1. Introduction
The development of assistive mobility devices for the visually impaired requires an interdisciplinary research approach that integrates advances in artificial intelligence, robotics, and human–computer interaction. One of the key strategies in assistive vision systems is sensory substitution, which enhances spatial awareness by converting visual information, most commonly, into auditory or tactile cues [
1,
2,
3].
To address these challenges, numerous solutions have been proposed using various sensors and feedback methods. These include depth cameras, ultrasonic and infrared sensors, RFID tags, and smartphone cameras to detect obstacles and gather spatial data. Feedback is typically delivered via audio, tactile, or vibrational signals, aiding users in safe navigation [
4].
However, real-world implementation of these technologies remains challenging due to issues related to system ergonomics, real-time processing, and adaptability to diverse environments.
The cited literature reviews show that stereovision and RGB-D sensors are commonly used to obtain depth information, enabling the identification of obstacles in a scene. Several assistive vision prototypes employ head-mounted sensors of this type, with sensory feedback provided through auditory or haptic signals [
5,
6,
7,
8,
9]. Stereovision is a passive technique that reconstructs 3D space from images captured at different viewpoints, operating effectively under natural lighting conditions. Its advantages include the use of low-cost cameras and well-established algorithms for depth computation. However, challenges such as high computational demands, sensitivity to lighting variations, and occlusion issues limit its reliability. RGB-D sensors, on the other hand, integrate active depth measurement methods, such as infrared projection, improving performance in low-light conditions. Nevertheless, structural lighting is ineffective for depth estimation in strong illumination (e.g., sunlight) or when dealing with reflective surfaces, such as glass or mirrors.
This work proposes a novel approach to assist the visually impaired in scene perception. It presents an empirical analysis of the feasibility of using generative multimodal models for image analysis. This involves selecting parameters for 3D scene segmentation algorithms for presenting non-visual scenes to blind users.
1.1. Challenges in Assistive Vision Systems
Developing practical assistive vision systems requires solving several key challenges. These include minimizing latency in obstacle detection and feedback, handling dynamic lighting and occlusions, designing ergonomic and non-intrusive wearables, avoiding cognitive overload, and maintaining affordability for wide adoption. To enhance usability, assistive systems must prioritize efficient data processing and intuitive feedback mechanisms while minimizing unnecessary complexity in 3D scene interpretation. Moreover, the level of detail in presenting information should depend on the environment in which a blind person is located. A different level of detail is required indoors, where floor irregularities and door thresholds are unexpected elements, and a different one in an outdoor environment, where there is no need to inform the user, for example, about plants growing on the lawn. As part of previous research and development work, assistive systems for visually impaired users were developed, involving both auditory and haptic representations of the surrounding environment. One solution employed spatialized audio cues to convey directional information [
7], while another used a vibrotactile belt equipped with multiple vibrating elements [
8]. In both systems, functionality was implemented allowing users to manually adjust scene reconstruction parameters depending on the specific environment, enabling personalized configuration for indoor versus outdoor navigation scenarios.
1.2. Obstacle Detection and the Role of the Ground Plane
The ground plane serves as a key reference for obstacle detection in assistive navigation. Correct estimation of the ground plane enables the differentiation of walkable and non-walkable areas, reducing false detections. The accuracy of obstacle detection is highly dependent on the quality of ground plane estimation, as errors in its determination can result in misclassification of obstacles or failure to detect potential hazards. Common approaches to ground plane estimation include the Hough transform in disparity space (U-V disparity), which extracts dominant planar structures but is sensitive to roll angle variations [
10,
11]; normal vector clustering, which groups surface normals for robust plane fitting, as implemented in the Sound of Vision project [
12]; RANSAC [
13] and least-squares methods, which are used for robust plane estimation from point cloud data; and Singular Value Decomposition (SVD), which provides optimal plane fitting in noisy environments. A common feature of these algorithms is that their use is possible only when it is certain that a ground plane is visible in the scene.
Referring to the “ground plane” is a simplification mainly relevant indoors with flat floors. Outdoors, uneven surfaces like cracks, curbs, and vegetation can be misidentified as obstacles by recognition algorithms. Lighting conditions impact 3D scene reconstruction and depth estimation accuracy, requiring careful parameter selection for obstacle detection. Moreover, the type of camera sensor used (e.g., stereo, LiDAR, structured light) significantly influences the quality of the 3D reconstruction, which in turn affects the optimal choice of parameters for segmenting obstacles and ground planes [
14]. Camera imperfections, such as lens contamination or sensor degradation, can further affect vision-based detection.
To effectively use the estimated ground plane for obstacle detection, it is necessary to define a distance threshold that separates points belonging to obstacles from those that lie on the ground. In practice, this threshold is often selected empirically [
15,
16]. For instance, in [
15], a threshold of 10cm was used, while in [
16], the threshold was set to 15cm. It is important to note that these values were determined for relatively regular and flat surfaces such as indoor floors or pavements. These studies did not account for more irregular terrains such as grass, gravel, or uneven natural ground. Therefore, the choice of an appropriate threshold should consider the type of depth sensor used, the characteristics of the scene, and environmental conditions. A threshold that is too low may result in false positive obstacle detections, whereas a threshold that is too high can cause real obstacles to be overlooked.
Three-dimensional scene analysis faces significant challenges due to the inherent complexity of real-world environments, which feature diverse object shapes, varying appearances influenced by lighting and viewpoint, and frequent occlusions [
14,
17]. Moreover, the scarcity of annotated 3D datasets, especially those reflecting diverse indoor and outdoor scenarios, limits the ability to train robust and transferable models [
14]. This limitation is particularly critical for traditional machine learning and computer vision models, which require extensive high-quality supervision and do not inherently possess generative or self-adaptive capabilities. Domain-specific differences, such as the variation in architectural styles, materials, and environmental dynamics, further hinder model generalization. Addressing these challenges requires ongoing progress in efficient, reliable methods. Priorities include managing limited annotated data, reducing the computational demands of 3D processing, and improving model generalization across diverse conditions.
This creates an opportunity for the use of generative AI and the application of multimodal models for image description and understanding. By analyzing recorded images, AI models can detect inconsistencies such as blurriness, unexpected noise patterns, or discrepancies in depth calculations, which may indicate camera malfunctions or adverse environmental conditions. Ensuring accurate and adaptive ground plane estimation is critical to enhancing navigation reliability. AI-driven approaches can aid in detecting environmental changes, such as wet or reflective surfaces, that could alter obstacle perception. Moreover, multimodal AI models can help improve terrain classification and lightning conditions, reducing the likelihood of false positive detections in complex environments.
1.3. Artificial Intelligence in Assistive Systems for the Visually Impaired
Generative artificial intelligence is already being used to support visually impaired individuals, although in a different context. For example, in [
18], ChatGPT was employed to enable conversational interaction for a blind user. The user communicates via voice, which is transcribed into text and sent to the model, while the model’s response is converted back into speech using a text-to-speech system. The Be My Eyes platform [
19] has integrated AI to provide visual assistance through a virtual volunteer powered by OpenAI’s GPT-4, allowing blind users to receive descriptions and contextual understanding of their surroundings via smartphone cameras.
It is worth noting that traditional artificial intelligence has been used for many years to support visually impaired individuals. As summarized in the review by Wang et al. [
20], applications include OCR-based text recognition and text-to-speech systems for reading assistance, smartphone tools for facial and object recognition, and obstacle avoidance systems using computer vision and sensors. These technologies have already contributed significantly to supporting the daily lives of people with visual impairments.
Furthermore, modern smartphones enable the deployment of lightweight AI object detection models combined with multimodal feedback, such as haptic and audio cues, to assist visually impaired users in real-time navigation. Such mobile applications demonstrate significant potential in improving accessibility and independence by recognizing objects and providing intuitive feedback in diverse environments [
20,
21].
2. Materials and Methods
The proposed method integrates conventional depth sensing with AI-based scene interpretation to improve the reliability and adaptability of assistive vision systems. In contrast to static parameter selection, this approach leverages multimodal generative models to dynamically analyze the recorded visual data and adjust the processing pipeline according to the current scene characteristics. This adaptive framework is designed to enhance ground plane estimation, improve obstacle detection, and ensure more effective information presentation to the user. The key components of the system include scene type recognition, evaluation of image quality and depth data consistency, and the selection of segmentation and classification parameters tailored to specific environmental conditions.
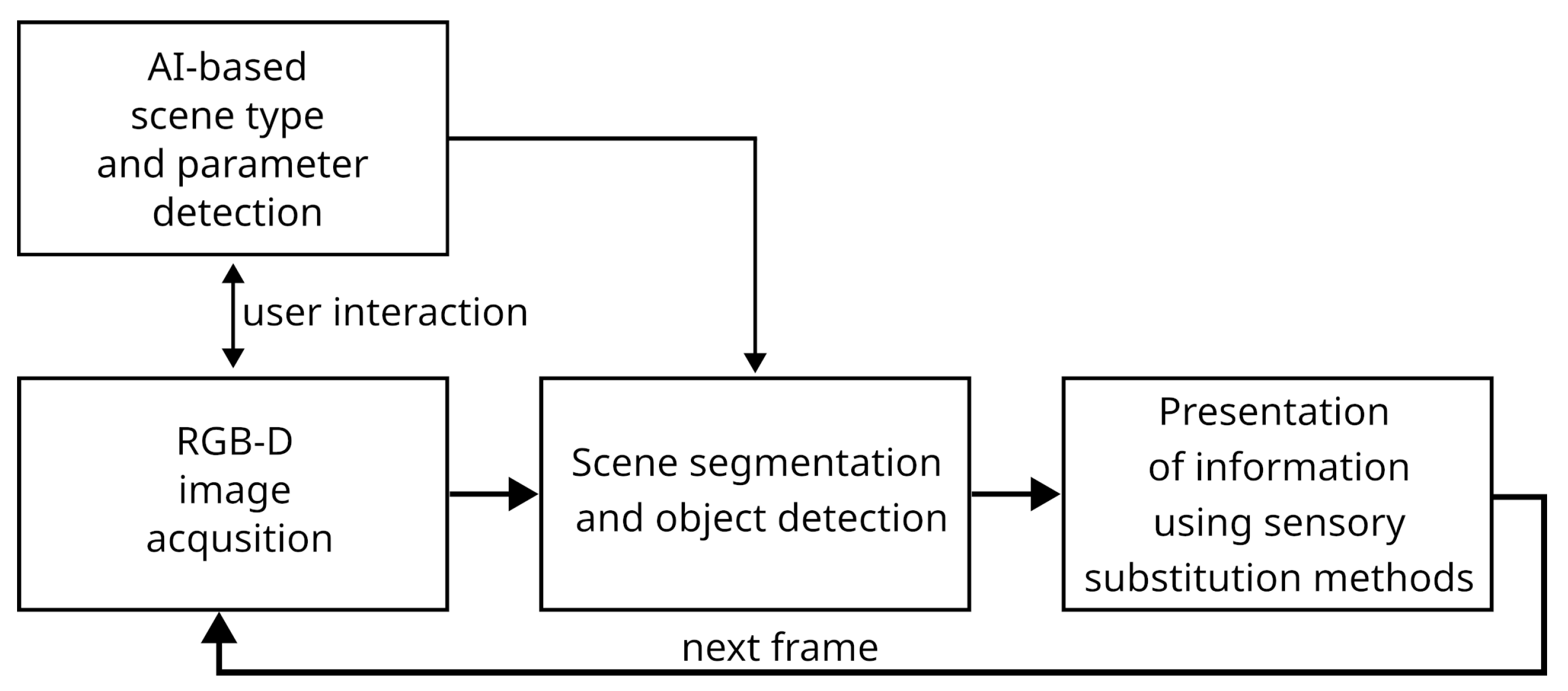
The concept of the AI-assisted algorithm is illustrated in
Figure 1. It begins with AI-based scene type and parameter detection, where artificial intelligence analyzes input data to classify the environment and extract relevant parameters. This process may involve image analysis and description to determine the structure and characteristics of the scene. By understanding these factors, the system can optimize further processing steps based on the specific context.
Following scene analysis, the extracted parameters inform subsequent processing steps, including segmentation, object detection, and 3D reconstruction. Scene information guides parameter selection for segmentation and object detection algorithms and informs how this information is conveyed to a blind user. For example, this involves selecting thresholds to separate the ground from obstacles, evaluating whether the ground plane can be estimated from the scene and assessing the reliability of the depth map based on lighting conditions.
Traditionally, image classification required the preparation of a comprehensive dataset followed by the training of conventional neural networks to assign images to predefined categories. The primary advantage of this approach was the unambiguous classification of an image into a specific class. However, a significant drawback was the necessity of curating extensive training datasets that accounted for all possible variations within a given category.
With the advent of generative artificial intelligence (genAI), which enables the creation of novel and unique content, models can now analyze image content without the need for prior task-specific training. Nevertheless, their effectiveness is highly dependent on the quality of prompt engineering, where carefully crafted prompts are designed to extract relevant information. Despite their advanced capabilities, these models are still constrained by the data they were originally trained on, meaning they may not generalize well to images that differ substantially from their training examples.
A key advantage of multimodal AI models is their ability to generate scene descriptions and provide contextual interpretations. They can predict a scene’s location, lighting conditions, time of year, and whether it is indoors or outdoors. Additionally, they support multi-class classification in a single prompt, recognizing multiple attributes at once, such as lighting type or the presence of objects like stairs or crossings. This greatly enhances their flexibility and applicability in image analysis.
Therefore, it was decided to evaluate the effectiveness of multimodal models in identifying scene parameters that can optimize segmentation for obstacle detection. The following models were tested: LLaVA13b, LLaVA [
22,
23,
24], LLaVA-Llama3 [
25] and MiniCPM-V [
26]. Specifically, the focus was on identifying objects that pose challenges for an assistive navigation system designed for visually impaired individuals in autonomous movement. To achieve this, four multimodal AI models were selected based on their ability to run on a standard PC without relying on commercial cloud-based solutions. This ensures compatibility with low-power and resource-constrained hardware platforms, such as Raspberry Pi or embedded systems, which are commonly used in mobile assistive devices. Additionally, the selected models are freely available, which facilitates transparency, reproducibility of results, and further customization. Their high performance and flexibility for local deployment, as recognized by the machine learning community, make these models a practical and scalable choice for real-world assistive applications.
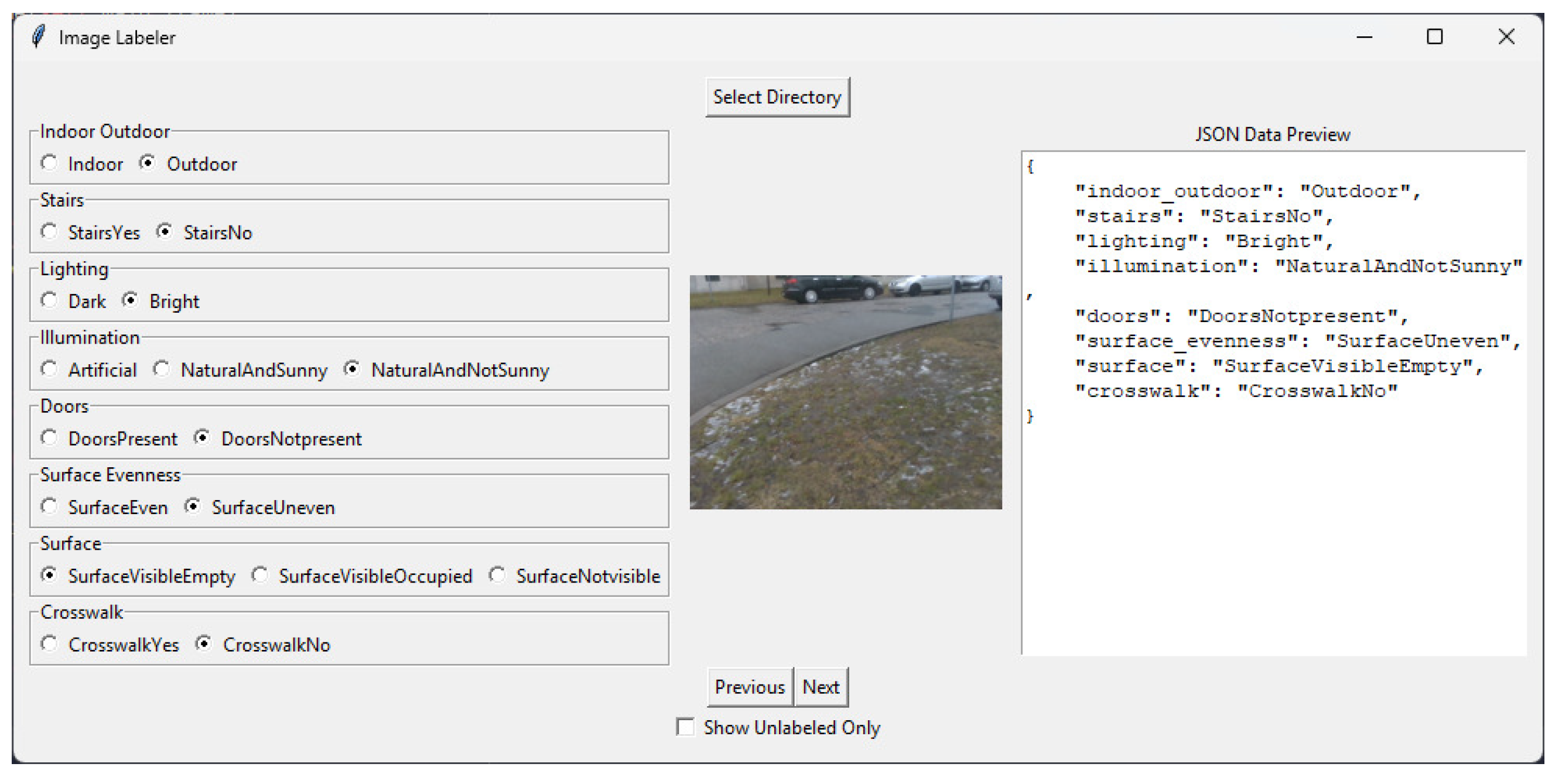
To evaluate the effectiveness of image classification into predefined categories, a dataset of approximately 200 images was collected using a stereovision system, which serves as an information source in an assistive system for visually impaired individuals. These images were gathered during the testing phase of the system’s functionality in real-world conditions. The dataset is diverse and includes both indoor and outdoor scenes, captured during nighttime and sunny daytime as well as across different seasons (Dataset S1). An application was developed (
Figure 2) to classify each image into the selected categories. The selected images from this dataset are presented in the
Figure 3.
Subsequently, a prompt was prepared, and each image was analyzed using three multimodal models. The prompt used for image analysis is presented below.
Analyze the provided image and determine the most appropriate options for each category below based only
on what is on the image. Provide your response in exactly 8 lines---one line per category---using only
the allowed values. Do not include any category names, punctuation, explanations, or extra text.
1. Determine the location type. Choose one from [Indoor, Outdoor]. Indoor means the image shows an
enclosed space, such as a room, hallway, or building interior. Outdoor means the image
captures an open space, such as a street, park, or other external environments.
2. StairsYes or StairsNo? Determine if stairs are visible. Choose one from [StairsYes, StairsNo].
StairsYes indicates the presence of stairs, defined as a series of steps designed for climbing
or descending. Stairs usually have distinct vertical and horizontal surfaces (risers and treads)
arranged in a sequence. Horizontal markings, such as those on crosswalks, should not be considered stairs.
3. Lighting conditions: Choose one from [Dark, Bright]. Dark refers to low light conditions, where
visibility might be limited. Bright indicates that the scene is well-lit, providing good visibility.
4. Illumination: Choose one from [Artificial, NaturalAndSunny, NaturalAndNotSunny].
Artificial means the scene is primarily lit by artificial light sources such as lamps, bulbs,
or other man-made lighting. This is typically observed in indoor environments or outdoor
nighttime scenes where natural light is absent. NaturalAndSunny indicates that the scene is
illuminated by direct sunlight. This is characterized by well-defined shadows and overexposed
areas caused by strong natural light. The weather is clear, and the lighting is consistent
with daylight conditions. NaturalAndNotSunny indicates natural daylight is present but without
direct sunlight. This is typical in overcast conditions, shaded areas, or when the sun is
obscured by clouds. Shadows may be soft or absent, and the lighting appears diffused
across the scene.
5. Doors: Choose one from [DoorsPresent, DoorsNotPresent].
DoorsPresent indicates that the image shows a physical structure designed to open and close,
typically mounted on hinges or sliding mechanisms. Doors often separate spaces (e.g., rooms,
buildings, or vehicles). Transparent glass panels, open doorways (without an actual door),
or windows should not be considered as doors. DoorsNotPresent means there are no visible
doors in the image. Note: Openings or frames without a physical door are not considered as
doors. Do not infer the presence of doors based on nearby buildings, roads, or crosswalks
unless the doors are clearly visible.
6. Ground Surface Evenness: Choose one from [SurfaceEven, SurfaceUneven].
SurfaceEven means the ground is smooth and flat, such as a sidewalk, road, or an indoor
floor, allowing for easier detection of a flat plane. SurfaceUneven refers to irregular or
bumpy ground, such as grass with clumps, unevenly shoveled snow, curbs, potholes, or
rough terrain.
7. Ground Surface Visibility: Choose one from [SurfaceVisibleEmpty,
SurfaceVisibleOccupied, SurfaceNotvisible]. SurfaceVisibleEmpty indicates the ground is
visible and largely unobstructed, with few or no obstacles. SurfaceVisibleOccupied means
the ground is visible but contains obstacles, such as furniture, vehicles, or other objects.
SurfaceNotvisible means the ground is not clearly visible in the image.
8. Crosswalk: Choose one from [CrosswalkYes, CrosswalkNo]. CrosswalkYes means a pedestrian
crosswalk (zebra) is clearly visible in the image. A valid crosswalk consists of alternating
rectangular stripes that are white and black, or white and red. The crosswalk must be
positioned directly in front of the observer (from the perspective of the person who
took the photo) and should be clearly intended for pedestrian use. Do not classify a scene
as CrosswalkYes if the crosswalk is only visible far in the background or outside the
primary walking area. CrosswalkNo indicates that there is no pedestrian crosswalk visible
in the scene. Note: Be careful not to confuse a pedestrian crosswalk with a bicycle lane
crossing. Bicycle crossings are typically red without alternating stripes, and they
are not classified as pedestrian crosswalks.
Each image class described in the prompt above is represented by at least a dozen images in the dataset. This ensures a sufficient level of variability and coverage for each category, allowing the models to be properly evaluated across different scene types. The dataset includes examples for all eight classification categories, such as indoor and outdoor environments, various lighting conditions, the presence or absence of doors and stairs, ground surface characteristics, and the visibility of crosswalks. This diversity supports a comprehensive assessment of the models’ classification capabilities in realistic and heterogeneous settings.
3. Results
The results are presented in
Table 1 and
Table 2, which show the best and worst outcomes for each class, based on five test runs for each model. The full results are provided in
Supplementary Material Dataset S1. During the evaluation, predefined keywords from the prompt were searched for within the model’s responses. If a given word appeared in the response, it was considered that the model correctly classified the image within the specified scope.
Generative models, including commercial ones, frequently deviated from the expected prompt format, sometimes returning alternative data structures (e.g., JSON instead of XML) or paraphrased responses. These inconsistencies reflect a broader limitation of current generative AI: the difficulty in producing reliably structured outputs in response to constrained queries. While this challenge can sometimes be mitigated through prompt refinement, it underscores the need for robust output post-processing or standardized response protocols when deploying such models in assistive applications.
It is also worth noting that due to the nondeterministic nature of generative AI, each execution of the same query (even with identical images) can yield different results. Identical input data still resulted in varying outputs across runs, highlighting challenges in ensuring consistency and reproducibility.
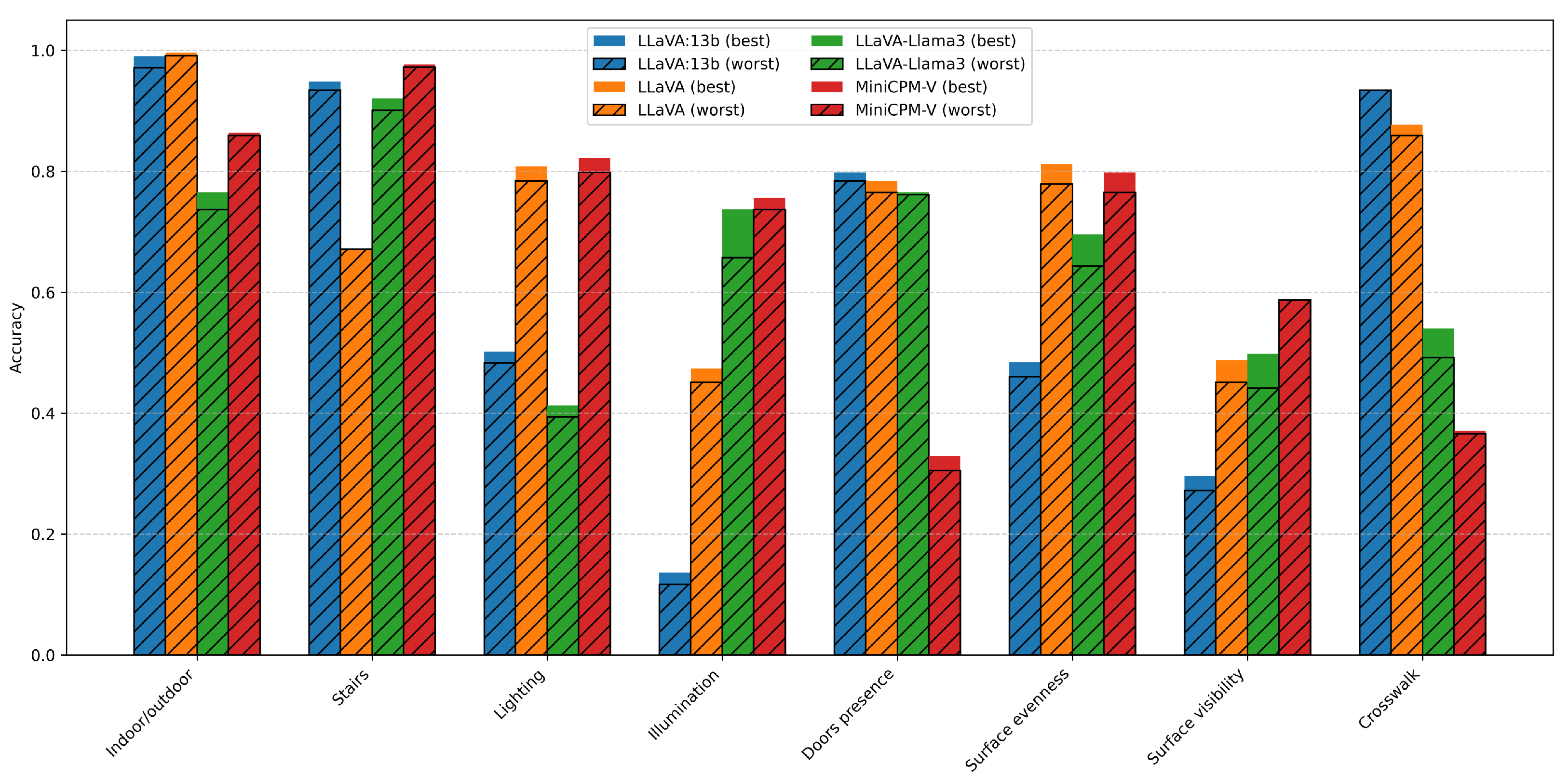
The evaluation results presented in
Table 3 and
Table 4, and in
Figure 5 indicate substantial variability in the classification performance of the analyzed multimodal AI models across different scene analysis categories. While models such as MiniCPM-V demonstrated high effectiveness in structured, visually salient tasks like stair detection and surface assessment, others, such as LLaVA-Llama3, exhibited greater difficulty in handling semantically complex or visually subtle attributes, such as illumination conditions and door presence.
Overall, none of the evaluated models achieved uniformly high performance across all categories. High accuracy was observed for straightforward binary tasks (e.g., indoor/outdoor classification), whereas tasks requiring the interpretation of nuanced visual cues (e.g., surface visibility, crosswalk detection) exhibited significantly lower precision, recall, and F1 scores. These discrepancies highlight both the potential and the current limitations of multimodal AI models in real-world assistive navigation contexts.
While the results are presented in terms of standard classification metrics, it should be noted that this approach primarily captures categorical accuracy and prompt conformity. Broader aspects such as semantic validity, reasoning consistency, or partial correctness in generative outputs remain beyond the scope of this evaluation but are important for real-world assistive use.
For metric computation, it was assumed that each classification task had two or three predefined possible responses. Although the models always returned exactly one of these options, the first response listed in the prompt (e.g., Indoor present: Yes) was treated as the positive class (true), while all alternative responses were considered as negative classes (false). This assumption enabled the application of standard binary classification metrics (precision, recall, F1 score, and accuracy) to each category individually, ensuring consistent evaluation across all models.
On a system with an Intel Core i9 (Intel, Santa Clara, CA, USA) and NVIDIA RTX 3060 (NVIDIA, Santa Clara, CA, USA), the models processed each image in 2–10 s—a speed comparable to the performance of commercial online models.
Additionally, the response speed of the models was evaluated when implemented on a portable device. For this purpose, a Raspberry Pi 5 platform equipped with 8 GB of RAM was used. In this case, after launching the model, the response time was only slightly dependent on the image resolution and ranged from approximately 1 to 5 min, depending on the model used. This lengthy response time effectively precludes the use of local models for real-time scene classification. However, by ensuring Internet access, it is possible to determine the scene type within a few seconds, which is an acceptable response time, assuming that scene detection occurs periodically or is triggered on user demand.
An attempt was also made to automatically select parameters based on rules defined using the Retrieval-Augmented Generation (RAG) technique, which relies on a knowledge base. Rules were prepared to guide the selection of parameters for the object detection algorithm. In this case, the models correctly provided segmentation thresholds for indoor/outdoor and day/night conditions but failed to return values within a given range. For example, when specifying a threshold for grass height, the expected output was a value between 20 and 30 cm, where 20 cm represents a neatly trimmed lawn and 30 cm indicates an uncut lawn with plants growing several centimeters high. However, the returned values were most often at the extremes rather than within the expected intermediate range.
This issue partly stems from the models’ limited ability to estimate detailed parameters, for example, the actual height of vegetation in a lawn. Additionally, local models lack the sophistication required to infer and select appropriate values from a knowledge base using image-derived information. As a result, they tend to perform context-sensitive parameter tuning, even when guided by predefined rules.
A much better solution would be to implement the knowledge base as a decision-making algorithm and to select the parameters required for 3D scene reconstruction based on the categories identified by the multimedal model, while using data from the depth map and inertial sensors to further refine these parameters.
4. Discussion
The evaluation of multimodal AI models revealed significant variations in their ability to classify images according to predefined categories relevant to assistive navigation systems for visually impaired users. The results highlight both the promise and the limitations of current generative models in supporting vision-based obstacle detection. Given the limited size of the dataset, the proposed methodology aligns with the primary objective of feasibility studies, that is, to evaluate the feasibility of using generative multimodal models to select parameters in 3D scene segmentation algorithms for assistive navigation systems designed for visually impaired individuals.
The LLaVA-13b and LLaVA models demonstrated high accuracy in basic binary classifications such as indoor/outdoor scene detection, consistently achieving above 97% accuracy. However, their performance varied significantly across more complex semantic interpretations. While LLaVA-13b achieved over 94% accuracy in stair detection, the LLaVA model achieved only 67%, demonstrating that certain prompts and task formulations remain challenging. Similarly, the models struggled with illumination estimation, where LLaVA-13b achieved only about 13% accuracy, highlighting difficulty in handling subtle visual cues.
MiniCPM-V delivered the most consistent performance across multiple categories, especially in distinguishing lighting conditions (over 80% accuracy) and surface evenness (close to 80%). However, it performed poorly in detecting door presence, achieving just around 30% accuracy in this category.
A noteworthy observation pertains to crosswalk detection. Although the LLaVA-13b model formally showed over 93% accuracy in this class, it is marked with an asterisk (*), indicating that despite five independent runs and the presence of 14 crosswalk instances in the test set, the model never correctly detected a crosswalk, not even as a false positive. This discrepancy underscores that a high accuracy score does not necessarily translate to real-world effectiveness, emphasizing the need for more granular, per-instance evaluation.
It is important to note that the annotations used for evaluation were created manually by human annotators and inevitably involved a degree of subjectivity. While certain scene attributes, such as distinguishing between sunny and overcast conditions, are relatively easy for a human observer to assess reliably, the models often struggled with such classifications. Furthermore, some annotation categories inherently depended on contextual interpretation that may not be accessible to AI models. For instance, the visibility of a crosswalk was evaluated with the assistive use case in mind, meaning that the crosswalk should be clearly visible in the immediate vicinity of the pedestrian. While human annotators could easily apply such contextual reasoning, AI models frequently failed to correctly prioritize or interpret such situational nuances.
Furthermore, the nondeterministic nature of generative AI caused identical input data and prompts to produce varied outputs across test runs. This inconsistency, even when instructions were precisely defined, presents a critical challenge for deploying these models in real-time, safety-critical applications. The non-determinism means that while the same input may yield a correct result once, repeated queries can produce different or incorrectly formatted responses, reducing the reliability needed for deterministic computer vision pipelines.
This study focuses on empirical evaluation and practical implementation, with less emphasis on deeper theoretical justification for AI model selection and interpretation. The limitations of prompt-based reasoning—including sensitivity to prompt wording, the non-deterministic nature of generative models, and potential biases from pretraining datasets—pose challenges that can be partly addressed by providing voice feedback about detected scene changes. This helps users to understand the basis for parameter adjustments in assistive navigation systems and improves user safety.
Nonetheless, the results suggest that multimodal models can effectively provide prior context for scene analysis, particularly in deciding whether specific algorithms, such as ground plane estimation or depth map segmentation, should be applied. For instance, correctly identifying outdoor environments with bright, direct sunlight could help avoid the use of RGB-D sensors susceptible to light interference, while detecting uneven ground can trigger different obstacle thresholds in segmentation algorithms.
The results highlight the importance of continued exploration into how generative AI can complement, rather than replace, deterministic visual processing in assistive systems. When used thoughtfully, multimodal models can contribute valuable contextual information, enriching the perception capabilities of systems designed to support the visually impaired.
Although the dataset included only around 200 images, the results still showed clear differences in how the models performed and revealed both strengths and weaknesses of the proposed approach. Even with a small number of examples, important challenges became visible, such as difficulty understanding complex scene details, inconsistent outputs, and variability in results across repeated runs. This highlights both the potential of the approach and the key issues that need to be addressed for real-world use.
5. Conclusions
The results show that multimodal models can determine the conditions under which a photo was taken, aiding in selecting parameters for 3D scene reconstruction. While real-time support is not yet feasible, they can assist with periodic detection and parameter control. However, forcing models to answer specific questions is challenging. They easily identified day or night and indoor or outdoor settings but struggled with details like pedestrian crossings or doors. Notably, when justifying answers, the model inferred doors simply because a building was present and assumed pedestrian crossings existed just because the scene depicted a city.
Despite these shortcomings, the use of AI models can significantly improve user experience, primarily by eliminating the need for manual parameter selection based on environmental conditions. Additionally, AI models can help diagnose system malfunctions by detecting issues such as dirt, obstructions, incorrect installation, or improper camera orientation relative to the ground.
Implementing such solutions on portable devices with limited computing power is impractical due to response time constraints. However, using AI models in a Software as Service (SaaS) approach with Internet access is viable, as servers can return results in seconds, often faster than dedicated commercial models that queue tasks.
Moreover, despite the models’ less-than-perfect classification accuracy, selecting segmentation algorithm parameters based on AI-derived scene information is entirely feasible. By combining AI-generated inferences with simple, interpretable messages delivered to the user, such as specifying for which type of scene the parameters were chosen, these models can meaningfully enhance the usability and reliability of assistive systems.
Future work will explore techniques such as model pruning to assess real-time feasibility. Additionally, the use of commercial models and background image analysis for parameter tuning will be considered.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}