1. Introduction
In the last decade, research regarding artificial intelligence (AI) related to photographic and visual data has garnered increasing attention, primarily due to the proliferation of algorithms for deep learning and their rapidly improving performance. These advancements have enabled a broad spectrum of applications across diverse domains. Notable examples include visual arts [
1,
2], health sciences [
3,
4,
5,
6,
7,
8], earth sciences [
9,
10,
11,
12], criminal investigations [
13,
14], engineering [
15,
16,
17,
18,
19,
20,
21,
22], and psychology [
23,
24]. The reason for these many examples is the widespread use of mobile devices that can take high-quality photographs [
25]. In addition, in disciplines where visual data plays a critical role, such as smart cities, space, and health, the fact that observation devices are of increasingly high quality in terms of hardware is motivating for artificial intelligence studies in these fields [
26].
In parallel with these developments, recent studies have explored image manipulation techniques for privacy and visual realism. For example, generative models have been used for facial anonymization [
27], while advanced filtering methods enhance details and correct illumination in images [
28,
29]. On the other hand, image filtering has gained attention for its role in robustness and clarity. Studies have introduced low-pass filters to defend against adversarial attacks [
30], analyzed filter types for mesh and texture preservation [
31], and proposed hybrid filtering methods for noise reduction and structural preservation [
32,
33].
Another area of research in this context focuses on synthetic media content. Current developments in generative artificial intelligence have significantly reshaped image-producing technologies, empowering computational models to produce highly realistic visuals that often closely resemble or are virtually indistinguishable from genuine imagery. While this progress brings innovation across fields such as art, entertainment, healthcare, and surveillance, it simultaneously poses significant challenges in the detection and authentication of synthetic media. Recent studies have tackled this issue from various angles: Pellicer et al. introduced a robust multimodal prototype-based approach (PUDD) to deepfake detection [
34]; Bhinge and Nagpal quantified how differently real and artificial images behave in vision models [
35]; Gallagher and Pugsley proposed a dual-input neural architecture to integrate structural and contextual cues [
36]; and Bartos and Akyol performed an comparative evaluation of deep learning-based methods for image authentication [
37]. Vora et al. explored the classification of various AI-generated content using machine learning and knowledge graphs [
38]. Other contributions, such as CIFAKE by Bird and Lotfi, emphasize interpretability in the classification of fake content [
39], while Kim et al. leveraged transfer learning for efficient adaptation to novel generative techniques [
40]. Together, these approaches reflect a growing consensus in the research community. Identifying artificial intelligence-generated photos is not merely a technical task, but a critical safeguard against misinformation, digital manipulation, and loss of trust in visual images. As generative models become more sophisticated, the urgency to develop reliable, explainable, and adaptive detection methods continues to intensify.
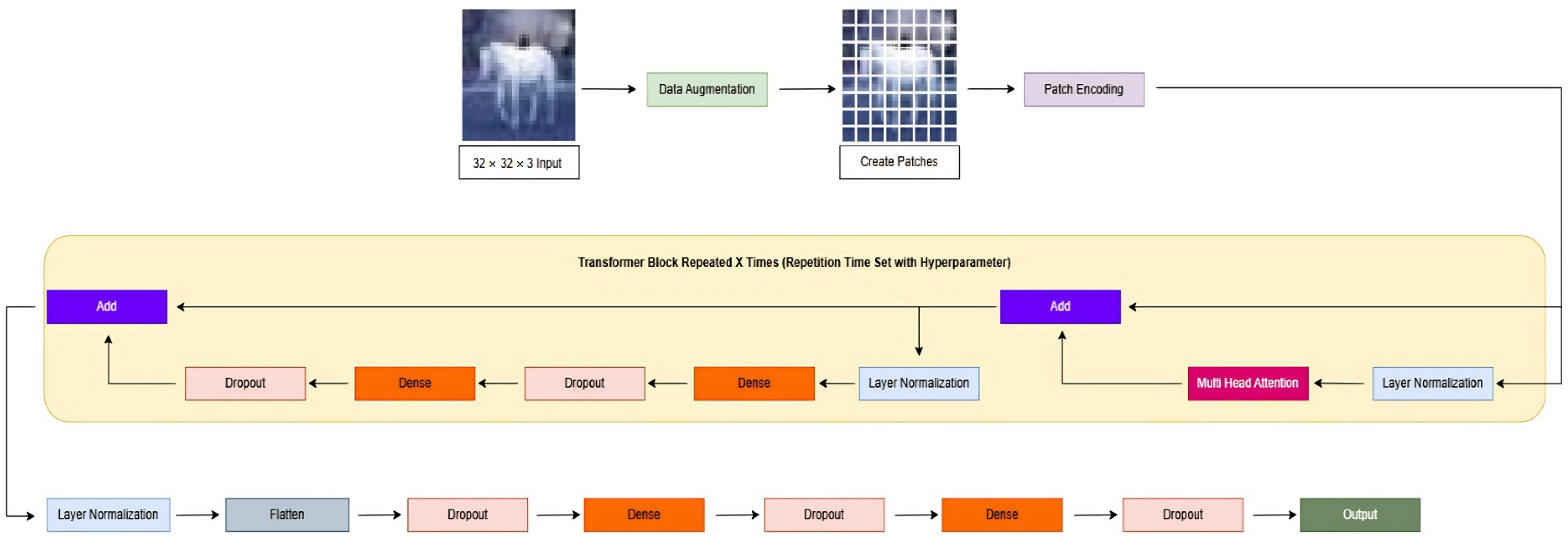
Traditionally, convolutional neural networks (CNNs) and transfer learning approaches have been the preferred methodologies for such detection tasks. Models like ResNet, pre-trained on massive datasets, have offered high performance across various classification problems. However, these architectures carry inherent limitations, particularly in their potential to model long-term reliance and the global environment within image data. Transformers, with their self-attention mechanisms, address these shortcomings elegantly. Vision Transformers (ViTs), recently adapted from their successful natural language processing (NLP) counterparts, have shown great promise in image classification tasks; yet their potential in the realm of artificially produced image recognition remains underexplored. This study introduces a Vision Transformer (ViT) architecture, termed Patch-Based Vision Transformer for Identifying Synthetic Media (PV-ISM), created for the purpose of binary classification, which involves separating artificial intelligence-generated photos from genuine ones. In order to train and assess the model, the CIFAKE dataset has been used. This dataset comprises real CIFAR-10 images and synthetically generated counterparts produced via Stable Diffusion 1.4. The results of the experiments show that the suggested model performs well, highlighting the effectiveness of transformer-based architectures in the domain of image authentication. The following are this work’s main contributions:
It is demonstrated that Vision Transformers, even without extensive pre-training or external datasets, can outperform conventional transfer learning models (e.g., ResNet50) on the task of synthetic image detection, achieving an accuracy of 96.60% versus 93.32%.
A comprehensive ablation study is conducted on hyperparameters such as patch size, image resolution, and epoch count, with their tangible influence on detection accuracy and model generalization being identified.
It is highlighted that, compared to transfer learning models, which require vast datasets and training time, PV-ISM is not only more time-efficient, but also maintains balanced classification performance across classes, as evidenced by a near-symmetric confusion matrix.
What emerges is not just a performance model, but an adaptable framework for identifying synthetic imagery—a task becoming increasingly vital in today’s digital ecosystem. Moreover, our findings suggest that the patch-based architecture of Vision Transformers aligns naturally with the structural patterns present in generated images, providing an edge in subtle feature discrimination.
The following is how the paper is structured:
Section 2 offers a detailed analysis of relevant research on synthetic image detection and transformer-based models. The suggested methodology is described in
Section 3, along with the architectural design of the model and training procedures.
Section 4 describes the experimental framework, presents the obtained results, and offers an in-depth analysis.
Section 5 presents experimental studies with the proposed model by using two more datasets. Finally,
Section 6 wraps up the study by summarizing the main conclusions and offering recommendations for further research paths.
2. Related Works
Our study presents a specialized classification task that focuses on distinguishing AI-generated images from real images. Numerous prior works have addressed this topic using similar or even identical datasets, largely because of the insufficient amount of reliable benchmark datasets that enable consistent performance evaluation and cross-method comparison. As a result, many studies exhibit similarities, with minor methodological variations. The following section gives a thorough rundown of current developments in AI-generated image identification.
Several studies have applied deep learning techniques to tackle this classification problem. A significant portion of existing research relies on transfer learning or various configurations of CNNs. These include both simple multi-layered CNNs and more complex architectures with fine-tuned parameters. Transfer learning remains one of the most frequently adopted methods, with many studies comparing different CNN architectures and reporting their relative performance [
38,
39,
41,
42,
43,
44].
For example, one study incorporated activation mapping to highlight the most discriminative features involved in identifying AI-generated images, building on standard CNN architectures [
39]. Another work compared Variational Autoencoders (VAEs) with Residual Neural Networks (ResNets), concluding that ResNet significantly outperforms VAEs in this domain [
37]. Similarly, a comparative analysis involving pre-trained models such as ResNet, VGGNet, DenseNet, and a custom CNN revealed that DenseNet, enhanced with an additional dense layer, achieved the best results [
45].
Additional research examined the performance of various pre-trained models, including VGG16, VGG19, ResNet101, ResNet152, DenseNet121, and DenseNet169, with DenseNet121 performing particularly well when extended with supplementary layers [
40]. Other studies have explored novel architectures beyond conventional transfer learning. One such work proposed a dual-input neural network that accepts two versions of the same image, leading to improved classification accuracy [
36].
Further comparative studies offer deeper insights. For instance, ResNet50, VGG16, EfficientNetV2B0, and MobileNetV3Small were evaluated on the CIFAKE dataset, with EfficientNetV2B0 delivering the best performance even without fine-tuning [
46]. Another study demonstrated the utility of prototype-based classification using similarity scores, improving training efficiency and inference accuracy [
34]. Likewise, comparisons between lightweight CNNs and EfficientNetV2B0 highlighted the latter’s superiority [
35]. Some studies also implement attention mechanisms, such as those used in PV-ISM, to further enhance detection performance [
47].
There have also been investigations into how image properties affect model performance. For example, one study explored the influence of background elements on detection accuracy, noting potential performance variations depending on visual context [
48]. Another method used the local binary pattern (LBP) in addition to fast Fourier transform (FFT) features to make use of texture and frequency-based information, thereby enriching the feature space [
49].
Moreover, under the domain of digital forensics, several studies have examined the detection of AI-edited images [
48,
50,
51,
52]. While this task differs from identifying fully AI-generated content, it shares significant overlap, as both involve artificial manipulations. Such edits often leverage similar generative techniques like GANs, VAEs, or transformers to add virtual elements rather than synthesizing complete images.
Lastly, comparative studies that evaluate models on shared datasets are common, often synthesizing insights across related inquiries [
44,
52,
53,
54]. With the exception of more novel approaches—such as FFT-based analysis, multi-input CNNs, and channel-wise classification—most works converge on transfer learning as the most accessible and effective strategy for this classification task. Notably, variants of DenseNet and ResNet frequently surpass alternative models in terms of robustness and accuracy.
From this comprehensive review, it is evident that transfer learning represents the most prevalent and effective method for distinguishing AI-generated images from real ones. Among the various transfer learning strategies, models based on DenseNet and ResNet architectures consistently achieve superior performance. Nonetheless, several unique and emerging techniques show potential for competing with or complementing these dominant approaches [
55].
Table 1 shows the accuracy performance of these traditional approaches.
4. Results and Discussion
This section contains the findings from the tests that were carried out and the evaluations of PV-ISM are presented. We include in-depth specifications of the computational environment that we used for this research to ensure the reproducibility of our studies. The experiments were conducted on a system running Ubuntu 22.04.5 LTS (Canonical Ltd., London, UK) as the operating system, equipped with an AMD Ryzen 9 7900X CPU (Advanced Micro Devices, Inc., Santa Clara, CA, USA), and GeForce RTX 3090 24G GPU (NVIDIA Corporation, Santa Clara, CA, USA), supported by 32 GB of RAM. The development environment was based on Python 3.10.12, and the primary deep learning framework utilized was TensorFlow 2.16.0-rc0 (Google LLC, Mountain View, CA, USA). For GPU acceleration, CUDA 12.2 was used as the communication agent between the TensorFlow framework and the GPU, with the NVIDIA driver version 535.183.01 specifically installed to ensure compatibility and performance.
Throughout the evaluation process, accuracy (
), defined in Equation (
10), is employed as the primary metric for comparison. To guarantee a thorough evaluation of model performance, in addition to (
), precision (
P), recall (
R), and F1 score (
), given in Equations (
11)–(
13), are also provided in the results.
R is the percentage of true positive cases that the model accurately recognized, whereas
P indicates the percentage of cases that were projected to be positive and turned out to be positive. The
score provides an accurate evaluation of recall and precision by taking the harmonic average of the two factors. These metrics, which are referred to above, are derived from the confusion matrix, which has four main elements. Accurate predictions are indicated as either true negative (
), which indicates that negative cases are correctly identified, or true positive (
), which indicates that positive cases are correctly discovered. Conversely, false positive (
) and false negative (
) are examples of classification errors, where a negative case is mistakenly predicted as positive and a positive case is mistakenly predicted as negative.
The analytical outcomes and performance metrics obtained from the implementation of PV-ISM on the CIFAKE dataset are presented. To address a wide range of potential scenarios, the model parameters were systematically adjusted to determine the most effective configuration. Several significant hyperparameters utilized throughout the study were the learning rate scheduler (LRS), batch size (BS), epoch number (EN), test set percentage (TSP), image resize (IS), patch size (PS), and transformer block (TB).
It was observed that the model demonstrated satisfactory performance even without fine-tuning. However, to ensure the stability and generalizability of the model, parameter optimization was conducted, and notable improvements were identified and are discussed in
Table 2.
One of the most evident findings from the fine-tuning process was the significant impact of the training epoch count on total accuracy. When trained with a low number of epochs, the model’s accuracy consistently ranged between 85% and 89%. Conversely, an increased number of epochs resulted in higher accuracy, although this came with a potential risk of overfitting.
In the search for an appropriate number of epochs, a progressive approach was adopted, starting from lower values and gradually increasing, considering the dataset size. Subsequently, an early stopping mechanism, which stopped if there was no improvement after 10 epochs, was integrated into the training process using the estimated optimal parameters. The evaluation revealed that the training process typically converged around 65 epochs, with no significant improvement in accuracy observed beyond this point.
Another important factor influencing performance was the learning rate scheduling strategy applied during training. To control the training dynamics, a learning rate scheduler was utilized, decreasing the learning rate by a scaling factor of 0.3 after three consecutive epochs, with the intention of refining the gradient descent process. However, this strategy unexpectedly resulted in a decrease in model performance. Consequently, the scheduler was excluded from the final training procedure, and the AdamW optimizer, recognized as a state-of-the-art optimization algorithm, was employed exclusively.
The next aspects to be considered were the image resize and patch size parameters. Image resize defines the upscaled size of the original image, addressing the issue of lower image resolution. Patch size represents the size of the patches in pixels. A slight decrease in the image resize parameter results in a performance improvement. A similar effect is observed when slightly adjusting the patch size parameter within a small window.
Furthermore, upon examining the minor percentage differences, it can be observed that reducing the test set percentage has a slight impact on performance. Since the test and evaluation sets are distinct, increasing the number of training images aids the model in identifying anomalies more effectively. The transformer block, inspired by Vaswani et al. [
66], also demonstrates similar characteristics: a balanced application of transformers improves accuracy, while excessive use may negatively affect performance.
For a comprehensive comparison, a state-of-the-art transfer learning model, ResNet50 initialized using ImageNet weights, was introduced. The ResNet50 model, which is trained on a massive image dataset, is particularly designed for classification tasks.
In
Table 3, a comparison between the ResNet50 transfer learning model and PV-ISM is provided. PV-ISM achieves an accuracy of 96.60%, which is 3.28 percentage points higher than ResNet50’s 93.32%. This indicates that, overall, PV-ISM classifies a higher proportion of images correctly. PV-ISM appears to have a slightly reduced rate of incorrect positive classifications based on the precision score, indicating its higher reliability in predicting real images. The most significant improvement is observed in recall, where PV-ISM achieves 96.6%, compared to ResNet50’s 90.43%, marking a substantial 6.17 percentage point increase. This shows that PV-ISM is considerably better at identifying all relevant instances, leading to fewer false negatives. The balanced performance, also reflected in the F1 score, suggests that PV-ISM has well-tuned parameters that work effectively in distinguishing AI-generated images from real ones, whereas the ResNet50 model exhibits more variation across metrics. This comparison demonstrates that while transfer learning with ResNet50 provides a strong baseline performance, PV-ISM offers significant improvements.
The performance of PV-ISM can be investigated in comparison with other studies, as presented in
Table 4. When using the same dataset, PV-ISM demonstrates superior performance relative to other studies, even outperforming highly information-dense transfer learning models. Moreover, when considering the duration times for training, the performance gap becomes even more pronounced. While transfer learning models are commonly trained on very large datasets with industrial-grade computational resources, PV-ISM achieves its results without such extensive resources.
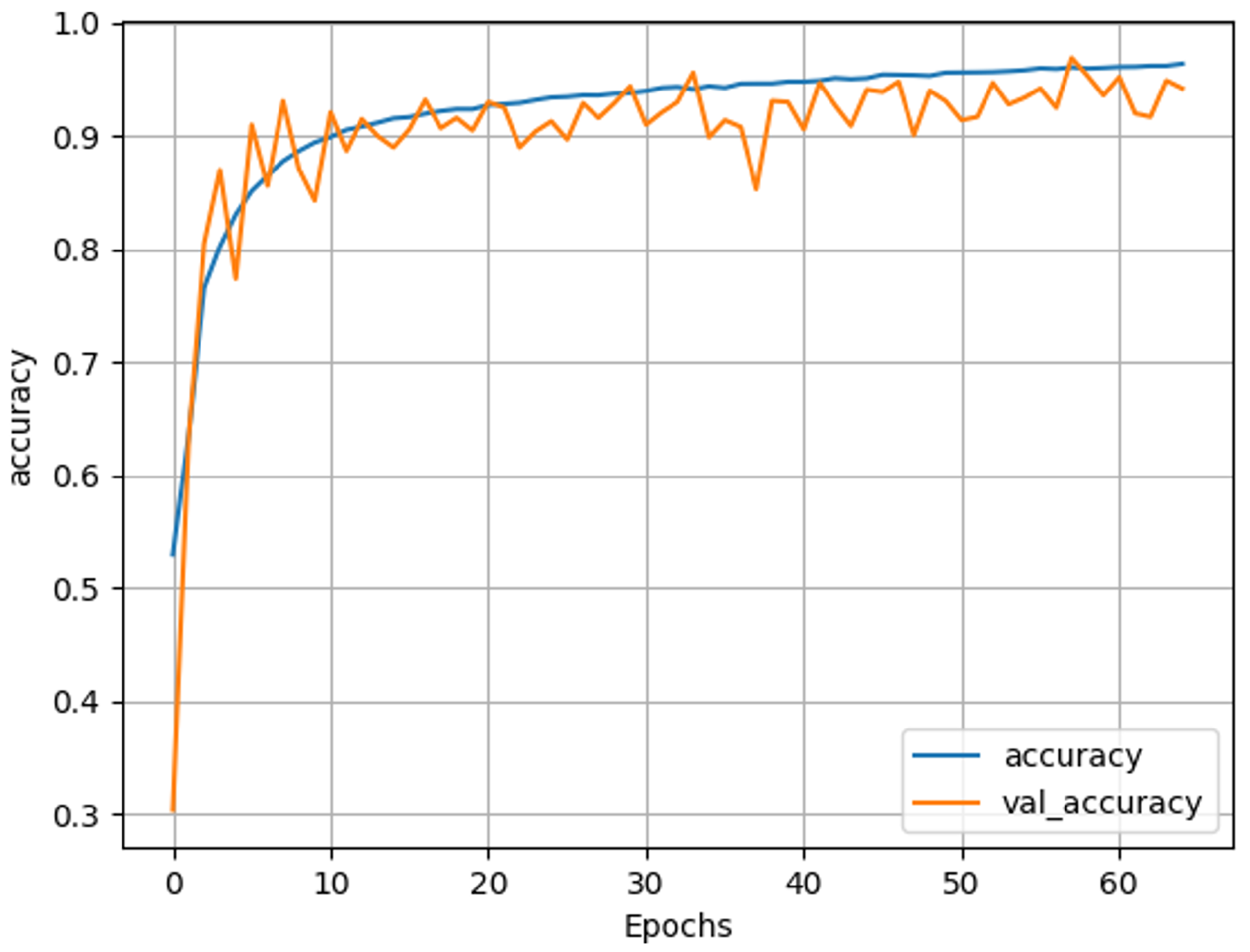
The best-performing model in our experiments, as presented in the final result in
Table 2, was the flattened transformer architecture, which achieved the highest accuracy on the CIFAKE dataset. The accuracy graph, shown in
Figure 10, illustrates how the model’s accuracy changed during training over 65 epochs. It can be observed that the training accuracy steadily increased and reached approximately 96% by the time the training was over. Also validation accuracy remained high, albeit with some minor fluctuations after the initial few epochs. These findings show that the model maintained good performance on unseen data, successfully learning to distinguish between real and false, AI-generated media images.
As shown in
Figure 10, the training accuracy increased consistently and reached over 96% toward the end of training. The validation accuracy also remained high, albeit with some minor oscillations, indicating that the model maintained strong generalization throughout the training process. This is supported by
Figure 11, which demonstrates a smooth and parallel decline in training and validation loss. The narrow gap between the two curves suggests minimal overfitting and confirms that the model is not memorizing the training data, but rather learning meaningful patterns.
Figure 11 demonstrates the loss rate throughout the training and validation sets which correspond to the accuracy graph. The training loss decreased smoothly as the number of epochs increased, suggesting that the model continued to improve during the training phase. The validation loss also remained low, despite some slight fluctuations. This behavior is typical and indicates that the model was able to generalize to new data without significant overfitting. The small difference between the training and validation loss further supports this conclusion.
Figure 12 presents the results through the confusion matrix for the evaluation set. The proposed model successfully predicted 970 fake images and 962 real images from a set of 1000 each. Only 30 fake images were misclassified as real, and 38 real images were misclassified as fake. These numbers demonstrate that the model performs well across both classes and does not exhibit a bias toward one class over the other. Thus, the outcomes validate the model’s accuracy and balance in recognizing between real and AI-generated images.
The confusion matrix in
Figure 12 further illustrates the model’s balanced performance. PV-ISM correctly classified 970 out of 1000 fake images and 962 out of 1000 real images, resulting in 30 false negatives and 38 false positives, respectively. This nearly symmetric outcome suggests that the model does not favor one class over the other. The low number of classification errors across both classes demonstrates the robustness of the model’s decision boundary and its applicability to real-world deepfake detection scenarios. Based on performance trends and model behavior, the patch encoding and transformer-based attention layers appear to be the most impactful. The patch-wise tokenization enables fine-grained feature localization, while the attention mechanism enhances global feature correlation, both essential for distinguishing subtle generative artifacts.
6. Conclusions
This study introduced PV-ISM, a Vision Transformer-based framework for distinguishing between real and AI-generated images. Beyond strong performance on the CIFAKE dataset, the results underscore the architectural advantage of patch-wise tokenization and attention-based modeling for capturing subtle generative artifacts.
Architecturally, PV-ISM diverges from conventional ViT models through several design choices. First, it integrates custom dense and dropout layers not only after but also within the transformer stack, improving non-linearity and regularization. Second, the model replaces the typical sigmoid-activated single-neuron output with a dual-logit strategy, outputting raw values per class before applying softmax externally. This offers greater flexibility in thresholding and interpretability. Importantly, PV-ISM achieves high performance without relying on pre-trained backbones or transfer learning, which makes it lightweight, fast, and adaptable for deployment in practical scenarios.
To evaluate generalizability, two additional experiments were conducted using the Real vs. Fake Faces (RVF-10K) and Art Images datasets. The RVF-10K dataset tested the model’s ability to detect facial deepfakes in realistic, high-resolution scenarios, while the Art Images dataset assessed PV-ISM’s robustness in stylistically abstract domains. In both cases, the model maintained strong classification performance, supporting its applicability across varying visual distributions and use cases.
These findings extend the potential impact of PV-ISM beyond technical benchmarks. As generative models continue to evolve, their misuse in journalism, forensics, and digital media poses growing risks. Robust detection systems like PV-ISM are therefore crucial for preserving visual trust in increasingly synthetic digital ecosystems.
Future work could investigate the scalability of PV-ISM to high-resolution datasets and real-time applications, explore its integration with multimodal data (e.g., video or audio), and advance interpretability tools to better understand attention mechanisms in transformer-based architectures.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}