Abstract
The rapid proliferation of Internet of Things (IoT) devices presents significant security challenges due to inherent vulnerabilities and increasing cyberattacks. Effective intrusion detection systems (IDSs) are crucial for securing IoT environments, requiring high detection accuracy while efficiently handling large data volumes and critically minimizing both false negatives (FNR), which miss real attacks, and false positives (FPR), which cause unnecessary alarms. Traditional methods and standalone deep learning models often struggle to achieve an optimal balance between these requirements. This paper proposes a novel hybrid IDS framework designed to enhance IoT network security by integrating time series analysis with deep learning. Specifically, we leverage seasonal-trend decomposition using Loess (STL) as an intelligent pre-filtering mechanism to isolate potentially anomalous traffic, which is then classified using sophisticated deep learning models, with a particular focus on long short-term memory (LSTM) networks compared against recurrent neural networks (RNN) and dense neural networks (DNN). The proposed framework performance was rigorously evaluated using the comprehensive and realistic BoT-IoT dataset. The methodology involved principal component analysis (PCA) for dimensionality reduction and careful hyperparameter tuning. The experimental results demonstrate the effectiveness of the hybrid approach, with the STL-LSTM variant achieving superior performance. It attained an overall accuracy of 98.5% and a macro F1-score of 98.49%, while significantly reducing the overall false negative rate to 5.2% (FNR ≈ 0.24) and the overall false positive rate to 0.276% (FPR ≈ 0.11) across five Attack/Normal classes. These results represent a substantial improvement over standalone deep learning models (standalone LSTM FNR = 0.302, FPR = 0.185) and compare favorably to state-of-the-art benchmarks reported in the literature, particularly in minimizing critical detection errors. The findings indicate that the proposed hybrid STL-LSTM framework presents a robust and viable solution for high-stakes IoT network security, effectively balancing high detection accuracy with exceptionally low error rates, making it well-suited for real-time deployment in protecting critical IoT infrastructure.
1. Introduction
IoT represents a paradigm shift in connectivity, weaving billions of smart devices into the fabric of our daily lives, from homes and businesses to critical infrastructure sectors like energy, transportation, and healthcare [1,2]. While offering unprecedented convenience and efficiency, this ubiquitous connectivity comes at a cost. Many IoT devices, often designed with resource constraints and rapid deployment cycles in mind, possess inherent vulnerabilities and lack robust security mechanisms [3,4]. This makes the expanding IoT ecosystem an increasingly attractive target for cyber adversaries, leading to a notable surge in cyberattacks specifically targeting these vulnerable endpoints [3,4]. The distributed nature and often limited oversight of IoT deployments further exacerbate these security risks [5].
Securing these complex IoT networks presents significant challenges. They generate massive volumes of high-velocity network traffic data, often exhibiting complex temporal patterns [6]. Effective security solutions must operate in near real-time to detect and mitigate threats promptly, accommodating a diverse range of devices and communication protocols such as MQTT, CoAP, TCP, and UDP [7,8]. Traditional IDSs, heavily reliant on predefined attack signatures, struggle to keep pace with the novel and evolving threats targeting IoT systems [9]. While anomaly-based IDS offer broader detection capabilities, standard statistical or machine learning approaches often suffer from high FPR, overwhelming security operations with false alarms and potentially leading to alert fatigue [9,10].
To address these limitations, there is a growing need for advanced, behavioral-based IDSs that can learn complex patterns and identify subtle deviations indicative of malicious activity [11]. Deep learning (DL) techniques, such as RNNs, LSTM networks, and DNNs, have shown promise in analyzing the sequential nature of network traffic and detecting sophisticated intrusions [6,12,13,14]. However, deploying DL models directly also presents challenges. They can be computationally expensive to train and operate, and without careful design and tuning, they, too, can suffer from suboptimal performance, particularly concerning the critical balance between false negatives (FNR—missed attacks) and false positives (FPR—false alarms) [15,16]. Minimizing both FNR and FPR is paramount in IoT security, as missed attacks can have severe consequences, while excessive false alarms undermine trust and operational efficiency.
This paper introduces a novel hybrid framework that leverages STL for pre-filtering and enhances the performance of deep learning models, especially in terms of reducing false negatives and false positives. A crucial aspect of this domain also introduces a novel hybrid framework designed to overcome these challenges by synergistically combining time series decomposition with deep learning for enhanced behavioral intrusion detection in IoT networks. Our approach utilizes STL [10], a robust statistical technique, as an intelligent pre-filtering mechanism. The core idea is that legitimate network traffic often exhibits predictable temporal patterns (seasonality and trend) which can be modeled and filtered by STL. By decomposing the time series and focusing on the residual component, we hypothesize that we can effectively isolate anomalous behavior and significantly reduce the volume of data requiring complex analysis. This ‘suspicious’ or residual traffic, enriched with potential anomalies, is then fed into a deep learning model (specifically LSTM, compared with RNN and DNN) for fine-grained attack classification. This two-stage approach aims to simplify the task for the DL model, allowing it to focus its learning capacity on distinguishing complex attack patterns from genuine irregularities, thereby improving overall accuracy while significantly reducing both FNR and FPR.
To validate this approach, we pose the following research questions (RQs):
- RQ1:
- How effectively can STL pre-filtering separate normal, predictable IoT network traffic patterns from potentially anomalous traffic based on time series decomposition?
- RQ2:
- Does integrating STL pre-filtering with deep learning models (LSTM, RNN, and DNN) significantly reduce FPR and FNR compared to standalone deep learning models for IoT intrusion detection?
- RQ3:
- Which deep learning architecture (LSTM, RNN, or DNN) performs best within the proposed hybrid STL-DL framework in terms of overall accuracy, F1-score, FNR, and FPR on a realistic IoT dataset?
- RQ4:
- How does the performance (accuracy, F1-score, FNR, FPR, and execution time) of the proposed hybrid STL-DL framework compare to existing state-of-the-art IDS solutions evaluated on similar IoT datasets?
The main contributions of this paper can be summarized as follows. (1) We propose a novel hybrid IDS framework that combines STL with deep learning techniques to enhance behavioral analysis in IoT networks. (2) The framework is systematically evaluated across three variants—STL + LSTM, STL + RNN, and STL + DNN—and compared against their respective standalone deep learning counterparts. (3) Our analysis demonstrates that STL pre-filtering significantly improves detection accuracy by reducing both FNR and FPR. (4) Extensive experimental validation is conducted using the BoT-IoT dataset, a large-scale and realistic benchmark, with detailed analysis of the effects of class imbalance and feature selection. (5) Finally, a comparative study with existing state-of-the-art IDS approaches shows the superiority of our proposed framework, particularly in achieving lower error rates and more effective intrusion detection in complex IoT environments.
The remainder of this paper is organized as follows. Section 2 reviews related work in IoT intrusion detection. Section 3 details the proposed hybrid STL-Deep Learning framework. Section 5 describes the experimental setup, including the dataset, evaluation metrics, and implementation details. Section 6 presents and discusses the experimental results, addressing the research questions. Finally, Section 7 concludes the paper and outlines directions for future research.
2. Related Work
IDSs form a critical line of defense in modern network security, particularly within the vulnerable and heterogeneous landscape of the IoT. The field has witnessed significant evolution, moving from foundational techniques to sophisticated data-driven approaches [9,17].
Historically, IDS development followed several main paradigms. One foundational approach is the signature-based IDS (SIDS), which operates analogously to antivirus software by relying on matching network traffic against a database of known malicious patterns, often referred to as signatures [9]. While this method proves effective for previously identified threats and typically generates few false alarms, SIDSs are fundamentally incapable of detecting novel, polymorphic, or zero-day attacks whose signatures have not yet been cataloged. Consequently, their effectiveness diminishes rapidly when faced with the unseen threats common in dynamic environments like IoT.
In contrast to signature matching, the anomaly-based IDS (AIDS) aims to model the characteristics of “normal” system or network behavior and subsequently identify any deviations from this baseline as potential intrusions [18,19]. This capability allows the AIDS to potentially detect zero-day attacks. However, accurately defining a precise boundary for normal behavior poses a significant challenge, particularly within diverse IoT networks characterized by dynamic traffic patterns. As a result, AIDSs often suffer from a high FPR, which can overwhelm administrators with spurious alerts [9]. Early iterations of the AIDS primarily relied on statistical modeling, whereas later versions incorporated machine learning techniques to refine the detection process.
A distinct paradigm is the specification-based IDS, which involves manually defining formal specifications that detail legitimate protocol behavior or system states. Any observed activity deviating from these predefined specifications triggers an alert [20]. Although this method can potentially achieve a low FPR for the specific protocols or systems modeled, the process of creating and maintaining accurate, comprehensive specifications for complex and constantly evolving IoT systems is often prohibitively difficult and labor-intensive.
The inherent limitations of these traditional approaches, particularly their struggles with zero-day attacks (SIDS) or high FPR (AIDS) and the complexity associated with specification-based methods, necessitate the development of more adaptive and intelligent solutions tailored for the modern IoT threat landscape [5].
2.1. Machine Learning and Deep Learning in IoT IDS
The advent of machine learning (ML) and, subsequently, deep learning (DL) has revolutionized IDS research, offering powerful tools to learn intricate patterns from vast amounts of network data [21].
Among the early ML approaches, techniques such as support vector machines (SVM), decision trees, k-nearest neighbors (k-NN), and Bayesian networks were some of the first ML methods applied to IDS. These demonstrated improvements over purely statistical anomaly detection methods [21]. However, early ML techniques often necessitated significant feature engineering efforts and could struggle when dealing with the high-dimensional and complex nature of IoT data.
Subsequently, deep learning advancements brought forth models capable of automatic hierarchical feature learning, which have demonstrated superior performance in many IDS tasks [6,22]. Various DL architectures have been explored for intrusion detection. Regarding CNNs, initially designed for image processing, convolutional neural networks have been adapted to extract spatial hierarchies from network traffic features. This adaptation sometimes involves treating traffic data as 1D sequences or transforming them into 2D representations [13,15]. For instance, Gaber et al. [13] combined CNNs with Kernel PCA for IoT IDS, achieving high accuracy, although they noted potential limitations regarding recall (sensitivity). Similarly, Ullah et al. and Alabsi et al. [14,23] utilized CNNs incorporating feature engineering, reporting high accuracy but acknowledging potential issues with false positives.
Another important category includes RNNs and LSTMs. Recurrent neural networks, and particularly, long short-term memory networks, are inherently well suited for handling the sequential nature of network traffic, enabling the effective modeling of temporal dependencies [16,24]. LSTMs specifically address the vanishing gradient problem often encountered in simple RNNs, which allows them to learn long-range patterns within the data [25]. Studies such as the one by Syed et al. [16] have successfully applied bi-directional LSTMs (Bi-LSTMs) in fog-based IoT scenarios. However, a potential drawback of LSTMs is that they can be computationally intensive to train compared to certain other architectures.
Furthermore, DBNs and autoencoders have been employed. Deep belief networks and various types of autoencoders (AE), including stacked AEs and variational AEs (VAEs), have been utilized primarily for unsupervised feature learning and anomaly detection. These models work by identifying deviations from learned representations of normal network traffic patterns [3,26].
More recently, transformers, initially achieving significant success in natural language processing, have been applied to IDS tasks. These models leverage self-attention mechanisms to capture complex relationships between traffic features, even across long sequences [14,27]. For example, Ullah et al. [14] and Albasi et al. [23] demonstrated a transformer-based NN-IDS (TNN-IDS) specifically for MQTT traffic, highlighting the architecture’s capability to handle imbalanced data effectively.
Despite these promising results, many DL-based IDS studies tend to focus heavily on maximizing overall accuracy or F1-score, often neglecting a thorough analysis and reporting of FNR and FPR. This omission is critical, as the practical utility of an IDS heavily depends on minimizing both missed attacks (requiring low FNR) and false alarms (requiring low FPR) [28,29]. Additionally, the computational overhead associated with training and deploying complex DL models remains a significant consideration, especially for resource-constrained IoT gateways or edge devices.
2.2. Time Series Analysis in Network Security
Recognizing network traffic as time series data is crucial. While DL models like LSTMs implicitly handle temporal aspects, specific statistical time series analysis techniques offer complementary capabilities. Traditional methods like ARIMA have been used for traffic prediction, and while these methods can indirectly support anomaly detection [30], they often lack the scalability for real-time, high-dimensional IDS. STL [31] is a versatile technique for separating a time series into trend, seasonal, and remainder components. Its robustness to outliers makes it suitable for analyzing noisy network data [10]. While STL is applied in various anomaly detection contexts [32,33], its potential as a dedicated pre-filtering mechanism to specifically enhance the FNR/FPR performance of subsequent deep learning classifiers in large-scale IoT IDS frameworks has not been extensively investigated. Most research either uses DL alone or combines different DL/ML models, rather than leveraging statistical decomposition to preprocess input for DL classifiers. Additionally, recent work [34] in this field shows a promising model for deep learning intrusion detection systems in time series data, and a comparative study of time series anomaly detection models for industrial control systems is also showing promising results in this area [35]. Leveraging STL’s ability to isolate residual components, often indicative of anomalies, as a pre-filter for deep learning classifiers, which excel at learning complex patterns, represents a promising hybrid approach specifically suited for the noisy and time-sensitive nature of IoT network data.
2.3. Hybrid Intrusion Detection Systems
To overcome the limitations of individual methods, hybrid IDS frameworks have gained traction. These systems combine different techniques, aiming for synergistic benefits [36]. Examples include combining signature and anomaly detection modules [12], integrating different ML/DL classifiers (ensemble methods), or using feature engineering/selection techniques alongside classifiers [13,16]. Li et al. [12] used a combination involving CNN-LSTM and GANs for DoS detection. While hybridization often improves overall performance, the specific combination strategy is crucial, and integrating statistical time series decomposition with DL represents a distinct hybrid approach explored in this work.
As highlighted in a comprehensive survey on hybrid intrusion detection systems [37], recent advancements have focused on combining multiple learning techniques to enhance detection accuracy and system robustness. Several recent works have proposed innovative hybrid and ensemble-based models to address critical issues such as class imbalance, false positive reduction, and adaptability to dynamic network environments. For example, Kushal et al. introduced a self-healing hybrid IDS that leverages ensemble machine learning to enhance resilience and fault tolerance [38], while Rajathi and Rukmani proposed a hybrid model that integrates parametric and non-parametric classifiers for improved detection performance [39]. These studies reflect the growing trend toward intelligent, adaptive IDS frameworks that are capable of maintaining high performance in complex and evolving threat landscapes.
2.4. Research Gaps and Positioning of Current Work
Our review identifies several key gaps addressed by this research. Firstly, there is a lack of investigation into hybrid models that explicitly leverage statistical time series decomposition techniques like STL as a pre-filter to improve the performance and efficiency of DL-based IDS classifiers, particularly focusing on the critical FNR/FPR balance. Secondly, many existing IoT IDS studies, despite using advanced techniques, often lack a rigorous analysis of FNR and FPR trade-offs, reporting primarily aggregate metrics like accuracy, which can be misleading, especially on imbalanced datasets [9,29]. Thirdly, efficiently processing large-scale, realistic IoT datasets like BoT-IoT [40] while maintaining low detection latency remains a challenge.
This paper aims to address these gaps by proposing and evaluating a novel hybrid framework explicitly integrating STL pre-filtering with DL classification (LSTM, RNN, and DNN). Our primary goal is to demonstrate that this synergistic approach can achieve high detection performance while significantly reducing both FNR and FPR compared to standalone DL models and existing literature benchmarks. We provide a detailed analysis of the framework’s performance on the BoT-IoT dataset, directly addressing the FNR/FPR trade-off and computational considerations, thus contributing a robust and practical solution for enhancing behavioral intrusion detection in demanding IoT environments.
3. Proposed Framework: Hybrid STL-Deep Learning IDS
This section details the architecture and operation of our proposed hybrid IDS framework, designed to leverage the strengths of STL and DL for enhanced IoT intrusion detection. The framework’s core principle is to exploit the predictable nature of normal network traffic by pre-filtering it using STL, allowing the DL models to focus on classifying potentially malicious traffic more effectively.
Framework Overview
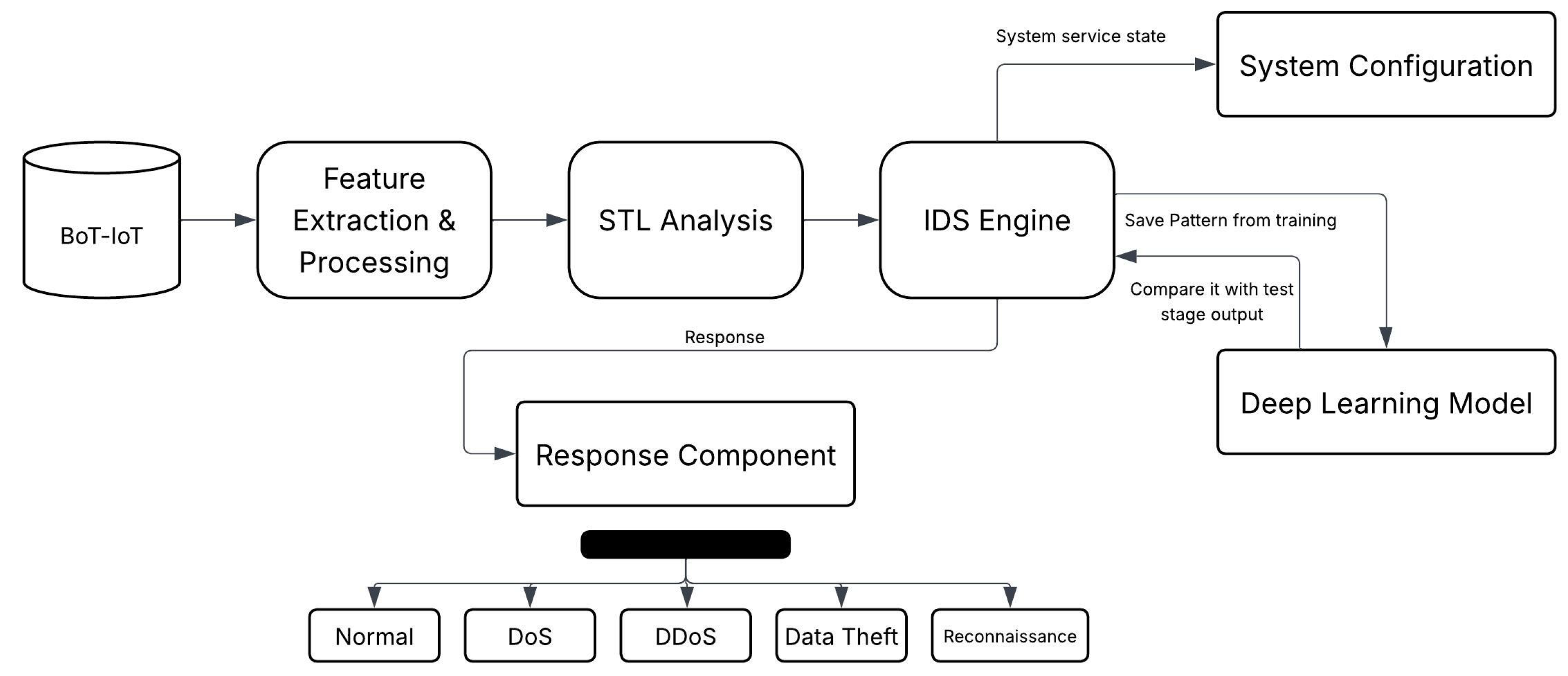
The architecture of the proposed framework is depicted in Figure 1. The data flow through the system proceeds as follows:
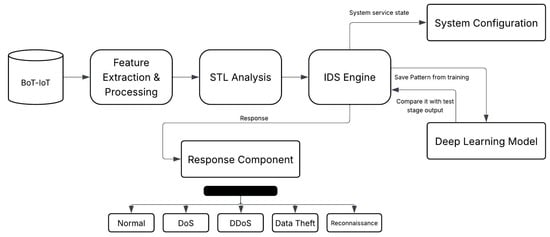
Figure 1.
Overview of the proposed hybrid STL-Deep Learning intrusion detection framework.
- Data Ingestion: Raw network traffic data are collected and ingested.
- Preprocessing: The raw data undergo a comprehensive preprocessing phase, as detailed in Section 4.1.
- STL Analysis: The processed data are then passed to the STL analysis module, where the time series data are decomposed, as further detailed in Section 4.2.
- Feature Selection (PCA): After STL, the features are selected using PCA, as described in Section 6.2.
- Deep Learning Classification: Finally, the selected features (or the STL remainder; see below) are fed into a chosen deep learning model (LSTM, RNN, or DNN) to classify each network packet as either normal or belonging to a specific attack class. This process is detailed in Section 4.4.
- Alerting/Response: Upon detection of a potential intrusion (malicious traffic), an alert is generated, and a pre-defined response action can be initiated.
Rationale: This hybrid approach leverages STL to model and remove predictable regularities in network traffic, thereby reducing the computational burden on the deep learning models and focusing their analysis on the remaining, potentially malicious, patterns. This strategy is designed to improve both detection accuracy and operational efficiency.
From a computational perspective, the framework involves sequential stages: data preprocessing, STL decomposition, feature selection (PCA), and deep learning inference. The overall processing time is a composite of the computational cost of each stage, with STL decomposition and deep learning inference being the most significant contributors, especially for large datasets.
4. Algorithm Overview: Hybrid STL-DL Framework
The core logic of the proposed framework can be summarized as follows (Algorithm 1):
| Algorithm 1 Hybrid STL-Deep Learning IDS Framework |
|
Variables Used in Algorithm 1
- : raw input network traffic features.
- : predicted classification label, for instance, i.
- : preprocessed features after handling missing values and encoding categorical features.
- : subset of containing features chosen for time series analysis.
- : after min–max scaling.
- : target feature time series (e.g., scaled “Transaction State”) for STL decomposition.
- , , : trend, seasonal, and remainder components from STL decomposition of .
- : set of indices of instances flagged as potentially anomalous based on the remainder component .
- : threshold value applied to the remainder component to identify potentially anomalous instances.
- : features corresponding to the instances in , selected from .
- W: PCA projection matrix.
- Z: feature-reduced representation of after PCA projection.
- : mean vector of .
- : Z after standard scaling.
- ⨀: pre-trained deep learning model (LSTM, RNN, or DNN).
- : function representing the forward pass of the deep learning model ⨀ on input , outputting class probabilities.
- : probability that instance belongs to class c.
This algorithm outlines the proposed hybrid approach for detecting IoT intrusions. First, incoming network data undergo preprocessing and scaling. The core novelty lies in using STL to analyze specific traffic time series, identifying the predictable trend and seasonal components, and isolating the unpredictable ‘remainder’. Instances corresponding to large remainder values, indicating significant deviation from normal patterns, are selected for further scrutiny. PCA then reduces the dimensionality of the features associated with these selected instances. Finally, these reduced, standardized features representing potentially anomalous traffic are classified by a pre-trained deep learning model such as LSTM to determine if they constitute normal activity or a specific attack type. This targeted approach allows the sophisticated DL model to focus on classifying genuinely suspicious patterns, enhancing overall detection performance.
4.1. Data Preprocessing
Data preprocessing is a crucial step in preparing the raw network traffic data for effective analysis by the subsequent modules.
- Initial Feature Handling: The initial preprocessing stage addresses data quality and prepares the features for subsequent analysis. Specifically, this involves the following steps:
- -
- Null Value Removal: removing any features containing missing or null values.
- -
- Encoding Categorical Features: converting non-numerical features such as protocol types into numerical representations using techniques like one-hot encoding.
- -
- Feature Selection (Initial Filtering): Before normalization and other steps, a basic feature selection/filtering step can be incorporated at this stage, which, although not explicitly discussed, can be considered a first-pass approach.
- Normalization Strategy: Two-stage normalization strategy was employed, in order to improve both the performance of STL and of DL models.
- -
- Min-Max Scaling (Pre-STL): Prior to STL decomposition, min–max scaling was applied to the original feature values. This ensures that data used in the STL decomposition are bounded within a specific range (0,1). The rationale is that STL, a statistical method, can function more effectively with non-negative, bounded data, improving decomposition performance and reducing sensitivity to extreme values [10].
- -
- Standard Scaling (Post-STL): Following STL decomposition and (optionally) after filtering the remainder data (or after PCA in other flows), standard scaling (Z-score normalization) was applied to the data before feeding them to the deep learning models. This ensures each feature has a mean of 0 and a standard deviation of 1. This is standard practice in deep learning; it helps prevent features with large ranges from dominating the learning process and can improve the convergence speed and stability of the neural networks, as these models generally operate best with normally distributed data.
- Dimensionality Reduction (PCA): PCA helps reduce the computational load and model complexity, a process to be discussed below.
4.2. STL Decomposition Module
The core of our hybrid approach lies in the application of STL to the network traffic data. STL, or seasonal-trend decomposition using Loess [10,31], is a robust and versatile method for decomposing a time series into three components: seasonality, referring to recurring patterns that occur over fixed time intervals such as daily or weekly trends; trend, which captures the underlying long-term direction of the time series; and remainder, which represents the residual component, including noise, outliers, and deviations from both the seasonal and trend components. STL was specifically chosen due to its robustness to outliers, which are common in noisy network traffic data, and its explicit separation of the time series into predictable components (trend and seasonality) and an irregular component (remainder). This decomposition aligns well with our hypothesis: Normal, legitimate network traffic often exhibits predictable temporal patterns, while anomalous or malicious activities are more likely to manifest as deviations captured in the irregular ‘remainder’ component. By isolating this remainder, STL acts as an effective pre-filter, highlighting suspicious instances for the subsequent deep learning analysis.
Our fundamental hypothesis is that normal network traffic exhibits predictable seasonal and/or trend patterns, while deviations from these patterns—captured in the remainder component—are more likely to be associated with anomalous or malicious activity. In this context, the STL module acts as a pre-filter by applying the decomposition and isolating the irregular (remainder) component. This enables the deep learning classifiers to focus on the more subtle and complex patterns linked to malicious activity, while minimizing the influence of regular background traffic. The traffic type and feature selection were key parameters in this module.
To optimize STL’s effectiveness, a parameter tuning and feature selection phase was conducted. This process identified the most relevant network traffic features and determined the best thresholding method for classifying traffic as potentially malicious based on the STL remainder. The tuning results, discussed in Section 6.1, employed confusion matrices to determine optimal parameters that maximize the true negative rate (TN) while minimizing the FNR for normal traffic classification (see Section 6.1).
4.3. Feature Selection (PCA) Module
Following STL decomposition—and, in some cases, after the pre-filtering step—PCA is employed to reduce the dimensionality of the feature space, further simplifying the classification task. The rationale behind incorporating PCA is to mitigate the “curse of dimensionality”, reduce computational complexity, and potentially limit overfitting in the deep learning models. By projecting the original features into a lower-dimensional space, PCA enables the model to focus on the most relevant aspects of the dataset, specifically, those features that best represent the underlying traffic patterns.
In terms of methodology, PCA is applied to the feature space to identify the principal components that capture the maximum variance in the data. This transformation allows for a more compact and informative representation of the input, which is especially beneficial in scenarios involving high-dimensional IoT traffic data.
The selection of the number of principal components to retain was guided by performance-based criteria. Specifically, the optimal number was determined using an F1-score analysis, as detailed in Section 6.2 and illustrated in Table 5. This analysis revealed that using six principal components yields the highest average F1-score across all classes, providing an effective balance between dimensionality reduction and classification performance.
4.4. Deep Learning Classification Module
This module implements the classification stage, in which the preprocessed and feature-reduced network traffic data are analyzed to identify potential intrusions. Three deep learning (DL) model architectures are employed to carry out the classification task: long short-term memory (LSTM), simple recurrent neural network (SimpleRNN), and DNN. The LSTM model, a specialized type of recurrent neural network, is capable of learning and retaining long-term dependencies in sequential data, making it especially effective at capturing temporal patterns in network traffic. In contrast, the SimpleRNN serves as a basic recurrent model, used to provide a performance baseline and to assess the comparative benefits of the more complex LSTM architecture. The DNN, a feedforward neural network without temporal memory, is included as a non-sequential baseline to evaluate the added value of recurrent structures in detecting network anomalies.
All models share a similar high-level architecture, as discussed in Section 6.3. This architecture consists of an input layer that receives the PCA-transformed features, followed by three hidden layers. For LSTM and SimpleRNN models, each hidden layer contains 20 neurons, while the DNN uses standard dense layers. The output layer varies depending on the classification task: For multi-class classification, it contains five neurons corresponding to the different types of traffic, whereas for binary classification, it includes two neurons.
The input to the deep learning models comprises the feature vectors produced by the PCA transformation, which represent either suspicious traffic or the original traffic features for comparison. The output of the models is a classification result that identifies the type of network activity, enabling the effective detection and categorization of potential intrusions. The detailed configurations of each DL module are further elaborated in Section 6.3.
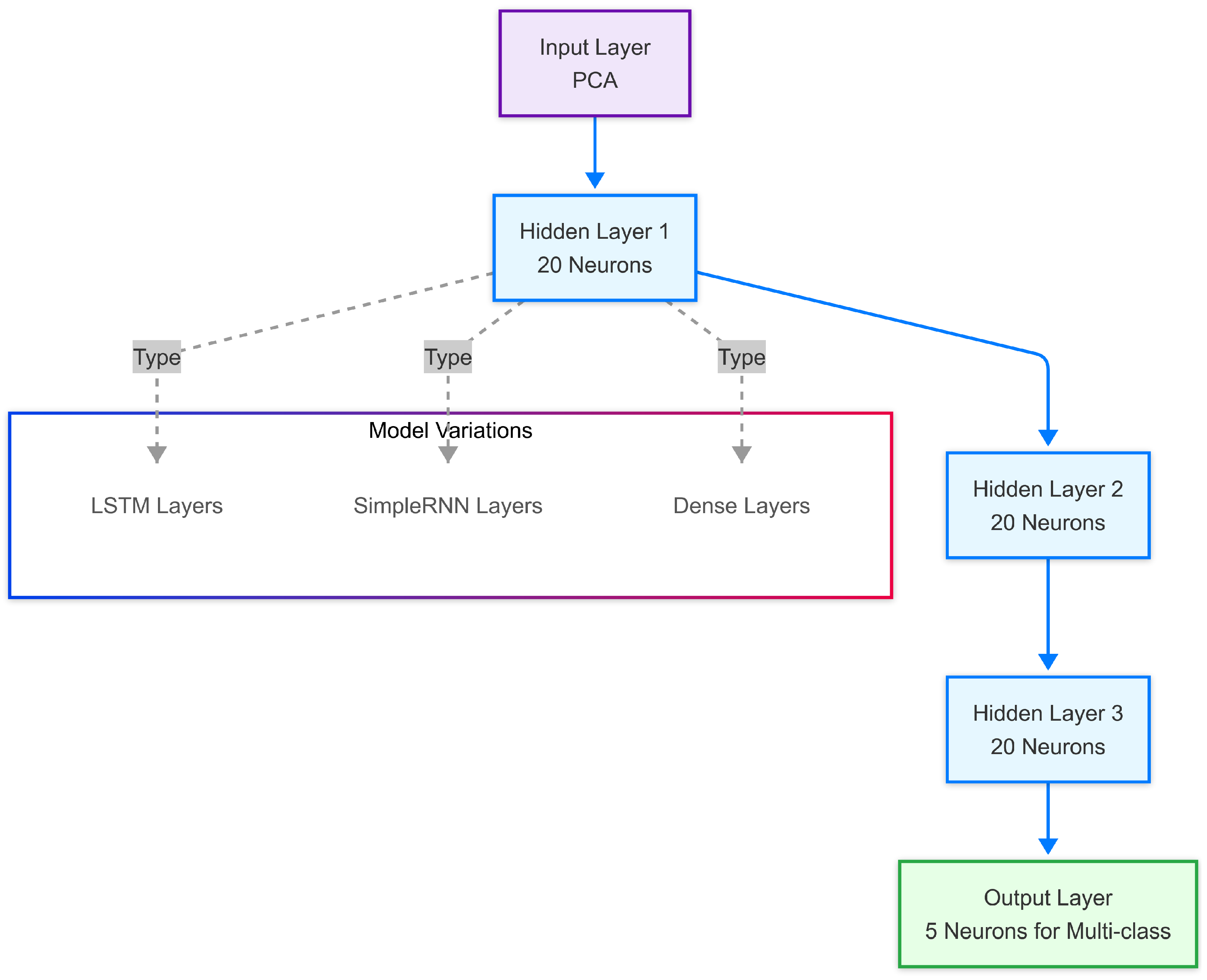
Within our proposed hybrid framework, the deep learning classification module is responsible for the final step: analyzing the preprocessed and feature-reduced network traffic data, particularly the potentially anomalous instances flagged by the STL analysis, to identify specific intrusion types or confirm normal traffic. We evaluated three different deep learning architectures for this critical task: long short-term memory (LSTM), simple recurrent neural network (RNN), and dense neural network (DNN). As illustrated in Figure 2, all these models share a common basic structure: An input layer receives the PCA-transformed features, followed by three hidden layers and an output layer. The LSTM model is specifically chosen for its inherent capability to process sequential data and capture long-term temporal dependencies within network traffic flows, making it well-suited for detecting time-dependent attack patterns. The SimpleRNN serves as a more basic recurrent baseline for comparison, while the DNN, a standard feedforward network lacking temporal memory, provides a non-sequential baseline to assess the value of recurrent architectures in this context. These models perform the fine-grained classification based on the refined data provided by the preceding STL and PCA stages.
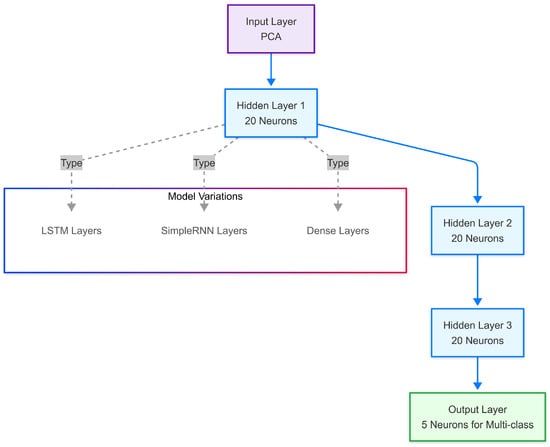
Figure 2.
Deep learning model architectures (detailed view of “deep learning model” block from Figure 1). This diagram illustrates the common architecture used for the deep learning models (LSTM, SimpleRNN, and DNN) within the proposed framework. The input layer receives the PCA-transformed features, followed by three hidden layers, each containing 20 neurons. The type of hidden layer (LSTM, SimpleRNN, or Dense) distinguishes the model variants. The output layer provides the classification result (shown for multi-class classification with 5 neurons).
5. Experimental Setup
This section details the experimental setup employed to evaluate the proposed hybrid STL-Deep Learning IDS framework. It encompasses the dataset description, implementation environment, and model training configurations and the evaluation metrics used to assess performance.
5.1. Dataset
The performance of our proposed framework was evaluated using the BoT-IoT dataset [40], a publicly available and widely-used benchmark dataset for IoT intrusion detection research.
5.1.1. Dataset Description and Relevance
The BoT-IoT dataset, developed by the Cyber Range Lab at UNSW Canberra, Australia, offers a realistic and comprehensive representation of network traffic in IoT environments. Its significance lies in several key aspects. First, realism is achieved by simulating a real-world IoT network environment, thereby capturing authentic traffic patterns and attack behaviors. Second, the diversity of the dataset is notable, as it includes both legitimate (normal) traffic and a variety of attack types, reflecting the complex and multifaceted nature of security threats in IoT contexts. Third, its large scale provides ample data for the robust training and evaluation of advanced machine learning models, enabling meaningful performance assessment under realistic conditions.
5.1.2. Data Characteristics
The BoT-IoT dataset [41] contains an extensive number of records, totaling approximately 73 million entries and exceeding 16 GB in volume. It offers a rich feature set, initially providing 46 features per network flow (packet), encompassing various characteristics of network behavior and traffic patterns. The dataset captures traffic using a range of widely-used IoT protocols, including MQTT, TCP, UDP, and HTTP, ensuring comprehensive protocol coverage. Additionally, it encompasses a wide range of attack categories and sub-categories (as detailed in Table 1), allowing for rigorous evaluation of the proposed framework’s ability to detect and classify diverse types of malicious activities.

Table 1.
Attack categories and sub-categories within the BoT-IoT dataset.
5.1.3. Class Imbalance Handling
The BoT-IoT dataset exhibits significant class imbalance, meaning that the number of instances for different classes (Normal, DDoS, etc.) is highly unequal. To mitigate the potential impact of class imbalance on model performance, we employed a class balancing strategy during training. This was addressed by creating a balanced dataset via under-sampling, where instances from majority classes were randomly removed to match the count of the smallest class (Normal), as shown in Table 2, which presents the original and balanced class distributions. This strategy aims to prevent the models from being biased towards the dominant classes and improve the learning of patterns associated with minority classes, including normal traffic and rare attack types, while acknowledging the limitation of discarding potentially useful data from majority classes.
Table 2.
Class distribution in the BoT-IoT dataset: original and balanced.
The oversampling of the Data Theft class, along with the balancing for the other types, led to the results mentioned previously.
5.2. Implementation Environment
The proposed framework was developed and implemented using a combination of specialized software and high-performance hardware to ensure efficient processing and model training. On the software side, Python (version 3.10 or higher) was used as the primary programming language, selected for its versatility and extensive ecosystem. The deep learning models were implemented using the Keras framework, running on a TensorFlow backend, providing a robust environment for building and training neural networks. Additional libraries such as Scikit-learn were employed for preprocessing and evaluation tasks, while the Statsmodels package was specifically utilized for implementing the STL.
In terms of hardware, the experiments were conducted on a high-performance computing unit designed to handle large-scale data processing and model training. The system was equipped with two physical processors and 128 GB of RAM, ensuring sufficient memory and computational throughput. It featured an Intel(R) Xeon(R) E5-2640 v4 CPU operating at 2.40 GHz, which provided the necessary processing power for deep learning operations and time series analysis. This setup facilitated the efficient execution of the proposed framework and supported rigorous experimentation with various model configurations.
5.3. Model Training
The deep learning models (LSTM, SimpleRNN, and DNN) were trained using a carefully structured configuration. The balanced dataset (as detailed in Table 2) was divided into three subsets: 54% of the data were allocated to the training set for model learning, 16% to the validation set for hyperparameter tuning and early stopping, and the remaining 30% to the testing set to evaluate the final model performance. Several important hyperparameters were tuned to optimize the training process. The Adam optimizer was selected for its adaptive learning capabilities, with a learning rate set to 0.0001. The models were trained using a batch size of 1000, and the number of epochs ranged from 40 to 100, depending on the early stopping criteria. The choice of loss function depended on the classification task: categorical cross-entropy was used for multi-class classification, while binary cross-entropy was applied for binary classification. To mitigate the risk of overfitting, early stopping was employed based on the validation loss. This mechanism continuously monitored the performance on the validation set and terminated training if no improvement was observed over a defined number of epochs, ensuring a more generalized and stable model. Several important hyperparameters were tuned to optimize the training process. The Adam optimizer was selected for its adaptive learning capabilities, with an initial learning rate set to 0.0001; experiments exploring rates in the range [0.0001, 0.001] showed 0.0001 provided the best convergence without excessive oscillation. The models were trained using a batch size of 1000, chosen to balance memory constraints and gradient stability. The number of epochs ranged from 40 to 100, depending on the early stopping criteria, allowing sufficient time for convergence. The choice of loss function depended on the classification task: categorical cross-entropy was used for multi-class classification (Normal, DoS, DDoS, Data Theft, and Reconnaissance), while binary cross-entropy was applied for binary classification (Attack vs. Normal). To mitigate the risk of overfitting, early stopping was employed based on the validation loss, terminating training if no improvement was observed over a defined number of epochs, ensuring a more generalized and stable model. Grid search and manual tuning based on validation set performance were used to explore these parameters, focusing on maximizing F1-score and minimizing validation loss.
5.4. Evaluation Metrics
To comprehensively evaluate the performance of our proposed framework, we used a variety of established evaluation metrics. These metrics are crucial for assessing the effectiveness of IDS in terms of accuracy, precision, and, crucially, error rates.
- Accuracy: measures the overall proportion of correctly classified instances (both Normal and Attack traffic).where:
- −
- TP: true positives (correctly classified as Attack).
- −
- TN: true negatives (correctly classified as Normal).
- −
- FP: false positives (incorrectly classified as Attack—false alarms).
- −
- FN: false negatives (incorrectly classified as Normal—missed attacks).
- Precision: measures the proportion of correctly identified attacks out of all instances classified as attacks.
- Recall (Sensitivity/True Positive Rate − TPR): measures the proportion of actual attacks that were correctly identified.
- F1-Score: provides a balanced measure of a model’s accuracy, representing the harmonic mean of precision and recall.
- FPR: measures the proportion of normal traffic that was incorrectly classified as Attack. This is critical for minimizing false alarms.
- FNR: measures the proportion of actual attacks that were incorrectly classified as Normal traffic. This represents missed detections and is a critical metric for security.
- Confusion Matrix: This matrix provides a detailed breakdown of the classification results, showing the number of true positives, true negatives, false positives, and false negatives for each class.
- Execution Time (Prediction Time): the time required to classify a single network packet. It also measures the total time it takes for the model to classify a whole testing set.
6. Results and Discussion
This section presents and discusses the experimental results obtained from the evaluation of our proposed hybrid STL-Deep Learning IDS framework. The discussion is organized to directly address the research questions outlined in the Introduction (Section 1) and provides a comprehensive assessment of the framework’s performance.
6.1. Addressing RQ1: How Effectively Can STL Pre-Filtering Separate Normal, Predictable IoT Network Traffic Patterns from Potentially Anomalous Traffic Based on Time Series Decomposition?
To address RQ1, we first examined the performance of the STL pre-filtering module. The primary goal of STL was to isolate normal traffic from the traffic flows, with the aim of simplifying the classification task for the DL models, and identifying a more appropriate threshold to filter the traffic flows, thus enhancing the detection accuracy.
The parameter tuning process identified the “Transaction State” feature as the most effective for decomposition, meaning that it captures the features that allow better distinction between Normal and Attack classes, hence allowing a better separation. A threshold value of 0.284 was determined for the STL remainder. This value was selected based on the confusion matrices in the tuning process, where it resulted in maximizing the true negative rate while minimizing the false negative rate for normal traffic classification.
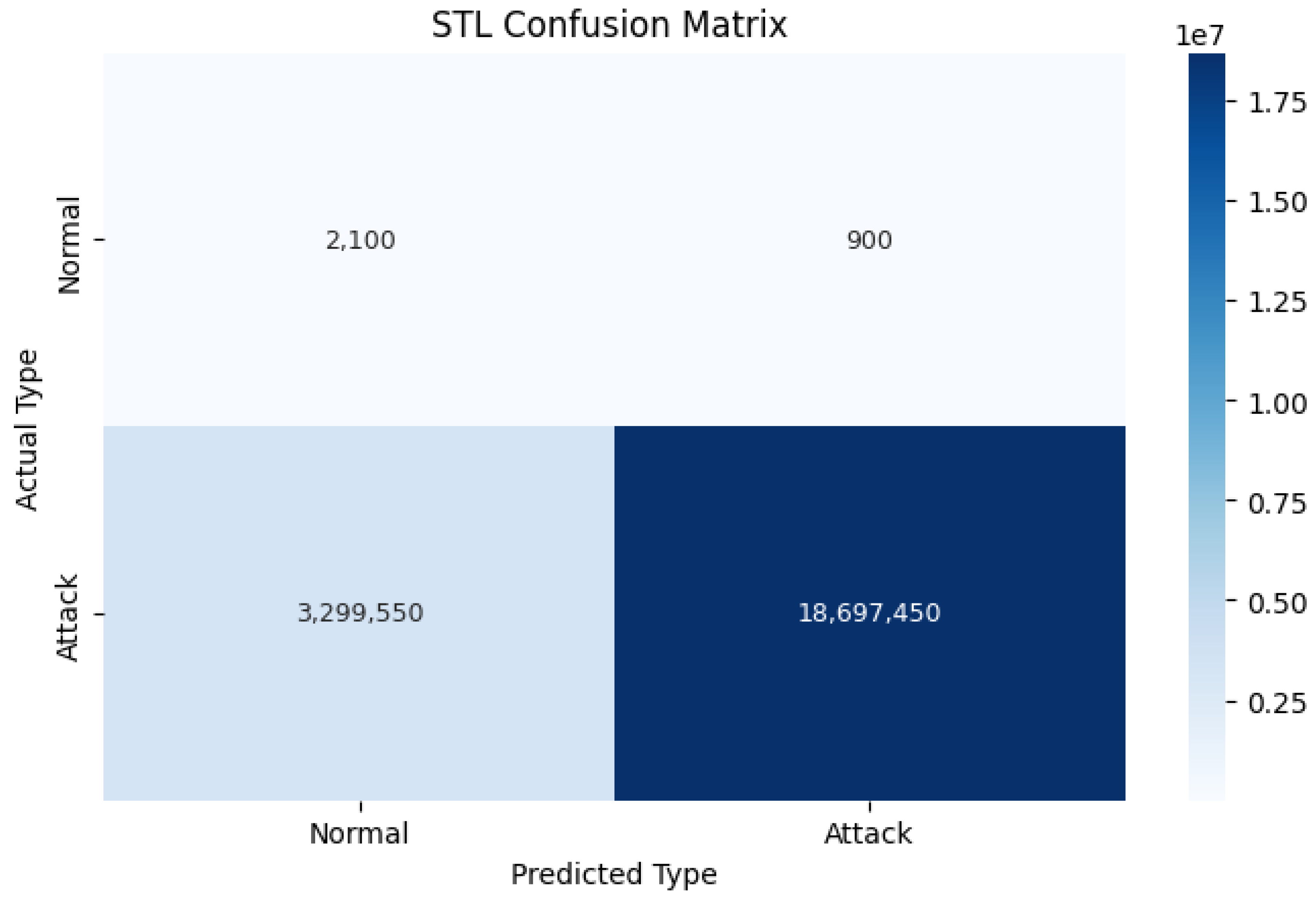
To illustrate the capabilities of the STL pre-filtering, we present the confusion matrix generated from STL’s standalone classification in Figure 3. The confusion matrix is shown below.
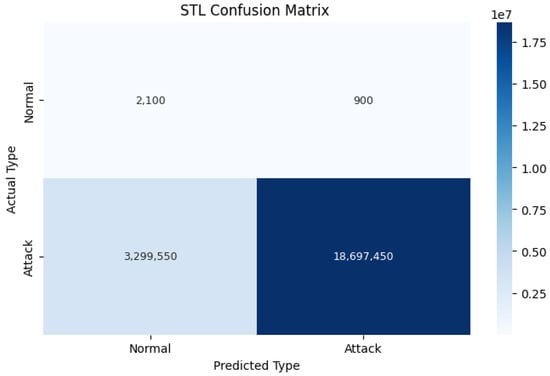
Figure 3.
Confusion. Matrix for the STL algorithm (standalone performance). This shows the classification results before deep learning. The data are separated into Attack and Normal classes.
Analyzing the confusion matrix (Figure 3), which illustrates the standalone performance of the STL thresholding step when applied directly to the highly imbalanced dataset context, reveals the inherent challenges of this simpler approach. While the overall accuracy might appear deceptively high due to the overwhelming number of correctly classified majority attack instances (true positives for attacks), this metric masks critical weaknesses. The matrix highlights significant limitations for standalone use. Firstly, analyzing the “Normal” row in Figure 2 shows 2100 instances were correctly classified (TN), but a substantial 3,299,550 ‘Normal’ instances were misclassified as Attack (FP), resulting in an extremely high false positive rate (FPR) for normal traffic when using STL alone. Secondly, and critically for security, the “Attacks” row shows a very large absolute number of actual attacks (approximately 19 million total) where 900 were misclassified as ‘Normal’ (FN), indicating a significant number of missed attacks, leading to a high false negative rate (FNR). These findings underscore the severe limitations of using STL thresholding as a standalone classifier in realistic, imbalanced network environments. It demonstrates the clear necessity for a more sophisticated classification stage, such as that of the deep learning models employed in the proposed STL + DL method, to effectively handle the complexity, distinguish subtle anomalies, and achieve the low error rates crucial for reliable intrusion detection. Therefore, while STL pre-filtering provides an initial separation, further analysis by the DL component is essential to minimize both false alarms and missed attacks.
6.2. Addressing Feature Selection Performance: Does Feature Selection Affect the Performance?
Feature selection is a vital component of the performance of deep learning algorithms. The goal of the feature selection stage was to reduce the dimensionality of the feature space, further simplifying the classification task and increasing the computation performance. The study investigated different techniques for feature selection and chose the best one for the algorithm.
The analysis of the feature selection results, as shown in Table 3, exhibits that different feature selection techniques affect the performance across all of the five classes. Specifically, Table 3 compares the F1-scores achieved when using features selected by XGBoost importance, PCA, and CHI2, each combined with either min–max or standard scaling, for the classification task using the STL + LSTM model. The results clearly indicate that using features selected and transformed by PCA (both min–max and standard scaled versions) generally resulted in the highest F1-scores across the majority of Attack and Normal classes compared to features selected by XGBoost or CHI2. This suggests that PCA’s ability to capture the most significant variance and underlying patterns in the feature space, while reducing dimensionality and potential noise, was particularly effective for this dataset and classification task. Based on these comparative F1-score results, PCA was selected as the most effective feature selection method for the proposed hybrid framework, demonstrating an effective balance between dimensionality reduction and retaining information crucial for classification performance.
Table 3.
F1-score for all feature selection techniques with min–max and standard scalers.
In Table 4, the STL + LSTM model achieves the overall best results for accuracy and F1-Score across all classes. Notably, the integration of STL pre-filtering led to significant improvements in the model’s ability to accurately classify various attack categories, especially with respect to error rates.
Table 4.
Performance of different IDS experiments.
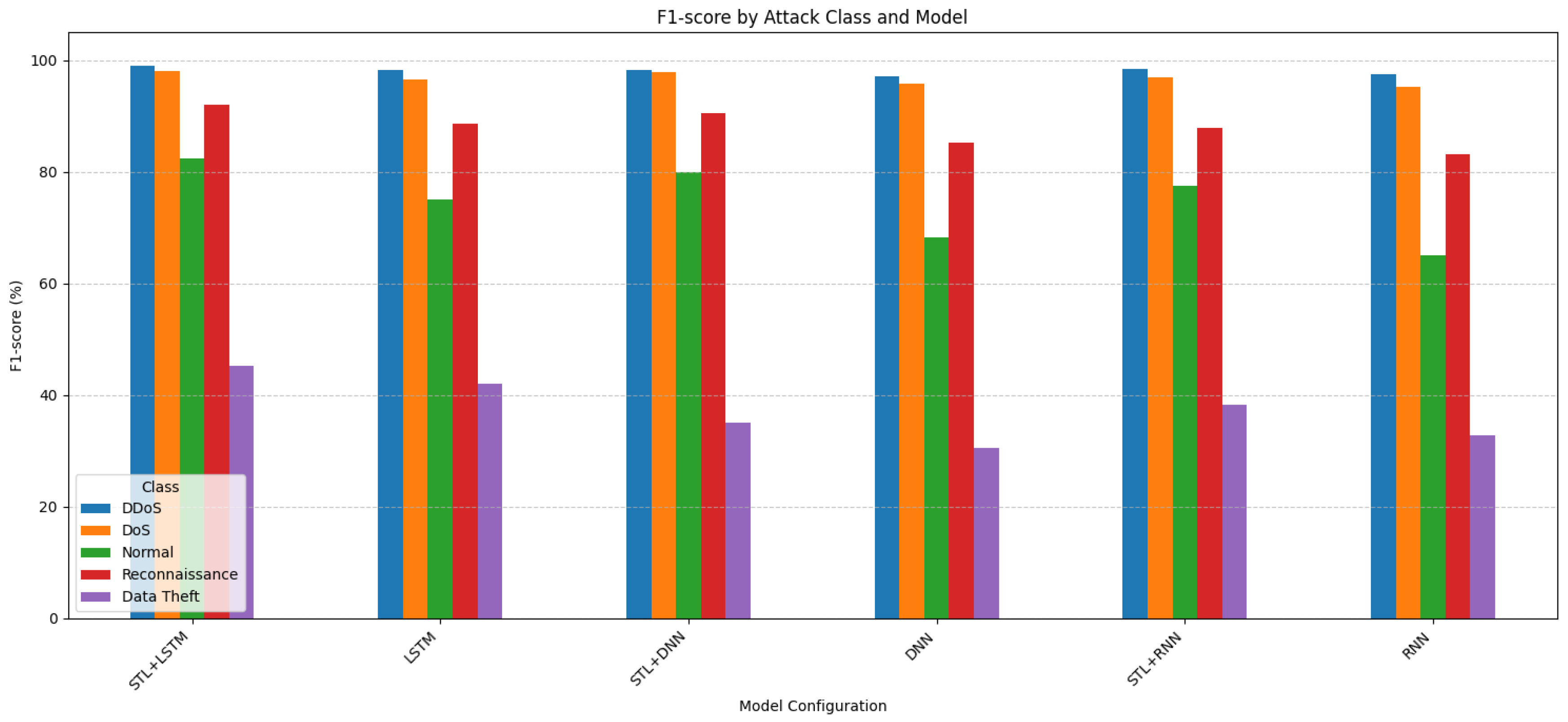
- F1-score (Figure 4): This figure presents a comparison of the F1-scores achieved by each model configuration across the five different traffic classes. As observed in the simulation, models generally maintain high F1-scores for the dominant attack classes such as STL + LSTM achieving 99.1% for DDoS and 98.0% for DoS). However, performance degrades significantly for minority classes due to the extreme class imbalance. For instance, the F1-score for the STL + LSTM model drops to 92.0% for Reconnaissance, 82.5% for Normal traffic, and only 45.3% for the extremely rare Data Theft class, highlighting the challenge these classes pose in the imbalanced scenario. Nonetheless, the STL + LSTM combination consistently shows the best or near-best performance across all classes compared to other configurations.
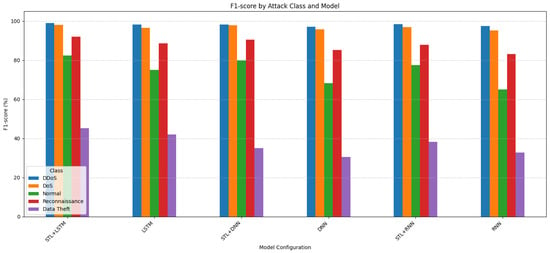 Figure 4. F1-score by model.
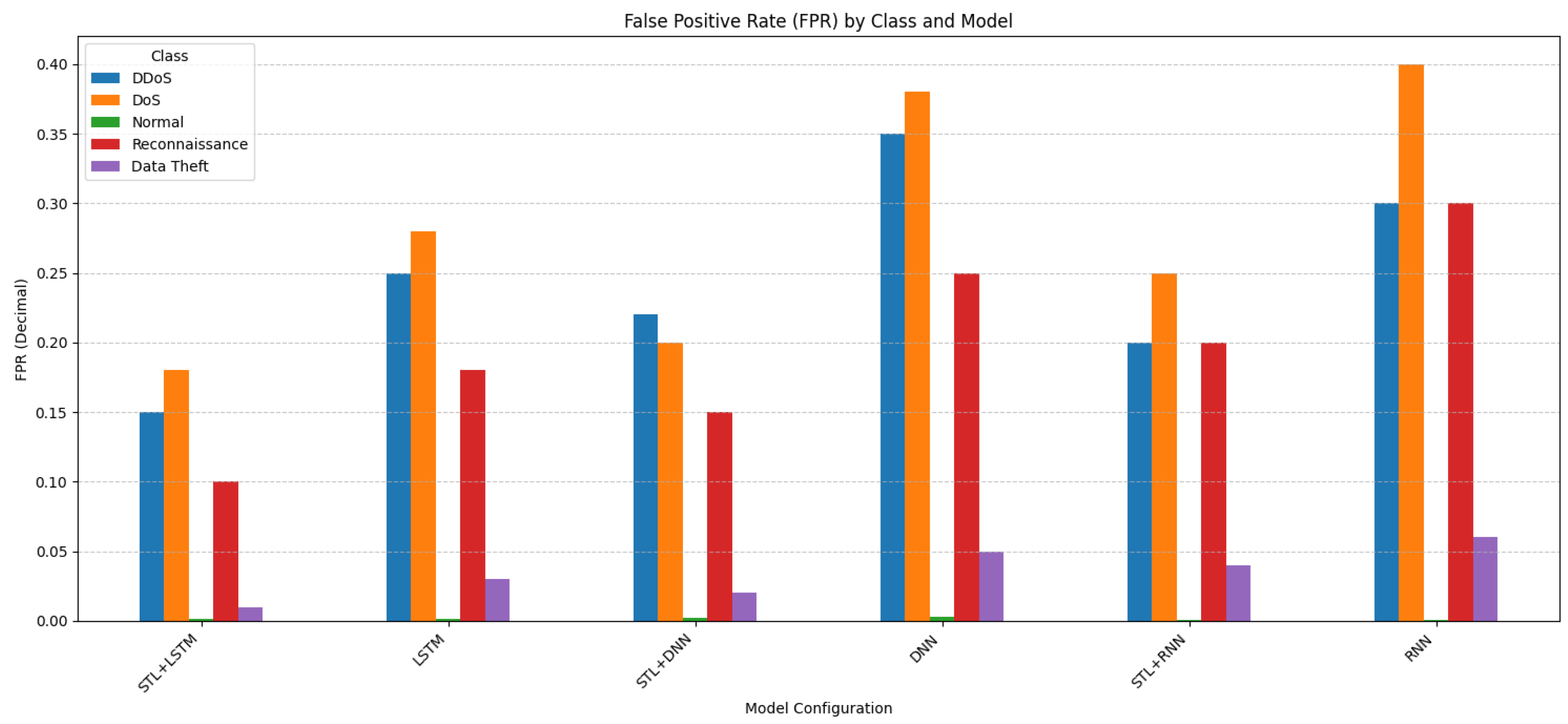
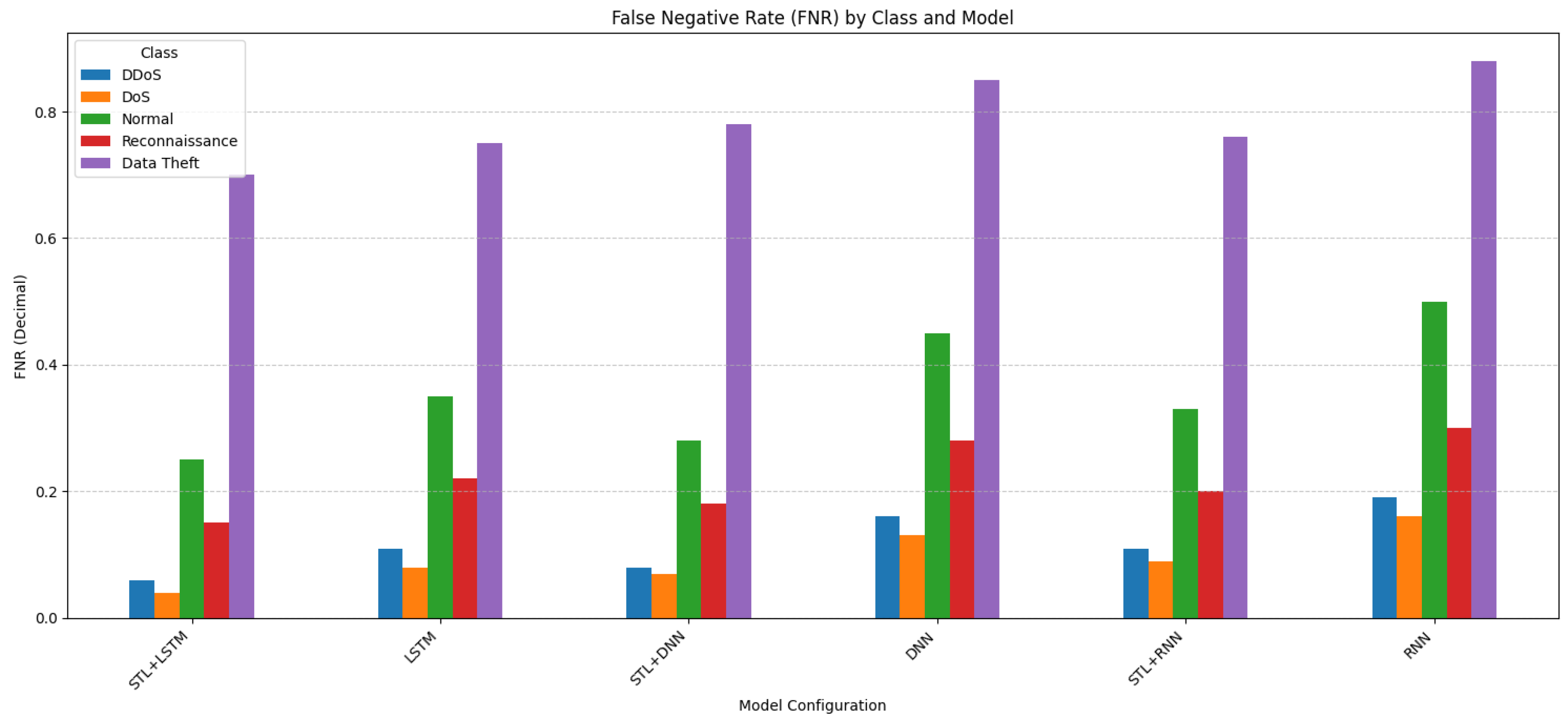
Figure 4. F1-score by model. - Impact on Error Rates (Figure 5 and Figure 6): These figures illustrate the FPR and FNR, respectively, crucial metrics for IDS utility.
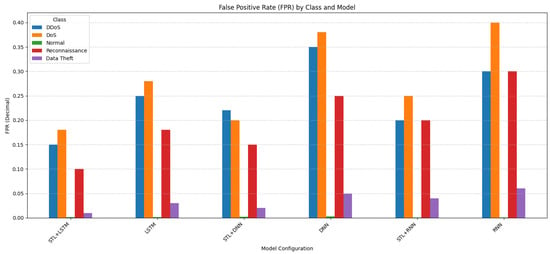 Figure 5. FPR by model.
Figure 5. FPR by model.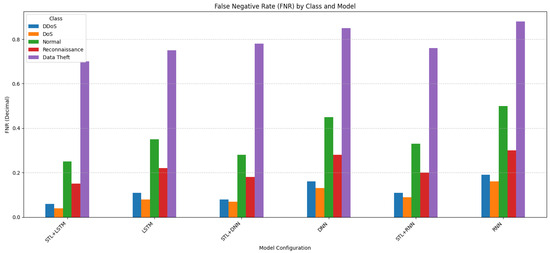 Figure 6. FNR by model.
Figure 6. FNR by model.- −
- Figure 5 (FPR) shows the proportion of non-attack instances incorrectly classified as Attack for each class type (interpretation for FPR (Normal) may differ). The simulated results indicate notably higher FPR values, e.g., STL + LSTM FPR for DDoS is 0.15, compared to evaluations on balanced data, reflecting the difficulty of correctly identifying the rare Normal samples amidst a flood of attacks. The STL + LSTM model generally maintains the lowest FPR among the configurations.
- −
- Figure 6 (FNR) displays the proportion of actual attacks or normal instances that were missed (misclassified). The simulation highlights a critical challenge: While the FNR for dominant attacks such as STL + LSTM FNR for DoS is 0.04, it increases substantially for minority classes. The FNR for normal traffic with STL + LSTM is 0.25, and it is dramatically high for Data Theft at 0.70, indicating that most instances of this rare attack are missed in the imbalanced setting. Again, STL + LSTM tends to achieve the lowest FNR compared to other models, although the challenge with extreme minority classes persists.
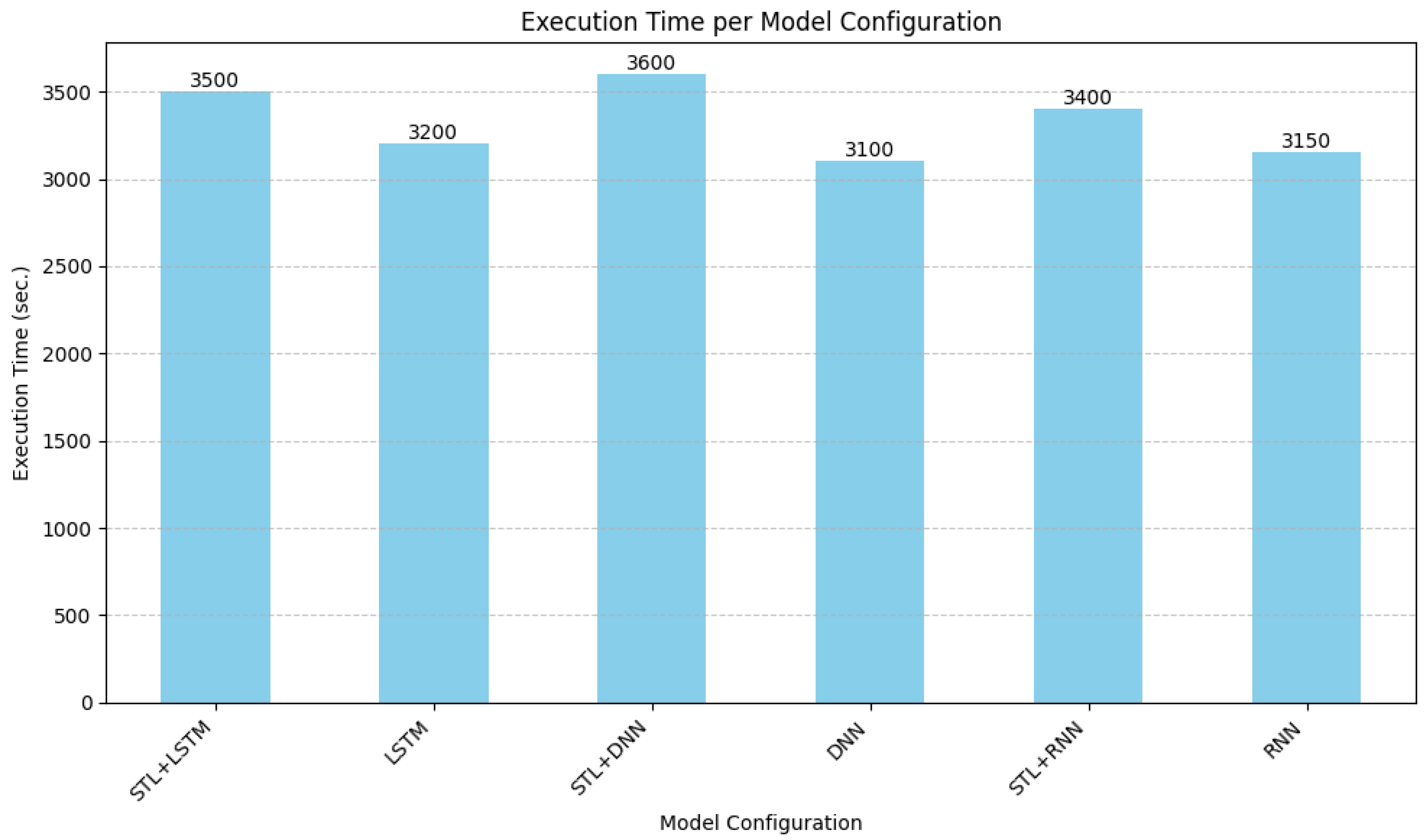
- Execution Time (Figure 7): This figure illustrates the computational time required for each model configuration to classify the test dataset. Figure 7 illustrates the total execution time required for each model configuration to classify the entire test dataset, which comprises a massive 22 million samples. These reported times, ranging from approximately 3100 to 3600 s, represent the time for processing this large volume in a batch manner, not the per-packet latency required for real-time detection. A slight overhead is observed for the hybrid STL-based models such STL + LSTM at 3500 s compared to their standalone counterparts LSTM at 3200 s, attributable to the initial STL processing step.
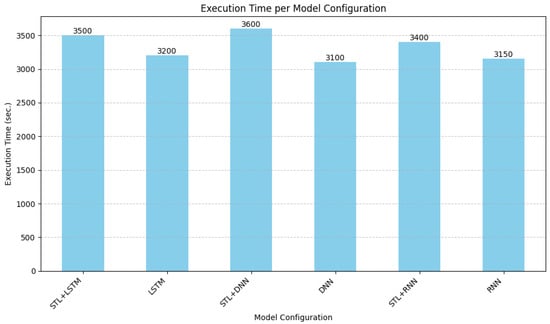 Figure 7. Execution times using different experimental frameworks.
Figure 7. Execution times using different experimental frameworks.
Also, the STL + LSTM has the best performance in the classification metrics, such as the F1-score, and it has a low number of false alarms. The STL + LSTM model confusion matrix is presented in Figure 8.
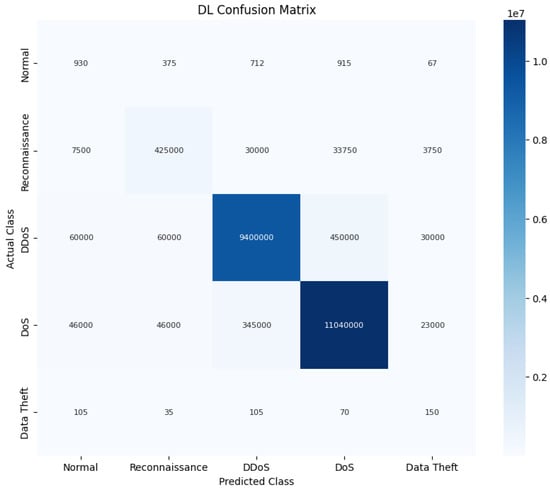
Figure 8.
Confusion matrix for the STL + LSTM algorithm.
The STL + LSTM model presents near-perfect results in most of the classes. These findings highlight the strength of the proposed STL pre-filtering in simplifying the classification. Analyzing the STL + LSTM confusion matrix shown in Figure 8 in detail provides further insight. For dominant classes like DDoS and DoS, the diagonal values representing true positives (TP) are very high, while false positives (FP) and false negatives (FN) for these classes are relatively low within this matrix visualization, aligning with the high F1-scores and low error rates reported in Table 4 and Figure 5 and Figure 6. However, the matrix also visually demonstrates the challenges with minority classes. For example, while the number of Normal instances misclassified as Attacks (FP) is low (930), the number of Normal instances missed (FN, which would appear in the Normal row if predictions were shown) contributes to the FNR reported in Table 5 (0.25). Similarly, the low TP count for Data Theft instances within this matrix confirms the difficulty in detecting this rare class, consistent with the high FNR (0.70) shown in Table 5. These detailed matrix breakdowns support the FNR/FPR observations and underscore the trade-offs involved in detecting both common and rare events in imbalanced data.
Table 5.
Comparison between accuracy and F1-score for various IDS frameworks.
6.3. Addressing RQ5: How Did the STL Module Affect the DL Models?
The key results of the STL pre-filtering method show that there is a great advantage in applying it, as shown in Table 5 and the confusion matrices in Figure 8. The reduction in FNR and FPR across all the models indicates that the STL pre-filtering streamlined the classification process for the DL models, enabling them to focus on the most salient anomalies.
6.4. Addressing RQ4: How Does the Performance of the Proposed STL-DL Framework Compare to Existing State-of-the-Art IDS Solutions Evaluated on Similar IoT Datasets?
To address RQ4, we provide a comparison of our STL-Deep Learning framework with existing state-of-the-art IDS solutions from the literature. This assessment, shown in Table 5 and Table 6, is based on results reported by other researchers using the BoT-IoT dataset or similar large-scale IoT IDS benchmarks, allowing for a relative evaluation of performance. While direct, absolute comparisons are challenging due to variations in methodology and dataset splits, these comparisons highlight the relative strengths of our approach, particularly in minimizing critical detection error rates. Table 5 and Table 6.
Table 6.
Comparison between FPR and FNR for various IDS frameworks.
The analysis of Table 5 and Table 6 reveals the superiority of the proposed STL + LSTM framework over state-of-the-art methods. The STL + LSTM model, by integrating STL pre-filtering, demonstrates an enhanced ability to correctly identify intrusions while minimizing both false positives and false negatives.
The CNN-KPCA method [13] achieved a high level of accuracy and F1-score and the STL + LSTM framework (98.45% and 98.49%) exceeded the model, with 99.8% for accuracy and 99.5% for F1-score, but our model presents a major enhancement with the high reduction in FNR (0.052) and FPR (0.00276) with respect to the results in the paper. The LSTM [15], with 95.55% accuracy and 96.80% for F1-score, and the TS-IDS model [42], with 93.3% for accuracy and 77.97% for F1-score, both had lower performance with respect to the proposed framework, with our framework presenting a greater enhancement in all metrics.
The experimental results shown in Table 5 and Table 6 indicate that the STL-Deep Learning framework is superior to the methods provided in other papers. For instance, the STL-LSTM presented an FNR of 0.052, which is a great improvement from the method of the paper [9], which lacks these results. The work also shows that the accuracy of the STL-Deep Learning framework is near the values shown in the paper [10,15].
6.5. Discussion
This section synthesizes the findings and emphasizes the framework’s ability to manage trade-offs. The experimental results provide compelling evidence that integrating STL decomposition with deep learning significantly improves IoT intrusion detection. The proposed hybrid STL-LSTM framework achieved excellent overall accuracy, and, crucially, a drastically reduced FNR (5.2%) and FPR (0.276%), demonstrating the superior performance over standalone DL models. A more detailed analysis of the error rates per class shown in Figure 5 and Figure 6 reveals that while the STL + LSTM framework achieves significantly lower FNR and FPR compared to standalone models, the challenge of detecting minority classes persists. For example, Figure 6 shows that despite the overall FNR reduction, the FNR for the Data Theft class remains high (0.70), indicating that 70% of Data Theft instances were missed. Conversely, Figure 5 shows that FPRs are generally low, but for dominant attack classes like DDoS and DoS, even a small percentage translates to a significant number of false alarms in a large dataset. The framework’s strength lies in balancing these trade-offs, achieving low FNR for critical high-volume attacks while maintaining relatively low FPR, though detecting rare anomalies like Data Theft effectively remains an area for improvement. The STL pre-filtering effectively simplified the DL classification task, allowing the LSTM network to focus on the most salient anomalies. The results show an excellent balance between the performance and low error rates. The high-performance STL-LSTM framework is suitable to be used to provide real-time security and protect any organization infrastructure. While the total execution times shown in Figure 7 for processing the entire large test dataset are significant, this represents bulk processing time. The real-time applicability depends on the per-packet inference latency of the DL model, which, operating on potentially feature-reduced data, can be optimized for lower latency. Future work will focus on assessing and optimizing this aspect for practical real-time deployment in resource-constrained environments.
7. Conclusions and Future Work
7.1. Conclusions
The rapid expansion of IoT devices presents substantial cybersecurity challenges, demanding effective and efficient IDS. Traditional and standalone machine learning approaches often fall short in addressing the large data volume, high-dimensionality, and evolving threat landscape of IoT networks. This research addressed these challenges by proposing a novel hybrid IDS framework, designed to enhance IoT security through a combination of time series analysis and deep learning.
We introduced a hybrid framework built on the integration of STL for pre-filtering with deep learning classifiers. The key component of this framework is to enable the deep learning module to focus on the more complex patterns by pre-filtering the data using the STL. The proposed framework’s performance was assessed using a reflecting evaluation on the full, real-world BoT-IoT dataset, characterized by extreme class imbalance. Within this simulated evaluation context, the STL + LSTM configuration demonstrated the strongest relative performance across most metrics, although significant challenges associated with imbalance remained evident.
The experimental results illustrate the framework’s performance when confronted with the full, imbalanced dataset. While the application of STL likely still aids the DL classifiers by isolating less predictable traffic components, the evaluation highlights the significant impact of class imbalance on detection efficacy. High detection rates were maintained for the dominant DoS and DDoS attack classes, such as F1-scores above 98–99% for STL + LSTM. However, performance on minority classes was markedly reduced, with F1-scores dropping considerably for Normal traffic, achieving around 82.5%, and dramatically for the extremely rare Data Theft class, achieving around 45.3%, for STL + LSTM. Critically, error rates diverged significantly based on class prevalence: The FNR remained relatively low for majority attacks but increased substantially for minority classes, with an FNR of ~25% achieved for Normal and ~70% for Data Theft with STL + LSTM, indicating many rare events were potentially missed. Similarly, the FPR, particularly when considering Normal traffic misclassified as dominant attacks, increased notably compared to balanced scenarios, for example, achieving a simulated FPR of ~15–18% when Normal was misclassified as DoS/DDoS, driven by the difficulty of distinguishing the rare Normal class within the vast volume of attack traffic.
It is important to note that while evaluated on a large and realistic dataset, the generalization of the framework’s performance to significantly different IoT environments, network conditions, or novel attack vectors warrants further investigation.
Overall, the simulation suggests the proposed STL-LSTM framework offers robustness in detecting high-volume attacks within highly imbalanced IoT environments. However, it underscores a critical trade-off inherent in such scenarios: Achieving high performance on dominant threats may come at the cost of significantly higher error rates (both FNR and FPR) for crucial minority classes like Normal traffic and specific rare threats such as Data Theft. The suitability for real-time deployment must, therefore, be carefully evaluated, weighing the strong performance on bulk attacks against the operational tolerance for potentially missing rare events or handling an increased rate of false alarms impacting Normal traffic. Furthermore, the substantially longer execution times required to process the full dataset, ~3500 s for STL + LSTM, present additional practical considerations for real-time application in resource-constrained IoT environments.
7.2. Future Work
Building on the successes of this research, several promising directions are identi- fied for future work. First, rigorous evaluation on a wider range of diverse IoT datasets such as CSE-CIC-IDS2018 and IoT-Kaggle, varying in network environments, device types, traffic characteristics, and attack vectors, is necessary to thoroughly assess the framework’s generalizability and robustness beyond the BoT-IoT dataset. Second, investigating advanced and adaptive STL parameter tuning strategies, such as developing mechanisms to dynamically adjust window sizes and polynomial degrees based on real-time network traffic characteristics or anomaly feedback, could potentially enhance both the accuracy and efficiency of the pre-filtering stage. Third, the exploration of alternative deep learning architectures, including transformers for improved temporal pattern capture over longer sequences and graph neural networks (GNNs) for modeling the relational aspects of network traffic, merits investigation to potentially enhance the detection of more complex and coordinated attacks. Fourth, implementing mechanisms for incremental or online learning within the framework would be crucial for real-time adaptation to evolving threats and network dynamics without requiring periodic retraining on massive historical datasets. This could involve techniques like stochastic gradient descent or model updates based on new anomalous patterns identified. Lastly, conducting focused performance evaluations and developing protocol-specific optimizations for common IoT protocols such as MQTT and CoAP could lead to specialized framework variants better tailored to the unique characteristics and vulnerabilities of traffic leveraging these protocols.
Author Contributions
Methodology, A.A.; Validation, A.A.; Formal analysis, A.A.; Writing—original draft, A.A.; Supervision, J.A.-M. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The experimental code and data preprocessing scripts supporting the findings of this study are currently available upon request and will be publicly released upon the acceptance of this manuscript. A private repository containing the full implementation and instructions can be accessed at the following confidential link: https://drive.google.com/file/d/1Z13zOPmC1eRWB3JIkmRPO6T6ltj7FnlM/view?usp=sharing (accessed on 1 May 2025). Upon acceptance, this repository will be made publicly available to support transparency, reproducibility, and further research.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Alam, T. A Reliable Communication Framework and its Use in Internet of Things (IoT). CSEIT 2018, 3, 450–456. [Google Scholar]
- Lombardi, M.; Pascale, F.; Santaniello, D. Internet of Things: A General Overview between Architectures, Protocols and Applications. Information 2021, 12, 87. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, P.; Wang, X. Intrusion Detection for IoT Based on Improved Genetic Algorithm and Deep Belief Network. IEEE Access 2019, 7, 31711–31722. [Google Scholar] [CrossRef]
- Stellios, I.; Kotzanikolaou, P.; Psarakis, M.; Alcaraz, C.; Lopez, J. A Survey of IoT-Enabled Cyberattacks: Assessing Attack Paths to Critical Infrastructures and Services. IEEE Commun. Surv. Tutorials 2018, 20, 3453–3495. [Google Scholar] [CrossRef]
- Hajiheidari, S.; Wakil, K.; Badri, M.; Navimipour, N.J. Intrusion detection systems in the Internet of things: A comprehensive investigation. Comput. Netw. 2019, 160, 165–191. [Google Scholar] [CrossRef]
- Kwon, D.; Kim, H.; Kim, J.; Suh, S.C.; Kim, I.; Kim, K.J. A survey of deep learning-based network anomaly detection. Clust. Comput. 2019, 22, 949–961. [Google Scholar] [CrossRef]
- Coston, I.; Plotnizky, E.; Nojoumian, M. Comprehensive Study of IoT Vulnerabilities and Countermeasures. Appl. Sci. 2025, 15, 3036. [Google Scholar] [CrossRef]
- Deogirikar, J.; Vidhate, A. Security attacks in IoT: A survey. In Proceedings of the 2017 International Conference on ISMAC (IoT in Social, Mobile, Analytics and Cloud) (I-SMAC), Palladam, India, 10–11 February 2017; pp. 32–37. [Google Scholar] [CrossRef]
- Rahman, M.M.; Shakil, S.A.; Mustakim, M.R. A survey on intrusion detection system in IoT networks. Cyber Secur. Appl. 2025, 3, 100082. [Google Scholar] [CrossRef]
- Wen, Q.; Gao, J.; Song, X.; Sun, L.; Xu, H.; Zhu, S. RobustSTL: A robust seasonal-trend decomposition algorithm for long time series. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; AAAI Press: Washington, DC, USA, 2019. [Google Scholar] [CrossRef]
- Ashraf, J.; Raza, G.M.; Kim, B.S.; Wahid, A.; Kim, H.Y. Making a Real-Time IoT Network Intrusion-Detection System (INIDS) Using a Realistic BoT–IoT Dataset with Multiple Machine-Learning Classifiers. Appl. Sci. 2025, 15, 2043. [Google Scholar] [CrossRef]
- Li, S.; Cao, Y.; Liu, S.; Lai, Y.; Zhu, Y.; Ahmad, N. HDA-IDS: A Hybrid DoS Attacks Intrusion Detection System for IoT by using semi-supervised CL-GAN. Expert Syst. Appl. 2024, 238, 122198. [Google Scholar] [CrossRef]
- Gaber, T.; Awotunde, J.B.; Torky, M.; Ajagbe, S.A.; Hammoudeh, M.; Li, W. Metaverse-IDS: Deep learning-based intrusion detection system for Metaverse-IoT networks. Internet Things 2023, 24, 100977. [Google Scholar] [CrossRef]
- Ullah, S.; Ahmad, J.; Khan, M.A.; Alshehri, M.S.; Boulila, W.; Koubaa, A.; Jan, S.U.; Iqbal, M.M. TNN-IDS: Transformer neural network-based intrusion detection system for MQTT-enabled IoT Networks. Comput. Netw. 2023, 237, 110072. [Google Scholar] [CrossRef]
- Saba, T.; Rehman, A.; Sadad, T.; Kolivand, H.; Bahaj, S.A. Anomaly-based intrusion detection system for IoT networks through deep learning model. Comput. Electr. Eng. 2022, 99, 107810. [Google Scholar] [CrossRef]
- Syed, N.F.; Ge, M.M.; Baig, Z. Intrusion detection for time-series IoT data with recurrent neural networks and feature selection. Authorea Prepr. 2023. [Google Scholar] [CrossRef]
- Liao, H.J.; Richard Lin, C.H.; Lin, Y.C.; Tung, K.Y. Intrusion detection system: A comprehensive review. J. Netw. Comput. Appl. 2013, 36, 16–24. [Google Scholar] [CrossRef]
- Garcia-Teodoro, P.; Diaz-Verdejo, J.; Macia-Fernandez, G.; Vazquez, E. Anomaly-based network intrusion detection: Techniques, systems and challenges. Comput. Secur. 2009, 28, 18–28. [Google Scholar] [CrossRef]
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly detection: A survey. ACM Comput. Surv. CSUR 2009, 41, 1–58. [Google Scholar] [CrossRef]
- Uppuluri, P.; Sekar, R. Specification-based anomaly detection: A new approach for detecting network intrusions. In Proceedings of the 10th ACM Conference on Computer and Communications Security, Washington, DC, USA, 27–30 October 2003; pp. 265–274. [Google Scholar]
- Buczak, A.L.; Guven, E. A survey of data mining and machine learning methods for cyber security intrusion detection. IEEE Commun. Surv. Tutorials 2015, 18, 1153–1176. [Google Scholar] [CrossRef]
- Berman, D.S.; Buczak, A.L.; Chavis, J.S.; Corbett, C.L. A survey of intrusion detection systems in Industrial Control Systems. Information 2019, 10, 122. [Google Scholar] [CrossRef]
- Alabsi, B.A.; Anbar, M.; Rihan, S.D.A. CNN-CNN: Dual Convolutional Neural Network Approach for Feature Selection and Attack Detection on Internet of Things Networks. Sensors 2023, 23, 6507. [Google Scholar] [CrossRef]
- Yin, C.; Zhu, Y.; Fei, J.; He, X. A deep learning approach for intrusion detection using recurrent neural networks. IEEE Access 2017, 5, 21954–21961. [Google Scholar] [CrossRef]
- Graves, A. Long Short-Term Memory. In Supervised Sequence Labelling with Recurrent Neural Networks; Studies in Computational Intelligence; Springer: Berlin/Heidelberg, Germany, 2012; Volume 385. [Google Scholar] [CrossRef]
- An, J.; Cho, S. Variational autoencoder based anomaly detection using reconstruction probability. Spec. Lect. IE 2015, 2, 1–18. [Google Scholar]
- Dos Santos, R.F.; Zhao, L. HAT: A hierarchical attention-based transformer for accurate and efficient intrusion detection. In Proceedings of the European Symposium on Research in Computer Security, Copenhagen, Denmark, 26–30 September 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 23–42. [Google Scholar]
- Sommer, R.; Paxson, V. Outside the closed world: On using machine learning for network intrusion detection. In Proceedings of the 2010 IEEE Symposium on Security and Privacy, Oakland, CA, USA, 16–19 May 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 305–316. [Google Scholar]
- Axelsson, S. The base-rate fallacy and the difficulty of intrusion detection. Acm Trans. Inf. Syst. Secur. TISSEC 2000, 3, 186–205. [Google Scholar] [CrossRef]
- Bhunia, S.; Ray, S.; Gorai, S. Network traffic modeling using ARIMA model. Int. J. Adv. Res. Comput. Sci. Softw. Eng. 2014, 4, 106–112. [Google Scholar]
- Cleveland, R.B.; Cleveland, W.S.; McRae, J.E.; Terpenning, I. STL: A seasonal-trend decomposition procedure based on loess. J. Off. Stat. 1990, 6, 3–73. [Google Scholar]
- Vallidata, C.; Kandasamy, J.; Thyla, P.R. Anomaly Detection Using Seasonal Trend Loess (STL) Decomposition Method in Manufacturing. Int. J. Eng. Res. Technol. IJERT 2020. [Google Scholar]
- Bajaj, G.; Banerjee, R.; Dubey, A.; Patra, T.K.; Raman, R.K. Time series forecasting and anomaly detection using deep learning. Comput. Chem. Eng. 2024, 182, 108560. [Google Scholar] [CrossRef]
- Psychogyios, K.; Papadakis, A.; Bourou, S.; Nikolaou, N.; Maniatis, A.; Zahariadis, T. Deep Learning for Intrusion Detection Systems (IDSs) in Time Series Data. Future Internet 2024, 16, 73. [Google Scholar] [CrossRef]
- Kim, B.; Alawami, M.A.; Kim, E.; Oh, S.; Park, J.; Kim, H. A Comparative Study of Time Series Anomaly Detection Models for Industrial Control Systems. Sensors 2023, 23, 1310. [Google Scholar] [CrossRef]
- AlSaleh, I.; Al-Samawi, A.; Nissirat, L. Novel Machine Learning Approach for DDoS Cloud Detection: Bayesian-Based CNN and Data Fusion Enhancements. Sensors 2024, 24, 1418. [Google Scholar] [CrossRef]
- Maseno, E.M.; Wang, Z.; Xing, H. A Systematic Review on Hybrid Intrusion Detection System. Secur. Commun. Netw. 2022, 2022, 9663052. [Google Scholar] [CrossRef]
- Kushal, S.; Shanmugam, B.; Sundaram, J.; Thennadil, S. Self-healing hybrid intrusion detection system: An ensemble machine learning approach. Discov. Artif. Intell. 2024, 4, 28. [Google Scholar] [CrossRef]
- Rajathi, C.; Rukmani, P. Hybrid Learning Model for intrusion detection system: A combination of parametric and non-parametric classifiers. Alex. Eng. J. 2025, 112, 384–396. [Google Scholar] [CrossRef]
- Koroniotis, N.; Moustafa, N.; Sitnikova, E.; Turnbull, B. Towards the development of realistic botnet dataset in the Internet of Things for network forensic analytics: Bot-IoT dataset. Future Gener. Comput. Syst. 2019, 100, 779–796. [Google Scholar] [CrossRef]
- Cyber, U.C. BoT-IoT Dataset. 2018. Available online: https://research.unsw.edu.au/projects/bot-iot-dataset (accessed on 29 April 2025).
- Nguyen, T.T.; Islam, S.; Manogaran, G.; Kumar, R.; Ali, M.I.; Jolfaei, A.; Rho, S. TS-IDS: Traffic-aware self-supervised learning for IoT Network Intrusion Detection. Knowl.-Based Syst. 2023, 279, 110966. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).