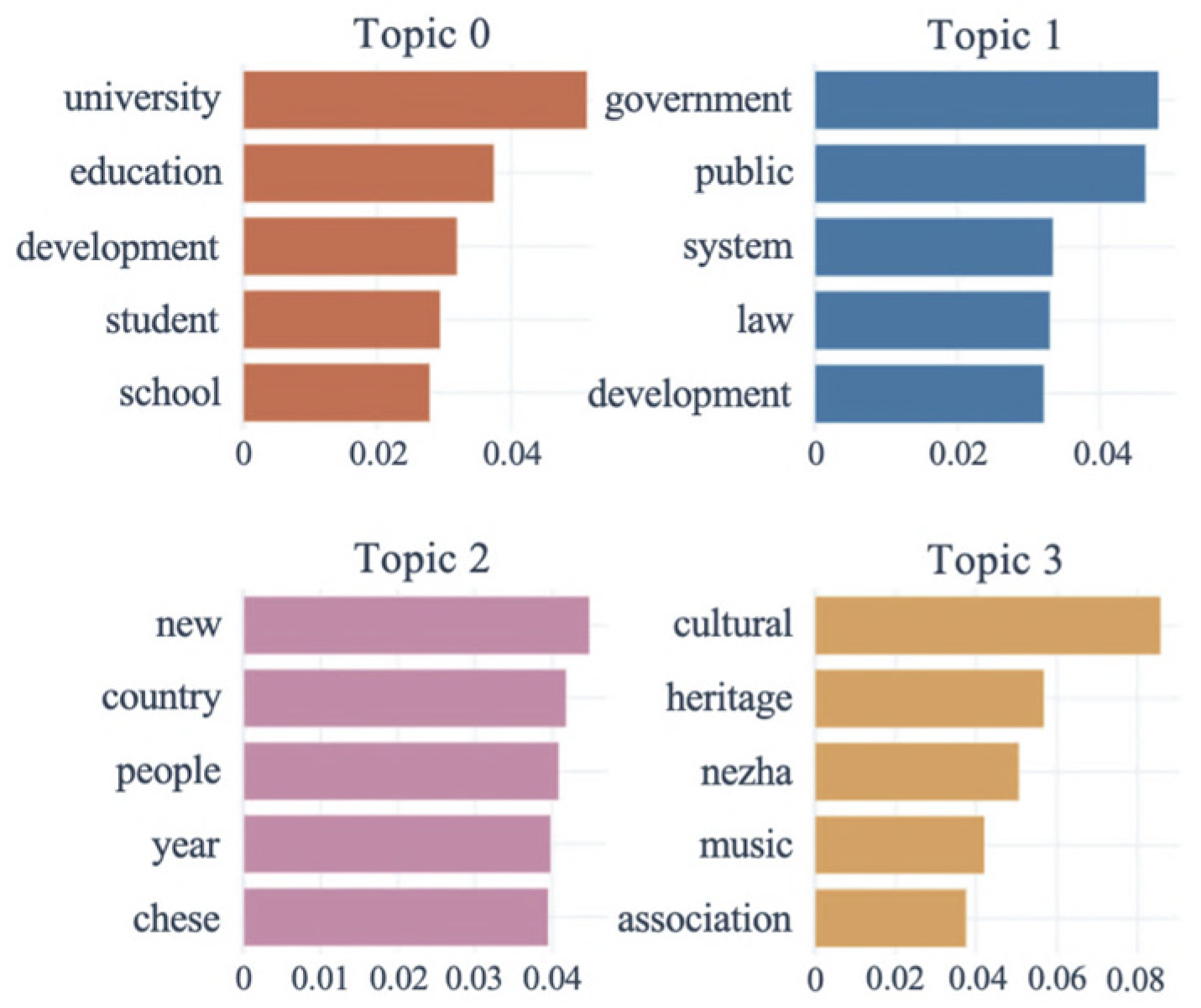
3.2.2. Topic Modeling
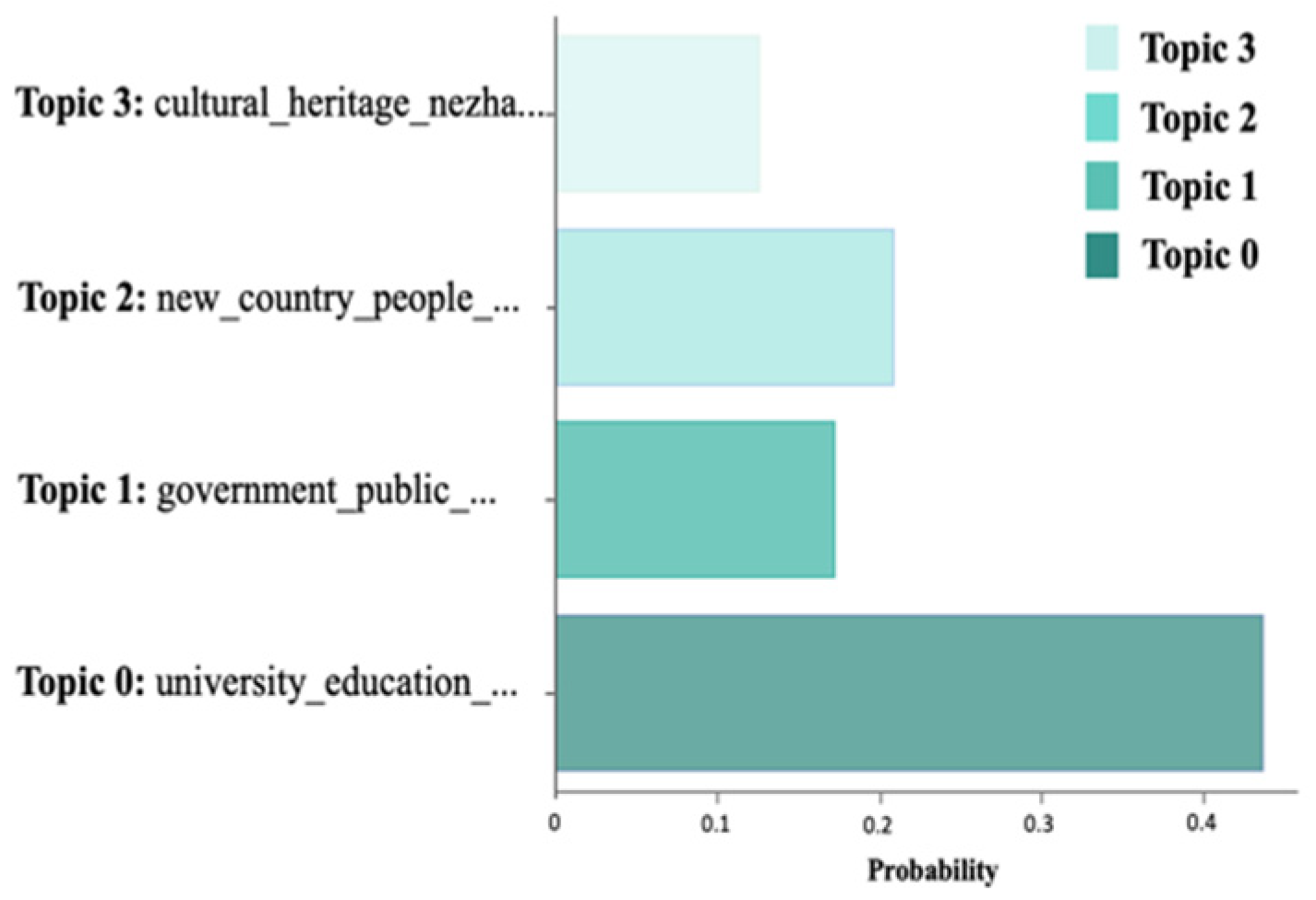
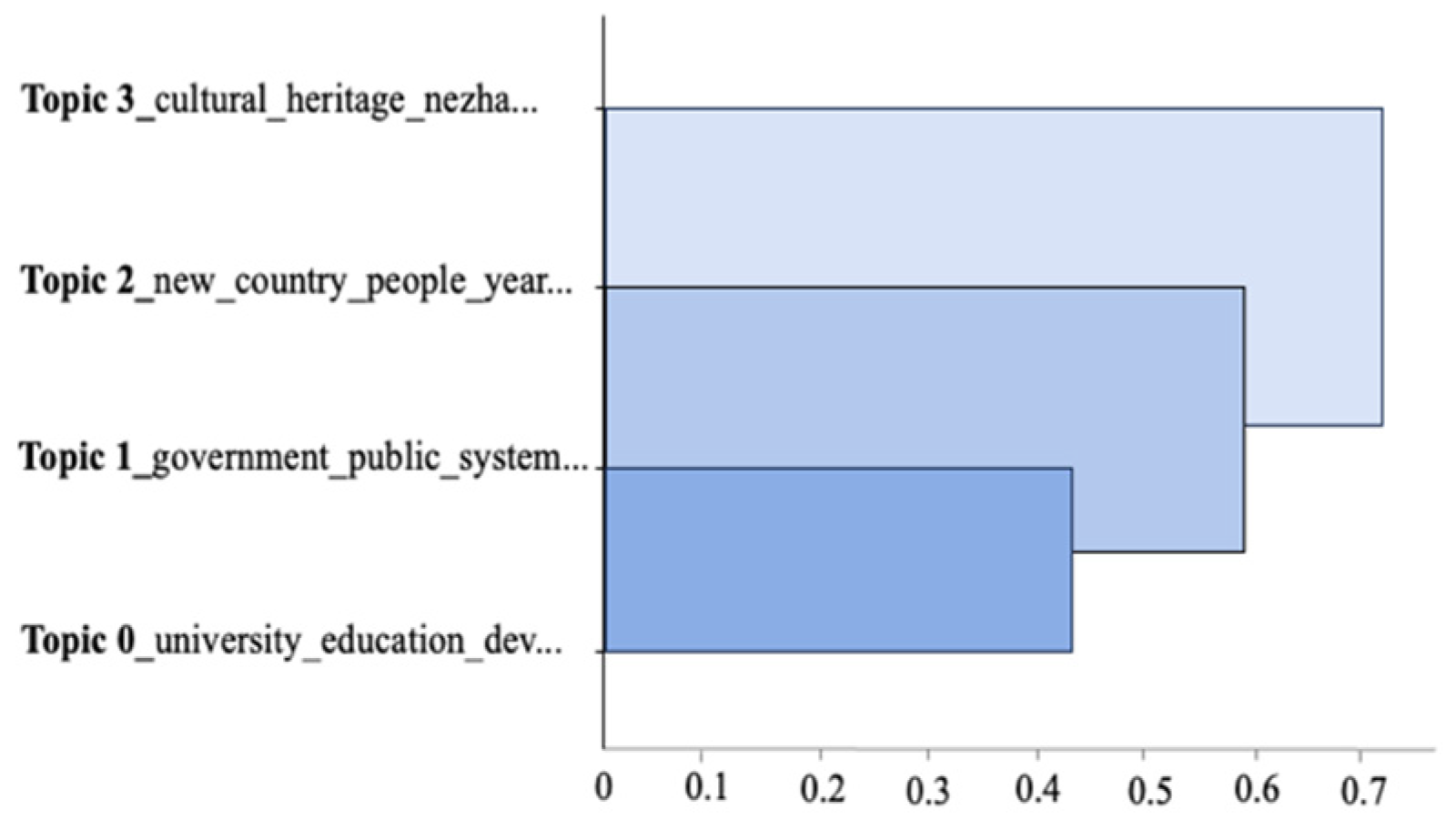
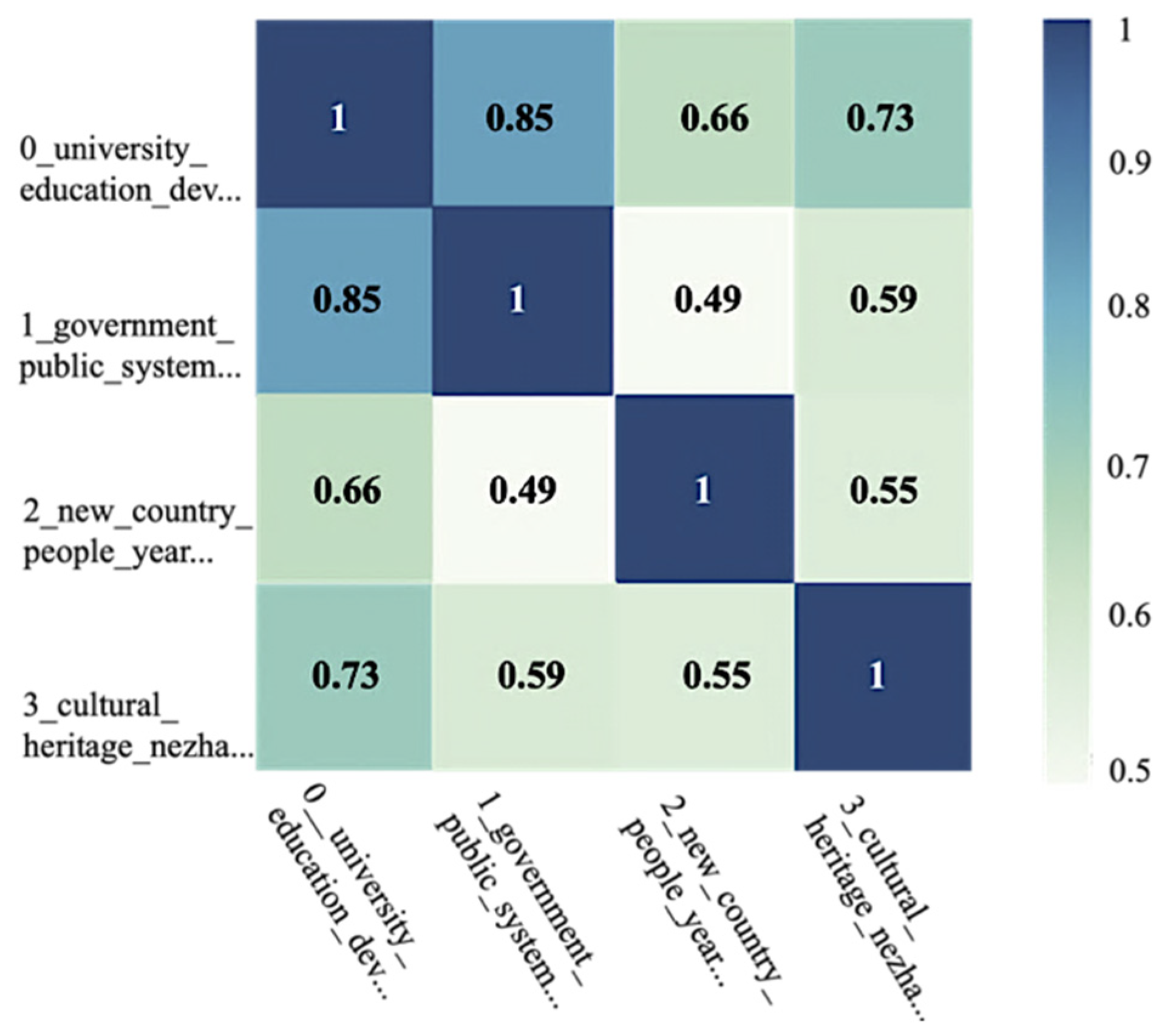
3.2.3. Result Visualization
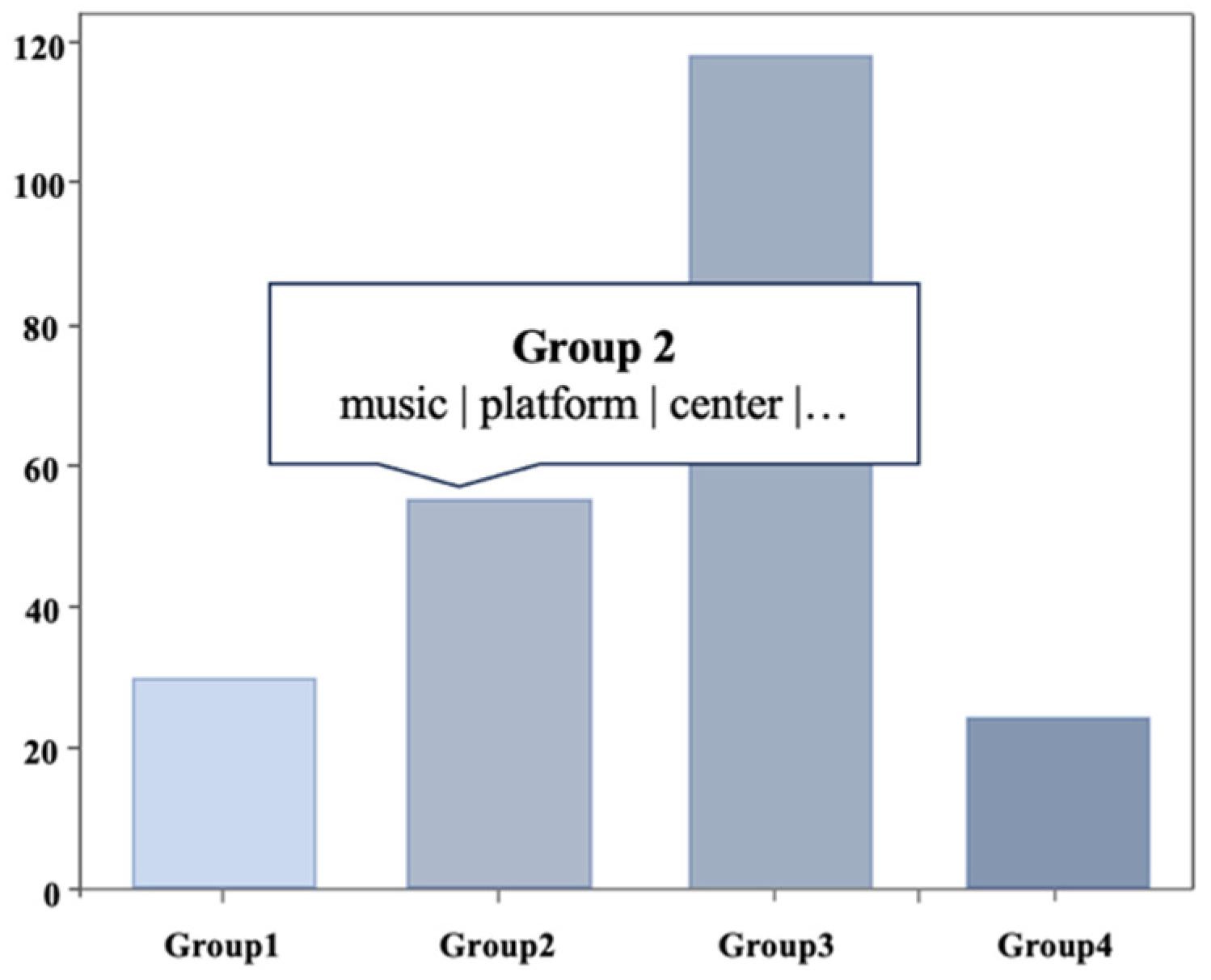
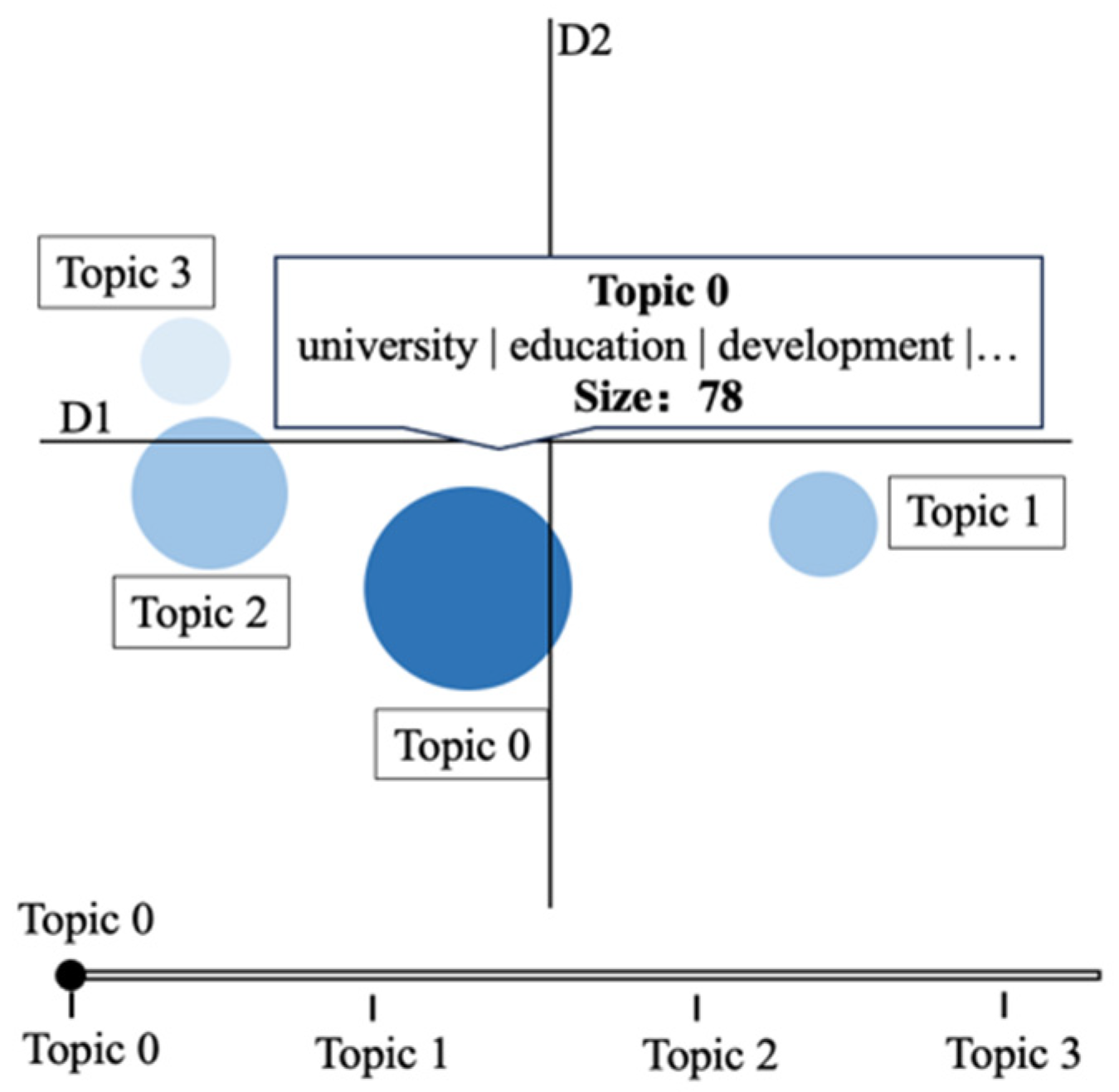
3.3. Function Demonstration
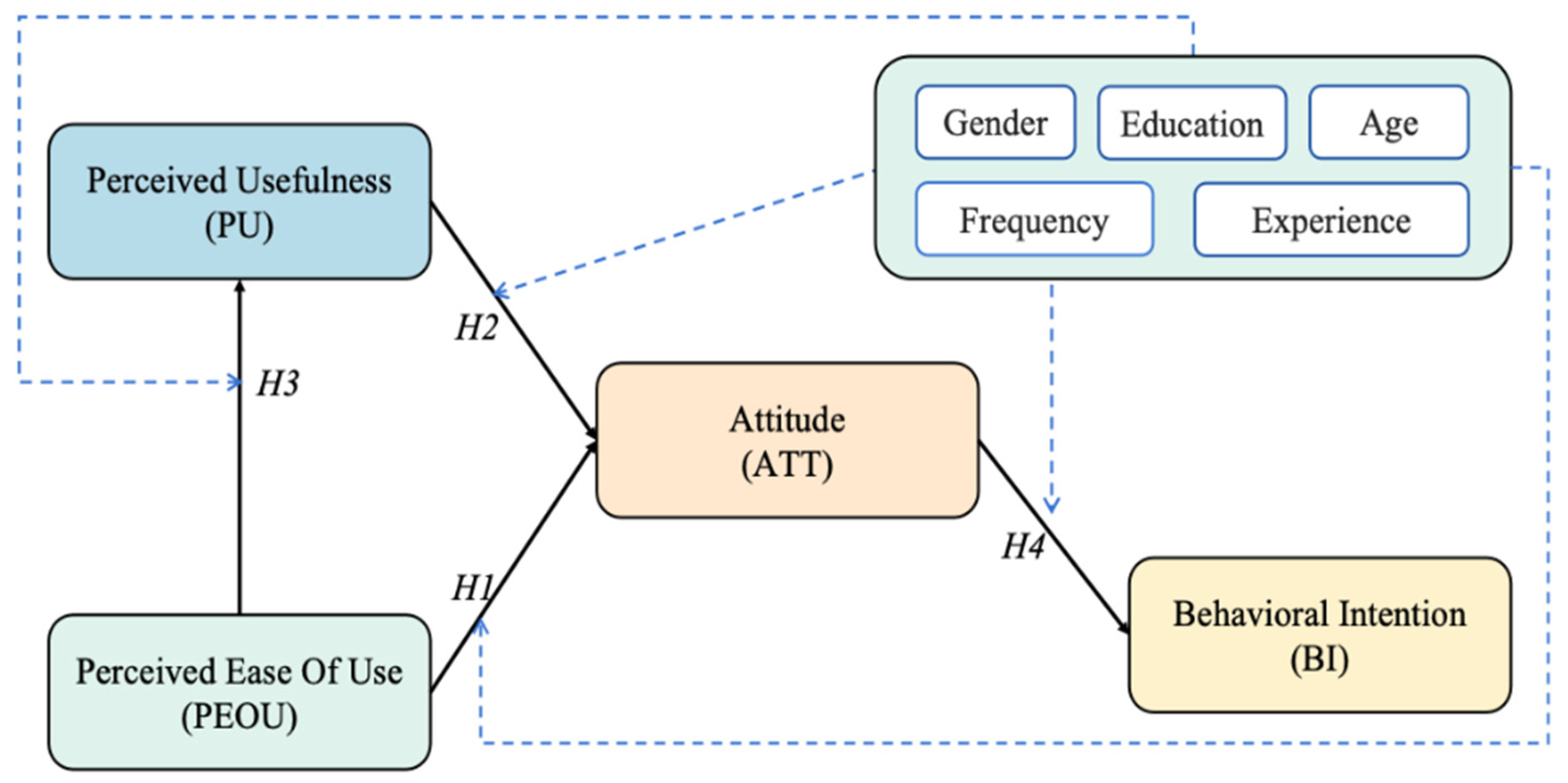
3.4. Assessment Model
4. Results
4.1. Results of T-Test
4.2. Sample Characteristics
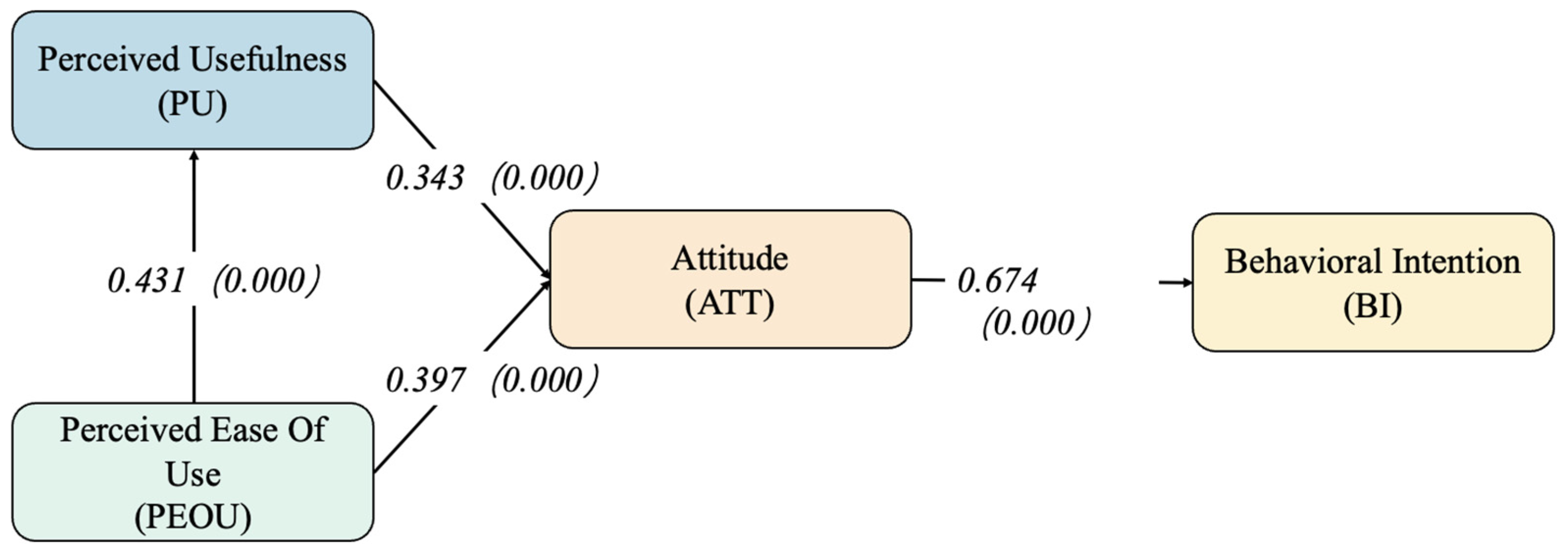
4.3. Results of SEM-PLS
5. Discussion
5.1. Evaluation and Implications
5.2. Limitations
5.3. Future Work
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kim, H.; Cho, I.; Park, M. Analyzing genderless fashion trends of consumers’ perceptions on social media: Using unstructured big data analysis through Latent Dirichlet Allocation-based topic modeling. Fash. Text. 2022, 9, 6. [Google Scholar] [CrossRef]
- Cano-Marin, E.; Mora-Cantallops, M.; Sanchez-Alonso, S. The power of big data analytics over fake news: A scientometric review of Twitter as a predictive system in healthcare. Technol. Forecast. Soc. Change 2023, 190, 122386. [Google Scholar] [CrossRef]
- Blasco-Arcas, L.; Lee, H.-H.M.; Kastanakis, M.N.; Alcañiz, M.; Reyes-Menendez, A. The role of consumer data in marketing: A research agenda. J. Bus. Res. 2022, 146, 436–452. [Google Scholar] [CrossRef]
- Pichiyan, V.; Muthulingam, S.; G, S.; Nalajala, S.; Ch, A.; Das, M.N. Web Scraping using Natural Language Processing: Exploiting Unstructured Text for Data Extraction and Analysis. Procedia Comput. Sci. 2023, 230, 193–202. [Google Scholar] [CrossRef]
- Lee, S.; Song, J.; Kim, Y. An Empirical Comparison of Four Text Mining Methods. J. Comput. Inf. Syst. 2010, 51, 1–10. [Google Scholar]
- Antons, D.; Grünwald, E.; Cichy, P.; Salge, T.O. The application of text mining methods in innovation research: Current state, evolution patterns, and development priorities. RD Manag. 2020, 50, 329–351. [Google Scholar] [CrossRef]
- Xuan Bach, N.; Le Minh, N.; Shimazu, A. A Reranking Model for Discourse Segmentation using Subtree Features. In Proceedings of the 13th Annual Meeting of the Special Interest Group on Discourse and Dialogue, Seoul, Republic of Korea, 5–6 July 2012; Lee, G.G., Ginzburg, J., Gardent, C., Stent, A., Eds.; Association for Computational Linguistics: Seoul, Republic of Korea, 2012; pp. 160–168. Available online: https://aclanthology.org/W12-1623/ (accessed on 3 January 2025).
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent Dirichlet Allocation. J. Mach. Learn. Res. 2003, 3, 933–1002. [Google Scholar]
- Lee, D.; Seung, H.S. Algorithms for Non-negative Matrix Factorization. In Advances in Neural Information Processing Systems; Neural Information Processing Systems Foundation: Denver, CO, USA, 2000; Volume 13, Available online: https://proceedings.neurips.cc/paper_files/paper/2000/hash/f9d1152547c0bde01830b7e8bd60024c-Abstract.html (accessed on 3 January 2025).
- Lee, J.-H.; Park, S.; Ahn, C.-M.; Kim, D. Automatic generic document summarization based on non-negative matrix factorization. Inf. Process. Manag. 2009, 45, 20–34. [Google Scholar] [CrossRef]
- Ghasiya, P.; Okamura, K. Investigating COVID-19 News Across Four Nations: A Topic Modeling and Sentiment Analysis Approach. IEEE Access Pract. Innov. Open Solut. 2021, 9, 36645–36656. [Google Scholar] [CrossRef]
- Zhu, Q.; Chen, R.; Pang, P.C.-I.; Li, J.; Mao, C. Identifying Kidney Stone Risk Factors Through Patient Experiences with a Large Language Model: Text Analysis and Empirical Study. J. Med. Internet Res. 2025, 27, e66365. [Google Scholar] [CrossRef]
- Liu, D.-R.; Huang, Y.; Jhao, J.-J.; Lee, S.-J. News recommendations based on collaborative topic modeling and collaborative filtering with generative adversarial networks. Data Technol. Appl. 2024, 58, 24–41. [Google Scholar] [CrossRef]
- Jelodar, H.; Wang, Y.; Orji, R.; Huang, S. Deep Sentiment Classification and Topic Discovery on Novel Coronavirus or COVID-19 Online Discussions: NLP Using LSTM Recurrent Neural Network Approach. IEEE J. Biomed. Health Inform. 2020, 24, 2733–2742. [Google Scholar] [CrossRef] [PubMed]
- Devadoss, A.K.V.; Thirulokachander, V.R.; Devadoss, A.K.V. Efficient daily news platform generation using natural language processing. Int. J. Inf. Technol. 2019, 11, 295–311. [Google Scholar] [CrossRef]
- Song, M.; Hu, C.; Yuan, J.; Zhang, A.; Liu, X. Toward an ecological civilization: Exploring changes in China’s land use policy over the past 35 years using text mining. J. Clean. Prod. 2023, 427, 139265. [Google Scholar] [CrossRef]
- Gan, L.; Yang, T.; Huang, Y.; Yang, B.; Luo, Y.Y.; Richard, L.W.C.; Guo, D. Experimental Comparison of Three Topic Modeling Methods with LDA, Top2Vec and BERTopic. In Artificial Intelligence and Robotics. ISAIR 2023; Lu, H., Cai, J., Eds.; Communications in Computer and Information Science; Springer: Singapore, 2024; Volume 1998. [Google Scholar] [CrossRef]
- Albarrak, M.; Pergola, G.; Jhumka, A. U-BERTopic: An Urgency-Aware BERT-Topic Modeling Approach for Detecting CyberSecurity Issues via Social Media. In Proceedings of the First International Conference on Natural Language Processing and Artificial Intelligence for Cyber Security, Lancaster, UK, 29–30 July 2024; Mitkov, R., Ezzini, S., Ranasinghe, T., Ezeani, I., Khallaf, N., Acarturk, C., Bradbury, M., El-Haj, M., Rayson, P., Eds.; International Conference on Natural Language Processing and Artificial Intelligence for Cyber Security: Lancaster, UK, 2024; pp. 196–211. Available online: https://aclanthology.org/2024.nlpaics-1.22/ (accessed on 5 January 2025).
- Cui, M.; Huang, R.; Hu, Z.; Xia, F.; Xu, X.; Qi, L. Semantic rule-based information extraction for meteorological reports. Int. J. Mach. Learn. Cybern. 2024, 15, 177–188. [Google Scholar] [CrossRef]
- Palmer, D.D. A Trainable Rule-Based Algorithm for Word Segmentation. In Proceedings of the 35th Annual Meeting of the Association for Computational Linguistics and 8th Conference of the European Chapter of the Association for Computational Linguistics, Madrid, Spain, 7–12 July 1997; pp. 321–328. [Google Scholar] [CrossRef]
- Vo, B.-K.H.; Collier, N. Twitter Emotion Analysis in Earthquake Situations. Int. J. Comput. Linguist. Appl. 2013, 4, 159–173. [Google Scholar]
- Beeferman, D.; Berger, A.; Lafferty, J. Statistical Models for Text Segmentation. Mach. Learn. 1999, 34, 177–210. [Google Scholar] [CrossRef]
- Khare, R.; An, Y. An empirical study on using hidden markov model for search interface segmentation. In Proceedings of the 18th ACM Conference on Information and Knowledge Management, Hong Kong, China, 2–6 November 2009; pp. 17–26. [Google Scholar] [CrossRef]
- Zhang, L.-Y.; Qin, M.; Zhang, X.-M.; Ma, H.-X. A Chinese word segmentation algorithm based on maximum entropy. Int. Conf. Mach. Learn. Cybern. 2010, 3, 1264–1267. [Google Scholar] [CrossRef]
- Vemulapalli, R.; Tuzel, O.; Liu, M.-Y.; Chellapa, R. Gaussian Conditional Random Field Network for Semantic Segmentation. 2016, pp. 3224–3233. Available online: https://openaccess.thecvf.com/content_cvpr_2016/html/Vemulapalli_Gaussian_Conditional_Random_CVPR_2016_paper.html (accessed on 9 January 2025).
- Xue, N.; Shen, L. Chinese Word Segmentation as LMR Tagging. In Proceedings of the Second SIGHAN Workshop on Chinese Language Processing, Sapporo, Japan, 11–12 July 2003; pp. 176–179. [Google Scholar] [CrossRef]
- Zhao, Y.; Fu, G. A MEMs-based Labeling Approach to Punctuation Correction in Chinese Opinionated Text. In Proceedings of the International Conference on Artificial Intelligence (ICAI), Las Vegas, NV, USA, 22–25 July 2013; pp. 329–335. [Google Scholar]
- Wang, Y.; Shi, C.; Xiao, B.; Wang, C.; Qi, C. CRF based text detection for natural scene images using convolutional neural network and context information. Neurocomputing 2018, 295, 46–58. [Google Scholar] [CrossRef]
- Koshorek, O.; Cohen, A.; Mor, N.; Rotman, M.; Berant, J. Text Segmentation as a Supervised Learning Task. arXiv 2018, arXiv:1803.09337. [Google Scholar] [CrossRef]
- Iosifov, I.; Iosifova, O.; Sokolov, V. Sentence Segmentation from Unformatted Text using Language Modeling and Sequence Labeling Approaches. In Proceedings of the 2020 IEEE International Conference on Problems of Infocommunications. Science and Technology (PIC S&T), Kharkiv, Ukraine, 6–9 October 2020; pp. 335–337. [Google Scholar] [CrossRef]
- Luo, R.; Xu, J.; Zhang, Y.; Zhang, Z.; Ren, X.; Sun, X. PKUSEG: A Toolkit for Multi-Domain Chinese Word Segmentation. arXiv 2022, arXiv:1906.11455. [Google Scholar] [CrossRef]
- Yogish, D.; Manjunath, T.N.; Hegadi, R.S. Review on Natural Language Processing Trends and Techniques Using NLTK. In Recent Trends in Image Processing and Pattern Recognition; Santosh, K.C., Hegadi, R.S., Eds.; Springer: Berlin/Heidelberg, Germany, 2019; pp. 589–606. [Google Scholar] [CrossRef]
- Grootendorst, M. BERTopic: Neural topic modeling with a class-based TF-IDF procedure. arXiv 2022, arXiv:2203.05794. [Google Scholar] [CrossRef]
- Albanese, N.C. Topic Modeling with LSA, pLSA, LDA, NMF, BERTopic, Top2Vec: A Comparison; Towards Data Science: 2022. Available online: https://towardsdatascience.com/topic-modeling-with-lsa-plsa-lda-nmf-bertopic-top2vec-a-comparison-5e6ce4b1e4a5/ (accessed on 15 January 2025).
- Lalitha, T.B.; Sreeja, P.S. Title-Based Topic Modeling on E-learning Web Content Titles Using BERTopic Model. In Fifth International Conference on Computing and Network Communications; Thampi, S.M., Chaudhary, V., Pathan, A.-S.K., Li, K.C., Krishnaswamy, D., Eds.; Springer Nature: Singapore, 2025; pp. 559–580. [Google Scholar] [CrossRef]
- Rachel J., J.L.; Bhuvaneswari, A.; Kumudha, M. Topic Modeling Based Clustering of Disaster Tweets Using BERTopic. In Proceedings of the 2024 MIT Art, Design and Technology School of Computing International Conference (MITADTSoCiCon), Pune, India, 25–27 April 2024; pp. 1–6. [Google Scholar] [CrossRef]
- Kirsh, I. Visualizing Web Users’ Attention to Text with Selection Heatmaps. In Web Engineering; Brambilla, M., Chbeir, R., Frasincar, F., Manolescu, I., Eds.; Springer International Publishing: Berlin/Heidelberg, Germany, 2021; pp. 517–520. [Google Scholar] [CrossRef]
- Wallace, L.G.; Sheetz, S.D. The adoption of software measures: A technology acceptance model (TAM) perspective. Inf. Manag. 2014, 51, 249–259. [Google Scholar] [CrossRef]
- Hair, J.F.; Risher, J.J.; Sarstedt, M.; Ringle, C.M. When to use and how to report the results of PLS-SEM. Eur. Bus. Rev. 2019, 31, 2–24. [Google Scholar] [CrossRef]
- Cheung, G.W.; Wang, C. Current Approaches for Assessing Convergent and Discriminant Validity with SEM: Issues and Solutions. Acad. Manag. Proc. 2017, 2017, 12706. [Google Scholar] [CrossRef]
- Venkatesh, V.; Morris, M.G.; Davis, G.B.; Davis, F.D. User Acceptance of Information Technology: Toward a Unified View. MIS Q. 2003, 27, 425–478. [Google Scholar] [CrossRef]
- Guo, J.; Yang, X.; Wang, Y.; Pang, P.C.-I.; Im, S.-K.; Li, J.; Yang, Y. Performance Evaluation and Application Potential of Small Large Language Models in Complex Sentiment Analysis Tasks. IEEE Access 2025, 13, 49007–49017. [Google Scholar] [CrossRef]
- Si, Y.-W.; Sun, L.; Pang, P.C.-I. Roles of Information Propagation of Chinese Microblogging Users in Epidemics: A Crisis Management Perspective. Internet Res. 2021, 31, 540–561. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Paired Differences | |||||||
|---|---|---|---|---|---|---|---|
| Mean | SD | 95% CI | t | df | Sig. | ||
| LLCI | ULCI | ||||||
| Time1-Time 2 | 87.88 | 34.15 | 82.31 | 93.44 | 31.20 | 146 | <0.001 |
| Demographic Information | Frequency | Percent (%) | |
|---|---|---|---|
| Gender | Male | 82 | 55.7 |
| Female | 65 | 44.2 | |
| Age in year | 18–20 | 36 | 24.4 |
| 21–25 | 57 | 38.7 | |
| 26–30 | 54 | 36.7 | |
| Education | Undergraduate | 51 | 34.6 |
| Master | 59 | 40.1 | |
| Doctor | 37 | 25.1 | |
| Past experience (Text mining-related) | Yes | 89 | 60.5 |
| No | 58 | 39.4 | |
| Frequency (Text mining tools) | Always | 65 | 44.2 |
| Sometime | 49 | 33.3 | |
| Never | 33 | 22.4 | |
| Used other tools before | Yes | 78 | 53 |
| No | 69 | 46.9 | |
| Attitude toward text mining knowledge | Yes, Need knows more | 55 | 37.4 |
| No | 58 | 39.4 | |
| Not sure | 34 | 23.1 | |
| Construct | Item | Factor Loading | Cronbach’s Alpha | AVE | Composite Reliability |
|---|---|---|---|---|---|
| PU | PU1 | 0.751 | 0.696 | 0.521 | 0.812 |
| PU2 | 0.750 | ||||
| PU3 | 0.618 | ||||
| PU4 | 0.758 | ||||
| PEOU | PEOU1 | 0.709 | 0.689 | 0.517 | 0.810 |
| PEOU2 | 0.758 | ||||
| PEOU3 | 0.646 | ||||
| PEOU4 | 0.758 | ||||
| ATT | ATT1 | 0.744 | 0.691 | 0.520 | 0.812 |
| ATT2 | 0.786 | ||||
| ATT3 | 0.676 | ||||
| ATT4 | 0.672 | ||||
| BI | BI1 | 0.719 | 0.649 | 0.586 | 0.809 |
| BI2 | 0.745 | ||||
| BI3 | 0.828 |
| ATT | BI | PEOU | PU | |
|---|---|---|---|---|
| ATT | 0.721 | |||
| BI | 0.674 ** | 0.766 | ||
| PEOU | 0.545 ** | 0.546 ** | 0.719 | |
| PU | 0.514 ** | 0.385 ** | 0.431 ** | 0.722 |
| Hypothesis (Path) | Coeff. | T-Value | p-Value | Conclusion |
|---|---|---|---|---|
| H1 (PU → ATT) | 0.343 | 4.599 | p < 0.001 | Supported |
| H2 (PEOU → ATT) | 0.397 | 5.246 | p < 0.001 | Supported |
| H3 (PEOU → PU) | 0.431 | 5.688 | p < 0.001 | Supported |
| H4 (ATT → BI) | 0.674 | 13.767 | p < 0.001 | Supported |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, Z.; Zou, H.; Pang, P.C.-I.; Chao, P.W.-O.; Ng, B.K. WordMap: Text Mining Application of Enhanced Corpus Segmentation and Semantic Topic Recognition. Appl. Sci. 2025, 15, 6632. https://doi.org/10.3390/app15126632
Wei Z, Zou H, Pang PC-I, Chao PW-O, Ng BK. WordMap: Text Mining Application of Enhanced Corpus Segmentation and Semantic Topic Recognition. Applied Sciences. 2025; 15(12):6632. https://doi.org/10.3390/app15126632
Chicago/Turabian StyleWei, Zhijian, Huiwen Zou, Patrick Cheong-Iao Pang, Penny Wong-On Chao, and Benjamin K. Ng. 2025. "WordMap: Text Mining Application of Enhanced Corpus Segmentation and Semantic Topic Recognition" Applied Sciences 15, no. 12: 6632. https://doi.org/10.3390/app15126632
APA StyleWei, Z., Zou, H., Pang, P. C.-I., Chao, P. W.-O., & Ng, B. K. (2025). WordMap: Text Mining Application of Enhanced Corpus Segmentation and Semantic Topic Recognition. Applied Sciences, 15(12), 6632. https://doi.org/10.3390/app15126632