
A Novel Solution for Reconstructing More Details High Dynamic Range Image


Abstract
1. Introduction
- Ability to enhance image details;
- Ability to extract image features;
- Ability to accurately align the poses of objects in images with different exposures;
- Ability to accurately fuse multiple exposure images.
2. Related Work
2.1. Datasets
2.2. Alignment-Based Method
2.3. Rejection-Based Method
2.4. Patch-Based Method
2.5. CNN-Based Method
2.6. Deblurring
2.7. Super-Resolution
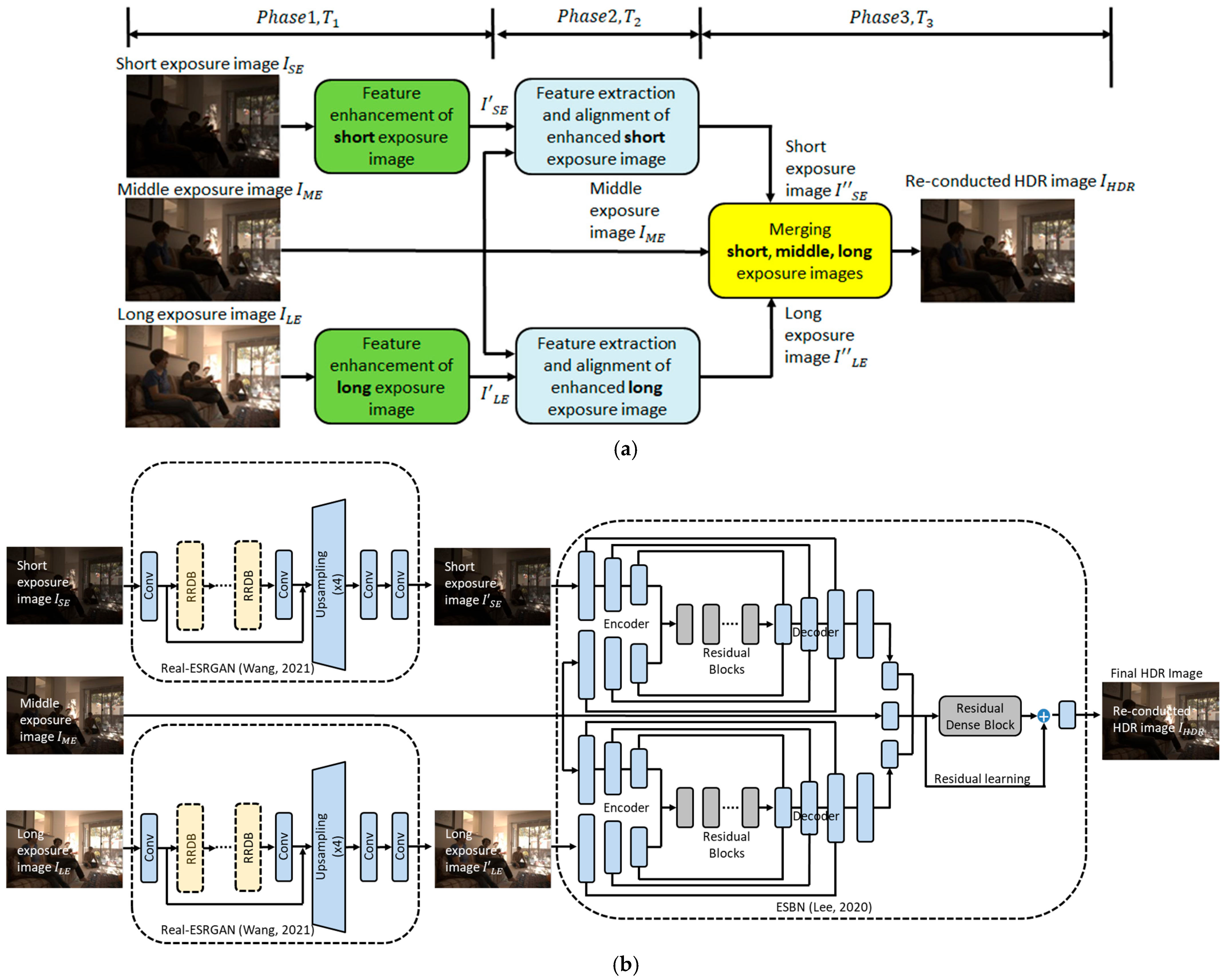
3. Methods
3.1. Enhance Image Details
3.2. Capture Highlight Details of Short-Exposure LDR Image
3.3. Capture Low-Light Details of Long-Exposure LDR Image
3.4. Fusion Images
3.5. Evaluation Metrics
3.6. Loss Functions
4. Results
4.1. Qualitative
4.2. Quantitative
4.3. Ablation Study
- Use super-resolution to only enhance long-exposure test images;
- Use super-resolution to only enhance middle-exposure test images;
- Use super-resolution to only enhance short-exposure test images.
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Guo, C.; Jiang, X. Lhdr: Hdr reconstruction for legacy content using a lightweight dnn. In Proceedings of the Asian Conference on Computer Vision, Macau SAR, China, 4–8 December 2022. [Google Scholar]
- Bogoni, L. Extending dynamic range of monochrome and color images through fusion. In Proceedings of the 15th International Conference on Pattern Recognition, ICPR-2000, Barcelona, Spain, 3–7 September 2000; IEEE: Piscataway, NJ, USA, 2000. [Google Scholar]
- Kang, S.B.; Uyttendaele, M.; Winder, S.; Szeliski, R. High dynamic range video. ACM Trans. Graph. (TOG) 2003, 22, 319–325. [Google Scholar] [CrossRef]
- Tomaszewska, A.; Mantiuk, R. Image Registration for Multi-Exposure High Dynamic Range Image Acquisition. 2007. Available online: https://scispace.com/pdf/image-registration-for-multi-exposure-high-dynamic-range-4tym59cxpm.pdf (accessed on 2 February 2025).
- Lee, C.; Li, Y.; Monga, V. Ghost-free high dynamic range imaging via rank minimization. IEEE Signal Process. Lett. 2014, 21, 1045–1049. [Google Scholar] [CrossRef]
- Oh, T.-H.; Lee, J.-Y.; Tai, Y.-W.; Kweon, I.S. Robust high dynamic range imaging by rank minimization. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 1219–1232. [Google Scholar] [CrossRef] [PubMed]
- Zhang, W.; Cham, W.-K. Gradient-Directed Multiexposure Composition. IEEE Trans. Image Process. 2011, 21, 2318–2323. [Google Scholar] [CrossRef] [PubMed]
- Sen, P.; Kalantari, N.K.; Yaesoubi, M.; Darabi, S.; Goldman, D.B.; Shechtman, E. Robust patch-based hdr reconstruction of dynamic scenes. ACM Trans. Graph. 2012, 31, 203:1–203:11. [Google Scholar] [CrossRef]
- Hu, J.; Gallo, O.; Pulli, K.; Sun, X. HDR deghosting: How to deal with saturation? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Kalantari, N.K.; Ramamoorthi, R. Deep high dynamic range imaging of dynamic scenes. ACM Trans. Graph. 2017, 36, 144:1–144:12. [Google Scholar] [CrossRef]
- Wu, S.; Xu, J.; Tai, Y.-W.; Tang, C.-K. Deep high dynamic range imaging with large foreground motions. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Yan, Q.; Gong, D.; Shi, Q.; van den Hengel, A.; Shen, C.; Reid, I.; Zhang, Y. Attention-guided network for ghost-free high dynamic range imaging. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Yan, Q.; Zhang, L.; Liu, Y.; Zhu, Y.; Sun, J.; Shi, Q.; Zhang, Y. Deep HDR imaging via a non-local network. IEEE Trans. Image Process. 2020, 29, 4308–4322. [Google Scholar] [CrossRef] [PubMed]
- Niu, Y.; Wu, J.; Liu, W.; Guo, W.; Lau, R. Hdr-gan: Hdr image reconstruction from multi-exposed ldr images with large motions. IEEE Trans. Image Process. 2021, 30, 3885–3896. [Google Scholar] [CrossRef] [PubMed]
- Ye, Q.; Xiao, J.; Lam, K.-m.; Okatani, T. Progressive and selective fusion network for high dynamic range imaging. In Proceedings of the 29th ACM International Conference on Multimedia, Chengdu, China, 20–24 October 2021. [Google Scholar]
- Liu, Z.; Lin, W.; Li, X.; Rao, Q.; Jiang, T.; Han, M.; Fan, H.; Sun, J.; Liu, S. ADNet: Attention-guided deformable convolutional network for high dynamic range imaging. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Chen, Y.; Jiang, G.; Yu, M.; Jin, C.; Xu, H.; Ho, Y.-S. HDR light field imaging of dynamic scenes: A learning-based method and a benchmark dataset. Pattern Recognit. 2024, 150, 110313. [Google Scholar] [CrossRef]
- Guan, Y.; Xu, R.; Yao, M.; Huang, J.; Xiong, Z. EdiTor: Edge-guided transformer for ghost-free high dynamic range imaging. ACM Trans. Multimed. Comput. Commun. Appl. 2024. [Google Scholar] [CrossRef]
- Hu, T.; Yan, Q.; Qi, Y.; Zhang, Y. Generating content for hdr deghosting from frequency view. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024. [Google Scholar]
- Li, H.; Yang, Z.; Zhang, Y.; Tao, D.; Yu, D. Single-image HDR reconstruction assisted ghost suppression and detail preservation network for multi-exposure HDR imaging. IEEE Trans. Comput. Imaging 2024, 10, 429–445. [Google Scholar] [CrossRef]
- Zhu, L.; Zhou, F.; Liu, B.; Goksel, O. HDRfeat: A feature-rich network for high dynamic range image reconstruction. Pattern Recognit. Lett. 2024, 184, 148–154. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar] [CrossRef]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26–30 June 2016. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Qiao, Y.; Change Loy, C. Esrgan: Enhanced super-resolution generative adversarial networks. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual dense network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Qiu, Y.; Wang, R.; Tao, D.; Cheng, J. Embedded block residual network: A recursive restoration model for single-image super-resolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar]
- Wang, X.; Xie, L.; Dong, C.; Shan, Y. Real-esrgan: Training real-world blind super-resolution with pure synthetic data. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Ayazoglu, M. Extremely lightweight quantization robust real-time single-image super resolution for mobile devices. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III. Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part II. Springer: Berlin/Heidelberg, Germany, 2016; pp. 694–711. [Google Scholar]
- Lee, S.-H.; Chung, H.; Cho, N.I. Exposure-structure blending network for high dynamic range imaging of dynamic scenes. IEEE Access 2020, 8, 117428–117438. [Google Scholar] [CrossRef]
- Yang, K.; Hu, T.; Dai, K.; Chen, G.; Cao, Y.; Dong, W.; Wu, P.; Zhang, Y.; Yan, Q. CRNet: A Detail-Preserving Network for Unified Image Restoration and Enhancement Task. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Seattle, WA, USA, 17–18 June 2024. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Karaimer, H.C.; Brown, M.S. A software platform for manipulating the camera imaging pipeline. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I. Springer: Berlin/Heidelberg, Germany, 2016; pp. 429–444. [Google Scholar]
- Liu, Y.-L.; Lai, W.-S.; Chen, Y.-S.; Kao, Y.-L.; Yang, M.-H.; Chuang, Y.-Y.; Huang, J.-B. Single-image HDR reconstruction by learning to reverse the camera pipeline. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Ramanath, R.; Snyder, W.E.; Yoo, Y.; Drew, M.S. Color image processing pipeline. IEEE Signal Process. Mag. 2005, 22, 34–43. [Google Scholar] [CrossRef]
- Tursun, O.T.; Akyüz, A.O.; Erdem, A.; Erdem, E. An objective deghosting quality metric for HDR images. In Computer Graphics Forum; Wiley Online Library: Hoboken, NJ, USA, 2016. [Google Scholar]
- Try Photomatix Pro. Available online: https://www.hdrsoft.com/download/photomatix-pro.html (accessed on 23 March 2025).
- Boitard, R.; Pourazad, M.T.; Nasiopoulos, P. High dynamic range versus standard dynamic range compression efficiency. In Proceedings of the 2016 Digital Media Industry & Academic Forum (DMIAF), Santorini, Greece, 4–6 July 2016; IEEE: Piscataway, NJ, USA, 2016. [Google Scholar]
- BT.709-6 (06/2015); Recommendation, Parameter Values for the HDTV Standards for Production and International Programme Exchange. ITU: Geneva, Switzerland, 2002.
- ITU-R BT.2020-1 (06/2014); Parameter Values for Ultra-High Definition Television Systems for Production and International Programme Exchange. ITU-T, Bt. 2020; ITU: Geneva, Switzerland, 2012.
- Nemoto, H.; Korshunov, P.; Hanhart, P.; Ebrahimi, T. Visual attention in LDR and HDR images. In Proceedings of the 9th International Workshop on Video Processing and Quality Metrics for Consumer Electronics (VPQM), Chandler, AZ, USA, 5–6 February 2015. [Google Scholar]
- Prabhakar, K.R.; Arora, R.; Swaminathan, A.; Singh, K.P.; Babu, R.V. A fast, scalable, and reliable deghosting method for extreme exposure fusion. In Proceedings of the 2019 IEEE International Conference on Computational Photography (ICCP), Tokyo, Japan, 5–17 May 2019; IEEE: Piscataway, NJ, USA. [Google Scholar]
- Pérez-Pellitero, E.; Catley-Chandar, S.; Leonardis, A.; Timofte, R. NTIRE 2021 challenge on high dynamic range imaging: Dataset, methods and results. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021. [Google Scholar]
- Yang, X.; Xu, K.; Song, Y.; Zhang, Q.; Wei, X.; Lau, R.W. Image correction via deep reciprocating HDR transformation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Vasu, S.; Shenoi, A.; Rajagopazan, A. Joint hdr and super-resolution imaging in motion blur. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; IEEE: Piscataway, NJ, USA. [Google Scholar]
- Cogalan, U.; Bemana, M.; Myszkowski, K.; Seidel, H.-P.; Ritschel, T. Learning HDR video reconstruction for dual-exposure sensors with temporally-alternating exposures. Comput. Graph. 2022, 105, 57–72. [Google Scholar] [CrossRef]
- Kim, J.; Kim, M.H. Joint demosaicing and deghosting of time-varying exposures for single-shot hdr imaging. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023. [Google Scholar]
- Conde, M.V.; Vasluianu, F.; Vazquez-Corral, J.; Timofte, R. Perceptual image enhancement for smartphone real-time applications. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 2–7 January 2023. [Google Scholar]
- Mantiuk, R.; Kim, K.J.; Rempel, A.G.; Heidrich, W. HDR-VDP-2: A calibrated visual metric for visibility and quality predictions in all luminance conditions. ACM Trans. Graph. (TOG) 2011, 30, 1–14. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Year | Size | Resolution | Type | Input | Output | Feature |
|---|---|---|---|---|---|---|---|
| HDREye [43] | 2015 | 46 | 1920 × 1080 | Syn. | 8 bit sRGB | 16 bit HDR | Static |
| Tursen [38] | 2016 | 17 | 1024 × 682 | Real | 8 bit sRGB | NA | Multi-exposure |
| Kalantari [10] | 2017 | 74 | 1500 × 1000 | Real | 14 bit Raw | 16 bit HDR | Multi-exposure |
| Prabhakar [44] | 2019 | 582 | Multiple | Syn. | 8 bit sRGB | 16 bit HDR | Multi-exposure |
| Liu [36] | 2020 | NA | 1536 × 1024 | Real + Syn. | 8 bit sRGB | 12~16 bit HDR | Single-exposure |
| NITIRE2021 [45] | 2021 | 1761 | 1920 × 1080 | Syn | 8 bit sRGB | 12 bit HDR | video sequences |
| Dataset | Sen [8] | Kalantari [10] | Wu [11] | Niu [14] | Lee [32] | Ours | |
|---|---|---|---|---|---|---|---|
| Kalantari | PSNR- | 40.95 | 42.74 | 41.64 | 43.92 | 44.03 1 | 41.50 |
| SSIM- | 0.9805 | 0.9877 | 0.9869 | 0.9905 | 0.9914 1 | 0.9877 | |
| PSNR-L | 38.31 | 41.22 | 40.91 | 41.57 1 | 41.18 | 37.84 | |
| SSIM-L | 0.9726 | 0.9848 | 0.9858 | 0.9865 | 0.9871 1 | 0.9788 | |
| HDR-VDP-2 | 55.72 | 60.51 | 60.50 | 65.45 | 63.02 | 66.05 1 |
| Dataset | Sen [8] | Kalantari [10] | Wu [11] | Niu [14] | Lee [32] | Ours | |
|---|---|---|---|---|---|---|---|
| Kalantari | Time(s) | 119.69 | 146.70 | 0.35 | 2.9 | 0.69 | 7.88 |
| Para(M) | NA | 0.30 | 16.61 | 2.56 | 15.26 | 34.86 |
| Dataset | Enhanced Lone Exposure | Enhanced Middle Exposure | Enhanced Short Exposure | |
|---|---|---|---|---|
| Kalantari | PSNR- | 37.700 | 33.874 | 37.738 |
| SSIM- | 0.9822 | 0.959 | 0.983 | |
| PSNR-L | 36.213 | 35.001 | 36.080 | |
| SSIM-L | 0.968 | 0.958 | 0.969 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hung, K.-C.; Lin, S.-F.; Lee, C.-H. A Novel Solution for Reconstructing More Details High Dynamic Range Image. Appl. Sci. 2025, 15, 5819. https://doi.org/10.3390/app15115819
Hung K-C, Lin S-F, Lee C-H. A Novel Solution for Reconstructing More Details High Dynamic Range Image. Applied Sciences. 2025; 15(11):5819. https://doi.org/10.3390/app15115819
Chicago/Turabian StyleHung, Kuo-Ching, Sheng-Fuu Lin, and Ching-Hung Lee. 2025. "A Novel Solution for Reconstructing More Details High Dynamic Range Image" Applied Sciences 15, no. 11: 5819. https://doi.org/10.3390/app15115819
APA StyleHung, K.-C., Lin, S.-F., & Lee, C.-H. (2025). A Novel Solution for Reconstructing More Details High Dynamic Range Image. Applied Sciences, 15(11), 5819. https://doi.org/10.3390/app15115819