1. Introduction
The field of 3D body reconstruction is crucial in various industries, such as virtual reality [
1], augmented reality [
2], and biomedical applications [
3]. This process involves reconstructing a detailed 3D model of the human body from a single 2D image [
4], a task fraught with challenges due to the ill-posed nature of obtaining three-dimensional data from two-dimensional representations [
5]. This complexity arises because multiple 3D points can project identically onto a 2D plane, introducing significant ambiguity in the reconstruction process. Despite these hurdles, advances in computational techniques continue to improve the precision and reliability of 3D body reconstruction [
6], broadening its applicability in fields such as medical imaging [
7], gaming [
8], and robotics [
9].
In particular, reconstructing an accurate 3D human form from imperfect and incomplete data requires advanced handling of non-rigid body dynamics and articulated joint movements [
10]. Recent breakthroughs in deep learning have enabled more sophisticated end-to-end reconstructions of human shapes [
11], including detailed meshes that capture complex articulations. Historically, deep neural networks have faced challenges, such as producing rugged, blurred, or distorted meshes [
12]. However, models such as Skinned MultiPerson Linear (SMPL) [
13] and its extension, SMPL eXpressive (SMPL-X) [
14], have revolutionized this domain. These models offer streamlined representations of 3D human figures. When integrated with deep learning techniques, they facilitate the extraction of robust image features and the regression of accurate body shape and pose parameters from standard RGB images. This enhanced methodology pushes the limits of what is possible in 3D human body cloud point reconstruction, promising increasingly accurate and versatile applications [
15].
Various technologies are used to estimate human pose [
16], including RGB cameras [
17], thermal cameras [
18], Hyperspetral [
19] and IR-Ultra-wideband (UWB) RADAR [
20]. Although infrared cameras excel in object detection under low-light conditions, particularly for objects with higher temperatures, they perform poorly with cooler objects. Alternatively, RGB cameras are challenged by low-light environments, although using them in the NIR spectrum can be costly. Single-pixel imaging (SPI) systems present a viable alternative [
21], which overcomes many limitations of conventional and thermal cameras in dim settings. SPI systems capture images by measuring the light reflected from an object using a single-pixel detector, even in the infrared spectral bands [
22]. Using deep learning, single-pixel imaging (SPI) can reconstruct high-quality images from sparse measurements. It is particularly effective for capturing 3D human body point clouds in challenging scenarios such as night-time surveillance or rescue operations. This capability establishes SPI as a leading method for detailed and accurate pose detection under low-light conditions. Deep learning techniques are highly recommended in such scenarios, and the Vision Transformer (ViT) [
23] is emerging as a robust approach to handling low-resolution data.
A key advantage of SPI over conventional cameras is its ability to capture data in the NIR spectrum, significantly enhancing 3D point cloud imaging [
24]. NIR imaging performs exceptionally well under low light conditions, providing superior clarity for object detection and tracking, an essential feature for advanced rescue applications [
25]. When combined with time-of-flight (TOF) sensors, SPI technology produces highly accurate 2D and 3D environmental images [
26]. This integration enhances the depth of the data, offering detailed insight into the spatial arrangement and motion of objects within a scene. Furthermore, SPI is not limited to low-light scenarios; it remains highly effective in challenging environments, such as those with dust or fog, where traditional cameras struggle, ensuring consistent and reliable 3D data acquisition under various conditions.
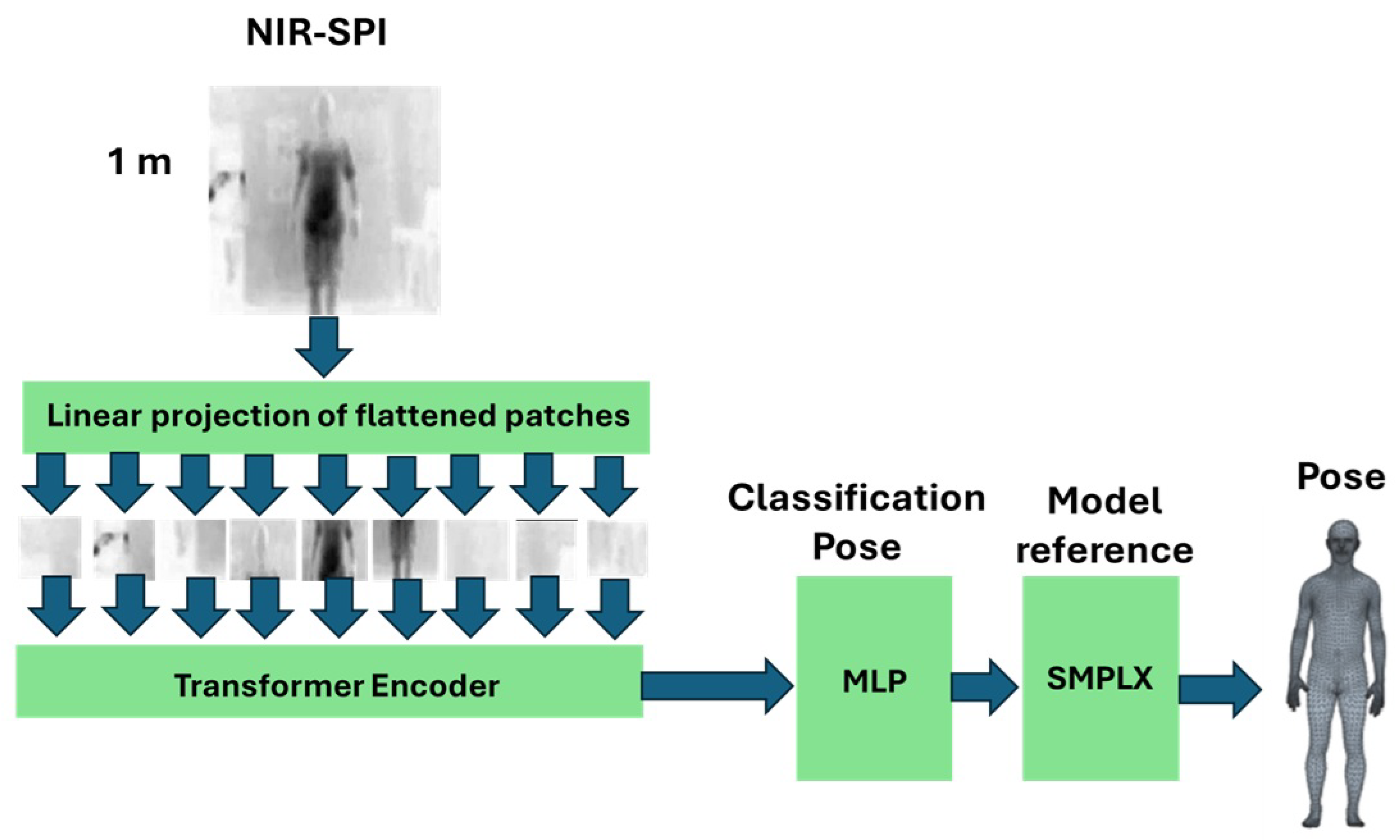
This study presents an SPI system with active illumination in the near-infrared (NIR) wavelength range of 850–1500 nm. The system utilizes single InGaAs photodetectors to capture NIR-SPI images, which are the foundation for generating 3D human meshes based on point clouds for depth perception. In addition, it incorporates a ViT-based classification model to determine the initial pose to implement an SMPL-X-based reconstruction framework. Our approach processes point clouds to generate high-fidelity 3D human meshes, using a self-supervised learning framework [
27] to enhance accuracy. We introduce a novel 3D human pose reconstruction method that surpasses previous state-of-the-art techniques by integrating a probabilistic human model with depth information. This innovation achieves a new benchmark in accuracy, outperforming ViT-based models and setting a new standard for handling missing data and low-resolution scenarios. The final output is a detailed and precise 3D representation of the human pose in the SMPL-X model, providing an accurate reconstruction of human figures in three dimensions. Therefore, in this work, we propose the following:
Exploring the capability of Single-Pixel Imaging for generating 3D human pose point clouds from low-resolution 2D images.
Implementation of the ViT (Vision Transformer) model applied to SPI images to define a pre-trained SMPL-X human pose model.
Testing a self-supervised Deep Learning model for 3D reconstruction from the point cloud.
This work addresses the challenging task of predicting 3D hand poses from low-resolution 2D images. This can be applied to sensors used in rescue operations where lighting conditions are difficult.
3. Single-Pixel Image Reconstruction
The Single-Pixel Imaging (SPI) technique [
21,
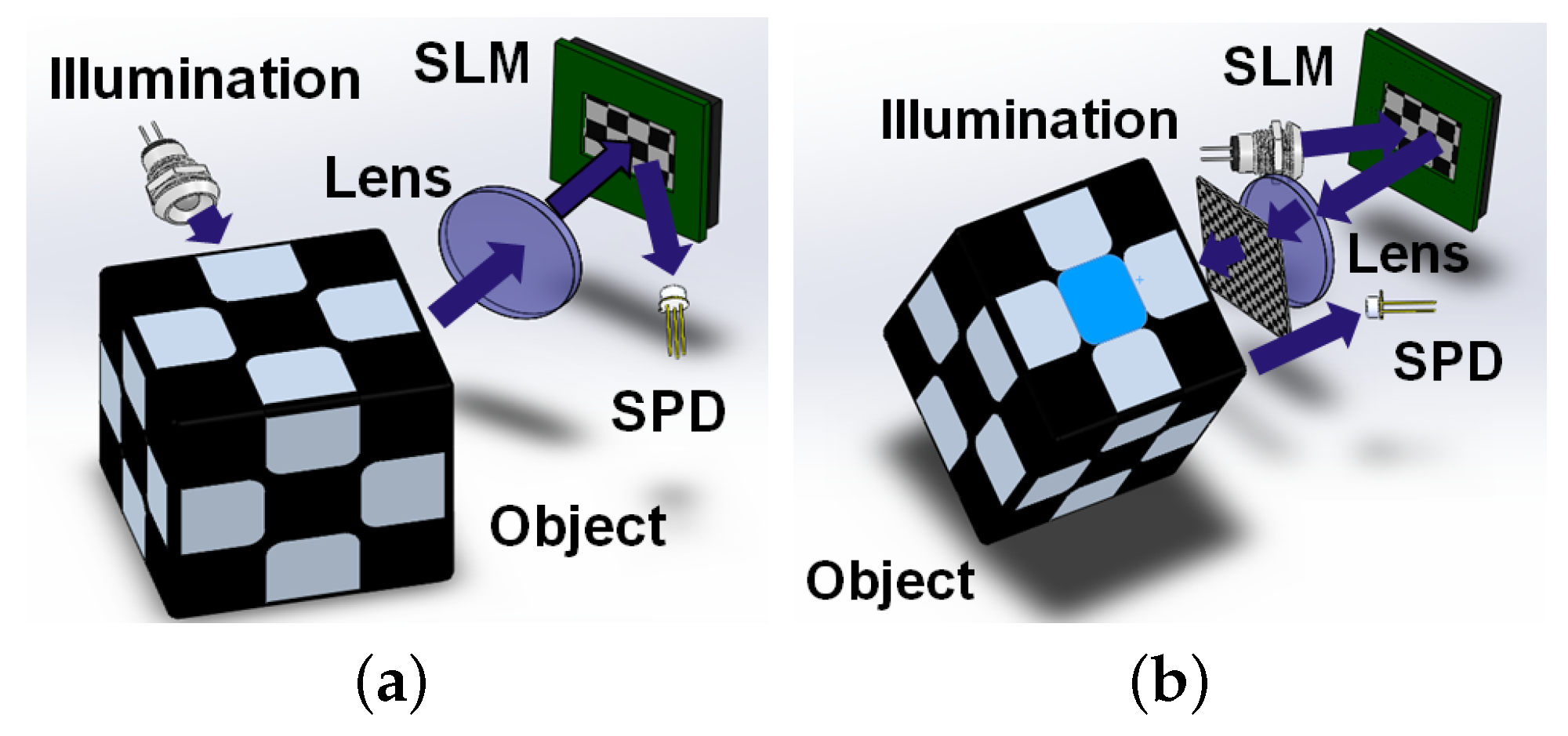
22], reconstructs images by measuring correlated intensity on a detector that lacks spatial resolution. SPI cameras employ spatial light modulators (SLMs), such as Digital Micro-Mirror Devices (DMD), to generate spatially structured light patterns (resembling Hadamard patterns) that interrogate a scene. These cameras function according to two main architectures: structured detection and structured illumination, as illustrated in
Figure 1.
In structured detection, an object is illuminated by a light source, and the reflected light is subsequently modulated by a Spatial Light Modulator (SLM) before being measured by a single-pixel (bucket) detector. In contrast, in structured illumination, represented by the modulation pattern
, the SLM is used to spatially modulate incident light before it illuminates the object
O. The light reflected from the object is captured by the bucket detector and subsequently converted into an electrical signal
, as defined in Equation (
1).
Here,
represents a constant factor influenced by the optoelectronic characteristics of the photodetector. The electrical signal generated by the photodetector is derived from the correlation between the spatial pattern of the light and the light reflected from the object. The corresponding sequence of electrical signals is produced by projecting a series of these spatial patterns. These signals are then computationally processed to reconstruct the image. Specifically, the image
is reconstructed from the captured signal
and the corresponding pattern
, as described in Equation (
2) [
22]
In this study, we used an array of 32 × 32 near-infrared LEDs (NIR-LEDs) that emit at a peak wavelength of 1550 nm for generating Hadamard-like patterns through active illumination. This wavelength was chosen to minimize the effect of water scattering and absorption coefficients. The LED array is positioned perpendicular to the lens’s focal plane, allowing the light patterns to be projected toward infinity. However, due to the dimensions of the matrix, the effective projection range is limited to 0.3–2 m.
3.1. Fusion Strategy for Enhancing TOF and Single-Pixel Imaging Resolution
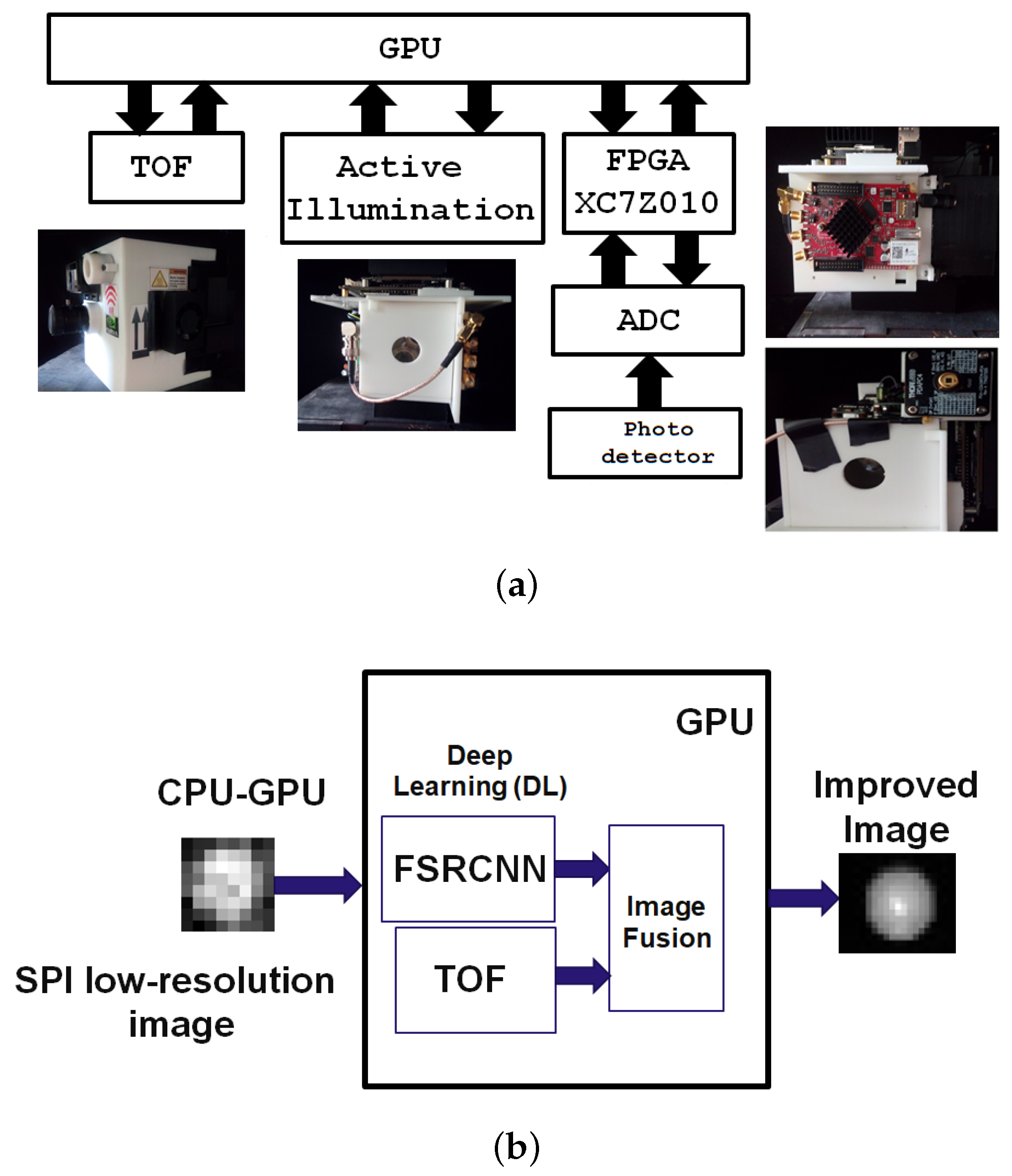
For fusing TOF imaging and low-resolution SPI to generate a high-resolution image to employ a Deep Learning-based Super-Resolution (SR) model (see
Figure 2b), which takes advantage of the complementary advantages of both modalities. The ToF depth map and the SPI intensity image are initially pre-processed and spatially registered. The ToF modality delivers precise structural depth information, while the SPI system contributes high-contrast intensity details. A dual-branch CNN extracts spatial features separately from TOF and SPI, with the TOF branch focusing on structural information (low-frequency components) and the SPI branch enhancing fine details and textures (high-frequency components). The extracted features are subsequently concatenated and passed through a Fusion Network, which learns to compute optimal blending weights to preserve essential structural information. To further enhance resolution, a Fast Super-Resolution Convolutional Neural Network (FSRCNN) [
26] is applied to upscale the fused low-resolution image, reconstructing high-quality textures and spatial details. Finally, a refinement layer removes artifacts and enhances sharpness, producing a high-resolution fused image with improved texture, depth consistency, and spatial clarity.
3.2. SPI Camera
Our study introduces structured illumination to improve image quality in difficult lighting conditions, such as solid backlighting and stray light interference. We utilized a time-of-flight (TOF) system with a wavelength of 850 nm and an InGaAs photodiode as the bucket detector, which operates at 1550 nm. Our proposed architecture, named NIR-SPI, comprises two primary components. The first component involves fundamental elements based on the single-pixel imaging principle, including an InGaAs photodetector (specifically the Thorlabs FGA015 diode operating at 1550 nm), a series of NIR-LEDs for light emission, a TOF system, and an analog-to-digital converter (ADC). For a visual depiction of this setup, see
Figure 2a. The second component includes a subsystem designed to process the electrical output of the bucket detector. The ADC digitizes the electrical signal, and the data is processed by an embedded system in a module (SoM) [
52], notably GPU-Jetson Xavier NX, also illustrated in
Figure 2a. This SOM is tasked with generating Hadamard-like patterns and processing the digitized data from the ADC. The OMP-GPU Algorithm is applied within the SoM to facilitate the generation of 2D images. The processing duration for each phase of the 2D image reconstruction is detailed. For more information on the SPI camera, further reading is recommended.
3.3. 2D Reconstruction Algorithm
We initiated the process by acquiring and digitizing the electrical signal
through an analog-to-digital conversion mechanism (ADC). This step involved projecting the signal with a Hadamard matrix, resulting in a vector of signals
(refer to Equation (
1)). We then applied the Orthogonal Matching Pursuit (OMP) algorithm (see Algorithm 1) to derive the image
(refer to Equation (
2)). Our goal was to satisfy condition
[
22]. To enhance the computational efficiency of the 2D SPI image reconstruction algorithm, matrix inversion was carried out using the Cholesky decomposition technique, as described in the literature [
53,
54]. This approach required us to compute the symmetric and positive Gram matrix, denoted
[
55]. Furthermore, an initial projection
was performed (see Algorithm 1, line 3) to support the implementation of the Cholesky method.
| Algorithm 1: OMP-GPU algorithm [55], Input: OMP-GPU algorithm input data: Patterns , input signal , Output: OMP-GPU algorithm output data: sparse representation that fulfills the relation . |
| 1:
procedure OMP-GPU(,):
| |
| 2:
set: =[1], k=1, | |
| 3:
set: , ,
| |
| 4:
while do | |
| 5:
| ▹ Finding the new atom |
| 6:
if then | |
| 7: | ▹ Solver |
| 8: | ▹ Update of Cholesky |
| 9:
| |
| 10: end if | |
| 11: | ▹ Solver |
| 12: | ▹ Matrix-sparse-vector product for each path |
| 13: | |
| 14: | ▹ Calculate error |
| 15: | ▹ Calculate norm |
| 16:
|
| 17: | ▹ increasing iteration |
| 18: end while | |
| 19: return | |
| 20: end procedure |
The matrix
G can be decomposed into two triangular matrices through Cholesky decomposition, expressed as
(see Equation (
3)). In this expression,
denotes the triangular Cholesky factor [
56] (refer to Algorithm 1, line 8). To address this matrix, we establish a system
. This system is addressed by considering it as a triangular system, formulated as
with
and
(see Algorithm 1, line 11). The matrix
is determined using the approach described in Equation (
3) [
55], where
(see Algorithm 1, line 7). For reconstructing the signal
, which involves transforming a vector image into an NxN matrix through a reshape operation, a stopping criterion is established by comparing the norm of the residual with a threshold
(see Algorithm 1, line 15), thus bypassing the need to compute the residual
(see Algorithm 1, lines 12–14). To improve algorithm efficiency, we suggest that it be deployed in the Compute Unified Device Architecture (CUDA) to facilitate parallel processing in the reconstruction task [
57] (see Algorithm 1).
To generate the final 2D image, we first obtain the SPI image using the method described in Algorithm 1 and then integrate it with post-processed depth data from a TOF system. This depth data is improved through a normalization technique. The FSRCNN network method, as detailed in [
26], fuses the initial input image with data from the TOF system. This fusion process enhances the image to two times its initial resolution, producing a final output image with dimensions of 64 × 64 pixels. The complete system illustrated in
Figure 2b details the processing algorithm of the proposed NIR-SPI vision system. This system starts with a low-resolution SPI image, processes it through the FSRCNN network [
26], and combines it with data from the TOF system.
3.4. SPI Acquisition Protocol
In developing the SPI camera, we focused on two crucial parameters essential to capture SPI images: the detector exposure time (
and the frequency of pattern projection
). We used a theoretical model of the NIR-SPI system [
58] to determine the appropriate exposure time. This model accounts for factors such as maximum measurement distance, scattering effects, and the correlation between photon incidence on the sensor and the noise threshold. We established the exposure time,
, to range between 80 and 120
s, optimal for measurement distances of 0.3 to 1 m. From this exposure time, we derived that the minimum frequency for the ADC must be at least 60 KHz. The frequency patterns are based on Equation (
4) [
59], using the parameter
to evaluate the efficiency at the individual pixel level. The ideal configuration occurs at
(where
F denotes the actual sensor pixel count), which facilitates the highest ADC measurement rate at the lowest sensor resolution (
= 125 MHz). This setup significantly improves the signal-to-noise ratio in outdoor conditions. When the design condition is below
, the frequency patterns limit the resolution of the measurement. In contrast, exceeding this value (
), the pattern generation frequency, defined within the range of
= 40 KHz, can achieve a measurement rate three times faster.
7. Conclusions
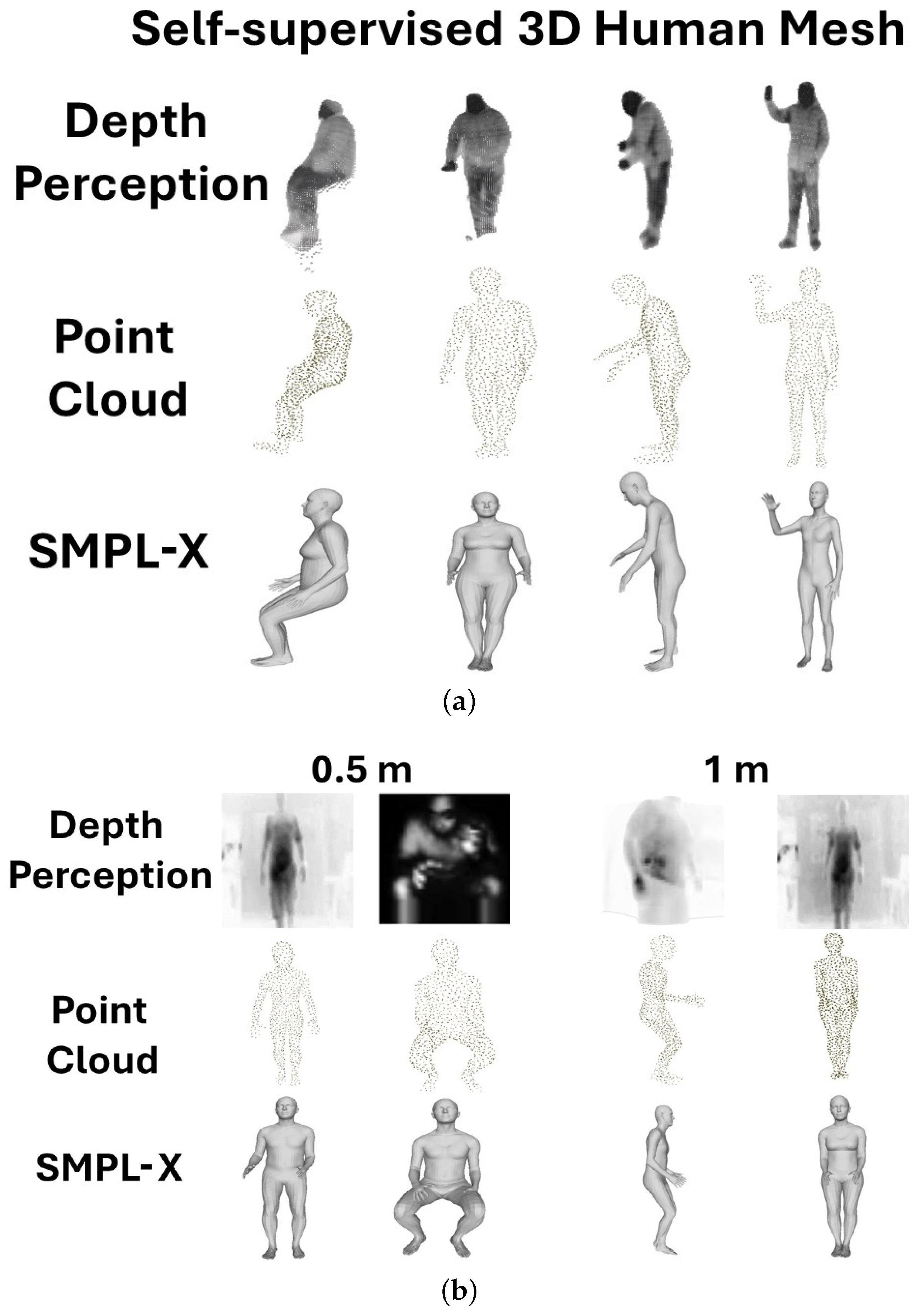
This work introduces a novel methodology that leverages NIR-SPI imaging to generate 3D human models through point cloud generation and integration of ViT classification in a self-supervised learning framework. The approach has demonstrated strong performance in creating accurate 3D reconstructions; however, accurately localizing the hands remains challenging because of the inherently low contrast of the NIR-SPI images. Despite this limitation, both qualitative and quantitative assessments (see
Table 3) indicate that the detection of core people retains high accuracy in the estimation of 3D poses, highlighting the potential of the method for single-image modeling of the human body—even at low resolutions (
Figure 8).
The experimental results show that our model achieves a V2V error of 36.1 mm, placing it between IPNET (28.2 mm) and VIBE (57.29 mm). Although our method does not produce the lowest V2V error, it significantly outperforms competing approaches in the mean per-joint position error (MPJPE), achieving a minimum deviation of approximately 39 mm. This suggests that, although our model may exhibit lower precision in vertex placement relative to IPNET, it demonstrates greater accuracy in estimating joint positions. PTF, which reports the second-lowest MPJPE (41.1 mm), also performs well, but our model maintains a slight advantage. These findings are highly pertinent to application domains such as motion capture and rescue operations, where precise joint localization is essential to achieve high-fidelity performance and realism. The relatively higher V2V error indicates potential areas for refinement, such as enhanced vertex placement strategies or the integration of more detailed surface geometry features. However, the method achieves a well-calibrated trade-off between vertex-level and joint-level accuracy, offering a robust and versatile solution for a wide range of human body estimation and tracking applications. Furthermore, it represents a significant advancement in the expressive reconstruction of body, hand, and facial features using NIR-SPI imaging, particularly under low-resolution conditions (see
Table 4 and
Table 5). Future research will aim to improve the accuracy at the vertex level while preserving or further improving the precision of the joint position.
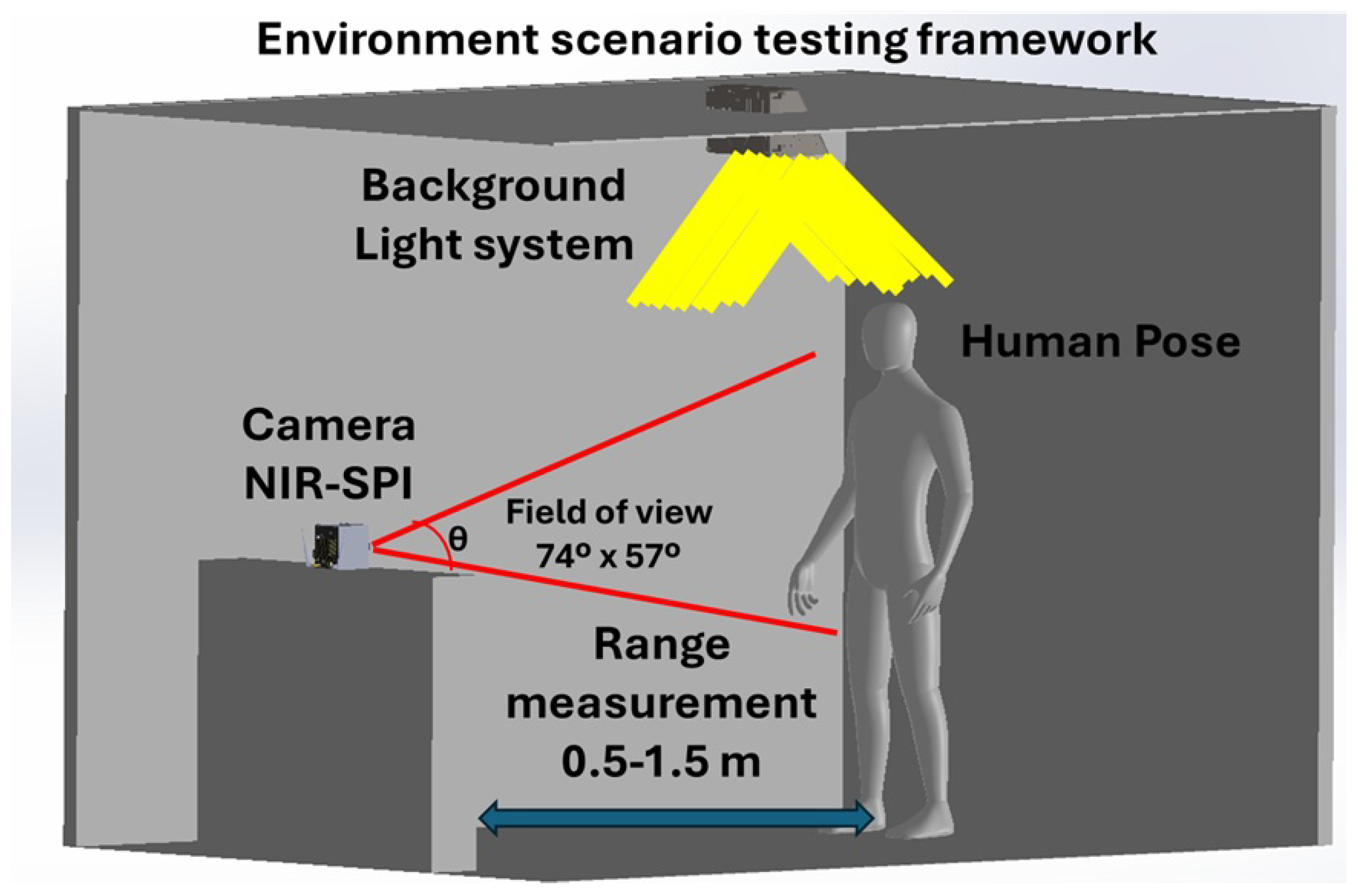
Although laboratory results for the NIR-SPI system are promising, real-world outdoor deployment introduces additional complexities, such as variable weather conditions, background clutter, and dynamic lighting. To overcome these challenges, future work will focus on adaptive calibration strategies, real-time environmental compensation algorithms, and advanced noise filtering techniques. Further efforts will involve integrating machine learning–driven correction mechanisms and implementing hardware-level optimizations to ensure robust and reliable system performance in diverse outdoor environments.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}