
CAA-RF: An Anomaly Detection Algorithm for Computing Power Blockchain Networks


Abstract
1. Introduction
1.1. Related Work
1.2. Contributions
- To address the issue of dataset scarcity, we designed and implemented a distributed, lightweight proof-of-stake blockchain model tailored for computational networks. This model not only simulates the operation, communication, and consensus processes of blockchain in a computational network environment but also enables the collection of key performance indicators and instrumental data during the normal operation of the blockchain system through the simulation process.
- In the research field of computational blockchain technology, the absence of publicly available datasets remains a fundamental issue. To tackle this, we designed and carried out a series of security attack experiments on computational blockchain networks, including Sybil attacks and denial-of-service (DoS) attacks. These experiments were designed to simulate various real-world attack scenarios, thereby compensating for the lack of data in existing studies. Through these experiments, we successfully captured and recorded a large volume of anomalous behavioral data from blockchain systems under attack. The collected data span multiple dimensions, including abnormal error rates and packet sizes, and provide detailed information on the system’s data reception during attack periods.
- We propose an adaptive anomaly detection method that integrates attention mechanisms, random forests, and convolutional neural networks. This method is trained on the dataset collected from the aforementioned distributed computational blockchain model. Furthermore, we designed a series of comparative experiments to evaluate the performance of our model against traditional machine learning methods and six deep learning approaches. The results show that our proposed method achieves more balanced performance in terms of both accuracy and F1-score.
1.3. Organization
2. Distributed Computing Power Blockchain Network Model
| Algorithm 1. Validator selected by a random number |
| Input: Node T |
| Output: Validator |
| for node = A, B, C, …, T do |
| for toNode = A, B, C, …, T do R ← send(node, toNode, R) |
| end for |
| end for |
| for node = A, B, C, …, Tdo |
| average ←AVG(R)) |
| e ←E(average) |
| Validator ← select(e) |
| End For |
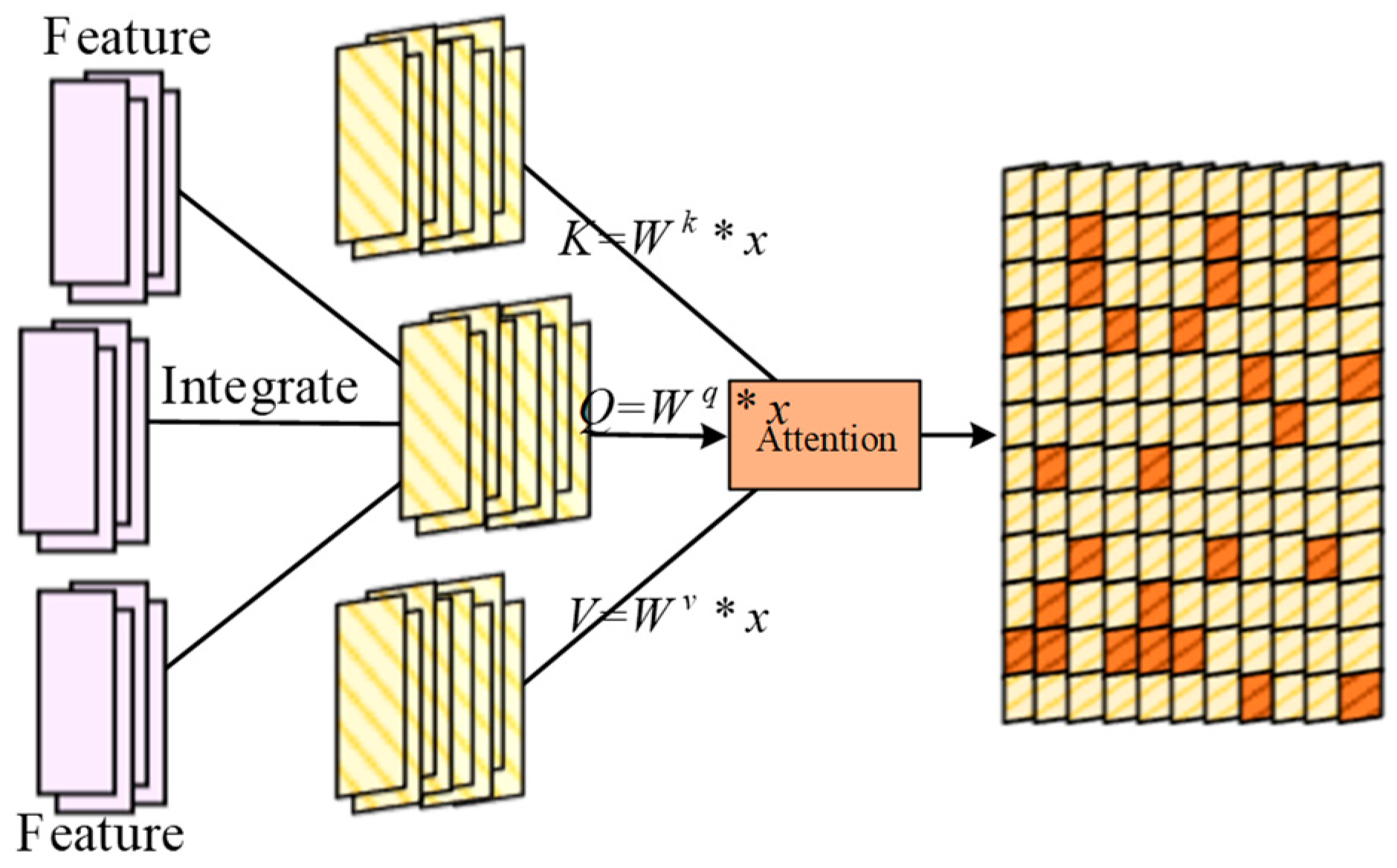
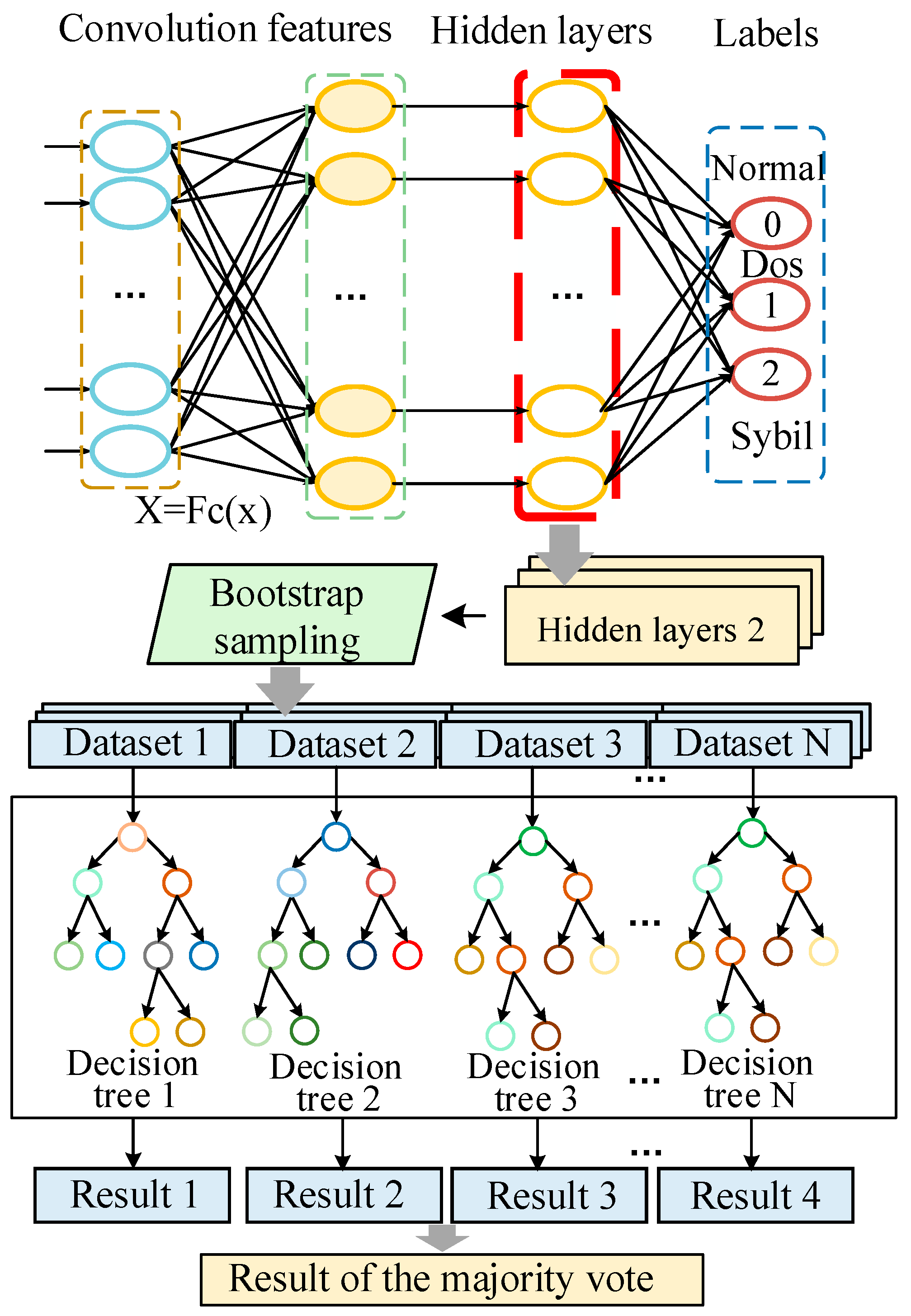
3. Network Anomaly Detection Strategy for Computing Power Blockchain Networks
| Algorithm 2. Random forest classification algorithm based on convolutional feature |
| Input: Network Traffic Data D = {X1, X2, X3, X4, …, X14, Y} |
| Output: Random Forest Classification Accuracy A2 |
| Standardize features D |
| Apply ADASYN oversampling to the dataset D |
| for i = 1 to n do |
| O ← CAA (Xi) |
| Loss ← LF(O, Y) |
| Backward |
| Update W |
| A1 ← Predict O |
| F ← CAA(Xi) |
| RF Fit(F, Y) |
| A2 ← RF(F) |
| End For |
4. Experimental Results and Analysis
4.1. Introduction to Datasets
4.2. Experimental Setting and Assessment Criteria
4.3. Performance Evaluation and Comparative Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, H.; Ye, S.; Cao, X.; Lin, Z. Real-time detection method for mobile network traffic anomalies considering user behavior security monitoring. In Proceedings of the 2021 International Conference on Computer, Blockchain and Financial Development (CBFD), Nanjing, China, 23–25 April 2021; pp. 11–16. [Google Scholar]
- Ige, T.; Kiekintveld, C. Performance Comparison and Implementation of Bayesian Variants for Network Intrusion Detection. In Proceedings of the 2023 IEEE International Conference on Artificial Intelligence, Blockchain, and Internet of Things (AI-BThings), Mount Pleasant, MI, USA, 16–17 September 2023; pp. 1–5. [Google Scholar]
- Latha, R.; Justin Thangaraj, S.J. Machine Learning Approaches for DDoS Attack Detection: Naive Bayes vs. Logistic Regression. In Proceedings of the 2023 Second International Conference on Smart Technologies for Smart Nation (SmartTechCon), Singapore, Singapore, 18–19 August 2023; pp. 1043–1048. [Google Scholar]
- Tharani, J.S.; Hóu, Z.; Charles, E.Y.A.; Rathore, P.; Palaniswami, M.; Muthukkumarasamy, V. Unified Feature Engineering for Detection of Malicious Entities in Blockchain Networks. IEEE Trans. Inf. Forensics Secur. 2024, 19, 8924–8938. [Google Scholar] [CrossRef]
- Grekov, M. Architecture of a Multistage Anomaly Detection System in Computer Networks. In Proceedings of the 2022 International Siberian Conference on Control and Communications (SIBCON), Tomsk, Russia, 17–19 November 2022; pp. 1–5. [Google Scholar]
- Kumaresan, S.J.; Senthilkumar, C.; Kongkham, D.; Beenarani, B.B.; Nirmala, P. Investigating the Effectiveness of Recurrent Neural Networks for Network Anomaly Detection. In Proceedings of the 2024 International Conference on Intelligent and Innovative Technologies in Computing, Electrical and Electronics (IITCEE), Bangalore, India, 24–25 January 2024; pp. 1–5. [Google Scholar]
- Kisanga, P.; Woungang, I.; Traore, I.; Carvalho, G.H.S. Network Anomaly Detection Using a Graph Neural Network. In Proceedings of the 2023 International Conference on Computing, Networking and Communications (ICNC), Honolulu, HI, USA, 20–22 February 2023; pp. 61–65. [Google Scholar] [CrossRef]
- Xu, G.; Zhou, J.; He, Y. Network Malicious Traffic Detection Model Based on Combined Neural Network. In Proceedings of the 2022 6th Asian Conference on Artificial Intelligence Technology (ACAIT), Changzhou, China, 9–11 December 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Wang, X.; Han, L.; Sun, S.; Xu, G. A Concept Drift Tolerant Abnormal Detection Method for Network Traffic. In Proceedings of the 2023 International Conference on Cyber-Enabled Distributed Computing and Knowledge Discovery (CyberC), Suzhou, China, 2–4 November 2023; pp. 323–330. [Google Scholar]
- Yang, D.; Hwang, M. Unsupervised and Ensemble-based Anomaly Detection Method for Network Security. In Proceedings of the 2022 14th International Conference on Knowledge and Smart Technology (KST), Chon buri, Thailand, 26–29 January 2022; pp. 75–79. [Google Scholar]
- Mehra, P.; Ahuja, M.S.; Aeri, M. Time Series Anomaly Detection System with Linear Neural Network and Autoencoder. In Proceedings of the 2023 International Conference on Device Intelligence, Computing and Communication Technologies, (DICCT), Dehradun, India, 17–18 March 2023; pp. 659–662. [Google Scholar]
- Li, Z.; Wang, Y.; Wang, P.; Su, H. PGAN:A Generative Adversarial Network based Anomaly Detection Method for Network Intrusion Detection System. In Proceedings of the 2021 IEEE 20th International Conference on Trust, Security and Privacy in Computing and Communications (TrustCom), Shenyang, China, 20–22 October 2021; pp. 734–741. [Google Scholar] [CrossRef]
- Yang, X.; Guo, Z.; Mai, Z. Botnet Detection Based on Machine Learning. In Proceedings of the 2022 International Conference on Blockchain Technology and Information Security (ICBCTIS), Huaihua, China, 15–17 July 2022; pp. 213–217. [Google Scholar]
- Kim, J.; Nakashima, M.; Fan, W.; Wuthier, S.; Zhou, X.; Kim, I.; Chang, S.Y. A Machine Learning Approach to Anomaly Detection Based on Traffic Monitoring for Secure Blockchain Networking. IEEE Trans. Netw. Serv. Manag. 2022, 19, 3619–3632. [Google Scholar] [CrossRef]
- Sun, Y.; Ochiai, H.; Esaki, H. Multi-Type Anomaly Detection Based on Raw Network Traffic. In Proceedings of the 2021 IEEE 18th Annual Consumer Communications & Networking Conference (CCNC), Las Vegas, NV, USA, 9–12 January 2021; pp. 1–2. [Google Scholar] [CrossRef]
- Li, C.; Huo, D.; Wang, Y.; Wang, S.; Deng, Y.; Zhou, Q. A deep learning based detection scheme towards DDos Attack in permissioned blockchains. In Proceedings of the 2024 27th International Conference on Computer Supported Cooperative Work in Design (CSCWD), Tianjin, China, 8–10 May 2024; pp. 2644–2649. [Google Scholar]
- Li, X.; Wang, C.; Tang, A. Entropy Change Rate for Traffic Anomaly Detection. In Proceedings of the 2021 IEEE 18th International Conference on Mobile Ad Hoc and Smart Systems (MASS), Denver, CO, USA, 4–7 October 2021; pp. 570–571. [Google Scholar] [CrossRef]
- Bosnyaková, B.; Babič, F.; Adam, T.; Biceková, A. Anomaly Detection in Blockchain Network Using Unsupervised Learning. In Proceedings of the 2025 IEEE 23rd World Symposium on Applied Machine Intelligence and Informatics (SAMI), Stará Lesná, Slovakia, 23–25 January 2025; pp. 221–224. [Google Scholar] [CrossRef]
- Zhan, X.; Yuan, H.; Wang, X. Research on Block Chain Network Intrusion Detection System. In Proceedings of the 2019 International Conference on Computer Network, Electronic and Automation (ICCNEA), Xi’an, China, 27–29 September 2019; pp. 191–196. [Google Scholar] [CrossRef]
- Dong, Y.; Wang, R.; He, J. Real-Time Network Intrusion Detection System Based on Deep Learning. In Proceedings of the 2019 IEEE 10th International Conference on Software Engineering and Service Science (ICSESS), Beijing, China, 18–20 October 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Sidharth, V.; Kavitha, C.R. Network Intrusion Detection System Using Stacking and Boosting Ensemble Methods. In Proceedings of the 2021 Third International Conference on Inventive Research in Computing Applications (ICIRCA), Coimbatore, India, 2–4 September 2021; pp. 357–363. [Google Scholar] [CrossRef]
- El-Attar, N.E.; Salama, M.H.; Abdelfattah, M.; Taha, S. A Comparative Analysis for Anomaly Detection in Blockchain Networks Using Machine Learning Techniques. In Proceedings of the 2024 34th International Conference on Computer Theory and Applications (ICCTA), Alexandria, Egypt, 14–16 December 2024; pp. 171–176. [Google Scholar] [CrossRef]
- Chen, Z.; Duan, J.; Kang, L.; Qiu, G. Supervised Anomaly Detection via Conditional Generative Adversarial Network and Ensemble Active Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 7781–7798. [Google Scholar] [CrossRef] [PubMed]
- Alabugin, S.K.; Sokolov, A.N. Applying of Recurrent Neural Networks for Industrial Processes Anomaly Detection. In Proceedings of the 2021 Ural Symposium on Biomedical Engineering, Radioelectronics and Information Technology (USBEREIT), Yekaterinburg, Russia, 13–14 May 2021; pp. 0467–0470. [Google Scholar] [CrossRef]
- Tang, H.; Xiong, W.; Deng, M.; Guo, Y. A Transformer Oil Temperature Anomaly Detection Method Based on LSTM-Attention. In Proceedings of the 2024 4th International Symposium on Artificial Intelligence and Intelligent Manufacturing (AIIM), Chengdu, China, 20–22 December 2024; pp. 310–313. [Google Scholar] [CrossRef]
- Li, J.; Liu, S.; Zou, J. E-Commerce Data Anomaly Detection Method Based on Variational Autoencoder. In Proceedings of the 2024 3rd International Conference on Artificial Intelligence, Internet of Things and Cloud Computing Technology (AIoTC), Wuhan, China, 13–15 September 2024; pp. 231–234. [Google Scholar] [CrossRef]
- Liu, J.; Qiao, M.; Du, L.; Zhang, W.; Wang, M.; Jin, K. Utilizing Deep Belief Networks for Power System State Estimation and Anomaly Detection. In Proceedings of the 2025 IEEE 5th International Conference on Power, Electronics and Computer Applications (ICPECA), Shenyang, China, 17–19 January 2025; pp. 250–255. [Google Scholar] [CrossRef]
- Raturi, R.; Kumar, A.; Vyas, N.; Dutt, V. A Novel Approach for Anomaly Detection in Time-Series Data using Generative Adversarial Networks. In Proceedings of the 2023 International Conference on Sustainable Computing and Smart Systems (ICSCSS), Coimbatore, India, 14–16 June 2023; pp. 1352–1357. [Google Scholar] [CrossRef]
- Wang, C.; Wei, W.; Long, Y.; Liu, J.; Luo, Z. Variational Autoencoder Based Anomaly Detection for AIOps of Power Grid Supercomputing Center. In Proceedings of the 2023 3rd International Conference on Energy Engineering and Power Systems (EEPS), Dali, China, 28–30 July 2023; pp. 1055–1058. [Google Scholar] [CrossRef]
- Zhang, W.; Xu, L.; Yu, Z.; Zhang, Z.; Liu, T.; Liu, S. MCVAE: Multi-channel Variational Autoencoder for Anomaly Detection. In Proceedings of the 2022 IEEE 13th International Symposium on Parallel Architectures, Algorithms and Programming (PAAP), Beijing, China, 25–27 November 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Nguyen, H.N.; Lan-Phan, T.; Song, C.-J. Generative Adversarial Network-Based Network Intrusion Detection System for Supervisory Control and Data Acquisition System. In Proceedings of the 2024 IEEE International Conference on Consumer Electronics-Asia (ICCE-Asia), Danang, Vietnam, 3–6 November 2024; pp. 1–3. [Google Scholar] [CrossRef]
- Zhang, Y.; Hao, H.; Zhang, T. Abnormal Detection and Fault Diagnosis Method of Bearing Based on Deep Convolutional Generative Adversarial Network. In Proceedings of the 2023 IEEE 11th Joint International Information Technology and Artificial Intelligence Conference (ITAIC), Chongqing, China, 8–10 December 2023; pp. 1604–1608. [Google Scholar] [CrossRef]
- Yan, S. Analysis on Blockchain Consensus Mechanism Based on Proof of Work and Proof of Stake. In Proceedings of the 2022 International Conference on Data Analytics, Computing and Artificial Intelligence (ICDACAI), Zakopane, Poland, 15–16 August 2022; pp. 464–467. [Google Scholar] [CrossRef]
- Li, X.; Yang, Y.; Li, B.; Li, M.; Zhang, J.; Li, T. Blockchain cryptocurrency abnormal behavior detection based on improved graph convolutional neural networks. In Proceedings of the 2023 International Conference on Data Security and Privacy Protection (DSPP), Xi’an, China, 16–18 October 2023; pp. 216–222. [Google Scholar] [CrossRef]
- Vubangsi, M.; Abidemi, S.U.; Akanni, O.; Mubarak, A.S.; Al-Turjman, F. Applications of Transformer Attention Mechanisms in Information Security: Current Trends and Prospects. In Proceedings of the 2022 International Conference on Artificial Intelligence of Things and Crowdsensing (AIoTCs), Nicosia, Cyprus, 26–28 October 2022; pp. 101–105. [Google Scholar] [CrossRef]
- Wang, W. Algorithm Research on Representation Learning and Graph Convolutional Networks in Anticancer Drug Response Prediction. Ph.D. Dissertation, Air Force Medical University, Xi’an, China, 2024; pp. 1–164. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Data 1 | Data 2 | Data 3 | Data 4 | Data 5 | Data 6 | Data 7 |
|---|---|---|---|---|---|---|---|
| Time series * | 39,444,544 | 46,552,288 | 34,195,072 | 4,560,320 | 40,707,168 | 41,166,464 | 55,643,680 |
| Duration (10−6 s) * | 73,008 | 10,013 | 0 | 10,018 | 29,335 | 0 | 5,142,993 |
| Length (B) * | 347 | 113 | 114 | 118 | 108 | 115 | 364 |
| cc_flow * | 19 | 15 | 1 | 17 | 16 | 4 | 16 |
| r1 (10−3) * | 190 | 150 | 12 | 170 | 160 | 40 | 160 |
| ec_flow * | 0 | 15 | 1 | 11 | 14 | 0 | 0 |
| r2 (10−3) * | 0 | 150 | 90 | 110 | 518 | 0 | 0 |
| r3 (10−3) * | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| cc_time * | 3 | 3 | 1 | 3 | 6 | 1 | 3 |
| r4 (10−3) * | 250 | 428 | 47 | 300 | 315 | 76 | 300 |
| ec_time * | 0 | 1 | 1 | 1 | 4 | 0 | 0 |
| r5 (10−3) * | 0 | 750 | 100 | 1000 | 1500 | 200 | 0 |
| r6 (10−3) * | 1000 | 750 | 500 | 750 | 600 | 1000 | 1000 |
| Control code * | 20 | 10 | 10 | 20 | 511 | 10 | 20 |
| Attack label * | 0 | 1 | 1 | 1 | 2 | 2 | 0 |
| Data | 0 | 1 | 2 |
|---|---|---|---|
| Train | 11,334 | 4753 | 5365 |
| Test | 2810 | 1171 | 1382 |
| Model | CPU Utilization (%) | Memory (MB) | Average Training Time Per Epoch (s) | Space Complexity | Time Complexity | FLOPS |
|---|---|---|---|---|---|---|
| CAA | 14.2 | 3271.8 | 20.16657 | 636187 | 25600000000 | 1269427394 |
| CAA-RF | 15.4 | 3498.3 | 20.40496 | 674587 | 27358208000 | 1340762638 |
| Auto | 11.4 | 3414.7 | 0.408983 | 4117 | 246,180,000 | 601,931,492 |
| GANs | 9.7 | 3428.5 | 4.951626 | 246,186 | 352,480,000 | 71,184,693 |
| LSTM | 19.2 | 5546.3 | 0.810934 | 206,211 | 8,207,360,000 | 10,120,866,978 |
| RNN | 36.4 | 3532.9 | 0.050418 | 32,103 | 1,276,000,000 | 25,308,412,560 |
| VAE | 10.4 | 3461.7 | 0.615854 | 2322 | 87,040,000 | 141,332,137 |
| DBN | 11.7 | 5154.2 | 0.764012 | 12,355 | 485,120,000 | 634,963,849 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jia, S.; Zhao, Y.; Zhang, Y.; Jia, B.; Lian, W. CAA-RF: An Anomaly Detection Algorithm for Computing Power Blockchain Networks. Appl. Sci. 2025, 15, 5804. https://doi.org/10.3390/app15115804
Jia S, Zhao Y, Zhang Y, Jia B, Lian W. CAA-RF: An Anomaly Detection Algorithm for Computing Power Blockchain Networks. Applied Sciences. 2025; 15(11):5804. https://doi.org/10.3390/app15115804
Chicago/Turabian StyleJia, Shifeng, Yating Zhao, Yang Zhang, Bin Jia, and Wenjuan Lian. 2025. "CAA-RF: An Anomaly Detection Algorithm for Computing Power Blockchain Networks" Applied Sciences 15, no. 11: 5804. https://doi.org/10.3390/app15115804
APA StyleJia, S., Zhao, Y., Zhang, Y., Jia, B., & Lian, W. (2025). CAA-RF: An Anomaly Detection Algorithm for Computing Power Blockchain Networks. Applied Sciences, 15(11), 5804. https://doi.org/10.3390/app15115804