4.3. Training Procedure
Different datasets were used for training and testing, based on the computational characteristics of each model, to simulate real-world conditions and evaluate performance under mobile deployment constraints.
The R(2+1)D and VST models were trained and evaluated using the original dataset, recorded at 30 fps. Since both models leverage complex spatio-temporal feature extraction mechanisms, using the full frame rate enabled them to retain the temporal information necessary for accurate sign language recognition.
The 3D CNN and MViT models were trained and evaluated using the secondary dataset. For MViTs, frames were systematically dropped to simulate real-time conditions on mobile devices, optimizing the model for environments with lower frame rates. The 3D CNN model is typically used with 16-frame inputs, so it was evaluated using this frame size to align with its standard architecture and ensure optimal performance under these conditions. Similarly, for MViTs, since they are designed for mobile environments, 16-frame input data was used, just like with 3D CNN models.
By employing different training strategies tailored to each model’s computational efficiency and intended deployment scenario, this study ensures a fair and practical evaluation of sign language recognition performance in both high-resource and real-time mobile environments. In other words, this study considers high-performance computing environments with a high frame rate where 30 frames of image data can be used to generate a single input clip, providing relatively high performance. Additionally, it considers mobile computing environments with lower computational performance, where only 16 frames of image data can be used to generate a single input clip. A set of common hyperparameters, as shown in
Table 8, was applied to maintain consistency in training across the different models.
As shown in
Table 8, the batch size was set to 4 for the Video Swin Transformer, 3D CNN, and R(2+1)D models, whereas MViT used a batch size of 2 to accommodate its more lightweight design. The input image resolution was 224 × 224 pixels for the transformer-based models (VST, MViT) and 112 × 112 pixels for the CNN-based models (3D CNN and R(2+1)D), considering their respective architectures. The number of frames per video clip varied across models, with VST and R(2+1)D using 30-frame clips, while 3D CNNs and MViTs were trained on 16-frame clips, balancing computational cost and temporal information capture. We also leveraged pre-trained weights for transfer learning, as summarized in
Table 9.
The pre-trained weights were selected based on their relevance to video recognition tasks. The 3D CNN model was trained from scratch due to the lack of suitable pre-trained weights, whereas the R(2+1)D, VST, and MViT models utilized pre-trained weights provided by Torchvision from large-scale datasets such as KINETICS400 and IMAGENET22K. These pre-trained weights significantly enhance feature extraction capabilities by enabling the models to leverage knowledge from large-scale video action recognition datasets, leading to improved generalization and faster convergence during training.
The loss function used was LabelSmoothingCrossEntropy, which helps improve generalization by preventing the model from becoming overly confident in its predictions. The learning rate was set to , a commonly used value that balances convergence speed and stability during training. Stochastic Gradient Descent (SGD) was chosen as the optimizer due to its robustness and effectiveness in optimizing deep learning models. The number of epochs was set to 200, ensuring sufficient training time for convergence while avoiding excessive overfitting.
4.4. Experimental Analysis
An experimental scenario was designed to evaluate the performance of our proposed method, focusing on three key metrics: accuracy, coverage, and inference speed. The experiment primarily compares two approaches: fixed clip generation and dynamic clip generation. In the first phase, we compare the impact of generating clips with fixed sizes ranging from 2 to 6 frames on the validation dataset. For each configuration, we measure the following:
Average Accuracy: The model’s ability to correctly identify sign language gestures.
Average Coverage: The proportion of video frames that contribute to the clip, reflecting how well the clip captures the content of the video on average.
Average Inference Time: The total processing time, reflecting the model’s overall inference efficiency.
The impact of different clip sizes on model performance is visualized in
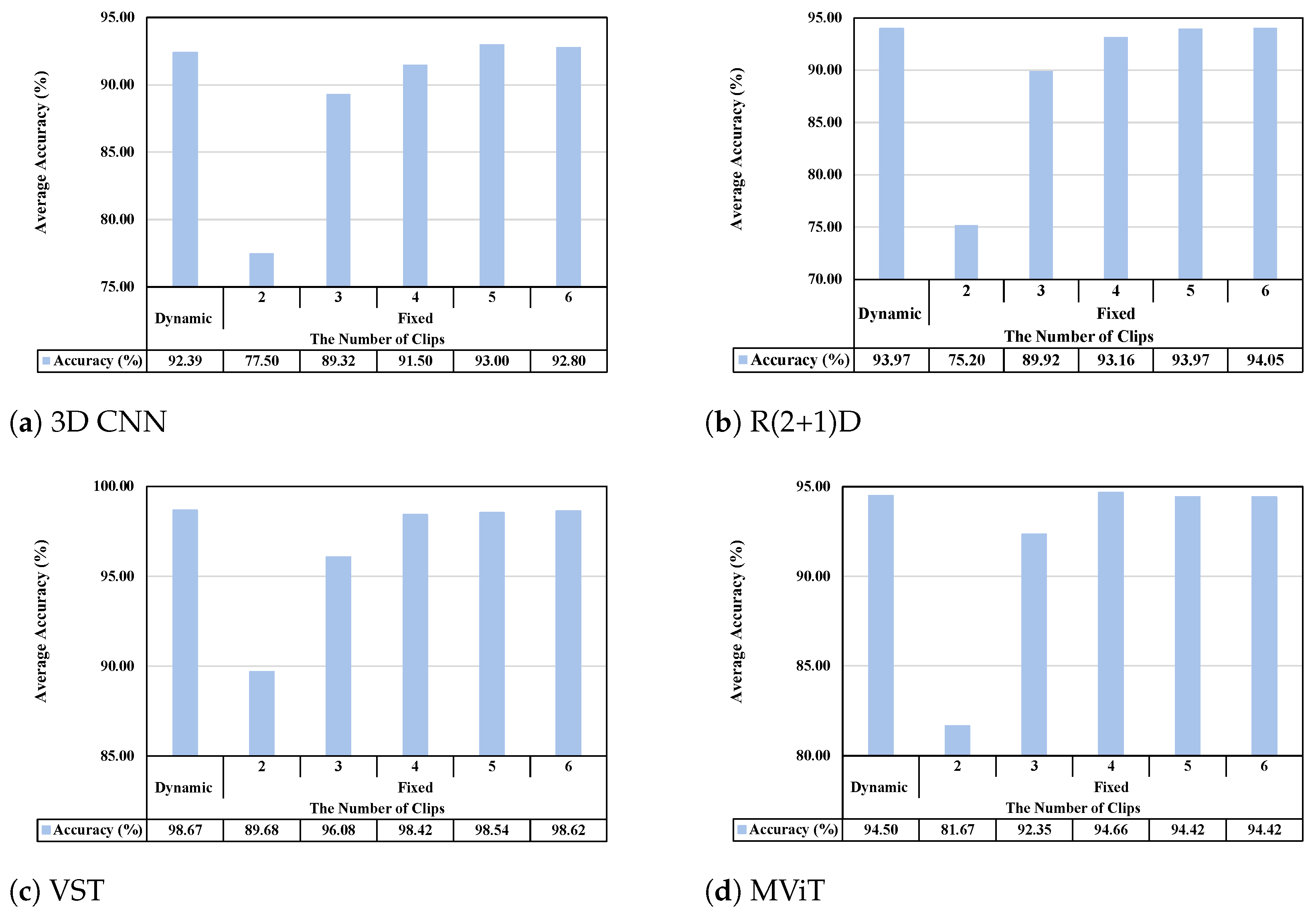
Figure 2, which presents the average accuracy for the fixed clip generation methods. The results demonstrate that increasing the clip size generally improves accuracy across all models; however, beyond a certain clip size, model accuracy either no longer increases or even decreases.
From the results, we observe that all models show improved accuracy as the clip size increases. However, after a clip size of 4, the accuracy gains become marginal, indicating a saturation point.
Table 10 shows the average coverage values for the different clip sizes. As shown in
Table 10, the coverage values increase as the number of clips increases.
A more detailed analysis of the trade-off between accuracy and computational efficiency is provided in
Figure 3, which illustrates the average inference time for each model at different clip sizes. As shown in
Figure 2 and
Figure 3, when examining the average accuracy and average inference time for each model at different clip sizes, we observe that, as the clip size increases, the average accuracy generally improves. However, this comes at the cost of increased average inference time. The VST model, while achieving the highest average accuracy, has the slowest average inference time, especially for larger clip sizes. In contrast, the MViT model maintains competitive average accuracy while having a lower average inference time compared to the other models.
Based on these observations, selecting an appropriate clip size requires balancing accuracy and real-time processing efficiency in terms of inference time. While increasing the clip size improves accuracy, the gains become marginal beyond a size of 4. Additionally, inference time continues to increase with larger clip sizes, making them less suitable for real-time applications. Therefore, we conclude that a clip size of 4 strikes the best balance between accuracy and computational efficiency.
A performance comparison between the proposed dynamic clip generation method and fixed clip generation methods is presented as follows. In the performance evaluation, we compared the performance of our dynamic clip generation method with the fixed method in terms of average accuracy, average coverage, and average inference time. Based on the observed experimental results, at a clip size of 4, the average coverage values are 0.96 for 3D CNNs and MViTs, and 1.04 for R(2+1)D and VSTs, as shown in
Table 10. Given these results, we define the optimal coverage threshold as 1. This value ensures a balanced trade-off between capturing meaningful gestures and maintaining efficiency in the processing time. Using this threshold, the dynamic clip generation method adjusts the number of clips to enhance both accuracy and inference speeds. In short, the dynamic clip generation method we proposed dynamically adjusts the number of clips to ensure that the coverage is 1 when generating clips from sign language videos based on the analysis of the experimental results.
Figure 4 shows the distribution of the number of clips generated for different models using the proposed dynamic clip generation method. As shown in the figure, each sign language recognition model using the proposed dynamic clip generation method dynamically generates the number of clips based on the length of the sign language video used for recognition. This variability suggests that adaptively allocating the number of clips based on optimal coverage is a reasonable approach, as it allows the model to assign more clips to complex and longer sign language videos, while using fewer clips for simpler ones. In doing so, this method efficiently balances computational cost and representational effectiveness, ensuring that each sign language video receives an appropriate level of granularity for accurate processing. To further evaluate the effectiveness of dynamic clip generation, we compare its accuracy with that of the fixed clip generation methods for each model.
Figure 5 compares the average accuracy between the dynamic and fixed methods across different models.
Figure 6 presents the comparison of average inference time between the dynamic and fixed methods across different models. As shown in
Figure 5 and
Figure 6, for 3D CNNs, the fixed method achieved the highest accuracy at 93.00%, with an inference time of 0.24 s using 5 clips, whereas the dynamic method had a slightly lower accuracy of 92.39%, but improved the inference time to 0.21 s, representing a 12.50% reduction. In R(2+1)D, the fixed method reached a 94.05% accuracy with an inference time of 0.054 s using 6 clips, while the dynamic method achieved a 93.97% accuracy but significantly reduced the inference time to 0.039 s—a 27.78% decrease. For VSTs, when using 6 clips, the fixed method achieved its best performance with 98.62% accuracy and an inference time of 0.49 s. However, the dynamic method not only slightly outperformed it with a 98.67% accuracy but also significantly reduced the inference time to 0.35 s, representing a 28.57% improvement. Lastly, for MViTs, the fixed method achieved its best performance with 4 clips, reaching a 94.66% accuracy and an inference time of 0.14 s. The dynamic method resulted in a slightly lower accuracy of 94.50% with the same inference time, indicating that the dynamic method did not provide any advantage in terms of inference time in this case.
When the number of clips is 2, we observe that the accuracy for all models (MViTs, 3D CNNs, R(2+1)D, and VSTs) is at its lowest. This indicates that, with only two clips, the generated clips do not adequately capture the temporal context of the video, resulting in a noticeable decrease in performance. In contrast, when the coverage value exceeds 1, the entire temporal information of the video will have already been used at least once. In the experiment, when the coverage value is greater than 1, the number of generated clips was 4 or more. Beyond this point, further increasing the number of clips does not lead to significant accuracy improvements. In some cases, excessive clip generation may potentially lead to minor accuracy degradation, as observed in our experiments with 3D CNNs, which showed lower accuracy with 6 clips compared to 5 clips, and MViTs, which demonstrated decreased performance with 5 clips compared to 4 clips. In other words, generating too many clips for recognition may not provide any benefit in terms of recognition accuracy and inference efficiency.
When comparing average inference times across different models, our results demonstrate significant computational efficiency gains with the dynamic method.
Table 11 presents a comparison between the dynamic method and the fixed method, which achieved the highest accuracy for each model. The table highlights key metrics, including the average number of clips generated, inference time (in seconds), inference time reduction rate, and clip reduction rate for each model.
It is important to note that although the number of clips is dynamically adjusted depending on the length of the video, each clip still contains a fixed number of frames (e.g., 16 or 30). As a result, shorter videos generate fewer clips, reducing the total number of frames passed through the model and effectively decreasing inference time.
For 3D CNNs, the dynamic method achieves a 12.50% reduction in inference time, with an average inference time of 0.21 s compared to 0.24 s for the fixed method. This reduction is accompanied by a slight decrease in the number of clips, with the dynamic method generating an average of 4.37 clips, compared to 5 clips for the fixed method. This suggests that by dynamically adjusting the number of clips based on video content, the dynamic method offers a more computationally efficient solution without significantly compromising accuracy.
Similarly, R(2+1)D shows a notable 27.78% reduction in inference time, decreasing from 0.054 s for the fixed method to 0.039 s for the dynamic method. In this case, the dynamic method generates slightly fewer clips (4.22 clips) compared to the fixed method (6 clips), demonstrating the method’s efficiency in optimizing clip generation without sacrificing performance.
For VSTs, the dynamic method achieves a 28.57% reduction in inference time, from 0.49 s for the fixed method to 0.35 s with dynamic clip generation. The number of clips generated in the dynamic approach (4.22 clips) is slightly lower than in the fixed approach (6 clips), further improving computational efficiency while maintaining high accuracy.
However, for MViTs, both the fixed and dynamic methods result in the same inference time of 0.14 s. The number of clips generated by both methods remains the same (4.37 clips for the dynamic method and 4 clips for the fixed method), but the dynamic method’s clip reduction rate is negative (−9.25%), suggesting that the dynamic method does not provide the same level of improvement for MViTs as it does for other models.
In summary, the dynamic clip generation method significantly reduces inference times for three out of the four models (3D CNNs, R(2+1)D, and VSTs), while also reducing the number of clips needed for video recognition. These results demonstrate that the dynamic method offers a substantial computational efficiency advantage in sign language recognition tasks, especially for models that benefit from flexible clip generation.
Overall, our results demonstrate that the dynamic clip generation method based on our proposed coverage metric delivers significant advantages across multiple models. Particularly impressive results were observed with R(2+1)D and VST, where we achieved inference time reductions of 27.78% and 28.57% respectively, while maintaining or even improving accuracy. By adjusting the number of clips according to each video’s temporal complexity, this method prevents computational waste while ensuring sufficient information capture. Our approach is particularly valuable for real-time video recognition applications where processing speed is critical without compromising recognition performance.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}