1. Introduction
Photovoltaic solar energy systems represent a reliable and efficient source of electricity generation. Globally, photovoltaic solar energy accounts for 13% of the total installed capacity for electricity production, generating 4% of the world’s electricity. By 2050, photovoltaic solar energy is expected to constitute 49% of the installed power if current policies continue. In this way, photovoltaic solar energy would increase from 31% of the installed renewable capacity to 66%, making it the renewable energy source with the most significant growth among the main sources [
1]. Alongside this expansion, wind power continues to play a complementary role, with the global installed capacity surpassing 1170 GW in 2024, led by strong deployment in China [
2]. Meanwhile, green hydrogen is emerging as a key solution for storing excess renewable energy and decarbonizing hard-to-electrify sectors. Although hydrogen is currently the most expensive form of hydrogen, compared to gray and blue hydrogen, recent techno-economic studies suggest that green hydrogen can benefit from declining renewable electricity costs, improvements in electrolyser efficiency, and government incentives. These factors are expected to reduce costs over time, supporting the broader integration of photovoltaic solar energy and other renewable sources into the energy system [
3].
However, multiple environmental and physical factors significantly affect the performance of photovoltaic solar panels [
4]. Elevated operating temperatures, for instance, can reduce panel efficiency by approximately 0.52% per degree Celsius increase in operating temperature, with a total efficiency drop of 27.4% when the temperature rises from 25 °C to 75 °C [
5]. In addition, working with suboptimal tilt angles can reduce the efficiency of photovoltaic panels. According to a numerical and experimental investigation by Mamun et al. [
6], for every 5° increments in the angle of surface tilt, efficiency falls by 0.35% and 0.33% for experimental and numerical cases, respectively. Ageing is also an important factor. A study conducted in Baghdad, Iraq, observed that monocrystalline photovoltaic modules exhibited a degradation rate of approximately 0.593% per year over an eight-year period, leading to a total performance loss of approximately 4.74% [
7].
One of the most important factors in the production of solar photovoltaic plants is the presence of dust. The presence of suspended particles in the atmosphere precipitates on the earth’s surface, taking into account environmental factors such as wind or relative humidity, among other physical factors. These particles, once settled on the solar panel, cause a reduction in the effective solar irradiance of the solar cells, thus decreasing the performance of the panel due to natural causes. This effect can decrease the performance of a PV plant by almost 20%, thus reducing the profitability of the installation [
8]. In a 50 MWp plant, these losses can account for a monthly reduction in production of up to 500 MWh with annual losses of more than EUR
[
9]. Mitigating these effects can also lead to a reduction in benefits, as it increases operational costs and the capital invested. This is especially notable in regions with arid and semi-arid climates, such as desert areas, where solar radiation levels are particularly high and airborne dust is highly intrusive [
10].
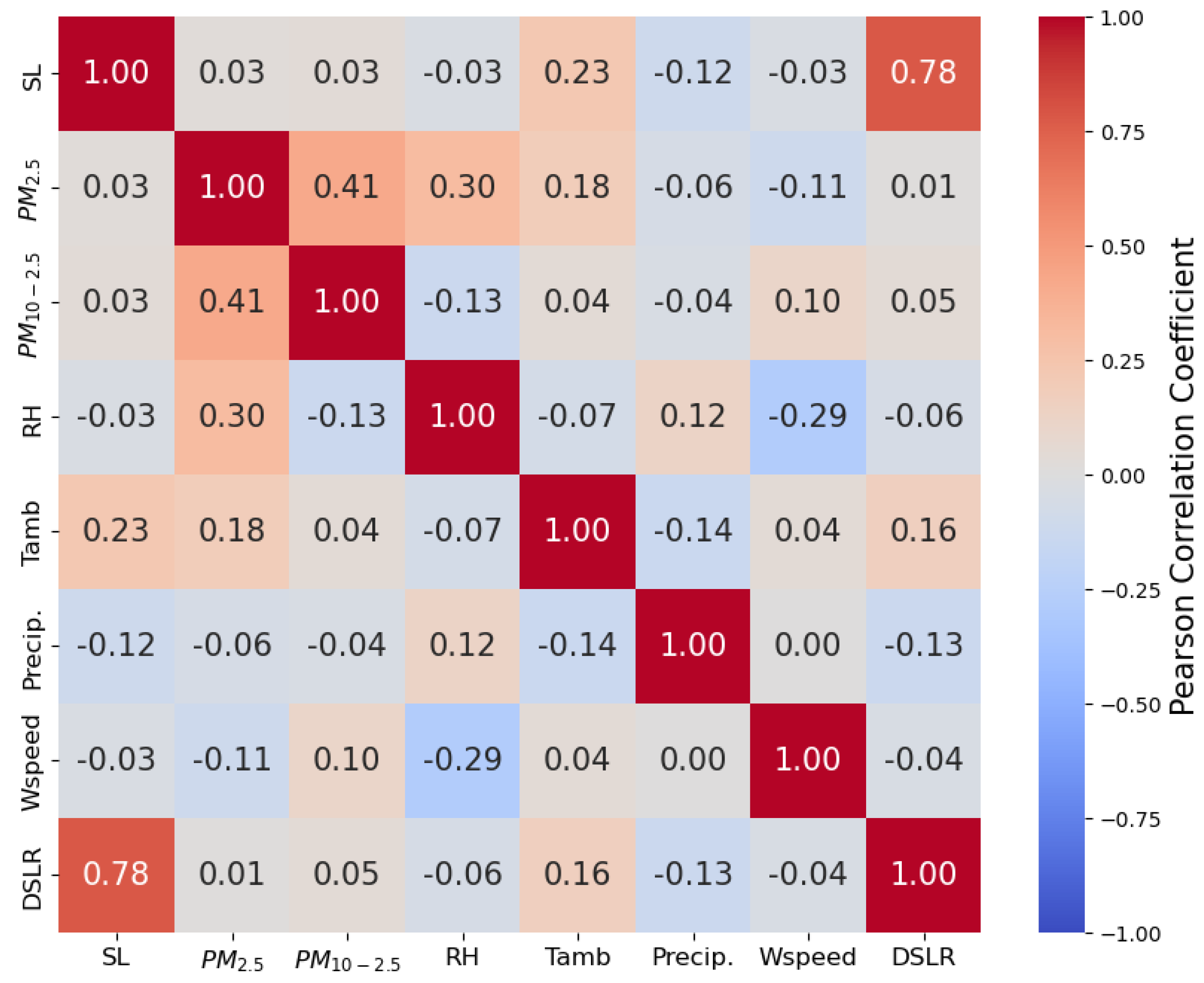
The role of meteorological variables in the influence of soil loss is crucial. For example, humidity has a negative impact on the power output of photovoltaic panels, turning dust into mud as it increases [
11]. It can also alter the irradiance non-linearly and irradiance itself causes large variations in short-circuit current linearity, affecting efficiency [
12]. Meanwhile, the wind speed can influence both the dust deposition and the cooling of the panels, leading to positive or negative effects depending on the speed and direction of the wind [
13].
The maintenance of the performance of solar panels has been closely linked to strategies for managing soils, with preventive and cleaning methods playing a significant role. Various approaches for anti-dust coatings have been studied and tested as preventive measures [
14,
15,
16]. Khan et al. (2024) experimented with various configurations of anti-dust coatings and tracking systems in the desert region of Saudi Arabia, achieving a reduction in soiling losses of up to 85 % by combining anti-soil coatings with tracking that includes vertical night stowage [
17].
There are different models in the literature that are used to estimate soiling losses, including both physical–statistical models and artificial intelligence models. Examples include an exponential model correlating dust deposition density with power losses [
18] and an optical model that calculates dust deposition based on particulate mass concentration, precipitation, and other variables [
19], and thereby determines the loss of light transmittance [
20]. In the field of machine learning, the most widely used models are artificial neural networks. Among the main disadvantages of current models are their high dependence on the location where the data for the model were obtained and their inflexibility when changing the design region [
21].
In this context, given the importance of modelling soiling losses in photovoltaic panels, in this work, we have developed various machine learning models tailored for this purpose. The focus has been on easily accessible meteorological variables, such as atmospheric temperature, wind speed, relative humidity, particulate matter (PM2.5, PM10), and others, which are continuously monitored worldwide and available from satellites. These models aim to create reliable estimations and can be extrapolated to different locations. Specifically, models were initially developed and tested for the location of Almería, Spain, and then evaluated for their ability to extrapolate to another location: Madrid, Spain. In particular, a global model was trained using combined data from both locations and demonstrated strong generalizability, achieving a root mean square error (RMSE) of 1.02% in predicting soil erosion losses. This result underscores the effectiveness and applicability of the approach in varying geographic and climatic conditions.
This article is organised into several sections. The Materials and Methods Section details the data acquisition process, including the sources and types of meteorological data used, as well as the data processing techniques applied to prepare the data for analysis. It also describes the development of four different machine learning approaches used to predict soiling losses in photovoltaic panels. The results present the outcomes of these models, evaluating their performance in the initial location (Almería), their extrapolation to a different location (Madrid), and the development and results of a global model trained on data from both locations. The Conclusions Section summarises the key findings of the study, emphasising the effectiveness and limitations of the developed models.
3. Results
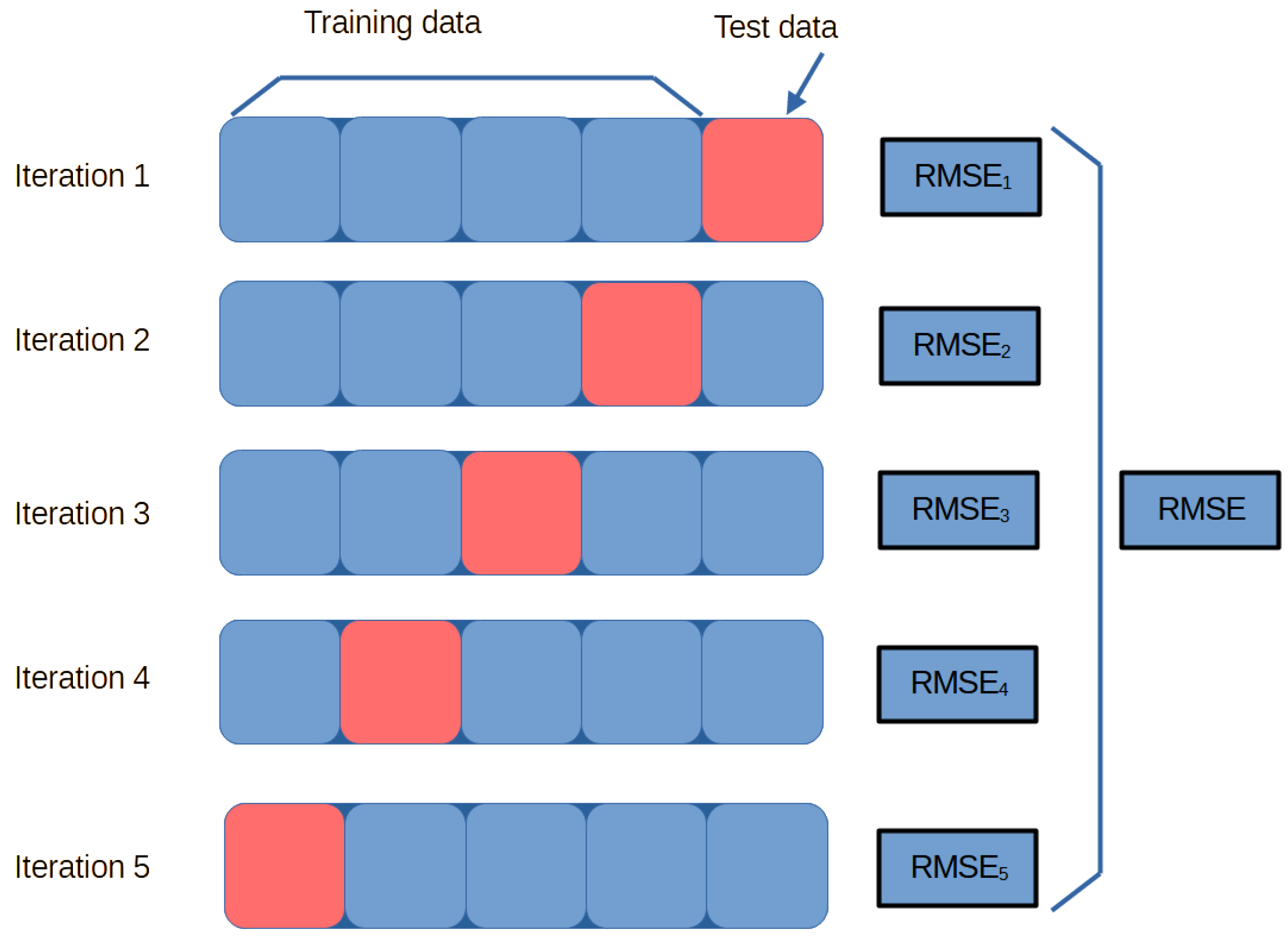
This section presents the results obtained during the evaluation phase of the models whose development has already been detailed. First, the evaluation metrics are outlined, followed by a detailed discussion of each model’s performance, as summarised in
Table 8. The models are categorised into three groups. The first group, referred to as Local Models, consists of models trained and evaluated using data from the CIESOL station, with both training and testing data originating from this station. The second group, Extrapolated Models, includes the same models trained on CIESOL data but tested on data from the CIEMAT station, assessing how well the models trained on CIESOL data generalise to CIEMAT data. Lastly, the Global Model was trained and evaluated using data from both locations. The development and analysis of this Global Model are discussed in the final subsection of this Results Section. Overall, the results evaluate how well these models estimate daily photovoltaic soiling losses in different contexts.
3.1. Evaluation Metrics
Several metrics were utilised to evaluate the performance of the proposed models. The mean bias error (Equation (
4)) represents whether a model overestimates or underestimates on average. The root mean square error (Equation (
5)) measures the average magnitude of prediction errors in a model. The normalized values of these were used (Equations (
6) and (
7)) to compare different models. Lastly, the coefficient of determination (Equation (
8)) between the estimated values and the observations was calculated to determine how well a linear regression can explain the relationship between these two variables. The more positive this coefficient, the more linearly correlated these variables are. If the coefficient of determination is negative, the mean of the data would be a better fit.
where
is the estimated value and
the predicted value for the i instance from a dataset of n instances.
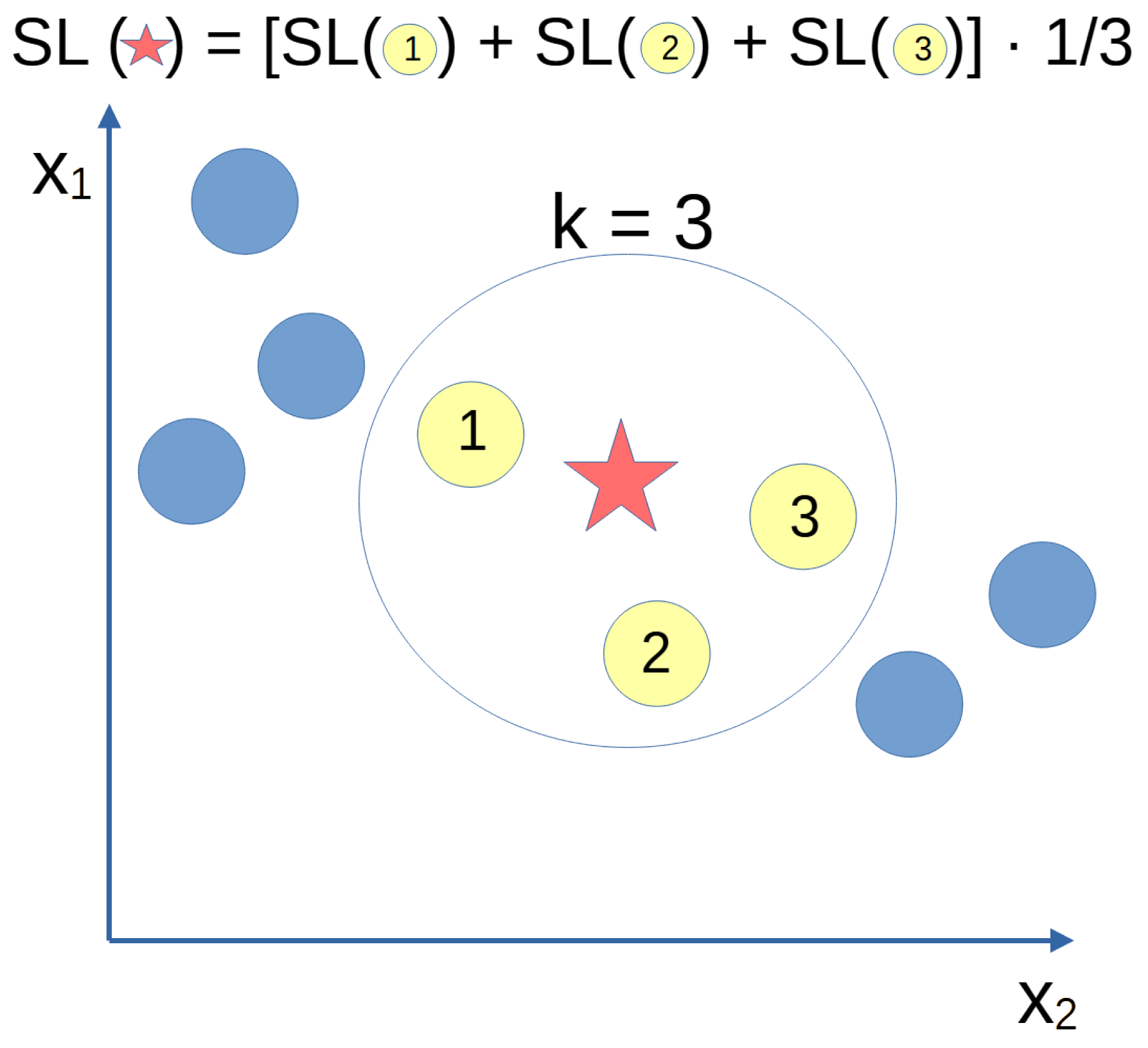
3.2. Results of kNN Model for PV Soiling Losses Estimation
This Section presents the results of the kNN model to estimate soiling losses.
3.2.1. kNN Model Evaluated on CIESOL Test Set
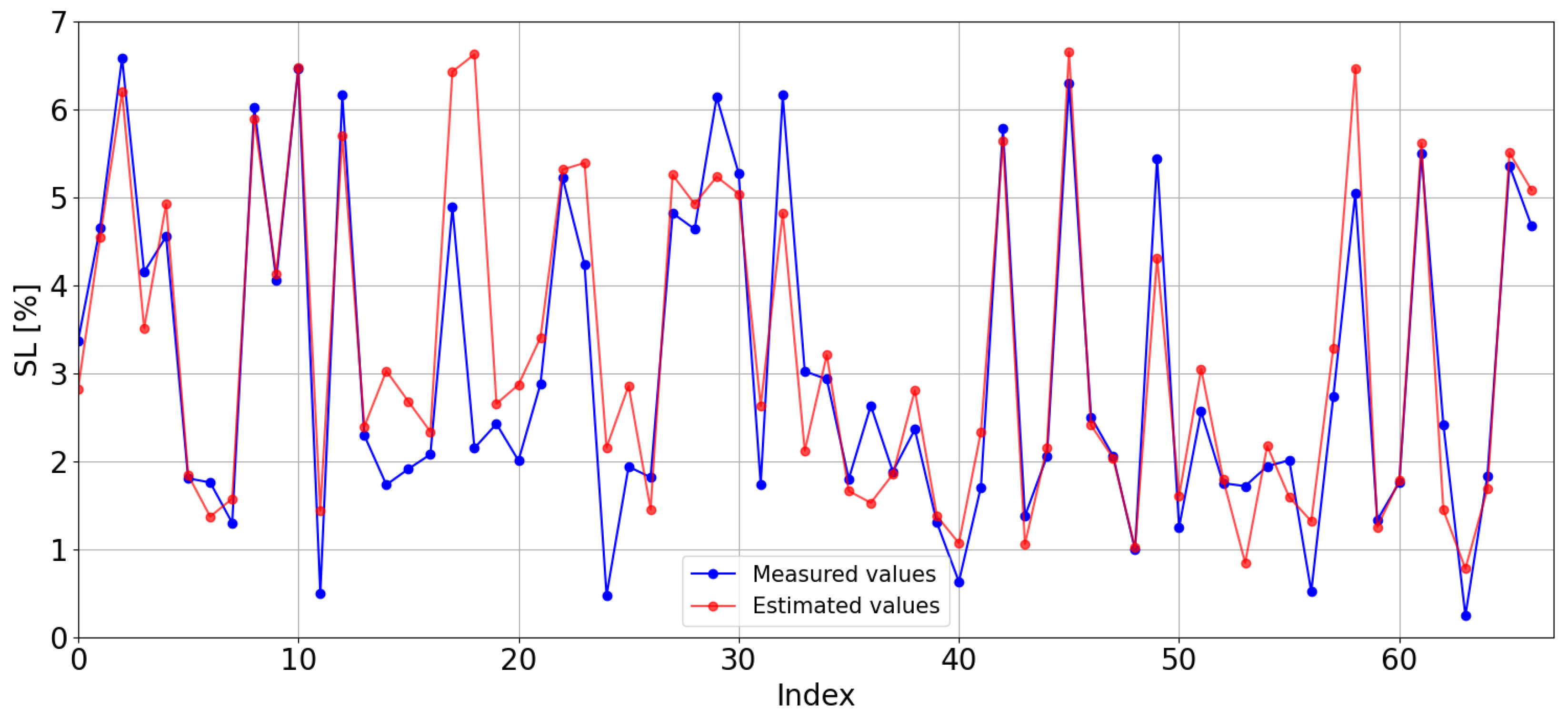
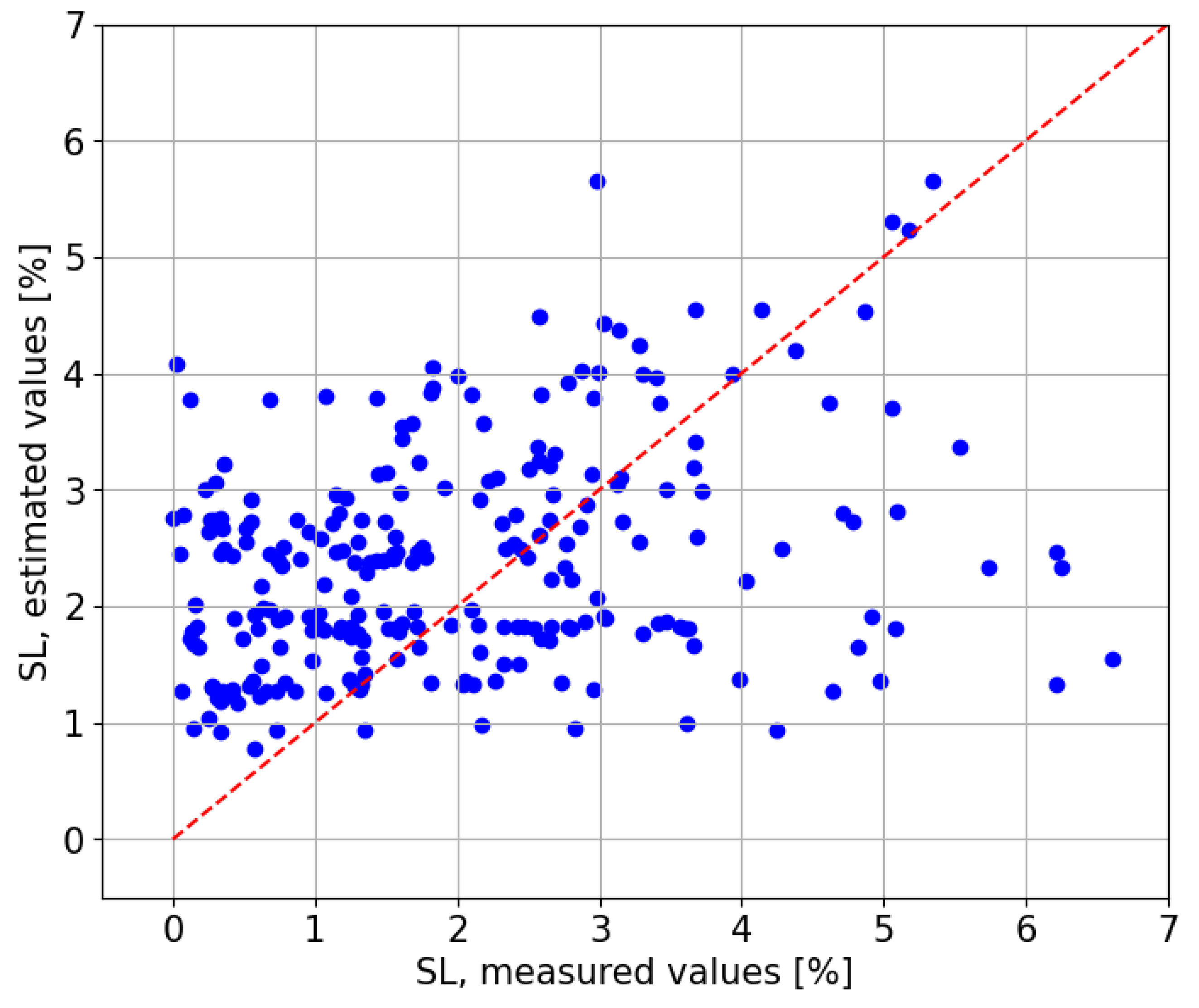
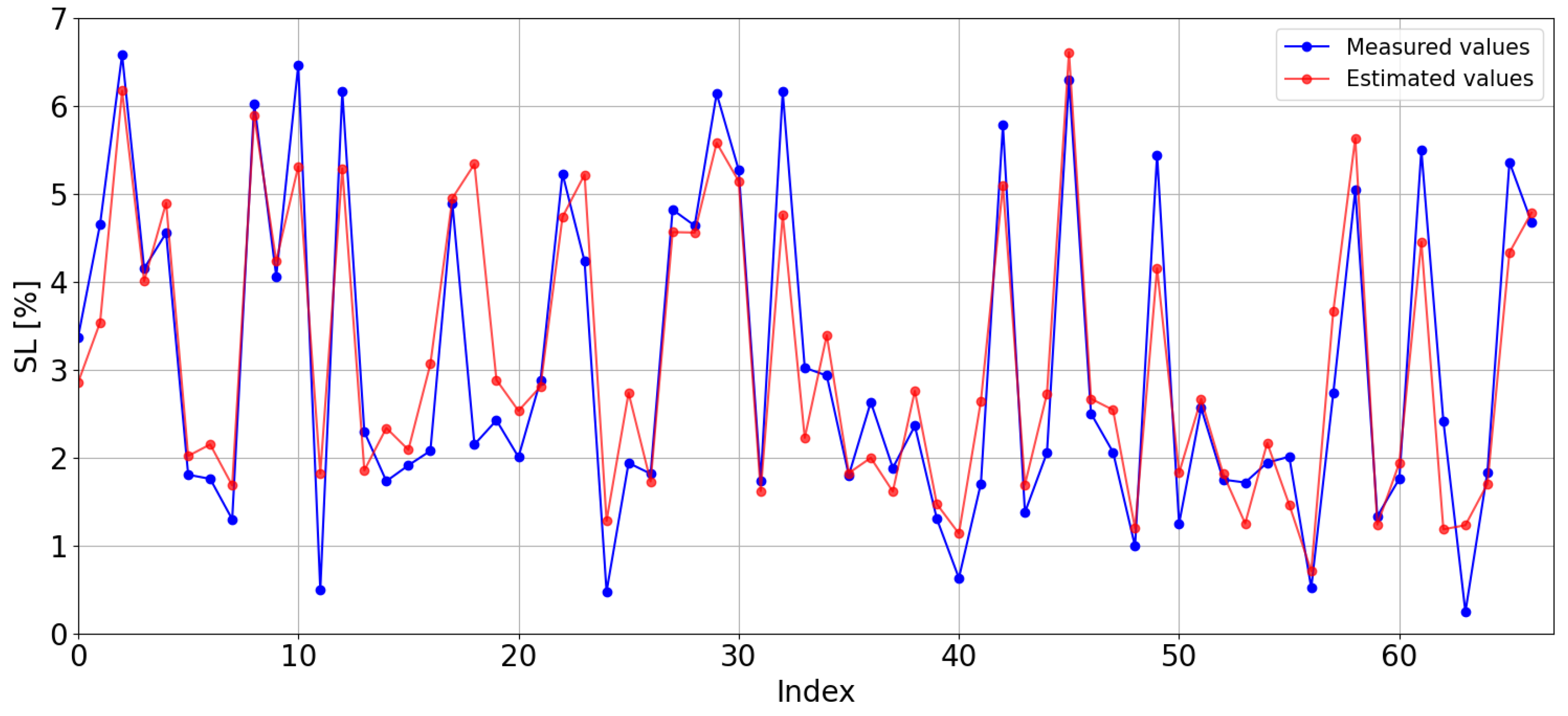
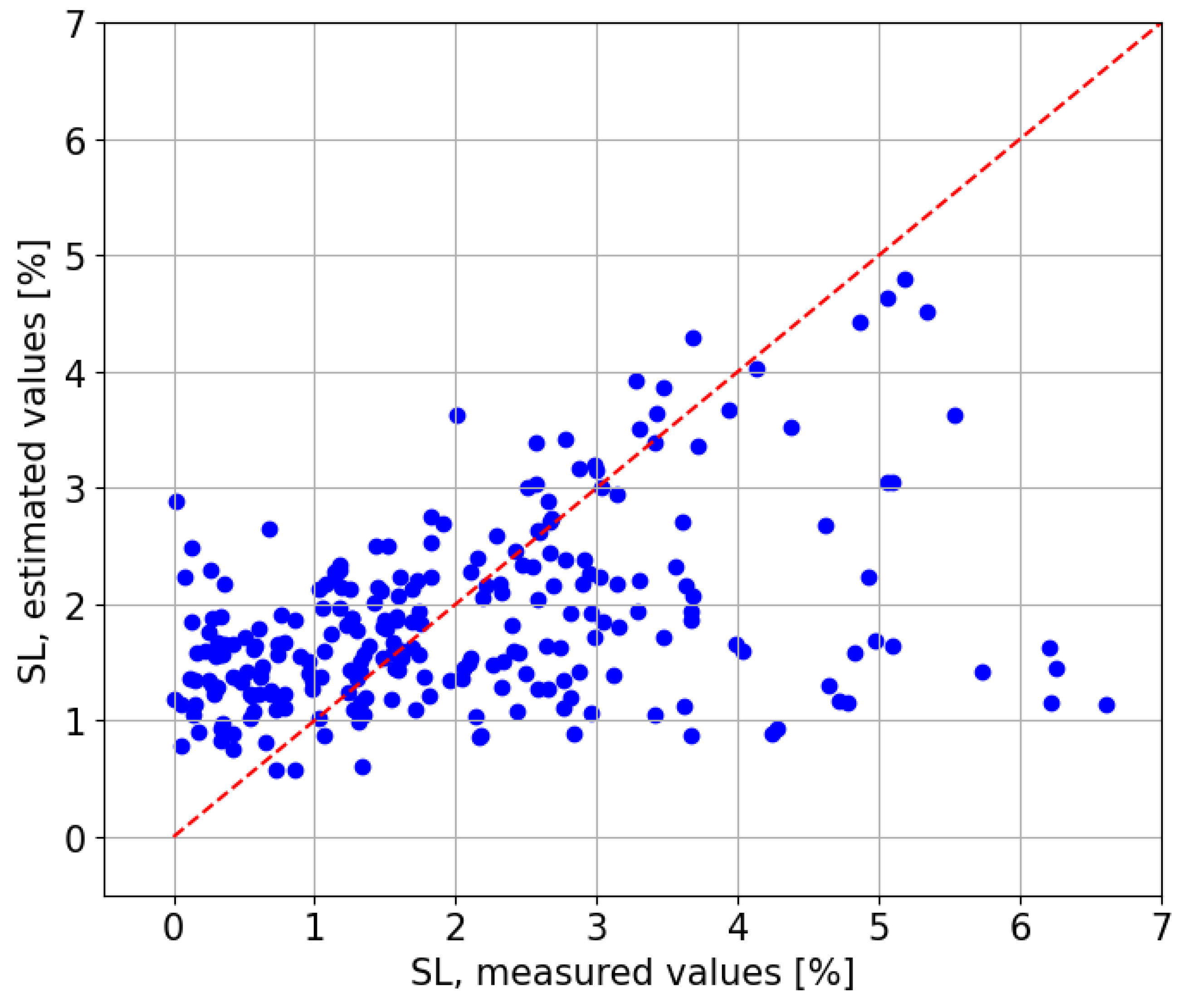
First, the estimations obtained with the kNN model trained with the data from the CIESOL station are displayed graphically along the observed (or real) values (see
Figure 11) for comparison. The model tends to overestimate, with estimated values generally being higher than the observed ones, resulting in an MBE of
, the highest value amongst all Local Models. The RMSE is
of SL.
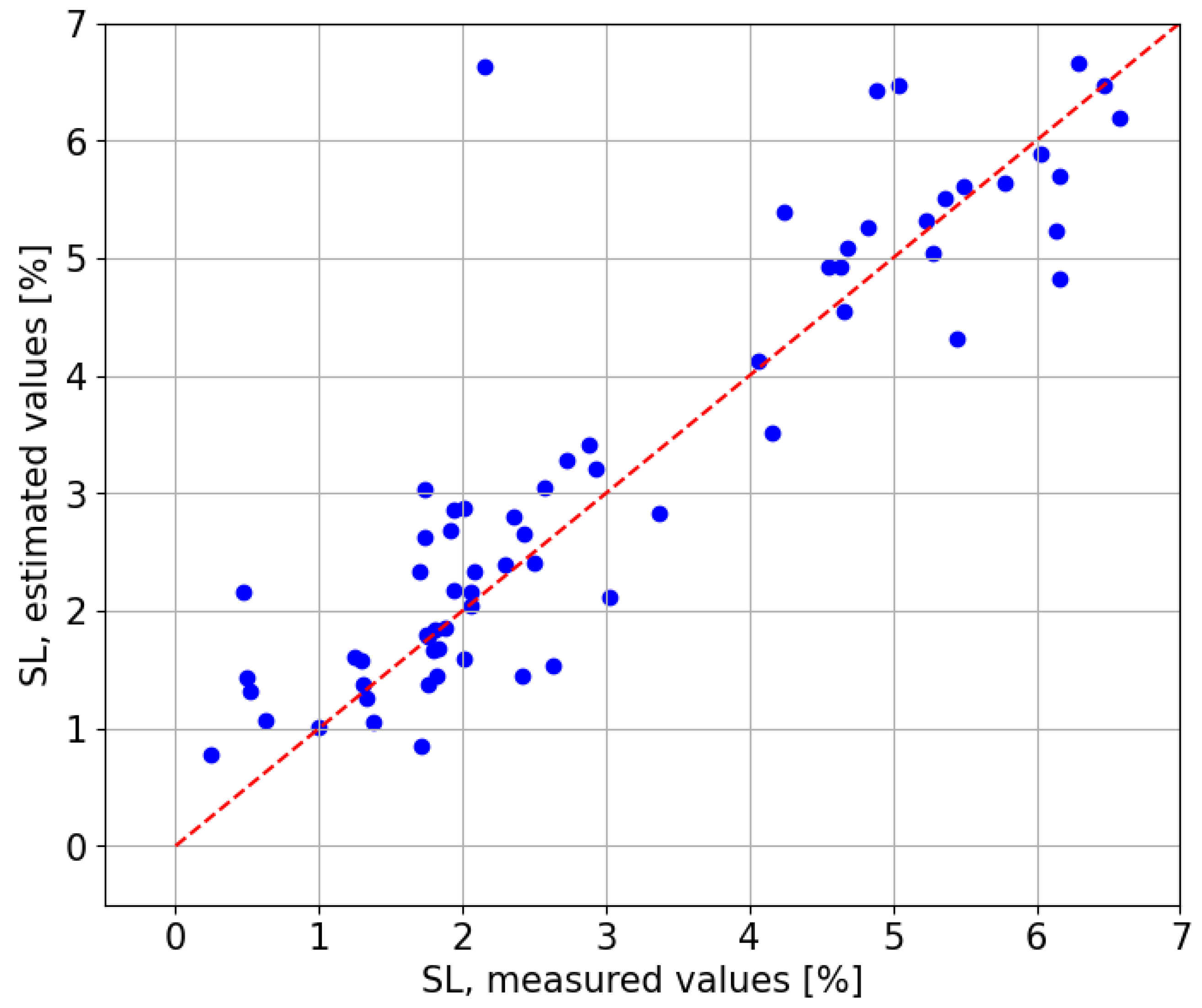
Figure 12 compares the estimated values against the observed values, revealing a clear positive relationship with a coefficient of determination of
. The red line represents the scenario in which the estimates perfectly match the observed values, which would result in an
of 1.
3.2.2. Extrapolation of the kNN Model to the CIEMAT Test Set
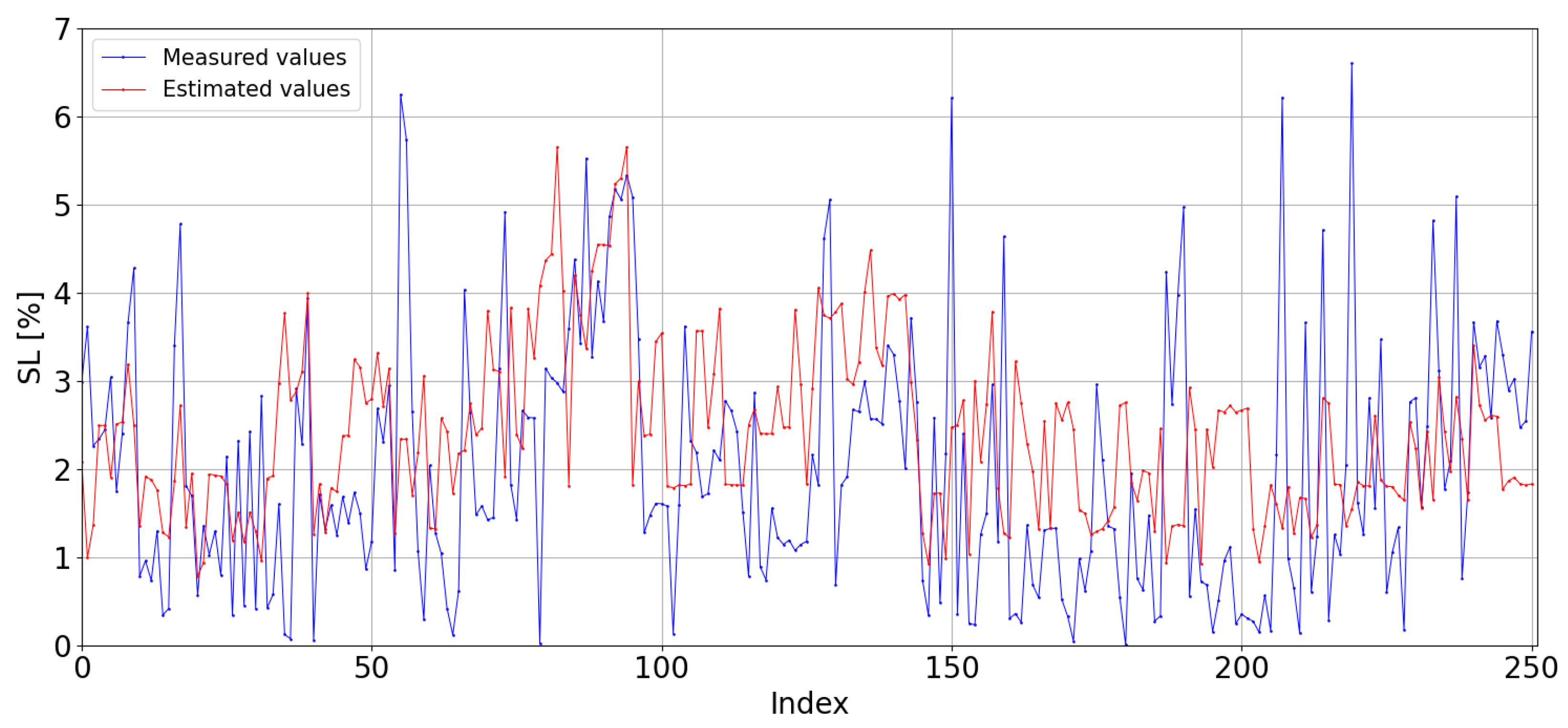
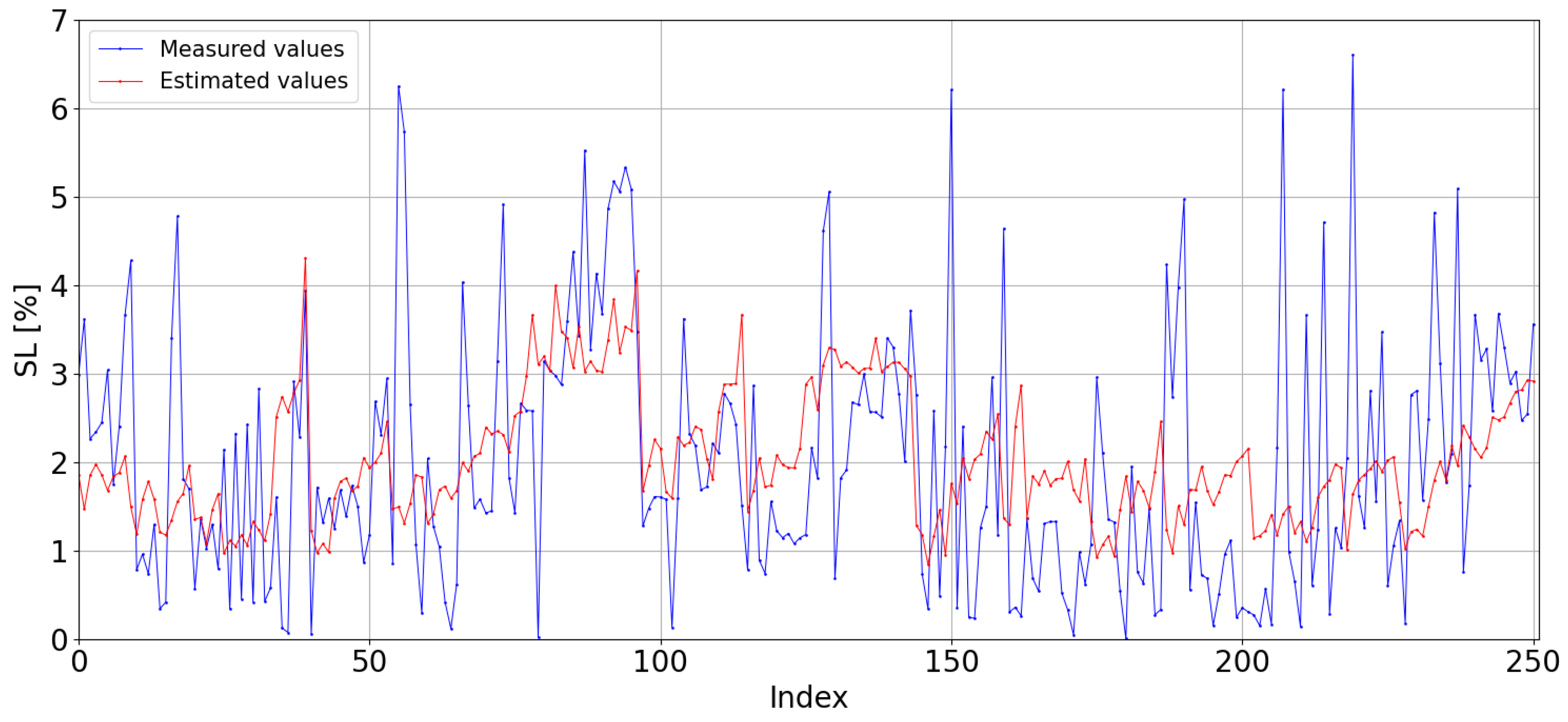
Extrapolating the kNN model to the dataset from the CIEMAT station results in an increase in both MBE (
) and RMSE (
). The model now makes greater overestimations compared to its performance on the CIESOL dataset, as seen in
Figure 13.
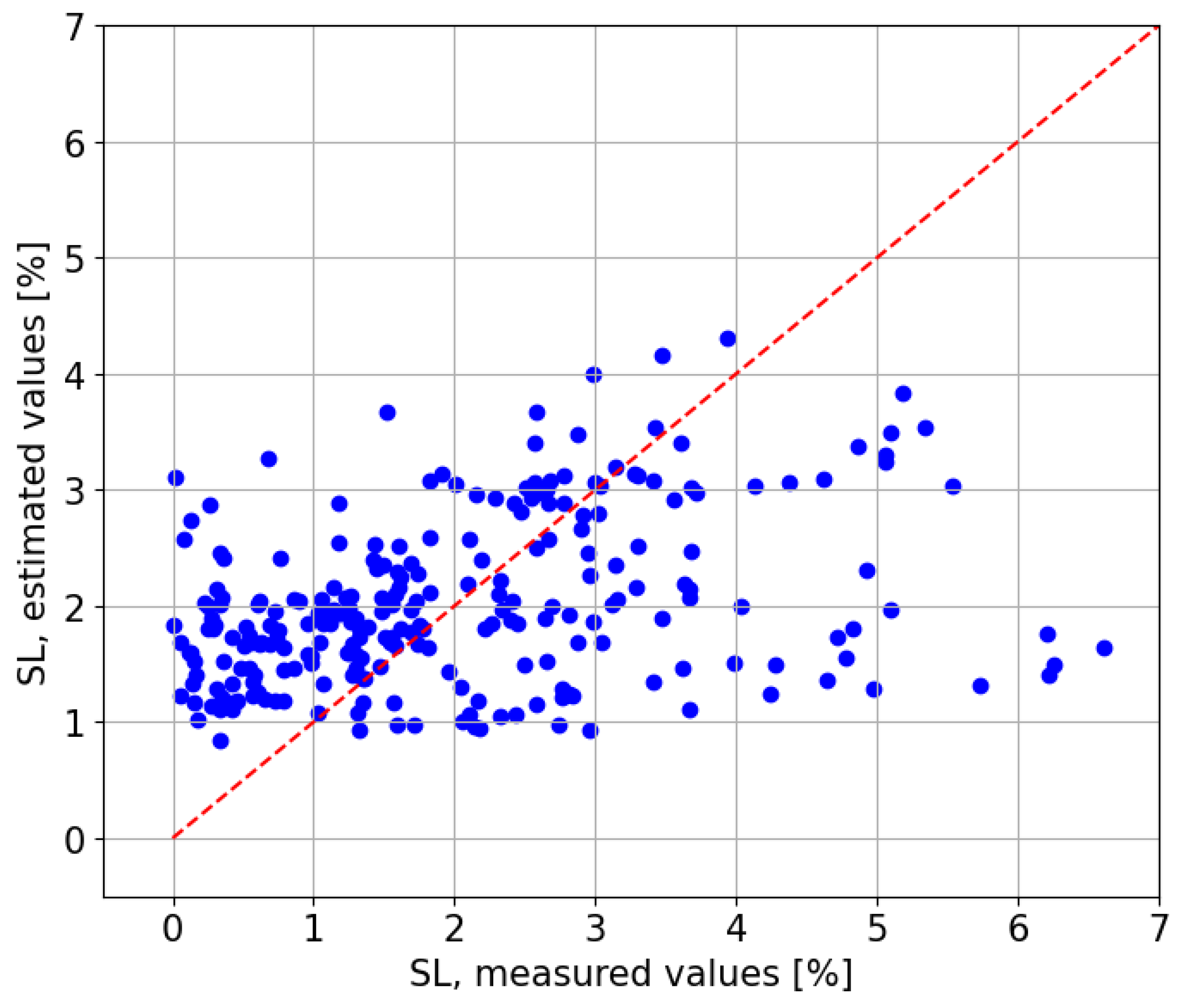
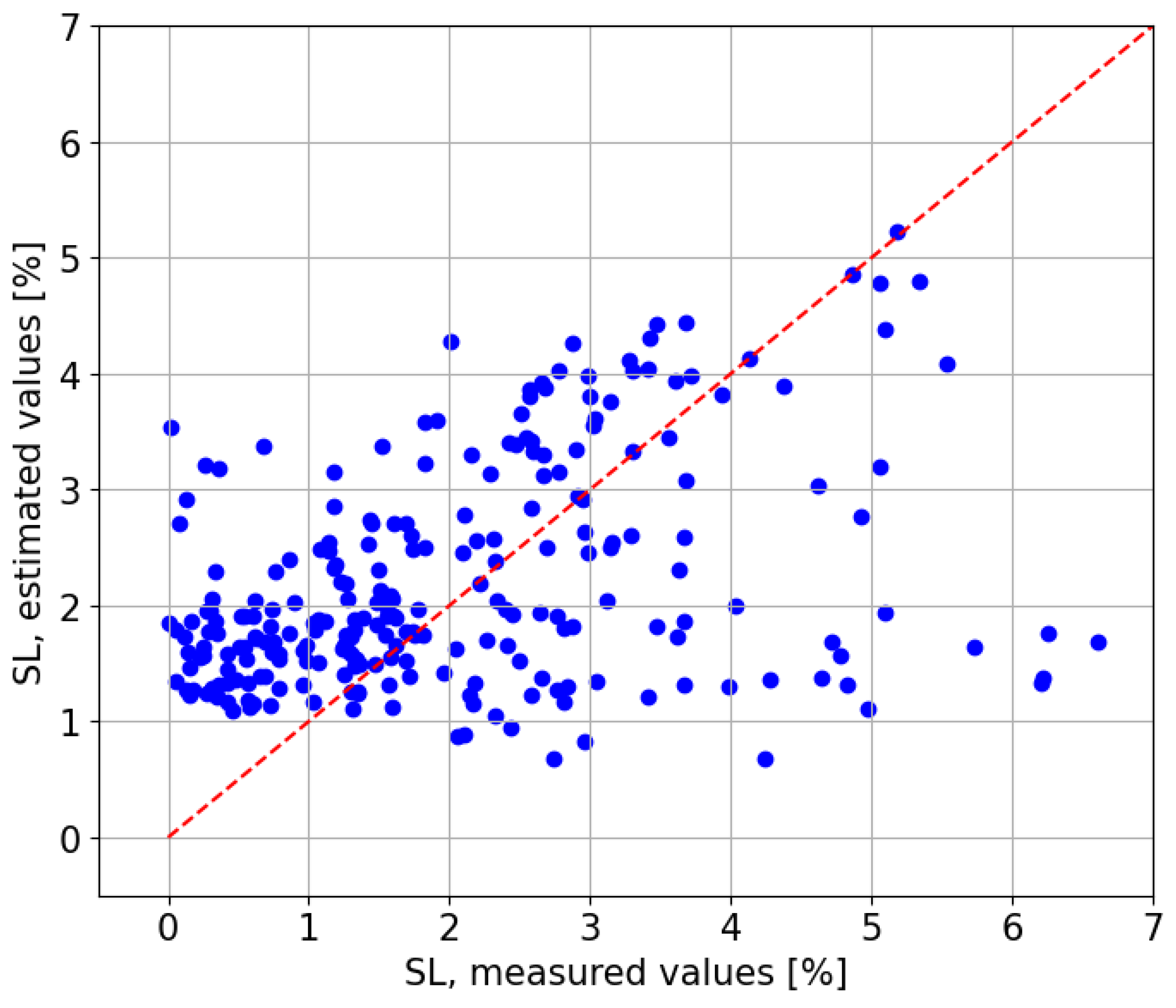
In terms of
, the model on the CIEMAT data produces a negative value of
. This means that a predictor that always returned the mean would explain the linear regression obtained from that scatter plot (see
Figure 14) better than the scatter plot itself.
3.3. Results of LightGBM Model for PV Soiling Losses Estimation
3.3.1. LightGBM Model Evaluated on CIESOL Test Set
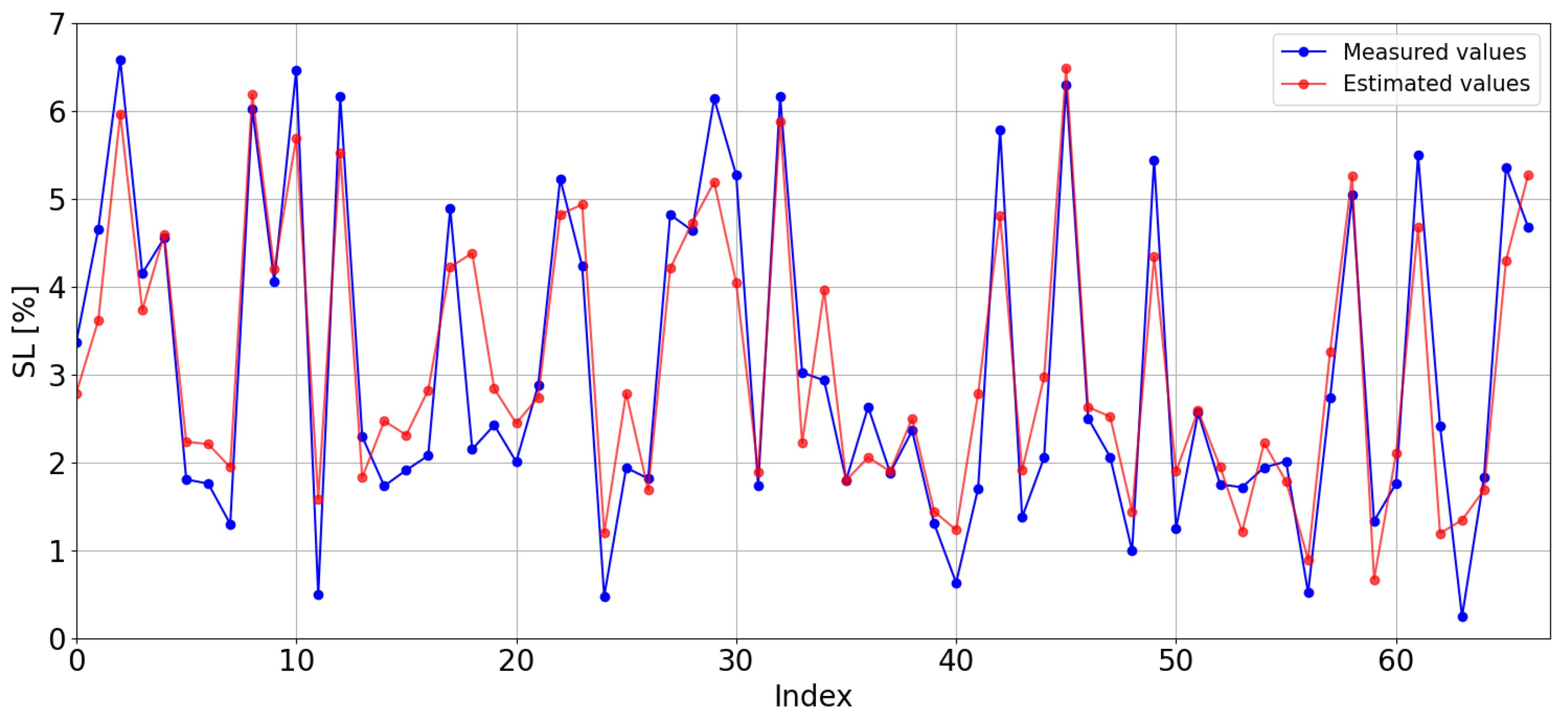
The estimations obtained with the LightGBM model trained with the CIESOL station data and the real values are shown in
Figure 15. The model tends to slightly overestimate, with estimated values generally being slightly higher than the observed ones (MBE =
). The RMSE is
of SL, the lowest value amongst Local Models.
Figure 16 compares the estimated values against the observed values, revealing a clear positive relationship with a coefficient of determination of
. The red line represents the perfect fit between the real values and the estimated values.
3.3.2. Extrapolation of the LightGBM Model to the CIEMAT Test Set
The extrapolation of the LightGBM model to the CIEMAT test set results in a model that neither generally overestimates nor underestimates (see
Figure 17), with a MBE of
, the closest value to zero amongst Extrapolated Models. The RMSE error increases significantly from
obtained in the Local Model to
in the Extrapolated Model (from
to
in normalised RMSE), the second lowest value for the ANN within the Extrapolated Model.
In terms of
, for the Extrapolated version of the LightGBM model, it shows a substantial decrease compared to the Local Model, from
to
, resulting in a scatter plot with a weakly positive linear relationship between estimated and observed values (see
Figure 18).
3.4. Results of CatBoost Model for PV Soiling Losses Estimation
Since CatBoost and LightGBM are both gradient boosting models, their structures are alike, leading to similar results.
3.4.1. CatBoost Model Evaluated on CIESOL Test Set
The estimated values obtained with the CatBoost model trained with data from the CIESOL station and the real values are displayed in
Figure 19. The model tends to slightly overestimate, with the estimated values generally being slightly higher than the observed ones (MBE =
). The RMSE is
of SL, the second-lowest value amongst the Local Models.
The estimated values obtained with the CatBoost model trained with data from the CIESOL station against the real values are displayed in
Figure 20. The
result is
.
3.4.2. Extrapolation of the CatBoost Model to the CIEMAT Test Set
The extrapolation of the CatBoost model to the CIEMAT test set results in a model that does not generally overestimate (see
Figure 21), with a MBE of
, the highest value amongst Extrapolated Models. The RMSE error significantly increases from
obtained in the Local Model to
in the Extrapolated Model (from
to
in normalised RMSE), similar to the result obtained for the LightGBM model.
In terms of
for the Extrapolated version of the CatBoost model, there is a substantial decrease compared to the Local Model, from
to
, a weakly linear relationship between estimated and observed values (see
Figure 22).
3.5. Results of the ANN Model for PV Soiling Losses Estimation
3.5.1. ANN Model Evaluated on CIESOL Test Set
The estimated values obtained with the ANN model trained with the data from the CIESOL station and the real values are displayed in
Figure 23. The model neither generally overestimates nor underestimates (MBE =
), achieving the lowest value not only within the Local Models but amongst all models. The RMSE obtained is
of SL, the highest value amongst Local Models, which is close to the value obtained by the kNN model (
).
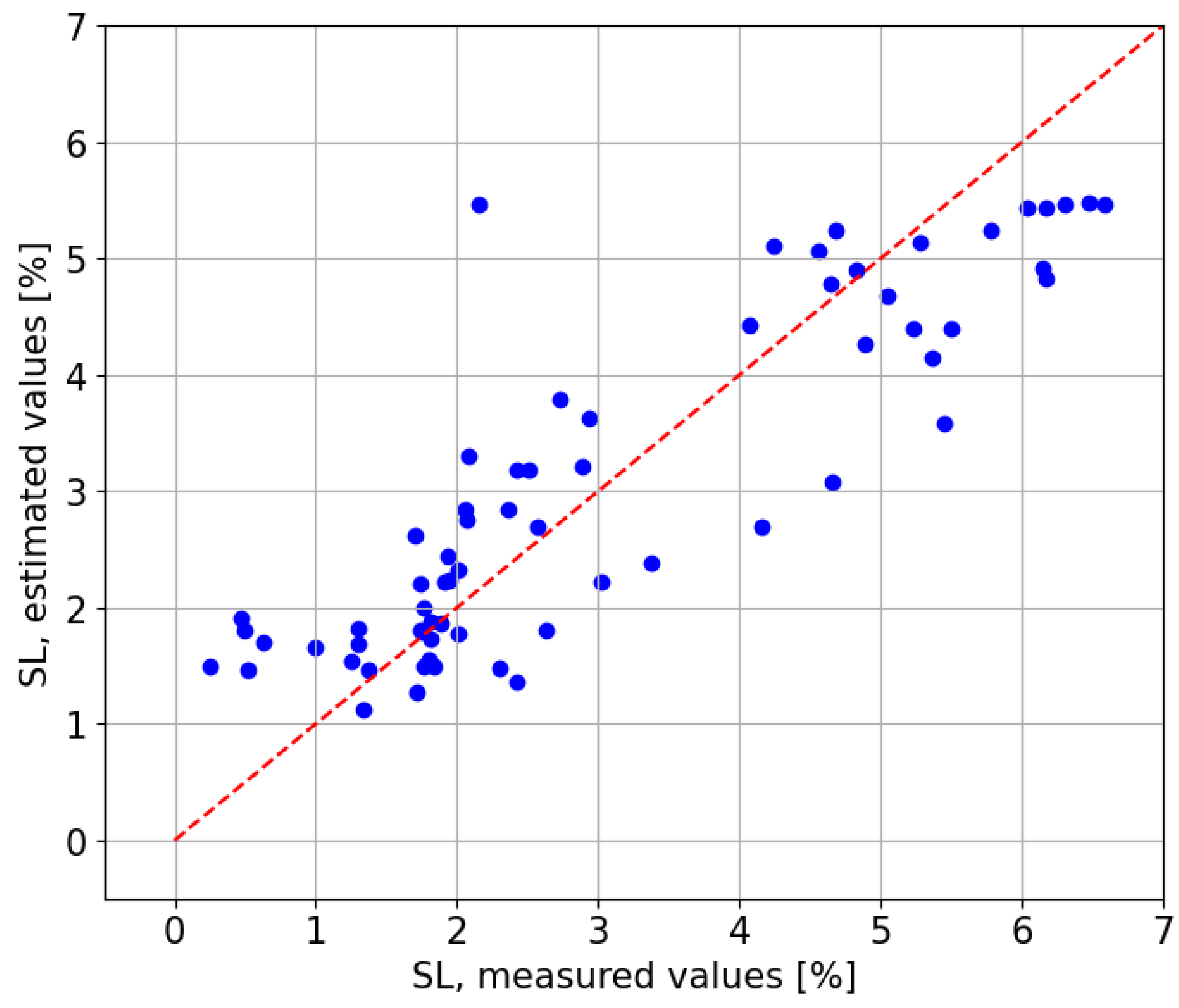
Figure 24 compares the estimated values against the observed values, revealing a clear positive relationship with a coefficient of determination of
. The red line represents the perfect fit between real values and estimated values. This value of
is the lowest obtained for a Local Model.
3.5.2. Extrapolation of the ANN Model to the CIEMAT Test Set
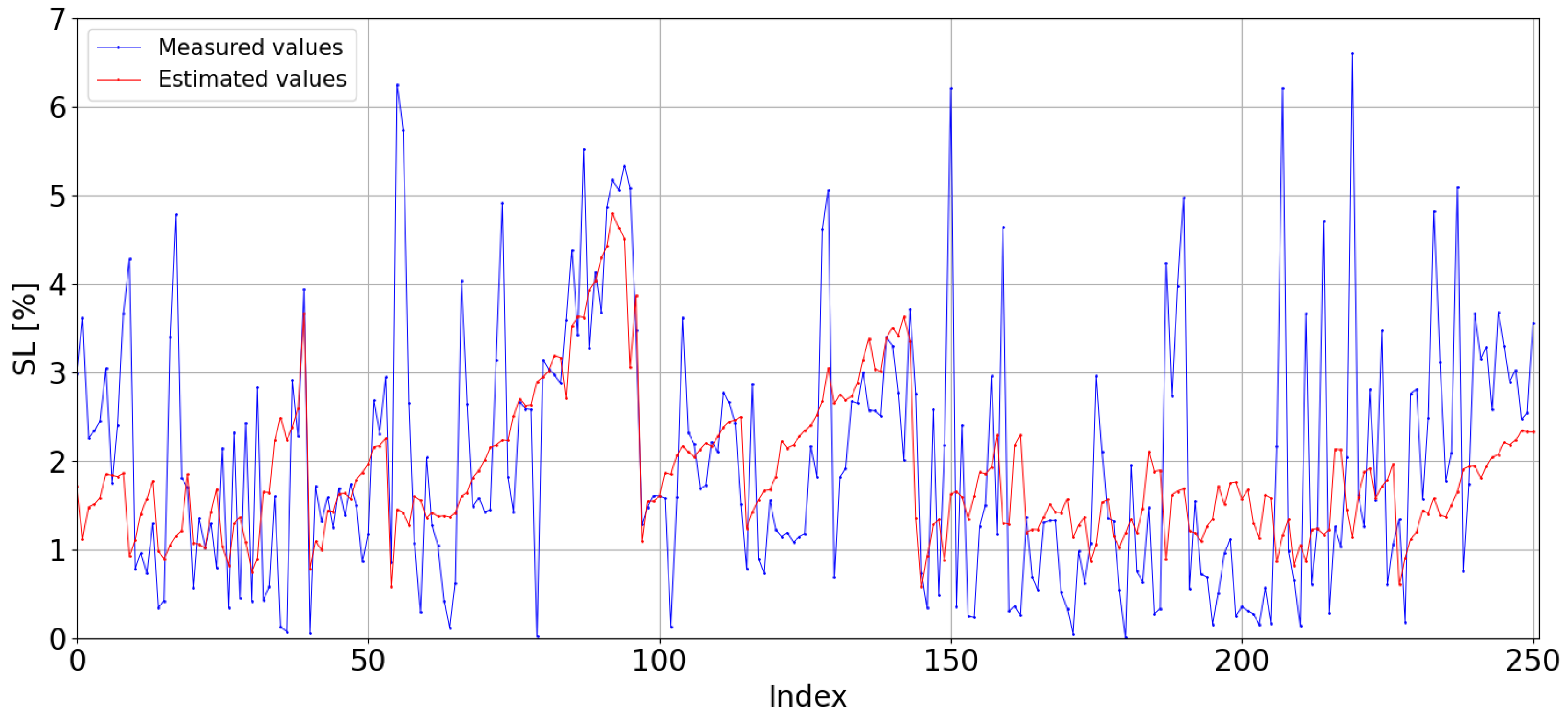
The extrapolation of the ANN model to the CIEMAT test set results in a model that largely underestimates (see
Figure 25), with a MBE of
, which is the lowest value amongst Extrapolated Models. The RMSE error significantly increases from
in the Local Model to
in the Extrapolated Model (from
to
in normalised RMSE), which is the lowest value amongst Extrapolated Models. Since the ANN Local Model obtained the highest errors within the Local Models and the ANN Extrapolated Model obtained the lowest errors, ANN is the model which achieves the smallest difference between models, making it the best for extrapolation.
In terms of
for the Extrapolated version of the ANN model, it has shown a substantial decrease compared to the Local Model, from
to
, a weak linear relationship between estimated and observed values (see
Figure 26); however, it is the highest value amongst Extrapolated Models, making ANN the best model in terms of extrapolation.
3.6. Comparison with Existing Literature
This study aims to assess whether machine learning models trained on data from a specific site can reliably estimate soiling losses when applied to a different geographical location. To this end, our results are compared with previously published models, particularly those presented by Lopez-Lorente et al. in
Characterizing soiling losses for photovoltaic systems in dry climates: A case study in Cyprus [
26]. Their work characterizes soiling losses using both physical and machine learning models evaluated with experimental data from Nicosia, Cyprus.
In that study, physical models developed at different locations in Cyprus were tested, offering a relevant benchmark for our models trained with Madrid (CIEMAT) data. On the other hand, the machine learning models were trained and tested using a two-year dataset from Cyprus, including meteorological variables, particulate concentration, and soiling losses. The data were split 50:50 for training and testing and will be used for comparison with the models developed in this paper trained and tested with data from Almeria (CIESOL).
The physical models used in the reference study include the following:
Kimber Model [
32]: this model estimates soiling losses based on daily soiling rate, rainfall threshold for cleaning, and a post-rain grace period.
You Model [
33]: this models efficiency loss as a function of dust deposition density, based on PM concentration and number of dry days.
Coello and Boyle Model [
19]: this model incorporates PM concentration, deposition velocity, rainfall, and the tilt angle of the PV panel.
In addition, three gradient boosting algorithms were used for machine learning: XGBoost, LightGBM, and CatBoost, as described and utilised in this paper.
Table 9 presents the comparative results using normalized metrics: normalized mean bias error (nMBE), normalized root mean square error (nRMSE), and the coefficient of determination (
). The Kimber model achieved the best nMBE (
), while the LightGBM model evaluated on the CIESOL dataset had the best performance for nRMSE (
) and
(
).
Two categories of models are considered:
Locally Evaluated Models: Models evaluated on data from the same location at which they were developed. This includes the CIESOL models and the boosting models from Cyprus. Among these, the best-performing model is LightGBM trained on CIESOL data (nMBE = 1.65%, nRMSE = 22.30%, = 0.86).
Extrapolated Models: Models evaluated on data from locations different from where they were trained. This group includes machine learning models tested on CIEMAT data and the physical models (Kimber, You, and Coello) applied in Cyprus. The Kimber model stands out in this group (nMBE = , = 0.56), while the Coello model achieved the best nRMSE (55.57%).
Machine learning models transferred to the CIEMAT dataset experienced performance degradation, with nRMSE values ranging from 66.12% to 76.32% and nMBE from 2.27% to 19.56%. These results, however, remain comparable to the physical model metrics.
Models trained and evaluated on CIESOL data showed strong predictive performance, surpassing the machine learning models developed for Cyprus. However, when applied to new geographical contexts (CIEMAT), their accuracy decreased considerably. Nevertheless, their normalized error metrics are still comparable to those of the physical models tested in Cyprus, suggesting a promising yet limited generalization capability of machine learning approaches for soiling loss estimation.
3.7. Global Model with Data from CIESOL and CIEMAT
In order to develop a model capable of estimating in different locations, data from both CIESOL and CIEMAT was combined as shown in
Table 10 to train an ANN following the same architecture as in
Figure 27. ANN was selected for the development of the global considering that ANN achieved the best results for an Extrapolated Model.
The Extrapolated Models struggled to accurately estimate across the entire dataset range. This issue arises because the soiling patterns used for training differ significantly between locations. Specifically, in the CIESOL dataset, which was used to train the Extrapolated Models, there were very few data points where SL fell below
. In contrast, the CIEMAT test data generally exhibited lower SL values, with instances below
being more common. As a result, the models underperformed in estimating SL values under
(see
Figure 18,
Figure 22 and
Figure 26), as these cases were not adequately represented in the training data. To ensure that the model learned from the entire range of soiling losses in both the training and testing datasets, stratification using binning was performed. This technique involves sorting the target variable values, dividing them into 10 bins, and then splitting the data in a way that maintains the distribution of these values in both training and test sets.
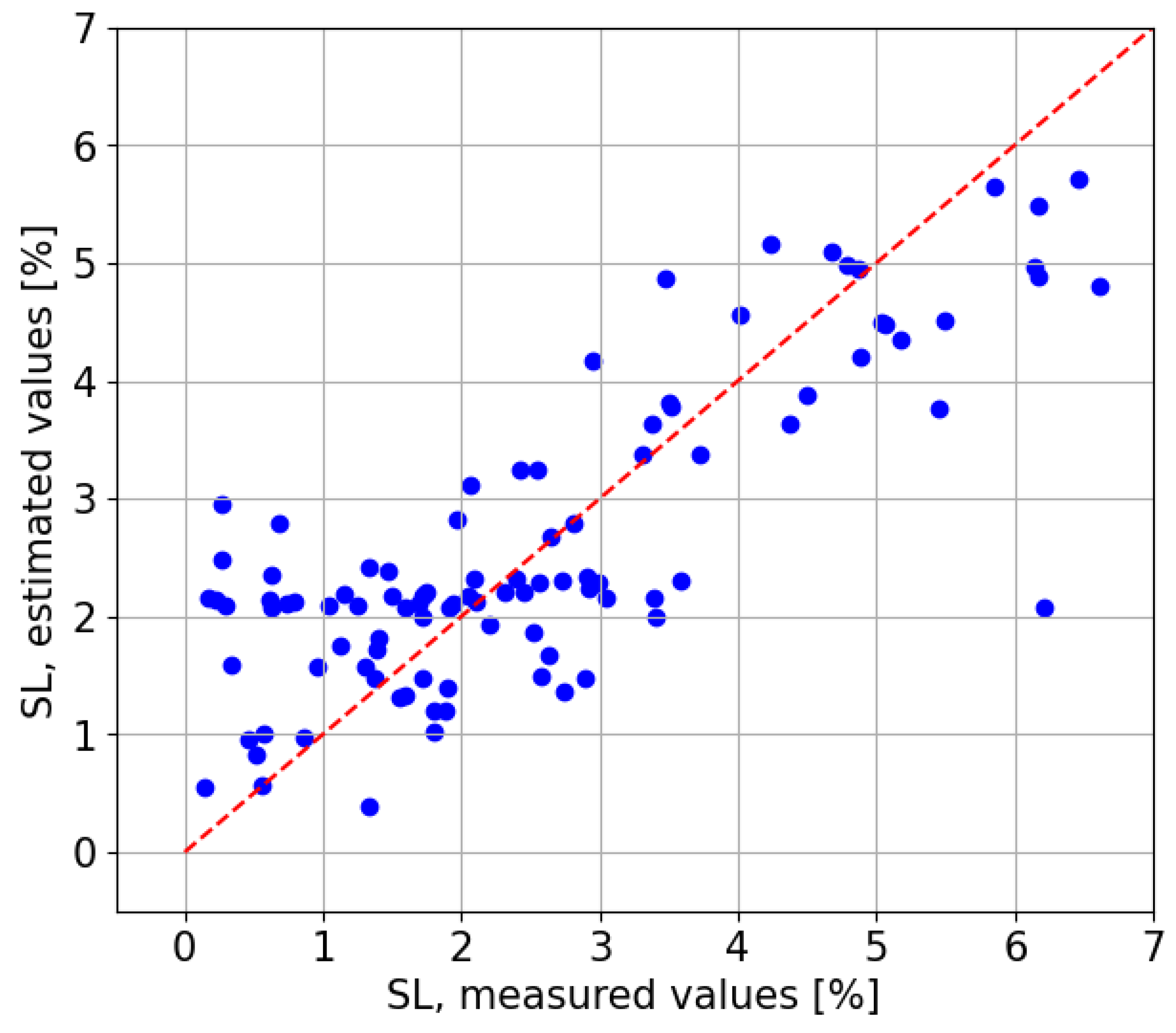
The results obtained are rather promising (see
Table 8). This model achieves an MBE of
(
) and a RMSE of
(nRMSE =
). As for the
between estimated and observed SLs, a coefficient of determination of
was obtained (see
Figure 28). This means that this Global Model trained with a combined dataset with data from both locations obtains a lower error than any Extrapolated Model (evaluated on CIEMAT test dataset). At the same time,
showed similar results to the Local Models (trained on the CIESOL training dataset and tested on the CIEMAT test dataset).
4. Discussion
The primary goal of this study was to develop and evaluate machine learning models for estimating soiling losses in photovoltaic solar panels and to assess their ability to generalize across different locations. A series of machine learning models were developed and tested, including LightGBM, artificial neural networks (ANNs), and others, to determine which would provide the most accurate soiling loss estimates.
Initially, local models were trained using data from a specific site. Among these models, LightGBM demonstrated the best performance, with an RMSE of 0.68% and a normalized RMSE (nRMSE) of 22.46%. This model also showed strong predictive power with an value of 0.86 when comparing the observed and predicted soiling losses. These results suggest that LightGBM is effective for local estimations, especially when trained on data that reflect the particular environmental conditions of the region where the model was developed.
However, when these models were tasked with extrapolating soiling losses to a different location from the one they were originally trained on, their performance worsened, particularly in predicting soiling losses below 1%, a range that was under-represented in the original training datasets. Extrapolation, a common challenge in machine learning models, highlighted the need for a model that could generalise well across regions with varying environmental conditions. Among the models tested, the ANN stood out as the most flexible, yielding the lowest RMSE and highest values during extrapolation. This flexibility made it the model of choice for constructing a Global Model that incorporated data from two different datasets: CIESOL and CIEMAT.
The Global Model was developed by merging data from both datasets and applying stratification to ensure robust performance across the full range of soiling losses. It significantly outperformed the extrapolated models, which were trained on a single location and tested on another. The Global Model achieved an RMSE of 1.02%, nRMSE of 40.50%, and
of 0.62, reflecting a significant improvement over the extrapolated models. In addition to outperforming the extrapolated models, the Global Model also demonstrated strong results when compared to well-established physical models evaluated in cross-location scenarios. For instance, the physical model developed by Coello and Boyle [
19], tested on Cyprus by López-Lorente et al. [
26] yielded a normalised MBE of
and a normalised RMSE of
, along with
of 0.55, compared to the
,
and
of nMBE, nRMSE and
, respectively, achieved by the Global Model.
5. Conclusions
In conclusion, the study successfully developed machine learning models for estimating soiling losses in PV systems. The models, particularly LightGBM for local predictions and the ANN for generalization across locations, performed well in their respective contexts. Whilst local models exhibited high accuracy in their original locations, the Global Model was able to generalise better, leading to a significant performance boost in terms of RMSE and compared to the extrapolated models. The Global Model showed strong performance because it was trained on a more diverse dataset that included a broader range of soiling conditions. In contrast, local models, although highly accurate within their own datasets, struggled to estimate soiling values that were uncommon in their training data. For example, soiling losses below 1% were rarely present in the CIESOL dataset, making it difficult for CIESOL-trained models to perform well on CIEMAT data, where such values are more frequent. This demonstrates the Global Model’s improved ability to generalise across varying environmental contexts. Additionally, the LightGBM model demonstrated strong performance due to its ability to handle non-linear relationships and perform well with relatively small datasets, making it a robust option for soiling loss estimation.
Future work should focus on enhancing both the performance and general applicability of the proposed models, particularly the Global Model. One of the most immediate steps is to test the current Global Model in a wider range of geographic locations with different environmental conditions. This would help evaluate its ability to generalise and identify potential areas where performance may decrease due to factors that are not present in the original training data. At the same time, the development of a new version of the Global Model that incorporates training data from a broader variety of locations is recommended. Including regions with diverse climates and a wider spectrum of soiling levels would allow the model to better represent the variability of environmental influences on soiling losses. This expansion is expected to improve its accuracy and make it more robust for global applications.
In addition, the integration of Geographic Information System (GIS) tools and satellite data represents a promising direction for enhancing the capabilities of soiling loss prediction models. These external data sources can provide real-time, location-specific information on key environmental variables such as atmospheric temperature, wind speed, relative humidity, and particulate matter. Incorporating this information into the models would enable more dynamic and geographically adaptable predictions. Furthermore, since the current models are based on accessible meteorological variables, they are well suited for integration with satellite and remote sensing platforms, which can help scale their application across broader regions without the need for extensive on-site measurements.
Further exploration of LightGBM is also encouraged. This model demonstrated strong results with local data and is well suited to handling large datasets and complex interactions between variables. Additional tuning and testing with larger and more varied datasets could improve its performance even further.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}