

Personalized Contextual Information Delivery Using Road Sign Recognition


Abstract
1. Introduction
2. Related Work
2.1. Object Detection
2.2. Chain of Thought (CoT)
2.3. Image Captioning Model
3. Proposed System
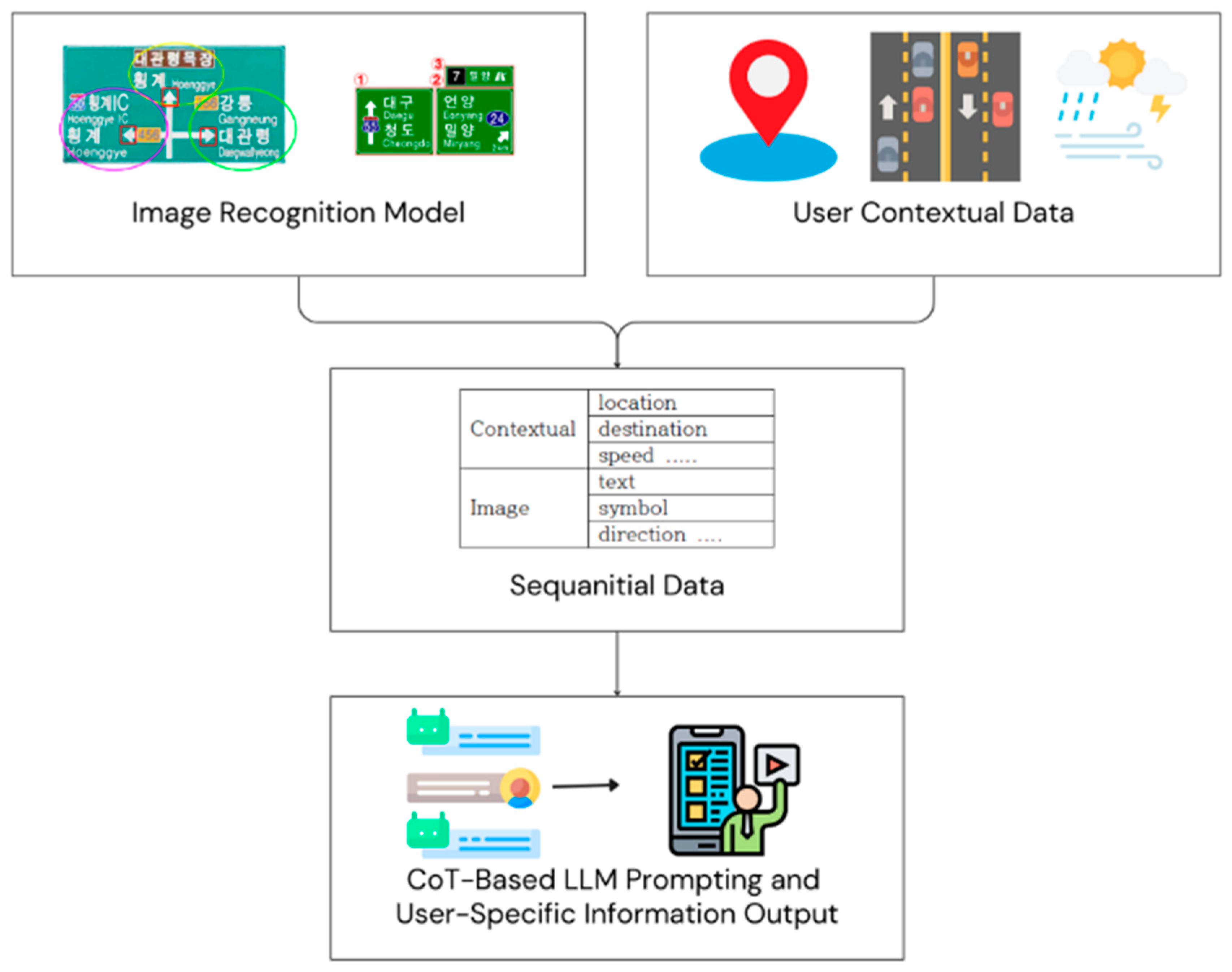
3.1. System Overview
3.2. Modular Components for Road Sign Recognition
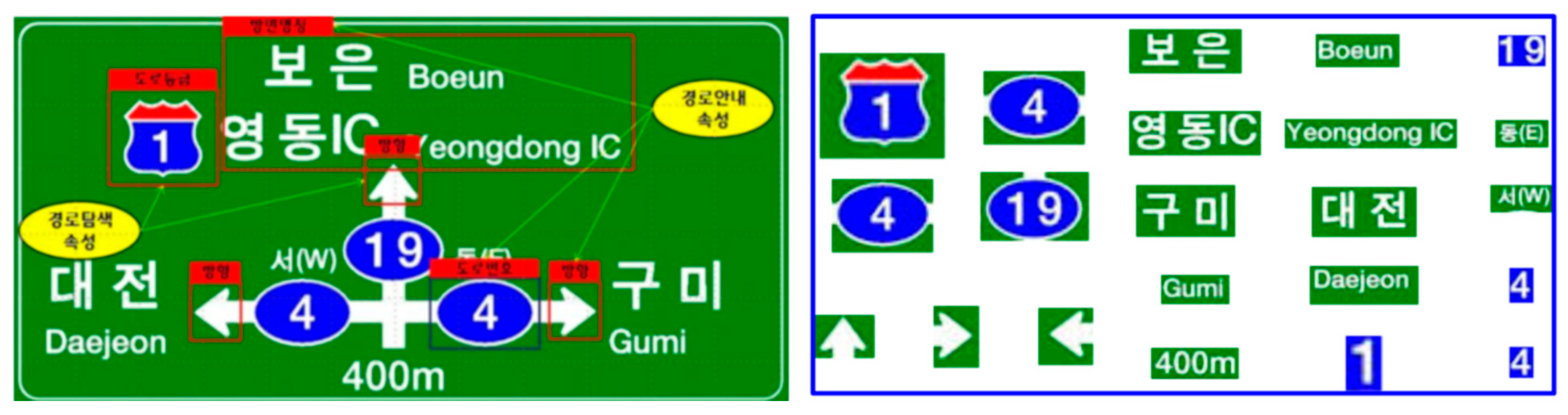
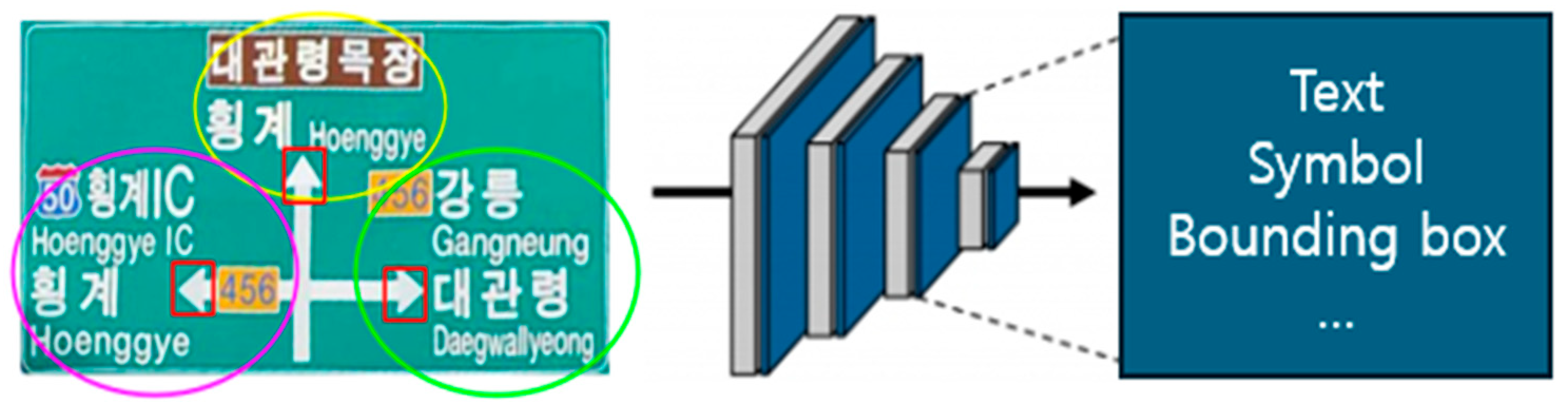
3.2.1. Object and Text Detection in Road Sign Images
3.2.2. Directional Information Extraction for Road Sign Objects
3.3. Contextual Information Integration
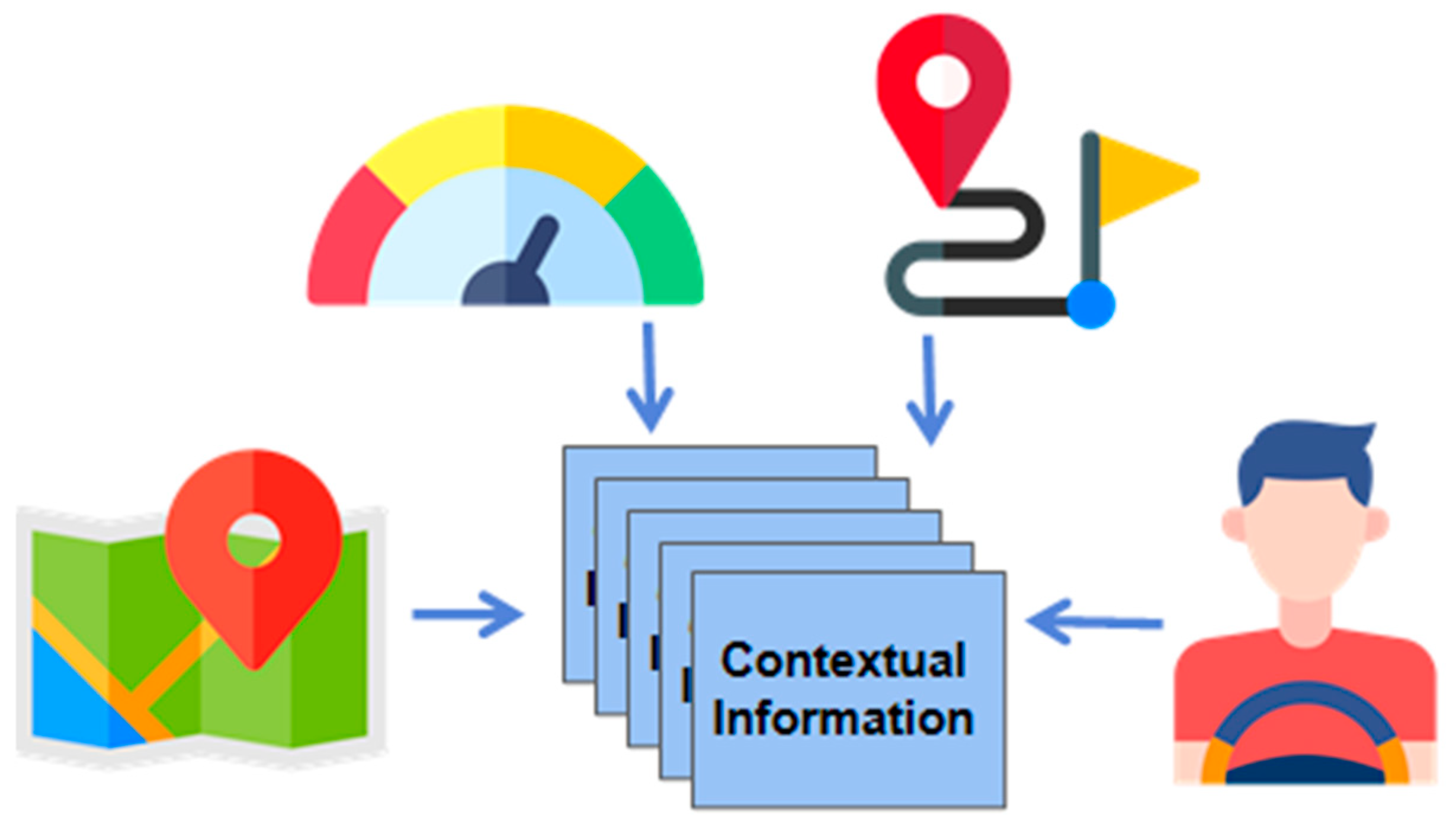
3.3.1. User Context
3.3.2. Chain of Thought-Based Information Processing
4. Experiments and Results
4.1. Road Sign Recognition Performance
4.2. Comparative Analysis with Image Captioning Models
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. Proc. IEEE Conf. Comput. Vis. Pattern Recognit. 2016, 2016, 779–788. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.; Liao, H.-Y. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhutdinov, R.; Bengio, Y. Show, Attend and Tell: Neural Image Caption Generation with Visual Attention. Proc. Int. Conf. Mach. Learn. 2015, 2015, 2048–2057. [Google Scholar]
- Anderson, P.; Fernando, B.; Johnson, M.; Gould, S. Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering. Proc. IEEE Conf. Comput. Vis. Pattern Recognit. 2018, 2018, 6077–6086. [Google Scholar] [CrossRef]
- Chen, L.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. Proc. IEEE Conf. Comput. Vis. Pattern Recognit. 2017, 2017, 2881–2890. [Google Scholar] [CrossRef]
- Baek, Y.; Lee, B.; Han, D.; Yun, S.; Lee, H. Character Region Awareness for Text Detection. Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. 2019, 2019, 9365–9374. [Google Scholar] [CrossRef]
- Xu, Y.; Zhang, J.; Wang, H. Sign-YOLO: Traffic Sign Detection Using Attention-Based YOLOv7. IEEE Trans. Intell. Transp. Syst. 2023, 25, 3452–3465. [Google Scholar] [CrossRef]
- Chen, L.; Liu, Z.; Yang, K. Cross-domain Few-shot In-context Learning for Enhancing Traffic Sign Recognition. arXiv 2024, arXiv:2407.05814. [Google Scholar]
- Nye, M.; Andreassen, A.J.; Gur-Ari, G.; Michalewski, H.; Austin, J.; Bieber, D.; Dohan, D.; Lewkowycz, A.; Bosma, M.; Luan, D.; et al. Show Your Work: Scratchpads for Intermediate Computation with Language Models. NeurIPS 2021, 2021, 10089–10100. [Google Scholar]
- Wang, T. Research on Multilingual Natural Scene Text Detection Algorithm. arXiv 2023, arXiv:2312.11153. [Google Scholar] [CrossRef]
- Zhang, X.; Karatzas, D.; Lu, S.; Zhu, X. Augmenting Scene Text Detection with Synthetic Data Using GANs. Proc. Int. Conf. Doc. Anal. Recognit. 2019, 2019, 1200–1210. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. Proc. IEEE Conf. Comput. Vis. Pattern Recognit. 2017, 2017, 2117–2125. [Google Scholar] [CrossRef]
- Kirillov, A.; He, K.; Girshick, R.; Rother, C.; Dollár, P. Panoptic Feature Pyramid Networks. Proc. IEEE Conf. Comput. Vis. Pattern Recognit. 2019, 2019, 6399–6408. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. Proc. IEEE Conf. Comput. Vis. Pattern Recognit. 2015, 2015, 3431–3440. [Google Scholar] [CrossRef]
- Wei, J.; Wang, X.; Schuurmans, D.; Le, Q.V.; Chi, E.H.; Zhou, D. Chain of Thought Prompting Elicits Reasoning in Large Language Models. arXiv 2022, arXiv:2201.11903. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. NeurIPS 2020, 2020, 1877–1901. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Source Image | Contextual Data | Extracted Data from Image Model |
|---|---|---|
 | Mokpo 60 km/h 15 sunny | ‘mokpo’, [94, 45, 111, 88] ‘27 km’, [274, 56, 292, 99] ‘illlo IC’, [89, 159, 103, 219] ‘14 km’, [273, 164, 293, 212] symbol 15, [29, 184, 89, 242] |
 | Paldang 50 km/h none cloudy | ‘Sudong’, [99, 160, 158, 201] ‘Maseok’, [101, 212, 154, 246] ‘Paldang’, [283, 163, 330, 202] ‘Deokso’, [286, 211, 335, 245] ‘창현교차로 (Changhyeon intersection)’, [227, 84, 342, 114] |
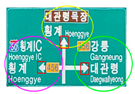 | Gangneung 50 km/h 456 cloudy | ‘Hoenggye IC’, [39, 135, 142, 195] ‘Hoenggye’, [184, 78, 346, 121] ‘Gangneung’, [377, 132, 482, 193] ‘Daegwallyeong’, [378, 214, 508, 271] symbol 456, [318, 131, 368, 163] |
| Source Image | Image Captioning Output | Relevant |
|---|---|---|
 | A close up of a street sign with a sky background | Not |
| A close up of a street sign with a street sign | Not | |
| A street sign on a pole on a street | Not | |
| Information boards with green and green signs | Not | |
| The image shows a green road sign, indicating the distances to the destinations | Moderate | |
 | A close up of street sign that reads Korean | Moderate |
| A close up of street sign with traffic light | Not | |
| A street sign that is on a pole | Not | |
| A sign in English and Korean with a green sign above it | Moderate | |
| The image shows a road sign with directions in Korean and English | Moderate | |
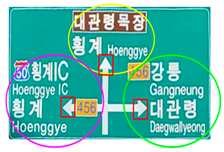 | A close up of a street sign with a sky background | Not |
| A close up of a street sign with a sign on it | Not | |
| A street sign on a street | Not | |
| Signs in Korean and signs indicating there | Not | |
| A road sign displaying directions and names of various locations | Moderate |
| System Data | Image Captioning Ouput | Relevant |
|---|---|---|
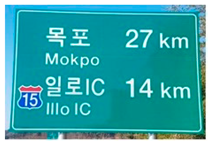 | 27 km remaining to reach your destination | Highly |
| Arrive in Mokpo in approximately 27 min | Highly | |
| There is an IlIlo IC, which is approximately 14 km away; this could be your next exit | Moderate | |
| 27 km left to Mokpo indicate that you are nearing | Highly | |
| The road number “15” is consistent throughout your route | Moderate | |
 | As you drive at 50 km/h, you may need to reduce speed when approaching Changhyeon Intersection | Highly |
| Paldong and Deokso as your next destinations on the right | Highly | |
| As Changhyeon Intersection is your current location, check for traffic or any signals | Highly | |
| Deokso is your right, indicating that it is in the same direction as Paldong | Highly | |
| Based on the signs, it appears that Paldong is located to your right | Highly | |
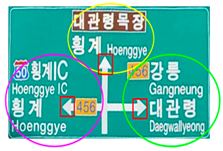 | You are heading toward Gangneung, which is indicated to be on your right | Highly |
| You are currently driving at 50 km/h on road number 456 | Moderate | |
| “Daegwallyeong” is also on your right, | Moderate | |
| Hoenggye IC to your left indicates an alternate route, so if traffic conditions worsen, that may be an option | Highly | |
| be prepared to adjust speed as you approach intersections | Moderate |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, B.; Seo, Y. Personalized Contextual Information Delivery Using Road Sign Recognition. Appl. Sci. 2025, 15, 6051. https://doi.org/10.3390/app15116051
Kim B, Seo Y. Personalized Contextual Information Delivery Using Road Sign Recognition. Applied Sciences. 2025; 15(11):6051. https://doi.org/10.3390/app15116051
Chicago/Turabian StyleKim, Byungjoon, and Yongduek Seo. 2025. "Personalized Contextual Information Delivery Using Road Sign Recognition" Applied Sciences 15, no. 11: 6051. https://doi.org/10.3390/app15116051
APA StyleKim, B., & Seo, Y. (2025). Personalized Contextual Information Delivery Using Road Sign Recognition. Applied Sciences, 15(11), 6051. https://doi.org/10.3390/app15116051