
A Biologically Inspired Trust Model for Open Multi-Agent Systems That Is Resilient to Rapid Performance Fluctuations



Abstract
1. Introduction
- CA demonstrated stable performance under various environmental changes;
- CA’s main strength was its resilience to fluctuations in the consumer population (unlike FIRE, CA does not depend on consumers for witness reputation, making it more effective in such scenarios);
- FIRE was more resilient to changes in the provider population (since CA relies on providers’ self-assessment of their capabilities, newly introduced providers—who lack prior experience—must learn from scratch);
- Among all environmental changes tested, the most detrimental to both models was frequent shifts in provider behavior, particularly when providers switched performance profiles, where FIRE exhibited greater resilience than CA.
2. Related Work
2.1. Trust Models for IoT Service Crowdsourcing
2.2. The Cold Start Problem
2.3. Agent Mobility
2.4. Dynamic Changes in Agents’ Behaviors
2.5. Assessing Trust from the Trustee’s Perspective
2.6. Mechanisms for Promoting Honest Behavior
3. Background
3.1. FIRE
- Interaction Trust (IT): Evaluates an agent’s trustworthiness based on its past interactions with the evaluator.
- Witness Reputation (WR): Assesses the target’s agent’s trustworthiness using feedback from witnesses—other agents that have previously interacted with it.
- Role-based Trust (RT): Determines trustworthiness based on role-based relationships with the target agent, incorporating domain knowledge such as norms and regulations.
- Certified Reputation (CR): Relies on third-party references stored by the target agent, which can be accessed on demand to assess trustworthiness.
3.2. CA Model
3.3. The CA Algorithm Used to Handle Dynamic Trustee Profiles
| Algorithm 1: CA v2, for agent |
| 1: while True do # --- broadcast a request message when a new task is perceived --- 2: when perceived a new task = (c, r) 3: broadcast message m = (request, i, task) # --- Receive/store a request message and initialize a new connection--- 4: when received a new message m = (request, j, task) 5: add m to message list M 6: if no existing connection co = (i, j, _, task) then 7: if there are similar connections co’ = (i,~j,_,task) from i to other agents for the same task then 8: create co = (i, j, avg_w, task), where avg_w = average of all weights for (i, ~j, _, task) 9: else 10: create co = (i, j, 0.5, task) # initialize weight to default initial trust 0.5 11: end if 12: end if # --- Select and Attempt task --- 13: select m = (request, j, task) from M such that co = (i, j, w, task) has the highest weight among all (i, k, w’, task) 14: if task is not visible or not done yet then 15: if canAccessAndUndertake(task) then 16: if w ≥ Threshold then 17: (result, performance) ← performTask(task) 18: end if 19: end if 20: end if 21: delete m from M # --- Update connection weight based on result --- 22: if result = success then 23: strengthen co using Equation (1) 24: else 25: weaken co using Equation (2) 26: end if # --- Dynamic profile update --- 27: for all failed connections co’ = (i, j, w’, task’) where w’ < Threshold and task’ = (c, r’) with r’ > r do 28: if performance ≥ minSuccessfulPerformance(task’) then 29: w’ ← Threshold # Give another chance on harder tasks 30: end if 31: end for 32: end while |
4. Enhancing Performance by Avoiding Unwarranted Task Executions
4.1. A Semi-Formal Analysis of the CA Algorithm to Identify and Avoid Unwarranted Task Executions
- Although induction is used to support Proposition 1, many conclusions rely more on empirical observation than on rigorous formal logic;
- The conclusions are drawn from specific experimental conditions (e.g., Threshold = 0.5, a = β = 0.1), whereas a purely formal analysis would typically strive to derive results that hold regardless of particular parameter values;
- Several conclusions are derived from example scenarios rather than universally valid logical proofs.
4.2. The Proposed CA Algorithm for the Early Detection of Bad Providers
| Algorithm 2: CA v3, for agent |
| # --- Initialize task-specific self-assessment memory --- 1: define i.bad_tasks as a map with default value false # assumes good unless proven otherwise 2: while True do # --- Broadcast a request message when a new task is perceived --- 3: when perceived a new task = (c, r) 4: broadcast message m = (request, i, task) # --- Receive/store a request message and initialize a new connection --- 5: when received a new message m = (request, j, task) 6: add m to message list M # --- Initialize a new connection --- 7: if no existing connection co = (i, j, _, task) then 8: if i.bad_tasks[task] = true and task.performance_level ∈ {PERFECT, GOOD, OK} then 9: create co = (i, j, 0.45, task) # cautious trust level for task-specific bad assessment 10: else if there are similar connections co’ = (i, ~j, _, task) from i to other agents for the same task then 11: create co = (i, j, avg_w, task), where avg_w = average of all weights for (i, ~j, _, task) 12: else 13: create co = (i, j, 0.5, task) # initialize to default trust 14: end if 15: else #if connection co = (i, j, _, task) exists # --- modify an existing connection if certain conditions hold--- 16: if i.bad_tasks[task] = true and task.performance_level ∈ {PERFECT, GOOD, OK} then 17: modify co = (i, j, 0.45, task) 18: end if 19: end if # --- Select and Attempt task --- 20: select m = (request, j, task) from M such that co = (i, j, w, task) has the highest weight among all (i, k, w’, task) 21: if task is not visible or not done yet then 22: if canAccessAndUndertake(task) then 23: if w ≥ Threshold then 24: (result, performance) ← performTask(task) # --- Re-evaluate task-specific self-assessment based on latest performance --- 25: if performance ≤ 0 then 26: i.bad_tasks[task] ← true 27: else 28: i.bad_tasks[task] ← false 29: end if 30: end if 31: end if 32: end if 33: delete m from M # --- Update connection weight based on result --- 34: if result = success then 35: strengthen co using Equation (1) 36: else 37: weaken co using Equation (2) 38: end if # --- Dynamic profile update --- 39: for all failed connections co’ = (i, j, w’, task’) where w’ < Threshold and task’ = (c, r’) with r’ > r do 40: if performance ≥ minSuccessfulPerformance(task’) then 41: w’ ← Threshold # Give another chance on harder tasks 42: end if 43: end for 44: end while |
5. Experimental Setup and Methodology
5.1. The Testbed
5.2. Experimental Methodology
- FIRE: consumer agents use the FIRE algorithm.
- CA_OLD: consumers use the previous version of the CA algorithm.
- CA_NEW: consumers use the new version of the CA algorithm.
- CA_OLD and CA_NEW;
- FIRE and CA_NEW.
6. Simulation Results
6.1. The Performance of the New CA Algorithm in Dynamic Trustee Profiles
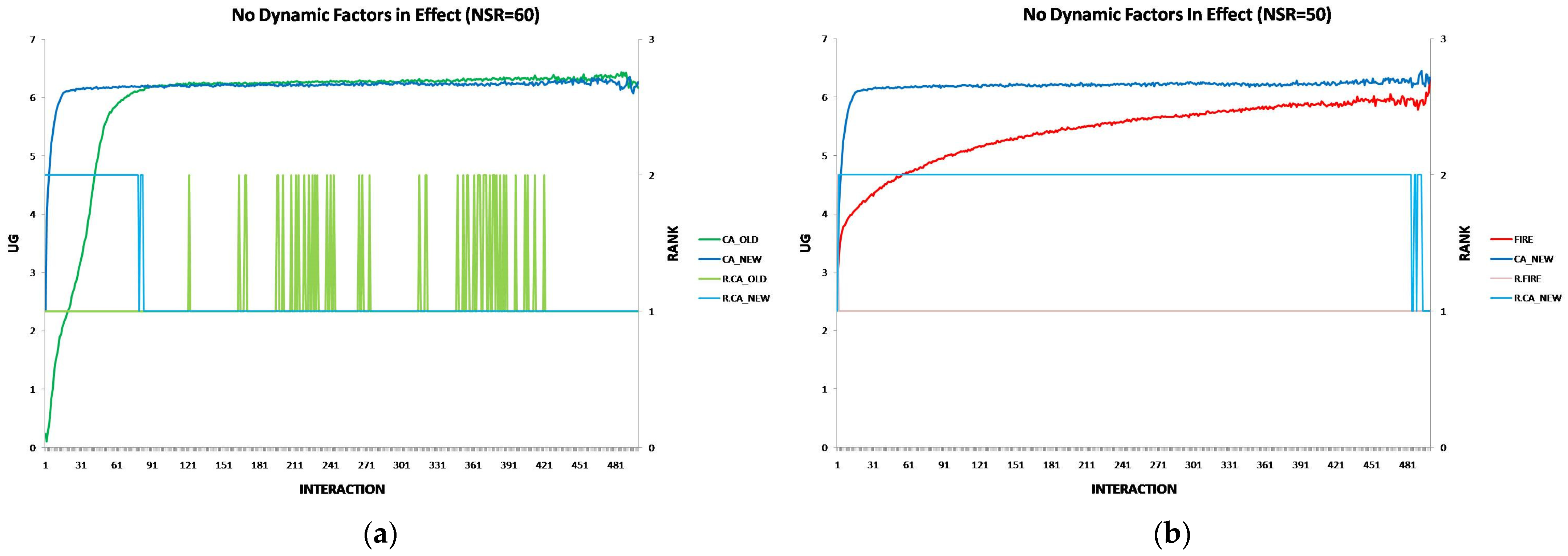
6.2. The Performance of the New CA Algorithm in the Static Setting
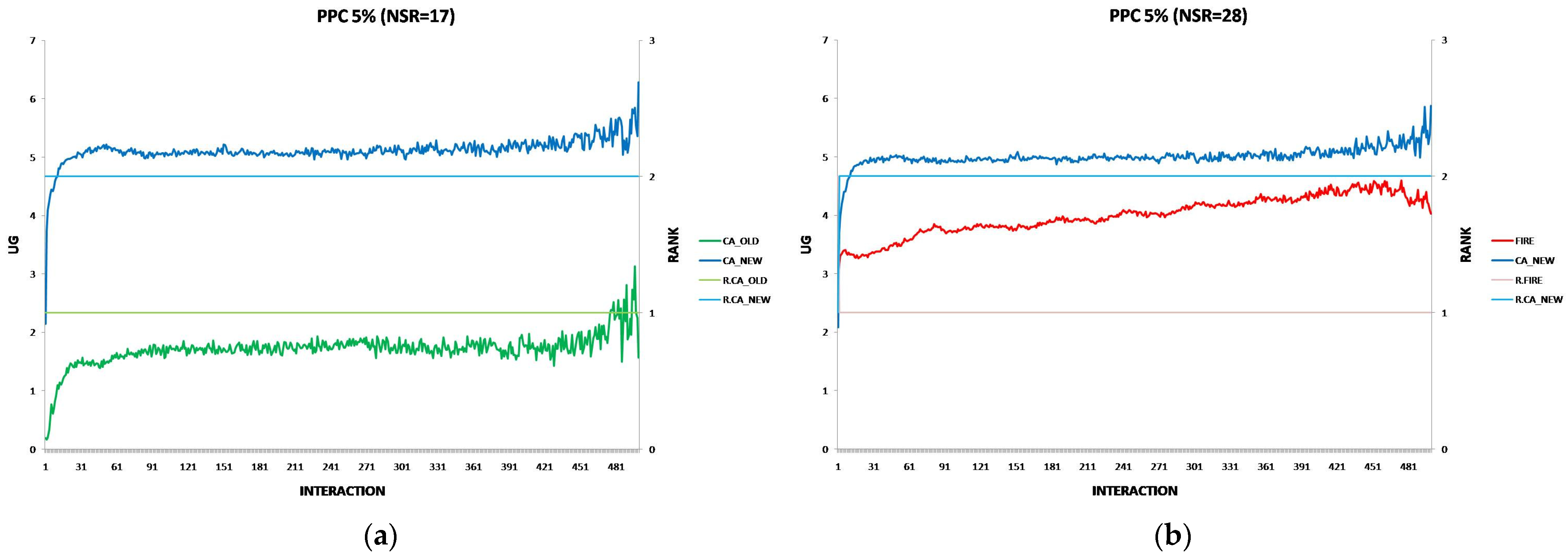
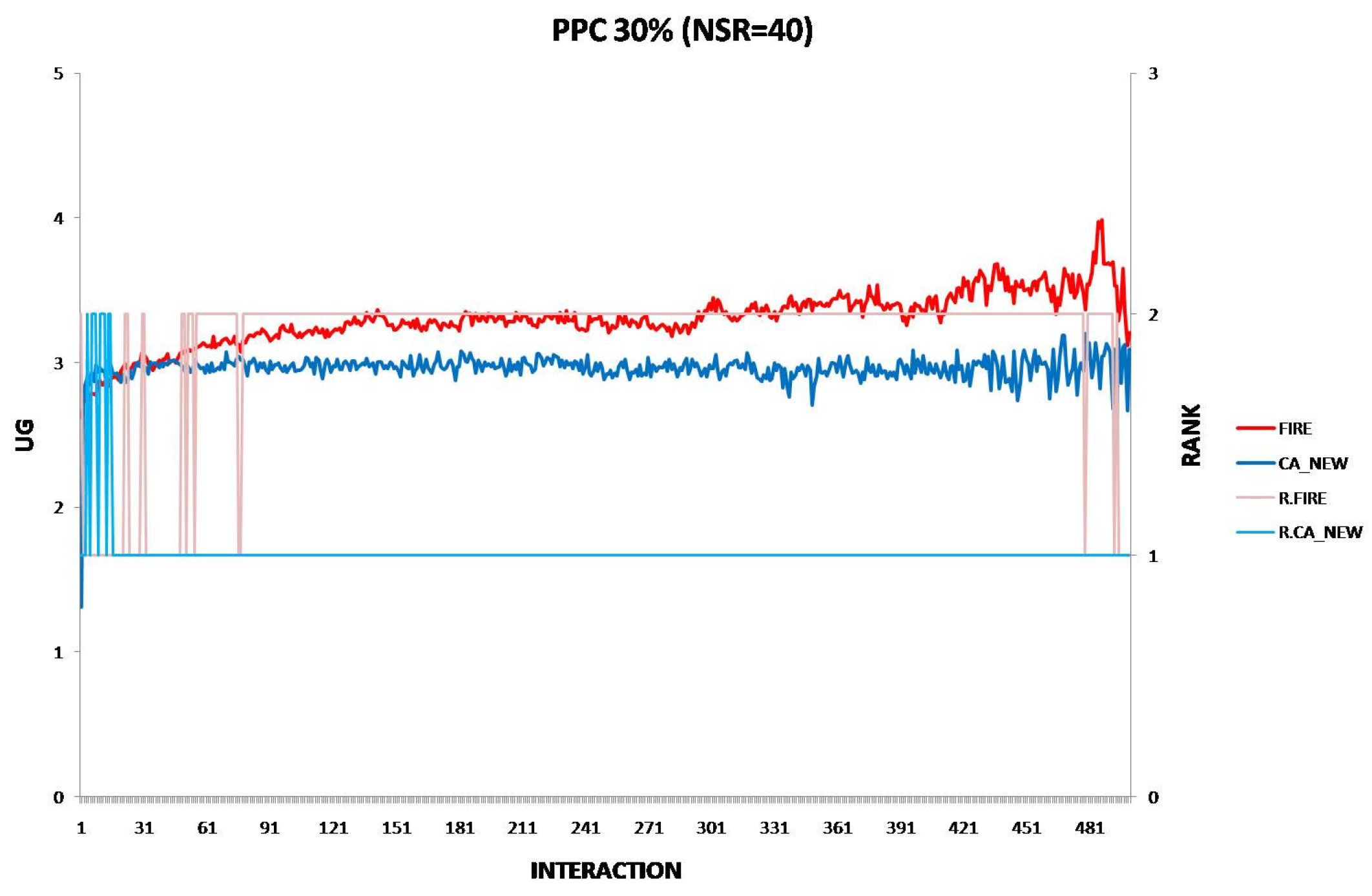
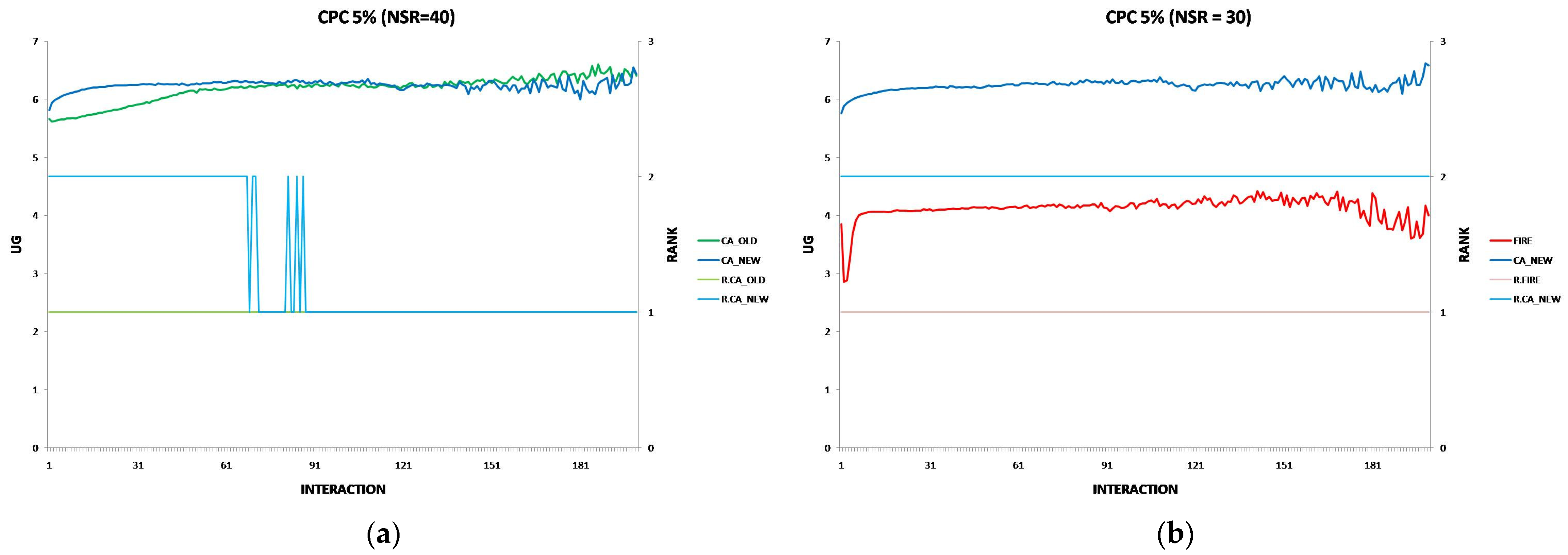
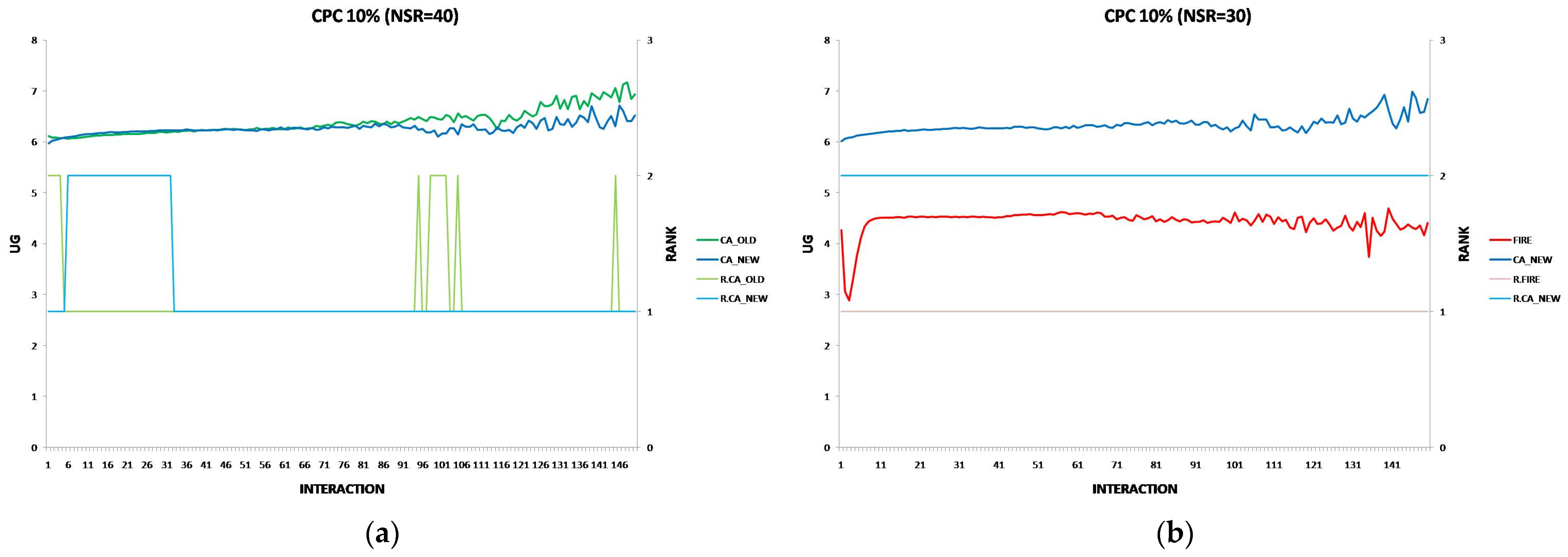
6.3. The Performance of the New CA Algorithm in Provider Population Changes
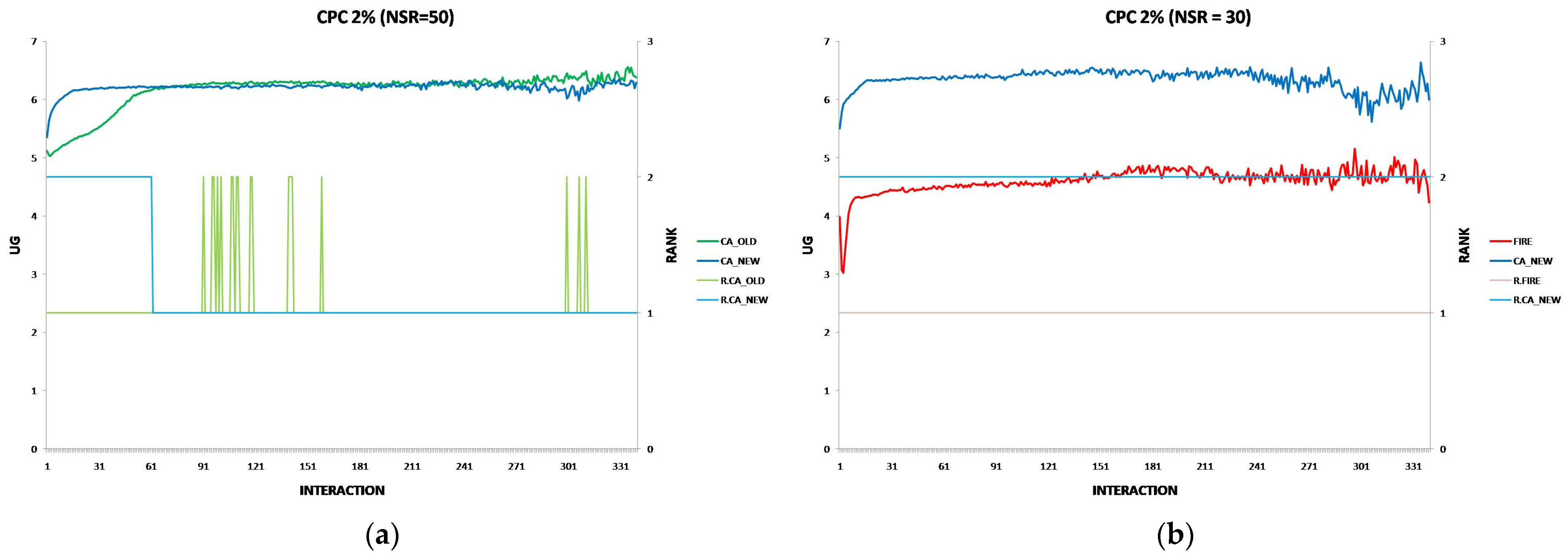
6.4. The Performance of the New CA Algorithm in Consumer Population Changes
6.5. The Performance of the New CA Algorithm in Consumer and Provider Location Changes
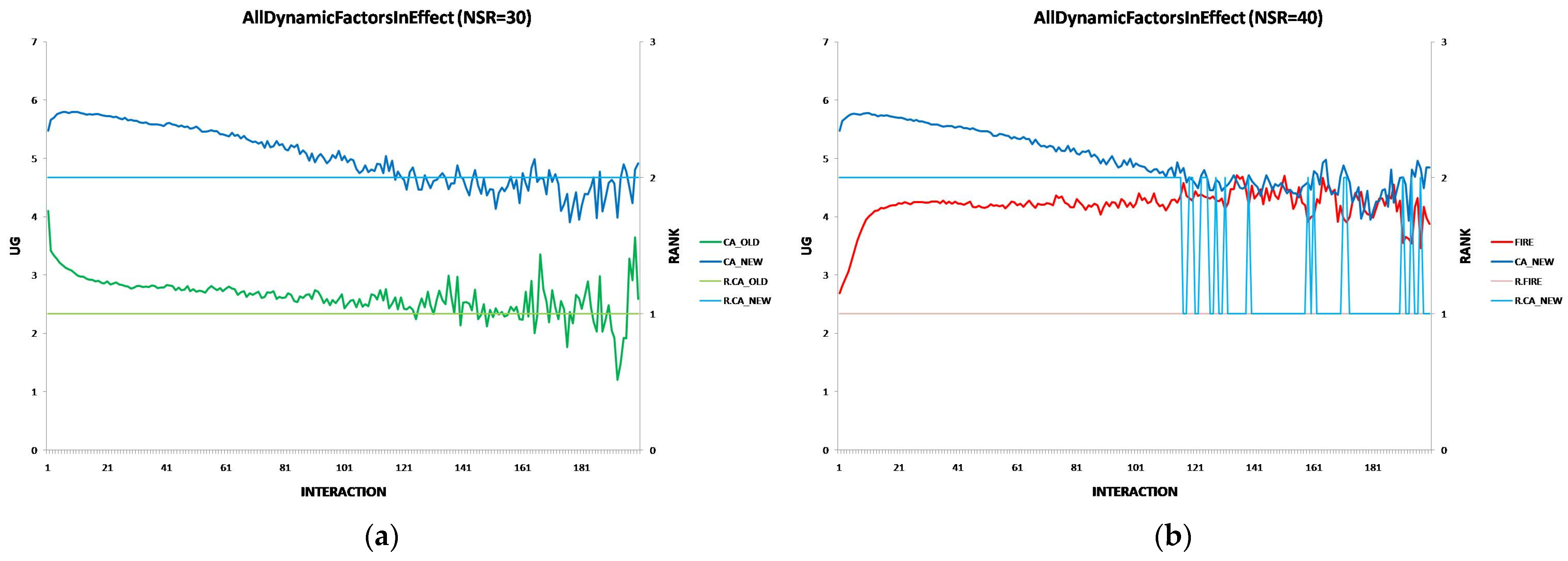
6.6. The Performance of the New CA Algorithm Under the Effects of All Dynamic Factors
6.7. An Overview of the Results
- Dynamic Trustee Profiles: CA_NEW outperforms CA_OLD across all interactions and shows resilience in handling provider performance fluctuations. While FIRE adapts more quickly in some cases, CA_NEW remains very competitive.
- Static Environment: CA_NEW surpasses CA_OLD in the initial interactions and consistently outperforms FIRE, except in the first interaction.
- Provider Population Changes: CA_NEW is more resilient than CA_OLD when provider population fluctuations increase up to 10%, maintaining better performance. However, as changes reach 30%, FIRE eventually outperforms CA_NEW, indicating FIRE’s resilience in this environmental change.
- Consumer Population Changes: CA_NEW generally achieves a higher UG than CA_OLD, though at high levels of consumer population changes, CA_OLD performs slightly better in the first interaction, suggesting that CA_OLD may be better for old service providers with stable capabilities. CA_NEW consistently outperforms FIRE under consumer population changes.
- Consumer and Provider Location Changes: CA_NEW shows improved performance over CA_OLD in initial interactions and outperforms FIRE in all interactions, except for the first one.
- Combined Dynamic Factors: When all dynamic factors are in effect, CA_NEW maintains superior performance over both CA_OLD and FIRE across all interactions, demonstrating its robustness in complex environments.
7. Towards a Comprehensive Evaluation of the CA Model
8. Trust-Related Attacks
9. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix A.1
Appendix A.2
- : Number of distinct known tasks stored or processed by the agent, where
- c is a task category.
- r is a set of requirements.
- n: Number of agents in the system.
- q: Number of incoming messages in the agent’s message list.
- m: Number of connections currently held by the agent. In the worst case, .
- 1.
- Initialization (line 1):
- Creating an empty structure: .
- 2.
- Message Handling and Connection Setup (lines 3–19):
- Broadcast to all agents (line 4): .
- Append message (line 6): .
- Connection handling (lines 7–14 or 15–19):
- Worst case (lines 7–14):
- Linear search in connections: .
- Find similar connections and average weights: .
- Total: .
- Alternative case (lines 15–19): .
- 3.
- Select and Attempt Task (lines 20–33):
- For each message (q in total), find the corresponding connection (worst-case linear search): .
- Other steps (task status, threshold check, performance evaluation): Each is .
- Message deletion (search + shift in list): .
- 4.
- Update Connection Weight (lines 34–38): Direct updates and conditionals: .
- 5.
- Dynamic Profile Update (lines 39–43):
- Iterate and filter all connections: .
- Search through task list: .
- Total Time Complexity: = , since, as stated, in the worst case, it is .
- : Map from tasks to Boolean: .
- Message list : Up to messages: .
- Connection list: At most one per known task per agent: .
- Local scalars and flags: .
References
- Fabi, A.K.; Thampi, S.M. A psychology-inspired trust model for emergency message transmission on the Internet of Vehicles (IoV). Int. J. Comput. Appl. 2020, 44, 480–490. [Google Scholar] [CrossRef]
- Jabeen, F.; Khan, M.K.; Hameed, S.; Almogren, A. Adaptive and survivable trust management for Internet of Things systems. IET Inf. Secur. 2021, 15, 375–394. [Google Scholar] [CrossRef]
- Hattab, S.; Lejouad Chaari, W. A generic model for representing openness in multi-agent systems. Knowl. Eng. Rev. 2021, 36, e3. [Google Scholar] [CrossRef]
- Player, C.; Griffiths, N. Improving trust and reputation assessment with dynamic behaviour. Knowl. Eng. Rev. 2020, 35, e29. [Google Scholar] [CrossRef]
- Jelenc, D. Toward unified trust and reputation messaging in ubiquitous systems. Ann. Telecommun. 2021, 76, 119–130. [Google Scholar] [CrossRef]
- Sato, K.; Sugawara, T. Multi-Agent Task Allocation Based on Reciprocal Trust in Distributed Environments. In Agents and Multi-Agent Systems: Technologies and Applications; Jezic, G., Chen-Burger, J., Kusek, M., Sperka, R., Howlett, R.J., Jain, L.C., Eds.; Springer: Singapore, 2021; Smart Innovation, Systems and Technologies; Volume 241. [Google Scholar] [CrossRef]
- Lygizou, Z.; Kalles, D. A biologically inspired computational trust model for open multi-agent systems which is resilient to trustor population changes. In Proceedings of the 13th Hellenic Conference on Artificial Intelligence (SETN ′24), Athens, Greece, 11–13 September 2024; Article No. 29. pp. 1–9. [Google Scholar] [CrossRef]
- Samuel, O.; Javaid, N.; Khalid, A.; Imran, M.; Nasser, N. A Trust Management System for Multi-Agent System in Smart Grids Using Blockchain Technology. In Proceedings of the 2020 IEEE Global Communications Conference (GLOBECOM 2020), Taipei, Taiwan, 7–11 December 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Khalid, R.; Samuel, O.; Javaid, N.; Aldegheishem, A.; Shafiq, M.; Alrajeh, N. A Secure Trust Method for Multi-Agent System in Smart Grids Using Blockchain. IEEE Access 2021, 9, 59848–59859. [Google Scholar] [CrossRef]
- Bahutair, M.; Bouguettaya, A.; Neiat, A.G. Multi-Perspective Trust Management Framework for Crowdsourced IoT Services. IEEE Trans. Serv. Comput. 2022, 15, 2396–2409. [Google Scholar] [CrossRef]
- Meyerson, D.; Weick, K.E.; Kramer, R.M. Swift trust and temporary groups. In Trust in Organizations: Frontiers of Theory and Research; Kramer, R.M., Tyler, T.R., Eds.; Sage Publications, Inc.: Thousand Oaks, CA, USA, 1996; pp. 166–195. [Google Scholar] [CrossRef]
- Wang, J.; Jing, X.; Yan, Z.; Fu, Y.; Pedrycz, W.; Yang, L.T. A Survey on Trust Evaluation Based on Machine Learning. ACM Comput. Surv. 2020, 53, 1–36. [Google Scholar] [CrossRef]
- Ahmad, I.; Yau, K.-L.A.; Keoh, S.L. A Hybrid Reinforcement Learning-Based Trust Model for 5G Networks. In Proceedings of the 2020 IEEE Conference on Application, Information and Network Security (AINS), Kota Kinabalu, Malaysia, 17–19 November 2020; pp. 20–25. [Google Scholar] [CrossRef]
- Kolomvatsos, K.; Kalouda, M.; Papadopoulou, P.; Hadjieftymiades, S. Fuzzy trust modeling for pervasive computing applications. J. Data Intell. 2021, 2, 101–115. [Google Scholar] [CrossRef]
- Wang, E.K.; Chen, C.M.; Zhao, D.; Zhang, N.; Kumari, S. A dynamic trust model in Internet of Things. Soft Comput. 2020, 24, 5773–5782. [Google Scholar] [CrossRef]
- Latif, R. ConTrust: A Novel Context-Dependent Trust Management Model in Social Internet of Things. IEEE Access 2022, 10, 46526–46537. [Google Scholar] [CrossRef]
- Alam, S.; Zardari, S.; Shamsi, J.A. Blockchain-Based Trust and Reputation Management in SIoT. Electronics 2022, 11, 3871. [Google Scholar] [CrossRef]
- Fragkos, G.; Minwalla, C.; Plusquellic, J.; Tsiropoulou, E.E. Local Trust in Internet of Things Based on Contract Theory. Sensors 2022, 22, 2393. [Google Scholar] [CrossRef]
- Pan, Q.; Wu, J.; Li, J.; Yang, W.; Guan, Z. Blockchain and AI Empowered Trust-Information-Centric Network for Beyond 5G. IEEE Netw. 2020, 34, 38–45. [Google Scholar] [CrossRef]
- Muhammad, S.; Umar, M.M.; Khan, S.; Alrajeh, N.A.; Mohammed, E.A. Honesty-Based Social Technique to Enhance Cooperation in Social Internet of Things. Appl. Sci. 2023, 13, 2778. [Google Scholar] [CrossRef]
- Ali, S.E.; Tariq, N.; Khan, F.A.; Ashraf, M.; Abdul, W.; Saleem, K. BFT-IoMT: A Blockchain-Based Trust Mechanism to Mitigate Sybil Attack Using Fuzzy Logic in the Internet of Medical Things. Sensors 2023, 23, 4265. [Google Scholar] [CrossRef]
- Kouicem, D.E.; Imine, Y.; Bouabdallah, A.; Lakhlef, H. Decentralized Blockchain-Based Trust Management Protocol for the Internet of Things. IEEE Trans. Dependable Secur. Comput. 2022, 19, 1292–1306. [Google Scholar] [CrossRef]
- Ouechtati, H.; Nadia, B.A.; Lamjed, B.S. A fuzzy logic-based model for filtering dishonest recommendations in the Social Internet of Things. J. Ambient. Intell. Hum. Comput. 2023, 14, 6181–6200. [Google Scholar] [CrossRef]
- Mianji, E.M.; Muntean, G.-M.; Tal, I. Trust and Reputation Management for Data Trading in Vehicular Edge Computing: A DRL-Based Approach. In Proceedings of the 2024 IEEE International Symposium on Broadband Multimedia Systems and Broadcasting (BMSB), Toronto, ON, Canada, 19–21 June 2024; pp. 1–7. [Google Scholar] [CrossRef]
- Marche, C.; Nitti, M. Trust-Related Attacks and Their Detection: A Trust Management Model for the Social IoT. IEEE Trans. Netw. Serv. Manag. 2021, 18, 3297–3308. [Google Scholar] [CrossRef]
- Kumari, S.; Kumar, S.M.D.; Venugopal, K.R. Trust Management in Social Internet of Things: Challenges and Future Directions. Int. J. Com. Dig. Syst. 2023, 14, 899–920. [Google Scholar] [CrossRef]
- Huynh, T.D.; Jennings, N.R.; Shadbolt, N.R. An integrated trust and reputation model for open multi-agent systems. Auton. Agents Multi-Agent Syst. 2006, 13, 119–154. [Google Scholar] [CrossRef]
- Lygizou, Z.; Kalles, D. A Biologically Inspired Computational Trust Model based on the Perspective of the Trustee. In Proceedings of the 12th Hellenic Conference on Artificial Intelligence (SETN ′22), Corfu, Greece, 7–9 September 2022; Article No. 7. pp. 1–10. [Google Scholar] [CrossRef]
- Cohen, P. Empirical Methods for Artificial Intelligence; The MIT Press: Cambridge, MA, USA, 1995. [Google Scholar]
- Lygizou, Z.; Kalles, D. Using Deep Q-Learning to Dynamically Toggle Between Push/Pull Actions in Computational Trust Mechanisms. Mach. Learn. Knowl. Extr. 2024, 6, 1413–1438. [Google Scholar] [CrossRef]
- Wang, J.; Yan, Z.; Wang, H.; Li, T.; Pedrycz, W. A Survey on Trust Models in Heterogeneous Networks. IEEE Commun. Surv. Tutor. 2022, 24, 2127–2162. [Google Scholar] [CrossRef]
- Fotia, L.; Delicato, F.; Fortino, G. Trust in Edge-Based Internet of Things Architectures: State of the Art and Research Challenges. ACM Comput. Surv. 2023, 55, 1–34. [Google Scholar] [CrossRef]
- Wei, L.; Wu, J.; Long, C. Enhancing Trust Management via Blockchain in Social Internet of Things. In Proceedings of the 2020 Chinese Automation Congress (CAC), Shanghai, China, 6–8 November 2020; pp. 159–164. [Google Scholar] [CrossRef]
- Amiri-Zarandi, M.; Dara, R.A. Blockchain-based Trust Management in Social Internet of Things. In Proceedings of the 2020 IEEE International Conference on Dependable, Autonomic and Secure Computing, International Conference on Pervasive Intelligence and Computing, International Conference on Cloud and Big Data Computing, International Conference on Cyber Science and Technology Congress (DASC/PiCom/CBDCom/CyberSciTech), Calgary, AB, Canada, 17–22 August 2020; pp. 49–54. [Google Scholar] [CrossRef]
- Hankare, P.; Babar, S.; Mahalle, P. Trust Management Approach for Detection of Malicious Devices in SIoT. Teh. Glas. 2021, 15, 43–50. [Google Scholar] [CrossRef]
- Talbi, S.; Bouabdallah, A. Interest-based trust management scheme for social internet of things. J. Ambient. Intell. Hum. Comput. 2020, 11, 1129–1140. [Google Scholar] [CrossRef]
- Sagar, S.; Mahmood, A.; Sheng, Q.Z.; Zhang, W.E. Trust Computational Heuristic for Social Internet of Things: A Machine Learning-based Approach. In Proceedings of the 2020 IEEE International Conference on Communications (ICC), Dublin, Ireland, 7–11 June 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Sagar, S.; Mahmood, A.; Sheng, M.; Zaib, M.; Zhang, W. Towards a Machine Learning-driven Trust Evaluation Model for Social Internet of Things: A Time-aware Approach. In Proceedings of the 17th EAI International Conference on Mobile and Ubiquitous Systems: Computing, Networking and Services (MobiQuitous ′20), Darmstadt, Germany, 7–9 December 2020; pp. 283–290. [Google Scholar] [CrossRef]
- Aalibagi, S.; Mahyar, H.; Movaghar, A.; Stanley, H.E. A Matrix Factorization Model for Hellinger-Based Trust Management in Social Internet of Things. IEEE Trans. Dependable Secur. Comput. 2022, 19, 2274–2285. [Google Scholar] [CrossRef]
- Ullah, F.; Salam, A.; Amin, F.; Khan, I.A.; Ahmed, J.; Alam Zaib, S.; Choi, G.S. Deep Trust: A Novel Framework for Dynamic Trust and Reputation Management in the Internet of Things (IoT)-Based Networks. IEEE Access 2024, 12, 87407–87419. [Google Scholar] [CrossRef]
- Alemneh, E.; Senouci, S.-M.; Brunet, P.; Tegegne, T. A Two-Way Trust Management System for Fog Computing. Future Gener. Comput. Syst. 2020, 106, 206–220. [Google Scholar] [CrossRef]
- Tu, Z.; Zhou, H.; Li, K.; Song, H.; Yang, Y. A Blockchain-Based Trust and Reputation Model with Dynamic Evaluation Mechanism for IoT. Comput. Netw. 2022, 218, 109404. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | FIRE Model | CA Model |
|---|---|---|
| Initiation of Trust Evaluation | Trustor initiates trust and selects a trustee | Trustee decides whether to engage with a task based on its trust level |
| Sources of Trust Information | Interaction trust (IT), witness reputation (WR), role-based trust (RT), certified reputation (CR) | Single source: trust learned via synaptic-style feedback from experience |
| Trust Update Mechanism | Weighted aggregation of direct and indirect trust evidence | Adjusts connection weights dynamically based on task success/failure feedback |
| Cold Start Handling | Leverages indirect trust (WR, CR) when no prior interaction exists (IT is unavailable) | Trustee initializes connection weight using prior experience or a default value |
| Scalability | Dependent on network structure. May suffer in large-scale systems due to reliance on witness availability | High: fully decentralized, with no inter-agent trust exchange |
| Communication Overhead | Moderate to high: requires trustor to query multiple witnesses for WR or providers for CR | Very low: no inter-agent trust exchange; all trust is stored and updated locally |
| Resilience to False Reports | Vulnerable to dishonest witnesses or biased CR | Resistant to recommendation attacks |
| Trust Storage | Distributed. Consumers store IT values locally, and providers store CR values locally | Fully local: trust is stored as neural-like weights in each trustee/provider |
| Biological Inspiration | None | Yes—based on synaptic plasticity and neural assembly formation |
| Symbol | Meaning |
|---|---|
| Agent identifiers | |
| Any agent other than | |
| A task defined by category and requirement | |
| r’ > r | Requirement r’ signifies a more difficult task than r |
| Request message from agent | |
| A connection between and , with weight representing the trust value of trustor for trustee for executing | |
| _ | Placeholder for any value |
| List of received request messages | |
| Trust threshold required to attempt a task | |
| Trust/connection weight |
| Tasks | Explanation of the Requirement |
|---|---|
| task1 = (service_ID, performance_level = PERFECT) | Performance must be equal to 10 |
| task2 = (service_ID, performance_level = GOOD) | Performance must be greater than or equal to 5 |
| task3 = (service_ID, performance_level = OK) | Performance must be greater than or equal to 0 |
| task4 = (service_ID, performance_level = BAD) | Performance must be greater than or equal to −5 |
| task5 = (service_ID, performance_level = WORST) | Performance must be greater than or equal to −10 |
| Consumer | Result | Final Weight of the New Connection | Average Weight |
|---|---|---|---|
| success | 0.55 | ||
| failure | 0.5275 | ||
| failure | 0.51175 | ||
| failure | 0.499544 |
| Profile | Performance Range | σp |
|---|---|---|
| Good | [PL_GOOD, PL_PERFECT] | 1.0 |
| Ordinary | [PL_OK, PL_GOOD] | 2.0 |
| Bad | [PL_WORST, PL_OK] | 2.0 |
| Performance Level | Utility Gained |
|---|---|
| PL_PERFECT | 10 |
| PL_GOOD | 5 |
| PL_OK | 0 |
| PL_BAD | −5 |
| PL_WORST | −10 |
| Simulation Variable | Symbol | Value |
|---|---|---|
| Number of simulation rounds | 500 | |
| Total number of provider agents | 100 | |
| 10 | |
| 40 | |
| 5 | |
| 45 | |
| Total number of consumer agents | 500 | |
| Range of consumer activity level | A | [0.25, 1.00] |
| Waiting time | 1000 msec |
| Parameters | Symbol | Value |
|---|---|---|
| Local rating history size | 10 | |
| IT recency scaling factor | −(5/ln(0.5)) | |
| Branching factor | 2 | |
| Referral length threshold | 5 | |
| Component coefficients | ||
| 2.0 | |
| 2.0 | |
| 1.0 | |
| 0.5 | |
| Reliability function parameters | ||
| −ln(0.5) | |
| −ln(0.5) | |
| −ln(0.5) | |
| −ln(0.5) |
| Parameters | Symbol | Value |
| Threshold | 0.5 | |
| Positive factor controlling the rate of increase in the strengthening of a connection | 0.1 | |
| Positive factor controlling the rate of decrease in the weakening of a connection | 0.1 |
| Criterion | CA Model Status | Remarks |
|---|---|---|
| Decentralization | Satisfied | Fully decentralized; no central authority |
| Subjectivity | Satisfied | Trust reflects trustor’s individual feedback |
| Context Awareness | Satisfied | Trust is task-specific |
| Dynamicity | Satisfied | Trust is updated after every task |
| Availability | Satisfied | Broadcast ensures redundancy |
| Integrity and Transparency | Satisfied | Local storage; accessible by the trustee |
| Scalability | Partially addressed | No large-scale evaluation; promising in simulations |
| Overhead | Partially addressed | Algorithm is simple; lacks complete formal complexity analysis—a proof sketch is provided in Appendix A.2 |
| Accuracy | Not yet evaluated | Needs empirical evaluation using metrics (Precision, Recall, etc.) |
| Robustness | Partially addressed | Resists false feedback; insider attack defense needs strengthening |
| Privacy Preservation | Partially addressed | No trust sharing; needs feedback protection mechanisms |
| Explainability | Satisfied | Supported via semi-formal analysis and empirical validation |
| User Acceptance | Not yet evaluated | No data on user preferences or quality of experience |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lygizou, Z.; Kalles, D. A Biologically Inspired Trust Model for Open Multi-Agent Systems That Is Resilient to Rapid Performance Fluctuations. Appl. Sci. 2025, 15, 6125. https://doi.org/10.3390/app15116125
Lygizou Z, Kalles D. A Biologically Inspired Trust Model for Open Multi-Agent Systems That Is Resilient to Rapid Performance Fluctuations. Applied Sciences. 2025; 15(11):6125. https://doi.org/10.3390/app15116125
Chicago/Turabian StyleLygizou, Zoi, and Dimitris Kalles. 2025. "A Biologically Inspired Trust Model for Open Multi-Agent Systems That Is Resilient to Rapid Performance Fluctuations" Applied Sciences 15, no. 11: 6125. https://doi.org/10.3390/app15116125
APA StyleLygizou, Z., & Kalles, D. (2025). A Biologically Inspired Trust Model for Open Multi-Agent Systems That Is Resilient to Rapid Performance Fluctuations. Applied Sciences, 15(11), 6125. https://doi.org/10.3390/app15116125