1. Introduction
As a core challenge in manufacturing production planning, scheduling optimization for complex workshops significantly enhances enterprise productivity and reduces operational costs [
1]. The flexible job shop scheduling problem (FJSP), an extension of the classical job shop scheduling problem (JSP), involves both process sequencing and machine allocation, rendering it NP-hard.
The approximate algorithm represented by metaheuristic optimization algorithm is a promising solution for FJSP. It can effectively mitigate the disadvantages of traditional exact algorithms such as high computational cost and difficulty in solving large-scale problems. Many studies have investigated this topic. Fei et al. [
2] considered two objective functions, maximum completion time and carbon emissions. They used an improved chimpanzee optimization algorithm to solve the multi-objective green flexible workshop scheduling problem. By introducing improved mechanisms, such as dynamic convergence factor and variable neighborhood search, the exploitation capabilities of the algorithm were enhanced. In addition, the effectiveness of the algorithm in reducing carbon emissions in flexible workshops was verified through experiments. Han et al. [
3] studied the integrated scheduling problem of FJSP and Automated Guided Vehicle (AGV) with the objective function of minimizing the maximum completion time. A new mixed integer linear programming model and dual population collaborative genetic algorithm was proposed. Xu et al. [
4] proposed a hybrid algorithm combining quantum particle swarm optimization and variable neighborhood search to efficiently solve FJSP with the goal of maximum completion time. The stability and applicability of the algorithm were verified through testing on standard test cases and an industrial case. Huang et al. [
5] used memetic algorithm to solve the problem of green type-2 fuzzy flexible workshop. Ensieh et al. [
6] proposed a simulation optimization framework for solving stochastic flexible job shop scheduling problems in the semiconductor manufacturing industry. Philipp et al. [
7] proposed a new solution algorithm based on quantum annealing, which combines the power of quantum annealing with classical techniques for calculating FJSP. Gong et al. [
8] proposed an FJSP model with flexible discrete operation order, considering that some job operations in the real job process do not have any order constraints. They verified the effectiveness of the model through CPLEX (a mathematical programming solver developed by IBM). In summary, most current FJSP models aim to minimize the maximum completion time as their core objective. Metaheuristic optimization algorithms have demonstrated significant advantages in solving the FJSP.
However, traditional FJSP has two limitations. First, it is too idealistic. Current research is mostly based on the assumption of static scheduling, generating the global optimal solution at once. This deviates from the actual production of the enterprises. In actual machining operations, the scheduling workload is generally greater than the equipment capacity. New parts will be rolled into production at regular production cycles. The scheduling plan should be a periodic rolling adjustment. Therefore, this article describes a rolling production mode (defined in
Section 3). The second limitation of traditional FJSP is that although FJSP has multiple scheduling objectives, current research mostly focuses on minimizing the maximum completion time as the core objective (without considering the delivery time of each workpiece). In the process of actual machining operations, each workpiece has an expected delivery date. On the one hand, enterprises need to avoid delays, and on the other hand, they hope to reduce equipment idle rates.
On this basis, this article proposes a flexible job shop scheduling model under the rolling production mode. The aim is to simultaneously maximize equipment utilization during the rolling production cycle and minimize total delay time to better meet the actual needs of enterprises. The Multi Objective Improved of Salp Swarm Algorithm (MISSA) is used to address this challenge. In order to extend the application of the SSA to workshop scheduling problems, a conversion strategy between real-coded vectors and integer-coded vectors is designed. In order to improve the quality of the initial population and accelerate the convergence speed of the algorithm, various heuristic strategies such as the maximum residual load rule and the shortest processing time rule are introduced. During the algorithm iteration process, corresponding global and local search strategies were designed for process sorting encoding and machine selection encoding to further enhance the exploitation capabilities of the improved algorithm. Finally, the feasibility of the improved strategy and the effectiveness of the improved algorithm were verified through comparative experiments.
3. Problem Description and Model
The flexible job shop scheduling problem in rolling production mode (FJSP-RPM) can be defined as: a batch of workpieces need to be processed in the current scheduling cycle of the workshop, including n workpieces (J1, J2, ..., Jn), which need to be processed on a total of m machines (M1, M2, ..., Mm). The quantity of workpieces exceeds the equipment’s production capacity. represents the jth process of workpiece i, represents the optional equipment set of the jth process of workpiece i, each process can be processed on any one of m devices with processing capacity, and equipment k can process more different workpieces process. Due to different performance characteristics of the equipment, the processing time for the same process varies among different devices. Each workpiece has a delivery deadline, where represents the delivery deadline for workpiece i. If the delivery time exceeds the delivery deadline, the manufacturer will face the risk of reputation loss and fines. The goal of job shop scheduling is to determine the processing sequence of the workpiece and the processing machine of the process, so that in the current scheduling cycle T, the equipment utilization rate is the highest, and the total tardiness of the workpiece is the lowest. The workshop executes processing according to the scheduling plan. When the scheduling cycle T is reached, the unfinished workpieces and new workpieces that need to be processed are re scheduled according to the goal of maximizing equipment utilization and minimizing total delay to obtain a new scheduling plan.
The assumptions that need to be met during the workpiece processing include:
All workpieces and machines can be put into use at time zero, and all workpieces are released at time zero.
Each machine can only complete one process at a time, and each process can only be executed by one machine at any given time.
The processing of workpieces must be strictly carried out in the order of the process, and no steps are allowed to be skipped.
Once processing begins, it must not be interrupted and must continue until the process is completed. It is not allowed to split working hours or be occupied by other workpieces.
Stop running the machine after completing the last process.
The transfer time of the workpiece during the processing is ignored.
The workpieces are independent of each other and there is no priority relationship.
Not considering dynamic factors such as machine malfunctions, order changes, and urgent order insertion.
The symbols and their meanings used in the model are shown in
Table 1.
The objective of the job shop scheduling is to minimize total delay time and maximize equipment utilization through optimal allocation of manufacturing equipment and sequencing of operations for pending workpieces. Based on the problem description above, we formulate a multi-objective scheduling model structured as:
Objective 1. Maximize equipment utilization. Indicates that the idle time of the equipment is the shortest in the current scheduling cycle. The calculation formula is:
Objective 2. Minimize the total delay time. If the delivery time exceeds the delivery deadline, the enterprise will face the risk of reputation loss and breach of contract fines. The calculation formula is:
s.t.
Equation (8) indicates that interruption is not allowed during the same machining process, while Equation (9) indicates that only one machine can be responsible for machining the process. Equation (10) represents the constraint on the processing sequence of the workpiece. Equation (11) indicates that the machine can only process one workpiece at a time. Equation (12) indicates that the start time must be after zero time. Equations (13) and (14) are 0–1 variable constraints.
4. Improvement of Salp Swarm Algorithm
The SSA simulates the predation and movement behavior of salps, searching the solution space. During the iterative search process, the algorithm can explore broad regions, significantly improving the probability of finding the optimal solution. However, when SSA approaches potential optimal solution regions, its weak exploitation capability leads to excessive time required to thoroughly search these areas, resulting in slower convergence. Additionally, the multi-objective flexible job shop scheduling problem is a discrete optimization problem, whereas the original SSA is primarily designed for continuous scenarios and cannot be directly applied to discrete domains.
In order to apply SSA to the discrete domain, this paper first designs a double layer encoding mechanism. Then improve the SSA algorithm in terms of initialization strategy, global search strategy, and local search strategy to enhance its exploitation capabilities.
To address the application field limitation, this study first designs a conversion strategy between real-coded vectors and integer-coded vectors, expanding the algorithm’s applicability. It then integrates heuristic strategies such as the shortest processing time rule and the maximum remaining load rule to initialize the algorithm’s population. During iterations, tailored global and local search strategies are developed for process-sorting encoding and machine-selection encoding, aiming to enhance exploitation capabilities. The specific design of the improved algorithm is detailed below.
4.1. Double Layer Encoding Mechanism
FJSP-RPM requires addressing two subproblems: determining the processing sequence of workpieces on different machines and assigning each process to appropriate equipment. To solve this problem, a double-layer encoding mechanism is proposed. Each solution comprises two components: a workpiece-sorting encoding vector and a machine-selection encoding vector. Both vectors have lengths equal to the total number of workpieces to be processed in the workshop.
The Ranked Order Value (ROV) is a data encoding method that converts continuous values into discrete sequences through ascending-order sorting and ordinal mapping. It is primarily used for scheduling optimization and continuous value discretization in algorithms. The standard procedure includes three steps: data sorting, ordinal assignment, and encoding conversion.
When decoding the real valued encoding vector to generate feasible scheduling schemes, the workpiece-sorting encoding vector is first transformed from the real-valued domain to the integer domain via ROV. For the machine-selection encoding vector, each value is multiplied by the number of available machines and then rounded to the nearest integer to determine the selected machine for the corresponding process.
As shown in
Table 2, a flexible workshop case involves three workpieces, each with a fixed process route. Multiple machines are available for each process, and processing times may vary across machines.
As shown in
Figure 2, for the workpiece sorting encoding vector, we first assign a position index to workpiece process and then perform ROV sorting on the real-valued vector. Subsequently, process numbers sharing identical ROV values are selected sequentially from left to right and placed into the index positions corresponding to the integer-process encoding vector, thereby converting the real-number vector into an integer vector.
For example, when ROV is 7, the corresponding position of the workpiece process is the first process of workpiece 1. Similarly, the final integer form of the process code is [3 2 1 2 1 3 1 2 3]. Each number represents a workpiece, and the number of times it appears in the code represents the corresponding number of processes for that workpiece. For example, the first digit “3” in the encoding represents the first process of workpiece 3.
The machine selects encoding vectors and allocates them using the following formula:
Among them, is the vector value at the ith position of the machine selection encoding vector, n is the total number of workpieces, is the integer value at the ith position obtained by conversion, representing the machine number selected for the current process among the available processing machines, and is the number of available processing machines for the current process.
As shown in
Figure 3, the machine selects the encoded real vector to correspond one-to-one with the process. Using Formula (15), the real vector is calculated and converted into an integer, representing the processing machine number selected for the corresponding process. For example, the first element 0.2 in the real number vector corresponds to the first process of workpiece 1. After calculation, the integer value “1” is generated, indicating that the first process of workpiece 1 is assigned to be processed by the first machine in the set of available processing machines. The available machines for the first process of workpiece 1 are
, so the machine
is selected to perform this process.
When converting the scheduling scheme into a position vector, for the machine selection encoding vector, the integer form of the machine selection encoding vector is converted into an individual position vector of the salp. The conversion formula is as follows:
Among them, is the real value at the ith position of the machine selected encoding real vector, and is the number of available processing machines for the current process. M is the total number of machines in the workshop, and is the integer value at the ith position of the integer vector.
For the process sorting integer encoding vector, first generate a random number sequence with the same length as the vector, sort the random number sequence to obtain ROV1. For the process sorting integer encoding vector, assign the corresponding ROV value of the process code to ROV2 in order of the process number. And then find the random value in ROV1 that corresponds to the ROV2 value to obtain the real number encoding vector.
As shown in
Figure 4, it is a schematic diagram of converting the process sorting encoding vector from an integer vector to a real vector. The initial process encoding integer vector is [3 2 1 2 1 3 2 1 3 3 3 3]. Based on the correspondence between the process encoding and position index shown in
Figure 2, ROV2 is obtained. Afterwards, a set of random number vectors between 0–1 is generated [0.13 0.24 0.63 0.38 0.72 0.76 0.21 0.98 0.56], sorted to obtain ROV1. The first process of workpiece 3 corresponds to a value of 7 in ROV2 and a real number of 0.72 in ROV1. Therefore, the value at the corresponding position in the real number vector is set to 0.72. Following this method, the complete real number vector is calculated as [0.72 0.38 0.13 0.56 0.21 0.76 0.63 0.24 0.98].
4.2. Decoding and Individual Evaluation
After determining the processing sequence of orders across production lines, the active scheduling decoding method [
26] is applied to decode the encoding scheme and derive the scheduling scheme. The quality relationships between solutions are evaluated using non-dominated sorting and crowding distance ranking methods.
4.3. Population Initialization
Population initialization constitutes a critical step in solving workshop scheduling problems, as the quality of generated solutions directly impacts the algorithm’s convergence efficiency and solution diversity. To ensure high-quality and diverse initial solutions, this study implements multiple initialization strategies for both machine selection and process sorting.
4.4. Global Search Strategy
The SSA does not rely on genetic operator evolution, but instead searches for the optimal individual of the problem through individual position movement. The advantage of this approach is that it can search for more space where potential optimal solutions may exist, but it will reduce search efficiency in workshop scheduling problems. Considering that genetic algorithms have strong global search capabilities, this paper combines crossover and mutation operators to improve the standard SSA and accelerate convergence speed.
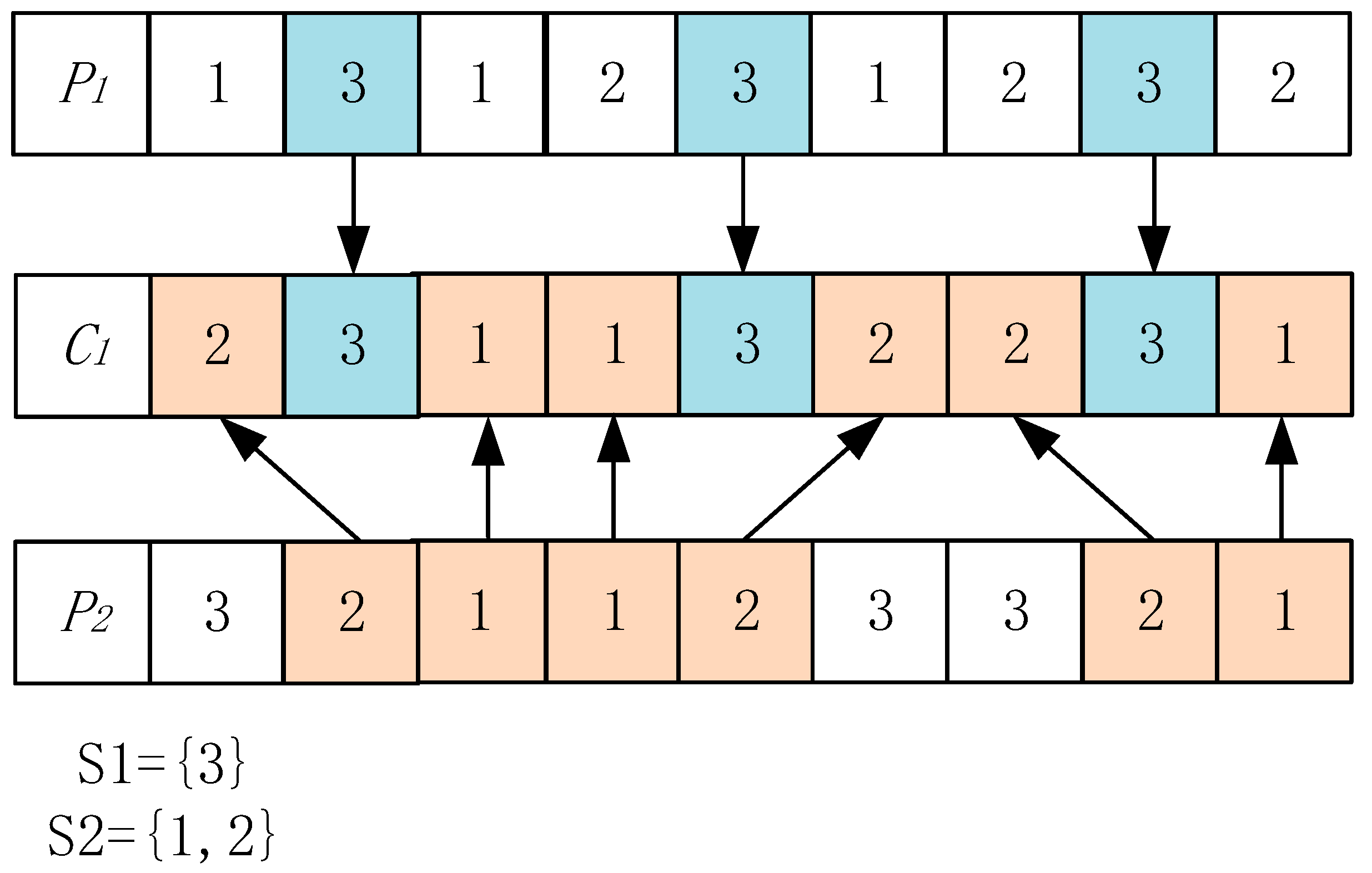
For the process sorting vector, choose the POX crossover method, as shown in
Figure 5:
- (1)
Divide the part set into two non empty subsets S1 and S2.
- (2)
Copy the genes belonging to set S1 from the selected parent individual P1.
- (3)
Fill the remaining positions in the offspring C1 with the genes from that belong to S2, preserving their order.
For the equipment selection part, a two-point crossover method is adopted:
- (1)
Randomly select two crossover points for two parent individuals.
- (2)
Exchange the equipment numbers corresponding to processes between the two crossover points in the parents to generate offspring.
4.5. Local Search Strategy
The SSA method employs a random search mechanism to explore the solution space by simulating the predation and mobility behaviors of salp populations, demonstrating strong global search capabilities. However, its drawback lies in prolonged search times when approaching regions containing potential optimal solutions due to the absence of effective local search strategies, resulting in poor convergence performance. To address this limitation, this paper proposes a variable neighborhood search strategy incorporating multiple neighborhood structures to enhance the algorithm’s optimization efficiency.
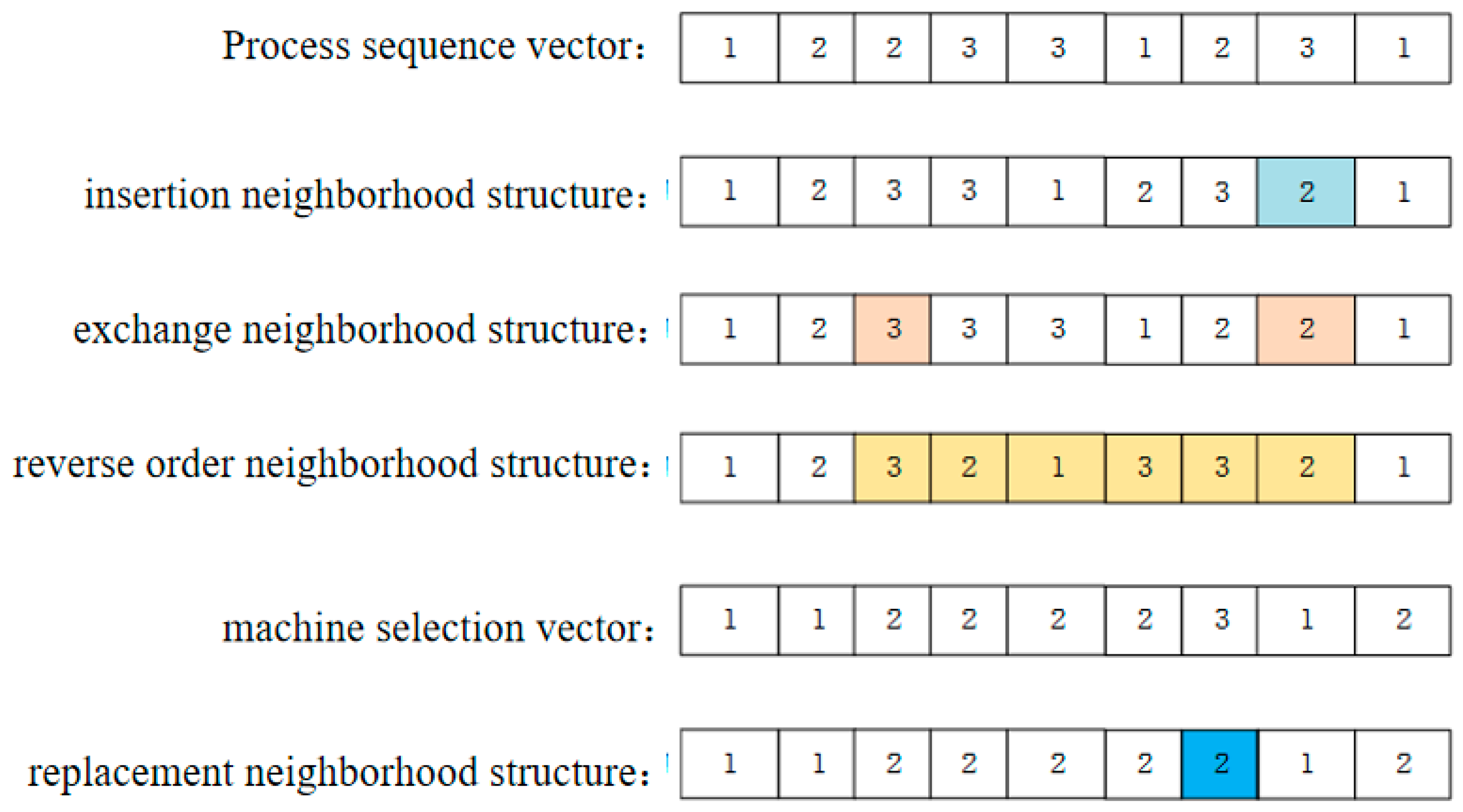
The specific neighborhood structure includes:
- (1)
Swap Neighborhood: Randomly select two different positive integers, then swap the values at these two positions on the process sorting encoding vector to generate neighborhood solutions.
- (2)
Insert Neighborhood: generate two different positive integers, insert the gene at the position of the first integer into the position of the second integer, and then adjust the order of process sorting encoding vectors.
- (3)
Reverse Order Neighborhood: Within the interval between two generated unequal positive integers, reverse the order of all gene values within that interval.
- (4)
Replace Neighborhood: Randomly select a parent machine to choose a process in the encoding, and replace the currently selected machine with other machines available for that process.
An example of neighborhood structure is shown in
Figure 6. Since the problem considered in this article is a multi-objective optimization problem, in the process of variable neighborhood search, the decision to accept new neighborhood solutions will be based on the dominance relationship. The specific steps are as follows:
- Step 1:
Define the neighborhood structure mentioned above.
- Step 2:
Select a solution from the population in sequence for neighborhood search.
- Step 3:
Use the above neighborhood structure to sequentially perform neighborhood search on the selected solutions and generate new neighborhood solutions.
- Step 4:
Compare the dominance relationship between neighboring solutions and the current solution. If the neighboring solution dominates the current solution, then accept the neighboring solution and perform a new neighborhood search on the newly generated neighboring solution.
- Step 5:
After all neighborhood searches are completed, stop the search for the current solution and repeat the process for the next solution in the population until all solutions have passed the neighborhood search.
By using a variable neighborhood search mechanism, the improved algorithm can thoroughly search for the neighborhood solutions of the current solution, greatly enhancing the algorithm’s local search capability.
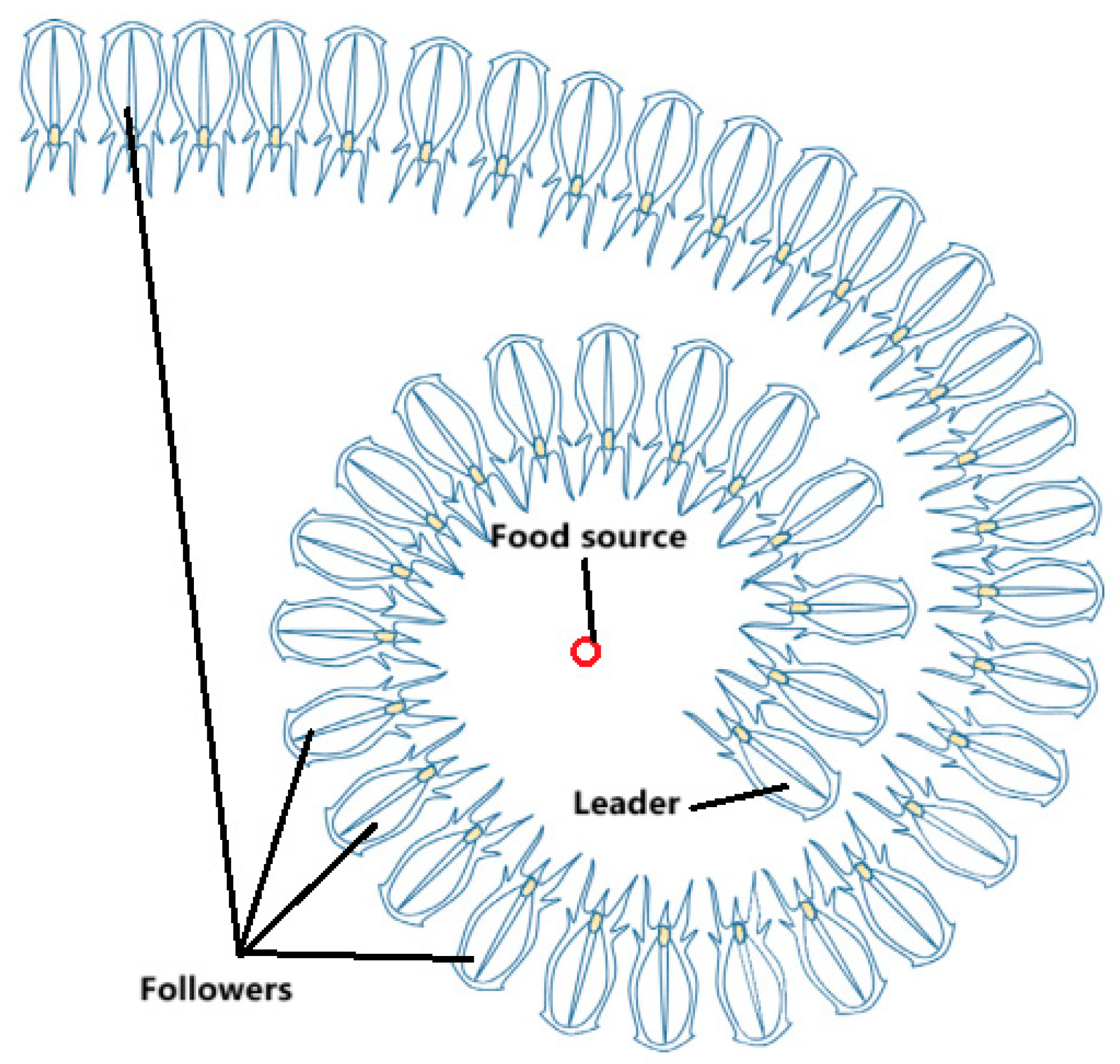
The calculation process of the MISSA is shown in Algorithm 1:
| Algorithm 1 MISSA Pseudo Code for Calculation Process |
| 1 Begin |
| 2 Initialize algorithm related parameters, including population size N, iteration times T, etc |
| 3 Generate an initial population using an improved initialization strategy, calculate the fitness value of each individual, and rank non dominated relationships and crowding levels |
| 4 Determine the optimal individual, namely the leader |
| 5 Set the optimal individual as the food source |
| 6 for t = 1:T |
| 7 for i = 1:N |
| 8 Convert integer encoding to real encoding, |
| 9 if i == 1 %Update leader |
| 10 Update the leader’s position using Equation (3) |
| 11 else %Update Followers |
| 12 Update the following position using Equation (5) |
| 13 end if |
| 14 end for |
| 15 Calculate the non dominated relationship and crowding degree between solutions, and update the population |
| 16 Convert real number encoding to integer encoding |
| 17 Using a global search strategy to update the population |
| 18 Local search strategy updates population |
| 19 Update optimal individuals and food sources |
| 20 end for |
| 21 Output the optimal frontier solution obtained from the solution |
4.6. Comparison with Basic Salp Swarm Algorithm
This study introduces three enhancement strategies to the basic SSA: population initialization strategy, global search strategy, and local search strategy. The population initialization improvement strategy integrates residual load, shortest processing time, and global/local machine allocation rules to improve the quality of initial solutions; The basic algorithm is only randomly generated and of poor quality. The global search improvement strategy introduces POX crossover and two-point crossover to enhance search efficiency; The basic algorithm relies on random movement and converges slowly. The local search improvement strategy adopts variable neighborhood search (swapping/inserting/reversing/replacing) to improve local accuracy; The basic algorithm only randomly searches and is prone to getting stuck in local optima.
The improvement strategy enhances the quality of population initialization and strengthens the exploration capability of the algorithm. It can solve the shortcomings of slow convergence, susceptibility to local optima, and unstable solution quality of basic SSA in FJSP.
It is worth noting that, the mutual conversion between real vector and integer vector increases the computational cost of encoding/decoding. Integrating mechanisms such as POX crossover and variable neighborhood search also leads to an increase in runtime. However, for the test cases mentioned below, this increase in running time can be ignored considering the benefits it produces.
5. Simulation Experiment
In order to verify the performance of the algorithm, 10 test cases were designed. The data for each test case in the scheduling problem, such as processing time, delivery time, and rolling production cycle, are shown in
Table 3. Program with MATLAB R2021b and run on an i7 processor with 3.3 GHz and 16 GB of memory. Select common NSGA2, NSGA3, and SPEA2 multi-objective optimization algorithms and compare them with MISSA. The algorithm performance indicators are calculated using convergence indicator GD (Generative Distance), diversity indicator Δ, and comprehensive indicator IGD (Inverted Generative Distance).
5.1. Parameter Design
The main experimental parameters that affect the performance of the MISSA include population size, number of iterations, and crossover probability. In order to determine the optimal parameter combination, this paper adopted the Taguchi orthogonal experimental method. A 3-factor 4-level experiment was designed:
Population size: [40, 60, 80, 100]
Number of iterations: [40, 60, 80, 100]
Crossover probability: [0.6, 0.7, 0.8, 0.9]
For the IGD index (the smaller the better), key parameter effects were screened through 16 sets of experiments. Signal-to-noise ratio (SNR) is the core indicator used in Taguchi method to measure the performance of parameter combinations. Calculate the SNR for each set of parameters using the following formula. Each experiment was repeated 10 times (i.e.,
n = 10 in the formula) to eliminate random errors:
The results are shown in the
Table 4:
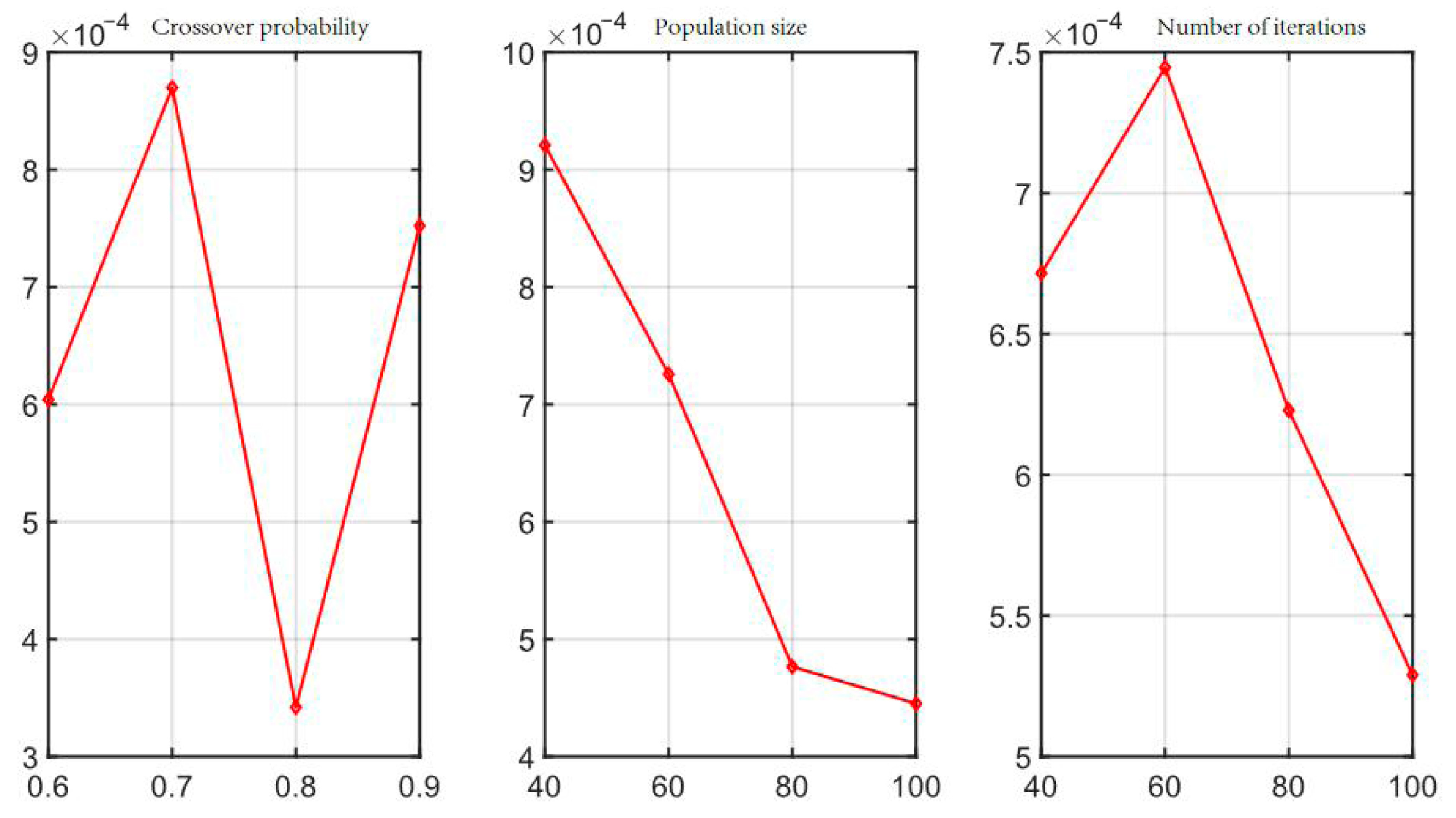
The parameter levels with the highest average SNR are: population size of 100 (80.2 dB); 100 iterations (79.6 dB); The crossover probability is 0.8 (78.9 dB).
To verify the above conclusion, the IGD index of the solution results was analyzed on the MK03 case. According to the experimental results shown in
Figure 7, the optimal parameters for the MISSA algorithm were ultimately determined to be: population size: 100, number of iterations: 100, crossover probability: 0.8.
Table 5 lists the initial parameter values for different algorithms for comparison of their performance.
5.2. Effectiveness Verification of Improvement Strategies
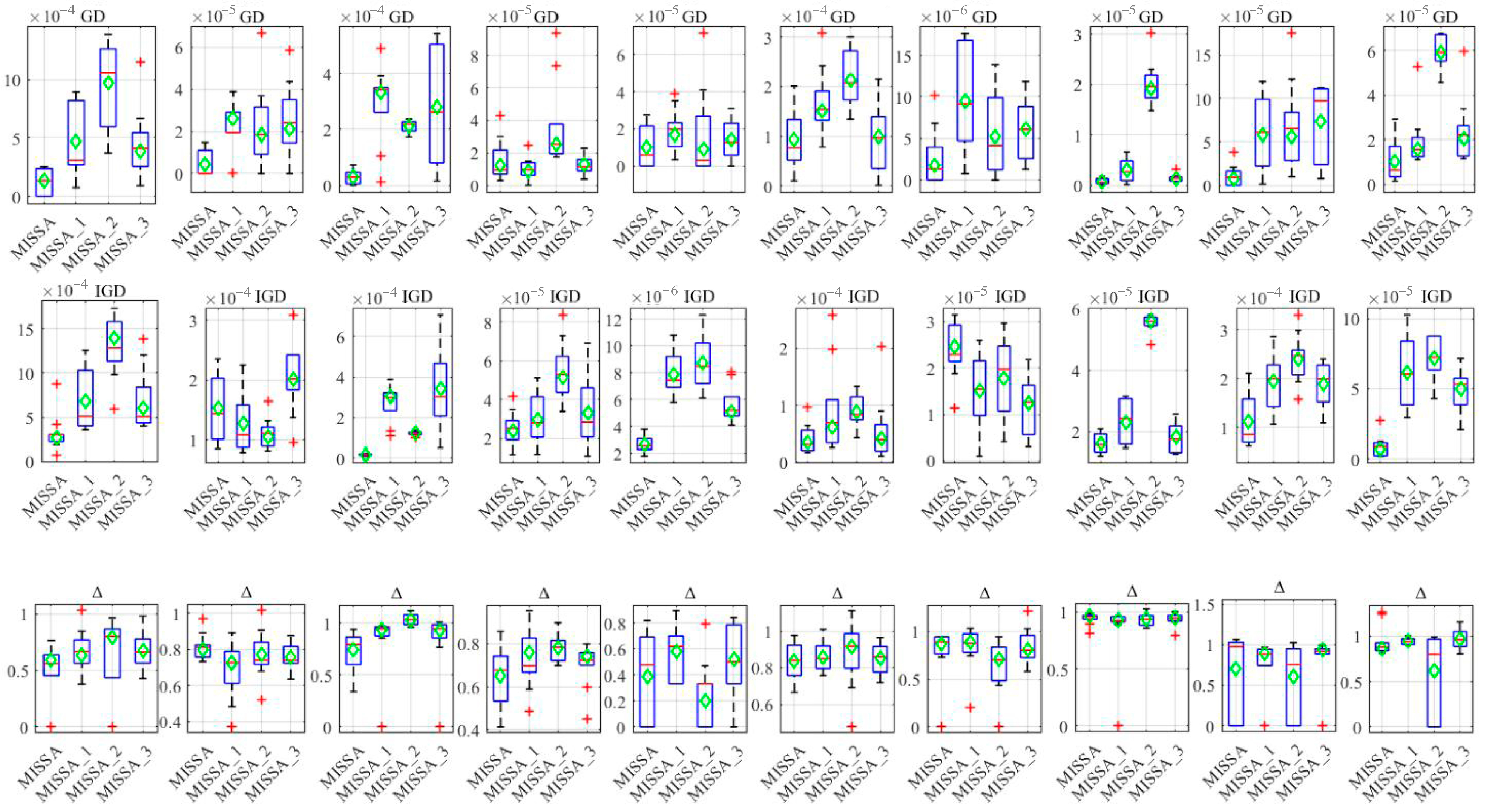
In order to verify the effectiveness of the proposed improvement strategy for the MISSA algorithm, three incomplete variants of the MISSA algorithm were designed, namely: ① MISSA_1, which introduces global and local search strategies on the basis of the original SSA, without including population initialization strategy. ② MISSA_2 introduces population initialization strategy and local search strategy, without including global crossover strategy ③ MISSA_3 includes population initialization strategy and global crossover strategy, but does not include local search strategy. For all cases, the algorithm is repeated ten times to eliminate the influence of policy randomness. To calculate the index values of the set solved by the algorithm, the solution sets obtained by the MISS A algorithm and its variants on the case are merged, and then sorted by non-dominated relationships to obtain the solution of the first dominated frontier. This first dominated frontier solution is then used as the optimal Pareto frontier solution set for the case. The performance of the algorithm was compared using three evaluation indicators, GD, IGD, and Δ. The comparison results are shown in
Table 6 and
Figure 8.
Table 7 lists the average values of ten solution results for MISS A and its variants on this test case, while
Figure 8 shows the indicator value box plot of the ten solution results obtained by the algorithm. From
Table 6 and
Figure 8, it can be seen that compared with the algorithm variant, the GD index values obtained by the MISSA algorithm are superior to those of the algorithm variant in 9 cases, and have significant advantages in some cases such as MK01, MK02, MK03, and MK09. In terms of IGD indicators, MISSA also outperforms the comparison algorithm in 8 cases. In terms of diversity index Δ value, the performance of MISSA and MISSA2 algorithms is superior to the other two algorithms. The GD and IGD indicators obtained by the three algorithms MISSA_1, MISSA_2, and MISSA_3 have their own advantages in different cases, proving that each improvement strategy proposed in this paper can improve the overall performance of the improved algorithm. In terms of algorithm stability, the MISSA algorithm outperforms the three variant algorithms in terms of GD and IGD indicators of the solution results.
Based on the above analysis, each improvement item effectively improves the performance of MISSA in solving FJSP-RPM problems, and the effect is significant.
5.3. Comparison Between MISSA and Other Optimization Algorithms
To verify the performance comparison between the MISSA and common multi-objective optimization algorithms such as NSGA2, NSGA3, and SPEA2, ten repeated comparison experiments were conducted on ten cases, and the performance indicators of the solution results were statistically analyzed. The comparison results are shown in
Table 7 and
Table 8 and
Figure 9 and
Figure 10.
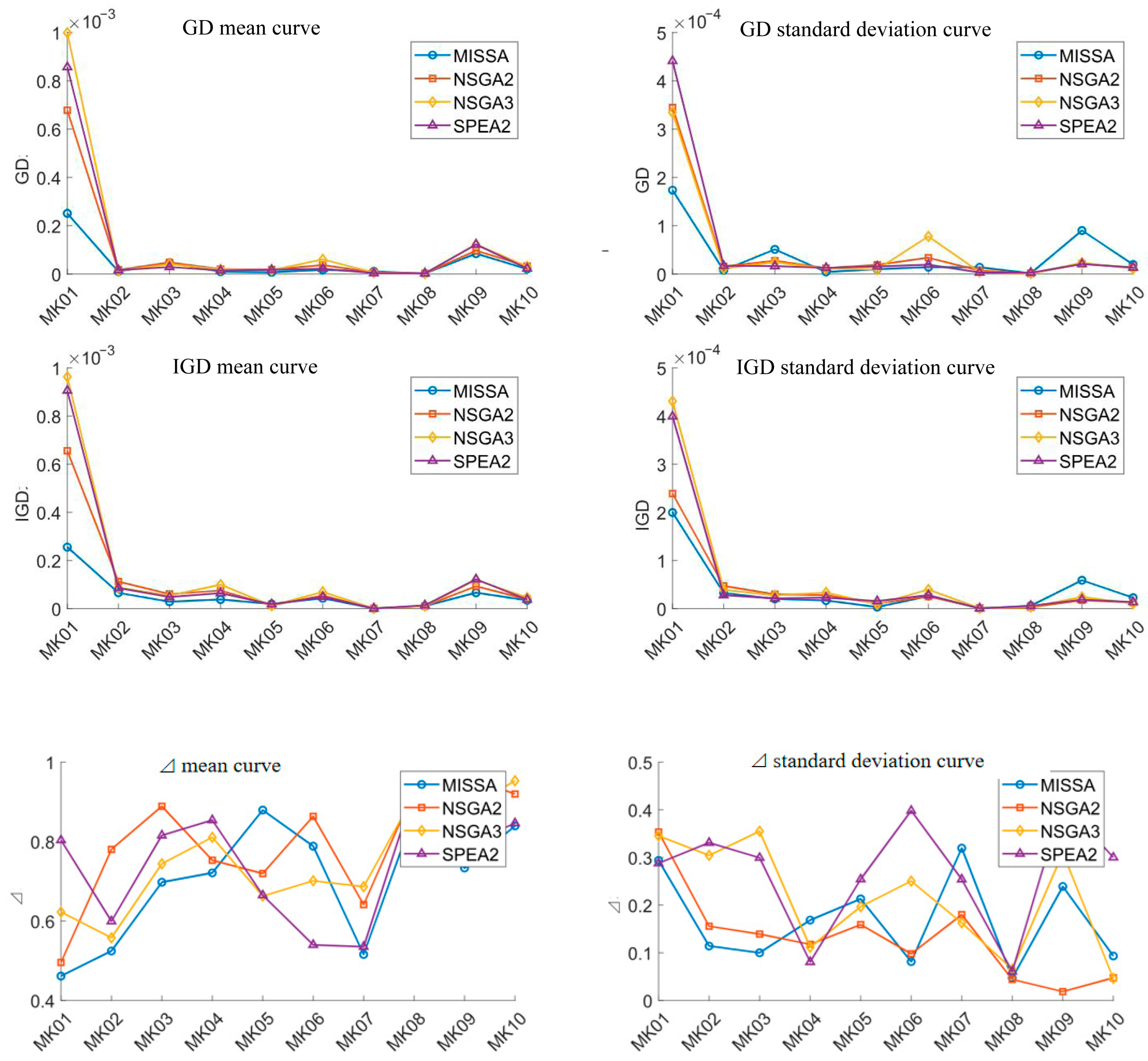
Table 7 and
Table 8 show the GD, IGD, and Δ index results obtained by the four algorithms. It can be seen from the table that compared with the other three algorithms, MISSA achieved smaller GD and IGD mean values in eight cases and smaller Δ mean values in seven cases in terms of solution quality, proving that the diversity and convergence of the solution set solved by MISSA are better. The quality of the obtained solution is higher. In terms of the stability of the solution results, it can be seen from the standard deviation data of different evaluation indicators in the table that the MISSA can achieve an absolute advantage, but still outperforms the comparison algorithm in a considerable number of cases.
To more clearly demonstrate the distribution of mean and standard deviation of indicators obtained through different algorithms for each test case,
Figure 9 shows the distribution curves of mean and standard deviation of indicators obtained by four comparative algorithms. It can be clearly seen from the graph that the differences between different algorithms are small, but the performance of the MISSA in solving the set is superior to the comparison algorithm in the vast majority of cases.
To observe the distribution of the solution sets obtained by different algorithms more intuitively,
Figure 10 shows the frontier solutions obtained by different algorithms, with points of different shapes representing the solution sets obtained by different algorithms. It can be clearly seen from the figure that the solution set solved by the MISSA basically dominates the frontier solutions obtained by the comparison algorithms, while the sets solved by the three comparison algorithms dominate each other, indicating that the solution set solved by the MISSA is closer to the Pareto frontier solutions of the case and has better solution set quality.
In summary, compared to NSGA2, NSGA3, and SPEA2 algorithms, MISSA has better global search and local optimization capabilities, and can more effectively solve the problems proposed in this paper.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}