
Privacy Auditing of Lithium-Ion Battery Ageing Model by Recovering Time-Series Data Using Gradient Inversion Attack in Federated Learning




Abstract
1. Introduction
- It is important to model the ageing of LIBs using degradation prediction through machine learning to enable better monitoring and predictive maintenance, which is critical for optimising electric vehicle performance and extending battery useful life.
- The security of existing transformer-based models is critical in the context of the FL framework. By identifying and quantifying privacy leaks using GIAs in the training scenarios, sensitive battery time-series data can be protected.
- Many FL systems incorporate differential privacy. Investigating whether these protections are effective for transformer-based models using privacy auditing is essential for improving the security of FL.
- The transformer-based time-series model for LIB ageing is trained, indicating its applicability in the energy sector to evaluate battery longevity, safety and remaining useful life.
- Differential privacy with Gaussian mechanism and with different multiplicative noise factors is incorporated into the battery ageing model to evaluate the privacy-preserving behaviour of the model against privacy leakage.
- The privacy auditing is elaborated using a model inversion approach. The reconstruction of LIB data from transformer-based model gradients is considered applicable in the case of FL. The model to be trained is inverted to extract information.
2. Background
2.1. Time-Series Federated Learning
2.2. Gradient Inversion Attacks
2.3. Protecting Time-Series Data with Differential Privacy
3. Methodology
3.1. Problem Definition and Our Approach
| Algorithm 1. Signal reconstruction pseudo-algorithm explained |
|
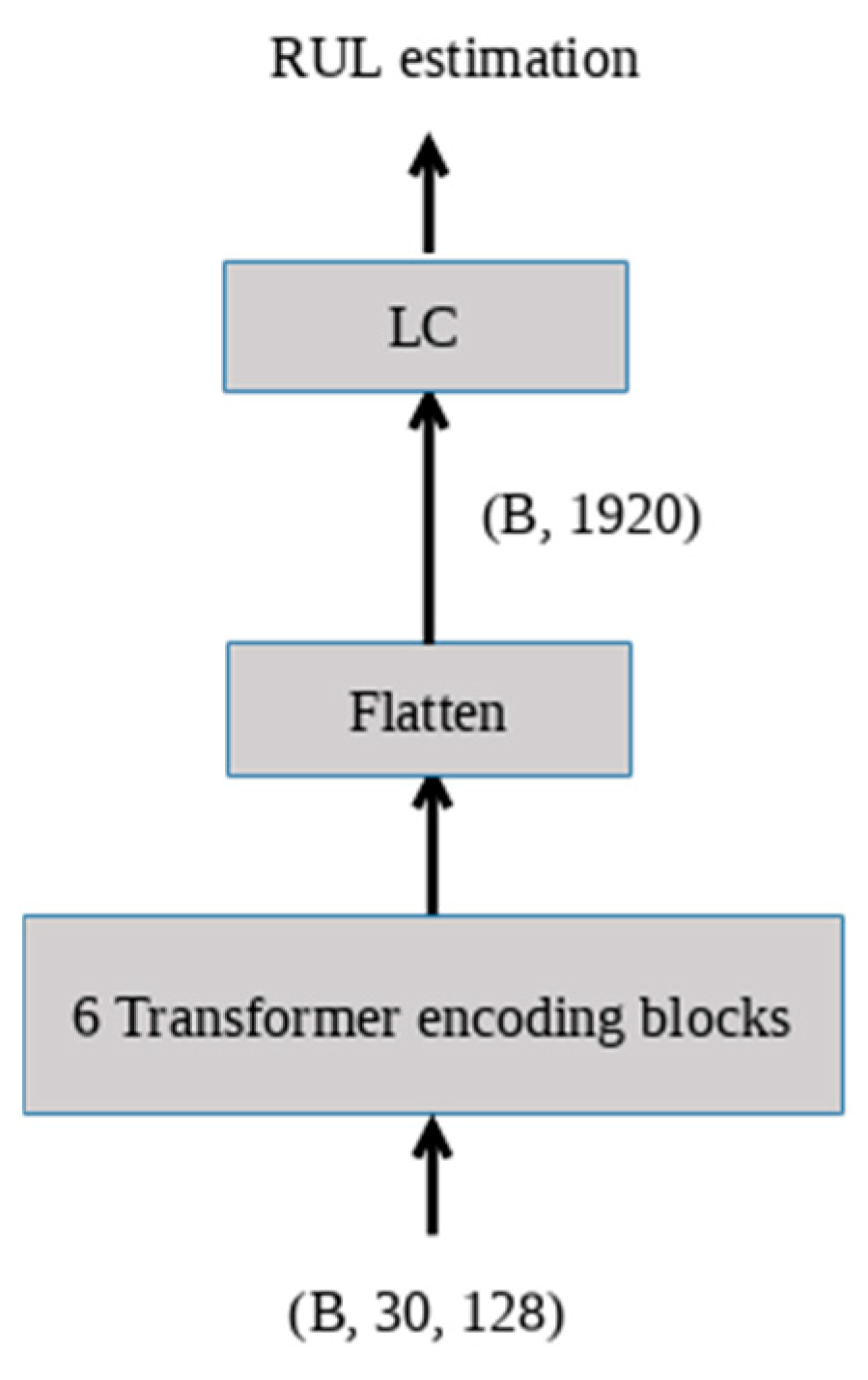
3.2. Experimental Details
3.3. Dataset
4. Experimental Results and Analysis
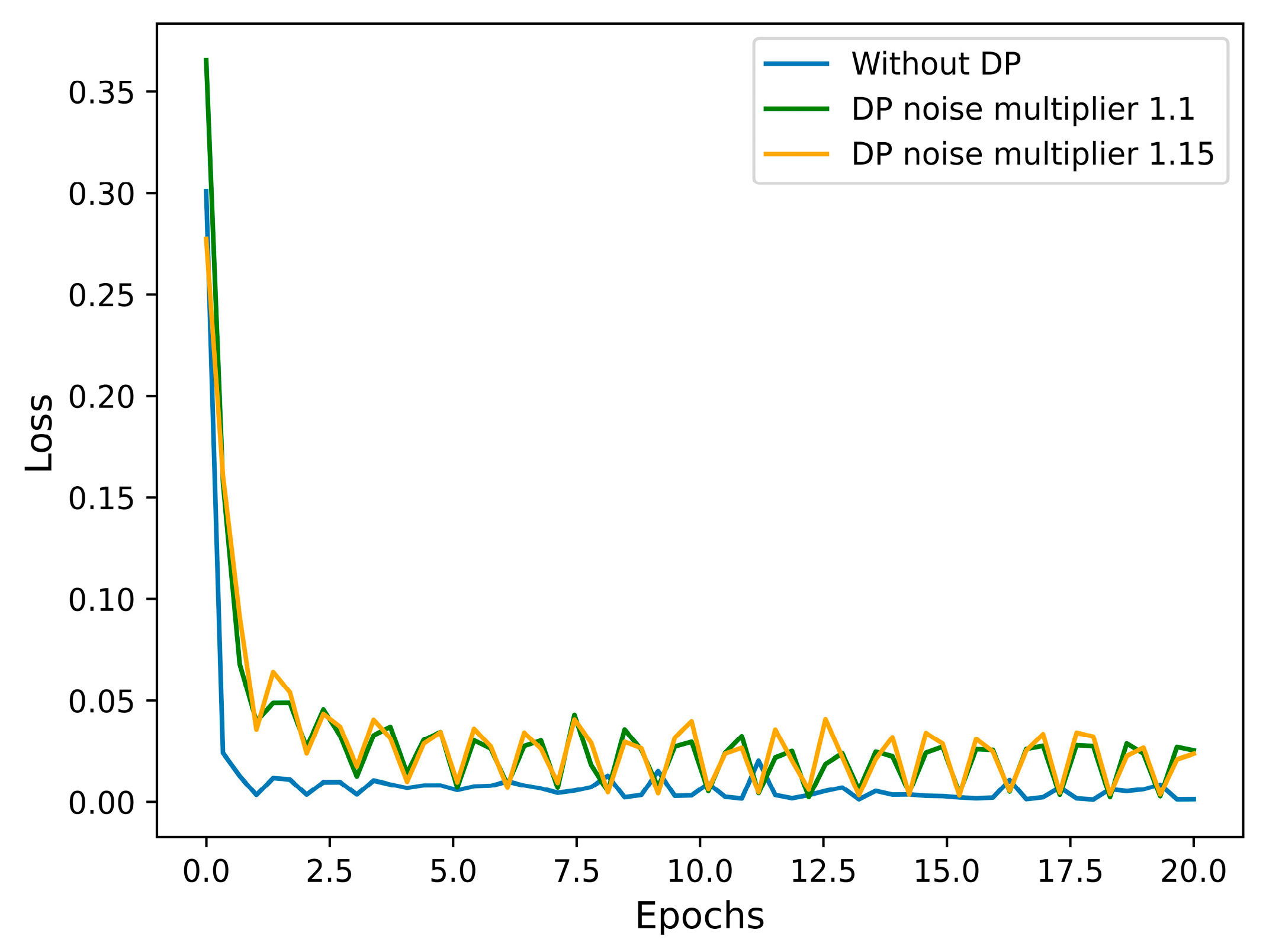
4.1. Differential Privacy Impact on Deep Learning Training Process
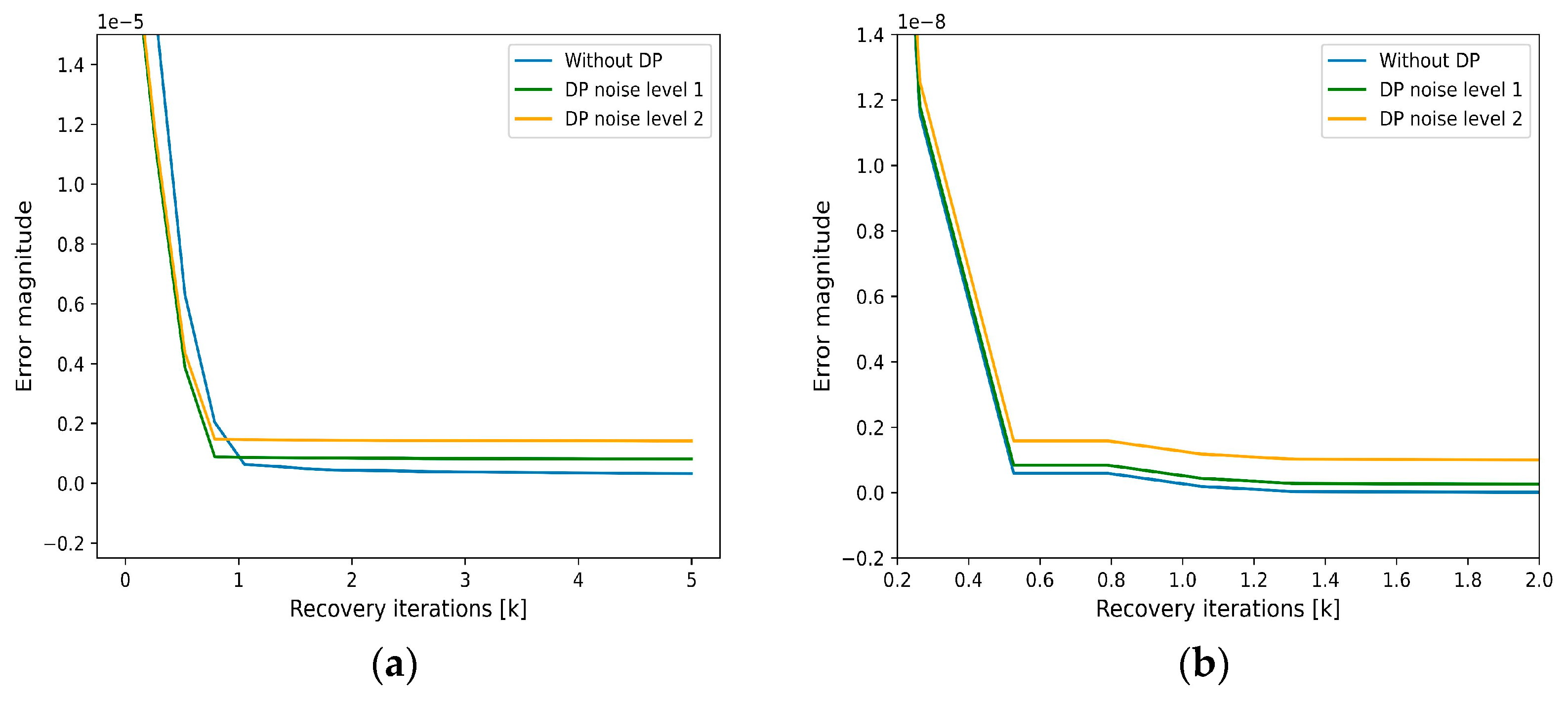
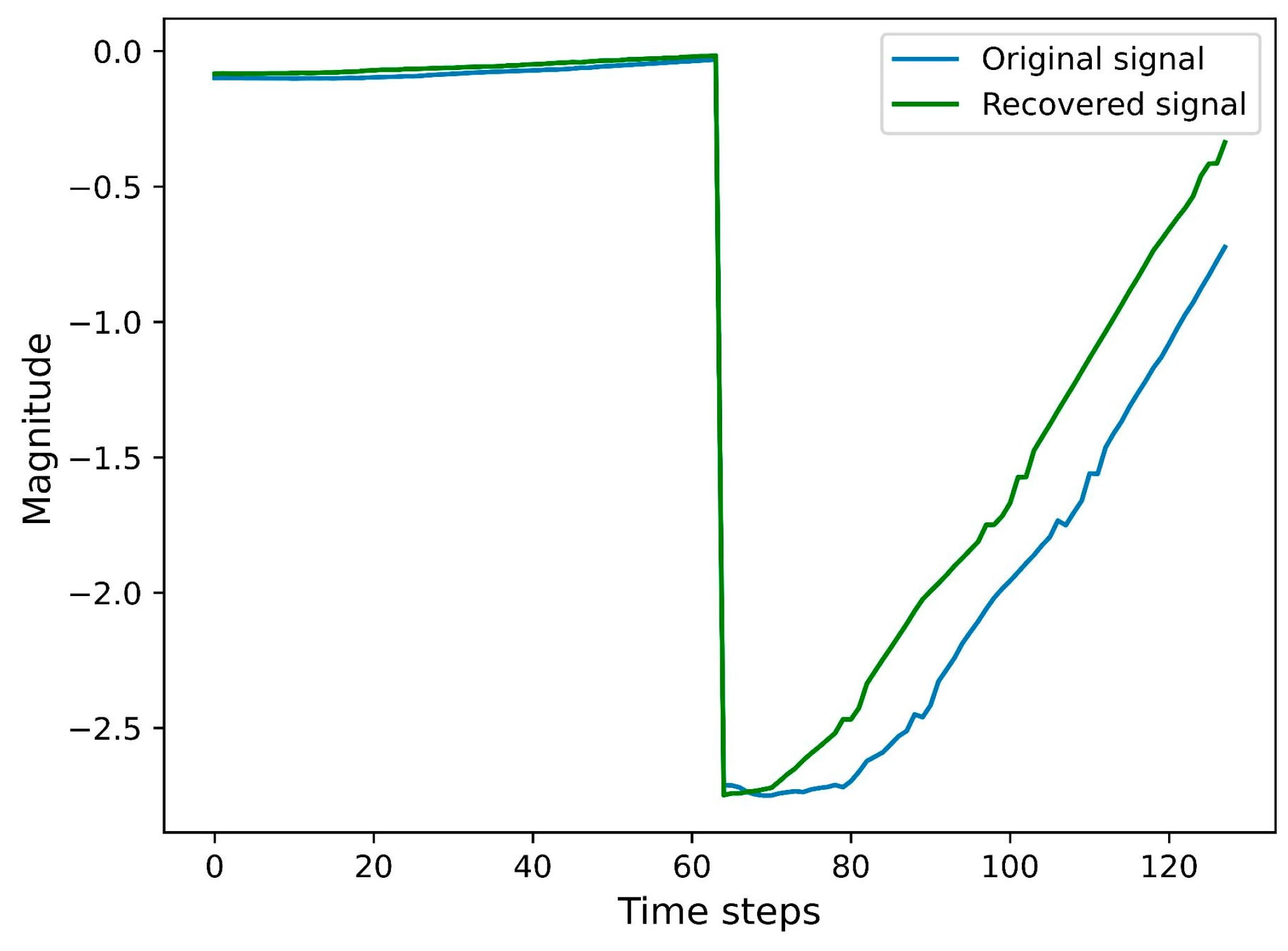
4.2. Signal Reconstruction with Gradient Inversion Attack Versus Deep Learning Level
5. Discussion and Future Research
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- McMahan, H.B.; Moore, E.; Ramage, D.; Agüera y Arcas, B.A. Communication-Efficient Learning of Deep Networks from Decentralized Data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics (AISTATS), Ft. Lauderdale, FL, USA, 20–22 April 2017; Volume 54, pp. 1273–1282. [Google Scholar]
- Cheng, X.; Li, C.; Liu, X. A Review of Federated Learning in Energy Systems. In Proceedings of the 2022 IEEE/AIS Industrial and Commercial Power System Asia (ICPS Asia), Shanghai, China, 8–11 July 2022; IEEE/IAS: Shanghai, China, 2022; pp. 2089–2095. [Google Scholar]
- Grataloup, A.; Jonas, S.; Meyer, A. A Review of Federated Learning in Renewable Energy Applications: Potential, challenges, and Future Directions. Energy AI 2024, 17, 100375. [Google Scholar] [CrossRef]
- Namatevs, I.; Sudars, K.; Nikulins, A.; Ozols, K. Privacy Auditing in Differential Private Machine Learning: The Current Trends. Appl. Sci. 2025, 15, 647. [Google Scholar] [CrossRef]
- Li, M.; Andersen, D.G.; Park, J.W.; Smola, A.J.; Ahmed, A.; Josifovski, V.; Long, J.; Shekita, E.J.; Su, B.-Y. Scaling Distributed Machine Learning with the Parameter Server. In Proceedings of the 11th {USENIX} Symposium on Operating Systems Design and Implementation ({OSDI} 14), Broomfield, CO, USA, 6–8 October 2014; pp. 583–598. [Google Scholar]
- Alsharif, M.H.; Kannadasan, R.; Wei, W.; Nisar, K.S.; Abdel-Aty, A.-H. A Contemporary Survey of Recent in Federated Leaning: Taxonomies, Applications, and Challenges. Internet Things 2024, 27, 101251. [Google Scholar] [CrossRef]
- Bonawitz, K.; Ivanov, V.; Kreuter, B.; Marcedone, A.; McMahan, H.B.; Patel, S.; Ramage, D.; Segal, A.; Seth, K. Practical Secure Aggregation for Federated Learning on User-Held Data. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communication Security (CCS’17), Dallas, TX, USA, 30 October–3 November 2017; pp. 1175–1191. [Google Scholar] [CrossRef]
- Qi, P.; Chiaro, D.; Guzzo, A.; Ianni, M.; Fortino, G.; Piccalli, F. Model Aggregation Techniques in Federated Learning: A Comprehensive Survey. Future Gener. Comput. Syst. 2024, 150, 272–293. [Google Scholar] [CrossRef]
- Shaffe, A.; Awaad, T.A. Privacy Attacks Against Deep Learning Models and Their Countermeasures. J. Syst. Archit. 2021, 114, 101940. [Google Scholar] [CrossRef]
- Tao, Z. Hierarchical Federated Learning with Gaussian Differential Privacy. In AISS’22: Proceedings of the 4th International Conference on Advanced Information Science and System; ACM International Conference Proceeding Series; ACM: New York, NY, USA, 2022; p. 186695. [Google Scholar]
- Rigaki, M.; Garcia, S. Stealing and Evading Malware Classifiers and Antivirus at Low False Positive Conditions. Comput. Secur. 2023, 129, 103192. [Google Scholar] [CrossRef]
- Sotthiwat, E.; Zhen, L.; Zhang, C.; Li, Z.; Goh, R.S.M. Generative Image Reconstruction Gradients. IEEE Trans. Neural Netw. Learn. Syst. 2025, 1, 21–31. [Google Scholar] [CrossRef] [PubMed]
- Feng, X.; Ma, Z.; Wang, Z.; Chegne, E.J.; Ma, M.; Abuadbba, A.; Bai, G. Uncovering Gradient Inversion Risks in Practical Language Model Training. In Proceedings of the CCS’24—2024 ACM SIGSAC Conference on Computers and Communication Security, Salt Lake City, UT, USA, 14–18 October 2024; ACM: New York, NY, USA, 2024; pp. 3525–3539. [Google Scholar]
- Chen, S.; Yuan, J.; Wang, Z.; Sun, Y. Local Perturbation-based Black-box Federated Learning Attack for Time Series Classification. Future Gener. Comput. Syst. 2024, 158, 488–500. [Google Scholar] [CrossRef]
- Wu, T.; Wang, X.; Qiao, S.; Xian, X.; Liu, Y.; Zhang, L. Small Perturbations are Enough: Adversarial attacks on Time Series Prediction. Inf. Sci. 2022, 587, 794–812. [Google Scholar] [CrossRef]
- Dinev, A. Evaluation of Advances in Battery Health Prediction for Electric Vehicles from Traditional Linear Filters to Least Machine Learning Approaches. Batteries 2024, 10, 356. [Google Scholar] [CrossRef]
- Kröger, T.; Belnarsch, A.; Bilfinger, P.; Ratzke, W. Collaborative Training of Deep Neural Networks for the Lithium-ion Battery Aging Prediction with Federated Learning. eTransportation 2023, 18, 100294. [Google Scholar] [CrossRef]
- Ali, M.A.; Da Silva, C.M.; Amon, C.H. Multiscale Modelling Methodologies of Lithium-Ion Battery Aging: A Review of Most Recent Developments. Batteries 2023, 9, 434. [Google Scholar] [CrossRef]
- Hatamizadeh, A.; Yin, H.; Roth, H.; Li, W.; Kautz, J.; Xu, D.; Molchanov, P. GradViT: Gradient Inversion of Vision Transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Oreleans, LA, USA, 19–24 June 2022; pp. 10021–10030. [Google Scholar] [CrossRef]
- Moshawrab, M.; Adda, M.; Bouzouane, A.; Ibrahim, H.; Raad, A. Reviewing Federated Learning Aggregation Algorithms; Strategies, Contributions, Limitations and Future Perspectives. Electronics 2023, 12, 2287. [Google Scholar] [CrossRef]
- Overman, T.; Klabjan, D. Continuous-Time Analysis in Federated Averaging. arXiv 2025, arXiv:2501.18870. [Google Scholar]
- Liu, W.; Zhang, X.; Duan, J.; Joe-Wong, C.; Zhou, Z.; Chen, X. Federated Learning at the Edge: An Interplay of Mini-Batch Size and Aggregation Frequency. In Proceedings of the IEEE INFOCOM–2023 IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Hoboken, NJ, USA, 17–20 May 2023. [Google Scholar] [CrossRef]
- Khalilian Gourtani, S.; Tsouvalas, V.; Ozcelebi, T.; Meratania, N. FedCode: Communication-Efficient Federated Learning via Transferring Codebook. In Proceedings of the 2024 IEEE International Conference on Edge Computing and Communication (IEEE EDGE 2024), San Francisco, CA, USA, 7–13 July 2024; pp. 99–109. [Google Scholar] [CrossRef]
- Li, X.; Huang, K.; Yang, W.; Wang, S.; Zhang, Z. On the Convergence of FedAvg on Non-IID Data. In Proceedings of the 8th International Conference on Learning Representations (ICLR 2020), OpenReview.net, Virtual Event, 26–30 April 2020. [Google Scholar]
- Xu, J.; Hong, C.; Huang, J.; Chen, L.Y.; Decouchant, J. AGIC: Approximate Gradient Inversion Attack on Federated Learning. In Proceedings of the 41st International Symposium on Reliable Distributed Systems (SRDS 2022), Vienna, Austria, 19–22 September 2022; Ceballos, C., Torres, H., Eds.; IEEE: Vienna, Austria, 2022; pp. 12–22. [Google Scholar]
- Liu, Q.; Liu, X.; Liu, C.; Wen, Q.; Liang, Y. TIME-FFM: Towards LM-Empowered Federated Foundation Model for Time Series Forecasting. In Advances in Neural Information Processing Systems 37 (NeurIPS 2024); Curran Associates, Inc.: Red Hook, NY, USA, 2024. [Google Scholar]
- Abdel-Sater, R.; Hamza, A.B. A Federated Large Language Model for Long-Term Time Series Forecasting. In Proceedings of the 27th European Conference on Artificial Intelligence (ECAI 2024), Santiago de Compostela, Spain, 19–24 October 2024; IOS Press: Amsterdam, The Neatherlands, 2024; Volume 392, pp. 2452–2459. [Google Scholar]
- Chen, S.; Long, G.; Jiang, J.; Zhang, C. Federated Foundation Models on Heterogeneous Time Series. arXiv 2024, arXiv:2412.08906. [Google Scholar] [CrossRef]
- Yu, C.; Shen, S.; Wang, S.; Zhang, K.; Zhao, H. Communication-Efficient Hybrid Federated Learning for E-health with Horizontal and Vertical Data Partitioning. arXiv 2024, arXiv:2404.10110. [Google Scholar] [CrossRef] [PubMed]
- Zhu, L.; Liu, Z.; Han, S. Deep Leakage from Gradients. In Advances in Neural Information Processing Systems, 32 (NeurIPS 2019); Curran Associates, Inc.: Sydney, NSW, Australia, 2019; pp. 14774–14784. [Google Scholar]
- Melis, L.; Song, C.; De Cristofaro, E.; Shmatikov, V. Exploiting Unintended Feature Leakage in Collaborative Learning. In Proceedings of the 2019 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 19–23 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 691–706. [Google Scholar]
- Wang, Z.; Song, M.; Zhang, Z.; Song, Y.; Wang, Q.; Qi, H. Beyond Inferring Class Representatives: User-level Privacy Leakage from Federated Learning. In Proceedings of the IEEE INFOCOM 2019-IEEE Conference on Computer Communications, Paris, France, 29 April–2 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 2512–2520. [Google Scholar]
- Zheng, L.; Cao, Y.; Jiang, R.; Taura, K.; Shen, Y.; Li, S.; Yoshikawa, M. Enhancing Privacy of Spatiotemporal Federated Learning against Gradient Inversion Attacks. In Proceedings of the 2023 ACM Web Conference (WWW 2023), Austin, TX, USA, 30 April–4 May 2023; Associtaion for Computing Machinery: New York, NY, USA, 2023; pp. 3804–3814. [Google Scholar]
- Li, B.; Gu, H.; Chen, R.; Li, J.; Wu, C.; Ruan, N.; Si, X.; Fan, L. Temporal Gradient Inversion Attacks with Robust Optimization. arXiv 2023, arXiv:2306.07883. [Google Scholar] [CrossRef]
- Zhang, R.; Gou, S.; Wang, J.; Xie, X.; Tao, D. A Survey on Gradient Inversion Attacks, Defense and Future Directions. In Proceedings of the 31st Joint Conference on Artificial Intelligence (IJCAI-22), Messe Wien, Vienna, 23–29 July 2022; Available online: https://www.ijcai.org/proceedings/2022/0791.pdf (accessed on 7 February 2025).
- Wu, R.; Chen, X.; Guo, C.; Weinberger, K.Q. Learning to Invert: Simple Adaptive Attacks for Gradient Inversion in Federated Learning. In Proceedings of the 39th Conference on Uncertainty in Artificial Intelligence (UAI 2023), PMLR, Pittsburgh, PA, USA, 31 July–4 August 2023; Volume 216, pp. 2293–2303. [Google Scholar]
- Huang, Y.; Gupta, S.; Song, Z.; Li, K.; Arora, S. Evaluating Gradient Inversion Attacks and Defenses in Federated Learning. In Advances in Neural Information Processing Systems 34 (NeurIPS 2021); Ranzato, M.A., Beygelzimer, A., Dauphin, Y., Liang, P.S., Wortman Vaughan, J., Eds.; Currant Associates, Inc.: Red Hook, NY, USA, 2021; pp. 7232–7241. [Google Scholar]
- Zhao, B.; Mopuri, K.R.; Bilen, H. idlg: Improved Deep Leakage from Gradients. arXiv 2020, arXiv:2001.02610. [Google Scholar]
- Geiping, J.; Bauermeister, H.; Dröge, H.; Moeller, M. Inverting Gradients–How easy is it to break privacy in federated learning? In Proceedings of the Advances in Neural Information Processing Systems; Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS), Virtual, 6–12 December 2020; Currant Associates, Inc.: Red Hook, NY, USA, 2020; Volume 33, pp. 16937–16947. [Google Scholar]
- Jeon, J.; Kim, J.; Lee, K.; Oh, S.; Ok, J. Gradient Inversion with Generative Image Prior. In Advances in Neural Information Processing Systems 34 (NeurIPS 2021); Ranzato, M.A., Beygelzimer, A., Dauphin, Y., Liang, P.S., Wortman Vaughan, J., Eds.; Currant Associates, Inc.: Red Hook, NY, USA, 2021; pp. 29898–29908. [Google Scholar]
- Fowl, L.; Geiping, J.; Czaja, W.; Goldblum, M.; Goldstein, T. Robbing the End: Directly Obtaining Private Data in Federated Learning with Modified Models. In Proceedings of the 10th International Conference on Learning Representations (ICLR 2022), OpenReview.net, Virtual Event, 25–29 April 2022. [Google Scholar]
- Zhang, X.; Li, M.; Chang, X.; Chen, J.; Roy-Chowdhury, A.K.; Suresh, A.T.; Oymak, S. FedYolo: Augmenting Federated Learning with Pretrained Transformers. arXiv 2023, arXiv:2307.04905. [Google Scholar]
- Sun, G.; Mendieta, M.; Dutta, A.; Li, X.; Chen, C. Towards Multi-modal Transformers in Federated Learning. arXiv 2024, arXiv:2404.12467. [Google Scholar]
- Wei, W.; Liu, L. Gradient Leakage Attack Resilient Deep Learning. IEEE Trans. Inf. Forensic Secur. 2022, 17, 303–316. [Google Scholar] [CrossRef]
- Gao, Y.; Xie, Y.; Deng, H.; Zhu, Z. Gradient Inversion Attack in Federated Learning: Exposing Text Data through Discrete Optimization. In Proceedings of the 31st International Conference on Computation Linguistics (COLING 2025), Abu Dhabi, UAE, 19–24 January 2025; pp. 2582–2591. [Google Scholar]
- Scheliga, D.; Mäder, P.; Seeland, M. PRECODE–A Generic Model Extension to Prevent Deep Gradient Leakage. In Proceedings of the 2022 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2022; pp. 3887–3896. [Google Scholar] [CrossRef]
- Abadi, M.; Chu, A.; Goodfellow, I.; McMahan, H.B.; Mironov, I.; Talwar, K.; Zhang, L. Deep Learning with Differential Privacy. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security (CCS), Vienna, Austria, 24–28 October 2016; pp. 308–318. [Google Scholar] [CrossRef]
- Dwork, C.; McSherry, F.; Nissim, K.; Smith, A. Calibrating Noise to Sensitivity in Private Data Analysis. In Theory of Cryptography; Halevi, S., Rabin, T., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; pp. 265–284. [Google Scholar]
- Dwork, C.; Roth, A. The Algorithmic Foundations Of Differential Privacy. In Found. Trends Theor. Comput. Sci. 2014, 9, 211–407. Available online: https://www.nowpublishers.com/article/Details/TCS-042 (accessed on 8 March 2025). [CrossRef]
- Cowan, E.; Shoemate, M.; Pereira, M. Hands-On Differential Privacy; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2024; ISBN 9781492097747. [Google Scholar]
- Balle, B.; Wang, Y.-X. Improving the Gaussian Mechanism for Differential Privacy: Analytical Calibration and Optimal Denoising. In Proceedings of the 35th International Conference on Machine Learning (ICML), Stockholm, Sweden, 10–15 July 2018; pp. 394–403. Available online: https://proceedings.mlr.press/v80/balle18a/balle18a.pdf (accessed on 14 May 2025).
- Li, X.; Qin, B.; Luo, Y.; Zheng, D. Differential Privacy Budget Allocation Algorithm Base on Out-of-Bag Estimation in Random Forest. Mathematics 2022, 10, 4338. [Google Scholar] [CrossRef]
- He, G.; Plagemann, T.; Benndorf, M.; Goebel, V.; Koldehofe, B. Differential Privacy for Protecting Private Patterens in Data Streams. In Proceedings of the 2023 39th International Conference on Data Engineering Workshop (ICDEW), Anaheim, CA, USA, 3–7 April 2023. [Google Scholar] [CrossRef]
- Bai, Y.; Yang, G.; Xiang, Y.; Wang, X. Generalized and Multiple-Queries-Oriented Privacy Budget Strategies in Differential Privacy via Convergent Series. In Security and Communication Networks; Wiley: Hoboken, NJ, USA, 2021; p. 5564176. [Google Scholar] [CrossRef]
- Wen, Q.; Zhou, T.; Zhang, C.; Chen, W.; Ma, Z.; Yan, J.; Sun, L. Transformers in Time Series: A Survey. In Proceedings of the 32nd International Conference on Artificial Intelligence (IJCAI-23), Macao, China, 19–25 August 2023. [Google Scholar]
- Zerveas, G.; Jayaraman, S.; Patel, D.; Bhamidipaty, A.; Eickhoff, C. A Transformer-based Framework for Multivariate Time Series Representation Learning. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD 2021), Virtual Event, 14–18 August 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 2114–2124. [Google Scholar]
- Wang, Y.; Zhu, J.; Kang, R. DESTformer: A Transformer Based on Explicit Seasonal-Trends Decomposition for Long-Term Series Forecasting. Appl. Sci. 2023, 13, 10505. [Google Scholar] [CrossRef]
- Pozatto, G.; Allam, A.; Onori, S. Lithium-ion Battery Aging Dataset Based on Electric Vehicle Real Driving Profiles. Data Brief. 2022, 41, 107995. [Google Scholar] [CrossRef]
- Liu, D.; Shadike, Z.; Lin, R.; Qian, K.; Li, H.; Li, K.; Wang, S.; Yu, Q.; Liu, M.; Ganapathy, S.; et al. Review of Recent Development of in Situ/Operando Characterization Techniques for Lithium Battery Research. Adv. Mater. 2019, 31, 1806620. [Google Scholar] [CrossRef]
- Harris, S.J.; Noack, M.M. Statistical and Machine Learning-based Durability-Testing Strategies for Energy Storage. Joule 2023, 7, 920–934. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| DP Levels | GIA with Random Updates | GIA with Probe Set |
|---|---|---|
| No DP | ~0.05 × 10−5 | ~1 × 10−10 |
| DP 1.1 | ~0.08 × 10−5 | ~0.02 × 10−8 |
| DP 1.15 | ~0.15 × 10−5 | ~0.1 × 10−8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sudars, K.; Namatevs, I.; Nikulins, A.; Ozols, K. Privacy Auditing of Lithium-Ion Battery Ageing Model by Recovering Time-Series Data Using Gradient Inversion Attack in Federated Learning. Appl. Sci. 2025, 15, 5704. https://doi.org/10.3390/app15105704
Sudars K, Namatevs I, Nikulins A, Ozols K. Privacy Auditing of Lithium-Ion Battery Ageing Model by Recovering Time-Series Data Using Gradient Inversion Attack in Federated Learning. Applied Sciences. 2025; 15(10):5704. https://doi.org/10.3390/app15105704
Chicago/Turabian StyleSudars, Kaspars, Ivars Namatevs, Arturs Nikulins, and Kaspars Ozols. 2025. "Privacy Auditing of Lithium-Ion Battery Ageing Model by Recovering Time-Series Data Using Gradient Inversion Attack in Federated Learning" Applied Sciences 15, no. 10: 5704. https://doi.org/10.3390/app15105704
APA StyleSudars, K., Namatevs, I., Nikulins, A., & Ozols, K. (2025). Privacy Auditing of Lithium-Ion Battery Ageing Model by Recovering Time-Series Data Using Gradient Inversion Attack in Federated Learning. Applied Sciences, 15(10), 5704. https://doi.org/10.3390/app15105704