Abstract
To address the issues of low efficiency and high omission rates in monitoring workers’ compliance with safety dress codes in intelligent factories, this paper proposes the SFA-YOLO network, an enhanced real-time detection model based on a Selective Feature Attention mechanism. This model enables inspection robots to automatically and accurately identify whether the workers’ attire meets the safety standards. First, this paper constructs a comprehensive dataset of safety attire, including images captured under various scenarios, personnel numbers, and operational conditions. All images are manually annotated to enhance the model’s generalization capability. The dataset contains 3966 images, covering four classes: vest, no-vest, helmet, and no-helmet. Second, the proposed model integrates the SFA mechanism to improve the YOLO architecture. This mechanism combines multi-scale feature fusion with a gated feature extraction module to improve detection accuracy, strengthening the model’s ability to detect occluded targets, partial images, and small objects. Additionally, a lightweight network structure is adopted to meet the inference speed requirements of real-time monitoring. The experimental results demonstrate that the SFA-YOLO model achieves a detection precision of 89.3% and a frame rate of 149 FPS in the safety attire detection task, effectively balancing precision and real-time performance. Compared to YOLOv5n, the proposed model achieves a 5.2% improvement in precision, an 11.5% increase in recall, a 13.1% gain in mAP@0.5, and a 12.5% improvement in mAP@0.5:0.95. Furthermore, the generalization experiment confirms the model’s robustness in various task environments. Compared with conventional YOLO models, the proposed method performs more stably in safety attire detection, offering a reliable technical foundation for safety management in intelligent factories.
1. Introduction
As Industry 4.0 advances, inspection robots have become increasingly common in intelligent factories. Integrating automated equipment, robotics, industrial networks, and artificial intelligence technologies has led to notable improvements in production efficiency and operational management. Nevertheless, personnel safety remains a critical concern for enterprises. In particular, compliance with safety dress codes, such as the proper wearing of helmets and vests, is closely related to operational safety and the personal safety of employees. Since improper use of safety equipment can lead to severe accidents, developing a reliable and efficient system for monitoring safety attire in intelligent manufacturing environments is critical. Conventional methods for safety attire inspection mainly depend on manual inspections or rule-based computer vision approaches [1]. However, manual inspections are inefficient and prone to human error. The automated attire detection based on visual inspection can real-time identify the wearing status of safety helmets, protective clothing, and other personal protective equipment. A certain automobile manufacturing company in Nanchang, Jiangxi, China, reduced its accident rate by 30% and lowered manual inspection costs by 40% through the implementation of this technology. Vision-based methods often face reduced accuracy in complex factory settings because of lighting changes, occlusions, and varying perspectives [2,3]. YOLO-based detection methods can automate safe attire detection. However, conventional YOLO networks have poor adaptability in complex environments. This paper proposes the SFA-YOLO model to address this problem. The main contributions of this paper are as follows:
- (a)
- This study constructs a self-built safety attire detection dataset for detecting safety attire in intelligent factory environments.
- (b)
- This research proposes an SFA module to enhance the detection speed and feature representation capability of the network.
- (c)
- Comparative and ablation experiments are conducted to verify the effectiveness of the proposed method.
- (d)
- Generalization experiments demonstrated that the proposed method exhibits strong generalization ability in the field of industrial inspection and can be extended to other detection tasks.
2. Related Works
In recent years, target detection models based on deep learning have achieved notable progress in computer vision tasks. As an end-to-end object detection algorithm, YOLO (You Only Look Once) is commonly used in object recognition and detection tasks for its efficiency and reliable performance. Substantial academic progress has been made in optimizing YOLO-based models. For instance, Ansah, P. A. K. et al. [4] proposed SB-YOLO-V8, a convolutional neural network based on YOLO optimized for real-time human detection in agricultural and urban environments. By incorporating Binary Adaptive Learning Optimization (ALO) and the Synthetic Minority Over-sampling Technique (SMOTE), the model effectively addresses data scarcity and class imbalance while enhancing feature extraction capability.
Fan, Q. S. et al. [5] introduce LUD-YOLO, a lightweight YOLOv8-based detection algorithm. It is designed to improve object detection in UAV autonomous missions. This method tackles the challenges of complex backgrounds, small objects, and occlusion. Experiments conducted on the VisDrone2019 and UAVDT datasets demonstrate its effectiveness, with ablation and comparative results confirming that the improved LUDY-N and LUDY-S models perform well across multiple evaluation metrics, demonstrating robustness and generalization capability. Similarly, Shuzhan Xu et al. [6] develop a coal–rock interface recognition model by integrating the YOLO real-time detection algorithm with a lightweight bilateral segmentation network. The model employs a regional similarity transformation function and the Dragonfly Algorithm to improve image quality and boundary segmentation in coal–rock scenarios. Comparative experiments with three benchmark models confirm its advantage in edge inference tasks, supporting intelligent coal mining development. Abulizi, Abudukelimu et al. [7] propose DM-YOLO, an improved tomato leaf disease detection method based on YOLOv9. The backbone network incorporates a lightweight dynamic upsampling module (DySample) to extract features from small lesions better and reduce background interference. Additionally, the MPDIoU loss function improves the localization of overlapping lesion boundaries, leading to more accurate detection. Pei Shaotong et al. [8] propose AHC-YOLO, a YOLO-based algorithm for detecting the hydrophobicity of composite insulators. The model incorporates a high-performance GPU network (HGNetv2), a Mixed Local Channel Attention mechanism (MLCA), a lightweight convolutional module (CSPPC), and the Inner-WIoU loss function. These components help reduce computational overhead and improve accuracy in skirt detection and hydrophobicity grading, making the model suitable for practical engineering use. N. Aishwarya et al. [9] develop a lightweight YOLO-based framework for skin cancer detection to improve early diagnosis accuracy. The study evaluates several models, including YOLOv3-tiny, YOLOv4-tiny, YOLOv5s, YOLOv7-tiny, and YOLOv8s, on the ISIC dataset for detecting and classifying nine types of skin cancer. The experimental results indicate that YOLOv5s outperforms in specific categories, while YOLOv8s achieves higher accuracy in others. It demonstrates the framework’s efficiency and deployment potential in embedded systems. He, L. et al. [10] propose an intelligent recognition algorithm for ferrography wear particles based on the convolutional block attention module (CBAM) and YOLOv5 to address challenges such as image blurring, complex backgrounds, particle overlap, and insufficient illumination in ferrography images. The CBAM module was integrated to strengthen the feature representation of wear particles and increase the model’s focus on relevant regions. Gong. X et al. [11] propose a novel hierarchical model aimed at addressing the limitation of ViT’s single-scale, low-resolution feature maps, which tend to lose fine-grained semantic information. The method adopts a convolutional vision Transformer as the backbone for feature extraction and fusion. An asymmetric structure is designed to compute cross-relations between the template and search branches, and different input selection strategies are introduced for the attention modules in both branches. Extensive experiments conducted on five mainstream datasets demonstrate the superior performance of the proposed method in visual tracking tasks.
Traditional YOLO algorithms offer high detection precision and fast inference in safety attire detection. However, low recall and mAP scores reduce their effectiveness in complex environments. Real-time object detection is critical in inspection robots operating under constrained computational resources. This necessitates lightweight network architectures. However, conventional lightweight networks often perform poorly in detection accuracy under complex environments. Existing methods use various techniques for object detection, including feature extraction, multi-scale fusion, and attention mechanisms. However, they do not employ the combination of partial convolution and gated attention. This combination can enhance the model’s ability to handle occluded regions, reduce the impact of noisy backgrounds, and improve the detection of small objects. To address this challenge, this study proposes a YOLO-based safety attire detection approach for intelligent factories, aiming to leverage the powerful feature extraction capabilities of deep learning to enhance both the accuracy and real-time performance of safety equipment recognition. The method introduces a novel Selective Feature Attention (SFA) mechanism to balance detection precision and computational efficiency, enabling real-time detection of safety attire. The proposed model achieves a detection precision of 89.3%, demonstrating its suitability for practical deployment in intelligent factory environments.
3. Inspection Robot Platform and Data Resources
3.1. Inspection Robot Platform
This study relies on an integrated real-time target detection platform for inspection robots to efficiently monitor and intelligently recognize personnel safety attire. The platform incorporates functionalities such as image acquisition, intelligent analysis, and safety alerting and can operate reliably in complex industrial environments. The platform is built around an autonomous mobile inspection robot with an embedded computing unit, high-definition camera, and wireless communication module. The robot autonomously navigates along a predefined path within the factory, capturing real-time images of personnel and quickly identifying whether workers wear safety vests and helmets and triggering alerts when necessary. As shown in Figure 1, the inspection robot platform utilizes a two-wheel differential drive mechanism, achieving a maximum speed of 1 m/s. It supports both manual remote operation and autonomous navigation. A high-definition camera mounted on a gimbal enables real-time object detection. We include images of workers in various working postures in the dataset to ensure high detection precision across different body positions. In addition, we perform repeated detection over short intervals to reduce the probability of false positives and missed detections. When the system identifies improper safety attire, it issues warnings through voice prompts or broadcasting and stores the corresponding detection results as evidence for future review. If multiple violations occur within a single inspection process, the platform sends alerts via the factory’s internal communication network. Safety managers then assess the severity of the violations and decide whether to initiate manual inspection.

Figure 1.
Inspection robot.
3.2. Safety Attire Dataset
This study constructs a custom dataset focusing on detecting safety helmets and vest usage among workers. The dataset is designed for safety monitoring applications in industrial environments such as construction sites and manufacturing plants. All images are annotated under the official YOLO labeling format. The dataset is compatible with mainstream object detection frameworks. The LabelImg 1.8.6 tool is employed to label each image during the annotation process. The dataset includes four categories: helmet (wearing a helmet), no-helmet (not wearing a helmet), vest (wearing a safety vest), and no-vest (not wearing a safety vest). The detailed annotation statistics are summarized in Table 1.

Table 1.
Attire classes and labels.
The dataset encompasses a variety of environments, including daytime, night-time, strong illumination, indoor and outdoor scenes, as well as both close-range and long-range views. The training, testing, and validation sets are split according to a 7:2:1 ratio.
This paper aims to enhance the robustness of the model. We also ensured the diversity of the dataset. The images are collected from multiple factory environments and construction sites. These locations are distributed across different regions. The dataset includes various lighting conditions. These include natural light, indoor lighting, and night-time illumination. It also contains diverse backgrounds. These include clean factory workshops, cluttered work areas, and warehouse zones. Such diversity reduces the risk of overfitting to a narrow visual context. The types of safety equipment in the images vary. These differences reflect the diversity of industrial safety conditions in the real world. We deliberately included such variations. This enhances the generalizability of the dataset. Three trained annotators labeled all the images. They follow a standardized annotation protocol. This protocol defines four safety attire categories: helmet, vest, no-helmet, no-vest. For any disagreements, the annotators reach a consensus through discussion. We apply common data augmentation techniques during training. These include random brightness adjustment, contrast adjustment, and the addition of Gaussian noise. These methods improve the model’s ability to generalize across different visual conditions.
This paper collects 3966 images from real-world field photography and publicly available web resources for training and validation. The dataset annotations are illustrated in Figure 2.

Figure 2.
Safety attire detection dataset.
3.3. Loss Function and Evaluation Metrics
SFA-YOLO employs specific loss functions and evaluation metrics to evaluate the effectiveness of the detection model and ensure robust performance under varying Intersection over Union (IoU) thresholds. These optimization strategies synergistically enhance the precision and generalization capability of SFA-YOLO in object detection tasks [12,13,14,15,16,17,18].
The loss function in object detection algorithms generally consists of the following components:
- Localization Loss
- 2.
- Confidence Loss
- 3.
- Classification Loss
The evaluation metrics commonly used in object detection algorithms typically include the following components:
- Precision Curve
The precision curve represents the proportion of correctly predicted positive samples among all samples predicted as positive. It is defined as follows:
Precision represents the accuracy of the model in detecting true objects. Many false positives (FP) can lead to low precision in object detection tasks. The precision of the SFA-YOLO model can be visualized using the precision (P) curve. A high precision indicates that the model effectively distinguishes true objects from background noise or false detections.
- 2.
- Recall Curve
The recall curve represents the proportion of correctly identified positive samples relative to the total number of actual positive samples. It is defined as follows:
Recall represents the model’s capability to detect all actual objects. The recall (R) curve helps reveal the comprehensiveness and robustness of the SFA-YOLO model in detection tasks. Particularly in scenarios involving complex backgrounds or small objects, evaluating the model’s ability to comprehensively identify as many targets as possible is essential.
- 3.
- F1 Score Curve
The F1 score is the harmonic mean of precision and recall. It is defined as follows:
The F1 score provides a comprehensive evaluation by considering both precision and recall. It is beneficial for imbalanced datasets or when false positives and negatives must be minimized. The F1 score curve demonstrates how the balance between precision and recall changes under different thresholds, offering insight into the overall performance of the SFA-YOLO model in complex detection tasks—especially where both precision and completeness are critical.
- 4.
- Precision–Recall (PR) Curve:
The PR curve illustrates the relationship between precision and recall at various confidence thresholds. Typically, recall is plotted on the x-axis and precision on the y-axis. This curve demonstrates the combined variation in precision and recall under different detection thresholds.
- 5.
- Mean Average Precision (mAP):
The mAP is a key metric for evaluating overall model performance in object detection tasks. It is computed as the area’s mean under the PR curves across all object classes.
As one of the most widely used evaluation metrics in object detection tasks, it reflects the model’s detection precision and recall performance across all object classes.
- 6.
- Frames Per Second (FPS):
In real-time tasks such as object detection, image recognition, and video analysis, FPS is a critical metric for evaluating the inference speed of a model. It is defined as follows:
It denotes the number of frames processed per second by the model. This metric reflects the model’s real-time detection or recognition capability in practical applications. Higher FPS reflects faster processing speed and better real-time performance.
By utilizing these comprehensive evaluation metrics, the actual performance of the SFA-YOLO model in intelligent factory safety attire detection tasks can be thoroughly assessed. This reveals the model’s strengths and weaknesses and informs future improvements.
4. SFA-YOLO Network
In safety attire detection for production environments, various complex environments and different postures of personnel pose challenges, which can deteriorate image conditions. Therefore, for the first time, we introduce the PCONV module, which excels at handling missing or occluded regions in images, and the CGLU module, which is effective at adjusting feature retention and suppression. The integration of these two modules effectively addresses these challenges.
4.1. SFA Method
The Selective Feature Attention (SFA) mechanism is based on the C3k2 module. It retains part of the original functionality and enhances the ability to select relevant features. The Bottleneck structure in C3k2 compresses critical feature information in specific tasks. This causes performance degradation, information loss, and reduced detection precision. This paper replaces the Bottleneck structure with Partial Convolution (PCONV) and Convolutional Gated Linear Unit (CGLU) modules to solve this problem. This replacement increases the focus on key features. PCONV (Partial Convolution) is a specialized convolution operation designed to handle missing or masked regions in images. It demonstrates superior performance in image-inpainting and occlusion-handling environments. CGLU (Convolutional Gated Linear Unit) is a gated activation mechanism. It selectively activates convolutional feature channels and effectively regulates feature retention and suppression, strengthening the model’s representational capacity. It increases the effectiveness of feature selection by combining PCONV and CGLU:
- (1)
- More effective handling of missing data
PCONV performs convolution only on valid regions and enables the network to handle images with missing parts. CGLU introduces a gated mechanism that optimizes feature selection by enhancing useful features and suppressing less relevant ones. This combination strengthens the network’s ability to recover missing or occluded areas in image restoration tasks.
- (2)
- Enhanced feature selectivity
The gated mechanism in CGLU allows the network to adjust feature activation based on the context of input features. The combination with PCONV enables the network to handle missing data and activates the most valuable features based on the context of the missing regions. The network infers missing features more accurately under partial loss or occlusion.
- (3)
- Improved robustness
CGLU enables the network to adjust the importance of different feature regions dynamically during partial convolution. This allows the network to select more relevant channels in missing areas and improves robustness against occlusion and incomplete data.
- (4)
- Stronger learning capability
The combination of PCONV’s partial convolution and CGLU’s gated activation allows the network to extract useful information from images with missing or occluded regions. The gating mechanism controls the selective flow of information. Even with partial data loss, the network still learns the complete structure of the image more effectively.
4.2. SFA-YOLO Network Architecture
The core of the SFA-YOLO network follows the one-stage detection approach of the YOLO series. As shown in Figure 3, this network structure follows the design principles of the YOLO series and applies the SFA mechanism. The model balances inference speed and precision and improves the detection of small targets like helmets and partially occluded targets like safety vests.
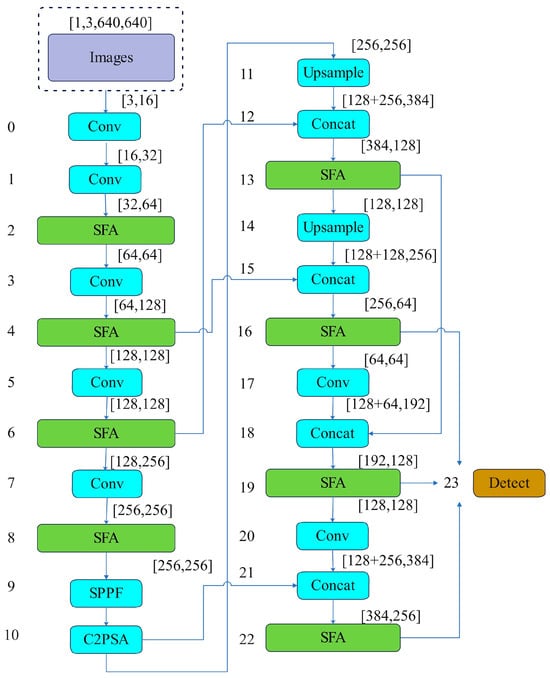
Figure 3.
Structure of the SFA-YOLO.
The Backbone is responsible for extracting features from the input image. It consists of convolutional layers and specialized modules such as the SFA block. The main modules are as follows:
- (1)
- The SFA block serves as the core component within the network and offers clear advantages. It balances lightweight design, computational efficiency, and memory usage. The SFA block strengthens the model’s feature selection ability and suits deep learning tasks with high real-time requirements. The model adjusts channel weights dynamically to focus on key regions and suppress irrelevant information. This improves detection precision and robustness. It runs efficiently on devices with limited computational resources and adapts well to complex environments and diverse tasks. The structure of the SFA module is shown in Figure 4.
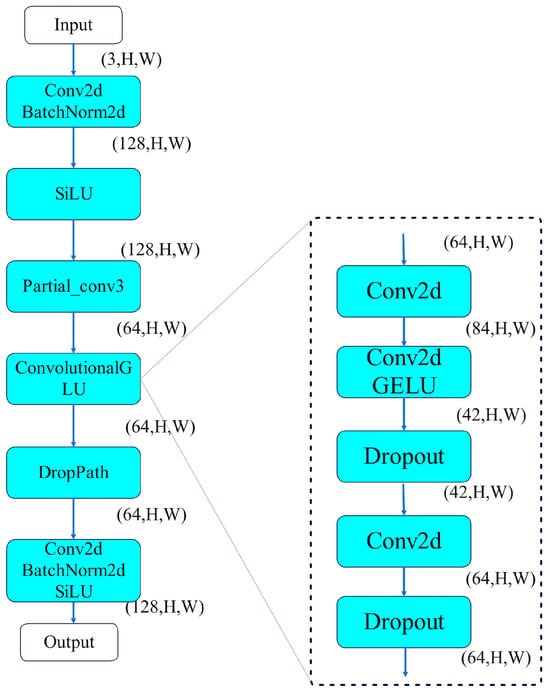 Figure 4. Structure of the SFA module.
Figure 4. Structure of the SFA module.
- (2)
- SPPF (Spatial Pyramid Pooling Fusion): SPPF strengthens the model’s multi-scale feature extraction ability by incorporating spatial pyramid pooling. It performs pooling operations at different scales, enabling the model to capture hierarchical and multi-size features [19]. This fusion enhances the model’s adaptability to object size and location variations while improving recognition in complex scenes [20,21,22,23,24]. Additionally, SPPF reduces feature map dimensions while preserving essential spatial information, improving computational efficiency and memory usage, which is especially useful for real-time object detection.
- (3)
- C2PSA (Cross-Stage Partial with Self-Attention) enhances feature extraction with a combination of the CSP (Cross Stage Partial) structure and the PSA (Pyramid Squeeze Attention) mechanism. It improves multi-scale feature representation and strengthens both channel and spatial attention. This design strengthens the effectiveness of feature extraction and information fusion. C2PSA uses channel attention to select important feature channels and suppress irrelevant information. This process improves the quality of feature representation. Meanwhile, spatial attention focuses on key regions in the image and strengthens target localization precision. This fused attention design increases model precision and robustness. In complex backgrounds, it helps the model recognize targets more effectively. The efficient structure of the C2PSA module maintains a strong performance while optimizing computational efficiency. It suits various deep learning tasks, especially in scenarios with fine feature extraction and precise localization requirements.
- (4)
- The upsampling module offers significant advantages in deep learning by effectively increasing the resolution of feature maps and enhancing the model’s ability to capture fine-grained details. The upsampling module restores spatial information by performing upsampling on low-resolution feature maps. It improves the model’s capacity for fine-grained processing in tasks such as object detection and semantic segmentation.
This module suits high-resolution output scenarios, such as generative adversarial networks (GANs) and multi-scale feature fusion tasks. At the same time, the upsampling module increases model efficiency under limited computational cost. It improves performance in complex tasks and supports various deep-learning applications related to image restoration and feature expansion.
- (5)
- The Detect module processes the features extracted by the backbone network and generates final predictions, including class labels, bounding boxes, and object confidence scores. The head consists of upsampling, concatenation, and convolution operations, producing outputs at multiple resolutions.
5. Experimental Results and Analysis
The experimental server environment is shown in Table 2.
Table 2.
Experimental server operating environment.
The hyperparameter configurations used in the experiments are shown in Table 3.
Table 3.
SFA-YOLO experiment hyperparameter configuration.
5.1. Personal Protective Equipment Image Detection
This study conducted comparative experiments between the proposed algorithm and several well-performing detection algorithms to evaluate the effectiveness of the SFA-YOLO algorithm in detecting personnel safety attire during inspections by intelligent factory inspection robots. The experiments are performed using a unified dataset and identical configuration.
The experimental results are shown in Figure 5. The scores displayed in the detection boxes indicate confidence scores. These scores reflect the reliability of object recognition in the image and help assess the performance of the proposed algorithm. The confidence score reflects the model’s estimation of the probability that a specific object exists. The value ranges from 0 to 1. A higher confidence score indicates greater certainty in the model’s prediction.

Figure 5.
Safety attire detection experiment.
In the nine subfigures in the three left columns of Figure 5, successful detection cases are presented, indicating a high recognition rate under sufficient lighting and clear contrast between the background and the target. The six subfigures in the two right columns of Figure 5 illustrate scenarios under other lighting conditions. When night-time illumination is sufficient, the model still performs reasonably well in recognition. However, under insufficient night-time lighting, the confidence scores decrease, accompanied by partial missed detections and a small number of false positives. Moreover, in cases where the image quality is poor, the detection model may encounter difficulties when multiple helmets or vests appear close to each other in the same frame. In such situations, the model may mistakenly merge two closely positioned objects into a single detection, leading to false identification. A higher recall can effectively reduce the number of missed detections. This ensures that fewer true instances are overlooked. It helps avoid false alarms and reduces the need for unnecessary manual intervention. This improves overall system reliability.
As shown in Figure 6, during the 500-epoch training process, the SFA-YOLO model approaches convergence within approximately the first 100 epochs. Precision, recall, mAP@0.5, and mAP@0.5:0.95 all approach 90%, demonstrating the SFA-YOLO model’s strong performance.
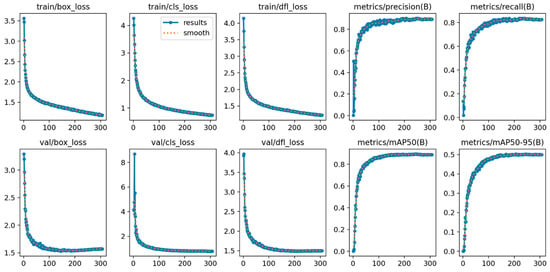
Figure 6.
SFA-YOLO algorithm training process.
The meanings of the other metrics in Figure 6 are as follows:
Box_loss: Bounding box loss. It measures the difference between the predicted and ground truth bounding box positions in object detection models.
Cls_loss: Classification loss. It measures the accuracy of the object detection model in classifying different classes.
Dfl_loss: Distribution Focal Loss. It assists box_loss by providing additional information. It optimizes the probability distribution of bounding box positions, further refining and improving the model’s accuracy in locating the boxes.
Each result receives a category label in object detection tasks to reflect the model’s classification performance across different classes. After training the SFA-YOLO model, the confusion matrix based on the validation set comprehensively evaluates overall performance. Figure 7 presents a comprehensive evaluation of the SFA-YOLO network performance based on multiple metrics, including the Precision curve (P-curve), Recall curve (R-curve), F1 score curve, and Precision–Recall (PR) curve. These performance metrics reflect the network’s behavior from multiple perspectives. A combined analysis of the four metrics clearly shows SFA-YOLO’s effectiveness across several key aspects. The results show that SFA-YOLO performs well across various evaluation metrics and proves its practical value in complex task environments.
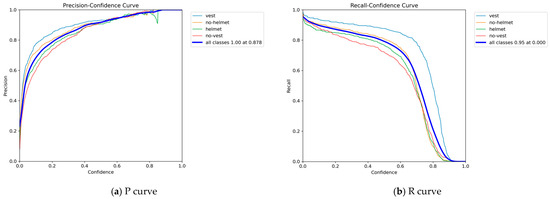
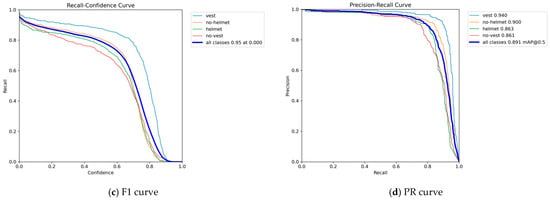
Figure 7.
P curve, R curve, F1 curve and PR curve performance indicators.
As shown in Figure 8, the results indicate that the classification performance of SFA-YOLO is superior, providing a comprehensive evaluation of the true performance of classification in the safety attire detection task. This lays a foundation for targeted improvements in future work.
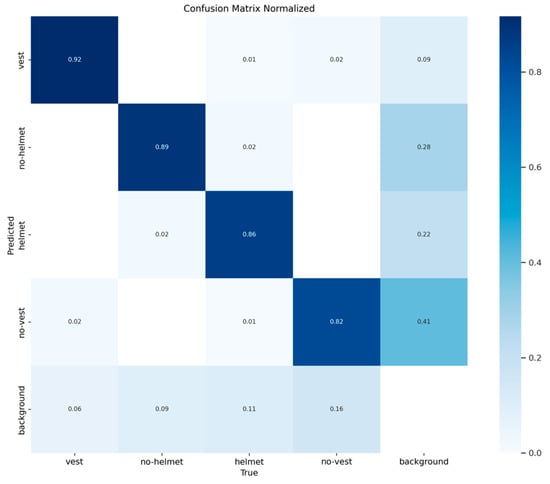
Figure 8.
Confusion_matrix of SFA-YOLO.
5.2. Performance Comparison of Different Detection Models
To verify the effectiveness of the proposed method for safety attire detection and to compare its performance, ViT, YOLOv7-tiny, YOLOv5s, YOLOv5n, ViT, CBAM,-YOLO, YOLOv8n, and YOLOXnano are trained for 500 epochs under the same dataset and experimental configuration. The results are listed in Table 4.
Table 4.
The performance comparison of the different algorithms.
As regards detection performance, SFA-YOLO reaches 149 FPS, and the processing time per image is 6.4 ms, far below the cycle of the robot control system (16 ms). This result confirms that SFA-YOLO meets the real-time requirements in high-speed processing scenarios. Compared with other lightweight networks, SFA-YOLO achieves clear advantages in precision, recall, mAP@0.5, and mAP@0.5:0.95.
The core idea of both CBAM-YOLO and SFA-YOLO focuses on enhancing the network’s attention to important features during the feature extraction stage, though they adopt different approaches. CBAM-YOLO enhances the model’s focus on key regions and features, but its adaptability to target occlusion or complex backgrounds is relatively poor. In this paper, the proposed SFA-YOLO builds upon the traditional YOLO framework and incorporates improvements to address issues such as target occlusion and complex backgrounds in safety attire detection. The experimental results demonstrate that, under sufficient lighting, the model can accurately detect even in the presence of occlusion. SFA-YOLO introduces PCONV and CGLU modules, which emphasize feature representation while maintaining a reasonable detection speed. Based on its performance on the safety attire detection dataset, SFA-YOLO shows greater suitability for this task.
The SFA-YOLO model has 2,240,356 parameters and achieves 5.7 GFLOPS. In practical detection tasks, the inspection program runs on a cloud server equipped with a GPU more powerful than the Nvidia RTX 3060. During detection, the GPU memory usage is about 2 GB.
In real-world detection tasks, inspections are usually conducted near well-lit production sites. For the few relatively dark scenes, light sources can be added to the inspection robot to improve image quality. Additionally, in intelligent factories, the division of labor in production environments is clear, and situations where personnel stand very close to each other are rare. As a result, such extreme conditions are rarely encountered in actual detection tasks. The detection accuracy remains at the same level as the experimental results.
When the detection model is applied to scenarios not covered by the training dataset, it may experience a decline in detection accuracy, along with increased false positive and false negative rates. The model may also become more sensitive to noise and lighting variations in unfamiliar environments, further reducing detection performance. In this case, additional images can be captured from the actual deployment site, annotated accordingly, and added into the training dataset for improved model robustness.
5.3. Ablation Experiment
This paper conducts ablation experiments by individually removing the SFA, SPPF, and C2PSA modules to evaluate their respective effectiveness.
After removing the SFA module, the FPS of SFA-YOLO drops to 130. It is a significant decrease. Meanwhile, precision, recall, mAP@0.5, and mAP@0.5:0.95 all showed a decline. This indicates that the SFA module effectively enhances the model’s feature extraction capability and contributes to detection speed.
Removing the SPPF module reduces the FPS of SFA-YOLO to 145. The difference from the original FPS is not significant. The recall rate slightly increased. Precision and mAP@0.5 decreased. mAP@0.5:0.95 remained almost unchanged. This indicates that SPPF affects the metrics but is not the main contributing factor. It can enhance recall while leading to a reduction in FPS.
Removing the C2PSA module increased the FPS of SFA-YOLO to 154, with only a small difference from the original FPS. Precision slightly improves, while recall, mAP@0.5, and mAP@0.5:0.95 remain largely unchanged. This indicates that C2PSA primarily enhances precision and FPS but is still not the main influencing factor.
Overall, all three core modules have an impact on the performance of SFA-YOLO. However, its performance is primarily determined by the SFA module. SPPF and C2PSA help SFA-YOLO balance FPS, precision, and recall, preventing significant degradation of the metrics. The impact of different modules on performance is shown in Table 5.
Table 5.
Performance of different modules.
5.4. The Generalizability of the SFA-YOLO Method
The previous experiments have already demonstrated the superior performance of the SFA-YOLO algorithm on the safety attire detection dataset. The MIMIC-CXR (MIMIC Chest X-ray) dataset is a publicly available collection of chest radiographs developed to facilitate research in medical image processing, disease diagnosis, and intelligent diagnostic systems. It comprises a large volume of accurately labeled X-ray images along with corresponding radiological reports, encompassing a wide spectrum of thoracic conditions, among which pneumonia is a key focus. The dataset includes more than 200,000 chest X-ray images that illustrate various pulmonary diseases such as pneumonia, tuberculosis, and pneumothorax, with most images originating from hospitalized patients. In total, 4194 images related to pneumonia were selected for detection purposes. This section further conducts experiments using a pneumonia detection dataset to evaluate the SFA-YOLO network’s generalization capability and analyze its detection performance on other public datasets. We used the open-source MIMIC Chest X-ray pneumonia dataset; the images were re-annotated using the LabelImg tool. As shown in Figure 9, the dataset contains five labels: Pneumonia Bacteria, Pneumonia Virus, Sick, Healthy, and Tuberculosis. To access the open-source MIMIC Chest X-ray pneumonia dataset, visit the following address: https://physionet.org/content/mimic-cxr/2.0.0/ (accessed on 1 January 2024).
Figure 9.
Pneumonia detection dataset.
Based on the results in Table 6, SFA-YOLO outperforms other YOLO-based algorithms on the pneumonia detection dataset. Although YOLOv7-Tiny and YOLOv5n achieve slightly higher precision, SFA-YOLO shows significantly better results in FPS, recall, mAP@0.5, and mAP@0.5:0.95. SFA-YOLO demonstrates a superior overall performance.
Table 6.
The performance comparison of the different algorithms.
Higher recall reflects stronger sensitivity of SFA-YOLO to features and reduces missed detections, which holds greater importance in pneumonia diagnosis. Higher mAP@0.5 and mAP@0.5:0.95 indicate that SFA-YOLO maintains more robust detection performance under various conditions. Higher FPS ensures the more excellent practical value of SFA-YOLO in real-time detection scenarios.
SFA-YOLO achieves the best results in recall, mAP@0.5, and mAP@0.5:0.95 on the safety attire and pneumonia detection datasets. Unlike other networks, the FPS consistently remains above 140 and shows no significant variation between the two datasets. These results demonstrate the stability and reliability of SFA-YOLO.
Previous experiments validate the generalization ability of SFA-YOLO using datasets from different domains. In this study, we also evaluate SFA-YOLO on other datasets from the industrial inspection field. We construct a worker behavior detection dataset and evaluate three behaviors: normal, play, and sleep. The worker behavior detection task shares certain similarities with the safety attire detection task.
Based on the results in Table 7, SFA-YOLO shows slightly lower precision compared to other classic networks. However, it achieves significantly higher recall, mAP@0.5, and mAP@0.5:0.95, indicating a superior performance on the employee behavior detection dataset.
Table 7.
The performance comparison of the different algorithms on the behavior detection dataset.
6. Conclusions
This paper proposes the SFA-YOLO model based on the Selective Feature Attention (SFA) mechanism to address the issues of low efficiency and high miss rate in safety attire detection for inspection robots in intelligent factories. The proposed model achieves a frame rate (FPS) of 149 and a precision of 89.3% on the safety attire dataset. It balances precision and efficiency and meets the practical requirements of automatic detection in intelligent factory inspection robots.
This method improves the C3k2 module and introduces the SFA mechanism. SFA integrates multi-scale feature fusion and a gated feature extraction strategy. PCONV and CGLU form the core of the SFA module. The mechanism enhances feature selection and handles the personal protective equipment dataset’s image loss, target overlap, and minor object issues. The experimental results show optimal precision in SFA-YOLO compared to that of classical YOLO models. The model also achieves near-top scores in the recall, mAP@0.5, and mAP@0.5:0.95. These results confirm strong overall performance. Generalization experiments prove its adaptability across domains. SFA-YOLO meets real-world detection demands. The mAP@0.5:0.95 score still allows for further improvements in the safety attire dataset. In real-world detection tasks, false positives and missed detections occasionally occur. These errors mainly happen under low-light conditions. In such cases, the model struggles to detect targets that resemble the background. It also has difficulty identifying occluded or closely adjacent targets. This limitation results in detection errors. Although this situation is rare, we can mitigate it by adding lighting to the inspection robot. In a factory production environment, personal protective equipment is not limited to helmets and vests; it may also include more comprehensive protective gear such as gloves, goggles, and safety shoes. The detection environment may also involve factors such as smoke, dust, or other conditions that can affect image quality. In our future research, we will address these issues more comprehensively by constructing a more extensive dataset. Additionally, we will incorporate more appropriate attention mechanisms in the model’s feature enhancement to further improve the model’s usability under these extreme conditions. In response to the false positive and missed detection cases reported by on-site users, we will improve both the dataset and the model to enhance its generalization capability.
Author Contributions
Conceptualization, R.S. and B.Z.; methodology, C.W.; software, R.S. and B.Z.; validation, R.S. and B.Z.; formal analysis, C.W.; investigation, R.S. and X.Q.; resources, C.W.; writing—original draft preparation, R.S.; writing—review and editing, B.Z.; funding acquisition, R.S. and C.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Ministry of Industry and Information Technology Project under grant (TC220H05X-04).
Institutional Review Board Statement
Not applicable for studies not involving humans or animals.
Informed Consent Statement
Not applicable for studies not involving humans.
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author.
Conflicts of Interest
Authors Ruohuai Sun and Bin Zhao were employed by the company SIASUN Robot & Automation Co., Ltd. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
- Vijayakumar, A.; Vairavasundaram, S. Yolo-based object detection models: A review and its applications. Multimed. Tools Appl. 2024, 83, 83535–83574. [Google Scholar] [CrossRef]
- Liu, L.; Ouyang, W.; Wang, X. Deep learning for generic object detection: A survey. Int. J. Comput. Vis. 2020, 128, 261–318. [Google Scholar] [CrossRef]
- Zhao, B.; Chang, L.; Liu, Z. Fast-YOLO Network Model for X-Ray Image Detection of Pneumonia. Electronics 2025, 14, 903. [Google Scholar] [CrossRef]
- Ansah, P.A.K.; Appati, J.K.; Owusu, E.; Boahen, E.K.; Boakye-Sekyerehene, P.; Dwumfour, A. SB-YOLO-V8: A Multilayered Deep Learning Approach for Real-Time Human Detection. Eng. Rep. 2025, 7, e70033. [Google Scholar] [CrossRef]
- Fan, Q.S. LUD-YOLO: A novel lightweight object detection network for unmanned aerial vehicle. Inf. Sci. 2025, 686, 121366. [Google Scholar] [CrossRef]
- Xu, S.; Jiang, W.; Liu, Q.; Wang, H.; Zhang, J.; Li, J.; Huang, X.; Bo, Y. Coal-rock interface real-time recognition based on the improved YOLO detection and bilateral segmentation network. Undergr. Space 2025, 21, 22–43. [Google Scholar] [CrossRef]
- Abudukelimu, A.; Ye, J.; Halidanmu, A.; Guo, W. DM-YOLO: Improved YOLOv9 model for tomato leaf disease detection. Front. Plant Sci. 2025, 15, 1473928. [Google Scholar]
- Pei, S.; Wang, W.; Wu, P.; Hu, C.; Sun, H.; Li, K.; Wu, M.; Lan, B. Detection of hydrophobicity grade of insulators based on AHC-YOLO algorithm. Sci. Rep. 2025, 15, 9673. [Google Scholar] [CrossRef] [PubMed]
- Aishwarya, N.; Kannaa, G.Y.; Seemakurthy, K. YOLOSkin: A fusion framework for improved skin cancer diagnosis using YOLO detectors on Nvidia Jetson Nano. Biomed. Signal Process. Control. 2025, 100, 107093. [Google Scholar] [CrossRef]
- He, L.; Wei, H. CBAM-YOLOv5: A promising network model for wear particle recognition. Wirel. Commun. Mob. Comput. 2023, 2023, 2520933. [Google Scholar] [CrossRef]
- Gong, X.; Zhang, Y.; Hu, S. ASAFormer: Visual tracking with convolutional vision transformer and asymmetric selective attention. Knowl.-Based Syst. 2024, 291, 111562. [Google Scholar] [CrossRef]
- Flores-Calero, M.; Astudillo, C.A.; Guevara, D.; Maza, J.; Lita, B.S.; Defaz, B.; Ante, J.S.; Zabala-Blanco, D.; Armingol Moreno, J.M. Traffic Sign Detection and Recognition Using YOLO Object Detection Algorithm: A Systematic Review. Mathematics 2024, 12, 297. [Google Scholar] [CrossRef]
- Sangaiah, A.K.; Yu, F.N.; Lin, Y.B.; Shen, W.C.; Sharma, A. UAV T-YOLO-rice: An enhanced tiny YOLO networks for rice leaves diseases detection in paddy agronomy. IEEE Trans. Netw. Sci. Eng. 2024, 11, 5201–5216. [Google Scholar] [CrossRef]
- Xiao, G.; Hou, S.; Zhou, H. PCB defect detection algorithm based on CDI-YOLO. Sci. Rep. 2024, 14, 7351. [Google Scholar] [CrossRef]
- Liu, Z.; Abeyrathna, R.M.R.D.; Sampurno, R.M.; Victor, M.N.; Tofael, A. Faster-YOLO-AP: A lightweight apple detection algorithm based on improved YOLOv8 with a new efficient PDWConv in orchard. Comput. Electron. Agric. 2024, 223, 109118. [Google Scholar] [CrossRef]
- Prinzi, F.; Insalaco, M.; Orlando, A.; Gagilo, S.; Vitable, S. A yolo-based model for breast cancer detection in mammograms. Cogn. Comput. 2024, 16, 107–120. [Google Scholar] [CrossRef]
- Lalinia, M.; Sahafi, A. Colorectal polyp detection in colonoscopy images using YOLO-V8 network. Signal Image Video Process. 2024, 18, 2047–2058. [Google Scholar] [CrossRef]
- Paul, A.; Machavaram, R.; Ambuj; Kumar, D.; Nagar, H. Smart solutions for capsicum Harvesting: Unleashing the power of YOLO for Detection, Segmentation, growth stage Classification, Counting, and real-time mobile identification. Comput. Electron. Agric. 2024, 219, 108832. [Google Scholar] [CrossRef]
- Sun, Q.; Li, P.; He, C.; Song, Q.; Chen, J.; Kong, X.; Luo, Z. A Lightweight and High-Precision Passion Fruit YOLO Detection Model for Deployment in Embedded Devices. Sensors 2024, 24, 4942. [Google Scholar] [CrossRef]
- Bhavana, N.; Kodabagi, M.M.; Kumar, B.M.; Ajay, P.; Muthukumaran, N.; Ahilan, A. POT-YOLO: Real-Time Road Potholes Detection using Edge Segmentation based Yolo V8 Network. IEEE Sens. J. 2024, 24, 24802–24809. [Google Scholar] [CrossRef]
- Azevedo, P.; Santos, V. Comparative analysis of multiple YOLO-based target detectors and trackers for ADAS in edge devices. Robot. Auton. Syst. 2024, 171, 104558. [Google Scholar] [CrossRef]
- Moksyakov, A.; Wu, Y.; Gadsden, S.A.; Yawney, J.; AlShabi, M. Object Detection and Tracking with YOLO and the Sliding Innovation Filter. Sensors 2024, 24, 2107. [Google Scholar] [CrossRef] [PubMed]
- Panigrahy, S.; Karmakar, S. Real-time condition monitoring of transmission line insulators using the YOLO object detection model with a UAV. IEEE Trans. Instrum. Meas. 2024, 73, 1–9. [Google Scholar] [CrossRef]
- Zhao, B.; Wu, C.; Chang, L.; Jiang, Y.; Sun, R. Research on Zero-Force control and collision detection of deep learning methods in collaborative robots. Displays 2025, 87, 102969. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).