
ETAFHrNet: A Transformer-Based Multi-Scale Network for Asymmetric Pavement Crack Segmentation


Abstract
1. Introduction
- (1)
- Accurate identification of intersecting cracks. In real scenarios, cracks often branch or intersect. Without sufficient receptive field or contextual awareness, models tend to miss or misclassify these areas [24].
- (2)
- Continuous modeling of long-range cracks. Cracks are typically thin and extended. In the absence of strong global context modeling, segmentation results become fragmented, particularly under high-resolution or multi-scale settings [7].
- (1)
- (2)
2. Related Work
2.1. Segmentation Model Evolution
2.2. Attention Mechanisms
2.3. Transformer Architectures
3. Methods
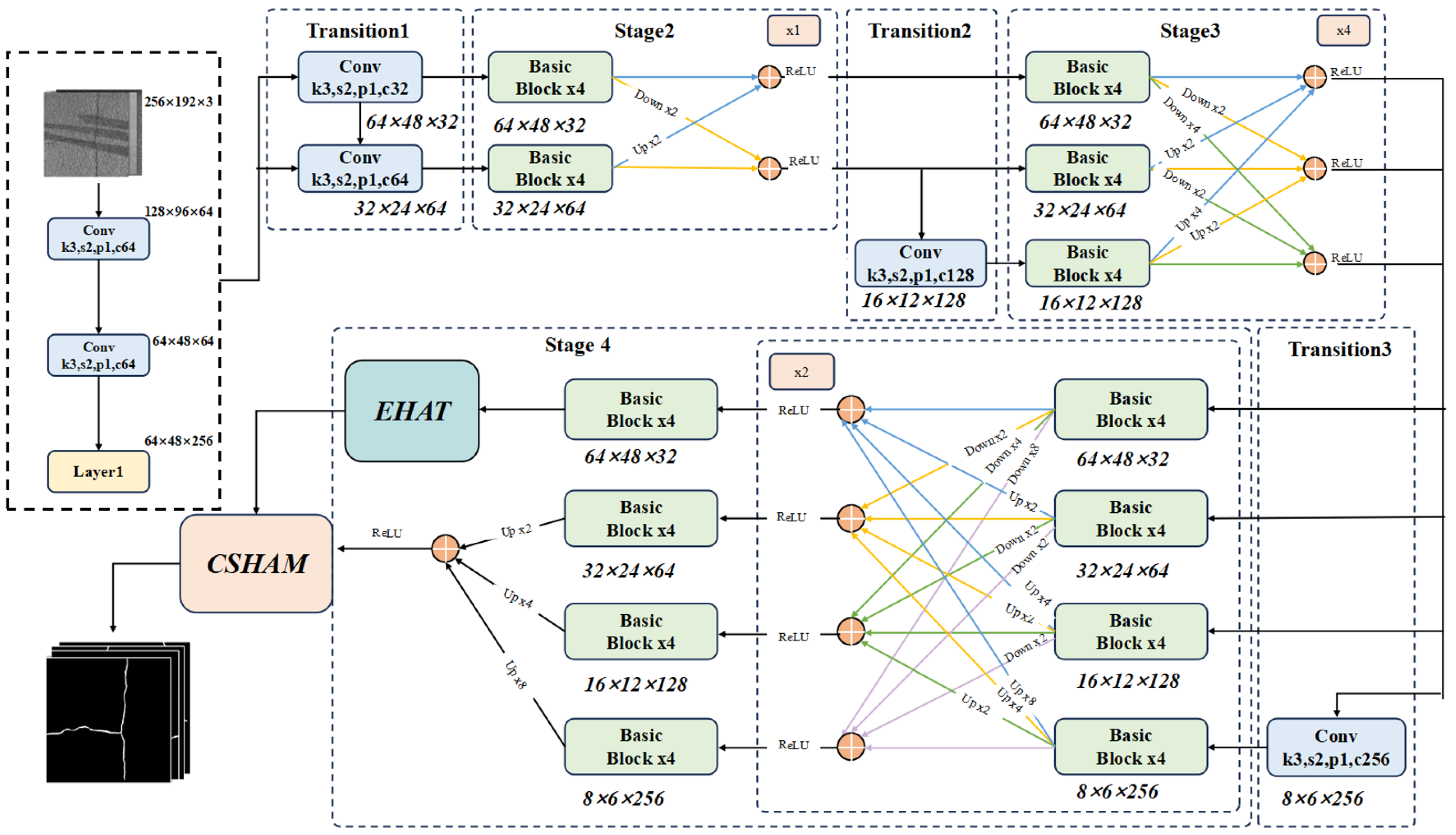
3.1. ETAFHrNet Architecture
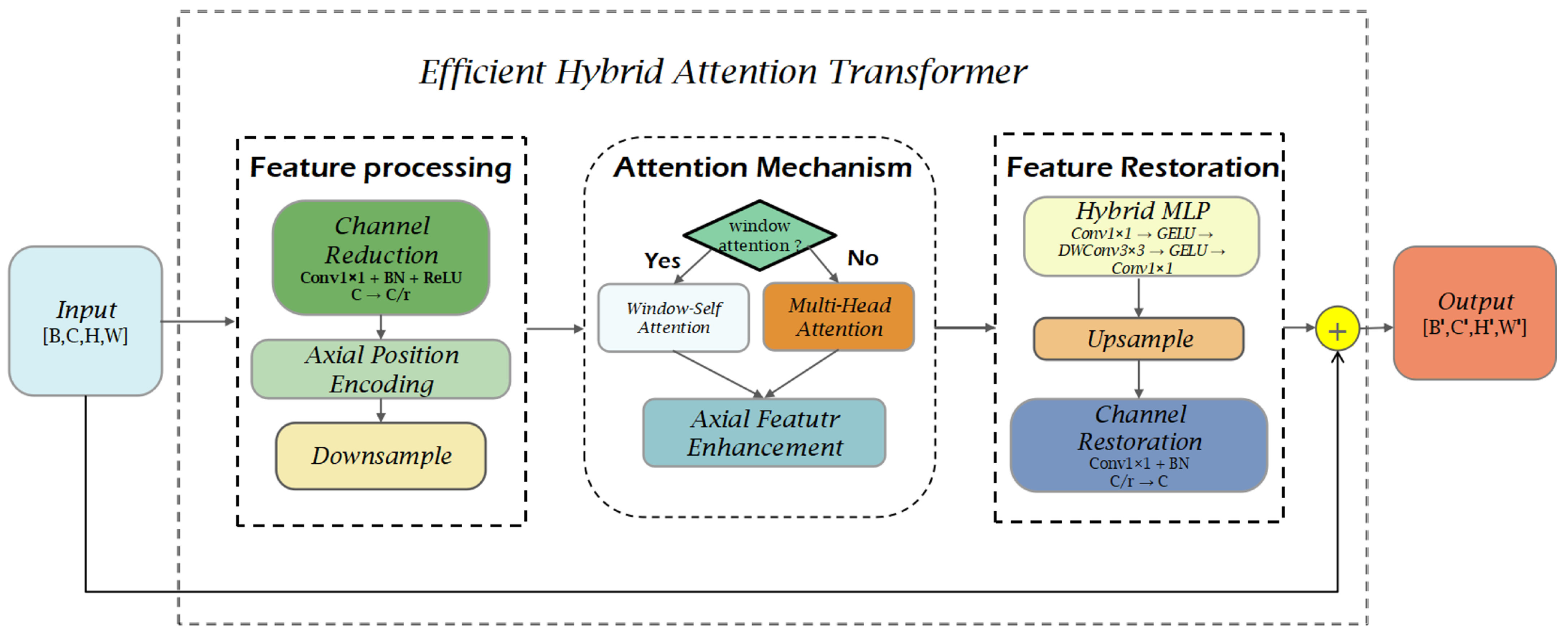
3.2. Efficient Hybrid Attention Transformer (EHAT) Module
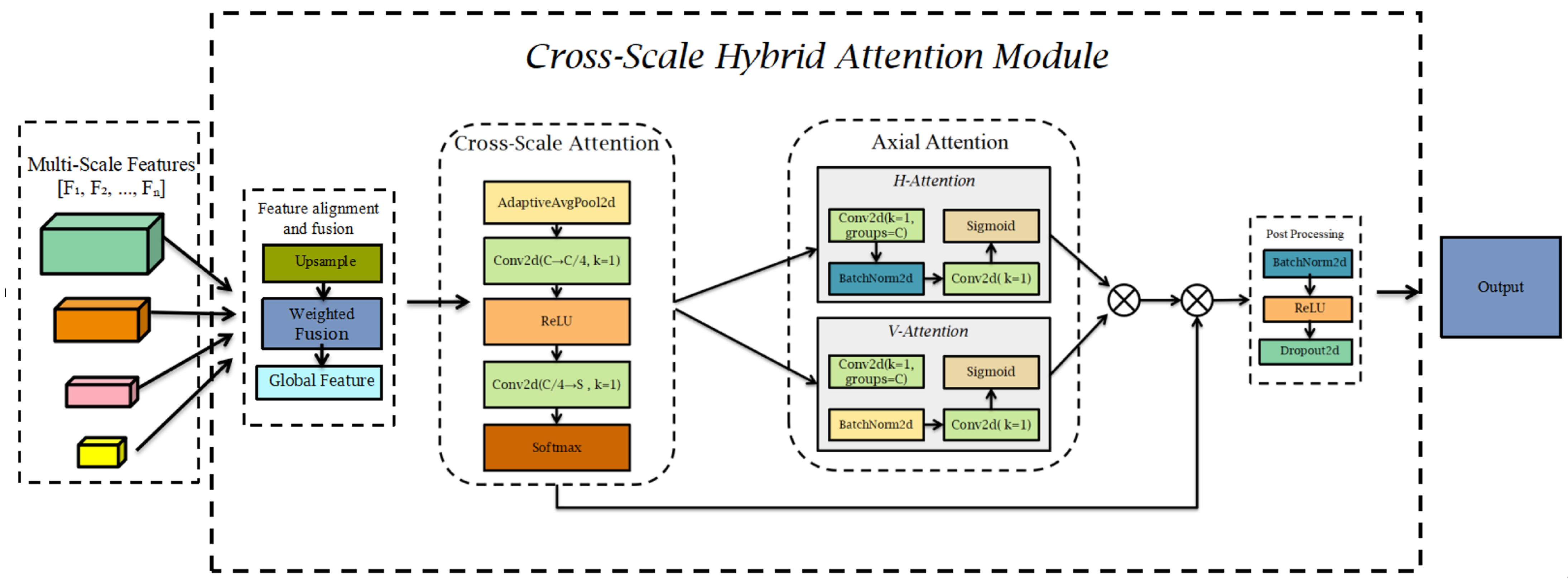
3.3. Cross-Scale Hybrid Attention Module (CSHAM)
4. Experimental Details
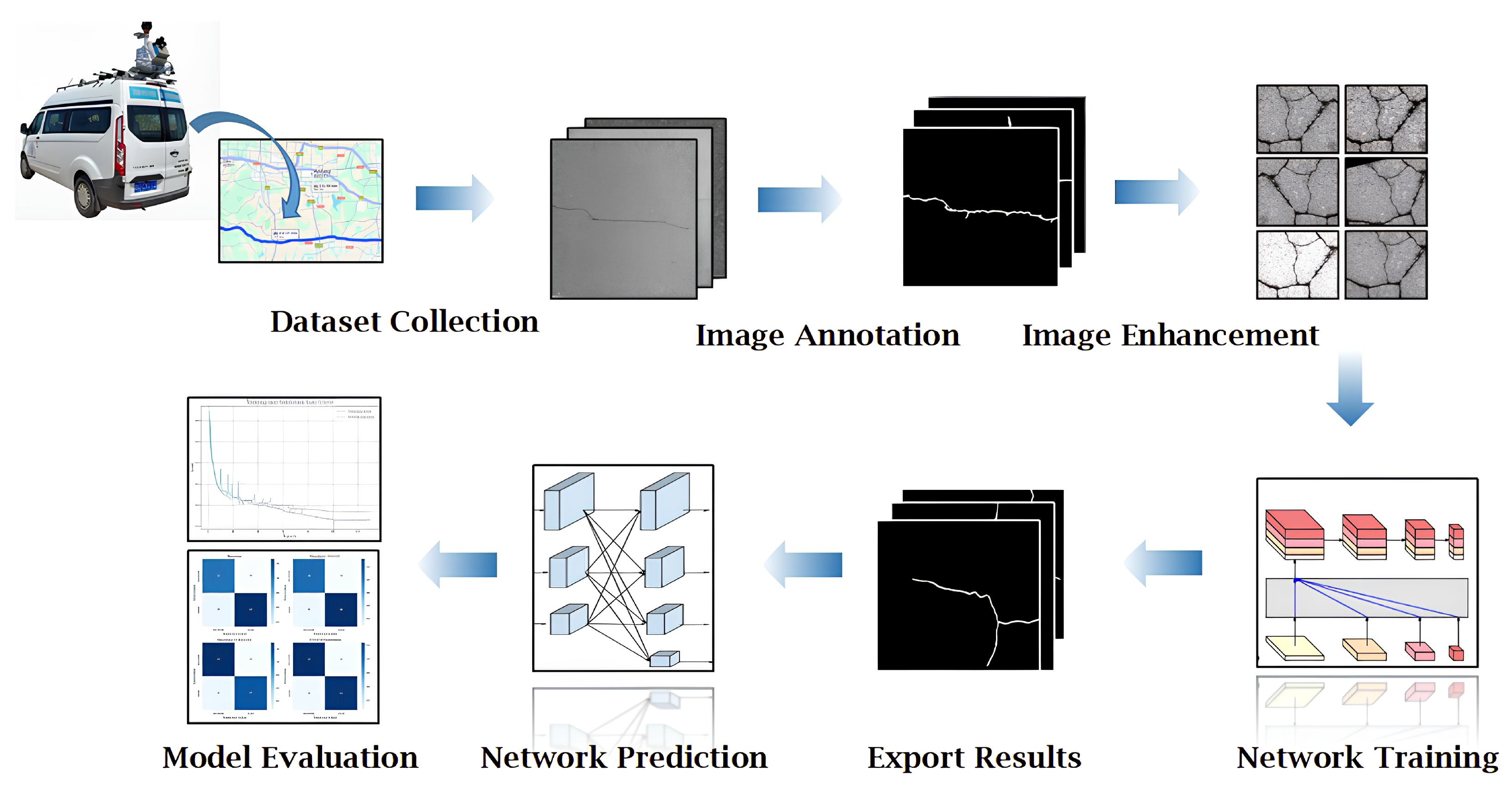
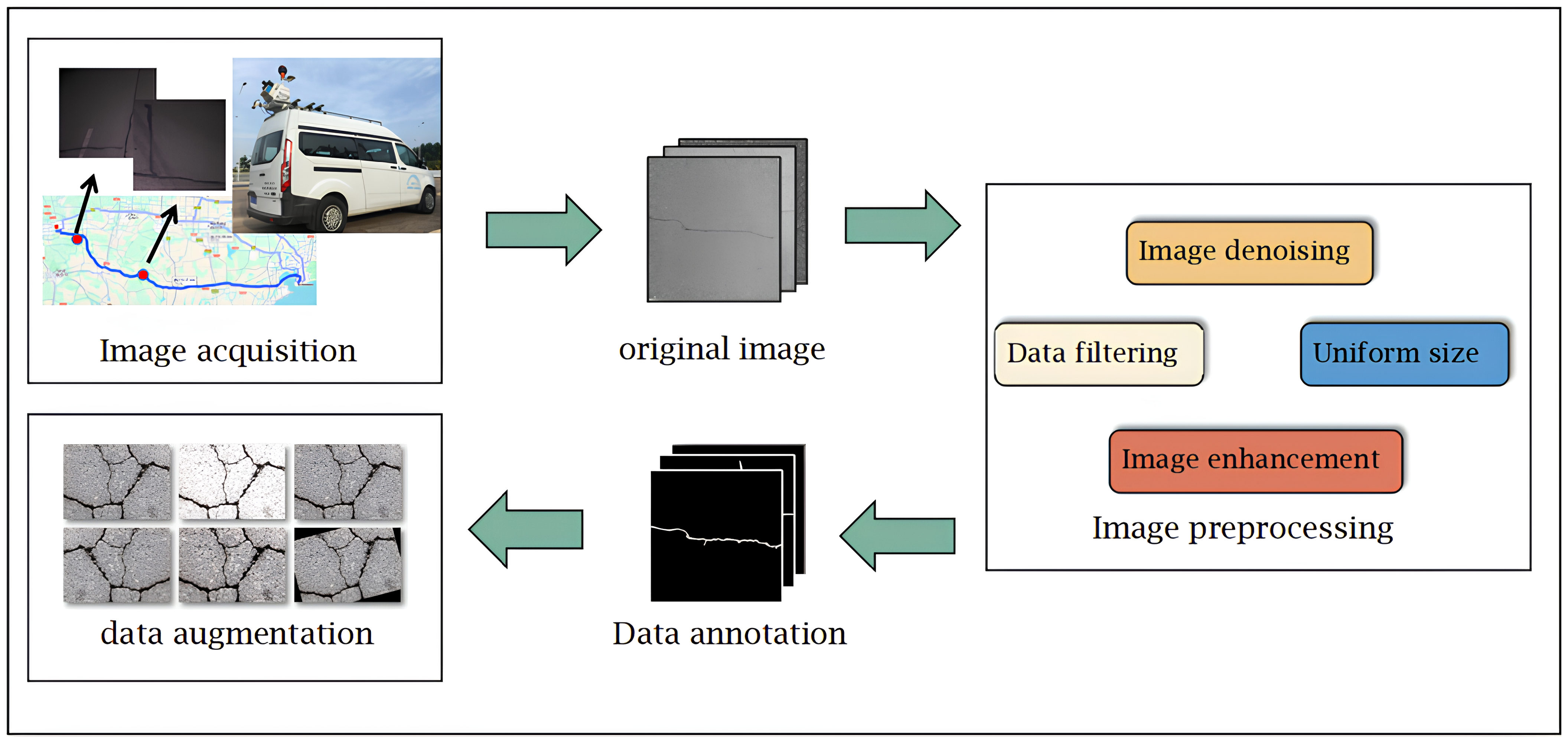
4.1. Dataset Preparation
4.2. Training Parameters and Methods
4.3. Methods for Evaluation
5. Results and Discussion
5.1. Influence of Semantic Labels and Transfer Learning on Model Performance
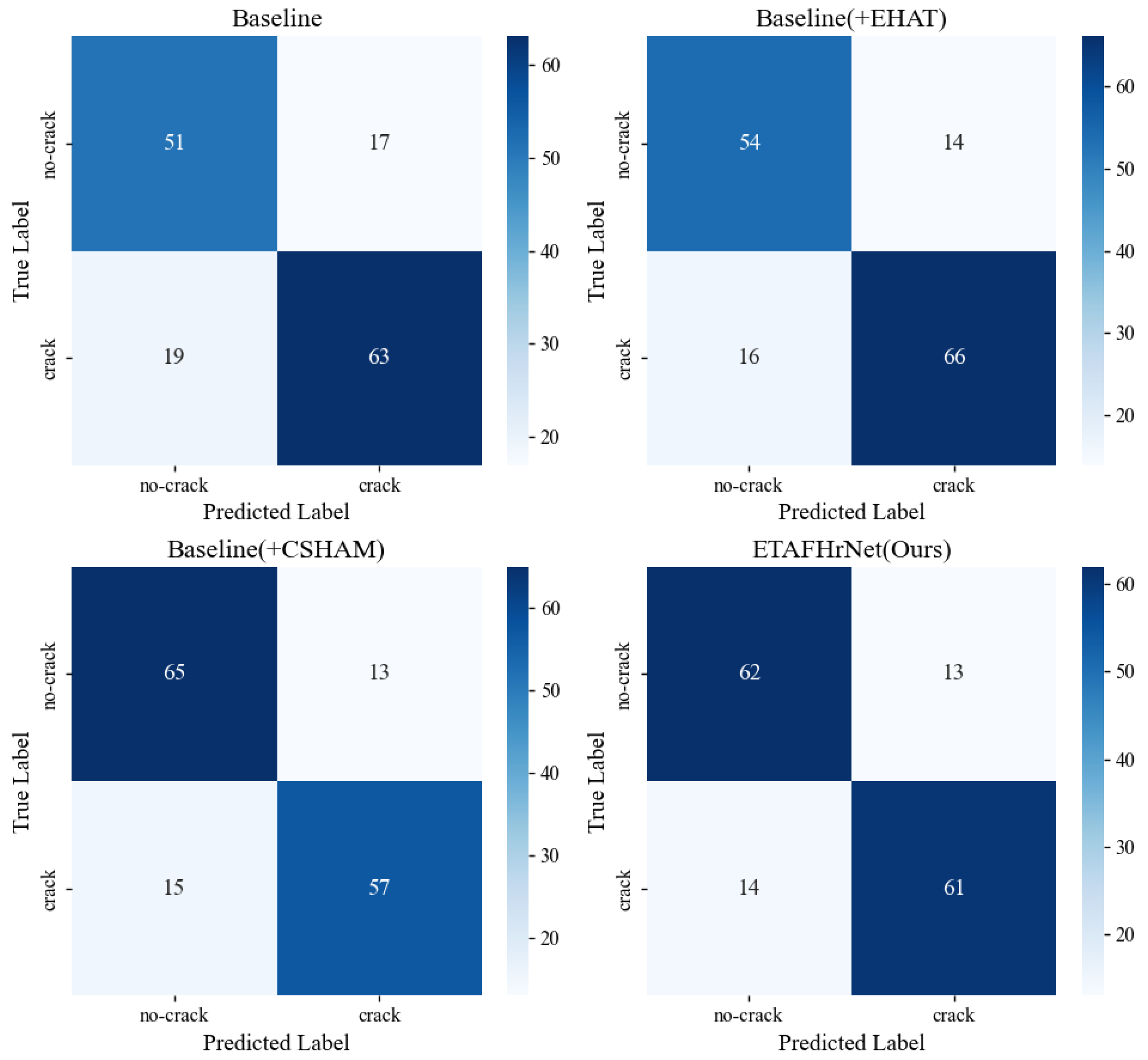
5.2. Ablation Experiment
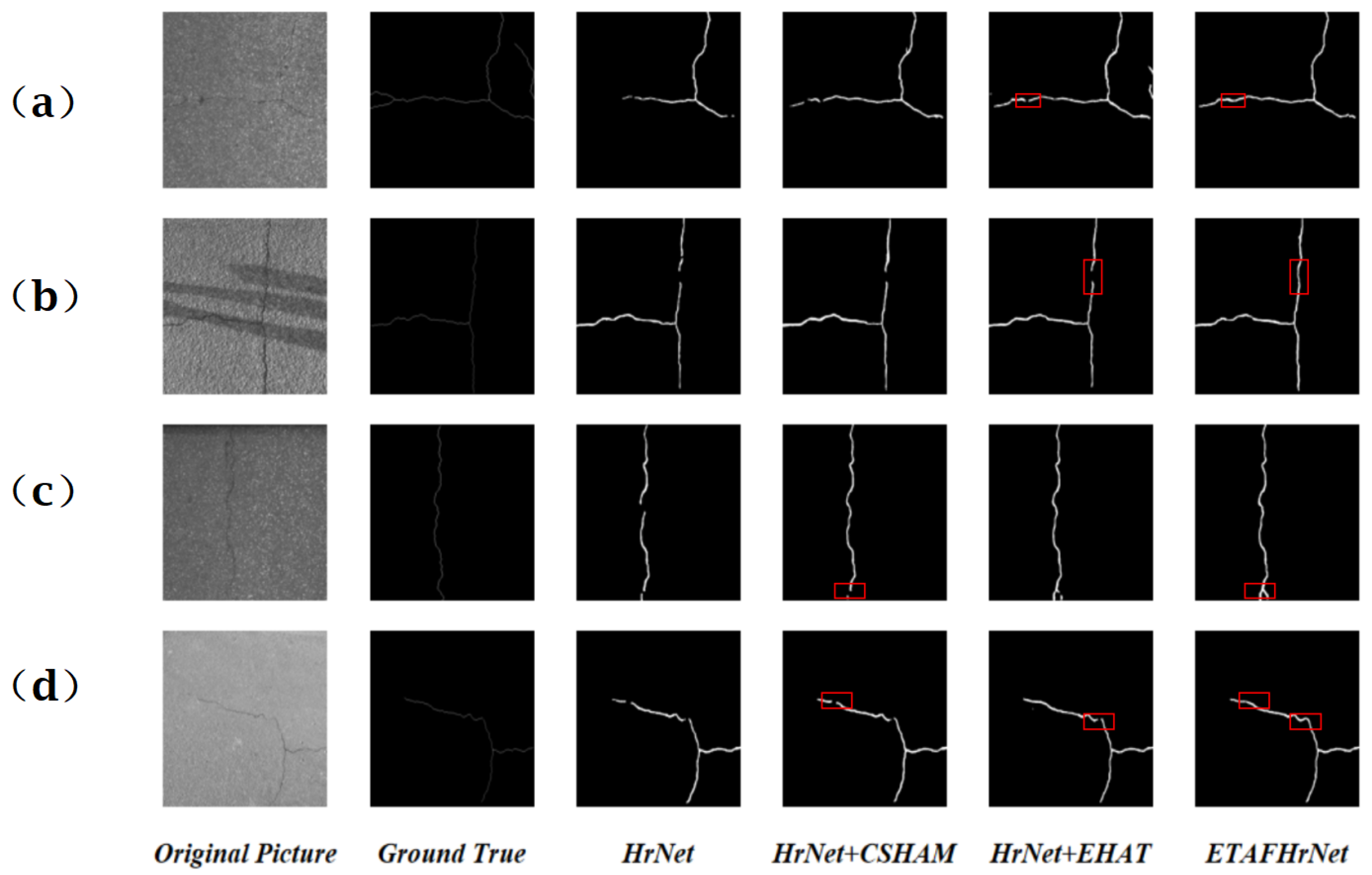
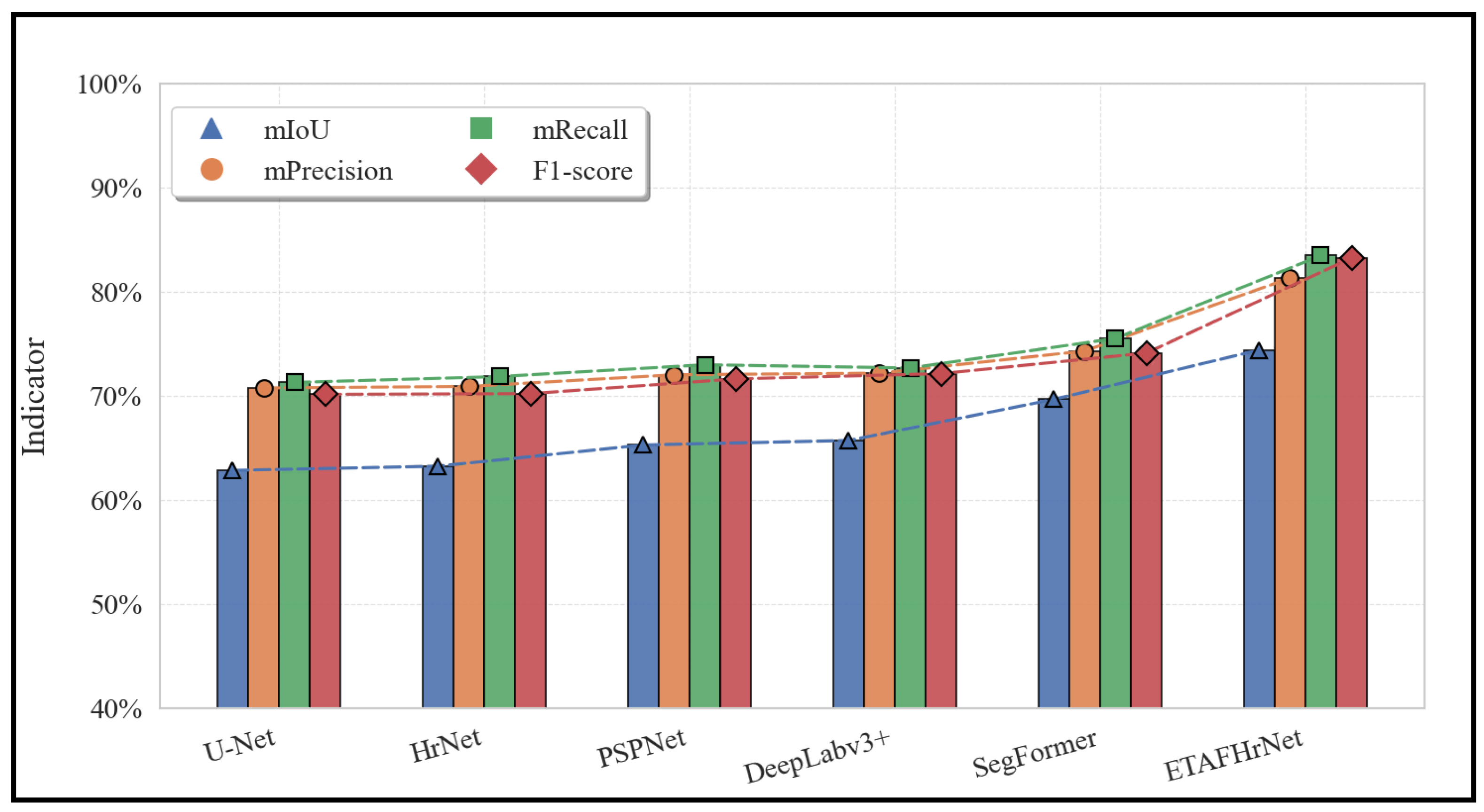
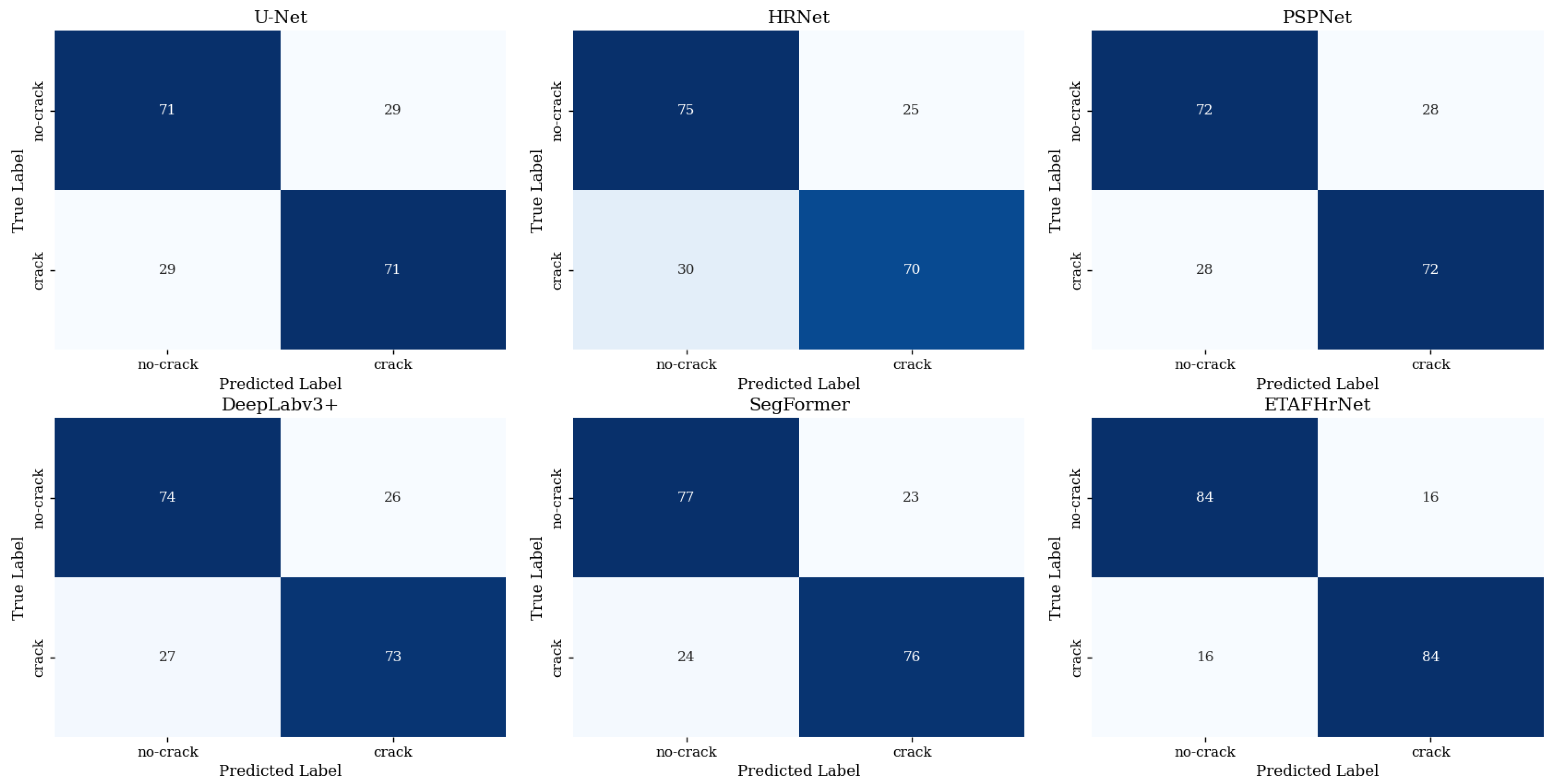
5.3. Comparison with Existing Advanced Methods
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Huyan, J.; Li, W.; Tighe, S.; Xu, Z.; Zhai, J. CrackU-net: A Novel Deep Convolutional Neural Network for Pixelwise Pavement Crack Detection. Struct. Control Health Monit. 2020, 27, e2551. [Google Scholar] [CrossRef]
- Ragnoli, A.; De Blasiis, M.R.; Di Benedetto, A. Pavement Distress Detection Methods: A Review. Infrastructures 2018, 3, 58. [Google Scholar] [CrossRef]
- Oliveira, H.; Correia, P.L. Automatic Road Crack Detection and Characterization. IEEE Trans. Intell. Transp. Syst. 2013, 14, 155–168. [Google Scholar] [CrossRef]
- Nafaa, S.; Essam, H.; Ashour, K.; Emad, D.; Mohamed, R.; Elhenawy, M.; Ashqar, H.I.; Hassan, A.A.; Alhadidi, T.I. Automated Pavement Cracks Detection and Classification Using Deep Learning. arXiv 2024, arXiv:2406.07674. [Google Scholar] [CrossRef]
- Mukherjee, R.; Iqbal, H.; Marzban, S.; Badar, A.; Brouns, T.; Gowda, S.; Arani, E.; Zonooz, B. AI Driven Road Maintenance Inspection. arXiv 2021, arXiv:2106.02567. [Google Scholar] [CrossRef]
- Li, Y.; Ma, R.; Liu, H.; Cheng, G. Real-Time High-Resolution Neural Network with Semantic Guidance for Crack Segmentation. Autom. Constr. 2023, 156, 105112. [Google Scholar] [CrossRef]
- Liu, Y.; Yao, J.; Lu, X.; Xie, R.; Li, L. DeepCrack: A Deep Hierarchical Feature Learning Architecture for Crack Segmentation. Neurocomputing 2019, 338, 139–153. [Google Scholar] [CrossRef]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep High-Resolution Representation Learning for Human Pose Estimation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5686–5696. [Google Scholar] [CrossRef]
- Yang, F.; Zhang, L.; Yu, S.; Prokhorov, D.; Mei, X.; Ling, H. Feature Pyramid and Hierarchical Boosting Network for Pavement Crack Detection. arXiv 2019, arXiv:1901.06340. [Google Scholar] [CrossRef]
- Fan, R.; Bocus, M.J.; Zhu, Y.; Jiao, J.; Wang, L.; Ma, F.; Cheng, S.; Liu, M. Road Crack Detection Using Deep Convolutional Neural Network and Adaptive Thresholding. arXiv 2019, arXiv:1904.08582. [Google Scholar] [CrossRef]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Computer Vision—ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2018; Volume 11211, pp. 833–851. [Google Scholar] [CrossRef]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-Local Neural Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. arXiv 2018, arXiv:1807.06521. [Google Scholar] [CrossRef]
- Li, H.; Xiong, P.; An, J.; Wang, L. Pyramid Attention Network for Semantic Segmentation. arXiv 2018, arXiv:1805.10180. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:2010.11929. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 9992–10002. [Google Scholar] [CrossRef]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers. arXiv 2021, arXiv:2105.15203. [Google Scholar] [CrossRef]
- Liu, H.; Miao, X.; Mertz, C.; Xu, C.; Kong, H. CrackFormer: Transformer Network for Fine-Grained Crack Detection. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 3763–3772. [Google Scholar] [CrossRef]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar] [CrossRef]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H.; et al. Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 6877–6886. [Google Scholar] [CrossRef]
- Ding, F. Crack Detection in Infrastructure Using Transfer Learning, Spatial Attention, and Genetic Algorithm Optimization. arXiv 2024, arXiv:2411.17140. [Google Scholar] [CrossRef]
- Huang, Y.; Shi, Z.; Wang, Z.; Wang, Z. Improved U-Net Based on Mixed Loss Function for Liver Medical Image Segmentation. Laser Optoelectron. Prog. 2020, 57, 221003. [Google Scholar] [CrossRef]
- Zhang, L.; Yang, F.; Daniel Zhang, Y.; Zhu, Y.J. Road Crack Detection Using Deep Convolutional Neural Network. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3708–3712. [Google Scholar] [CrossRef]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H. Restormer: Efficient Transformer for High-Resolution Image Restoration. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 5718–5729. [Google Scholar] [CrossRef]
- Chen, C.F.R.; Fan, Q.; Panda, R. CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 347–356. [Google Scholar] [CrossRef]
- Tian, D.; Han, Y.; Liu, Y.; Li, J.; Zhang, P.; Liu, M. Hybrid Cross-Feature Interaction Attention Module for Object Detection in Intelligent Mobile Scenes. Remote Sens. 2023, 15, 4991. [Google Scholar] [CrossRef]
- Wang, H.; Zhu, Y.; Green, B.; Adam, H.; Yuille, A.; Chen, L.C. Axial-DeepLab: Stand-Alone Axial-Attention for Panoptic Segmentation. In Computer Vision—ECCV 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; Volume 12349, pp. 108–126. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar] [CrossRef]
- Sun, K.; Zhao, Y.; Jiang, B.; Cheng, T.; Xiao, B.; Liu, D.; Mu, Y.; Wang, X.; Liu, W.; Wang, J. High-Resolution Representations for Labeling Pixels and Regions. arXiv 2019, arXiv:1904.04514. [Google Scholar] [CrossRef]
- Yin, Z.; Liang, K.; Ma, Z.; Guo, J. Duplex Contextual Relation Network For Polyp Segmentation. In Proceedings of the 2022 IEEE 19th International Symposium on Biomedical Imaging (ISBI), Kolkata, India, 28–31 March 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–5. [Google Scholar] [CrossRef]
- Xu, C.; Zhang, Q.; Mei, L.; Chang, X.; Ye, Z.; Wang, J.; Ye, L.; Yang, W. Cross-Attention-Guided Feature Alignment Network for Road Crack Detection. ISPRS Int. J. Geo-Inf. 2023, 12, 382. [Google Scholar] [CrossRef]
- Lin, H.; Cheng, X.; Wu, X.; Yang, F.; Shen, D.; Wang, Z.; Song, Q.; Yuan, W. CAT: Cross Attention in Vision Transformer. arXiv 2021, arXiv:2106.05786. [Google Scholar] [CrossRef]
- Guo, F.; Liu, J.; Lv, C.; Yu, H. A Novel Transformer-Based Network with Attention Mechanism for Automatic Pavement Crack Detection. Constr. Build. Mater. 2023, 391, 131852. [Google Scholar] [CrossRef]
- Li, C.; Fan, Z.; Chen, Y.; Sheng, W.; Wang, K.C.P. CrackCLF: Automatic Pavement Crack Detection Based on Closed-Loop Feedback. IEEE Trans. Intell. Transp. Syst. 2024, 25, 5965–5980. [Google Scholar] [CrossRef]
- Chen, L.C.; Yang, Y.; Wang, J.; Xu, W.; Yuille, A.L. Attention to Scale: Scale-Aware Semantic Image Segmentation. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3640–3649. [Google Scholar] [CrossRef]
- Ho, J.; Kalchbrenner, N.; Weissenborn, D.; Salimans, T. Axial Attention in Multidimensional Transformers. arXiv 2019, arXiv:1912.12180. [Google Scholar] [CrossRef]
- Chen, Y.; Cheng, H.; Wang, H.; Liu, X.; Chen, F.; Li, F.; Zhang, X.; Wang, M. EAN: Edge-Aware Network for Image Manipulation Localization. IEEE Trans. Circuits Syst. Video Technol. 2025, 35, 1591–1601. [Google Scholar] [CrossRef]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar] [CrossRef]
- Guo, J.; Han, K.; Wu, H.; Tang, Y.; Chen, X.; Wang, Y.; Xu, C. CMT: Convolutional Neural Networks Meet Vision Transformers. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 12165–12175. [Google Scholar] [CrossRef]
- Chen, Y.; Dai, X.; Chen, D.; Liu, M.; Dong, X.; Yuan, L.; Liu, Z. Mobile-Former: Bridging MobileNet and Transformer. arXiv 2021, arXiv:2108.05895. [Google Scholar] [CrossRef]
- Chen, Y.; Dai, X.; Chen, D.; Liu, M.; Dong, X.; Yuan, L.; Liu, Z. Mobile-Former: Bridging MobileNet and Transformer. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 5260–5269. [Google Scholar] [CrossRef]
- Wu, Z.; Liu, Z.; Lin, J.; Lin, Y.; Han, S. Lite Transformer with Long-Short Range Attention. arXiv 2020, arXiv:2004.11886. [Google Scholar] [CrossRef]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11531–11539. [Google Scholar] [CrossRef]
- Zou, R.; Song, C.; Zhang, Z. The Devil Is in the Details: Window-Based Attention for Image Compression. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 17471–17480. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar] [CrossRef]
- Tolstikhin, I.; Houlsby, N.; Kolesnikov, A.; Beyer, L.; Zhai, X.; Unterthiner, T.; Yung, J.; Steiner, A.; Keysers, D.; Uszkoreit, J.; et al. MLP-Mixer: An All-MLP Architecture for Vision. arXiv 2021, arXiv:2105.01601. [Google Scholar] [CrossRef]
- Shao, D.; Ren, L.; Ma, L. MSF-Net: A Lightweight Multi-Scale Feature Fusion Network for Skin Lesion Segmentation. Biomedicines 2023, 11, 1733. [Google Scholar] [CrossRef]
- Jia, G.; Song, W.; Jia, D.; Zhu, H. Sample Generation of Semi-automatic Pavement Crack Labelling and Robustness in Detection of Pavement Diseases. Electron. Lett. 2019, 55, 1235–1238. [Google Scholar] [CrossRef]
- Maguire, M.; Dorafshan, S.; Thomas, R.J. SDNET2018: A Concrete Crack Image Dataset for Machine Learning Applications; Utah State University: Logan, UT, USA, 2018. [Google Scholar] [CrossRef]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A Comprehensive Survey on Transfer Learning. arXiv 2019, arXiv:1911.02685. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. arXiv 2014, arXiv:1409.0575. [Google Scholar] [CrossRef]
- Loshchilov, I.; Hutter, F. SGDR: Stochastic Gradient Descent with Warm Restarts. arXiv 2016, arXiv:1608.03983. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar] [CrossRef]
- Jamal, M.A.; Brown, M.; Yang, M.H.; Wang, L.; Gong, B. Rethinking Class-Balanced Methods for Long-Tailed Visual Recognition From a Domain Adaptation Perspective. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 7607–7616. [Google Scholar] [CrossRef]
- Cui, Y.; Jia, M.; Lin, T.Y.; Song, Y.; Belongie, S. Class-Balanced Loss Based on Effective Number of Samples. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 9268–9277. [Google Scholar] [CrossRef]
- Wu, B.; Xu, C.; Dai, X.; Wan, A.; Zhang, P.; Yan, Z.; Tomizuka, M.; Gonzalez, J.; Keutzer, K.; Vajda, P. Visual Transformers: Token-Based Image Representation and Processing for Computer Vision. arXiv 2020, arXiv:2006.03677. [Google Scholar] [CrossRef]
- Wang, Y.; Liu, C.; Fan, Y.; Niu, C.; Huang, W.; Pan, Y.; Li, J.; Wang, Y.; Li, J. A Multi-Modal Deep Learning Solution for Precise Pneumonia Diagnosis: The PneumoFusion-Net Model. Front. Physiol. 2025, 16, 1512835. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Configuration Items | Configuration |
|---|---|
| Operating System | Windows 11 |
| Deep Learning Framework | PyTorch 1.10.0 |
| Processor | Intel Core i7-12700k |
| RAM | 32 GB |
| GPU | NVIDIA GeForce RTX 3070 Ti (8 GB) |
| GPU Memory | 8 GB |
| CUDA Version | 11.3 |
| Model | Classes | mIoU (%) | mRecall (%) | mPrecision (%) | F1-Score (%) |
|---|---|---|---|---|---|
| U-Net | two | 62.85 | 70.76 | 71.23 | 71.90 |
| three | 59.62 | 67.48 | 68.07 | 67.77 | |
| DeepLabv3_Plus | two | 65.72 | 73.25 | 73.86 | 73.92 |
| three | 62.47 | 70.09 | 70.54 | 70.31 | |
| HRNet | two | 63.49 | 72.98 | 70.34 | 71.58 |
| three | 60.15 | 69.11 | 67.32 | 68.20 | |
| ETAFHrNet | two | 74.41 | 83.84 | 84.51 | 83.11 |
| three | 71.08 | 79.21 | 76.64 | 79.42 |
| Model | Transfer Learning | mIoU (%) | mRecall (%) | mPrecision (%) | F1-Score (%) |
|---|---|---|---|---|---|
| U-Net | No | 59.12 | 66.32 | 67.28 | 67.45 |
| Yes | 62.85 | 70.76 | 71.23 | 71.90 | |
| DeepLabv3_Plus | No | 61.47 | 69.15 | 69.87 | 69.90 |
| Yes | 65.72 | 73.25 | 73.86 | 73.92 | |
| HRNet | No | 60.08 | 68.44 | 68.93 | 68.71 |
| Yes | 63.49 | 72.98 | 70.34 | 71.58 | |
| SegFormer | No | 63.58 | 71.72 | 72.13 | 72.25 |
| Yes | 69.21 | 76.52 | 76.88 | 76.73 | |
| ETAFHrNet | No | 66.32 | 74.65 | 75.15 | 75.38 |
| Yes | 74.41 | 83.84 | 84.51 | 83.11 |
| Model | EHAT | CSHAM | mIoU (%) | mPrecision (%) | mRecall (%) | F1-Score (%) | FPS | Params (M) |
|---|---|---|---|---|---|---|---|---|
| HRNet | No | No | 63.49 | 72.98 | 70.34 | 71.58 | 14.51 | 45.0 |
| Yes | No | 70.18 | 81.08 | 77.05 | 78.93 | 22.83 | 47.5 | |
| No | Yes | 72.69 | 79.95 | 80.96 | 81.45 | 22.64 | 48.2 | |
| Yes | Yes | 74.41 | 83.84 | 84.51 | 83.11 | 28.56 | 50.6 |
| Model | mIoU (%) | mPrecision (%) | mRecall (%) | F1-Score (%) | FPS | Params (M) |
|---|---|---|---|---|---|---|
| U-Net | 62.85 | 70.76 | 71.23 | 71.90 | 15.37 | 31.0 |
| HRNet | 63.49 | 72.98 | 70.34 | 71.58 | 14.51 | 45.0 |
| PSPNet | 64.32 | 71.85 | 72.64 | 72.24 | 17.22 | 42.6 |
| DeepLabv3+ | 65.72 | 73.25 | 73.86 | 73.92 | 19.84 | 42.0 |
| SegFormer | 69.21 | 76.52 | 76.88 | 76.73 | 21.34 | 64.0 |
| ETAFHrNet | 74.41 | 83.84 | 84.51 | 83.11 | 28.56 | 50.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tan, C.; Liu, J.; Zhao, Z.; Liu, R.; Tan, P.; Yao, A.; Pan, S.; Dong, J. ETAFHrNet: A Transformer-Based Multi-Scale Network for Asymmetric Pavement Crack Segmentation. Appl. Sci. 2025, 15, 6183. https://doi.org/10.3390/app15116183
Tan C, Liu J, Zhao Z, Liu R, Tan P, Yao A, Pan S, Dong J. ETAFHrNet: A Transformer-Based Multi-Scale Network for Asymmetric Pavement Crack Segmentation. Applied Sciences. 2025; 15(11):6183. https://doi.org/10.3390/app15116183
Chicago/Turabian StyleTan, Chao, Jiaqi Liu, Zhedong Zhao, Rufei Liu, Peng Tan, Aishu Yao, Shoudao Pan, and Jingyi Dong. 2025. "ETAFHrNet: A Transformer-Based Multi-Scale Network for Asymmetric Pavement Crack Segmentation" Applied Sciences 15, no. 11: 6183. https://doi.org/10.3390/app15116183
APA StyleTan, C., Liu, J., Zhao, Z., Liu, R., Tan, P., Yao, A., Pan, S., & Dong, J. (2025). ETAFHrNet: A Transformer-Based Multi-Scale Network for Asymmetric Pavement Crack Segmentation. Applied Sciences, 15(11), 6183. https://doi.org/10.3390/app15116183