

Low-Scalability Distributed Systems for Artificial Intelligence: A Comparative Study of Distributed Deep Learning Frameworks for Image Classification

 , ,
, ,  ,
,  , and
, and 
Abstract
1. Introduction
- It demonstrates how an LSDS-HPC setup with recycled hardware can maximize the efficiency and accuracy of image classification.
- It promotes the reuse of devices considered obsolete for complex tasks.
- The results obtained aim to facilitate research in various areas, opting for the use of low-scalability distributed systems when a large budget is not available to acquire specific equipment for high-performance computing.
- It allows researchers and scientists to choose a distributed training framework for their distributed deep learning models. This highlights the importance of reusing obsolete hardware to reduce e-waste in computer labs, research centers, companies, and industries.
- Finally, empirical speedups across different frameworks and infrastructures are presented to reinforce the optimal choice of the distributed training framework.
2. Related Works
3. Materials and Methods
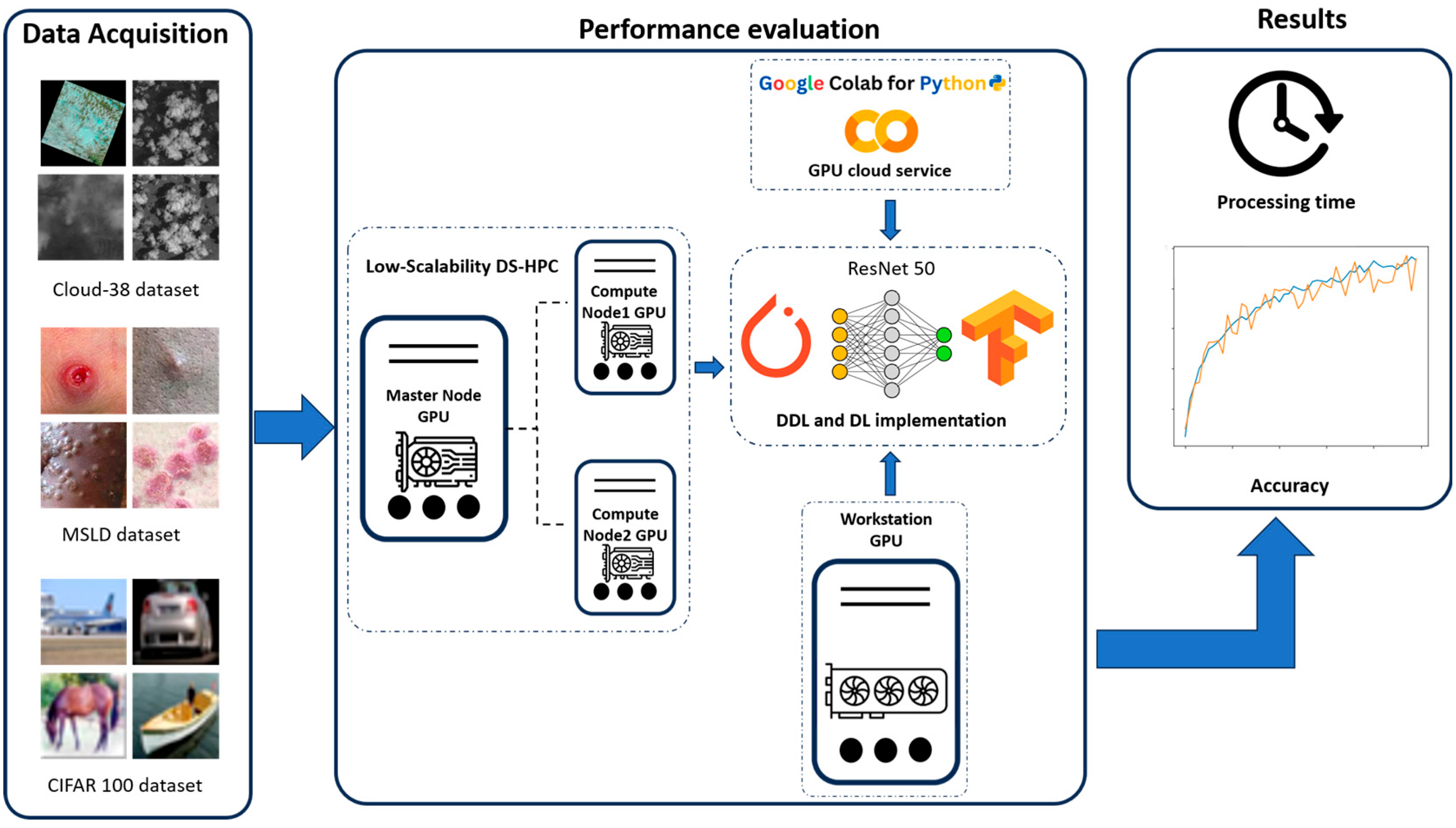
3.1. Data Acquisition
3.2. Description of Distributed Systems
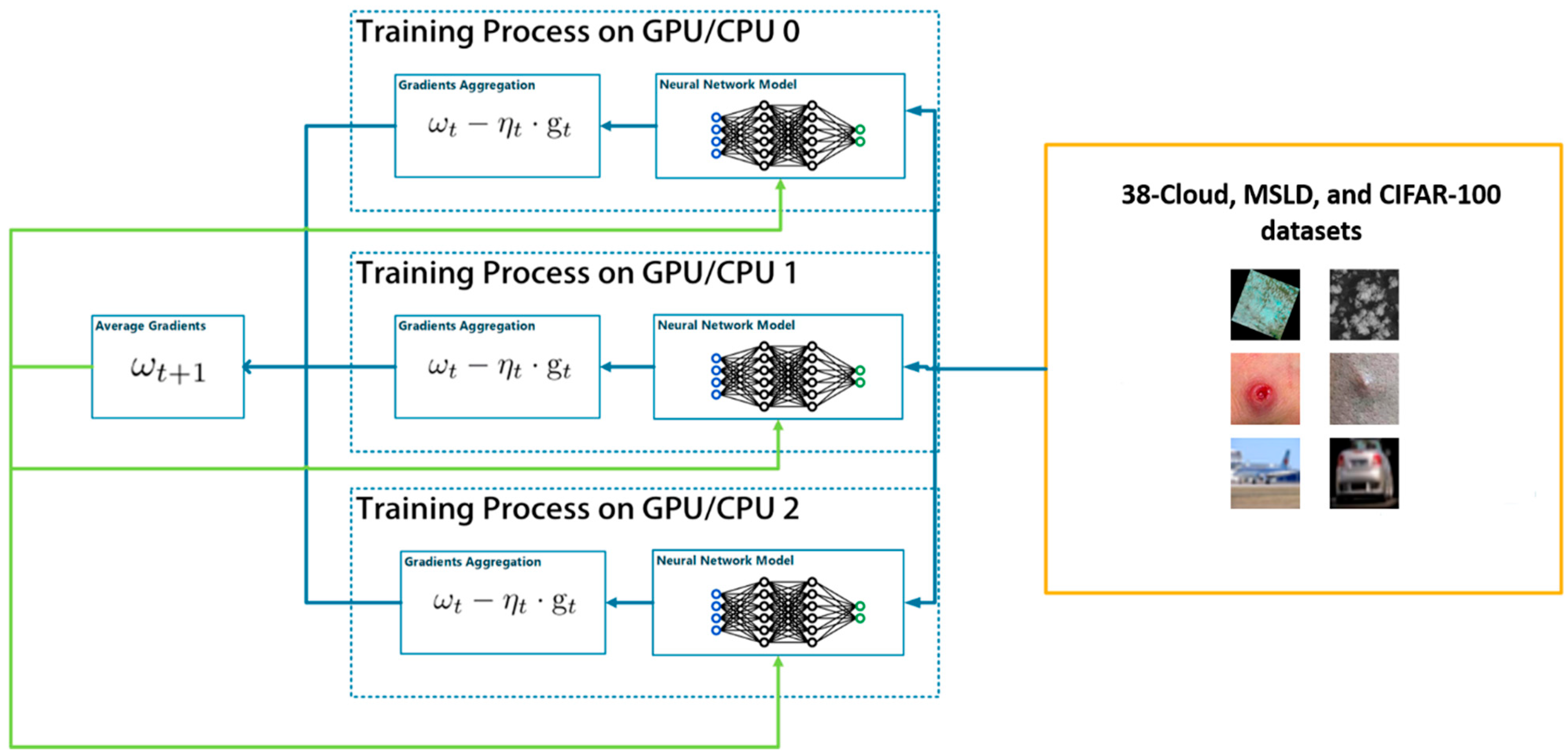
3.2.1. Data Parallelism
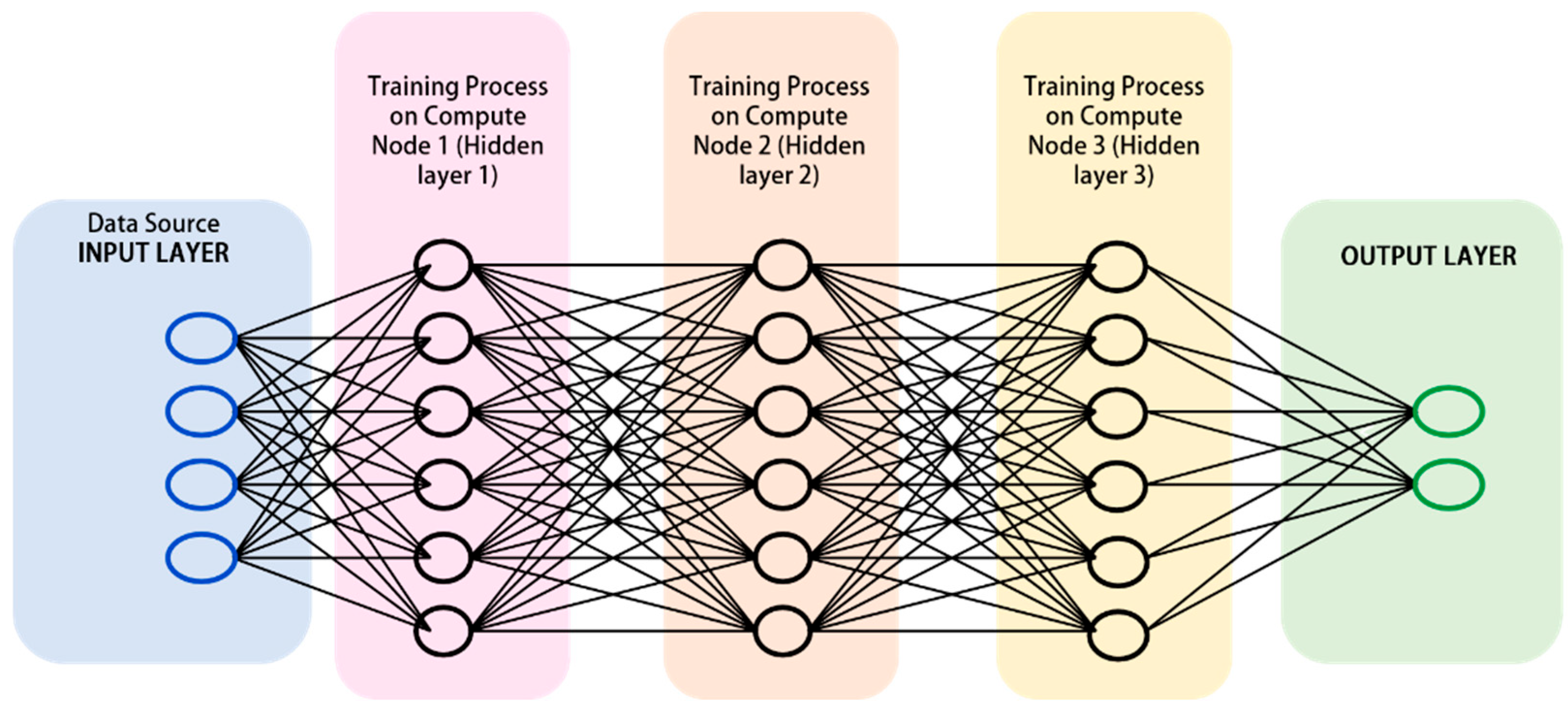
3.2.2. Model Parallelism
3.3. Distributed Deep Learning
- Speedup is the overall speedup achieved by parallelizing the computation.
- is the fraction of the computation that must be executed sequentially.
- is the fraction of the computation that can be executed in parallel;
- P is the number of processors or processing units, and
- is the execution time without parallelism;
- is the execution time with a distributed strategy.
3.3.1. Distributed Training Frameworks
3.3.2. Distributed System Environment Configuration
3.3.3. CNN ResNet50 Model Description
3.3.4. Hyperparameter Definition and Model Evaluation Metrics
4. Results
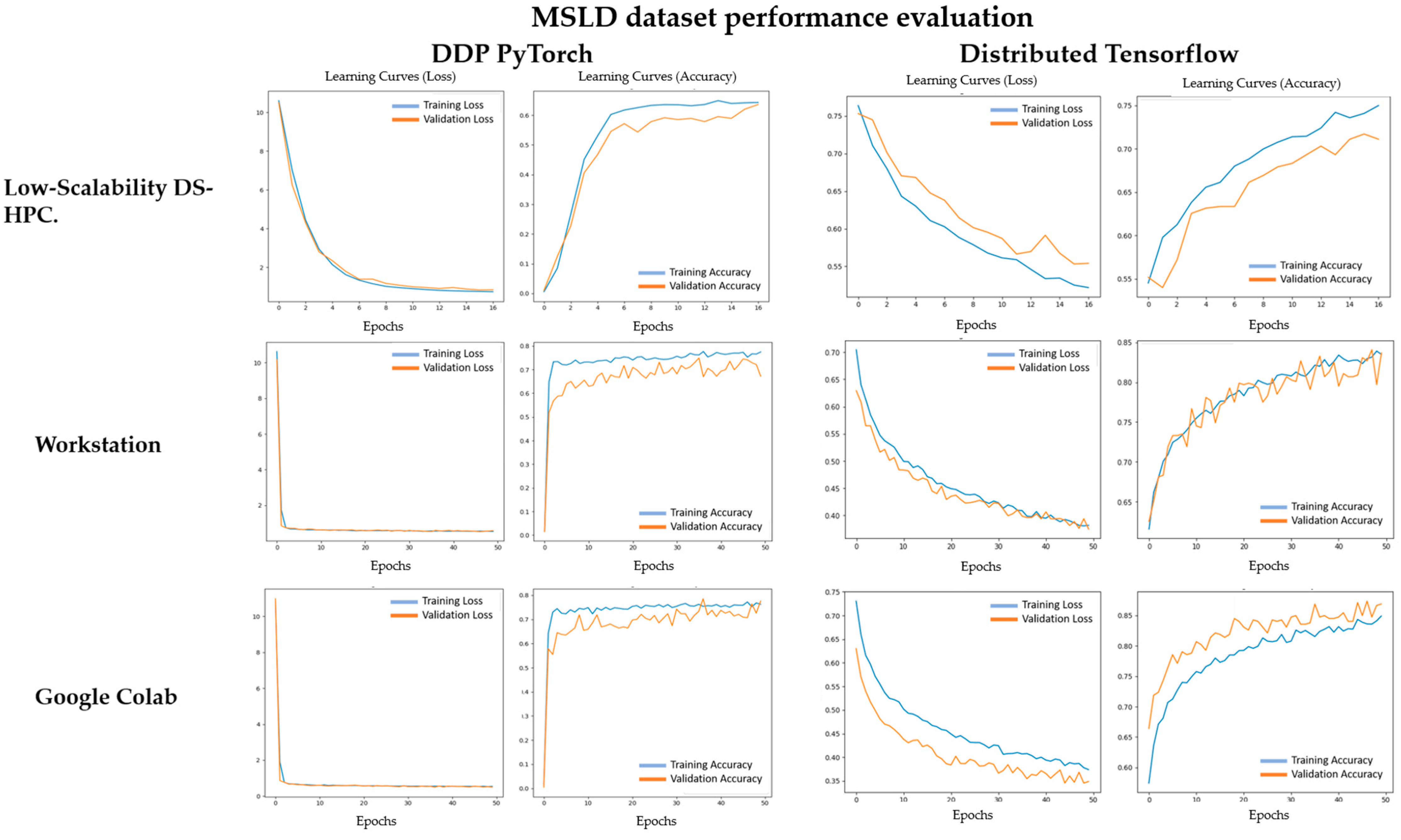
4.1. Processing Time
4.2. Performance Evaluation of Distributed Frameworks
5. Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Janiesch, C.; Zschech, P.; Heinrich, K. Machine learning and deep learning. Electron. Mark. 2021, 31, 685–695. [Google Scholar] [CrossRef]
- Roy, A. Artificial neural networks. ACM SIGKDD Explor. Newsl. 2000, 1, 33–38. [Google Scholar] [CrossRef]
- Zhang, F.; Petersen, M.; Johnson, L.; Hall, J.; O’Bryant, S.E. Hyperparameter tuning with high performance computing machine learning for imbalanced Alzheimer’s disease data. Appl. Sci. 2022, 12, 6670. [Google Scholar] [CrossRef] [PubMed]
- Straccia, U. Reasoning within fuzzy description logics. J. Artif. Intell. Res. 2001, 14, 137–166. [Google Scholar] [CrossRef]
- PJothi, N. Fault diagnosis in high-speed computing systems using big data analytics integrated evolutionary computing on the Internet of Everything platform. Deleted J. 2024, 20, 2177–2191. [Google Scholar] [CrossRef]
- Li, J.; Monroe, W.; Ritter, A.; Jurafsky, D.; Galley, M.; Gao, J. Deep reinforcement learning for dialogue generation. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 2–4 November 2016. [Google Scholar] [CrossRef]
- Zhang, C.; Sargent, I.; Pan, X.; Li, H.; Gardiner, A.; Hare, J. An object-based convolutional neural network (OCNN) for urban land use classification. Remote Sens. Environ. 2018, 216, 57–70. [Google Scholar] [CrossRef]
- Lv, X.; Ming, D.; Lu, T.; Zhou, K.; Wang, M.; Bao, H. A new method for region-based majority voting CNNs for very high resolution image classification. Remote Sens. 2018, 10, 1946. [Google Scholar] [CrossRef]
- Kim, Y.; Choi, H.; Lee, J.; Kim, J.-S.; Jei, H.; Roh, H. Towards an optimized distributed deep learning framework for a heterogeneous multi-GPU cluster. Clust. Comput. 2020, 23, 2287–2300. [Google Scholar] [CrossRef]
- Liu, J.; Wu, Z.; Feng, D.; Zhang, M.; Wu, X.; Yao, X.; Yu, D.; Ma, Y.; Zhao, F.; Dou, D. HeterPS: Distributed deep learning with reinforcement learning based scheduling in heterogeneous environments. Future Gener. Comput. Syst. 2023, 148, 106–117. [Google Scholar] [CrossRef]
- Sun, P.; Feng, W.; Han, R.; Yan, S.; Wen, T. Optimizing network performance for distributed DNN training on GPU clusters: ImageNet/AlexNet training in 1.5 minutes. arXiv 2019, arXiv:1902.06855. [Google Scholar]
- Bhangale, U.; Durbha, S.S.; King, R.L.; Younan, N.H.; Vatsavai, R. High performance GPU computing based approaches for oil spill detection from multi-temporal remote sensing data. Remote Sens. Environ. 2017, 202, 28–44. [Google Scholar] [CrossRef]
- Graziani, M.; Eggel, I.; Deligand, F.; Bobák, M.; Andrearczyk, V.; Müller, H. Breast histopathology with high-performance computing and deep learning. Comput. Inform. 2021, 39, 780–807. [Google Scholar] [CrossRef]
- Plaza, A.; Du, Q.; Chang, Y.L.; King, R.L. High performance computing for hyperspectral remote sensing. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2011, 4, 528–544. [Google Scholar] [CrossRef]
- Pop, F. High performance numerical computing for high energy physics: A new challenge for big data science. Adv. High Energy Phys. 2014, 2014, 507690. [Google Scholar] [CrossRef]
- Singh, V.K.; Sheng, Q. Bridging the science and technology by modern mathematical methods and high performance computing. Appl. Math. 2021, 66, 2. [Google Scholar] [CrossRef]
- Wang, Z.; Yu, D.; Shen, S.; Zhang, S.; Liu, H.; Yao, S. Select Your Own Counterparts: Self-Supervised Graph Contrastive Learning with Positive Sampling. IEEE Trans. Neural Netw. Learn. Syst. 2025, 36, 4–6453. [Google Scholar] [CrossRef]
- Xu, P.; Shi, S.; Chu, X. Performance Evaluation of Deep Learning Tools in Docker Containers. In Proceedings of the 2017 3rd International Conference on Big Data Computing and Communications (BIGCOM), Chengdu, China, 10–12 August 2017. [Google Scholar] [CrossRef]
- Bahrampour, S.; Ramakrishnan, N.; Schott, L.; Shah, M. Comparative Study of Deep Learning Software Frameworks. arXiv 2015, arXiv:1511.06435. [Google Scholar] [CrossRef]
- Du, X.; Xu, Z.; Wang, Y.; Huang, S.; Li, J. Comparative Study of Distributed Deep Learning Tools on Supercomputers. In Algorithms and Architectures for Parallel Processing; Vaidya, J., Li, J., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2018; Volume 11334, pp. 121–135. [Google Scholar] [CrossRef]
- Hegde, V.; Usmani, S. Parallel and Distributed Deep Learning. arXiv 2016, arXiv:1605.04591. [Google Scholar] [CrossRef]
- Krizhevsky, A. Learning Multiple Layers of Features from Tiny Images. Tech. Rep. 2009. Available online: https://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf (accessed on 30 April 2025).
- Mohajerani, S.; Krammer, T.A.; Saeedi, P. A Cloud Detection Algorithm for Remote Sensing Images Using Fully Convolutional Neural Networks. In Proceedings of the 2018 IEEE 20th International Workshop on Multimedia Signal Processing (MMSP), Vancouver, BC, Canada, 29–31 August 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Mohajerani, S.; Saeedi, P. Cloud-Net: An End-to-End Cloud Detection Algorithm for Landsat 8 Imagery. arXiv 2019, arXiv:1901.10077. [Google Scholar]
- Gürbüz, S.; Aydin, G. Monkeypox Skin Lesion Detection Using Deep Learning Models. In Proceedings of the 2022 International Conference on Computers and Artificial Intelligence Technologies (CAIT), Istanbul, Turkey, 21–23 July 2022; pp. 66–70. [Google Scholar]
- Kshemkalyani, A.D.; Singhal, M. Distributed Computing: Principles, Algorithms, and Systems, 1st ed.; Cambridge University Press: New York, NY, USA, 2008. [Google Scholar]
- Hajibaba, M.; Gorgin, S. A Review on Modern Distributed Computing Paradigms: Cloud Computing, Jungle Computing and Fog Computing. J. Comput. Inf. Technol. 2014, 22, 69–84. [Google Scholar] [CrossRef]
- Cisco Systems. Cisco Fog Computing Solutions Unleash the Power of the Internet of Things. Available online: https://docplayer.net/20003565-Cisco-fog-computing-solutions-unleash-the-power-of-the-internet-of-things.html (accessed on 12 December 2024).
- Merenda, M.; Porcaro, C.; Iero, D. Edge Machine Learning for AI-Enabled IoT Devices: A Review. Sensors 2020, 20, 2533. [Google Scholar] [CrossRef] [PubMed] [PubMed Central]
- Sunny, R.T.; Thampi, S.M. Survey on Distributed Data Mining in P2P Networks. arXiv 2012, arXiv:1205.3231. [Google Scholar] [CrossRef]
- Misirli, J.; Casalicchio, E. An Analysis of Methods and Metrics for Task Scheduling in Fog Computing. Future Internet 2024, 16, 16. [Google Scholar] [CrossRef]
- Wang, L.; Tao, J.; Ranjan, R.; Marten, H.; Streit, A.; Chen, J.; Chen, D. G-Hadoop: MapReduce across distributed data centers for data-intensive computing. Future Gener. Comput. Syst. 2013, 29, 739–750. [Google Scholar] [CrossRef]
- Koutris, P.; Salihoglu, S.; Suciu, D. Algorithmic Aspects of Parallel Data Processing. Found. Trends Databases 2018, 8, 239–370. [Google Scholar] [CrossRef]
- Shallue, C.; Lee, J.; Antognini, J.; Sohl-Dickstein, J.; Frostig, R.; Dahl, G. Measuring the Effects of Data Parallelism on Neural Network Training. J. Mach. Learn. Res. 2018, 20, 1–49. [Google Scholar]
- Shoeybi, M.; Patwary, M.; Puri, R.; LeGresley, P.; Casper, J.; Catanzaro, B. Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism. arXiv 2019, arXiv:1909.08053. [Google Scholar]
- Chen, T.; Xu, B.; Zhang, C.; Guestrin, C. Training Deep Nets with Sublinear Memory Cost. arXiv 2016, arXiv:1604.06174. [Google Scholar]
- Jiang, Y.; Zhu, Y.; Lan, C.; Yi, B.; Cui, Y.; Guo, C. A Unified Architecture for Accelerating Distributed DNN Training in Heterogeneous GPU/CPU Clusters. In Proceedings of the 14th USENIX Conference on Operating Systems Design and Implementation (OSDI’20), 4–6 November 2020; pp. 463–479. [Google Scholar]
- Sergeev, A.; Del Balso, M. Horovod: Fast and easy distributed deep learning in TensorFlow. arXiv 2018, arXiv:1802.05799. [Google Scholar]
- Gu, J.; Chowdhury, M.; Shin, K.G.; Zhu, Y.; Jeon, M.; Qian, J.; Liu, H.; Guo, C. Tiresias: A GPU Cluster Manager for Distributed Deep Learning. In Proceedings of the 16th USENIX Conference on Networked Systems Design and Implementation (NSDI’19), Boston, MA, USA, 26–28 February 2019; pp. 485–500. [Google Scholar]
- Nguyen, T.T.; Wahib, M.; Takano, R. Efficient MPI-AllReduce for Large-Scale Deep Learning on GPU-Clusters. Concurr. Comput. Pract. Exp. 2021, 33, e5574. [Google Scholar] [CrossRef]
- NVIDIA. NVIDIA Collective Communications Library (NCCL). Available online: https://docs.nvidia.com/deeplearning/nccl/index.html (accessed on 10 April 2025).
- Awan, A.A.; Manian, K.V.; Chu, C.-H.; Subramoni, H.; Panda, D.K. Optimized Large-Message Broadcast for Deep Learning Workloads: MPI, MPI+NCCL, or NCCL2? Parallel Comput. 2019, 85, 141–152. [Google Scholar] [CrossRef]
- Hill, M.D.; Marty, M.R. Amdahl’s Law in the Multicore Era. Computer 2008, 41, 33–38. [Google Scholar] [CrossRef]
- Végh, J. How Amdahl’s Law Limits the Performance of Large Artificial Neural Networks. Brain Inf. 2019, 6, 4. [Google Scholar] [CrossRef] [PubMed]
- TensorFlow. Distributed Training with TensorFlow. Available online: https://www.tensorflow.org/guide/distributed_training?hl=es-419 (accessed on 10 April 2025).
- PyTorch. Distributed Training Overview. Available online: https://pytorch.org/tutorials/beginner/dist_overview.html (accessed on 10 April 2025).
- Google. Colaboratory FAQ. Available online: https://research.google.com/colaboratory/intl/es/faq.html (accessed on 10 April 2025).
- Google. Administrar Google Colab para Organizaciones. Available online: https://support.google.com/a/answer/13177581 (accessed on 10 April 2025).
- NVIDIA Corporation. GeForce GTX 1050 Ti. NVIDIA. 2016. Available online: https://www.nvidia.com/es-la/geforce/products/10series/geforce-gtx-1050/ (accessed on 21 March 2025).
- Intel Corporation. Intel® Core™ i7-7700K Processor (8M Cache, up to 4.50 GHz). Intel ARK. 2017. Available online: https://ark.intel.com/products/97129 (accessed on 21 March 2025).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Horovod: Distributed Training Framework for TensorFlow, Keras, PyTorch, and MXNet. Available online: https://horovod.readthedocs.io/en/latest/keras.html (accessed on 25 May 2025).
- Available online: https://top500.org/ (accessed on 11 April 2025).
- Liu, Y.; Wang, X.; Hu, E.; Wang, A.; Shiri, B.; Lin, W. VNDHR: Variational Single Nighttime Image Dehazing for Enhancing Visibility in Intelligent Transportation Systems via Hybrid Regularization. IEEE Trans. Intell. Transp. Syst. 2025, 2025, 1–15. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | Approach | Highlights |
|---|---|---|
| Kim et al. [9] | Optimization for heterogeneous multi-GPU clusters, using Tensorflow as a distributed processing framework, with the goal of improving resource utilization without sacrificing training accuracy. | Improving computational performance by reducing I/O bottlenecks and efficiently increasing resource utilization on heterogeneous multi-GPU clusters using Distributed Tensorflow. |
| Xu et al. [18] | Performance evaluation of DL tools (such as TensorFlow, Caffe, and MXNet) running in virtualized environments with Docker containers, compared to running directly on the host operating system. | The use of Docker containers generates minimal overhead in the training performance of DL models. Tests showed almost negligible performance differences between the native and containerized environments, and the evaluated tools maintained consistent and stable performance, validating their use in both production and experimental environments. |
| Bahrampour et al. [19] | Comparison of five DL frameworks (Caffe, Neon, TensorFlow, Theano, and Torch) evaluating their extensibility, hardware utilization, and computational performance (training and execution times) on both CPUs and multithreaded GPUs, testing different architectures, including convolutional networks. | Performance was found to vary depending on the framework, network architecture, and hardware environment, so the choice of framework should consider these factors. Torch was the most efficient on both CPUs and GPUs and the most extensible. |
| Du et al. [20] | Systematic comparison of DDL tools—specifically TensorFlow, MXNet, and CNTK—running on supercomputers. Their computational efficiency, scalability, and performance when training complex models in HPC environments are analyzed. | Provide a comprehensive evaluation of the performance of distributed tools on HPC architectures, considering both speed and scalability. Practical and comparable metrics such as training time, speedup, and computational resource monitoring are used to measure the efficiency of computational resource usage during DL model training. |
| Hegde et al. [21] | An overview of parallel and DDL, addressing both the theoretical principles and practical challenges for efficiently deploying models on parallel infrastructures. It focuses on explaining the various parallelization techniques and their impact on training performance. | The balance between computation and communication is critical to achieving real improvements in speed and scalability. Data parallelism is most efficient for tasks where the model is small or moderately sized and is trained on large amounts of data. |
| Infrastructure | Components | Description |
|---|---|---|
| Workstation | GPU | Asus NVIDIA RTX 3070 (Taipei, Taiwan) |
| CPU | AMD Ryzen 9 5900X (Santa Clara, CA, USA) | |
| RAM | 96 GB/8 GB VRAM | |
| Operating System | Windows 11 | |
| TensorFlow | Ver. 2.10.1 | |
| PyTorch | Ver. 2.0.1 + cu117 | |
| Python | Ver. 3.9.18 | |
| Low-Scalability DS-HPC | GPU | Gigabyte NVIDIA GTX 1050ti x 3 (Taipei, Taiwan) |
| CPU | Intel i7-7700K x 3 (Santa Clara, CA, USA) | |
| RAM | 16 GB x 3/4 GB VRAM x 3 | |
| Operating System | Ubuntu Server 22.04.4 LTS | |
| TensorFlow | Ver. 2.17.0 | |
| PyTorch | Ver. 2.0.1 + cu117 | |
| Python | Ver. 3.9.18 | |
| Google Colaboratory | GPU | NVIDIA T4 (Santa Clara, CA, USA) |
| CPU | N/A | |
| RAM | 16 GB VRAM | |
| Operating System | GNU/Linux | |
| TensorFlow | 2.18.0 | |
| PyTorch | Ver. 2.6.0 + cu124 | |
| Python | Ver. 3.11.12 |
| Dataset | Hyperparameter | Value |
|---|---|---|
| Cloud-38 | Input | 192 × 192 |
| Epochs | 50 | |
| Batch size | 8 | |
| Optimizer | SGD | |
| Learning rate | 0.003 | |
| Loss function | Cross-Entropy | |
| MSLD | Input | 244 × 244 |
| Epochs | 50 | |
| Batch size | 32 | |
| Optimizer | SGD | |
| Learning rate | 0.001 | |
| Loss function | Cross-Entropy | |
| CIFAR-100 | Input | 32 × 32 |
| Epochs | 50 | |
| Batch size | 128 | |
| Optimizer | SGD | |
| Learning rate | 0.001 | |
| Loss function | Cross-Entropy |
| Infrastructure | Dataset | Distributed Data Parallel PyTorch | Distributed Tensorflow |
|---|---|---|---|
| Time Processing | Time Processing | ||
| Workstation | Cloud | 4 h 12 m 22 s | 5 h 18 m 18 s |
| MSLD | 12 m 14 s | 19 m 36 s | |
| CIFAR 100 | 24 m 8 s | 37 m 41 s | |
| Low-Scalability DS-HPC | Cloud | 3 h 2 m 15 s | 3 h 37 m 8 s |
| MSLD | 10 m 32 s | 37 m 54 s | |
| CIFAR 100 | 1 h 51 8 s | 10 m 52 s | |
| Google Colaboratory | Cloud | 4 h 27 m 6 s | 5 h 21 m 4 s |
| MSLD | 17 m 43 s | 52 m 36 s | |
| CIFAR 100 | 37 m 4 s | 1 h 13 m 13 s |
| Infrastructure | Dataset | Processing Time in Seconds | Speedup | ||
|---|---|---|---|---|---|
| DDP PyTorch | Dist. Tensorflow | DDP PyTorch | Dist. Tensorflow | ||
| Workstation | Cloud | 15,142 | 19,098 | 15,142/10,935 = 1.38x | 19,098/13,028 = 1.47x |
| MSLD | 734 | 1176 | 734/632 = 1.16x | 1176/2274 = 0.51x | |
| CIFAR 100 | 1448 | 2261 | 1448/6668 = 0.21x | 2261/652 = 3.47x | |
| Low-Scalability DS-HPC | Cloud | 10,935 | 13,028 | N/A | |
| MSLD | 632 | 2274 | |||
| CIFAR 100 | 6668 | 652 | |||
| Google Colaboratory | Cloud | 16,026 | 19,264 | 16,026/10,935 = 1.47x | 19,264/13,028 = 1.48x |
| MSLD | 1063 | 3156 | 1063/632 = 1.68x | 3156/2274 = 1.39x | |
| CIFAR 100 | 2224 | 4393 | 2224/6668 = 0.03x | 4393/652 = 6.74x | |
| Infrastructure | Dataset | Distributed Data Parallel PyTorch | Distributed Tensorflow | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Accuracy | Loss | Accuracy | Loss | ||||||
| Training | Validation | Training | Validation | Training | Validation | Training | Validation | ||
| Workstation | Cloud | 0.9649 | 0.9672 | 0.0990 | 0.0863 | 0.9027 | 0.9121 | 0.2135 | 0.2688 |
| MSLD | 0.8042 | 0.7590 | 0.5050 | 0.4830 | 0.8349 | 0.8070 | 0.3861 | 0.3884 | |
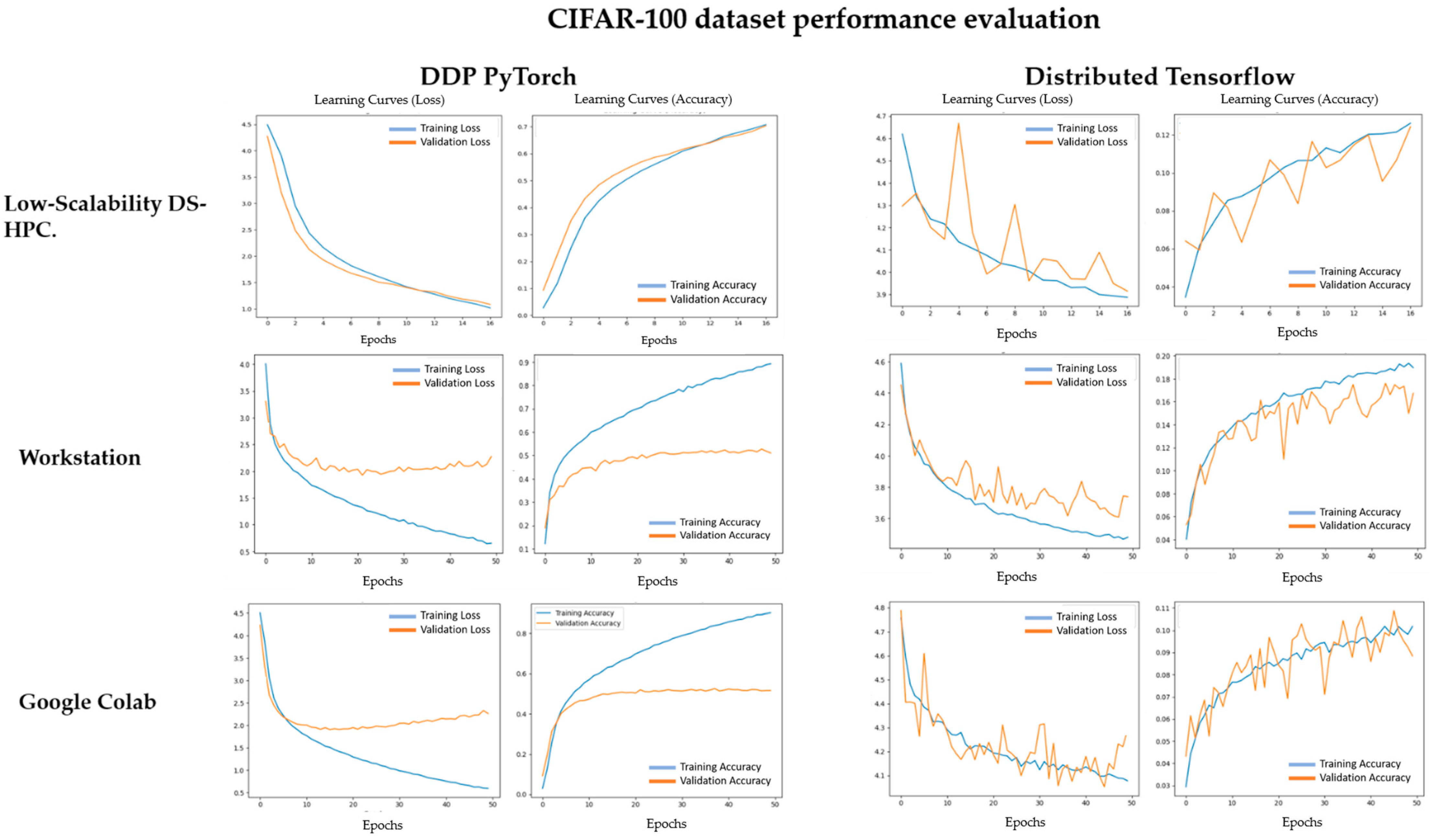
| CIFAR 100 | 0.8876 | 0.4892 | 0.6431 | 1.9475 | 0.1917 | 0.1695 | 3.4325 | 3.6841 | |
| Low-Scalability DS-HPC | Cloud | 0.7687 | 0.7951 | 0.4118 | 0.3721 | 0.9305 | 0.9125 | 0.1676 | 0.2303 |
| MSLD | 0.6511 | 0.6278 | 0.7229 | 0.7953 | 0.7504 | 0.7171 | 0.5183 | 0.5532 | |
| CIFAR 100 | 0.7077 | 0.7038 | 1.0173 | 1.038 | 0.1258 | 0.1192 | 3.9149 | 3.9252 | |
| Google Colab | Cloud | 0.9713 | 0.9710 | 0.0795 | 0.0730 | 0.9557 | 0.1106 | 0.9558 | 0.1183 |
| MSDL | 0.7722 | 0.7857 | 0.5235 | 0.5065 | 0.8392 | 0.8960 | 0.3688 | 0.3454 | |
| CIFAR 100 | 0.6202 | 0.4637 | 1.5279 | 2.0078 | 0.1037 | 0.1089 | 4.0670 | 4.0532 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rivera-Escobedo, M.; López-Martínez, M.d.J.; Solis-Sánchez, L.O.; Guerrero-Osuna, H.A.; Vázquez-Reyes, S.; Acosta-Escareño, D.; Olvera-Olvera, C.A. Low-Scalability Distributed Systems for Artificial Intelligence: A Comparative Study of Distributed Deep Learning Frameworks for Image Classification. Appl. Sci. 2025, 15, 6251. https://doi.org/10.3390/app15116251
Rivera-Escobedo M, López-Martínez MdJ, Solis-Sánchez LO, Guerrero-Osuna HA, Vázquez-Reyes S, Acosta-Escareño D, Olvera-Olvera CA. Low-Scalability Distributed Systems for Artificial Intelligence: A Comparative Study of Distributed Deep Learning Frameworks for Image Classification. Applied Sciences. 2025; 15(11):6251. https://doi.org/10.3390/app15116251
Chicago/Turabian StyleRivera-Escobedo, Manuel, Manuel de Jesús López-Martínez, Luis Octavio Solis-Sánchez, Héctor Alonso Guerrero-Osuna, Sodel Vázquez-Reyes, Daniel Acosta-Escareño, and Carlos A. Olvera-Olvera. 2025. "Low-Scalability Distributed Systems for Artificial Intelligence: A Comparative Study of Distributed Deep Learning Frameworks for Image Classification" Applied Sciences 15, no. 11: 6251. https://doi.org/10.3390/app15116251
APA StyleRivera-Escobedo, M., López-Martínez, M. d. J., Solis-Sánchez, L. O., Guerrero-Osuna, H. A., Vázquez-Reyes, S., Acosta-Escareño, D., & Olvera-Olvera, C. A. (2025). Low-Scalability Distributed Systems for Artificial Intelligence: A Comparative Study of Distributed Deep Learning Frameworks for Image Classification. Applied Sciences, 15(11), 6251. https://doi.org/10.3390/app15116251