1. Introduction
Deepfakes are hyper-realistic manipulated media generated using various advanced deep learning (DL) techniques. Deepfake videos are produced by superimposing one person’s facial features onto another person’s face through techniques such as face replacement, facial reenactment, face editing, and complete face synthesis [
1,
2], among others. Recently, deepfakes have become a public concern due to their potential for misuse and the spread of false information [
3,
4,
5]. Various deepfake creation methods are readily available for use, and anyone interested can use them to easily modify existing media, presenting a false representation of reality where individuals appear to be speaking or performing actions that never actually took place. Additionally, the manipulation of these videos is carried out on a frame-by-frame basis, making deepfakes seem more realistic and believable. Consequently, deepfake creation techniques have been used to manipulate images and videos, causing celebrities and politicians to be depicted as saying or doing things that are untrue.
The applications of deepfake videos can range from creative uses such as creating realistic special effects or replacing an actor in the film and entertainment industry to potentially harmful attacks, such as using deepfakes to create misleading videos for criminal purposes [
6,
7]. In the realm of politics, deepfakes have been utilized to create fake political videos, war propaganda, and videos intended to influence elections. This has led to widespread concern about the potential for malicious actors to use deepfakes to spread false information, erode the credibility of political candidates, or even pose a threat to national security. The dissemination of misleading and false information through deepfakes can have real-life consequences, making it imperative to address the need for accurate and reliable deepfake video detection techniques.
Deepfake video detection attempts to detect whether a given video has been tampered with or manipulated using deepfake techniques. The challenge of detecting deepfakes has inspired researchers and technology companies to develop various deep learning methods to identify tampered videos [
1,
3,
8,
9,
10,
11]. Currently, deepfake detection methods often rely heavily on visual features [
12,
13,
14,
15]. Visual features-based detection can be on a frame-by-frame basis [
16] or use the temporal relationship in the differences between frames over time [
17,
18]. However, these methods mostly encounter challenges in detecting deepfakes that differ from their training data, thus failing to detect deepfakes sufficiently. In recent years, the rapid progress made in advanced generative models like Generative Adversarial Networks (GANs) [
19,
20,
21], Variational Autoencoders (VAEs) [
22,
23], and Diffusion Models (DMs) [
24] has made it even more challenging to detect deepfakes based on visual artifacts alone, as deepfakes leave little to no trace of visual clues that help to distinguish them from images of the real world. Several authors have proposed alternative detection methods, such as utilizing biological signals [
25], geometric features [
26], frequency information [
27], spatial features with temporal information [
28,
29] and generative adversarial network fingerprints [
30], as potential solutions to the difficulties in detecting deepfakes. Another approach to spotting deepfake videos involves examining the consistency of pixels or groups of similar pixels [
31]. Current deepfake video detection methods generate competitive results when it comes to identifying manipulated videos, but they often fail to generalize to more diverse videos, particularly in environments with different facial poses, light angles, and movements [
32].
In an effort to provide more generalization, we propose a novel architecture called the Generative Convolutional Vision Transformer (GenConViT), aimed at detecting a diverse set of fake videos. Our proposed architecture leverages both visual artifacts and the latent data distribution of the data in its detection process.
GenConViT has two main components: a generative part and a feature extraction part. The generative part utilizes two different models (an Autoencoder (AE) [
33] and VAE), to learn the latent data distribution of the training data. The feature extraction component employs ConvNeXt [
34] and the Swin Transformer [
35] to extract relevant visual features. Our proposed model addresses the limitations of current detection methods by identifying both the visual artifacts and the latent data distribution, making it capable of detecting a wider range of fake videos. Extensive experimental results demonstrate that GenConViT produces competitive results compared to other state-of-the-art deepfake detection models.
In summary, our paper makes the following contributions to this area of research:
GenConViT: We propose the Generative Convolutional Vision Transformer for deepfake video detection. Our method utilizes an AE and VAE to generate images, extracts the visual features of the original and generated image using ConvNeXt and the Swin Transformer, and then uses the extracted features to detect whether a video is a deepfake video.
By training our model on more than 1 million images extracted from five large deepfake datasets and detecting both their visual and latent features, our proposed method aims to enhance its deepfake detection performance compared to that of previously proposed methods.
We thoroughly evaluated GenConViT on more than 3972 videos collected from five deepfake video datasets, demonstrating its robust performance under diverse experimental settings.
While our approach achieves a strong performance, our comprehensive ablation study (a leave-one-dataset-out study) indicates a potential limitation in the generalizability of deepfake detection methods, particularly when faced with out-of-distribution data. This is an area for future work.
The remainder of this article is structured as follows: An overview of existing studies is presented in
Section 2. The proposed Generative Convolutional Vision Transformer (GenConViT) deepfake detection framework and the datasets used are detailed in
Section 3. Experiments are discussed in
Section 4, and an ablation study is performed in
Section 4.4.2. Finally, the conclusions are drawn in
Section 6.
3. Proposed Deepfake Detection Method
In this section, we propose a deepfake detection framework based on a Generative Convolutional Vision Transformer (GenConViT), which we introduce for the first time.
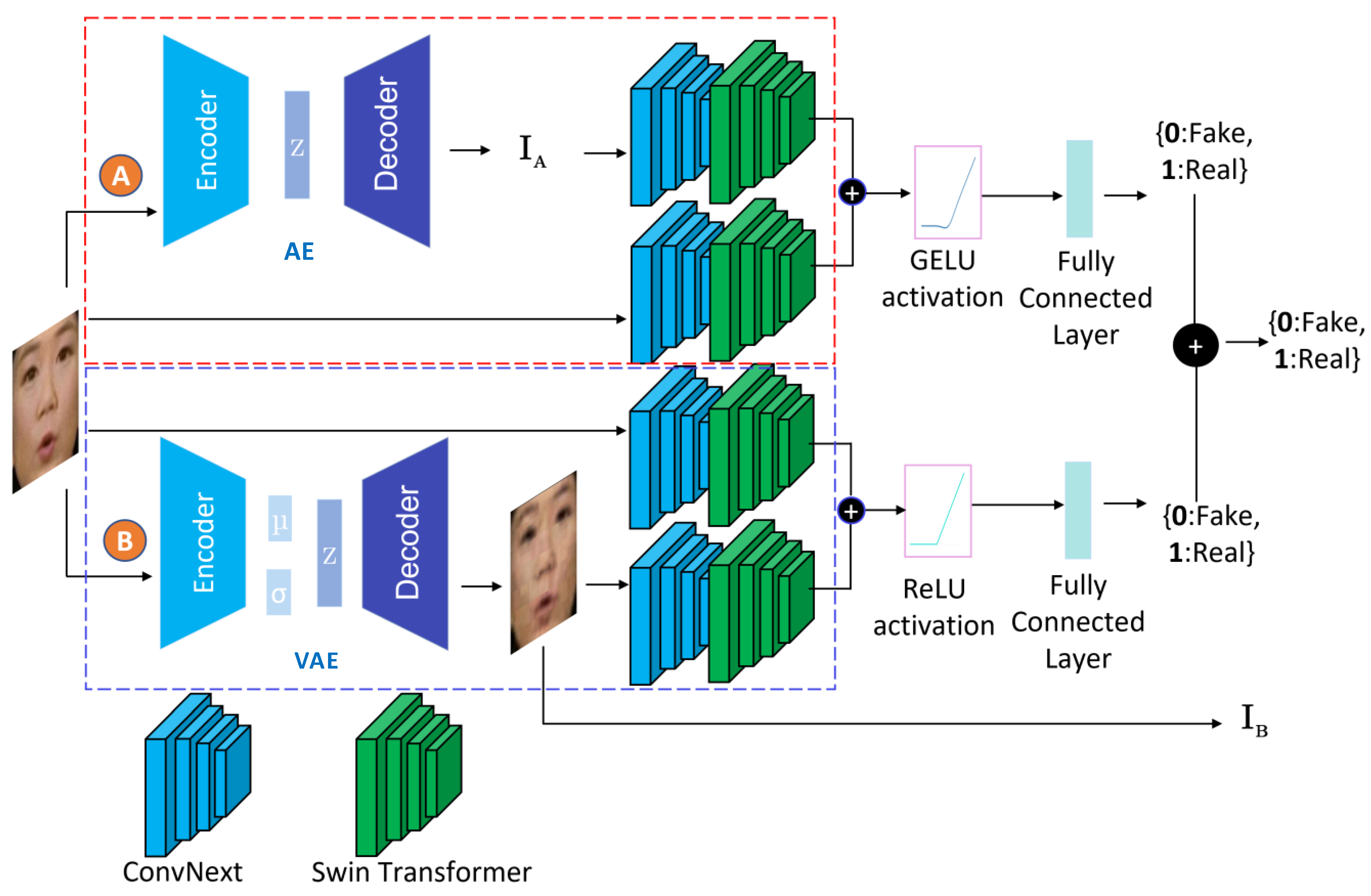
The proposed Generative Convolutional Vision Transformer model transforms the input facial images to latent spaces and extracts visual clues and hidden patterns from within them to determine whether a video is real or fake. The proposed GenConViT model is shown in
Figure 1. It has two independently trained networks (
A and
B) and four main modules: an Autoencoder (AE), a Variational Autoencoder (VAE), a ConvNeXt layer, and a Swin Transformer. The first network (
A) includes an AE, a ConvNeXt layer, and a Swin Transformer, while the second network (
B) includes a VAE, a ConvNeXt layer, and a Swin Transformer. The first network uses an AE to transform images to a Latent Feature (LF) space, maximizing the model’s class prediction probability, indicating the likelihood that a given input is a deepfake. The second network uses a VAE to maximize the probability of correct class prediction and minimize the reconstruction loss between the sample input image and the reconstructed image. Both AE and VAE models extract LFs from the input facial images (extracted from video frames), which capture hidden patterns and correlations present in the learned deepfake visual artifacts. The ConvNeXt and Swin Transformer models form a novel hybrid model: ConvNeXt-Swin. The ConvNeXt model acts as the backbone of the hybrid model, using a CNN to extract features from the input images. The Swin Transformer, with its hierarchical feature representation and attention mechanism, further extracts the global and local features of the input. The two networks each have two ConvNeXt-Swin models, which both take a
RGB image as their input, as well as an LF extracted by either the AE (
) or the VAE (
). The use of the ConvNeXt-Swin hybrid model enables the learning of relationships among the LFs extracted by the AE and VAE.
3.1. Autoencoder and Variational Autoencoder
An AE and a VAE consist of two networks: an Encoder and a Decoder. The Encoder of the AE maps an input image
to a latent space
, where
K is the number of channels (features) in the output and
and
are the height and width of the output feature map, respectively. The Decoder of the AE maps the latent space
to an output image
. The Encoder of the AE is composed of five convolutional layers with width starting from 3 and expanding up to 256, with kernels of size
and a stride of 2. Each convolutional layer is followed by ReLU non-linearity and Max pooling of kernel size
and stride 2. The output of the Encoder is a
down-sampled LF. The Decoder is composed of five transposed convolutional layers with a width starting at 256 and ending at 3, with kernels of size
and stride of 2. Each transposed convolutional layer is followed by ReLU non-linearity. The output of the Decoder,
, is a reconstructed feature space of the input image with dimensions
. In this case,
has dimensions
. The details of this configuration are shown in
Table 2.
The goal of the VAE is to learn a meaningful latent representation of the input image and reconstruct the input image by performing random sampling of the latent space while minimizing the reconstruction loss. The Encoder of the VAE maps an input image X to a probability distribution over a latent space , in which and are the mean and variance of the learned distribution, respectively.
The Encoder of the VAE is composed of four convolutional layers with widths starting from 3 and expanding up to 128, with kernels of size
and a stride of 2. Each convolutional layer is followed by Batch Normalization (BN) and LeakyReLU non-linearity. The use of Batch Normalization also serves as a regularizer, mitigating the risk of overfitting during training. The Decoder is composed of four transposed convolutional layers with widths starting from 256 and reducing to 3, with kernels of size
and a stride of 2. Each transposed convolutional layer is followed by LeakyReLU non-linearity. The output of the Decoder,
, is an image reconstructed from the input image with the dimensions
. In this case,
has dimensions
. The details of this configuration are shown in
Table 3. The choice of convolutional layers for both the AE and VAE is due to the computing power and memory we had, model accuracy, the extensive experiment, and the training time. To find the optimal hyperparameters for both the AE and VAE components, we experimented with latent sizes ranging from 8 to 1024 (i.e., 8, 64, 128, 256, 512, 1024) and various downsampling widths. We settled on 128 latent channels and 5 downsampling layers, since that setup minimized both the validation MSE and Cross-Entropy loss.
3.2. ConvNeXt-Swin Hybrid
The ConvNeXt-Swin Transformer architecture is a hybrid CNN–Transformer model that combines the strengths of ConvNeXt [
34] and Swin Transformer [
35] architectures for deepfake detection tasks. The ConvNeXt model is a CNN architecture that has shown an impressive performance in image recognition tasks by extracting high-level features from images through a series of convolutional layers. The Swin Transformer is a transformer-based model that uses a self-attention mechanism to extract both local and global features.
The GenConViT model leverages the strengths of both architectures by using ConvNeXt as the backbone for feature extraction and the Swin Transformer for feature processing. In our proposed method, the ConvNeXt architecture extracts high-level features from images, which are then passed through a HybridEmbed module to embed the features into a compact and informative vector. The resulting vector is then passed to the Swin Transformer model. The ConvNeXt backbone consists of multiple convolutional layers that extract high-level features from the input images and the LFs from the AE or VAE. We used pre-trained ConvNeXt and Swin Transformer models, which were trained on an ImageNet dataset.
After extracting learnable features using the ConvNeXt backbone, we pass the feature maps through the HybridEmbed module. The HybridEmbed module is designed to extract feature maps from the ConvNeXt, flatten them, and project them to an embedding dimension of 768. It consists of a convolutional layer which takes the feature maps from the backbone and reduces their channel dimension to the desired embedding dimension. The resulting feature maps are flattened and transposed to obtain a sequence of feature vectors, which are then further processed by the Swin Transformer.
The GenConViT’s network A consists of two Hybrid ConvNeXt-Swin models that take in an LF of size generated by the AE () and an input image of the same size. The models output a feature space of size 1000, which is then concatenated. A linear mapping layer of 2 then transforms this combined feature vector into a class prediction, corresponding to the probabilities of the real and fake classes. Network B has the same configuration as A, but it uses the VAE and outputs both a class prediction probability and a reconstructed image of in size. Finally, the predictions of network A and network B are averaged to obtain the final real/fake prediction.
In summary, our proposed GenConViT method introduces a hybrid architecture for deepfake detection, combining the feature extraction capabilities of the pre-trained ConvNeXt-Swin architecture with generative components that use an AE and VAE. This setup helps our model to capture subtle inconsistencies in deepfake videos. GenConViT has a total of 695M trainable parameters and requires approximately 6.855 GFLOPs for a single forward pass on a 224 × 224 px input image, and its average per-frame inference time is 0.10 s (NVIDIA RTX 4090 (Santa Clara, CA, USA)). The open-source code for GenConViT is available at
https://github.com/erprogs/GenConViT (accessed on 9 June 2025).
4. Evaluation
We conducted extensive experiments on various configurations of the AE and VAE, as well as different variants of the CNN and Transformer models. Our findings suggest that a hybrid architecture using ConvNeXt and the Swin Transformer performs well. We first describe the experimental setup in
Section 4.1. Then, the results are presented and discussed in
Section 4.2, and a comparison with the state of the art is carried out in
Section 4.3. Finally, the limitations of our method are analyzed in
Section 4.4.
4.1. Experimental Setup
To assess GenConViT’s performance, we used multiple evaluation metrics, including classification accuracy, F1 score, the Receiver Operating Characteristic (ROC) curve, and Area Under the Curve (AUC) values.
4.1.1. Implementation Details
Networks
A and
B were trained to classify real and fake videos, while
B was additionally trained to reconstruct the images, some examples of which are shown in
Figure 2.
Therefore, network
A was trained using the Cross-Entropy loss, while network
B was trained using the Cross-Entropy and MSE losses. Network A is optimized for real vs. fake classification, so we used Cross-Entropy loss. Because we were focusing on classification objectives, we employed a larger batch size (32) for training. Network B is optimized for two goals: (i) real vs. fake classification and (ii) the reconstruction of each 224 × 224 input image. To enforce high reconstruction quality, we added an MSE term to the same Cross-Entropy objective for the reconstructed images. Since using MSE increases memory usage, we used a batch size of 16 for training. By using both losses, we encouraged the encoder to learn representations that both discriminate between real and fake images and minimize pixel-level reconstruction errors, as such by capturing better latent artifacts. We used the
timm [
71] library to load the class definitions and the weights of the pretrained ConvNeXt and Swin Transformer. Due to our limited resources and large training dataset, we implemented the "tiny" model versions of both architectures, namely
and
, both of which are trained on ImageNet-1k.
Both networks
A and
B were trained using the Adam optimizer with a learning rate of
and weight decay of
. The Albumentation [
72] library was used for data augmentation, and the following augmentation techniques were used with a strong augmentation rate of
: RandomRotate, Transpose, HorizontalFlip, VerticalFlip, GaussNoise, ShiftScaleRotate, CLAHE, Sharpen, IAAEmboss, RandomBrightnessContrast, and HueSaturationValue. The training data was normalized. The batch size for network
A was set to 32 and for network
B it was set to 16. Both networks were trained for 30 epochs.
4.1.2. Datasets
In our work, we utilized five datasets to train, validate, and test our model: DFDC [
73,
74], TrustedMedia (TM) [
75], DeepfakeTIMIT (TIMIT) [
76,
77], Celeb-DF (v2) [
78,
79], and FaceForensics++ (FF++) [
80]. DFDC and FF++ are well-known benchmark datasets for deepfake detection. TM is created using a diverse range of deepfake manipulation techniques.
The DFDC dataset is the largest publicly available dataset and contains over 100,000 high-resolution real and fake videos. The dataset was created using 3426 volunteers, and the videos were captured in various natural settings, at different angles, and under different lighting conditions. The dataset was created using eight deepfake creation techniques.
The FF++ dataset comprises 1000 original videos collected from YouTube, which have been manipulated using four automated face manipulation methods: Deepfakes, Face2Face, FaceSwap, and NeuralTextures [
81]. The dataset includes compressed videos with quantization parameters of
and
and various video resolutions. The TM dataset consists of 4380 fake and 2563 real videos, with multiple video and audio manipulation techniques used. The TM dataset is used only in the training phase. The Celeb-DF (v2) dataset consists of 890 real videos and 5639 deepfake videos.
We randomly extracted approximately 30 frames per video from each dataset to ensure diversity in our training data. To mitigate the different ratios between fake and real videos in the DFDC and TM datasets, we extracted a higher number of frames from their real videos. The DFDC dataset has a ratio of 6:1 for fake to real videos, and TM has approximately a 2:1 ratio.
By using a variety of datasets that utilize multiple deepfake creation techniques and videos captured in multiple settings, we aim to enable better generalization and robustness to varying environments. Notably, our model is trained (and evaluated) using significantly more datasets than those used for previous models (see
Table 1).
4.1.3. Video Preprocessing
We preprocessed the frames of the videos in the datasets so that we could work with images that only contained information about faces and were correctly labeled. The preprocessing component in DL plays a critical role in preparing raw datasets for training, validation, and testing. The proposed model focuses on the face region, which is crucial in deepfake generation and synthesis mechanisms. We therefore preprocessed the videos using a series of image processing operations. These operations included the following steps:
- 1.
Extracting the face region from each video using the OpenCV, face_recognition [
82], and BlazeFace [
83] face recognition deep learning libraries;
- 2.
Resizing the input (facial) image to a RGB format, where the dimensions of the input image are , with representing the height, representing the width, and representing the RGB channels;
- 3.
Verifying the quality of extracted face-region images manually (only for the DFDC dataset).
After the face regions were extracted, we manually reviewed DFDC image frames to fix two problems. As noted in [
74], (1) DFDC deepfake videos may contain pristine frames and (2) face regions may not always be accurately detected by the face recognition frameworks used to extract them, leading to some frames in the training dataset containing no faces [
60]. To address this issue, we manually reviewed the images and excluded images that did not contain a face or were deemed to be a real image within the fake class. This approach allowed us to curate a fake class dataset comprising only relevant and potentially manipulated face images. In the future, we could opt for using automated methods rather than achieving this manually. For example, to filter real from fake frames within a deepfake video, an initial model could be trained on a small, manually filtered subset of images and could then classify the remaining subset into real and deepfake images. This classification could significantly speed up the manual verification process.
As a result of applying the preprocessing steps to the datasets, we collected a total of 1,004,810 images. To train, validate, and test our model, the images were divided into a ratio of approximately 80:15:5, resulting in 826,756 images for training, 130,948 images for validation, and 47,106 images for testing. Note that this preprocessed test set was only used for internal evaluation; the main experiments conducted in this paper were performed on videos (in contrast to individual frames). Namely, for our evaluation, we held back 3972 videos from the DFDC, DeepfakeTIMIT, Celeb-DF (v2), and FF++ datasets for testing. To create a single prediction per video, we extracted 15 frames from each video and averaged the resulting predictions.
4.2. Experimental Results and Discussion
In this section, we present the experimental results and discuss the performance of our proposed GenConViT model.
Table 4 summarizes the accuracy of the proposed GenConViT model, as well as its internal networks A and B, on the evaluation datasets. The table also shows its accuracy for the real and fake samples separately, to show potential discrepancies in its performance. Note that the TIMIT dataset does not contain any real videos.
The results demonstrate that GenConViT delivers strong performance across various datasets. The individual networks A and B also both demonstrate decent performances, but are outperformed by their combination. While networks A and B individually achieve 94% accuracy on average, the full GenConViT ensemble improves upon the average accuracy of network A by 2.2% and network B by 1.79%, indicating the benefit of using both models for detection. From
Table 4, we can also see that the model has an average 5% increase in accuracy on the Celeb-DF (v2) dataset. Additionally, its measured performance is similar for both real and fake videos, except for Celeb-DF (v2), for which it has a worse accuracy in detecting real videos compared to fake videos.
For completeness,
Table 5 and
Table 6 present the AUC value and F1 score, respectively. To further investigate GenConViT’s performance,
Figure 3 presents the resulting ROC curve. Both networks A and B lead to relatively similar results.
Overall, the proposed GenConViT model has an average accuracy of and an AUC value of across the tested datasets. These results highlight our model’s robust performance in detecting deepfake videos, demonstrating its potential for practical applications in the field.
4.3. Comparison with State of the Art
We compared our GenConViT model with several other state-of-the-art methods on the DFDC dataset (
Table 7), the FF++ dataset (
Table 8), and the three subsets of FF++ (
Table 9). It is worth noting that the testing subdatasets of the DFDC and FF++ are usually not shared in the scientific literature. Hence, the exact datasets evaluated may differ, although comparing the reported values gives an idea of how their performances compare.
Table 1 lists the datasets used by other deepfake detection models for training and evaluation. Note again that
Table 1 shows that our dataset is trained and evaluated using the most datasets.
From
Table 7 (DFDC dataset), we can observe that previous approaches achieved accuracy values ranging from
to
on the DFDC dataset. Notable models included Khan [
18] (
), Thing [
84] (
), and Seferbekov [
69] (
). Some models excelled in additional metrics, such as the STDT [
28] model, with its
accuracy,
AUC, and
F1 score. In comparison to previous approaches, our proposed model demonstrated an excellent performance, achieving an average accuracy of
, an AUC of
, and an F1 score of
.
4.4. Limitation Analysis
This subsection analyzes two aspects of the proposed method: the consistency of its performance on the datasets (in
Section 4.4.1) and its generalization through an out-of-distribution ablation study (in
Section 4.4.2). The mitigation strategies used are subsequently described in
Section 5.
4.4.1. Lower Performance on Celeb-DF v2: Feature Visualization
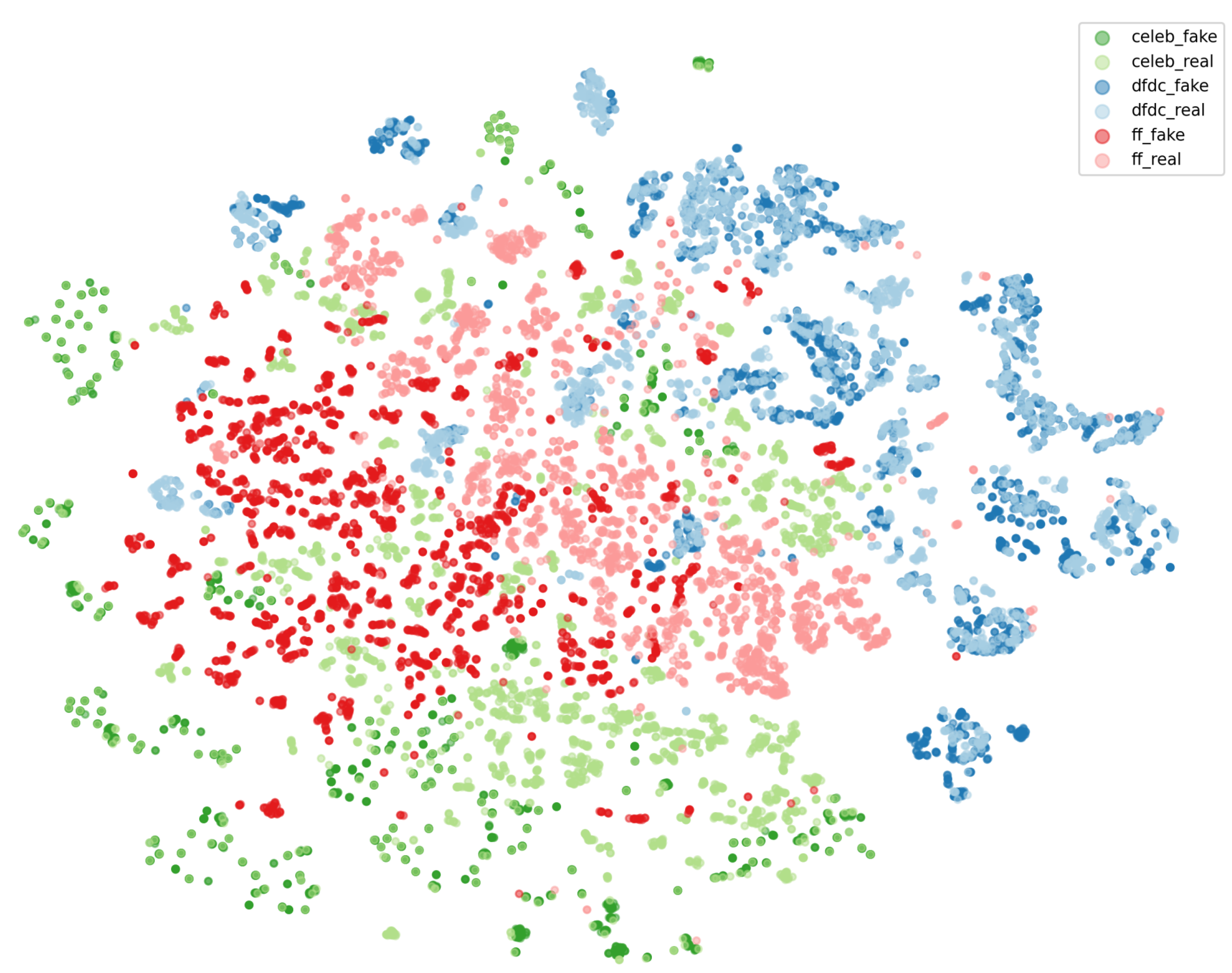
Table 4 demonstrates that our model’s performance on the Celeb-DF (v2) dataset is lower than its performance on the other datasets. To further analyze this,
Figure 4 shows the t-SNE visualization of our model’s VAE’s latent embeddings on three datasets (Celeb-DF (v2), DFDC, and FF++). We observe a clustering based on the dataset source (i.e., in green, red and blue). Within these clusters, we observe that the separation between real vs. fake clusters is not always strong and they heavily overlap. Specifically, fake and real Celeb-DF (v2) embeddings overlap more than the fake and real embeddings from DFDC or FF++. This may explain the model’s lower performance on the Celeb-DF (v2) dataset.
Section 5 discusses future strategies to improve its performance.
4.4.2. Generalization: Out-of-Distribution Ablation Study
To evaluate the generalization capability of our proposed model, we conducted an out-of-distribution (OOD) ablation study. We trained our model on four of the five available datasets, holding back the fifth dataset entirely (it was unseen during training and validation). We repeated this procedure using different held-back datasets and systematically varied the hyperparameters (such as the layers of the CNN depth, width, and learning rates) to select the best performing model variant. Moreover, to optimize computation, we performed training for ablation experiments on a randomly selected subset of approximately 5% of the images from the training datasets. Note that other datasets were not evaluated against out-of-domain deepfakes, hence their potential limitations may not have been actively exposed.
Table 10 summarizes the performance of the model across various scenarios. In each scenario, the column labeled “Held- out” denotes the dataset excluded from training, whereas the column labeled “Test set” denotes the dataset used for the evaluation. Then, the other columns present the model’s performance on the test set when training used all test datasets except for the held-back dataset. Cells highlighted in bold text represent significant drops in performance due to holding back the corresponding dataset during training.
We found that our model struggled to detect fake videos in the held-back dataset in an OOD setting, indicating that it still faces challenges in generalizing to unseen, more hyper-realistic deepfake images. Notably, when the model encounters a fully unseen hyper-realistic dataset, it struggles to detect fake videos, resulting in a substantial drop in accuracy in the fake class. Most notably, in the Celeb-DF (v2) hold-out scenario, the model’s overall accuracy on Celeb-DF (v2) was as low as 55.67%, with an 11.56% accuracy on fake samples. We also note that the full model had the most difficulties with Celeb-DF (v2), as discussed in
Section 4.4.1, which may explain its particularly low accuracy in the ablation study.
These results suggest that although our model performs well on in-domain data (TM, DeepfakeTIMIT, DFDC, and FF++), it faces challenges in generalizing to significantly different or higher-fidelity deepfakes. These experiments suggest that deeper or wider CNN architectures alone do not necessarily guarantee improved robustness to domain shifts. Despite experimenting with various hyperparameters (e.g., layer depth, width, and learning rates), the drop in fake detection accuracy remained significant when the held-back dataset was substantially different from the training sets.
Another noteworthy observation is that certain datasets, like DeepfakeTIMIT, appear easier to generalize to. This may be due to their relatively simpler manipulations. In contrast, datasets such as Celeb-DF (v2) or DFDC contain higher-quality forgeries and more varied manipulations, creating a more challenging OOD scenario. Consequently, our study underscores the importance of curating diverse, high-fidelity training sets when aiming to build robust deepfake detection models. Therefore, our proposed GenConViT model was trained on five datasets that represented a large variety of deepfakes and settings.
We have identified several possible reasons for the lower accuracy results in our OOD ablation study:
Overfitting to Known Artifacts: Even with latent AE/VAE encoding, GenConViT’s ConvNeXtSwin backbone may rely on domain-specific cues that do not transfer to unseen forgeries. As different datasets contain different generators, the artifacts from certain generators may not be representative of those from other generators.
More Realistic Deepfake Generation: Datasets such as Celeb-DF (v2) use advanced deepfake generation methods which are difficult to detect. For example, Celeb-DF (v2), DFDC, and FF++ have subtler boundaries and lower noise-level residuals than the TIMIT dataset, as well as fewer warping artifacts. This makes it particularly hard for our leave-one-out model to spot these deepfake features when they were not seen during training.
Ablation Sampling: Note that ablation is performed on randomly selected subsets of our training datasets without replacement (10k samples for each dataset). In contrast, the full model is trained on more than 1M images. Hence, although we deem the training on subsets to be representative enough to analyze the model’s generalization performance, it must be carefully compared to the performance of the full model.
Lack of Temporal Information: GenConViT relies on each frame independently and has no way of processing temporal information. Temporal artifacts may contain more generalizable features.
Overall, these findings confirm that while our model achieves a promising performance on in-domain data, it remains sensitive to domain shifts, particularly when encountering previously unseen or more realistic deepfake manipulations. This remains an area for future work to explore; several strategies for this are discussed further in
Section 5.
5. Future Work
This section discusses strategies for future research tackling our proposed model’s limitations (as discussed in
Section 4.4). In essence, although our proposed deepfake detection model’s performance is high for some datasets, the main limitation is that its performance is lower for some datasets that were seen during training (e.g., Celeb-DF (v2), as discussed in
Section 4.4.1), and other datasets that were not seen during training (i.e., that are out of distribution, demonstrating its limited generalization, as discussed in
Section 4.4.2).
To tackle these limitations, the deepfake classification model could incorporate additional features that allow it to generalize better. For example, a recent effective approach to synthetic image detection is using latent representations from pretrained foundation models such as CLIP [
85].
Still, even with more generalizable features, deepfake detection models will continue to struggle with OOD samples. Therefore, another viable strategy would be to perform out-of-distribution detection prior to deepfake classification [
86]. This way, we would know when the model’s output cannot be trusted due to the input being OOD.
Finally, another strategy is to perform one-class training for deepfake detection. That is, by only considering real samples during training, we avoid overfitting to specific deepfake generators altogether. Such models can be trained in a multi-task manner, e.g., to jointly reconstruct disturbed real faces and perform deepfake detection [
87]. Note that this strategy bears similarities to the face reconstruction used in the VAE of network B in our proposed GenConViT, and hence may be a particularly viable direction for future research.


 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}