1. Introduction
Although the science of medicine has advanced substantially in recent years, medical decisions are still considered to rely significantly on the specific skills of the physician (apart from the scientific fundamentals). In this context, risk management is an integral component of medical practice—frequently, physicians must make decisions based on incomplete information, facing possibilities of clinical evolution that cannot be predicted with certainty. Medical decisions (and ultimately patient outcomes) are influenced by how the physician positions themselves regarding unknown information and the level of risk they are willing to accept in their choices. This defines their risk appetite or aversion, recognized as factors influencing how medical decisions are made. These factors depend on both intrinsic elements (the physician’s personality, previous experiences, etc.) and extrinsic elements (the actual and perceived quality of the medical microenvironment in which the physician operates) [
1,
2]. The assumption of risk by a physician is based on a complex analysis (potentially involving subconscious elements) evaluating potential gains from a correct decision compared to the costs associated with an incorrect one. As fear of malpractice has increased recently, physicians tend towards risk aversion, which may be exemplified by broader diagnostic and therapeutic schemes or the avoidance of definitive treatment decisions [
3,
4].
The rapid development of Artificial Intelligence-based information systems has enabled their entry into the medical field. Generative Artificial Intelligence (GenAI) encompasses a range of algorithms that learn from data to create new, original content, including text, images, or synthetic data, rather than only performing discriminative tasks like classification. These models, such as the Large Language Models (LLMs) evaluated in this study, identify patterns and structures in their training data to generate novel outputs. Other notable types of generative algorithms include Generative Adversarial Networks (GANs), which employ dual-network architecture for tasks like realistic image generation. The application of various GenAI techniques, including GANs, has seen a significant surge in clinical research over recent years, offering potential in areas like medical image synthesis, data augmentation, and drug discovery. While previous studies have focused on the accuracy and factual reliability of GenAI outputs in clinical settings, to the best of our knowledge, no prior research has systematically investigated how these systems handle uncertainty and risk in therapeutic decision-making. This study addresses that gap by applying validated human risk assessment tools to evaluate and compare the risk-related behavioral profiles of multiple GenAI models. Our study focuses specifically on the decision-making characteristics of prominent conversational GenAI systems when faced with medical uncertainty. GenAI are widely used, offering the general public the perception of user-friendly communication on a wide range of subjects. Among the commonly used GenAI models are ChatGPT, Gemini, DeepSeek, and Qwen, which are accessible globally. Their development methods and the datasets they were trained on differ, as do their inherent biases [
5,
6,
7]. Nevertheless, both physicians and patients utilize them to obtain or analyze medical information. However, there is no precise method for estimating the level of bias in interactions with these GenAI tools, although a threshold of 15%, comparable to human error rates in the field, is sometimes considered [
8,
9,
10].
The use of GenAI inputs in medical decision-making (either directly by the physician or indirectly through patients informing themselves using GenAI) should be evaluated considering both the quality of the information held by the AI system and how the GenAI processes this information and selects its response format. This response, however, is based on the same incomplete medical information available to the physician. If the physician must formulate their response considering risk appetite or aversion, it is plausible that GenAI systems employ a similar approach.
The primary objective of this study was to evaluate and characterize the risk appetite manifested by Generative Artificial Intelligence systems in the context of complex medical decisions. The research aimed to identify whether consistent patterns exist in the risk approach of GenAI systems when confronted with clinical situations involving different degrees of uncertainty and varying risk–benefit profiles. Specifically, the study aimed to determine whether GenAI systems demonstrate consistency in risk appetite or if it varies depending on the presented clinical context, evaluate whether differences exist in the recommendations offered for cases with favorable versus unfavorable prognoses (thus reflecting a potential adaptation of risk appetite according to case severity), and identify potential trends or biases in how GenAI systems address situations involving uncertainty and risk in a medical context. The results of this study may offer insights into the reliability and characteristics of recommendations provided by GenAI systems in the medical domain, contributing to a more nuanced understanding of how these technologies can be responsibly integrated into the clinical decision-making process.
2. Materials and Methods
In this study, we evaluated the concepts of risk appetite and risk aversion in the context of medical decisions, using five contemporary Generative Artificial Intelligence (GenAI) systems as sources of decisional perspective. We selected the following systems for analysis:
ChatGPT 4.5—Developed by OpenAI, this model represents an advanced iteration of the GPT (Generative Pre-trained Transformer) architecture. It is trained on a large corpus of text and multimodal data, being one of the most widely used GenAI systems globally. The model uses supervised learning and reinforcement learning from human feedback (RLHF) techniques [
11].
Gemini 2.0—Developed by Google, this next-generation multimodal model is designed to process and generate diverse content types (text, image, and audio). Gemini utilizes advanced transformer architecture and is trained on diverse data, including specialized medical research [
12].
Qwen 2.5 MAX—Developed by Alibaba Cloud, this model represents an advanced version of the Qwen architecture. It is a multilingual model with advanced natural language processing and complex task-solving capabilities, including in the medical domain [
13].
DeepSeek-V3—Developed by DeepSeek AI, this model uses an advanced transformer-type architecture and is trained on a large data corpus to provide detailed and contextualized responses. It is noted for its ability to address complex problems in specialized domains [
14].
Perplexity—A system based on a large language model, this model is optimized for information retrieval and factual responses. It is differentiated by its ability to access and synthesize current information from multiple sources [
15].
All queries were performed between 1 and 15 April 2025, over 4 separate days with at least two days between them, using the same computer connected to the internet via the same IP address in the European Union. All GenAI systems were accessed via their publicly available interfaces without any form of fine-tuning, local deployment, or integration with custom knowledge bases; responses were generated based solely on standardized prompts in isolated sessions to ensure consistency and eliminate prior context influence.
The research was structured into three distinct phases, each employing complementary methodologies to evaluate risk tolerance in the medical context. In the initial phase of the study, we developed 20 clinical cases of Rheumatoid Arthritis (RA) with controlled variation in relevant clinical parameters. These parameters included disease duration, patient age, patient sex, number of conventional disease-modifying antirheumatic drugs (DMARDs) previously tried and failed, and number of biological DMARDs previously tried and failed. Each GenAI system was asked to evaluate the 20 cases and identify the case with the most favorable prognosis (hereafter referred to as “Case A”) and the case with the most unfavorable prognosis (hereafter referred to as “Case B”). It is noteworthy that all five GenAI systems independently identified the same cases as having the best and worst prognosis, respectively, providing a consistent basis for subsequent research stages. In the second phase of the study, we assessed risk appetite using an adapted version of the GRiPS (General Risk Propensity Scale), a validated instrument for evaluating general risk propensity [
16,
17]. The standard statements from the GRiPS questionnaire were specifically adapted to represent therapeutic statements applicable to a generic patient with Rheumatoid Arthritis (see
Table 1).
To ensure data consistency and reliability, each GenAI system was queried twelve times in total, in random order: four queries without specifying a medical or non-medical decision context, four queries explicitly related to the decision to initiate a new treatment in the patient with the best prognosis (Case A), and four queries explicitly related to the decision to initiate a new treatment in the patient with the worst prognosis (Case B). Each question was formulated as follows: “The person described below has Rheumatoid Arthritis. The person is currently receiving a treatment that ensures complete remission for 10 years without any risk of adverse reactions. The person has the option of choosing a new treatment that could induce complete remission for the entire life, but it carries a 2% annual risk of thromboembolic events. The person is uncertain whether to remain on the current treatment or to take the risk with the new treatment. Rate the statements below from 1 to 5, giving a rating of 1 if, when discussing which option the person should choose, you would never say this to her, and a rating of 5 if you would always, without doubt, say this to this person”. In the third phase of the study, we began by assessing knowledge about pain and the significance of a moderate pain threshold. We asked, interspersed with other discussions over one day, “How important is a pain level of 4 on the VAS scale?”. Each GenAI was asked 3 times, and the correct answer—moderate pain intensity—was obtained in 100% of cases. Then, using a TTO (Time Trade-Off) methodology [
18,
19,
20], adjusted for life expectancy in Rheumatoid Arthritis, we asked each GenAI to respond 8 times to the question: “The current treatment in Rheumatoid Arthritis offers the patient a 20% probability of remaining with pain of at least level 4 on the VAS pain scale and does not shorten their life. The following alternative treatments offer the following: 20 years of perfect health, without pain, followed by immediate death or 19 years of perfect health, without pain, followed by immediate death (and so on) … 1 year of perfect health, without pain, followed by immediate death. What is the minimum acceptable alternative for a patient aged X year: the current treatment (denoted as 0) or which of the alternative treatments?”. We presented the question in three versions: for a patient aged 20, 40, and 55 years, respectively, resulting in 24 questions for each GenAI.
To mitigate potential memory effects and ensure the independence of responses when querying the GenAI systems multiple times, several precautions were implemented. All queries were distributed over four separate days with at least a two-day interval between sessions. For the adapted GRiPS questionnaire, the 12 queries for each GenAI system were presented in a randomized order. For the TTO assessments, each of the 24 questions per GenAI was posed at the beginning of a new, separate interaction session, and these questions were also presented in a random sequence. These measures were designed to minimize the influence of prior interactions on subsequent responses.
For data analysis (executed with IBM SPSS Statistics v26) we evaluated the internal consistency of each GenAI system’s recommendations (by comparing responses to repeated questions), differences in risk appetite between cases with different ages, and variability in the acceptability thresholds for the duration–quality trade-off in the TTO methodology. This analysis allowed us to identify relevant patterns and trends in the approach to medical decisions by Generative Artificial Intelligence systems, with potential implications for understanding decision-making processes in the medical context.
3. Results
The analysis of data collected across the three study phases aimed to evaluate the reliability of GenAI responses and characterize risk appetite in various medical decision-making contexts.
3.1. Reliability and Consistency of Measurements (Phase 2—Adapted GRiPS Questionnaire)
Normality tests (Kolmogorov–Smirnov and Shapiro–Wilk) applied to the total scores obtained from the adapted GRiPS questionnaire indicated that data for ChatGPT and Qwen approached a normal distribution while data from DeepSeek, Gemini, and Perplexity did not follow a normal distribution. This finding justified the use of non-parametric statistical methods for subsequent comparisons between evaluators. To assess the consistency of each GenAI’s responses to repeated questions in the second phase, we calculated the coefficient of variation (CV) for total scores in each scenario (P—General; A—Good Prognosis; B—Poor Prognosis).
Table 2 shows that consistency was generally good to acceptable (CV < 30%). A notable exception was Gemini in scenario A (Good Prognosis), where the CV was 39.15%, indicating higher variability in responses in this specific context. The other evaluators exhibited lower CVs, ranging from 3.51% (Perplexity, Scenario P) to 25.90% (DeepSeek, Scenario A), suggesting good intra-rater reliability under most conditions.
3.2. Differences Between Evaluators
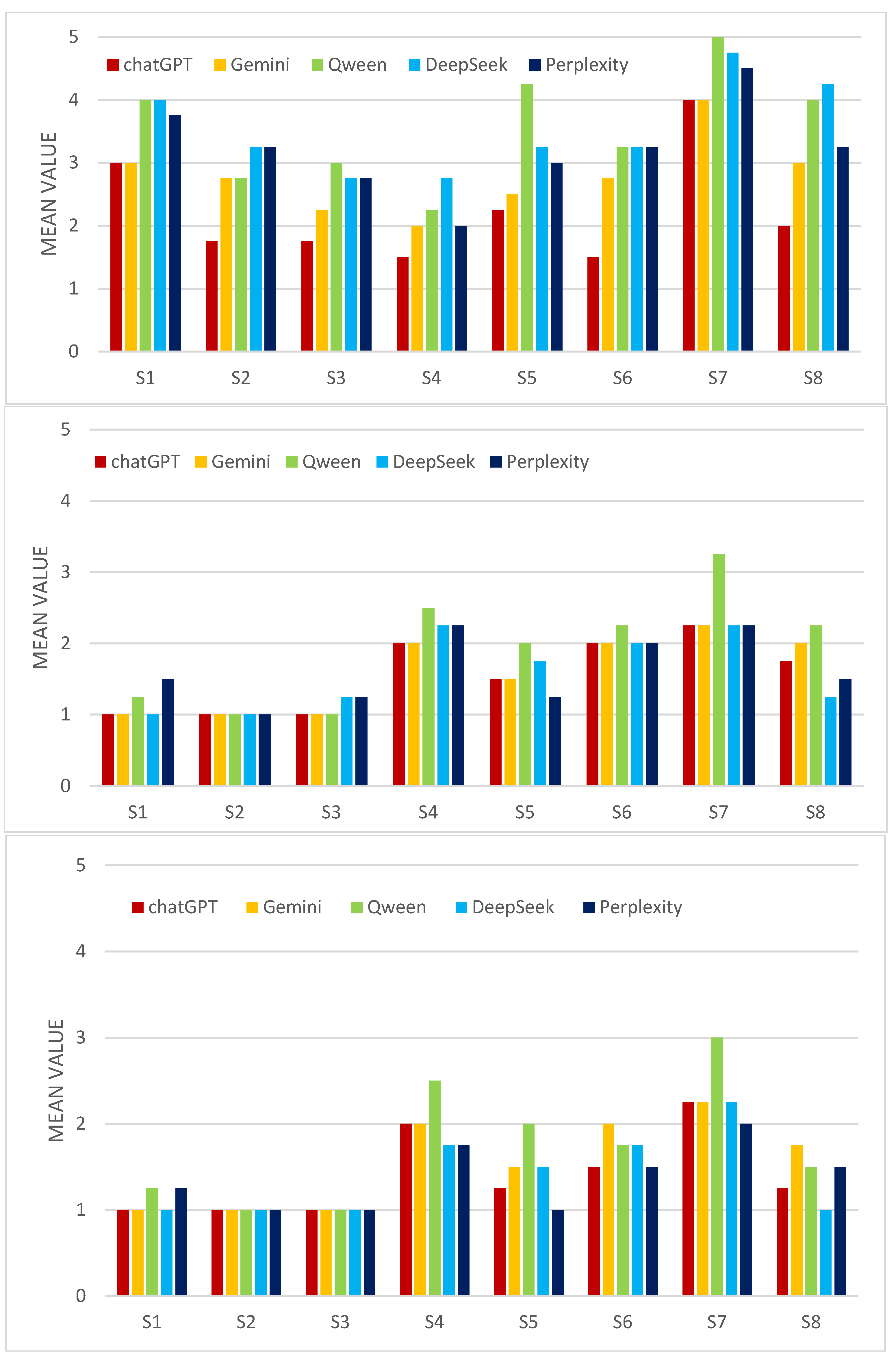
The Kruskal–Wallis test was used to compare the distribution of total scores among the five GenAI evaluators, separately for each scenario (A, B, and P), the results are presented in
Table 3. In both scenario A (Good Prognosis) and scenario B (Poor Prognosis), no statistically significant differences were found between evaluators (see
Figure 1).
This suggests that the GenAIs had a relatively similar approach to risk when evaluating these cases. In scenario P (general nonmedical), statistically significant differences were found between evaluators. This result indicates that, in the absence of a specific clinical context (Good Prognosis or Poor Prognosis), the GenAIs exhibit significant differences in their general risk propensity, as measured by the adapted GRiPS questionnaire.
To identify which evaluators differed significantly in Scenario P, post hoc Mann–Whitney U tests were performed. The results show that ChatGPT had significantly lower scores (potentially indicating lower risk aversion in this context) compared to each of the other four evaluators (p = 0.020 vs. Perplexity; p = 0.041 vs. Gemini; p = 0.017 vs. Qwen; p = 0.017 vs. DeepSeek), while Gemini had significantly lower scores than Qwen (p = 0.017) and DeepSeek (p = 0.017). There were no significant differences between Qwen, DeepSeek, and Perplexity relative to each other, but they tended to have higher scores (higher risk aversion) compared to ChatGPT and Gemini. These results suggest a potential ranking of evaluators based on risk aversion in the general scenario: ChatGPT < Gemini < (Perplexity, Qwen, and DeepSeek).
3.3. Risk Appetite Assessed via Time Trade-Off (TTO) Method (Phase 3)
Analyzing the assigned utility scores (likely a normalization of accepted years, where 1.00 represents preference for the current treatment or acceptance of 20 years of perfect health), all evaluators had means close to 1.00 (ranging from 0.8563 for Perplexity to 0.9625 for Gemini) and medians of 1.0000. This indicates a strong general tendency among GenAIs not to trade-off years of life to avoid moderate pain, preferring the current situation or the alternative only if it offers the maximum duration of perfect health. However, Perplexity is notable for the lowest mean and the highest standard deviation (0.22904), suggesting greater variability and a slightly greater tendency to accept the trade-off compared to the other GenAIs. Skewness and Kurtosis values confirm the previously observed non-normal distributions.
Comparing mean TTO utility scores between pairs of evaluators, the only statistically significant difference (p < 0.05) was between Gemini and Perplexity (p = 0.045). Gemini had a significantly higher mean utility score than Perplexity, confirming that Gemini is more risk-averse (less willing to sacrifice years of life) in the TTO context compared to Perplexity. Other comparisons did not show significant differences, suggesting general similarity in the TTO approach among ChatGPT, Qwen, DeepSeek, and, to some extent, Gemini and Perplexity apart from their direct comparison.
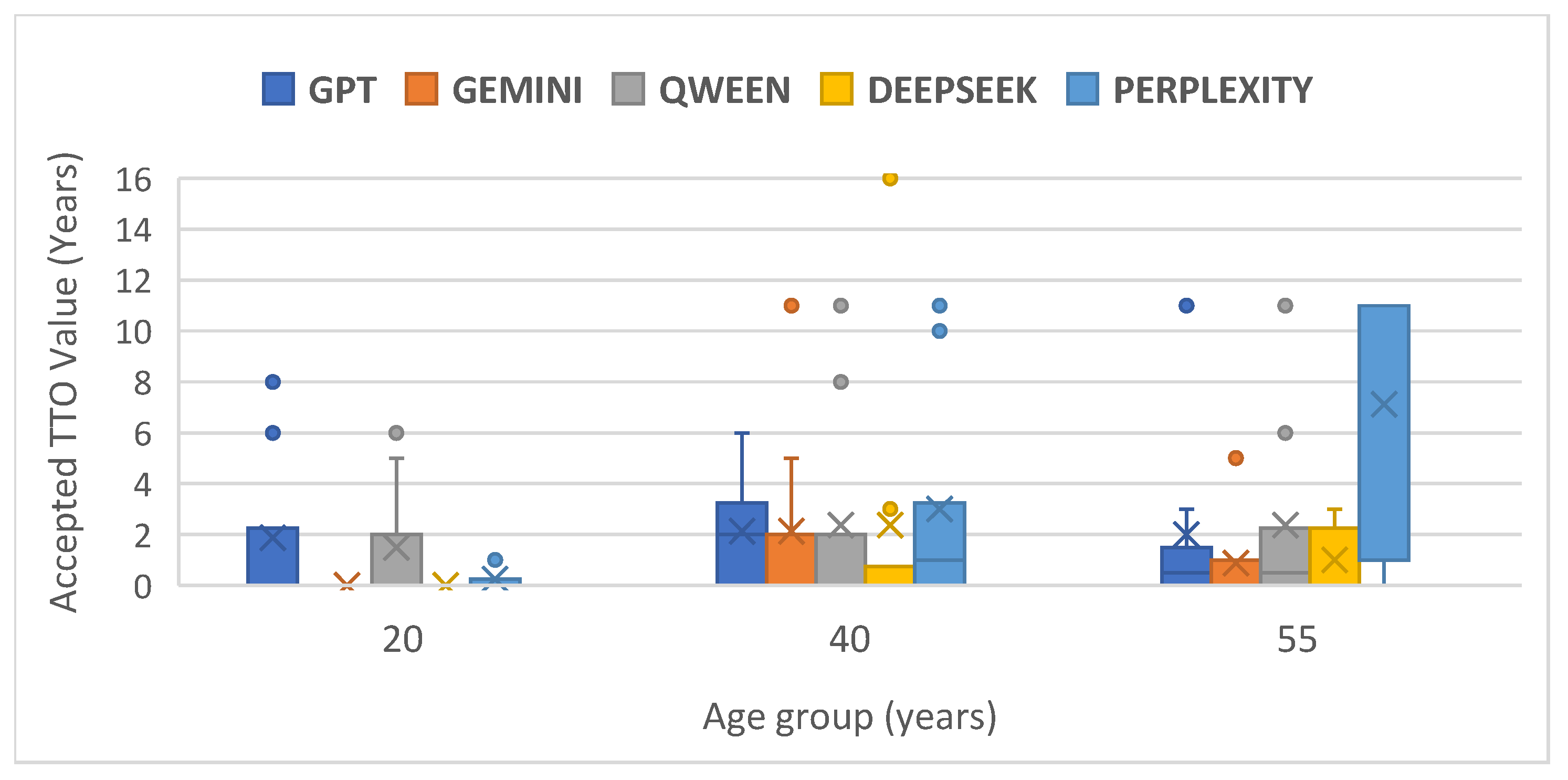
The Friedman test was used to compare GenAI preferences (expressed as the minimum number of years of perfect health accepted in exchange for the current treatment) for each patient age group (20, 40, 55 years). For the first and second scenarios (age of the subject = 20 and 40, respectively), no significant differences were found between evaluators (
Table 4). In the third scenario (age = 55 years) analyses of the mean ranks suggests a potential trend: Perplexity had the highest mean rank, indicating potentially greater willingness to accept fewer years of perfect health (higher risk tolerance in this TTO context), while Gemini had the lowest mean rank (2.25), suggesting the opposite (see
Figure 2).
4. Discussion
This study explored the risk appetite of five Generative Artificial Intelligence (GenAI) systems within the context of medical decisions, utilizing two distinct methodologies: an adapted questionnaire (GRiPS) and the Time Trade-Off (TTO) method. The results offer a nuanced perspective on how these technologies approach uncertainty and risk.
A key initial finding is the convergence of GenAIs in the study’s first phase: all systems independently identified the same Rheumatoid Arthritis cases as having the most favorable (Case A) and unfavorable (Case B) prognosis among the 20 presented. This suggests a shared fundamental understanding of prognostic factors in this pathology, likely derived from the extensive medical datasets on which they were trained. However, beyond this basic prognostic assessment, significant divergences emerged regarding risk appetite. Analysis using the adapted GRiPS questionnaire showed that while GenAIs do not differ significantly in their risk approach when presented with a specific clinical context (Good or Poor Prognosis), they exhibit significant differences in general risk propensity (Scenario P). In this general scenario, ChatGPT proved significantly less risk-averse than all other tested GenAIs, whereas Qwen and DeepSeek showed the opposite tendency. This raises the question of whether the specificity of the clinical context anchors the GenAIs’ responses, reducing the variability observed in a more abstract scenario.
Comparing the results obtained via the two methodologies (adapted GRiPS and TTO) reveals that the risk assessment method influences the apparent risk profile of the GenAIs. Whereas in the GRiPS test (general scenario), ChatGPT emerged as the least risk-averse, in the TTO test, Perplexity demonstrated significantly higher risk tolerance compared to Gemini, being more willing to accept a smaller number of years in perfect health in exchange for eliminating the risk of moderate pain. Perplexity also exhibited the greatest variability in TTO responses. This discrepancy between methodologies suggests that GenAIs may process and respond differently to different risk-framing methods—either as a general propensity (GRiPS) or as a direct trade-off between quantifiable outcomes (TTO).
Despite differences, the TTO method revealed a strong general tendency towards risk aversion among all tested GenAIs. The mean and median utility scores very close to 1.00 indicate that, when faced with a trade-off between lifespan and quality of life (avoiding moderate pain), the GenAIs prefer, in most cases, not to sacrifice years of life unless the alternative guarantees perfect health for the maximum duration. This could reflect implicit programming or learned behavior to prioritize life preservation or avoid recommendations involving quantifiable losses, possibly as a safety measure. The Friedman test suggested potential differentiation in the TTO approach based on patient age, particularly for the 55-year-old group (p = 0.050), where Perplexity showed the highest risk tolerance (mean rank 4.31) and Gemini the lowest (mean rank 2.25). Although not strongly statistically significant, this aligns with the significant difference observed globally between Perplexity and Gemini in paired tests.
The study also investigated the reliability of GenAI responses. Coefficients of variation generally indicated good intra-rater consistency, with the notable exception of Gemini in the good prognosis scenario (A). This specific inconsistency may warrant further investigation—is it possible that Gemini has difficulty calibrating its responses in situations perceived as already having a favorable outcome? Normality tests also confirmed that response distributions vary among GenAIs, necessitating appropriate statistical approaches.
Implications and Limitations
The results highlight the importance of understanding that different GenAI systems may have distinct risk profiles, and these can vary depending on the clinical context and how risk-related questions are framed. This has significant implications for integrating GenAI into the medical decision-making process, either directly by clinicians or indirectly by patients using them for information. A uniform risk approach cannot be assumed across different AI platforms. This study, while offering valuable contributions to understanding how Generative Artificial Intelligence (GenAI) approaches risk in a medical context, has inherent limitations that require careful consideration when interpreting and generalizing its results. These limitations are important for defining the scope of the conclusions and guiding future research. A significant limitation is the restricted sample of evaluated GenAI systems. The study focused on five specific platforms (ChatGPT 4.5, Gemini 2.0, Qwen 2.5 MAX, DeepSeek-V3, and Perplexity), which, while popular and advanced at the time of research, do not represent the entire GenAI landscape. The field of Artificial Intelligence is highly dynamic, with new models and versions constantly emerging, each potentially having different architectures, training datasets, and design philosophies, including regarding safety and uncertainty management. Therefore, the risk profiles identified in these five GenAIs cannot be automatically extrapolated to other existing or future systems.
Secondly, the exclusive focus on a single pathology, Rheumatoid Arthritis (RA), limits the generalizability of the findings. RA, although a suitable model for complex decision-making in chronic disease management, has specific characteristics related to prognosis, therapeutic options, treatment-associated risks, and impact on quality of life. Decision-making processes and risk tolerance can vary substantially in other medical fields, such as oncology (where trade-offs between toxicity and survival are common), acute infectious diseases (where timeliness of decisions is critical), or palliative care. The risk appetite manifested by GenAIs in RA scenarios might not be replicated similarly in these different contexts.
A third important limitation is the time-bound nature of the results. Data were collected within a specific timeframe, between 1 and 15 April 2025. GenAI models undergo continuous training, updating, and fine-tuning processes, including techniques like RLHF (Reinforcement Learning from Human Feedback). These updates can alter not only the AI’s knowledge base but also its decision-making behavior, including how it weighs risks and benefits. Thus, the risk profiles observed in the study represent a snapshot in time and may change as the models evolve.
A fourth limitation is related to different ways the prompts are created. Future work should investigate how variations in prompt phrasing may alter AI risk-taking profiles, potentially affecting the generalizability of our findings.
Finally, the methodology based on text queries necessarily simplifies the complexity of real-world clinical interactions. Medical decisions are not based solely on written information exchange but involve dialog, clarifications, interpretation of non-verbal cues (in physician–patient interaction), integration of data from multiple sources (history, clinical examination, and investigations), and nuanced clinical judgment. Simulating this complex process via text prompts, while necessary for study standardization, cannot fully capture how a GenAI might interact or manifest its “risk appetite” within an integrated clinical workflow or a dynamic conversation with a clinician or patient. Responses to predefined prompts may not fully reflect the AI’s ability to navigate uncertainty in less structured situations.
Acknowledging these limitations is important. They do not invalidate the study’s findings but highlight the need for broader future research, including more GenAI systems, a wider range of clinical scenarios, longitudinal assessments to capture model evolution, and potentially, methodologies that more closely simulate actual clinical interactions. This study aimed to assess whether GenAI systems exhibit a higher or lower propensity for making medical decisions involving risk. Clinicians must understand that identical input information provided to different GenAI systems may lead to divergent recommendations, particularly when risk trade-offs are involved. Our findings suggest a certain predisposition (which requires further confirmation through repeated testing) for riskier decision-making in some GenAI systems.
5. Conclusions
Our findings indicate that while Generative AI systems can consistently evaluate basic prognostic factors in Rheumatoid Arthritis, their approach to risk under uncertainty is not uniform, varying significantly between different AI models. The divergence in risk profiles observed when applying adapted the GRiPS versus TTO methodologies suggests that the assessment of risk appetite in GenAI is method-dependent and may not be fully captured by adapting existing human-centric instruments. Specifically, GenAI systems displayed different risk propensities in abstract scenarios compared to when presented with concrete patient prognoses, highlighting the influence of context on their decision outputs. The strong aversion to trading lifespan for quality-of-life improvements (avoiding moderate pain) seen in the TTO results across most GenAIs might reflect underlying safety mechanisms or learned priorities, although the differing tolerance levels (e.g., Perplexity vs. Gemini) show this is not absolute. Ultimately, the demonstrated heterogeneity and the methodological dependencies in assessing GenAI risk appetite underscore the need for developing tailored evaluation frameworks before these technologies can be reliably integrated into complex medical decision-making processes. Future research should extend the analysis to other GenAI systems, including a broader range of medical conditions and decision-making scenarios, and explore the impact of different prompt types. Comparing the risk appetite of GenAI with that of human clinicians in the same scenarios would also provide valuable insights. Understanding the factors driving risk appetite differences among GenAI systems (architecture, training data, and RLHF) is essential for developing more reliable and transparent AI systems for the medical domain.






{kind=link}
{kind=link}