1. Introduction
Hand gesture recognition (HGR) plays a crucial role in various applications, including human–computer interaction, sign language recognition, augmented reality, and robotics [
1,
2]. Unlike traditional input methods like the mouse and keyboard, vision-based interfaces offer a practical alternative due to the intuitive nature of hand gestures [
3]. In some scenarios, static hand gestures might suffice for capturing simple commands through spatial cues. On the other hand, more complex dynamic gestures require precise motion interpretation. For example, touchless screen manipulation has gained significant importance in our hygiene-conscious world, reducing the need for physical contact [
4,
5].
Among the different approaches to HGR, skeleton-based recognition has gained attention for its ability to capture hand dynamics efficiently while being robust to background, lighting, and appearance variations [
2]. However, despite the growing interest and recent progress in this field [
6,
7,
8,
9,
10,
11], advancement is still limited by the lack of large-scale datasets containing dense, frame-level annotations of hand landmarks. This limitation is particularly evident in continuous gesture sequences captured under realistic conditions, where challenges such as motion blur, occlusion, and spontaneous hand motion frequently occur. Building reliable gesture recognition models for these settings demands annotations that are not only spatially precise but also temporally consistent. Yet, producing such annotations remains a significant bottleneck due to the manual effort required to label landmarks frame by frame.
Recent deep learning models for hand pose estimation [
12,
13] offer fast automatic detection of hand landmarks that can serve as a valuable starting point for annotation. Nevertheless, their outputs often suffer from inconsistencies across frames, as well as incomplete or missing detections, especially in complex poses or low-quality frames. As a result, manual refinement is crucial to address these issues and ensure both temporal and spatial coherence. Without such refinement, HGR models trained on noisy or incomplete annotations may struggle to accurately capture the true temporal dynamics of gestures, ultimately compromising recognition performance.
To address the mentioned challenges, we introduce IPN HandS, an extension of our IPN Hand dataset [
5] enriched with high-quality hand skeleton and temporal gesture annotations. Alongside this dataset, we present a novel annotation tool designed to ease the annotation process. By integrating automatic landmark detection, inter-frame interpolation, copy–paste functionalities, and manual refinement capabilities, our tool reduces the average annotation time from 70 to 27 min in videos of about 4000 frames long, enabling large-scale annotation with improved efficiency.
Figure 1 illustrates the enhancement in annotation quality achieved through our refined IPN HandS annotations. It compares our annotations to the outputs of commonly used hand pose estimators, such as MediaPipe Hands [
12] and MediaPipe Holistic [
13]. The comparison focuses on a single frame that exhibits motion blur, which is a frequent and recurrent issue in video-based HGR applications. Further examples of annotation errors can be found in
Section 4.3.
We showcase the quality of our refined annotations by training a simple yet effective LSTM-based HGR model on the IPN HandS dataset. This model is evaluated using both our refined data and the noisier annotations generated by MediaPipe estimators. The results indicate accuracy improvements of about 12% and 8% when compared to models trained solely on MediaPipe Hands [
12] and Holistic [
13] annotations, respectively. These findings underscore the importance of high-quality annotations in advancing skeleton-based HGR methods.
The main contributions of this paper can be summarized as follows:
We introduce a practical annotation tool that combines automatic initialization, interactive refinement, and temporal editing to efficiently generate high-quality hand skeleton annotations from video frames.
We present IPN HandS, an extended version of the IPN Hand dataset [
5], enriched with over 800,000 frame-level hand skeleton annotations and refined temporal gesture boundaries.
We provide a detailed experimental evaluation showing that models trained on IPN HandS significantly outperform those trained on MediaPipe-based annotations, highlighting the impact of annotation quality on LSTM-based HGR performance.
In addition, the annotation tool and the IPN HandS dataset will be made publicly available at Github [
14] to support reproducible research. This aims to provide the community with practical resources for developing more accurate and efficient HGR models, as well as for annotating other datasets that require frame-level hand skeletons. The remainder of the paper is structured as follows.
Section 2 reviews related work on annotation tools, HGR datasets, and skeleton-based recognition methods.
Section 3 presents the IPN HandS annotation tool.
Section 4 introduces the IPN HandS dataset, describing the annotation process and dataset statistics.
Section 5 evaluates the impact of our refined annotations on HGR performance, outlining the LSTM-based model, experimental setup, and accuracy improvements.
Section 6 discusses the broader implications of our tool and the role of high-quality annotations in HGR. Finally,
Section 7 concludes the paper and outlines future directions.
2. Related Work
This section reviews related work, focusing on skeleton-based annotation tools, HGR datasets, and methods to contextualize our contributions with the IPN HandS dataset and annotation tool.
2.1. Skeleton-Based Annotation Tools
Accurately annotating hand skeletons in video is labor-intensive, and usually, researchers rely on general-purpose annotation tools. For instance, Label Studio [
15] is a versatile web-based platform supporting multiple annotation formats, including key points, bounding boxes, and text labels. While it integrates machine learning-assisted annotations, its landmark labeling lacks native support for skeleton visualization, making pose estimation cumbersome. LabelImg [
16] is a lightweight and offline tool commonly used for object detection annotation. Although it allows landmark labeling, it does not inherently support joint connections, requiring external post-processing to structure skeletons. VIA (VGG Image Annotator) [
17] is a simple, browser-based tool designed for efficient manual annotation, offering point-based labeling but without built-in pose structures or automation. Despite their utility, these tools present limitations for skeleton annotation. Label Studio’s configurability comes at the cost of complexity, requiring custom setups for skeletal connections. LabelImg and VIA, though easy to use, lack automation and structured skeleton representation, making frame-by-frame annotations time-consuming.
On the other hand, advances in computer vision have led to approaches like MediaPipe [
12], which provides automatic hand landmark detection using deep learning, significantly reducing manual annotation effort. The easy-to-use and high-performance real-time hand tracking makes this approach a widely employed tool to generate skeleton-based annotations for hand gesture recognition datasets [
10,
11,
18,
19,
20]. However, MediaPipe often suffers from inconsistencies, especially in complex poses or motion-blurred frames (as shown in
Figure 1), necessitating manual correction.
In summary, none of the reviewed tools provide efficient and user-friendly tools tailored explicitly for video-based hand skeleton annotation. Therefore, we introduce an annotation tool that integrates automatic pose detection with manual refinement and interpolation. Unlike existing tools, our approach reduces annotation effort by leveraging automatic landmark detection while enabling precise adjustments and smooth transitions between frames.
2.2. Skeleton-Based HGR Datasets
Skeleton-based HGR datasets are essential for training models that efficiently capture hand dynamics while remaining robust to background and lighting variations. For instance, the SHREC 2017 dataset [
21], introduced through the SHREC’17 competition, contains 14 dynamic hand gesture classes (28 classes if considering two finger configurations per gesture) performed by 28 participants, captured with an Intel RealSense depth camera. This dataset is based on the Dynamic Hand Gesture (DHG-14/28) dataset [
22], which provides 2800 isolated gesture sequences with 3D hand landmark annotations (22 landmarks per hand) from 20 subjects. Similarly, the Briareo dataset [
23] was captured using depth sensors and infrared stereo cameras for dynamic hand gesture recognition in an in-car environment. The dataset contains 12 classes performed 3 times by 40 subjects with a total of 120 sequences per gesture (each sequence lasts at least 40 frames). These datasets consist of short, isolated gesture clips recorded in controlled settings, providing high-quality skeleton data but lacking real-world complexity.
In contrast to existing skeleton-based HGR datasets, our IPN HandS focuses on continuous, real-world gesture recognition scenarios captured with standard RGB cameras. The dataset includes 50 subjects performing 14 gesture classes, which encompass both static postures and dynamic movements, all recorded in long, uninterrupted video sequences. As shown in
Table 1, it comprises over 5000 annotated gesture instances and around 800,000 frames that feature dense, frame-level hand skeleton annotations. Unlike previous datasets relying on depth or infrared sensors and consisting of isolated gestures, IPN HandS captures continuous gesture sequences in natural environments with varying lighting conditions and complex backgrounds. This design closely mimics real-world HGR applications, particularly those involving touchless screen interactions.
Table 1 provides a comparison of the aforementioned skeleton-based HGR benchmarks. IPN HandS stands out as the only large-scale dataset fully captured in RGB, making it the most accessible modality for real-world implementations. Its continuous nature, diverse range of gestures, and extensive scale establish it as a more representative and challenging benchmark for the development and evaluation of HGR systems in unconstrained settings.
2.3. Skeleton-Based HGR Methods
Skeleton-based HGR methods leverage the structural and temporal information of hand landmarks, making them especially effective for dynamic gesture recognition. Deep learning has driven significant advances in skeleton-based HGR [
6,
7,
8,
9,
10,
11], particularly with recurrent architectures such as Long Short-Term Memory (LSTM) networks [
24]. LSTM excels at modeling temporal sequences, making it suitable for capturing the dynamics of actions and gestures over time, effectively capturing dynamic gesture patterns [
25]. It has been traditionally used in HGR for classifying gesture sequences based on skeletal data.
A different approach is based on Graph Convolutional Networks (GCNs) [
26], which are designed for graph-structured data. GCNs emerged as a powerful alternative, treating hand skeletons as structured graphs where nodes (joints) and edges (bones) encode spatial dependencies [
26]. GCN-based approaches [
11,
27,
28] have demonstrated state-of-the-art performance in skeleton-based gesture recognition by jointly learning spatial and temporal dynamics.
Transformers have also gained attention in skeleton-based HGR [
7,
29]. Unlike RNNs and GCNs, Transformers rely on self-attention mechanisms to capture long-range dependencies in motion sequences, improving performance on complex gestures. Across all of these methods, high-quality annotations remain crucial, since noisy or inconsistent skeletons can significantly degrade model accuracy. By refining hand-landmark annotations, our approach enhances data reliability, directly benefiting HGR model performance.
The recent literature also highlights the growing relevance of Artificial Intelligence-based Internet of Things (AIoT) gesture recognition and sim-to-real adaptive learning strategies in practical deployments. For example, Qi et al. [
30] provide a comprehensive review of human activity recognition in AIoT systems, categorizing techniques and applications that emphasize lightweight, adaptive, and resource-efficient solutions. While our current study focuses on accurate single-hand annotations from RGB data, future work could explore how such annotations support AIoT-specific constraints and generalization in diverse, real-world settings.
3. IPN HandS Annotation Tool
The purpose of the IPN HandS annotation tool is to provide a practical and efficient environment for annotating hand skeletons in video sequences, with a particular focus on datasets used for hand gesture recognition (HGR). Unlike general-purpose annotation tools, which often require frame-by-frame manual labeling and lack specialized support for skeletal structures, our tool combines automatic landmark detection with user-friendly refinement mechanisms to significantly reduce annotation time and improve consistency. The tool was designed specifically to overcome the limitations of existing software by supporting high-resolution landmark editing, interpolated corrections across frames, and seamless visualization of temporal gesture segments. These features make it particularly well-suited for refining noisy automatic detections (e.g., from MediaPipe), ensuring the annotated skeletons are reliable and coherent enough to be used as training data in skeleton-based HGR models.
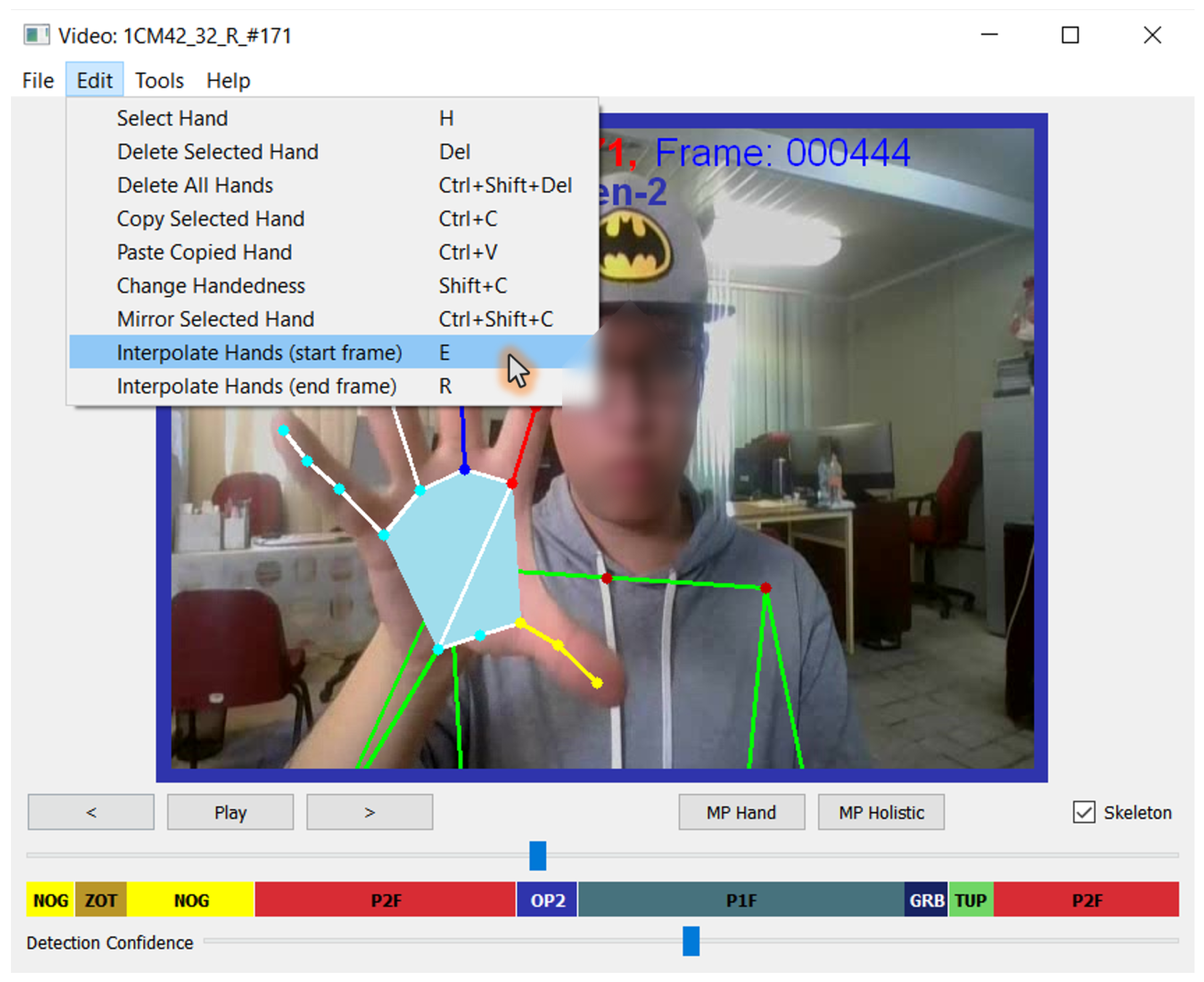
The graphical user interface of the annotation tool is shown in
Figure 2. At the center of the interface is the video display panel, where annotated frames and, when available, the estimated hand and body skeleton (toggled by the checkbox) are visualized. The top of the interface includes a traditional menu bar offering access to diverse functions. Below the display panel, a set of navigation buttons allows the user to move frame by frame or play through the sequence, while buttons labeled
MP Hands and
MP Holistic trigger single-frame landmark estimation using the corresponding MediaPipe models. Beneath the control buttons, a horizontal slider enables quick navigation through the video sequence, allowing annotators to efficiently jump across frames. This is followed by a color-coded annotation timeline, which shows the temporal segmentation of gesture classes as defined by the original IPN Hand dataset. Each color corresponds to a gesture label, helping annotators identify and focus on gesture-specific segments. Finally, at the bottom of the interface, a confidence slider is used to adjust the detection threshold for the single-frame estimation tools, providing flexibility in handling uncertain or partially visible gestures.
In general, the annotation process focuses on the efficient refinement of hand skeletons over long video sequences that contain multiple instances of gestures. To initialize the annotations, the MediaPipe Holistic model [
13] is applied to all frames of a given video. This generates preliminary hand and body landmark detections, which are automatically saved and serve as a first-pass estimation for each frame. Annotators then navigate through the sequence by referencing the temporal segmentation of gesture classes, allowing them to focus on relevant gesture intervals. During this process, frames can be efficiently reviewed one by one, and if the initial detections are inaccurate, hand landmarks can be re-estimated using alternative models (MP Hands [
12] and MP Holistic [
13]) or by manually adjusting hand poses. The annotation process is supported by interpolation and copy–paste functionalities, which reduce the need for frame-by-frame correction and improve efficiency when refining sequences that exhibit consistent motion or contain static gestures. Once all necessary refinements are complete, the final annotations are saved for use in training hand gesture recognition models.
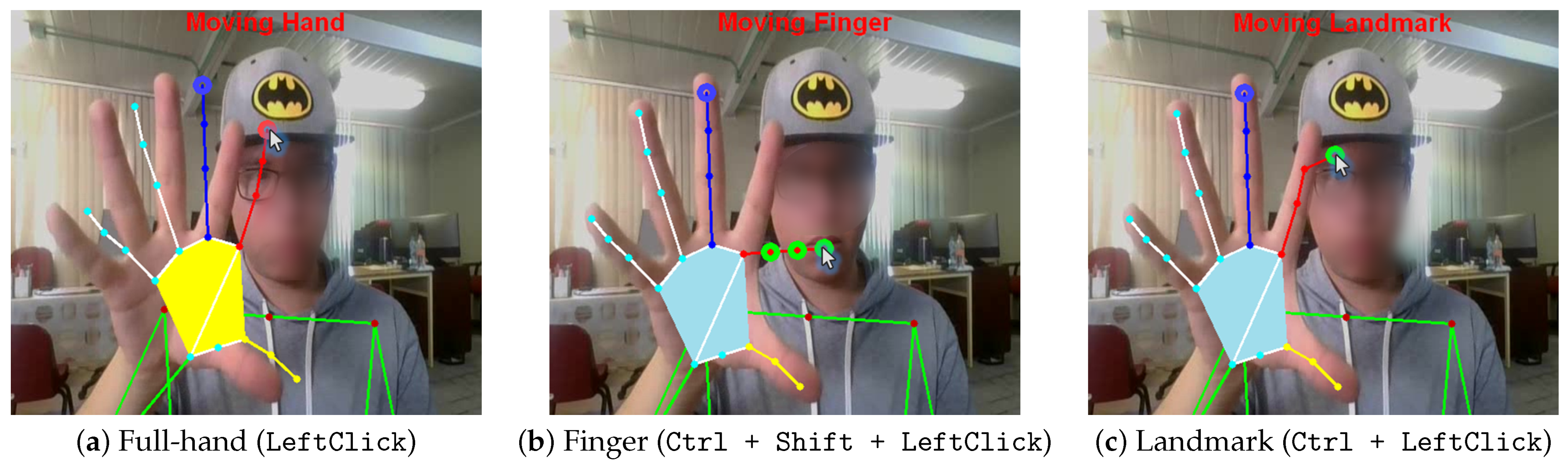
To facilitate the correction of inaccurate detections, the tool provides a set of interactive editing capabilities. As illustrated in
Figure 3, the annotator can perform fine-grained modifications to the hand skeletons by manually selecting and dragging individual landmarks, adjusting entire fingers, or repositioning the full hand. These operations enable intuitive corrections to spatial inaccuracies commonly introduced by automatic estimators, particularly in challenging frames with motion blur or occlusion. In addition to direct manipulation, the tool includes functionality for interpolating landmark positions between two selected frames, which is especially effective for continuous gestures involving smooth transitions. For static gestures or repeated poses, annotations can also be copied and pasted across frames, eliminating the need to repeat identical adjustments. Together, these tools enable the annotator to efficiently achieve temporally consistent and spatially accurate hand landmark annotations with minimal manual effort. To further streamline the process, each interactive operation is paired with an intuitive and easily accessible keyboard shortcut. For example, dragging a landmark is initiated using simple key combinations (
Ctrl + LeftClick), and interpolation is triggered through a pair of dedicated shortcut keys (
E and
R).
Building upon these functionalities, our proposed tool was used to annotate the entire IPN Hand dataset [
5], comprising over 800,000 video frames. This large-scale application not only validated the reliability of the tool in practice but also demonstrated its efficiency in producing consistent and precise hand skeleton annotations. The integration of features such as automatic initialization, manual refinement, interpolation, and copy–paste mechanisms enables annotators to efficiently manage long gesture sequences while minimizing repetitive effort.
Table 2 summarizes the main capabilities offered by the tool, each contributing to the balance between annotation speed and accuracy.
Annotation Efficiency Evaluation
To quantify the efficiency of our proposed annotation tool, we conducted a controlled experiment comparing its performance against a conventional annotation workflow based on the VIA (VGG Image Annotator) interface [
17] developed by the University of Oxford, Oxford, UK. In both conditions, initial hand landmarks were estimated using the MediaPipe Holistic model [
13]. The task involved manually correcting and completing annotations for 15 videos, each containing 25 gesture instances (375 total) and covering approximately 58,000 frames. A single expert annotator performed this evaluation to ensure consistency across tools and eliminate skill-based variability. While this setup prevents inter-annotator agreement analysis, it allowed for a focused assessment of tool efficiency under controlled conditions.
Table 3 summarizes the average annotation time measured in minutes per video, per gesture instance, and per frame. The VIA-based process required over 70 min per video, whereas our IPN HandS tool reduced this to just 26.5 min on average, resulting in a 2.6× speedup. This gain demonstrates that the integration of automatic initialization, interactive refinement, and interpolation in our tool substantially reduces annotation time while maintaining high spatial and temporal precision. The efficiency of our tool enabled us to annotate the entire IPN Hand dataset at scale, supporting the creation of IPN HandS.
4. IPN HandS Dataset
The IPN Hand dataset [
5] is a video-based benchmark for hand gesture recognition (HGR), consisting of continuous RGB recordings of 50 subjects performing a predefined set of gestures. It includes 13 gesture classes specifically designed for touchless screen interaction, covering both static poses and dynamic movements such as pointing, clicking, and zooming. Unlike isolated gesture datasets, IPN Hand features long, uninterrupted video sequences, each containing multiple gesture instances embedded in natural motion. Recordings were captured across approximately thirty diverse indoor scenes, exhibiting significant variation in lighting conditions, camera viewpoints, and background complexity, including both static and dynamic environments. The dataset was explicitly designed with two challenging real-world scenarios: one in which continuous gestures are executed without transition states between them, and another where subjects perform natural, non-gesture hand movements between gestures. These conditions make IPN Hand particularly demanding and realistic for continuous gesture recognition. In total, the dataset comprises 4218 labeled gesture instances and over 800,000 frames, with manually annotated temporal boundaries. Due to its scale and complexity, IPN Hand remains an active benchmark widely used in recent research on HGR [
10,
11,
18,
19,
20].
Building on the original IPN Hand dataset, we introduce IPN HandS, an extended version that incorporates frame-level hand skeleton annotations. These annotations were designed to support skeleton-based HGR by adding precise spatial representations that were not available in the original version. Each frame of gesture instances in the dataset now consistently includes one or two annotated hand skeletons, defined by 21 landmarks per hand, making it suitable for training sequence-based gesture recognition models. In addition to the spatial annotations, we implemented two key refinements to improve consistency and classification accuracy. These include a manual revision of the temporal boundaries across all gesture instances and restructuring of the gesture taxonomy to better distinguish overlapping motion patterns. IPN HandS thus enhances the temporal richness of the original dataset with dense spatial supervision, offering a comprehensive benchmark for evaluating gesture recognition under realistic and dynamic conditions.
4.1. Annotation Process and Temporal Refinement
Skeleton annotations were created using the annotation tool described in
Section 3. The process began by initializing all frames in a video sequence with landmarks estimated by the MediaPipe Holistic model [
13]. Each annotated hand was represented by 21 landmarks per frame, enabling precise modeling of finger articulation and hand posture. While this provided a solid baseline, the automatic predictions often exhibited frame-to-frame inconsistencies or errors, especially in motion-blurred frames or complex poses, as further analyzed in
Section 4.3. These estimates were then reviewed and refined by a single expert annotator using our interactive editing tools, which allowed for adjustments to individual landmarks, fingers, or entire hands as needed. The use of a single experienced annotator ensured consistency across all videos and eliminated inter-annotator variability. Moreover, the high efficiency of our tool made it feasible to inspect and revise annotations at frame-level granularity, supporting both spatial and temporal refinement at scale.
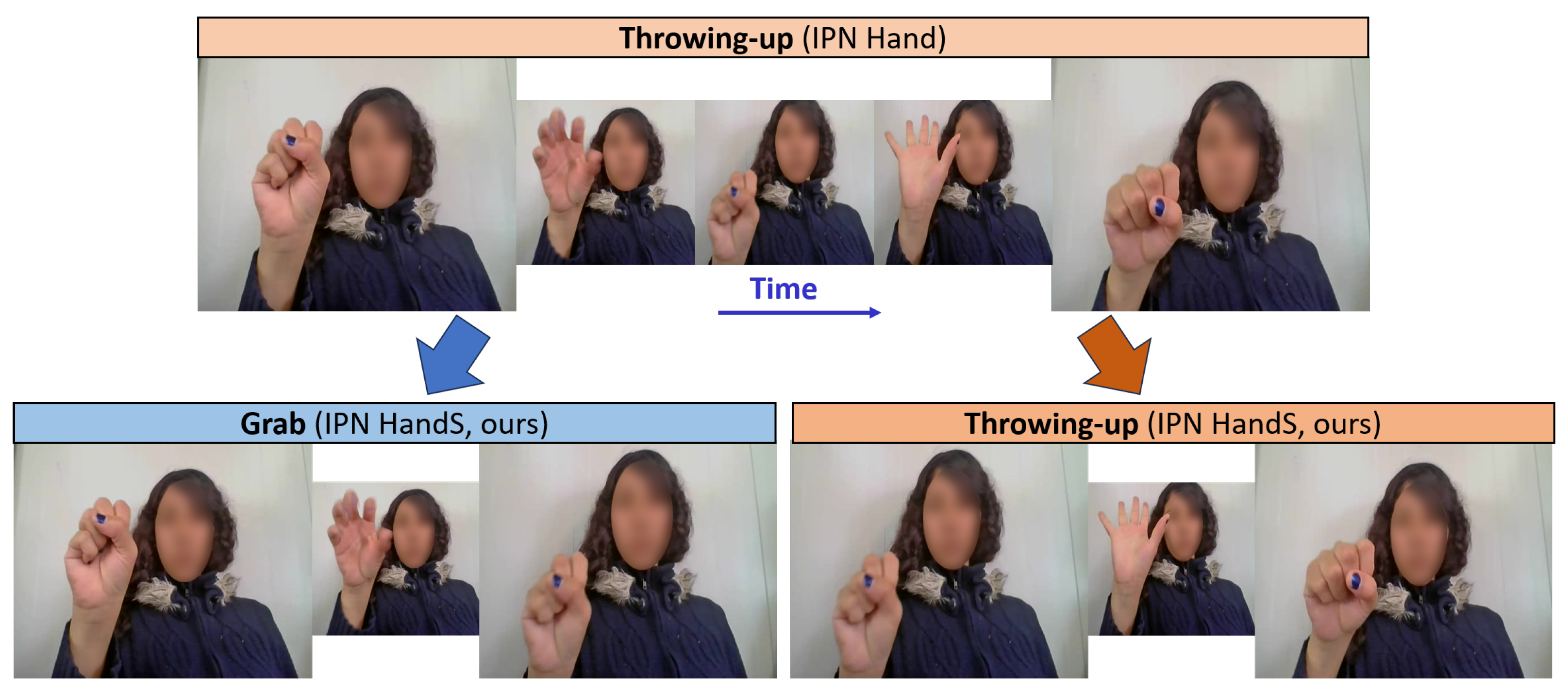
Beyond skeleton annotation, we restructured the gesture taxonomy to improve class separability, similarly to our previous work [
31]. In the original dataset, some dynamic gestures like throwing-up, throwing-down, and related movements included an initial grabbing motion that was visually and semantically distinct. To capture this nuance, we introduced a new gesture class,
grab, which isolates this initial component from the subsequent throwing gestures.
Figure 4 illustrates this refinement, where a single sequence previously labeled as “throwing-up” is now separated into “grab” followed by “throwing-up”. This change enhances classification accuracy by better aligning gesture labels with observable motion patterns.
We also performed a systematic revision of the temporal boundaries for all gesture instances. In many cases, the annotated start and end points failed to capture the full motion or included irrelevant transitions. Thus, each gesture sequence was manually inspected and adjusted to ensure its temporal limits precisely reflected the actual onset and offset of the gesture. As shown in
Figure 5, these corrections eliminate ambiguity and reduce noise in the training data, especially for gestures with subtle or short transitions such as zoom-in and zoom-out.
In total, annotating the full IPN HandS dataset (comprising 200 videos) required 5160 min (approximately 86 h) using our annotation tool, with an average of 25.8 min per video. The ability to annotate such a large-scale dataset with high precision and manageable effort underscores the practical value of our tool and supports the public release of the annotations for future research in skeleton-based gesture recognition.
4.2. Dataset Statistics
The refined IPN HandS dataset comprises a total of 7770 instances across approximately 800,000 video frames. Each gesture instance is labeled with precise start and end frames and is accompanied by dense hand skeleton annotations. All frames from gesture instances are annotated with at least one hand skeleton, while several contain two. For non-gesture segments, the number of visible hands varies, including frames with zero, one, or two hands, due to natural hand movement and occlusion. Overall, the dataset includes over 700 thousand individual hand skeletons, averaging approximately 0.9 annotated hands per frame.
Table 4 provides a detailed breakdown of the 14 gesture classes, showing the number of instances, total annotated frames, and average gesture duration per class. The no-gesture category accounts for over 2500 segments, representing roughly one-third of the dataset. This highlights the importance of modeling background activity and distinguishing intentional gestures from spontaneous hand motion. Among the gestures, pointing actions (
P1F,
P2F) exhibit the longest durations, while classes such as clicking and grabbing are shorter but frequent in interactive settings. Note that all videos were recorded at 30 frames per second (fps), meaning the shortest gestures span approximately 630 milliseconds (19 frames). Excluding pointing actions, the average duration across gesture classes is around 1.1 s (33 frames), making these fast and compact motions especially challenging for recognition systems that must detect and classify subtle temporal patterns within a limited window. At the same time, this also underscores the importance of precise temporal annotation, since any misalignment in gesture boundaries may result in the omission or distortion of the entire gesture sequence, ultimately degrading model performance.
Figure 6 illustrates the gesture classes of IPN HandS using overlaid hand skeletons. Each column shows sequential frames spanning the start, motion, and end of a gesture instance.
4.3. Analysis of Automatic Annotation Quality
To better understand the necessity of manual refinement, we conducted a detailed comparison of annotation quality between our refined IPN HandS and the outputs from MediaPipe Hands [
12] and MediaPipe Holistic [
13]. We analyzed both the temporal consistency and spatial precision of the hand keypoints produced by these models, using IPN HandS as the reference. Specifically, we measured (i) the rate of missed detections, defined as frames where no valid hand landmarks were returned, and (ii) the keypoint error, computed as the normalized average Euclidean distance between corresponding landmarks across all detected frames. This evaluation was performed per gesture class to reveal gesture-specific patterns in annotation errors and to assess the reliability of automatic methods across various motion dynamics and hand configurations.
Table 5 presents the rate of missed detections and average keypoint errors across all gesture classes. Pointing gestures (Point-1F, Point-2F) show high rates of both missed detections and spatial errors, highlighting their sensitivity to temporal instability. In contrast, clicking gestures exhibit fewer missed detections but suffer from higher spatial errors and larger standard deviations, indicating inconsistent keypoint placement. While MediaPipe Holistic outperforms MediaPipe Hands overall, both models demonstrate substantial variability, reinforcing the need for manual refinement to ensure reliable and temporally coherent annotations.
Figure 7 shows a temporal sequence of a pointing gesture annotated by MediaPipe Hands, MediaPipe Holistic, and our refined IPN HandS labels. The highlighted regions illustrate common failure cases in the automatic methods, including spatial drift and frame-level inconsistencies, which are effectively corrected in the refined annotations. In summary, the analysis confirms that while MediaPipe Holistic offers slight improvements over MediaPipe Hands, both automatic methods suffer from significant spatial and temporal inconsistencies, particularly in challenging gesture classes. These results highlight the limitations of fully automatic annotation pipelines and underscore the importance of manual refinement, as enabled by our IPN HandS. The resulting annotations provide a consistent and high-quality benchmark for skeleton-based HGR. In the following section, we demonstrate their utility by training recognition models using the refined annotations.
5. Hand Gesture Recognition Evaluation
To validate the utility of the IPN HandS annotations, we conducted a set of experiments using a standard sequence-based HGR model. In particular, we trained models on three different sets of annotations: our manually refined IPN HandS dataset, and two baselines derived from automatic landmark estimations using MediaPipe Hands [
12] and MediaPipe Holistic [
13], respectively. This section outlines the model setup, training configuration, and evaluation protocol. The goal of these experiments is to demonstrate how improvements in annotation quality translate into measurable gains in gesture recognition accuracy.
5.1. Model Architecture
We adopted a recurrent neural architecture based on Long Short-Term Memory (LSTM) [
24] units to evaluate the impact of annotation quality on recognition performance, specifically for skeleton-based HGR using time-delimited sequences of annotated hand landmarks. LSTMs are a class of recurrent neural networks (RNNs) capable of modeling temporal dependencies in sequential data through gated memory cells that regulate the flow of information over time [
25]. Their design enables them to effectively capture both short-term and long-term motion patterns, making them particularly suitable for recognizing hand gestures, which often unfold across multiple frames with varying temporal dynamics.
In our setup, the input to the model is a sequence of 2D hand skeletons, where each frame is represented by a 42-dimensional feature vector corresponding to the flattened coordinates of 21 hand landmarks. We focus on the primary active hand, selecting a single hand per frame, as the IPN HandS dataset is constructed to support single-hand gesture recognition. Gesture instances are processed as fixed-length temporal sequences sampled from annotated gesture intervals.
The LSTM model consists of three stacked unidirectional LSTM layers, each with 256 hidden units, followed by a fully connected layer that maps the final hidden state of the sequence to 14 gesture class logits. A dropout layer is applied between the LSTM layers to improve generalization. The model is trained from scratch using a standard cross-entropy loss function and optimized with the Adam algorithm.
5.2. Experimental Setup
We trained three separate models to evaluate how annotation quality affects gesture recognition performance. Each model was trained on the same set of gesture-labeled sequences, using annotations derived from one of the following sources: our manually refined IPN HandS dataset, MediaPipe Hands [
12], and MediaPipe Holistic [
13]. All annotations were applied to the same 200 videos, ensuring consistency in gesture class distribution and video content across models.
To ensure subject-independent evaluation, and following the IPN Hand [
5] configuration, we split the 50 subjects in the dataset into 37 for training and 13 for testing, resulting in 148 and 52 videos, respectively. From these, we obtained a total of 3797 gesture instances for training and 1380 for testing, excluding
No-Gesture segments. Each instance corresponds to a gesture-specific temporal interval annotated with hand landmarks for a single active hand. Only the 14 gesture classes were used for training and evaluation; background frames were excluded to focus the classification task on intentional gesture recognition.
We prepared gesture sequences using a fixed maximum length of 64 frames and a sliding window with a stride of 32. Thus, longer gestures, particularly for pointing classes (
P1F and
P2F), were fragmented into overlapping clips to ensure temporal consistency without exceeding the sequence length constraint. Conversely, no padding or interpolation was applied to shorter sequences, which represent most of the non-pointing gestures, as shown in
Table 4. In other words, this approach avoids artificial stretching or padding of variable-duration gestures, preserving the natural dynamics of the gesture.
Evaluation was conducted at the gesture instance level. Each input sequence was classified as a whole, and predictions were compared against the ground-truth labels for the corresponding gesture intervals. We report the overall classification accuracy, average recall (the unweighted mean of per-class recall values), and normalized confusion matrices. Average recall reflects the classification performance averaged across all gesture classes, regardless of class frequency, allowing for a more balanced assessment. Each model was trained for 30 epochs with a batch size of 64 sequences, a learning rate of 0.001, and a dropout rate of 0.3. No additional temporal smoothing or spatial augmentation was applied. In addition, to ensure statistical robustness, all experiments were repeated over three independent runs. Hence, we report the mean and standard deviation for both accuracy and average recall.
5.3. Experimental Results
Table 6 summarizes the classification accuracy and average recall of models trained and evaluated using a single annotation source. The model trained and evaluated on IPN HandS annotations achieved the best performance overall, with an accuracy of 91.2% and an average recall of 78%. In contrast, models trained and tested using MediaPipe-based annotations yielded significantly lower recall values, 62.7% for MP Hands and 66.9% for MP Holistic, despite achieving relatively high overall accuracy. This discrepancy stems from the class imbalance in the dataset, where a large proportion of instances belong to pointing gestures
P1F and
P2F (more than a 10× difference, as shown in
Table 4). These classes tend to dominate the predictions, inflating the overall accuracy even when less frequent gestures are poorly recognized. Average recall, by contrast, treats all classes equally and, therefore, more accurately reflects per-class consistency and generalization. The average recall gap between the IPN HandS model and MediaPipe highlights the importance of high-quality spatial and temporal annotations for improving the recognition of all gesture categories, not just the most common ones.
To further explore the generalization capacity of models trained on different annotation types,
Table 7 presents the cross-annotation results. Specifically, we tested models trained on IPN HandS against MediaPipe annotations, and vice versa. When trained on IPN HandS and tested on MediaPipe annotations, performance remains strong: 87% accuracy and 74.5% recall on MP Hands, and 89.6% accuracy with 74.7% recall on MP Holistic. These results reflect substantial improvements of about 12% and 8% in average recall compared to training and testing on MP Hands and MP Holistic annotations, respectively. This improvement reflects the model’s ability to generalize to noisy test annotations, thanks to the high-quality spatial and temporal consistency it learned during training.
Conversely, the models trained on MediaPipe annotations perform worse when evaluated on IPN HandS. For example, a model trained on MP Hands yields only 61.1% recall on IPN HandS data, underscoring that models trained on noisier annotations fail to capture the nuanced patterns needed for reliable recognition. Even the more stable MP Holistic variant achieves just 67.1% recall when tested on refined annotations. In summary, training on the temporally consistent and spatially accurate annotations provided by IPN HandS not only improves in-domain performance but also significantly enhances model robustness under cross-annotation evaluation. These findings confirm the value of manual refinement for building models that generalize beyond their training distribution and are less sensitive to the noise and inconsistencies typically found in automatic pose estimators.
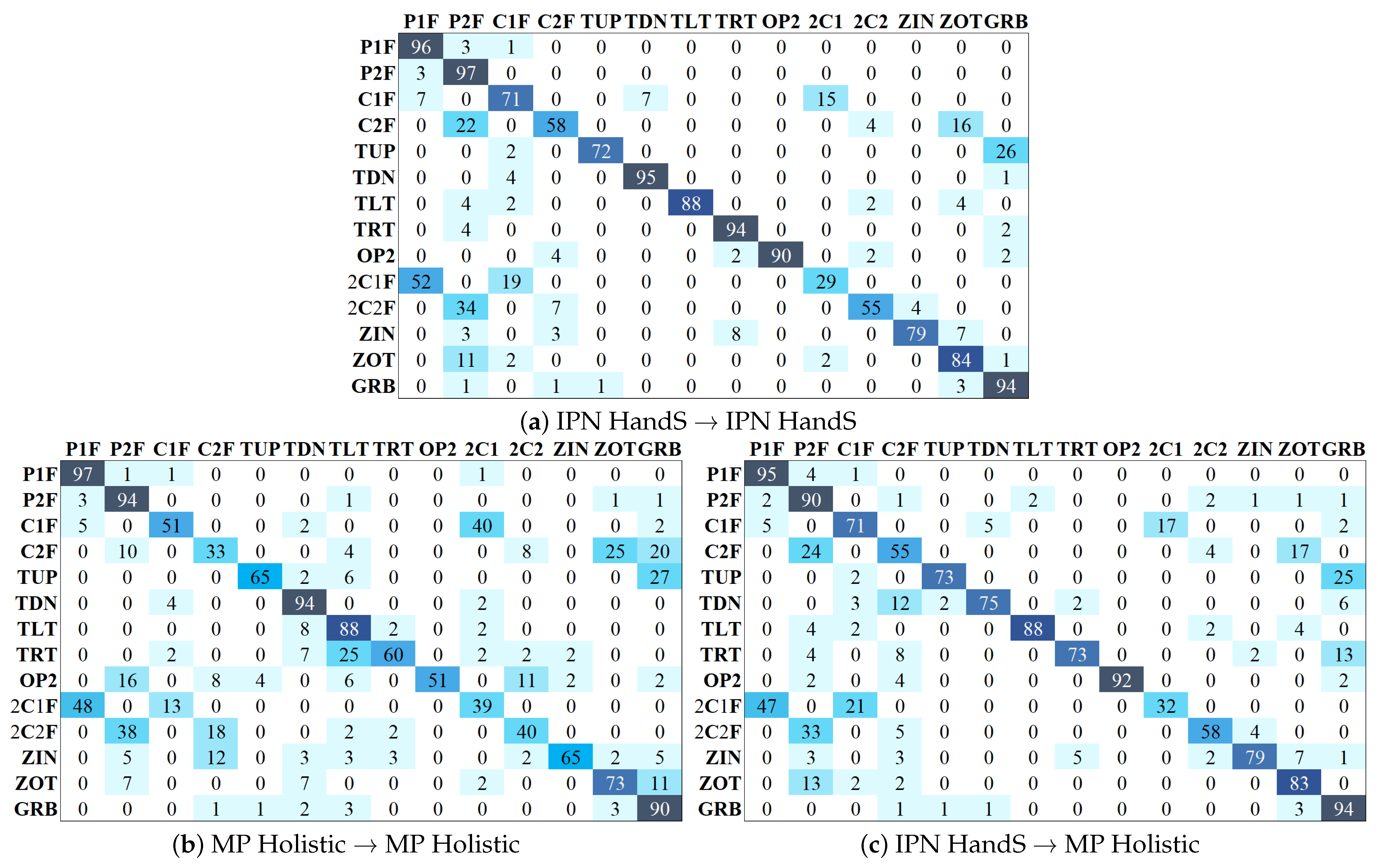
Figure 8 shows the normalized confusion matrices for three key evaluation scenarios: training and testing on IPN HandS annotations, training and testing on MP Holistic annotations, and training on IPN HandS with testing on MP Holistic. The improvements enabled by our refined annotations are particularly evident in gestures with fine spatial differences, such as distinguishing between one-finger (
C1F) and two-finger clicking (
C2F), or between zoom-out (
ZOT) and grab gestures (
GRB). Classes like throwing-left (
TLT) and throwing-right (
TRT), which are frequently misclassified when trained with MediaPipe outputs, show more concentrated and accurate predictions when trained with IPN HandS. One notable exception is the
2C1F class, which shows reduced performance in the IPN HandS model compared to those trained with automatic annotations. This may result from its high dynamics and spatial similarity to
P1F, as well as the greater variability in its execution, making it more sensitive to precise annotation. While our refined skeletons improve overall consistency, they may also sharpen class boundaries in ways that amplify confusion in ambiguous cases. Nevertheless, the observed improvements across most classes demonstrate that annotation quality is a crucial factor in advancing skeleton-based hand gesture recognition.
6. Discussion
The results presented in the previous section demonstrate the substantial impact of annotation quality on skeleton-based HGR. By integrating spatially accurate and temporally consistent annotations, IPN HandS significantly improves recognition performance across gesture classes. However, despite these advantages, some gesture classes remain challenging. The 2C1F class, in particular, shows consistently lower recall and is frequently misclassified as P1F, even when trained on IPN HandS. This class exhibits high intra-class variability in finger articulation and orientation, and often visually overlaps with other single-finger gestures like P1F and C1F. Interestingly, this confusion appears asymmetric: while 2C1F is often mistaken for P1F, the reverse is less common. Moreover, a similar pattern does not occur between structurally analogous classes such as 2C2F and P2F, suggesting that the confusion is not solely due to general gesture ambiguity but may be rooted in class-specific motion patterns or labeling subjectivity.
These findings indicate a potential trade-off between annotation precision and the model’s ability to generalize under ambiguous class definitions. To address this, future work could explore data augmentation strategies that increase intra-class variability during training or leverage multi-hand and body-pose context to resolve ambiguities. In addition, supporting multi-hand annotations or integrating 3D hand pose estimation could offer richer spatial information to better disambiguate subtle gestures. These issues also highlight the necessity for more robust recognition models that can effectively utilize fine-grained annotations without overfitting to narrow gesture variants.
We expect that more advanced architectures, such as Graph Convolutional Networks (GCNs) [
28], Transformers [
7], or hybrid models [
10], could further benefit from the spatial and temporal consistency provided by the high-quality annotations of the IPN HandS dataset. Future work could explore these architectures to validate whether the performance gains observed with IPN HandS generalize across model families. However, in this study, we deliberately chose a simple LSTM baseline to isolate and evaluate the effect of annotation quality, independent of model complexity.
On the other hand, the IPN HandS dataset offers more than a benchmark for HGR. Its precise landmark annotations across continuous videos create new opportunities for research in areas like temporal segmentation, gesture spotting, and motion pattern analysis. Additionally, the availability of consistent hand pose sequences under various conditions establishes a solid foundation for training and evaluating hand pose estimators, especially in specific applications such as sign language recognition, interactions in augmented reality (AR) and virtual reality (VR), and teleoperation. Recent developments in context-aware sim-to-real adaptation for human–robot shared control [
32] emphasize the importance of robust, transferable recognition systems in surgical and robotics applications. The temporal coherence and annotation reliability of IPN HandS could facilitate such transfer learning approaches by offering cleaner motion sequences and reduced noise, thus enhancing generalization to real-world, safety-critical scenarios.
In addition to our IPN HandS dataset, our contribution has broader implications for dataset development and HGR methodology. For instance, our annotation tool provides a practical solution for large-scale video-based landmark annotation. Its design effectively balances automation with manual control, supporting diverse correction strategies while minimizing annotator effort. The IPN HandS tool achieved a 2.6× speedup in annotation time compared to a conventional VIA-style interface. This improvement enabled us to annotate over 800,000 frames within a manageable timeframe, making the creation of IPN HandS possible without compromising annotation quality. Therefore, our tool can be easily adapted for other video datasets that require detailed spatiotemporal annotations, including areas beyond gesture recognition. However, extending the tool to more complex tasks such as sign language recognition would require additional features, including multi-hand support, richer temporal context visualization, and potentially the integration of body or facial expressions to capture co-articulation. While not currently implemented, these enhancements are part of our planned future work.
7. Conclusions
In this work, we introduced IPN HandS, a refined hand gesture dataset that provides frame-level hand skeleton annotations for continuous video sequences, supported by a dedicated annotation tool. To evaluate the impact of annotation quality, we trained a simple LSTM-based recognition model on different annotation sources and showed that models trained on IPN HandS significantly outperformed those trained on MediaPipe-based annotations. Our refined annotations significantly improved overall accuracy and recall, especially for gesture classes with subtle hand pose variations. These findings emphasize the importance of spatially and temporally consistent annotations in enhancing skeleton-based hand gesture recognition. On the other hand, the IPN HandS annotation tool enhances the annotation process by incorporating automatic initialization, manual refinement, and interpolation. This advancement enables the large-scale labeling of the entire dataset at a significantly faster rate compared to traditional interfaces.
Together, the dataset and tool offer practical and scalable resources for advancing research in hand gesture recognition and related domains. We will publicly release both the IPN HandS dataset and the annotation tool to support reproducible research and enable broader adoption in the community. In future work, we aim to explore more advanced recognition architectures that fully utilize the structure of IPN HandS annotations. Additionally, we plan to expand the annotation tool to support more complex tasks, such as sign language recognition.
Author Contributions
Conceptualization, G.B.-G. and H.T.; methodology, G.B.-G.; software, G.B.-G.; validation, J.O.-M. and G.S.-P.; formal analysis, G.S.-P.; investigation, G.B.-G.; data curation, J.O.-M.; writing—original draft preparation, G.B.-G.; writing—review and editing, G.B.-G. and J.O.-M.; visualization, G.B.-G.; supervision, G.S.-P. and H.T.; project administration, H.T. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by a Research Grant (S) from the Tateisi Science and Technology Foundation.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The IPN HandS annotations and annotation tool introduced in this study will be made publicly available at [The IPN HandS Dataset] [
14] under a Creative Commons Attribution 4.0 License. The original IPN Hand dataset used in this work, including the video recordings, is already publicly available and documented in [
5]. All annotations provided in this work are derived from that dataset.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Guo, L.; Lu, Z.; Yao, L. Human-machine interaction sensing technology based on hand gesture recognition: A review. IEEE Trans. Hum.-Mach. Syst. 2021, 51, 300–309. [Google Scholar] [CrossRef]
- Shin, J.; Miah, A.S.M.; Kabir, M.H.; Rahim, M.A.; Al Shiam, A. A methodological and structural review of hand gesture recognition across diverse data modalities. IEEE Access 2024, 12, 142606–142639. [Google Scholar] [CrossRef]
- Asadi-Aghbolaghi, M.; Clapés, A.; Bellantonio, M.; Escalante, H.J.; Ponce-López, V.; Baró, X.; Guyon, I.; Kasaei, S.; Escalera, S. Deep learning for action and gesture recognition in image sequences: A survey. In Gesture Recognition; Springer: Berlin/Heidelberg, Germany, 2017; pp. 539–578. [Google Scholar]
- Zengeler, N.; Kopinski, T.; Handmann, U. Hand gesture recognition in automotive human–machine interaction using depth cameras. Sensors 2019, 19, 59. [Google Scholar] [CrossRef] [PubMed]
- Benitez-Garcia, G.; Olivares-Mercado, J.; Sanchez-Perez, G.; Yanai, K. IPN Hand: A Video Dataset and Benchmark for Real-Time Continuous Hand Gesture Recognition. In Proceedings of the 25th International Conference on Pattern Recognition, ICPR 2020, Milan, Italy, 10–15 January 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 4340–4347. [Google Scholar]
- Shin, S.; Kim, W.Y. Skeleton-based dynamic hand gesture recognition using a part-based GRU-RNN for gesture-based interface. IEEE Access 2020, 8, 50236–50243. [Google Scholar] [CrossRef]
- Zhu, P.; Liang, C.; Liu, Y.; Jiang, S. Multi-Grained Temporal Clip Transformer for Skeleton-Based Human Activity Recognition. Appl. Sci. 2025, 15, 4768. [Google Scholar] [CrossRef]
- Ikne, O.; Allaert, B.; Wannous, H. AG-MAE: Anatomically Guided Spatio-Temporal Masked Auto-Encoder for Online Hand Gesture Recognition. In Proceedings of the International Conference on 3D Vision, Singapore, 25–28 March 2025. [Google Scholar]
- Balaji, P.; Prusty, M.R. Multimodal fusion hierarchical self-attention network for dynamic hand gesture recognition. J. Vis. Commun. Image Represent. 2024, 98, 104019. [Google Scholar] [CrossRef]
- Kaur, A.; Bansal, S. SILK-SVM: An Effective Machine Learning Based Key-Frame Extraction Approach for Dynamic Hand Gesture Recognition. Arab. J. Sci. Eng. 2024, 50, 7721–7740. [Google Scholar] [CrossRef]
- Ikne, O.; Slama, R.; Saoudi, H.; Wannous, H. Spatio-temporal sparse graph convolution network for hand gesture recognition. In Proceedings of the 2024 IEEE 18th International Conference on Automatic Face and Gesture Recognition (FG), Istanbul, Turkiye, 27–31 May 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1–5. [Google Scholar]
- Zhang, F.; Bazarevsky, V.; Vakunov, A.; Tkachenka, A.; Sung, G.; Chang, C.L.; Grundmann, M. MediaPipe Hands: On-Device Real-Time Hand Tracking. arXiv 2020, arXiv:2006.10214. [Google Scholar]
- Grishchenko, I.; Bazarevsky, V. MediaPipe Holistic—Simultaneous Face, Hand and Pose Prediction, on Device. Google AI Blog (Online). 2020. Available online: https://ai.googleblog.com/2020/12/mediapipe-holistic-simultaneous-face.html (accessed on 12 May 2025).
- Benitez-Garcia, G.; Olivares-Mercado, J.; Sanchez-Perez, G.; Takahashi, H. The IPN HandS Dataset. 2025. Available online: https://gibranbenitez.github.io/IPN_Hand (accessed on 12 May 2025).
- Tkachenko, M.; Malyuk, M.; Holmanyuk, A.; Liubimov, N. Label Studio: Data Labeling Software. 2020. Available online: https://github.com/HumanSignal/label-studio (accessed on 12 May 2025).
- Tzutalin. LabelImg: Graphical Image Annotation Tool. 2015. Available online: https://github.com/tzutalin/labelImg (accessed on 12 May 2025).
- Dutta, A.; Zisserman, A. The VIA Annotation Software for Images, Audio and Video. In Proceedings of the 27th ACM International Conference on Multimedia, New York, NY, USA, 21–25 October 2019. MM ’19. [Google Scholar]
- Nguyen, T.T.; Nguyen, N.C.; Ngo, D.K.; Phan, V.L.; Pham, M.H.; Nguyen, D.A.; Doan, M.H.; Le, T.L. A continuous real-time hand gesture recognition method based on skeleton. In Proceedings of the 2022 11th International Conference on Control, Automation and Information Sciences (ICCAIS), Hanoi, Vietnam, 21–24 November 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 273–278. [Google Scholar]
- Peral, M.; Sanfeliu, A.; Garrell, A. Efficient hand gesture recognition for human-robot interaction. IEEE Robot. Autom. Lett. 2022, 7, 10272–10279. [Google Scholar] [CrossRef]
- Ansar, H.; Ksibi, A.; Jalal, A.; Shorfuzzaman, M.; Alsufyani, A.; Alsuhibany, S.A.; Park, J. Dynamic hand gesture recognition for smart lifecare routines via K-Ary tree hashing classifier. Appl. Sci. 2022, 12, 6481. [Google Scholar] [CrossRef]
- De Smedt, Q.; Wannous, H.; Vandeborre, J.P.; Guerry, J.; Le Saux, B.; Filliat, D. Shrec’17 track: 3D hand gesture recognition using a depth and skeletal dataset. In Proceedings of the Eurographics Workshop on 3D Object Retrieval, Lyon, France, 23–24 April 2017; pp. 1–6. [Google Scholar]
- De Smedt, Q.; Wannous, H.; Vandeborre, J.P. Skeleton-based dynamic hand gesture recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1–9. [Google Scholar]
- Manganaro, F.; Pini, S.; Borghi, G.; Vezzani, R.; Cucchiara, R. Hand gestures for the human-car interaction: The briareo dataset. In Proceedings of the Image Analysis and Processing–ICIAP 2019, Trento, Italy, 9–13 September 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 560–571. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Cai, J.; Hu, J.; Tang, X.; Hung, T.Y.; Tan, Y.P. Deep historical long short-term memory network for action recognition. Neurocomputing 2020, 407, 428–438. [Google Scholar] [CrossRef]
- Chen, M.; Wei, Z.; Huang, Z.; Ding, B.; Li, Y. Simple and deep graph convolutional networks. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 13–18 July 2020; pp. 1725–1735. [Google Scholar]
- Liu, J.; Wang, X.; Wang, C.; Gao, Y.; Liu, M. Temporal decoupling graph convolutional network for skeleton-based gesture recognition. IEEE Trans. Multimed. 2023, 26, 811–823. [Google Scholar] [CrossRef]
- Cui, H.; Huang, R.; Zhang, R.; Hayama, T. Dstsa-gcn: Advancing skeleton-based gesture recognition with semantic-aware spatio-temporal topology modeling. Neurocomputing 2025, 637, 130066. [Google Scholar] [CrossRef]
- Zhao, D.; Li, H.; Yan, S. Spatial–Temporal Synchronous Transformer for Skeleton-Based Hand Gesture Recognition. IEEE Trans. Circuits Syst. Video Technol. 2023, 34, 1403–1412. [Google Scholar] [CrossRef]
- Qi, W.; Xu, X.; Qian, K.; Schuller, B.W.; Fortino, G.; Aliverti, A. A Review of AIoT-based Human Activity Recognition: From Application to Technique. IEEE J. Biomed. Health Inform. 2025, 29, 2425–2438. [Google Scholar] [CrossRef] [PubMed]
- Benitez-Garcia, G.; Takahashi, H. Multimodal Hand Gesture Recognition Using Automatic Depth and Optical Flow Estimation from RGB Videos. In Proceedings of the 23rd International Conference on New Trends in Intelligent Software Methodologies, Tools and Techniques (SoMeT_24). Front. Artif. Intell. Appl. 2024, 389, 506–519. [Google Scholar]
- Zhang, D.; Wu, Z.; Chen, J.; Zhu, R.; Munawar, A.; Xiao, B.; Guan, Y.; Su, H.; Hong, W.; Guo, Y.; et al. Human-Robot Shared Control for Surgical Robot Based on Context-Aware Sim-to-Real Adaptation. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 7694–7700. [Google Scholar]
Figure 1.
Comparison of hand skeleton annotations for a single frame with motion blur. (
a) MediaPipe Hands [
12], showing inaccurate finger landmarks. (
b) MediaPipe Holistic [
13], with partial improvement but persistent errors. (
c) IPN HandS, refined using our annotation tool, accurately captures the active finger’s position.
Figure 1.
Comparison of hand skeleton annotations for a single frame with motion blur. (
a) MediaPipe Hands [
12], showing inaccurate finger landmarks. (
b) MediaPipe Holistic [
13], with partial improvement but persistent errors. (
c) IPN HandS, refined using our annotation tool, accurately captures the active finger’s position.
Figure 2.
The user interface of the IPN HandS annotation tool. The main display shows the annotated video frame along with gesture labels, timeline navigation, and confidence adjustment. The expanded Edit menu illustrates core functionalities such as hand selection, deletion, handedness changes, mirroring, copy–paste, and the interpolation of hand landmarks across frames.
Figure 2.
The user interface of the IPN HandS annotation tool. The main display shows the annotated video frame along with gesture labels, timeline navigation, and confidence adjustment. The expanded Edit menu illustrates core functionalities such as hand selection, deletion, handedness changes, mirroring, copy–paste, and the interpolation of hand landmarks across frames.
Figure 3.
Interactive annotation capabilities of the IPN HandS tool. (a) Full-hand repositioning, activated by clicking and dragging a landmark without modifiers. (b) Finger-level adjustment, enabled by holding Ctrl + Shift and clicking on a fingertip to drag all associated landmarks. (c) Individual landmark refinement by holding Ctrl and clicking on any point to reposition it.
Figure 3.
Interactive annotation capabilities of the IPN HandS tool. (a) Full-hand repositioning, activated by clicking and dragging a landmark without modifiers. (b) Finger-level adjustment, enabled by holding Ctrl + Shift and clicking on a fingertip to drag all associated landmarks. (c) Individual landmark refinement by holding Ctrl and clicking on any point to reposition it.
Figure 4.
Gesture taxonomy refinement. The initial grabbing motion, previously embedded within the throwing gestures, is now separated as a distinct “grab” class, enabling more precise gesture definitions and improving classification accuracy.
Figure 4.
Gesture taxonomy refinement. The initial grabbing motion, previously embedded within the throwing gestures, is now separated as a distinct “grab” class, enabling more precise gesture definitions and improving classification accuracy.
Figure 5.
Temporal refinement of the zoom-in gesture. The original annotation (top) fails to delimit the core gesture motion, while the refined version (bottom) more accurately captures the start and end boundaries.
Figure 5.
Temporal refinement of the zoom-in gesture. The original annotation (top) fails to delimit the core gesture motion, while the refined version (bottom) more accurately captures the start and end boundaries.
Figure 6.
Gesture classes of IPN HandS with hand skeleton annotations. Each column depicts sequential frames for a gesture instance from top to bottom, highlighting its temporal evolution. Gestures P1F, C1F, and 2C1F are not shown, as they are the one-finger variants of P2F, C2F, and 2C2F, respectively.
Figure 6.
Gesture classes of IPN HandS with hand skeleton annotations. Each column depicts sequential frames for a gesture instance from top to bottom, highlighting its temporal evolution. Gestures P1F, C1F, and 2C1F are not shown, as they are the one-finger variants of P2F, C2F, and 2C2F, respectively.
Figure 7.
Frame-by-frame comparison of a pointing gesture annotated by (a) MediaPipe Hands, (b) MediaPipe Holistic, and (c) the refined IPN HandS annotations. Green ellipses highlight spatial drift, and magenta boxes indicate missed detections or temporal instability.
Figure 7.
Frame-by-frame comparison of a pointing gesture annotated by (a) MediaPipe Hands, (b) MediaPipe Holistic, and (c) the refined IPN HandS annotations. Green ellipses highlight spatial drift, and magenta boxes indicate missed detections or temporal instability.
Figure 8.
Normalized confusion matrices for three evaluation settings. (a) Model trained and tested on IPN HandS. (b) Model trained and tested on MediaPipe Holistic annotations. (c) Model trained on IPN HandS and tested on MediaPipe Holistic annotations.
Figure 8.
Normalized confusion matrices for three evaluation settings. (a) Model trained and tested on IPN HandS. (b) Model trained and tested on MediaPipe Holistic annotations. (c) Model trained on IPN HandS and tested on MediaPipe Holistic annotations.
Table 1.
Comparison of publicly available skeleton-based HGR video datasets.
Table 1.
Comparison of publicly available skeleton-based HGR video datasets.
| Dataset | Subjects | Gestures | Instances | Data Modality |
|---|
| DHG-14/28 [22] | 20 | 14/28 | 2800 | Depth |
| SHREC’17 [21] | 28 | 14/28 | 2800 | Depth |
| Briareo [23] | 40 | 12 | 1440 | Depth, IR |
| IPN HandS (ours) | 50 | 14 | 5177 | RGB |
Table 2.
Main features of the IPN HandS annotation tool.
Table 2.
Main features of the IPN HandS annotation tool.
| Feature | Description |
|---|
| Automatic Initialization | Applies pose estimation to all frames using MediaPipe Holistic [13] to generate preliminary annotations. |
| Frame-level Re-estimation | Allows landmark re-detection with adjustable detection confidence on individual frames using either MediaPipe Hands or Holistic, depending on accuracy needs. |
| Manual Refinement | Supports interactive adjustment of the entire hand, individual fingers, or single landmarks, with keyboard shortcuts and undo actions, as shown in Figure 3. |
| Copy–Paste Annotations | Enables the duplication of hand annotations across frames for static poses or repeated gestures. |
| Hand Interpolation | Interpolates hand landmarks between two annotated frames, streamlining the annotation of continuous dynamic gestures. |
| Class-Timeline | Includes a gesture-segmented timeline to guide the annotator’s focus and support consistent frame-level annotations. |
Table 3.
Average annotation time per video, gesture instance, and frame using a conventional tool (VIA) versus our IPN HandS tool.
Table 3.
Average annotation time per video, gesture instance, and frame using a conventional tool (VIA) versus our IPN HandS tool.
| Tool | Total Time (min) | Per Video | Per Instance | Per Frame (s) |
|---|
| VIA-style Tool | 1054.2 | 70.3 | 2.8 | 1.1 |
| IPN HandS (ours) | 397.4 | 26.5 | 1.1 | 0.4 |
Table 4.
Statistics of our IPN HandS dataset. Duration is measured in frames.
Table 4.
Statistics of our IPN HandS dataset. Duration is measured in frames.
| Gesture | Name | Instances | Total Frames | Avg. Duration () |
|---|
| No-Gesture | NOG | 2593 | 261,599 | 101 (118) |
| Point-1F | P1F | 1222 | 221,811 | 182 (95) |
| Point-2F | P2F | 1191 | 224,976 | 189 (97) |
| Click-1F | C1F | 204 | 6021 | 29 (10) |
| Click-2F | C2F | 186 | 5665 | 30 (8) |
| Th-Up | TUP | 201 | 6525 | 31 (9) |
| Th-Down | TDN | 200 | 5529 | 27 (8) |
| Th-Left | TLT | 197 | 6255 | 30 (9) |
| Th-Right | TRT | 195 | 6230 | 30 (9) |
| Open-2 | OP2 | 194 | 10,690 | 52 (14) |
| 2Click-1F | 2C1F | 199 | 10,084 | 50 (15) |
| 2Click-2F | 2C2F | 215 | 10,681 | 49 (15) |
| Zoom-In | ZIN | 231 | 8901 | 36 (12) |
| Zoom-Out | ZOT | 208 | 7868 | 35 (12) |
| Grab | GRB | 534 | 8621 | 19 (6) |
| Total (Gestures) | | 5177 | 539,857 | 56 (23) |
| Total (All) | | 7770 | 801,456 | 106 (115) |
Table 5.
Per-gesture comparison of missed detections and keypoint error between MediaPipe Hands and MediaPipe Holistic, using IPN HandS annotations as ground truth. Values are reported as percentages with standard deviation in parentheses ().
Table 5.
Per-gesture comparison of missed detections and keypoint error between MediaPipe Hands and MediaPipe Holistic, using IPN HandS annotations as ground truth. Values are reported as percentages with standard deviation in parentheses ().
| | Missed Detections | Keypoint Error |
|---|
| Gesture | MP Hands ()
| MP Holistic ()
| MP Hands ()
| MP Holistic ()
|
|---|
| Point-1F | 13.51 (15.8) | 12.89 (15.3) | 18.34 (35.6) | 11.51 (31.0) |
| Point-2F | 17.96 (16.9) | 14.74 (15.1) | 18.32 (32.3) | 12.95 (32.6) |
| Click-1F | 8.23 (11.3) | 7.88 (12.6) | 12.19 (26.8) | 7.92 (26.6) |
| Click-2F | 6.78 (8.0) | 4.80 (6.0) | 12.13 (29.8) | 7.85 (30.3) |
| Th-Up | 7.89 (9.2) | 6.56 (9.0) | 8.81 (15.3) | 5.64 (15.4) |
| Th-Down | 14.26 (15.5) | 20.46 (18.6) | 7.41 (14.7) | 9.59 (14.9) |
| Th-Left | 13.42 (13.7) | 11.11 (13.3) | 7.21 (14.0) | 6.07 (14.6) |
| Th-Right | 16.72 (16.6) | 11.67 (14.7) | 7.61 (14.8) | 7.16 (16.3) |
| Open-2 | 3.19 (4.6) | 1.94 (5.3) | 4.07 (12.3) | 2.37 (12.5) |
| 2Click-1F | 7.85 (12.1) | 6.57 (12.1) | 12.00 (25.1) | 7.97 (22.2) |
| 2Click-2F | 7.96 (11.3) | 6.19 (9.8) | 11.58 (25.5) | 7.03 (24.7) |
| Zoom-In | 6.17 (10.1) | 7.21 (13.1) | 6.32 (14.0) | 4.81 (18.0) |
| Zoom-Out | 4.88 (11.2) | 5.85 (11.3) | 4.73 (14.7) | 3.74 (13.4) |
| Grab | 4.25 (9.2) | 3.87 (9.1) | 4.67 (11.8) | 3.88 (13.5) |
| Total | 9.51 (11.8) | 8.70 (11.8) | 9.67 (20.5) | 7.04 (19.0) |
Table 6.
Gesture classification results. Accuracy and average recall are reported as percentages with standard deviation () over three runs.
Table 6.
Gesture classification results. Accuracy and average recall are reported as percentages with standard deviation () over three runs.
| Annotations | Accuracy () | Average Recall () |
|---|
| IPN HandS | 91.2 (1.4) | 78.0 (1.2) |
| MP Hands | 87.5 (1.0) | 62.7 (2.0) |
| MP Holistic | 89.2 (0.6) | 66.9 (0.7) |
Table 7.
Cross-annotation gesture classification results. Accuracy and average recall are reported as percentages with standard deviation () over three runs.
Table 7.
Cross-annotation gesture classification results. Accuracy and average recall are reported as percentages with standard deviation () over three runs.
| Train Annotations | Test Annotations | Accuracy () | Average Recall () |
|---|
| IPN HandS | MP Hands | 87.0 (1.8) | 74.5 (0.8) |
| IPN HandS | MP Holistic | 89.6 (0.8) | 74.7 (1.2) |
| MP Hands | IPN HandS | 86.6 (0.8) | 61.1 (0.6) |
| MP Hands | MP Holistic | 86.2 (2.4) | 58.9 (1.9) |
| MP Holistic | IPN HandS | 90.1 (1.2) | 67.1 (0.8) |
| MP Holistic | MP Hands | 89.9 (2.1) | 66.5 (1.6) |
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).




 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}