
Integrating Graph Neural Networks and Large Language Models for Stance Detection via Heterogeneous Stance Networks


Abstract
1. Introduction
- We propose a heterogeneous stance network that systematically models indirect stance relationships, effectively addressing the challenge of implicit stance expression.
- We develop two distinct methodologies: a GNN-based approach for supervised settings and an LLM-based zero-shot method, enabling robust stance detection in diverse scenarios.
- Our framework establishes new state-of-the-art results on benchmark datasets across both supervised and zero-shot settings, demonstrating its superiority over the existing approaches.
2. Related Work
2.1. Supervised Approaches
2.2. Zero-Shot Approaches
2.3. Social and Ideological Dimensions of Stance
3. Methodology
3.1. Formal Task Definition
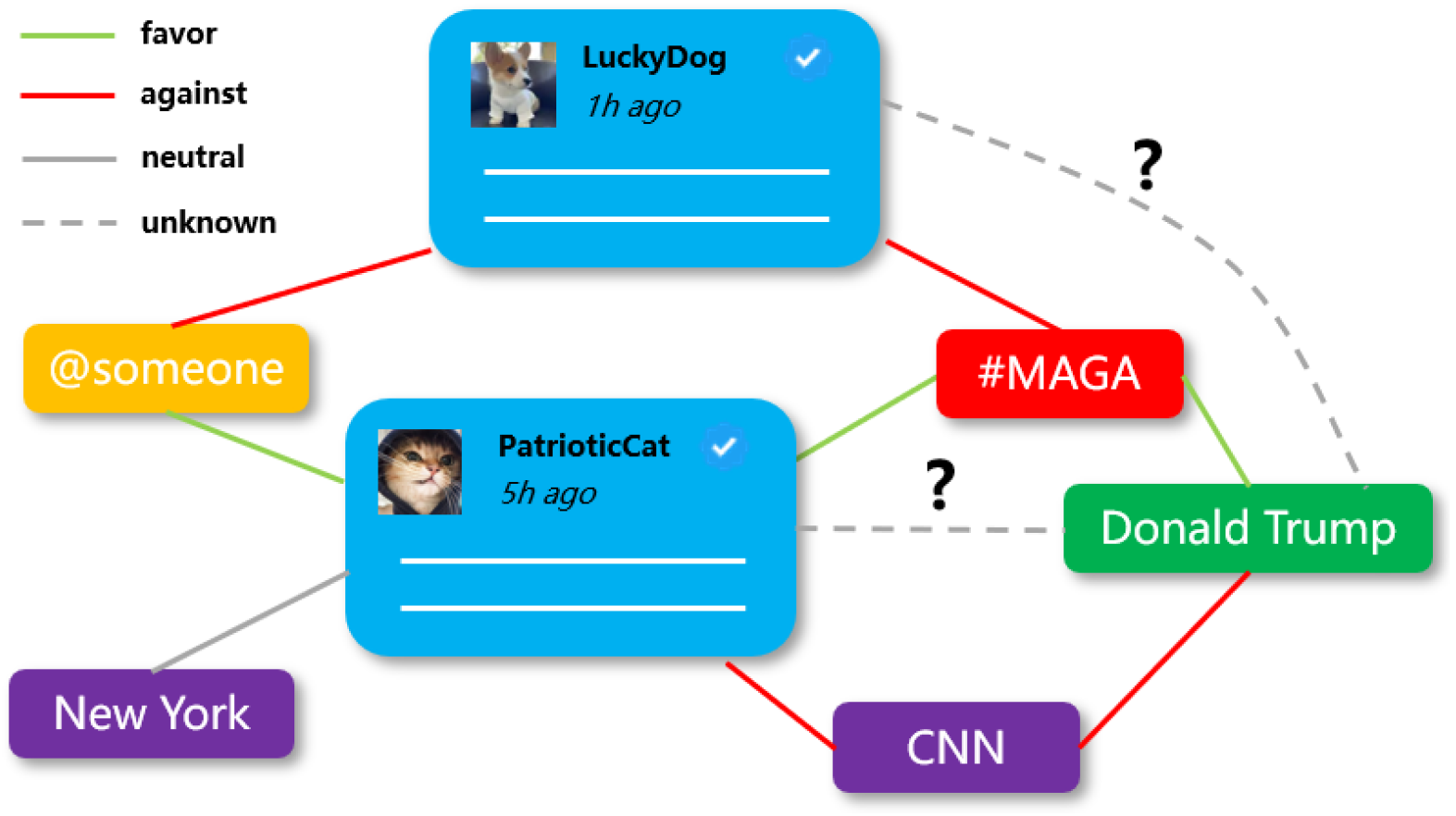
3.2. Heterogeneous Stance Network
3.2.1. Network Definition
- Posts: Each post that expresses a stance toward a target is represented as a node in the network.
- Targets: These nodes represent the subjects or entities toward which stance is expressed. Examples include political figures, organizations, or controversial topics.
- Entities: Entities extracted from posts enrich contextual understanding. Depending on the dataset characteristics, entity nodes can be further categorized. For instance, in the case of “X” (formerly Twitter) data, entity nodes include the following: (1) hashtags: represent hashtags used in posts, which often serve as implicit stance indicators; (2) users: represent user mentions, capturing relationships between different social media users; (3) named entities: represent named entities such as people, organizations, or locations mentioned in the text.
- Favor Edges: Indicating a positive or supportive stance.
- Against Edges: Indicating an opposing or negative stance.
- Neutral Edges: Indicating the absence of a strong stance.
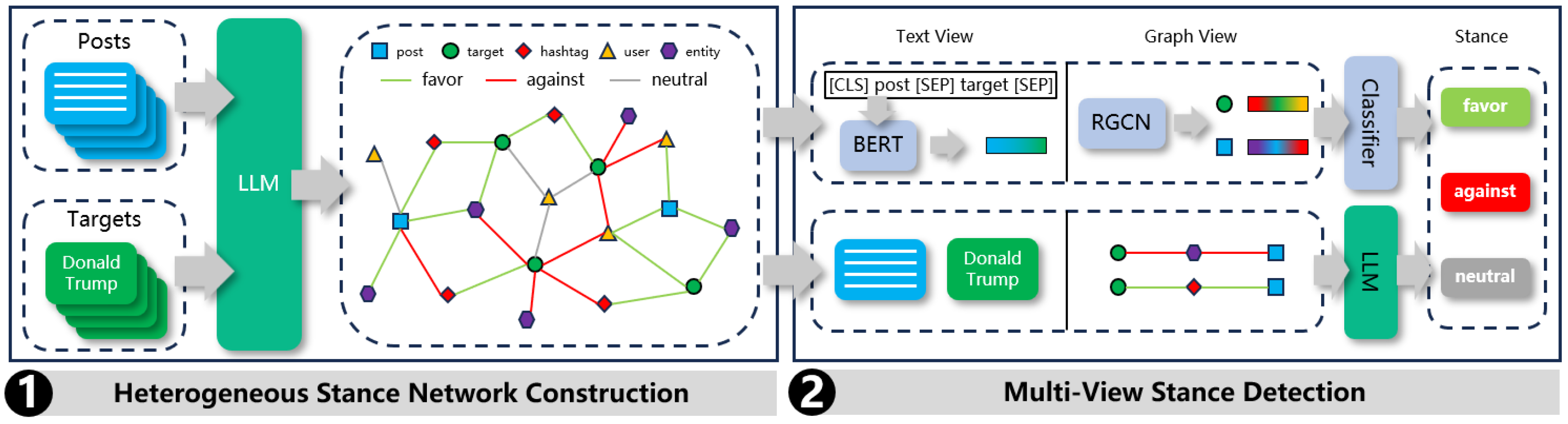
3.2.2. Network Construction
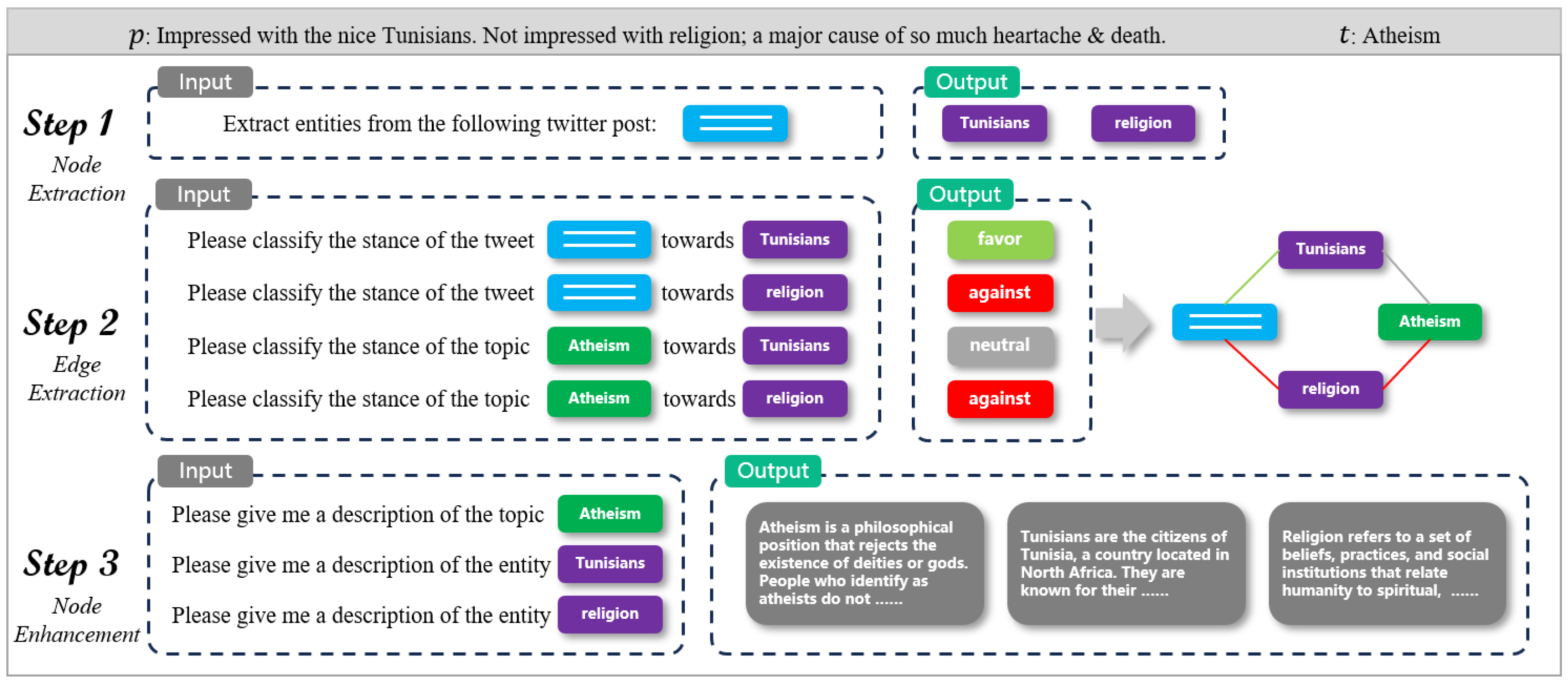
3.3. Multi-View Stance Detection
3.3.1. GCN Approach
3.3.2. LLM Approach
4. Experiments
4.1. Experimental Setup
4.1.1. Datasets
4.1.2. Evaluation
4.1.3. Baselines
4.1.4. Implementation Details
4.2. The Overall Comparison
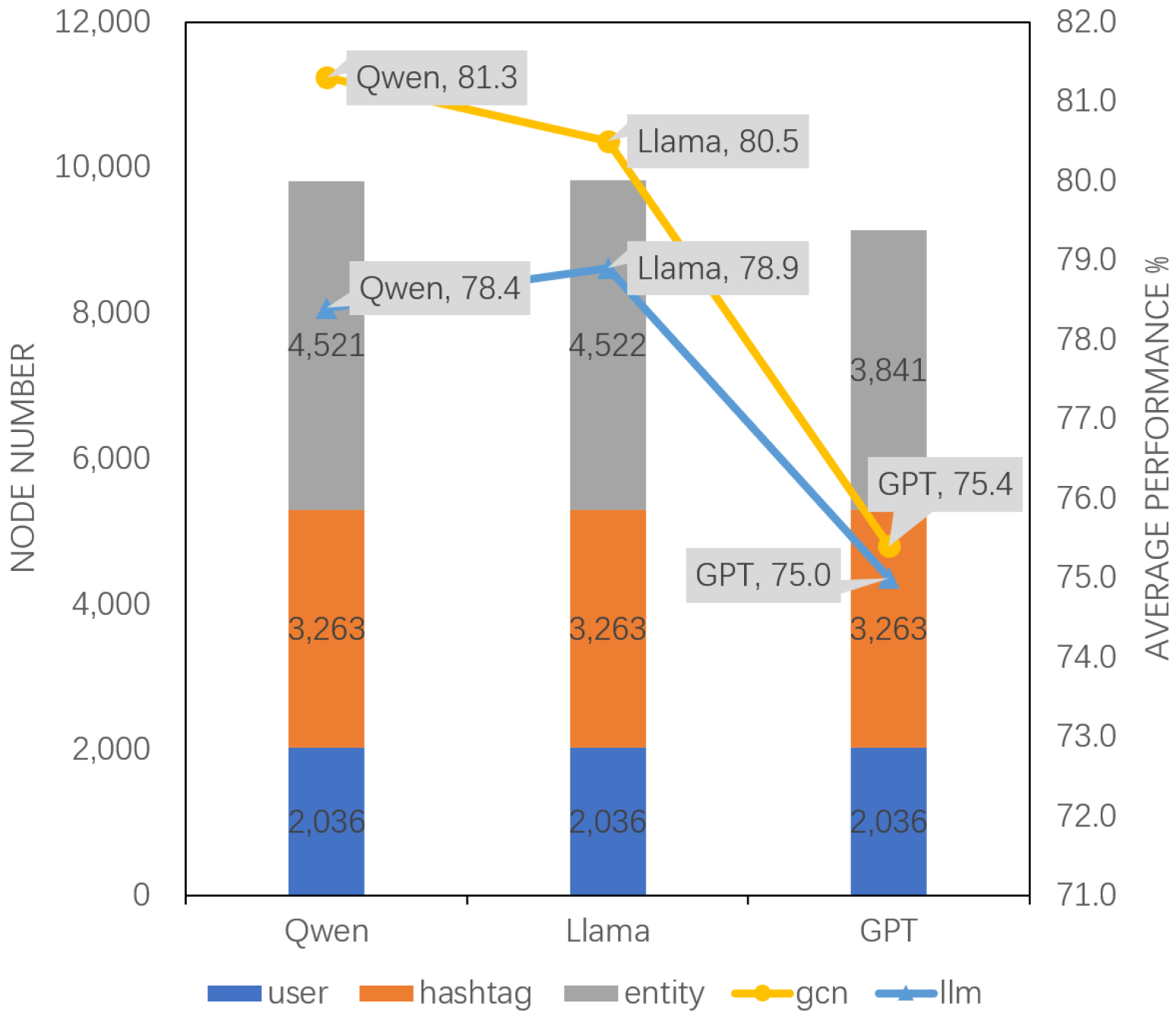
4.3. Comparison of Different LLMs
4.4. Ablation Studies
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| NLP | Natural Language Processing |
| BERT | Bi-directional Encoder Representations from Transformers |
| LLM | Large Language Model |
| GNN | Graph Neural Network |
| HSN | Heterogeneous Stance Network |
| GCN | Graph Convolutional Network |
| RGCN | Relational Graph Convolutional Network |
| MVSD | Multi-View Stance Detection |
| GPU | Graphics Processing Unit |
Appendix A. Details of the Propmts

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Function | Prompt |
|---|---|
| Extracting entities from tweet (step 1) | In the following tweet, identify entities (concepts, people, events, etc.) that indirectly express a stance toward the target. These should be things that are not the target itself but are related to it and help to express an opinion about it. If multiple entities are found, please separate them with commas. Return ‘None’ if no entities are found. Tweet: [tweet] Target: [target] |
| Classifying the stance between the tweet and the entity (step 2) | Classify the stance of the following tweet towards the entity as either ‘favor’, ‘against’, or ‘neutral’. If it is ambiguous or unclear, return ‘neutral’. DO NOT RETURN ANYTHING ELSE. Tweet: [tweet] Entity: [entity] |
| Classifying the stance between the target and the entity (step 2) | According to the tweet, classify the stance between the entity and the target as either ‘favor’, ‘against’, or ‘neutral’. If it is ambiguous or unclear, return ‘neutral’. DO NOT RETURN ANYTHING ELSE. Tweet: [tweet] Entity: [entity] Target: [target] |
| Enhancing textual description of the entity (step 3) | Please briefly describe [entity]. If you do not know, return ‘unknown’. |
References
- Mohammad, S.; Kiritchenko, S.; Sobhani, P.; Zhu, X.; Cherry, C. SemEval-2016 Task 6: Detecting Stance in Tweets. In Proceedings of the 10th International Workshop on Semantic Evaluation (SemEval-2016), San Diego, CA, USA, 16–17 June 2016. [Google Scholar] [CrossRef]
- Küçük, D.; Can, F. Stance Detection: A Survey. ACM Comput. Surv. 2020, 53, 12. [Google Scholar] [CrossRef]
- ALDayel, A.; Magdy, W. Stance detection on social media: State of the art and trends. Inf. Process. Manag. 2021, 58, 102597. [Google Scholar] [CrossRef]
- Bar-Haim, R.; Bhattacharya, I.; Dinuzzo, F.; Saha, A.; Slonim, N. Stance Classification of Context-Dependent Claims. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 1, Long Papers; Lapata, M., Blunsom, P., Koller, A., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2017; pp. 251–261. [Google Scholar] [CrossRef]
- Wei, P.; Mao, W.; Zeng, D. A Target-Guided Neural Memory Model for Stance Detection in Twitter. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the North American Chapter of the Association for Computational Linguistics, Minneapolis, MN, USA, 2–9 June 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Allaway, E.; McKeown, K. Zero-Shot Stance Detection: A Dataset and Model using Generalized Topic Representations. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP); Webber, B., Cohn, T., He, Y., Liu, Y., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 8913–8931. [Google Scholar] [CrossRef]
- Liang, B.; Chen, Z.; Gui, L.; He, Y.; Yang, M.; Xu, R. Zero-Shot Stance Detection via Contrastive Learning. In Proceedings of the WWW ’22: Proceedings of the ACM Web Conference, Virtual, 25–29 April 2022; pp. 2738–2747. [Google Scholar] [CrossRef]
- Allaway, E.; Srikanth, M.; McKeown, K. Adversarial Learning for Zero-Shot Stance Detection on Social Media. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies; Toutanova, K., Rumshisky, A., Zettlemoyer, L., Hakkani-Tür, D., Beltagy, I., Bethard, S., Cotterell, R., Chakraborty, T., Zhou, Y., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 4756–4767. [Google Scholar] [CrossRef]
- Liang, B.; Zhu, Q.; Li, X.; Yang, M.; Gui, L.; He, Y.; Xu, R. JointCL: A Joint Contrastive Learning Framework for Zero-Shot Stance Detection. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers); Muresan, S., Nakov, P., Villavicencio, A., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2022; pp. 81–91. [Google Scholar] [CrossRef]
- Zhang, B.; Ding, D.; Jing, L. How would Stance Detection Techniques Evolve after the Launch of ChatGPT? arXiv 2022, arXiv:2212.14548. [Google Scholar]
- Huang, H.; Zhang, B.; Li, Y.; Zhang, B.; Sun, Y.; Luo, C.; Peng, C. Knowledge-enhanced Prompt-tuning for Stance Detection. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2023, 22, 1–20. [Google Scholar] [CrossRef]
- Lan, X.; Gao, C.; Jin, D.; Li, Y. Stance Detection with Collaborative Role-Infused LLM-Based Agents. Proc. Int. AAAI Conf. Web Soc. Media 2024, 18, 891–903. [Google Scholar] [CrossRef]
- Zhou, Y.; Cristea, A.I.; Shi, L. Connecting Targets to Tweets: Semantic Attention-Based Model for Target-Specific Stance Detection. In Proceedings of the WISE 18th International Conference, Puschino, Russia, 7–11 October 2017. [Google Scholar]
- Sun, Q.; Wang, Z.; Zhu, Q.; Zhou, G. Stance Detection with Hierarchical Attention Network. In Proceedings of the International Conference on Computational Linguistics, Santa Fe, NM, USA, 21–25 August 2018. [Google Scholar]
- Li, Y.; Sosea, T.; Sawant, A.; Nair, A.J.; Inkpen, D.; Caragea, C. P-Stance: A Large Dataset for Stance Detection in Political Domain. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021; Zong, C., Xia, F., Li, W., Navigli, R., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; Volume ACL/IJCNLP 2021, pp. 2355–2365. [Google Scholar] [CrossRef]
- Patra, B.G.; Das, D.; Bandyopadhyay, S. JU_NLP at SemEval-2016 Task 6: Detecting Stance in Tweets using Support Vector Machines. In Proceedings of the International Workshop on Semantic Evaluation, San Diego, CA, USA, 16–17 June 2016. [Google Scholar]
- Lai, M.; Cignarella, A.T.; Farías, D.I.H. iTACOS at IberEval2017: Detecting Stance in Catalan and Spanish Tweets. In Proceedings of the Second Workshop on Evaluation of Human Language Technologies for Iberian Languages (IberEval 2017), Murcia, Spain, 19 September 2017. [Google Scholar]
- Rajendran, G.; Chitturi, B.; Poornachandran, P. Stance-In-Depth Deep Neural Approach to Stance Classification. Procedia Comput. Sci. 2018, 132, 1646–1653. [Google Scholar] [CrossRef]
- Augenstein, I.; Rocktäschel, T.; Vlachos, A.; Bontcheva, K. Stance Detection with Bidirectional Conditional Encoding. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing; Su, J., Carreras, X., Duh, K., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2016; pp. 876–885. [Google Scholar] [CrossRef]
- Xu, C.; Paris, C.; Nepal, S.; Sparks, R. Cross-Target Stance Classification with Self-Attention Networks. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers); Gurevych, I., Miyao, Y., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; pp. 778–783. [Google Scholar] [CrossRef]
- Zhang, C.; Li, Q.; Song, D. Aspect-based Sentiment Classification with Aspect-specific Graph Convolutional Networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP); Inui, K., Jiang, J., Ng, V., Wan, X., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 4567–4577. [Google Scholar] [CrossRef]
- Liang, B.; Fu, Y.; Gui, L.; Yang, M.; Du, J.; He, Y.; Xu, R. Target-adaptive Graph for Cross-target Stance Detection. In Proceedings of the WWW’21: Proceedings of the Web Conference 2021, Ljubljana Slovenia, 19–23 April 2021; Leskovec, J., Grobelnik, M., Najork, M., Tang, J., Zia, L., Eds.; ACM: New York, NY, USA, 2021; pp. 3453–3464. [Google Scholar] [CrossRef]
- Li, Y.; Caragea, C. Multi-Task Stance Detection with Sentiment and Stance Lexicons. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP); Inui, K., Jiang, J., Ng, V., Wan, X., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 6299–6305. [Google Scholar] [CrossRef]
- Liu, G.T.; Zhang, Y.J.; Wang, C.L.; Lu, M.Y.; Tang, H.L. Comparative learning based stance agreement detection framework for multi-target stance detection. Eng. Appl. Artif. Intell. 2024, 133, 108515. [Google Scholar] [CrossRef]
- Liu, G.; Zhao, K.; Zhang, L.; Bi, X.; Lv, X.; Chen, C. A Survey of Zero-Shot Stance Detection. In Natural Language Processing and Chinese Computing; Wong, D.F., Wei, Z., Yang, M., Eds.; Springer: Singapore, 2025; pp. 107–120. [Google Scholar]
- Zhang, H.; Li, Y.; Zhu, T.; Li, C. Commonsense-based adversarial learning framework for zero-shot stance detection. Neurocomputing 2024, 563, 126943. [Google Scholar] [CrossRef]
- Chunling, W.; Yijia, Z.; Xingyu, Y.; Guantong, L.; Fei, C.; Hongfei, L. Adversarial Network with External Knowledge for Zero-Shot Stance Detection. In Proceedings of the 22nd Chinese National Conference on Computational Linguistics; Sun, M., Qin, B., Qiu, X., Jiang, J., Han, X., Eds.; Chinese Information Processing Society of China: Beijing, China, 2023; pp. 824–835. [Google Scholar]
- Zou, J.; Zhao, X.; Xie, F.; Zhou, B.; Zhang, Z.; Tian, L. Zero-Shot Stance Detection via Sentiment-Stance Contrastive Learning. In Proceedings of the 2022 IEEE 34th International Conference on Tools with Artificial Intelligence (ICTAI), Macao, China, 31 October–2 November 2022; pp. 251–258. [Google Scholar] [CrossRef]
- Zhao, X.; Zou, J.; Tian, L.; Xie, F.; Wang, H.; Wu, H.; Zhou, B.; Tian, J. A Unified Framework for Unseen Target Stance Detection based on Feature Enhancement via Graph Contrastive Learning. In Proceedings of the 45th Annual Meeting of the Cognitive Science Society, CogSci 2023, Sydney, NSW, Australia, 26–29 July 2023; Goldwater, M.B., Anggoro, F.K., Hayes, B.K., Ong, D.C., Eds.; Cognitive Science Society: Seattle, WA, USA, 2023. [Google Scholar]
- Jiang, Y.; Gao, J.; Shen, H.; Cheng, X. Zero-shot stance detection via multi-perspective contrastive learning with unlabeled data. Inf. Process. Manag. 2023, 60, 103361. [Google Scholar] [CrossRef]
- Liu, R.; Lin, Z.; Tan, Y.; Wang, W. Enhancing Zero-shot and Few-shot Stance Detection with Commonsense Knowledge Graph. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021. [Google Scholar]
- Zhu, Q.; Liang, B.; Sun, J.; Du, J.; Zhou, L.; Xu, R. Enhancing Zero-Shot Stance Detection via Targeted Background Knowledge. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, Madrid, Spain, 11–15 July 2022; pp. 2070–2075. [Google Scholar] [CrossRef]
- Li, A.; Zhao, J.; Liang, B.; Gui, L.; Wang, H.; Zeng, X.; Wong, K.; Xu, R. Mitigating Biases of Large Language Models in Stance Detection with Calibration. arXiv 2024, arXiv:2402.14296. [Google Scholar]
- Williams, H.T.; McMurray, J.R.; Kurz, T.; Hugo Lambert, F. Network analysis reveals open forums and echo chambers in social media discussions of climate change. Glob. Environ. Chang. 2015, 32, 126–138. [Google Scholar] [CrossRef]
- Alkhalifa, R.; Zubiaga, A. Capturing Stance Dynamics in Social Media: Open Challenges and Research Directions. Int. J. Digit. Humanit. 2022, 3, 115–135. [Google Scholar] [CrossRef]
- Schlichtkrull, M.; Kipf, T.N.; Bloem, P.; van den Berg, R.; Titov, I.; Welling, M. Modeling Relational Data with Graph Convolutional Networks. In The Semantic Web; Springer International Publishing: Cham, Switzerland, 2018; pp. 593–607. [Google Scholar] [CrossRef]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep Sparse Rectifier Neural Networks. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Lauderdale, FL, USA, 11–13 April 2011. [Google Scholar]


| Dataset | Targets | Samples | Favor/Against/Neutral |
|---|---|---|---|
| SEM16 | 5 | 4870 | 1240/1574/2056 |
| P-Stance | 3 | 21,574 | 7645/7432/6497 |
| Category | Model | SEM16 (%) | ||||||
|---|---|---|---|---|---|---|---|---|
| DT | HC | FM | LA | AT | CC | avg | ||
| supervised | BiCond | - | 56.1 | 52.9 | 61.2 | 55.3 | 35.6 | 52.2 |
| BERT | - | 61.3 | 59.0 | 63.1 | 60.7 | 38.8 | 56.6 | |
| CrossNet | - | 60.2 | 55.7 | 61.3 | 56.4 | 40.1 | 54.7 | |
| ASGCN | - | 61.0 | 58.7 | 63.2 | 59.5 | 40.6 | 56.6 | |
| TPDG | - | 73.4 | 67.3 | 74.7 | 64.7 | 42.3 | 64.5 | |
| MVSD(GCN) | - | 84.7 | 70.3 | 77.1 | 76.7 | 68.1 | 75.4 | |
| zero-shot | TOAD | 49.5 | 51.2 | 54.1 | 46.2 | 46.1 | 30.9 | 46.3 |
| JointCL | 50.5 | 54.8 | 53.8 | 49.5 | 54.5 | 39.7 | 50.5 | |
| GPT3.5-direct | 62.3 | 66.2 | 60.5 | 60.3 | 20.6 | 56.9 | 54.5 | |
| COLA | 68.5 | 81.7 | 63.4 | 71.0 | 70.8 | 65.5 | 70.2 | |
| MB-Cal | 72.8 | 80.3 | 75.8 | 68.8 | 66.5 | 71.0 | 72.5 | |
| MVSD(LLM) | 76.1 | 82.0 | 79.9 | 77.7 | 56.9 | 77.3 | 75.0 | |
| Category | Model | P-Stance (%) | |||
|---|---|---|---|---|---|
| Trump | Biden | Sanders | avg | ||
| supervised | BiCond | 73.0 | 69.4 | 64.6 | 69.0 |
| BERT | 67.7 | 73.1 | 68.2 | 69.7 | |
| CrossNet | 58.0 | 65.0 | 53.0 | 58.7 | |
| ASGCN | 77.0 | 78.4 | 70.8 | 75.4 | |
| TPDG | 76.8 | 78.1 | 71 | 75.3 | |
| MVSD(GCN) | 83.4 | 86.7 | 74.0 | 81.4 | |
| zero-shot | TOAD | 53.0 | 68.4 | 62.9 | 61.4 |
| JointCL | 62.0 | 59.0 | 73.0 | 64.7 | |
| GPT3.5-direct | 82.1 | 82.0 | 79.0 | 81.0 | |
| COLA | 86.6 | 84.0 | 79.7 | 83.4 | |
| MB-Cal | 85.1 | 85.1 | 81.1 | 83.8 | |
| MVSD(LLM) | 85.8 | 84.6 | 82.0 | 84.1 | |
| Model | Qwen-2.5 | Llama-3.1 | GPT-3.5 |
|---|---|---|---|
| LLM-Direct | 70.3 | 75.1 | 54.5 |
| MVSD(LLM) | 78.4 | 78.9 | 75.0 |
| MVSD(GCN) | 81.3 | 80.5 | 75.4 |
| Model | Average Perf. |
|---|---|
| MVSD(GCN) | 75.4 |
| w/o R | 62.4 |
| w/o H-node | 72.2 |
| w/o U-node | 73.0 |
| w/o E-node | 71.5 |
| w/o Att | 72.7 |
| MVSD(LLM) | 75.0 |
| w/o H-node | 70.2 |
| w/o U-node | 71.4 |
| w/o E-node | 68.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, X.; Liu, B.; Hu, H.; Cai, Y.; Guo, M.; Ma, X. Integrating Graph Neural Networks and Large Language Models for Stance Detection via Heterogeneous Stance Networks. Appl. Sci. 2025, 15, 5809. https://doi.org/10.3390/app15115809
Chen X, Liu B, Hu H, Cai Y, Guo M, Ma X. Integrating Graph Neural Networks and Large Language Models for Stance Detection via Heterogeneous Stance Networks. Applied Sciences. 2025; 15(11):5809. https://doi.org/10.3390/app15115809
Chicago/Turabian StyleChen, Xinyi, Bo Liu, Huaping Hu, Yiqing Cai, Mengmeng Guo, and Xingkong Ma. 2025. "Integrating Graph Neural Networks and Large Language Models for Stance Detection via Heterogeneous Stance Networks" Applied Sciences 15, no. 11: 5809. https://doi.org/10.3390/app15115809
APA StyleChen, X., Liu, B., Hu, H., Cai, Y., Guo, M., & Ma, X. (2025). Integrating Graph Neural Networks and Large Language Models for Stance Detection via Heterogeneous Stance Networks. Applied Sciences, 15(11), 5809. https://doi.org/10.3390/app15115809