2. Related Work
Ref. [
1] conducted an extensive survey on machine learning techniques for cybersecurity, covering a decade of research. The authors systematically reviewed various ML applications in intrusion detection, spam filtering, and malware detection across computer and mobile networks. Their comprehensive study outlined the effectiveness of different ML methods, including deep learning and traditional classifiers, and highlighted critical evaluation metrics and common cybersecurity datasets. However, the study focused mainly on text-based threats and did not explore the complexities of image-based spam detection, which remains a growing challenge in modern digital communications. As machine learning (ML) models can learn from complex datasets, they have been used more frequently to detect picture spam to address this issue. To detect patterns and identify spam text in images, they can be trained on large datasets. In the research on image spam identification, multiple machine learning models, including Support Vector Machines (SVMs), Naive Bayes, Logistic Regression, and XGBoost, have shown great potential in spam detection [
2]. However, most existing studies lack a unified preprocessing pipeline or comparative analysis, making it difficult to assess the relative performance of these models under consistent conditions.
Ref. [
3] has shown that machine learning techniques can improve image spam detection by analyzing low-level image texture features. This research evaluated various ML classifiers, including decision trees, Support Vector Machines, Bayesian Networks, and random forests, on publicly available datasets. The authors observed that the random forest model outperformed other models and achieved 98.6% precision. Despite strong results, the study’s reliance on basic texture features could limit its robustness. The research carried out in [
4] proposed an image-based spam detection using a deep learning model to increase performance. They added four sub-models to an already existing spam detection model. The research conveyed that added submodels increased the capability to detect spam images but remained computationally heavy and hard to deploy in real time.
The authors in [
5] evaluate the effectiveness of ML methods for email spam detection. They discuss how models such as Logistic Regression and Naive Bayes can achieve up to 99% accuracy. The findings highlight the importance of ML in classifying spam versus non-spam messages. However, email-based spam detection differs significantly from image spam detection in the handling features. In [
6], the authors were focused on SMS spam detection, proposing a hybrid deep learning model combining convolutional neural networks (CNNs) and gated recurrent units (GRUs). They achieved an accuracy of 99.07% and highlighted the effectiveness of hybrid architectures in handling textual data, emphasizing the importance of optimal hyperparameter tuning for improved spam detection performance. In a detailed study on the weaknesses and capabilities of several models, the authors in [
7] used the spam email dataset along with numerous approaches and identified challenges and limitations when using ensemble frameworks, such as the need for hyperparameter tuning for good accuracy and performance. Similarly, the research conducted in [
8] suggested combining random forest and decision tree to obtain better accuracy for spam classification. These studies mostly address spam in structured text forms and do not explore spam that blends images and text.
In [
9], the authors proposed an approach that combines optical character recognition, natural language processing, and a machine learning algorithm to detect image spam more effectively. This combination improves the models’ performance and also provides a more robust method for analyzing image-based spam content. The research does not address the performance implications of utilizing images that contain styled or formatted text. Another significant contribution to image spam detection comes from [
10], in which a new dataset of spam images was introduced, which were challenging to detect with existing methods. The authors found that both PCA and SVM models achieved high accuracy with low computational complexity. More research in spam detection uses deep learning model techniques. In the research conducted in [
11], the authors showed that deep learning models such as Long Short-Term Memory (LSTM) and convolutional neural networks (CNNs) can surpass traditional ML methods by automatically extracting features. Additionally, ref. [
12] offers an even more accurate alternative compared to methods like Optical Character Recognition and SVM, emphasizing the evolving role of advanced ML algorithms in countering image and email spam. Regarding the image spam filtering methods, in [
13], the authors introduced a deep learning-based approach by utilizing pre-trained convolutional neural networks (CNNs), including InceptionV3, DenseNet121, ResNet50, VGG16, and MobileNetV2. Their framework leveraged transfer learning, data augmentation, and replaced the fully connected layers with a Support Vector Machine (SVM) classifier, significantly improving accuracy and computational efficiency. A study found that the SVM performed exceptionally well in detecting image spam, overcoming traditional methods due to its ability to learn from visual data and adapt to various image variations [
14]. Experiments conducted on standard datasets demonstrated that ResNet50 was the best-performing model, achieving an accuracy of 99.87%. Despite impressive accuracy, the high resource demand of these deep learning models can be a barrier for real-time applications.
Looking for a suitable ML technique for image spam detection, XGBoost has gained attention for its ensemble learning technique, which merges the output of multiple decision trees to improve the overall prediction accuracy. However, it is not easy to reasonably tune the hyperparameters. To obtain greater accuracy from XGBoost, it requires prior knowledge of researchers and their experience in parameter tuning, as well as a great deal of time [
15]. Lastly, SVM has also been used in spam classification tasks due to its strong handling of high-dimensional data [
16]. Several studies have proven that SVM can classify images when combined with feature extraction techniques. However, SVM models require extensive tuning of their parameters in complex image datasets. These two models have allowed for adaptive learning, so they can continuously improve accuracy by adapting to new types of spam images. This is crucial given the constantly evolving tactics of spammers [
17]. However, studies considering XGBoost and SVM rarely offer comparative benchmarks against deep learning models on the same dataset. To address the gaps identified in prior research, including inconsistent benchmarking, limited comparative evaluation, and less processing power utilization, our study experimented on multiple machine learning models under identical conditions to determine which model achieves higher accuracy and fewer false positives.
Comparative Analysis of Machine Learning Models
Supervised learning models have to go through numerous research cycles to achieve the correct output. As the name suggests, the supervisor is the one who instructs the model on what the input is and what the corresponding output should be. The supervisor primarily trains the model with labels [
18]. Then, models use these labels for classification purposes. The supervised learning models are trained on a dataset, which is always divided into a training and a test set. The training set is the data passed into the model for the training, and the test data are used to test the accuracy of the model and how well it can classify. There are many supervised learning models that can predict continuous target variables. Logistic Regression is used for binary classification tasks. Furthermore, decision trees are also used for both classification and regression. Moreover, Support Vector Machine focuses on classification tasks by finding the optimal hyperplane to separate different classes.
Furthermore, ensemble learning includes merging multiple models to create a stronger model with better accuracy. Popular ensemble methods include random forests, which are collections of decision trees used for classification and regression tasks; gradient boosting, which builds strong models by sequentially combining weaker ones for regression problems; and AdaBoost, an ensemble technique that improves weak classifiers for binary classification tasks. These ensemble methods have the strengths of multiple models to improve performance, making them powerful tools for complex tasks (
Figure 1).
For the comparative analysis given in this paper, we selected XGBoost, Support Vector Machine, ResNet50, Logistic Regression, LightGBM, and VGG16 to ensure a comprehensive evaluation of diverse learning paradigms, including classical machine learning, ensemble learning, and deep learning. Each model represents a unique approach to the classification of spam images. ResNet50 was selected for the comparative analysis due to its proven architectural strengths and robust performance in complex image classification tasks. Its ability to effectively manage structured data and deliver high accuracy with minimal false positives has been consistently demonstrated in prior research [
13]. Additionally, ResNet50 integrates techniques such as gradient boosting and regularization, enhancing its predictive power while reducing the risk of overfitting. Support Vector Machines (SVMs) have also gained prominence as a reliable and widely adopted method for classification, particularly in image-based spam detection, due to their effectiveness in high-dimensional spaces and strong generalization capabilities. In [
20], the authors explored the effectiveness of SVMs trained on a diverse set of image features to classify spam content. The research highlights the use of a linear SVM to analyze and quantify the relative importance of various visual features, demonstrating the model’s ability to distinguish between spam and legitimate images with high precision. Drawing from these insights, we selected SVM for our comparative analysis due to its proven performance in image spam detection tasks.
LightGBM is an ensemble model, developed by Microsoft, and is renowned for its speed and efficiency. It utilizes histogram-based learning and leaf-wise tree growth strategies to enable faster training and lower memory usage than traditional boosting methods. However, as highlighted in [
21], the LightGBM model shows sensitivity to noisy data. LightGBM is also designed to use less memory by training faster, supporting distributed and parallel computing, and handling large data [
22]. These characteristics make LightGBM excellent for image spam detection, where rapid processing of images is required.
Furthermore, XGBoost was created by Chen and Guestrin [
23], who drew up a robust methodology for regression and classification. Numerous Kaggle Machine competitions have highlighted and included the use of XGBoost for classification. As XGBoost is based on the gradient boosting framework, it continuously adds new decision trees to fit a value to improve accuracy and performance. It has gained popularity due to its scalability and accuracy, and incorporates regularization techniques to prevent overfitting. The research by [
24] integrated CNNs with gradient-boosting techniques to enhance detection accuracy and resulted in 88% F1-score. Furthermore, XGBoost and LightGBM have consistently achieved top results in many structured data competitions.
VGG16 is a deep learning model and was selected for this research due to its strong and consistent performance in image classification tasks. Its straightforward layer structure makes it effective at learning patterns from image data, which is important for detecting spam images. In the study by [
13], VGG16 achieved the second-highest accuracy and AUC, showing that it performs well compared to other models. This makes VGG16 a reliable choice for comparing it with both traditional and ensemble-based models in our analysis.
Logistic Regression is a highly successful machine learning algorithm that calculates probabilities using discrete and continuous data and classifies newly entered data [
25]. Based on probability, it is decided whether that feature vector belongs to a specific class or not. Logistic Regression demonstrated outstanding performance in spam detection. In the comparison given in [
26], it achieved an accuracy of 0.981 and a precision score of 0.972, indicating its strong ability to correctly identify spam images while minimizing false negatives. Also, Logistic Regression has been effectively applied in spam detection frameworks, particularly in multi-modal architectures where it serves as a probabilistic fusion layer. In [
27], authors proposed a CNN-LSTM-based spam filter, integrating outputs via logistic regression, achieving over 98% accuracy on hybrid image/text datasets. These results highlight Logistic Regression as a competitive traditional model, offering both simplicity and reliability. Therefore, this model is included in our comparative analysis.
These models were selected to represent a range of classification approaches: traditional (SVM, Logistic Regression), deep residual (ResNet50), ensemble-based (XGBoost, LightGBM), and deep learning (VGG16). This allows for a balanced evaluation across algorithmic families. By incorporating these models, the research aims to compare their accuracy, false positive rates, and effectiveness in identifying true positives, which are key metrics for evaluating the reliability and robustness of image spam detection.
3. Methodology
Machine learning is essential for image spam detection because traditional rule-based methods struggle to identify spam embedded in images. Unlike text-based spam, where keywords and patterns are easy to analyze, image spam disguises malicious content within visuals, making it harder for traditional filters to detect. In addition, ML models continuously adapt to evolving spam tactics, improving detection accuracy and reducing false positives. In this paper, the performance of six machine learning models is evaluated.
3.1. Dataset and Preprocessing
3.1.1. Dataset Description
For our experiments, a dataset was used to train and test an image-based spam model. The original dataset was obtained from [
28] and consists of 928 spam images collected from real spam emails and over 800 ham (non-spam) images. The original record has 4 columns: Serial Number (the row number), File Name, Image Size, and Label (binary; 0 and 1 denoting ham and spam, respectively). The dataset was later carefully scrutinized and finalized with 678 ham images and 520 spam images as uploaded at [
29]. As displayed in
Figure 2, data augmentation was also conducted to artificially increase the diversity of a training dataset by applying realistic transformations to existing images [
30]. A total of 301 additional samples were generated by data augmentation, which consisted of 150 ham and 151 spam images.
To proceed with the training and testing process, we used a new dataset, ensuring a balanced distribution for effective model evaluation. The dataset was split into 70% training and 30% testing data. The augmented images were subsequently added only to the training dataset to improve generalization and prevent overfitting. Ham images represent benign content, while spam images include advertisements, scams, or irrelevant promotional content. The original RGB format of some ham images is given in
Figure 3, which, in order to enable more efficient processing during the classification pipeline, is subsequently converted to grayscale, as shown in
Figure 4.
Figure 5 illustrates the original RGB format of some spam images, which is also subsequently converted to grayscale, as shown in
Figure 6.
3.1.2. Preprocessing
To ensure a fair and consistent comparison, all models were trained using a standardized preprocessing pipeline and feature space. Images were resized to 64 × 64 pixels, converted to grayscale, and then flattened into 1D vectors to serve as input features. The StandardScaler was applied to normalize the feature set, ensuring zero mean and unit variance across pixel values. To address high dimensionality and improve computational efficiency, Principal Component Analysis (PCA) was employed for dimensionality reduction. While flattening simplifies the input for traditional machine learning models, it eliminates the spatial structure of images, which may degrade performance. Nevertheless, this approach was adopted to maintain uniform conditions across all models. An exception was made for ResNet50 and VGG16, which were evaluated using RGB images resized to 224 × 224 pixels, in accordance with their pre-trained configurations optimized for color image inputs.
3.2. Models
Parameters: The model was trained with class_weight = ‘balanced’ to address class imbalance and probability=True to enable probability-based predictions. Linear kernel was utilized.
Model Training: An SVM classifier was trained using the linear kernel to optimize the decision boundary for spam vs. ham classification.
Parameters: Logistic Regression was trained with max_iter = 1000 to ensure convergence, particularly due to the complexity of the dataset.
Model Training: The model was trained to classify spam and ham images, applying a linear decision boundary.
Parameters: XGBoost was trained with max_depth = 6 to balance training time and model complexity.
Model Training: XGBoost, a gradient-boosting model, was trained to classify spam and ham images using ensemble learning to improve accuracy.
Parameters: LightGBM was trained with boosting_type = ‘gbdt’, learning_rate = 0.05, and max_depth = 7. The model utilized 100 estimators and was trained over 20 epochs with a batch size of 32 to balance training efficiency and model accuracy.
Model Training: LightGBM, a gradient boosting model, was trained to classify spam and ham images. It used an ensemble of decision trees to improve classification accuracy through boosting.
Parameters: VGG16 was fine-tuned with a pre-trained ImageNet base. The convolutional layers were frozen, and more fully connected layers were added to classify spam and ham images. Training was carried out with a batch size of 32 and 10 epochs.
Model Training: VGG16, a CNN, was used for classifying spam and ham images. The pre-trained weights from ImageNet allowed for effective extraction of features, and the model was fine-tuned with additional dense layers for classification. As VGG16 is optimized for RGB images of size 224 × 224, this was utilized for training the model.
Parameters: ResNet50 was initialized with pre-trained ImageNet weights, the base model layers were frozen to retain learned features, and a custom head was added, which consisted of a GlobalAveragePooling2D layer, followed by a dense layer with 128 ReLU units.
Model Training: ResNet50, a deep convolutional neural network, is highly utilized for transfer learning and classification tasks. It can extract high-level image features and is trained for the binary classification task of distinguishing between spam and ham images. ResNet50 is also optimized for 224 × 224 RGB images and these images were used for training the model.
3.3. Evaluation and Performance Metrics
Regarding model evaluation, a 5-fold cross-validation approach was used to assess performance. This method splits the data into five folds while maintaining the class distribution of spam and ham images. Each model was trained and tested across five iterations, with one fold held out for testing and the others used for training in each round. The final performance metrics are the average scores across all folds. This approach reduces the risk of overfitting and provides a more robust estimation of the model’s performance compared to a single train/test split.
Furthermore, the following metrics were used for the evaluation of the models:
Accuracy: Identifies the percentage of correctly classified instances.
AUC (Area Under the Curve): Measures the model’s ability to distinguish between spam and ham images. A larger AUC value indicates better performance.
Precision, Recall, and F1-Score: These metrics are particularly useful when utilizing imbalanced datasets, as they offer insights into how well the model identifies spam (precision), avoids false negatives (recall) and calculates the mean of precision and recall (F1-score)
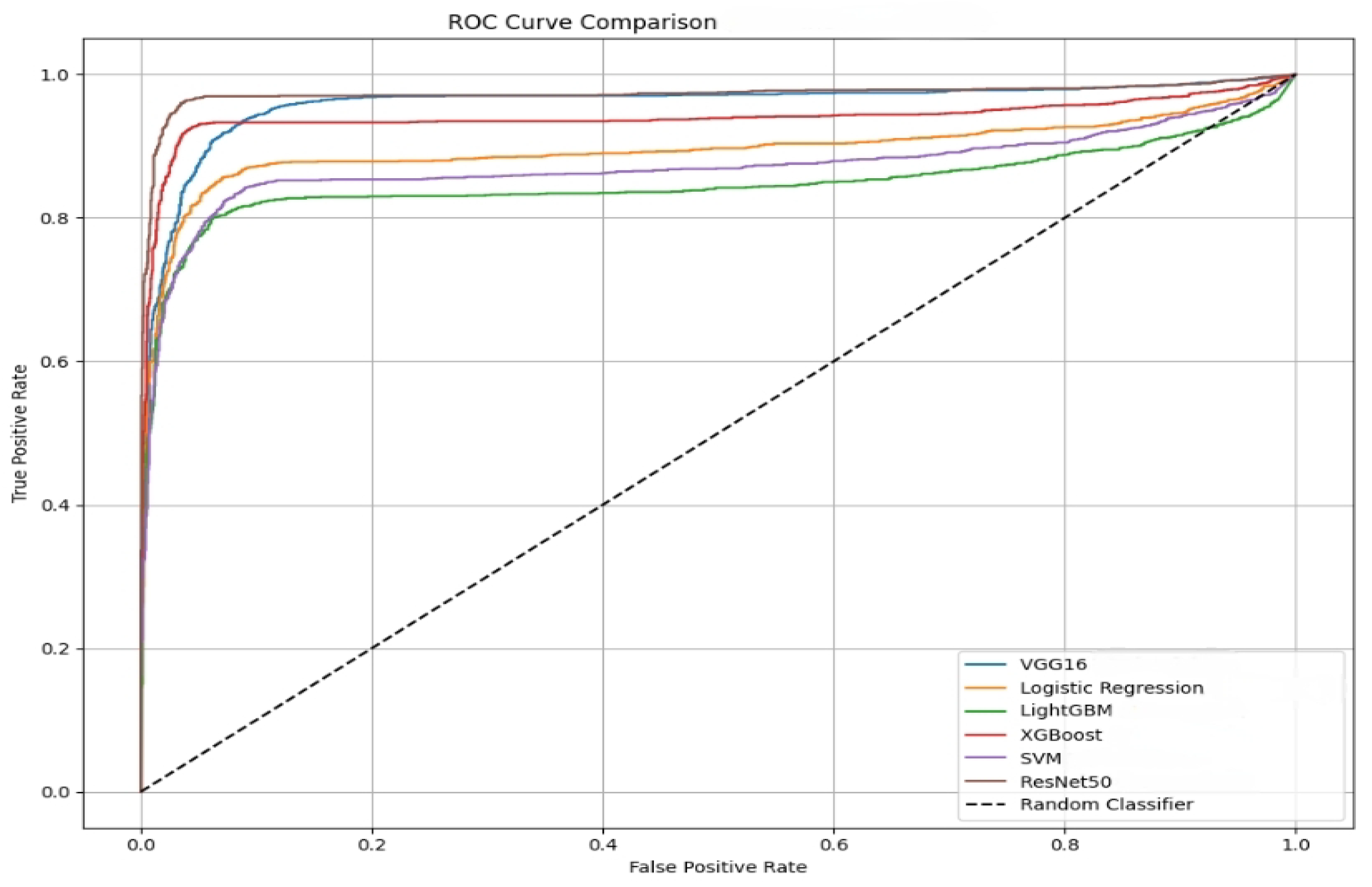
ROC Curve: Plots true positive rate against false positive rate to evaluate classifier performance. A curve closer to the top left indicates better classification.
AUC Variance: Estimated through bootstrapping, it indicates the consistency of the model’s performance, with lower variance suggesting greater reliability.
Confusion Matrix: The confusion matrix highlights the performance of the model. It displays the number of true positives, true negatives, false positives, and false negatives.
Classification Report: Provides a comprehensive view of the model’s performance across various metrics like precision, recall, F1-score, and support.
3.4. Experimentation Setup
Our experiments were carried out using the Google Colab environment
https://colab.research.google.com/, accessed on 4 March 2025. Running the command
!cat /proc/cpuinfo revealed that the system is equipped with an Intel Xeon CPU @ 2.20 GHz, consisting of two processing units (siblings) with one core per processor. The processor operates at 2200.162 MHz and includes hyper-threading capabilities. Although security vulnerabilities like Spectre, Meltdown, and L1TF are present, mitigations may be in place. The system architecture supports 46-bit physical and 48-bit virtual addressing, facilitating efficient memory management.
5. Discussion
As highlighted in
Table 1, the models were evaluated using confusion matrices, AUC scores, and other relevant metrics. The detailed results for each model are as follows:
The SVM model demonstrated a robust ability to distinguish between spam and non-spam instances, achieving an AUC of 0.91. This indicates a high probability that the model will rank a randomly chosen positive instance (spam) higher than a negative one (non-spam). The confusion matrix reveals a true positive (TP) rate of 37% and a true negative (TN) rate of 47%, suggesting balanced performance in identifying both classes. The SVM model performed better with a high AUC when a linear kernel was utilized, indicating good discrimination between spam and ham images.
However, the false positive (FP) rate of 9% and false negative (FN) rate of 7% indicate that the model occasionally misclassifies non-spam as spam and misses some spam instances. The number of false positives and false negatives suggest the model can be further optimized, though it demonstrated robust performance overall. The AUC variance of 0.000277 reflects that its performance is consistent.
Logistic Regression achieved better performance than SVM with an AUC score of 0.94 AUC. The model showed a TP rate of 38% and a TN rate of 49%, with FP and FN rates of 8% and 6%, respectively. These metrics suggest that Logistic Regression is effective in reducing the number of false negatives. The low AUC variance (0.000171) also highlights the model’s reliability across different data subsets. Logistic Regression’s consistent performance makes it an excellent baseline model.
XGBoost demonstrated robust performance in image-based spam detection, achieving a TP rate of 40% and a TN rate of 52%, with only 3% FN and 4% FP. The model attained a high AUC score of 0.97 with a low AUC variance of 0.000049, indicating consistent performance across different data splits. These results highlight XGBoost’s strong ability to correctly distinguish between spam and non-spam images with minimal misclassification. Although slightly outperformed by ResNet50, XGBoost remains a competitive and interpretable ensemble-based model, particularly well suited for structured visual data tasks.
LightGBM delivered moderate performance with a TP rate of 36% and a TN rate of 47%. The model exhibited 8% FN and 9% FP, reflecting a balanced approach to spam detection. It achieved an AUC score of 0.91 and an AUC variance of 0.000215, suggesting stable classification capability with room for improvement in reducing misclassification. Although it did not outperform other ensemble-based models, like XGBoost, LightGBM demonstrated good discrimination between spam and non-spam images.
ResNet50 outperformed all other models by achieving a TP rate of 42% and a TN rate of 53%, with only 1% FN and 3% FP. The model recorded the highest AUC score of 0.99 and the lowest AUC variance of 0.000009, indicating exceptional classification ability.
VGG16 also demonstrated strong performance, matching ResNet50 with a TP rate of 42% and a minimal FN rate of 1%. However, its TN rate was comparatively lower at 44%, and it produced a higher false positive rate of 13%, suggesting reduced specificity in classifying non-spam (ham) content. The model attained an AUC score of 0.93 with a variance of 0.000167, reflecting reliable but less stable performance relative to ResNet50.
This study evaluated the performance for image-based spam detection of six machine learning and deep learning models based on AUC scores, ROC curves and variances. Among all models, ResNet50 achieved the highest AUC score of 0.99 with the lowest variance of 0.000009, demonstrating exceptional and consistent classification performance. XGBoost followed with an AUC of 0.97 and variance of 0.000049, benefiting from its ensemble-based learning capability to effectively separate spam from ham images. Logistic Regression also performed reliably, achieving an AUC of 0.94 with a variance of 0.000171, making it a lightweight yet effective model for this task.
While VGG16 achieved a slightly lower AUC of 0.93 and variance of 0.000167, it showed better performance when RGB images were used instead of grayscale and with appropriate hyperparameter tuning. LightGBM and SVM models both achieved an AUC of 0.91, with LightGBM showing a slightly lower variance of 0.000215 compared to SVM’s variance of 0.000277, indicating similar performance but with SVM being slightly less stable. The AUC confidence intervals indicate the range within which the true AUC is expected to lie with 95% confidence, based on bootstrapped resampling. Models such as ResNet50 and XGBoost exhibit the narrowest confidence intervals ([0.985, 0.997] and [0.960, 0.987], respectively), reflecting high stability and consistent performance. In contrast, models like SVM and LightGBM have wider intervals, suggesting greater variability in their classification ability. Overall, the AUC confidence intervals add statistical rigor to the evaluation, enabling a more reliable comparison of model robustness.
The classification reports were generated. The corresponding recall, precision, and F1-scores for each model are presented in
Table 2. These values were obtained as the mean results across the five-fold cross-validation, ensuring consistency and robustness of the model’s performance across different data splits. Among the models tested for image-based spam detection, VGG16 performed well in identifying spam with a recall of 97%, meaning it detected most spam messages. However, its precision for spam was 77%, indicating some false positives. For non-spam, it achieved high precision (97%) but lower recall (76%). Despite this trade-off, the F1-score for the spam class was 0.85 and 0.86 for non-spam. Furthermore, Logistic Regression demonstrated well-balanced performance across all metrics. For spam, it achieved a precision of 84% and a recall of 88%; for non-spam, the precision and recall were 89% and 86%, respectively. The resulting F1-scores were 0.86 for spam and 0.88 for non-spam, indicating consistent and reliable classification performance across both classes. Moreover, LightGBM maintained consistent performance, achieving a precision of 80% and a recall of 83% for spam, and a precision of 85% and a recall of 83% for non-spam. The corresponding F1-scores were 0.82 for spam and 0.84 for non-spam, indicating balanced effectiveness across both classes. SVM performed similarly, slightly better in some cases, with an F1-score of 0.83 for spam and 0.85 for on-spam, showing a decent balance between both classes. XGBoost and ResNet50 were the top performers. XGBoost achieved precision and recall scores above 91% for both classes, with an F1-score of 0.92 for spam and 0.93 for non-spam classes. ResNet50 outperformed all other models, achieving a precision of 93% and a recall of 97% for spam, and a precision of 97% and a recall of 94% for non-spam. The F1-score for both classes was 0.95, highlighting the model’s exceptional and consistent performance across the dataset.
ResNet50, XGBoost, and Logistic Regression emerged as the most effective models, with ResNet50 leading both in performance and consistency. The high AUC and low variance values indicate that these models not only classified spam images correctly but also did so consistently across folds, making them suitable candidates for deployment in spam detection systems.
While VGG16 is known for its success in image classification, its performance in grayscale image spam detection was significantly lower. However, the results improved considerably when RGB images and tuning techniques were applied. SVM achieved reasonable results but exhibited a tendency toward false negatives, indicating a need for further optimization.
In summary, ResNet50 outperformed all other models, showing strong generalization and minimal variance. XGBoost and Logistic Regression also demonstrated robust and stable results. LightGBM and SVM performed moderately well. Future research could explore the real-time deployment of deep learning models and assess their scalability and robustness in dynamic spam detection environments.
This study assessed the model performance using cross-data training to examine the models accuracy with unseen image-based spam. Later, this study used a different dataset from Kaggle which included 811 ham photos and 930 spam images to validate the model’s performance [
31]. The spam image dataset was preprocessed identically, resized and passed through the same pipeline. Importantly, the model was neither re-trained nor subjected to hyperparameter tuning on this external dataset. Instead, it was used strictly for inference to assess the model’s robustness. The risk of the model overfitting to a single source of dataset was decreased by testing it on a different dataset. After evaluation, ResNet50 achieved an impressive 98% accuracy, reinforcing its effectiveness in spam image classification. Due to its superior accuracy, low variance, and consistent performance across datasets, ResNet50 stands out as the most reliable model for this task.
The execution times recorded during inference varied across the models, reflecting differences in computational complexity. ResNet50 was relatively efficient for a deep learning model, completing inference in 38 s. XGBoost followed with a time of 48 s, benefiting from its optimized tree-based structure. LightGBM and SVM demonstrated similar performance, both completing in 50 s. VGG16 and Logistic Regression each required 54 s, with the latter being unexpectedly slower due to preprocessing overhead. These results demonstrate that while multiple models achieved efficient performance, ResNet50 combines high accuracy, minimal execution time, and strong generalization, making it the most suitable candidate for image-based spam detection systems.



 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}