1. Introduction
Named-entity recognition (NER) holds a crucial position in the field of natural language processing [
1]. In information-extraction tasks, it can accurately identify key information such as the names of people, locations, and organizations from vast amounts of text, transforming unstructured text into structured data, thereby providing strong support for subsequent data analysis and decision making [
2].
Traditional named-entity recognition methods based on sequence labeling highly depend on a large amount of labeled data [
3]. This data helps the model learn the relationship between entities and context, as well as the characteristics of entity categories, enabling it to perform well when annotating new texts. At this stage, LAFFERTY J et al. [
4] have proposed the conditional random field (CRF) model for sequence-labeling tasks. The CRF model can automatically identify and capture features and patterns in sequences by learning the mapping from input sequences to output label sequences. HUANG et al. [
5] proposed a model based on bidirectional long short-term memory networks (BiLSTM) and CRF for sequence labeling. This model uses the BiLSTM network as the context encoding layer, which can better capture long-term dependencies in the sequence. MA et al. [
6] have introduced CNN units based on the BiLSTM-CRF model to extract morphological information from word characters, thereby improving the model’s final performance.
In recent years, with the successive emergence and development of large-scale pre-trained models (e.g., Bert [
7], GPT [
8,
9,
10], RoBERTa [
11], T5 [
12], ERNIE [
13,
14,
15], etc.), the large-scale training parameters have enabled these large models to possess better knowledge representation and transfer learning capabilities, thereby achieving the latest and optimal results in many natural language processing tasks. Souza et al. [
16] proposed a BERT-CRF model for the NER task, combining BERT’s transfer capabilities with CRF’s structured prediction, achieving results better than those of the aforementioned baseline methods. However, both traditional sequence labeling methods and fine-tuning modes of downstream tasks based on large models require a large amount of sample data during the training phase. In practical applications, obtaining large-scale labeled data may face difficulties, requiring industry experts to spend a lot of time and effort to complete it manually [
17]. In small-sample scenarios, due to the limited labeled data, it is difficult for the model to learn the complex features and constraints of different entity types, leading to unsatisfactory entity-recognition results.
To harness the potential of large models in small-sample-data scenarios, researchers have adopted a range of methods, including transfer learning [
18], contrastive learning [
19], knowledge graph injection [
20], and prompt learning [
21]. These methods have been used to enhance a model’s generalization ability, thereby improving its performance on small samples. Among these, prompt learning, as an emerging model adaptation paradigm, has emerged as a particularly efficient and flexible solution for model applications in small-sample-data scenarios through the embedding mechanism of natural language prompts, garnering widespread attention from researchers in the field. CUI et al. [
22] proposed TemplateNER, which was the first to apply the prompt method to NER, predicting entity types by manually constructing discrete templates and enumerating all possible entity spans. The model has been shown to significantly outperform traditional sequence labeling methods in cross-domain and few-shot setting. However, the prediction results are heavily dependent on the quality of the template design, and the introduction of a large number of negative samples leads to severe efficiency issues. Ma et al. [
23] introduced the soft template prompt learning method, incorporating a small number of learnable parameters as prompt guidance in the self-attention layer of pre-trained models, compensating for the shortcomings of manually designed prompt templates. Shen et al. [
24] designed a dual-slot multi-prompt template for entity types and positions, extracting all entities by predicting each prompt slot. This avoids the efficiency issues of enumerating spans and achieves a single round of prediction for all entities. This method provides a new approach for using prompts in NER tasks, but its model design is relatively simple. It utilizes the positional information of entities without considering the boundary information of the entity heads and tails, leaving room for further improvement in Chinese NER tasks.
Compared to English, Chinese NER faces many unique challenges. The structure of Chinese is complex, and Chinese characters themselves do not have natural delimiters, making the boundaries between words ambiguous [
25]. This makes both character-based and word-based sequence labeling quite challenging. If the model cannot effectively handle nested relationships, it is prone to recognition errors. These factors make Chinese named-entity recognition much more difficult than that of English, placing higher demands on the model’s performance. A series of experiments conducted in [
26,
27,
28,
29,
30] have demonstrated that the incorporation of boundary information into the encoding and decoding layers of the model can effectively enhance the model’s accuracy in Chinese natural language tasks.
Regarding the issues identified in the aforementioned Chinese NER task, after comprehensively considering the advantages and disadvantages of various methods, we propose a Chinese few-shot named-entity recognition model that integrates multi-label prompts and boundary information (MPBCNER). First, the MPBCNER uses a pre-trained large model as the encoding layer, introducing a template composed of entity label prompt words and entity position prompt slots at the model input layer. This better utilizes the prior knowledge of the pre-trained model during training and prediction phases, enhancing the model’s performance in small-sample scenarios. Secondly, we used a graph attention network to construct a boundary information extraction module, allowing the model to focus more on features near the boundaries when recognizing entities, thereby improving the accuracy of entity boundary recognition. Finally, we use a pointer network as the model’s decoding layer, cleverly avoiding the complexity and inefficiency brought by predicting enumerated spans. Meanwhile, the structure of the pointer network has a certain degree of feature similarity with the boundary information network, which allows it to better learn the boundary features of Chinese entities, providing significant advantages in handling Chinese samples and nested entities.
3. MPBCNER Model
In this section, we first describe the overall framework of the model, and then introduce the implementation details of each module of the model, including the construction of prompt templates, the encoding and decoding layers, the auxiliary training of the starting position prompt, and the entity boundary feature extraction in the graph attention network implementation. The overall structure of the model is shown in
Figure 1.
3.1. Prompt Template
The prompt template affects the quality of the model’s feature output. Hard prompts, entirely designed by humans using natural language, have high interpretability but may not fully align with the PLM’s understanding. Soft prompts, on the other hand, automatically optimize by introducing learnable parameters to adapt to different tasks but cannot explain their rationality. We have combined the characteristics of both soft and hard prompt to design a new NER prompt template.
By default, each prompt consists of three parts: a start position slot
, an end position slot
, and learnable contextual tokens
. Specifically, our model fills in a set of prompts for each type of entity and then concatenates all the prompts with the original text to use as input. For the sentence
“北京银行在广西设立分行 (Bank of Beijing opens branch in Guangxi)”, we set two entity types: “地点 (Location)”, “组织 (Organization)”. The input sequence
with prompt is represented as:
Generally, for a sequence composed of
tokens with
entity types, the input sequence
with a prompt can be represented as:
where “
” represents the
-th prompt.
is the soft prompt consisting of learnable contextual tokens. Specifically, we added a set of trainable embedding matrices
for the PLM encode as prompt parameters, where
is the number of transformer layers. In the model-training phase, the PLM parameters are frozen and the prompt parameters are the only trainable parameters. Meanwhile, we used label words embedding as hard prompts to complete the initialization of the soft prompt.
3.2. Encoder Layer
For a given input sentence
spliced by the sentence
and
prompts, we used PLM to encode and then obtain the hidden representation
:
Then, by indexing on the corresponding position of , we can obtain the encoding of the sentence and the encodings of the two prompt slots, denoted as , , and , where , .
In the subsequent experiments, we will use different PLMs for encoding to explore the impact of PLMs on the model.
3.3. GAT-Based Boundary Information Fusion Layer
The graph attention network (GAT) is a neural network model that has been specifically designed to process graph-structured data. It introduces an attention mechanism that enables the model to assign different weights to the neighboring nodes of each node during graph data processing. This mechanism facilitates the enhanced capture of the complex relationships between nodes and the local structures within the graph data, thereby improving the model’s ability to understand and represent the intricate patterns present in the data.
While PLM is capable of effectively extracting contextual features, its ability to capture boundary information features within the input text is limited. To address this, the present paper proposes employing GAT to extract features based on the internal dependency relationships present in the input text. This approach involves mining the word and character dependency relationships within the text to extract the boundary features of entities. Consequently, this enhances the accuracy of entity recognition.
In this study, a sequence of Chinese text is treated as a graph-structured network, with each character in the sequence considered a node in the graph. In particular, we use DDParser [
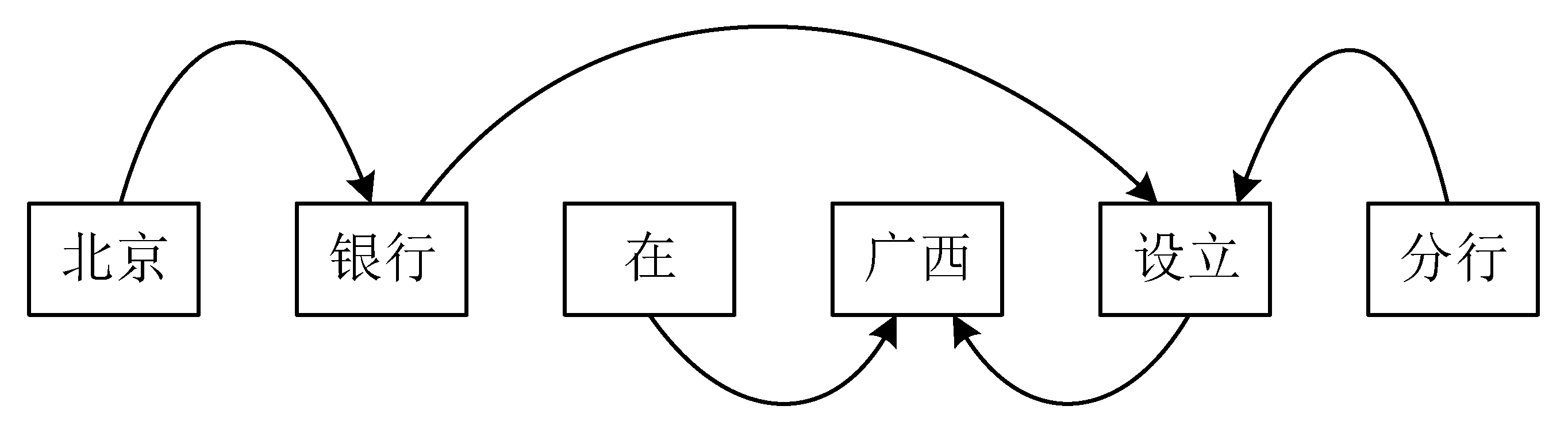
42] to obtain the dependencies of the input sequence and then construct a directed graph based on the dependencies, where the directed edges point to the center word of a given word, and the directed edges are labeled with the specific type of dependency, and the words located at the beginning of the directed edges depend on the words located at the end of the directed edges in some kind of dependency relationship. For a Chinese text sequence “北京银行在广西设立分行 (Bank of Beijing opens branch in Guangxi)”, the syntactic dependency relationship graph is shown in
Figure 2.
In this sentence, “北京” is a qualifying modifier for “银行”, “北京银行” and “设立” have a subject–predicate relationship, “在” and “广西” are in a verb–object relationship, etc. Since the model in this paper is character-based, each character in a word has the same dependency relationship with the word. Meanwhile, to retain the feature information of the node itself, it is assumed that each word is related to itself. Each node in the graph will have a ring pointing to itself. According to the dependency relationship between nodes, the elements at the corresponding positions in the dependency matrix are set to 1, and the remaining elements are set to 0. According to the above rules, the dependency matrix of the input sequence is constructed.
In a directed graph, nodes that have a dependency relationship with entities reflect the existence of the entities to a certain extent. Meanwhile, directed edges containing dependency information can assist in distinguishing entity boundaries and identifying the categories of entities.
To more clearly extract features related to boundary information between entities, we built a GAT to capture dependencies between words. Firstly, a linear transformation is done on the input features of each node to map the feature dimension from
to
:
where
is sharing weight matrices.
is the original feature vector of node
.
Then, the attention coefficient
indicates the importance of node
to node
:
where
is the attention function, implemented by a single-layer feedforward neural network.
is the weight vector.
In order to compare the importance of different neighboring nodes, the
function is used to normalize all attention coefficients:
where
is the neighborhood nodes of node
.
To enhance the model’s representational capacity, GAT introduces a multi-head attention mechanism. A GAT operation with
independent attention heads can be expressed as:
where
is the activation function.
The GAT layer takes the node dependency matrix and the character vector representation that integrates lexical information as input and uses the attention mechanism to calculate each node, thereby obtaining the feature representation of each node. The text dependency relationship features extracted by the GAT layer can effectively distinguish entity boundaries, thereby significantly improving the accuracy of named-entity recognition.
3.4. Feature Fusion Layer
Although GAT has shown significant effectiveness in capturing internal dependencies within entities, there is still room for improvement in clearly defining entity boundaries. To address this shortcoming, we treat entity boundary detection as a binary classification task and train it simultaneously with the NER. This approach allows us to provide clearer and more accurate entity boundary information to the NER model, thereby enhancing the overall performance of the model.
During the training phase, we used two separate MLP networks to predict the start and end positions of entities:
where
and
are the hidden feature representation of two prompt slot positions.
Then, we added the hidden features of the entity to the output of the GAT layer:
where
is the final input for the point network.
,
, and
are learnable weight matrices.
At the feature fusion layer, by fusing boundary features and entity location features, we obtain a hidden vector representation after multi-feature fusion. It will further improve the model’s recognition of Chinese entities.
3.5. Decode Layer
We chose a pointer network as the model’s decoding layer. On one hand, the pointer network primarily focuses on the start and end positions of entities, which is consistent with the two auxiliary tasks of our method, making it well-suited for our work. On the other hand, the pointer network addresses the issue of entity nesting, which sequence labeling struggles to resolve, making it more practical for Chinese NER tasks.
The core of the pointer network is to select entity boundaries in the input sequence through the attention mechanism. For a feature sequence output
, the attention weight calculation formula for the pointer network is:
The pointer network uses binary cross-entropy loss to predict whether each position is the start or end of an entity:
The overall loss function
of the model consists of
and
together and:
where
is the weight parameter, and we set it to 0.5.
4. Experiment
4.1. Datasets
This study conducted experiments on a manually collected dataset in the field of Chinese government auditing and three public datasets, OntoNotes V5.0 [
43], Weibo NER [
44], and MSRA [
45].
4.1.1. The Government Auditing Dataset
Due to the particularity of the field of government auditing, there is a lack of relevant publicly available dataset resources. We manually collected and created a small amount of sample data from the publicly available information on various government websites. After data cleaning, we obtained 1000 samples, involving four types of entities: time, unit, project, and amount. In our subsequent experiments, we will refer to it as GA.
4.1.2. OntoNotes V5.0 Dataset
The dataset is a Chinese dataset and consists of texts from the news domain.
4.1.3. Weibo NER Dataset
The dataset contains annotated NER messages drawn from the social media Sina Weibo.
4.1.4. MSRA Dataset
The dataset is released by Microsoft Research Asia, which contains data on multiple entity nested types.
4.2. Experiment Environment
The experimental code is developed based on the PyTorch 2.3.0 framework, and the cloud GPU server is used as the experimental runtime environment. The experimental environment specifics are shown in
Table 1.
The experimental parameters setting are shown in
Table 2.
In configuring the pre-trained language model, we established a maximum input length for the text sequence of 512 units. We leveraged 12 transformer layers to facilitate semantic encoding and feature extraction. The learning rate was set to 1 × 10−5, aiming to enhance the model’s learning velocity and convergence. Additionally, to boost training efficiency and the model’s generalization capacity, we set the number of epochs to 8 and the batch size to 10.
4.3. Evaluation Indicators
This paper uses the F1 score as an evaluation metric. Precision (
) refers to the ratio of the number of correctly identified named entities to the total number of identified named entities. Recall (
) refers to the ratio of the number of correctly identified named entities to the total number of entities. Precision is the ratio of the number of correctly predicted samples to the total number of samples, and
is the harmonic mean of precision and recall. The calculation formula is:
Among them, represents the number of samples predicted as positive and actually positive, represents the number of samples predicted as positive but actually negative, represents the number of samples predicted as negative but actually positive, and represents the number of samples predicted as negative and actually negative. Accuracy and score can comprehensively evaluate the performance of the NER model.
4.4. Baselines
In this work, we conducted experimental comparisons with the following baseline methods to verify the performance of the model in the small-sample scenarios NER task, including based on sequence labeling (BERT-CRF [
16]), based on span (SpERT [
46]), based on machine reading comprehension (BERT-MRC [
47]), based on sequence generation (BARTNER [
48]), and based on prompt learning (TemplateNER [
22], PromptNER [
24]).
These methodologies employ distinct pre-trained language models as encoders. Consequently, the experimental results provide the performance of GLK on various PLMs, including Bert, RoBERTa, and ERNIE. Bert is the most classical large language model. RoBERTa is based on the architecture of BERT with key modifications and optimizations. RoBERTa provides richer linguistic contextual information by using larger datasets (e.g., a combination of BookCorpus and OpenWebText) for training, which helps to improve the model’s generalization ability. In addition, it dynamically adjusts hyperparameters, such as the learning rate, batch size, etc., to optimize the learning efficiency and effectiveness of the model. ERNIE is a knowledge-enhanced pre-trained language model. ERNIE focuses not only on word representation but also on phrase, entity, and sentence representation, and this multi-granularity knowledge modeling helps to capture the rich structure in the language and improves semantic comprehension.
6. Conclusions
In this paper, we designed a dual-position slot template combining soft and hard prompts, using entity label words as a hard prompt to complete the initialization of the prompt slots, and the position cue slots and the NER task jointly involved in the training could be learned to correspond to the start and end position features of the labeled entities. We also utilized graph attention networks to complete the extraction of entity boundary features. Compared with the baseline approach, our model achieved better performance in Chinese flat and nested NER and low-resource scenarios after fusing positional and boundary features.
At the same time, the model still has some shortcomings. One is the use of a GAT and a pointer network for feature extraction of data. There is a problem with operational efficiency, and the use of a sparse matrix can be considered to improve the operational efficiency of the model. The other is that for each class of entity type, a corresponding pointer network is needed for decoding, and the use of a global pointer network can be considered to avoid this problem.





{kind=link}
{kind=link}