1. Introduction
Internet of Things (IoT) and Artificial Intelligence (AI) are reshaping the way we live. IoT is penetrating every aspect of our modern society. It features the explosion of interconnected devices generating vast amounts of real-world data, driving significant and innovative insights to improve our lives. Simultaneously, emerging LLMs like the GPT series have shown a remarkable ability to understand and process complex information [
1,
2]. The power of Large Language Models (LLMs) arises from a vast amount of training data, while IoT systems are excellent means to provide such data. Combining the two fields is a natural move. This, however, incurs significant challenges. A core question is how we can leverage the intelligence of resource-hungry LLMs to make sense of the massive, diverse, and often sensitive data streams produced by countless IoT devices, especially when the data is mostly heterogeneous, multimodality, high-dimensional, sparse, and needs to be processed quickly and, in many cases, locally [
3,
4,
5]. This is further elaborated on below.
Sending huge volumes of IoT data to a central cloud for AI analysis is often not practical [
6]. It can be too slow for applications needing real-time responses (like industrial control or autonomous systems), consumes too much bandwidth, and raises significant privacy concerns [
7]. Many critical IoT applications simply demand intelligence closer to the data source [
3]. On the other hand, while LLMs possess the analytical power needed for complex IoT tasks, they face their own hurdles: they require massive datasets for training, and accessing the rich, real-world, but often private, data held on distributed IoT devices is difficult [
8]. Moreover, deploying these powerful models effectively within the constraints of real-world distributed systems like IoT remains a significant challenge, considering limited hardware resources and power supply, data access, and privacy. This is precisely where Federated Learning (FL) enters the picture [
9]. FL revolutionizes traditional approaches by enabling collaborative model training across decentralized data sources, eliminating the need for raw data centralization. This creates a compelling opportunity: using FL to train powerful LLMs on diverse, distributed IoT data while preserving user privacy and data locality [
10,
11]. This combination promises smarter, more responsive, and privacy-respecting systems, potentially leading to more efficient factories, safer autonomous vehicles, or more personalized healthcare, all leveraging local data securely. However, integrating these three sophisticated technologies (IoT, LLMs, FL) creates unique complexities and challenges related to efficiency, security, fairness, and scalability [
12]. Given the significance of the integration and the increasing attention it has gained recently, this review aims to provide a timely overview of the state of the art in synergizing IoT, LLMs, and FL, particularly for edge environments, hoping to highlight current capabilities, identify key challenges, and inspire future research directions that enable intelligent, privacy-preserving, and resource-efficient edge intelligence systems. Specifically, we will explore the architectures, methods, inherent challenges, and promising solutions, highlighting why this three-way integration is crucial for building the next generation of intelligent, distributed systems.
The burgeoning interest in deploying advanced AI models like LLMs within distributed environments like IoT, often facilitated by techniques such as FL and edge computing, has spurred a number of valuable survey papers. While these reviews provide essential insights, they typically focus on specific sub-domains or pairwise interactions. Some representative survey works are reviewed below.
Table 1 summarizes their primary focus and key differentiating aspects alongside our current work.
Qu et al. [
13] focus on how mobile edge intelligence (MEI) infrastructure can support the deployment (caching, delivery, training, inference) of LLMs, emphasizing resource efficiency in mobile networks. Their core contribution lies in detailing MEI mechanisms specifically tailored for LLMs, especially in caching and delivery, within 6G.
Adam et al. [
14] provide a comprehensive overview of FL applied to the broad domain of IoT, covering FL fundamentals, diverse IoT applications (healthcare, smart cities, autonomous driving), architectures (CFL, HFL, DFL), a detailed FL-IoT taxonomy, and challenges like heterogeneity and resource constraints. LLMs are treated as an emerging FL trend within the IoT ecosystem.
Friha et al. [
15] examine the integration of LLMs as a core component of edge intelligence (EI) , detailing architectures, optimization strategies (e.g., compression, caching), applications (driving, software engineering, healthcare, etc.), and offering an extensive analysis of the security and trustworthiness aspects specific to deploying LLMs at the edge.
Cheng et al. [
10] specifically target the intersection of FL and LLMs, providing an exhaustive review of motivations, methodologies (pre-training, fine-tuning, Parameter-Efficient Fine-Tuning (PEFT), backpropagation-free), privacy (DP, HE, SMPC), and robustness (Byzantine, poisoning, prompt attacks) within the “Federated LLM” paradigm, largely independent of the specific application domain (like IoT) or deployment infrastructure (like MEI).
While prior reviews cover areas like edge resources for LLMs [
13], FL for IoT [
14], edge LLM security [
15], or federated LLM methods [
10], they mainly look at pairs of these technologies. This survey distinctively examines the combined power and challenges of integrating all three, including IoT, LLMs, and FL, particularly for privacy-focused intelligence at the network edge. This synergy is depicted in
Figure 1. It illustrates a conceptual framework in which synergistic AI solutions emerge from the integration of IoT, LLMs, FL, and privacy-preserving techniques (PETs). Each component contributes uniquely, where IoT provides pervasive data sources, LLMs offer powerful reasoning and language capabilities, FL supports decentralized learning, and PETs ensure data confidentiality, together forming a foundation for scalable, intelligent, and privacy-aware edge AI systems.
More specifically, this review provides a comprehensive analysis of the state of the art regarding architectures, methodologies, challenges, and potential solutions for integrating IoT, LLMs, and FL, with a specific emphasis on achieving privacy-preserving intelligence in edge computing environments. We explore architectural paradigms conducive to edge deployment based on [
3], investigate key enabling techniques including PEFT methods like low-rank adaptation (LoRA) [
16] and distributed training strategies such as Split Federated Learning (SFL) [
17,
18], and systematically analyze the inherent multifaceted challenges spanning resource constraints, communication efficiency, data/system heterogeneity, privacy/security threats, fairness, and scalability [
3]. Mitigation strategies are discussed alongside critical comparisons highlighting advantages and disadvantages. We survey recent applications to illustrate practical relevance [
19]. While existing surveys may cover subsets of this intersection, such as FL for IoT [
20,
21] or FL for LLMs [
22], this review offers a unique contribution by focusing specifically on the three-way synergy (IoT + LLM + FL) and its implications for privacy-preserving edge intelligence [
10]. We aim to provide a structured taxonomy of relevant techniques, critically compare their suitability for resource-constrained and distributed IoT settings, identify research gaps specifically arising from this unique technological confluence, and propose targeted future research directions essential for advancing the field of trustworthy, decentralized AI [
23].
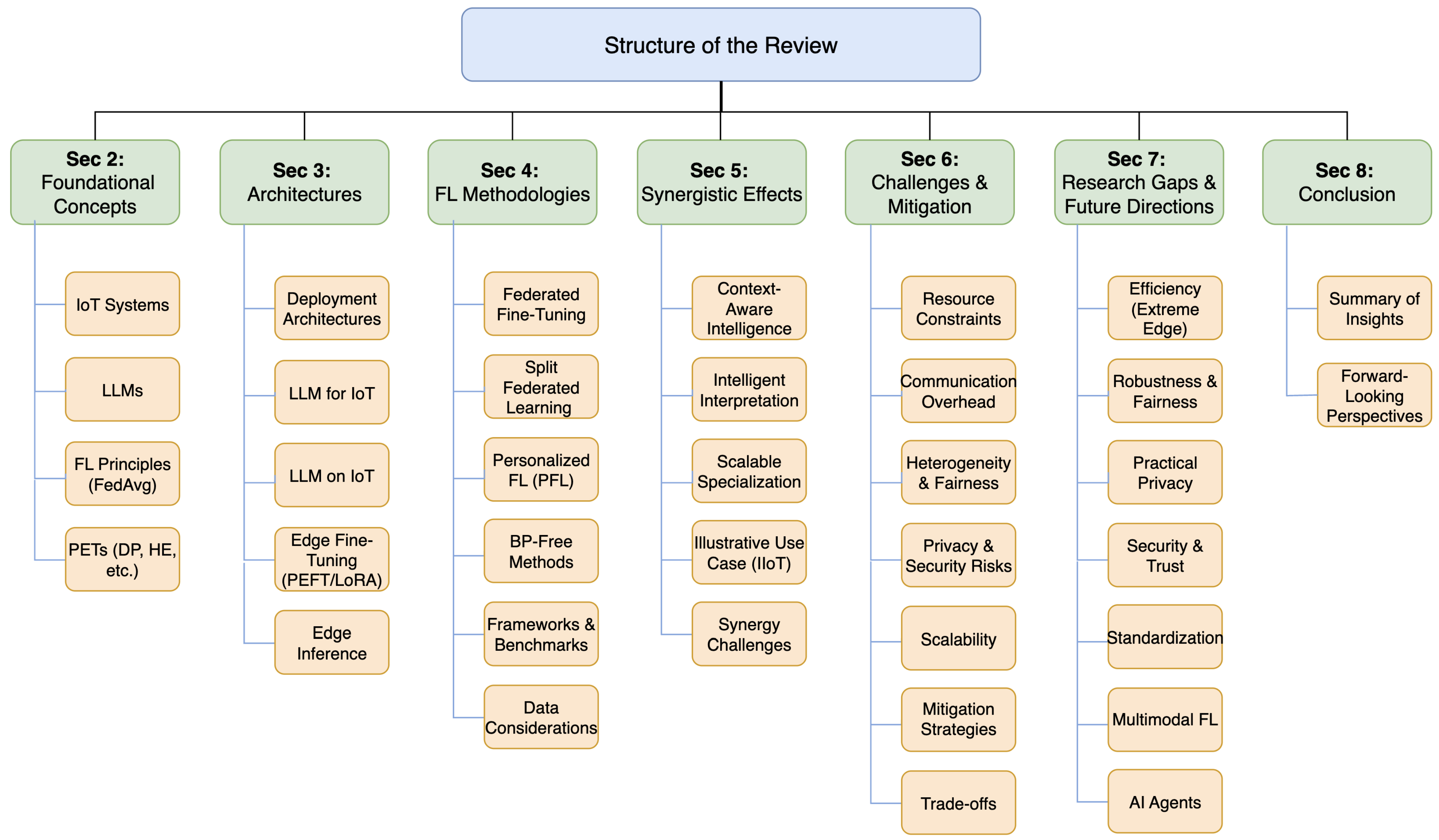
As summarized in
Figure 2, the subsequent sections are structured as follows:
Section 2 introduces foundational concepts related to IoT systems, LLMs, FL principles, and PETs.
Section 3 discusses architectural considerations for deploying LLMs within IoT ecosystems.
Section 4 examines FL methodologies specifically adapted for LLM training and fine-tuning in this context, including frameworks and data considerations.
Section 5 analyzes the unique synergistic effects arising from the integration of IoT, LLMs, and FL, highlighting emergent capabilities.
Section 6 provides an expanded analysis of key challenges encountered in the integration, discusses mitigation strategies, and evaluates inherent trade-offs.
Section 7 identifies critical research gaps and elaborates on future research directions stemming from the synergistic integration.
Section 8 concludes the review, summarizing the key insights and forward-looking perspectives on privacy-preserving, intelligent distributed systems enabled by IoT, LLMs, and FL.
To ensure a comprehensive and systematic review, we adopted a structured literature search and selection methodology.
Search Strategy and Databases: We conducted extensive searches in prominent academic databases, including Google Scholar, IEEE Xplore, ACM Digital Library, Scopus, and ArXiv (for pre-prints). The search was performed between February 2024 and May 2025 to capture the most recent advancements.
Search Keywords: A combination of keywords was used, including, but not limited to “Internet of Things” OR “IoT” AND “Large Language Models” OR “LLMs” AND “Federated Learning” OR “FL”; “LLMs on edge devices”; “Federated LLMs for IoT”; “privacy-preserving LLMs in IoT”; “LoRA for Federated Learning”; “Split Federated Learning for LLMs”; “efficient LLM deployment on IoT”; “AIoT AND LLMs”; “Industrial IoT AND Federated Learning”.
Inclusion Criteria: Papers were included if they were peer-reviewed journal articles, conference proceedings, or highly cited pre-prints directly relevant to the integration of IoT, LLMs, and FL. We prioritized studies that discussed system architectures, methodologies, applications, challenges, or future directions related to this tripartite synergy, particularly those addressing resource constraints and privacy in IoT environments.
Exclusion Criteria: Papers were excluded if they focused solely on one technology without significant discussion of its integration with the other two, were not written in English, or were not accessible in full text. Short abstracts, posters, and non-academic articles were also excluded.
Literature Screening and Selection Statistics: Our initial search across the specified databases (Google Scholar, IEEE Xplore, ACM Digital Library, Scopus, and ArXiv using keywords such as ((“Internet of Things” OR “IoT”) AND (“Large Language Models” OR “LLMs”) AND (“Federated Learning” OR “FL”)) AND (“Edge Computing” OR “Privacy”)) yielded 223 unique articles. After screening titles and abstracts for relevance to the tripartite synergy of IoT, LLMs, and FL, particularly in edge environments, 160 articles were retained. These 160 articles underwent a full-text review against our predefined inclusion and exclusion criteria. From this detailed assessment, 78 articles were identified as directly pertinent to the core research questions of this review and were selected for in-depth data extraction and synthesis. The final manuscript cites a total of 135 references, which encompass these 78 core articles along with foundational papers and other supporting literature.
Bias Assessment and Mitigation: To ensure a balanced review, potential sources of bias were considered. Publication bias, the tendency to publish positive or significant results, was mitigated by including pre-prints from ArXiv, allowing for the inclusion of recent and ongoing research that may not yet have undergone peer review. To counteract database bias, we utilized multiple prominent and diverse academic databases. Furthermore, keyword bias was addressed by developing a comprehensive list of search terms, including synonyms and variations, related to IoT, LLMs, FL, and their intersection with edge computing and privacy. The selection and data extraction were primarily conducted by two authors, with discrepancies resolved through discussion to minimize individual researcher bias.
Data Extraction and Synthesis: Relevant information regarding methodologies, challenges, proposed solutions, applications, and future trends was extracted from the selected papers. This information was then synthesized to identify common themes, research gaps, and the overall state of the art, forming the basis of this review.
5. Synergistic Effects of Integrating IoT, LLMs, and Federated Learning
The previous sections have laid the groundwork by introducing the core concepts and individual capabilities of IoT, LLM and FL. While pairwise integrations—such as applying LLMs to IoT data analytics [
105], using FL for privacy-preserving IoT applications [
20,
21], or employing FL to train LLMs [
23]—offer significant advancements, they often encounter inherent limitations [
10]. Centralized LLM processing of IoT data raises critical privacy and communication bottlenecks [
13]; traditional FL models struggle with the complexity and scale of raw IoT data [
14]; and federated LLMs without direct access to real-world IoT streams lack crucial grounding and context [
7].
This section argues that the true transformative potential lies in the synergistic convergence of all three technologies, IoT, LLMs, and FL, explicitly enhanced by Privacy-Enhancing Technologies [
49]. This three-way integration creates a powerful ecosystem where the strengths of each component compensate for the weaknesses of the others, enabling capabilities and solutions that are fundamentally unattainable or significantly less effective otherwise [
45]. We posit that this synergy is not merely additive but multiplicative, paving the way for a new generation of advanced, privacy-preserving, context-aware distributed intelligence operating directly at the network edge [
15]. We will explore this “1 + 1 + 1 > 3” effect through three core synergistic themes, building upon the motivations discussed in works like [
56].
5.1. Theme 1: Privacy-Preserving, Context-Aware Intelligence from Distributed Real-World Data
The Challenge: LLMs thrive on vast, diverse, and timely data to develop nuanced understanding and maintain relevance [
8]. IoT environments generate precisely this type of data—rich, real-time, multimodal streams reflecting the complexities of the physical world [
7,
49]. However, this data is inherently distributed across countless devices and locations [
14], and often contains highly sensitive personal, operational, or commercial information, making centralized collection legally problematic (e.g., GDPR, HIPAA compliance [
21]), technically challenging (bandwidth costs, latency [
13]), and ethically undesirable [
5,
22]. Relying solely on public datasets limits LLM grounding and domain specificity [
10].
The Synergy (IoT + LLM + FL): Federated Learning acts as the crucial enabling mechanism [
9] that allows LLMs to tap into the rich, distributed data streams generated by IoT devices without compromising data locality and privacy [
15]. IoT provides the continuous flow of real-world, multimodal data (the “what” and “where”) [
14]. FL provides the privacy-preserving framework for collaborative learning across these distributed sources (the “how”) [
10]. The LLM provides the advanced cognitive capabilities to learn deep representations, understand context, and extract meaningful intelligence from this data (the “why” and “so what?”) [
69].
Emergent Capability: This synergy empowers LLMs to maintain robust general capabilities while dynamically adapting to specific real-world contexts. By leveraging fresh, diverse, and privacy-sensitive IoT data, these models achieve continuous grounding in evolving environments. This allows for the following:
Hyper-Personalization: Training models tailored to individual users or specific environments (e.g., a smart home assistant learning user routines from sensor data via FL [
14]).
Real-time Domain Adaptation: Continuously fine-tuning LLMs (e.g., using PEFT like LoRA [
61]) with the latest IoT data to adapt to changing conditions (e.g., adapting a traffic prediction LLM based on real-time sensor feeds from different city zones [
106]).
Enhanced Robustness: Learning from diverse, real-world IoT data sources via FL can make LLMs more robust to noise and domain shifts compared to training solely on cleaner, but potentially less representative, centralized datasets [
44].
5.2. Theme 2: Intelligent Interpretation and Action Within Complex IoT Environments
The Challenge: IoT environments produce data that is often complex, noisy, unstructured, and multimodal (e.g., raw sensor time series, machine logs, video feeds, acoustic signals) [
14]. Traditional FL, while preserving privacy, often employs simpler models that struggle to extract deep semantic meaning or perform complex reasoning on such data [
49]. Conversely, powerful LLMs, while capable of understanding complexity [
15], lack the direct connection to the physical world for sensing and actuation and struggle with distributed private data access [
107].
The Synergy (IoT + LLM + FL): LLMs bring sophisticated natural language understanding, reasoning, and generation capabilities to the table [
1], allowing the system to interpret intricate patterns, correlate information across different IoT modalities, and even generate human-readable explanations or reports [
105]. FL provides the means to train these powerful LLMs collaboratively using the relevant complex IoT data distributed across the network [
61]. Crucially, IoT devices provide the physical grounding, acting as the sensors collecting the complex data and potentially as actuators executing decisions derived from LLM insights [
3]. Furthermore, LLMs can enhance the FL process itself by intelligently guiding client selection based on interpreting the relevance or quality of their IoT data, or even assisting in designing personalized FL strategies [
15].
Emergent Capability: The combination allows for systems that can deeply understand complex physical environments and interact intelligently within them. This goes beyond simple data aggregation or pattern matching:
Contextual Anomaly Detection: Identifying subtle anomalies in IIoT machine behavior by correlating multi-sensor data and unstructured logs, understood and explained by an LLM trained via FL [
108]. Causal Reasoning in Smart Cities: Using FL-trained LLMs to analyze diverse IoT data (traffic, pollution, events) to infer causal relationships and predict cascading effects [
14,
106]. Goal-Oriented Dialogue with Physical Systems: Enabling users to interact with complex IoT environments (e.g., a smart factory floor) using natural language, where an LLM interprets the request, queries relevant IoT data (potentially involving FL for aggregation), and generates responses or even commands for actuators [
15].
5.3. Theme 3: Scalable and Adaptive Domain Specialization at the Edge
The Challenge: Deploying large, general-purpose LLMs directly onto resource-constrained IoT devices is often infeasible due to their size and computational requirements [
62]. While smaller, specialized models can run on the edge, training them from scratch for every specific IoT application or location is inefficient and does not leverage the power of large pre-trained models [
15]. Centralized fine-tuning of large models for specific domains requires access to potentially private or distributed IoT data [
13].
The Synergy (IoT + LLM + FL): FL combined with PEFT techniques like LoRA [
70] provides a highly scalable and resource-efficient way to specialize pre-trained LLMs for diverse IoT domains using distributed edge data [
13,
60]. IoT devices/edge servers provide the specific local data needed for adaptation [
14]. PEFT ensures that only a small fraction of parameters need to be trained and communicated during the FL process, drastically reducing computation and communication overhead [
61,
82]. The base LLM provides the powerful foundational knowledge, while FL+PEFT enables distributed, privacy-preserving specialization [
71].
Emergent Capability: This synergy enables the mass customization and deployment of powerful, specialized AI capabilities directly within diverse IoT environments. Key outcomes include the following:
Locally Optimized Performance: Models fine-tuned via FL+PEFT on local IoT data will likely outperform generic models for specific edge tasks (e.g., a traffic sign recognition LLM adapted via FL to local signage variations [
14]).
Rapid Adaptation: New IoT devices or locations can quickly join the FL process and adapt the shared base LLM using PEFT without needing massive data transfers or full retraining [
10].
Resource-Aware Deployment: Allows for leveraging powerful base LLMs even when end devices can only handle the computation for small PEFT updates during FL training [
79], or optimized inference models (potentially distilled using FL-trained knowledge [
86]). Frameworks like Split Federated Learning can further distribute the load [
17,
18].
5.4. Illustrative Use Case: Predictive Maintenance in Federated Industrial IoT
Consider a scenario involving multiple manufacturing plants belonging to different subsidiaries of a large corporation, or even different collaborating companies [
108]. Each plant operates similar types of critical machinery (e.g., CNC machines, robotic arms) equipped with various sensors (vibration, temperature, acoustic, power consumption—the IoT component). The goal is to predict potential machine failures proactively across the entire fleet to minimize downtime and optimize maintenance schedules, while ensuring that proprietary operational data and specific machine performance characteristics from one plant are not shared with others.
Below, we summarize the limitations without synergy.
To address the issues highlighted above, a synergistic solution (IoT + LLM + FL) is illustrated next.
This integrated system can achieve highly accurate, context-aware predictive maintenance across multiple entities by leveraging diverse operational data (IoT) through privacy-preserving collaborative learning (FL), powered by the deep analytical and interpretive capabilities of LLMs, all achieved efficiently using PEFT. This outcome would be significantly harder, if not impossible, to achieve with only two of the three components.
5.5. Challenges Arising from the Synergy
While powerful, the tight integration of IoT, LLMs, and FL introduces unique challenges beyond those of the individual components:
Cross-Domain Data Alignment and Fusion: Effectively aligning and fusing heterogeneous, multimodal IoT data streams within an FL framework before feeding them to an LLM requires sophisticated alignment and representation techniques [
105].
Resource Allocation Complexity: How to jointly optimize computation (LLM inference/training, FL aggregation), communication (IoT data upload, FL updates), and privacy (PET overhead) across heterogeneous IoT devices, edge servers, and potentially the cloud specifically for this integrated task [
13].
Model Synchronization vs. Real-time Needs: Balancing the need for FL model synchronization (potentially slow for large LLM updates [
10]) with the real-time data processing and decision-making requirements of many IoT applications.
Emergent Security Vulnerabilities: New attack surfaces emerge at the interfaces, e.g., malicious IoT data poisoning FL training specifically to mislead the LLM’s interpretation [
109], or FL privacy attacks aiming to reconstruct sensitive IoT context interpreted by the LLM [
110]. Verifying the integrity of both IoT data and FL updates becomes critical [
15].
5.6. Concluding Remarks on Synergy
The convergence of IoT, Large Language Models, and Federated Learning represents a fundamental paradigm shift in designing intelligent distributed systems. As demonstrated, their synergy unlocks capabilities far exceeding the sum of their individual parts. By enabling powerful LLMs to learn from diverse, real-world, privacy-sensitive IoT data through the secure framework of FL, we can create adaptive, context-aware, and specialized AI solutions deployable at the network edge. This synergy directly addresses the limitations inherent in previous approaches, paving the way for truly intelligent, efficient, and trustworthy applications across critical domains like Industrial IoT, autonomous systems, and smart infrastructure. While unique challenges arise from this tight integration, they also define fertile ground for future research focused on realizing the full, transformative potential of this powerful technological triad.
7. Research Gaps and Future Directions
The IoT, LLMs, and FL have seen rapid progress, establishing a notable current state of development and research. However, despite these advancements, substantial challenges persist. This section aims to provide a structured overview by first briefly acknowledging key aspects of the current landscape within specific domains of this integration. Building on this, we then identify critical research gaps, supported by detailed evidence and insights from recent literature. Finally, based on these identified gaps, we delineate promising future directions for advancing the synergistic application of these technologies.
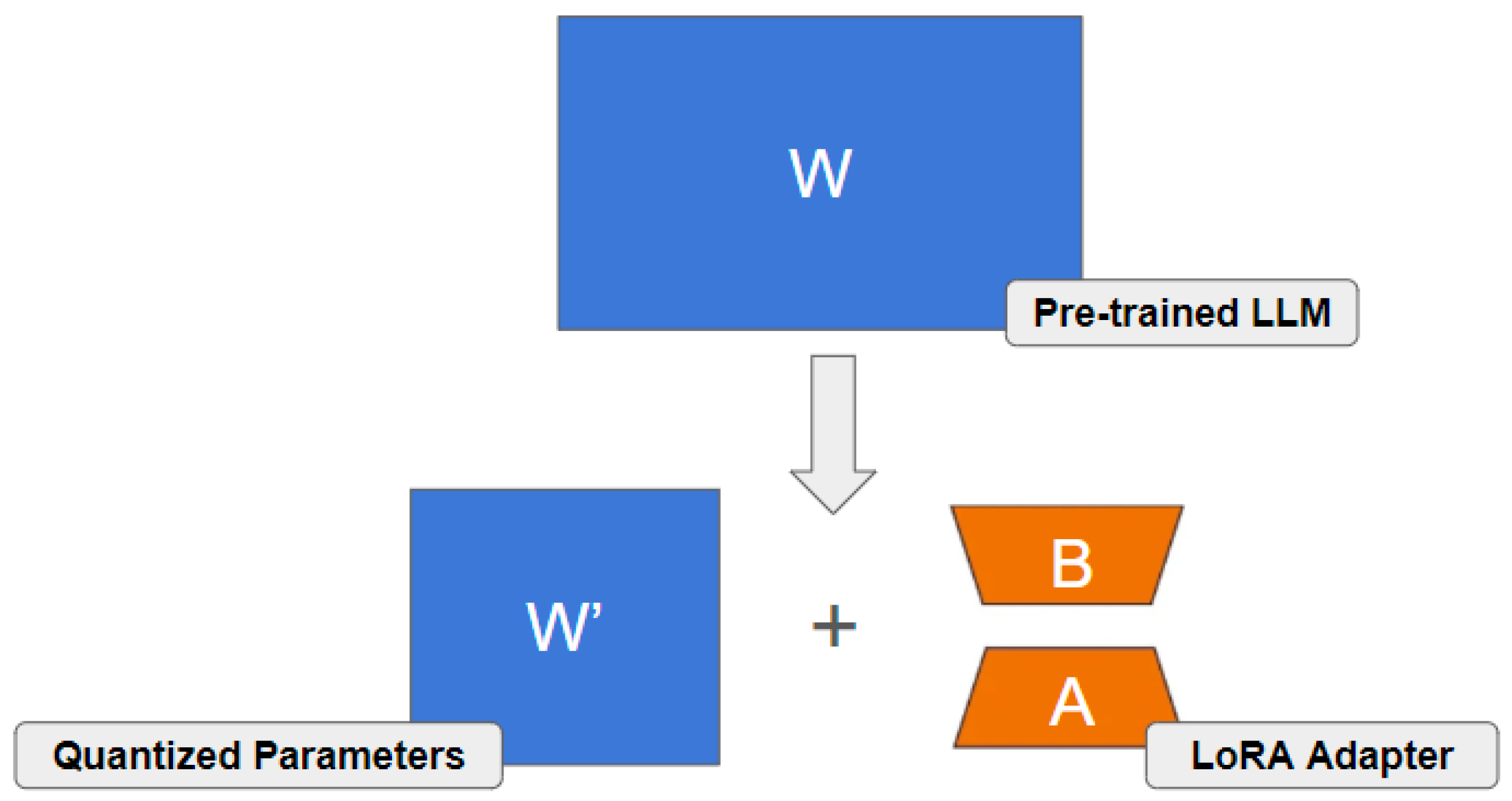
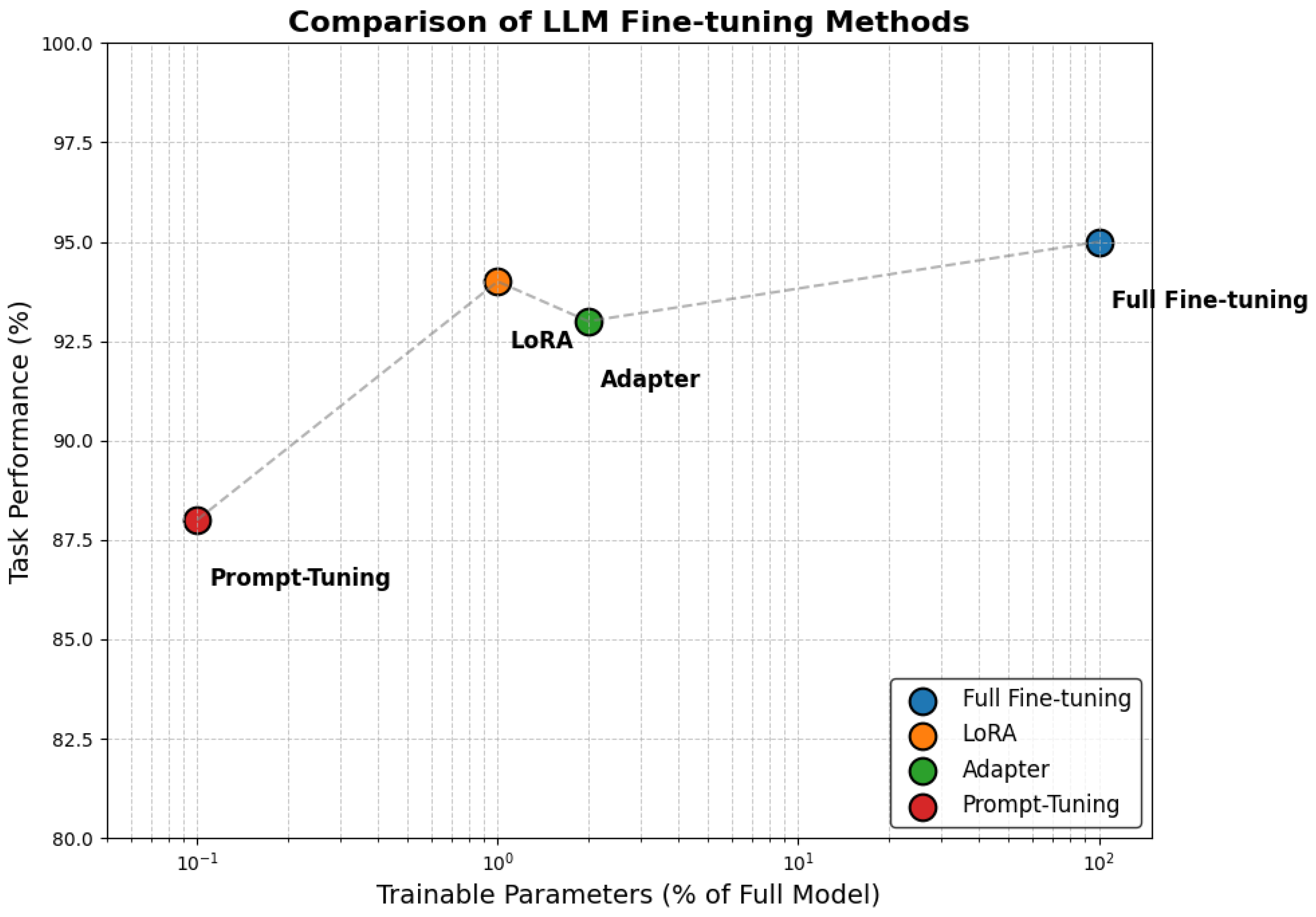
Efficiency for Extreme Edge: LLMs are notoriously resource-intensive, but edge IoT devices often operate on milliwatts of power with kilobytes of RAM. Techniques like QLoRA [
62] reduce fine-tuning memory use by combining 4-bit quantization and low-rank adaptation, making LLMs tractable for edge execution. Similarly, SparseGPT achieves one-shot pruning with negligible accuracy drop on billion-parameter models [
67]. SmoothQuant enhances post-training quantization by aligning activations and weights to improve stability under int8 quantization [
68]. Backpropagation-free training is emerging as a potential direction to eliminate memory-heavy gradient calculations; the survey in [
87] reviews biologically inspired and forward–forward alternatives relevant to constrained hardware. These are particularly promising when combined with hardware-aware co-design, as advocated in [
3], for FL in 6G IoT networks.
Robustness to Heterogeneity and Fairness: Extreme client heterogeneity in IoT-FL, both in data and hardware, poses serious convergence and fairness challenges. Pfeiffer et al. [
24] analyze system-level disparities and advocate for client-specific adaptation layers. Carlini et al. [
37] further highlight how adversarial alignment in neural networks can propagate biases, underscoring the need for fairness constraints in model design. Multi-prototype FL, as discussed in the Wevolver report [
12], enables clients to specialize on subsets of prototypes that better represent their local distributions. Deng et al. [
73] propose a hierarchical knowledge transfer scheme that separates global, cluster, and local models, reducing the negative transfer from outlier clients. Formal fairness-aware FL protocols, however, are still lacking.
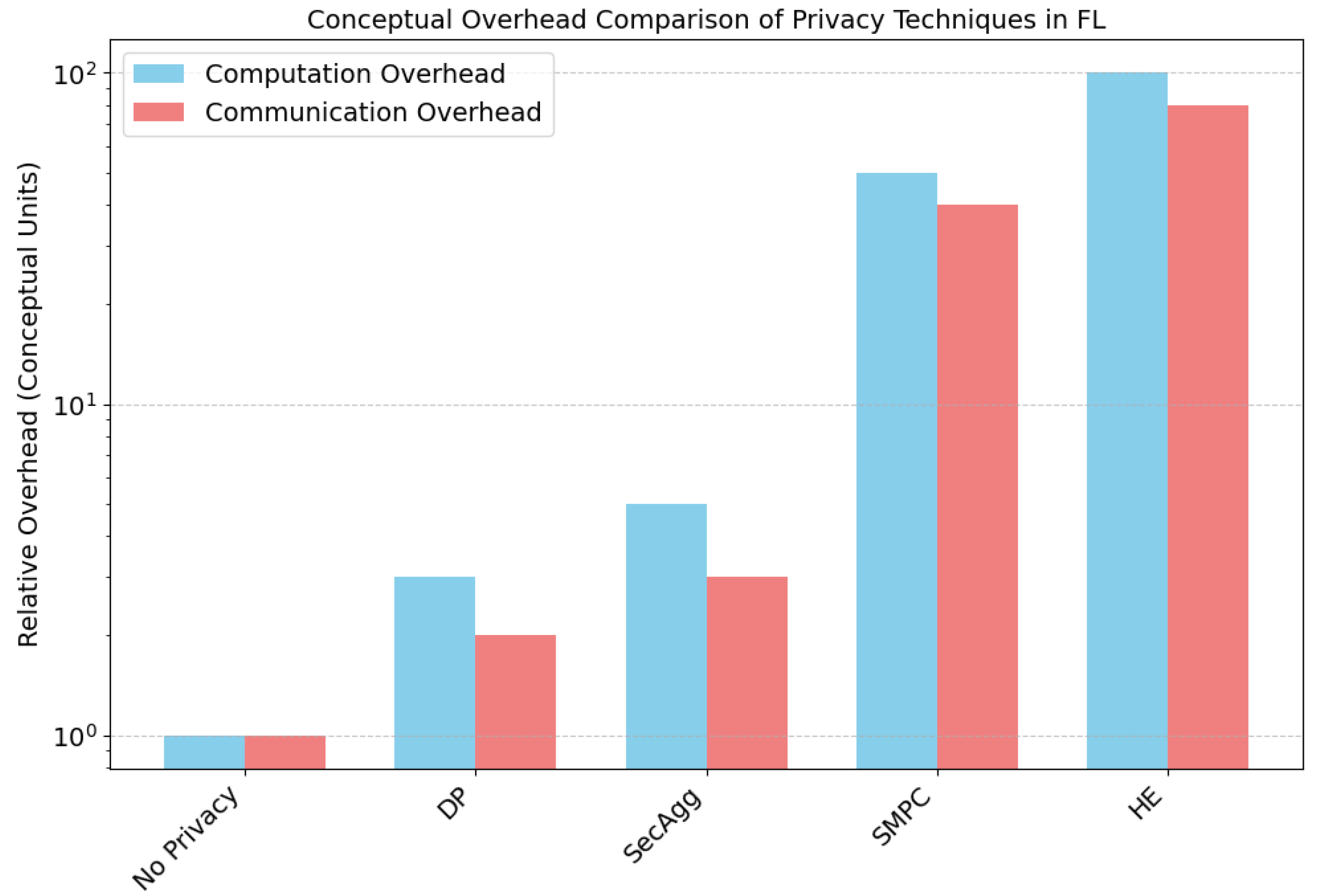
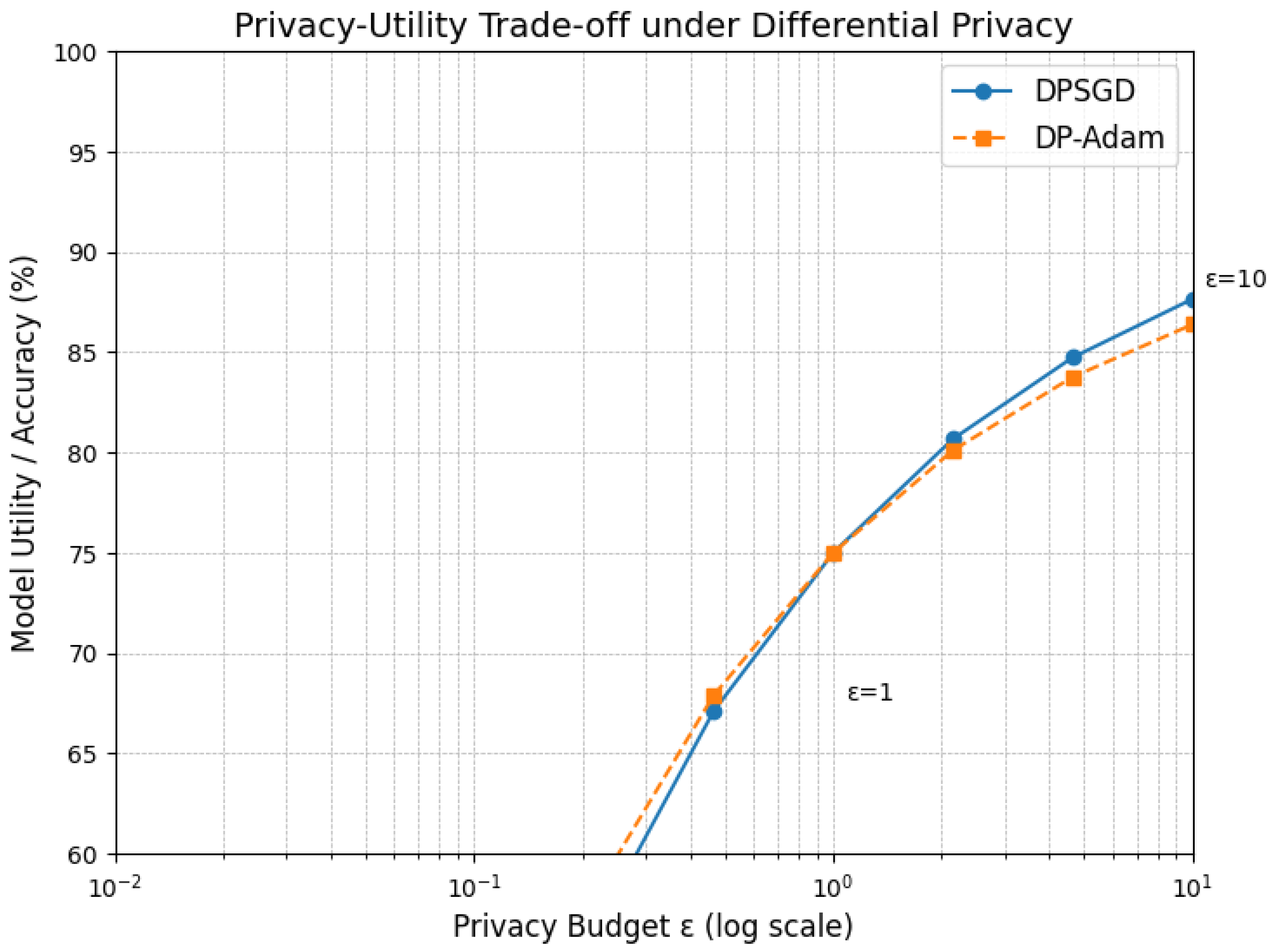
Practical Privacy Guarantees: Applying PETs to LLM-based FL is non-trivial. While traditional DP mechanisms such as those in [
45,
48] remain foundational, Ahmadi et al. [
49] show that when applied to LLMs in FL, DP introduces substantial performance degradation unless combined with hybrid masking and adaptive clipping strategies. Liu et al. [
70] propose DP-LoRA, which selectively adds noise only to low-rank adaptation matrices, achieving a trade-off between utility and formal privacy. Yet, computational cost remains high. HE and SMPC offer stronger privacy but with significant communication and computational overheads unsuitable for IoT [
53,
55]. Efficient and scalable PET integration into low-power FL deployments remains an open issue.
Advanced Security and Trust: Foundation models open new attack surfaces in FL. Li et al. [
118] demonstrate that compromised foundation models can inject imperceptible backdoors into global models during federated fine-tuning. Wu et al. [
119] study adversarial adaptations where model updates mimic benign behavior, bypassing current anomaly detection. Existing aggregation defenses like Krum [
116] and Bulyan [
126] struggle when attackers use model-aligned poisoning. Fan et al. [
124] propose using zero-knowledge proofs for secure update verification in FL, though integration into LLM systems is yet to be tested. Decentralized trust frameworks with verifiable integrity, such as those discussed in [
42], could mitigate these threats in IoT federations.
Standardization and Benchmarking: Most existing FL benchmarks are designed for small NLP tasks (e.g., FedNLP [
98]), lacking scale and modality diversity. Zhang et al. [
97] introduce FederatedGPT to benchmark instruction tuning under FL settings, incorporating metrics like alignment score and robustness. FederatedScope-LLM [
96] goes further, providing end-to-end support for parameter-efficient tuning (e.g., LoRA, prompt tuning) across diverse datasets. However, neither covers streaming sensor data, nor evaluates under network constraints typical in IoT. A comprehensive benchmark must include multimodal tasks, model size variability, privacy/utility/fairness trade-offs, and realistic simulation environments [
129].
Multimodal Federated Learning: IoT deployments naturally involve multimodal data. ImageBind [
130] demonstrates crossmodal LLMs trained on image, audio, depth, and IMU inputs in a single embedding space, but assumes centralized training. Cui et al. [
105] highlight the challenges of decentralized multimodal alignment, including inter-client modality mismatch and unbalanced contributions. Communication-efficient multimodal fusion techniques and modality-specific adapters are needed. Sensor-based FL must incorporate asynchronous updates and crossmodal imputation to be practical in the real world.
Federated Learning for AI Agents: Li et al. [
131] envision LLM-based AI agents capable of perception, planning, and actuation across decentralized IoT systems. Such agents require lifelong learning and task adaptation, which traditional FL lacks. PromptFL [
80] proposes learning shared prompts instead of entire models, while FedPrompt [
81] enhances this with privacy-preserving prompt updates. These methods significantly reduce communication and allow client-specific behavior, but lack the reasoning and memory modules required by generalist agents. Integration with reinforcement FL and safe exploration policies is a future direction.
Continual Learning and Adaptability: The temporal nature of IoT data leads to frequent concept drift. Shenaj et al. [
132] propose online adaptation techniques but do not consider privacy. Wang et al. [
107] review continual FL methods including regularization-based and rehearsal-based strategies. Xia et al. [
108] propose FCLLM-DT, which maintains temporal awareness via digital twins. These approaches should be enhanced with memory-efficient adaptation and forgettable modules that meet legal obligations on data deletion.
Legal, Ethical, and Economic Considerations: Federated LLMs operating across jurisdictions must comply with evolving data governance policies. Cheng et al. [
10] outline open legal questions in multi-party FL, such as liability for biased decisions and model misuse. Qu et al. [
13] emphasize ethical concerns such as disproportionate access to computing resources and biased training data. Witt et al. [
43] review incentive mechanisms like token-based payments or fairness-based credit allocation, critical for encouraging client participation. However, these are rarely tested in LLM-specific scenarios, and no consensus exists on equitable reward strategies.
Machine Unlearning and Data Erasure: Hu et al. [
133] propose erasing LoRA-tuned knowledge via gradient projection and local retraining to remove specific client data contributions without damaging generalization. Patil et al. [
134] leverage influence functions to reduce a sample’s effect on final predictions, but require full access to model internals. Qiu et al. [
135] address federated unlearning by designing reverse aggregation schemes, though practical validation on LLMs is absent. Verifiability and efficiency of unlearning remain open problems, especially in decentralized, heterogeneous FL contexts.
8. Conclusions
Before summarizing our findings, it is important to acknowledge certain limitations of this review. While we endeavored to conduct a comprehensive search across multiple prominent databases and included pre-prints to capture the latest advancements, the selection process may be subject to inherent biases. Our exclusion of non-English language articles and the specific keywords chosen might have inadvertently omitted some relevant studies. Furthermore, the field of integrating IoT, LLMs, and FL is exceptionally dynamic; consequently, new developments may have emerged subsequent to our literature search cutoff in May 2025 that are not encompassed in this work. The review’s primary focus on the tripartite synergy also means that related pairwise integrations or broader technological aspects might have received less exhaustive coverage than in specialized surveys. These factors should be considered when interpreting the scope and conclusions of this review.
Bringing together the IoT, LLMs, and FL creates a powerful combination. This review has explored how this three-way synergy, backed by strong privacy techniques, paves the way for smarter, more responsive, and trustworthy distributed systems, achieving results that are not available when these technologies are used in pairs. We have mapped out the motivations, the edge-focused architectures, the key methods like PEFT and SFL that make it work, and importantly, the significant challenges involved. Making this powerful integration a reality means tackling some tough hurdles head-on. We need to find ways to run demanding LLMs on resource-limited IoT devices using FL, manage data sharing across networks without overwhelming them, handle the inherent diversity in IoT data and systems, and ensure fairness for everyone involved. Above all, protecting user privacy and securing the entire system against attack, all while meeting legal requirements, is absolutely critical. Despite these difficulties, researchers are actively finding solutions. We are seeing progress with techniques like model compression, smarter communication strategies, personalized learning, advanced privacy methods, and robust ways to combine model updates, though finding the right balance is always key. Encouragingly, real-world applications are starting to emerge, showing the clear value of using FL to let LLMs learn from distributed IoT data privately and effectively.
However, there is still a gap between this potential and widespread, reliable use. To close this gap, the research community needs to focus on several key areas. We urgently need breakthroughs in on-device efficiency for tiny edge devices, more robust algorithms that can handle messy real-world data and potential attacks, reliable ways to guarantee privacy and fairness, standard benchmarks to measure progress fairly, and clear thinking on the legal, ethical, and economic implications. By taking on these challenges with focused, collaborative research, we can unlock the true promise of this technological convergence. Getting this right means building a future with distributed AI systems that are not only powerful and efficient but also fundamentally trustworthy and respectful of data rights, impacting critical areas from industry to healthcare and beyond.




 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}