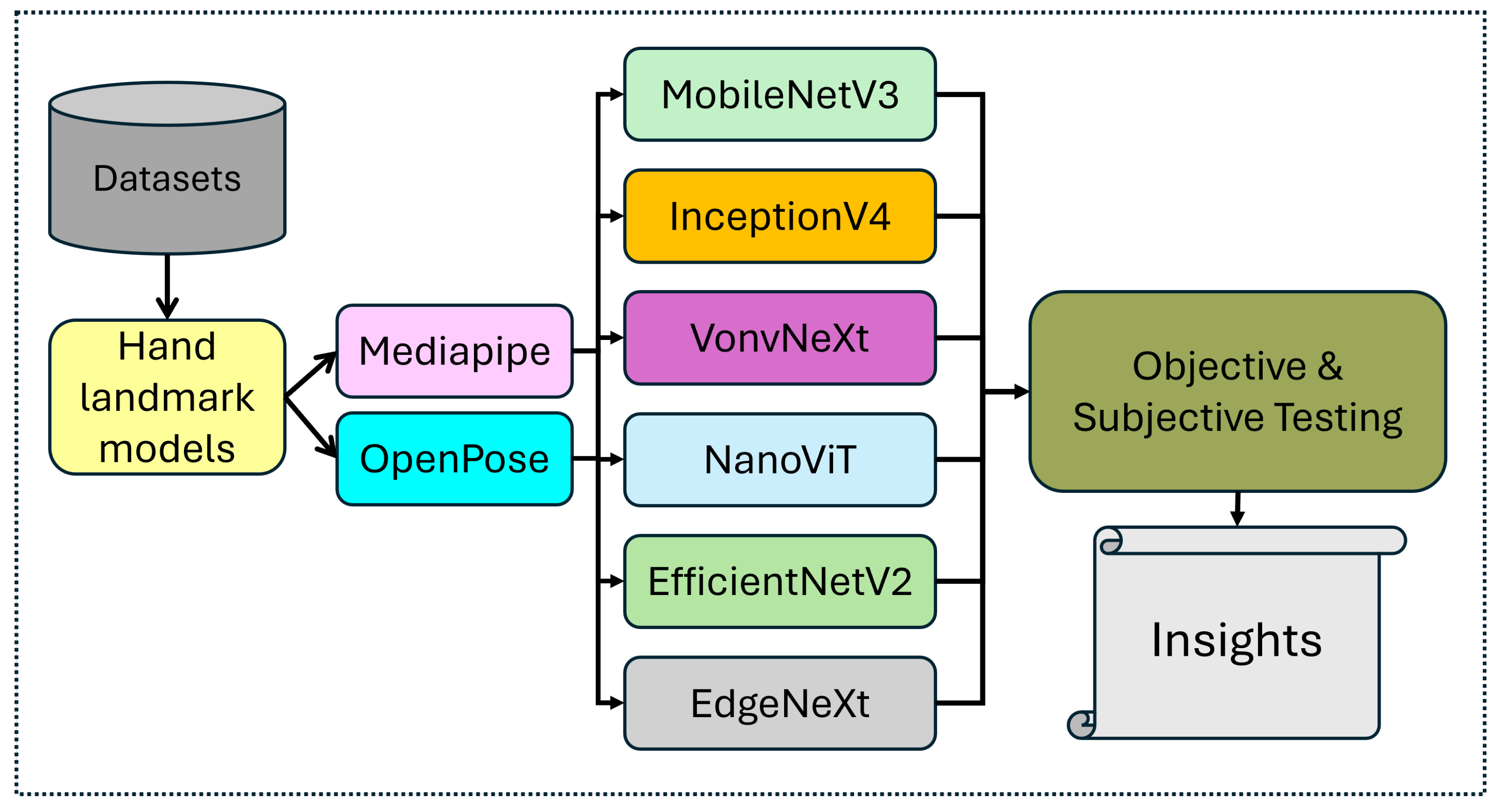
1. Introduction
The demand for both quantity and quality of services continues to increase in the field of hand gesture recognition (HGR) [
1]. Face-to-Face communication relies heavily on hand gestures [
2]. In human–computer interaction systems, hand gesture applications offer a touchless interface [
3]. HGR plays an important role in various applications [
2], including human–computer interaction (HCI), virtual reality (VR), sign-language interpretation, drone control, and smart home control applications, as shown in
Figure 1, highlighting its significant importance in modern technology [
4,
5]. Although hand gesture recognition is an active field of computer vision, there are many challenges that exist currently. One of those challenges is the availability of a suitable dataset that can generalize a model during training to perform well in real-world scenarios [
6].
Hand gesture classification for practical application scenarios is a challenging task and requires careful design of the dataset and selection of a pre-trained model [
7]. Therefore, it is crucial to take into account both the selection of lightweight models for the training and the availability of datasets [
8]. By exploiting pre-trained data in the form of transfer learning, the need for a large dataset can be omitted [
1]. The important contributions of a quality dataset and a well-trained model are occasionally disregarded, even though researchers frequently concentrate on improving model performance [
9]. Due to performance complexity, this omission may result in high hardware needs and impracticability for real-time applications [
10]. Our goal is to investigate and select an ideal model and dataset for HGR.
Access to a large dataset is critical for the success of any machine learning (ML) method, especially when handling complex problems like hand gesture recognition [
11]. In this regard, datasets designed expressly for hand gesture recognition play an important role in furthering research and development in this particular field [
12]. These datasets hold both static and dynamic gestures and are very diverse in nature to help generalize models during training [
13]. Through careful experiments and testing, researchers can gain insights into the requirements for acquiring data useful for real-world applications like vision-based HCI, drone control, and sign-language interpretation [
14,
15], as having diverse hand gesture datasets is essential.
Similarly, choosing the best pre-trained deep learning model for hand gesture recognition requires a careful selection procedure [
12]. A lot of time is wasted on the experimental evaluation study by the researches in this phase [
16]. It also depends on the type of dataset that is going to be used in the transfer learning process [
17]. In this study, we focused on identifying the best lightweight model that performs well on the targeted datasets for real-time hand gesture recognition while also exploring which dataset aligns best with each model in terms of performance. Therefore, we analyzed six state-of-the-art lightweight models, such as InceptionV4 [
18], NanoViT [
19], EfficientNet [
20], EdgeNeXt [
21], ConvNeXt [
22], and MobileNetV3 [
23], on four widespread benchmark datasets, each having rich contents and characteristics of hand gestures. This study aims to determine not only the most suitable model but also the dataset–model combinations that maximize performance for real-world scenarios.
Through our study, we analyze the overall nature of the datasets [
24,
25] and transfer learning models. The factors effecting the quality and nature of the dataset, including the size of the dataset [
26], the diversity of the subjects (also trained to perform gestures) [
27], different lighting conditions [
28], the quality of the data acquisition sensor and calibration, the resolution of the image, and the overall design and collection of gestures [
29], are very important. Such factors contribute to the model adaptability for use in real-world scenarios [
30,
31].
In summary, this study not only fills the gap by evaluating several lightweight transfer learning models and datasets but also offers valuable insights for researchers and developers who aim to build a real-time hand gesture recognition module. By including subjective test results under different environmental conditions, this study further offers guidelines for creating an effective dataset for applications, like drone control, sign-language interpretation, computer vision-based HCI, and more. We summarize our contributions as follows:
This study presents an evaluation of five state-of-the-art lightweight deep learning models (including transformer-based) for hand gesture recognition.
This study presents subjective and objective performance evaluations to assess the datasets’ quality and their impact on the models’ performances.
In this study, we also exploit the Mediapipe hand landmark [
32] (MHL) and OpenPose [
33] models for the extraction of keypoints and assess the dataset quality by its success and failure rate in detecting landmarks under diverse lighting conditions and image quality.
This study also highlights the trade-offs between the models’ complexities and accuracies in real-time application scenarios related to hand gesture recognition, offering practical guidelines for lightweight model selection in HGR systems.
The rest of this paper is organized as follows.
Section 3 describes the methodology, while the detailed results are reported in
Section 4, which are discussed comprehensively in
Section 5. Finally, we conclude our work in
Section 6 with possible future research directions.
2. Related Work
Hand gesture recognition has been extensively used for real-world application scenarios, like drone control, sign-language interpretation, computer vision-based HCI, and more [
7,
13]. Several studies have reported the insights gained related to datasets, models, and performance improvement. Due to the computational complexity of convolutional neural networks (CNNs), the focus has shifted to lightweight models to achieve performance accuracy [
10]. Similarly, with the popularity of these data-hungry models, the focus is always on the creation of a large dataset targeting quantity alone while ignoring the quality. Several factors contribute to the quality of a dataset, i.e., biases, lighting conditions, the type of sensor used, the distances and locations of objects in the frames, the number of subjects involved, etc. So, while studies have shown deep interest in improving the accuracy of the models, fewer efforts have been made to analyze the nature and diversity of datasets, which affects the overall performance of a model in training.
Yu et al. [
34] evaluated several HGR techniques for drone control. They focused on the model’s accuracy in real time. While they reported performance comparison results of several models, their study lacked an evaluation of benchmark datasets. Diliberti et al. [
35] investigated CNN-based models for real-world scenarios. Despite their high accuracy, due to their high computational complexities, these models were unable to be used in real-time scenarios for embedded systems. Unlike lightweight models, CNNs are the least suitable for diverse scenarios and real-world applications. Another notable work reported by Sethuraman et al. [
36] investigated a lightweight model for HGR. While the approach mostly focused on model size reduction, the study lacked an exploration of a benchmark dataset for improving the applicability in a real-world allocation scenario. Last but not the least, Jiang and Shu et al. [
37] investigated HGR methods, including sensor-based and vision-based approaches. Although they briefly provided the trade-off between accuracy, lightweight models, and applicability in real-world scenarios, the study lacked a comparison of transfer learning models against benchmark datasets for real-time applications, like drone control and vision-based HCI systems.
Hence, most studies have often overlooked the crucial aspect of dataset analysis and the use of a suitable transfer learning model. A recent advancement in hand gesture recognition has been significant due to the availability of diverse datasets and ML techniques, but challenges still exist in robust and precise gesture classification, especially in real-time interaction-based systems (i.e., drone control, sign-language processing, etc.). Several studies have utilized various datasets to study and assess hand gesture recognition, for example, the Egogesture [
38], NVGesture [
39], Jester [
40], and SignLanguage [
41] datasets have been extensively used in the literature, each reporting reasonable accuracy by their respective authors.
To address the gap discussed above, we discuss our detailed pipeline in the following sections.
5. Discussion
In this study, a comprehensive evaluation was performed on the models and benchmark datasets through comprehensive objective and subjective testing. The performance evaluation results generated insightful thoughts that can be worth discussing in the following sections.
5.1. Models’ Performance Analysis
We evaluated six lightweight models in this study. InceptionV4 [
18], NanoViT [
19], EfficientNet [
20], EdgeNeXt [
21], ConvNeXt [
22], and MobileNetV3 [
23] showed diverse yet significant insights on the selected benchmark datasets. Due to the nature of the dataset and model’s architecture, some achieved high accuracy and others struggled in generalizing the training data.
For all the datasets, InceptionV4 [
18] and EfficientNet [
20] performed the best, followed by MobileNetV3 [
23], showing their ability to manage variations in the data while maintaining excellent accuracy. Even with noise and irregular motions, strong feature extraction was made possible using InceptionV4’s Inception modules, which can analyze spatial and temporal information with remarkable accuracy. Similarly, because of the compound scaling technique in EfficientNet [
20], it can maintain the input data’s dimensions and keep the network size compact, while it is yet to reach maximum performance accuracy with minimal computing. This has made it possible to perform well across all the datasets when generalizing the model. Hence, both models were able to perform reasonably when exposed to subjective testing under different test scenarios as listed in
Table 2,
Table 7, and
Table 9.
On the other hand, ConvNeXt [
22] and EdgeNeXt [
21] performed less than ideal on a number of datasets. Although effective, ConvNeXt’s [
22] solely convolutional architecture lacks the depth necessary to perform well in generalization on datasets with substantial intra-class variability and irregular gesture execution. Its inability to grasp fine-grained spatial connections that are essential for hand gesture identification was caused by its dependence on conventional convolutional hierarchies. However, because of its lower model complexity, EdgeNeXt’s [
21] lightweight transformer-based architecture has trouble extracting spatial and temporal characteristics from gesture sequences, even though it was designed for resource-constrained contexts. Their overall effectiveness and suitability for difficult datasets were hampered by these constraints.
The lightweight vision transformer NanoViT [
19] performed in the middle tier, outperforming ConvNeXt [
22] and EdgeNeXt [
21] but not InceptionV4 [
45] or EfficientNet [
20]. Because NanoViT’s self-attention mechanisms enabled it to grasp the global context well, it was able to withstand a certain amount of dataset fluctuation. However, it was unable to fully use complicated patterns due to its relatively shallow design and smaller parameter count, especially in datasets that required in-depth spatial and temporal knowledge. Although NanoViT [
19] provided a balance between accuracy and computing efficiency, its trade-offs made it less useful for datasets with a lot of different gestures.
5.2. Datasets’ Performances Evaluation
The results presented in
Section 4.1 and
Section 4.2 are quite revealing in several ways. Despite having fewer samples per class compared to the Jester and EgoGesture datasets, the sign-language dataset was still the most effective. This can be attributed to several factors: The images in the dataset have a reasonable resolution, which enhances the clarity and quality of the data for use with the MHL model. The gesture duration in this dataset is consistent, ensuring uniform video sample lengths. Unlike other datasets, which exhibit standard deviations of 0.49, 2.38, and 2.48 s per clip, this dataset maintains a minimal standard deviation of 0.21 s per clip, avoiding overly short or lengthy clips. These details are presented in
Table 1.
Similarly, in this dataset, hand gestures are captured with sharp-edge definition and minimal motion distortion (no blurriness) ensuring a successful detection rate for hand landmarks using the MHL model. This is due to the well-trained subjects who performed the gestures at an optimal speed, neither too fast nor too slow. This judgment was made by carefully analyzing the dataset’s image quality and the contents of the image frames. For a cross-dataset comparison, the blurriness index was estimated by analyzing the motion blur levels across frames in each dataset (see
Table A1 and
Figure A1 in the
Appendix A and
Appendix B). We considered edge sharpness and pixel variance as key indicators, assigning values based on the relative frequency of blurred images. As observed, Jester exhibited the highest blurriness, followed by NVGesture, EgoGesture, and sign-language. This indicates that gestures in certain datasets were performed with less precision, likely due to the lack of proper training among subjects, leading to inconsistencies in movement and reduced model performance. Also, the detection rate of hand landmarks was notably high for the sign-language dataset with the MHL model, contributing to its effectiveness.
On the other hand, the Jester dataset, despite having a large number of samples per class, based on the information presented in
Table 1, had the following limitations revealed, which make this dataset the least effective:
The resolution of frames in the Jester dataset is very low, i.e.,
, which is not suitable for the MHL model, resulting in a low detection rate of hand landmarks as shown in
Figure 4 and
Figure 5. The standard deviation
of the gesture clips (duration in seconds) reveals that there is a huge difference in the length of the gesture clips in the Jester dataset, as shown in
Table 1, resulting in too many random short and long clips and thus eventually leading to redundant data. Similarly, most of the frames in this dataset are not clear, because of the low resolution, as shown in
Figure 3. The observed variability and inconsistency in the Jester dataset suggest that such measures were not implemented, potentially affecting the dataset’s reliability. Previous studies have highlighted the role of trained subjects in maintaining dataset consistency and quality during gesture recognition tasks [
48]. Biases introduced in a dataset play a crucial role in its effectiveness [
9]. All three datasets besides sign-language exhibit a bias, as most gestures are performed with the right hand. When exposed to cross-hand testing, model performance declined. The cross-hand testing was employed to highlight a bias in the datasets (NVGesture, Jester, and EgoGesture), as the gestures in these datasets were mostly recorded predominantly using one hand, leading to errors when subjects used their less-practiced hand, affecting recognition accuracy. This lowered the performance as can be seen in the Results
Section 4.2, under
Table 4,
Table 5,
Table 6 and
Table 7. These results show the performance drops of the individual datasets under different test scenarios. It can be seen clearly from the graph showing the evaluation metrics for cross-hand testing, where the three datasets have lower performance (besides the sign-language dataset). The lighting conditions have affected all the datasets’ performance as shown in the aforementioned tables.
EgoGesture and NVGesture were medium performers and they have limitations and advantages but can be improved for use in real-world scenarios if data augmentation is applied to them (removing biases and applying transformations can improve the performance) [
46,
47]. In reflecting upon the results (
Section 4), it becomes evident that the challenges confronted across the datasets extend beyond the crassness of hand gestures alone. Factors such as the lighting conditions, image resolution, variable length sequences with maximum deviation, and inherent biases present in the datasets play pivotal roles in shaping the model’s adaptability and robustness in real-world application scenarios. The sign-language dataset showed some resilience while staying the most effective to different test scenarios.
In summary, the comparative evaluation of the six models across the selected hand gesture recognition benchmarks reveals a consistent performance hierarchy: InceptionV4 > EfficientNet > MobileNetV3 > NanoViT > ConvNeXt > EdgeNeXt. Similarly, among the benchmarks, SignLanguage performed best overall, followed by EgoGesture, NVGesture, and Jesture, indicating that dataset quality shaped by balanced class distribution, subject diversity, effective augmentation, minimized bias, consistent sequence lengths, and varied conditions plays a critical role in model generalization. These findings underscore the importance of both architectural efficiency and data quality when designing gesture recognition systems, especially for real-time or resource-constrained environments.
5.3. Limitations
Despite the fact that this study can be very helpful in situations where dataset creation and careful model selections are needed, it has a number of limitations that should be noted. The generalization of the results may be limited by the fact that, although we tested our models on four benchmark datasets, these datasets might not accurately reflect the variety of real-world situations, such as variances in lighting, backdrops, and cultural gestures. Furthermore, the datasets did not include professional people making motions, which resulted in inconsistent data that would have impacted the models’ functionality. It is possible that our dependence on the MHL and OpenPose model as the main feature extractor skewed the findings in favor of models that fit this particular representation well, possibly ignoring alternative feature extraction techniques.
Additionally, the main emphasis of this investigation was solely focused on temporal-level data processing, without consideration of any segmentation techniques, which might not adequately represent or consider the factors contributing due to the continuous data frames coming in feed to the system. Meanwhile, we did not thoroughly examine other important aspects like latency, energy consumption, and resistance to adversarial inputs, all of which are essential for real-time deployment in safety-critical applications, like drone control and other HCI systems. We also solely focused on performance evaluation matrices, including subjective as well as objective testing. The thoroughness of our findings may be limited since, although our exploration included six lightweight models, alternative designs like enhanced fine-tuned MobileNet [
23] or ShuffleNet [
49] were not taken into account. Lastly, even though this study focused on hand gesture detection for vision-based control systems, it is unclear if it will apply to other fields, like virtual reality or healthcare. These drawbacks point to areas that need more investigation to improve the scalability and resilience of gesture recognition systems.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}