

A Survey of Machine Learning Methods for Time Series Prediction

Abstract
1. Introduction
2. Methodology
- Focus on Time Series Applications: the research must address problems involving time series data;
- Utilization of Advanced TBML Methods: studies must implement advanced TBML architectures, particularly gradient-boosted decision trees or similar structures (e.g., XGBoost 2.1.4, LightGBM, or CatBoost 1.2.7);
- Utilization of Advanced Neural Network (NN) Architectures: papers must explore sophisticated NN architectures, including but not limited to recurrent neural networks (RNN), feedforward neural networks (FFNN), convolutional neural networks (CNN), long short-term memory networks (LSTM), gated recurrent units (GRU), or Transformers;
- Direct Comparisons Using Identical Datasets: the research must present comparative evaluations of at least one TBML and one DL architecture under identical experimental setups, ensuring consistent datasets and conditions.
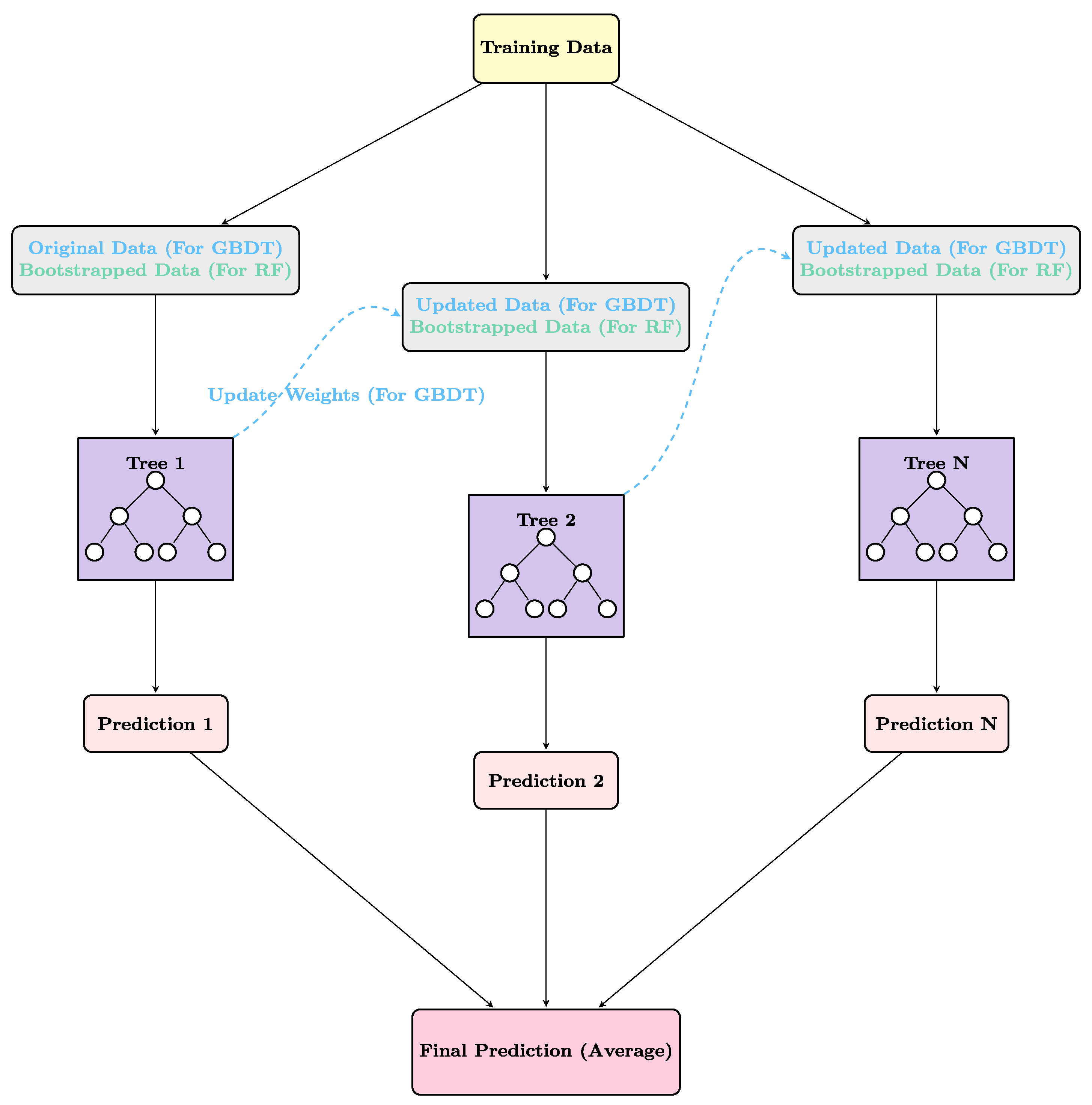
3. Tree-Based Machine Learning Architectures
3.1. Random Forests
3.2. Gradient-Boosted Decision Trees
3.2.1. XGBoost
3.2.2. LightGBM
3.2.3. CatBoost
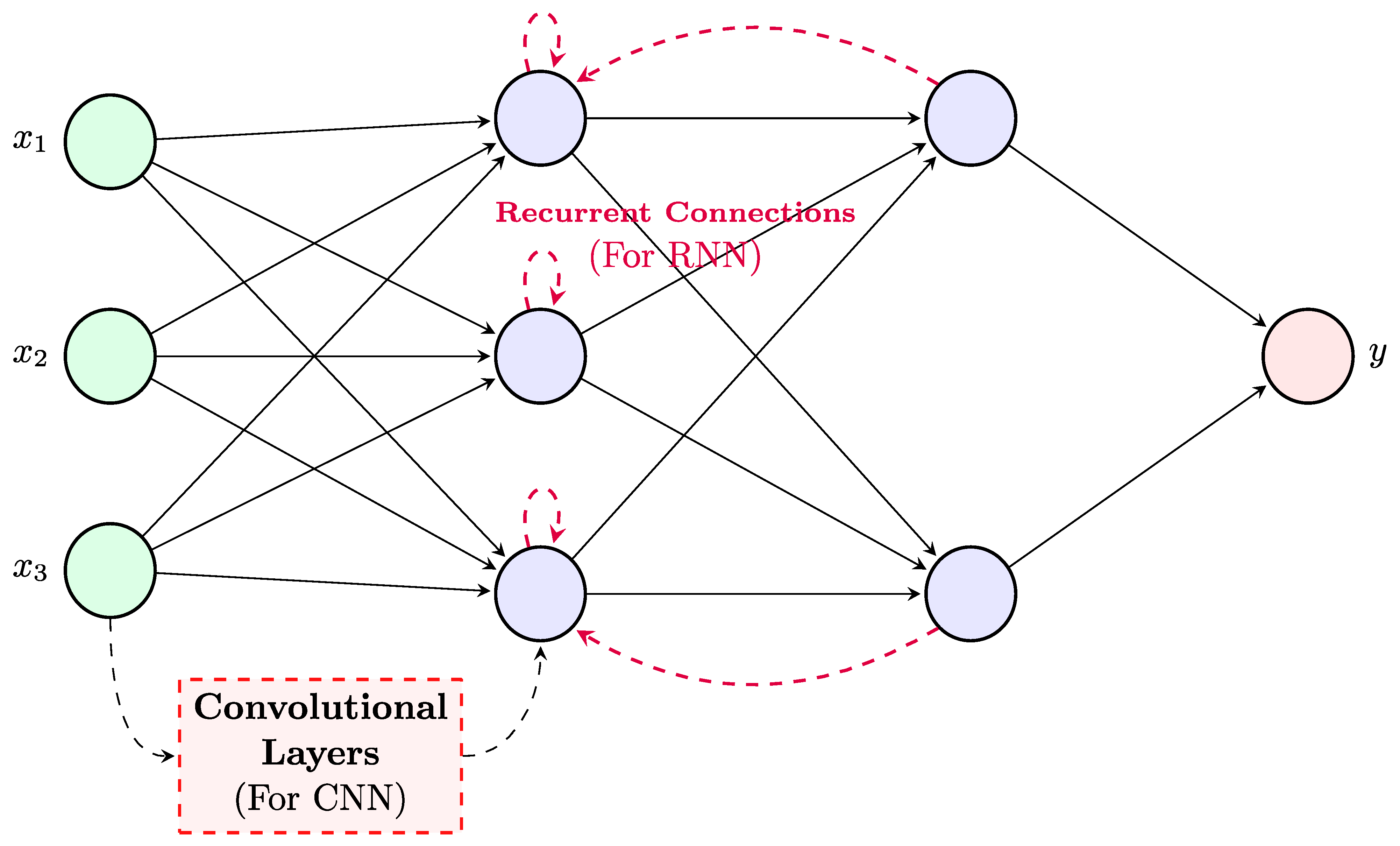
4. Deep Learning Architectures
4.1. Feed-Forward Neural Networks
Convolutional Neural Networks
4.2. Recurrent Neural Networks
4.3. Attention-Based Architectures
5. Experimental Results and Discussion
5.1. Data Preprocessing
5.2. Evaluation Metrics
5.3. Results
5.3.1. Overall Model Performance
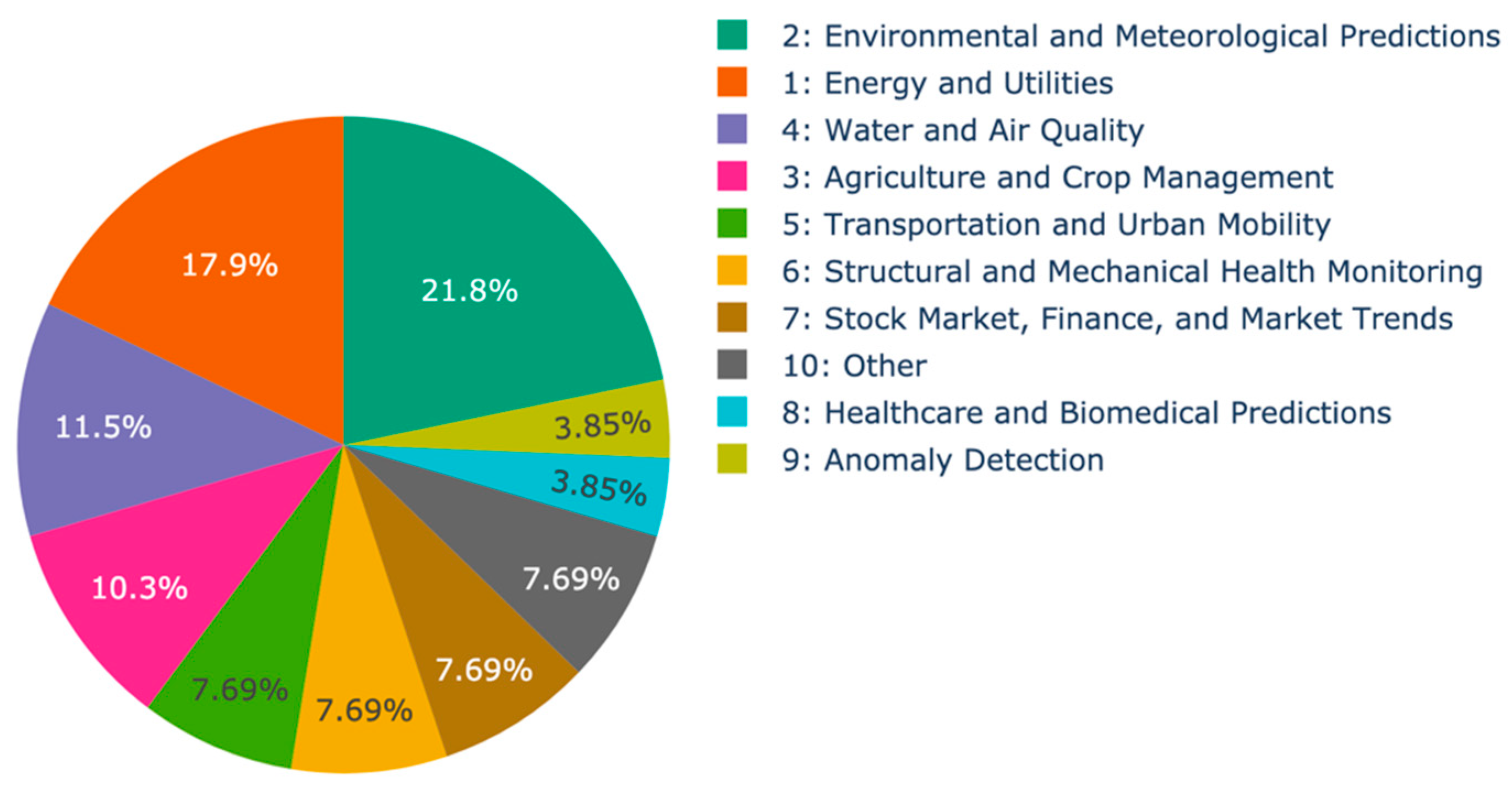
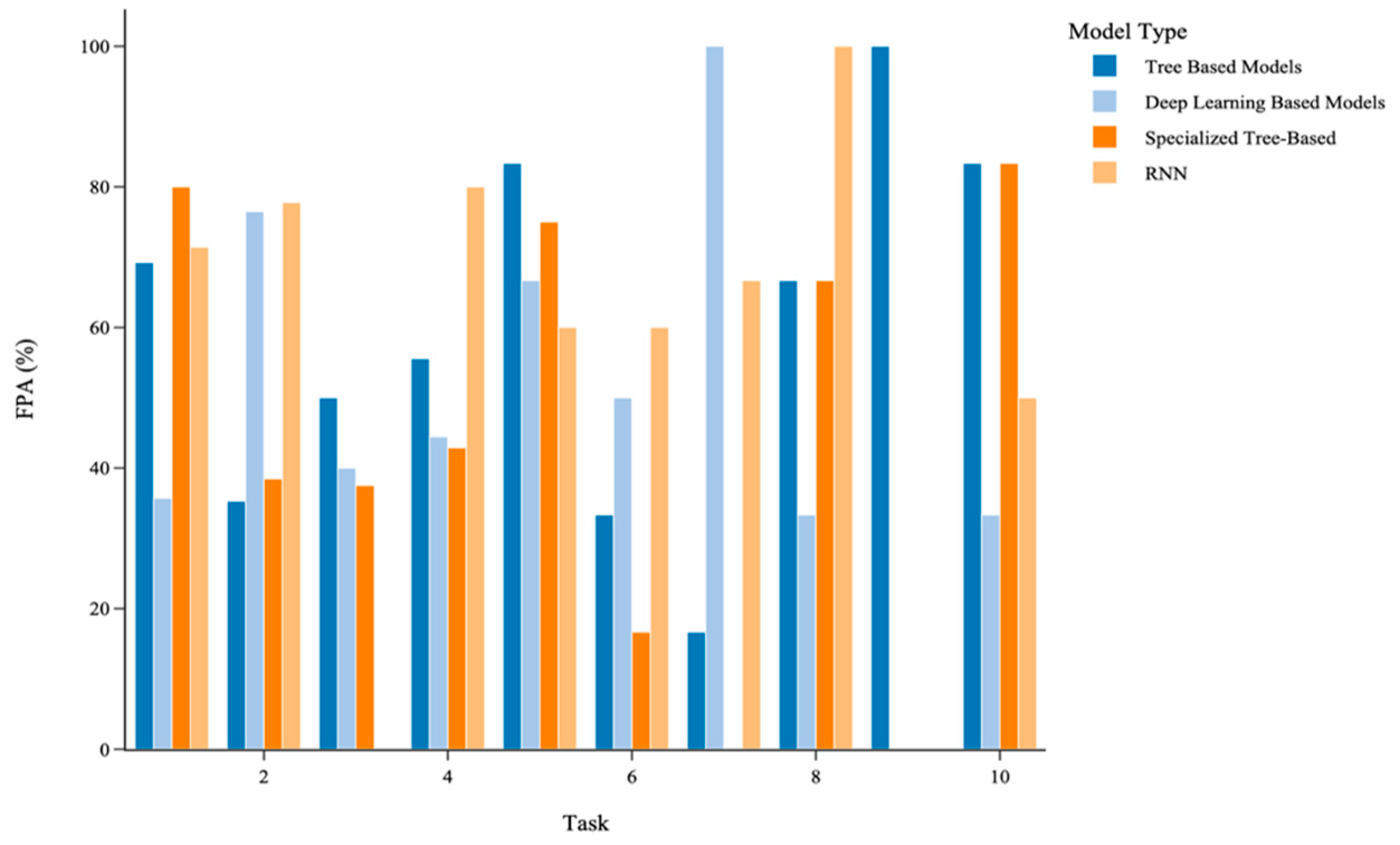
5.3.2. Task-Specific Model Performance Analysis
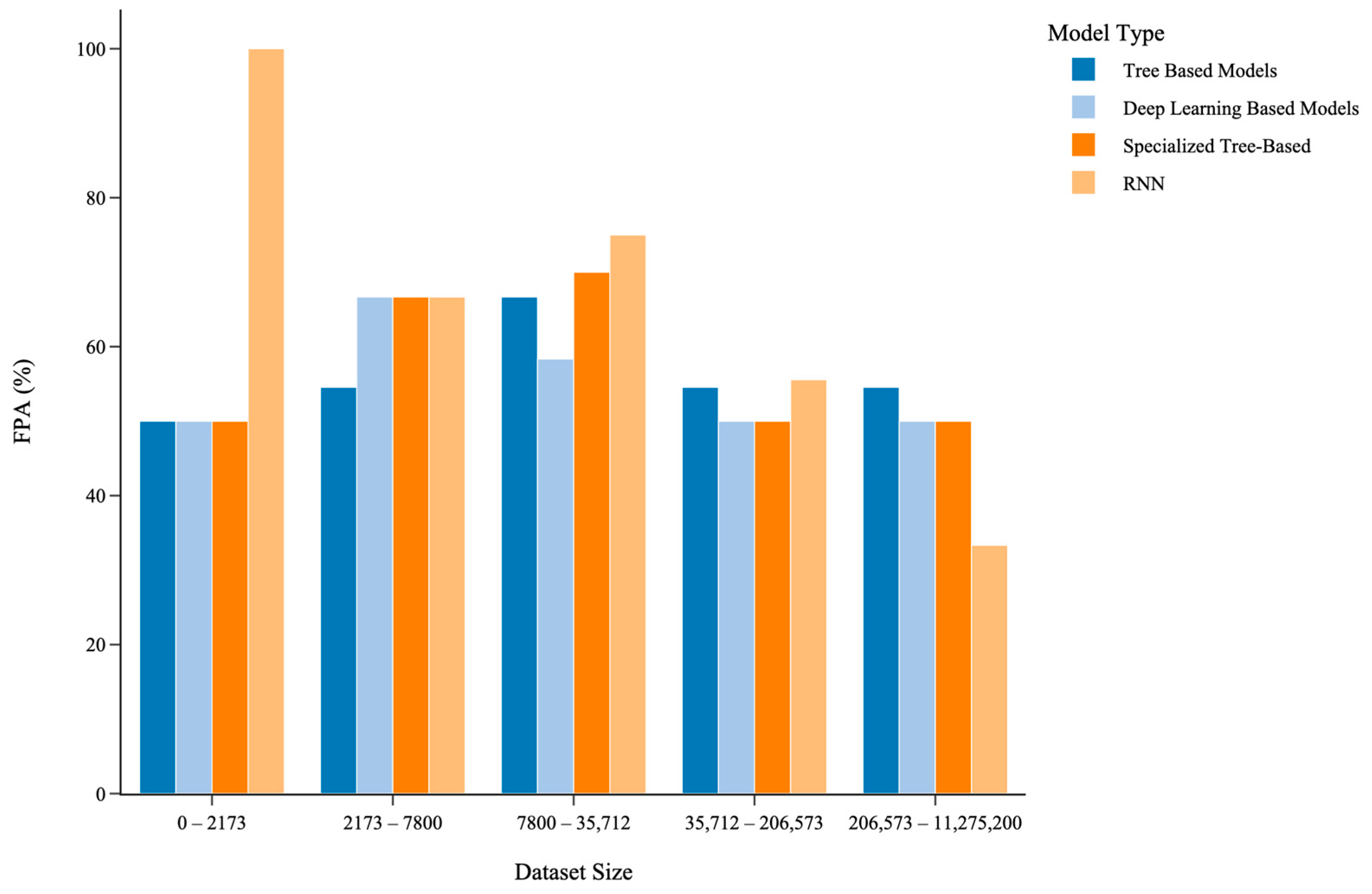
5.3.3. Impact of Dataset Size on Model Performance
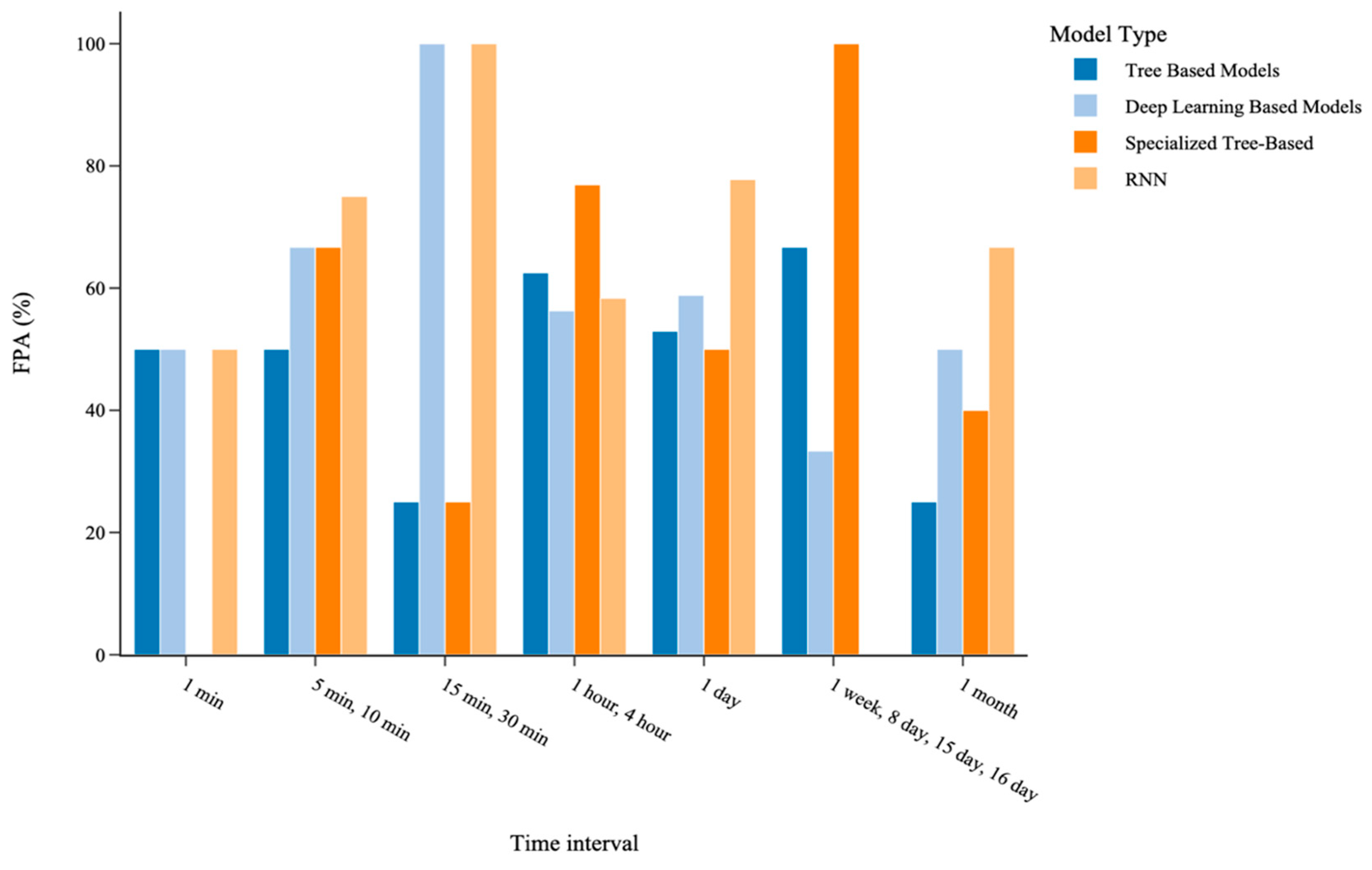
5.3.4. Impact of Data Time Interval on Model Performance
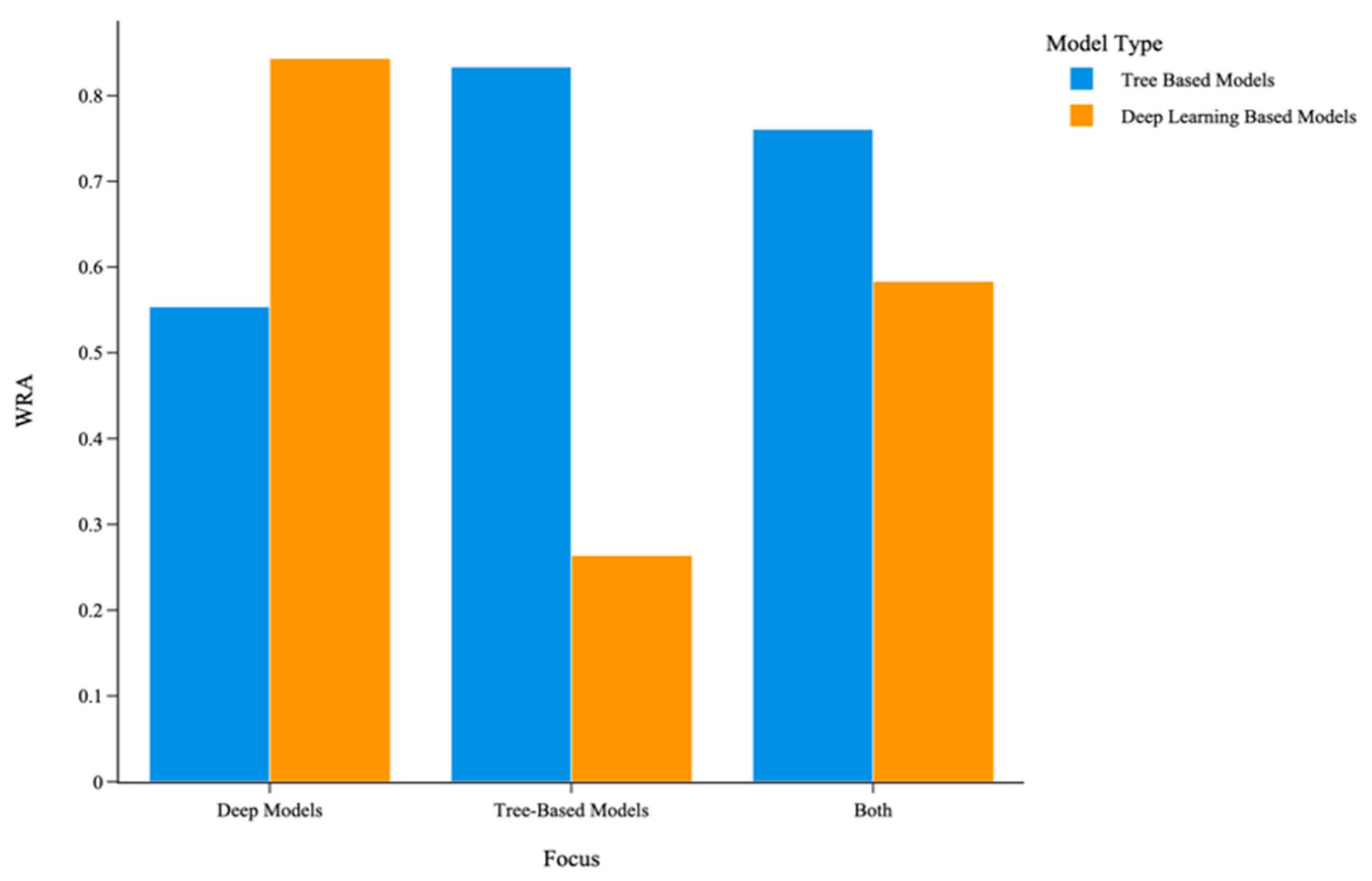
5.3.5. Impact of Research Focus on Observed Model Performance
- Deep Learning-Focused Papers:When the primary focus of the paper is on deep learning models, DL models outperform TBML models significantly. The FPA score for DL models is 33.79% higher, and the WRA score is 0.2891 points higher than TBML models. This finding suggests that papers with a DL emphasis may introduce methodological, architectural, or experimental advantages tailored to highlight the DL performance.
- Tree-Based Model-Focused Papers:Conversely, when papers focus on TBML models, the observed performance skews in favor of TBML models. In this category, TBML models achieve a 66.67% higher FPA score and a 0.5694 higher WRA score compared to DL models. These results indicate that TBML-focused research often optimizes conditions or design choices that favor these methods.
- Balanced Focus Papers:In papers with no specific emphasis on either model class, TBML models slightly outperform DL models. The FPA score for TBML models is 15.23% higher, and the WRA score is 0.1771 points higher than DL models. This finding suggests that when research is conducted without bias toward a specific model class, TBML models may have a slight advantage, potentially due to their relative simplicity and robustness in a range of scenarios.
5.3.6. Model Training Time Analysis
5.3.7. Analysis of Error Metrics in Model Evaluation
Error Metrics for Classification Models
- False Positive Rate (FPR);
- Kappa Coefficient (KC);
- Positive Predictive Value (PPV);
- Negative Predictive Value (NPV);
- Receiver-Operating Characteristic (ROC) Curve;
- Matthews Correlation Coefficient (MCC);
- Area Under the ROC Curve (AUC);
- Sensitivity;
- Specificity;
- Recall;
- Precision;
- F1 Score;
- Accuracy.
Error Metrics for Regression Models
- Index of Agreement (IA);
- Normalized Mean Absolute Percentage Error (NMAPE);
- Prediction of Change in Direction (POCID);
- Mean Normalized Bias (MNB);
- Normalized Mean Bias Error (NMBE);
- Root Mean Squared Percentage Error (RMSPE);
- Root Squared Logarithmic Error (RMSLE);
- Mean;
- Percent Bias (PBIAS);
- R;
- Mean Absolute Scaled Error (MASE);
- Symmetric Mean Absolute Error (SMAPE);
- Coefficient of Variation of the Root Mean Square Error (CVRMSE);
- Nash–Sutcliffe Efficiency (NSE);
- Domain-Specific Error Metrics;
- Mean Squared Error (MSE);
- Mean Absolute Percentage Error (MAPE);
- R2;
- Mean Absolute Error (MAE);
- Root Mean Squared Error (RMSE).
5.3.8. Hyperparameter Optimization Techniques
5.3.9. Comparative Analysis of Hybrid Models
Performance of Hybrid Models vs. Individual Models
- Study [44]: a 2D CNN, 3D CNN, and XGBoost model each outperformed a hybrid RNN-CNN model;
- Study [80]: RF and XGBoost models surpassed multiple hybrid models, including CNN-LSTM, CNN-GRU, RNN-GRU, and RNN-LSTM configurations;
- Study [81]: a CatBoost model outperformed a spatio-temporal attention-based CNN and Bi-LSTM hybrid model.
Hybrid Models Compared to Other Hybrids
- Study [45]: a hybrid CNN-LSTM-Attention model outperformed a CNN-LSTM model, which in turn outperformed an LSTM-Attention model;
- Study [48]: CEEMDAN decomposition was applied to both an XGBoost and DL model. The hybrid XGBoost-CEEMDAN model performed better than its DL-based counterpart;
- Study [72]: a Bi-LSTM-LightGBM hybrid outperformed a Bi-LSTM-FFNN hybrid;
- Study [73]: LSTM models with decomposition techniques, Variational Mode Decomposition (VMD) and Empirical Mode Decomposition (EMD), were compared. The LSTM-VMD hybrid outperformed the LSTM-EMD hybrid;
- Study [74]: an Attention-based Bi-LSTM hybrid model performed better than an Attention-based Bi-GRU hybrid model;
- Study [80]: among four hybrid DL models, CNN-LSTM demonstrated the best performance, followed by CNN-GRU, RNN-GRU, and RNN-LSTM;
- Study [65]: four hybrid models were compared, with relative performances as follows: LSTM-XGBoost > FFNN-XGBoost > LSTM-MLR > FFNN-MLR;
5.4. Analysis
- TBML Models: these outperform in tasks related to energy and utilities, transportation and urban mobility, anomaly detection, and miscellaneous applications;
- DL Models: these outperform in tasks related to environmental and meteorological predictions, structural and mechanical health monitoring, and financial/market trend forecasting;
- SPTB Models: these outperform in tasks related to transportation and miscellaneous applications, while RNN models dominate in environmental, healthcare, and finance-related tasks;
- RNN Models: these outperform in tasks related to Environmental and Meteorological Predictions, Water and Air Quality, Structural and Mechanical Health Monitoring, Stock Market/Finance/Market Trends, and Healthcare and Biomedical Predictions.
- Feature Sensitivity: GBDT models are less affected by redundant or removed features, whereas the ANN performance drops significantly when redundant features are added [8];
- Feature Selection: When all features are provided, XGBoost consistently delivers the best performance. However, when variables are selected using forward selection, other DL models begin to outperform it. Interestingly, the XGBoost model utilizing all features outperforms the XGBoost model that uses only the forward-selected features [15];
- Domain-Specific Findings: LightGBM produces more accurate results for top research terms in emerging topics, even though it generally has higher errors than NN [37];
- Inference Time: One study reported inference times for their models. They compared an XGBoost model (0.001 s) with an LSTM model (0.311 s) and a Bi-LSTM model (1.45 s), finding XGBoost to be 311 times faster than Bi-LSTM and 1450 times faster than LSTM. This drastically faster inference time emphasizes its practicality in time-sensitive applications [74];
- Simulated vs. Real-World Data: LightGBM matches the neural network performance on simulated data, but outperforms on real-world datasets [51];
6. M5 and M6 Forecasting Competitions
6.1. M5 Forecasting Competition
6.1.1. M5 Accuracy Competition
- First Place: combined recursive and non-recursive LightGBM models to create 220 models, where the average of 6 models was used to forecast the series, each exploiting a different learning approach and training set;
- Second Place: created 50 LightGBM models, 5 for each of the 10 stores, utilizing a DL neural network to adjust multipliers based on historical sales data for each store;
- Third Place: employed 43 recursive neural networks (LSTMs) incorporating over 100 features;
- Fourth Place: created 40 non-recursive LightGBM models;
- Fifth Place: utilized seven recursive LightGBM models.
6.1.2. M5 Uncertainty Competition
- First Place: utilized 126 LightGBM models, one for each quantile and aggregation level;
- Second Place: combined recursive LightGBM models, statistical methods, and simple time series forecasting techniques;
- Third Place: employed a hybrid approach integrating LightGBM and neural networks;
- Fourth Place: used two LSTM-based neural networks;
- Fifth Place: implemented 280 LightGBM models in a comprehensive ensemble.
6.2. M6 Forecasting Competition
6.3. Takeaways from M5 and M6 Forecasting Competitions
7. Conclusions
8. Future Work
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lim, B.; Zohren, S. Time-series forecasting with deep learning: A survey. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 2021, 379, 20200209. [Google Scholar] [CrossRef]
- Liu, Z.; Zhu, Z.; Gao, J.; Xu, C. Forecast Methods for Time Series Data: A Survey. IEEE Access 2021, 9, 91896–91912. [Google Scholar] [CrossRef]
- Zhong, L.; Hu, L.; Zhou, H. Deep learning based multi-temporal crop classification. Remote Sens. Environ. 2019, 221, 430–443. [Google Scholar] [CrossRef]
- Ke, J.; Zheng, H.; Yang, H.; Chen, X. Short-term forecasting of passenger demand under on-demand ride services: A spatio-temporal deep learning approach. Transp. Res. Part C Emerg. Technol. 2017, 85, 591–608. [Google Scholar] [CrossRef]
- Ju, Y.; Sun, G.; Chen, Q.; Zhang, M.; Zhu, H.; Rehman, M.U. A Model Combining Convolutional Neural Network and LightGBM Algorithm for Ultra-Short-Term Wind Power Forecasting. IEEE Access 2019, 7, 28309–28318. [Google Scholar] [CrossRef]
- Rafi, S.H.; Nahid Al, M.; Deeba, S.R.; Hossain, E. A Short-Term Load Forecasting Method Using Integrated CNN and LSTM Network. IEEE Access 2021, 9, 32436–32448. [Google Scholar] [CrossRef]
- Galicia, A.; Talavera-Llames, R.; Troncoso, A.; Koprinska, I.; Martínez-Álvarez, F. Multi-step forecasting for big data time series based on ensemble learning. Knowl. -Based Syst. 2019, 163, 830–841. [Google Scholar] [CrossRef]
- Bagherzadeh, F.; Mehrani, M.-J.; Basirifard, M.; Roostaei, J. Comparative study on total nitrogen prediction in wastewater treatment plant and effect of various feature selection methods on machine learning algorithms performance. J. Water Process Eng. 2021, 41, 102033. [Google Scholar] [CrossRef]
- Kang, Y.; Ozdogan, M.; Zhu, X.; Ye, Z.; Hain, C.; Anderson, M. Comparative assessment of environmental variables and machine learning algorithms for maize yield prediction in the US Midwest. Environ. Res. Lett. 2020, 15, 064005. [Google Scholar] [CrossRef]
- Chakraborty, D.; Elzarka, H. Advanced machine learning techniques for building performance simulation: A comparative analysis. J. Build. Perform. Simul. 2019, 12, 193–207. [Google Scholar] [CrossRef]
- Zheng, J.; Zhang, H.; Dai, Y.; Wang, B.; Zheng, T.; Liao, Q.; Liang, Y.; Zhang, F.; Song, X. Time series prediction for output of multi-region solar power plants. Appl. Energy 2020, 257, 114001. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, C.; Jiang, Y.; Sun, L.; Zhao, R.; Yan, K.; Wang, W. Accurate prediction of water quality in urban drainage network with integrated EMD-LSTM model. J. Clean. Prod. 2022, 354, 131724. [Google Scholar] [CrossRef]
- Mazzia, V.; Khaliq, A.; Chiaberge, M. Improvement in Land Cover and Crop Classification based on Temporal Features Learning from Sentinel-2 Data Using Recurrent-Convolutional Neural Network (R-CNN). Appl. Sci. 2020, 10, 238. [Google Scholar] [CrossRef]
- Barrera-Animas, A.Y.; Oyedele, L.O.; Bilal, M.; Akinosho, T.D.; Delgado, J.M.D.; Akanbi, L.A. Rainfall prediction: A comparative analysis of modern machine learning algorithms for time-series forecasting. Mach. Learn. Appl. 2022, 7, 100204. [Google Scholar] [CrossRef]
- Shin, Y.; Kim, T.; Hong, S.; Lee, S.; Lee, E.; Hong, S.; Lee, C.; Kim, T.; Park, M.S.; Park, J.; et al. Prediction of Chlorophyll-a Concentrations in the Nakdong River Using Machine Learning Methods. Water 2020, 12, 1822. [Google Scholar] [CrossRef]
- Luo, J.; Zhang, Z.; Fu, Y.; Rao, F. Time series prediction of COVID-19 transmission in America using LSTM and XGBoost algorithms. Results Phys. 2021, 27, 104462. [Google Scholar] [CrossRef]
- Gong, M.; Bai, Y.; Qin, J.; Wang, J.; Yang, P.; Wang, S. Gradient boosting machine for predicting return temperature of district heating system: A case study for residential buildings in Tianjin. J. Build. Eng. 2020, 27, 100950. [Google Scholar] [CrossRef]
- Wang, Z.; Hong, T.; Li, H.; Ann Piette, M. Predicting city-scale daily electricity consumption using data-driven models. Adv. Appl. Energy 2021, 2, 100025. [Google Scholar] [CrossRef]
- Yang, Y.; Heppenstall, A.; Turner, A.; Comber, A. Using graph structural information about flows to enhance short-term demand prediction in bike-sharing systems. Comput. Environ. Urban Syst. 2020, 83, 101521. [Google Scholar] [CrossRef]
- Wei, Z.; Zhang, T.; Yue, B.; Ding, Y.; Xiao, R.; Wang, R.; Zhai, X. Prediction of residential district heating load based on machine learning: A case study. Energy 2021, 231, 120950. [Google Scholar] [CrossRef]
- Zahoor Ali, K.; Muhammad, A.; Javaid, N.; Malik, N.S.; Shafiq, M.; Choi, J.-G. Electricity Theft Detection Using Supervised Learning Techniques on Smart Meter Data. Sustainability 2020, 12, 8023. [Google Scholar] [CrossRef]
- Hussein, E.A.; Thron, C.; Ghaziasgar, M.; Bagula, A.; Vaccari, M. Groundwater Prediction Using Machine-Learning Tools. Algorithms 2020, 13, 300. [Google Scholar] [CrossRef]
- Su, H.; Wang, A.; Zhang, T.; Qin, T.; Du, X.; Yan, X.-H. Super-resolution of subsurface temperature field from remote sensing observations based on machine learning. Int. J. Appl. Earth Obs. Geoinf. 2021, 102, 102440. [Google Scholar] [CrossRef]
- Kumar, V.; Kedam, N.; Sharma, K.V.; Mehta, D.J.; Caloiero, T. Advanced Machine Learning Techniques to Improve Hydrological Prediction: A Comparative Analysis of Streamflow Prediction Models. Water 2023, 15, 2527. [Google Scholar] [CrossRef]
- Jing, Y.; Hu, H.; Guo, S.; Wang, X.; Chen, F. Short-Term Prediction of Urban Rail Transit Passenger Flow in External Passenger Transport Hub Based on LSTM-LGB-DRS. IEEE Trans. Intell. Transp. Syst. 2021, 22, 4611–4621. [Google Scholar] [CrossRef]
- Li, Y.; Bao, T.; Gao, Z.; Shu, X.; Zhang, K.; Xie, L.; Zhang, Z. A new dam structural response estimation paradigm powered by deep learning and transfer learning techniques. Struct. Health Monit. 2022, 21, 770–787. [Google Scholar] [CrossRef]
- Yu, G.; Zhang, S.; Hu, M.; Wang, Y.K. Prediction of Highway Tunnel Pavement Performance Based on Digital Twin and Multiple Time Series Stacking. Adv. Civ. Eng. 2020, 2020, 8824135. [Google Scholar] [CrossRef]
- Torres, J.F.; Martínez-Álvarez, F.; Troncoso, A. A deep LSTM network for the Spanish electricity consumption forecasting. Neural Comput. Appl. 2022, 34, 10533–10545. [Google Scholar] [CrossRef]
- Ge, Y.; Wang, Q.; Wang, L.; Wu, H.; Peng, C.; Wang, J.; Xu, Y.; Xiong, G.; Zhang, Y.; Yi, Y. Predicting post-stroke pneumonia using deep neural network approaches. Int. J. Med. Inform. 2019, 132, 103986. [Google Scholar] [CrossRef]
- Li, G.; Zhang, A.; Zhang, Q.; Wu, D.; Zhan, C. Pearson Correlation Coefficient-Based Performance Enhancement of Broad Learning System for Stock Price Prediction. IEEE Trans. Circuits Syst. II Express Briefs 2022, 69, 2413–2417. [Google Scholar] [CrossRef]
- Sundararajan, K.; Garg, L.; Srinivasan, K.; Ali Kashif, B.; Jayakumar, K.; Ganapathy, G.P.; Senthil Kumaran, S.; Meena, T. A Contemporary Review on Drought Modeling Using Machine Learning Approaches. Comput. Model. Eng. Sci. 2021, 128, 447–487. [Google Scholar] [CrossRef]
- Wu, W.; Chen, J.; Yang, Z.; Tindall, M.L. A Cross-Sectional Machine Learning Approach for Hedge Fund Return Prediction and Selection. Manag. Sci. 2021, 67, 4577–4601. [Google Scholar] [CrossRef]
- López Santos, M.; García-Santiago, X.; Echevarría Camarero, F.; Blázquez Gil, G.; Carrasco Ortega, P. Application of Temporal Fusion Transformer for Day-Ahead PV Power Forecasting. Energies 2022, 15, 5232. [Google Scholar] [CrossRef]
- Shangguan, Q.; Fu, T.; Wang, J.; Fang, S.e.; Fu, L. A proactive lane-changing risk prediction framework considering driving intention recognition and different lane-changing patterns. Accid. Anal. Prev. 2022, 164, 106500. [Google Scholar] [CrossRef] [PubMed]
- Prodhan, F.A.; Zhang, J.; Yao, F.; Shi, L.; Pangali Sharma, T.P.; Zhang, D.; Cao, D.; Zheng, M.; Ahmed, N.; Mohana, H.P. Deep Learning for Monitoring Agricultural Drought in South Asia Using Remote Sensing Data. Remote Sens. 2021, 13, 1715. [Google Scholar] [CrossRef]
- Khan, P.W.; Byun, Y.C.; Park, N.; Waqas Khan, P.; Byun, Y.-C.; Lee, S.-J.; Park, N. Machine Learning Based Hybrid System for Imputation and Efficient Energy Demand Forecasting. Energies 2020, 13, 2681. [Google Scholar] [CrossRef]
- Liang, Z.; Mao, J.; Lu, K.; Ba, Z.; Li, G. Combining deep neural network and bibliometric indicator for emerging research topic prediction. Inf. Process. Manag. 2021, 58, 102611. [Google Scholar] [CrossRef]
- Cui, Z.; Qing, X.; Chai, H.; Yang, S.; Zhu, Y.; Wang, F. Real-time rainfall-runoff prediction using light gradient boosting machine coupled with singular spectrum analysis. J. Hydrol. 2021, 603, 127124. [Google Scholar] [CrossRef]
- Shen, M.; Luo, J.; Cao, Z.; Xue, K.; Qi, T.; Ma, J.; Liu, D.; Song, K.; Feng, L.; Duan, H. Random forest: An optimal chlorophyll-a algorithm for optically complex inland water suffering atmospheric correction uncertainties. J. Hydrol. 2022, 615, 128685. [Google Scholar] [CrossRef]
- Teinemaa, I.; Dumas, M.; Leontjeva, A.; Maggi, F.M. Temporal stability in predictive process monitoring. Data Min. Knowl. Discov. 2018, 32, 1306–1338. [Google Scholar] [CrossRef]
- Kwon, D.H.; Kim, J.B.; Han, Y.H. Time Series Classification of Cryptocurrency Price Trend Based on a Recurrent LSTM Neural Network. J. Inf. Process. Syst. 2019, 15, 694–706. [Google Scholar] [CrossRef]
- Geng, L.; Che, T.; Ma, M.; Tan, J.; Wang, H. Corn Biomass Estimation by Integrating Remote Sensing and Long-Term Observation Data Based on Machine Learning Techniques. Remote Sens. 2021, 13, 2352. [Google Scholar] [CrossRef]
- Ngarambe, J.; Irakoze, A.; Yun, G.Y.; Kim, G. Comparative Performance of Machine Learning Algorithms in the Prediction of Indoor Daylight Illuminances. Sustainability 2020, 12, 4471. [Google Scholar] [CrossRef]
- Seydi, S.T.; Amani, M.; Ghorbanian, A. A Dual Attention Convolutional Neural Network for Crop Classification Using Time-Series Sentinel-2 Imagery. Remote Sens. 2022, 14, 498. [Google Scholar] [CrossRef]
- Pan, S.; Yang, B.; Wang, S.; Guo, Z.; Wang, L.; Liu, J.; Wu, S. Oil well production prediction based on CNN-LSTM model with self-attention mechanism. Energy 2023, 284, 128701. [Google Scholar] [CrossRef]
- Paudel, D.; de Wit, A.; Boogaard, H.; Marcos, D.; Osinga, S.; Athanasiadis, I.N. Interpretability of deep learning models for crop yield forecasting. Comput. Electron. Agric. 2023, 206, 107663. [Google Scholar] [CrossRef]
- Ghimire, S.; Nguyen-Huy, T.; Al-Musaylh, M.S.; Deo, R.C.; Casillas-Pérez, D.; Salcedo-Sanz, S. A novel approach based on integration of convolutional neural networks and echo state network for daily electricity demand prediction. Energy 2023, 275, 127430. [Google Scholar] [CrossRef]
- Zhu, X.; Guo, H.; Huang, J.J.; Tian, S.; Zhang, Z. A hybrid decomposition and Machine learning model for forecasting Chlorophyll-a and total nitrogen concentration in coastal waters. J. Hydrol. 2023, 619, 129207. [Google Scholar] [CrossRef]
- Ravichandran, T.; Gavahi, K.; Ponnambalam, K.; Burtea, V.; Mousavi, S.J. Ensemble-based machine learning approach for improved leak detection in water mains. J. Hydroinform. 2021, 23, 307–323. [Google Scholar] [CrossRef]
- Li, L.; Dai, S.; Cao, Z.; Hong, J.; Jiang, S.; Yang, K. Using improved gradient-boosted decision tree algorithm based on Kalman filter (GBDT-KF) in time series prediction. J. Supercomput. 2020, 76, 6887–6900. [Google Scholar] [CrossRef]
- Hewamalage, H.; Bergmeir, C.; Bandara, K. Global models for time series forecasting: A Simulation study. Pattern Recognit. 2022, 124, 108441. [Google Scholar] [CrossRef]
- Li, Y.; Yang, C.; Sun, Y. Dynamic Time Features Expanding and Extracting Method for Prediction Model of Sintering Process Quality Index. IEEE Trans. Ind. Inform. 2022, 18, 1737–1745. [Google Scholar] [CrossRef]
- Srivastava, P.R.; Eachempati, P. Deep Neural Network and Time Series Approach for Finance Systems: Predicting the Movement of the Indian Stock Market. J. Organ. End User Comput. 2021, 33, 204–226. [Google Scholar] [CrossRef]
- Ting, P.Y.; Wada, T.; Chiu, Y.L.; Sun, M.T.; Sakai, K.; Ku, W.S.; Jeng, A.A.K.; Hwu, J.S. Freeway Travel Time Prediction Using Deep Hybrid Model—Taking Sun Yat-Sen Freeway as an Example. IEEE Trans. Veh. Technol. 2020, 69, 8257–8266. [Google Scholar] [CrossRef]
- Shi, J.; He, G.; Liu, X. Anomaly Detection for Key Performance Indicators Through Machine Learning. In Proceedings of the 2018 International Conference on Network Infrastructure and Digital Content (IC-NIDC), Guiyang, China, 22–24 August 2018; pp. 1–5. [Google Scholar]
- Joseph, R.V.; Mohanty, A.; Tyagi, S.; Mishra, S.; Satapathy, S.K.; Mohanty, S.N. A hybrid deep learning framework with CNN and Bi-directional LSTM for store item demand forecasting. Comput. Electr. Eng. 2022, 103, 108358. [Google Scholar] [CrossRef]
- Safat, W.; Asghar, S.; Gillani, S.A. Empirical Analysis for Crime Prediction and Forecasting Using Machine Learning and Deep Learning Techniques. IEEE Access 2021, 9, 70080–70094. [Google Scholar] [CrossRef]
- Qiu, H.; Luo, L.; Su, Z.; Zhou, L.; Wang, L.; Chen, Y. Machine learning approaches to predict peak demand days of cardiovascular admissions considering environmental exposure. BMC Med. Inform. Decis. Mak. 2020, 20, 83. [Google Scholar] [CrossRef]
- Ribeiro, A.M.N.C.; do Carmo, P.R.X.; Endo, P.T.; Rosati, P.; Lynn, T. Short- and Very Short-Term Firm-Level Load Forecasting for Warehouses: A Comparison of Machine Learning and Deep Learning Models. Energies 2022, 15, 750. [Google Scholar] [CrossRef]
- Priyadarshi, R.; Panigrahi, A.; Routroy, S.; Garg, G.K. Demand forecasting at retail stage for selected vegetables: A performance analysis. J. Model. Manag. 2019, 14, 1042–1063. [Google Scholar] [CrossRef]
- Chen, H.; Guan, M.; Li, H. Air Quality Prediction Based on Integrated Dual LSTM Model. IEEE Access 2021, 9, 93285–93297. [Google Scholar] [CrossRef]
- Ibañez, S.C.; Dajac, C.V.G.; Liponhay, M.P.; Legara, E.F.T.; Esteban, J.M.H.; Monterola, C.P. Forecasting Reservoir Water Levels Using Deep Neural Networks: A Case Study of Angat Dam in the Philippines. Water 2022, 14, 34. [Google Scholar] [CrossRef]
- Pham Hoang, V.; Trinh Tan, D.; Tieu Khoi, M.; Hoang Vuong, P.; Tan Dat, T.; Khoi Mai, T.; Hoang Uyen, P.; The Bao, P. Stock-Price Forecasting Based on XGBoost and LSTM. Comput. Syst. Sci. Eng. 2022, 40, 237–246. [Google Scholar] [CrossRef]
- Farsi, M. Application of ensemble RNN deep neural network to the fall detection through IoT environment. Alex. Eng. J. 2021, 60, 199–211. [Google Scholar] [CrossRef]
- Nan, S.; Tu, R.; Li, T.; Sun, J.; Chen, H. From driving behavior to energy consumption: A novel method to predict the energy consumption of electric bus. Energy 2022, 261, 125188. [Google Scholar] [CrossRef]
- Comert, G.; Khan, Z.; Rahman, M.; Chowdhury, M. Grey models for short-term queue length predictions for adaptive traffic signal control. Expert Syst. Appl. 2021, 185, 115618. [Google Scholar] [CrossRef]
- Liu, S.; Zeng, A.; Lau, K.; Ren, C.; Chan, P.-w.; Ng, E. Predicting long-term monthly electricity demand under future climatic and socioeconomic changes using data-driven methods: A case study of Hong Kong. Sustain. Cities Soc. 2021, 70, 102936. [Google Scholar] [CrossRef]
- Abdikan, S.; Sekertekin, A.; Narin, O.G.; Delen, A.; Balik Sanli, F. A comparative analysis of SLR, MLR, ANN, XGBoost and CNN for crop height estimation of sunflower using Sentinel-1 and Sentinel-2. Adv. Space Res. 2023, 71, 3045–3059. [Google Scholar] [CrossRef]
- Phan, Q.T.; Wu, Y.K.; Phan, Q.D.; Lo, H.Y. A Novel Forecasting Model for Solar Power Generation by a Deep Learning Framework with Data Preprocessing and Postprocessing. IEEE Trans. Ind. Appl. 2023, 59, 220–231. [Google Scholar] [CrossRef]
- Guan, S.; Wang, Y.; Liu, L.; Gao, J.; Xu, Z.; Kan, S. Ultra-short-term wind power prediction method based on FTI-VACA-XGB model. Expert Syst. Appl. 2024, 235, 121185. [Google Scholar] [CrossRef]
- Wang, X.; Li, Y.; Qiao, Q.; Tavares, A.; Liang, Y. Water Quality Prediction Based on Machine Learning and Comprehensive Weighting Methods. Entropy 2023, 25, 1186. [Google Scholar] [CrossRef]
- Li, Z.; Ma, E.; Lai, J.; Su, X. Tunnel deformation prediction during construction: An explainable hybrid model considering temporal and static factors. Comput. Struct. 2024, 294, 107276. [Google Scholar] [CrossRef]
- Pavlov-Kagadejev, M.; Jovanovic, L.; Bacanin, N.; Deveci, M.; Zivkovic, M.; Tuba, M.; Strumberger, I.; Pedrycz, W. Optimizing long-short-term memory models via metaheuristics for decomposition aided wind energy generation forecasting. Artif. Intell. Rev. 2024, 57, 45. [Google Scholar] [CrossRef]
- Zrira, N.; Kamal-Idrissi, A.; Farssi, R.; Khan, H.A. Time series prediction of sea surface temperature based on BiLSTM model with attention mechanism. J. Sea Res. 2024, 198, 102472. [Google Scholar] [CrossRef]
- Mangukiya, N.K.; Sharma, A. Alternate pathway for regional flood frequency analysis in data-sparse region. J. Hydrol. 2024, 629, 130635. [Google Scholar] [CrossRef]
- Zhang, L.; Wang, C.; Hu, W.; Wang, X.; Wang, H.; Sun, X.; Ren, W.; Feng, Y. Dynamic real-time forecasting technique for reclaimed water volumes in urban river environmental management. Environ. Res. 2024, 248, 118267. [Google Scholar] [CrossRef]
- Zhao, Z.-h.; Wang, Q.; Shao, C.-s.; Chen, N.; Liu, X.-y.; Wang, G.-b. A state detection method of offshore wind turbines’ gearbox bearing based on the transformer and GRU. Meas. Sci. Technol. 2024, 35, 025903. [Google Scholar] [CrossRef]
- Singh, R.B.; Patra, K.C.; Samantra, A.; Singh, R.B.; Patra, K.C.; Pradhan, B.; Samantra, A. HDTO-DeepAR: A novel hybrid approach to forecast surface water quality indicators. J. Environ. Manag. 2024, 352, 120091. [Google Scholar] [CrossRef]
- Inbar, O.; Avisar, D. Enhancing wastewater treatment through artificial intelligence: A comprehensive study on nutrient removal and effluent quality prediction. J. Water Process Eng. 2024, 61, 105212. [Google Scholar] [CrossRef]
- Oyucu, S.; Dümen, S.; Duru, İ.; Aksöz, A.; Biçer, E. Discharge Capacity Estimation for Li-Ion Batteries: A Comparative Study. Symmetry 2024, 16, 436. [Google Scholar] [CrossRef]
- Saravanan, K.S.; Bhagavathiappan, V. Prediction of crop yield in India using machine learning and hybrid deep learning models. Acta Geophys. 2024, 72, 4613–4632. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.-Y. LightGBM: A highly efficient gradient boosting decision tree. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 3149–3157. [Google Scholar]
- Prokhorenkova, L.; Gusev, G.; Vorobev, A.; Dorogush, A.V.; Gulin, A. CatBoost: Unbiased boosting with categorical features. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, Montréal, QC, Canada, 3–8 December 2018; pp. 6639–6649. [Google Scholar]
- Svozil, D.; Kvasnicka, V.; Pospichal, J.í. Introduction to multi-layer feed-forward neural networks. Chemom. Intell. Lab. Syst. 1997, 39, 43–62. [Google Scholar] [CrossRef]
- Gu, J.; Wang, Z.; Kuen, J.; Ma, L.; Shahroudy, A.; Shuai, B.; Liu, T.; Wang, X.; Wang, G.; Cai, J.; et al. Recent advances in convolutional neural networks. Pattern Recognit. 2018, 77, 354–377. [Google Scholar] [CrossRef]
- Sherstinsky, A. Fundamentals of Recurrent Neural Network (RNN) and Long Short-Term Memory (LSTM) network. Phys. D Nonlinear Phenom. 2020, 404, 132306. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Yu, Z.; He, X.; Montillet, J.-P.; Wang, S.; Hu, S.; Sun, X.; Huang, J.; Ma, X. An improved ICEEMDAN-MPA-GRU model for GNSS height time series prediction with weighted quality evaluation index. GPS Solut. 2025, 29, 113. [Google Scholar] [CrossRef]
- Makridakis, S.; Spiliotis, E.; Assimakopoulos, V. M5 accuracy competition: Results, findings, and conclusions. Int. J. Forecast. 2022, 38, 1346–1364. [Google Scholar] [CrossRef]
- Makridakis, S.; Spiliotis, E.; Assimakopoulos, V.; Chen, Z.; Gaba, A.; Tsetlin, I.; Winkler, R.L. The M5 uncertainty competition: Results, findings and conclusions. Int. J. Forecast. 2022, 38, 1365–1385. [Google Scholar] [CrossRef]
- Makridakis, S.; Spiliotis, E.; Hollyman, R.; Petropoulos, F.; Swanson, N.; Gaba, A. The M6 Forecasting Competition: Bridging the Gap Between Forecasting and Investment Decisions. Int. J. Forecast. 2024, in press. [Google Scholar] [CrossRef]
- Woo, G.; Liu, C.; Kumar, A.; Xiong, C.; Savarese, S.; Sahoo, D. Unified training of universal time series forecasting transformers. In Proceedings of the 41st International Conference on Machine Learning, Vienna, Austria, 21–27 July 2024; p. 2178. [Google Scholar]
- Lin, L.; Li, Z.; Li, R.; Li, X.; Gao, J. Diffusion models for time-series applications: A survey. Front. Inf. Technol. Electron. Eng. 2024, 25, 19–41. [Google Scholar] [CrossRef]
- Oh, Y.; Kam, S.; Lee, J.; Lim, D.-Y.; Kim, S.; Bui, A. Comprehensive Review of Neural Differential Equations for Time Series Analysis. arXiv 2025. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Time Series Prediction Task | Frequency | Group |
|---|---|---|---|
| 1 | Total Electricity Consumption (Demand) | 8 | 1 |
| 2 | Load Forecasting | 2 | 1 |
| 3 | Electricity Theft Prediction | 1 | 1 |
| 4 | Heating Load Prediction | 1 | 1 |
| 5 | Return Temperature of District Heating System | 1 | 1 |
| 6 | Electricity Consumption of an Electric Bus | 1 | 1 |
| 7 | Solar Power Forecasting | 3 | 2 |
| 8 | Wind Power Forecasting | 2 | 2 |
| 9 | Rainfall Prediction (Including Rainfall Runoff) | 2 | 2 |
| 10 | Drought Prediction | 2 | 2 |
| 11 | River Inflow Prediction (Including Reclaimed Water Volumes) | 2 | 2 |
| 12 | Subsurface Temperature (Including Sea Surface Temperature) | 2 | 2 |
| 13 | Reservoir Water Level Prediction | 1 | 2 |
| 14 | Flood Frequency | 1 | 2 |
| 15 | Groundwater Availability | 1 | 2 |
| 16 | Indoor Daylight Illuminances Prediction | 1 | 2 |
| 17 | Crop Yield (Including Corn Biomass, Crop Height) | 5 | 3 |
| 18 | Crop Classification | 3 | 3 |
| 19 | Water Quality Prediction (Including Chlorophyll-a and Wastewater Treatment) | 8 | 4 |
| 20 | Air Quality | 1 | 4 |
| 21 | Passenger Demand (Includes Bike Sharing, Urban Rail Passenger Flow) | 3 | 5 |
| 22 | Travel Time Prediction | 1 | 5 |
| 23 | Future Traffic of Mobile Base Stations in Urban Areas | 1 | 5 |
| 24 | Traffic Queue Length | 1 | 5 |
| 25 | Tunnel Deformation Prediction | 1 | 6 |
| 26 | Dam Structural Health Prediction | 1 | 6 |
| 27 | Highway Tunnel Pavement Performance | 1 | 6 |
| 28 | Predict Temperature Trend of Wind Turbine Gearbox | 1 | 6 |
| 29 | Discharge Capacity Estimation for Li-Ion Batteries | 1 | 6 |
| 30 | Sintering Process Prediction | 1 | 6 |
| 31 | Stock Price (Including Crypto/Stock Trend) | 3 | 7 |
| 32 | Hedge Fund Return Prediction | 1 | 7 |
| 33 | Store Item Demand | 1 | 7 |
| 34 | Vegetables Demand | 1 | 7 |
| 35 | Post-Stroke Pneumonia Prediction | 1 | 8 |
| 36 | Predict Peak Demand Days of Cardiovascular Admissions | 1 | 8 |
| 37 | COVID-19 New Cases Prediction | 1 | 8 |
| 38 | Anomaly Detection for Web Services | 1 | 9 |
| 39 | Leak Detection | 1 | 9 |
| 40 | Fall Detection | 1 | 9 |
| 41 | Global Models for Various Tasks (Simulated and Real World) | 1 | 10 |
| 42 | Predicting Emerging Research Topics | 1 | 10 |
| 43 | Lane Changing Risk | 1 | 10 |
| 44 | Predictive Process Monitoring | 1 | 10 |
| 45 | Oil Well Production | 1 | 10 |
| 46 | Crime Prediction | 1 | 10 |
| Metric | TBML Training Advantage (%) |
|---|---|
| Study [4] | 4010.33 |
| Study [20] | 181.81 |
| Study [29] | −22.55 |
| Study [67] | 1251.81 |
| Study [43] | 142.66 |
| Study [45] | 7196.53 |
| Study [74] | 905,140 |
| Study [51] | 235,559.39 |
| Study [55] | 10,145.98 |
| Study [66] | 100,140 |
| Median | 5603.43 |
| Mean | 126,934.94 |
| Dataset Size | Best-Performing Model Class | Best-Performing Model Subclass |
|---|---|---|
| Small (0–2173) | TBML/DL | RNN |
| Small/Medium (2173–7800) | DL | SPTB/RNN |
| Medium (7800–35,712) | TBML | RNN |
| Medium/Large (35,712) | TBML | SPTB/RNN |
| Large (206,573-11,275,200) | TBML | SPTB |
| Task Category | Best-Performing Model Class | Best-Performing Model Subclass |
| Energy and Utilities | TBML | SPTB |
| Environmental and Meteorological | DL | RNN |
| Agriculture and Crop Management | TBML | SPTB |
| Water and Air Quality | TBML | RNN |
| Transportation and Urban Mobility | TBML | SPTB |
| Structural and Mechanical Health Monitoring | DL | RNN |
| Stock Market, Finance, and Market Trends | DL | RNN |
| Healthcare and Biomedical Predictions | TBML | RNN |
| Anomaly Detection | TBML | SPTB/RNN |
| Other | TBML | SPTB |
| Time Interval | Best-Performing Model Class | Best-Performing Model Subclass |
| 1 min | TBML/DL | RNN |
| 5, 10 min | DL | RNN |
| 15, 30 min | DL | RNN |
| 1, 4 h | TBML | SPTB |
| 1 day | TBML/DL | RNN |
| 1 week, 8 day, 15 day, 16 day | TBML | SPTB |
| 1 month | DL | RNN |
| Computational Efficiency | Best-Performing Model Class | Best-Performing Model Subclass |
| Training Time | TBML | SPTB |
| Inference time | TBML | SPTB |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hall, T.; Rasheed, K. A Survey of Machine Learning Methods for Time Series Prediction. Appl. Sci. 2025, 15, 5957. https://doi.org/10.3390/app15115957
Hall T, Rasheed K. A Survey of Machine Learning Methods for Time Series Prediction. Applied Sciences. 2025; 15(11):5957. https://doi.org/10.3390/app15115957
Chicago/Turabian StyleHall, Timothy, and Khaled Rasheed. 2025. "A Survey of Machine Learning Methods for Time Series Prediction" Applied Sciences 15, no. 11: 5957. https://doi.org/10.3390/app15115957
APA StyleHall, T., & Rasheed, K. (2025). A Survey of Machine Learning Methods for Time Series Prediction. Applied Sciences, 15(11), 5957. https://doi.org/10.3390/app15115957