
Machine Learning-Driven Acoustic Feature Classification and Pronunciation Assessment for Mandarin Learners


Abstract
1. Introduction
2. Experimental Procedure and Design
2.1. Experimental Subjects and Speech Data Collection
2.2. Correlation Analysis
- Calculate the mean deviation for all vowels of each learner to generate a deviation dataset;
- Convert Mandarin proficiency levels into ordinal numeric variables;
- Call the pearsonr () function to compute the correlation coefficient (r) and p-value;
- Control for multiple comparison errors using the Bonferroni correction.
3. Experimental Results and Analysis
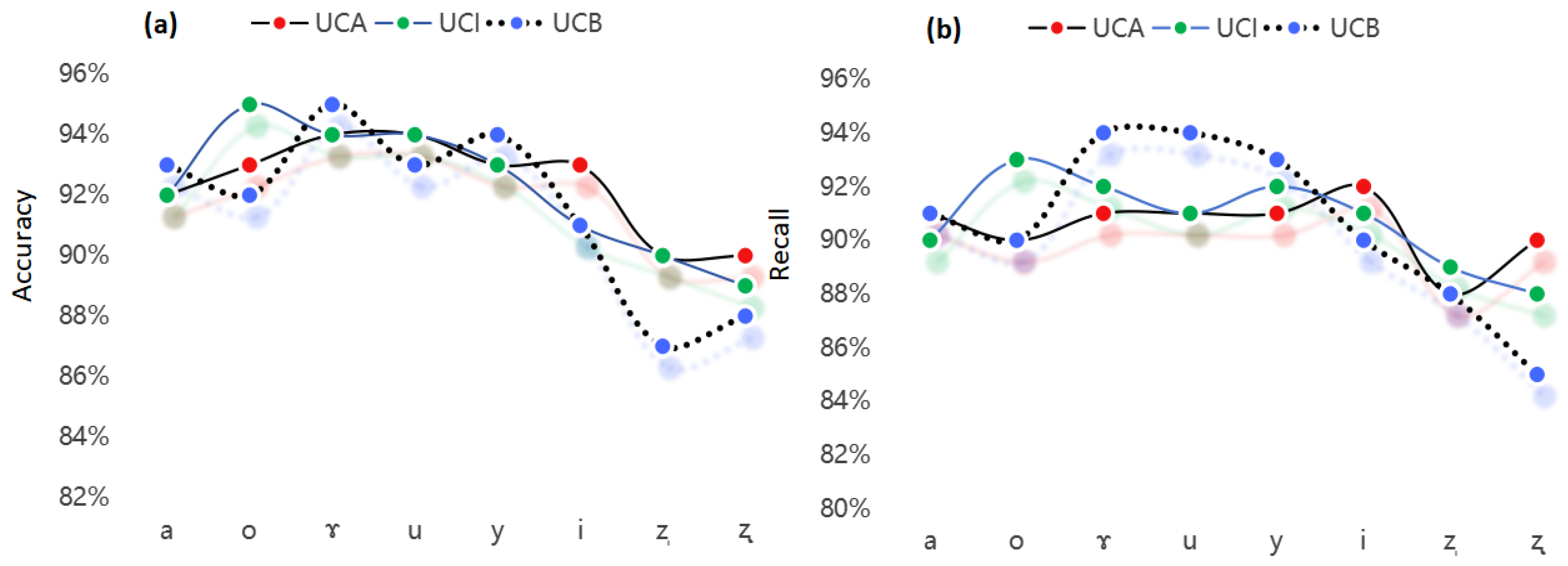
3.1. Classification Results and Analysis Based on Support Vector Machine
 ” are slightly lower (90% and 88–90%, respectively), possibly related to the specificity of the pronunciation position, but their performance remains significantly better than the elementary level group.” is slightly lower (accuracy of 91% and 89%, respectively), possibly due to the complexity of tongue position control. Overall, the intermediate level group demonstrates stable performance for most vowels, but there is still room for improvement in apical vowels and high front vowels.
” are slightly lower (90% and 88–90%, respectively), possibly related to the specificity of the pronunciation position, but their performance remains significantly better than the elementary level group.” is slightly lower (accuracy of 91% and 89%, respectively), possibly due to the complexity of tongue position control. Overall, the intermediate level group demonstrates stable performance for most vowels, but there is still room for improvement in apical vowels and high front vowels.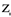 ” and “” is significantly poorer, with accuracy values of 87% and 88% and recall values of 88% and 85%, respectively. This result reflects the pronunciation difficulties faced by elementary learners in apical vowels, possibly related to native language interference or insufficient oral muscle control. Moreover, the recall for vowel “i” is only 90%, indicating that elementary learners also exhibit a certain degree of instability in their pronunciation of high front vowels.
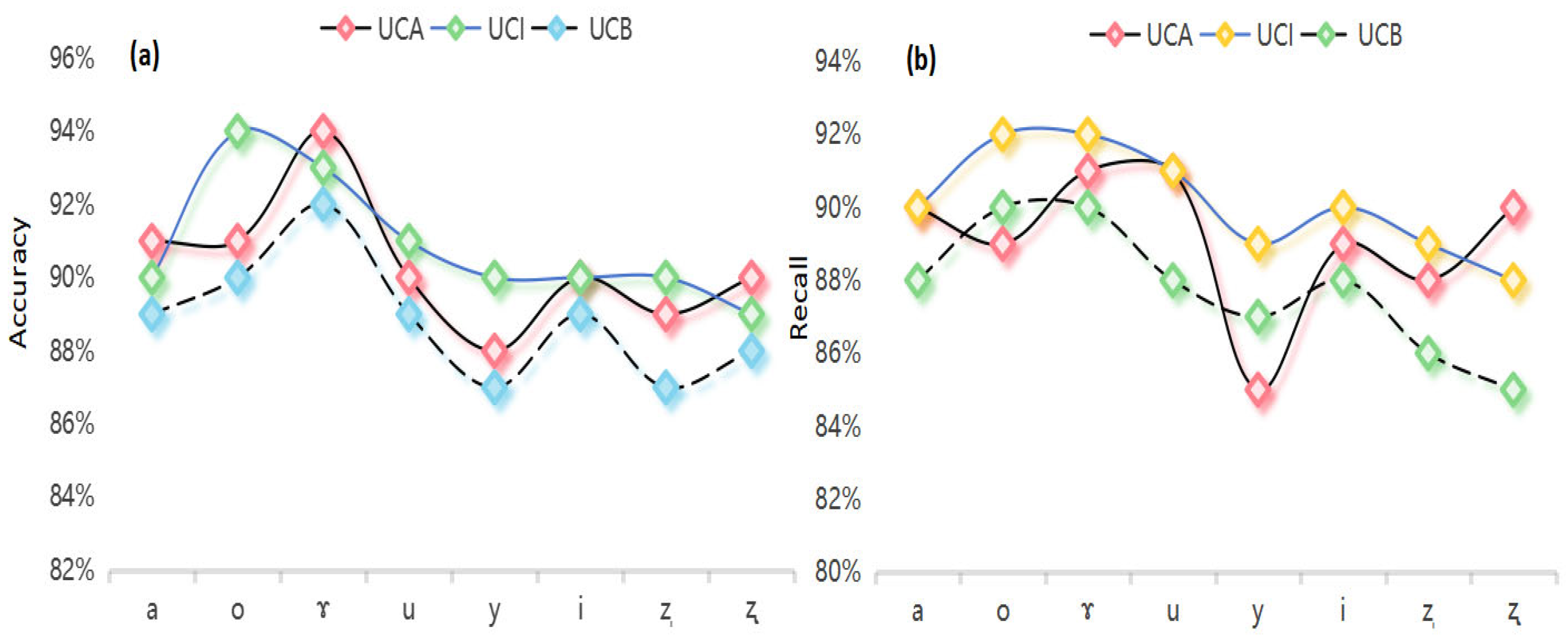
” and “” is significantly poorer, with accuracy values of 87% and 88% and recall values of 88% and 85%, respectively. This result reflects the pronunciation difficulties faced by elementary learners in apical vowels, possibly related to native language interference or insufficient oral muscle control. Moreover, the recall for vowel “i” is only 90%, indicating that elementary learners also exhibit a certain degree of instability in their pronunciation of high front vowels.3.2. Vowel Classification Results and Analysis Based on ID3 Algorithm
” decreases (accuracy ≤ 90%), reflecting the pronunciation instability of intermediate learners in some complex vowels. The UCB has an average accuracy of 89.0% and a recall of 87.9%, with vowels “ɤ” and “o” performing relatively well (accuracy ≥ 90%), but the accuracy and recall for apical vowels “ẓ” and “” are significantly lower (87–88% and 85–86%, respectively), indicating that elementary learners have obvious difficulties in pronouncing these vowels, possibly related to native language interference or the specificity of the pronunciation position.3.3. Calculation Results of Vowel Acoustic Deviation
4. Conclusions and Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yoon, S.Y.; Hasegawa, J.M.; Sproat, R. Landmark-based automated pronunciation error detection. In Proceedings of the Interspeech, ISCA, Makuhari, Japan, 26–30 September 2010. [Google Scholar]
- Yilahun, H.; Zhao, H.; Hamdulla, A. FREDC: A Few-Shot Relation Extraction Dataset for Chinese. Appl. Sci. 2025, 15, 1045. [Google Scholar] [CrossRef]
- Bogach, N.; Boitsova, E.; Chernonog, S.; Lamtev, A.; Lesnichaya, M.; Lezhenin, I.; Novopashenny, A.; Svechnikov, R.; Tsikach, D.; Vasiliev, K.; et al. Speech processing for language learning: A practical approach to computer-assisted pronunciation teaching. Electronics 2021, 10, 235. [Google Scholar] [CrossRef]
- Golonka, E.M.; Bowles, A.R.; Frank, V.M.; Richardson, D.L.; Freynik, S. Technologies for foreign language learning: A review of technology types and their effectiveness. Comput. Assist. Lang. Learn. 2014, 27, 70–105. [Google Scholar] [CrossRef]
- Van Doremalen, J.; Boves, L.; Colpaert, J.; Cucchiarini, C.; Strik, H. Evaluating automatic speech recognition-based language learning systems: A case study. Comput. Assist. Lang. Learn. 2016, 29, 833–851. [Google Scholar] [CrossRef]
- Ming, Y. Application of Speech Recognition and Assessment in Chinese Learning. Ph.D. Thesis, Beijing Jiaotong University, Beijing, China, 2008. [Google Scholar]
- Baevski, A.; Zhou, Y.; Mohamed, A.; Auli, M. wav2vec 2.0: A framework for self-supervised learning of speech representations. Adv. Neural Inf. Process. Syst. 2020, 33, 12449–12460. [Google Scholar]
- Shaw, J.A.; Foulkes, P.; Hay, J.; Evans, B.G. Revealing perceptual structure through input variation: Cross-accent categorization of vowels in five accents of English. Lab. Phonol. 2023, 14, 1–38. [Google Scholar] [CrossRef]
- Wang, S.Y.; Peng, G. Language, Speech and Technology; Shanghai Education Press: Shanghai, China, 2006. [Google Scholar]
- Yuan, J.; Cai, X.; Church, K. Improved contextualized speech representations for tonal analysis. In Proceedings of the Interspeech, Dublin, Ireland, 20–24 August 2023. [Google Scholar]
- Chen, C.; Bunescu, R.; Xu, L.; Liu, C. Tone classification in Mandarin Chinese using convolutional neural networks. In Proceedings of the Interspeech, San Francisco, CA, USA, 8–12 September 2016. [Google Scholar]
- Yan, J.Z. A study of the formant transitions between the first syllable with vocalic ending and the second syllable with initial vowel in the disyllabic sequence in standard Chinese. Annu. Rep. Phon. Res. 1995, 41–53. [Google Scholar]
- Wang, Y.J.; Deng, D. Japanese Learners’ Acquisition of “Similar Vowels” and “Unfamiliar Vowels” in Standard Chinese. Chin. Teach. World 2009, 2, 262–279. [Google Scholar]
- Zhou, Z.C.; Wang, M.J.; Yu, S.Y. Study on Vowel Formant Trajectories of the First Syllable in Chinese Disyllables. Audio Eng. 2007, 31, 8–13. [Google Scholar]
- Assmann, P.F.; Nearey, T.M. Relationship between fundamental and formant frequencies in voice preference. J. Acoust. Soc. Am. 2007, 122, 35–43. [Google Scholar] [CrossRef] [PubMed]
- Gendrot, C.; Decker, M.A. Impact of duration and vowel inventory size on formant values of oral vowels: An automatic analysis from eight languages. In Proceedings of the International Congress of Phonetic Sciences, Saarbrücken, Germany, 6–10 August 2007; pp. 1417–1420. [Google Scholar]
- Dong, B.; Zhao, Q.W.; Yan, Y.H. Research on Objective Testing Method for Pronunciation Level of Finals in Standard Chinese Based on Formant Pattern. Acta Acust. 2007, 32, 122–128. [Google Scholar]
- Amami, R.; Ben Ayed, D.; Ellouze, N. An empirical comparison of SVM and some supervised learning algorithms for vowel recognition. arXiv 2015, arXiv:1507.06021. [Google Scholar]
- Hafiz, A.M. K-Nearest Neighbour and Support Vector Machine Hybrid Classification. Int. J. Imaging Robot. 2019, 19, 33–41. [Google Scholar]
- Neumeyer, L.; Franco, H.; Digalakis, V.; Weintraub, M. Automatic scoring of pronunciation quality. Speech Commun. 2000, 30, 83–93. [Google Scholar] [CrossRef]
- Neumeyer, L.; Franco, H.; Weintraub, M.; Price, P. Automatic text-independent pronunciation scoring of foreign language student speech. In Proceedings of the Fourth International Conference on Spoken Language Processing, ICSLP 96, ISCA, Philadelphia, PA, USA, 3–6 October 1996; pp. 1457–1480. [Google Scholar]
- Franco, H.; Abrash, V.; Precoda, K.; Bratt, H.; Rao Gadde, V.R.; Butzberger, J.; Rossier, R.; Cesari, F. The SRI EduSpeak™ system: Recognition and pronunciation scoring for language learning. In Proceedings of the Integrating Speech Technology in (Language) Learning, InSTIL, ISCA, Dundee, UK, 29–30 August 2000; pp. 121–125. [Google Scholar]
- Hillenbrand, J.; Getty, L.A.; Clark, M.J.; Wheeler, K. Acoustic characteristics of American English vowels. J. Acoust. Soc. Am. 1995, 97, 3099–3111. [Google Scholar] [CrossRef] [PubMed]
- Hsu, C.W.; Chang, C.C.; Lin, C.J. A practical guide to support vector classification. J. Mach. Learn. Res. 2016, 17, 1–16. [Google Scholar]
- Lee, H.; Kim, S. Improving speech recognition accuracy using formant analysis in multilingual contexts. Speech Commun. 2019, 108, 55–63. [Google Scholar]
- Eskenazi, M. An overview of spoken language technology for education. Speech Commun. 2009, 51, 832–844. [Google Scholar] [CrossRef]
- Zhang, Y.P. Research and Application of Decision Tree Improvement Algorithm in Speech Synthesis System. Ph.D. Thesis, University of Science and Technology of China, Hefei, China, 2012. [Google Scholar]
- Li, H. Statistical Learning Methods; Tsinghua University Press: Beijing, China, 2012; pp. 95–124. [Google Scholar]
- Burges, C.J.C. A tutorial on support vector machines for pattern recognition. Data Min. Knowl. Discov. 1998, 2, 121–167. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Zhou, Z.H. Machine Learning; Tsinghua University Press: Beijing, China, 2016; pp. 73–85. [Google Scholar]
- Quinlan, J.R. C4.5: Programs for Machine Learning; Morgan Kaufmann: San Francisco, CA, USA, 1993; pp. 17–42. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Group | Number of Male Participants (Average Score) | Number of Female Participants (Average Score) | Total Number | Mandarin Proficiency Level |
|---|---|---|---|---|
| UCB (Elementary Level Group) | 6 (57) | 6 (55) | 12 | Beginner |
| UCI (Intermediate Level Group) | 10 (65) | 10 (67) | 20 | Intermediate |
| UCA (Advanced Level Group) | 9 (83) | 9 (82) | 18 | Advanced |
| MC (Mandarin Chinese) | 5 (87) | 5 (89) | 10 | Standard |
| Vowel | UCA (Advanced Level Group) | UCI (Intermediate Level Group) | UCB (Elementary Level Group) | |||
|---|---|---|---|---|---|---|
| Accuracy | Recall | Accuracy | Recall | Accuracy | Recall | |
| a | 92% | 91% | 92% | 90% | 93% | 91% |
| o | 93% | 90% | 95% | 93% | 92% | 90% |
| ɤ | 94% | 91% | 94% | 92% | 95% | 94% |
| u | 94% | 91% | 94% | 91% | 93% | 94% |
| y | 93% | 91% | 93% | 92% | 94% | 93% |
| i | 93% | 92% | 91% | 91% | 91% | 90% |
| ẓ | 90% | 88% | 90% | 89% | 87% | 88% |
| 90% | 90% | 89% | 88% | 88% | 85% |
| Vowel | UCA | UCI | UCB | |||
|---|---|---|---|---|---|---|
| Accuracy | Recall | Accuracy | Recall | Accuracy | Recall | |
| a | 91% | 90% | 90% | 90% | 89% | 88% |
| o | 91% | 89% | 94% | 92% | 90% | 90% |
| ɤ | 94% | 91% | 93% | 92% | 92% | 90% |
| u | 90% | 91% | 91% | 91% | 89% | 88% |
| y | 88% | 85% | 90% | 89% | 87% | 87% |
| i | 90% | 89% | 90% | 90% | 89% | 88% |
| ẓ | 89% | 88% | 90% | 89% | 87% | 86% |
| 90% | 90% | 89% | 88% | 88% | 85% |
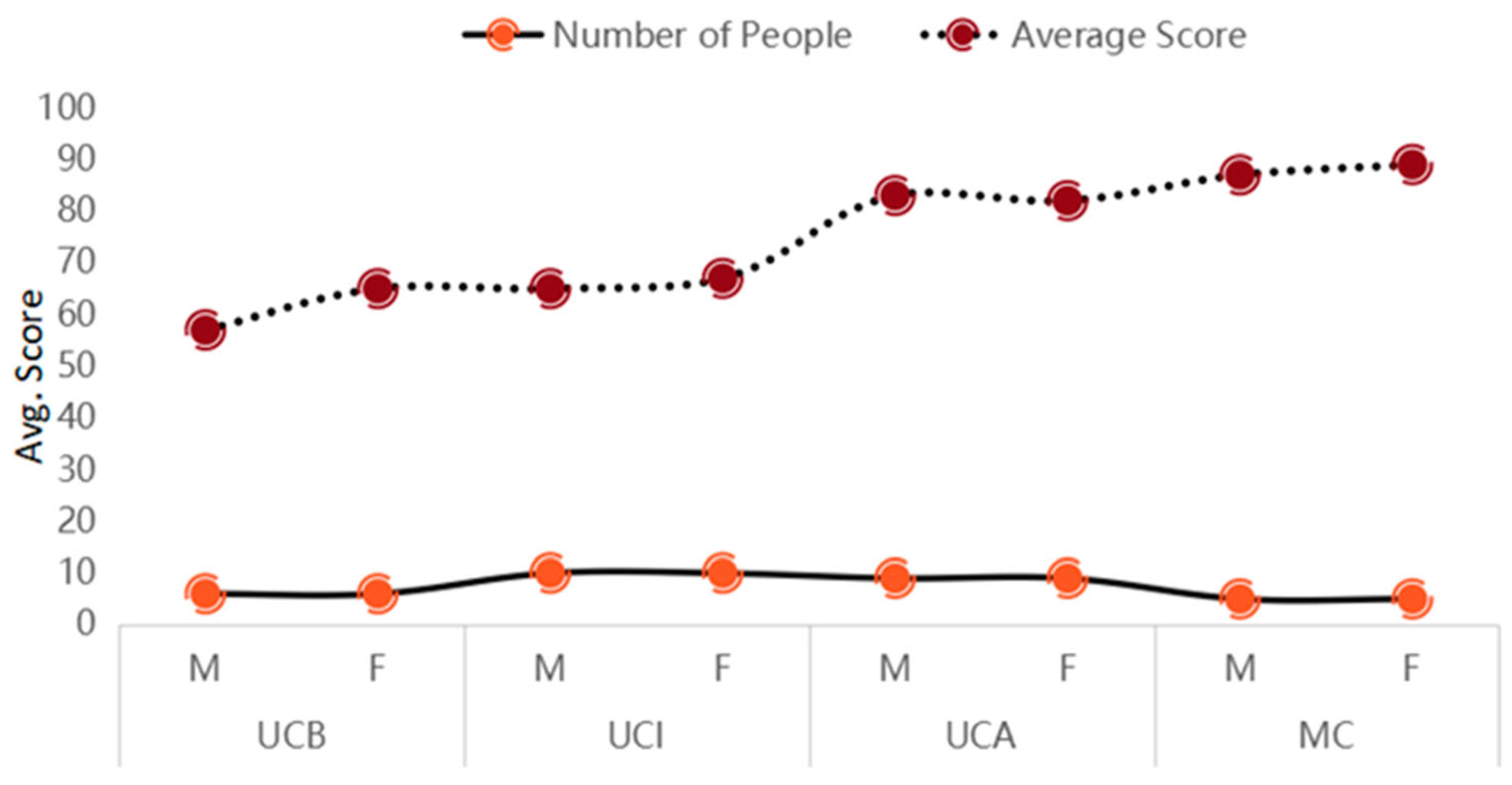
| Vowel | UCA Deviation (Bark) | UCI Deviation (Bark) | UCB Deviation (Bark) |
|---|---|---|---|
| a | 0.09 | 0.08 | 0.11 |
| o | 0.26 | 0.19 | 0.12 |
| ɤ | 0.47 | 0.40 | 0.43 |
| u | 0.14 | 0.38 | 0.52 |
| y | 0.18 | 0.06 | 0.61 |
| i | 0.16 | 0.14 | 1.01 |
| ẓ | 0.09 | 0.28 | 2.61 |
| ̩ | 0.11 | 0.10 | 0.08 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Arkin, G.; Abdukelim, T.; Yilahun, H.; Hamdulla, A. Machine Learning-Driven Acoustic Feature Classification and Pronunciation Assessment for Mandarin Learners. Appl. Sci. 2025, 15, 6335. https://doi.org/10.3390/app15116335
Arkin G, Abdukelim T, Yilahun H, Hamdulla A. Machine Learning-Driven Acoustic Feature Classification and Pronunciation Assessment for Mandarin Learners. Applied Sciences. 2025; 15(11):6335. https://doi.org/10.3390/app15116335
Chicago/Turabian StyleArkin, Gulnur, Tangnur Abdukelim, Hankiz Yilahun, and Askar Hamdulla. 2025. "Machine Learning-Driven Acoustic Feature Classification and Pronunciation Assessment for Mandarin Learners" Applied Sciences 15, no. 11: 6335. https://doi.org/10.3390/app15116335
APA StyleArkin, G., Abdukelim, T., Yilahun, H., & Hamdulla, A. (2025). Machine Learning-Driven Acoustic Feature Classification and Pronunciation Assessment for Mandarin Learners. Applied Sciences, 15(11), 6335. https://doi.org/10.3390/app15116335