1. Introduction
Pork serves as the primary source of animal protein in China, and its quality is intricately linked to the nation’s health. Therefore, it is essential to evaluate the behavior of the domestic pig to guarantee the quality and safety of pork. Artificial farming, a complex and enduring agricultural method, poses significant obstacles because of its labor-intensive and insufficiently mechanized characteristics [
1]. Consequently, developing a model for recognizing domestic pig behavior is very significant.
The advent of target detection algorithms enables the rectification of these deficiencies, with current techniques classified into traditional and deep learning-based categories. Conventional target detection algorithms predominantly depend on manually crafted features and traditional machine learning methods, utilizing sliding windows or region segmentation to scan the image and then employing manually extracted features to define the target’s appearance. Such algorithms exhibit restricted generalization capability, and the sliding window approach results in computational inefficiency [
2].
Deep learning algorithms for target detection fall into two categories: two-stage and one-stage [
3]. Two-stage algorithms, such as R-CNN [
4], Fast R-CNN [
5], and Faster R-CNN [
6], employ region proposal methods to identify candidate regions. These zones are utilized for classification and bounding-box regression, resulting in high accuracy but reduced speed. Single-stage algorithms (e.g., YOLO [
7] and SSD [
8]) immediately anticipate target categories and locations from the image, omitting the region recommendation phase, which enhances speed and is conducive to real-time applications.
The second method of deep learning for domestic pig behavior recognition has attracted considerable interest from researchers in recent years. The multi-type pig behavior recognition method has been a prominent research area in pig behavior identification, owing to its improved adaptability and proficiency in accurately recognizing various common pig actions and behaviors [
9]. Wang et al. [
10] proposed an instance classification method inspired by the image grid concept in YOLO, transforming image instance segmentation into a classification problem. Lizhong Dong [
11] introduced a method for identifying pig behavior by leveraging the animal’s gestures and temporal characteristics. This approach integrated the OpenPose algorithm with YOLOv5s to detect and estimate the pig’s gestures, analyzing 20 main body regions. The twenty essential components of the pig’s anatomy are examined, and the skeleton is removed to identify three behaviors: standing, walking, and lying. Shuqin Tu et al. [
12] created a system for behavior recognition and tracking of group-reared pigs with the YOLOv5s depth model in conjunction with the enhanced DeepSort algorithm. Utilizing the outcomes of the YOLOv5s model classification, the enhanced DeepSort algorithm was employed to facilitate behavior identification throughout the tracking process, thereby alleviating the issue of frequent identity number fluctuations resulting from the overlapping and obscuring of pigs. Shao et al. [
13] employed YOLOv5 to isolate individual pigs from herd photos, integrated it with the DeepLab v3+ semantic segmentation technique to delineate pig outlines, and identified standing, prone, side-lying, and exploratory behaviors utilizing a deep separable convolutional network. Ji et al. [
14] employed the enhanced YOLOX to identify pig postural behaviors and implemented a streamlined copy–paste and label-smoothing technique to effectively address the category imbalance issue resulting from a scarcity of sitting examples in the dataset.
Modern behavior recognition methods using deep learning have improved in accuracy, but they often use complex models that are heavy and require a lot of resources, making it difficult to use them in real-time on smaller swine farms [
15]. This paper offers a lightweight pig behavior identification system, YOLOv8-PigLite, derived from YOLOv8, leveraging the high detection accuracy of the YOLOv8n model and its efficacy in detecting multi-scale targets. This paper presents a two-branch bottleneck module within the C2f module, comprising one branch utilizing average pooling and deep convolution (DWConv), and the other employing maximum pooling and DWConv, aimed at enhancing multi-scale feature representation. Additionally, we substitute conventional convolution in the convolution module with integration into the SE module to further diminish the recognition error rate. Furthermore, we implement BiFPN to replace the original FPN in the neck network, thereby streamlining the network structure and augmenting feature-processing capabilities, resulting in a lightweight, high-precision, real-time performance system with exceptional robustness and generalization ability. We present a behavior recognition technique for farmed pigs exhibiting exceptional generalization capability.
2. Dataset Preparation
This study’s dataset is derived from the subsequent dataset, Pig Behavior Recognition Dataset (PBRD) [
16], in order to validate the model’s efficacy. The dataset comprises 11,862 photos in six categories: Lying, Sleeping, Investigating, Eating, Walking, and Mounted. The training set comprises 9344 photos, while the validation set contains 2518 images. The category-wise sample distribution of the PBRD dataset is shown in
Figure 1a.
To verify the superiority of the proposed algorithm in pig behavior recognition, two publicly available datasets from Roboflow, Comportamentos and Behavior_Pig were integrated to form a new external dataset named Comp. This dataset contains a total of 8103 images covering behavior categories: Lying, Sleeping, Eating, Walking, Mounted, and Drinking. The category-wise sample distribution of the Comp dataset is illustrated in
Figure 1b.
4. Experiments and Analysis
4.1. Confusion Matrix
The confusion matrix is a tool used to evaluate how well a classification model works by comparing its predictions to the real results, with columns showing predicted categories and rows showing actual categories [
27].
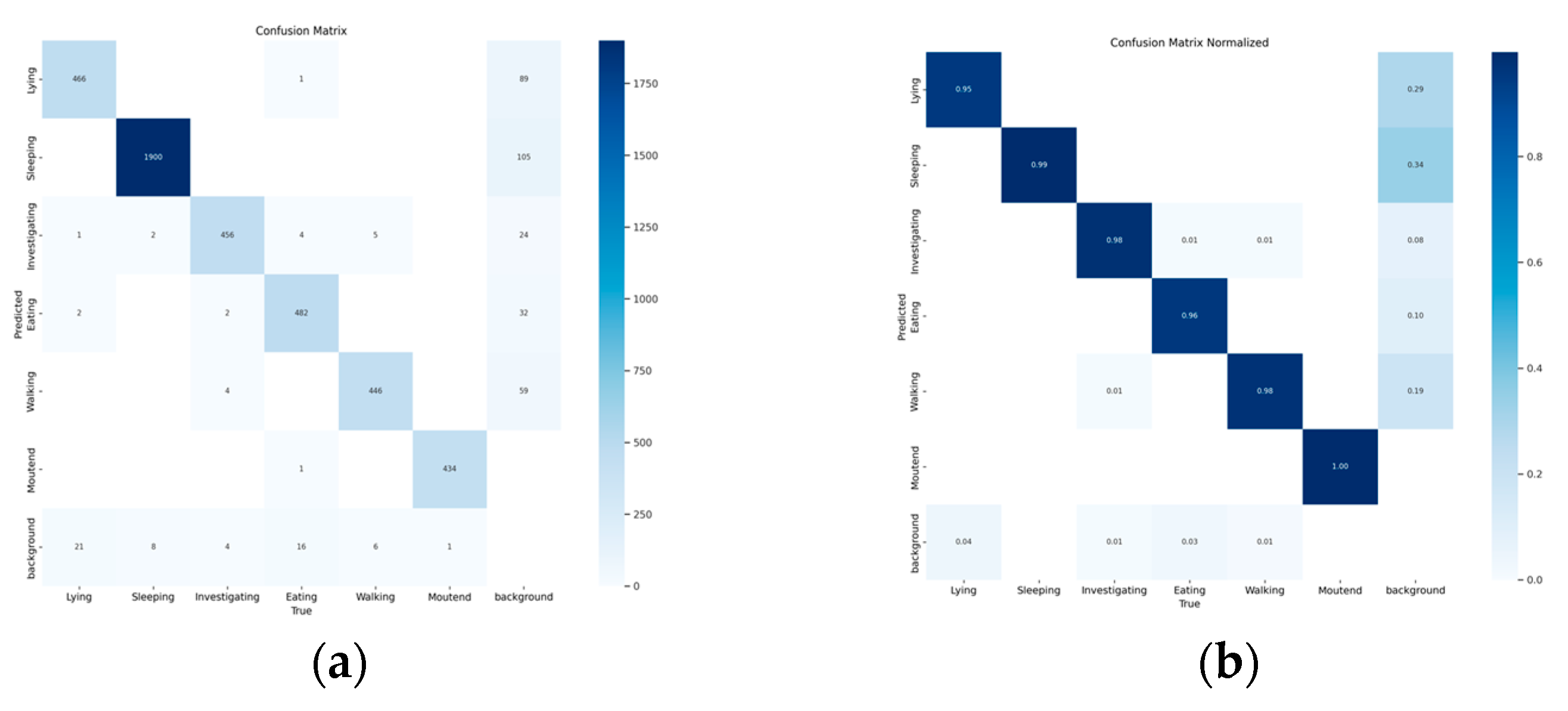
Figure 7 presents the confusion matrix analysis of the proposed YOLOv8-PigLite model for the pig behavior classification task.
Figure 7a displays the absolute prediction counts, indicating that the model demonstrates excellent classification performance for behaviors such as Sleeping (with 1900 correct predictions), Mounted (434), and Lying (466), showcasing its strong ability to accurately distinguish these categories. However, some misclassifications are observed in categories such as Investigating and Eating, where visual similarity and complex image backgrounds occasionally cause samples to be confused with the background or other behavior types.
Figure 7b shows the normalized confusion matrix, further emphasizing the model’s high detection accuracy across most categories. These results confirm the effectiveness and reliability of the YOLOv8-PigLite model.
4.2. Experimental Results
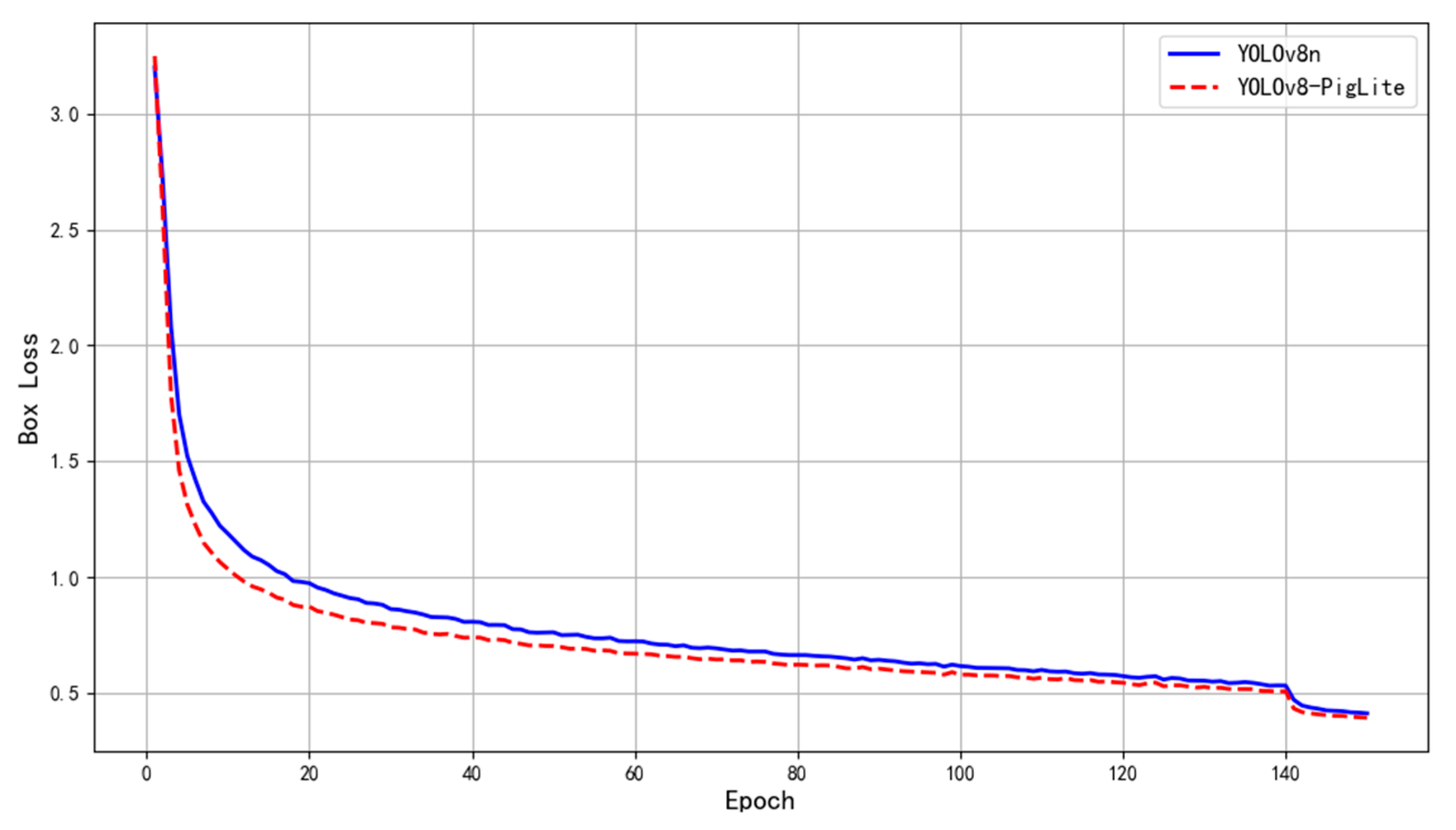
The training set inputs of YOLOv8n and the improved method YOLOv8-PigLite are utilized to compare the convergence of loss values.
Figure 8 illustrates that the convergence rate of the enhanced algorithm surpasses that of the original model, demonstrating that the methodology proposed in this study not only diminishes model complexity and enhances detection performance but also offers a notable advantage in convergence speed.
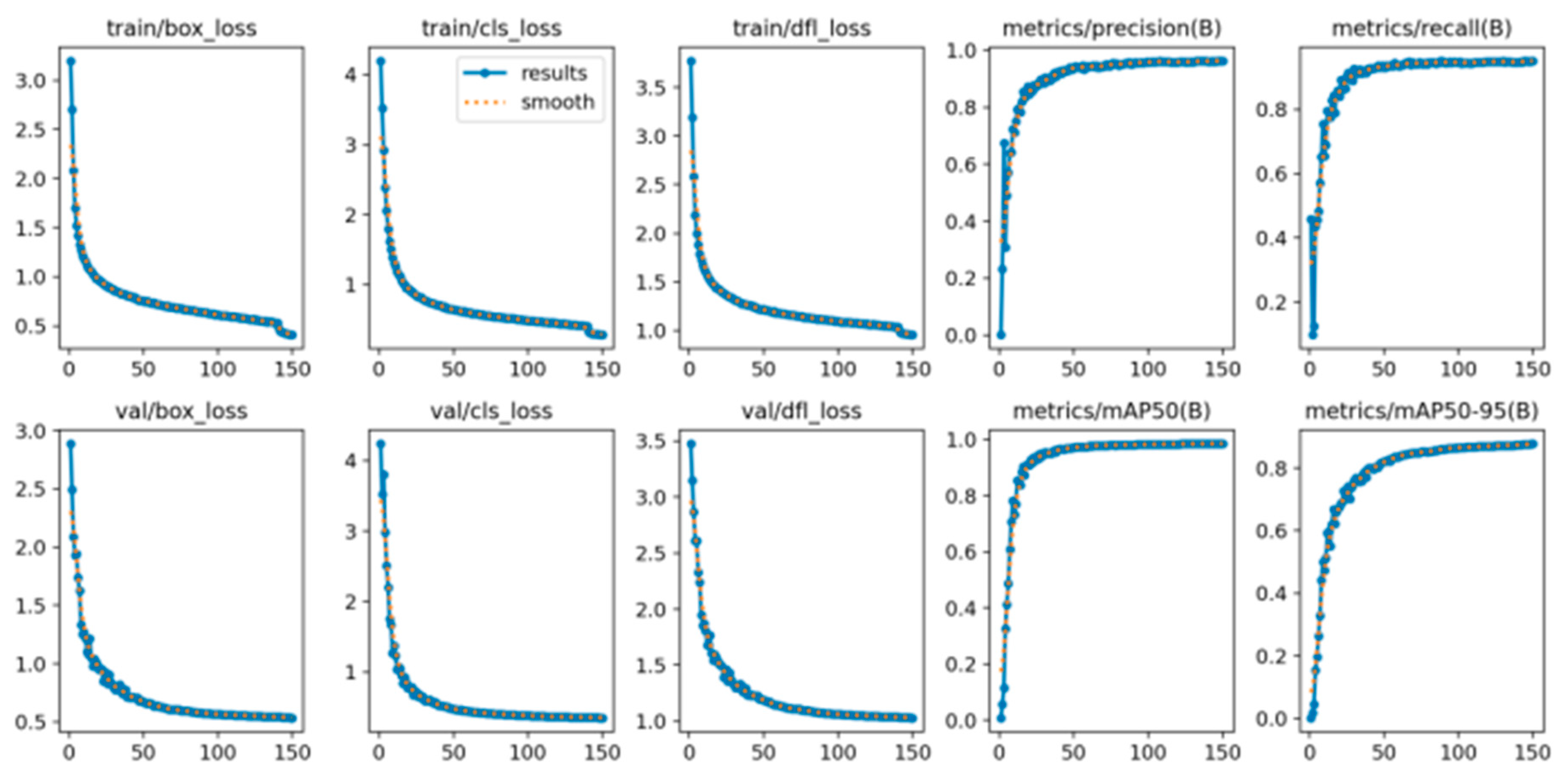
To assess the detection efficacy of the lightweight YOLOv8-PigLite technique, we present a series of graphs depicting loss and performance parameters during the training and validation phases. This study evaluates three categories of losses: bounding-box loss (box_loss), classification loss (cls_loss), and distribution focus loss (dfl_loss). The bounding-box loss assesses the positional difference between the predicted and reference bounding boxes, the classification loss evaluates the variance between the predicted and actual categories, and the distribution focus loss improves the box loss by refining the probability distribution of the bounding-box position. The initial three columns of the
Figure 9 exhibit a notable alteration in the loss levels by the 50th iteration. Following 150 iterations, box_loss decreases to 0.41 and cls_loss reduces to 0.24, demonstrating a comparable trend in the validation set and signifying the model’s efficacy in target localization and classification tasks. The value of the loss function currently oscillates within a narrow range, indicating convergence and improved outcomes.
The evaluation metrics in the final two columns of the
Figure 9 indicate that, at the onset of training, precision, recall, and mAP exhibit varying degrees of volatility, primarily due to the initial randomization of model parameters and the heterogeneity of the training data. As iterations progress, these metrics exhibit consistent enhancement: precision rises from 0.01 to 0.96, recall advances from 0.09 to 0.95, and, notably, mAP@50 attains a substantial value of 0.98, thereby affirming the model’s exceptional accuracy and robustness in detecting domestic pig behavior.
4.3. Heat Map Analysis
To further analyze the model’s detection performance and visually demonstrate the improvement effects, in this paper, three behavioral images of domestic pigs were selected for heat map visualization. The heat map is a visualization tool that can visually present the distribution of data, the area of interest of the model, and the importance of features in a color-changing manner. In the heatmap, each data point is assigned a specific color, with the shade of the color reflecting the data intensity at that location. We use warm colors (e.g., red) to represent high-intensity areas and cool colors (e.g., blue) to represent low-intensity areas. In this paper, a gradient-based CAM (Grad-CAM) method is used to obtain the heat map of the model [
28] in order to reveal the model’s focus patterns on the behavioral characteristics of domestic pigs.
The heatmap comparison in
Figure 10 demonstrates that, compared to YOLOv8n, the improved YOLOv8-PigLite model exhibits significant enhancements in attention distribution. In the first column images, the improved model concentrates attention on the pig’s head and limbs, producing clearer contours that markedly improve the recognizability of pig behaviors. In the second column images, where targets are smaller and inverted, increasing recognition difficulty, the improved model shows a substantial increase in high-intensity red regions, effectively enhancing target visibility and recognition accuracy. In the third column images, for mounting behaviors, YOLOv8-PigLite focuses on the pig’s head and limbs, enabling the precise identification of behaviors such as “one pig placing its forelimbs on another’s back.” In contrast, YOLOv8n’s heatmaps reveal a more scattered attention distribution, with non-critical areas (e.g., the pig’s back) exhibiting high activation, indicating significant interference from background noise during feature extraction.
Overall, the YOLOv8-PigLite heatmaps show a notable improvement in the boundary clarity of activation regions and more concentrated coverage of high-intensity red areas, robustly validating the model’s superior performance in perceiving behavioral features. The improved model effectively suppresses responses in non-critical areas, significantly reducing background noise interference, as evidenced by the increased proportion of cooler (low-intensity) regions in the heatmaps, thereby enhancing the purity of feature extraction. Furthermore, the improved boundary clarity in the heatmaps reflects substantial advancements in YOLOv8-PigLite’s spatial focus and information discrimination capabilities. In summary, the heatmap results not only visually demonstrate the enhanced detection performance of the improved model but also confirm its ability to achieve synergistic optimization of detection accuracy and inference efficiency under a lightweight design, providing a solid visual foundation for further model optimization.
4.4. Contrast Experiment with Mainstream Algorithm
To further validate the superiority of the YOLOv8-PigLite algorithm, a comparison was conducted with two-stage (Faster R-CNN) and single-stage deep learning-based target detection techniques (SSD, YOLOv3-tiny, YOLOv5n, YOLOv8n, and YOLOv9s) on domestic pig datasets.
The test results in
Table 2 show that the YOLOv8-PigLite algorithm we are referring to in this paper is much better than the faster R-CNN and SSD algorithms when it comes to accuracy, parameter count, and floating-point computation. Although YOLOv8-PigLite achieves a recall rate of 96.3%, which is marginally lower, the difference is not statistically significant. The YOLOv8-PigLite algorithm works better than the YOLOv3-tiny, YOLOv5n, and YOLOv9s algorithms when it comes to precision, recall, mean average precision, parameter count, and floating-point operations. Compared to the standard algorithm YOLOv8n, YOLOv8-PigLite reduces the number of parameters and GFLOPs by 59.80% and 39.50%, respectively. This paper’s method, YOLOv8-PigLite, exhibits the lowest parameters and GFLOPs among the seven algorithms, with values of 1.21 M and 4.9 GFLOPs, respectively. It approaches the optimal metrics, indicating excellent accuracy and a lightweight design.
4.5. Statistical Analysis
To evaluate the statistical significance of the performance enhancement, we executed five separate training and testing sessions for each model using the Comp division dataset. The results of the statistical analysis show that the precision, recall, and mAP measures follow a normal distribution; therefore, we conducted paired t-tests for these metrics [
29]. The
t-test is a commonly used statistical significance test designed to evaluate whether the difference between the means of two groups is statistically significant. In significance testing, the
p-value represents the probability of observing the current result, or a more extreme one, under the null hypothesis (i.e., no difference between the means of the two groups). Typically, the significance level (α) is set at 0.05, serving as the threshold for determining statistical significance. A
p-value greater than 0.05 indicates that the observed difference is not statistically significant.
Table 3 compares the performance metrics of YOLOv8n and the improved model YOLOv8-PigLite, including precision, recall, and mAP@50%, using a
t-test. The results show that the mean precision of YOLOv8-PigLite increased from 96.06 ± 0.30% to 96.38 ± 0.19%, with a
p-value of 0.0054 (
p < 0.05), indicating that this improvement is statistically significant. Conversely, the recall decreased from 94.60 ± 0.34% to 94.38 ± 0.33%, with a
p-value of 0.0402 (
p < 0.05), suggesting that this decline is also statistically significant. For the mAP@50% metric, the
p-value of 0.6974 (>0.05) for both models indicates no significant difference. Additionally, YOLOv8-PigLite reduced the parameter count from 3.01 M to 1.21 M and GFLOPs from 8.1 to 4.9, markedly enhancing resource efficiency. In summary, the improved model demonstrates a significant increase in precision, a significant decrease in recall, and a notable advantage in resource efficiency.
4.6. Ablation Experiments
Ablation tests were conducted to illustrate the enhancement effect of C2f-DualDW, GSConvSE, and BiNeck on the lightweight algorithm described in this research.
Table 4 illustrates the following: Group 1 studies utilize the YOLOv8n algorithm as a benchmark model for comparison with later experiments. Group 2 experiments involve modifications to the C2f module solely based on the backbone network, resulting in a small accuracy enhancement, while the number of parameters and floating-point computations are decreased by 26.57% and 24.69%, respectively. Group 3 experiments enhance the convolution module based on Group 2, maintaining similar accuracy, with subsequent reductions in parameters and floating-point computations of 19.00% and 14.75%, respectively. Group 4 experiments focus on optimizing the neck network from Group 3, achieving a slight accuracy improvement, alongside reductions in parameters and floating-point computations of 32.40% and 5.76%, respectively. The data analysis indicates that each enhancement of the algorithm diminishes the computational demands and complexity of the model.
In addition, to further validate the effectiveness of the algorithm, we use the fixed frame rate method [
30] to compare the frame rates (frames per second,
FPS) of the benchmark algorithm and the improved algorithm, as shown in Equation (8).
In this context,
t represents the time required for processing each frame, measured in milliseconds.
Table 2 shows that the better algorithm YOLOv8-PigLite boosts the
FPS by 32.61% compared to the standard algorithm, proving that the improved algorithm is more efficient.
4.7. Model Generalization Test
To further evaluate the advancement of the proposed algorithm in pig behavior recognition, the publicly available Comp dataset was used for additional experiments. This dataset extends the behavior categories of the current study by including the Drinking class, thereby covering more key pig behaviors and validating the generalization capability of the algorithm. The experimental results are presented in
Table 5.
This paper’s approach, YOLOv8-PigLite, demonstrates superior performance metrics compared to the benchmark model, YOLOv8n, on the Comp dataset, even after undergoing lightweighting. Specifically, the precision (P) on the PBRD dataset exhibits a modest enhancement, although the recall (R) and mean average precision at 50 (mAP@50) remain rather stable; on the Comp dataset, the metrics for YOLOv8-PigLite are equivalent to those of YOLOv8n. The experimental findings conclusively demonstrate the superiority of this paper’s algorithm in domestic pig behavior recognition, encompassing a broader range of key behaviors while maintaining or enhancing performance and ensuring a lightweight model. This offers advantageous support for achieving efficient and precise identification of domestic pig behavior in practical applications.
5. Conclusions
This study addresses the challenges of excessive model parameters and high computational complexity in pig behavior recognition by proposing a lightweight algorithm based on YOLOv8n, named YOLOv8-PigLite. The algorithm introduces optimized improvements to the original model’s C2f module and convolution operations, and significantly reduces parameters in the neck network, thereby lowering overall computational cost while effectively maintaining detection accuracy. Additionally, a dual-branch structure and SE attention modules are incorporated to enhance the model’s ability to capture behavioral features, further reducing misclassification rates. Experimental results demonstrate that YOLOv8-PigLite achieves a significant reduction in both parameter count and floating-point operations compared to the baseline and other classical detection models, while maintaining strong generalization ability and recognition accuracy on a public pig behavior dataset. The model performs comparably to the original YOLOv8 in terms of precision and recall, while offering improved efficiency and stability. With its lightweight design and ease of deployment, YOLOv8-PigLite is particularly suitable for small- and medium-sized farms with limited computing resources. It enables real-time recognition and early warning of abnormal pig behaviors, effectively alleviating the inefficiencies of traditional manual monitoring, and holds substantial practical value and application potential.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}