1. Introduction
The rapid development of autonomous driving systems (ADSs) has led to an exponential increase in software and hardware complexity. This trend is further accelerated by the emergence of autonomous aerial vehicles (AAVs), which extend autonomous technology beyond ground vehicles and introduce even more complex safety challenges [
1]. These developments highlight the importance of sophisticated verification methodologies to ensure overall system safety [
2,
3,
4]. As the level of autonomous driving advances, driver intervention progressively diminishes, which inevitably shifts the responsibility for accidents caused by system defects or limitations toward the manufacturers [
5,
6]. Therefore, ADSs must perform robustly under various driving conditions and unpredictable circumstances, which necessitates simulation-based verification frameworks that can evaluate system behavior quantitatively and reproducibly [
7,
8].
Real-vehicle testing conducted on actual roads offers clear advantages in terms of directly validating systems in real driving situations and naturally reflecting the many variables and uncertainties inherent in real-world environments. However, such testing involves fundamental constraints, including difficulties in ensuring reproducibility, limitations in implementing extreme situations, substantial costs, and safety concerns [
9,
10,
11]. To overcome these limitations, X-in-the-loop simulation (XILS) has been widely adopted, with representative methodologies including model-in-the-loop simulation (MILS), software-in-the-loop simulation (SILS), and hardware-in-the-loop simulation (HILS) [
12,
13,
14].
However, such simulation-based verification methods cannot perfectly reflect the dynamic characteristics of actual vehicles. Among the various XILS approaches, this limitation has prompted a growing interest in vehicle-in-the-loop simulation (VILS), which integrates simulation environments with real vehicles to achieve higher fidelity [
15,
16].
VILS is considered highly credible as it enables not only repetitive and safe reproduction of various scenarios, but also precise evaluation based on the physical responses of actual vehicles [
17,
18]. However, existing research has focused primarily on verification at a simple functional level, with very few systematic methodologies available for quantitatively evaluating the credibility of simulation platforms [
19]. Thus, although research is being actively conducted to validate ADSs through XILS, a system for quantitatively evaluating the credibility of the simulation platforms as a virtual tool chain remains to be developed.
Given the critical importance of reliable simulation platforms for ADS validation, standardized evaluation frameworks have become essential. Recognizing these challenges, the United Nations Economic Commission for Europe (UNECE) has included credibility-assessment principles for virtual tool chains in its SAE Level 2 ADS Driver Control Assistance Systems (DCAS) regulation (ECE/TRANS/WP.29/2024/37) [
20]. According to the DCAS regulation, credibility defines whether a simulation is fit for its intended purpose, based on a comprehensive assessment of five key characteristics of modeling and simulation: capability, accuracy, correctness, usability, and fitness for purpose. The concept of credibility in this regard is distinct from simply reliability. Whereas reliability refers to the consistency of results obtained under the same conditions, credibility is a metric that comprehensively quantifies how well a simulation reflects the relevant real-world system. Thus, for a simulation platform to be deemed credible, it must not only be reliable (i.e., capable of providing reproducible results) but also offer fidelity (i.e., the ability to accurately replicate the physical characteristics and behavior of the actual system) [
21].
For example, even if a vehicle simulation demonstrates high reliability, its value as a validation tool can be undermined if the vehicle dynamics model is inaccurate or the sensor characteristics are not appropriately represented. In such cases, although reproducibility is ensured, real-world vehicle maneuvers are not accurately reflected.
Therefore, a systematic framework for evaluating XILS platforms based on UNECE’s credibility principles is a critical necessity for ADS validation. By verifying that the XILS results would be valid in real-world driving environments, a systematic credibility-assessment framework can serve as a trustworthy foundation for the development of ADSs. Such a framework is also expected to facilitate the establishment of an efficient development process that can overcome the limitations of real-world testing and reduce development costs and time while enabling safe testing of risk scenarios.
2. Related Work
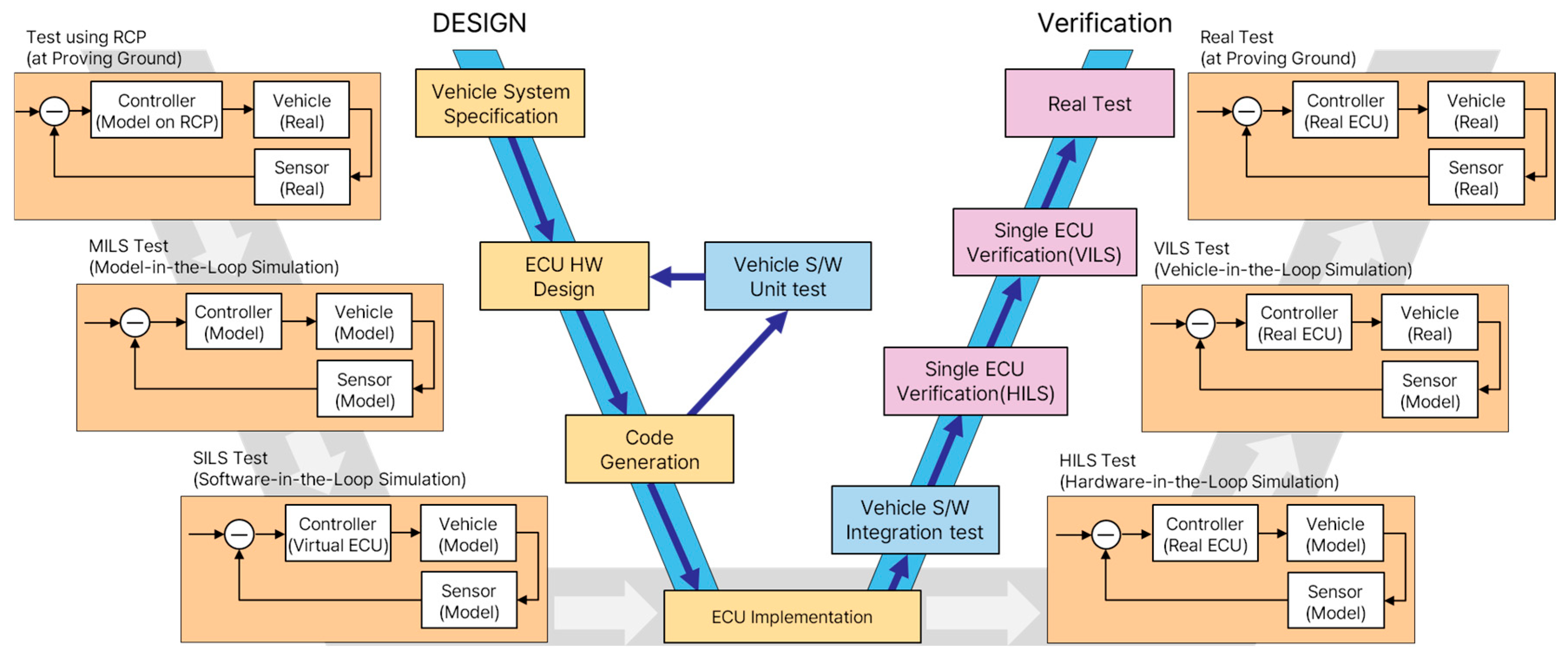
XILS-based techniques have been actively researched and utilized as a systematic approach to verifying ADS safety. As shown in
Figure 1, a key component in the development and validation of ADSs, XILS is categorized into MILS, SILS, HILS, and VILS based on the development stage and constitutes the final step before real-world validation [
22].
Figure 1 illustrates the hierarchical integration of XILS technologies within the V-Model development framework. The figure demonstrates systematic progression from early-stage MILS for algorithm verification, through SILS for software validation, HILS for real-time hardware integration testing, to VILS for comprehensive vehicle-level validation, culminating in real vehicle testing. With the continued progress in simulation research, though, the characteristics and limitations of each XILS phase are becoming clearer. Specifically, MILS enables rapid verification of control algorithms and vehicle models within a purely software environment, thus being an effective tool for securing algorithm stability during the initial development phase [
23]. However, it is limited by its inability to reflect real hardware characteristics. SILS leverages virtual electronic control unit (ECU) models to systematically validate control software functionality and evaluate software code performance before hardware integration [
24]. However, aspects such as actual hardware data structures and computational delays are difficult to emulate perfectly. HILS incorporates real ECUs and hardware for real-time validation and a comprehensive assessment of hardware–software interactions, but it fails to reproduce the complexity of real vehicle dynamics [
25,
26,
27]. To overcome these stage-specific limitations, recent research has focused on VILS, an advanced approach that integrates a real vehicle with a virtual environment, maintaining the vehicle’s dynamic characteristics while enabling safe testing across various virtual scenarios [
28].
To address the limitations of existing XILS approaches while maintaining vehicle dynamic fidelity, Son et al. [
29] proposed a proving ground (PG)-based VILS system that recreates a real proving ground as a high-definition (HD) map-based virtual road. The system comprises four key components: virtual road generation, real-to-virtual synchronization, virtual traffic behavior generation, and perception sensor modeling. This design preserves the vehicle’s true dynamic characteristics while enabling safe, repeatable testing of various scenarios in a virtual environment. Unlike dynamometer-based VILS, it can be implemented with only a proving ground and does not require large-scale dynamometers or over-the-air (OTA) equipment, which significantly reduces initial infrastructure costs and operational risks. Additionally, by utilizing a virtual road derived from an actual test site, it enhances the reproducibility of experiments. Given these advantages, we adopted the PG-based VILS platform for our XILS case study. Simulation platforms for the evaluation and verification of ADSs have been continuously developed and refined. However, before assessing the consistency of results between real-world experiments and simulations, the credibility of the simulation platform itself must be confirmed.
Oh [
30,
31] proposed a methodology to implement the AD-VILS platform designed for evaluating ADSs and developed a technique to assess the platform’s reliability based on key test parameters relevant to ADSs. They quantitatively evaluated consistency by comparing these key parameters between real-vehicle tests and VILS tests based on statistical indicators. Furthermore, they proposed a scenario-based reliability evaluation method to verify whether VILS testing could partially replace real-world testing or be effective in specific scenarios. Based on the indices of consistency between real-vehicle tests and VILS tests, they derived correlation and applicability metrics to evaluate the platform’s overall reliability. However, existing credibility-assessment techniques for XILS platforms still have significant limitations. Major issues include their focus on evaluating advanced driver assistance system (ADAS) functions without sufficiently considering the overall dynamic behavior of the vehicle. Furthermore, most verification frameworks are limited to low-speed scenarios, which hinders reliability verification under higher-speed conditions. Additionally, the requirement for repeating independent experiments under different speed conditions represents a significant structural inefficiency.
Therefore, we propose a novel framework for evaluating the credibility of XILS platforms as a virtual tool chain for ADS validation. The strategy involves statistical and mathematical comparisons between the results of XILS tests and real-vehicle tests, with similarity and consistency metrics calculated for each test. These metrics are determined from the perspectives of parameters, scenarios, and dynamics, and the calculated consistency enables evaluation across three aspects: parameter-based reliability, scenario-based reliability, and dynamics-based fidelity. Ultimately, the credibility of the XILS platform is determined based on the results of these three types of analyses. Furthermore, to ensure efficient credibility evaluation, geometric similarity analysis is performed. The credibility evaluation metrics, derived from experimental data obtained through tests conducted under various speed conditions within the same scenario, are visualized on spider charts. The use of geometric shape comparison metrics allows quantitative analysis of the similarity between two shapes, demonstrating that speed is not the dominant factor when assessing scenario credibility. Additionally, the analysis of geometric similarities between different scenarios suggests the possibility of establishing a representativeness assessment framework, where certain scenarios can serve as proxies for the credibility assessment of others.
The systematic credibility evaluation framework proposed herein is expected to efficiently verify whether virtual XILS test results remain valid in real-world driving environments, thereby serving as a dependable foundation for the development of ADSs.
The remainder of this paper is structured as follows:
Section 3 explains the proposed credibility-assessment methodology, which is based on an integrated evaluation framework that considers not only reliability but also fidelity while reflecting dynamic consistency.
Section 4 introduces the procedures for efficiently verifying the credibility of XILS platforms, which is followed by a test to determine whether the speed condition is the dominant factor when assessing a given scenario. The credibility-assessment results across various speed conditions within the same scenario are visualized through spider charts, and the similarity between shapes is quantitatively analyzed through geometric shape comparison. This similarity analysis serves as the basis for evaluating the efficiency of credibility validation. Furthermore, we extend the geometric shape comparison to scenarios involving different driving maneuvers to establish a methodology for confirming whether certain scenarios can represent others.
Section 5 describes the experimental environment created for the real-vehicle tests and VILS tests and discusses the validity of the methods outlined in
Section 3 and
Section 4 based on experimental results. Finally,
Section 6 presents the implications of our findings for the credibility assessment of simulation platforms, states the limitations of this study, and outlines future research directions.
3. Proposed Credibility Evaluation Methodology
Before utilizing XILS environments for ADS validation, the credibility of the XILS platform itself must be rigorously assessed.
It is important to clarify the distinction between credibility, reliability, and fidelity as used in this framework. Following UNECE DCAS regulations, credibility represents a comprehensive assessment that encompasses both reliability (the consistency and repeatability of results under identical conditions) and fidelity (the accuracy with which simulation models reproduce real-world physical characteristics and behaviors). While reliability focuses on reproducibility and consistency between repeated tests, fidelity emphasizes the physical accuracy of dynamic responses. Credibility, therefore, serves as an overarching metric that ensures a simulation platform is both consistent in its outputs and accurate in its representation of real-world phenomena, making it fit for its intended validation purpose.
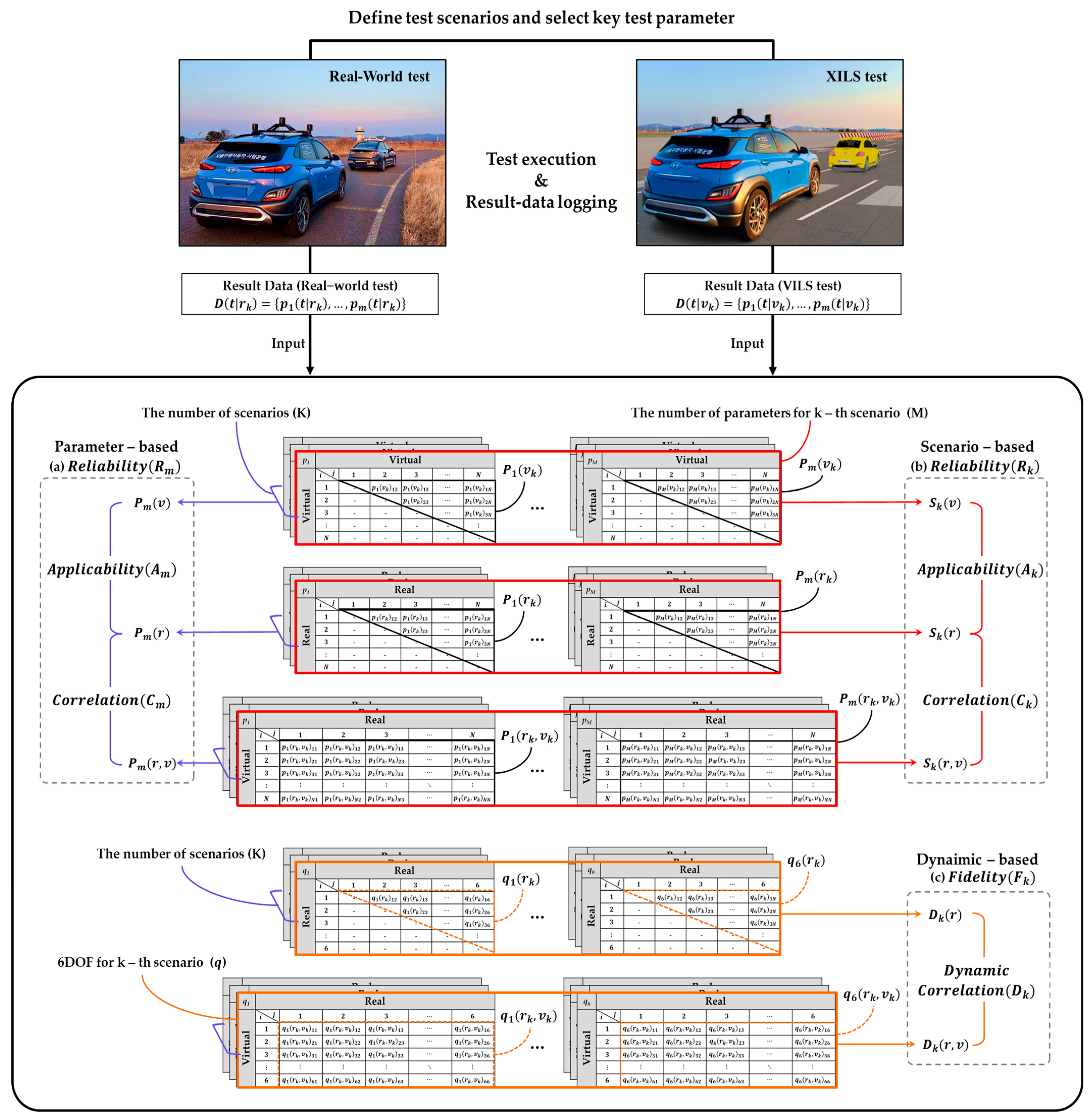
We propose a framework to quantify the credibility of XILS through a comprehensive assessment from parameter-based, scenario-based, and dynamics-based perspectives (
Figure 2).
Figure 2 presents the comprehensive three-dimensional credibility evaluation framework for XILS platforms, building upon the reliability assessment methodology established by Oh [
31]. The framework illustrates a systematic matrix-based comparison structure that processes similarity calculations between different test configurations (virtual–virtual, real–real, and virtual–real combinations) across multiple dimensions. The core of the methodology centers on structured similarity matrices where each table represents different comparison types indicated by the (virtual, real) labels at the top and left sides. Within each matrix, black-bordered cells represent the similarity comparison results for individual parameters (one of m parameters) between specific test iterations, enabling detailed component-level analysis. Red-bordered horizontal sections encompass the similarity results for all m parameters within a single scenario (one of k scenarios), providing scenario-level aggregated comparisons. Blue-bordered vertical stacks represent similarity results for a single parameter (one of m parameters) across all k scenarios, facilitating parameter-level cross-scenario analysis. These multi-layered matrix structures feed into the three parallel evaluation streams: (1) Parameter-based reliability assessment utilizes the blue-bordered parameter stacks to calculate correlation indices
and applicability indices
for each of the m key parameters, identifying specific modeling deficiencies in simulation components; (2) scenario-based reliability assessment leverages the red-bordered scenario sections to compute scenario-level correlation
and applicability
indices, determining replacement feasibility of real-world tests; (3) dynamics-based fidelity assessment employs additional orange-bordered matrices that specifically compare six-degree-of-freedom motion characteristics between virtual and real test configurations, yielding dynamic correlation indices
. Validation test scenarios and key test parameters are defined, and data are then collected by performing repeated real-world and XILS tests under identical conditions. The collected data are analyzed across three core dimensions before being integrated into the final credibility assessment.
The parameter-based reliability assessment involves calculating the applicability index () and correlation index () for each key test parameter. The applicability index determines whether XILS tests offer better repeatability and reproducibility than real-world tests, quantifying the consistency of individual component models within the XILS platform in maintaining their outputs across multiple test iterations. The correlation index measures the similarity between real-world and XILS tests at the parameter level, reflecting the accuracy of the simulation component models with reference to the respective parameters. The parameter-based reliability () is then evaluated based on whether these two indices meet their defined evaluation criteria.
Scenario-based reliability assessment involves calculating the applicability index () and correlation index () for each scenario. The scenario applicability index quantifies how consistently XILS test results align with real-world test results in a given scenario, while the scenario correlation index measures the overall similarity between real-world and XILS tests at the scenario level. The scenario-based reliability () is then determined based on whether these two indices meet their predefined evaluation criteria.
Dynamics-based fidelity assessment involves calculating the dynamic correlation index () centered on the vehicle’s six-degree-of-freedom (6DOF) motion characteristics. This index measures the similarity between real-world tests and XILS tests based on information on the vehicle’s three types of translational movements and three types of rotational movements. The dynamics-based fidelity () is then evaluated based on whether meets the defined evaluation criterion.
When the parameter-based reliability (), scenario-based reliability (), and dynamics-based fidelity () have all been validly assessed, the XILS platform is deemed credible. This multi-dimensional approach minimizes the potential biases arising from single-perspective evaluations and comprehensively verifies the credibility of the XILS platform for ADS validation.
We employed the comparative analysis techniques proposed by Oh [
31] to measure the similarity between the datasets from the real-world and XILS tests. Oh [
31] proposed a comprehensive similarity evaluation metric that combines the correlation coefficient (
) for integrated comparison, the Zilliacus error (
) for point-to-point comparison, and the Geers metric (
) to analyze magnitude and phase errors separately.
The correlation coefficient
is defined by Equation (1), where
and
represent the two datasets to be compared, and
denotes the number of sample data points, with each data point indexed by
from 0 to
[
32]. The correlation coefficient ranges from −1 to 1, where values closer to 1 indicate stronger positive linear relationships between the dataset trends. The Zilliacus error
is calculated using Equation (2), which normalizes the sum of absolute point-wise errors
by the sum of absolute values of the reference dataset; lower f
2 values indicate better point-to-point agreement between the two datasets [
33]. The Geers metric
is calculated as the square root of the sum of the squares of the magnitude error
and phase error
, as expressed in Equation (3). The magnitude error
in Equation (4) quantifies the energy ratio between datasets through their squared sums, while the phase error
in Equation (5) measures temporal alignment differences using normalized cross-correlation [
34]. This technique enables separate evaluations of amplitude differences and temporal synchronization between the datasets.
Finally, the combined similarity metric (
) is calculated as the weighted sum of these three indicators, as shown in Equation (6). Here,
, and
represent the weighting factors for the three metrics, which can be adjusted according to their respective importance levels. In this study, equal weighting
was applied to ensure balanced consideration of all three similarity aspects. However, these weights can be adjusted according to specific testing requirements and the relative importance of each metric for different evaluation contexts. Since the complete mathematical derivation and information regarding each metric have already been provided by Oh [
31], in-depth discussion is omitted in this paper.
We used this integrated similarity index to evaluate the reliability of XILS from a parameter perspective and a scenario perspective, as explained in
Section 3.2 and
Section 3.3, respectively. The evaluation of the XILS platform’s fidelity from a dynamics perspective is described in
Section 3.4.
3.1. Definitions of Scenarios and Parameters
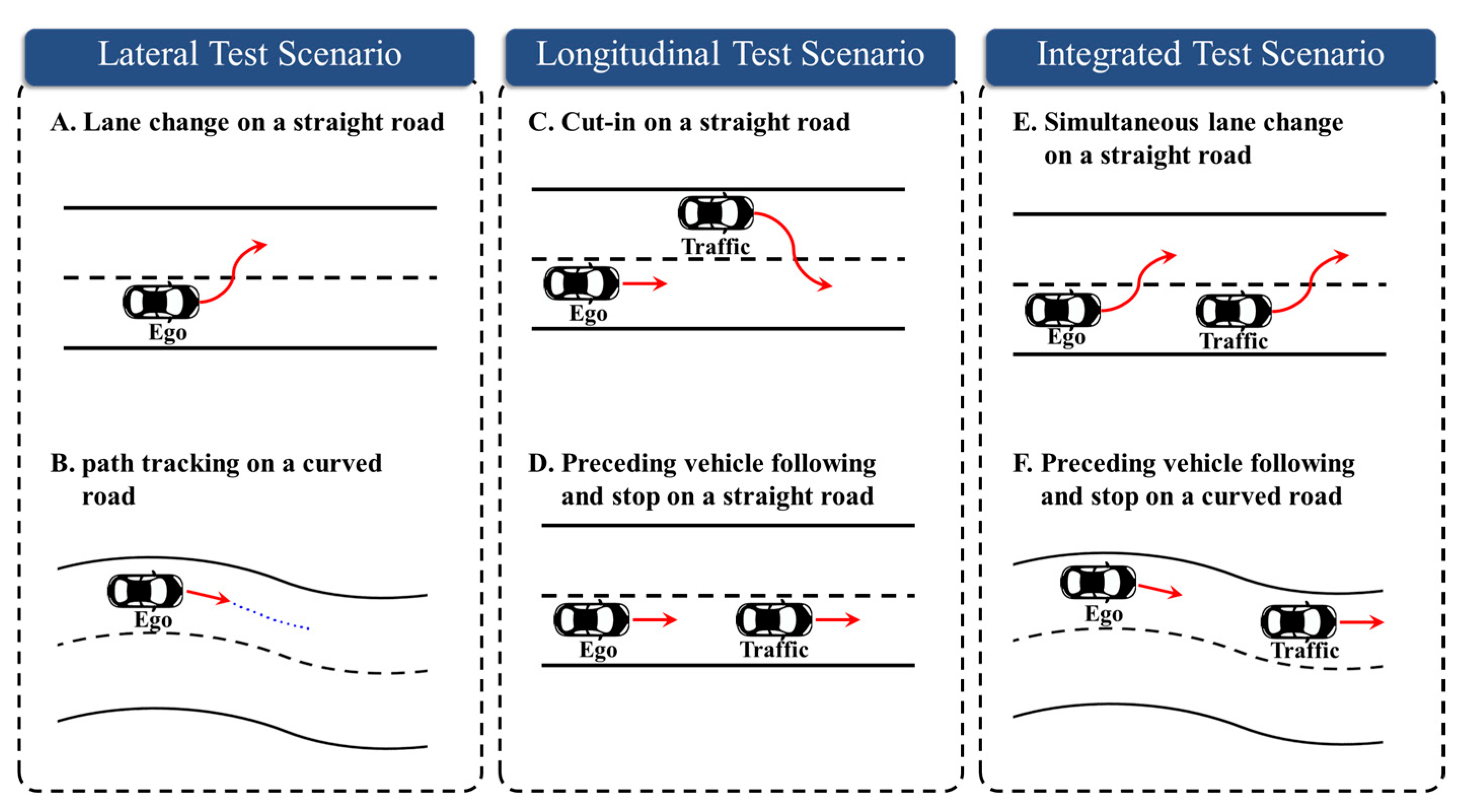
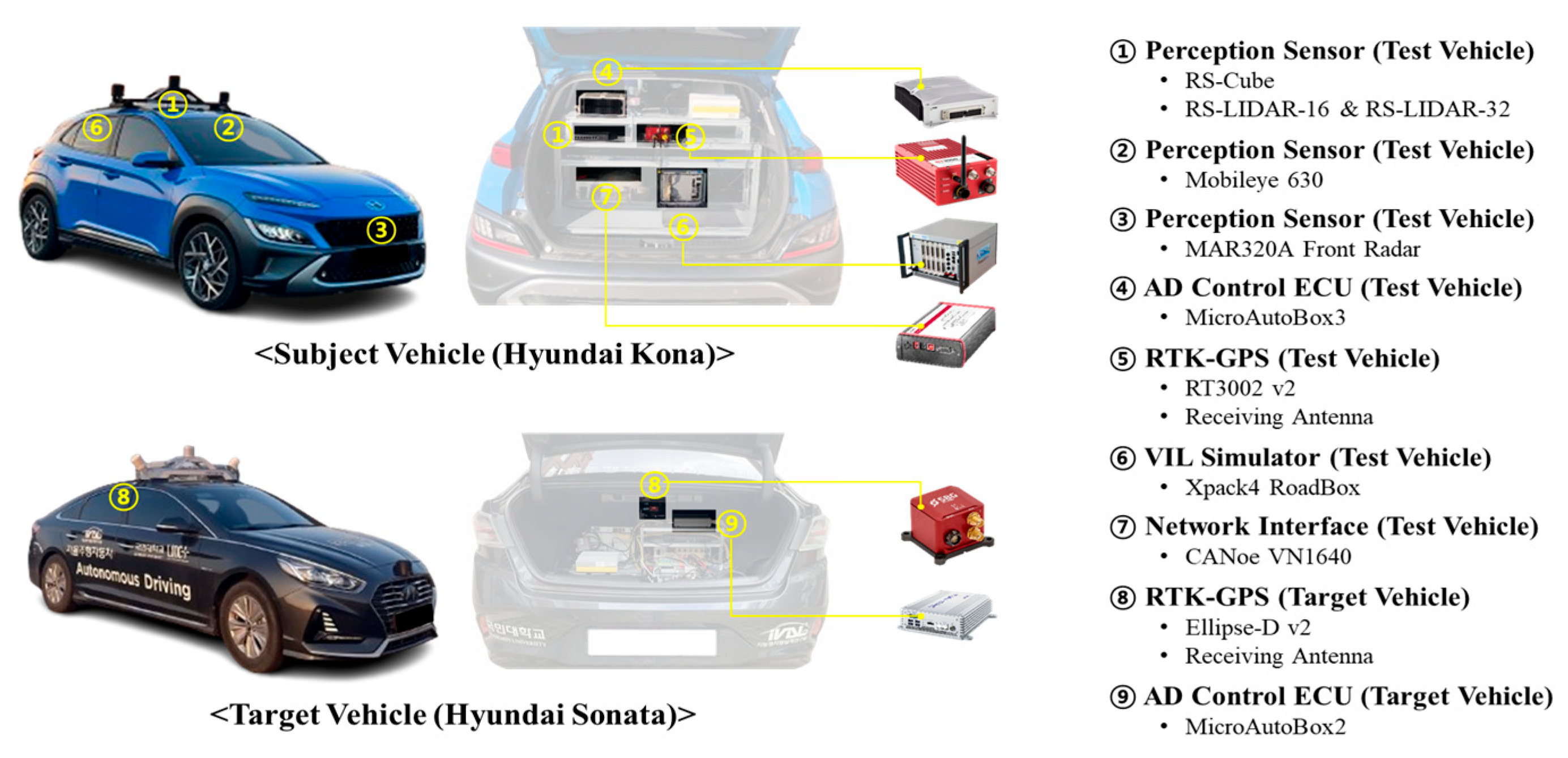
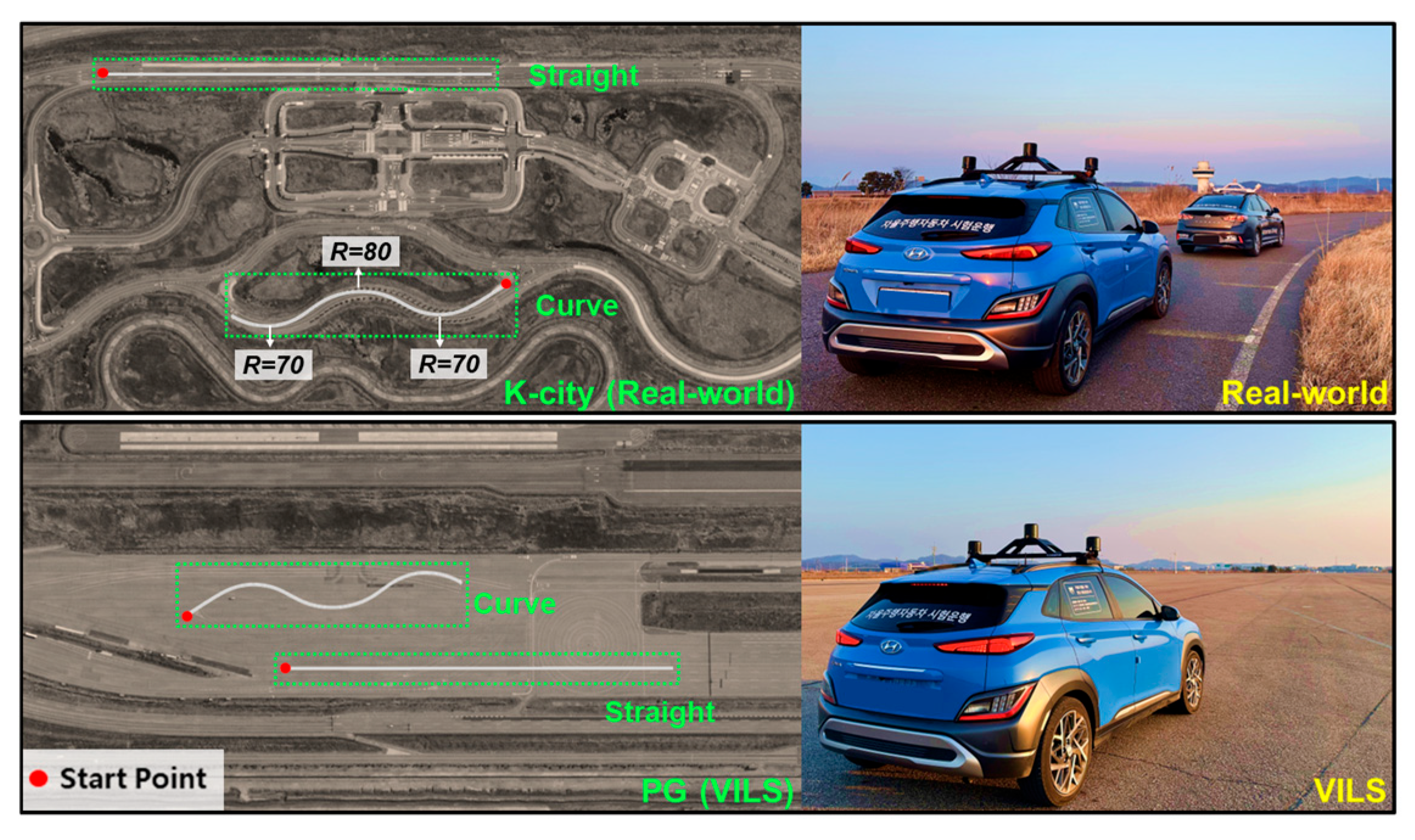
To evaluate the credibility of XILS platforms, the test scenarios and key test parameters must be systematically defined. This section outlines the scenario selection criteria and the key parameters used in the proposed evaluation framework. We constructed six test scenarios based on driving conditions and maneuver types. Based on the control characteristics, these scenarios are categorized into lateral (A and B), longitudinal (C and D), and integrated (E and F) evaluation.
Figure 3 illustrates each scenario.
The lateral evaluation scenarios were designed to verify the steering performance and lateral stability of the subject vehicle. Scenario A represents a situation where the subject vehicle changes lanes on a straight road without any external environmental influence, while driving at speeds of 30 km/h, 50 km/h, and 70 km/h. Scenario B evaluates the vehicle’s ability to stably follow a trajectory created based on information provided by the global positioning system (GPS) sensor on an S-shaped road, while driving at speeds of 20 km/h, 40 km/h, and 60 km/h.
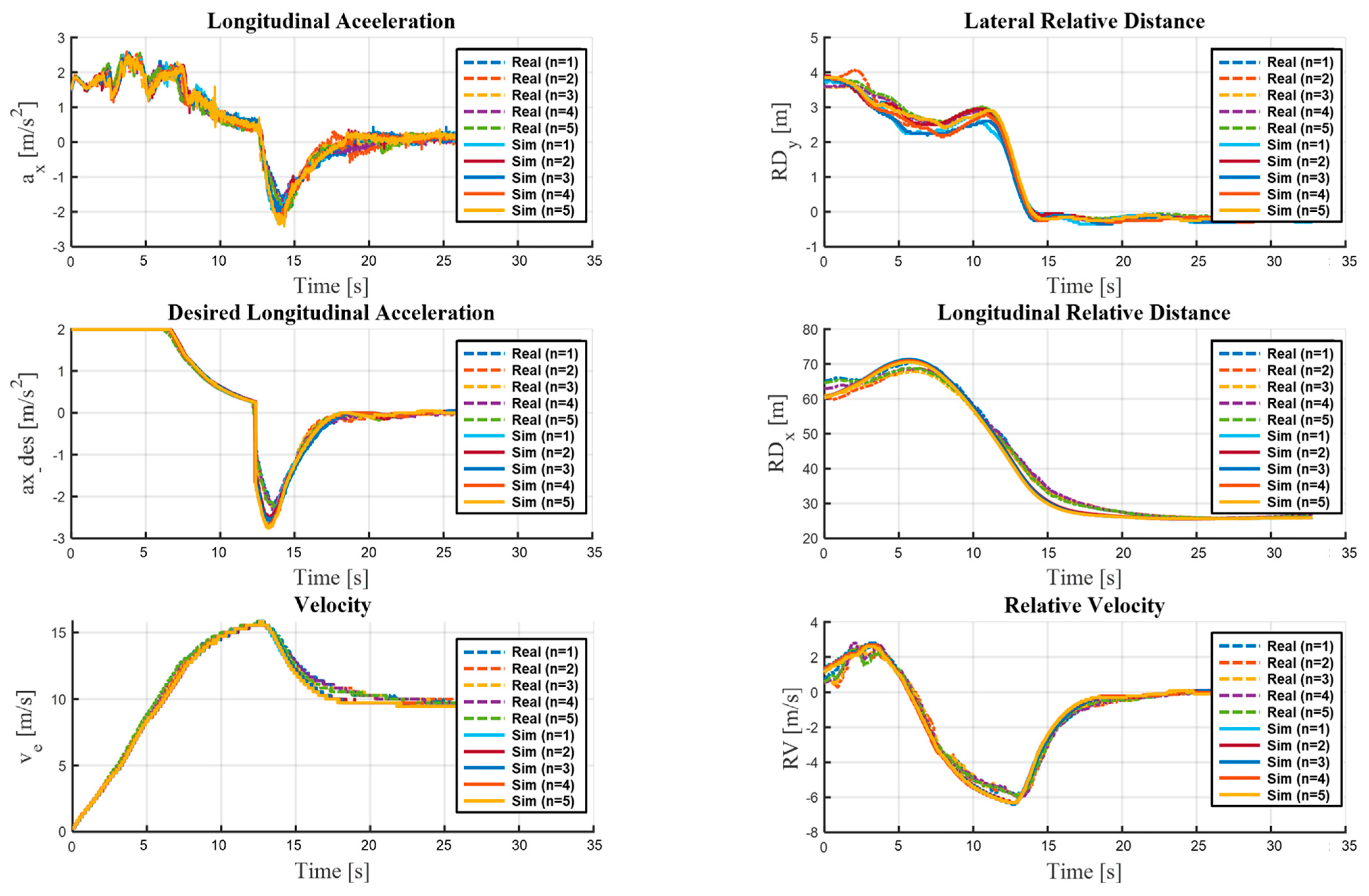
The longitudinal evaluation scenarios were intended to verify the subject vehicle’s speed control and its interaction with a target vehicle. Scenario C involves a cut-in maneuver on a straight road, designed to evaluate the effectiveness of the adaptive cruise control function in maintaining a safe distance from the vehicle ahead. Scenario D focuses on testing the subject vehicle’s ability to maintain a constant distance behind a slower target vehicle on a straight road. In both scenarios, the subject vehicle’s speeds are 60 km/h, 80 km/h, and 100 km/h, while the target vehicle’s speeds are 40 km/h, 60 km/h, and 80 km/h.
The integrated evaluation scenarios were designed to analyze complex situations requiring simultaneous lateral and longitudinal control. Scenario E evaluates the subject vehicle’s ability to perform steering and speed control while maintaining a stable distance from the vehicle ahead when both vehicles simultaneously change lanes on a straight road. In this scenario, the subject vehicle’s speeds are set at 60 km/h, 80 km/h, and 100 km/h, while the target vehicle’s speeds are set at 40 km/h, 50 km/h, and 80 km/h. Scenario F comprehensively assesses the subject vehicle’s lateral stability and longitudinal following control while it drives behind the target vehicle on a curved road. In this scenario, the subject vehicle’s speeds are 40 km/h, 60 km/h, and 80 km/h, while the target vehicle’s speeds are 30 km/h, 40 km/h, and 50 km/h.
In all six scenarios, the target vehicle utilizes a speed control method to maintain the specified target speeds; however, it may or may not reach the target speeds depending on the situation. By conducting experiments under these diverse scenarios, the performance of the ADS and the credibility of the XILS platform can be comprehensively evaluated.
Table 1 lists the main test parameters used in this study, which are defined as internal signals reflecting the core operations of the ADS and consist of vehicle status information, object data based on perception sensors, and control commands.
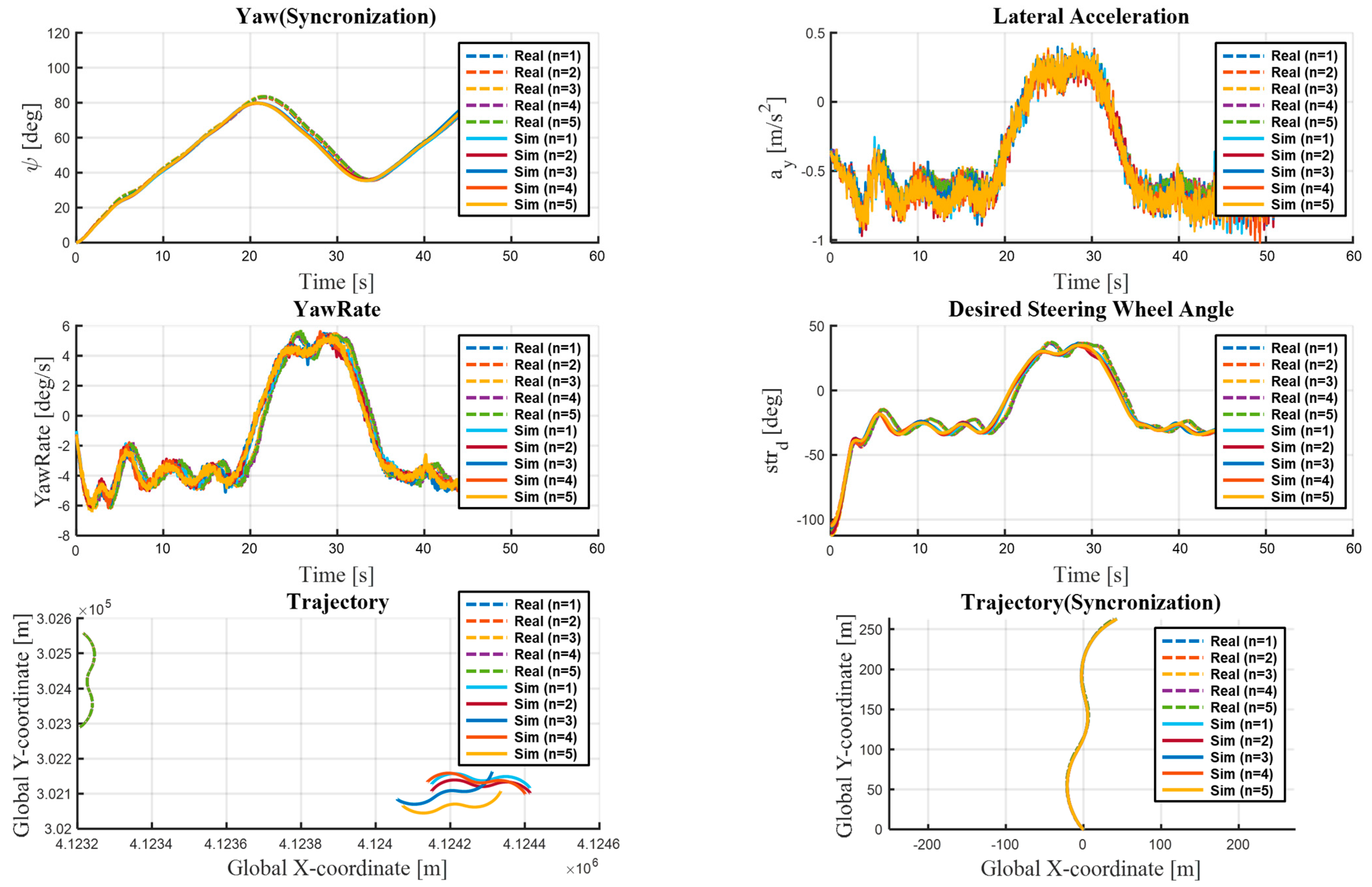
For the lateral evaluation scenarios (A and B), lateral acceleration (), yaw rate (), and target steering angle () were selected as the primary metrics. These parameters are instrumental for a precise quantitative assessment of lateral control performance during lane-change maneuvers and curved-road navigation.
For the longitudinal evaluation scenarios (C and D), we employed longitudinal acceleration (), vehicle speed (), target longitudinal acceleration (), relative longitudinal distance (), relative lateral distance (), and relative speed (RV) as the core evaluation metrics. These measures are paramount for robust evaluation of whether a safe following distance is maintained and if speed is suitably regulated relative to a lead vehicle.
In the integrated assessment scenarios (E and F), the lateral and longitudinal metrics were combined to ensure a holistic assessment framework for analyzing system performance under complex maneuvering conditions.
The simulations in this study were performed in a VILS environment built using IPG CarMaker HIL 10.2, a high-fidelity autonomous driving and vehicle dynamics simulation software program. A realistic test environment was implemented using a high-fidelity vehicle dynamics model and an object list-based perception sensor model. Specifically, we focused on evaluating the accuracy of the relative distance and relative velocity to analyze the effects of sensor noise and uncertainty on the performance of the ADS [
35,
36,
37]. This approach contributed to improving the similarity between simulated and actual driving and enhancing the credibility of the evaluation results.
3.2. Parameter-Based Reliability Evaluation
We adopted the parameter-based reliability evaluation method proposed by Oh [
31], which enables the accuracy of the simulation component models used in XILS to be verified indirectly. For each scenario, we conducted
N identical trials of both the XILS test and the real-vehicle test and compared the obtained parameter values to calculate three types of consistency indices: intra-XILS consistency (
), intra-real-vehicle consistency (
), and XILS–real-vehicle consistency (
). Based on these indices, the correlation index
and the application index
are calculated as shown in Equations (7) and (8), respectively, as follows:
The correlation index
represents the similarity between the results of the XILS tests and the real-vehicle tests, with values close to 100% indicating highly accurate simulation models. The applicability index
exceeding 100% means that the repeatability and reproducibility of the XILS test are better than those of the real-vehicle test. The XILS platform is considered to achieve parameter-based reliability
when all criteria in Equation (9) are met:
where
and
denote the correlation evaluation criterion and the applicability evaluation criterion, which are defined in Equations (10) and (11), respectively:
where
denotes the minimum value among the maximum consistency indices for the real-vehicle tests, and
is the average deviation between the maximum and minimum consistency indices of these tests. These criteria imply that the normalized consistency of the XILS trials must exceed that of the real-vehicle trials to guarantee superior repeatability and reproducibility.
The evaluation criteria
and
are established based on empirical data analysis to ensure statistical robustness. As detailed in Oh ([
31], Equations (19)–(24)),
is derived from the principle that XILS-to-real-world consistency must exceed the normalized consistency observed within real-world tests alone, with
accounting for inherent experimental variability. The criterion
assumes ideal simulation repeatability
while incorporating the same variability measure, ensuring XILS demonstrates superior reproducibility compared to real-world testing conditions.
This method enables prior identification of any specific parameters that could undermine the XILS platform’s reliability, whereby the accuracy of the corresponding simulation models can be refined accordingly. As the complete derivation of the parameter-based evaluation equation is provided by Oh [
31], it is omitted herein.
3.3. Scenario-Based Reliability Evaluation
We employed the scenario-based reliability assessment method proposed by Oh [
31], the primary objective of which is to assess whether XILS tests can effectively replace real-vehicle tests in a given scenario. For each scenario, we conducted
N trials of both the XILS and real-vehicle tests to calculate three types of scenario consistency indices: intra-XILS consistency (
), intra-real-vehicle consistency (
), and XILS–real-vehicle consistency (
). Based on these indices, the scenario correlation index
and the applicability index
are calculated as shown in Equations (12) and (13):
A scenario correlation index
close to 100% indicates a very high similarity between the XILS and real-vehicle test results in that scenario, while an applicability index
exceeding 100% indicates that the repeatability and reproducibility of the XILS tests are better than those of the real-vehicle tests. The XILS platform is deemed to attain scenario-based reliability
when all the criteria in Equation (14) are met:
where
and
denote the correlation evaluation criterion and the applicability evaluation criterion, which are defined in Equations (15) and (16), respectively:
where
denotes the minimum value among the maximum scenario consistency indices for the real-vehicle tests, and
is the average deviation between the maximum and minimum consistency indices across these tests. These criteria imply that the normalized consistency of the XILS trials must exceed that of the real-vehicle trials to guarantee superior repeatability and reproducibility.
The scenario evaluation-based thresholds
and
follow the same statistical framework as parameter-based criteria but are applied at the scenario evaluation. Following the methodology detailed in Oh ([
31], Equations (34)–(39)), these thresholds are derived from the distribution of consistency indices across all test scenarios, ensuring that evaluation criteria reflect realistic performance expectations while maintaining statistical validity for scenario-specific assessments.
This method allows for pre-assessing whether XILS can effectively replace real-vehicle testing in a given scenario, thereby enhancing the efficiency of simulation-based validation. The complete derivation of the scenario-based evaluation equation is excluded from this paper as it has been provided by Oh [
31].
3.4. Dynamics-Based Fidelity Evaluation
While the parameter-based and scenario-based evaluations discussed earlier are useful for quantifying the consistency between real-vehicle tests and XILS tests, they cannot fully capture the complex physical phenomena that a vehicle experiences during actual driving. For example, the vertical behavior of a vehicle when driving on irregular surfaces, the interaction between translational and rotational motions due to crosswinds, and the nonlinear lateral dynamics that occur during sudden steering cannot be fully assessed through simple input–output comparisons [
38,
39,
40]. If these vehicle dynamics characteristics under real disturbance conditions are not properly reflected in the simulation model, applying results obtained from the virtual environment to real-world situations can lead to unpredictable errors and compromise safety [
41,
42,
43]. Therefore, we propose a dynamics-based evaluation method to assess how faithfully the simulation reproduces the physical dynamics of the vehicle. Simulations using 3DOF models have been performed to quantitatively analyze the longitudinal and lateral behavior of vehicles, and various control strategies and driving stability techniques have been developed accordingly [
44,
45]. However, as these models do not fully incorporate the roll, pitch, and yaw variations of the vehicle, they cannot accurately reproduce the dynamic responses observed in real vehicles during high-speed driving, during sudden steering, or under complex road and weather conditions [
46,
47]. Moreover, with the focus of previous research being on system verification, the physical credibility of simulation platforms themselves has yet to be appropriately assessed.
To overcome these limitations, we introduce a 6DOF model that can precisely evaluate the accuracy of the simulation platform in reproducing the complex dynamic responses of the vehicle body. This method enables objective comparison of the dynamic consistency between the results of simulations and actual tests under various disturbance conditions. The proposed 6DOF model accounts for the vehicle’s longitudinal (
), lateral (
), and vertical (
) translational motions, along with its roll (
), pitch (
), and yaw (
) rotational motions; thus, it can describe the vehicle’s complete dynamics by assuming it to be a rigid body based on Newton–Euler equations [
48,
49]. However, as Coriolis and gyroscopic effects are minimal for vehicles in contact with the ground, these terms are omitted to simplify the model [
50,
51]. This exclusion significantly reduces the computational load of the simulation while enabling more intuitive and efficient comparison with actual experimental data.
The 6DOF model-based dynamics evaluation significantly enhances the physical credibility of the simulation platform by considering both translational and rotational motions, which 3DOF models fail to achieve. Thus, this evaluation method provides an essential foundation for verifying the credibility of autonomous driving simulation platforms and improving the adaptability of ADSs to real-world driving environments.
The equation of a vehicle’s translational motion explains the relationship between the forces acting when a vehicle moves in space and the resulting acceleration. Considering
to be the vehicle’s mass and
to be Earth’s gravitational acceleration, the forces acting on the vehicle can be defined based on Newton’s second law (
). Along the vehicle’s
X-axis (forward–backward direction) and
Y-axis (left–right direction), the force is the product of the respective mass and acceleration values. Along the
Z-axis (vertical direction), the influence of gravitational acceleration must be additionally considered. Accordingly, these translational motions can be represented by Equation (17), which mathematically expresses the vehicle’s motion in each direction. Here,
and
represent the vehicle’s acceleration along the X-, Y-, and Z-axes, respectively [
52].
The equation of a vehicle’s rotational motion explains the relationship between torque (moment) and angular acceleration when the vehicle rotates around each axis. Rotational motion is defined by the relationship
, which corresponds to Newton’s second law. Here, the moment of inertia (
) along each axis quantifies an object’s resistance to rotational motion. The rotational motions of a vehicle can be represented by Equation (18), which can be utilized to predict and control the vehicle’s attitude changes. Here,
,
, and
denote the roll moments generated around the X-, Y-, and Z-axes of the vehicle;
, and
represent the vehicle’s moments of inertia in the roll, pitch, and yaw directions; and
,
, and
represent the corresponding angular accelerations, respectively [
53].
To quantitatively assess the dynamic consistency between simulation tests and real-vehicle tests, the normalized root-mean-square error (NRMSE) was adopted as the primary evaluation metric. NRMSE expresses the deviation between two datasets in a standardized form, enabling objective comparison between variables of different scales [
54]. In this study, the credibility of the simulation model was evaluated by systematically quantifying the differences between the simulation results and experimental data based on NRMSE. This evaluation methodology is defined by Equations (19) and (20):
where
and
denote the experimental and simulation data, respectively;
is the total number of data samples; and
and
refer to the maximum and minimum values of the experimental or simulation dataset, respectively. The dynamic consistency index, derived from the test parameters in the 6DOF motion equations, is computed by cross-comparing the
-th and
-th repetitions of the XILS and real-vehicle tests. When the
-th scenario is repeated
times in both the XILS and real tests, the results for the
-th DOF in the
-th XILS repetition and the
-th real-test repetition are denoted by
and
, respectively. Based on the comparison metric
, the dynamic similarity indices for the three types of comparisons between the
-th and
-th repetitions can be expressed by Equations (21)–(23):
Equation (23) constitutes a multi-valued dynamic similarity index considering the cross-comparison between repeated tests. To represent these values as a single value for each scenario, Equations (24)–(26) are utilized:
The values computed through the three types of comparisons based on Equation (26) represent the dynamic consistency index of the
q-th DOF parameter for the
k-th scenario. Next, the dynamic consistency indices for all DOFs are weighted and averaged based on Equations (27)–(29) to allow the three types of dynamic consistency indices for the
k-th scenario to be expressed as a single value:
The weighting factors in Equations (27)–(29) for the dynamic consistency indices were set to equal values ( = 1/6 for each DOF) to ensure balanced representation of all six degrees of freedom in the dynamics-based evaluation. These weights can be modified based on the specific vehicle dynamics characteristics being emphasized in the evaluation.
Finally, the dynamic correlation index
is defined as the ratio of the dynamic consistency index for the inter-real-vehicle-test comparisons to that for the XILS–real-vehicle comparisons, as expressed in Equation (30):
approaches 100% as the consistency between the two tests increases, indicating that the simulation component models associated with the 6DOF parameters are highly accurate. Finally, the dynamics-based fidelity
of the XILS platform is determined based on whether
satisfies the specified acceptance criteria, as expressed in Equation (31):
where
denotes the dynamic correlation evaluation criterion for
. As detailed in Equations (32)–(36),
is established on the principle that the dynamic consistency between XILS and real-vehicle tests must be greater than or equal to the dynamic consistency observed between repeated real-vehicle tests.
In Equations (32)–(36), and respectively, represent the maximum and minimum values of the dynamic consistency index of the -th DOF parameter in each of the k-th scenarios, refers to the minimum value among all values across the k-th scenarios, and indicates the average of the maximum deviations in the consistency indices of the principal DOF parameters across all k-th scenarios.
The dynamic correlation threshold is established using a data-driven approach that considers the natural variability inherent in 6DOF vehicle dynamics. As shown in Equations (32)–(36), this threshold is derived from the statistical distribution of dynamic consistency indices across all degrees of freedom, ensuring that XILS platforms demonstrate a dynamic fidelity that meets or exceeds the baseline consistency observed in repeated real-world tests, thereby guaranteeing adequate capture of complex vehicle physical behavior.
If the parameter-based reliability (), scenario-based reliability , and dynamics-based fidelity () all satisfy their respective evaluation criteria, the XILS implementation under evaluation is considered a credible simulation platform for validating ADSs.
4. Proposed Geometric Similarity Evaluation Methodology
Simulation-based ADS validation is more time-efficient and cost-effective than real-vehicle testing. However, when calculating the credibility of simulation for multiple speed conditions, especially across numerous scenarios, substantial resources are still consumed. Considering the countless situations in which ADSs must operate, a systematic approach is required to improve validation efficiency.
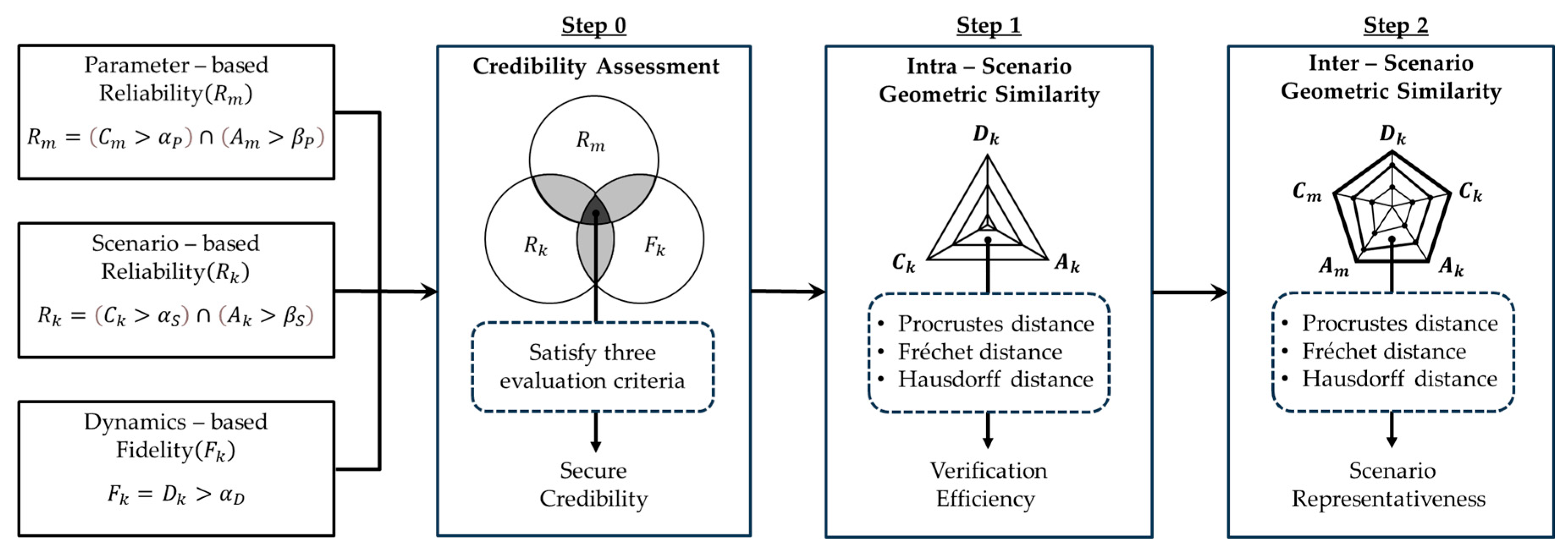
Herein, we propose an efficient credibility verification methodology based on geometric similarity evaluation, as illustrated in
Figure 4. In Step 0, three evaluation metrics—parameter-based reliability
, scenario-based reliability
, and dynamics-based fidelity
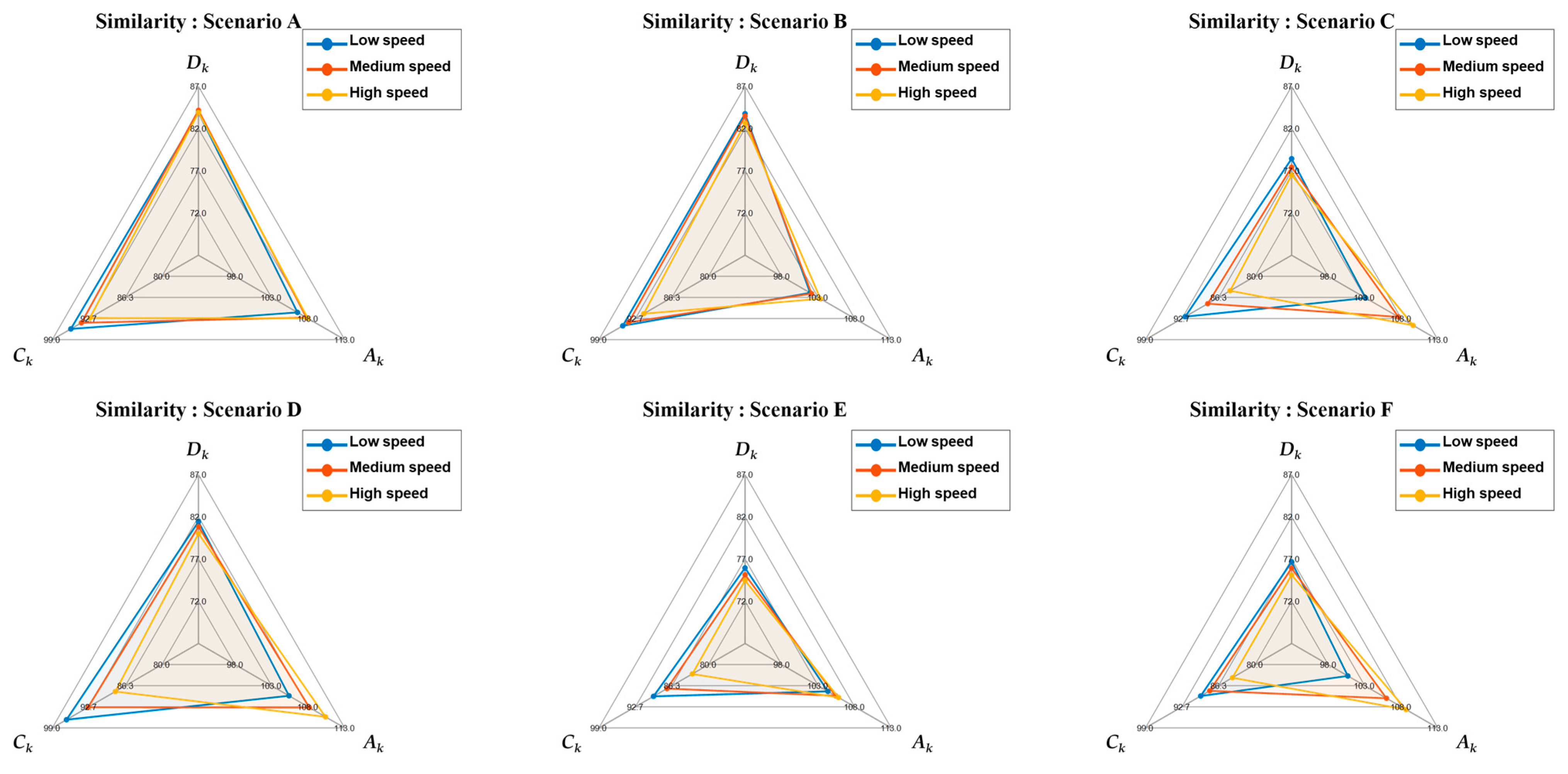
—are utilized to determine credibility. In Step 1, we evaluate credibility under different speed conditions (low, medium, and high) within the same scenario and visualize the derived evaluation metrics through a spider chart. The geometric similarity between the shapes is analyzed using the Procrustes, Fréchet, and Hausdorff distance techniques. These techniques evaluate the efficiency of the verification process by quantitatively determining whether speed is a dominant factor in the credibility assessment for a given scenario. In Step 2, we additionally evaluate the geometric similarity between different scenarios. This involves verifying whether a particular scenario can represent many other scenarios during credibility assessment.
The proposed assessment framework ensures the credibility of the XILS platforms used to test ADSs while significantly reducing the verification time and cost compared with traditional independent verification approaches. The complete methodology is detailed in
Section 4.1 and
Section 4.2.
The Procrustes distance quantifies the similarity between two sets of points by optimally aligning them to their common center via rotation, translation, and scaling, before minimizing the sum of the squared errors between the points [
55]. This least-squares criterion aligns each configuration’s centroid and allows structural differences to be analyzed via linear transformations, enabling global shape comparison without requiring explicit point-to-point correspondences. Specifically, optimal rotation and scaling solutions are obtained by performing an eigen-decomposition of the transformation matrix between the two configurations.
In Equation (37), the Procrustes distance quantifies similarity based on the global alignment between two point sets . Here, denotes the number of points in each shape, denotes the dimensionality of the space in which each point resides, and each row of the matrix corresponds to a single -dimensional point. Procrustes alignment involves applying the scaling factor , the rotation matrix , and the translation vector to , in that order, which transforms it into . We compute the sum of the squared Frobenius norms of the differences between corresponding points in the transformed point set and ; subsequently, we define the minimal value of this sum as the Procrustes distance . Here, is a column vector of ones, and multiplying it by ensures that the same translation vector is applied uniformly to all points. A smaller optimized Frobenius norm indicates that the two point sets are globally well aligned, implying structural similarity.
The Fréchet distance is often illustrated through the analogy of finding the shortest leash length needed to connect a person and a dog as they each walk along their respective curves [
56]. This metric captures both the ordering of points along the curves and the overall path flow; hence, it is well suited for comparing time-series data or trajectory-based shapes. Specifically, the discrete Fréchet distance approximation enables efficient computation of this metric in
O(
pq) time via a dynamic programming-based algorithm.
In Equation (38), is the Fréchet distance, which quantifies the overall path-flow similarity between two point sets . Each point set is treated as a trajectory of sequentially connected points, where and denote the -th and -th points on the corresponding trajectories, respectively. The correspondence between the two sets is defined by an order-preserving path within the collection of such paths. The distances are computed based on the standard Euclidean norm. The Fréchet distance then evaluates the similarity between the trajectories by choosing among all possible paths the one that minimizes the maximum distance between matched points. Hence, a smaller value implies that the two trajectories maintain the same ordering and share similar shapes.
The Hausdorff distance is a metric that measures the distance of every point in Set A from its nearest neighbor in Set B and then finds the maximum value among these nearest-point-pair distances in both directions. Thus, this term quantifies the largest local dissimilarity between two shapes [
57]. Because it does not require explicit point-to-point correspondences, it robustly captures shape mismatches even in the presence of small positional errors. Therefore, it is widely used in image comparison and pattern recognition. Additionally, algorithms that approximate the Hausdorff distance on a binary raster grid have been proposed to efficiently compute the minimum over all possible translations.
In Equation (39),
represents the Hausdorff distance, which quantifies the maximum local discrepancy between two shapes, i.e., the degree of structural mismatch. The first term reflects the extent to which
deviates from
, while the second term measures the discrepancy in the opposite direction. The maximum of these two values represents the largest bidirectional distance. A smaller
indicates that the shapes overlap consistently, whereas a larger value suggests a significant local mismatch (i.e., an outlier). All distances are calculated based on the Euclidean norm.
As shown in Equation (40), the geometric similarity
between two shapes in this study was calculated as a weighted sum of the distance-based metrics from the three perspectives mentioned earlier. This metric was then used to evaluate geometric similarity, as explained in
Section 4.1 and
Section 4.2 4.1. Geometric Similarity Evaluation
To ensure the credibility of XILS platforms, previous studies have introduced parameter-based and scenario-based evaluation metrics. Herein, we present a new dynamics-based metric. A simulation is deemed credible only when each of these metrics satisfies its predefined evaluation criterion. However, evaluating a single scenario separately under multiple speed conditions increases the number of required tests exponentially, thereby extending both the duration of the process and raising the resource demand. To overcome this challenge, we propose a methodology that quantitatively analyzes the geometric similarity between different speed conditions within the same scenario, which enables the credibility of the platform under untested conditions to be predicted from the results of a single-speed trial. By allowing the overall reliability to be inferred from one experiment, this approach significantly reduces the number of tests needed—and thus the associated time and cost—while also revealing potential compromising factors during the inference process. Hence, this integrated evaluation framework can enhance both the credibility and efficiency of XILS assessments.
Geometric similarity evaluation leverages two scenario-based reliability metrics, namely applicability (
) and correlation (
), together with a dynamics-based fidelity metric, namely dynamic correlation (
). Parameter-based metrics are deliberately excluded from this analysis as they are unsuitable for inter-scenario comparisons and cannot be used to compare different speed conditions within the same scenario. Each metric is rendered as a triangular polygon on a spider chart for each speed condition, which enables a quantitative assessment of geometric similarity across low, medium, and high speeds within a single scenario. By jointly evaluating the structural characteristics of these spider-chart polygons and the interactions among the three metrics, this geometric analysis facilitates a more precise and efficient credibility assessment of XILS platforms. The proposed geometric similarity indices are formulated in Equations (41)–(44):
where
,
, and
denote the evaluation-metric vectors for the
k-th scenario under low-speed (L), medium-speed (M), and high-speed (H) conditions, respectively.
is the geometry-based similarity score for the
k-th scenario across its speed conditions, representing the average geometric similarity among the three speed levels; a higher
indicates greater structural likeness across speed variations. Finally, as shown in Equation (45), the effectiveness of XILS for the same scenario
is evaluated based on whether these similarity scores satisfy a predefined evaluation criterion:
where
denotes the geometric similarity evaluation criterion for
. As expressed in Equations (46)–(50),
represents the minimum guaranteed level of geometric similarity among the three speed conditions within a given scenario. If
equals or exceeds
, the XILS platform’s credibility can be verified based on the results under a single speed condition. The evaluation criterion
, representing the minimum acceptable level of geometric similarity, is derived in a data-driven manner from the distribution of geometric similarity scores across all scenarios. Accordingly, similarity evaluation based on
relies on the principle that no geometric similarity score may fall below this value.
In Equations (46)–(50), and respectively, denote the maximum and minimum geometric similarity indices across the different speed conditions within the same scenario. , and denote the geometry-based similarity indices between low and medium speeds, between medium and high speeds, and between high and low speeds, respectively. represents the smallest of the values. In the k-th scenario, denotes the average of the maximum deviations in the geometric similarity indices across all scenarios. Thus, we can conclude that for all scenarios where exceeds , the geometric similarity between different speed conditions is sufficient, which allows us to assess the credibility of a given scenario without performing individual experiments for different speed levels.
4.2. Scenario Representativeness Evaluation
Building on the process described in
Section 4.1, we extended our methodology to assess whether certain entire scenarios can represent other geometrically similar scenarios. Accordingly, based on the premise that the credibility of an XILS platform for different scenarios can be evaluated based on the results from specific representative scenarios for which the platform has already been confirmed to be credible, we propose a scenario representativeness evaluation framework involving geometric similarity calculations between different scenarios.
The evaluation metrics used for the scenario representativeness assessment include parameter-based applicability (
) and correlation (
), scenario-based applicability (
) and correlation (
), and dynamics-based correlation (
). The two parameter-based metrics (Am and Cm) are averaged across the different speed conditions (low, medium, and high) within each scenario to obtain a single value that represents the overall parameter applicability and correlation for each scenario. For each
k-th scenario, the parameter evaluation scores for each speed condition are calculated as follows:
represents the applicability and correlation evaluation score for XILS data under the low-speed condition in the
k-th scenario.
represents the applicability and correlation evaluation score for real data under the low-speed condition in the
-th scenario.
represents the applicability and correlation evaluation score between XILS data and real data under the low-speed condition in the
-th scenario. The evaluation scores for the medium-speed (
) and high-speed (
) conditions are derived in the same manner. Accordingly, the average parameter evaluation scores across speed conditions in the
k-th scenario are calculated as shown in Equations (51)–(53):
Through this process, a single average value for the parameter-based reliability evaluation indices can be derived for each scenario. Based on these average values, the correlation index
and applicability index
are calculated using the parameter-based reliability evaluation formulas presented earlier. This yields new
and
values for each scenario, which are used to evaluate the representativeness of different scenarios. For each
-th scenario, a scenario representativeness vector is constructed by integrating the previously calculated indicators corresponding to each speed condition, as shown in Equations (54)–(56):
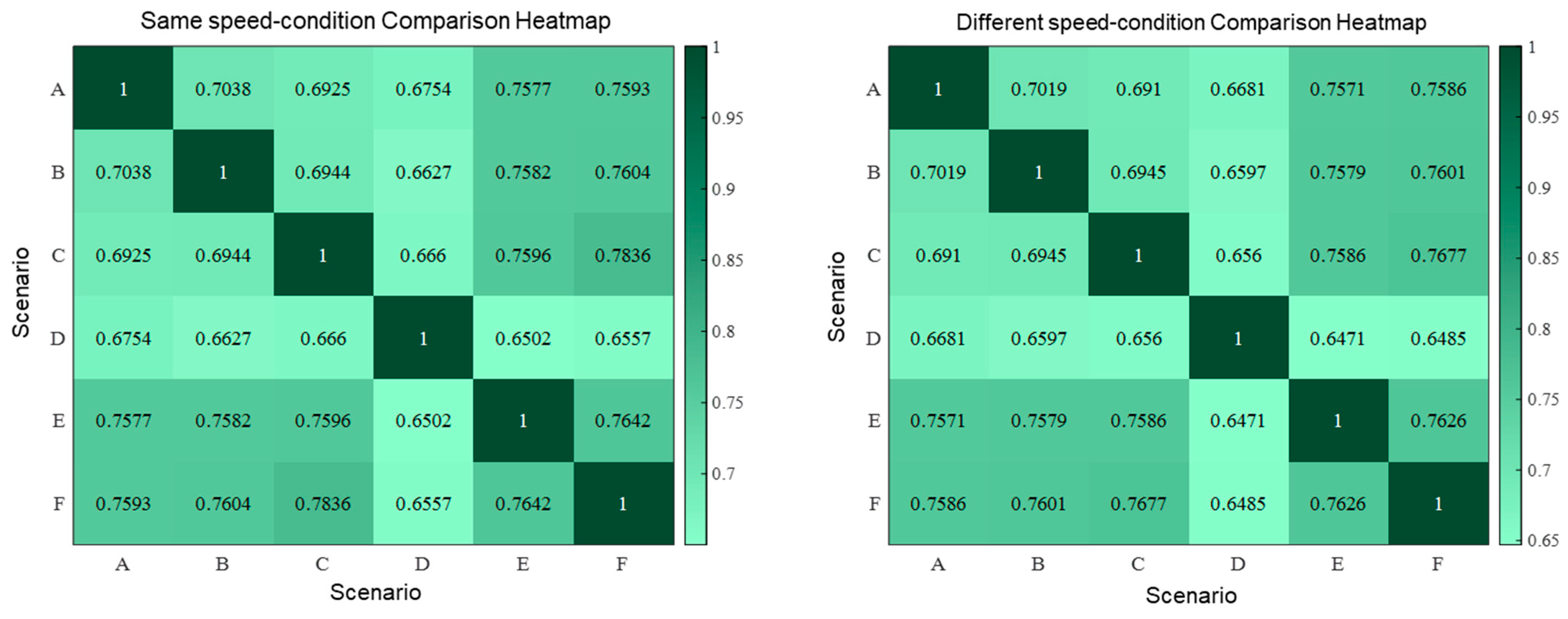
Using , and , we quantitatively evaluate the representativeness of a scenario based on its geometric similarity to other scenarios. For this purpose, two comparison methods are proposed: comparison across the same speed condition and comparison across different speed conditions.
The same-speed comparison involves calculating the geometric similarity between different scenarios by comparing the representativeness vectors of each scenario under identical speed conditions. When the number of scenarios is
, the number of possible scenario pairs is
, and the comparisons are performed across all three speed conditions
for each scenario pair. The geometric similarity under each speed condition is quantified by comparing the representativeness vectors
and
as shown in Equation (57):
The different-speed comparison involves evaluating the representativeness of a scenario across different speed conditions, i.e., verifying whether a specific scenario’s representativeness is maintained across various operating conditions. Such an assessment is important for determining the versatility of scenarios. The speed-condition set
contains six distinct condition pairs
, and the geometric similarity assessments are performed across all heterogeneous condition pairs for scenario pairs (
i,
j). Each comparison is designated as
, and the overall different-speed similarity score is calculated as shown in Equation (58):
Thus, for each pair of scenarios, two comparison scores can be calculated, whereby a total of individual scenario representativeness scores are obtained for K scenarios. Therefore, the total number of similarity scores is . The scenario representativeness scores calculated in this manner are visualized as a heatmap and serve as the basis for selecting representative scenarios for credibility assessment.
6. Conclusions
Herein, we proposed an integrated verification framework to comprehensively evaluate the credibility of XILS platforms for ADS validation. Through parameter-based and scenario-based evaluations, we quantitatively demonstrated the correlation between VILS and real-vehicle tests and their applicability. Additionally, we introduced a dynamics-based evaluation method, which enables an integrated credibility assessment of the VILS platform. Accordingly, the platform can be deemed credible if it satisfies specific evaluation criteria for parameter-based reliability, scenario-based reliability, and dynamics-based fidelity indicators.
After conducting the credibility assessment, we visualized each evaluation indicator through spider charts and performed similarity evaluations using three geometric indicators: the Procrustes, Fréchet, and Hausdorff distance metrics. Thus, we empirically demonstrated that for a given scenario, credibility can be verified under specific representative speed conditions rather than individually testing all velocity conditions. Furthermore, through geometric similarity evaluations between different scenarios, we highlighted the possibility that an integrated behavior scenario could represent certain other scenarios for credibility evaluation.
Nevertheless, the experiments in this study covered limited scenarios, driving situations, and velocity conditions. To provide clearer guidance for future research and strengthen the generalizability of the proposed framework, several essential areas warrant further investigation: (1) Environmental scenarios including urban traffic environments with complex intersections and pedestrian interactions, highway scenarios with high-speed merging and convoy driving, and adverse weather conditions such as rain, fog, snow, and varying road surface friction that significantly affect vehicle dynamics and sensor performance; (2) operational conditions encompassing extreme speed ranges (very low speeds < 10 km/h for parking scenarios and high speeds > 120 km/h for highway scenarios), sensor degradation and failure modes including partial occlusion and noise interference, and edge cases such as construction zones and emergency vehicle interactions. These expanded experimental conditions would provide a more comprehensive validation framework and enhance the statistical significance of the geometric similarity analysis across diverse operational domains. Therefore, future studies should pursue credibility verification across these diverse and challenging scenarios to fully validate the robustness and applicability of the proposed methodology.
In conclusion, the proposed framework provides a standardized platform for XILS-based ADS verification. The integrated credibility evaluation and geometric similarity evaluation methodologies are expected to facilitate the commercialization of safe autonomous driving technology by improving the efficiency of systematic verification processes.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}