
Anomaly Detection in Network Traffic via Cross-Domain Federated Graph Representation Learning

Abstract
1. Introduction
2. Background
2.1. Network Traffic Anomaly Detection
2.2. Graph Neural Networks
2.3. Federated Learning
3. Related Works
3.1. Network Traffic Anomaly Detection Based on Machine Learning
3.2. Network Traffic Anomaly Detection Based on Graph Neural Networks
3.3. Network Traffic Anomaly Detection Based on Federated Learning
4. Methods
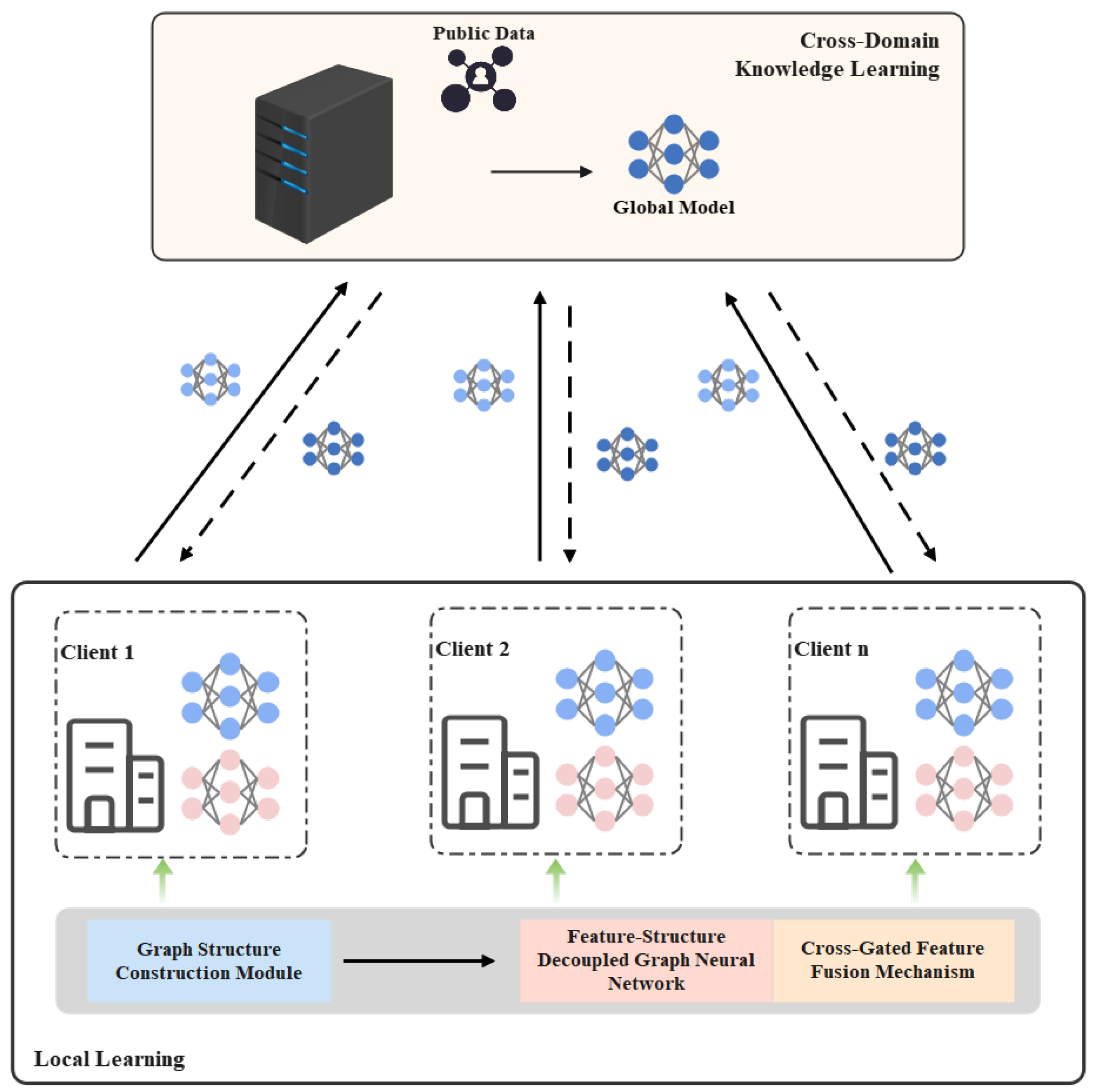
4.1. AD-FG Framework
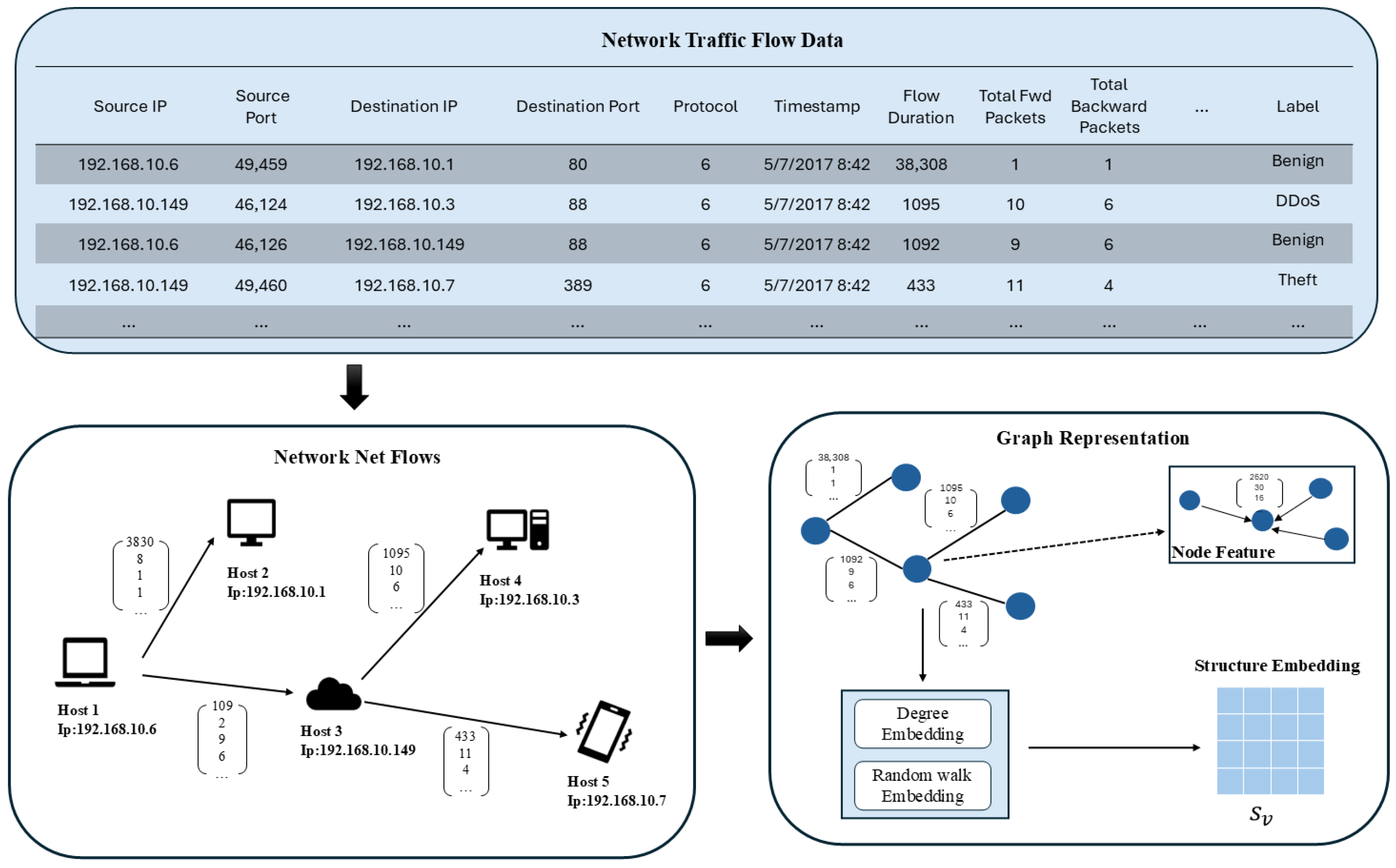
4.2. Graph Structure Construction Module
4.3. Federated Collaborative Learning Module
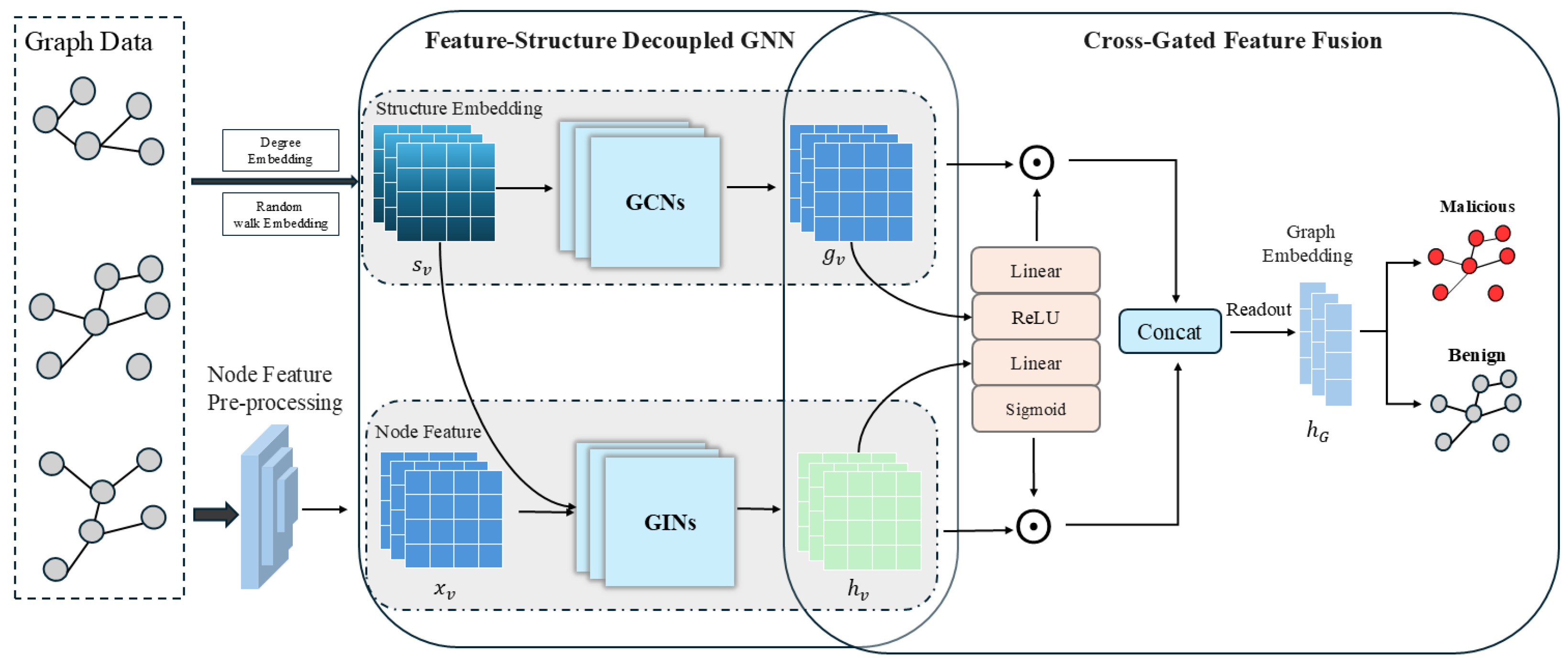
4.3.1. Feature-Structure Decoupled Graph Neural Network
4.3.2. Cross-Gated Feature Fusion Mechanism
4.4. Cross-Domain Knowledge Learning Module
5. Experiments and Results
5.1. Experimental Set-Up
5.1.1. Dataset and Parameter Settings
- Graph construction: Nodes in the graph are identified with IPs, and directed edges are created based on the source and destination IPs of each flow. Since the flow features provided by the dataset are edge features, the features of the incoming and outgoing edges connected to the nodes are accumulated as node features.
- Normalization: The features of the nodes and the adjacency matrix of the graph are normalized, the node features are normalized according to the degree, and the adjacency matrix is taken to be normalized based on the random walk.
- Graph segmentation: The size of the graph can be determined according to the actual requirements, such as the attack period to be detected, the amount of network communication, and the size of the network. According to the size of the dataset used in the experiment, a topology graph was constructed every 500 graph flows in chronological order.
- Graph labeling: If there are anomalous flows in the graph, then the graph is labeled as malicious; otherwise, it is labeled as benign.
- Dimension of degree-based structure embedding : {8, 16, 32, 64, 128};
- Dimension of random walk-based structure embedding : {8, 16, 32, 64, 128};
- Learning rate: {, , , };
- Weight decay: {, , , }.
5.1.2. Baseline
- Local: Each client trained local models based on local data and did not communicate with other clients.
- FedProx [32]: Based on FedAvg, a regular term was introduced into the original loss function to alleviate the problem of non-independent homogeneous distribution among clients.
- FedAvg [5]: The clients sent all learnable parameters to the server and received aggregated parameters from the server for the next round of training.
- FedSage [33]: The extraction of graph information was achieved using the two steps of aggregation and splicing combined with the GraphSAGE sampling algorithm.
- GCFL [34]: A federated learning approach based on graph clustering, with federated searching for clients where graphs with similar structures and features were located and training graph models between clients within the same cluster using FedAvg.
- MemAE-EIF [35]: Unsupervised detection methods based on deep autoencoders and Isolation Forest.
- CTGCN [36]: Modeling network devices and communications as graphs to capture changes in communications over time and detect anomalous traffic patterns by aggregating neighbor information through convolutional operations.
- DyGCN [37]: A GCN was used to capture the graph structure features of each time period to mine the abnormal substructure in the graph and identify network anomalies.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|
| Local | 85.21 | 83.68 | 61.26 | 70.71 |
| FedAvg | 85.02 | 82.25 | 61.94 | 70.66 |
| FedProx | 85.14 | 85.38 | 59.10 | 69.85 |
| FedSage | 85.37 | 86.82 | 58.70 | 70.04 |
| GCFL | 84.43 | 79.18 | 63.15 | 70.27 |
| MemAE-EIF | 83.50 | 74.31 | 69.72 | 71.46 |
| CTGCN | — | 87.80 | 50.23 | 63.90 |
| DyGCN | — | 77.77 | 66.48 | 71.68 |
| AD-FG (Ours) | 90.20 | 89.63 | 70.94 | 79.19 |
5.2. Results
5.2.1. Comparative Performance Results
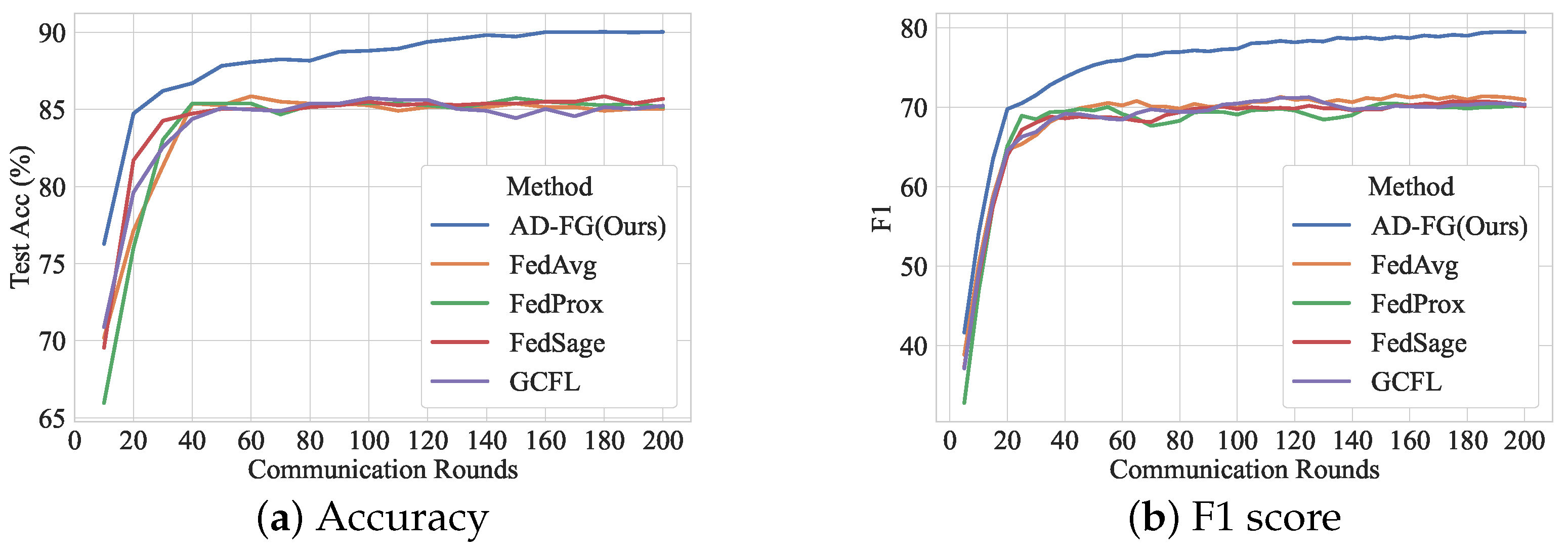
5.2.2. Convergence Analysis
5.2.3. The Effect of the Number of Local Training Rounds
5.2.4. Ablation Experiment
5.2.5. Client Number Comparison
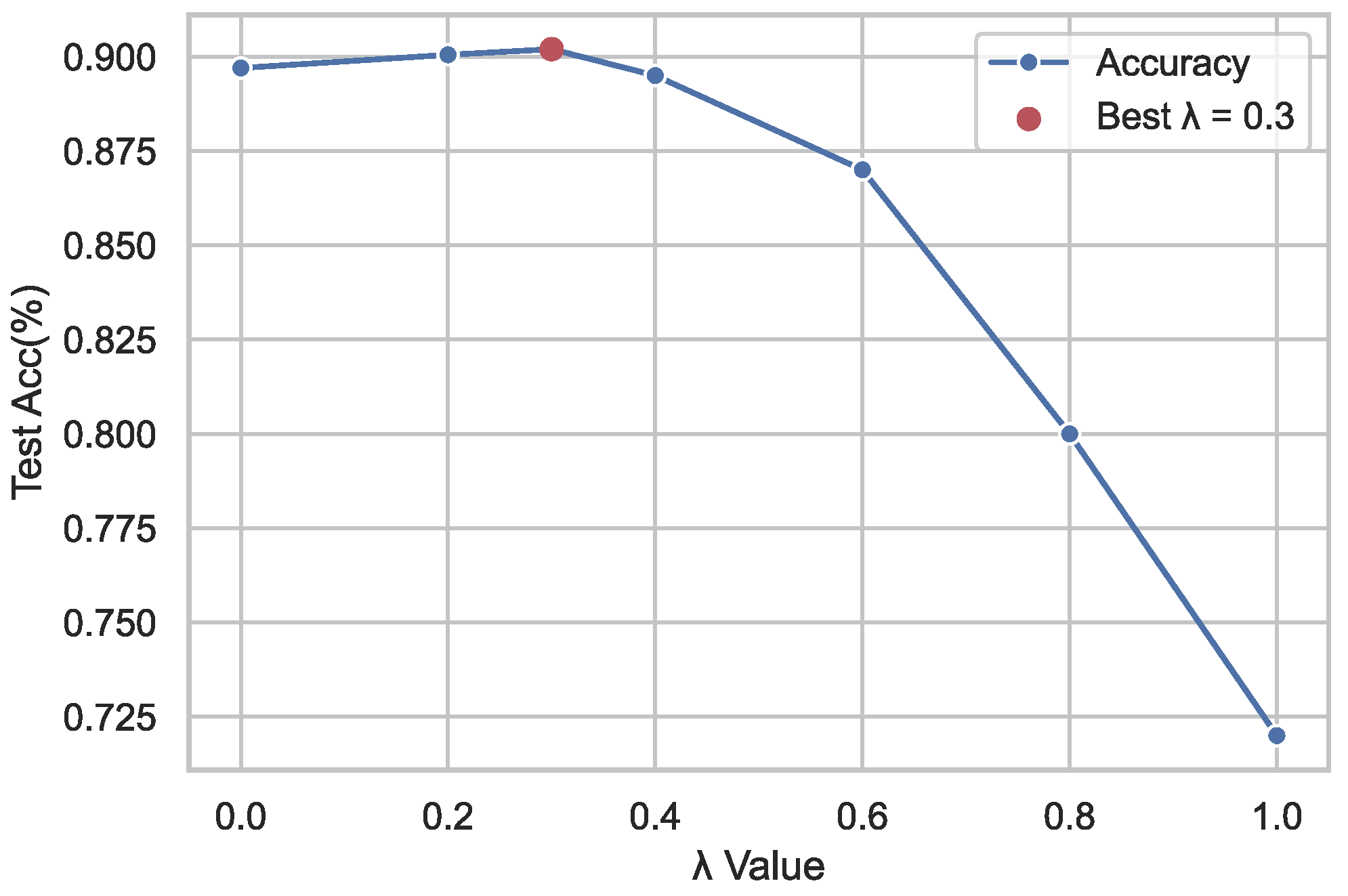
5.2.6. Effect of on Global Model Integration
6. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Roy, S. A comprehensive Survey on Network Traffic Anomaly Detection Using Deep Learning. Preprints 2024. [Google Scholar] [CrossRef]
- Alshamrani, A.; Myneni, S.; Chowdhary, A.; Huang, D. A survey on advanced persistent threats: Techniques, solutions, challenges, and research opportunities. IEEE Commun. Surv. Tutorials 2019, 21, 1851–1877. [Google Scholar] [CrossRef]
- Wang, N.; Wen, X.; Zhang, D.; Zhao, X.; Ma, J.; Luo, M.; Nie, S.; Wu, S.; Liu, J. Tbdetector: Transformer-based detector for advanced persistent threats with provenance graph. arXiv 2023, arXiv:2304.02838. [Google Scholar]
- Van Langendonck, L.; Castell-Uroz, I.; Barlet-Ros, P. Towards a graph-based foundation model for network traffic analysis. In Proceedings of the 3rd GNNet Workshop on Graph Neural Networking Workshop, Los Angeles, CA, USA, 9–12 December 2024; pp. 41–45. [Google Scholar]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; Agüera y Arcas, B. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics (AISTATS), Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Zhou, J.; Cui, G.; Hu, S.; Zhang, Z.; Yang, C.; Liu, Z.; Wang, L.; Li, C.; Sun, M. Graph neural networks: A review of methods and applications. AI Open 2020, 1, 57–81. [Google Scholar] [CrossRef]
- Zhao, Y.; Liu, H.; Duan, H. HGNN-GAMS: Heterogeneous Graph Neural Networks for Graph Attribute Mining and Semantic Fusion. IEEE Access 2024, 12, 191603–191611. [Google Scholar] [CrossRef]
- Alsamhi, S.H.; Myrzashova, R.; Hawbani, A.; Kumar, S.; Srivastava, S.; Zhao, L.; Curry, E. Federated learning meets blockchain in decentralized data-sharing: Healthcare use case. IEEE Internet Things J. 2024, 11, 19602–19615. [Google Scholar] [CrossRef]
- Myakala, P.K.; Jonnalagadda, A.K.; Bura, C. Federated learning and data privacy: A review of challenges and opportunities. Int. J. Res. Publ. Rev. 2024, 5, 1867–1879. [Google Scholar] [CrossRef]
- Nguyen, C.; Costa, A. Anomaly Detection in Network Traffic using Machine Learning Techniques. ITSI Trans. Electr. Electron. Eng. 2024, 13, 1–7. [Google Scholar]
- Ma, Q.; Sun, C.; Cui, B. A novel model for anomaly detection in network traffic based on support vector machine and clustering. Secur. Commun. Netw. 2021, 2021, 2170788. [Google Scholar] [CrossRef]
- Al-Saleh, A. A balanced communication-avoiding support vector machine decision tree method for smart intrusion detection systems. Sci. Rep. 2023, 13, 9083. [Google Scholar] [CrossRef]
- Vibhute, A.D.; Patil, C.H.; Mane, A.V.; Kale, K.V. Towards detection of network anomalies using machine learning algorithms on the NSL-KDD benchmark datasets. Procedia Comput. Sci. 2024, 233, 960–969. [Google Scholar] [CrossRef]
- Lin, K.; Xu, X.; Xiao, F. MFFusion: A multi-level features fusion model for malicious traffic detection based on deep learning. Comput. Netw. 2022, 202, 108658. [Google Scholar] [CrossRef]
- Guarino, S.; Vitale, F.; Flammini, F.; Faramondi, L.; Mazzocca, N.; Setola, R. A two-level fusion framework for cyber-physical anomaly detection. IEEE Trans. Ind.-Cyber-Phys. Syst. 2023, 2, 1–13. [Google Scholar] [CrossRef]
- Zheng, L.; Li, Z.; Li, J.; Li, Z.; Gao, J. AddGraph: Anomaly Detection in Dynamic Graph Using Attention-based Temporal GCN. In Proceedings of the IJCAI, Macao, China, 10–16 August 2019; pp. 4419–4425. [Google Scholar]
- Chang, L.; Branco, P. Graph-based solutions with residuals for intrusion detection: The modified e-graphsage and e-resgat algorithms. arXiv 2021, arXiv:2111.13597. [Google Scholar]
- Guo, W.; Qiu, H.; Liu, Z.; Zhu, J.; Wang, Q. GLD-Net: Deep Learning to Detect DDoS Attack via Topological and Traffic Feature Fusion. Comput. Intell. Neurosci. 2022, 2022, 4611331. [Google Scholar] [CrossRef]
- Lo, W.W.; Layeghy, S.; Sarhan, M.; Gallagher, M.; Portmann, M. E-graphsage: A graph neural network based intrusion detection system for iot. In Proceedings of the NOMS 2022–2022 IEEE/IFIP Network Operations and Management Symposium, Budapest, Hungary, 25–29 April 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–9. [Google Scholar]
- Caville, E.; Lo, W.W.; Layeghy, S.; Portmann, M. Anomal-E: A self-supervised network intrusion detection system based on graph neural networks. Knowl.-Based Syst. 2022, 258, 110030. [Google Scholar] [CrossRef]
- Altaf, T.; Wang, X.; Ni, W.; Liu, R.P.; Braun, R. NE-GConv: A lightweight node edge graph convolutional network for intrusion detection. Comput. Secur. 2023, 130, 103285. [Google Scholar] [CrossRef]
- Marfo, W.; Tosh, D.K.; Moore, S.V. Enhancing network anomaly detection using graph neural networks. In Proceedings of the 2024 22nd Mediterranean Communication and Computer Networking Conference (MedComNet), Nice, France, 11–13 June 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1–10. [Google Scholar]
- Marfo, W.; Tosh, D.K.; Moore, S.V. Network anomaly detection using federated learning. In Proceedings of the MILCOM 2022-2022 IEEE Military Communications Conference (MILCOM), Rockville, MD, USA, 28 November–2 December 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 484–489. [Google Scholar]
- Karunamurthy, A.; Vijayan, K.; Kshirsagar, P.R.; Tan, K.T. An optimal federated learning-based intrusion detection for IoT environment. Sci. Rep. 2025, 15, 8696. [Google Scholar] [CrossRef]
- Jianping, W.; Guangqiu, Q.; Chunming, W.; Weiwei, J.; Jiahe, J. Federated learning for network attack detection using attention-based graph neural networks. Sci. Rep. 2024, 14, 19088. [Google Scholar] [CrossRef]
- Dong, B.; Chen, D.; Wu, Y.; Tang, S.; Zhuang, Y. Fadngs: Federated learning for anomaly detection. IEEE Trans. Neural Netw. Learn. Syst. 2024, 36, 2578–2592. [Google Scholar] [CrossRef]
- Tan, Y.; Liu, Y.; Long, G.; Jiang, J.; Lu, Q.; Zhang, C. Federated learning on non-iid graphs via structural knowledge sharing. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 9953–9961. [Google Scholar]
- Dwivedi, V.P.; Luu, A.T.; Laurent, T.; Bengio, Y.; Bresson, X. Graph neural networks with learnable structural and positional representations. arXiv 2021, arXiv:2110.07875. [Google Scholar]
- Liu, Y.; Zheng, Y.; Zhang, D.; Lee, V.C.; Pan, S. Beyond smoothing: Unsupervised graph representation learning with edge heterophily discriminating. In Proceedings of the AAAI conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 4516–4524. [Google Scholar]
- D’Addato, M.; Antolini, A.; Renzini, F.; Elgani, A.M.; Perilli, L.; Scarselli, E.F.; Gnudi, A.; Magno, M.; Canegallo, R. Nanowatt Clock and Data Recovery for Ultra-Low Power Wake-Up Based Receivers. In Proceedings of the 2020 International Conference on Embedded Wireless Systems and Networks, Lyon, France, 17–19 February 2020; pp. 224–229. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Li, T.; Sahu, A.K.; Zaheer, M.; Sanjabi, M.; Talwalkar, A.; Smith, V. Federated optimization in heterogeneous networks. Proc. Mach. Learn. Syst. 2020, 2, 429–450. [Google Scholar]
- Zhang, K.; Yang, C.; Li, X.; Sun, L.; Yiu, S.M. Subgraph federated learning with missing neighbor generation. Adv. Neural Inf. Process. Syst. 2021, 34, 6671–6682. [Google Scholar]
- Wang, B.; Li, A.; Pang, M.; Li, H.; Chen, Y. Graphfl: A federated learning framework for semi-supervised node classification on graphs. In Proceedings of the 2022 IEEE International Conference on Data Mining (ICDM), Orlando, FL, USA, 28 November–1 December 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 498–507. [Google Scholar]
- Carrera, F.; Dentamaro, V.; Galantucci, S.; Iannacone, A.; Impedovo, D.; Pirlo, G. Combining unsupervised approaches for near real-time network traffic anomaly detection. Appl. Sci. 2022, 12, 1759. [Google Scholar] [CrossRef]
- Liu, J.; Xu, C.; Yin, C.; Wu, W.; Song, Y. K-core based temporal graph convolutional network for dynamic graphs. IEEE Trans. Knowl. Data Eng. 2020, 34, 3841–3853. [Google Scholar] [CrossRef]
- Gu, Y.; Zhang, X.; Xu, H.; Wu, T. DyGCN: Dynamic Graph Convolution Network-based Anomaly Network Traffic Detection. In 2024 IEEE 23rd International Conference on Trust, Security and Privacy in Computing and Communications (TrustCom), Sanya, China, 17–21 December 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1838–1843. [Google Scholar]
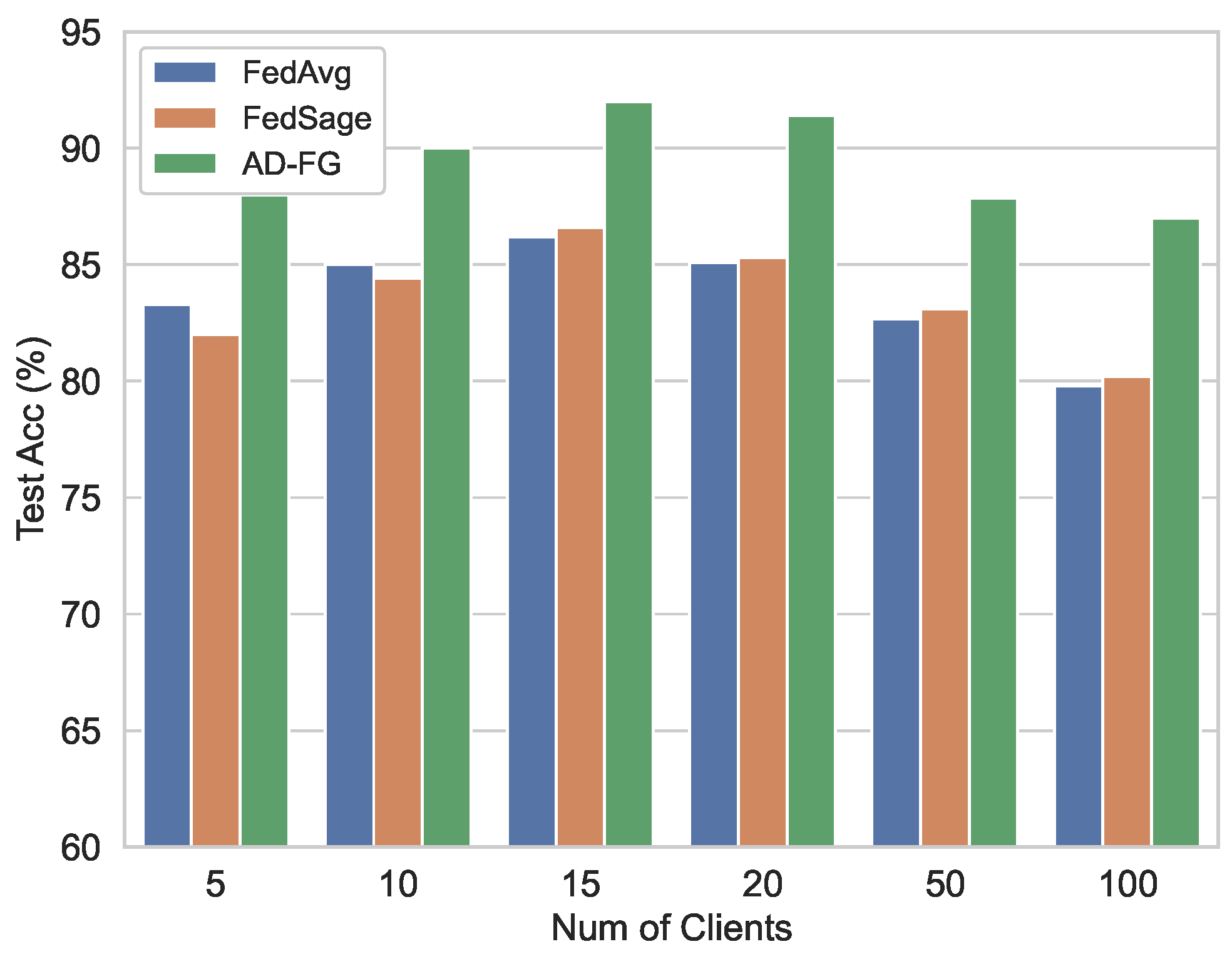
| Dataset | Number of Nodes | Number of Edges | Time Duration | Number of Graphs | Attack Type |
|---|---|---|---|---|---|
| CIC-IDS 2017 | 19,211 | 2,824,000 | 5 days | 5650 | 14 |
| Network Traffic Type | Quantity (Flows) |
|---|---|
| Benign | 2,273,097 |
| DoS Hulk | 231,073 |
| PortScan | 158,930 |
| DDoS | 128,027 |
| DoS GoldenEye | 10,293 |
| FTP-Patator | 7938 |
| SSH-Patator | 5897 |
| DoS Slowloris | 5796 |
| DoS Slowhttptest | 5499 |
| Bot | 1966 |
| Web Attack Brute Force | 1507 |
| Web Attack XSS | 652 |
| Infiltration | 36 |
| Web Attack SQL Injection | 21 |
| Heartbleed | 11 |
| Methods | Epochs | |||
|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |
| FedAvg | 85.02 | 86.94 | 88.58 | 89.70 |
| FedSage | 85.37 | 87.41 | 89.17 | 88.94 |
| AD-FG | 90.20 | 91.12 | 93.41 | 92.29 |
| Dual-Channel GNN | Cross-Gated | Cross-Domain | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|---|---|
| × | × | × | 85.02 | 82.25 | 61.94 | 70.66 |
| ✓ | × | × | 89.23 | 88.12 | 69.58 | 77.76 |
| ✓ | ✓ | × | 89.70 | 88.78 | 69.25 | 77.81 |
| ✓ | ✓ | ✓ | 90.20 | 89.63 | 70.94 | 79.19 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, Y.; Liu, Z.; Pang, J. Anomaly Detection in Network Traffic via Cross-Domain Federated Graph Representation Learning. Appl. Sci. 2025, 15, 6258. https://doi.org/10.3390/app15116258
Zhao Y, Liu Z, Pang J. Anomaly Detection in Network Traffic via Cross-Domain Federated Graph Representation Learning. Applied Sciences. 2025; 15(11):6258. https://doi.org/10.3390/app15116258
Chicago/Turabian StyleZhao, Yanli, Zongduo Liu, and Junjie Pang. 2025. "Anomaly Detection in Network Traffic via Cross-Domain Federated Graph Representation Learning" Applied Sciences 15, no. 11: 6258. https://doi.org/10.3390/app15116258
APA StyleZhao, Y., Liu, Z., & Pang, J. (2025). Anomaly Detection in Network Traffic via Cross-Domain Federated Graph Representation Learning. Applied Sciences, 15(11), 6258. https://doi.org/10.3390/app15116258