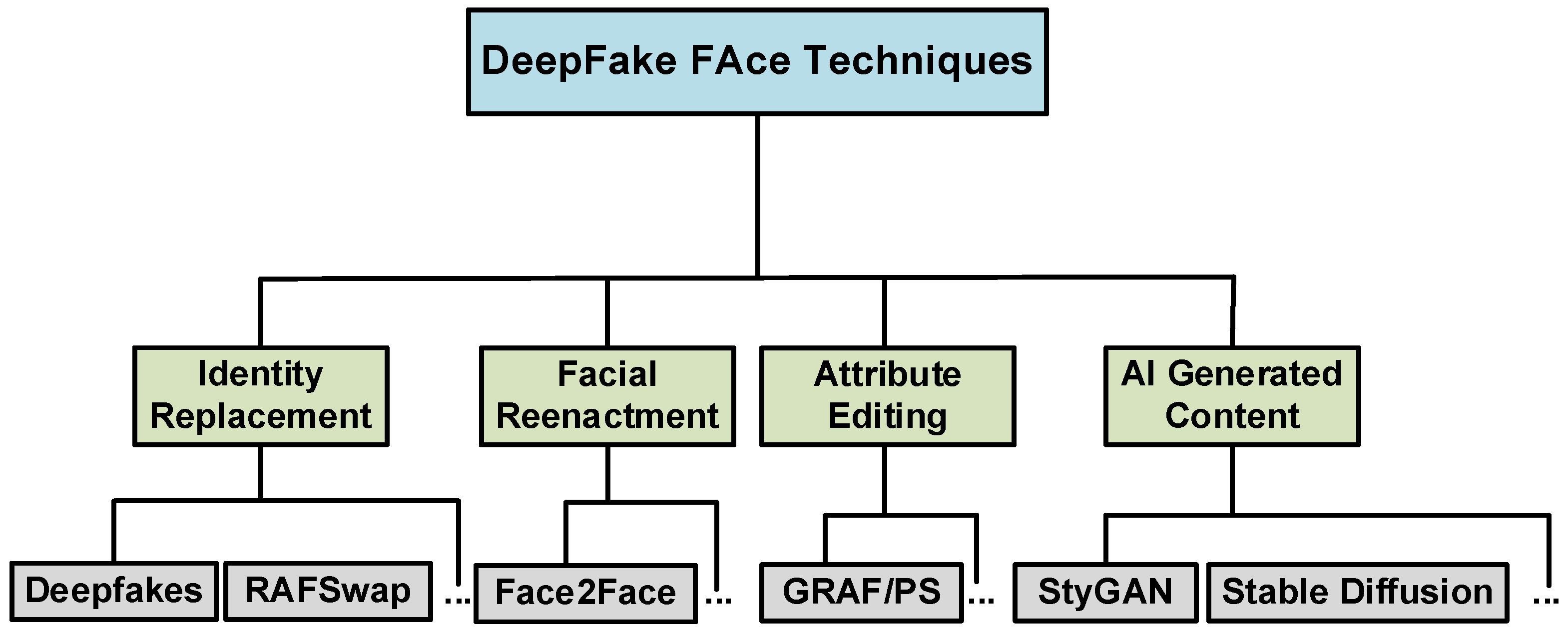
Against the backdrop of booming social media and digital technologies, the rise of deep forgery techniques poses a serious threat to information security and social stability. Highly realistic synthesized images and audio make them the vanguard of disinformation dissemination and privacy invasion, challenging personal privacy and information security. With the advancement of deep learning technology, deep face forgery technology is gradually becoming a new security challenge. The performance of traditional detection methods becomes more and more vulnerable in the face of highly realistic deep images. Especially in recent years, the rise of advanced technologies such as Generative Adversarial Network (GAN) [
1] and Diffusion Model (DP) [
2] has made synthetic face images more and more realistic and difficult to distinguish from real face images. This makes traditional face detection methods face serious challenges in recognizing deeply faked images. At the same time, the emergence of adversarial attacks has provided new tools and strategies to the producers of forged images, making it more difficult for existing detection systems to detect forged images. Therefore, there is an urgent need for researchers to come up with more efficient and robust deep forgery face detection techniques to secure digital identity and privacy. Deep forgery face detection serves as a key application in the field of intelligent visual security surveillance. It can more effectively identify and block behaviors that attempt to evade surveillance systems through fake face images. Key applications such as authentication and security applications, social media and online platforms, video forensics and investigations, and personal privacy protection. Fake face videos may be harmless in intent and have advanced research in video generation across industries. However, once they are maliciously used to disseminate false information, harass individuals, or defame celebrities, they have attracted significant attention on social platforms globally, particularly hampering the credibility of digital media. As a result, fake face video detection has become a key challenge in the field of AI security. However, the emergence of sample adversarial attacks has further elevated the difficulty of detection. These attacks introduce tiny perturbations on the original image that alter the image almost imperceptibly but are effective in spoofing deep forgery detection models and distorting their outputs to avoid detection.
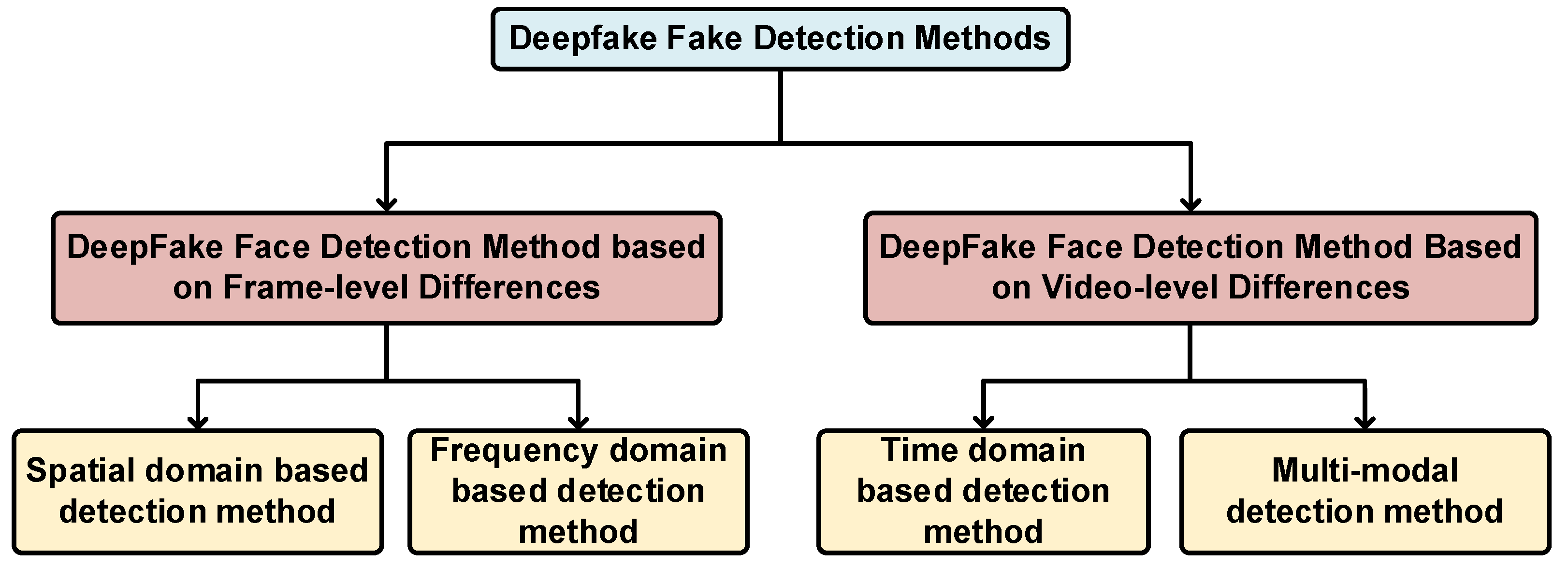
Currently, the detection models on deepfake face video are more often using CNN methods that target the face features in each frame and CNN+LSTM methods that focus on the features between frame and frame images. Xing et al. [
3] proposed a deepfake face video detection model based on 3DCNNS, which notices the time-domain features and spatial-domain features of deepfake fake face video feature inconsistencies to achieve higher detection accuracy and robustness. Fu et al. [
4] first revealed that deepfake detection’s generalization challenges stem not only from forgery method discrepancies but also position bias (over-relying on specific image regions) and content bias (misusing irrelevant information). They proposed a transformer-based feature-reorganization framework that eliminates biases through latent space token rearrangement and mixing, significantly enhancing cross-domain generalization across benchmarks. Siddiqui et al. [
5] proposed integrating vision transformers with DenseNet-based neural feature extractors, achieving state-of-the-art vision transformer performance without relying on knowledge distillation or ensemble methods. Frank et al. [
6] found that the discrete cosine transform (DCT) of the deepfake image and the real image show significant differences in the frequency domain. Sabir et al. [
7] designed a framework for detecting deepfake videos using inter-frame temporal information, which achieved the SOTA at that time. Gu et al. [
8] utilized the spatio-temporal inconsistency in Deepfake to propose the three templates of SIM, TIM, and ISM, which form the STILBlock plug-in module that can be inserted into a convolutional neural network to spatio-temporal information and perform spatio-temporal information fusion to complete the output of the deep forgery detection results. Kroiß et al. [
9] implemented efficient synthetic/fake facial image detection using a pre-trained ResNet-50 architecture modified with adapted fully connected output layers, trained via transfer learning and fine-tuning on their “Diverse Facial Forgery Dataset”. R et al. [
10] introduced TruthLens, a semantic-aware interpretable deepfake detection framework that simultaneously authenticates images and provides granular explanations (e.g., “eye/nose authenticity”), uniquely addressing facial manipulation deepfakes through unified multi-scale forensic analysis validated via multi-dataset experiments. Cheng et al. [
11] proposed a directional progressive learning framework redefining hybrid forgeries as pivotal anchors in the “real-to-deepfake” continuum. They systematically implemented a Directional Progressive Regularizer (OPR) to enforce discrete anchor distributions and a feature bridging module for smooth transition modeling, demonstrating enhanced forgery information utilization through extensive experiments. Choi et al. [
12] detected temporal anomalies in synthetic videos’ style latent vectors using StyleGRU and style attention modules, experimentally validating their cross-dataset robustness and temporal dynamics’ critical role in detection generalization. Cozzolino et al. [
13] demonstrated the breakthrough potential of pre-trained vision-language models (CLIP) for cross-architecture AI-generated image detection under few-shot training, achieving state-of-the-art in-domain performance through a lightweight detection strategy with 13% robustness improvement. VTD-Net [
14] is a frame-based deep forgery video identification method using CNN, Xception [
13], and LSTM [
15]. In VTD-Net, faces are extracted from video frames using a multi-task cascaded CNN, and then the Xception network is used to learn the distinguishing features between real and fake faces. Coccomini et al. [
16] further improved the model by combining Vision Transformer [
17] in the accuracy performance in deep forgery identification tasks. Chen et al. [
18] proposed DiffusionFake, enhancing detection generalization by reverse-engineering forgery generation through feature injection into frozen pre-trained diffusion models for source/target image reconstruction, effectively disentangling forgery features to improve cross-domain robustness. Zhao et al. [
19] developed an Interpretable Spatiotemporal Video Transformer (ISTVT) featuring a novel spatiotemporal self-attention decomposition mechanism and self-subtraction module to capture spatial artifacts and temporal inconsistencies, enabling robust deepfake detection. MesoNet [
20] distinguishes whether the content is forged or not by detecting the mid-level semantics of the forged faces in the video. This approach can automatically and efficiently detect forged videos generated by forgeries such as deepfake and Face2Face methods. Li et al. [
21] proposed a FaceX-Ray model for forgery detection by determining the boundaries of face fusion. Liu et al. [
22] emphasized the importance of mobility, i.e., cross-library detection accuracy, and achieved the best migration performance in forgery detection. Wang et al. [
23] used a multiscale vision transformer to capture the local inconsistencies existing in faces at different scales, in resistance to compression algorithms by strong robustness, and achieved significant results on mainstream datasets. Lu et al. [
24] proposed a new long-range attention mechanism to capture global semantic inconsistencies in forgery samples, which reduces the complexity of the model and achieves good detection results.
Therefore, to address the above problems, this manuscript proposes an improved deep forgery face detection method mainly focusing on the existing deep-learning-based deep forgery detection methods with noise artifacts, insufficient feature extraction capability in the face of a deep forgery identification task, and poor detection performance in the face of sample confrontation attack. The framework of deepfake face detection and adversarial attack defense method based on multi-feature decision fusion is shown in
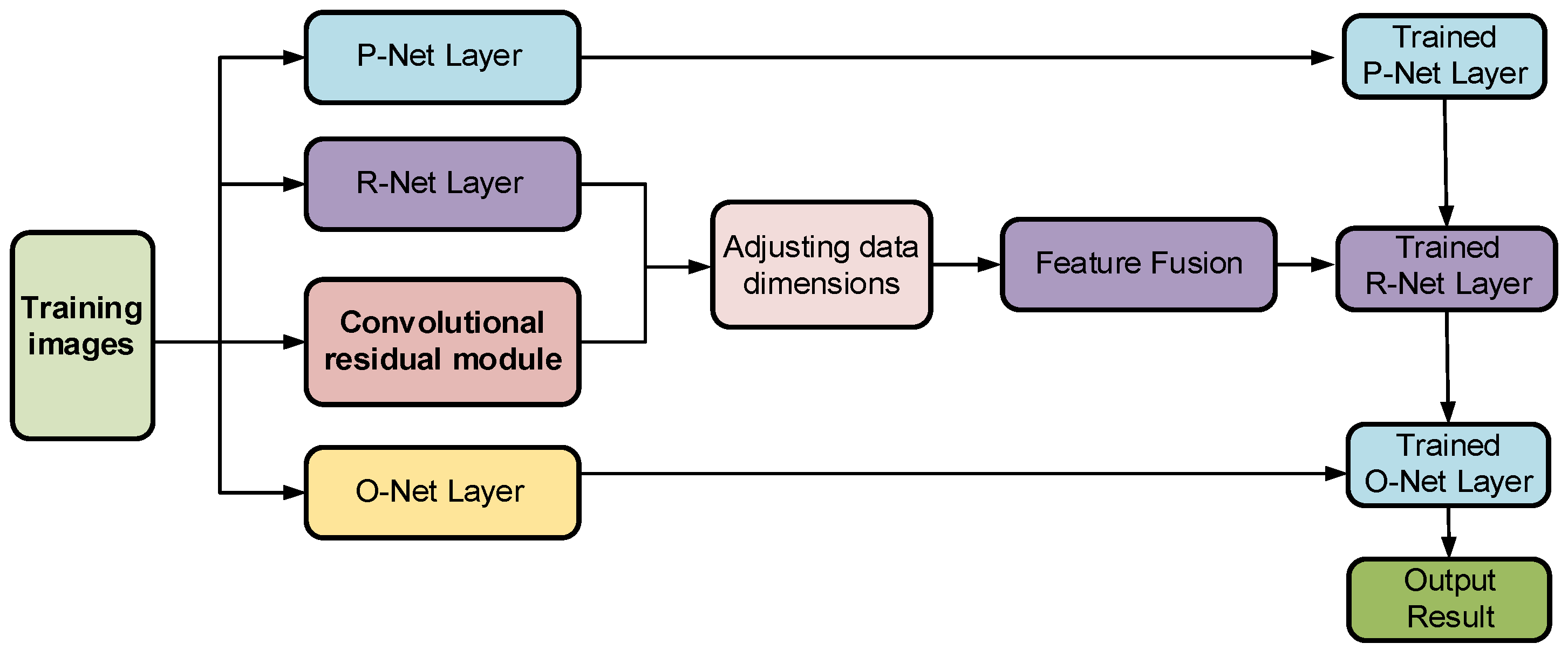
Figure 1, which includes the use of improved IMTCNN to accurately extract face faces and a diffusion model for noise reduction and de-artificing of the forgery face data, the addition of the SENet attention mechanism to the FG-TEFusionNet network, WADAN, and an image texture enhancement module on the FG-TEFusionNet network to improve the deep neural network for the acquisition of deep information and texture features of the face in the video image; add samples in the network during the training process against the attack I-FGSM algorithm to generate samples against the attack; and then use Adversarial Training for defense, for the accuracy, robustness, and security of the experimental dataset for the research and analysis.
(1) The IMTCCN architecture was systematically improved to achieve high-precision facial feature extraction through the integration of a diffusion model, which effectively suppresses noise and artifacts. Qualitative evaluations and quantitative metrics jointly validate the enhanced operational efficacy of this optimized framework.
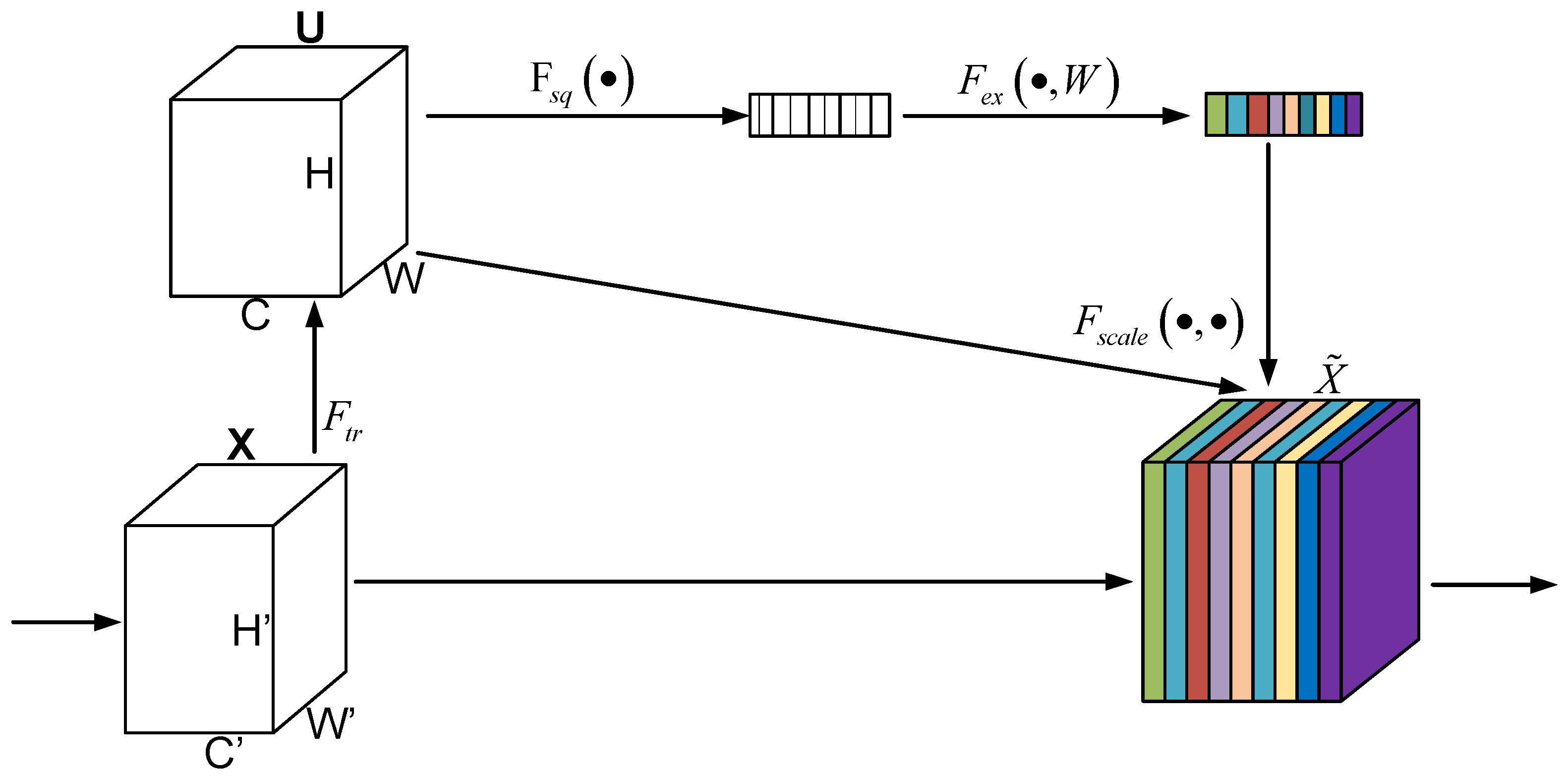
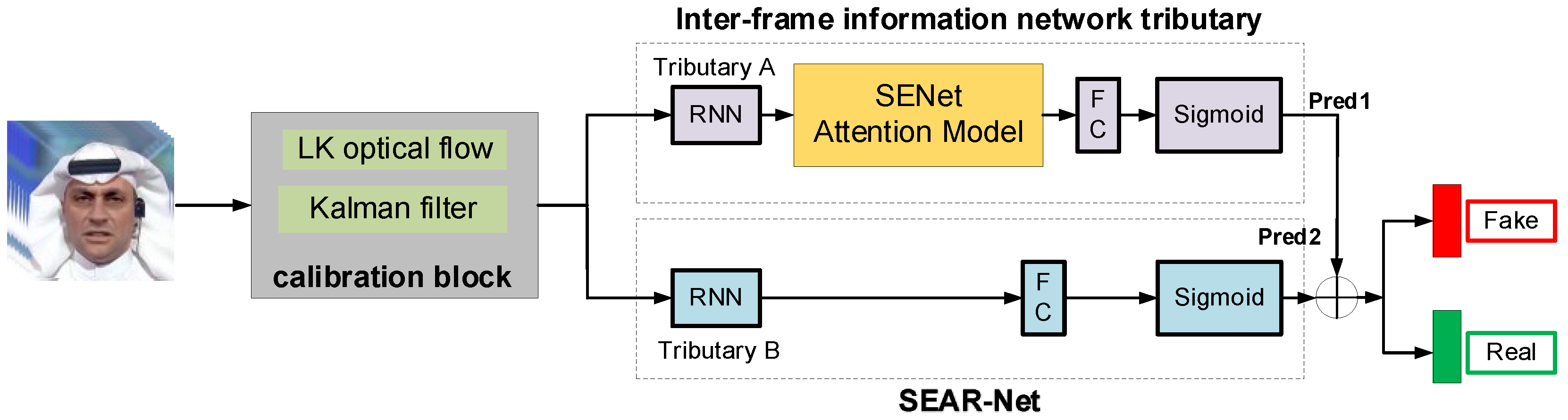
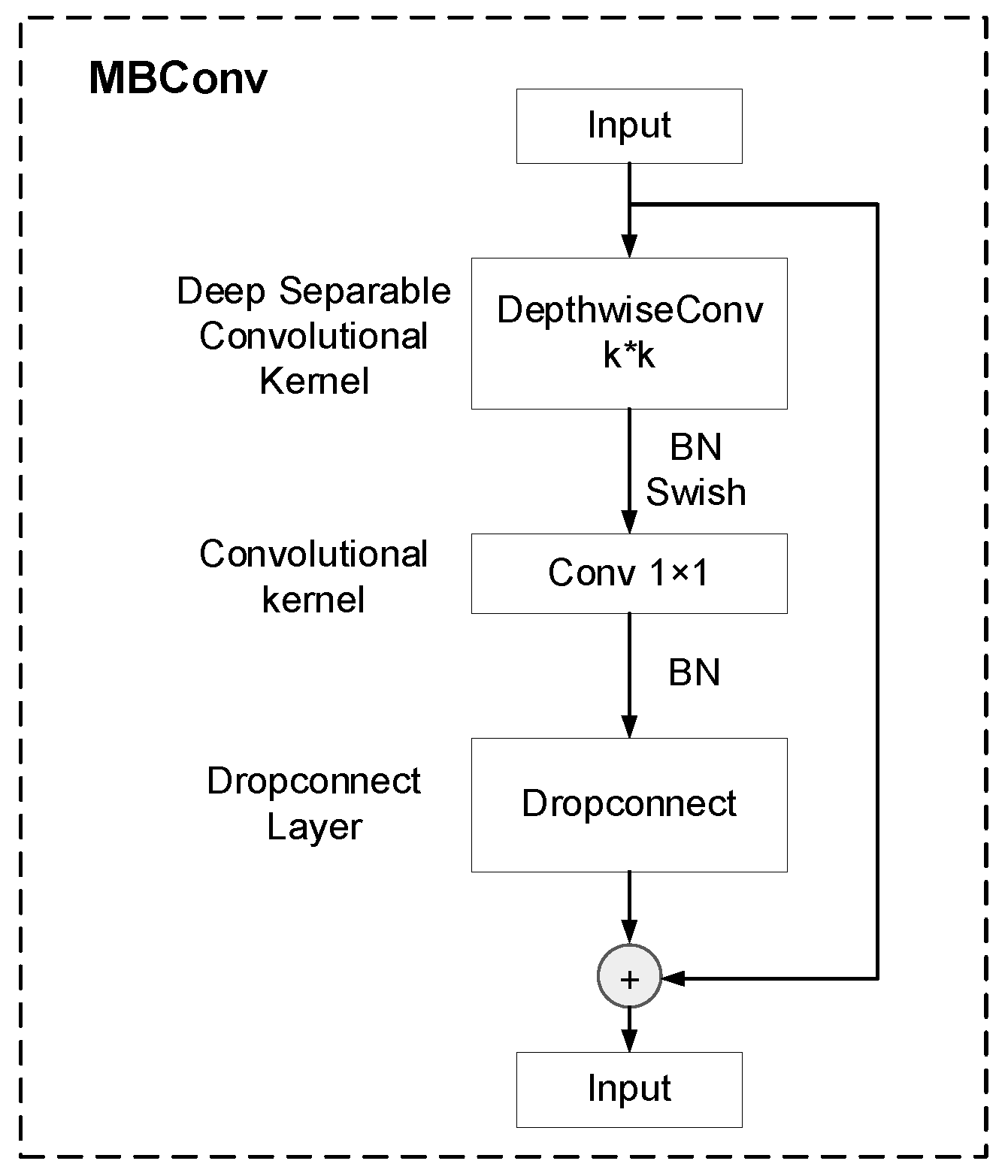
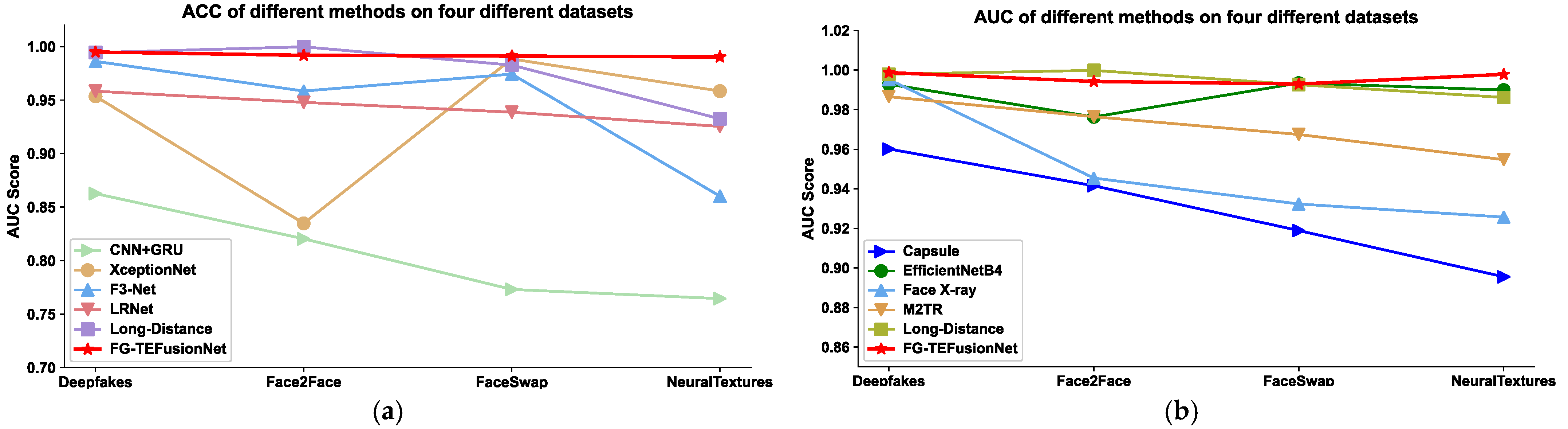
(2) A novel multi-feature decision fusion model named FG-TEFusionNet is proposed for deepfake detection, which consists of two specialized modules: the SEAR-Net and the TE-WSDAN-DDNet. The SEAR-Net enhances inter-frame dependency modeling by integrating SENet attention mechanisms into a dual-stream RNN architecture based on the LRNet baseline, enabling preliminary predictions through frame-sequence correlation analysis. Simultaneously, the TE-WSDAN-DDNet embeds a Gram image texture module within the EfficientNet backbone, fusing feature maps from the Weakly Supervised Data Augmentation Network (WSDAN) to overcome geometric method limitations through deep texture pattern extraction. A voting mechanism synergistically combines geometric and textural features to generate final detection results, achieving state-of-the-art (SOTA) performance on the FaceForensics++ and Celeb-DF datasets.
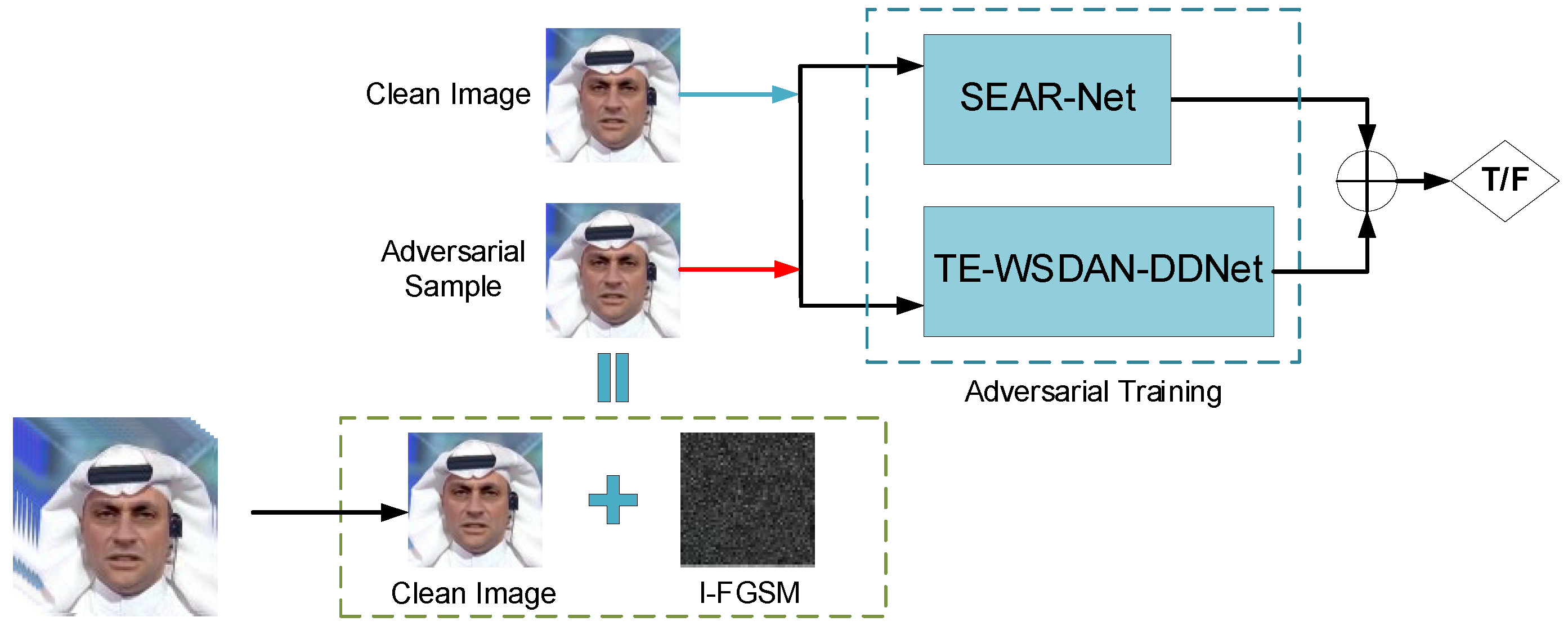
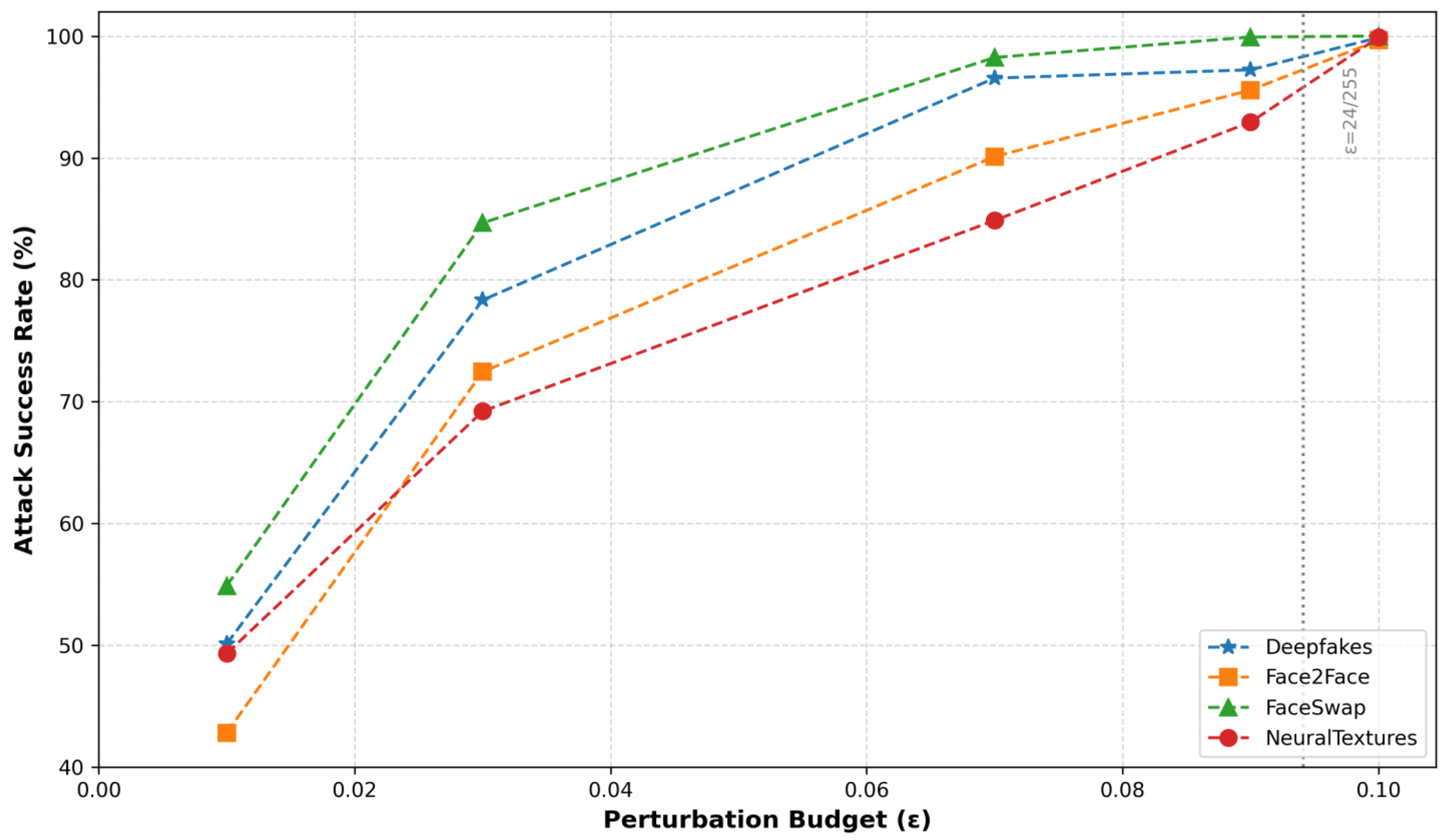
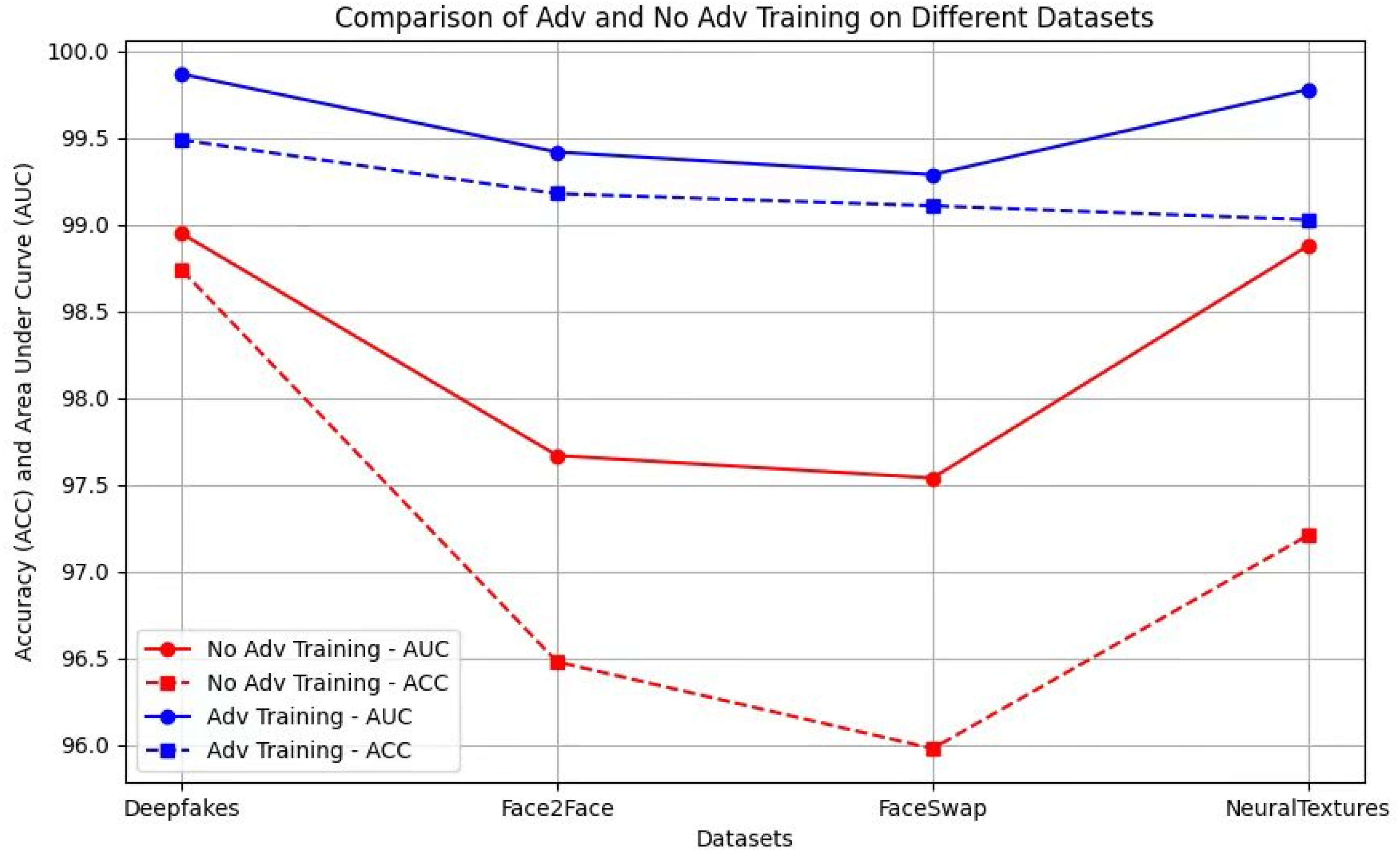
(3) An adversarial training methodology was implemented to enhance defense robustness by incorporating I-FGSM-generated adversarial samples during training. The experimental results indicate that under adversarial training conditions, the success rate of adversarial attacks on the model significantly decreases, effectively improving the model’s detection accuracy.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}