1. Introduction
The Bangla characters, also known as the Bengali script (Bengali: Bangla bôrṇômala), represent a writing system of profound cultural and historical importance. Spoken by over 278 million people, approximately
of the world’s largest population, it is ranked seventh globally as of 2022 [
1]. Bengali is the primary language in Bangladesh and is widely spoken in the Indian states of West Bengal, Assam, and Tripura [
2]. The script traces its origins to the ancient Brahmic family of scripts, from which many South Asian writing systems, including Devanagari (used for Sanskrit and Hindi), evolved. Over the centuries, the Bengali script developed into a distinctive system, diverging from closely related scripts such as Oriya and Assamese through unique stylistic and structural adaptations.
Due to its flexibility and expressive capacity, the Bengali script has historically been employed not only for writing the Bengali language but also for transcribing Sanskrit texts in the Bengal region. As one of the most widely used writing systems globally, it plays a vital role in regional communication, education, and the preservation of cultural heritage.
The script comprises vowels, consonants, diacritical marks, conjunct consonants, numerals, and punctuation. It includes eleven vowel graphemes (swôrôbôrnô), which represent six basic vowel sounds and two diphthongs, used in both Bengali and Assamese. One of the key complexities of the script lies in conjunct consonants (juktakkhôr), where clusters of up to four consonants merge to form visually complex shapes, significantly complicating segmentation and recognition. The Bengali numeral system is based on a positional base-10 structure and uses 10 distinct digits (0–9) for numeric representation. Accurate identification and classification of these diverse components require sophisticated recognition systems capable of handling the script’s high visual density and structural complexity.
Deep learning-based character recognition in Bengali presents unique challenges due to the script’s structural complexity and distinctive visual features. While traditional optical character recognition (OCR) techniques have proven effective for scripts with simpler character sets, they often perform suboptimally when applied to the Bengali script. This limitation arises from the presence of visually similar graphemes with subtle structural differences, as well as complex conjunct consonants and overlapping diacritical marks. These features complicate segmentation and accurate classification in conventional OCR systems.
The goal of this research is to develop a robust deep learning model that can effectively recognize and classify individual printed Bangla characters. Rather than relying on the conventional pipeline involving separate stages like segmentation, handcrafted feature extraction, and classification, this study adopts a more streamlined approach using a single-shot object detection method based on the YOLO (You Only Look Once) framework.
We specifically focus on an improved version of YOLOv11, which is designed for high-speed inference and strong recognition accuracy. This upgraded architecture is tailored to handle the unique visual complexity of Bangla characters, many of which share subtle structural similarities. The system processes the entire image in one forward pass, enabling real-time recognition with lower computational cost.
The architecture of our proposed model, as depicted in the diagram, is organized into three main sections: the backbone, neck, and detection head.
At the core of the backbone is ResNet50, a deep residual network responsible for extracting rich feature representations from input images. This backbone is particularly effective in maintaining performance across deeper layers by mitigating the vanishing gradient problem through shortcut connections.
Following the backbone, a Spatial Pyramid Pooling Fast (SPPF) module is used to enhance receptive fields and capture features at multiple scales. This is further augmented by the C2PSA block, which integrates self-attention mechanisms to strengthen both spatial and channel-wise feature learning. As shown in the left portion of the diagram, the C2PSA module uses a series of convolutional layers and PSA blocks, followed by concatenation, to enrich the feature maps before passing them forward.
The neck of the network utilizes several C3k2 modules, which are variations of convolutional blocks designed to either use grouped convolutions (C3k = True) or bottleneck structures (C3k = False), depending on the configuration. These are detailed in the top-right section of the diagram. These blocks help in refining and combining features across different scales through concatenation and upsampling layers.
Finally, the model outputs predictions through the 11 Detect head, which operates on three different scales. As illustrated in the bottom-right corner of the diagram, the detection head includes a series of convolutional and depthwise convolution layers with different kernel sizes (3 × 3 and 1 × 1). These layers handle the tasks of bounding box regression, object classification, and loss calculation for each predicted region.
To validate the effectiveness of our model, we conduct a comparative evaluation against YOLOv5 using a custom dataset of annotated Bangla characters. The results focus on detection accuracy, precision, recall, and inference speed.
Overall, this study shows that the enhanced YOLOv11 model, with its modified backbone, attention mechanisms, and multi-scale detection heads, is well suited for recognizing Bangla script. The proposed approach offers a fast and accurate solution, which could be valuable for applications like educational tools, digital archiving, and broader multilingual OCR systems.
4. Analysis and Findings from Experiments
4.1. Experimental Setup and Parameter Configuration
The hardware and software environment used for training and evaluating the proposed Bangla alphabet detection model is outlined in
Table 2. The setup is optimized for deep learning tasks, ensuring efficient training and inference.
4.2. Building the Dataset
A comprehensive printed image dataset was developed for Bangla character detection, including a total of 60 unique classes: 11 vowels (
Table 3), 39 consonants (
Table 4), 10 numeric digits (
Table 5), and 24 compound characters. Each class consists of 500 annotated samples, resulting in a total of 35,265 labeled images, which are divided into training (70%), validation (20%), and testing (10%) subsets.
The dataset includes variations in font style and visual complexity, as illustrated in
Figure 2. Several characters are visually similar, which poses a challenge for detection models; examples of such cases are listed in
Table 6.
Manual annotation was performed using the LabelImg tool, with each character assigned a unique class ID to ensure precise localization and classification. To enhance generalization, various data augmentation techniques were applied, including brightness adjustment, horizontal flipping, scaling, and rotation. These augmentations expose the model to a wider range of visual variations, thereby improving robustness and accuracy.
Training was conducted using the default YOLO parameters, such as input resolution and anchor box dimensions. This ensured consistent performance evaluation while maintaining a balance between training time and detection accuracy, ultimately supporting reliable real-world deployment.
4.3. Evaluation Overview
Preprocessing transforms raw images into a standardized format, ensuring compatibility with the input requirements of the detection model. Due to varying font styles, the size and dimensions of characters differ across images [
18].
The proposed detection system performs dual tasks:
To evaluate the combined effectiveness of these tasks, we employ Mean Average Precision (mAP), a widely used metric in object detection that integrates both localization and classification performance.
The Intersection over Union (IoU) metric assesses the overlap between the predicted bounding box and the ground-truth bounding box. It is defined as the ratio of the intersection area to the union area of the two boxes:
A prediction is considered a true positive (TP) if its IoU with the ground-truth box exceeds a predefined threshold (0.5); otherwise, it is labeled a false positive (FP). Using this criterion, precision is computed as follows:
To obtain a comprehensive evaluation, we calculate AP at multiple IoU thresholds ranging from 0.5 to 0.95 in steps of 0.05. The mean Average Precision (mAP) over all
C classes is then calculated:
4.3.1. Additional Metrics
To supplement mAP, we also report the following:
Accuracy: the ratio of correct predictions to total predictions.
Recall: the proportion of actual positives correctly identified by the model.
F1 Score: the harmonic mean of precision and recall, providing a balanced measure.
4.3.2. Average Precision (AP)
AP is computed as the area under the precision–recall (P-R) curve. The interpolated precision is used to ensure that the precision at each recall level is maximized over all higher recall levels. The AP calculation is given as follows:
where
and
are consecutive recall values, and
is defined as
This formulation ensures that the precision–recall curve is non-increasing, improving robustness in performance measurement.
4.4. Result Analysis
This application is designed to recognize significant Bangla letters and common phrases encountered in daily life. It utilizes both the original YOLOv11 and an improved YOLOv11 model. The enhanced YOLOv11 version was employed to train the algorithm for 150 epochs using annotations formatted according to the YOLO standard. The model’s performance was evaluated using precision (P), recall (R), and mean average precision (mAP), with the Intersection over Union (IoU) metric ranging from 0.5 to 0.95.
In typical object detection training, two key inputs are provided: the ground-truth bounding boxes, which define the exact locations of the objects within the image, and the predicted bounding boxes generated by the model. Due to inherent model constraints and data variability, some discrepancies between the predicted and actual bounding boxes are to be expected. Evaluating the model’s performance based on predicted bounding boxes can be complex, as the degree of alignment between predicted and ground-truth boxes may vary across different observations. The coordinates of its top-left corner define each bounding box and include the object’s width and height dimensions along the x and y axes.
Otherwise, the class is not considered positive. As the training progresses, metric graphs clearly depict slopes that illustrate the effectiveness of the proposed method in achieving accurate alphabet prediction.
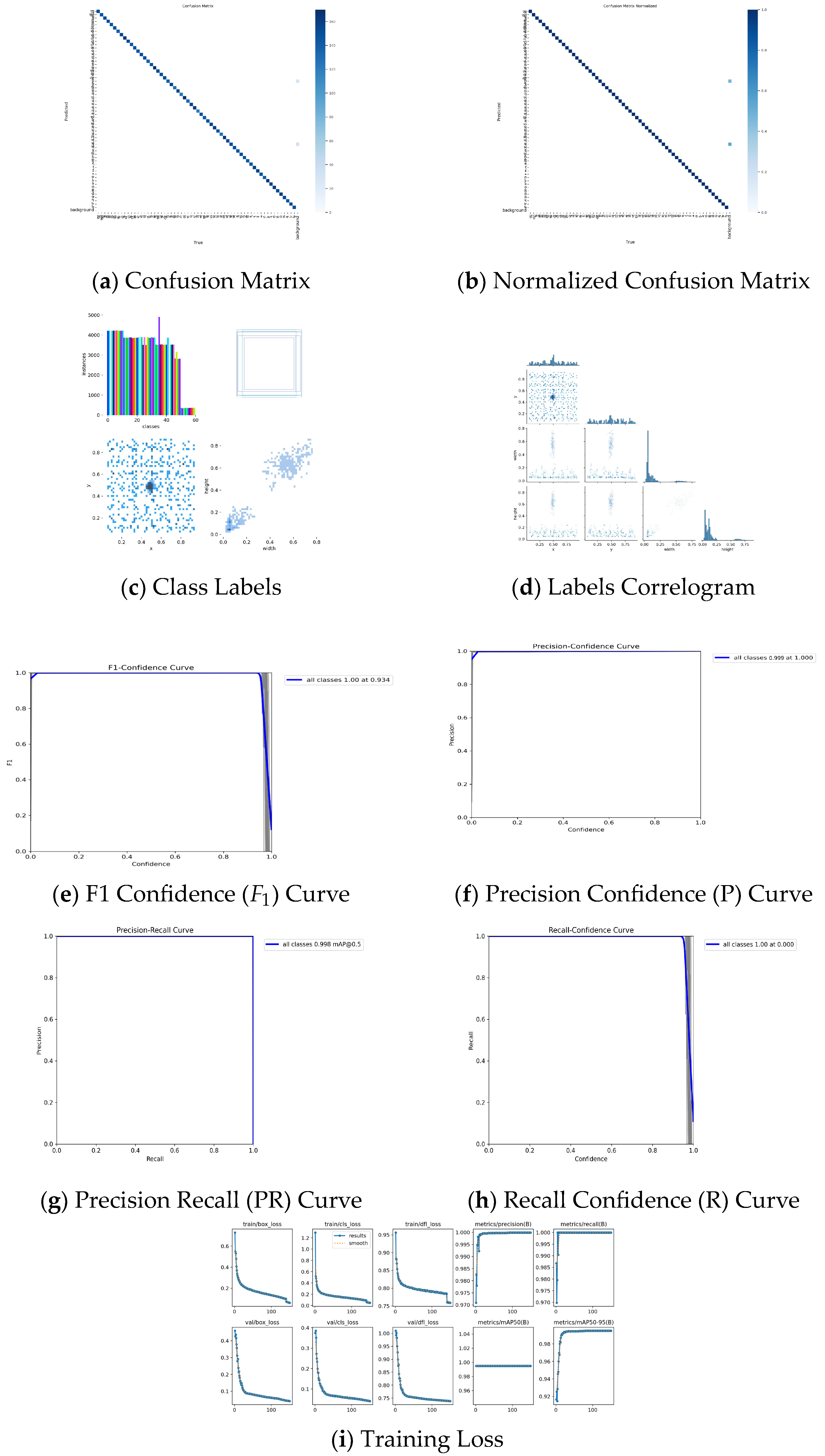
Table 7 shows the values of recall, accuracy, and F1 score. Furthermore, we add that for IoU thresholds of 0.5 and 0.95, the mAP scores were recorded at 0.998 and 0.989, respectively, as presented in
Figure 3g,i. These results underscore the efficacy of our approach in accurately predicting the Bangla letters.
In the F1 score graph, both IoU measurements at 0.5 and 0.95 yield similarly relevant outcomes. The confidence value that optimizes recall (R), as illustrated in
Figure 3h, and accuracy, as depicted in
Figure 3f, is 0.999. This is comparable to the best F1 score of 0.934, as shown in
Figure 3e. It is generally recommended to prioritize a higher F1 score alongside a more confident prediction. The F1 score curve can be a useful tool to strike the optimal balance between precision and recall, ensuring both efficiency and accuracy.
The graph in
Figure 3i shows the loss, precision, recall, and mAP functions for both the training and validation sets. The first three graphs in the top-left corner represent the training loss functions, all of which consistently decrease over time, indicating steady improvement in model performance. Similarly, the three bottom-left graphs show the validation loss functions, which also exhibit a downward trend, confirming that the model’s generalization is improving as training progresses. Moreover,
Figure 3a–d provides a detailed view of class-level prediction behavior. The confusion matrices highlight accurate predictions and occasional misclassifications, while the class labels and correlogram curves further validate the model’s robustness across different Bangla characters.
Notably, the object loss function experiences a slight peak around the 20th epoch, but this is followed by a resumption of the declining trend after a few epochs, suggesting that the model is adapting to the complexity of the data. The accuracy and recall functions show a continuous upward trajectory, further supporting the conclusion that the model is learning effectively.
The mAP50 metric steadily approaches a value of one by the 150th epoch, which signifies that the model achieves near-perfect detection performance at a 50% Intersection over Union (IoU) threshold. This indicates that as over-detection occurs, the model’s detection capabilities improve, resulting in higher mAP scores.
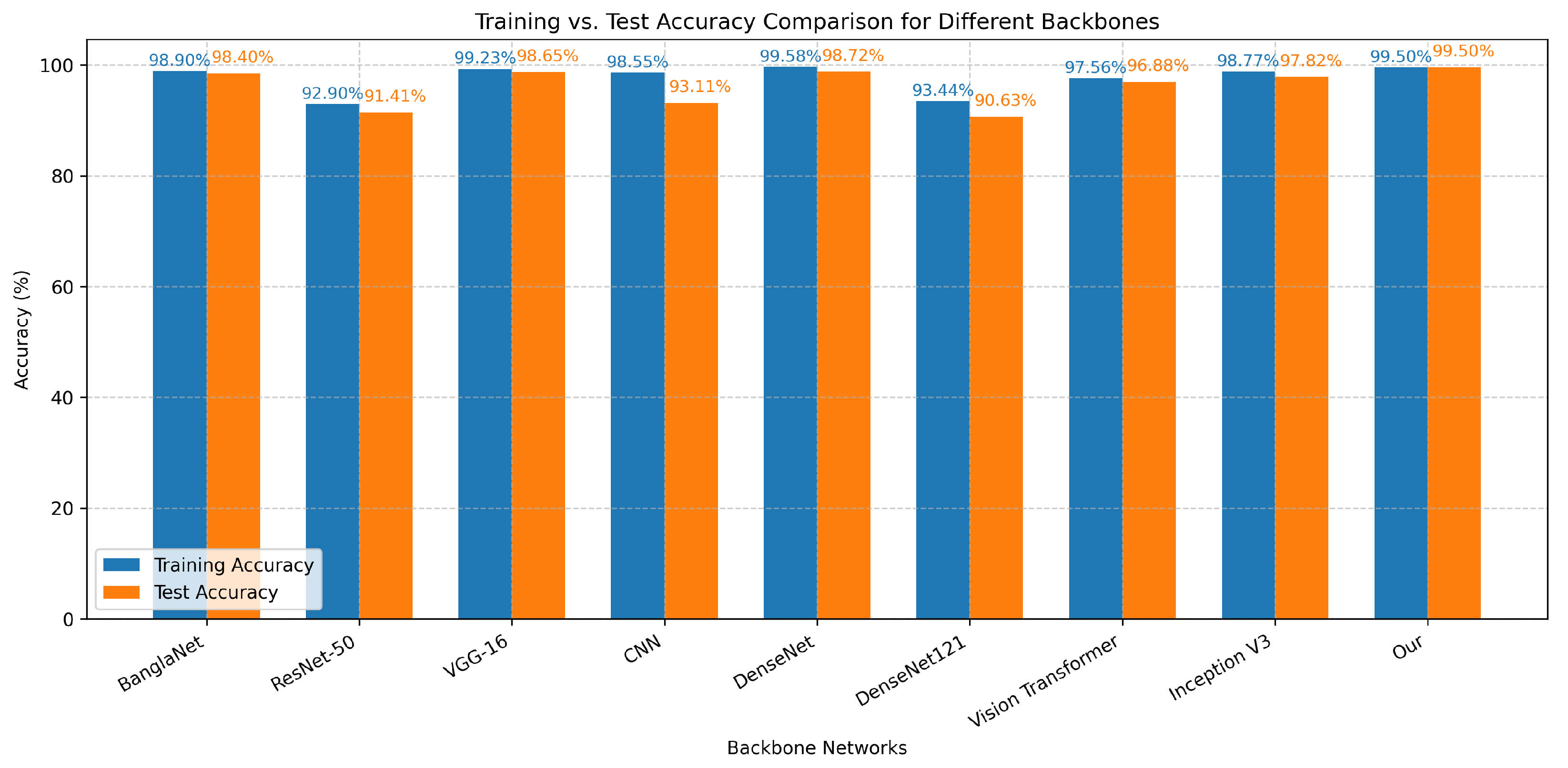
We further investigate the performance of Bangla character recognition using a variety of advanced CNN models. In this study, we employed models such as BanglaNet, ResNet-50, VGG-16, CNN, DenseNet, DenseNet121, Vision Transformer, Inception V3, and our method on a custom dataset. The performance results for classification are presented in
Figure 4.
As anticipated, DenseNet121 and ResNet-50 exhibit lower accuracy performance compared to other models, especially during testing for DenseNet121 and training for ResNet-50. However, YOLOv11 outperforms all other models, providing the best accuracy, as reflected in both training and testing performance. These results highlight the efficiency and robustness of the YOLOv11 model for Bangla character recognition tasks.
4.4.1. Classification of Letters or Characters
After completing model training, we employed the trained model to perform character prediction. The model’s primary task is to accurately identify letters within an image. Once characters are detected, the model generates predictions in the form of test words and images based on the recognized letters. During the detection phase, predicted bounding boxes are overlaid onto the input image, visually highlighting the identified characters.
Initially, the model was trained using a classification-based approach on individual characters. Following this, various test images were used to evaluate its performance. The model generates output based on the detected characters, and these are visually marked within the image using bounding boxes. The resulting annotated images are saved in the same directory as the training outputs. Additionally, the model’s weight parameters are automatically stored in the train folder after each training session. Each time the model is retrained, a new “exp” folder is created to log the corresponding results.
For testing, either a single image or a folder containing multiple images can be provided as input. If a folder path is specified, the model processes and predicts all images within that directory. By default, the output is stored in a designated results folder. This setup supports character predictions on both static images and video frames. Notably, the model achieved a character recognition accuracy of on the test images.
To facilitate accurate predictions, each Bangla character was labeled to form distinct classes. This labeling allows the model to effectively identify characters in both images and videos during inference. As shown in
Figure 5,
Figure 6 and
Figure 7, a new detection folder was created to store the model’s outputs, including predicted labels and their associated confidence scores. Once the model successfully recognizes a character, it annotates the corresponding image and displays the output accordingly.
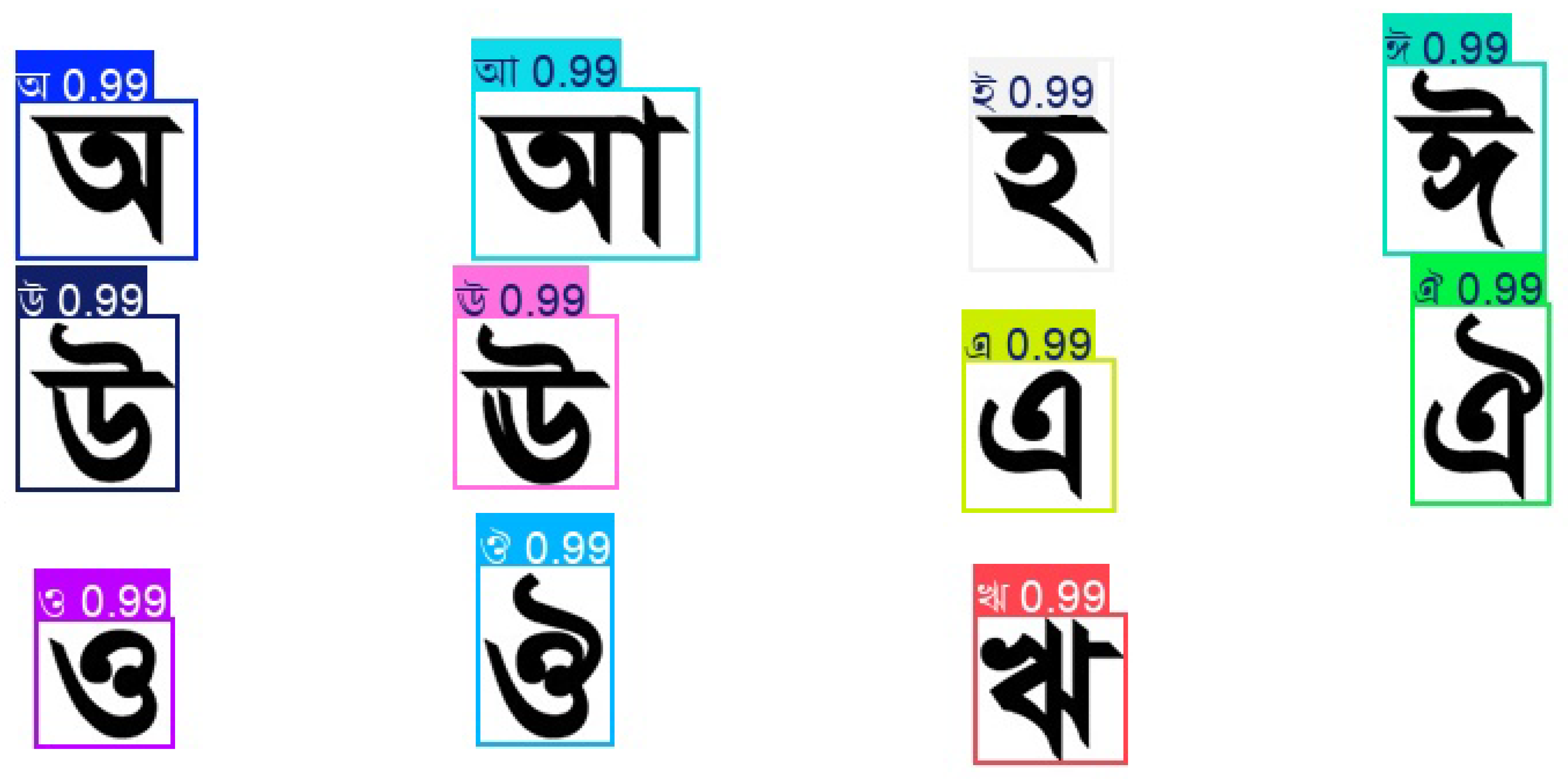
4.4.2. False Detection Using the Original YOLOv11
The original YOLOv11 model demonstrated several false detections when recognizing Bangla characters, as illustrated in
Figure 8. Despite reporting high confidence levels (up to 0.99 for each class), some predictions did not match the actual characters present in the image. These errors highlight the model’s difficulty in distinguishing visually similar letters, often due to overlapping structural features among certain Bangla characters.
These misclassifications can be attributed to several factors, including class imbalance, suboptimal feature extraction, and limited ability to differentiate fine-grained visual details. Expanding the dataset, particularly with samples of visually ambiguous characters, is critical for improving model performance. In addition, applying advanced data augmentation methods and fine-tuning the training parameters can further reduce false detections and enhance overall detection accuracy.
4.4.3. Correct Detection Using the Improved YOLOv11 Algorithm
After improving the YOLOv11 model, a noticeable reduction in false positives was observed, as presented in
Figure 9. The enhanced model shows a significantly better ability to differentiate visually similar characters. These improvements were achieved through a combination of advanced feature extraction techniques, optimized training procedures, and more effective data augmentation strategies.
Although the model consistently reports high confidence scores (approximately 0.99 for each class), occasional misclassifications persist, indicating the need for further refinement. Notable enhancements include the integration of label smoothing to mitigate overconfidence, the use of GIoU and DIoU loss functions to improve bounding box localization, and the implementation of refined attention mechanisms (such as C2PSA) to better capture subtle visual distinctions. Moreover, addressing class imbalances through dataset balancing and targeted augmentation significantly boosted the model’s generalization capabilities, leading to more robust and accurate Bangla character recognition.
5. Conclusions
This study introduces an enhanced version of the YOLOv11 architecture, built upon the modified YOLOv5 framework, for the effective detection and classification of printed Bangla alphabet characters. The proposed model incorporates a ResNet50 backbone and attention mechanisms to enhance feature representation and detection accuracy. Experimental results demonstrate that our approach significantly outperforms existing models in terms of mean average precision (mAP), precision, recall, and F1 score, based on a custom-labeled Bangla alphabet dataset.
One of the most challenging aspects of Bangla alphabet recognition is distinguishing visually similar characters and conjunct consonants. Our model exhibits strong resilience in such cases, achieving an accuracy of up to 99.9% under optimal training conditions. We found that training for 150 epochs provided the best balance between accuracy and overfitting, making it the most effective configuration in our experiments.
LetterSpace=-2.0 Despite these promising results, there are a few limitations. The model has been tested exclusively on printed Bangla characters, and its performance on handwritten or cursive text remains unverified. Additionally, the current dataset does not include noisy backgrounds or real-world scenes, which may affect the model’s ability to generalize effectively.
Looking ahead, we aim to extend this framework to handle handwritten Bangla characters and adapt to more complex image conditions, such as varying lighting, occlusion, and background noise. We also plan to explore real-time Bangla script recognition from video streams and mobile-captured images. These future directions will further test the robustness and applicability of our proposed model in practical OCR systems for low-resource languages.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}