
NRNH-AR: A Small Robotic Agent Using Tri-Fold Learning for Navigation and Obstacle Avoidance


Abstract
1. Introduction
- The development of a small autonomous physical robot capable of exploring narrow spaces that humans cannot enter. However, the size of the robot is scalable depending on applications.
- The reduction in the time steps required to explore the static and/or dynamic environments, with three learning phases, the SSL phase, the USL phase, and the DRL phase, fused in this order.
- The use of the tri-fold learning design optimizes resource usage, such as memory space and computational cost, which is an important factor for the small autonomous physical robot.
2. Materials and Methods
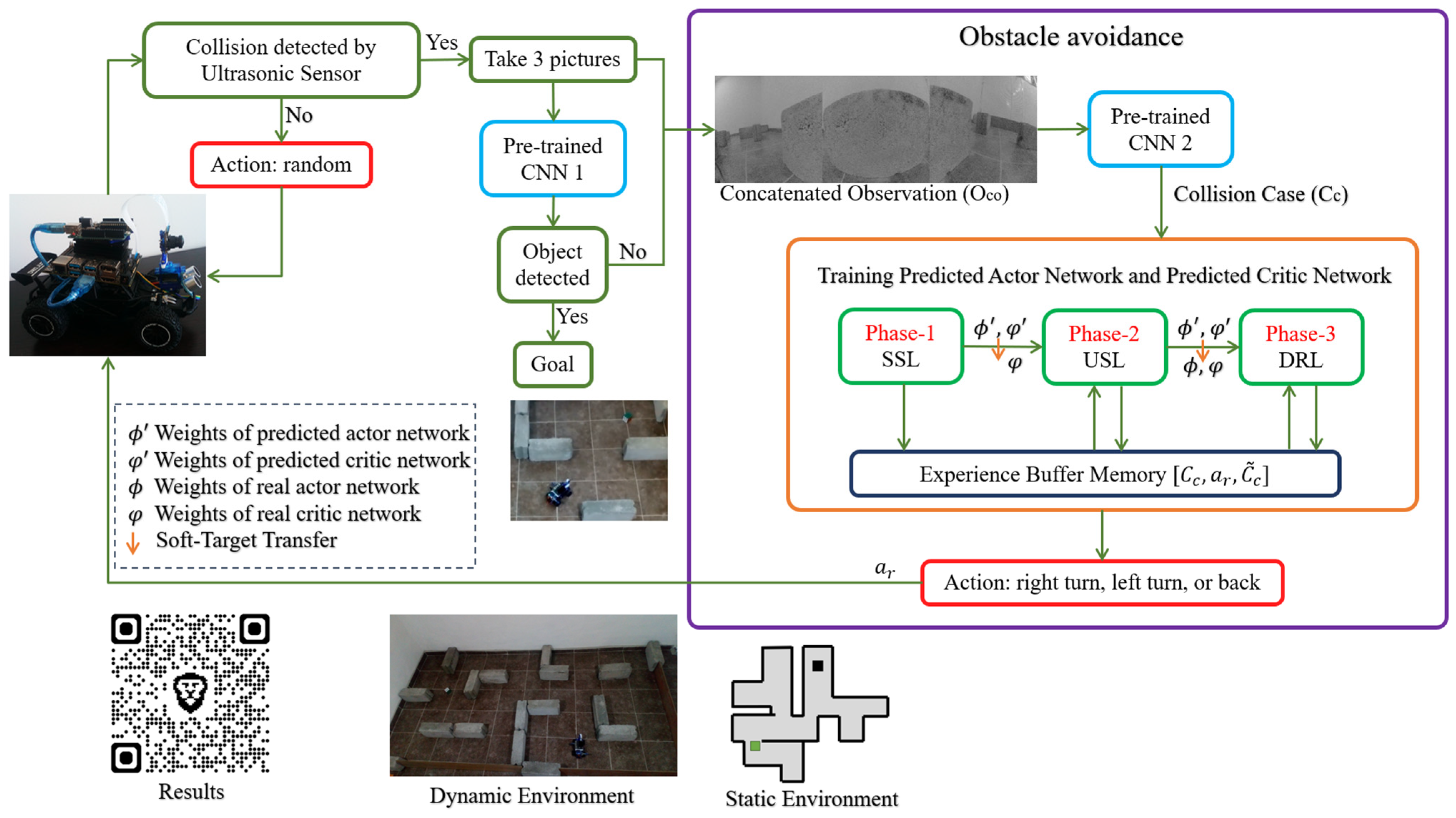
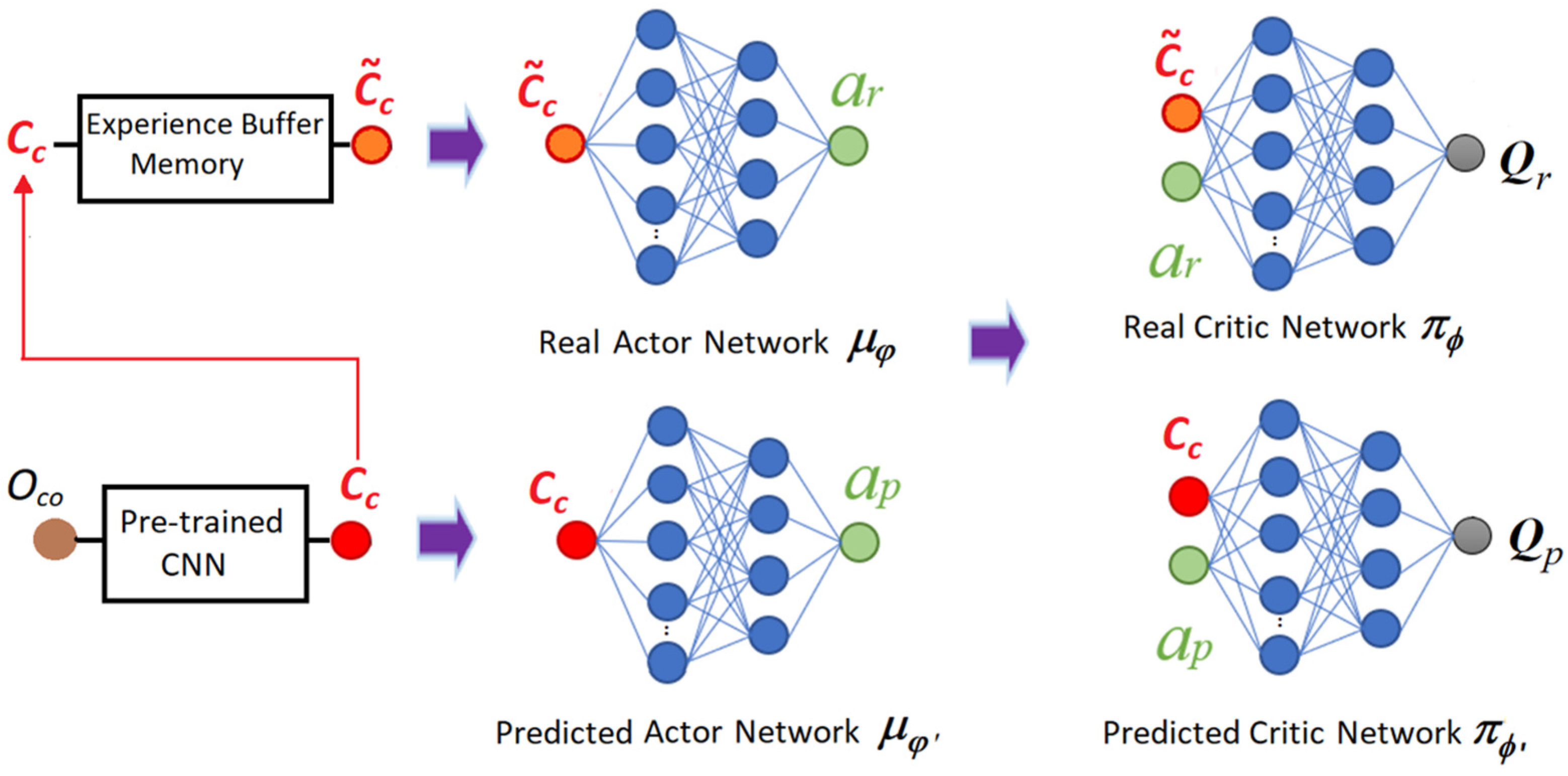
2.1. Overview of the NRNH-AR Algorithm
2.2. Vision-Based Environmental Understanding
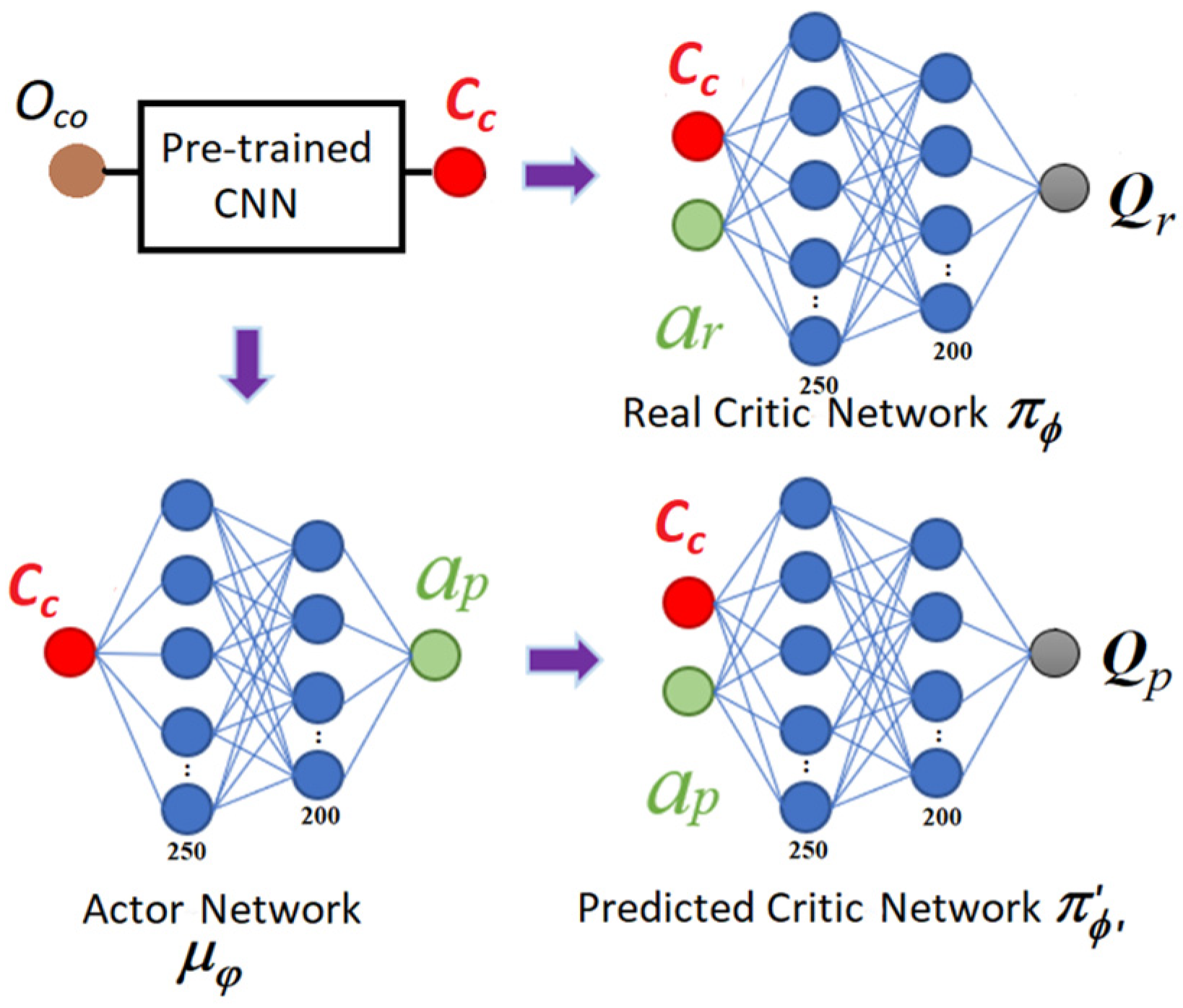
2.3. Self-Supervised Learning Phase
2.4. Unsupervised Learning Phase
2.5. Deep Reinforcement Learning Phase
2.6. Characteristics of the Components Used
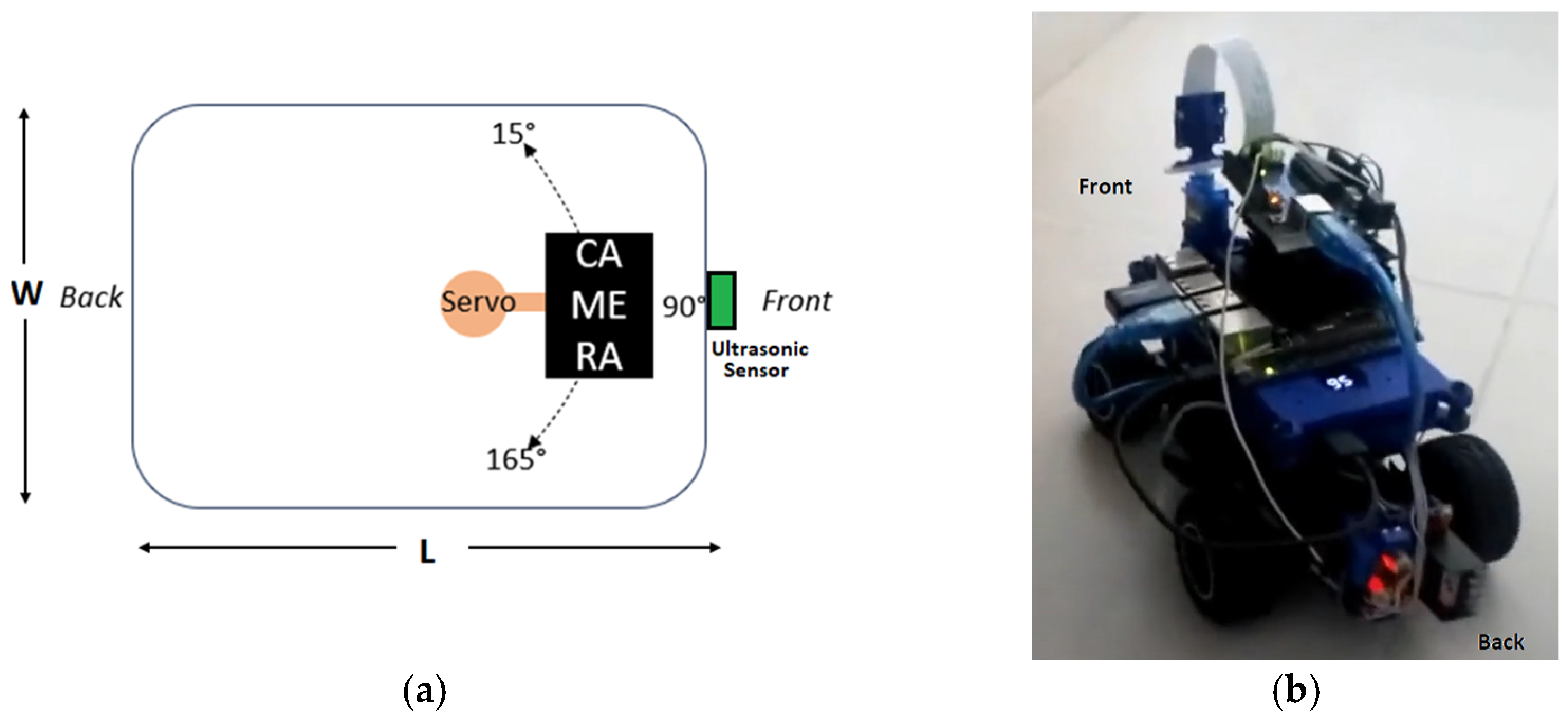
2.7. Robotic Agent Configuration
3. Experiments
3.1. Static Environment
3.2. Dynamic Environment
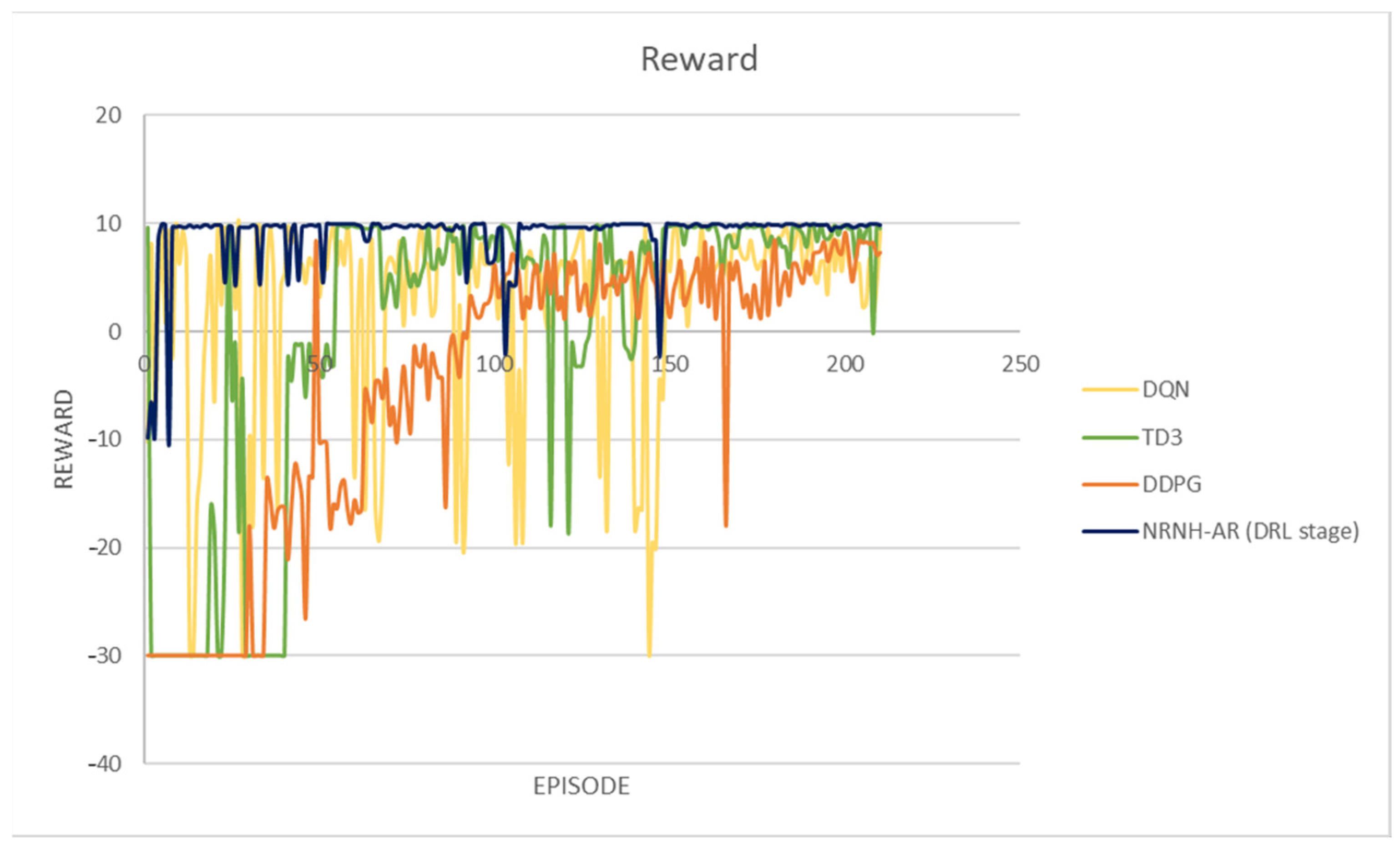
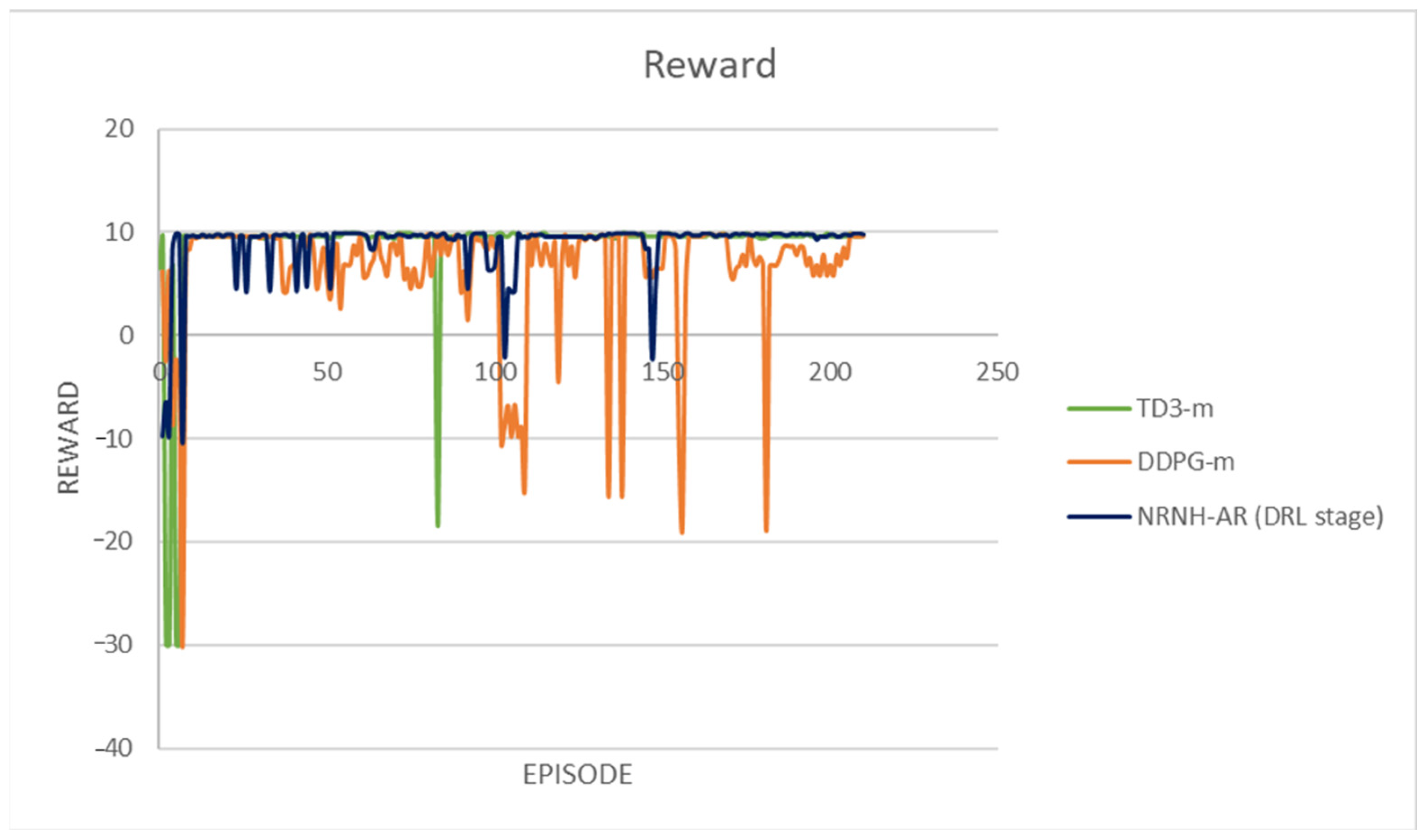
4. Results
- Experience Buffer Size was the amount of experience generated during each learning phase. In the NRNH-AR algorithm, for each time step after an action is selected, the experience performed is added into the experience buffer memory. This number is equivalent to the time steps required for the convergence of each learning phase.
- Computational Cost was measured as the average occupation percentage of the GPU of the Jetson Nano during each learning phase. For example, in the case of SSL, the average occupation is, on average, 10% of the full capacity of the Jetson Nano’s GPU. In contrast, in the DRL phase, on average, 90% of the total capacity must be used to solve the problem.
- Learning Oscillation was calculated as the standard deviation from the average learning level A in each phase. As expected, in the SSL phase, the robotic agent randomly selects an action to gain environmental information as quickly as possible, so the oscillation of the learning level is larger compared with the following two learning phases. The robotic agent acquires experience and evolves by updating the connection weights of the predicted actor network, learning is established, and oscillation is reduced. As mentioned before, the connection weights of the predicted actor network are updated to maximize the quality of the action performed.
- Reaction Delay was defined as the time elapsed from the robotic agent taking three images to performing a corresponding action. This value is essential in real applications because the total elapsed time from the start to detecting the target object is proportional to this value. From Table 4, the reaction delay is only 0.1 s in all learning phases, indicating a possible real-world application.
Static Environment
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Velocities of the Agent
References
- Wen, T.; Wang, X.; Zheng, Z.; Sun, Z. A DRL-based Path Planning Method for Wheeled Mobile Robots in Unknown Environments. Comput. Electr. Eng. 2024, 118, 109425. [Google Scholar] [CrossRef]
- Bar, N.F.; Karakose, M. Collaborative Approach for Swarm Robot Systems Based on Distributed DRL. Eng. Sci. Technol. Int. J. 2024, 53, 101701. [Google Scholar] [CrossRef]
- Tang, W.; Wu, F.; Lin, S.-W.; Ding, Z.; Liu, J.; Liu, Y.; He, J. Causal Deconfounding Deep Reinforcement Learning for Mobile Robot Motion Planning. Knowl.-Based Syst. 2024, 303, 112406. [Google Scholar] [CrossRef]
- Cui, T.; Yang, Y.; Jia, F.; Jin, J.; Ye, Y.; Bai, R. Mobile Robot Sequential Decision Making using a Deep Reinforcement Learning Hyper-heuristic Approach. Expert Syst. Appl. 2024, 257, 124959. [Google Scholar] [CrossRef]
- Kim, D.; Carballo, D.; Di Carlo, J.; Katz, B.; Bledt, G.; Lim, B.; Kim, S. Vision aided Dynamic Exploration of Unstructed Terrain with Small-Scale Quadruped Robot. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 Agust 2020. [Google Scholar] [CrossRef]
- Bayati, M.; Fotouhi, R. A Mobile Robotic Platform for Crop Monitoring. Adv. Robot. Autom. 2018, 7, 186. [Google Scholar] [CrossRef]
- Yoosuf, L.; Gafoor, A.; Nizam, Y. Designing and Testing a Robot for Removing Sharp Metal Objects from Roads. AIP Conf. Proc. 2024, 3245, 020004. [Google Scholar] [CrossRef]
- Ge, L.; Fang, Z.; Li, H.; Zhang, L.; Zeng, W.; Xiao, X. Study of a Small Robot for Mine Hole Detection. Appl. Sci. 2023, 13, 13249. [Google Scholar] [CrossRef]
- Balachandram, A.; Lal, S.A.; Sreedharan, P. Autonomous Navigation of an AMR using Deep Reinforcement Learning in a Warehouse Environment. In Proceedings of the IEEE 2nd Mysore Sub Section International Conference (MysuruCon), Mysuru, India, 16–17 October 2022. [Google Scholar] [CrossRef]
- Ozdemir, K.; Tuncer, A. Navigation of Autonomous Mobile Robots in Dynamic Unknown Environments Based on Dueling Double Deep Q Networks. Eng. Appl. Artif. Intell. 2024, 139, 109498. [Google Scholar] [CrossRef]
- Zhang, B.; Li, G.; Zhang, J.; Bai, X. A Reliable Traversability Learning Method Based on Human-Demonstrated Risk Cost Mapping for Mobile Robots over Uneven Terrain. Eng. Appl. Artif. Intell. 2024, 138, 109339. [Google Scholar] [CrossRef]
- Li, P.; Chen, D.; Wang, Y.; Zhang, L.; Zhao, S. Path Planning of Mobile Robot Based on Improved TD3 Algorithm in Dynamic Environment. Heliyon 2024, 10, e32167. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; Shi, N.; Zhao, L.; Zhang, M. Deep Reinforcement Learning Path Planning and Task Allocation for Multi-Robot Collaboration. Alex. Eng. J. 2024, 109, 418–423. [Google Scholar] [CrossRef]
- Cheng, B.; Xie, T.; Wang, L.; Tan, Q.; Cao, X. Deep Reinforcement Learning Driven Cost Minimization for Batch Order Scheduling in Robotic Mobile Fulfillment Systems. Expert Syst. Appl. 2024, 255, 124589. [Google Scholar] [CrossRef]
- Xiao, H.; Chen, C.; Zhang, G.; Chen, C.L.P. Reinforcement Learning-Driven Dynamic Obstacle Avoidance for Mobile Robot Trajectory Tracking. Knowl.-Based Syst. 2024, 297, 111974. [Google Scholar] [CrossRef]
- Sun, H.; Zhang, C.; Hu, C.; Zhang, J. Event-Triggered Reconfigurable Reinforcement Learning Motion-Planning Approach for Mobile Robot in Unknown Dynamic Environments. Eng. Appl. Artif. Intell. 2023, 123, 106197. [Google Scholar] [CrossRef]
- Deshpande, S.V.; Ra, H.; Ibrahim, B.S.K.K.; Ponnuru, M.D.S. Mobile Robot Path Planning using Deep Deterministic Policy Gradient with Differential Gaming (DDPG-DG) Exploration. Cogn. Robot. 2024, 4, 156–173. [Google Scholar] [CrossRef]
- Zhang, F.; Xuan, C.; Lam, H.-K. An Obstacle Avoidance-Specific Reinforcement Learning Method Based on Fuzzy Attention Mechanism and Heterogeneous Graph Neural Networks. Eng. Appl. Artif. Intell. 2024, 130, 107764. [Google Scholar] [CrossRef]
- Alonso, L.; Riazuelo, L.; Montesana, L.; Murillo, A.C. Domain Adaptation in LiDAR Semantic Segmentation by Aligning Class Distributions. In Proceedings of the International Conference on Informatics in Control, Automation and Robotics (ICINCO), Virtual, 6–8 July 2020. [Google Scholar] [CrossRef]
- Escobar-Naranjo, J.; Caiza, G.; Ayala, P.; Jordan, E.; Garcia, C.A.; Garcia, M.V. Autonomous Navigation of Robots: Optimization with DQN. Appl. Sci. 2023, 13, 7202. [Google Scholar] [CrossRef]
- Sun, X.; Zhang, Q.; Wei, Y.; Liu, M. Risk-Aware Deep Reinforcement Learning for Robot Crowd Navigation. Electronics 2023, 12, 4744. [Google Scholar] [CrossRef]
- Sathyamoorthy, A.J.; Liang, J.; Patel, U.; Guan, T.; Chandra, R.; Manocha, D. DenseCAvoid: Real-time Navigation in Dense Crowds using Anticipatory Behaviors. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020. [Google Scholar] [CrossRef]
- Tang, Y.C.; Qi, S.J.; Zhu, L.X.; Zhuo, X.R.; Zhang, Y.Q.; Meng, F. Obstacle Avoidance Motion in Mobile Robotics. J. Syst. Simul. 2024, 36, 1–26. [Google Scholar] [CrossRef]
- Vasquez, C.; Nakano, M.; Velasco, M. Practical Application of Deep Reinforcement Learning in Physical Robotics. In Proceedings of the 3rd International Conference on Intelligent Software Methodologies, Tools, and Techniques (SOMET 2024), Cancun, Mexico, 24–26 September 2024. [Google Scholar] [CrossRef]
- Howard, A.; Sandler, M.; Chen, B.; Wang, W.; Chen, L.-C.; Tan, M.; Chu, G.; Vasudevan, V.; Zhu, Y.; Pang, R.; et al. Searching for MobileNetV3. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Collision Case | Class Case () |
|---|---|
| [0 1 0] | 1 |
| [0 1 1] | 2 |
| [1 1 0] | 3 |
| [1 1 1] | 4 |
| Layer Name | Parameters |
|---|---|
| Input | 150 × 150 × 1 |
| Conv1 | 3 × 3 × 32 |
| Maxpool 1 | 2 × 2 |
| Conv2 | 2 × 2 × 64 |
| Maxpool 2 | 2 × 2 |
| Fc1/ReLU | 120 |
| Fc2/SoftMax | 4 |
| Hardware | Technical Specifications |
|---|---|
| JETSON NANO NVIDIA, California, USA | GPU 128-core Maxwell CPU Quad-core ARM A57 a 1.43GHz 4Gb RAM 64bits |
| CAMERA Shenzhen City Wazney Electronic Technology Co., Futian District, China | Webcam HD 1080p USB Plug and Play |
| ULTRASONIC SENSOR Shenzhen Robotlinking Technology Co., Futian District, China | HC-SR04, Measuring range 2 cm to 400 cm, 5 v |
| MOTORS Shenzhen Jixin Micro Motor Co., Baoan District, China | 3–50 v tension nominal, 14,425–23,000 rpm 0.11–0.486 A |
| SERVOMOTOR Yueqing Yidi Electronic Co., Zhejiang, China | Torque 2.5 kg/cm, 4.8–6 v, 32 × 32 × 12 mm |
| BATTERY Dongguan Wiliyoung Electronics Co., Guangdong Province, China | 10,000 mA, Port de 5 v/2 A, 67.6 × 15.9 × 142.8 mm |
| PHASE | Experience Buffer Size | Computational Cost | Learning Oscillation | Reaction Delay |
|---|---|---|---|---|
| SSL | 50 | 10% | 0.4127 | 0.1 s |
| USL | 640 | 60% | 0.0939 | 0.1 s |
| DRL | 850 | 90% | 0.0034 | 0.1 s |
| Method | Hardware | Software | Obstacle Evasion | * Episodes | * Accuracy | Simulation | Physical Robot |
|---|---|---|---|---|---|---|---|
| GNND Multi-Robot [21] | 3.2 GHz i7-8700 CPU and an Nvidia GTX 1080Ti GPU with 32 | 2D cluttered | Yes | 3.0 × 104 | 99.50% | Yes | No |
| I3A [19] | Velodyne VLP-16 | SemanticKitti | Yes | 5.6 × 106 | 52.50% | Yes | No |
| FAM-HGNN [18] | 2.2 GHz i7-10870 CPU Nvidia GeForce RTX 3060 GPU with 6 GB | OpenAI gym | Yes | 1.0 × 107 | 96.00% | Yes | No |
| DQN algorithm [20] | Intel core i7 8GBRAM, Nvidia 940mx | ROS Gazebo | Yes | 400 | 90.00% | Yes | No |
| DenseCAvoid [22] | Intel Xeon 3.6 GHz processor and an Nvidia GeForce RTX 2080Ti GPU | Gazebo 8.6 | No | 300 | 85.00% | Yes | No |
| DQN algorithm [9] | Raspberry Pi 3 | ROS Gazebo | Yes | 1500 | 60.00% | Yes | Yes |
| Ours | Jetson Nano 4GB 64bits | Python 3.12.5 | Yes | 210 | 97.62% | Yes | Yes |
| DQN | DDPG | TD3 | OUR | DDPG-m | TD3-m | |
|---|---|---|---|---|---|---|
| Accuracy | 81.90% | 56.19% | 68.57% | 97.62% | 86.19% | 96.19 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vasquez-Jalpa, C.; Nakano, M.; Velasco-Villa, M.; Lopez-Garcia, O. NRNH-AR: A Small Robotic Agent Using Tri-Fold Learning for Navigation and Obstacle Avoidance. Appl. Sci. 2025, 15, 8149. https://doi.org/10.3390/app15158149
Vasquez-Jalpa C, Nakano M, Velasco-Villa M, Lopez-Garcia O. NRNH-AR: A Small Robotic Agent Using Tri-Fold Learning for Navigation and Obstacle Avoidance. Applied Sciences. 2025; 15(15):8149. https://doi.org/10.3390/app15158149
Chicago/Turabian StyleVasquez-Jalpa, Carlos, Mariko Nakano, Martin Velasco-Villa, and Osvaldo Lopez-Garcia. 2025. "NRNH-AR: A Small Robotic Agent Using Tri-Fold Learning for Navigation and Obstacle Avoidance" Applied Sciences 15, no. 15: 8149. https://doi.org/10.3390/app15158149
APA StyleVasquez-Jalpa, C., Nakano, M., Velasco-Villa, M., & Lopez-Garcia, O. (2025). NRNH-AR: A Small Robotic Agent Using Tri-Fold Learning for Navigation and Obstacle Avoidance. Applied Sciences, 15(15), 8149. https://doi.org/10.3390/app15158149