
Recent Advances in Efficient Dynamic Graph Processing




Abstract
1. Introduction
- Applications. Specifically, dynamic graph processing has many real applications including:
- -
- Social network analysis. In a social network, users are connected by social relationships, such as friendships, professional collaborations, or online interactions. We can identify influential users through betweenness/closeness centrality [17,18], which is crucial for targeted advertising and information diffusion. Besides, in platforms such as Facebook, Twitter, and Instagram, there are applications for community detection, aiming to find cohesive and tightly connected user groups [19,20,21]. The shortest path can also be used to measure the close relationship between users [22,23]. Moreover, dynamic graph partitioning is an effective technique in social networks for balancing server workloads [24].
- -
- Biology science. A biological network is a graph-based representation of interactions between biological entities, such as genes, proteins, cells, or organisms. In biological network analysis, centrality can pinpoint essential proteins/genes in Protein–Protein Interaction (PPI) networks [17,25,26,27]. Moreover, cohesive subgraphs also play an important role in biological networks such as k-core/truss/clique. For example, they can be used to identify groups of genes with similar expression patterns, which may indicate shared functions between genes [28].
- -
- Transportation network. A transportation network is a system of interconnected routes (roads, railways, airways, etc.) and nodes (intersections, stations, airports) that enable the movement of people and goods. In transportation networks, centrality can be used to identify critical transport hubs for infrastructure planning [26]. Besides, dynamic shortest path algorithms enable real-time navigation updates [29].
- -
- Financial data analysis. A financial graph is a network representation of financial relationships, transactions, and dependencies between entities such as banks, companies, individuals, and assets. Dynamic centrality can identify suspicious transaction patterns [30]. Evolving community detection can reveal money laundering networks [31,32]. Moreover, time-dependent financial graphs have risk. For risk assessment, dynamic cohesive subgraph or community can detect tightly coupled risky assets.For market analysis, dynamic graph clustering can be used to track evolving stock correlations [33].
- Challenges. Specifically, the challenges of dynamic graph processing can be listed as follows:
- -
- High frequency of updates. For instance, in online social networks, the graphs are typically large and continually evolving. As of 2023, Facebook has approximately 2.9 billion monthly active users. On average, there are over 50 million posts, comments, and likes per minute. This translates to about 72 billion interactions per day [34]. Twitter has around 461 million monthly active users as of 2023, about 6,000 tweets are posted every second, which amounts to approximately 500 million tweets per day [35].
- -
- High requirement of efficiency. Many applications that rely on dynamic graph processing require real-time or near-real-time response. For instance, fraud detection in financial services or targeted advertising in social media platforms demand immediate analysis of new connections or patterns within the graphs [36].
- -
- High time complexity of update computation. Graphs are inherently complex structures, and performing graph analysis such as path traversal, community detection, or centrality measures can be computationally intensive. For instance, searching many community models, such as clique and biclique, is proven to be an NP-hard problem [16]. As the graph changes, these operations need to be updated efficiently without recalculating from scratch, especially in large-scale scenarios.
- -
- Centrality. Measure the importance of vertices in graphs. Typical definitions of centrality include betweenness centrality, closeness centrality, and eccentricity. They can be utilized in several application domains such as social media, advertising push, and online search engines.
- -
- Graph Coloring. Assign a color to each vertex such that no two adjacent vertices share the same color. Graph coloring has many practical applications including register allocation, making schedule, and map coloring, and can also be an optimized technique for other graph problems such as clique enumeration and graph partitioning.
- -
- Cohesive Subgraph. Discover dense groups of vertices in graphs. Typical cohesive subgraph models include clique, biclique, k-core, k-truss, their diverse variants, and community models. They are widely applied in community detection, recommendation systems, and anomaly detection.
- -
- Path Traversal. Path traversal is a foundational graph computation problem, including depth-first search, shortest distance queries, and reachability queries, and is known to have direct applications in various fields, especially in road networks, such as path planning, navigation, and traffic control.
- -
- Graph Separation. Graph separation aims to separate the graph into many partitions or clusters. One is to divide the whole graph into several partitions which is important in distributed graph computing systems. Another is to find dense clusters in graphs, for instance, SCAN is the most representative algorithm for clustering.
- General analysis. Dynamic graph algorithms have made significant progress in efficiently handling dynamic networks, leveraging incremental updates (e.g., localized re-computation in k-core maintenance or betweenness centrality) and parallel/distributed processing (e.g., parallel betweenness updates). These techniques drastically reduce re-computation overhead compared to static approaches. Many algorithms, such as those for dynamic DFS and shortest paths, achieve linear or near-optimal update times by exploiting structural properties or incremental label propagation. However, when handling highly dynamic and large-scale graphs, some algorithms (e.g., exact clique enumeration) remain impractical due to NP-hardness or excessive memory usage. Efficiency is heavily influenced by factors such as update rate and frequency (e.g., the number of updates), graph size and structure (e.g., arboricity in coloring or core-truss hierarchies). While recent work has improved scalability via parallelism and approximation, challenges remain in streaming graph support, tight theoretical bounds, and handling complex graph types.
- Contributions. In summary, our main contributions are the following:
- (a)
- First, we provide a systematic classification of existing research on dynamic graph processing. For each class of works, we review the State-of-the-Art and representative works.
- (b)
- Second, we summarize three computational complexity models, including boundedness, semi-boundedness and relative boundedness. Specifically, we theoretically analyze the efficiency of algorithms among different research topics on dynamic graphs.
- (c)
- Third, we make discussions on the potential directions of future works, which will promote the development of dynamic graph processing.
2. Preliminaries
- -
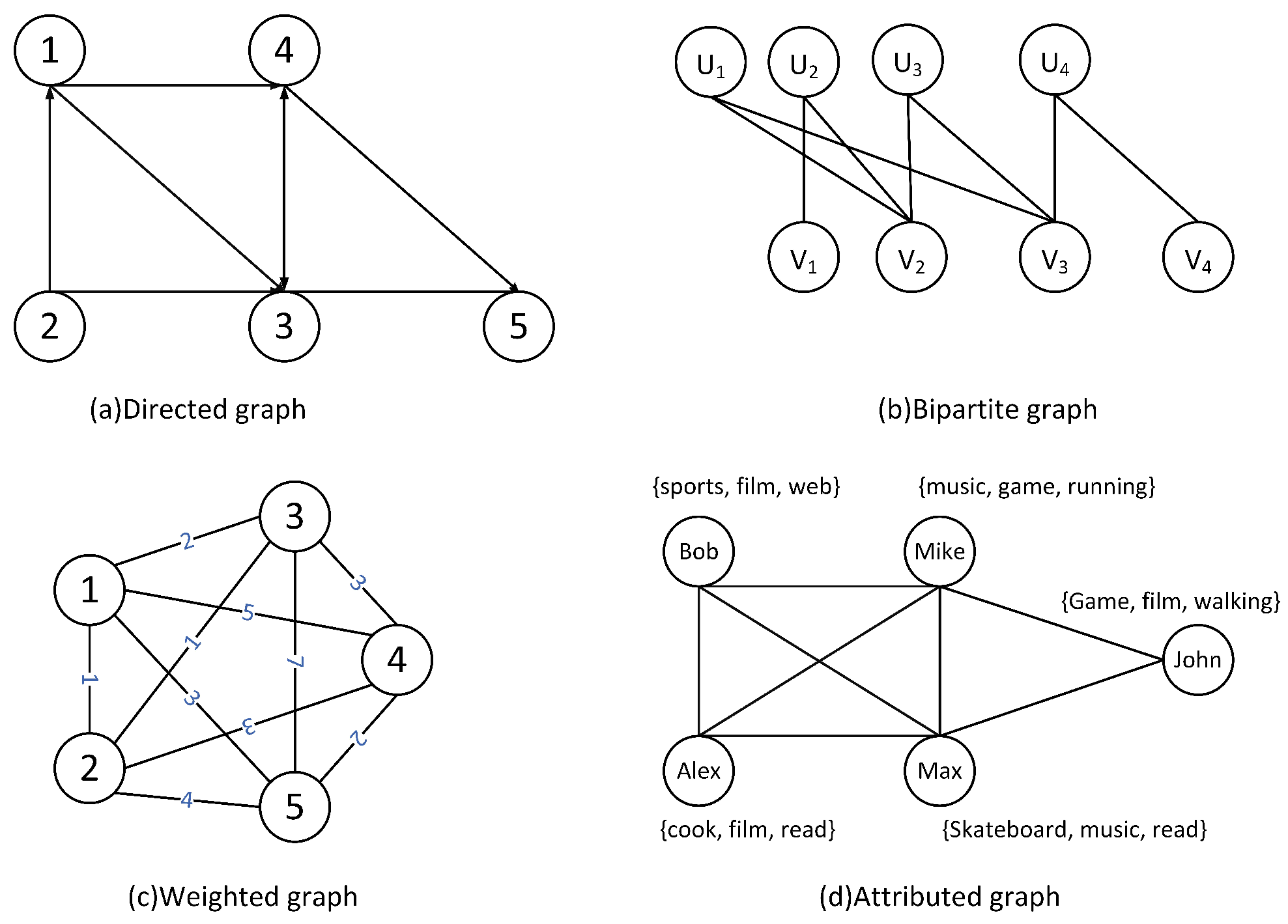
- Directed Graph. For a directed graph , each edge of G means a direct relationship between u and v, denoted as . In addition, a directed acyclic graph (DAG) is a directed graph that has no cycles. Figure 2a depicts a directed graph with five nodes.
- -
- Bipartite Graph—a bipartite graph is a graph whose vertices can be divided into two disjoint and independent sets, U and V, denoted as , such that every edge connects a vertex in U to one in V. Figure 2b depicts a bipartite graph.
- -
- Weighted Graph—a weighted graph has a number assigned to each of its edges, called its weight. The weight can be used to represent distances, influence or capacities. Figure 2c depicts a weighted graph where each edge has a weight.
- -
- Attributed Graph—an attributed graph is defined as , where is the node (edge) set and A is the set of attributes associated with nodes. For each node , it has a set of attributes . Figure 2d illustrates an attributed graph, in which each vertex represents a user in a social network, and the associated keywords capture the user’s interests.
- -
- Incremental Dynamic—a dynamic graph is incremental dynamic if only vertices or edges are inserted into G.
- -
- Decremental Dynamic—a dynamic graph is decremental dynamic if only vertices or edges are deleted into G.
- -
- Fully Dynamic—fully dynamic graphs match the scenarios such that there are not only vertices or edges additions but also vertices or edges deletions.
- -
- Streaming Dynamic—the graph evolves over time through a continuous stream of updates, where nodes and edges are added or removed incrementally.
3. Computational Complexity Model
4. Algorithms
4.1. Centrality
4.1.1. Betweenness Centrality
4.1.2. Closeness Centrality
4.1.3. Eccentricity
4.2. Graph Coloring
4.2.1. Vertex Coloring
4.2.2. Edge Coloring
4.3. Cohesive Subgraph Search
4.3.1. Clique Model
4.3.2. Biclique Model
4.3.3. Core Model
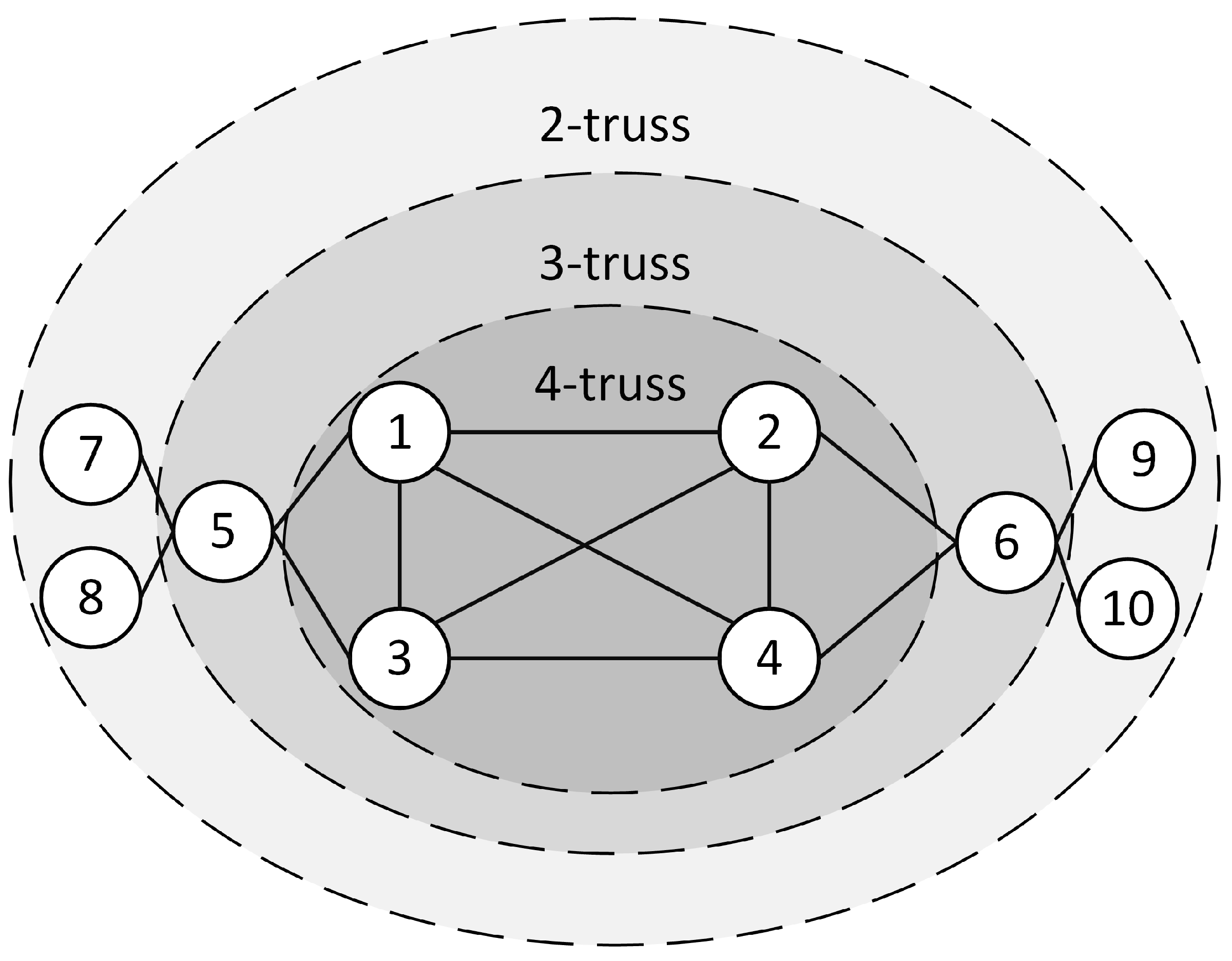
4.3.4. Truss Model
4.3.5. Community Search
4.4. Path Traversal
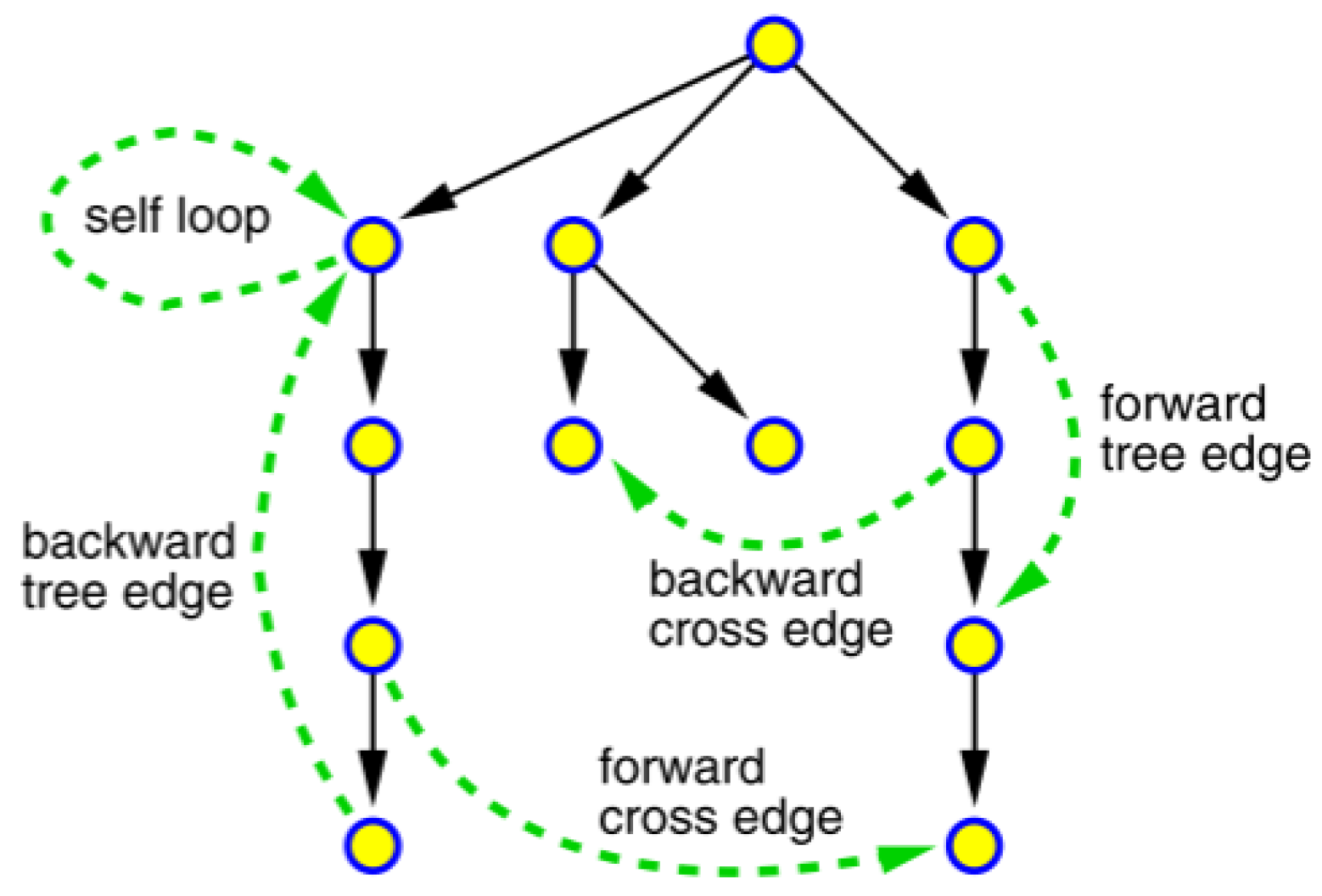
4.4.1. Depth-First Search
4.4.2. Shortest Distance Queries
4.4.3. Reachability Queries
4.5. Graph Separation
4.5.1. Graph Partitioning
4.5.2. Graph Clustering
5. Systems
6. Future Work
6.1. Optimizations for High Efficiency
6.2. Dynamic Algorithms for Various Types of Graphs
- -
- Attributed graphs—extend algorithms to account for attributed graphs, which are critical for applications such as social network analysis where metadata can provide important context.
- -
- Uncertain graphs—develop methods that can handle uncertainty in graph data, such as probabilistic edges, which are common in real-world networks like communication or transportation systems.
- -
- Signed graphs—incorporate positive and negative relationships between nodes into the analysis, which is essential for understanding dynamics in social networks, recommendation systems, and more.
- -
- Temporal graphs—analyze graphs that change over time, capturing the evolution of relationships and identifying patterns or anomalies that occur at different vertices in time.
6.3. Parallel and Distributed Approaches for Large-Scale Graphs
6.4. Efficient Approaches for Streaming Graphs
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Shen, Z.; Fei, J.; Xia, Z. SNGPLDP: Social network graph generation based on personalised local differential privacy. Int. J. Auton. Adapt. Commun. Syst. 2024, 17, 159–180. [Google Scholar] [CrossRef]
- Berners-Lee, T.; Fischetti, M. Weaving the Web—The Original Design and Ultimate Destiny of the World Wide Web by Its Inventor; HarperBusiness: New York, NY, USA, 2000. [Google Scholar]
- Brandão, M.A.; Moro, M.M.; Lopes, G.R.; de Oliveira, J.P.M. Using link semantics to recommend collaborations in academic social networks. In Proceedings of the WWW, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 833–840. [Google Scholar]
- Mukhtar, S. Protein-Protein Interactions: Methods and Protocols; Methods in Molecular Biology; Springer: New York, NY, USA, 2023. [Google Scholar]
- Buluç, A.; Meyerhenke, H.; Safro, I.; Sanders, P.; Schulz, C. Recent Advances in Graph Partitioning. In Algorithm Engineering—Selected Results and Surveys; Springer: Cham, Switzerland, 2016; Volume 9220, pp. 117–158. [Google Scholar]
- Aynaud, T.; Guillaume, J. Static community detection algorithms for evolving networks. In Proceedings of the WiOpt, Avignon, France, 31 May–4 June 2010; pp. 513–519. [Google Scholar]
- Chen, Z.; Yuan, L.; Lin, X.; Qin, L.; Yang, J. Efficient Maximal Balanced Clique Enumeration in Signed Networks. In Proceedings of the WWW, Taipei, China, 20–24 April 2020; pp. 339–349. [Google Scholar]
- Mittal, A.; Jain, P.; Mathur, S.; Bhatt, P. Graph Coloring with Minimum Colors: An Easy Approach. In Proceedings of the International Conference on Communication Systems and Network Technologies, Katra, India, 3–5 June 2011; pp. 638–641. [Google Scholar]
- Ghaffari, M.; Su, H.H. Distributed degree splitting, edge coloring, and orientations. In Proceedings of the Twenty-Eighth Annual ACM-SIAM Symposium on Discrete Algorithms, Barcelona, Spain, 16–19 January 2017; pp. 2505–2523. [Google Scholar]
- Riedy, E.J.; Meyerhenke, H.; Ediger, D.; Bader, D.A. Parallel Community Detection for Massive Graphs. In Proceedings of the PPAM, Torun, Poland, 11–14 September 2011; Volume 7203, pp. 286–296. [Google Scholar]
- de Barros, C.D.T.; Mendonça, M.R.F.; Vieira, A.B.; Ziviani, A. A Survey on Embedding Dynamic Graphs. ACM Comput. Surv. 2023, 55, 10:1–10:37. [Google Scholar] [CrossRef]
- Kazemi, S.M.; Goel, R.; Jain, K.; Kobyzev, I.; Sethi, A.; Forsyth, P.; Poupart, P. Representation Learning for Dynamic Graphs: A Survey. J. Mach. Learn. Res. 2020, 21, 70:1–70:73. [Google Scholar]
- Fournier-Viger, P.; He, G.; Cheng, C.; Li, J.; Zhou, M.; Lin, J.C.W.; Yun, U. A survey of pattern mining in dynamic graphs. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2020, 10, e1372. [Google Scholar] [CrossRef]
- Monical, C.; Stonedahl, F. Static vs. dynamic populations in genetic algorithms for coloring a dynamic graph. In Proceedings of the GECCO, Genetic and Evolutionary Computation Conference, Vancouver, BC, Canada, 12–16 July 2018; pp. 469–476. [Google Scholar]
- Li, C.; Han, J.; He, G.; Jin, X.; Sun, Y.; Yu, Y.; Wu, T. Fast computation of SimRank for static and dynamic information networks. In Proceedings of the EDBT, Lausanne, Switzerland, 22–26 March 2010; pp. 465–476. [Google Scholar]
- Das, A.; Sanei-Mehri, S.; Tirthapura, S. Shared-memory Parallel Maximal Clique Enumeration from Static and Dynamic Graphs. ACM Trans. Parallel Comput. 2020, 7, 5:1–5:28. [Google Scholar] [CrossRef]
- Lee, M.; Lee, J.; Park, J.Y.; Choi, R.H.; Chung, C. QUBE: A quick algorithm for updating betweenness centrality. In Proceedings of the WWW, Lyon, France, 16–20 April 2012; pp. 351–360. [Google Scholar]
- Green, O.; McColl, R.; Bader, D.A. A Fast Algorithm for Streaming Betweenness Centrality. In Proceedings of the SocialCom/PASSAT, Amsterdam, The Netherlands, 3–5 September 2012; pp. 11–20. [Google Scholar]
- Lin, Z.; Zhang, F.; Lin, X.; Zhang, W.; Tian, Z. Hierarchical Core Maintenance on Large Dynamic Graphs. Proc. VLDB Endow. 2021, 14, 757–770. [Google Scholar] [CrossRef]
- Yu, D.; Wang, N.; Luo, Q.; Li, F.; Yu, J.; Cheng, X.; Cai, Z. Fast Core Maintenance in Dynamic Graphs. IEEE Trans. Comput. Soc. Syst. 2022, 9, 710–723. [Google Scholar] [CrossRef]
- Zhang, Y.; Yu, J.X. Unboundedness and Efficiency of Truss Maintenance in Evolving Graphs. In Proceedings of the SIGMOD, Amsterdam, The Netherlands, 30 June–5 July 2019; pp. 1024–1041. [Google Scholar]
- Vieira, M.V.; Fonseca, B.M.; Damazio, R.; Golgher, P.B.; Reis, D.d.C.; Ribeiro-Neto, B. Efficient search ranking in social networks. In Proceedings of the Sixteenth ACM Conference on Conference on Information and Knowledge Management, Lisbon, Portugal, 6–10 November 2007; pp. 563–572. [Google Scholar]
- Wehmuth, K.; Ziviani, A. Daccer: Distributed assessment of the closeness centrality ranking in complex networks. Comput. Netw. 2013, 57, 2536–2548. [Google Scholar] [CrossRef]
- Nicoara, D.; Kamali, S.; Daudjee, K.; Chen, L. Hermes: Dynamic Partitioning for Distributed Social Network Graph Databases. In Proceedings of the EDBT, Brussels, Belgium, 23–27 March 2015; pp. 25–36. [Google Scholar]
- Lee, M.; Choi, S.; Chung, C. Efficient algorithms for updating betweenness centrality in fully dynamic graphs. Inf. Sci. 2016, 326, 278–296. [Google Scholar] [CrossRef]
- Tripathy, A.; Green, O. Scaling betweenness centrality in dynamic graphs. In Proceedings of the HPEC, Waltham, MA, USA, 25–27 September 2018; pp. 1–7. [Google Scholar]
- Narayanan, S. The Betweenness Centrality of Biological Networks. Ph.D. Thesis, Virginia Tech, Blacksburg, VA, USA, 2005. [Google Scholar]
- Liu, B.; Yuan, L.; Lin, X.; Qin, L.; Zhang, W.; Zhou, J. Efficient (α, β)-core computation in bipartite graphs. VLDB J. 2020, 29, 1075–1099. [Google Scholar] [CrossRef]
- Cela, A.; Jurik, T.; Hamouche, R.; Natowicz, R.; Reama, A.; Niculescu, S.I.; Julien, J. Energy optimal real-time navigation system. IEEE Intell. Transp. Syst. Mag. 2014, 6, 66–79. [Google Scholar]
- Vilella, S.; Capozzi, A.; Fornasiero, M.; Moncalvo, D.; Ricci, V.; Ronchiadin, S.; Ruffo, G. Weirdnodes: Centrality based anomaly detection on temporal networks for the anti-financial crime domain. Appl. Netw. Sci. 2025, 10, 14. [Google Scholar] [CrossRef]
- Li, X.; Cao, X.; Qiu, X.; Zhao, J.; Zheng, J. Intelligent anti-money laundering solution based upon novel community detection in massive transaction networks on spark. In Proceedings of the CBD, Shanghai, China, 13–16 August 2017; pp. 176–181. [Google Scholar]
- Dreżewski, R.; Sepielak, J.; Filipkowski, W. The application of social network analysis algorithms in a system supporting money laundering detection. Inf. Sci. 2015, 295, 18–32. [Google Scholar] [CrossRef]
- Ansari, Y. Multi-Cluster Graph (MCG): A Novel Clustering-Based Multi-Relation Graph Neural Networks for Stock Price Forecasting. IEEE Access 2024, 12, 154482–154502. [Google Scholar] [CrossRef]
- Facebook. Facebook Newsroom. 2023. Available online: https://about.fb.com/news/ (accessed on 20 February 2025).
- Twitter. Twitter Blog. 2023. Available online: https://blog.twitter.com/ (accessed on 20 February 2025).
- Lyu, B.; Qin, L.; Lin, X.; Zhang, Y.; Qian, Z.; Zhou, J. Maximum and top-k diversified biclique search at scale. VLDB J. 2022, 31, 1365–1389. [Google Scholar] [CrossRef]
- Shukla, K.; Regunta, S.C.; Tondomker, S.H.; Kothapalli, K. Efficient parallel algorithms for betweenness-and closeness-centrality in dynamic graphs. In Proceedings of the ICS, Barcelona, Spain, 29 June–2 July 2020; pp. 1–12. [Google Scholar]
- Hayashi, T.; Akiba, T.; Yoshida, Y. Fully Dynamic Betweenness Centrality Maintenance on Massive Networks. Proc. VLDB Endow. 2015, 9, 48–59. [Google Scholar] [CrossRef]
- Jamour, F.T.; Skiadopoulos, S.; Kalnis, P. Parallel Algorithm for Incremental Betweenness Centrality on Large Graphs. IEEE Trans. Parallel Distrib. Syst. 2018, 29, 659–672. [Google Scholar] [CrossRef]
- Kas, M.; Wachs, M.; Carley, K.M.; Carley, L.R. Incremental algorithm for updating betweenness centrality in dynamically growing networks. In Proceedings of the ASONAM, Niagara Falls, ON, Canada, 25–28 August 2013; pp. 33–40. [Google Scholar]
- Bergamini, E.; Meyerhenke, H.; Staudt, C. Approximating Betweenness Centrality in Large Evolving Networks. In Proceedings of the ALENEX, San Diego, CA, USA, 5 January 2015; pp. 133–146. [Google Scholar]
- Simard, F.; Magnien, C.; Latapy, M. Computing Betweenness Centrality in Link Streams. J. Graph Algorithms Appl. 2023, 27, 195–217. [Google Scholar] [CrossRef]
- Goel, K.; Singh, R.R.; Iyengar, S.; Gupta, S. A Faster Algorithm to Update Betweenness Centrality after Node Alteration. In Proceedings of the WAW, Cambridge, MA, USA, 14–15 December 2013; Volume 8305, pp. 170–184. [Google Scholar]
- Kas, M.; Carley, K.M.; Carley, L.R. Incremental closeness centrality for dynamically changing social networks. In Proceedings of the ASONAM, Niagara Falls, ON, Canada, 25–28 August 2013; pp. 1250–1258. [Google Scholar]
- Sariyüce, A.E.; Saule, E.; Kaya, K.; Çatalyürek, Ü.V. STREAMER: A distributed framework for incremental closeness centrality computation. In Proceedings of the CLUSTER, Indianapolis, IN, USA, 23–27 September 2013; pp. 1–8. [Google Scholar]
- Yen, C.; Yeh, M.; Chen, M. An Efficient Approach to Updating Closeness Centrality and Average Path Length in Dynamic Networks. In Proceedings of the ICDM, Dallas, TX, USA, 7–10 December 2013; pp. 867–876. [Google Scholar]
- Shao, Z.; Guo, N.; Gu, Y.; Wang, Z.; Li, F.; Yu, G. Efficient closeness centrality computation for dynamic graphs. In Proceedings of the DASFAA, Jeju, Republic of Korea, 24–27 September 2020; pp. 534–550. [Google Scholar]
- Li, W.; Qiao, M.; Qin, L.; Zhang, Y.; Chang, L.; Lin, X. Eccentricities on small-world networks. VLDB J. 2019, 28, 765–792. [Google Scholar] [CrossRef]
- Solomon, S.; Wein, N. Improved dynamic graph coloring. ACM Trans. Algorithms (TALG) 2020, 16, 41. [Google Scholar] [CrossRef]
- Sallinen, S.; Iwabuchi, K.; Poudel, S.; Gokhale, M.B.; Ripeanu, M.; Pearce, R.A. Graph colouring as a challenge problem for dynamic graph processing on distributed systems. In Proceedings of the SC, Salt Lake City, UT, USA, 13–18 November 2016; pp. 347–358. [Google Scholar]
- Preuveneers, D.; Berbers, Y. ACODYGRA: An agent algorithm for coloring dynamic graphs. Symb. Numer. Algorithms Sci. Comput. 2004, 6, 381–390. [Google Scholar]
- Barba, L.; Cardinal, J.; Korman, M.; Langerman, S.; van Renssen, A.; Roeloffzen, M.; Verdonschot, S. Dynamic Graph Coloring. Algorithmica 2019, 81, 1319–1341. [Google Scholar] [CrossRef]
- Yuan, L.; Qin, L.; Lin, X.; Chang, L.; Zhang, W. Effective and Efficient Dynamic Graph Coloring. Proc. VLDB Endow. 2017, 11, 338–351. [Google Scholar] [CrossRef]
- Bhattacharya, S.; Chakrabarty, D.; Henzinger, M.; Nanongkai, D. Dynamic algorithms for graph coloring. In Proceedings of the Twenty-Ninth Annual ACM-SIAM Symposium on Discrete Algorithms, New Orleans, LA, USA, 7–10 January 2018; pp. 1–20. [Google Scholar]
- Barenboim, L.; Maimon, T. Fully-dynamic graph algorithms with sublinear time inspired by distributed computing. Procedia Comput. Sci. 2017, 108, 89–98. [Google Scholar] [CrossRef]
- Huang, Z.; Yuan, L.; Sui, H.; Chen, Z.; Yang, S.; Yang, J. Edge Coloring on Dynamic Graphs. In Proceedings of the DASFAA, Tianjin, China, 17–20 April 2023; pp. 137–153. [Google Scholar]
- Duan, R.; He, H.; Zhang, T. Dynamic edge coloring with improved approximation. In Proceedings of the Thirtieth Annual ACM-SIAM Symposium on Discrete Algorithms, San Diego, CA, USA, 6–9 January 2019; pp. 1937–1945. [Google Scholar]
- Christiansen, A.B.G. The power of multi-step vizing chains. In Proceedings of the 55th Annual ACM Symposium on Theory of Computing, Orlando, FL, USA, 20–23 June 2023; pp. 1013–1026. [Google Scholar]
- Bhattacharya, S.; Costa, M.; Panski, N.; Solomon, S. Nibbling at long cycles: Dynamic (and static) edge coloring in optimal time. In Proceedings of the 2024 Annual ACM-SIAM Symposium on Discrete Algorithms (SODA), Alexandria, VA, USA, 7–10 January 2024; pp. 3393–3440. [Google Scholar]
- Bhattacharya, S.; Costa, M.; Panski, N.; Solomon, S. Arboricity-dependent algorithms for edge coloring. arXiv 2023, arXiv:2311.08367. [Google Scholar]
- Christiansen, A.B. Deterministic Dynamic Edge-Colouring. arXiv 2024, arXiv:2402.13139. [Google Scholar]
- Stix, V. Finding all maximal cliques in dynamic graphs. Comput. Optim. Appl. 2004, 27, 173–186. [Google Scholar] [CrossRef]
- Das, A.; Svendsen, M.; Tirthapura, S. Incremental maintenance of maximal cliques in a dynamic graph. VLDB J. 2019, 28, 351–375. [Google Scholar] [CrossRef]
- Yu, T.; Jiang, T.; Bah, M.J.; Zhao, C.; Huang, H.; Liu, M.; Zhou, S.; Li, Z.; Zhang, J. Incremental Maximal Clique Enumeration for Hybrid Edge Changes in Large Dynamic Graphs. IEEE Trans. Knowl. Data Eng. 2024, 36, 1650–1666. [Google Scholar] [CrossRef]
- Sun, S.; Wang, Y.; Liao, W.; Wang, W. Mining Maximal Cliques on Dynamic Graphs Efficiently by Local Strategies. In Proceedings of the ICDE, San Diego, CA, USA, 19–22 April 2017; pp. 115–118. [Google Scholar]
- Das, A.; Tirthapura, S. Incremental Maintenance of Maximal Bicliques in a Dynamic Bipartite Graph. IEEE Trans. Multi Scale Comput. Syst. 2018, 4, 231–242. [Google Scholar] [CrossRef]
- Wang, R.; Liao, M.; Qin, C. An Efficient Algorithm for Enumerating Maximal Bicliques from a Dynamically Growing Graph. In Proceedings of the ICNC-FSKD, Kunming, China, 20–22 July 2019; pp. 329–337. [Google Scholar]
- Aksu, H.; Canim, M.; Chang, Y.; Korpeoglu, I.; Ulusoy, Ö. Distributed $k$ -Core View Materializationand Maintenance for Large Dynamic Graphs. IEEE Trans. Knowl. Data Eng. 2014, 26, 2439–2452. [Google Scholar] [CrossRef]
- Hua, Q.; Shi, Y.; Yu, D.; Jin, H.; Yu, J.; Cai, Z.; Cheng, X.; Chen, H. Faster Parallel Core Maintenance Algorithms in Dynamic Graphs. IEEE Trans. Parallel Distrib. Syst. 2020, 31, 1287–1300. [Google Scholar] [CrossRef]
- Sariyüce, A.E.; Gedik, B.; Jacques-Silva, G.; Wu, K.; Çatalyürek, Ü.V. Incremental k-core decomposition: Algorithms and evaluation. VLDB J. 2016, 25, 425–447. [Google Scholar] [CrossRef]
- Wang, N.; Yu, D.; Jin, H.; Qian, C.; Xie, X.; Hua, Q. Parallel Algorithm for Core Maintenance in Dynamic Graphs. In Proceedings of the ICDCS, Atlanta, GA, USA, 5–8 June 2017; pp. 2366–2371. [Google Scholar]
- Jin, H.; Wang, N.; Yu, D.; Hua, Q.; Shi, X.; Xie, X. Core Maintenance in Dynamic Graphs: A Parallel Approach Based on Matching. IEEE Trans. Parallel Distrib. Syst. 2018, 29, 2416–2428. [Google Scholar] [CrossRef]
- Aridhi, S.; Brugnara, M.; Montresor, A.; Velegrakis, Y. Distributed k-core decomposition and maintenance in large dynamic graphs. In Proceedings of the DEBS, Irvine, CA, USA, 20–24 June 2016; pp. 161–168. [Google Scholar]
- Li, R.; Yu, J.X.; Mao, R. Efficient Core Maintenance in Large Dynamic Graphs. IEEE Trans. Knowl. Data Eng. 2014, 26, 2453–2465. [Google Scholar] [CrossRef]
- Bai, W.; Jiang, Y.; Tang, Y.; Li, Y. Parallel Core Maintenance of Dynamic Graphs. IEEE Trans. Knowl. Data Eng. 2023, 35, 8919–8933. [Google Scholar] [CrossRef]
- Guo, B.; Sekerinski, E. Parallel Order-Based Core Maintenance in Dynamic Graphs. In Proceedings of the ICPP, Salt Lake City, UT, USA, 7–10 August 2023; pp. 122–131. [Google Scholar]
- Luo, Q.; Yu, D.; Cheng, X.; Cai, Z.; Yu, J.; Lv, W. Batch Processing for Truss Maintenance in Large Dynamic Graphs. IEEE Trans. Comput. Soc. Syst. 2020, 7, 1435–1446. [Google Scholar] [CrossRef]
- Luo, Q.; Yu, D.; Cheng, X.; Sheng, H.; Lyu, W. Exploring Truss Maintenance in Fully Dynamic Graphs: A Mixed Structure-Based Approach. IEEE Trans. Comput. 2023, 72, 707–718. [Google Scholar] [CrossRef]
- Tian, A.; Zhou, A.; Wang, Y.; Chen, L. Maximal D-truss Search in Dynamic Directed Graphs. Proc. VLDB Endow. 2023, 16, 2199–2211. [Google Scholar] [CrossRef]
- Ebadian, S.; Huang, X. Fast Algorithm for K-Truss Discovery on Public-Private Graphs. In Proceedings of the IJCAI, Macao, China, 10–16 August 2019; pp. 2258–2264. [Google Scholar]
- Li, L.; Jiang, Y. Parallel Truss Maintenance of Dynamic Graphs. In Proceedings of the ICPADS, Danzhou, China, 17–21 December 2023; pp. 208–215. [Google Scholar]
- Huang, X.; Cheng, H.; Qin, L.; Tian, W.; Yu, J.X. Querying k-truss community in large and dynamic graphs. In Proceedings of the SIGMOD, Snowbird, UT, USA, 22–27 June 2014; pp. 1311–1322. [Google Scholar]
- Sahu, S.; Kothapalli, K.; Banerjee, D.S. Shared-Memory Parallel Algorithms for Community Detection in Dynamic Graphs. In Proceedings of the IPDPS, San Francisco, CA, USA, 27–31 May 2024; pp. 250–259. [Google Scholar]
- Zakrzewska, A.; Bader, D.A. A dynamic algorithm for local community detection in graphs. In Proceedings of the ASONAM, Paris, France, 25–28 August 2015; pp. 559–564. [Google Scholar]
- Zakrzewska, A.; Bader, D.A. Fast incremental community detection on dynamic graphs. In Proceedings of the PPAM, Krakow, Poland, 6–9 September 2015; pp. 207–217. [Google Scholar]
- Shang, J.; Liu, L.; Xie, F.; Chen, Z.; Miao, J.; Fang, X.; Wu, C. A Real-Time Detecting Algorithm for Tracking Community Structure of Dynamic Networks. arXiv 2014, arXiv:1407.2683. [Google Scholar]
- Nathan, E.; Zakrzewska, A.; Riedy, E.J.; Bader, D.A. Local Community Detection in Dynamic Graphs Using Personalized Centrality. Algorithms 2017, 10, 102. [Google Scholar] [CrossRef]
- Duan, D.; Li, Y.; Jin, Y.; Lu, Z. Community mining on dynamic weighted directed graphs. In Proceedings of the CIKM-CNIKM, Hong Kong, China, 6 November 2009; pp. 11–18. [Google Scholar]
- Wang, C.D.; Lai, J.H.; Yu, P.S. Dynamic community detection in weighted graph streams. In Proceedings of the SDM, Suzhou, China, 23–25 September 2013; pp. 151–161. [Google Scholar]
- Yang, B.; Wen, D.; Qin, L.; Zhang, Y.; Wang, X.; Lin, X. Fully Dynamic Depth-First Search in Directed Graphs. Proc. VLDB Endow. 2019, 13, 142–154. [Google Scholar] [CrossRef]
- Chen, L.; Duan, R.; Wang, R.; Zhang, H.; Zhang, T. An Improved Algorithm for Incremental DFS Tree in Undirected Graphs. In Proceedings of the SWAT, Malmö, Sweden, 18–20 June 2018; pp. 16:1–16:12. [Google Scholar]
- Nakamura, K.; Sadakane, K. Space-Efficient Fully Dynamic DFS in Undirected Graphs. Algorithms 2019, 12, 52. [Google Scholar] [CrossRef]
- Baswana, S.; Gupta, S.K.; Tulsyan, A. Fault tolerant and fully dynamic DFS in undirected graphs: Simple yet efficient. arXiv 2018, arXiv:1810.01726. [Google Scholar]
- Baswana, S.; Chaudhury, S.R.; Choudhary, K.; Khan, S. Dynamic DFS in undirected graphs: Breaking the O (m) barrier. In Proceedings of the SODA, Arlington, VA, USA, 10–12 January 2016; pp. 730–739. [Google Scholar]
- Franciosa, P.G.; Gambosi, G.; Nanni, U. The Incremental Maintenance of a Depth-First-Search Tree in Directed Acyclic Graphs. Inf. Process. Lett. 1997, 61, 113–120. [Google Scholar] [CrossRef]
- Baswana, S.; Khan, S. Incremental algorithm for maintaining a DFS tree for undirected graphs. Algorithmica 2017, 79, 466–483. [Google Scholar] [CrossRef]
- Baswana, S.; Goel, A.; Khan, S. Incremental DFS algorithms: A theoretical and experimental study. In Proceedings of the SODA, New Orleans, LA, USA, 7–10 January 2018; pp. 53–72. [Google Scholar]
- Baswana, S.; Choudhary, K. On dynamic DFS tree in directed graphs. In Proceedings of the MFCS, Milan, Italy, 24–28 August 2015; pp. 102–114. [Google Scholar]
- Karczmarz, A.; Sankowski, P. Fully Dynamic Shortest Paths and Reachability in Sparse Digraphs. In Proceedings of the ICALP, Paderborn, Germany, 10–14 July 2023; pp. 84:1–84:20. [Google Scholar]
- D’Angelo, G.; D’Emidio, M.; Frigioni, D. Fully Dynamic 2-Hop Cover Labeling. ACM J. Exp. Algorithmics 2019, 24, 1.6:1–1.6:36. [Google Scholar] [CrossRef]
- Yu, Z.; Yu, X.; Koudas, N.; Chen, Y.; Liu, Y. A Distributed Solution for Efficient K Shortest Paths Computation Over Dynamic Road Networks. IEEE Trans. Knowl. Data Eng. 2024, 36, 2759–2773. [Google Scholar] [CrossRef]
- Feng, Q.; Peng, Y.; Zhang, W.; Lin, X.; Zhang, Y. DSPC: Efficiently Answering Shortest Path Counting on Dynamic Graphs. In Proceedings of the EDBT, Paestum, Italy, 25–28 March 2024; pp. 116–128. [Google Scholar]
- Probst Gutenberg, M.; Vassilevska Williams, V.; Wein, N. New algorithms and hardness for incremental single-source shortest paths in directed graphs. In Proceedings of the STOC, Chicago, IL, USA, 22–26 June 2020; pp. 153–166. [Google Scholar]
- Greco, S.; Molinaro, C.; Pulice, C. Efficient Maintenance of Shortest Distances in Dynamic Graphs. IEEE Trans. Knowl. Data Eng. 2018, 30, 474–487. [Google Scholar] [CrossRef]
- Akiba, T.; Iwata, Y.; Yoshida, Y. Dynamic and historical shortest-path distance queries on large evolving networks by pruned landmark labeling. In Proceedings of the WWW, Seoul, Republic of Korea, 7–11 April 2014; pp. 237–248. [Google Scholar]
- Lin, Y.; Chen, X.; Lui, J.C. I/O efficient algorithms for exact distance queries on disk-resident dynamic graphs. In Proceedings of the ASONAM, Paris, France, 25–28 August 2015; pp. 440–447. [Google Scholar]
- Chan, E.P.F.; Yang, Y. Shortest Path Tree Computation in Dynamic Graphs. IEEE Trans. Comput. 2009, 58, 541–557. [Google Scholar] [CrossRef]
- Aioanei, D. Lazy Shortest Path Computation in Dynamic graphs. Comput. Sci. 2012, 13, 113–138. [Google Scholar] [CrossRef]
- Qin, Y.; Sheng, Q.Z.; Falkner, N.J.G.; Yao, L.; Parkinson, S. Efficient computation of distance labeling for decremental updates in large dynamic graphs. World Wide Web 2017, 20, 915–937. [Google Scholar] [CrossRef]
- Zhu, A.D.; Lin, W.; Wang, S.; Xiao, X. Reachability queries on large dynamic graphs: A total order approach. In Proceedings of the SIGMOD, Snowbird, UT, USA, 22–27 June 2014; pp. 1323–1334. [Google Scholar]
- Vaquero, L.; Cuadrado, F.; Logothetis, D.; Martella, C. Adaptive partitioning for large-scale dynamic graphs. In Proceedings of the SOCC, Santa Clara, CA, USA, 1–3 October 2013; pp. 1–2. [Google Scholar]
- Huang, J.; Abadi, D. LEOPARD: Lightweight Edge-Oriented Partitioning and Replication for Dynamic Graphs. Proc. VLDB Endow. 2016, 9, 540–551. [Google Scholar] [CrossRef]
- Li, H.; Yuan, H.; Huang, J.; Cui, J.; Yoo, J. Dynamic graph repartitioning: From single vertex to vertex group. In Proceedings of the DASFAA, Jeju, Republic of Korea, 24–27 September 2020; pp. 482–497. [Google Scholar]
- He, Y.; Coutino, M.; Isufi, E.; Leus, G. Dynamic Bi-Colored Graph Partitioning. In Proceedings of the EUSIPCO, Belgrade, Serbia, 29 August–2 September 2022; pp. 692–696. [Google Scholar]
- Fan, W.; Liu, M.; Tian, C.; Xu, R.; Zhou, J. Incrementalization of Graph Partitioning Algorithms. Proc. VLDB Endow. 2020, 13, 1261–1274. [Google Scholar] [CrossRef]
- Tsourakakis, C.; Gkantsidis, C.; Radunovic, B.; Vojnovic, M. Fennel: Streaming graph partitioning for massive scale graphs. In Proceedings of the WSDM, New York, NY, USA, 24–28 February 2014; pp. 333–342. [Google Scholar]
- Xu, N.; Chen, L.; Cui, B. LogGP: A Log-based Dynamic Graph Partitioning Method. Proc. VLDB Endow. 2014, 7, 1917–1928. [Google Scholar] [CrossRef]
- Zhang, F.; Wang, S. Effective Indexing for Dynamic Structural Graph Clustering. Proc. VLDB Endow. 2022, 15, 2908–2920. [Google Scholar] [CrossRef]
- Kumar, D.K.S.; D’Mello, D.A. DPISCAN: Distributed and parallel architecture with indexing for structural clustering of massive dynamic graphs. Int. J. Data Sci. Anal. 2022, 13, 199–223. [Google Scholar] [CrossRef]
- Mai, S.T.; Amer-Yahia, S.; Assent, I.; Birk, M.S.; Dieu, M.S.; Jacobsen, J.; Kristensen, J. Scalable Interactive Dynamic Graph Clustering on Multicore CPUs. IEEE Trans. Knowl. Data Eng. 2019, 31, 1239–1252. [Google Scholar] [CrossRef]
- Ju, W.; Li, J.; Yu, W.; Zhang, R. iGraph: An incremental data processing system for dynamic graph. Front. Comput. Sci. 2016, 10, 462–476. [Google Scholar] [CrossRef]
- Ediger, D.; McColl, R.; Riedy, J.; Bader, D.A. Stinger: High performance data structure for streaming graphs. In Proceedings of the HPEC, Waltham, MA, USA, 10–12 September 2012; pp. 1–5. [Google Scholar]
- Feng, G.; Meng, X.; Ammar, K. DISTINGER: A distributed graph data structure for massive dynamic graph processing. In Proceedings of the IEEE Big Data, Santa Clara, CA, USA, 29 October–1 November 2015; pp. 1814–1822. [Google Scholar]
- Sha, M.; Li, Y.; He, B.; Tan, K. Accelerating Dynamic Graph Analytics on GPUs. Proc. VLDB Endow. 2017, 11, 107–120. [Google Scholar] [CrossRef]
- Ekle, O.A.; Eberle, W. Anomaly Detection in Dynamic Graphs: A Comprehensive Survey. ACM Trans. Knowl. Discov. Data 2024, 18, 192:1–192:44. [Google Scholar] [CrossRef]
- Gao, H.; Liao, X.; Shao, Z.; Li, K.; Chen, J.; Jin, H. A survey on dynamic graph processing on GPUs: Concepts, terminologies and systems. Front. Comput. Sci. 2024, 18, 184106. [Google Scholar] [CrossRef]
- Hanauer, K.; Henzinger, M.; Schulz, C. Recent advances in fully dynamic graph algorithms—A quick reference guide. ACM J. Exp. Algorithmics 2022, 27, 1–45. [Google Scholar] [CrossRef]
- Ramalingam, G.; Reps, T.W. On the Computational Complexity of Dynamic Graph Problems. Theor. Comput. Sci. 1996, 158, 233–277. [Google Scholar] [CrossRef]
- Teitelbaum, T.; Reps, T. The Cornell program synthesizer: A syntax-directed programming environment. Commun. ACM 1981, 24, 563–573. [Google Scholar] [CrossRef]
- Fan, W.; Hu, C.; Tian, C. Incremental graph computations: Doable and undoable. In Proceedings of the SIGMOD, Chicago, IL, USA, 14–19 May 2017; pp. 155–169. [Google Scholar]
- Fan, W.; Wang, X.; Wu, Y. Incremental graph pattern matching. ACM Trans. Database Syst. 2013, 38, 18:1–18:47. [Google Scholar] [CrossRef]
- Ramalingam, G.; Reps, T.W. An Incremental Algorithm for a Generalization of the Shortest-Path Problem. J. Algorithms 1996, 21, 267–305. [Google Scholar] [CrossRef]
- Brandes, U. A faster algorithm for betweenness centrality. J. Math. Sociol. 2001, 25, 163–177. [Google Scholar] [CrossRef]
- Cohen, E.; Delling, D.; Pajor, T.; Werneck, R.F. Computing classic closeness centrality, at scale. In Proceedings of the COSN, Dublin, Ireland, 1–2 October 2014; pp. 37–50. [Google Scholar]
- Dijkstra, E.W. A note on two problems in connexion with graphs. Numer. Math. 1959, 1, 269–271. [Google Scholar] [CrossRef]
- Floyd, R.W. Algorithm 97: Shortest path. Commun. ACM 1962, 5, 345. [Google Scholar] [CrossRef]
- Ramalingam, G.; Reps, T. On the Computational Complexity of Incremental Algorithms; Technical Report; University of Wisconsin-Madison Department of Computer Sciences: Madison, WI, USA, 1991. [Google Scholar]
- West, D.B. Introduction to Graph Theory; Prentice Hall: Upper Saddle River, NJ, USA, 2001; Volume 2. [Google Scholar]
- Li, W.; Qiao, M.; Qin, L.; Zhang, Y.; Chang, L.; Lin, X. Exacting Eccentricity for Small-World Networks. In Proceedings of the ICDE, Paris, France, 16–19 April 2018; pp. 785–796. [Google Scholar]
- Alishahi, M. On the dynamic coloring of graphs. Discret. Appl. Math. 2011, 159, 152–156. [Google Scholar] [CrossRef]
- Zuckerman, D. Linear Degree Extractors and the Inapproximability of Max Clique and Chromatic Number. Theory Comput. 2007, 3, 103–128. [Google Scholar] [CrossRef]
- Lewis, R.M.R. A Guide to Graph Colouring—Algorithms and Applications; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Bhyravarapu, S.; Kumari, S.; Reddy, I.V. Dynamic Coloring on Restricted Graph Classes. In Proceedings of the CIAC, Larnaca, Cyprus, 13–16 June 2023; pp. 112–126. [Google Scholar]
- Li, S.; Wang, K.; Lin, X.; Zhang, W.; He, Y.; Yuan, L. Querying Historical Cohesive Subgraphs over Temporal Bipartite Graphs. In Proceedings of the 2024 IEEE 40th International Conference on Data Engineering (ICDE), Utrecht, The Netherlands, 13–16 May 2024; pp. 2503–2516. [Google Scholar]
- Cohen, J. Trusses: Cohesive subgraphs for social network analysis. Natl. Secur. Agency Tech. Rep. 2008, 16, 1–29. [Google Scholar]
- Greene, D.; Doyle, D.; Cunningham, P. Tracking the Evolution of Communities in Dynamic Social Networks. In Proceedings of the ASONAM, Odense, Denmark, 9–11 August 2010; pp. 176–183. [Google Scholar]
- Clauset, A.; Newman, M.E.; Moore, C. Finding community structure in very large networks. Phys. Rev. E-Stat. Nonlinear Soft Matter Phys. 2004, 70, 066111. [Google Scholar] [CrossRef] [PubMed]
- Görke, R.; Maillard, P.; Schumm, A.; Staudt, C.; Wagner, D. Dynamic graph clustering combining modularity and smoothness. J. Exp. Algorithmics 2013, 18, 1. [Google Scholar] [CrossRef]
- Kherad, M.; Dadras, M.; Mokhtari, M. Community detection based on influential nodes in dynamic networks. J. Supercomput. 2024, 80, 24664–24688. [Google Scholar] [CrossRef]
- Tarjan, R.E. Depth-First Search and Linear Graph Algorithms. SIAM J. Comput. 1972, 1, 146–160. [Google Scholar] [CrossRef]
- Hopcroft, J.E.; Karp, R.M. An n^5/2 algorithm for maximum matchings in bipartite graphs. SIAM J. Comput. 1973, 2, 225–231. [Google Scholar] [CrossRef]
- Hopcroft, J.E.; Tarjan, R.E. Efficient Algorithms for Graph Manipulation [H] (Algorithm 447). Commun. ACM 1973, 16, 372–378. [Google Scholar] [CrossRef]
- Tarjan, R.E. Finding Dominators in Directed Graphs. SIAM J. Comput. 1974, 3, 62–89. [Google Scholar] [CrossRef]
- Cormen, T.H.; Leiserson, C.E.; Rivest, R.L.; Stein, C. Introduction to Algorithms, 3rd ed.; MIT Press: Cambridge, MA, USA, 2009. [Google Scholar]
- Sibeyn, J.F.; Abello, J.; Meyer, U. Heuristics for semi-external depth first search on directed graphs. In Proceedings of the SPAA, Winnipeg, MB, Canada, 10–13 August 2002; pp. 282–292. [Google Scholar]
- Reif, J.H. Depth-First Search is Inherently Sequential. Inf. Process. Lett. 1985, 20, 229–234. [Google Scholar] [CrossRef]
- Reif, J.H. A Topological Approach to Dynamic Graph Connectivity. Inf. Process. Lett. 1987, 25, 65–70. [Google Scholar] [CrossRef]
- Miltersen, P.B.; Subramanian, S.; Vitter, J.S.; Tamassia, R. Complexity Models for Incremental Computation. Theor. Comput. Sci. 1994, 130, 203–236. [Google Scholar] [CrossRef]
- Shen, C.Y.; Huang, L.H.; Yang, D.N.; Shuai, H.H.; Lee, W.C.; Chen, M.S. On finding socially tenuous groups for online social networks. In Proceedings of the SIGKDD, Halifax, NS, Canada, 13–17 August 2017; pp. 415–424. [Google Scholar]
- Li, J.; Wang, X.; Deng, K.; Yang, X.; Sellis, T.; Yu, J.X. Most influential community search over large social networks. In Proceedings of the ICDE, San Diego, CA, USA, 19–22 April 2017; pp. 871–882. [Google Scholar]
- Rozenshtein, P.; Anagnostopoulos, A.; Gionis, A.; Tatti, N. Event detection in activity networks. In Proceedings of the SIGKDD, New York, NY, USA, 24–27 August 2014; pp. 1176–1185. [Google Scholar]
- Chen, Z.; Feng, B.; Yuan, L.; Lin, X.; Wang, L. Fully Dynamic Contraction Hierarchies with Label Restrictions on Road Networks. Data Sci. Eng. 2023, 8, 263–278. [Google Scholar] [CrossRef]
- Feng, B.; Chen, Z.; Yuan, L.; Lin, X.; Wang, L. Contraction hierarchies with label restrictions maintenance in dynamic road networks. In Proceedings of the International Conference on Database Systems for Advanced Applications, Tianjin, China, 17–20 April 2023; pp. 269–285. [Google Scholar]
- Narváez, P.; Siu, K.; Tzeng, H. New dynamic SPT algorithm based on a ball-and-string model. IEEE/ACM Trans. Netw. 2001, 9, 706–718. [Google Scholar] [CrossRef]
- Liang, Y.; Chen, C.; Wang, Y.; Lei, K.; Yang, M.; Lyu, Z. Reachability preserving compression for dynamic graph. Inf. Sci. 2020, 520, 232–249. [Google Scholar] [CrossRef]
- Meunier, L.; Zhao, Y. Reachability Queries on Dynamic Temporal Bipartite Graphs. In Proceedings of the SIGSPATIAL/GIS, Hamburg, Germany, 13–16 November 2023; pp. 97:1–97:11. [Google Scholar]
- Hanai, M.; Suzumura, T.; Tan, W.J.; Liu, E.; Theodoropoulos, G.; Cai, W. Distributed edge partitioning for trillion-edge graphs. arXiv 2019, arXiv:1908.05855. [Google Scholar] [CrossRef]
- Predari, M.; Esnard, A. A k-way greedy graph partitioning with initial fixed vertices for parallel applications. In Proceedings of the PDP, Heraklion, Greece, 17–19 February 2016; pp. 280–287. [Google Scholar]
- Petroni, F.; Querzoni, L.; Daudjee, K.; Kamali, S.; Iacoboni, G. Hdrf: Stream-based partitioning for power-law graphs. In Proceedings of the CIAM, Melbourne, Australia, 18–23 October 2015; pp. 243–252. [Google Scholar]
- Li, H.; Liu, Y.; Yuan, H.; Yang, S.; Yun, J.; Qiao, S.; Huang, J.; Cui, J. Research on dynamic graph partitioning algorithms: A Survey. J. Softw. 2023, 34, 539–564. [Google Scholar]
- Mondal, J.; Deshpande, A. Managing large dynamic graphs efficiently. In Proceedings of the SIGMOD, Scottsdale, AZ, USA, 20–24 May 2012; pp. 145–156. [Google Scholar]
- Mondal, J.; Deshpande, A. EAGr: Supporting continuous ego-centric aggregate queries over large dynamic graphs. In Proceedings of the SIGMOD, Snowbird, UT, USA, 22–27 June 2014; pp. 1335–1346. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Problem | Fully Dynamic | Incremental Dynamic | Decremental Dynamic | Streaming Dynamic | Single Update | Batch Update | |
|---|---|---|---|---|---|---|---|
| Centrality | Betweenness Centrality | [17,25,26,37,38,39] | [17,18,25,26,38,39,40,41] | [17,25,26,37,38,39] | [18,26,42] | [17,26,38,39,43] | [25,37,41] |
| Closeness Centrality | [37,44,45,46,47] | [37,44,45,46,47] | [37,44,45,46,47] | [45] | [44,45,46,47] | [37] | |
| Eccentricity | [48] | [48] | [48] | - | [48] | - | |
| Graph Coloring | Vertex Coloring | [49,50,51] | [49,50,51,52,53] | [49,50,51,52,53] | - | [49,52,53,54] | [50,51] |
| Edge Coloring | [55] | [54,55,56,57,58,59,60,61] | [54,55,56,59,60,61] | - | [54,55,56,57,58,61] | [59,60] | |
| Cohesive Subgraph | Clique | [62] | [16,62,63,64,65] | [62,63,65] | - | [65] | [16,62,63,64] |
| Biclique | - | [66,67] | - | - | [67] | [66] | |
| k-core | - | [19,20,68,69,70,71,72,73,74,75,76] | [19,20,68,69,70,71,72,73,74,75,76] | - | [70,74] | [19,20,68,69,71,72,73,75,76] | |
| k-truss | - | [21,77,78,79,80,81,82] | [21,77,78,79,81,82] | - | [21,79,80,82] | [77,78,79,81] | |
| Community | [83] | [83,84,85,86,87,88] | [83,84,87] | [89] | [84,89] | [83,85,86,87,88] | |
| Path Traversal | DFS | [90,91,92,93,94] | [90,91,92,93,94,95,96,97] | [90,91,92,93,94,98] | - | [90,91,92] | [91,92,93,94,95,96,98] |
| Shortest Distance | [99,100,101] | [99,100,101,102,103,104,105,106,107,108] | [99,100,101,102,103,104,107,108,109] | - | [100,103,105,106,109] | [99,101,102,104,106,107,108] | |
| Reachability | - | [110] | - | - | [110] | - | |
| Graph Separation | Graph Partition | [111,112,113,114] | [24,111,112,113,114,115] | [111,112,113,114] | [111,116,117] | [111] | [112,113,115] |
| Clustering | [118] | [118,119,120] | [118] | - | [118,120] | [119] | |
| Systems | Systems | - | [121] | - | [122,123,124] | - | - |
| Problem | Algorithm | Graph Type | Update Mode | Fully Dynamic | Incremental Dynamic | Decremental Dynamic | Streaming Dynamic |
|---|---|---|---|---|---|---|---|
| Betweenness centrality | QUBE [17] | General | Single | ✓ | ✓ | ✓ | ✗ |
| Betweenness centrality | Green [18] | General | Single | ✗ | ✓ | ✗ | |
| Betweenness centrality | Lee [25] | Weighted | Batch | ✓ | ✓ | ✗ | |
| Betweenness centrality | Lee [25] | General | Batch | ✓ | ✓ | ✗ | |
| Betweenness centrality | Green+ [26] | General | Single (parallel) | ✓ | ✓ | ✓ | ✓ |
| Betweenness centrality | iCentral [39] | General | Single (parallel) | ✓ | ✓ | ✗ | |
| B&C centrality | Shukla [37] | General | Batch (parallel) | ✓ | ✓ | ✗ | |
| Closeness centrality | Kas [44] | Directed & weighted | Single | ✓ | ✗ | ||
| Closeness centrality | STREAMER [45] | General | Single (distributed) | ✓ | ✓ | ✓ | ✓ |
| Closeness centrality | CENDY [46] | General | Single | ✓ | ✓ | ✗ | |
| Closeness centrality | IUA [47] | General | Single | ✓ | ✓ | ✗ | |
| Eccentricity | ECC-DY [48] | General | Single | ✓ | ✓ | ✗ |
| Problem | Algorithm | Graph Type | Update Mode | Fully Dynamic | Incremental Dynamic | Decremental Dynamic | Streaming Dynamic |
|---|---|---|---|---|---|---|---|
| Vertex coloring | Barba [52] | General | Batch | ✓ | ✓ | ✓ | ✗ |
| -coloring | Bhattacharya [54] | General | Single | ✓ | ✓ | ✗ | |
| ()-coloring | Bhattacharya [54] | General | Single | ✓ | ✓ | ✗ | |
| -coloring | Solomon [49] | General | Single | ✓ | ✓ | ✗ | |
| Vertex coloring | ACODYGRA [51] | General | Batch | ✓ | ✓ | ✓ | ✗ |
| Vertex coloring | Sallinen [50] | General | Batch (distributed) | ✓ | ✓ | ✓ | ✗ |
| Vertex coloring | Yuan [53] | General | Single | ✓ | ✓ | ✓ | ✗ |
| Problem | Algorithm | Graph Type | Update Mode | Fully Dynamic | Incremental Dynamic | Decremental Dynamic | Streaming Dynamic |
|---|---|---|---|---|---|---|---|
| MCE | Stix [62] | General | Batch | ✓ | ✓ | ✗ | |
| MCE | Sun [65] | General | Single | ✗ | ✗ | ||
| MCE | Das [63] | General | Batch | ✗ | ✓ | ✗ | |
| MCE | SOMEi [64] | General | Batch | ✓ | ✓ | ✓ | ✗ |
| MCE | ParIMCE [16] | General | Batch (parallel) | ✗ | ✓ | ✗ | ✗ |
| MBE | DynamicBC [66] | Bipartited | Batch | ✗ | ✗ | ✗ | |
| MBE | IMBS [67] | Bipartited | Single | ✗ | ✓ | ✗ | ✗ |
| Problem | Algorithm | Graph Type | Update Mode | Fully Dynamic | Incremental Dynamic | Decremental Dynamic | Streaming Dynamic |
|---|---|---|---|---|---|---|---|
| Core maintenance | Aksu [68] | General | Batch (distributed) | ✓ | ✓ | ✓ | ✗ |
| Core maintenance | Hua [69] | General | Batch (parallel) | ✓ | ✗ | ||
| Core maintenance | Aridhi [73] | General | Batch (distributed) | ✓ | ✓ | ✓ | ✗ |
| Core maintenance | Wang [71] | General | Batch (parallel) | ✓ | ✗ | ||
| Core maintenance | Jin [72] | General | Batch (parallel) | ✓ | ✗ | ||
| Core maintenance | Li [74] | General | Single | ✓ | ✓ | ✗ | |
| Core maintenance | TRAVERSAL [70] | General | Single | ✓ | ✓ | ✗ | |
| Core maintenance | Lin [19] | General | Batch | ✓ | ✗ | ||
| Core maintenance | Yu [20] | General | Batch | ✓ | ✗ | ||
| Core maintenance | Yu [20] | General | Batch (parallel) | ✓ | ✗ | ||
| Core maintenance | Bai [75] | General | Batch (parallel) | ✓ | ✗ | ||
| Core maintenance | Guo [76] | General | Batch (parallel) | ✓ | ✗ |
| Problem | Algorithm | Graph Type | Update Mode | Fully Dynamic | Incremental Dynamic | Decremental Dynamic | Streaming Dynamic |
|---|---|---|---|---|---|---|---|
| Truss maintenance | Zhang [21] | General | Single | ✓ | ✓ | ✓ | ✗ |
| Truss maintenance | Luo [77] | General | Batch | ✓ | ✗ | ||
| Truss maintenance | Li [81] | General | Batch (parallel) | ✓ | ✗ | ||
| Truss maintenance | Luo [78] | General | Batch (parallel) | ✓ | ✗ | ||
| Truss maintenance | Ebadian [80] | General | Single | ✗ | ✓ | ✗ | ✗ |
| Problem | Algorithm | Graph Type | Update Mode | Fully Dynamic | Incremental Dynamic | Decremental Dynamic | Streaming Dynamic |
|---|---|---|---|---|---|---|---|
| DFS-Tree | Franciosa [95] | DAG | Batch | ✗ | ✗ | ✗ | |
| DFS-Tree | Baswana [96] | General | Batch | ✗ | ✗ | ✗ | |
| DFS-Tree | Baswana [98] | DAG | Batch | ✗ | ✗ | ✗ | |
| DFS-Tree | Baswana [94] | General | Batch | ✓ | ✗ | ||
| DFS-Tree | Chen [91] | General | Batch | ✓ | ✗ | ||
| DFS-Tree | Nakamura [92]-A 1 | General | Batch | ✓ | ✗ | ||
| DFS-Tree | Nakamura [92]-B 1 | General | Batch | ✓ | ✗ | ||
| DFS-Tree | Baswana [93] | General | Batch | ✓ | ✓ | ✗ |
| Problem | Algorithm | Graph Type | Update Mode | Fully Dynamic | Incremental Dynamic | Decremental Dynamic | Streaming Dynamic |
|---|---|---|---|---|---|---|---|
| Partitioning | Vaquero [111] | General | Single | ✓ | ✓ | ✓ | ✓ |
| Partitioning | LogGP [117] | General | Single | ✗ | ✗ | ✗ | ✓ |
| Partitioning | Hermes [24] | General | (distributed) | ✗ | ✓ | ✗ | ✗ |
| Partitioning | Leopard [112] | General | Batch | ✓ | ✓ | ✓ | ✗ |
| Partitioning | Li [113] | General | Batch | ✓ | ✓ | ✗ | |
| Partitioning | IncDNE [115] | General | Batch | ✗ | ✓ | ✗ | ✗ |
| Partitioning | IncKGGGP [115] | General | Batch | ✗ | ✓ | ✗ | ✗ |
| Clustering | danySCAN [120] | Weighted | Single | ✗ | ✓ | ✗ | ✗ |
| Clustering | BOTBIN [118] | General | Single | ✓ | ✓ | ✗ | |
| Clustering | DPISCAN [119] | General | Batch (distributed & parallel) | ✗ | ✗ | ✗ |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Z.; Liang, K.; Yuan, L.; Zhang, W.; Yang, Z. Recent Advances in Efficient Dynamic Graph Processing. Appl. Sci. 2025, 15, 6003. https://doi.org/10.3390/app15116003
Chen Z, Liang K, Yuan L, Zhang W, Yang Z. Recent Advances in Efficient Dynamic Graph Processing. Applied Sciences. 2025; 15(11):6003. https://doi.org/10.3390/app15116003
Chicago/Turabian StyleChen, Zi, Keke Liang, Long Yuan, Wenjie Zhang, and Zhengyi Yang. 2025. "Recent Advances in Efficient Dynamic Graph Processing" Applied Sciences 15, no. 11: 6003. https://doi.org/10.3390/app15116003
APA StyleChen, Z., Liang, K., Yuan, L., Zhang, W., & Yang, Z. (2025). Recent Advances in Efficient Dynamic Graph Processing. Applied Sciences, 15(11), 6003. https://doi.org/10.3390/app15116003