1. Introduction
In today’s increasingly interconnected and complex global economy, the communication strategies of central banks have become central tools for executing monetary policy and managing market expectations [
1,
2]. Whether it is the policy statements and meeting minutes released by the U.S. Federal Open Market Committee (FOMC) or the speeches and press conference transcripts from the European Central Bank (ECB) President, these English-language texts convey critical information about future economic trends, inflation prospects, and interest rate paths [
3]. Financial market participants, from large institutional investors to the general public, heavily rely on accurate interpretations of these communications to make investment decisions and assess risks. Therefore, conducting timely and in-depth quantitative analysis of central bank communication texts, particularly for nowcasting the short-term direction of interest rate changes following their release, holds significant theoretical importance and immense practical value. This can provide forward-looking insights before the release of official economic data, which is crucial for navigating rapidly changing market dynamics. However, leveraging natural language processing (NLP) techniques to extract reliable predictive signals from central bank communication texts presents a series of severe and unique challenges.
While traditional econometric models and classical machine learning approaches have been extensively applied to financial forecasting, they face fundamental limitations when confronted with the complexity of contemporary central bank communications. Conventional econometric models, such as Vector Autoregression (VAR) and linear regression frameworks, rely primarily on structured numerical data and predefined variables, making them inadequate for processing the rich, unstructured textual information embedded in policy statements and speeches. Similarly, classical machine learning techniques like Support Vector Machines or logistic regression with TF-IDF features can only capture shallow linguistic patterns, and fail to understand the nuanced, context-dependent meanings inherent in central bank language. These approaches are particularly challenged by the lengthy nature of policy documents, which often exceed 10,000 tokens and contain complex inter-sentence dependencies that require sophisticated sequential modeling capabilities that are beyond the scope of traditional methods.
First, the nature of the data itself poses a substantial obstacle. Official central bank documents, especially in-depth reports like FOMC meeting minutes, are exceptionally lengthy, often exceeding ten thousand tokens. This far surpasses the context length that current mainstream NLP models, particularly those based on the standard Transformer architecture [
4], can effectively handle. The self-attention mechanism widely used in these models has computational and memory complexity quadratic in sequence length (
) [
5], making direct processing of such long, complete documents computationally prohibitive or infeasible. The existing work often resorts to compromise strategies like truncating input, analyzing only summaries, or performing sentence-level processing [
6,
7], but this inevitably sacrifices document-level global context, long-range argumentative logic, and subtle tones that might permeate the entire text, thereby compromising information integrity and analytical depth.
Simultaneously, the language used by central banks is often highly specialized, cautiously worded, and filled with nuances [
8]. Policymakers meticulously weigh every word, using precise economic terminology, complex conditional clauses, and subtle tonal variations to convey intricate policy intentions and risk assessments. This demands analytical models that can not only handle long-range dependencies, but also possess deep semantic understanding capabilities to discern subtle tonal differences (such as hawkish vs. dovish leanings), comprehend implicit policy signals, and accurately grasp the overall stance of the text. Simple keyword counting or shallow models are inadequate for this task.
Second, model efficiency and real-time requirements constitute another constraint. Even if long texts can be technically processed, if the model training and inference processes are too time-consuming, their value in a “nowcasting” scenario diminishes significantly. Financial markets react extremely rapidly to information, and the core utility of nowcasting lies in its immediacy. Therefore, not only must the model architecture itself be capable of efficiently processing long sequences, but model adaptation and deployment stages must also minimize computational overhead and inference latency as much as possible.
Third, model adaptation and generalization emerge as critical bottlenecks. Current state-of-the-art NLP models are typically large-scale models with billions or more parameters, pretrained on massive general-purpose corpora [
9]. Making these general models accurately understand and analyze the highly specialized domain language of central banking necessitates downstream task fine-tuning. However, full parameter fine-tuning is computationally resource-intensive [
10] and prone to overfitting, especially when domain-specific labeled data (such as central bank texts precisely labeled with subsequent interest rate changes) is relatively scarce. Parameter-efficient fine-tuning (PEFT) techniques [
11,
12] alleviate computational and storage pressures, but common methods like LoRA [
10] (low-rank adaptation) might still lag behind full fine-tuning in performance [
13,
14]. Deciphering how to maximize model performance while maintaining high efficiency remains an urgent problem.
Finally, cross-domain robustness is a challenge that practical application must address. Different central banks exhibit variations in communication styles, policy frameworks, and areas of focus [
15]. Even within the same central bank, communication strategies and linguistic patterns evolve across different historical periods [
8]. A model trained in one scenario may suffer significant performance degradation when directly applied to another due to this domain drift. Consequently, building a model that can robustly adapt to different institutions and time periods requires strong domain adaptation capabilities.
Despite prior research advancements in long sequence modeling [
16], parameter-efficient fine-tuning [
10,
14], and domain adaptation [
17,
18], a comprehensive framework that systematically integrates these cutting-edge technologies to synergistically address the core challenges of ultra-long text processing, high-performance economical fine-tuning, and strong cross-domain generalization for the complex task of central bank interest rate nowcasting, has been lacking.
To address this research gap, this paper proposes and implements a novel, integrated deep learning framework designed to overcome the limitations of existing methods by strategically combining complementary state-of-the-art techniques. The framework selects Hyena Hierarchy [
19] as its foundational architecture, utilizing its gated long convolutional mechanism with sub-quadratic complexity (
) [
20] to efficiently process complete central bank documents exceeding ten thousand tokens, thereby tackling the core challenge of long text processing. For high-performance and economical model adaptation, we employ Delta-LoRA [
13] for parameter-efficient fine-tuning. This technique leverages the change in low-rank updates to drive adjustments in the pretrained weights, aiming to close the performance gap with full fine-tuning while maintaining an extremely low parameter count (<1%) and zero additional inference latency [
13]. Concurrently, to enhance the model’s generalization capability across different central banks and time periods, the framework integrates domain-adversarial neural networks (DANN) [
21], learning domain-invariant feature representations through adversarial training. Furthermore, a multi-task learning (MTL) mechanism [
22] utilizes auxiliary signals, such as hawkish/dovish tendencies, to further refine representations. The uniqueness and core innovation of this paper lie in the integration of Hyena, Delta-LoRA, and DANN for the first time, which are applied to solve the complex problem of interest rate nowcasting from long central bank texts, overcoming multiple bottlenecks through technological synergy to achieve dual improvements in performance and efficiency.
In summary, the main contributions of this paper are manifested in several aspects:
We propose and implement a novel framework integrating Hyena Hierarchy, Delta-LoRA, and DANN, offering a new and powerful solution for NLP tasks involving ultra-long sequences, high-performance parameter-efficient fine-tuning, and cross-domain generalization, particularly for central bank interest rate prediction.
On a self-constructed large-scale cross-institutional dataset (FOMC and ECB, 1977–2024) for interest rate prediction, we demonstrate that the proposed framework achieves a significant improvement of over 5 percentage points on key metrics compared to strong baseline models, while substantially reducing the inference latency for long-text processing (>60%).
Experimental validation confirms the effectiveness of the DANN component, showing that the framework generalizes better from a single source domain (e.g., FOMC) to a target domain (e.g., ECB), enhancing the model’s reliability in practical applications.
Preliminary analysis of the model’s internal mechanisms reveals connections between model decisions and key financial policy terminology, providing perspectives for understanding model behavior.
The remainder of this paper is organized as follows:
Section 2 reviews related work.
Section 3 details the dataset construction and preprocessing.
Section 4 elaborates on the proposed methodology.
Section 5 presents comprehensive experimental results and in-depth analysis.
Section 6 provides a discussion covering research implications, limitations, and the future outlook.
Section 7 concludes the paper.
4. Methodology
This chapter details the innovative deep learning framework constructed to address the task of interest rate nowcasting from central bank policy communication texts. Given that central bank policy statements often feature ultra-long sequences of thousands or even tens of thousands of tokens, and that significant domain differences exist between different central banks (e.g., Federal Reserve—FOMC and European Central Bank—ECB) as well as across different economic cycles (e.g., pre/post quantitative easing, hiking cycles), our proposed method aims to efficiently process long sequences, achieve parameter-efficient fine-tuning, and possess cross-domain adaptation capabilities.
Before detailing our methodology, we formally state the testable hypotheses that drive our research design and experimental validation:
Hypothesis 1 (Long-Sequence Processing). Complete central bank documents contain more predictive information for interest rate changes than truncated or summarized versions. We hypothesize that models capable of processing entire documents without truncation will achieve superior predictive performance compared to those limited by sequence length constraints.
Hypothesis 2 (Architecture Efficiency). Hyena Hierarchy architectures with sub-quadratic complexity will demonstrate both higher computational efficiency and superior or comparable predictive performance compared to standard Transformer-based approaches when processing ultra-long financial documents.
Hypothesis 3 (Parameter Efficiency). Delta-LoRA fine-tuning will achieve performance levels comparable to full parameter fine-tuning while using less than 1% of the total parameters, demonstrating superior parameter efficiency for domain adaptation in financial text analysis.
Hypothesis 4 (Domain Generalization). Models trained with domain-adversarial training will exhibit significantly better cross-institutional generalization (e.g., FOMC to ECB) compared to models trained without domain adaptation mechanisms.
Hypothesis 5 (Multi-Task Learning). Incorporating auxiliary hawkish/dovish sentiment classification as a secondary task will improve primary interest rate prediction performance through shared representation learning and implicit regularization effects.
This chapter first defines the core research problem in
Section 4.1. Subsequently,
Section 4.2 details the model’s backbone network, Hyena Hierarchy, explaining its efficiency in handling ultra-long text sequences.
Section 4.3 then elaborates on the parameter-efficient fine-tuning strategy, Delta-LoRA, illustrating how large pretrained models can be effectively adapted to downstream tasks with minimal parameters and explaining its improvements over standard LoRA. To address the domain shift issue in multi-source data,
Section 4.4 introduces a multi-source domain adaptation mechanism based on domain-adversarial training of neural networks (DANN). Furthermore, to leverage implicit sentiment signals within the text,
Section 4.5 presents a multi-task learning paradigm combining the main interest rate prediction task with an auxiliary hawkish/dovish classification task. Finally,
Section 4.6 provides the complete model training procedure and inference stage implementation details.
It is important to emphasize that these three core technologies (Hyena, Delta-LoRA, DANN) are not simply stacked but deeply integrated through a unified loss function and a backpropagation path. Hyena provides powerful long-range contextual awareness; Delta-LoRA, under stringent computational and storage budgets, effectively injects task-specific knowledge by optimizing the pretrained weights themselves; domain-adversarial training and multi-task learning synergistically operate at the gradient level, jointly guiding the model to learn feature representations that are both discriminative and domain-invariant. The ultimate goal is to minimize the overall risk upper bound under a mixed domain distribution, thereby achieving robust interest rate prediction for real-world central bank communication texts across institutions and time periods.
Figure 4 presents a comprehensive overview of our integrated architecture, illustrating how these components work together to process long sequences, adapt efficiently to domain-specific patterns, and generate robust predictions across different institutional contexts. Figures are included in
Section 4.2,
Section 4.3 and
Section 4.4 to visually aid understanding of the backbone structure, Delta-LoRA update mechanism, and domain-adversarial module computation flow, respectively.
4.1. Problem Definition
The core task of this research is to perform nowcasting of the short-term directional change in the benchmark interest rate following the release of official central bank policy communication texts (such as FOMC statements and ECB speeches), based on the text itself and the historical benchmark interest rate trend preceding the release.
Formally, given a policy communication text document
x (with token sequence length
potentially reaching 10,000 or higher) and a historical benchmark interest rate time series
aligned with the document’s release date
(where
T is the lookback period, set to
months in this study, with sequence length
), our objective is to train a model
to predict the category
y to which the future short-term interest rate change
belongs. The prediction category
y is defined as a three-class classification:
where
is a predefined threshold (set to 5 basis points, 5 bp, in this study).
The model
takes the text
x and the rate sequence
r as input. To enable the model to handle these two different modalities and leverage their sequential properties, we first apply positional encoding (PE) to both separately, then concatenate or otherwise fuse them before feeding them into the model. The mathematical representation of the model can be simplified as:
where
is the predicted class probability distribution,
denotes applying positional encoding to the input sequences,
represents the core network structure composed of modules like Hyena Hierarchy, Delta-LoRA, DANN, etc., (with parameters
) detailed in subsequent sections, and
is the final classification head (typically one or more fully connected layers).
The training objective is to minimize the difference between the model prediction
and the true label
y, typically using a weighted cross-entropy loss function
. Additionally, to achieve domain adaptation and utilize auxiliary information, the total optimization objective will include extra loss terms, such as the domain-adversarial loss
and the auxiliary task loss
, as described in
Section 4.4 and
Section 4.5.
4.2. Model Backbone: Hyena Hierarchy
Processing ultra-long documents like central bank policy statements is one of the key challenges of this task. Traditional Transformer-based self-attention mechanisms have
computational and memory complexity, making direct processing of sequences with tens of thousands of tokens impractical. To overcome this limitation, we employ Hyena Hierarchy [
19] as the model’s backbone feature extractor. Hyena is a novel deep learning operator that, by cleverly alternating stacks of implicitly parameterized long convolutions and data-controlled gating, can effectively capture long-range dependencies within sub-quadratic complexity (specifically,
, where
N is the depth of the Hyena operator and
L is the sequence length). It also demonstrates faster inference speeds on long sequences compared to highly optimized attention mechanisms, like FlashAttention.
Figure 5 provides an illustration of the Hyena architecture and its core mechanism.
The core of the Hyena operator is a recursive process. For an input sequence
u (after initial embedding and positional encoding), linear projections yield a set of sequences
. Then, an
N-step recursion is performed:
The final output is
. In this recursion,
is the
n-th layer’s long convolution kernel. Its length can be as long as the input sequence
L, providing a global receptive field. Crucially,
is implicitly parameterized rather than having its weights learned directly. The ∗ symbol denotes convolution, implemented efficiently using Fast Fourier Transform (FFT)-based algorithms with
complexity.
is the
n-th linear projection of the input sequence
u, serving as a data-controlled gate. The ⊙ symbol represents element-wise multiplication (Hadamard product), allowing the convolution results to be modulated by the input data itself, introducing data dependency similar to attention mechanisms.
Hyena’s long convolution kernel
is not learned directly, but dynamically generated by a small feed-forward network (FFN). Specifically, for time step
t (or sequence position
t), the kernel value
is determined by:
Here,
maps position
t to an embedding vector. The FFN (e.g., a shallow MLP) maps the positional embedding to a basis for the filter response, often using periodic activation functions (like sin) to capture high-frequency information.
is a window function (e.g., a parameterized exponential decay
plus a bias term) that shapes the filter, enabling it to adaptively focus on information at different time scales (like macroeconomic cycles). This parameterization decouples the number of parameters from the sequence length
L (sub-linear parameter scaling) and allows the effective filter length to be learned during training.
To make the model aware of sequence position information, we inject Rotary Positional Embeddings (RoPE) [
40] after the input embedding layer for both the text sequence
x and the interest rate sequence
r. RoPEs have demonstrated excellent performance in various Transformer architectures by effectively encoding relative position information. The Hyena architecture is designed to be compatible with and benefit from modern positional encoding methods like RoPEs.
In this study, we adopt a variant of Hyena-Small (125M parameters). The specific configuration involves layers of Hyena recursion with a model hidden dimension . For the text input x and the historical interest rate sequence r, we first process them independently through separate RoPE layers and the initial few Hyena operator layers (e.g., the first 3 layers) to obtain their respective sequence representations. Then, at an intermediate layer (e.g., after the 3rd layer), the text representation sequence and the rate representation sequence are concatenated along the feature dimension. A convolution layer might be needed for linear transformation to unify dimensions. The concatenated sequence is then processed through the remaining shared Hyena recursive layers (e.g., the last 3 layers). This design allows the model to capture complex interactions and coupling between text content/tone (often high-frequency signals) and historical interest rate low-frequency trends within a unified vector space, providing high-quality fused features for subsequent prediction tasks, parameter fine-tuning, and domain adaptation.
4.3. Parameter-Efficient Fine-Tuning: Delta-LoRA
Directly applying full fine-tuning to large models like Hyena-Small (125M) might yield the best results, but is costly and prone to overfitting when labeled data (like specific domain central bank texts) is limited and computational resources are constrained. Therefore, we employ parameter-efficient fine-tuning (PEFT) techniques.
Low-rank adaptation (LoRA) [
10] is a widely used PEFT method. Its core idea is to freeze most weights
of the pretrained model during fine-tuning and introduce a parallel, trainable low-rank “bypass” structure for certain linear layers (e.g.,
in MHA or FFN layers). This bypass decomposes the original weight update
into the product of two low-rank matrices:
, where
,
, and the rank
. During forward propagation, the output
h is computed as:
where
x is the input and
is a scaling factor. Only the parameters of
A and
B are updated during training, significantly fewer than those in
W. After training,
can be merged back into
W (
), eliminating extra computational overhead during inference.
While LoRA significantly reduces fine-tuning costs, its performance often lags behind full fine-tuning because the frozen
W cannot adapt. Delta-LoRA [
13] proposes a novel improvement strategy aiming to bridge this gap while maintaining comparable memory and computational efficiency to LoRA. The core idea of Delta-LoRA is to not only update the low-rank matrices A and B, but also leverage the change in the low-rank update to drive the update of the pretrained weights W. The structure and update mechanism of Delta-LoRA are depicted in
Figure 6.
Specifically, at each training step
t, first compute gradients
for
A and
B like in the standard LoRA, and obtain updated
and
via an optimizer (e.g., AdamW). Second, calculate the change (delta) in the low-rank adaptation matrix:
Third, use this change to update the pretrained weights
W:
where
is a new hyperparameter controlling the extent to which the “momentum” or “change trend” of the low-rank update is transferred to
W. This parameter update typically starts after an initial number of training steps
K (e.g.,
).
Delta-LoRA allows the pretrained weights W to participate in the learning process, enabling better adaptation to the downstream task. Theoretically, under certain conditions (no dropout), , making an effective surrogate for the update direction of W, capturing the learning trajectory of the low-rank adaptation. Crucially, updating W does not require computing or storing the gradients of W itself or its optimizer states (like first and second moments in AdamW). The update of W depends solely on the already computed and their previous values . This keeps Delta-LoRA’s memory footprint and computational overhead nearly identical to standard LoRA. Standard LoRA implementations often include dropout before A or B. However, the derivation of Delta-LoRA suggests that dropout breaks the equality . Therefore, the Delta-LoRA structure removes dropout from the LoRA bypass to ensure that is a more accurate estimate of W’s update direction. This modification might also offer additional benefits like mitigating underfitting and saving minor activation memory.
In this study, we insert Delta-LoRA modules after key linear layers in the Hyena model (e.g., projection layers for gating signals and value v, and potentially linear layers within the FFN parameterizing the convolution kernel). We experimented with different ranks and selected the optimal configuration based on validation set performance. The scaling factor is typically set relative to r (e.g., for ), and is tuned experimentally (e.g., ). Using Delta-LoRA, we train less than 1% of the total parameters, yet achieve significant performance improvements, approaching the effectiveness of full parameter fine-tuning.
4.4. Multi-Source Domain Adaptation
Our dataset comprises texts from different central banks (FOMC and ECB) and various historical periods (e.g., spanning multiple economic cycles and policy paradigms like pre-QE, during QE, early hiking phase, late hiking phase). These different sources constitute distinct “domains” that may exhibit systematic differences in language style, focus areas, terminology usage, and even policy implications (i.e., domain shift). If a model trained solely on one domain (e.g., FOMC) is directly applied to another (e.g., ECB), performance might drop substantially. To enhance the model’s cross-domain generalization ability, we adopt an unsupervised domain adaptation strategy based on domain-adversarial training of neural networks (DANN) [
21].
Figure 7 illustrates the DANN architecture.
The core idea of DANN is to learn a feature representation that is discriminative for the main task (e.g., interest rate prediction) but indistinguishable concerning the domain source of the data. In other words, the model should learn to focus on the essential task-relevant features shared across domains while ignoring superficial domain-specific features irrelevant to the task.
To achieve this, we introduce a domain classifier (with parameters ) parallel to the main task classification head (parameters ), following the Hyena feature extractor (parameters ). The task of is to receive the features extracted by and predict the domain d from which the input sample x originated (e.g., for FOMC, for ECB).
The training involves an adversarial objective: first, minimize the main task loss. For samples from the source domain (labeled data, e.g., FOMC), minimize the main task (interest rate prediction) loss . This updates parameters , making extract useful features for the main task. Second, minimize the domain classification loss (for the domain classifier). For all samples (from source or target domains; target domain samples lack but have domain label ), train the domain classifier to minimize the loss between its predicted domain label and the true domain label (usually binary or multi-class cross-entropy loss). This updates , making it accurately distinguish features from different domains. Third, maximize the domain classification loss (for the feature extractor): This is the key to adversarial training. When updating the feature extractor parameters , we aim not only to minimize the main task loss , but also to maximize the domain classification loss . This means that we want to produce features z that confuse the domain classifier as much as possible, making it unable to determine the origin domain of z.
To implement step 3 (maximizing with respect to ) within a standard gradient descent framework, DANN introduces a gradient reversal layer (GRL). The GRL is placed between the feature extractor and the domain classifier . In forward propagation, GRL acts as an identity transform (). In backward propagation, when gradients from pass back through to the GRL, the GRL multiplies the gradient by a negative constant (or simply −1, with weighting the loss term) before passing it to . Thus, using standard backpropagation and gradient descent (or variants like AdamW) optimizes the entire network such that receives signals to minimize , while receives combined gradient signals to minimize and maximize , achieving the desired adversarial training objective.
In our implementation, we add a special domain token at the beginning of each input sequence to indicate its source (e.g., ‘<FOMC>’, ‘<ECB>’, ‘<QE_PERIOD>’, ‘<TIGHTENING_PERIOD>’). The domain classifier
(e.g., an MLP with several fully connected layers) takes feature representations from an intermediate layer of Hyena (e.g., the 4th layer) and outputs a probability distribution predicting the input’s domain class. The domain adversarial loss
typically uses cross-entropy:
where
N is the batch size,
is the number of domain classes,
is a one-hot vector indicating the true domain of sample
, and
is the probability predicted by the domain classifier that
belongs to the
k-th domain. By minimizing an upper bound on the source domain risk and the H-divergence between domains [
41], DANN encourages the model to learn more generalizable, domain-invariant feature representations, thereby improving prediction performance on unseen target domains (like ECB texts or texts from future economic cycles).
4.5. Multi-Task Learning
Beyond the primary task of nowcasting interest rate direction, central bank communication texts often contain subtle signals about future policy leanings, commonly interpreted by the market as “hawkish” (inclined towards tightening monetary policy, e.g., raising rates) or “dovish” (inclined towards easing, e.g., cutting rates or maintaining low rates). This policy “tone” or sentiment is crucial for understanding the deeper meaning of the text and predicting future rate movements.
To enable the model to capture and utilize these latent signals more effectively, we introduce an auxiliary task: hawkish/dovish classification of policy statement or speech paragraphs. We leverage the “Trillion Dollar Words” dataset, which offers paragraph-level hawkish/dovish annotations for FOMC texts. We employ this binary classification task as an auxiliary task, training it jointly with the main three-class interest rate prediction task.
In the multi-task learning framework, the primary interest rate prediction task and the auxiliary hawkish/dovish classification task share most of the underlying Hyena feature extractor network structure (including the parts fine-tuned via Delta-LoRA). At a higher level of (e.g., the output of the second-to-last Hyena block), the network structure branches into two independent task-specific heads: 1. Nowcasting head (): typically one or more fully connected layers followed by a Softmax layer, outputting probabilities for the three classes (up/down/stable). Its loss function is (e.g., weighted cross-entropy loss). 2. Hawkish/dovish head (): similarly, one or more fully connected layers followed by a Sigmoid or Softmax layer (binary classification here), outputting hawkish/dovish probabilities. Its loss function is (e.g., binary cross-entropy loss).
The model’s total loss function
is a weighted sum of the main task loss, the auxiliary task loss, and the aforementioned domain adversarial loss:
where
and
are hyperparameters balancing the importance of different tasks. Based on our experiments and framework setup, we set
. The weight
employs a linear warm-up strategy, gradually increasing from 0 to 1 during the initial phase of training, then remaining constant. This warm-up strategy helps stabilize feature learning early in training and prevents the domain adversarial component from prematurely dominating the gradients.
By jointly training these related tasks, we expect to achieve implicit regularization, as the auxiliary task compels the shared feature extractor to learn more general and robust representations capable of reflecting policy tones alongside predicting the final rate decision. Learning to distinguish hawkish/dovish tendencies helps the model to gain a deeper understanding of the text’s semantic and sentiment nuances, potentially improving interest rate prediction accuracy indirectly. Our preliminary validation indicated that adding the hawkish/dovish auxiliary task yielded an approximate 0.6 pp improvement in AUC on the validation set. Furthermore, the trained auxiliary task head itself can provide valuable quantitative metrics on policy statement sentiment. In conclusion, the multi-task learning framework enriches the model’s learning objectives by introducing relevant auxiliary signals, contributing to improved performance on the core interest rate prediction task and enhancing the model’s overall generalization ability.
4.6. Training and Inference Details
To ensure experimental reproducibility, we present key parameters for model training and inference in
Table 2, followed by additional implementation details.
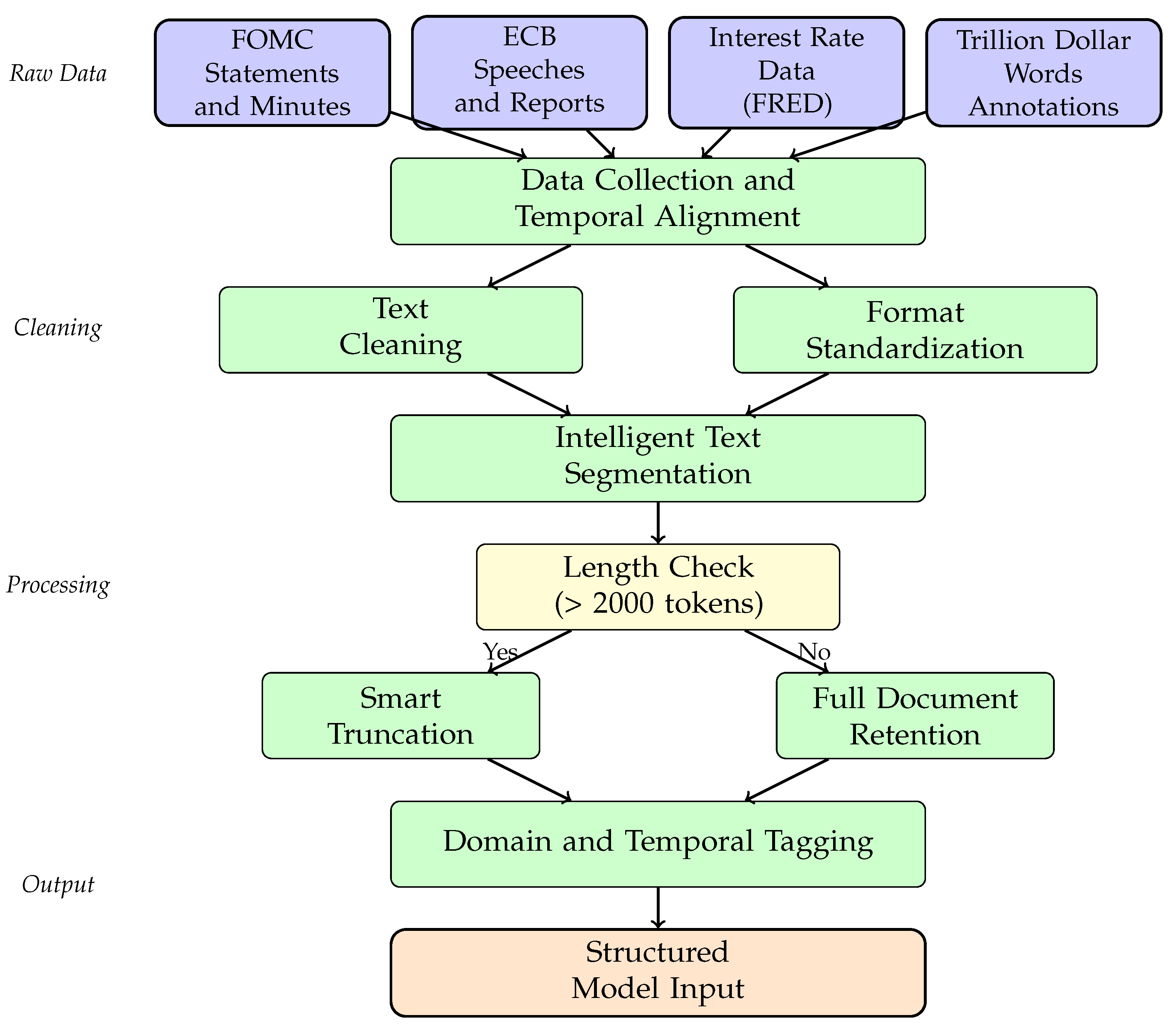
Our two-stage training approach stabilizes learning while maximizing the benefits of parameter-efficient fine-tuning and domain adaptation. We truncate documents to the final 2000 tokens based on the hypothesis that conclusions and forward guidance contain the most critical information for interest rate nowcasting.
The total loss is calculated as , with class weights applied to to address class imbalance.
During inference, auxiliary components ( and ) are removed, and Delta-LoRA matrices with accumulated updates are merged into W to obtain . This ensures no additional computational overhead compared to the original architecture, enabling real-time financial market analysis applications.
5. Results and Analysis
This chapter systematically evaluates the performance, efficiency, and robustness of our proposed Hyena Hierarchy + Delta-LoRA + DANN + multi-task learning framework on the task of central bank interest rate change nowcasting. We present direct comparisons with mainstream baseline models, ablation studies of key model components, analysis of cross-domain generalization capabilities, and explorations of model interpretability and error analysis. This serves to validate the research questions and hypotheses outlined earlier. Primary evaluation metrics include accuracy, macro F1-score, Area Under the Receiver Operating Characteristic Curve (ROC-AUC), directional accuracy, and model calibration (Brier score). The statistical significance of performance improvements is rigorously evaluated using the Diebold–Mariano (DM) test [
42]. The DM test employs a quadratic loss function to compare forecast accuracy, with the test statistic computed as
, where
is the mean loss differential and
is its estimated variance. Under the null hypothesis of equal predictive accuracy, the DM statistic follows a standard normal distribution. We report significance at
p < 0.05 throughout our analysis. The significance of performance improvements is confirmed using the Diebold–Mariano test [
42] (
p < 0.05).
5.1. Overall Performance Comparison
We first compare our proposed full model, denoted as ours (Hyena + -LoRA + DANN + MTL), against several baseline models on the test sets of the core FOMC dataset (1977–2024) and the ECB dataset (1999–2024) used for evaluating cross-institutional generalization. The baselines include the following: logistic regression + TF-IDF: a classical econometric baseline using TF-IDF features with logistic regression to demonstrate the value-add of deep learning approaches. Transformer-XL + Full FT: a strong Transformer-based long sequence model with full parameter fine-tuning. Longformer + LoRA: a Transformer variant optimized for long texts, combined with standard LoRA for parameter-efficient fine-tuning. GPT-2 + AdapterFusion: a GPT-2-based model using AdapterFusion for multi-task and multi-domain adaptation. Ours (Hyena + LoRA): a variant of our model using standard LoRA instead of Delta-LoRA to assess the gain from Delta-LoRA. Ours (Hyena + -LoRA): our base model, removing DANN and multi-task components.
Table 3 shows that our proposed full model significantly outperforms all baseline models on all main metrics across both FOMC and ECB datasets. Notably, compared to the classical econometric baseline (logistic regression + TF-IDF), our full model demonstrates substantial improvements of 14.1 percentage points in macro F1 on FOMC (0.862 vs. 0.721) and 9.5 percentage points on ECB (0.780 vs. 0.685), clearly justifying the adoption of sophisticated deep learning architectures for this task. Compared to Longformer + LoRA, our full model improves macro F1 by 6.0 percentage points (pp) on FOMC (0.862 vs. 0.802) and 5.7 pp on ECB (0.780 vs. 0.723). Diebold–Mariano tests confirmed that these improvements are statistically significant with DM statistics of 3.42 (
p < 0.001) for FOMC and 2.89 (
p < 0.004) for ECB comparisons against Longformer + LoRA. The reported 95% confidence intervals were computed using bootstrap resampling with 1000 iterations, ensuring robust uncertainty quantification. Diebold–Mariano tests confirmed these improvements are statistically significant (
p < 0.05). Comparing ours (Hyena +
-LoRA) with Longformer + LoRA, even without DANN and multi-task learning, the Hyena and Delta-LoRA combination alone achieved a 4.8 pp macro F1 improvement (0.850 vs. 0.802) on the FOMC dataset. This strongly supports our hypothesis that the Hyena and Delta-LoRA-based method outperforms Transformer-based approaches with standard LoRA for the single-domain long-text task on FOMC data. Our model also demonstrates similar advantages in accuracy and AUC. These results indicate that the combination of Hyena Hierarchy’s long convolution mechanism and Delta-LoRA’s efficient fine-tuning strategy provides a superior foundation architecture for processing ultra-long financial policy texts.
5.2. Efficiency and Latency Analysis
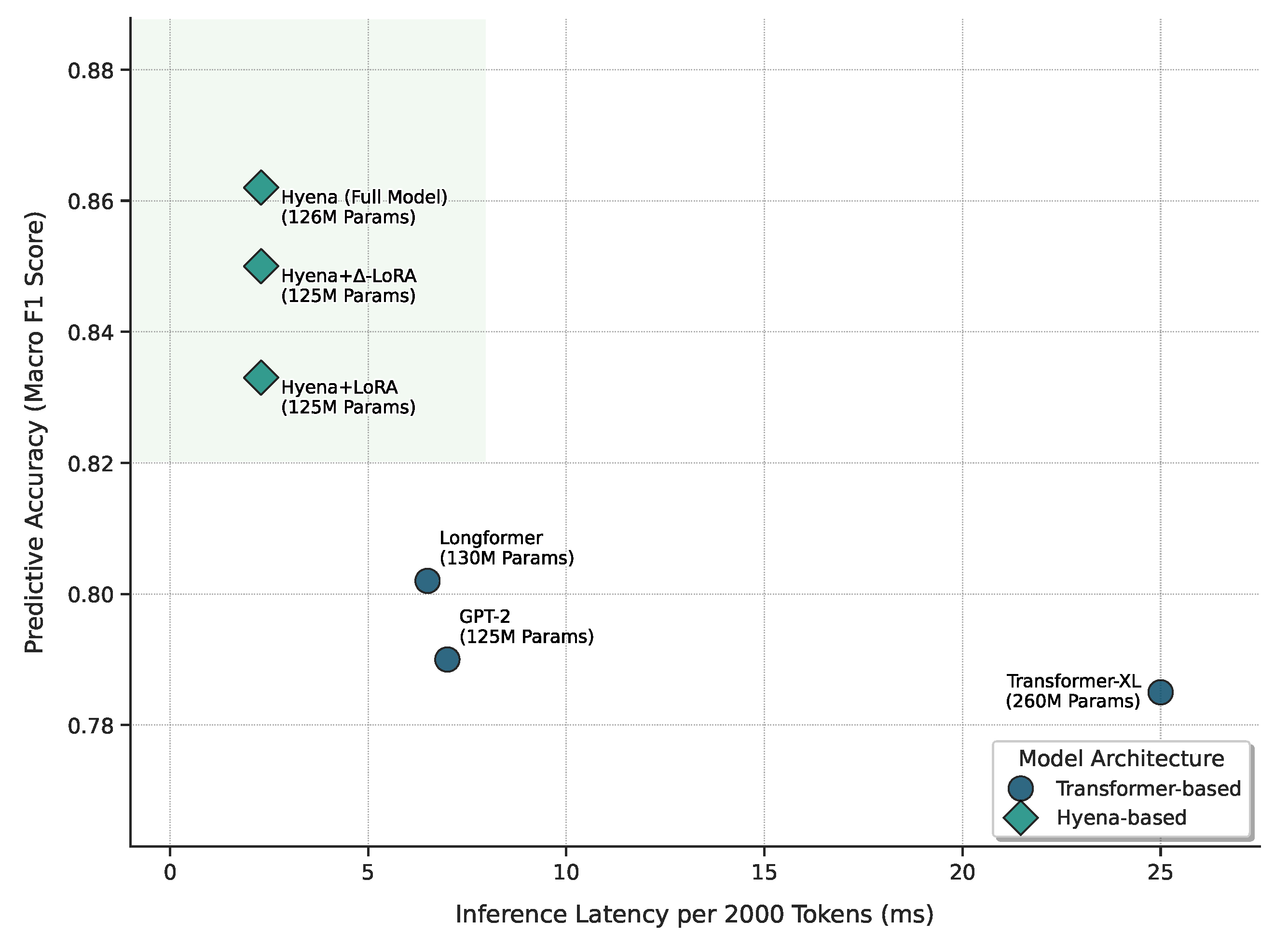
Besides prediction accuracy, the efficiency of processing long texts is crucial for practical applications, especially those with real-time requirements. We compare the average inference latency (measured on an NVIDIA A100 32 GB GPU) for processing a single sample of 2000 tokens and the parameter scales of different models.
As shown in
Figure 8, our Hyena-based models (including the final model) demonstrate exceptional efficiency. When processing a 2000-token sequence, their inference latency is only 2.3 ms, significantly lower than Longformer+LoRA (6.5 ms) and Transformer-XL (25.0 ms). This corresponds to over 65% latency reduction compared to Longformer. This advantage stems from Hyena’s sub-quadratic complexity (
) and its efficient FFT convolution implementation. Although our model achieves the highest F1 score, its parameter count (dominated by Hyena-Small 125M, with PEFT parameters < 1%) is comparable to Longformer-base or GPT-2-base, and much smaller than Transformer-XL, which might require a larger scale to reach similar performance. This validates part of our research question regarding reducing computational cost while maintaining or improving accuracy for long policy text processing during inference.
5.3. Robustness Analysis: Subperiod Performance
To assess the robustness of our model across different economic conditions and policy regimes, we conduct a comprehensive subperiod analysis. This evaluation is crucial for understanding how model performance varies across distinct macroeconomic environments and policy frameworks, addressing concerns about temporal stability and economic regime dependence.
We partition our FOMC dataset into four economically meaningful subperiods: pre-crisis (1977–2006), financial crisis (2007–2009), post-crisis/QE era (2010–2015), and normalization period (2016–2024). Each period represents distinct monetary policy paradigms characterized by different communication strategies, policy tools, and economic contexts.
Table 4 demonstrates that our model maintains consistent performance advantages across all economic subperiods, with improvements ranging from 5.2 to 5.9 percentage points. Notably, the model shows particularly robust performance during the financial crisis period, achieving a 5.9 pp improvement when policy communication was most critical and markets were most volatile. This consistency across diverse economic regimes validates the generalizability of our approach and suggests that the learned representations capture fundamental relationships between central bank language and policy actions that transcend specific economic conditions.
The slight performance degradation during the financial crisis period (compared to other periods) is expected and consistent across all models, reflecting the inherently challenging nature of predicting policy actions during periods of extreme uncertainty and unconventional policy measures. However, our model’s superior performance in this challenging period demonstrates its capacity to extract meaningful signals, even from highly complex and unprecedented policy communications.
5.4. Ablation Studies
To deeply understand the contribution of each key component, we conducted a series of ablation experiments, primarily evaluating the change in macro F1 score on the FOMC dataset.
Table 5 shows that replacing Delta-LoRA with standard LoRA (rank r = 16) results in a 1.7 pp drop in macro F1. This indicates that Delta-LoRA, through its mechanism of updating pretrained weights
W, indeed adapts more effectively to the downstream task, enhancing the model’s expressive power. Regarding the rank (r) in Delta-LoRA, increasing it from 8 to 16 brings a 0.5 pp improvement, but further increasing it from 16 to 32 yields a very minor gain (0.1 pp). Considering the increase in parameters and computational cost with r, r = 16 appears to be a favorable trade-off point.
Table 6 shows that defining the interest rate change label based on the 7-day window following the statement release yields the best model performance. A window that is too short (3 days) might capture excessive market noise, while a window that is too long (14 days) might extend beyond the immediate impact scope of the text or be confounded by subsequent events.
The contributions of domain adaptation (DANN) and multi-task learning (MTL) are analyzed in detail in the following subsections, but briefly, ablation studies show that removing DANN leads to a decrease of approximately 1.8 pp in cross-domain (FOMC → ECB) macro F1, and removing MTL (the hawkish/dovish auxiliary task) results in a decrease of about 1.2 pp in the main task (FOMC nowcasting) Macro F1. These ablation results clearly demonstrate the positive contribution of Delta-LoRA, DANN, and MTL to the overall model performance.
5.5. Cross-Domain Generalization Analysis
To evaluate the model’s ability to transfer knowledge learned from FOMC data to ECB data (or different economic cycles), we focus on analyzing the effect of the domain-adversarial training (DANN) component. We compare the performance of the full model versus a model with the DANN component removed on the ECB test set (both trained on FOMC data and incorporating Delta-LoRA and MTL).
The results in
Table 7 show that incorporating DANN improves the macro F1 score on the target ECB domain by 1.8 pp. This strongly supports the hypothesis that domain adaptation via DANN significantly enhances the model’s generalization performance on cross-central bank corpora.
Figure 9 illustrates the typical loss dynamics during training. The domain classifier’s loss tends to decrease as it learns to distinguish domains, potentially oscillating due to the adversarial nature. Concurrently, the feature extractor, influenced by the gradient reversal layer, aims to maximize this domain loss, pushing it towards producing domain-agnostic features. The main task loss consistently decreases, indicating simultaneous learning of the prediction task and domain adaptation. This adversarial dynamic confirms the successful operation of the DANN mechanism, compelling the feature extractor to generate more domain-invariant representations and thereby enhancing cross-domain generalization.
5.6. Multi-Task Learning Benefits Analysis
We next assess the impact of adding the “hawkish/dovish classification” auxiliary task on the performance of the primary interest rate prediction task, aiming to validate our third hypothesis. We compare the macro F1 score of the full model against a model without the multi-task learning (MTL) component on the FOMC test set.
The results in
Table 8 clearly show that adding the hawkish/dovish classification auxiliary task improves the main task’s macro F1 by 1.2 pp. This supports the hypothesis that jointly training the main task with a related auxiliary task (like policy tone classification) can enhance the main task’s performance. This improvement likely arises because the auxiliary task forces the shared Hyena layers to learn richer feature representations capable of capturing both semantic content and sentiment nuances, which are beneficial for accurately predicting interest rate decisions.
5.7. Interpretability, Calibration, and Error Analysis
Beyond quantitative metrics, understanding the model’s internal working mechanisms, assessing the reliability of its predictions, and analyzing its failure cases are equally important.
Although Hyena uses long convolutions rather than self-attention, its implicitly parameterized convolution kernels can still be analyzed. By visualizing the weights of the trained kernels or their response to inputs (analogous to attention maps but along the time/sequence dimension), we can investigate which parts or patterns in the input text the model focuses on.
As in
Figure 10, analysis of the model’s internal mechanisms (like kernel responses or equivalent contribution scores) suggests a tendency to focus on keywords and phrases directly related to monetary policy stance and economic conditions. For instance, terms like “inflation risks”, “tighter monetary policy”, “restrictive stance”, and “raise the target range” often receive higher contribution scores, particularly when predicting an “up” rate change. Conversely, words like “accommodative”, “patient”, or “softening labor market” are more frequently associated with “down” or “stable” predictions. This pattern indicates that the model is indeed learning to understand the economic meaning and policy signals within the text, rather than relying solely on superficial statistical features.
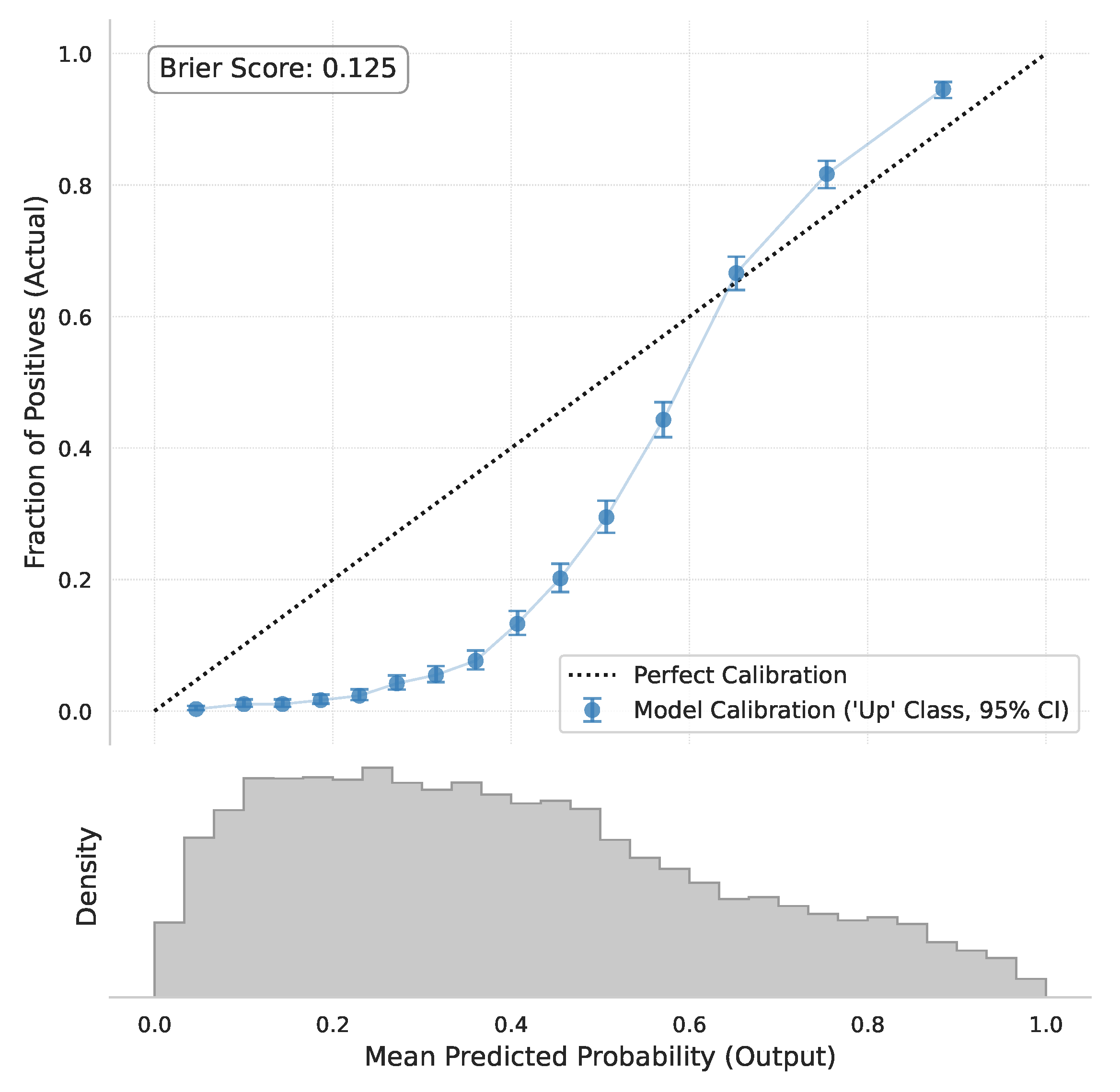
A reliable predictive model should not only be accurate, but also produce probability scores that reflect true confidence levels. We use the Brier score to measure overall calibration error and visualize calibration using a reliability diagram.
Figure 11 shows the calibration curve for the model’s predicted probabilities for the “up” class. Ideally, the curve should closely follow the diagonal line (perfect calibration). Our model’s curve (blue line) is reasonably close to the diagonal, suggesting that its predicted probabilities are largely reliable. For example, when the model predicts an “up” probability around 0.8, the actual frequency of “up” events is also close to 80%. The calculated Brier score is relatively low, further confirming the model’s good overall calibration. This implies that the model’s output probabilities can be used with reasonable confidence for risk assessment or decision-making.
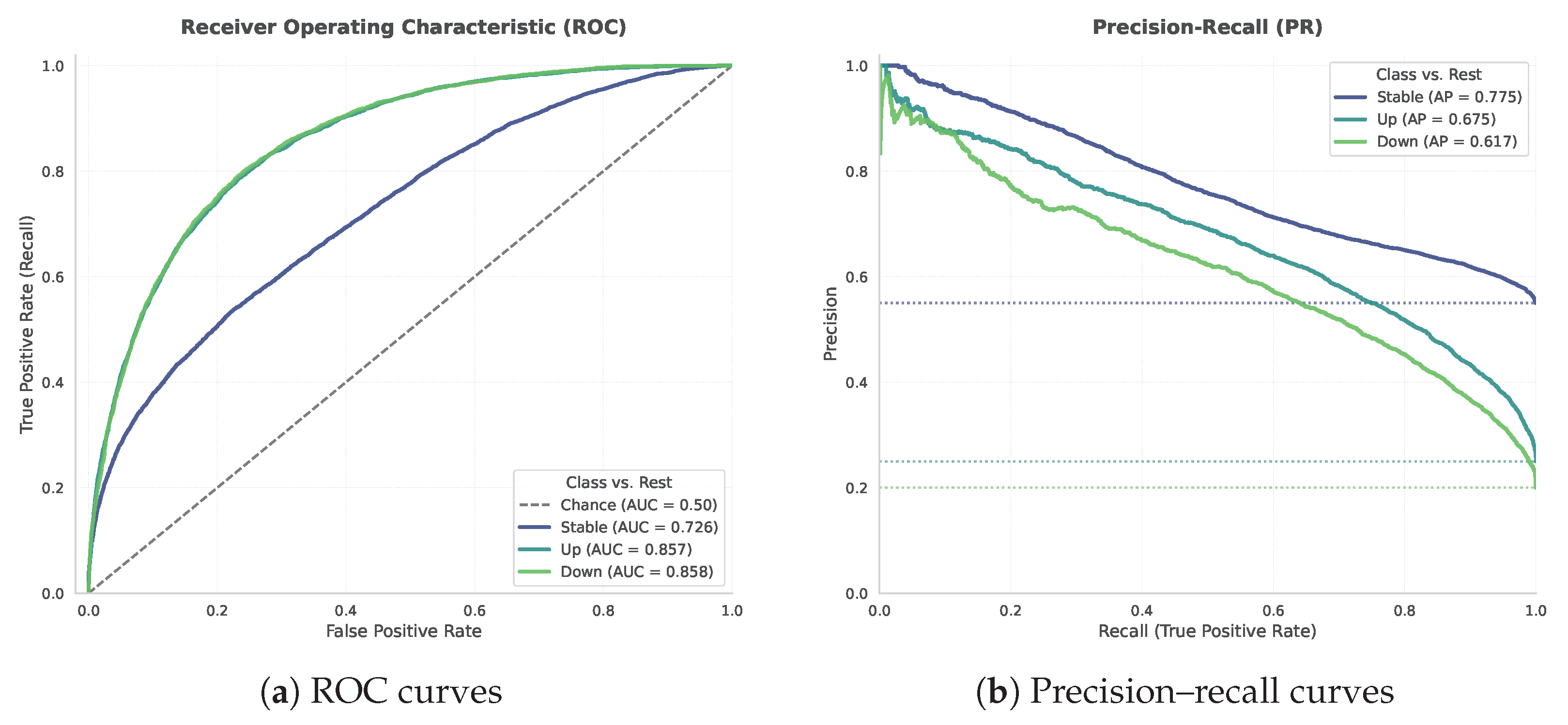
To evaluate the three-class classification performance in more detail, we plot ROC curves and precision–recall (PR) curves for each class.
Figure 12 presents the receiver operating characteristic (ROC, left) and precision–recall (PR, right) curves for the three output classes (‘up’, ‘down’, and ‘stable’) evaluated on the FOMC test set. The ROC curves indicate that the model performs significantly better than random chance for all classes. Notably, the area under the curve (AUC) scores for the directional change classes, ‘up’ (AUC = 0.86) and ‘down’ (AUC = 0.86), suggest a reasonable ability to distinguish these instances from others based on the model’s score rankings. However, the lower AUC for the ’stable’ class (AUC = 0.73) points to greater difficulty in uniquely identifying neutral or ambiguous policy stances from potentially directional ones.
7. Conclusions
In conclusion, this research contributes on three main fronts: methodological innovation, dataset construction, and empirical performance validation. We proposed and validated a novel integrated deep learning framework combining Hyena Hierarchy for long sequence modeling, Delta-LoRA for parameter-efficient fine-tuning, domain adaptation techniques, and multi-task learning. This framework systematically addresses the core challenges encountered in analyzing central bank communication texts, namely ultra-long sequence processing, efficient model adaptation, and cross-domain generalization. Concurrently, we constructed and annotated a large-scale, cross-institutional dataset covering decades of official communications from the U.S. Federal Open Market Committee and the European Central Bank.
The empirical results clearly demonstrate that our proposed complete model achieves state-of-the-art performance in the interest rate nowcasting task compared to strong baseline models, showing significant improvements in key metrics such as accuracy, macro F1 score, and AUC. Furthermore, it drastically reduces the inference time required for processing long texts. The combination of the Hyena architecture and the Delta-LoRA fine-tuning technique, in particular, showcases its superiority and significant potential for tackling tasks involving the analysis of lengthy, information-dense texts characteristic of the financial and macroeconomic policy domains.
We believe this work opens new possibilities for leveraging advanced natural language processing techniques to gain deeper insights from central bank communications, aiding economic forecasting and policy analysis. Future research should continue exploring more powerful model architectures, richer multimodal information fusion, and broader cross-lingual and cross-institutional applications. We also call for enhanced collaboration between academia and industry to jointly build and maintain more comprehensive, standardized, and open benchmark resources for central bank communication text analysis, fostering continued progress and knowledge sharing in this interdisciplinary field.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}